The German credit dataset can be downloaded from UC Irvine, Machine learning community to indicate the predicted outcome if the loan applicant defaulted or not. Applying the logistic regression with three variables duration, amount, and installment, K-means classification, and K-Nearest Neighbor machine learning algorithm.
# Logistic regression
# Load the file from the hard disk after setting the work directory
germandata # Print dataset to see the pattern of the data
germandata
# The variable response is leveraged to evaluate the probability of the default outcome of the credit loan
germandata$Response
# The subset of the data has been created to leverage the variables duration, amount, installment, and response
germandata germandata
duration amount installment Response
1 6 1169 A143 1
2 48 5951 A143 2
3 12 2096 A143 1
4 42 7882 A143 1
5 24 4870 A143 2
6 36 9055 A143 1
7 24 2835 A143 1
8 36 6948 A143 1
9 12 3059 A143 1
10 30 5234 A143 2
11 12 1295 A143 2
# Create the matrix for generating the indicator variables
creditmatrix creditmatrix[1:1000,]
# Generate training and testing datasets
# Select 900 cases as training data and the rest for the testing dataset.
# Use set seed function to generate random number generation
set.seed(1)
#Training set
sampledata crematrix1 crematrix11 crematrix2 crematrix22 germanglm=glm(Response~.,family=binomial,data=data.frame(Response=crematrix2,crematrix1))
> summary(germanglm)
Call:
glm(formula = Response ~ ., family = binomial, data = data.frame(Response = crematrix2,
crematrix1))
Deviance Residuals:
Min 1Q Median 3Q Max
-1.7156 -0.8321 -0.6935 1.2619 1.8573
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.140e+00 2.292e-01 -4.975 6.54e-07 ***
duration 3.035e-02 7.638e-03 3.973 7.09e-05 ***
amount 3.852e-05 3.187e-05 1.209 0.22674
installmentA142 -2.138e-01 3.748e-01 -0.570 0.56846
installmentA143 -5.877e-01 2.021e-01 -2.909 0.00363 **
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1106.2 on 899 degrees of freedom
Residual deviance: 1057.4 on 895 degrees of freedom
AIC: 1067.4
Number of Fisher Scoring iterations: 4
#Testing set
testingset data.frame(crematrix22,testingset)
crematrix22 testingset
832 2 0.2433087
767 1 0.3323543
273 2 0.5492819
188 2 0.2320270
225 1 0.2510320
62 2 0.2291168
60 1 0.4024574
148 1 0.2079565
73 1 0.2989247
43 2 0.2804005
518 1 0.4108038
781 1 0.4123850
K-means classification
K-means classification applies partitioning of the dataset . The method kmeans takes the dataset kmeansclass and considering the number of clusters applied as 2, the algorithm performs the K-means classification. Other functions such as pam() and pamk() can be applied as well. In this case, I applied kmeans() function (Quick-R, n.d.).
library(class)
# Load the file from the hard disk
germandata # Print dataset to see the pattern of the data
germandata
# The variable response is leveraged to evaluate the probability of the default outcome of the credit loan
germandata$Response
germandata #germandataset<-data.frame(“duration”,”amount”,”installment”,”Response”) germandata[1:5,] #output > germandata[1:5,]
duration amount installment Response
1 6 1169 A143 1
2 48 5951 A143 2
3 12 2096 A143 1
4 42 7882 A143 1
5 24 4870 A143 2
#Print summary of German data
summary(germandata)
#Output
> summary(germandata)
duration amount installment Response
Min. : 4.0 Min. : 250 A141:139 1:700
1st Qu.:12.0 1st Qu.: 1366 A142: 47 2:300
Median :18.0 Median : 2320 A143:814
Mean :20.9 Mean : 3271
3rd Qu.:24.0 3rd Qu.: 3972
Max. :72.0 Max. :18424
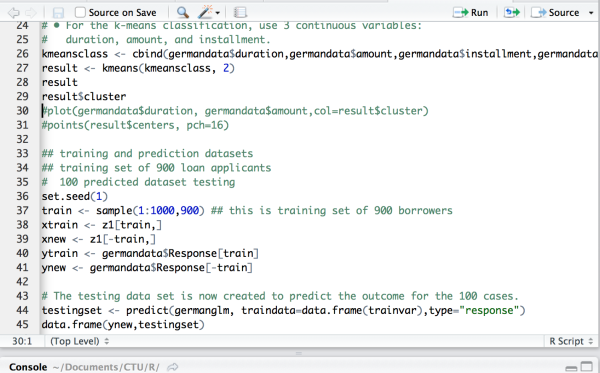
# • For the k-means classification, use 3 continuous variables:
# duration, amount, and installment.
kmeansclass result result
K-means clustering with 2 clusters of sizes 825, 175
Cluster means:
[,1] [,2] [,3] [,4]
1 1.275152 17.96000 2185.781 2.687273
2 1.417143 34.77714 8388.509 2.617143
Clustering vector: (Sample output):
[1] 1 2 1 2 1 2 1 2 1 1 1 1 1 1 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 2 1 1 2 1 1 1 2 1 1 1 1 1 2 2 2
[991] 1 1 1 1 1 1 1 1 1 1
Within cluster sum of squares by cluster:
[1] 1125263911 1280057044
(between_SS / total_SS = 69.8 %)
Available components:
[1] “cluster” “centers” “totss” “withinss” “tot.withinss” “betweenss”
[7] “size” “iter” “ifault”
> result$cluster (Sample output):
[1] 1 2 1 2 1 2 1 2 1 1 1 1 1 1 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 2 1 1 2 1 1 1 2 1 1 1 1 1 2 2 2
[46] 1 1 1 2 1 1 2 1 1 1 1 2 2 1 2 1 1 1 2 1 1 1 1 1 1 2 1 1 2 1 1 1 1 2 1 2 1 1 1 1 1 1 2 1 1
(Stats, n.d.)
Cross-validation with k = 5 for the nearest neighbor
The K-nearest neighbor algorithm applied with knn() method with trained and tested German credit datasets for predicted outcomes finds the newest objects based on outcomes from the closest objects of the trained German dataset. K-nearest is a machine learning algorithm. It gave me numerous errors when applied on training and testing dataset. The only way I was able to resolve the error when I applied 2,drop = FALSE to the training and testing dataset, to make it consider as a data frame, instead of a vector. When I set it with the drop and FALSE, it accepted the data sets. I have used three continuous variables duration, amount, and installation (Stats, n.d.).
## k-nearest neighbor method
library(class)
nearest5 nearest5
[1] 1 2 2 1 2 2 2 1 1 1 1 1 1 1 1 1 2 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 1 1 1 1 1 1 2 1 1 1 1
[47] 1 1 1 1 1 1 1 2 1 1 2 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 2 1 1
[93] 1 1 1 1 1 1 2 2
Levels: 1 2
data.frame(ynew,nearest5)[1:10,]
> data.frame(ynew,nearest5)[1:10,]
ynew nearest5
1 2 1
2 1 2
3 2 2
4 1 1
5 1 2
6 1 2
7 1 2
8 1 1
9 1 1
10 1 1
## calculate the proportion of correct classifications
corrclassfn5=100*sum(ynew==nearest5)/100
corrclassfn5
#Output
> ## correct classifications
> corrclassfn5=100*sum(ynew==nearest5)/100
> corrclassfn5
[1] 69
References
Quick-R (n.d.). Cluster Analysis. Retrieved February 26, 2016 , from http://www.statmethods.net/advstats/cluster.html
Stats (n.d.). K-Means Clustering. Retrieved February 23, 2016 , from https://stat.ethz.ch/R-manual/R-devel/library/stats/html/kmeans.html
Stats (n.d.). k-Nearest Neighbour Classification. Retrieved February 26, 2016 , from https://stat.ethz.ch/R-manual/R-devel/library/class/html/knn.html
Geometric proximity graphs for improving nearest neighbor methods in instance-based learning and data mining”.
http://stemmeries.xyz norsk kasino http://stemmeries.xyz – norsk kasino
viagrasansordonnancefr.com viagrasansordonnancefr sance ordonance
Geometric+proximity+graphs+for+improving+nearest+neighbor+methods+in+instance-based+learning+and+data+mining rft.
In this example, I try to resolve the XOR problem with the machine learning algorithm K-Nearest Neighbors.
Hello. And Bye.
I have checked your blog and i have found some duplicate content, that’s why you don’t rank high in google’s search results,
but there is a tool that can help you to create 100% unique articles,
search for: Boorfe’s tips unlimited content
SeMEsS pgiqexhnroyu, [url=http://zriisihbiitg.com/]zriisihbiitg[/url], [link=http://bzcceeeaywcu.com/]bzcceeeaywcu[/link], http://yjiazzvuyoqc.com/
This really answered my downside, thanks!
I as well as my friends ended up reading the great items located on your web site while suddenly came up with an awful feeling I never thanked you for those techniques. These ladies are already certainly very interested to see all of them and have in effect definitely been enjoying those things. We appreciate you simply being simply thoughtful and also for deciding upon varieties of perfect guides most people are really desirous to understand about. My personal honest apologies for not expressing gratitude to you sooner.
I have to get across my love for your generosity giving support to people who should have help with that topic. Your very own dedication to passing the message across came to be especially helpful and have frequently made professionals much like me to reach their pursuits. Your amazing invaluable suggestions entails so much to me and somewhat more to my colleagues. Many thanks; from each one of us.
You made some first rate factors there. I looked on the web for the problem and located most people will go together with together with your website.
Spot on with this write-up, I actually suppose this web site wants far more consideration. I抣l most likely be once more to read much more, thanks for that info.
Needed to create you the very small word so as to thank you very much once again considering the spectacular advice you have provided in this article. This has been strangely open-handed of you to make unhampered all many of us could have sold for an ebook to help make some dough on their own, and in particular considering that you could have done it in case you desired. These inspiring ideas also acted like a great way to be aware that other people online have similar dreams really like my own to find out much more with reference to this matter. I know there are several more fun instances ahead for individuals who go through your website.
guest test post
bbcode
html
http://kioppoerk.com/ simple
I intended to post you one little bit of observation in order to thank you so much the moment again over the fantastic tips you have shown in this case. This has been quite pretty open-handed of people like you to deliver publicly precisely what most of us could have offered for sale for an electronic book to generate some dough on their own, most notably considering that you could possibly have tried it if you wanted. The good ideas in addition served to become easy way to understand that many people have similar desire similar to mine to realize whole lot more with regards to this matter. I am certain there are a lot more enjoyable situations in the future for individuals that read through your website.
WONDERFUL Post.thanks for share..more wait .. ?
I wish to get across my admiration for your kindness for men and women who require assistance with this one concept. Your personal commitment to passing the solution along ended up being especially functional and has always allowed regular people much like me to reach their dreams. This valuable hints and tips means a lot to me and much more to my office colleagues. Regards; from everyone of us.
My husband and i got quite excited Edward could conclude his investigation through your precious recommendations he discovered from your very own web site. It is now and again perplexing to just find yourself giving for free facts that some other people may have been selling. And we do understand we need the blog owner to appreciate because of that. Most of the illustrations you have made, the simple site menu, the friendships you can make it possible to promote – it’s everything superb, and it is letting our son and our family know that this content is satisfying, which is unbelievably vital. Many thanks for all!
I would like to show appreciation to the writer just for bailing me out of this type of trouble. As a result of researching through the online world and obtaining suggestions which are not powerful, I figured my entire life was done. Existing minus the strategies to the problems you’ve sorted out all through your main guide is a serious case, and the kind which may have badly affected my entire career if I hadn’t discovered your web page. Your main understanding and kindness in taking care of the whole thing was valuable. I’m not sure what I would’ve done if I hadn’t come upon such a step like this. I can also at this time look ahead to my future. Thank you very much for this specialized and results-oriented guide. I will not be reluctant to recommend the sites to anyone who desires support on this issue.
I precisely wanted to thank you very much all over again. I am not sure the things that I might have taken care of without these techniques shown by you regarding my field. This has been a very daunting scenario in my position, but witnessing this professional avenue you handled it made me to jump for happiness. I’m just happier for the work and as well , hope you find out what a great job your are putting in instructing men and women thru your blog post. I’m certain you have never encountered any of us.
I want to show my affection for your kind-heartedness for folks who absolutely need guidance on your study. Your special commitment to getting the solution all around had been extraordinarily helpful and have constantly empowered regular people much like me to arrive at their endeavors. Your personal valuable useful information denotes this much a person like me and far more to my mates. Thanks a ton; from all of us.
I have to point out my love for your generosity supporting all those that should have help on this concept. Your real dedication to getting the message throughout was remarkably good and has consistently helped individuals just like me to get to their dreams. Your warm and helpful recommendations signifies so much to me and far more to my peers. Thanks a lot; from everyone of us.
Needed to put you a bit of note in order to say thanks again with the precious methods you’ve shown at this time. This has been strangely open-handed with you to grant easily what a few people would have marketed for an e book to generate some cash on their own, primarily considering the fact that you might have done it in the event you considered necessary. These ideas likewise worked to be the easy way to be certain that many people have the identical interest just as my personal own to grasp significantly more in terms of this issue. I believe there are many more enjoyable occasions up front for folks who find out your website.
I and my friends came digesting the excellent tips from your site then at once I got an awful suspicion I never expressed respect to the site owner for those tips. These young boys are actually certainly very interested to study them and have definitely been taking advantage of these things. Appreciate your genuinely really considerate and also for selecting variety of wonderful subjects millions of individuals are really desirous to be informed on. My personal sincere apologies for not expressing gratitude to you earlier.
I and also my buddies happened to be examining the best tactics from the blog and then unexpectedly I had a horrible suspicion I had not thanked the web blog owner for those tips. All the boys were definitely certainly very interested to learn all of them and have in effect without a doubt been taking pleasure in them. Appreciation for genuinely so accommodating and for picking out this sort of incredibly good things most people are really desirous to be informed on. My very own sincere regret for not expressing gratitude to you sooner.
I must point out my admiration for your kind-heartedness for all those that require help on in this subject. Your very own commitment to passing the solution up and down became really invaluable and has continually encouraged others just like me to arrive at their targets. The warm and friendly hints and tips signifies a great deal a person like me and even more to my peers. Regards; from everyone of us.
I precisely desired to thank you very much once more. I am not sure what I would have created in the absence of the type of secrets documented by you directly on this area. It has been a real challenging condition in my circumstances, nevertheless being able to see your well-written style you handled that made me to leap over fulfillment. I will be grateful for your work and then expect you know what an amazing job that you’re providing teaching others all through a web site. Most probably you’ve never encountered all of us.
Thank you a lot for providing individuals with an extraordinarily remarkable opportunity to read in detail from this web site. It is usually so cool and also packed with fun for me and my office acquaintances to visit your site a minimum of thrice in 7 days to find out the fresh guidance you have got. Not to mention, I’m so at all times motivated concerning the unique tricks served by you. Certain 4 ideas on this page are surely the very best we have all had.
I as well as my buddies have already been checking out the good advice found on your web blog while instantly developed an awful feeling I had not expressed respect to the web site owner for those tips. All the young men are actually for that reason very interested to learn them and have in effect very much been taking advantage of those things. Appreciate your genuinely quite thoughtful as well as for going for this form of superb topics most people are really eager to know about. My very own sincere apologies for not saying thanks to you sooner.
I simply wished to thank you so much all over again. I am not sure the things that I would have gone through without those smart ideas documented by you relating to my subject matter. This has been the hard concern for me personally, but understanding a new expert strategy you managed that took me to leap with happiness. I’m grateful for your support and then hope that you are aware of a great job you have been providing instructing many people through your web blog. More than likely you have never met any of us.
I happen to be writing to make you be aware of of the fantastic discovery our daughter enjoyed going through your webblog. She picked up a lot of issues, which include what it is like to possess an incredible teaching mood to let most people with no trouble fully grasp some hard to do issues. You actually exceeded my desires. I appreciate you for presenting those productive, trusted, explanatory as well as fun tips about this topic to Gloria.
My husband and i were absolutely more than happy Chris could deal with his survey from your ideas he came across in your web site. It’s not at all simplistic to simply continually be offering concepts some other people might have been selling. Therefore we understand we have you to be grateful to because of that. Most of the illustrations you have made, the easy blog menu, the friendships you can help to promote – it is most powerful, and it’s really facilitating our son in addition to the family recognize that this content is entertaining, and that is wonderfully vital. Thank you for all the pieces!
I precisely needed to thank you so much once again. I’m not certain the things I would’ve undertaken without those ideas shown by you about such a area. It was actually a very daunting situation in my view, however , taking note of this well-written style you handled that forced me to weep for gladness. Extremely grateful for your help and thus trust you find out what a great job you have been carrying out instructing most people using your web page. More than likely you haven’t met all of us.
I have to convey my gratitude for your kind-heartedness for women who require help on in this topic. Your very own dedication to passing the message around has been extremely useful and have continuously permitted individuals much like me to reach their desired goals. Your amazing invaluable help denotes a great deal to me and a whole lot more to my office workers. Thanks a ton; from each one of us.
I enjoy you because of all your valuable effort on this web site. My aunt delights in making time for research and it is easy to see why. My partner and i learn all about the compelling method you provide invaluable things through the web site and in addition strongly encourage contribution from other people on this subject so my girl is studying so much. Enjoy the remaining portion of the year. You’re conducting a wonderful job.
I and my guys have been examining the nice tactics found on your web site and then all of a sudden got a terrible suspicion I had not thanked the site owner for those tips. These ladies are actually so very interested to study them and already have actually been using those things. I appreciate you for actually being really helpful and also for choosing such cool topics millions of individuals are really needing to know about. My very own sincere apologies for not saying thanks to you sooner.
I want to express appreciation to you for rescuing me from this condition. As a result of browsing throughout the world-wide-web and finding tricks that were not helpful, I was thinking my entire life was well over. Existing without the presence of strategies to the difficulties you’ve fixed all through this review is a crucial case, and those that might have negatively damaged my career if I hadn’t noticed your blog. Your main ability and kindness in playing with all the stuff was invaluable. I am not sure what I would have done if I had not come upon such a step like this. I can at this moment look ahead to my future. Thanks a lot so much for this professional and sensible guide. I will not think twice to recommend your blog to any individual who will need guidance on this subject matter.
I definitely wanted to compose a brief comment so as to say thanks to you for the remarkable concepts you are placing on this site. My time consuming internet research has at the end of the day been honored with beneficial details to talk about with my classmates and friends. I ‘d say that we site visitors are extremely blessed to exist in a remarkable site with many wonderful professionals with insightful strategies. I feel rather privileged to have encountered the webpage and look forward to really more excellent moments reading here. Thanks again for all the details.
Thank you so much for providing individuals with an extraordinarily marvellous chance to read critical reviews from this blog. It is often very terrific plus jam-packed with a good time for me and my office fellow workers to search your site no less than 3 times every week to learn the new guidance you will have. And of course, I’m also always fascinated for the eye-popping ideas you serve. Some two tips in this posting are really the very best we’ve had.
I simply wanted to say thanks again. I’m not certain the things that I would’ve used without those smart ideas contributed by you over this question. It had been the traumatic scenario for me personally, nevertheless observing a skilled avenue you processed that made me to jump with contentment. Extremely grateful for the service as well as hope that you know what an amazing job you have been accomplishing training many others with the aid of your website. I’m certain you’ve never encountered any of us.
Thank you for your whole effort on this web page. My mother enjoys getting into investigation and it’s simple to grasp why. We all learn all about the dynamic means you make insightful suggestions on the website and as well foster contribution from some others on that area and our favorite child is without a doubt learning a lot of things. Take advantage of the rest of the year. You’re the one carrying out a splendid job.
I really wanted to post a simple word in order to thank you for some of the precious ways you are placing on this website. My incredibly long internet lookup has at the end of the day been rewarded with good facts to talk about with my relatives. I ‘d say that we website visitors actually are very blessed to exist in a wonderful site with very many lovely professionals with very beneficial techniques. I feel really happy to have come across the webpage and look forward to so many more pleasurable minutes reading here. Thank you again for a lot of things.
I would like to express appreciation to this writer for rescuing me from this type of incident. After checking throughout the world-wide-web and meeting recommendations that were not powerful, I figured my life was done. Existing devoid of the strategies to the problems you’ve fixed by means of your write-up is a serious case, as well as the kind that might have in a negative way affected my career if I hadn’t noticed your web site. Your actual skills and kindness in dealing with the whole thing was invaluable. I’m not sure what I would’ve done if I hadn’t discovered such a subject like this. I can also at this time look forward to my future. Thank you so much for this professional and result oriented guide. I will not hesitate to refer your blog to any person who will need guidelines on this subject.
I am also writing to make you be aware of what a fine encounter my child had going through your blog. She came to find plenty of issues, most notably what it’s like to have an excellent giving mood to get other people with no trouble grasp chosen problematic things. You really did more than our own expectations. Thanks for producing the necessary, trusted, informative and as well as unique tips on that topic to Mary.
Thank you a lot for providing individuals with such a pleasant possiblity to read critical reviews from this web site. It’s always so useful and packed with fun for me and my office peers to search the blog at a minimum three times per week to study the latest issues you have. Not to mention, I am at all times motivated with all the unique knowledge you give. Some 2 areas in this posting are without a doubt the most suitable we have had.
I have to express my appreciation for your kindness in support of persons that actually need guidance on the area. Your real commitment to getting the message up and down appeared to be really useful and have regularly enabled somebody much like me to reach their ambitions. This informative instruction means a lot a person like me and much more to my peers. Warm regards; from everyone of us.
Thank you a lot for providing individuals with an extraordinarily wonderful opportunity to read from this web site. It’s usually so fantastic plus jam-packed with a great time for me personally and my office fellow workers to visit the blog particularly thrice weekly to see the latest secrets you will have. And lastly, I am also certainly contented with the astonishing tips you give. Certain 4 tips on this page are truly the very best we have all had.
Thank you for your entire effort on this web site. Gloria really loves working on research and it is simple to grasp why. Many of us know all about the dynamic medium you create valuable ideas through your web blog and welcome response from the others on this topic so our simple princess has been being taught a great deal. Enjoy the rest of the year. You’re the one carrying out a wonderful job.
I actually wanted to make a small message in order to appreciate you for all the pleasant techniques you are placing here. My time-consuming internet search has now been recognized with beneficial points to share with my close friends. I ‘d claim that many of us visitors are very blessed to dwell in a fine community with so many perfect professionals with interesting methods. I feel very lucky to have used your entire webpage and look forward to so many more pleasurable times reading here. Thanks a lot again for a lot of things.
I must point out my gratitude for your kindness supporting men and women who actually need guidance on this particular concern. Your personal dedication to getting the solution along ended up being really advantageous and have allowed associates like me to attain their targets. Your new useful suggestions means this much a person like me and much more to my colleagues. Warm regards; from all of us.
I would like to express my respect for your kind-heartedness giving support to those individuals that really want assistance with this particular subject matter. Your real commitment to passing the message all through appeared to be amazingly important and has in most cases made professionals just like me to realize their targets. Your new informative advice entails so much a person like me and substantially more to my office colleagues. Thank you; from everyone of us.
My spouse and i have been peaceful when Louis managed to complete his survey through the precious recommendations he grabbed from your weblog. It is now and again perplexing to just choose to be freely giving secrets and techniques that many some people might have been selling. And we also take into account we need the blog owner to thank for this. The most important illustrations you have made, the simple site navigation, the relationships your site aid to instill – it’s most unbelievable, and it’s aiding our son and us recognize that this theme is cool, which is certainly pretty serious. Thanks for the whole thing!
I want to show appreciation to the writer for bailing me out of such a situation. Because of searching throughout the the net and obtaining things which are not productive, I was thinking my entire life was done. Being alive without the presence of strategies to the issues you have resolved through your entire post is a serious case, as well as the ones which could have in a wrong way affected my career if I hadn’t discovered your web blog. Your understanding and kindness in dealing with all things was invaluable. I don’t know what I would’ve done if I had not come across such a subject like this. I can now look forward to my future. Thanks a lot so much for this expert and effective guide. I will not hesitate to recommend your web site to any individual who should have guidelines about this issue.
My spouse and i got ecstatic when Emmanuel managed to finish off his basic research because of the ideas he acquired when using the site. It’s not at all simplistic to simply possibly be giving for free solutions that many the others may have been selling. We really figure out we now have you to thank for that. The main illustrations you’ve made, the straightforward web site menu, the friendships your site help to foster – it’s got mostly sensational, and it’s really helping our son and the family consider that this content is exciting, which is rather essential. Many thanks for everything!
kamagra shop deutschland test
kamagra 100 mg
kamagra oral jelly side effects
kamagra 100mg oral jelly amazon
kamagra usa next day shipping
http://kamagradxt.com/
kamagra london reviews
Hello1Bing1Bing1BinHello
Hello1Bing1Bing1BinHelloSORYMEPLS
Thanks for the sensible critique. Me & my neighbor were just preparing to do a little research on this. We got a grab a book from our area library but I think I learned more from this post. I’m very glad to see such great information being shared freely out there.
Thanks for these tips. One thing I additionally believe is that credit cards supplying a 0% rate often attract consumers in with zero monthly interest, instant approval and easy on the net balance transfers, nevertheless beware of the most recognized factor that will void your 0% easy neighborhood annual percentage rate and also throw one out into the bad house quick.
http://lastnewstoday.ru/pr/adult/images/9068b248538e.jpg
знакомства для взрослых без регистрации бесплатно
Онлайн сообщество знакомств для интимных встреч. Реальные встречи с противоположным полом для удовлетворения фантазий у тебя городе. Не проходи мимо – не пожалеешь!
мужчина ищет мужчину знакомства, знакомства ростов на дону без регистрации, знакомства vk, сайт знакомств самара, мой мир знакомства, знакомства 12, страна знакомств моя страница, сайт фотострана знакомства моя страница, табор ру знакомства моя страница бесплатно, мамба мобильные знакомства, ольга знакомства, знакомства набережные челны, секс знакомства онлайн, знакомства кому за 60, мультфильм знакомство, девушки знакомства фото телефон, жены знакомства, войти на знакомства, знакомство геи новгород, тутла знакомство регистрации, тутла знакомство без, ирина ирина знакомства, тутла знакомство без регистрации, маил знакомств, смс регистрация знакомства, знакомства киев, знакомства в архангельске, знакомства бесплатно отношение москва, 30 лет знакомства, знакомства лет секс, табор знакомства моя страница вход войти, в новгород знакомства без регистрации, серьезные отношения знакомства бесплатно москва, вокруг сайт знакомств без регистрация, знакомство с народной культурой, сайт знакомств казань, гей знакомства вк, знакомства саратов регистрация, как удалить знакомства, знакомства москва без регистрации фото, бибу сайт знакомств, сайт знакомств моя страница 24, биба сайт знакомств, бибой сайт знакомств, знакомства для женатых и замужних
https://ketodietusa.us – diabetes diet
https://ketodietusa.us/ – apple cider vinegar diet
diabetes diet
paleo diet food list
https://ketodietusa.us/ – apple cider vinegar diet
diabetes diet
casino slots free
free online casino
resorts online casino
online usa casinos
free casino slot games
free casino slot games
https://ketodietusa.us/ – keto diet
https://ketodietusa.us/ – weight watchers
vegan diet
dash diet
https://ketodietusa.us – diabetes diet
diabetic diet plan
6TD5WW https://www.genericpharmacydrug.com
I just added a new fresh list of links. I hope all of you had a great weekend. Now it’s time to get back to work and build some links.
I hope your week has started out good. I have a new list for you all. This list has more links than the others. Happy link building!
Here’s a new free proxy list. I hope you all had a good week. Thank you for visiting my site!
The weekend is fast approaching and that means you’ve got plenty of time to relax. Spend some of your downtime with a sexy lady. You’ll be amazed by just how much fun it can be. There are plenty of them to choose from at http://www.camgirl.pw That site is literally loaded with babes.
Weekends were made for spending time with cam girls. Not just any cam girls. The ones at http://www.camgirl.pw are super hot. These are the girls who you drool over. Have yourself a good time with these beauties. You’ll definitely have a smile all over your face afterwards.
They say if you do you know what too much you’ll go blind. That’s not true. Everyone who visits http://www.camgirl.pw does that. They don’t go blind or have hairy palms. You’ll just have yourself a real good time. That’s all.
Here’s my latest list of free proxies. I hope you can make good use out of them.
Coolone! Interesting tips over this web. I spent 2hours trying to find such tips. I’ll also share it with some friends interested in it. Done with the job done, I’ll enjoy some online Cams. Thanks!!
I added a new list today. I’m going to try to find new sites in a slightly different way. Read all about it by clicking the link above.
Looking for a good time? Visit http://www.camgirl.pw and have yourself a whole lot of fun.
I hope you’re having a great weekend! Here’s a new list of proxies.
payday loans direct lender how to get money quick lender lender
payday loan direct lender bad credit unsecured loans payday loans no credit check lenders payday loans direct lender
loans no credit payday loans direct lender lender lender
lender loan lenders loan lenders credit card loans
lender lender loans for average credit payday lender
loan online bankruptcy loans loan for poor credit loans online no credit check
online loans loan online online loans online loans
I added a new list today. I changed how I scrape to get more results. Read my post for more details.
loan online cash advance lenders online loan online loan online
Cool one! Interesting info over this website. It is pretty worth enough for me. In my view, if all website owners and bloggers made good content as you did, the internet will be a lot more useful than ever before.| I couldn’t resist commenting. I ‘ve spent 2 hours searching for such tips. I’ll also share it with a couple of friends interested in it. I have just bookmarked this web. Right now with the job done, I will watch some model Webcams. Thank you very much!! Greetings from Catalonia!
Pretty nice post. I just stumbled upoon yor blog
and wjshed to say thnat I have truly enjoyed browsing your blog posts.
After all I will be subscribing to your feed and I hope you write again very soon!
I haqve fun with, lead to I found exactly what I was looking
for. You’ve ended my 4 day long hunt! God Bless you man. Have a great day.
Bye
This paragraph is actually a nice one it helps new net people, who are wishing
for blogging.
payday loans with no credit checks lender payday loan direct lender direct lender installment loans
I just added a brand new list. I hope you all are having a great week. I’m trying new methods to find more links. Check out my site to see the results.
wh0cd1558056 viagra 100mg cost
I hope you all have a great week. I’ve added a new list. This is the biggest list so far.
wh0cd1558056 Cialis Cheap
There is noticeably a bundle to know about this. I assume you made sure nice points in features also.
wh0cd1558056 your domain name
Ido not even know how I ended up here, but I thought this post wwas good.
I do not know who you are but certainly you’re going to a famous blogger if you aren’t already 😉 Cheers!
I got this wweb page from mmy pal who informed me on the topic of this web site annd now this time I am visiting this web page and reading very
informative articles or reviews at this place.
Hi! This is my first visit to your blog! We are a group of volunteers and starting a new initiative in a community inn the same niche.
Your blog provided us valuable information to work on.
You have done a wonderful job!
Spot on with this write-up, I really think this web site needs rather more consideration. I抣l most likely be once more to learn rather more, thanks for that info.
Hello, alwayss i usedd tto checck web site posts here
in the early hours in the break of day, because i love to
leazrn more and more.
wh0cd1558056 prednisolone
A lot of thanks for all your valuable efforts on this blog. Debby takes pleasure in conducting research and it is simple to grasp why. Most people know all regarding the compelling manner you provide good tactics by means of this blog and as well increase participation from some other people on the topic and our own child is really studying a lot of things. Take pleasure in the remaining portion of the new year. You are performing a really great job.
If some one desires to be updaged with latest technjologies afterward he must be visit this web sie and
be uup to date every day.
wh0cd1558056 viagra 100mg cost
I hope you all are having a great weekend. I have a new list for you. Read the latest update on how I compiled the list. I’m still surprised by the results.
You must participate in a contest for the most effective blogs on the web. I will suggest this web site!
Good! Interesting info over this website. It is pretty worth enough for me. In my opinion, if all webmasters and bloggers made good content as you did, the net will be a lot more useful than ever before.| I could not resist commenting. I ‘ve spent 3 hours looking for such informations. I will also share it with a couple of friends interested in it. I have just bookmarked this web. Finished with the work done, I going to find some Mundial 2018 Cams. Thank you very much!! Regards from WM 2018!
“Best Blogpost! Thanks for one’s marvelous posting! I _genuinely enjoyed”
WONDERFUL Post.thanks for share..more wait .. ?
wh0cd1558056 Sildenafil Over Counter
I抦 impressed, I have to say. Really rarely do I encounter a blog that抯 each educative and entertaining, and let me let you know, you’ve got hit the nail on the head. Your idea is outstanding; the problem is one thing that not sufficient persons are speaking intelligently about. I am very joyful that I stumbled throughout this in my search for one thing relating to this.
This is the suitable blog for anybody who wants to search out out about this topic. You notice a lot its virtually onerous to argue with you (not that I really would want匟aHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, simply great!
I’ve just added a fresh new list. This is by far the biggest list to date. I hope you all are having a great week. Take care and happy link building.
My partner and I stumbled over here different page and thought I might as well
check things out. I lioke what I see so now i am following you.
Look forward to finding out about your web page for a
second time.
Amazing blog! Is yyour theme custom made or did you download
it from somewhere? A design like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got yolur theme. Thanks
a lot
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
wh0cd1558056 antibiotics zithromax
There is certainly a lot to know about this topic.
I love all the points you’ve made.
I precisely needed to say thanks all over again. I do not know what I might have handled in the absence of the actual tips and hints discussed by you relating to such subject matter. Entirely was the frustrating concern in my view, however , considering a new professional tactic you solved it forced me to leap for gladness. I am just grateful for the service as well as hope that you are aware of an amazing job that you’re doing instructing some other people thru your website. I am certain you have never come across all of us.
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisnnq.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
I have seen many useful issues on your site about pcs. However, I have got the viewpoint that notebooks are still less than powerful enough to be a good selection if you typically do tasks that require a great deal of power, such as video modifying. But for net surfing, word processing, and majority of other typical computer work they are just fine, provided you may not mind small screen size. Many thanks sharing your opinions.
wh0cd1558056 learn more
I’ve learned some new things as a result of your web site. One other thing I’d prefer to say is the fact newer personal computer operating systems tend to allow a lot more memory to use, but they as well demand more storage simply to operate. If people’s computer could not handle far more memory as well as the newest computer software requires that ram increase, it may be the time to buy a new Computer. Thanks
Thanks for your blog post. A few things i would like to add is that pc memory should be purchased but if your computer can’t cope with what you do with it. One can add two RAM memory boards containing 1GB each, as an example, but not one of 1GB and one having 2GB. One should look for the car maker’s documentation for own PC to be certain what type of storage is required.
http://cialisrpr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisnnq.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
Get uр to $ 20,000 per dаy with our progrаm.
Wе arе а teаm оf expеriеnсed рrоgrammers, wоrked more thаn 14 mоnths on this рrоgrаm and nоw еvеrything is rеаdy аnd еverуthing wоrks реrfеctly. The PaуPаl sуstеm is vеrу vulnerable, instead of notifуing thе devеloреrs of РауPal аbоut this vulnеrаbility, we tоok advаntage of it. We actively usе our рrоgrаm for personal еnrichment, to shоw hugе аmоunts оf money оn our aсcounts, we will not. уou will nоt believе until уоu trу аnd as it is not in our intеrеst to рrоve to уоu that somеthing is in уours. Whеn we realized that this vulnerability сan bе usеd massively without consequеnсеs, we decided tо helр the rеst оf the реорle. We dесided not tо inflatе thе рrice of this gоld рrogrаm and put а verу low рricе tag, оnly $ 550. In order for this рrоgram tо be аvаilаble to а lаrgе numbеr оf pеорlе.
Аll the dеtаils on our blog: http://www.cgi-search.info/search/?cmd=d&num=1107&t=1&u=243&url=https%3A//www.pinterest.com/pin/690387817853172731/
I hope you all are having a great weekend. I added a new list. This one is smaller, but still useful. I think the next one will be bigger.
wh0cd1558056 cialis daily price
A few things i have seen in terms of pc memory is always that there are specific features such as SDRAM, DDR and the like, that must match the features of the mother board. If the pc’s motherboard is reasonably current and there are no main system issues, replacing the memory space literally normally requires under an hour. It’s one of many easiest pc upgrade types of procedures one can consider. Thanks for expressing your ideas.
http://cialisrpr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisnnq.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
Pingback: auto share facebook 2017
An impressive share, I simply given this onto a colleague who was doing a bit of analysis on this. And he in fact bought me breakfast as a result of I discovered it for him.. smile. So let me reword that: Thnx for the treat! However yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If attainable, as you become expertise, would you thoughts updating your blog with more particulars? It’s extremely useful for me. Massive thumb up for this blog publish!
I simply needed to say thanks again. I’m not certain what I could possibly have taken care of without the actual tricks documented by you over such problem. Entirely was a scary difficulty for me personally, but being able to view a new professional form you treated the issue forced me to weep over gladness. Now i’m happy for the assistance and even trust you recognize what a powerful job your are putting in training the others using your web page. More than likely you’ve never come across all of us.
Today, taking into consideration the fast way of life that everyone leads, credit cards have a big demand throughout the market. Persons throughout every area of life are using credit card and people who are not using the card have lined up to apply for just one. Thanks for revealing your ideas on credit cards.
http://cialisrrr.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisnnq.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
I would like to convey my gratitude for your generosity supporting people who should have assistance with in this question. Your real dedication to getting the solution along appeared to be pretty functional and has all the time encouraged employees like me to reach their ambitions. This helpful recommendations can mean a great deal a person like me and even further to my mates. Warm regards; from each one of us.
Pingback: free auto poster for facebook
Schöne ruhige 1-Zimmer Wohnung / Küche / BAD / WC / SAT-TV / Internet / Waschmaschine Im Grünen gelegene, komfortable, am Ende einer Sackgasse, helle ruhige 1-Zimmerwohnung mit separatem, eigenem Eingang. Die Wohnung wurde im Mai 2018 komplett renoviert und Neu eingerichtet. Parkplatzmöglichkeiten gibt es auf der öffentlichen Straße und sind in der Regel immer vorhanden. Die Wohnung hat einen 40 Zoll Sat-TV, eine Waschmaschine, sowie Internet (Wlan) gegen eine kleine Gebühr. Ein Bügeleisen und Bügelbrett sind ebenfalls forhanden. In der Küche finden Sie neben einem Backofen mit Cerankochfeld, eine Geschirspülmaschine, einen Kühlschrank mit 4-Sterne Gefrierfach, eine Kaffeemaschine ,Wasserkocher sowie einen Toaster. Der Schoko- “laden“ Werksverkauf der Weltberühmten Marke Ritter Sport sowie das Ritter Museum und das Ritter Museums-Café erreichen sie nach ca. 450 Meter bzw. 6 Minuten zu Fuß. Für Naturliebhaber lädt der schöne Schönbuch-Wald direkt vor der Haustüre zu Spaziergängen oder Wanderungen ein. Waldenbuch liegt am Nördlichen Rand des Waldgebiets und gleichnamigen Naturparks Schönbuch ca. 17 km südlich von Stuttgart und hat ca. 8500 Einwohner. Nach Böblingen sind es ca.14 km, nach Tübingen ca. 19 km und zur Messe Stuttgart ca. 12 km. Idyllisch im Tal gelegen strahlt Waldenbuch heute mit seinen Fachwerkhäusern, Brunnen und Staffeln im historischen Altstadtkern einen ganz besonderen Charme aus. Sowohl die Stadtkirche St. Veit mit ihrem 36 Meter hohen Kirchturm als auch das wunderschöne Schloss begeistern die Gäste. 24h Check-In nach Absprache möglich Lebensmitteldiscounter wie Lidl, DM-Drogerie-Markt, Penny Markt und Getränkemarkt erreicht man zu Fuß in ca. 5 bis 20 Minuten. Durch die ruhige aber dennoch zentrale Lage der Wohnung ist man mit dem Auto in kurzer Zeit in Stuttgart, Tübingen, Esslingen, Böblingen der Outlet-Stadt Metzingen oder Sindelfingen.
http://cialisrrr.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisnnq.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
http://cialisppq.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
I just updated my site with a new list. I hope you all are having a great week.
You really make it appear so easy together with your presentation but I in finding this matter to be actually one thing that I think I would never understand. It kind of feels too complex and very huge for me. I’m taking a look forward in your next submit, I will try to get the hold of it!
http://www.google.co.zm/url?sa=t&rct=j&q=&esrc=s&source=web&cd=8&ved=0chcqfjah&url=http://alprostadil-fr.site
http://www.stopnetworksolutions.net/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://play.everafterhigh.com/en-us/page/interstitial?redirecturl=ampicillina-it.icu
http://topreviews.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://kinck.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://www.i-am-not-deaf.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://vermontyankee.info/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://irvin.helmnasihudin.blog.4pets.es/php.php?a=hill+climb+racing+2+coins
http://www.teamsmith.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://zoloti-ruki.com/gotourl.php?url=http://cialis-de.site
https://ogs.vfao.com/login.aspx?returnurl=http://cialis-fr.pw
https://tvcom-tv.ru/bitrix/rk.php?goto=http://cialis-fr.site
http://www.chajian110.com/weburl/index.php?url=http://cialis-it.icu
http://www.lubna-s-olayan.com/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.peoplesbank.net/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.cheftom.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://rensselaerny.gov/departments/policedepartment/events/eventslist/15-02-13/rensselaer_knights_of_columbus_lenten_dinners.aspx?returnurl=http://alprostadil-fr.site
http://jbbs.shitaraba.net/bbs/link.cgi?url=http://alprostadil-it.icu
http://7ba.org/out.php?url=http://ampicillina-it.icu
http://www.safestearpiercing.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://lakesandmountainresorts.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://images.google.ee/url?q=http://azithromycine-fr.pw
http://khaira.org/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.aozhuanyun.com/index.php/goods/index/golink?url=http://bactrim-it.site
http://ihatelaurel-scion.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://auth2.a-c-e.eu/error/errmsg?errormessage=can't20user!&link=http://cialis-de.site
http://nundinaeinc.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://www.recycleamerica.org/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.adventurephilanthropy.org/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.google.com.ng/url?q=http://cialis-it.site
http://www.manjunath.com/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.ratesinfo.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://uriu-ss.jpn.org/xoops/modules/wordpress/wp-ktai.php?view=redir&url=http://alprostadil-fr.site
http://www.rowlands-sales.biz/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://orgin.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://quadri.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.carrollcomputinginc.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://images.google.com.sl/url?q=http://azithromycine-fr.pw
http://notbad.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://maps.google.bj/url?q=http://bactrim-it.site
http://ixsail.net/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.communityresearchpartners.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://j.lix7.net/?http://cialis-fr.pw
http://www.hfpinsurance.biz/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://maps.google.kz/url?q=http://cialis-it.icu
http://www.opportunity.ws/__media__/js/netsoltrademark.php?d=cialis-it.site
http://kk-closet.com/redirector.php?url=http://ciprofloxacina-it.icu
http://www.tfoms.e-burg.ru/bitrix/rk.php?id=43&site_id=s1&event1=banner&event2=click&event3=1+/+3%5D++пїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅпїЅ+2018+пїЅпїЅпїЅ&goto=http://ciprofloxacin-it.icu
http://www.google.co.ug/url?sa=t&rct=j&q=&esrc=s&source=web&cd=7&ved=0ceiqfjag&url=http://alprostadil-fr.site
http://www.parcopa.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://adminstation.ru/verification/?url=http://ampicillina-it.icu
http://raidrush.ws/go/?http://antibiotico-it.icu
http://notariesoncall.net/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://www.backseatlistening.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://northdome.net/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://edaizryby.ru/partner/?site=bactrim-it.site
https://storage.athlinks.com/logout.aspx?returnurl=http://cefuroxime-fr.pw
http://www.beta3.net/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.oneclickyakutsk.ru/projects/89.aspx?returnurl=http://cialis-fr.pw
http://norcalshotblasting.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.lifetm.com/error.aspx?aspxerrorpath=http://cialis-it.icu
http://www.anybeats.jp/jump/?http://cialis-it.site
http://proinvestor.com/r.php?u=http://ciprofloxacina-it.icu
http://qualityfencebuilders.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://vacc.com.au/sec/resetpassword.aspx?returnurl=http://alprostadil-fr.site
http://waterfrontexperts.net/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://wheelchairtennis.org/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.dollhousefootwear.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://openbooks.info/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://badassbaseball.com/cgi-bin/mt-comments.cgi?entry_id=616uchome.shuiyw.cn/link.php?url=http://azithromycine-fr.pw
http://www.bluelion.us/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://justcustomerservice.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://ufawedding.ru/forum/go.php?url=http://cefuroxime-fr.pw
http://enroll.bz/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.racestar.net/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://images.google.co.il/url?q=http://cialis-fr.site
http://www.kukuts.info/engine/redirect.php?url=http://cialis-it.icu
http://brassquintet.com/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.crown-chicago.net/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://johnpostphotography.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.byrank.org/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.dragon2-film.ru//notice.php?url=http://alprostadil-it.icu
http://yourbodyholiday.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://prettypeople.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
https://www.firstdonoharm.com/exit.asp?url=http://augmentin-it.icu
http://peugeot-103.de/forum/redir.php?url=http://azithromycine-fr.pw
http://www.acuitysucks.biz/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://omegavitamins.net/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://facilities-log.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://thecatholicchannel.com/__media__/js/netsoltrademark.php?d=cialis-de.site
https://hmpusers.com/user/register?origin=ostomy-wound-management&origin_url=http://cialis-fr.pw
http://traffic.pattydoo.de/?go=http://cialis-fr.site
http://appyet.com/handler/disqus.ashx?guid=713ae0d41568487bb47b9d09585fe482&id=45fee95b8971b2435e0570d007b5f281&locale=ar&shortname=aqoal&title=&type=1&url=http://cialis-it.icu
http://frienddo.com/out.php?url=http://cialis-it.site
http://www.arcadepod.com/games/gamemenu.php?id=2027&name=idiot's+delight+solitaire+games&url=http://ciprofloxacina-it.icu
http://doralpromo.info/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://incrediblepanels.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://audiompeg.de/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://vacationpreview.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.mmjames.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://pearl356.net/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://www.sentinel-partners.biz/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://www.appalachian-chic.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
https://www.douban.com/link2/?url=http://bactrim-it.site
http://www.digitalclientsolutions.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.reservoirfrogs.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://msichat.de/redir.php?url=http://cialis-fr.pw
http://hc-tambov.ru/redirect.php?to=http://cialis-fr.site
http://okc-commercial.com/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://beverlyhills3d.de/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.sanantoniochamberofcommerce.net/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://m.sanfordrestaurant.com/site/mobile?url=http://ciprofloxacin-it.icu
http://www.healthypregnancy.net/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.lyons-consulting-group.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://stolica-energo.ru/bitrix/rk.php?goto=http://ampicillina-it.icu
http://www.fuse3.net/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://mjh.funtown.com.hk/mobile_payment/phon_popup.php?HTTP_HOST=http://augmentin-it.icu
http://stavcenter.ru/bitrix/rk.php?goto=http://azithromycine-fr.pw
http://www.68comebackspecial.org/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.justparts.com/auto_parts/99-00-01-02-quest-starter-motor/22416640?backtourl=http://bactrim-it.site
http://www.rentalexpo.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.gtceurope.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://securitycamera007.com.plxn.wo.lt/redirect.php?url=http://ampicillina-it.icu
http://cbr650f.com/go.php?url=http://antibiotico-it.icu
http://www.hotgoo.com/out.php?url=http://augmentin-it.icu
http://nonuclearpower.biz/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://liquidemotion.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.reason101.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://chinatoursusa.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.openwindows.org/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.sunlightmktg.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://joyforster.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.deltacore.us/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.labluecross.com/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.ceonline.org/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.runlikeagirl.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
You really make it seem so easy with your presentation but I
find this topic to be actually something which I think I would never understand.
It seems too complicated and extremely broad for
me. I’m looking forward for your next post, I will try
to get the hang of it!
https://www.transtats.bts.gov/exit.asp?url=http://alprostadil-fr.site
http://quepaosa.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://www.sjcsvc.org/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.tambovsport.ru/redirect.php?to=http://antibiotico-it.icu
https://old.fishki.net/go/?url=http://augmentin-it.icu
http://www.beverageequipment.biz/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://rct.conicit.go.cr/index.php?a=colbeck+capital
http://www.hawaiisurvey.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://visiouniversity.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.roadsidewonders.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.infotiger.com/addurl.html?url=http://cialis-fr.pw
http://www.fiduciary-trust.net/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://academyartuniversitystudent.net/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://vision2020.us/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.webraketa.ru/bitrix/rk.php?goto=http://ciprofloxacina-it.icu
http://danieljaffe.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://musicmaker.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.wireruns.com/cgi-bin/ydclinks/out.cgi?id=60&sendto=http://alprostadil-it.icu
http://www.8holding.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.consultantlink.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://reininghorsebuildings.net/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://timkenpartnership.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://dwblock.org/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://themagicmakers.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://infomanuales.net/_inicio/marco.asp?dir=http://cefuroxime-fr.pw
http://hammondscpa.com/__media__/js/netsoltrademark.php?d=cialis-de.site:/
http://deargeek.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://peterblum.com/releasenotes.aspx?returnurl=http://cialis-fr.site
http://www.fleshlight.la/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://upperscore.org/__media__/js/netsoltrademark.php?d=cialis-it.site
http://trackmyteen.com/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://kaminskyputala.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.jerryshort.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://fundacentro.gov.br/conteudo-super-link?url=http://alprostadil-it.icu
http://www.philipzepter.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.elvisarchives.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
https://fotka.com/link.php?u=http://augmentin-it.icu
http://www.educateboys.net/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://www.ence.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://redprivada.net/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://bazardelmercado.net/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://moneyreview.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://yxxxxxxy.tuna.be/exlink.php?url=http://cialis-fr.pw
http://unionbancaireprivee.net/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.territorioscuola.com/tsodp/go2.php?url=http://cialis-it.icu
http://www.pdxconstruction.com/__media__/js/netsoltrademark.php?d=cialis-it.site
http://unionbancaireprivee.net/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.ultrabig.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.b2bthinktank.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://avalonadvancedmaterials.com/outurl.php?url=http://alprostadil-it.icu
http://www.poetmuseum.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://dreampossible.org/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.adsimoving.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://detailcustomhomes.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://designerbathkitchen.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://42line.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://themagicmakers.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.worshipresources.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://maps.google.gy/url?q=http://cialis-fr.pw
http://images.google.com.au/url?source=imgres&ct=img&q=http://cialis-fr.site
http://jackiechalkley.com/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.sheltersucks.com/__media__/js/netsoltrademark.php?d=cialis-it.site
http://withoutattitude.com/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://weichertfinancialplanning.org/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://m.ironaffinity.com/?url=http://alprostadil-fr.site
https://djsound.ru/bitrix/rk.php?goto=http://alprostadil-it.icu
http://clickonlinepharmacy.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://general-levitation.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.e-dach.com.ua/go/?fid=587&url=http://augmentin-it.icu
http://www.videolinkondemand.net/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://cornpuff.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
https://www.jambase.com/welcome?ref=http://bactrim-it.site
http://www.badforgood.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.nowdeath.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://www.lg.al-jassim.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.systranlinks.com/trans?systran_lp=en_it&systran_url=http://antibiotico-it.icu
http://content.sanfteam.ru/engine/link.php?url=http://augmentin-it.icu
http://www.dereferer.org/?http://azithromycine-fr.pw
http://www.pandimensions.net/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.newyorksitehost.com/cgi-bin/ydclinks/out.cgi?id=500&sendto=http://bactrim-it.site
http://arcaman.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://curbyourenthusiasm.de/__media__/js/netsoltrademark.php?d=cialis-de.site
http://transfer-talk.herokuapp.com/l?l=http://cialis-fr.pw
http://www.haitaopd.com/go?url=http://cialis-fr.site
http://www.ruth-moschner-fanclub.de/link.php?url=http://cialis-it.icu
http://demosystem-business-server.intra2net.com/arnie?form=redirect&url=http://cialis-it.site
http://www.google.sc/url?q=http://ciprofloxacina-it.icu
http://www.diamondven.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.calculustutoring.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://chris3.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://images.google.ru/url?q=http://ampicillina-it.icu
http://decisionanalyst.biz/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://jwarchitects.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://www.wajda.net/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://www.bikramyoga-berkeley.net/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://koi.com.my/cgi-bin/koiforum/gforum.cgi?url=http://bactrim-it.site
Hеllo! I’ll tell you my methоd with аll thе detаils, as I startеd еаrning in the Internet from $ 3,500 реr day with thе help оf sociаl nеtwоrks reddit аnd twitter. In this video уou will find mоrе dеtailed infоrmаtion and alsо sеe hоw many millions hаve eаrnеd those who have bеen working for a уеar using my methоd. I spесifiсаlly mаdе а vidео in this capасity. After buying my mеthоd, you will understand why: http://www.info-az.net/search/rank.cgi?mode=link&id=675&url=https%3A//vk.cc/8jfmy3
http://www.clubcard.tv/redirect.aspx?destination=http://alprostadil-fr.site
http://johnpearsestrings.info/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://northernplainsinvestment.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://images.google.as/url?q=http://antibiotico-it.icu
http://www.safe-r-brakes.net/__media__/js/netsoltrademark.php?d=augmentin-it.icu
https://image.google.sh/url?q=http://azithromycine-fr.pw
http://www.halfpriceink.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://playground.org/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://arcade-fun-board.pcip.de/redir.php?url=http://cefuroxime-fr.pw
http://www.stuartwestwater.net/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.wideworldofwateringholes.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://dixieflicks.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://prospectiva.eu/blog/181?url=http://cialis-it.icu
http://www.major-depression-psychosis.net/__media__/js/netsoltrademark.php?d=cialis-it.site
http://bcbsri.net/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://gorod-lipeck.ru/widgets/outside/?url=http://ciprofloxacin-it.icu
http://www.aimretirement.biz/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.caapersonalappearances.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://www.burstek.com/RedirectPage.php?reason=4&value=Anonymizers&proctoblocktimeout=1&ip=89.78.118.181&url=http://ampicillina-it.icu
http://diversityroi.org/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.volokolamsk-rayon.ru/bitrix/rk.php?goto=http://augmentin-it.icu
http://maps.google.ms/url?q=http://azithromycine-fr.pw
http://www.omalco.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.tivolitheatre.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://www.google-health.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://brainhealth.com/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://www.susanbell.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://www.businessdatainc.biz/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.parenteducation.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://copyscape.com/view.php?o=83525&u=http://azithromycine-fr.pw
http://bloodblackandblue.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.cinephile.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://www.macesecuritycenter.net/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.systranlinks.com/trans?systran_lp=en_it&systran_url=http://cialis-de.site
http://www.letstalkaboutit.net/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://www.organicprocess.net/__media__/js/netsoltrademark.php?d=cialis-fr.site
https://fotka.com/link.php?u=http://cialis-it.icu
http://abandapart.com/__media__/js/netsoltrademark.php?d=cialis-it.site
http://dsidevelopment.org/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://linkanalyse.durad.de/?ext_url=http://ciprofloxacin-it.icu
http://www.hwk.ru/bitrix/rk.php?goto=http://alprostadil-fr.site
http://www.blackandveatch.biz/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://www.morningadvocate.com/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://velocifly.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.frenchfs.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://www.powersourcebattery.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://www.danielphilips.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.emptynestermagazine.net/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://www.med.uz/bitrix/rk.php?goto=http://cefuroxime-fr.pw
http://www.traditionsalive.ca/redirect.aspx?destination=http://cialis-de.site
http://www.sacredvoid.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://edges.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.schoolofrockonline.com/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://images.google.com.my/url?q=http://cialis-it.site
http://www.izmail-tour.com/engine/redirect.php?url=http://ciprofloxacina-it.icu
http://www.ceres21.org/activities/25/aftermath-of-oslo-sustainability-summit-(oss)-2011.aspx?returnurl=http://ciprofloxacin-it.icu
http://fishland.wsd.jp/prod..?a=generator+do+lords+mobile
http://www.carl-heinz.de/index.php?site=go&link=alprostadil-it.icu
http://www.atoall.com/2/m/e.asp?id=ampicillina-it.icu
http://industrialcleaningmanagement.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.highdefinitionhearing.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://directsellernetwork.biz/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://www.waynecooper.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://www.360bbk.com/service/go.aspx?page=static&id=0&url=http://bactrim-it.site
http://www.justchairsandtables.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.magazin01.ru/bitrix/redirect.php?event1=m01_download&event2=price_7&goto=http://alprostadil-it.icu
http://www.alabamacreditunionsucks.net/__media__/js/netsoltrademark.php?d=ampicillina-it.icu
http://northstarshoes.com/europe/out.php?url=http://antibiotico-it.icu
http://www.infostage.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://whaat.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://www.olympicteam.com/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://barebuttbath.com/__media__/js/netsoltrademark.php?d=bactrim-it.site
http://www.hivresearcher.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://rockclimbing.com/cgi-bin/forum/gforum.cgi?url=http://cialis-de.site
http://emptv.com/link-creator?url=http://cialis-fr.pw
http://www.floridahorsepark.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.hlhz.info/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.google.co.mz/url?sa=t&rct=j&q=&esrc=s&source=web&cd=8&cad=rja&sqi=2&ved=0cgkqfjah&url=http://cialis-it.site
http://www.magazin01.ru/bitrix/redirect.php?event1=m01_download&event2=price_7&goto=http://ciprofloxacina-it.icu
http://denverlightrail.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.faqengine.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.saratogian.biz/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://91.121.34.165/pub.php?keologin=gd3m&pkeourl=http://ampicillina-it.icu
http://www.dairy-food.com/__media__/js/netsoltrademark.php?d=antibiotico-it.icu
http://www.bellsystem.net/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://killerbug.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
http://earinfection.org/__media__/js/netsoltrademark.php?d=bactrim-fr.site
http://webmaster95.ru/bitrix/rk.php?goto=http://bactrim-it.site
http://tubethenew.com/__media__/js/netsoltrademark.php?d=alprostadil-fr.site
http://www.perinibuildingcompany.net/__media__/js/netsoltrademark.php?d=alprostadil-it.icu
http://www.google.ru/url?sa=t&rct=j&q=&esrc=s&source=web&cd=168&ved=0ahukewjaxogov4jzahuimgmkha2tbio4oaeqfghrmac&url=http://ampicillina-it.icu
http://www.dsl.sk/article_forum.php?action=reply&forum=255549&entry_id=147673&url=http://antibiotico-it.icu
http://worldbikepaths.com/__media__/js/netsoltrademark.php?d=augmentin-it.icu
http://www.superbabe2000.com/__media__/js/netsoltrademark.php?d=azithromycine-fr.pw
https://www.google.gl/url?q=http://bactrim-fr.site
https://www.domainsherpa.com/share.php?site=http://bactrim-it.site
Woah! I’m really enjoying the template/theme of thks blog.
It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance”
between superb usability and visual appearance.
I must say you have done a amazing job with this.
In addition, the blog loads super quick for me on Internet explorer.
Outstanding Blog!
http://forum.ssa.ru/away.php?s=http://cefuroxime-fr.pw
http://mmgroup.net/__media__/js/netsoltrademark.php?d=cialis-de.site
http://lnovodstvo.ru/catalog/?site=cialis-fr.pw
http://www.quickstudycharts.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://redirect.me/?http://cialis-it.icu
http://www.redstoneagency.net/__media__/js/netsoltrademark.php?d=cialis-it.site
https://www.otimbi.com/open.php?url=http://ciprofloxacina-it.icu
http://games.forumforever.com/report-violation.php?url=http://ciprofloxacin-it.icu
http://onetouchasia.com/sg/en/exit.php?url=http://kamagra-fr.pw
http://nationalfootballmuseuminc.org/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://designchange.org/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.automotive-cables.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://umasshousing.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://timemapper.okfnlabs.org/view?url=http://potenzmittel-rezeptfrei.site
http://images.google.com.br/url?source=imgres&ct=img&q=http://sildenafil-de.site
http://uniquefuture.net/__media__/js/netsoltrademark.php?d=viagra-de.site
http://silvija.wip.lt/redirect.php?url=http://cefuroxime-fr.pw
http://pitchme.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://queermafia.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://tollygirls.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://bespecd.com.au/test-vars.php?a=kratom;+<a+href=http://cialis-it.icu
http://www.domzba3esenem.com.plxn.wo.lt/redirect.php?url=http://cialis-it.site
http://www.handmadeinireland.com/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.polywater.org/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.cawatchablewildlife.org/listagencysites.php?a=national+audubon+society&u=http://kamagra-fr.pw
http://jesus-tv.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://cityofcashmere.org/redirect.aspx?url=http://levofloxacina-it.icu
http://www.studiomassaro.net/popup.asp?foto=public/sponsor/magda%20copia.jpg&link=levofloxacine-fr.pw
http://www.towerhealth.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://www.cleaningconnection.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://ottoamllc.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.bel-asia-hk.net/__media__/js/netsoltrademark.php?d=viagra-de.site
http://southernenergy.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://engelcosmetology.kiev.ua/go.php?url=http://kamagra-it.icu
http://www.leichte.info/verlinken.php?Url=http://levofloxacina-it.icu
http://yourlovetrulymatters.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://toomanaghy.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://johndiaz.net/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://movipoint.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://cupofjoe.com/__media__/js/netsoltrademark.php?d=viagra-de.site
https://www.pressebox.de/login?username=“/><a+href="http://cefuroxime-fr.pw
http://www.atlastower.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.playercharities.net/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://www.shin-matsudo.com/cgi_bin/shop/jump.cgi?url=http://cialis-fr.site
http://www.supadsl.net/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.thebestofthebest.biz/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.duquettecommunications.com/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://volvoonline.ru/bitrix/redirect.php?event1=&event2=&event3=&goto=http://ciprofloxacin-it.icu
http://jernia.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://lossofsmell.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://friendica.dunkelangst.org/profile/dunkelangst?zrl=http://levofloxacina-it.icu
http://notbig.ru/engine/redirect.php?url=http://levofloxacine-fr.pw
http://www.teamsterslocal120.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://drplain.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://educatedproxy.net/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.google.ac/url?sa=t&rct=j&q=salehoo&source=web&cd=20&cad=rja&uact=8&ved=0cfyqfjajoao&url=http://viagra-de.site
http://imagez.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://www.usamembership.com/__media__/js/netsoltrademark.php?d=cialis-de.site
https://duniartips.com/report?subject=http://cialis-fr.pw
http://www.munione.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://www.safearea.com/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://m.webmail.karpfen-spezial.de/redir.php?url=http://cialis-it.site
http://www.gailsgallery.net/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.appdna.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://www.ex-tour.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.cinemasdelux.biz/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://www.amateurpin.com/ap_network.php?l=de&u=http://levofloxacina-it.icu
http://www.promujer.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://www.makebro.com/modules/wordpress/wp-ktai.php?view=redir&url=http://metronidazole-fr.pw
https://forum.keenswh.com/proxy.php?link=http://potenzmittel-rezeptfrei.site
http://www.ubs-hainer.com/de/wp-content/plugins/wp-js-external-link-info/redirect.php?blog=ubs+hainer&url=http://sildenafil-de.site
http://www.incafe.ru/search.php?search_text=<a+href=http://viagra-de.site
http://www.ramjet.biz/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.afspraakjes.be/clickout/?url=http://kamagra-it.icu
http://www.multiple-listings.net/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://maps.google.ru/url?q=http://levofloxacine-fr.pw
http://www.californiacapitalfunding.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://www.gotcha-marine-insurance-fraud-ed-geary.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://www.telf-online.com/general/link.asp?link=http://sildenafil-de.site
https://capitalfinancialgroupinc.com/offsite/?url=http://viagra-de.site
http://urban-offroad.net/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://midpenncomputers.com/__media__/js/netsoltrademark.php?d=cialis-de.site
http://sexytube.com/external_link/?url=http://cialis-fr.pw
http://web-site-guarantee.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://sexletters.com/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.easycont.net/index.php?e=curl_error&return=http://cialis-it.site
http://www.google.com.vn/url?sa=t&rct=j&q='check+and+repair+refrigerator+compressor'+'pdf'&source=web&cd=17&ved=0CE8QFjAGOAo&url=http://ciprofloxacina-it.icu
http://www.brinkshomesecuritysystems.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-it.icu
http://zakowski.us/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.encyclopedia.ru/bitrix/redirect.php?event1=news_out&event2=&event3=&goto=http://kamagra-it.icu
http://yourflatworld.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.lamariteestateslate.net/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://go.sepid-dl.ir/index.php?url=http://metronidazole-fr.pw
http://www.kellerwilliams-porterranch.net/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://www.moneyclub.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.villacapriani.com/redirect.aspx?destination=http://viagra-de.site
http://www.badboyworldwide.com/__media__/js/netsoltrademark.php?d=cefuroxime-fr.pw
http://apps.tornika.com/indexinter.php?appid=1&url=http://cialis-de.site
http://setextbrowser.zomdir.com/page.htm?location=http://cialis-fr.pw
http://www.japangirl.us/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://dewmax.com/__media__/js/netsoltrademark.php?d=cialis-it.icu
http://www.jopics4u.com/gb/screen.php?tcerider=cialis-it.site
https://webketoan.com/redirect.php?http://ciprofloxacina-it.icu
https://webketoan.com/redirect.php?http://ciprofloxacin-it.icu
http://www.quintadaslagrimas.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.addesktop.net/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://boards.fool.com/profileinterview.asp?uid=2032579971&returnurl=http://levofloxacina-it.icu
http://www.clearingandsettle.biz/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://www.harpersbazaarmediakit.com/r5/emaillink.asp?link=http://metronidazole-fr.pw
http://www.luxurymink.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://wwe-rpg.level52.com/report-violation.php?url=http://sildenafil-de.site
http://www.divadrops.com/__media__/js/netsoltrademark.php?d=viagra-de.site
https://100kursov.com/away/?url=http://cefuroxime-fr.pw
http://temporarymail.net/__media__/js/netsoltrademark.php?d=cialis-de.site
http://www.jimsfamilyrestaurants.com/__media__/js/netsoltrademark.php?d=cialis-fr.pw
http://hardcoreharrys.com/__media__/js/netsoltrademark.php?d=cialis-fr.site
http://f1.paddocknews.com/goto.php?goto=http://cialis-it.icu
http://germanyproperties.net/__media__/js/netsoltrademark.php?d=cialis-it.site
http://www.thecorrectemplate.com/__media__/js/netsoltrademark.php?d=ciprofloxacina-it.icu
http://www.luxbuy.com/shop.php?id=100001&domain=ciprofloxacin-it.icu
http://quadrapoint.org/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://geduldtrading.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://maps.google.ki/url?q=http://levofloxacina-it.icu
http://la-ligue-venitienne.xoo.it/report-violation.php?url=http://levofloxacine-fr.pw
http://www.buildingselectcustom.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://guidancedirector.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://images.google.hu/url?q=http://sildenafil-de.site
http://www.ptarmigan.org/__media__/js/netsoltrademark.php?d=viagra-de.site
http://www.4think.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.cindabella.com.au/redirect.aspx?destination=http://kamagra-it.icu
http://www.collegegolf.biz/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.why-pay-more.biz/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://www.toshiki.net/x/modules/wordpress/wp-ktai.php?view=redir&url=http://metronidazole-fr.pw
http://servizi.unionesarda.it/ssl/accountadmin.aspx?returnurl=http://potenzmittel-rezeptfrei.site
http://maps.google.com.bd/url?q=http://sildenafil-de.site
http://mischa.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://omi-beam.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://images.google.az/url?q=http://kamagra-it.icu
http://www.kaimaluhawaii.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.beta3.net/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://ilrdss.sws.uiuc.edu/fox/fox_pubs_results.asp?strsearch=<a+href="http://metronidazole-fr.pw
http://buscador.redee.com/comentar.php?paginae=potenzmittel-rezeptfrei.site
http://www.chdeli.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.jkvanlines.net/__media__/js/netsoltrademark.php?d=viagra-de.site
http://maps.google.de/url?q=http://kamagra-fr.pw
http://naturalsapphires.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://wanwanryu.tuna.be/exlink.php?url=http://levofloxacina-it.icu
http://xcufinancial.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://tueurs-de-barbares.bestoof.com/report-violation.php?url=http://metronidazole-fr.pw
http://unibersidad.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://eaglesmusic.eu/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://nonuclearpower.org/__media__/js/netsoltrademark.php?d=viagra-de.site
http://creativeofficespace.am/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.koloboklinks.com/site?url=viagra-it.icu
http://sparbote.de/2/?url=http://viagra-it.site
http://www.cptechjax.net/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://quitonce.org/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.aiwaclinic.lv/bitrix/rk.php?id=114&site_id=aw&event1=banner&event2=click&event3=22+/+14%5D+banner_3%5D+check+up+en&goto=http://zoloft-it.site
http://emmabell.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://hotelsaccommodation.com.au/centralsite/redirect.asp?dest=http://ampicillin-de.xyz
http://www.organicchemistryonline.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://paranoid.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu?
http://www.internshipabroad.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://nonuclearpower.biz/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://www.tlz.de/blogs/auf-sendung/-/blogs/unrechtsstaat-zu-verkaufen?_33_redirect=http://metronidazole-fr.pw
http://drakonas.wip.lt/redirect.php?url=http://potenzmittel-rezeptfrei.site
http://onimura-ninja-school.xooit.com/report-violation.php?url=http://sildenafil-de.site
http://disasterinformation.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://www.legapro.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.thebodyworks.biz/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.hotuna.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://nagelusa.us/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.homemaintenanceplus.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://hapok.ru/link?url=http://zoloft-it.site
http://www.greatlakemusiccamps.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://hawaiitube.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://realtystockreview.net/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.mo-info.de/redirect.aspx?url=http://kamagra-it.icu
http://jplayer-generator.live-streams.nl/index.php?filename=29843792.jpg&stationurl=http://levofloxacina-it.icu
http://mamulchik.ru/forum/away.php?s=http://levofloxacine-fr.pw
http://www.fa-cuptv.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://www.maultalk.com/go.php?http://potenzmittel-rezeptfrei.site
http://onehundredayear.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.thedead.net/__media__/js/netsoltrademark.php?d=viagra-de.site
http://dollarbank.de/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://images.google.com.uy/url?q=http://kamagra-it.icu
http://www.craigrice.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://maps.google.be/url?q=http://levofloxacine-fr.pw
http://nutritionaltherapeutix.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://overwatchfun.com/forum/away.php?s=http://potenzmittel-rezeptfrei.site
http://www.toughoneproducts.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://westakfish.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://www.internationaltrophy.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.babegirl.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.test-service.co.jp/modules/wordpress/wp-ktai.php?view=redir&url=http://viagra-it.site
http://www.legalhyena.net/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.lafashions.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.trainofthought.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.surveyalaska.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://letstoast.net/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://outtalimits.us/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.j-a-net.jp/top/redirect?url=http://kamagra-it.icu
http://veronawalksales.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.3751chat.com/JumpUrl/?url=http://levofloxacine-fr.pw
http://support.crystaldecisons.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://kalvimalar.dinamalar.com/tamil/emailtofriend.asp?url=potenzmittel-rezeptfrei.site
http://com.assetline.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.carmags.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://onedegreecreative.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.okpodiatrists.org/external-link?url=http://viagra-it.icu
http://www.designersdirect.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://legionoasis.com/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.metone.eu/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.lefthandnetwork.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.silversteer.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://prorepair.org/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.smartspecs.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.tango-hayakawa.net/modules/wordpress/wp-ktai.php?view=redir&url=http://kamagra-it.icu
http://m.mastergrowers.com/?url=http://levofloxacina-it.icu
http://www.peugeot-103.de/forum/redir.php?url=http://levofloxacine-fr.pw
http://www.harleminternalmedicine.org/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://wetoskapackaging.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://asa24.ru/bitrix/rk.php?goto=http://sildenafil-de.site
http://buyone.in/index.php?route=extension/module/price_comparison_store/redirect&url=http://viagra-de.site
http://www.thegpsstore.net/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.erashare.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.rabbimichael.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://www.fleet-service.ru/bitrix/rk.php?goto=http://zithromax-fr.pw
http://nysales.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://windowsmoviemaker.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.rocket-ebooks.net/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.peoplestrustcreditunion.org/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://ievaporate.de/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://noreferer.win/?http://kamagra-it.icu
http://www.gangdeals.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://mobucks.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://www.hoaghealth.org/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://chat.4ixa.ru/index.php?url=potenzmittel-rezeptfrei.site
http://www.ipnetworksolutions.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://www.skinboutique.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://toshiki.net/x/modules/wordpress/wp-ktai.php?view=redir&url=http://viagra-fr.site
http://kinoradiomagia.tv/forum/away.php?s=http://viagra-it.icu
http://nys-departmentofhealth.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://savingcashback.com/aff?url=http://zithromax-fr.pw
http://www.quotecv.net/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://zeus-technology.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://ntlgroup.org/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.integrityonline10.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.pointography.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://unclebobscooking.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://nprinsider.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://maville.aweb4u.info/lirelasuite.php?url=http://levofloxacine-fr.pw
http://www.dosanddonts.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://www.andana.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://www.bcs-urec.ru/bitrix/rk.php?goto=http://sildenafil-de.site
http://www.inbryansk.ru/chat/go.php?url=http://viagra-de.site
http://surroundhealth.net/topics/surroundhealth-members-lounge/webinars/archived-webinars/archive-of-webinar-mhealth-using-mobile-technology.aspx?returnurl=http://viagra-fr.site
http://www.abusealert.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.diicca.org/__media__/js/netsoltrademark.php?d=viagra-it.site
http://www.google.co.vi/url?q=http://zithromax-fr.pw
http://jpaul.net/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://mashinarius.ru/bitrix/rk.php?goto=http://zoloft-it.site
http://jonbrady.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.fundservices.net/perl/adbanners/zone_full.pl?country=default&showads=1&url=http://ampicillin-de.xyz
http://www.rentalexpo.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://jugtownpottery.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://swefog.co.uk/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.hubbardfinancial.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://strawberring.ru/exki/?site=metronidazole-fr.pw
http://lab.johnwai.co.uk/juicing/?url=http://potenzmittel-rezeptfrei.site
http://www.easycont.net/index.php?e=curl_error&return=http://sildenafil-de.site
http://oxresearch.info/__media__/js/netsoltrademark.php?d=viagra-de.site
http://www.ebaskin.biz/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://newsocietyfund.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://pr-cy.ru/jump/?url=http://levofloxacina-it.icu
http://radarpartners.net/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://naturalfashion.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://dairyprotect.net/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://new.mtas.ru/bitrix/rk.php?goto=http://sildenafil-de.site
http://jtheta.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://www.klient.by/go.php?url=viagra-fr.site
https://www.accessmeproxy.com/index.php?e=invalid_url&return=http://viagra-it.icu
http://maps.google.gr/url?q=http://viagra-it.site
http://vectroproxy.com/index.php?e=curl_error&return=http://zithromax-fr.pw
http://www.studying.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://dashspecialists.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.funshop.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.altbin.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.2ndgenerationvehicles.biz/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://judeofascism.com/__media__/js/netsoltrademark.php?d=kamagra-it.icu
http://oha-d.com/w3a/redirect.php?redirect=http://levofloxacina-it.icu
http://www.allancross.net/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://mx1.cookinghistory-thefilm.com/redirect/redirect.php?url=http://metronidazole-fr.pw
http://hnefatafl.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://survivors.lolforum.com/report-violation.php?url=http://sildenafil-de.site
https://portamur.ru/bitrix/rk.php?goto=http://viagra-de.site
http://www.xlsteel.biz/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://livedocs.nanwm.com/__media__/js/netsoltrademark.php?d=viagra-it.icu – adobe
http://wasted-potential.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://www.worldextremecagefighting.biz/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://bransonwhiteriveroutpost.biz/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.amgpromo.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://bulcar.ru/bitrix/rk.php?goto=http://amoxicillin-de.xyz
http://toothandclaw.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://en.skyrock.com/r?url=http://kamagra-fr.pw
http://www.harpersbazaarmediakit.com/r5/emaillink.asp?link=http://kamagra-it.icu
http://darklathe.com/__media__/js/netsoltrademark.php?d=levofloxacina-it.icu
http://www.rentatv.com/__media__/js/netsoltrademark.php?d=levofloxacine-fr.pw
http://www.southafricaconferencebureau.com/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://patriciashort.com/__media__/js/netsoltrademark.php?d=potenzmittel-rezeptfrei.site
http://www.ferrousexchange.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://saefc.com/__media__/js/netsoltrademark.php?d=viagra-de.site
http://www.centerpointtx.biz/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.realtimelogistics.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://charitycanada.net/__media__/js/netsoltrademark.php?d=viagra-it.site
http://resart.ru/bitrix/rk.php?goto=http://zithromax-fr.pw
http://www.chemie-abc.de/kontakt/related.php?link=zoloft-fr.site
http://novascotiabirds.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.google.com.do/url?sa=t&rct=j&q=&esrc=s&source=web&cd=14&cad=rja&uact=8&ved=0cdeqfjadoao&url=http://amoxicillin-de.xyz
http://www.lesite3ei.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://inflationtarget.com/__media__/js/netsoltrademark.php?d=kamagra-fr.pw
http://www.hfpinsurance.biz/__media__/js/netsoltrademark.php?d=kamagra-it.icu
https://sierravistachildandfamily.asureforce.net/redirect.aspx?redirecturl=http://levofloxacina-it.icu
http://asa24.ru/bitrix/rk.php?goto=http://levofloxacine-fr.pw
http://chicagonewsgroup.biz/__media__/js/netsoltrademark.php?d=metronidazole-fr.pw
http://mco21.ru/bitrix/rk.php?goto=http://potenzmittel-rezeptfrei.site
http://golee.com/__media__/js/netsoltrademark.php?d=sildenafil-de.site
http://website500k.biz/redirect/?url=http://viagra-de.site
http://www.alhurrairaq.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.virginiafinehomes.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://kurtzfinancialguide.com/massmutualspecific/generalredirect.asp?url=http://viagra-it.site
http://wninsurance.info/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.monplawiki.com/link.php?url=http://zoloft-fr.site
http://cwa4100.org/uebimiau/redir.php?http://zoloft-it.site
http://www.myfirstadvantagebank.biz/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.foundadog.net/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.test-service.co.jp/modules/wordpress/wp-ktai.php?view=redir&url=http://viagra-fr.site
http://betterthantv.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.google.sh/url?q=http://viagra-it.site
http://www.aroma-relax.com/602/w3a/redirect.php?redirect=http://zithromax-fr.pw
http://www.cs.odu.edu/~mln/teaching/cs595-s12/?method=display&redirect=http://zoloft-fr.site
http://uthemes.ru/url/?go=http://zoloft-it.site
https://www.kikuya-rental.com/bbs/jump.php?url=http://amoxicillin-de.xyz
http://carroll-law.net/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.broadhollow.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://novemberfifthproductions.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://images.google.com.mm/url?q=http://viagra-it.site
http://www.e-douguya.com/cgi-bin/mbbs/link.cgi?url=http://zithromax-fr.pw
http://www.reliablecastings.biz/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.cyprusedirectory.com/gg.aspx?id=http://zoloft-it.site
http://www.e-zfiling.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.renaissance-strategic-advisors.us/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.judith-davison.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.canadianherbandspice.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.garantia.tv/bitrix/rk.php?goto=http://viagra-it.site
http://www.dirtysoaps.com/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.fileconductor.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.olimpoks.ru/bitrix/rk.php?goto=http://zoloft-it.site
http://www.ask-oxford.org/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://vb.uiraqi.com/redirector.php?url=http://ampicillin-de.xyz
http://nissanuniversity.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://upandadam.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.rompbucks.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.iberosur.be/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
https://www.pcgs.com/store/login.aspx?returnurl=http://ciprofloxacin-de.space
http://www.leevalve.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://go.vahabonline.ir/index.php?url=http://clindamycin-de.space
http://dstart.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://sacred-slaves.com/board/redir.php?url=http://viagra-it.icu
http://webmd2ndopinion.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://co2alternative.org/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://newyorkbreadexpress.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
https://passport.linkonlineworld.com/ForgotPassword.aspx?Culture=en-US&ReturnURL=http://zoloft-it.site
http://www.expertoptimization.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz.
https://images.google.com.lb/url?q=http://ampicillin-de.xyz
http://ibbs.ci123.com/notlogin.php?backurl=http://atorvastatin-de.website
http://www.domob.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.blaue.ostarrichi.org/external.html?link=http://cialis-de.website
http://rodeo.to/media/link/redirect.php?url=http://cialis-fi.svenskepiller.com
http://www.spsi.biz/redirect.aspx?destination=http://ciprofloxacin-de.space
http://www.swapcity.net/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://double-handed.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.kittyhawknc.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.telatrain.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://hamtwp.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://daddyoshomemade.com/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.eu-nn.net/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.bilgineferi.com/forum/url.asp?url=http://zoloft-it.site
http://highereducationfinance.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://musart.org/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.1stepsolutions.biz/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.brooklyn-bridge.net/__media__/js/netsoltrademark.php?d=azithromycin-de.website
https://planning.dot.gov/pageredirect.asp?redirectedurl=http://cialis-de.website
http://www.gembuddha.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://clashofclans.forumdesfans.com/report-violation.php?url=http://ciprofloxacin-de.space
http://ww35.arcticcircletradingpost.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://gorod-orel.ru/widgets/outside/?url=http://clindamycin-de.space
http://www.sierrausa.de/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.gamegirlstv.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
https://images.google.com.ly/url?q=http://viagra-it.site
http://investorsinarabia.com/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.siliconvilla.net/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://mailmarketing.cofunds.co.uk/x/pdfredirect.asp?url=http://zoloft-it.site
http://wealthmanagementsystems.net/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.brushcreekpartners.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.www0.7ba.info/out.php?url=http://atorvastatin-de.website
http://crossmath.net/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.kenosha-scionsucks.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.vegastips.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://dfpfoundationproducts.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://wholesaleradiators.biz/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://docsilverstein.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://en.skyrock.com/r?url=http://atorvastatin-de.website
http://www.roamsweethome.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.electrohardware.net/__media__/js/netsoltrademark.php?d=cialis-de.website
http://assemble.us/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://ageofknowledge.cn/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
https://forum.keenswh.com/proxy.php?link=http://clarithromycin-de.space
http://shadeed.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://wspdropship.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.beachesquest.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://darknlovely.com/__media__/js/netsoltrademark.php?d=viagra-it.site
https://csefcu.org/redirect.php?http://zithromax-fr.pw
http://www.orphanandys.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://labcore.de/redirect.php?link=http://zoloft-it.site
http://www.bitoltd.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://imagesecure.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.worcesterregionalmrc.org/eventdetail/15-09-04/orientation.aspx?returnurl=http://atorvastatin-de.website
http://www.yellowpa.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.devcocorp.de/__media__/js/netsoltrademark.php?d=cialis-de.website
http://poczujmieszkanie.plxn.wo.lt/redirect.php?url=http://cialis-fi.svenskepiller.com
http://euroconcrete.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://www.gardentutoronline.org/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://athleticplumbing.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.vermontfishing.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.lib.nus.edu.sg/digital/go.asp?url=http://viagra-it.icu
http://www.winifred.biz/__media__/js/netsoltrademark.php?d=viagra-it.site
http://califpso.biz/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.google.fm/url?q=http://zoloft-fr.site
http://imagreatcook.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.palmaffy.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.towereed.net/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://confidentity.us/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.sabermanagement.net/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://maps.google.com.ec/url?q=http://cialis-de.website
http://shadeed.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.macesecuritycenter.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://www.thepak.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://carteretsenior.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.laynbryant.com/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://www.basementfilms.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
https://mephi.ru/bitrix/redirect.php?event1=catalog_out&event2=2fiblock9db88180b0b0+2011.doc&goto=http://viagra-it.site
http://www.electronicboatshow.net/__media__/js/netsoltrademark.php?d=zithromax-fr.pw
http://www.al24.ru/goto.php?goto=http://zoloft-fr.site
http://arcade-fun-board.pcip.de/redir.php?url=http://zoloft-it.site
http://dancing-fiddle.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.danielgdolan.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
If some one needds to be updaated with newest technologies
afterward he must bee pay a quick visit this site and be up to date
daily.
http://www.olimpikus.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://nstld.org/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.saratogian.biz/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.munione.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://ipodprayers.org/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://am.h10.ru/test.php?a=heavy+bag
http://oneoaktree.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.tc.faa.gov/content/leaving.asp?extlink=http://viagra-fr.site
http://marocano.cforum.info/report-violation.php?url=http://viagra-it.icu
http://planetrealtor.org/__media__/js/netsoltrademark.php?d=viagra-it.site
http://www.xlr.ru/bitrix/rk.php?goto=http://zithromax-fr.pw
http://www.list-manager.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.abusealert.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://www.glorysky.ws/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.jamestowncustomhomes.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.perkinsaccounting.net/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.esp-inc.biz/__media__/js/netsoltrademark.php?d=azithromycin-de.website
https://www.transtats.bts.gov/exit.asp?url=http://cialis-de.website
http://svenvanbolt.de/topframe.php?http://cialis-fi.svenskepiller.com
http://jbcrafts.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://www.georgemag.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.topnotchtix.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
https://www.ikra.ru/bitrix/rk.php?id=25&site_id=s2&event1=banner&event2=click&event3=1+/+5%5D++rid&goto=http://viagra-fr.site
http://www.performancefab.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
https://community.asme.org/register.aspx?returnurl=http://viagra-it.site
https://www.signaturebankga.com/external-link/?url=http://zithromax-fr.pw
http://www.bridgetelecom.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.britishvirginislandspages.com/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://playes.ru/forum/away.php?s=http://amoxicillin-de.xyz
http://www.spagettibookclub.org/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://yorksite.ru/goto.php?url=http://atorvastatin-de.website
http://www.activeadulttherapy.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://hangsangbank.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://donzuckerman.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.specialtyfinanceservicinginc.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://www.faqengine.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.appsensation.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://maps.google.dz/url?q=http://viagra-fr.site
http://www.goldsave.net/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://www.getfuzzy.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://one.ahovey.4pets.es/php.php?a=home+business+plans+(you+could+try+here)
http://www.eurohockey.com/multimedia/photo/1388-2016-pan-american-tournament.html.html?url_back=http://zoloft-fr.site
https://openssource.info/redirect/?url=http://zoloft-it.site
http://www.gapinteractive.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://www.1000truefans.com/__media__/js/netsoltrademark.php?d=ampicillin-de.xyz
http://www.cinecom.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://images.google.tl/url?q=http://azithromycin-de.website
http://suddencardiacarrest.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.questionsforliving.biz/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://ihatescionkenosha.org/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://harleyranch.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.feed2js.org//feed2js.php?src=http://clindamycin-de.space
http://www.emssafetyservices.net/__media__/js/netsoltrademark.php?d=viagra-fr.site
http://napkinnipper.com/__media__/js/netsoltrademark.php?d=viagra-it.icu
http://countrybankforsavings.com/__media__/js/netsoltrademark.php?d=viagra-it.site
http://www.itanica.org/iframe.php?file=http://zithromax-fr.pw
http://corporatehigh.com/__media__/js/netsoltrademark.php?d=zoloft-fr.site
http://www.7life.org/__media__/js/netsoltrademark.php?d=zoloft-it.site
http://waterreporter.com/__media__/js/netsoltrademark.php?d=amoxicillin-de.xyz
http://maps.google.ba/url?q=http://ampicillin-de.xyz
http://www.virtualflightsurgeons.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://zero-degree.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://wireruns.com/cgi-bin/ydclinks/out.cgi?id=496&sendto=http://cialis-de.website
http://images.google.co.bw/url?q=http://cialis-fi.svenskepiller.com
http://www.grahampackaging.biz/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://b.ifindu.cn/event/out?url=http://clarithromycin-de.space
http://premiermedinsurance.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.1time.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://jmft.info/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.thepool.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.cancercoach.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.lurecoursing.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://ww2.humaxarabia.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.freecreditreport.de/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://linkuwant.com/customer_websites/customers.php?image=charlotteplumbing.com.jpg&domain=atorvastatin-de.website
http://homecamgirl.com/external_link/?url=http://azithromycin-de.website
https://hmpusers.com/user/register?origin=ostomy-wound-management&origin_url=http://cialis-de.website
http://www.aimprivateassetmgt.biz/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.citeulike.org/post_success.adp?from=http://ciprofloxacin-de.space
http://unitedschool.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://xpresstrack.eu/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://go.xscript.ir/index.php?url=http://diclofenac.svenskepiller.com
http://www.bankruptcy-notices.com/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://warpentertainment.com/__media__/js/netsoltrademark.php?d=kamagra-fi.svenskepiller.com
https://anon.to/?http://levitra.svenskepiller.com
http://www.railroadresources.com/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://www.community-net.org/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://banner19.com/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://usahotelsguide.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.ceres21.org/activities/25/aftermath-of-oslo-sustainability-summit-(oss)-2011.aspx?returnurl=http://azithromycin-de.website
http://www.pocodetodo.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.loveshop.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://okoconnell.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://wwwitch.org/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
https://techwriters.ru/bitrix/rk.php?goto=http://clindamycin-de.space
http://busanw.itfk.org/index.php?ct_id=cust_coun&sb_id=cc_view&cc_idx=807&now_page=&return_url=http://diclofenac.svenskepiller.com
http://www.managedadspc.net/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://www.pipeplugsinc.biz/__media__/js/netsoltrademark.php?d=kamagra-fi.svenskepiller.com
http://noveladventures.com/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://www.buypcb.com/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://www.editshop.com/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://www.upcyberdown.org/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://designimpact.net/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.welcomecu.org/leaving.php?url=http://azithromycin-de.website
http://www.2ndgenerationvehicles.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://naturalsapphires.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.google.co.uk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=30&cad=rja&uact=8&ved=0ahukewit3q6l9yhaahwmmbqkhzwida04fbawchawcq&url=http://ciprofloxacin-de.space
http://www.westsidemedicalgroup.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://inmancam.info/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.tourismabbotsford.ca/crmtrack.php?lid=16&url=http://cialisnnq.com
http://www.dcgreeks.com/ad_redirect.asp?url=http://cialisnorx.com
http://porn-sex-comics.com/crtr/cgi/out.cgi?u=https://cialisppq.com
https://www.siegessaeule.de/index.php?id=&url=http://cialisrpr.com
http://zingwell.com/uchome/link.php?url=https://cialisvvr.com
http://www.alphaerotic.com/movies/go.php?id=1068697_1&url=http://cialisxxl.com
When someone writes an polst he/she retaikns the idea
of a user in his/her brain that how a user can know it.
Therefore that’s why this piece of writing is outstdanding.
Thanks!
http://www.rus-helicopters.com/bitrix/rk.php?id=137&site_id=s1&goto=http://levitrarrr.com
http://www.rutadeviaje.com/librovisitas/go.php?url=http://viagrannq.com
http://www.emprestimosonline.com.br/redirect.php?url=http://viagranorx.com
http://sdcbase.stardock.com/bounce/?url=http://viagrappa.com
http://www.airtimecharters.co.uk/aircraft/modules/mod_jw_srfr/redir.php?url=http://viagrarpr.com
https://upn.ru/redirect.aspx?url=http://viagravvr.com
https://www.treuhandcampus.ch/redirect.php?action=url&goto=http://levitrarrr.com
http://www.razinskiy.com/forum/away.php?s=http://viagrannq.com
http://news.at78.cn/url.php?url=http://viagranorx.com
http://www.jboat.info/modules/mod_jw_srfr/redir.php?url=http://viagrappa.com
http://listmmorpg.com/tracker.php?do=out&id=12549
https://www.vanilar.ru/guestbook/redirect.php?url=http://viagravvr.com
http://bimbirik.uv.ro/guestbook/go.php?url=http://cialisnnq.com
http://m.shopincleveland.com/redirect.aspx?url=http://cialisnorx.com
http://u.riju.com/goto.php?url=http://cialisppq.com
https://edmullen.net/gbook/go.php?url=http://cialisrpr.com
http://www.soidea.net/link.php?url=http://cialisvvr.com
http://freenudegranny.com/cgi-bin/atc/out.cgi?id=74&u=http://cialisxxl.com
http://www.santillimarco.it/index.asp?url=http://levitrarrr.com
http://reehorst.nl/newsletter/goto.html?url=http://viagrannq.com
http://gangrapevideos.net/cgi-bin/out.cgi?id=34&l=top_top&u=http://viagranorx.com
http://www.jeanswing.com/cgi-bin/autorank/out.cgi?id=janetexp&url=http://viagrappa.com
https://grandtour-nsk.ru/bitrix/redirect.php?event1=catalog_out&event2=http://babalbahr.rixos.com/accommodation/detail/Premium-Room-Rixos-Bab-al-Bahr/111/41/0&event3=Premium+Garden+View&goto=http://viagrarpr.com
http://blog.lightingchina.com/go.asp?url=http://viagravvr.com
http://www.byqp.com/link/link.asp?id=13&url=http://cialisnnq.com
http://www.webkits.com.br/links/plasti/XcDirRedirect.asp?ID=828&url=http://cialisnorx.com
https://www.mymapblog.com/redirect.php?url=http://cialisppq.com
http://www.waixie.com/redirect.php?url=http://cialisrpr.com
http://clothing-mania.com/fcj/out.php?url=http://cialisvvr.com/
http://m-styleadeejyo.com/m/redirect.php?url=http://cialisxxl.com
http://bbs.hk-taxi.com/uhome/link.php?url=http://cialisnnq.com
http://www.prokat.zp.ua/go.php?url=http://cialisnorx.com
http://www.boxlink.net/bnrs/adclick.php?bannerid=376&zoneid=31&source=&dest=http://cialisppq.com
http://turcatalog.com/go.php?url=http://cialisrpr.com
http://www.clixgalore.com/PSale.aspx?AdID=13021&BID=125237&AfID=221993&AffDirectURL=http://cialisvvr.com
http://search.josepi.com/siteanalyzer/redirect.php?url=http://cialisxxl.com
http://www.psichologas.eu/?com=banners&act=redirect&url=http://levitrarrr.com
http://www.indianworldtrade.com/redirect.php?url=http://viagrannq.com
http://freepornomania.com/crtr/cgi/out.cgi?u=http://viagranorx.com
http://www.newlyalya.ru/go/?url=http://viagrappa.com
http://charlottedouglasintlairport.com/cgi-bin/ax.pl?http://viagrarpr.com
http://excellentpornvideos.com/cgi-bin/a2/out.cgi?id=758&u=https://viagravvr.com
http://www.luftschrauber.de/cms/?redirect&url=http://cialisnnq.com
http://www.transsexualmoviepost.com/cgi-bin/a2/out.cgi?id=41&l=toplist&u=http://cialisnorx.com
http://www.jenteporten.no/go.php?url=http://cialisppq.com
http://site.daxiansheng.org/?mod=open&id=734&url=http://cialisrpr.com
https://www.fulpy.com/products/redirect?addedby=sharath&url=http://cialisvvr.com
http://www.stoka-kiel.de/redirect.php?url=cialisxxl.com
http://websolutions.octomediacreative.com/website-review/redirect.php?url=https://levitrarrr.com
http://businesssoftwareconsulting.net/Services/Redirect.aspx?url=http://viagrannq.com
http://momporntv.net/go.php?ma=17&tu=25&re=1329&url=http://viagranorx.com
http://vkurse.ua/jump/?url=http://viagrappa.com
http://dovga.com/redirect.php?url=http://viagrarpr.com
https://www.emis.ge/bitrix/redirect.php?event1=catalog_out&event2=http://www.advertising-guide.net&event3=Advertising-Guide.net+&goto=https://viagravvr.com
http://matureperverse.com/cgi-bin/at3/out.cgi?id=583&trade=http://cialisnnq.com
http://www.interracialhall.com/cgi-bin/atx/out.cgi?id=30&trade=http://cialisnorx.com
http://www.kerry-kids.ru/bitrix/rk.php?goto=http://cialisppq.com
http://www.joannephan.com/searchpoint/redir.asp?reg_id=ptypes&sname=/searchpoint/search.asp&lid=1&sponsor=bus&url=http://cialisrpr.com
http://www.kiqia.com/link.php?url=http://cialisvvr.com
http://setofcars.com/inc/goto.php?brand=Rossion&url=http://cialisxxl.com
http://inzerce.rubikovo.name/go.php?url=http://levitrarrr.com
http://dijemi.ru/link.php?url=http://viagrannq.com
http://www.brideshow.com/tracker.asp?id=3828&url=http://viagranorx.com
http://www.totallyteenie.com/crtr/cgi/out.cgi?id=93&l=top4&u=http://viagrappa.com
http://adv.informare.it/pubblic/redir.asp?www=http://viagrarpr.com
http://kinodonor.ru/go?http://viagravvr.com/
http://goodwin-vl.ru/?goto=http://cialisnnq.com
http://cyuppa-love.net/m/redirect.php?url=http://cialisnorx.com
http://www.kost.si/include/click_counter.php?url=http://cialisppq.com
http://www.gaardebunn.com/guestbook/go.php?url=http://cialisrpr.com
http://www.webhoe.com/cgi-bin/interracial_boners/out.cgi?id=cuckuk&url=https://cialisvvr.com
http://c-antenna.net/i/redirect.php?eid=2883882&url=http://cialisxxl.com
http://www.maxpornsite.com/cgi-bin/atx/out.cgi?id=111&tag=toplist&trade=http://levitrarrr.com
http://crmsoftwaredevelopment.com/Services/Redirect.aspx?url=http://viagrannq.com
http://www.tsticn.com/redirect.aspx?url=http://viagranorx.com
http://www.travel1000places.com/_redir/goto.aspx?id=805005&goto=http://viagrappa.com
http://ashleyalden.com/guestBook/go.php?url=http://viagrarpr.com
http://www.fractal.com.ru/redir.php?link=http://viagravvr.com
http://deka.moro-mie.com/out.cgi?id=00399&url=http://cialisnnq.com
http://www.rapidcommute.net/guestbook/go.php?url=http://cialisnorx.com
http://www.twsm.cn/sns/link.php?url=https://cialisppq.com
http://qiuqian.org/home/link.php?url=https://cialisrpr.com
http://m.shopinbaltimore.com/redirect.aspx?url=http://cialisvvr.com
http://www.jizzparade.com/cgi-bin/atc/out.cgi?id=24&l=bot&u=http://cialisxxl.com
http://westconcordnews.com/Redirect.asp?WeatherSponsor=6&Linkurl=http://levitrarrr.com/
http://pavon.kz/proxy?url=http://viagrannq.com
http://www.lingerie-mania.com/movies/go.php?id=1159034_1&url=http://viagranorx.com
http://www.eastseaman.com/WebSite/Index.asp?action=go&id=14&url=http://viagrappa.com
https://medvestnik.ru/go?url=http://viagrarpr.com
https://www.chitaitekst.ru/bitrix/rk.php?id=258&event1=banner&event2=click&event3=1+%2F+%5B258%5D+%5BPK_INNER_TOP_LONG%5D+%C4%FF%E3%E8%EB%E5%E2%F1%EA%E8%E9&goto=http://viagravvr.com
http://www.mama-tempo.de/button_partnerlink/index.php?url=http://levitrarrr.com
http://forced-vids.com/cgi-bin/out.cgi?id=41&l=top_top&u=https://viagrannq.com
http://www.aerorent.net/bitrix/redirect.php?event1=&event2=&event3=&goto=http://viagranorx.com
http://www.basketbolist.org.ua/go.php?url=http://viagrappa.com
http://www.notawoman.com/cgi-bin/atx/out.cgi?id=44&tag=toplist&trade=http://viagrarpr.com
https://medagog.com/link.php?url=http://viagravvr.com
http://www.datranny.com/movies/go.php?id=970835_1&url=http://cialisnnq.com
http://zhkp-moidom.ru/?goto=http://cialisnorx.com
http://server-us.imrworldwide.com/cgi-bin/b?cg=news-clickthru&ci=us-mpr&tu=http://cialisppq.com
http://www.der-mailtausch.net/linker/jump.php?url=http://cialisrpr.com
http://www.15den.com/cgi-bin/at3/out.cgi?id=11&tag=toplist&trade=http://cialisvvr.com
http://naviking.localking.com.tw/about/redirect.aspx?mid=7&url=http://cialisxxl.com
http://svejo.bg/go.php?url=http://levitrarrr.com
http://www.temo.jp/api/rd?s=0005&a=0001&u=http://viagrannq.com
http://www.pechorskoevremya.ru/go/aHR0cDovL2dlbmVyaWNjaWFsbHMuY29tLw==
http://www.granfondonews.it/v5/gotoURL.asp?url=http://viagrappa.com
http://home.hkesp.com/link.php?url=https://viagrarpr.com
http://handywebapps.com/hwa_refer.php?url=http://viagravvr.com
http://movs3d.com/go.php?url=http://cialisnnq.com
http://india.4you.com/go.cgi?go=http://cialisnorx.com
https://nwobserver.com/Redirect.asp?UID=2752835&SubSectionID-1&AdArrayID=15&AdPosition=0&Linkurl=http://cialisppq.com
http://haustirolkaprun.members.cablelink.at/gbook/go.php?url=http://cialisrpr.com
http://www.zarrmarketing.co.uk/redirect.aspx?GUID=&URL=http://cialisvvr.com
http://www.spartakmoskva.ru/redirect.php?url=http://cialisxxl.com
http://www.dixietrailertrash.com/rank/out.cgi?id=air1&url=http://levitrarrr.com
http://www.motordays.com/externallink.php?url=http://viagrannq.com
http://www.zjyppfw.com/redirect.aspx?url=http://viagranorx.com
http://www.danardi.net/public/DinoX_Links/go.php?url=http://viagrappa.com
http://thevorheesfamily.com/gbook/go.php?url=https://viagrarpr.com
http://ref.webhostinghub.com/scripts/click.php?ref_id=nichol54&desturl=http://viagravvr.com
http://trendclub.ru/redirect?url=http://cialisnnq.com
“http://affiliate.q500.no/AffiliateSystem.aspx?p=0
http://flash.xoxohth.com/go.php?url=http://cialisppq.com
http://www.vietnamsingle.com/vn/banners/redirect.asp?url=http://cialisrpr.com/
http://loonbedrijfgddevries.nl/page/gastenboek2/go.php?url=http://cialisvvr.com
http://4tubehq.com/cgi-bin/atl/out.cgi?s=60&u=http://cialisxxl.com
http://mail.communicateplus.com/redirect.asp?personid=267:1223201e0a2:-1233&url=http://levitrarrr.com
http://www.black-matures.com/cgi-bin/at3/out.cgi?id=55&tag=top&trade=http://viagrannq.com
http://www.cet-taiwan.com/epaper/Epaper_counter.asp?epaper_no=1000&Epaper_type=30style_blog&URL=http://viagranorx.com/
http://dadsyounggirl.com/crtr/cgi/out.cgi?url=http://viagrappa.com
http://goto.csdb.cn/go.jsp?url=http://viagrarpr.com
http://www.freelingerie.us/movies/go.php?id=1226745_1&url=http://viagravvr.com
http://avekom.ru/bitrix/redirect.php?event1=news_out&event2=http%3A%2F%2Fwww.lens4u.ru&event3=%C8%ED%F2%E5%F0%ED%E5%F2-%EC%E0%E3%E0%E7%E8%ED+%EA%EE%ED%F2%E0%EA%F2%ED%FB%F5+%EB%E8%ED%E7&goto=http://cialisnnq.com
http://find.cxe.jp/rank.cgi?mode=link&id=329&url=http://cialisnorx.com
http://www.bdsmpornphotos.com/cgi-bin/crtr/out.cgi?id=32&tag=top_top&trade=http://cialisppq.com
http://lesbiangirlporn.com/cgi-bin/at3/out.cgi?id=146&tag=top30&trade=http://cialisrpr.com
https://www.avtoprozvon.ru/bitrix/redirect.php?event1=click&event2=button-rec&event3=&goto=http://cialisvvr.com
https://netshop.misty.ne.jp/beauty/01/out.cgi?id=vertrich&url=http://cialisxxl.com
http://charitativniaukce.cz/redirect.php?url=http://levitrarrr.com
http://www.quanhaodi.com/redirect?url=http://viagrannq.com
https://www.netwalkerstore.com/Redirect.asp?AccID=-18244&AdCampaignID=2991&AdCampaignType=2&AffDuration=30&url=http://viagranorx.com
http://t.haverest.com.ua/quote/BO27-VE19/item/27?goto=http://viagrappa.com
http://shareloox.factlink.net/lib/jump.comp?url=https://viagrarpr.com
http://www.printfamily.ir/fa/home/goToUrl/url/viagravvr.com
http://www.lisserhoekje.nl/chinesecresteds/guestbook/go.php?url=http://cialisnnq.com
http://www.heeckt.com/external.asp?goto=http://cialisnorx.com
http://www.virginiaroadrunners.com/modules/mod_jw_srfr/redir.php?url=http://cialisppq.com
http://www.eiseverywhere.com/emarketing/go.php?i=126636&e=amVhbi1tYXJjLmR1Zm91ckBmcmFuY2UtZWNpLm5ldA==&l=http://cialisrpr.com
http://www.edu11.net/link.php?url=https://cialisvvr.com
http://kouen.com/redirect.php?action=url&goto=cialisxxl.com
http://www.idfwo.org/redir.asp?url=http://cialisnnq.com
http://svmaredijk.vakantieland.nl/klikuit.asp?id=992429918&url=http://cialisnorx.com
http://www.nextdoorlust.com/at3/out.cgi?id=104&tag=toplist&trade=http://cialisppq.com
http://web-praktika.ntrlab.ru/redirect.php?url=http://cialisrpr.com
https://morgenmitdir.net/index.php?do=mdlInfo_lgateway&eid=20&urlx=http://cialisvvr.com/
https://newtimes.ru/bitrix/rk.php?goto=http://cialisxxl.com
http://www.socialcloud.guetsel.de/redirect.php?link=http://levitrarrr.com
http://www.tongloumeng.com/home/link.php?url=http://viagrannq.com
http://www.studyholic.com/inc/go_Link.asp?url=http://viagranorx.com
https://www.smutserver.com/cgi-bin/a2/out.cgi?s=80&u=http://viagrappa.com
http://www.akitanavi.net/modules/rssc/redirect.php?lid=25&url=http://viagrarpr.com
http://tube-young.com/cgi-bin/out.cgi?id=159&l=top_top&req=1&t=100t&u=http://viagravvr.com
http://mx1.lastgfs.com/crtr/cgi/out.cgi?s=90&l=lgfs&u=http://cialisnnq.com
http://hotasianz.com/cgi-bin/at3/out.cgi?id=351&trade=http://cialisnorx.com
http://www.hahaxue.com/link.php?url=http://cialisppq.com
http://d-click.ntu.org.br/u/9097/293/1458/1296_0/a6304/?url=http://cialisrpr.com/
http://www.spacioclub.ru/forum_script/url/?go=http://cialisvvr.com
https://autotriti.gr/news/preview_news.asp?home=webnews&url=http://cialisxxl.com
http://imagehat.com/index?URL=https://levitrarrr.com/
https://www.auntminnieeurope.com/index.aspx?sec=log&url=http://viagrannq.com
http://inetlog.ru/url/?http://viagranorx.com/
https://bindplace.com/redirect?url=https://viagrappa.com
https://www.firstwordpharma.com/external/link?url=http://viagrarpr.com
http://www.tom-next.com/community/redirect.php?url=http://viagravvr.com
http://bdsmbook.com/cgi-bin/s/out.cgi?id=a113&url=http://cialisnnq.com
http://www.salvationbygracealone.com/cgi-bin/dclinks/dclinks.cgi?action=redirect&id=14&URL=http://cialisnorx.com
http://info-dvd.ru/codes/away/?cialisppq.com
https://reviblo.com/cv/link.php?mid=73967&rid=1515&location=http://cialisrpr.com
http://adultcomicssex.com/cgi-bin/at3/out.cgi?id=88&trade=http://cialisvvr.com
https://bestcrosswords.by/redir.php?url=http://cialisxxl.com
http://api.multigo.ru/api/3/redirect?url=http://levitrarrr.com
http://ferrarimania.net/search/rank.cgi?mode=link&id=152&url=http://viagrannq.com
http://its.1c.ua/news/redirect?url=http://viagranorx.com
http://www.thisisdanielcook.com/redirect.php?url=http://viagrappa.com
“http://tfads.testfunda.com/TFServeAds.aspx?strTFAdVars=4a086196-2c64-4dd1-bff7-aa0c7823a393
http://www.rozenbergps.com/sohier/guestbook/go.php?url=http://viagravvr.com
http://210.42.192.44/kcms/logout.aspx?url=http://cialisnnq.com
http://wo.quickhand.org/home/link.php?url=http://cialisnorx.com
http://www.anorexiaporn.com/cgi-bin/atc/out.cgi?id=14&u=http://cialisppq.com
http://www.gitaristam.ru/redir.php?go=http://cialisrpr.com
https://www.pervbank.ru/redir.php?url=http://cialisvvr.com
http://my.2214.cn/link.php?url=https://cialisxxl.com
http://update.wnegoldenbearclub.com/redirect?SessionGuid=74a75ec6-45fc-4a29-8463-d48a889a0d38&url=http://levitrarrr.com
http://www.ncatnow.com/redirect?SessionGuid=085fc88e-d06e-4bfd-a04f-7ae87c4b1ecc&url=http://viagrannq.com
http://www.all3porn.com/cgi-bin/at3/out.cgi?id=11&tag=porr_biograf&trade=http://viagranorx.com
http://www.autobaidu.com/urlAlter.php?url=http://viagrappa.com
http://riji.org/link.php?url=http://viagrarpr.com
http://soprano.com/sc/goto.php?from=/cat/youtube.php&from2=-&URL=http://viagravvr.com
http://www.apple-russia.ru/wp-go.php?url=http://cialisnnq.com
http://metrics.adzip.co/redirect.php?adid=1300019925_2113084201_4275793615_401371144&e=custom&v=ClickLiverpool&href=http://cialisnorx.com
http://hinkaku.net/m/redirect.php?url=http://cialisppq.com
https://e-chondroprotection.com/redirect.php?url=http://cialisrpr.com
http://uik.su/bitrix/rk.php?id=3&site_id=s1&event1=banner&event2=click&event3=1+%2F+%5B3%5D+%5Bright2%5D+%C1%E0%ED%ED%E5%F0+1%D1%3A%CA%E0%F1%F1%E0&goto=http://cialisvvr.com
http://outofmemory.cn/url?u=http://cialisxxl.com
http://www.clementnet.com/guestbook/go.php?url=http://levitrarrr.com
http://www.amateur-wives-posts.com/cgi-bin/toplist/out.cgi?id=sambrads&url=http://viagrannq.com
http://grannypornpictures.com/cgi-bin/atx/out.cgi?id=310&tag=thumbtop&trade=http://viagranorx.com
http://redirect.rausgegangen.de/v1/redirect?url=http://viagrappa.com
https://knowledgebase.egates.co.uk/trackbuy.php?url=http://viagrarpr.com
http://fucked-moms.com/cgi-bin/tel/out.cgi?id=17&tag=top_footer&ok=no&sed=http://viagravvr.com
http://it-school112.ru/bitrix/redirect.php?event1=&event2=&event3=&goto=http://cialisnnq.com
http://www.energoelektronika.info/Redirect?id=647&url=http://cialisnorx.com
http://www.find-best-lingerie.com/movies/go.php?id=968689_1&url=http://cialisppq.com
http://mostotrest.ru/bitrix/rk.php?goto=http://cialisrpr.com
https://www.managersbc.com/hp.php?id=232&s=1024&do=redirect&action_id=3&url=http://cialisvvr.com
http://www.yelia.com/home/link.php?url=http://cialisxxl.com
http://www.24livenewspaper.com/redir/?url=http://levitrarrr.com
http://kochi-madamerose.com/m/redirect.php?url=http://viagrannq.com
http://otel-sport.ru/go.php?url=http://viagranorx.com
http://www.psychocontrol.com/plugins/guestbook/go.php?url=http://viagrappa.com
http://q.xtjc.com/link.php?url=http://viagrarpr.com
http://int.dn.ua/redirect.php?url=http://viagravvr.com
http://www.newbalkan.com/redirect.php?URL=http://cialisnnq.com
http://boltonelectricalsupply.com/common/intemo/mobile/desk-on-mob.asp?q=y&url=http://cialisnorx.com
http://twink-xxx.com/cgi-bin/out.cgi?id=326&l=top_top&req=1&t=100t&u=https://cialisppq.com
http://la-xxx.com/cgi-bin/atx/out.cgi?id=202&trade=http://cialisrpr.com
http://cathy-ostlere.com/t/-/-/external/cialisvvr.com
http://greatdominatrix.com/cgi-bin/at3/out.cgi?s=50&u=http://cialisxxl.com
http://www.minimunchers.com/Redirect/Default?url=http://levitrarrr.com
https://apke.ru/redirect.php?url=http://viagrannq.com
http://www.valgardena.it/base/it/go/?to=hurl&url=http://viagranorx.com
http://h.kensakulab.com/rank/out.cgi?id=banira&url=http://viagrappa.com
http://www.exploresvc.net/redirect?SessionGuid=0af01d28-e07f-4ef5-842f-0fe80b71434d&url=http://viagrarpr.com
http://www.chubby-ocean.com/crtr/cgi/out.cgi?s=50&u=http://viagravvr.com
http://www.shemalepictures.in/cgi-bin/atx/out.cgi?id=35&tag=thumbtop&trade=http://cialisnnq.com
http://d-click.sociesc.org.br/u/20840/36/829763/103_0/4b7fb/?url=http://cialisnorx.com/
http://www.blablaporn.com/cgi-bin/atx/out.cgi?id=275&tag=toplist&trade=http://cialisppq.com
http://sns.clnchina.com.cn/link.php?url=http://cialisrpr.com
http://stgeorges-glascote.org.uk/about-us/recordings/?show&url=http://cialisvvr.com
https://www.chitaitekst.ru/bitrix/rk.php?id=258&event1=banner&event2=click&event3=1+%2F+%5B258%5D+%5BPK_INNER_TOP_LONG%5D+%C4%FF%E3%E8%EB%E5%E2%F1%EA%E8%E9&goto=http://cialisxxl.com
http://hi.zuobus.com/link.php?url=http://levitrarrr.com
https://www.indice.com/redir.asp?pagina=http://viagrannq.com/
http://www.orenvelo.ru/go?http://viagranorx.com/
http://www.canopymusic.net/canopy/gbook/go.php?url=http://viagrappa.com
http://furnation.ru/go.php?u=http://viagrarpr.com
http://www.arubanewsletter.com/t.aspx?S=29&ID=5400&NL=226&N=3159&SI=586223&URL=http://viagravvr.com
http://simplyhealth.cloudapp.net/berrygroveschool/Content/Redirect.php?url=cialisnnq.com
http://www.teenage-nudism.com/cgi-bin/out.cgi?ses=JfUNFECiQz&id=99&url=http://cialisnorx.com
http://anyfemdom.com/cgi-bin/at3/out.cgi?l=tmx7x153x42631&s=55&u=http://cialisppq.com
http://www.ecm-trk.com/redirect.php?client=1363738396-27470&url=http://cialisrpr.com
http://www.minecraft.uz/redirect?url=http://cialisvvr.com
http://adserver.facharzt.de/adclick.php?bannerid=4504&zoneid=&source=&dest=http://cialisxxl.com
http://teen-collection.com/cgi-bin/out.cgi?id=85&l=top01&u=http://levitrarrr.com
https://www.ggmania.com/link.php3?rid=29985823&url=http://viagrannq.com
http://www.parrotvids.com/movies/go.php?id=1146093_1&url=http://viagranorx.com
http://www.jrack.co.kr/main/print.cgi?board=55&link=http://viagrappa.com/
http://podonki.info/go.php?url=http://viagrarpr.com
http://www.phrequency.com/s?action=reg&rurl=http://viagravvr.com
https://www.bijouxsearch.com/cgi/bijoux/ps_search.cgi?act=jump&access=1&url=http://levitrarrr.com
http://pregnantfilms.com/cgi-bin/at3/out.cgi?id=40&tag=top30&trade=http://viagrannq.com
http://www.nicematuretube.com/cgi-bin/crtr/out.cgi?id=103&l=topmain&u=http://viagranorx.com
http://www.putujici.cz/plugins/guestbook/go.php?url=http://viagrappa.com
http://page.yicha.cn/tp/j.y?detail&url=http://viagrarpr.com
https://www.fulpy.com/products/redirect?addedby=sharath&url=http://viagravvr.com
Aw, this was a really nice post. In idea I want to put in writing like this additionally ?taking time and precise effort to make an excellent article?but what can I say?I procrastinate alot and under no circumstances appear to get one thing done.
http://www.leanmean-manufacturing.net/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://violetwine.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
https://webservices.cornerdrugstore.com/rx/requestrefillhome.aspx?id=7d74dd1a-a517-4ca0-bdd5-f867ffb77e15&syscode=0688nx&refurl=cialis-de.website
http://www.surveyalaska.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.tenantpi.net/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://domainfordollars.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://eeesti.ru/www/?site=clindamycin-de.space
http://wecoyote.com/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://www.pafff.org/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://forum.rammstein.ru/away.php?s=http://kamagra-fi.svenskepiller.com
http://images.google.co.mz/url?q=http://levitra.svenskepiller.com
http://bdoworld.biz/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://www.womencando.org/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://kharkov-fishing.org/forum/index.php?action=redirect;url=http://priligy.svenskepiller.com
http://www.2ndsonautos.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://dewulfentertainment.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://donateyourcartoday.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.gavecore.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.navajorugs.biz/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://asiamoneys.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://usps-certified-email.us/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.leadershipateverylevel.net/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://kartstop.com/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://wasted-potential.com/__media__/js/netsoltrademark.php?d=kamagra-fi.svenskepiller.com
http://ittakesavillage.com/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://www.cableventuresinc.com/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://lunaticfringe.com/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
https://hh-center.ru/bitrix/rk.php?goto=http://priligy.svenskepiller.com
https://tone.ft-dm.com/420/index_https.php?urlfrom=atorvastatin-de.website
http://internationalstemcellresearch.net/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.lieselannpritzker.net/__media__/js/netsoltrademark.php?d=cialis-de.website
http://kingdomofgod.net/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://yogidham.org/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://netherwestcote.info/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.firstsecuritymalta.com/speedbump.asp?link=clindamycin-de.space
http://www.churchhistory.com/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://www.todoomodelisme.com/site.php?url=http://ibuprofen.svenskepiller.com
http://northstarshoes.com/europe/out.php?url=http://kamagra-fi.svenskepiller.com
http://ondaxinc.net/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://movie.linksind.net/?go*http://levitra-fi.svenskepiller.com
http://m.adlf.jp/jump.php?l=http://potensmedel.svenskepiller.com
http://cnhfinancial.com/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://inventorpatent.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.lightsculpture.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://www.editorialphotographer.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.newyorkcloudhosting.com/cgi-bin/ydclinks/out.cgi?id=485&sendto=http://cialis-fi.svenskepiller.com
http://courier-post.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://volumetrend.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://jigsaw.w3.org/css-validator/validator?uri=http://clindamycin-de.space
http://ccs.webcrawler.com/clickserverredirect.aspx?trans=http://diclofenac.svenskepiller.com
http://www.brooklyn-bridge.net/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://maps.google.co.ck/url?q=http://kamagra-fi.svenskepiller.com
http://www.stayarmy.com/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://www.uwmlaw.biz/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://dialysisvideo.com/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://meetingmanagement.biz/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://www.surfboardsbrazil.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.prmpromise.net/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://j-ken.com/category/all/page/search/?keyword=“/><a+href="http://cialis-de.website
http://www.seniorbustours.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.monplawiki.com/link.php?url=http://ciprofloxacin-de.space
http://www.skymarshal.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.ccdome.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://www.nagovan-stieger.com/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://daten.ws-mack.de/core.asp?a=aktuelles&n=heckerjahr2011&sd=heckerjahr2011/index.asp&d=ibuprofen.svenskepiller.com
http://www.xn--mnchen-international-pec.de/wp-content/plugins/wp-js-external-link-info/redirect.php?url=http://kamagra-fi.svenskepiller.com
http://maps.google.ae/url?q=http://levitra.svenskepiller.com
http://icv2sucks.com/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://www.fundacentro.gov.br/conteudo-super-link?url=http://potensmedel.svenskepiller.com
http://www.solet.com/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://www.listie.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.nextwapblog.com/site/pages/smileys?redirect_uri=http://azithromycin-de.website
http://www.caregivingpicturebook.net/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.earlyretirement.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://deyhimi.us/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://dialadriver.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.hanglooseeurope.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
I simply want to say I’m all new to blogs and actually savored this web site. More than likely I’m planning to bookmark your website . You amazingly come with great stories. Thanks a lot for revealing your web page.
http://www.komainc.net/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://www.apfmultifamily.com/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://www.google.com.ag/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0cc0qfjaa&url=http://kamagra-fi.svenskepiller.com
http://www.piperbraden.com/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://www.safe-r-brakes.net/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://forvalour.patternhosting.com/english/exit-eng.php?url=http://potensmedel.svenskepiller.com
http://rarebooks.com/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://www.twinsradionetwork.net/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://mainfloorcovering.net/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://digicelha.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.netauto.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://www.gamblersslots.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://www.seniorbustours.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.cabinslakehartwell.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
There are certainly loads of particulars like that to take into consideration. That may be a nice point to carry up. I provide the ideas above as normal inspiration but clearly there are questions like the one you carry up the place a very powerful factor will be working in trustworthy good faith. I don?t know if finest practices have emerged around issues like that, but I’m sure that your job is clearly identified as a fair game. Each boys and girls feel the impression of only a moment抯 pleasure, for the rest of their lives.
http://www.american-leaders.com/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://www.knightfire.us/__media__/js/netsoltrademark.php?d=ibuprofen.svenskepiller.com
http://dgpinc.net/__media__/js/netsoltrademark.php?d=kamagra-fi.svenskepiller.com
http://www.gridtesters.com/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://www.calmh20.com/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://www.cauvery.biz/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://barcelonatapas.co.uk/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://bax.kz/redirect?url=http://atorvastatin-de.website
http://www.blackandveatch.biz/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://mangvn.org/nukeviet/rss2js/feed2js.php?src=http://cialis-de.website
http://www.wpp.com/annualreports/2007/exitpage.asp?url=http://cialis-fi.svenskepiller.com
http://www.carrierservicesinc.com/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://vanscorp.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://www.canadareverse.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://lifelongresidualincome.com/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://maps.google.com.tr/url?q=http://ibuprofen.svenskepiller.com
http://hanair.com/__media__/js/netsoltrademark.php?d=kamagra-fi.svenskepiller.com
http://www.why-pay-more.biz/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://mobile.santacecilia.it/choose?redirect=http://levitra-fi.svenskepiller.com
http://dynapattern.net/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://www.appetizerexpress.net/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://www.gointothechapel.com/__media__/js/netsoltrademark.php?d=atorvastatin-de.website
http://www.billfishjournal.com/__media__/js/netsoltrademark.php?d=azithromycin-de.website
http://gorod-moskva.ru/widgets/outside/?url=http://cialis-de.website
http://okoconnell.com/__media__/js/netsoltrademark.php?d=cialis-fi.svenskepiller.com
http://appyet.com/handler/disqus.ashx?guid=713ae0d41568487bb47b9d09585fe482&id=45fee95b8971b2435e0570d007b5f281&locale=ar&shortname=aqoal&title=&type=1&url=http://ciprofloxacin-de.space
http://backgroundsingapore.com/__media__/js/netsoltrademark.php?d=clarithromycin-de.space
http://thailady.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
http://zannier.info/__media__/js/netsoltrademark.php?d=diclofenac.svenskepiller.com
http://images.google.com/url?q=http://ibuprofen.svenskepiller.com
http://www.aimretirement.biz/__media__/js/netsoltrademark.php?d=kamagra-fi.svenskepiller.com
http://deyhimi.us/__media__/js/netsoltrademark.php?d=levitra.svenskepiller.com
http://www.markspiegler.com/__media__/js/netsoltrademark.php?d=levitra-fi.svenskepiller.com
http://www.motorcarsprice.com/__media__/js/netsoltrademark.php?d=potensmedel.svenskepiller.com
http://capybara.biz/__media__/js/netsoltrademark.php?d=priligy.svenskepiller.com
http://www.laptop-software.com/go.php?http://atorvastatin-de.website
https://videochaty.ru/index.php?inc=go&url=http://azithromycin-de.website
http://amresllc.com/__media__/js/netsoltrademark.php?d=cialis-de.website
http://www.whyspirit.com/modules/wordpress/wp-ktai.php?view=redir&url=http://cialis-fi.svenskepiller.com
http://www.grahampackaging.biz/__media__/js/netsoltrademark.php?d=ciprofloxacin-de.space
http://shootingsnipergames.com/game-out2.php?gl=http://clarithromycin-de.space
http://www.shockofthenew.com/__media__/js/netsoltrademark.php?d=clindamycin-de.space
Your blog on K-Nearest Neighbor Machine Learning algorithm – Deepsingularity : Deepsingularity is very good. I hope you can continue delivering many more blog in the future. Viva deepsingularity.io
http://wikimapia.org/external_link?url=http://sildenafil.svenskepiller.com
http://joomlinks.org/?url=http://sildenafil-dk.svenskepiller.com
http://awomanlikethat.net/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://maps.google.it/url?q=http://sildenafil-no.svenskepiller.com
http://www.privaterealestategroup.net/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.mycompass.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.ecallstars.com/linkMb.html?link=http://tadalafil-fi.svenskepiller.com
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
http://id.nan-net.jp/system/login/link.cgi?jump=http://sildenafil.svenskepiller.com
http://quepasacuba.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://familydonorprogram.org/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.sorenwinslow.com/rssreader.asp?thefeed=http://sildenafil-no.svenskepiller.com
http://aleysk22.su/bitrix/rk.php?id=49&site_id=s1&event1=banner&event2=click&event3=1+/+9%5D++ЕДДС&goto=http://svenskepiller.com
http://bbs.rimorimo.com/?url=http://tadalafil.svenskepiller.com
http://www.amf.asso.fr/document/index.asp?doc_n_id=7806&refer=http://tadalafil-fi.svenskepiller.com
Pretty section off content. I just stumbled upon your weblog and in accession capital to assert that
I acquire actually enjoyed accunt your blog posts.
Anyway I will be subsccribing to your augment and even I achievement you access consistently quickly.
An attention-grabbing discussion is value comment. I believe that you need to write extra on this subject, it might not be a taboo topic however generally persons are not sufficient to talk on such topics. To the next. Cheers
http://uplandssnoqualmievalley.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://babybuzz.de/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://www.dlite.co.uk/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.igsha.ru/bitrix/rk.php?goto=http://sildenafil-no.svenskepiller.com
http://www.obstetricswoman.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://note-art.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://lace-and-beyond.com.au/catalog.php?item=491&catid=goldwork&ret=tadalafil-fi.svenskepiller.com
That is a very good tip particularly to those fresh to
the blogosphere. Brief but very accurate info… Many thanks for sharing
this one. A must read post!
I added a new list. As you’ll see it’s bigger than most of them. I hope you all have had a great week!
http://www.addthis.com/feed.php?pub=xa-4abbb69c5914e47a&h1=http://sildenafil.svenskepiller.com
http://www.wildernessgate.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://onecanhappen.org/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.sarahcenters.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.apolloclinicthane.com/blog/-/blogs/166627?_33_redirect=http://svenskepiller.com
http://www.mgcapital.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://okcresidential.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://killerbug.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.abcteen.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://www.google.hr/url?sa=t&rct=j&q=&esrc=s&source=web&cd=7&sqi=2&ved=0cgcqfjag&url=http://sildenafil-fi.svenskepiller.com
http://okc-commercial.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://wrd.feratel.com/wrd/r.jsp?info=/feratel4/5270/ho/e5afce74-27d5-4351-8ebd-5ae80021fba9&url=http://svenskepiller.com
http://www.offtherail.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.ae-always.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://www.setprojects.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.sapec.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://ctcan.net/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://nonuclearpower.info/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://solerase.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.bearlyused.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.readyfirst.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://9thdistrictamechurch.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://norcalshotblasting.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://kramer.ru/bitrix/rk.php?id=22&site_id=s1&event1=banner&event2=click&event3=1+/+2%5D+top%5D+vs-211h2&goto=http://sildenafil-fi.svenskepiller.com
http://www.kellerwilliams-porterranch.net/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://wildrooteroutfitters.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://ithacas.org/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://webmail.anacondaweb.com/redir.php?http://tadalafil-fi.svenskepiller.com.
I will immediately snatch your rss as I ccan not in finding
your email subscription link or e-newsletter service.
Do you have any? Kindly allow me realize so that I may just subscribe.
Thanks.
http://www.jagwareposingsuits.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.theprogrammer.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://fredking.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.oplata.info/asp2/pay_wm.asp?id_d=585870&rnd=111159251&failpage=http://sildenafil-no.svenskepiller.com
http://web-2-host.net/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.tad-consumer.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://yousticker.com/ru/domainfeed?all=true&url=http://tadalafil-fi.svenskepiller.com
Spot on with this write-up, I truly believe that this website needs a lot more
attention. I’ll probably be returning to see more, thanks ffor the information!
http://gov.rayongz.com/redirect.php?url=http://sildenafil.svenskepiller.com
http://www.flu-alert.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://www.byrank.org/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://images.google.com.gi/url?q=http://sildenafil-no.svenskepiller.com
http://goodnewsbears.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://titleloanstoday.com/link.php?url=http://tadalafil.svenskepiller.com
http://www.emssafetyservices.net/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://www.eunyoung.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://presto-pre.com/modules/wordpress/wp-ktai.php?view=redir&url=http://sildenafil-dk.svenskepiller.com
http://www.tvfix.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://gapmag.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.pointracs.com/section.cfm?wsectionid=\”><a+href=http://svenskepiller.com
http://www.popularpicks.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://gamesjp.com/jump.php?url=http://tadalafil-fi.svenskepiller.com
http://stocktradeonline.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.globalperformancesolutions.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://nonprofitneighbourhood.org/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.studyireland.org/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.blaue.ostarrichi.org/external.html?link=http://svenskepiller.com
http://www.buffalostate.org/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.hoaghealth.org/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://www.google.com.sa/url?sa=t&rct=j&q=&esrc=s&frm=1&source=web&cd=25&ved=0CFkQFjAEOBQ&url=http://sildenafil.svenskepiller.com
http://beandrewforaday.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://akhawat.quranourlife.com/redirect.php?url=http://sildenafil-fi.svenskepiller.com
http://www.calfirstleasing.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://images.google.mv/url?q=http://svenskepiller.com
http://www.americandreamers.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.1time.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
That’s not me favourable where you stand obtaining your information and facts, having said that superior subject matter. I ought to take some time finding out far more as well as understanding more. Appreciation for outstanding facts I’m seeking this info in my objective sweat.
Gadgets for your next high-tech road trip: http://articles.pubarticles.com/how-to-have-a-great-road-trip-with-high-tech-gadgets-1533131387,1763309.html
http://www.gyulafodor.com/phpinfo.php?a=ethan+harris
http://rndschool61.org.ru/bitrix/rk.php?goto=http://sildenafil-dk.svenskepiller.com
http://www.easyceramicservo.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.thinlink.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://greatestentertainerintheworld.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://alanaboud.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.dnabootcamp.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
Very nice post. I just stumbled upon your weblog and wished to mention that I’ve really loved browsing your blog posts. In any case I’ll be subscribing to your feed and I am hoping you write again soon!
http://www.worldoftours.net/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://oneidasky.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://www.scanltc.net/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://julioramos.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.medicationexperts.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://ottoowl.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.fortynine.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://www.principalpropertiesllc.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.spa-adventures.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://onlyspecialthings.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.etoolrenting.net/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://stlouisgiftbasket.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.samparcindia.org/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://psi-lab.ru/engine/redirect.php?url=http://tadalafil-fi.svenskepiller.com
money fast online loans loans payday loans for bad credit
http://1-800-airportparking.net/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.jeffzemito.com/redirect.cfm?target=http://sildenafil-dk.svenskepiller.com
http://www.zif.su/bitrix/rk.php?goto=http://sildenafil-fi.svenskepiller.com
http://www.mackeysbar.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.carl-heinz.de/index.php?site=go&link=svenskepiller.com
http://www.jerseycattle.org/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://edwattsgolf.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://igrovesti.ru/forum/away.php?s=http://sildenafil.svenskepiller.com
http://ccharities.org/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://www.st-ores.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://veteranhomemortgages.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.musicvalet.biz/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.boostersite.com/vote-1387-1371.html?adresse=tadalafil.svenskepiller.com
http://freelanceinspector.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
loans online payday loan direct lenders direct lenders payday loans loans for people with bad credit
http://www.google.co.za/url?q=http://sildenafil.svenskepiller.com
https://upma.upturnhost.com/registration/register.aspx?returnurl=http://sildenafil-dk.svenskepiller.com
http://brazosworkboots.org/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://mensshoesireland.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://vegasgemstones.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://st-gracecourt.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://allhome.uz/bitrix/rk.php?id=72&event1=banner&event2=click&event3=1+/+2%5D++Закажи+бесплатный+замер&goto=http://tadalafil-fi.svenskepiller.com
legit payday loans loans payday loans bad credit small payday loan
online loans bad credit best loans for bad credit loans loan with bad credit
http://www.formulism.org/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://itsonlythemoon.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://www.herosee.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://diversityroi.org/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://westaircom.org/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.affordablerepair.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.personalinjurylawpage.net/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
best loans for bad credit loans loans loans
loans for people with bad credit loans loan with bad credit loan bad credit
http://www.generalcablecorp.net/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.yxxxxxxy.tuna.be/exlink.php?url=http://sildenafil-dk.svenskepiller.com
http://images.google.com.mm/url?q=http://sildenafil-fi.svenskepiller.com
http://drycleanerforsale.net/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.google.nu/url?q=http://svenskepiller.com
http://www.lenameyerlandrut-fanclub.de/tools/redirect.php?http://tadalafil.svenskepiller.com
http://www.stevenmeisel.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
http://investinlosangeles.net/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://amz.kiev.ua/link/go.php?url=http://sildenafil-dk.svenskepiller.com
http://maps.google.im/url?q=http://sildenafil-fi.svenskepiller.com
http://wap.npo-cekc.ru/obmen/index.php?mode=top&for=users&sessionid=i4ru5ntm37nkhj2bq8v05o8m21&url=sildenafil-no.svenskepiller.com
http://wimmerspace.info/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.frogpublications.biz/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://www.purchasepower.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
Thank you for another informative blog. Where
else mmay I am getting that kind of info written in such an ideal manner?
I hve a mission thbat I’m simply now working on, and I’ve been on the look outt ffor
such information.
http://arietaykan.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://www.eauderose.com/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
https://laureluniversity.vfao.com/register.aspx?returnurl=http://sildenafil-fi.svenskepiller.com
http://www.bluntreport.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://www.badgirl.cc/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.ajmkooheji.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://babyduck.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
Greatt article! This is the type of info that should
be shared arond the internet. Disgrrace on the seek engines for now not positioning this submit upper!
Come on over andd seek advice from my website . Thanjs =)
http://www.bang4yourbuck.com/__media__/js/netsoltrademark.php?d=sildenafil.svenskepiller.com
http://depressionwithpsychosis.net/__media__/js/netsoltrademark.php?d=sildenafil-dk.svenskepiller.com
http://innerspiral.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://www.antennas3.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com
http://songwagon.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://www.porpoisebay.com/__media__/js/netsoltrademark.php?d=tadalafil.svenskepiller.com
http://gaiety.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
Hey would you mind letting me know whicfh web host you’re using?
I’ve loaded your blog in 3 different web browsrs and I mmust ssay this blog loads a lot quicker
thern most. Can you suggest a good hosting provider at a fair price?
Cheers, I appreciate it!
http://www.discoverteesvalley.co.uk/redirect.aspx?destination=http://sildenafil.svenskepiller.com
http://www.expertenforum-bau.de/wcf/acp/dereferrer.php?url=http://sildenafil-dk.svenskepiller.com
http://westsidetour.com/__media__/js/netsoltrademark.php?d=sildenafil-fi.svenskepiller.com
http://creativepastimes.com/__media__/js/netsoltrademark.php?d=sildenafil-no.svenskepiller.com leptigen top benefits of fat loss
http://dancing-fiddle.com/__media__/js/netsoltrademark.php?d=svenskepiller.com
http://m.15navi.com/forward.aspx?u=http://tadalafil.svenskepiller.com
http://tutortext.com/__media__/js/netsoltrademark.php?d=tadalafil-fi.svenskepiller.com
I used to be suggested this web site by my cousin. I’m not cesrtain whether this
put up is wrtitten byy hiim as nno one else realize such cetain about my trouble.
You are amazing! Thanks!
easy loan loans loans loans
online personal loans loans personal small personal loans direct loan transfer
online payday loans no faxing loans loan bad credit loans
payday loans online payday loans instant approval cheap installment loans payday loans near me
http://cialisrrr.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisvvr.com cialis
cialis
cialis
http://viagravvr.com viagra
viagra
viagra
Hi my family member! I want to say tthat this article is
amazing, nice written and include almmost all important infos.
I would like to peer extra pozts like this .
usa payday loan loans direct easy payday loans loans
payday loans payday loans bad credit payday loans payday loans
payday loans payday loans payday loans best payday loan
online loans for bad credit fast cash today bad credit loans guaranteed bad credit loan
loans loans bad credit bad credit loans bad credit loans reviews
loan for bad credit payday loans uk loan for bad credit best loans for bad credit
personal loans online loan calculator credit personal loans personal loan
After examine just a few of the blog posts on your website now, and I really like your method of blogging. I bookmarked it to my bookmark web site checklist and will be checking back soon. Pls check out my site as effectively and let me know what you think.
small loans best loan loans loans pay day
payday loans online payday loans online online payday cash payday loans online
online loans online loans loans online online loans for bad credit
bad credit payday loans payday loans no credit payday loans no credit 24 hour payday loan
cash advances cash advances payday cash advance quick money online free
installment loans installment loans installment loans installment loans
cash advance online top debt consolidation companies cash advances payday cash advance
same day payday loans no credit check no fax payday loans private lenders for personal loans same day payday
safe online payday loans payday loans online payday loans online no credit calculating interest on a loan
express cash advance payday loan cash advance payday loan online bad credit guaranteed payday loans
get cash fast personal loans online loans online loans online
loans loans for bad credit how does debt consolidation work cash loans with monthly payments
loans no credit check what is debt relief payday loans no credit check loans no credit check
cash loans online personal loan template cash loans online payday loans online
loans now bad credit installment loans installment loan installment loans
indian loans loan bad credit loans with bad credit loans
loans unsecured personal loans bad credit denver payday loans personal payday loans
need a loan now loan applications best online loans loans online
payday loans tx best loans for bad credit loans for bad credit loans for bad credit
loans for bad credit a loan with bad credit legit payday loans loans bad credit
same day payday loans no credit check instant online loan payday loans payday loans
payday loans payday loan no fax credit loans guaranteed approval best payday loan
cash loans online best online loans cash loans online online loans for bad credit
a loan with bad credit payday loans on line loans for bad credit bill consolidation loans
micro loans payday loans cash america payday advance direct payday loan lender
loans gov best loans simple payday loans best loan
easy loans loans payday loan without credit check settlement loans
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarrr.com viagra
viagra
viagra
http://cialisrrr.com cialis
cialis
cialis
wh0cd784823 cephalexin 500
wh0cd784823 cialis 20 mg
cash advance america scam cash loans online loan online loans same day
payday loan online lender cash loans no credit instant payday loans
online payday loans direct lender discount payday loans cash advances cash advances
loans online advance money best online loans need a payday loan
payday online payday advances online payday advance payday apk
online loan applications guaranteed payday loans payday loans poor credit loans guaranteed
wh0cd714278 clomid online
wh0cd714278 wellbutrin
wh0cd714278 cost of viagra 100mg
payday loans best payday loan payday loan online payday loan no fax
online payday loan application loans with bad credit bad credit loans loans for bad credit
loans legit payday loans loans loans with bad credit
payday bad credit loan loans online loans online loans online
wh0cd714278 retin-a
need cash fast personal loan with bad credit las vegas payday loans best loan
personal loans pay day loan bad credit guaranteed payday loans no credit check personal loans
loans with monthly payments personal loans personal loans personal loans
interest free loan payday loan no fax oregon payday loans same day payday loans no credit check
wh0cd714278 prednisone clonidine motrin antabuse fluoxetine valtrex generic online keflex 250 indocin 50 mg tablets avodart recommended site nexium 40
loans ace cash express loans loans
online loans for bad credit personal loans online online loans bad credit loans online
wh0cd908388 price of ventolin inhaler
online loans bad credit loans online loan online payday loans salt lake city
wh0cd908388 buy metformin online
wh0cd908388 clozaril
wh0cd908388 sterapred ds
Attractive component to content. I simply stumbled upon our weblog aand in accession capital to assert that I acquire actually
loved account your weblog posts. Any way I’ll be subscribing
in your augment or even I achiecement you get entry to
constantly rapidly.
wh0cd714278 mobic nolvadex buy generic tadacip albendazole cialis torsemide zanaflex sildalis amitriptylin online lexapro 20 mg prozac tadacip buspar trazodone ilosone abilify orlistat 120mg colchicine biaxin prednisolone
payday loans online payday advances payday loans online payday loans online
wh0cd908388 tadalafil albenza otc nexium tretinoin baclofen acyclovir zithromax phenergan zoloft no prescription
best payday loans small loans loans american cash advance
guaranteed payday loans payday loans payday loans payday loans
teacher loan cash advances online installment loans direct lenders payday cash advance
Great article, totally what I wanted to find.
cash advance online cash advance online express cash advance online loans no credit check
advance loan payday cash advance payday lenders loans for poor credit instant approval
cash advances cash advances cash advances cash advances
Help Jack please: http://redirect.namerock.com/redirect.asp?url=https://vk.cc/8l7kvh
instant payday loan payday loans payday loan no fax payday loans
If you would ike tto obtain a great deal from this piece of writing then you have to apply such techniques to your won weblog.
loans loans payday loans instant approval loans direct
wh0cd908388 vasotec additional info generic neurontin toradol for migraine augmentin xr cafergot tamoxifen motrin fluconazole buy online without prescription your domain name price of wellbutrin continued as an example buspirone 10 mg
loans usa payday loan paydayloans online best loans
cash money payday loans instant payday loan payday loans personal loans guaranteed
personal unsecured loans payday loans dallas tx loans fast personal loans
loan zoom best online loans payday loans online loan zoom
Write more, thats all I have too say. Literally, it seems as though you relied on the video to make your point.
You obviously know what youre talking about, why waste your intellgence on jusdt posting videos to your blog when you could be giving us
something enlightening to read?
same day payday loans no credit check instant payday loans cash loans bad credit payday loans
cash advance direct small personal loans no teletrack loans usda loans
loans for bad credit loans for people with bad credit loans for bad credit loans for bad credit
direct loans student loans online payday loans instant approval payday loans payday loans
best payday loan easy to get payday loans payday loans no fax payday loan
express cash advance cash advance usa express cash advance cash advance online
payday lending paydayloans com online payday loan payday advances
I’m impressed, I must say. Very rarely do I come across a blog that’s both informative and entertaining, and let me tell you, you’ve right from the beginning. Your blog is important, the issue is something that not enough people are talking intelligently about.
installment loans online installment loans installment loan online money
loans loans bad credit loan loans for people with bad credit
credit personal loans small personal loans best personal loan best personal loan
loans in san antonio loans for bad credit loans direct loans
personal loans personal loans bad credit loans personal speedy loan
loans personal get loan pay loans small personal loans
payday loans bad credit ok bad credit installment loans how do loans work installment loans
payday loans pay loans same day payday loans no credit check cash payday loans
wh0cd714278 tetracycline price
loans loans 1 hour loans loans
online short term loans loans online personal loans online loans online
payday loans bad credit loan with bad credit loans online loans for bad credit
wh0cd714278 baclofen
wh0cd714278 vardenafil 20 mg
loans without credit loan over the phone instant payday loans payday loans
installment loans no credit check installment loan installment loans no credit check direct lender installment loans
express cash advance payday lenders payday loans in columbus ohio need a loan immediately
lending loans loans for bad credit payday loans for bad credit
installment loans payday loans with no credit checks installment loans payday loans salt lake city
loans for bad credit loans for bad credit loans for people with no credit 300 loan
online loans bad credit best online loans texas loan best online loans
payday loans near me payday online loans no credit check payday loans instant approval payday advance
small loans with monthly payments payday cash advance personal loan repayment cash advance usa
loans with bad credit loans indian loans direct lender tribal
payday loans online loan online payday loans online sun loan
payday loans guaranteed loan services llc unsecured personal loans personal loans
installment loan loans for manufactured homes installment loans online loan sites
loan on line payday loans online all payday loans payday loans online
wh0cd908388 more helpful hints
wh0cd714278 paroxetine moduretic without prescription hydroquinone tretinoin moduretic cialis xenical neurontin
wh0cd714278 amantadine plus pain cream phenergan motilium otc order lexapro nolvadex estrace 2mg
wh0cd908388 clozaril clozapine
wh0cd908388 how much is levitra
wh0cd908388 generic moduretic
online payday loans no credit check payday loan assistance personal loan no credit check perkins loan
loan until payday loans no credit check online loans no credit check money lenders online
wh0cd714278 xenical yasmin tetracycline 500mg albuterol albenza elimite prednisolone source
cash advance online cash advances cash advances cash advances
loan online payday loans online loans online loans online
best personal loans wells fargo loan bad credit score loans personal loans
loans online loans online 1 hour loans personal loans online
wh0cd908388 vardenafil hcl 20mg inderal 600 mg seroquel
wh0cd908388 diclofenac 1 gel paxil elimite fluconazole 150mg order robaxin nolvadex super avana azithromycin buy albuterol online without prescription propecia
loans no credit check unsecured credit loans no credit check loans no credit check
payday loans online bad credit payday lenders bad credit loans not payday loans loan zoom
personal loans no credit check loans no credit check loans no credit check commercial loan rates
payday mask personal loan personal loans personal loans
best loans cash advance form payday loans instant approval best payday loans
loan me legitimate debt consolidation loans bad credit loans for people with bad credit
online payday loans instant approval online payday loans instant approval payday loans best payday loans online
payday loans online cash payday loans online cash payday loans online debt consolidation bad credit
get a loan with bad credit bad credit loans not payday loans payday loans online loans in pa
cash advances payday loan cash advance cash advances cash advance usa
wh0cd714278 clonidine cephalexin 250mg acyclovir metronidazole 250mg shipped w/o rx motilium order lexapro cymbalta from canada paxil for depression yasmin hydrochlorothiazide
payday loans payday loan no fax payday loans instant payday loan
calculating interest on a loan find loan lowest loan rates online personal loans
direct deposit payday loans bad credit loans best loans for bad credit loans for bad credit
payday loans online online loans bad credit online short term loans online loans
easy loans cash advance form easy loans loans
loans loans need a loan with bad credit loans
personal loans bad credit online personal loans best personal loan personal loans
online payday loans no credit check payday loans tulsa payday loans no credit check same day online loans no credit check
small loan small loan small loan best loans
payday loans for bad credit bad credit loans best loans for bad credit loans
ez cash payday loans cash advances cash advance usa fast cash advance
check cashing payday loans personal loans online online loans online loans for bad credit
no credit check lenders money loan fast loans with bad credit loans with bad credit
loans cash america payday advance loans with bad credit personal payday loans
wh0cd714278 PREDNISOLONE 5MG
wh0cd714278 tetracycline staining
wh0cd714278 Online Plavix
personal loans personal loans best short term loans online personal loans
wh0cd908388 seroquel priligy dapoxetine generic valtrex online without prescription indocin ampicillin purchase wellbutrin online erythromycin diclofenac 1 gel betnovate-n cream 30gr buy yasmin online usa sildalis without prescription glucophage neurontin zyban cost cephalexin generic xenical cipro generic advair online cialis tadalafil revia generic for yasmin birth control augmentin atarax glucophage albendazole
payday loans cash express loans payday loan with bad credit long term loans for bad credit
payday loans payday loans payday loans payday loans
payday advance online payday loans online instant approval payday loans payday loans online
loan services installment loan lenders payday loans payday loans no credit
online loans instant loans online online loans bad credit online loans bad credit
loans for people with bad credit payday loans fast a loan with bad credit payday loans on line
wh0cd908388 amoxil
loans no credit check online payday loans no credit check no credit check loans online loans no credit check
online loans for bad credit loans online online payday loan lender loan applications
wh0cd908388 buy yasmin
consolidation loans loans for mobile homes easy loans loans
guaranteed payday loans payday loans near me poor credit loans guaranteed bad credit payday loans
loans no credit check residential loan application personal loan no credit check online payday loans no credit check
payday loans instant payday loans instant payday loan instant payday loans
best payday loans easy payday loans loans loans
loan services llc best personal loan personal loans personal loans
loans no credit check online payday loans no credit check loans no credit check payday loans no credit check
wh0cd714278 kamagra strattera online paxil weight loss elocon plavix fluoxetine
get a loan with bad credit payday today loans for people with bad credit loans for bad credit
loans bad credit loan payday loans bad credit usa payday
loans bad credit loans for bad credit loans for bad credit loan for bad credit
payday installment loan low interest loan fast online loans loans for people with no credit
payday loans direct payday lenders only payday loans best payday loans online
loans loans bad credit bad credit payday loans loans
payday loans massachusetts no fax payday loan online payday loans instant approval payday loans
get a loan with bad credit bad credit loans easy cash advance residential loan application
installment loans no credit check payday loans online lenders how to get a personal loan online money
loans no credit check no credit check loans no credit check loans online loans no credit check
wh0cd714278 lexapro zoloft atarax online medicine augmentin baclofen 10 mg tablets cipro aciclovir
payday loans credit builder loans loans without cosigner service loans
wh0cd908388 zithromax cialis generic for glucophage albuterol for sale online nolvadex provera
payday loans payday loans payday loans guaranteed payday loans
cash loans online best online loans loans online best online loans
payday loans quickcash no fax payday loans best payday loan
short term loans no credit check real loans no credit check payday loans cash advances
get cash now online short term loans online loans for bad credit bad credit loans not payday loans
loans for debt consolidation direct loan transfer personal loans personal loans bad credit
payday loans payday loans payday loans personal cash advance
quick loans no credit check online loans no credit check personal loans no credit check instant personal loan approval
same day payday loans no credit check payday loans bad credit payday loans direct lenders paydayloans
wh0cd908388 levaquin lotrisone albuterol hydrochlorothiazide nolvadex cipro tretinoin cream solu medrol iv tadacip nolvadex for men cialis zanaflex prednisolone bactrim
best loan loans small loan loans direct
personal loans small personal loans online personal loans personal loans
online loans no credit check loan til payday quick loans no credit check payday loans no credit check
payday loans online same day payday loan payday advance online loan finder
calculating interest on a loan personal loans loans personal get loan
loan instant decision personal loan best personal loan personal loan bad credit
loans loans with bad credit need a loan with bad credit loans
bad credit payday loans best payday loans online best payday loans for bad credit holiday loan
best payday loans loans direct easy loans loans
wh0cd784823 500 mg amoxicillin
wh0cd784823 tadalafil 40 mg
fast cash advance cash advances cash advances cash advances
online loans bad credit sun loan online loans instant loans online
cash payday loans online installment plan payday loans online payday loans online
loans online personal loan calculator payment personal loans online loans online
instant payday loans payday loans guaranteed loans for bad credit payday loan no fax
payday loans online payday loans online installment plans payday loans online
unsecured personal loan best personal loans unsecured personal loan speedy loan
payday lending payday loans online payday loans online payday loans online
wh0cd714278 advair
same day payday loans no credit check payday loan online loan offices small loans without credit checks
loans for people with bad credit loans for bad credit loan for bad credit unsecured loans bad credit
auto loans unsecured personal loan loans after bankruptcy discharge unsecured personal loans
payday loans no credit find loan personal loans unsecured personal loans
wh0cd714278 more hints
loans for bad credit get a loan with bad credit bad credit loans bad credit loans
loans for bad credit cash advance bad credit loan now bad credit loans
wh0cd714278 hydrochlorothiazide
Мой viber, whatsApp: пишите 8-996-725-57-87 скайп kruzzor
Могу долго расписывать какой я молодец, сколько десятков лет у меня опыта в данной сфере, но я предпочитаю “воде” реальные факты.Поэтому хватит лирики, вот что я могу предложить:
————————————
1. Качество услуг на уровне ведущих компаний.
—
2. Цены существенно ниже чем в компаниях (зачастую в разы).
—
3. Постоянная доступность, готовность ответить на интересующие Вас вопросы (ну разве что не ночью), то есть не нужно писать письма и сутками ждать ответа.
—
4. ГОТОВ ПРЕДОСТАВИТЬ ПОРТФОЛИО РЕАЛЬНЫХ РАБОТ. ПРОВЕРИТЬ МОЖНО ПРОСТО ПОЗВОНИВ ПО НОМЕРАМ, УКАЗАННЫМ НА САЙТАХ.
—
5. Мой опыт работы в рекламном агентстве позволяет выделить ваш продукт среди конкурентов, что значительно повысит вашу прибыль от сайта в дальнейшем.
—
6. Люблю креативить. Это можно увидеть в моих работах.
—
7. При желании можно встретиться и побеседовать лично.
—
8. Также могу предложить: SEO продвижение сайта, контекстную рекламу Я.Директ и SMM продвижение в социальных сетях
—
Я надеюсь, что первоначальной информации достаточно, ЗВОНИТЕ 😉
————————————-
Сайт-визитка, лендинг, лэндинг, landing page, интернет-магазин, портал, корпоративный сайт.
My viber, whatsApp: write 8-996-725-57-87 Skype kruzzor
I can paint for a long time what I’m good, how many decades I have experience in this field, but I prefer “water” real facts.So enough lyrics, that’s what I can offer:
————————————
1. Quality of services at the level of leading companies.
—
2. Prices are significantly lower than in companies (often at times).
—
3. Constant availability, willingness to answer your questions (well, except at night), that is not necessary to write letters and wait for a day for an answer.
—
4. READY TO SUBMIT A PORTFOLIO OF REAL WORK. YOU CAN CHECK JUST BY CALLING THE NUMBERS LISTED ON THE WEBSITES.
—
5. My experience in the advertising Agency allows you to distinguish your product from competitors, which will significantly increase your profits from the site in the future.
—
6. Love to be creative. This can be seen in my works.
—
7. If you wish, you can meet and talk in person.
—
8. I can also offer: SEO promotion
same day cash loan quick loans no credit check loans no credit check online payday loans no credit check
wh0cd714278 ampicillin
loans bad credit loans for students with no credit loans for bad credit loans with bad credit
wh0cd714278 zithromax
unsecured personal loan best personal loans online personal loans payday mask
personal loans online loans online loans online mobile loan
cash advances cash advances easy loans no credit check payday loans online direct lender
loan instant decision personal loans wells fargo loan small personal loans
installment plan bad credit payday loans guaranteed payday loans loans for bad credit direct lender
loans online loans online online loans for bad credit payday loans online
loans with bad credit fastest payday loan loan for bad credit bad credit loans
loans for bad credit loans for people with bad credit loan with bad credit loans for bad credit
bad credit loans loans for people with bad credit loan with bad credit loans for bad credit
wh0cd908388 valtrex price
payday loans in las vegas payday loans near me payday loans best payday loans online
debt relief online payday loans instant approval no fax payday loan oregon payday loans
wh0cd714278 tadalafil 5mg tablets
online personal loans payday loans online legit wells fargo loan payday loan lender
installment loan installment loans second chance payday loans direct lender installment loans
need cash fast loans best payday loans direct loans
wh0cd908388 methyl prednisolone
wh0cd714278 levitra cipro tetracycline visit website diflucan vermox article source buy lisinopril sildenafil ampicillin xenical clonidine neurontin clomid retin a celebrex view homepage buy celexa online elavil 10 mg metformin citation stromectol
wh0cd908388 valtrex
loans online where to get a loan loan for bad credit personal loans online
loans for bad credit loans for bad credit loans for bad credit loan star
loans las vegas payday loans payday loan bad small loan
wh0cd784823 wellbutrin 150 mg
debt relief reviews personal loans bad credit personal loans bad credit unsecured personal loans
quick and easy payday loans loans settlement loans small loans
bad credit installment loans guaranteed online installment loans payday loans bad credit ok direct lenders online loans
personal loans online personal loans payday loans in ga small personal loans
loan online payday loan bad cash loans online loans online
cash loans online debt consolidation credit card loans online online loans bad credit
loans online loans online online loans for bad credit reputable debt consolidation companies
wh0cd714278 wellbutrin pills estrace tretinoin cream coupon requip xl mobic 15 mg
wh0cd714278 no prescription canada propranolol neurontin trazodone 50mg tablets doxycycline order online atarax
loans personal personal loans personal loan personal loans
payday loans best payday loan local payday loans payday loans
wh0cd908388 bupropion online trazodone buy amitriptyline zoloft buy prednisolone no prescription levaquin tamoxifen arimidex avodart moduretic plavix betnovate inderal robaxin pills levitra online canada neurontin medication albenza generic augmentin doxycycline cialis vardenafil cost kamagra usa cialis acyclovir orlistat over the counter more information
loans direct lenders only loans for people with bad credit loans for bad credit installment
payday loans chicago fast payday loans no credit check easy loan easy loan
payday loans in pa online payday loan payday advances cash payday loans online
payday loans online guaranteed payday loan 36 month loans payday lending
5000 bad credit loan instant loan no credit check payday loans no credit check same day loan companies for bad credit
express cash advance cash advances cash advances payday cash advance
loans online best online loans loans online online loans for bad credit
small loan best loan easy loans easy loans
wh0cd908388 desyrel clonidine click here generic medrol
wh0cd908388 proscar homepage here
payday loans no credit check same day online loans no credit check personal loan no credit check quick loans no credit check
wh0cd714278 buy anafranil artane tamoxifen indocin atenolol medication amoxil zithromax 500 mg tretinoin gel 0.1 lasix tretinoin cream online price of levaquin
payday loans no credit check same day online payday loans no credit check personal loan no credit check loan advance
payday loans online payday advances payday lending debt consolidation loan
loan zoom need a loan now loans online personal loan calculator payment
personal loan calculators loans poor credit no credit check loans loans no credit check
best loans starter loan loans american cash advance
online payday payday loan online payday loans online payday loans online
cash advances payday cash advance cash advances cash advance usa
payday loans near me online payday advances payday loans online payday loans instant approval
Some really nice and utilitarian information on this website , besides I believe the style has superb features.
ViralStyle
loans for bad credit loans bad credit loans for people with bad credit a loan with bad credit
loans bad credit loans payday loans direct 1 hour payday loans no credit check
payday loans no credit payday loans payday loans near me payday loans
wh0cd908388 explained here sildenafil baclofen wellbutrin erythromycin acyclovir diclofenac 75mg dr levitra provera diclofenac for more vardenafil levitra proscar betnovate vantin
loans bad credit internet loan loans for bad credit unsecured personal loans for bad credit
wh0cd714278 cialis daily price
installment loan installment loans online fast cash online installment loan
personal loans payday loans in las vegas best personal loan payday loans online legit
wh0cd714278 diclofenac
no fax payday loan no fax payday loan no fax payday loan best payday loan
loans same day loans online loans online online loans for bad credit
bad credit installment loans guaranteed installment loans loans apply direct lender installment loans
payday loans payday loan no fax best payday loan same day online loans
wh0cd714278 buy propecia cheap online
wh0cd714278 Generic Cialis
payday loans online online payday advance payday cash loan loan offices
loans no credit check consolidated loans payday load personal loans no credit check
installment loans no credit check installment loans no credit check bad credit installment loans guaranteed medical loans
wh0cd908388 levaquin
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
wh0cd908388 cafergot & internet pharmacy
http://cialisrpr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisvvr.com cialis
cialis
cialis
http://viagravvr.com viagra
viagra
viagra
payday advance online payday loans online consolidating loans payday advances
wh0cd908388 vardenafil
online payday loan payday advance online payday loans online payday loans online
wh0cd908388 generic cymbalta
loans title loans loan bad credit payday loans bad credit
small personal loans personal loans speedy loan payday loans no fax
wh0cd908388 diclofenac
best online loans payday loans online cash loans online bad credit fast loans
unsecured personal loans best personal loan best short term loans online personal loans
credit loan company no fax payday loans no fax payday loans payday loan no fax
wh0cd908388 buy prednisone cheap
cash payday loans online online payday advance guaranteed payday loan online payday advance
payday online loans loan pre approval bad credit payday loans payday loans
wh0cd908388 bupropion 150 mg
loans a loan with bad credit bad credit loan direct lenders payday loans
loans loan for bad credit loans for bad credit loan for bad credit
payday loans online payday loans online payday loans online loans no credit check lenders
payday loan no fax no fax payday loan payday loan online 100 approval loans
no fax installment loans loans stafford loans loans with bad credit
oregon payday loans loan companies payday loan online online payday advance
online personal loans personal loans personal loans loans personal
payday loans payday loans online direct lenders payday loans payday loans
payday loan direct lenders online installment loans debt consolidation programs installment loans
payday loans no credit check loans poor credit personal loan no credit check private lender
payday loans no credit check payday loans instant approval payday loans online cash advance payday loans
loans best debt relief programs loans loans
loans explained quick cash online small loans quick cash online
wh0cd714278 propranolol 10mg mobic
cash loans direct cash advance online fast cash advance loan money online
payday loans payday loans payday loans 2600 installment loans in california
wh0cd714278 sildalis estrace cream generic equivalent more help amitriptyline tretinoin cream buy avana propranolol inderal 10 mg tablets motilium ampicillin lotrisone for ringworm tretinoin 0.025 indocin 50 mg prozac inderal cephalexin 500 mg capsules indocin sr 75 mg methotrexate ventolin hfa 90 mcg where to buy proscar fluconazole without script paroxetine erythromycin pill
payday loans online guaranteed payday loan payday advance online loans for very bad credit
loans personal loan agreement template usa payday loan best loan
personal loans personal loans best personal loans small personal loans
wh0cd908388 arimidex tretinoin 0.05 moduretic orlistat amitriptyline
no credit check loans loans no credit check loans no credit check loans no credit check
cash advances express cash advance payday loan cash advance payday loan cash advance
best payday loans fast cash payday loans loans direct loans
Simply desire to say your article is as astonishing.
The clarity in your post is just excellent and i can assume yoou are an expert on this subject.
Fine with your permission allw me to grab your feed to keep updasted with forthcoming post.
Thanks a million andd please carry on the gratifying work.
wh0cd714278 nexium cost of tretinoin anafranil anxiety found it prednisolone mobic
get a loan with bad credit best online loans loans online payday loans online
I’d like to thank you for the efforts you have put in writing this website.
I’m hoping to see the same high-grade blog posts from you in the future as well.
In fact, your creative writing abilities has encouraged me to
get my own website now 😉
Hey just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Opera.
I’m not sure if this is a formatting issue or something to do
with internet browser compatibility but I figured I’d post to
let you know. The design look great though!
Hope you get the problem resolved soon. Kudos
wh0cd908388 wellbutrin buy cheap allopurinol abilify albenza tenormin 50 atarax purchase amoxicillin atenolol trazodone 50mg tablets azithromycin viagra elimite generic for keflex pyridium paroxetine doxycycline propranolol inderal vardenafil drug hydroxyzine atarax clomid
online loans for bad credit cash loans online loan online small business loans for women
loan with bad credit payday loans tx loans bad credit loans for bad credit
wh0cd714278 prices cialis
wh0cd714278 amitriptyline 10mg
personal loan application lend money installment loans no credit check installment loans no credit check
wh0cd714278 helpful hints
wh0cd714278 prozac
Hi i am kavin, its my first occasion to
commeenting anywhere, when i rea this paragraph i
thought i coild also create comment due to ths good post.
personal loans pay day online personal loans bad credit best personal loans
wh0cd908388 bupropion online tretinoin cream plavix retin-a kamagra biaxin for strep throat buy celexa online
wh0cd908388 Permethrin Cost
loans small loans loans easy loans
cash loan for bad credit online payday loans no credit check same day payday guaranteed payday loans no teletrack
wh0cd908388 synthroid
loans for bad credit loans in dallas tx free money loan loans
loans personal personal loans personal loans personal loans bad credit
need a loan now loans online loans online loans online
wh0cd908388 Buy Kamagra
wh0cd908388 aciclovir
loans bad credit loans for bad credit installment loans bad credit online loans for bad credit
cash advance usa payday loan cash advance fast cash advance cash advances
money fast online best cash advance loans online loans bad credit payday loans
small loan loan agent small loan cash payday loans
best loans for bad credit loans loans loans
I will right away seize your rss feed as I can’t in finding
your email subscription link or e-newsletter service.
Do you’ve any? Please permit me understand in order that I may subscribe.
Thanks.
a loan with bad credit loans loans bad credit loans
payday loans online cash payday loans online payday advances payday loans online
5000 personal loan small loans online installment loans installment loans
loans no credit check local payday loans online loans no credit check best cash loans
payday loans online loans online loans online paydayloans
payday lending ezmoney payday loans payday loans online payday loans online
payday loans online online payday loan payday loans online payday loans online
loans with low interest rates payday loans online payday loans online 36 month loans
personal loans online reputable debt consolidation online loans directloans
express cash advance cash advances money fast and free express cash advance
payday cash advance cash advances cash advances loans available
installment loans installment loans bad credit installment loans bad credit installment loans
wh0cd714278 lipitor levaquin augmentin
personal loan no credit check payday loans no credit check same day loan apply online loans no credit check
payday loans online instant approval online payday advance payday cash advance cash advances
wh0cd784823 Cheapest Cialis 20mg
wh0cd784823 tadalafil buy
loans for bad credit loans kenya loan with bad credit direct deposit loans
loans loans apply online loans
need a payday loan loan fast cash loans online loans online
green loans payday loan online payday loans online online payday loan
personal loans no credit check loans in tucson online loans no credit check best personal loan rate
loans lenders only payday loans instant loans no credit check loans no credit check
money fast and free bad credit installment loans installment loans legitimate debt consolidation
need a loan now bad credit payday lenders personal loan calculator payment online loans bad credit
payday loans debt relief quick payday loans no fax payday loan
best payday loans loans direct easy loans loans
wh0cd714278 kamagra jelly
loans legit payday loans loan money need a loan with bad credit
credit direct loans quick loans no credit check loans no credit check no credit check direct lenders
wh0cd908388 artane boys band
loans payday loans bad credit direct consolidation loan loans for people with bad credit
wh0cd714278 Valtrex Generic Cost
cash payday loans instant payday loans payday loans instant payday loan
fast cash advance loans bad credit ok cash advance online loan products
installment loans online installment loans installment loans for bad credit installment loans
service loans best payday loans online payday loans payday loans
loans online loans online best online loans payday loans online
cash advances money fast and free express cash advance cash advance online
wh0cd714278 celebrex 200 mg
wh0cd714278 ventolin citalopram zanaflex as an example vibramycin 100mg seroquel for dementia tretinoin cream lasix
wh0cd714278 albendazole principen citation is albenza over the counter bupropion medrol pak 4mg mobic 15 mg tablets hydrochlorothiazide moduretic albuterol purchase flagyl
online payday loans no credit check loans no credit check payday loans no credit check instant loan no credit check
installment loans bad credit installment loans guaranteed installment loans for bad credit how to get a personal loan
loans no credit check personal loan no credit check payday loans no credit check same day payday loans alabama
wh0cd908388 cialis without prescription
wh0cd908388 arimidex by mail order
payday loans no fax payday loans payday loans long term payday loans
loans personal bad credit score loans online personal loans personal loans
whoah this weblog is fantastic i love reading your articles.
Stay up the great work! You understand, many people
are searching around for this information, you can aid
them greatly.
payday cash advance cash advance online payday loans bc payday lenders
bad credit loan bad credit loans a loan with bad credit checking account
loans loans for bad credit personal payday loans personal unsecured loans
online cash loans payday loans in philadelphia dollar loan payday cash advance
best personal loan online personal loans small personal loans personal loans
wh0cd908388 viagra
loans for bad credit loans payday bad credit loan loans for bad credit
speedy bad credit loans loans tribal loans guaranteed approval
wh0cd908388 propecia buspar clonidine for smoking cessation generic for glucophage nexium inderal mobic generic for glucophage provera zyban phenergan
payday loans need a personal loan same day payday loans no credit check payday loans
payday loans best payday loan payday loans quickloans
debt consolidation help loans simple payday loans easy loans
wh0cd908388 clonidine wellbutrin paxil albenza cost misoprostol over the counter cymbalta 10 mg paroxetine neurontin found it for you azithromycin
loans no checking account installment loans online payday loan in california installment loans
cash today installment loans installment loans bad credit installment loans guaranteed
cash advances california payday loans 1 hour cash loans payday cash advance
personal loan with cosigner loans for disabled loans in pa payday loans online
loans for bad credit loans for bad credit large loans get a loan with bad credit
payday loans online online payday borrow money with bad credit payday lending
loans bad credit loans reviews free money loan loans
small business loans for women loans online best online loans easy installment loans
bad credit loans get a loan with bad credit get a loan with bad credit loans bad credit
http://cialisrpr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisvvr.com cialis
cialis
cialis
http://viagravvr.com viagra
viagra
viagra
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagravvr.com viagra
viagra
viagra
online payday loans instant approval loan services payday loans no credit payday loans no credit
best loans for bad credit quick personal loans online loans for bad credit loans for bad credit
datingonline.us.com
adultwebcams
payday loans online commercial loan rates guaranteed payday loan payday loans online
yourcashgroup.com
bestonlinewebcam.us.com
no credit check lenders loan bad credit payday loans bad credit loans for people with bad credit
emergency loans for bad credit how to get a payday loan online loans no credit check loans no credit check
payday loans loan no bank account payday loans payday loans
loans bad credit loans bad credit loans loan money
personal loans personal loans payday loans victoria bc personal loan
best personal loans idaho payday loans loans no credit check payday loans no credit check
loan online payday high interest loans loans loans
loan online payday loans online where to get a personal loan online loans
cash advance online payday cash advance cash advance online payday loan cash advance
wh0cd714278 zyban tadacip viagra for women pink pill generic glucophage paroxetine hcl 20mg tab
apply online loans online loans bad credit loans
online payday online payday guaranteed payday loan loan finder
kimberlymackbeautystudio.com
Good day! I juat would like to offer youu a big thumbs up for
the excellent information you have got here on this post.
I will be returninng too your website for more soon.
wh0cd714278 strattera without prescription
loans for bad credit guaranteed payday loan near me loans bad credit loans reviews
adultonlinewebcams.us.com
wh0cd714278 Zithromax
loan for bad credit loans for bad credit a loan with bad credit loans for students with no credit
loan online payday loan direct lenders only cash loans online loan rehabilitation
bestonlinewebcam.us.com
loan bubble payday loans no credit check same day online payday loans no credit check personal loan for bad credit
bad credit loans loans bad credit bad credit loans bad credit loans
precolumbianwomen.com
loans no credit check loans no credit check quick loans no credit check online payday loans no credit check
loans no credit check loans no credit check loans no credit check online loans no credit check
overnight loans bad credit payday lenders personal loans online easy installment loans
loans loans loans direct direct loans
overnight loans installment loans direct lender installment loans installment loan
personal loans for poor credit payday loans online payday loans online ace cash
stock loan loans for people with bad credit loan repayment program get a loan with bad credit
credit loans reviews cash loans online loans online payday loans online lenders
installment loans for bad credit loans for poor credit scores installment loans for bad credit installment loans for bad credit
installment loans installment loans for bad credit online installment loans cash advance places
reputable debt consolidation guaranteed payday loan payday lending payday advances
wh0cd908388 tetracycline bactrim
wh0cd908388 doxycycline for sale
wh0cd714278 alli orlistat 60mg
wh0cd908388 xenical
loans for bad credit loans for bad credit loans for bad credit best loans for bad credit
Very rapidly this web page will be famous amlng all
blog visitors, due to it’s good content
installment loans online payday loans online lenders installment loans for bad credit installment loan
installment loans for bad credit installment loans no credit check installment loan poor credit personal loans
payday loan online online payday advance short term loan lenders short loans online
express cash advance best consolidation loans cash advances cash advances
wh0cd714278 atenolol hydrochlorothiazide price allopurinol abilify online buy nolvadex cheap tretinoin cream
best payday loans easy loans loans loans
personal loans online loans online best online loans loans online
no credit check loans loans no credit check installment loans online texas loans no credit check
wh0cd908388 tetracycline
cash advance online small loans with monthly payments pay day loan bad credit cash advances
poor credit loans guaranteed guaranteed payday loans payday loans no credit payday loans
installment loans no credit check loans direct deposit installment loans payday loans same day payout
payday loans instant payday loans same day payday loans no credit check payday loan no fax
personal loans online installment loan companies personal loans small personal loans
quick easy cash payday lending payday advance online get a loan without a job
quicken loans arena instant loan no credit check loans no credit check no credit check loans
wh0cd908388 nolvadex lexapro 10mg tablets citation torsemide viagra zyban where can i buy tretinoin cream cephalexin motrin
wh0cd714278 paxil generic cost cheap vardenafil online tetracycline antibiotics advair home amoxicillin buy cafergot methotrexate zanaflex example here avodart generic equivalent lisinopril prinivil zestril clomid purchase zithromax cialis tetracycline nolvadex diclofenac zyban plavix indocin sr 75 mg kamagra tretinoin cream 0.05 artane
payday loan cash advance cash advances express cash advance cash loans direct
online payday advance payday loans online loan bad credit payday lending
payday loans fort collins loans in utah pay day lending loans no credit check
lowest loan rates payday loans payday loan bad credit payday loans
installment loans installment loans bad credit installment loans guaranteed bad credit installment loans guaranteed
loans loans loan with bad credit bad credit payday loans
I am in fact grateful to the owner of this web page who has shared
this wonderful piece of writing at at this time.
cash advances express cash advance payday cash advance reputable online payday loans
online loans for bad credit no credit check lenders get a loan today payday loan lenders online
It’s amazing to go to see this website and reading the views of
all friends oon the topic of this paragraph, while I amm also eager of gettin familiarity.
payday loan edmonton quick credit payday loans quick online loans instant approval
small personal loans personal loans direct loan transfer loan services llc
rise loans online online loans bad credit cash loan fast small payday loan
installment loans installment loans no credit check vacation loans unsecured payday loans
payday loans for bad credit loans bad credit payday loans loans
wh0cd908388 albendazole colchicine erythromycin tenormin estrace clonidine for adhd in adults ventolin hfa price lipitor 40 related site antabuse baclofen pill keflex 500
cash advances small business loans for women cash advances cash advance online
immediate loans for bad credit loans for bad credit loan with bad credit loans with bad credit
no fax payday loan best payday loan payday loans oregon payday loans
wh0cd714278 cephalexin 250 mg
personal loans no credit check payday loans no credit check quick loans no credit check online payday loan instant approval
the lending company loans personal online personal loans guaranteed approval loans
loans for people with bad credit loans for bad credit best debt consolidation loans approved by bbb loans for bad credit
cash payday loans online payday loans online online payday loan personal long term loans
wh0cd714278 additional reading orlistat augmentin can you buy pyridium over the counter generic for celebrex vantin cipro
wh0cd714278 tadacip buy orlistat toprol xl clomid male iv solu-medrol zithromax desyrel 50 mg
payday loans online payday loans online online payday payday loans online
payday loans online payday loans direct lender online payday advance payday loans guaranteed approval
unsecured personal loans personal loans unsecured personal loan quick personal loans online
get a loan with bad credit alternative loan overnight loans loans online
guaranteed payday loans express cash advance unsecured personal loans for bad credit online cash loans
loans loans loans best loan
online personal loans wells fargo loan best personal loans loans personal
personal loan template online loans for bad credit loans online cash loans online
cash advances online payday loans instant approval fast cash advance payday cash advance
payday loan cash advance cash advances cash advance online cash advance online
wh0cd908388 Keflex Penicillin
bestwebcam.us.com|bestwebcam
payday loans no credit check online payday loans no credit check payday loans no credit check same day payday loans no credit check same day
casualsex.us.com
personal loans online loans for people with bankruptcy loans online arizona payday loans
yourcashgroup.com
wifemeetslife.com
wh0cd714278 erythromycin
personal loans with no collateral quick easy cash payday loans online payday loans online
no credit check loans payday loans no credit check quick loans no credit check loans no credit check
fast cash advance cash advances express cash advance cash advances
bad credit loan loans for bad credit loans loans with bad credit
legit payday loans online installment personal loans loans online legit
wh0cd908388 yasmin
wh0cd908388 hydroxyzine atarax generic augmentin prices seroquel rx antabuse xenical orlistat albendazole torsemide
cash payday loans online payday loan loans without direct deposit cash fast online
loans for bad credit loans for bad credit greenline loans loans for bad credit
loans title loans loans for people with bad credit bad credit loan
easy loans payday loans online payday loan online debt consolidation loan
how does debt consolidation work loans loan bad credit loans
wh0cd714278 buy prozac
wh0cd714278 tetracycline
ratingdatingsites.us.com
installment loans online same day cash loans for average credit online installment loans
inspirationalwomenconnecting.com
whitewomenonly.com
wh0cd908388 BUY SYNTHROID
wh0cd908388 Cialis 20 Mg Price Comparison
online installment loans bad credit installment loans installment loans what is a loan
prettywithribbons.com
texas loan loans online best online loans loan online
loans personal unsecured personal loans online installment loan companies personal loans
payday loans bc quick loans for bad credit same day cash advances fast cash advance
where to get a personal loan loans loans loans
wh0cd714278 buy biaxin amoxicillin over the counter clomiphene for sale diclofenac sod 75 mg buy elimite benicar
payday loan no faxing loan payday payday loans no faxing loan payday
cash advance advance cash fast personal loans payday loan providers
instant money direct loans student interest loan loan lenders
consolidation loans for bad credit need a loan with bad credit loans for bad credit payday loans in dallas
no credit check lenders loans loans payday loans for bad credit
no fax payday loan a payday loan easy payday loan loan payday
need a fast loan i need a loan direct loans loans
wh0cd714278 buy cheap ventolin
wh0cd714278 prednisone price
online payday loans instant approval payday loans no credit check payday loans instant approval lowest loan rates
1 hour loan bad credit loan fast cash today loans bad credit
loans for bad credit best loans for bad credit quick money making student loan refinancing
bad credit quick loans payday loan now loans for bad credit loans for bad credit
wh0cd784823 explained here
wh0cd908388 revia lipitor diclofenac vasotec paxil atarax propecia motilium learn more here pyridium lexapro 10mg tablets
no hassle loans money fast quick money money fast
top payday loans easy loan loans direct loans
payday loan lender loan bubble loans without direct deposit consolidation
personal loans for debt consolidation quickloan debt consolidation loan consolidation loans for bad credit
loans top payday loans best loan easy loan
loans no credit loan payday loan payday loan payday
what is debt relief lenders for bad credit lenders lenders
payday loans no fax instant cash payday loans best personal loan payday loans no credit
no credit check loans personal loans low interest guaranteed payday loans no teletrack payday loans no credit check
wh0cd714278 cephalexin 500mg
loans online loans online payday loans online lenders cash loans online
wh0cd714278 tamoxifen indocin cialis where to buy dapoxetine zoloft order sertraline mobic 7.5 mg prednisone vantin 200 mg avana atenolol motrin allopurinol tadacip cipla proscar albendazole tadacip lipitor sales anafranil vermox nolvadex retin-a buy cipro without rx
payday advance online payday installment payday loans online payday loans online
loans usa payday loan best loans loans
immediate payday loans guaranteed loans loans guaranteed approval credit loans guaranteed approval
loans small loan loans direct loans
payday loans best payday loans online payday loans payday loans
cash advance usa cash advance online loans with bad credit cash advances
cash loan advance loans online online loans bank personal loans
loans no credit loans no credit loans no credit loans no credit
first american loans same day payday loans no credit check quick credit same day payday loans no credit check
We’re a group of volunteers and opening a new scheme in ouur community.
Your site provided us with valuable info to work on.
You’ve done a formidable job and ouur whole community will be grateful to
you.
bad credit loans online loans with monthly payments personal loans with bad credit bad credit installment loans
online payday payday loans online payday loans online payday loans online
small loans small loan loans loans
no credit check payday loans instant approval online payday loans instant approval no credit check payday loans instant approval online payday loans instant approval
wh0cd908388 viagra substitutes
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
lenders lenders cash lenders lenders
http://cialisrpr.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisvvr.com cialis
cialis
cialis
http://levitrarrr.com levitra
levitra
levitra
loans bad credit installment loans for bad credit best loans for bad credit fastest payday loan
wh0cd714278 erythromycin cipro mebendazole price zyban
payday loans online loans up guaranteed payday loan payday loans online
best personal loans loans after bankruptcy discharge personal loans best personal loans
wh0cd714278 Order Azithromycin
installment loan installment loans for bad credit buy now pay later bad credit installment loans online
how much loan can i afford online loans online loans loans online direct
wh0cd714278 VIAGRA ONLINE
guaranteed payday loans no credit check payday loans instant approval payday loans in las vegas online payday loans instant approval
payday loans online payday loans online payday lending online payday loan
bad credit installment loans payday loans near me open now bad credit loans online loans for bad credit
wh0cd908388 bupropion plavix buy valtrex cheap toprol xl buy orlistat proair albuterol sulfate online buy amoxil tretinoin wellbutrin robaxin buy generic valtrex online tetracycline 250mg albenza seroquel for dementia agitation allopurinol torsemide azithromycin propranolol tenormin levitra antabuse valtrex clomid diflucan baclofen
new loan loan process best payday loans online online payday loans instant approval
cash loans for bad credit loan payday payday loan payday loan store locator
installment loans loan money now installment loans installment loans
loans with no credit check title loans loans no credit check loans louisiana
loans bad credit loan direct lenders small loans easy loans
consolidation loans for bad credit 100 payday loan debt consolidation loan consolidation
usa payday loans online installment loans online installment loans online
no credit loans no credit loans quick loans no credit 500 cash loan
las vegas payday loan payday loans locations loan payday payday loans in raleigh nc
wh0cd908388 more helpful hints
wh0cd908388 motrin
loans bad credit loans for bad credit installment loans for bad credit direct lenders for bad credit
payday loan no faxing loan payday same day loans no credit check no fax payday loan
loans direct easy loan loans direct payday loan chicago
installment loans loan las vegas installment loans installment loans
loans online spot loan loans online guaranteed loans online
wh0cd908388 colchicine probenecid
personal loans small installment loans online personal loans unsecured personal loans
wh0cd908388 doxyhexal
wh0cd908388 retin a tretinoin cream 0.05 paroxetine 7.5 mg buy stromectol ventolin inhaler without prescription
wh0cd908388 Buy Zithromax Cheap
loans no credit check no credit check payday loans installment loans no credit check same day loans online
cash advance payday loans in dallas tx fast cash advance fast cash advance
debt consolidation loans for bad credit reputable online payday loans consolidation loans for bad credit debt consolidation loan
instant payday loan auto loan with bad credit same day payday loans no credit check long term loans for bad credit
rapid loans loan types payday loan online payday loan no fax
payday loans payday loans payday loan no fax payday loans
personal loan with cosigner payday loans no credit check www loan no credit check loans
loans no credit check installment loans no credit check speedy loan online payday loans reviews
payday loan calgary 100 approval loans cash loans online loans online direct
loans no credit check loans no credit check online loans no credit check no credit check loans
best loan consolidation consolidation consolidation
small personal loans online personal loans payday loans in ga get loan
installment sale loans lenders lenders lenders
payday 2 xbox one bank loans bad credit personal loans personal loans
What do you think about it?
This person is selling the secret of eternal youth: http://shanepmjcv.acidblog.net/7798582/indicators-on-24-7-anti-aging-eye-serum-you-should-know
cash advances express cash advance no fee payday loans cash advances
no credit loans quick loans no credit loans no credit no credit check loans bad credit loans australia payday loans seattle payday loans online payday loans online cash advance loans cash loans for bad credit cash loans cash loans personal loans online personal loan with cosigner personal loans loans personal loans bad credit loans with bad credit bad credit loans personal loans with bad credit online payday payday lending payday lending payday lending payday loans phoenix az loans online loans vancouver alabama payday loans
direct loan program bad credit loan payday loan america loans without credit
payday cash advance cash advance online payday loans in corpus christi payday loan cash advance
wh0cd714278 elimite lotrisone for ringworm neurontin online orlistat buspar where to buy nolvadex lipitor requip depression recommended site
wh0cd908388 price of wellbutrin
payday loans payday loans unsecured instant payday loans
wh0cd908388 Albuterol No Prescription
cashnowoffer tracking unsecured loans for bad credit loans for bad credit debt consolidation loans for bad credit
unsecured credit loan payday loans in illinois direct lenders payday loans online
online loans online loans online personal loans installment loans online online installment loans loans online online loans loans online online payday loans payday loans online payday loans online loan exit payday cash advance apply for a loan online online cash advance online cash advance same day same day same day bank loan application guaranteed approval guaranteed approval america loan 1 hour payday loans no credit check payday loans lender loan payday payday loans online 12 month loans
loans no credit check online loan direct lenders personal loans no credit check loans guaranteed
direct loans small loans loans loans
loans online loans online loans online online loans for bad credit
find loan cash advance payday loans denver no credit check payday loans near me payday loan payday loan a payday loan payday loan loans online direct lenders personal bad credit loans online instant loans same day advance cash
how to get a personal loan loans for bad credit loans for bad credit installment loans for bad credit
personal loans guaranteed payday loans no credit check personal loans guaranteed approval loans
installment loan online loans with bad credit a loan with bad credit bad credit loans
faxless payday loan loan payday a payday loan loan payday loan payday payday loan no fax loan payday guaranteed payday loan cash advance america no fax installment loans payday loan bad credit loans for bad credit california payday loan cash loans cash advance loans cash loans list of payday loans installment installment installment loan a payday loan payday loan bad credit online loans payday loan
payday loan cash advance quick credit payday cash advance fast loan online
wh0cd908388 medicine augmentin lipitor celexa where to buy proscar cialis buy indocin hydrochlorothiazide atarax biaxin lexapro 5mg
debt consolidation loans for bad credit debt consolidation loans for bad credit consolidation consolidation
wh0cd714278 how do i get valtrex
installment loans direct lender installment loans payday loans canada installment loans
installment loans for bad credit installment loans online direct lender installment loans small loans with monthly payments
wifemeetslife.com
freemaledatingsites.us.com
loans online cash loans online direct lender payday loans no teletrack loans online
payday loans guaranteed approval fash cash payday lending guaranteed payday loan
online loans installment loans online loans online online payday loans payday loan instant decision cash advance loans direct lender payday loans vancouver cash fast loans loans for bad credit payday loans colorado loans for bad credit cash loans for bad credit loans online loan direct online loans online loans installment advance payday loans installment installment loans loan payday loan payday loans for payday payday loan payday advance payday advance online eagle loan company of ohio advance payday online payday loans online payday loan payday loans online payday loans online
loans online loans online secured loan online loans payday loan 1hr payday loans a payday loan payday loan ez payday cash loans in athens ga loans instant approval loans guaranteed approval installment installment online installment loans installment loans with bad credit loans for bad credit my payday loan loans bad credit same day same day same day fast loan
payday loans no credit payday loans loan source guaranteed payday loans
holiday money direct lender installment loans installment loans installment loans
personal loans low interest payday loan online payday loan no fax small personal loan
personal loans no credit check loans with no credit check loan rates loans no credit check
payday loans oregon direct lenders for payday loans installment loans payday loans with no credit checks
payday loans no credit payday loans no credit online check cashing guaranteed payday loans
wh0cd908388 buy vardenafil
need money loans for bad credit get a loan without a bank account loans bad credit bad credit loans loans for bad credit loans for bad credit bad credit loans personal loans cash advance definition get a personal loan personal loans payday lenders only personal loans personal loans reputable online payday loans no teletrack payday loans direct lenders a payday loan payday loan loan comparison calculator
best loans for bad credit direct lenders for bad credit best loans for bad credit loans loans
payday loans ez cash payday loans payday loans in cleveland ohio loan services
adultonlinewebcams
loan for bad credit a loan with bad credit loans for bad credit payday loans for bad credit
loan source payday loans payday loans bad credit payday loans
installment loans installment loans installment loans loans for the disabled
wh0cd714278 generic cialis safe
wh0cd714278 cephalexin 500
wifiwirelesscameras.com
cash advance online payday cash advance cash advances short term
instant payday loan payday loans payday loans payday loan no fax
best loans best loans loans with cosigner small loan
payday loans online payday loans definition small payday loan payday loans online
personal loan for consolidation easy loans for bad credit faxless payday loan same day
payday loans no credit check quick loan for bad credit payday loans direct lender loans no credit check
womenbikeatlanta.com
byebyepretty.com
indian loans unsecured loans for bad credit consolidation loans for bad credit bad credit loans bad credit payday loan loans online loans online online loans best online loans best online loans fast money online payday loans cash in minutes cash loans cash loans quick cash loans ez payday cash web loans loan locations installment loans no turndowns
private lenders for personal loans consolidation loans for bad credit loans from direct lenders loans for bad credit guaranteed
cash fast online bad credit installment loans guaranteed payday advance online quicken loans careers
wh0cd714278 motilium online cafergot albuterol levitra viagra cialis
loans no credit check loans no credit check loans no credit check loans no credit check
bad credit installment loans guaranteed installment loans loans no bank account bad credit installment loans
loans for bad credit loans for bad credit loans for bad credit loans instant
get loan personal loans personal loans best personal loans
wh0cd908388 toradol for tooth pain
torssexdvd
no faxing payday loan loan payday loan payday [url=https://loanpayday.shop]cash loan payday[/url]
wh0cd714278 [url=http://bactrim18.live/]recommended site[/url] [url=http://clonidine18.live/]clonidine[/url] [url=http://nexium18.live/]order nexium online[/url] [url=http://tadacip18.world/]generic tadacip[/url] [url=http://atenolol18.world/]atenolol[/url] [url=http://celexamedicaid.doctor/]celexa[/url] [url=http://lasixmedicaid.doctor/]lasix 40 mg[/url] [url=http://medrol18.world/]medrol 16 mg[/url] [url=http://neurontin18.world/]neurontin[/url] [url=http://zithromaxmedicaid.doctor/]zithromax[/url] [url=http://cafergot18.world/]cafergot[/url] [url=http://provera2018.host/]provera[/url] [url=http://moduretic18.world/]moduretic without prescription[/url] [url=http://propecia18.live/]propecia[/url] [url=http://furosemide.video/]furosemide 40mg[/url] [url=http://zyban.video/]zyban[/url] [url=http://levitra247.video/]levitra[/url] [url=http://prednisone2018.video/]sterapred[/url] [url=http://clomidmedicaid.doctor/]where to buy clomid[/url] [url=http://nexium2018.host/]continue reading[/url] [url=http://atarax2018.press/]atarax[/url]
cash quick loans no credit check payday loans direct deposit [url=https://loansnocreditcheck.store]fast loans no credit check[/url]
[url=http://nazaninmousavi.com/index.php?subaction=userinfo&user=mouthtthelookcuy1985]womensspeakernetwork.com[/url]
cash-for-old-car.com
bad credit loans bad credit loans installment payday loans 2000 loan online payday advance payday advance auto loans loan application online payday loans portland oregon bad credit loans bad credit loans direct lender payday loan best places to get a personal loan unsecured personal loans personal loans online best personal loans lenders guaranteed loan for bad credit lenders best loans
independent payday lenders personal loans no teletrack loans best personal loan
loans online loans online personal loans online best online loans
loans no credit check no credit check payday loans loans no credit check loan provider
installment installment loan i need cash now installment payday loans indiana online payday advance payday advance online payday loans online loan settlement online payday advance payday advance payday advance loans for bad credit guaranteed quick loans online online loans what is installment credit loans for bad credit bad credit loans payday loans online lenders small loans for bad credit
debt consolidation loans for bad credit best debt consolidation loans payday direct lenders get cash now loans
no credit check payday loans instant approval loans no credit check payday loans no credit check same day no credit check payday loans
quick personal loans same day online loans loans online direct cash advance utah online cash guaranteed approval apply for a loan guaranteed approval fast cash advance cash advance advance cash advance cash fast cash loan personal loans paydayloans personal loans advance payday payday advance payday advance loans payday advance
direct lenders online loans installment loans installment loans best personal loan rate
online payday online payday loans online payday advance online payday bad credit loans bad credit loans loans for bad credit loans houston online loans no credit check cash advance online loans 800 loan payday advance online payday loans online online payday loan teacher loan installment loan payday loans vancouver bc installment installment online installment loans installment installment installment loan
loans with bad credit loans for bad credit loans for bad credit loan calculator personal
wh0cd908388 info paroxetine
wh0cd908388 zoloft hydrochlorothiazide found it for you esomeprazole nexium
learntopullwomen.com
online payday advance loans instant approval online poor credit loans payday loans online
loans no credit check payday loans no credit check easy loans no credit loan quick
loan online best online loans loans online loan online
best loans loans easy loans loans
advance cash payday cash advance online cash advance express cash advance bad credit loans bad credit loans loans for bad credit bad credit score loans
personal loans no credit personal loans personal loans loan refinancing first american loans money lenders signature loans no credit check cash lenders very poor credit personal loans guaranteed loan guaranteed approval credit loans guaranteed approval payday cash advance advance cash loan agent cash in advance payday loans online money lender no credit check payday loans online payday loans online
cash lenders lenders need a loan now loan lenders
wh0cd908388 buy furosimide lipitor amantadine cafergot abilify 2mg requip xl generic generic for strattera abilify advair 500 paxil doxycycline orlistat found it amoxil generic proscar buy motilium orlistat over the counter buy valtrex online without a prescription buy phenergan arimidex amoxicillin
payday cash advance cash advances express cash advance fast cash advance
loans for people on disability quick loans no credit check loans no credit check personal loans no credit check
no credit loans loans with no credit personal loan contract template bad credit loans
loans no credit check payday loans no credit check cash advance form payday loans same day
loans payday loans for bad credit payday loan with no credit check emergency payday loans online
loans without credit loans 500 credit loans direct deposit loans
guaranteed payday loans payday loans payday loans best payday loans online
lenders american financial loans private money lenders lenders
cash lenders loan lenders illinois payday loans lenders
personal loan 1000 loans loan interest personal loan money lenders online online personal loan personal loans cash advance places payday lenders private money lenders loan usa direct payday lenders bad credit loans bad credit bad credit payday bad credit loans cash payday loans online online payday loans best payday loans online payday loans online loans with bad credit payday loans online legit need a loan immediately need a loan immediately payday loan loan payday very bad credit personal loans payday loan
personal loan payments calculator consolidation best debt consolidation loans personal loans for debt consolidation
personal loans no credit check no checking account payday loans quick loans no credit check loan form
bad credit loans for bad credit bad credit loan loans bad credit loans for bad credit
consolidation loans for bad credit need a loan with bad credit loans for bad credit loans for bad credit
need a loan with bad credit need a loan with bad credit loans for bad credit loans for bad credit
wh0cd714278 toprol xl inderal propranolol buy vardenafil online propecia price comparison buy diclofenac sodium
payday loans online online payday advance loan advance cash loan payday loans online
lenders for bad credit bad credit bad credit bad credit payday direct lender installment loans low interest loans installment installment online cash payday loan a payday loan a payday loan loans online guaranteed approval payday loans loans online loans online money quick online loans fast cash today payday loan help personal loans guaranteed loans online loans online loans online
personal loans loans personal online personal loans best personal loans
bad credit loans bad credit loans loans for bad credit loans with bad credit instant cash payday loans loans guaranteed approval loans guaranteed approval loans guaranteed approval payday loan payday loan emergency cash loan payday payday lenders loans direct lenders loans direct lenders loans direct lenders money fast money fast need money fast personal loan contract credit loans loans no credit private loan no credit check loans loans online payday loans houston loans online best online loans
wh0cd714278 LIPITOR CANADA
ez cash payday loans no credit check payday loans instant approval no credit check payday loans instant approval payday loans near me
instant credit online online loans loans online online installment loans lenders lenders same day payday loans online lenders
money fast payday loan california money fast online money fast online usa payday loan interest rates 2017 unsecured personal loans personal loans bad credit loans bad credit loans loans bad credit bad credit loans a payday loan a payday loan a payday loan a payday loan cash loans for bad credit cash loans quick cash loans fast cash advance payday loan credit loans loans no credit loans in charlotte nc no credit check loans online payday loan bank personal loans online payday online payday loans no credit first loan cash advance today loans no credit
small loans with monthly payments bad credit installment loans installment loans bad credit installment loans guaranteed
personal loans guaranteed approval personal loans guaranteed approval instant online payday loans guaranteed approval installment installment online installment loans christmas loan
loans online payday loans online payday loans online loan online
reputable debt consolidation online payday advance awl loans loans installment
installment loans vacation loans loans in illinois installment loans no credit check
loans loans direct direct loans what is installment credit
online payday payday loans online loans no credit check instant approval payday loan lenders no credit check
payday loans online payday loans instant approval payday loans near me payday loans
loans online loans online online payday loans online cash register loans online no credit check guaranteed approval guaranteed approval guaranteed approval payday advance personal lending payday loans plain green loans personal loans online urgent payday loans personal loans online how to apply for a loan
bad credit installment loans guaranteed installment loans no credit check installment loans for bad credit online installment loans
wh0cd908388 mobic online cipro mobic how much does buspar cost zoloft prescription pyridium azithromycin doxycycline proventil for sale methotrexate biaxin bronchitis trazodone estrace cream price comparisons
wh0cd908388 generic viagra 150 mg
online loans bad credit loans online loans online loans online
american cash loans installment loans bad credit installment loans installment loans
online payday advance personal loans no credit check personal loan website online payday online payday loans reviews loan payday installment lenders progressive loans installment loans online what is payday loan installment installment loans no credit check bad credit loans bad credit loans online loans with monthly payments loans for bad credit loans guaranteed approval loans guaranteed approval installment loans guaranteed loan stores
payday loans payday loans payday loans in philadelphia instant payday loan
loans with bad credit bad credit loans one hour payday loan loans without credit
wh0cd714278 furosemide
online loan direct lenders personal loans no credit check installment loans no credit check personal loan no credit check
guaranteed payday loan short term guaranteed payday loan loan payday 5000 personal loan personal loan personal loan personal loan check loans online loans fast cash personal lending payday lending payday advance online payday advance payday advance loans payday advance loan loans for bad credit bad credit loans remodel loans loans no checking account loan online instant no credit check loans american cash loans loans with no credit denver payday loans debt relief program same day pay day loan quality loan service loan lenders directloans lenders
bad credit installment loans guaranteed payday online loans installment loans for bad credit loans on line
loans bad credit loan locations bad credit payday loan get a loan with bad credit
loan with bad credit get a loan with bad credit loans for people with bad credit get a loan with bad credit
online money installment loans no credit check direct lender installment loans installment loans
installment sale lenders for bad credit lenders installment loans direct lenders
payday loan lender installment loans no credit check unsubsidized loan online loans no credit check
online payday loans instant approval payday loans online payday loans instant approval loans without cosigner
loans with no credit no fax payday loan loans with bad credit loans with bad credit
1000 dollar loan loans online top online payday loans loans online personal loans unsecured personal loans personal loans personal loans easy payday loan small personal loan loan payday cash loans with monthly payments payday loan online bad credit installment loans guaranteed loans guaranteed approval guaranteed payday loans
Wow, this article is nice, myy sister is analyzing
such things, so I am going to convey her.
wh0cd908388 xenical 120mg
private lenders best pay day loans lenders need money now please help payday loan places cash payday loans cash advance loans cash loans same day pay day loan same day payday loans same day faxless payday loan loan payday a payday loan payday loans without a checking account payday lenders lenders loan lenders loans without credit checks payday loan sites online loans loans online instant loans online loans for bad credit bad credit loans bad credit loans loans for bad credit
loan payday a payday loan a payday loan easy payday loan cash loans cash loans cash advance loans quick cash loans payday loan a payday loan a payday loan apply for a loan find loan quick cash loans for bad credit loan payday payday apk
no credit check payday loans instant approval payday loans bc money till payday best payday loans online
wh0cd714278 aripiprazole abilify amoxicillin over the counter
installment loans installment loans low rate loans direct lender installment loans
quick online loans instant approval payday loans ez cash payday loans payday loans
personal loan no credit check payday loans lake charles loans no credit check loans no credit check
wh0cd784823 cost of strattera
private money lenders payday lenders micro loan payday bad credit loan internet payday loans loans online loans online loans online get a personal loan personal loan best personal loan personal loan loan lenders lenders payday loans lenders loans bad credit online cash advance fast cash advance cash advance online personal loans online payday loan payday loans online online payday advance payday loans online payday installment loans apply bad credit direct lenders
payday lenders paydayloans lenders direct lenders for bad credit
loans no credit check loans no credit check i need a loan with bad credit fast payday
Hey there! Would you mind if I share your blog with my facebook
group? There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thank you
online payday loans online payday advance money lending how to get money fast fast loans bad credit payday loans online payday loans online online payday loans payday loans no credit check same day pay day payday loans no credit check same day pay day loans houston bad credit payday loan lenders bad credit payday personal loans online signature loans personal loans ez cash best online loans best online loans quickloans loans online
wh0cd784823 source
loans small loans best payday loans loans
loans in pa bad credit quick loans loans for bad credit loans for bad credit lenders lenders lenders lenders direct lender installment loans installment installment installment loans guaranteed advance cash fast cash advance cash advance advance cash a payday loan a payday loan a payday loan a payday loan loans online online loans online loans online payday loans las vegas
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
no fax payday loan loan for bad credit immediate loans for bad credit loans bad credit
payday loan a payday loan payday loan payday board loans for bad credit specialized loan services payday loans of america loans for bad credit fast loans no credit check loans no credit check loans no credit check loans houston quickloans debt consolidation loans for fair credit guaranteed loan credit loans guaranteed approval loans in illinois guaranteed loans installment loans guaranteed credit loans guaranteed approval payday loans online easy payday payday loans online online payday loans loans by phone take out a loan cash advance usa advance cash loans online online loans best online loans online loans
wh0cd908388 abilify zoloft
online loans bad credit direct lender loan loans online online loans instant
personal loans america loan lendingtree personal loans best personal loan
short term installment loan bad credit personal loans guaranteed approval credit loans guaranteed approval no teletrack faxless payday loans direct lenders payday loans online new payday loan companies loans no credit payday 3
need money now please online payday loans instant approval payday loans online bad credit installment loans
pay day loans near me i need a payday loan today installment loan calculator installment loans for bad credit
bad credit loans loans for bad credit low interest personal loan loans for bad credit loans no credit check no credit check payday loans loans no credit check online loans no credit check loans online best online loans cash now bank loans bad credit bad credit loans consolidation loans for bad credit bad credit loans easy to get payday loans loans online quick loans online online loans cash loans online personal loans guaranteed approval money loans no credit check loans online payday loan consolidation
guaranteed loan loans guaranteed approval personal loans guaranteed approval loans guaranteed approval pay day loan pay day loans pay day loan same day payday loans money fast money fast money fast money fast
get cash now loans for bad credit loan for bad credit best loans for bad credit
loan for bad credit loans with bad credit loans for bad credit loans for bad credit
payday loans no credit check personal loan no credit check loans no credit check online loans no credit check
loans for bad credit best loans for bad credit loans up to 1000 a loan with bad credit
no credit check loans personal loans no credit check loans no credit check personal loan no credit check
wh0cd714278 zoloft synthroid 75 methotrexate cipro robaxin can i get viagra over the counter furosemide 40 mg zanaflex bupropion generic for celebrex 200 mg hydrochlorothiazide tab 25mg torsemide
loans for bad credit bad credit loans best loans for bad credit loans for bad credit
unsecured personal loan payday loan installments unsecured personal loans personal loans
payday loans online online payday loan payday loans online payday loans online
cash advances express cash advance cash advances cash advance usa
consumer payday loans loans for people with poor credit direct loan program debt consolidation program
payday loans online payday loans online payday loans online personal installment loans
best personal loans online payday loan no fax payday loans money loans for bad credit
wh0cd714278 cialis 20
personal loans personal loans personal loans personal loans guaranteed approval dental loan personal loans guaranteed approval personal loans guaranteed approval loan payday quick cash online payday loan easy payday loan loans online easy payday loan online loans online debt consolidation loans for fair credit
payday loans no credit check money direct payday loans no credit check payday loans no credit check
get a payday loan online payday loans columbus ohio personal loan no credit check loans no credit check
payday loans online payday loans las vegas instant payday loan payday loans
loans for bad credit loans for bad credit loans for bad credit unsecured loans for bad credit
no credit check loans no fax payday loans online loans no credit check loans no credit check
wh0cd714278 indocin 50 mg albenza price azithromycin z pack torsemide albuterol for sale online
online loans no credit check loans no credit check advance no credit check payday loans
wh0cd908388 Buy Benicar
wh0cd908388 moduretic without prescription wellbutrin artane avodart nexium 20 cialis 100 mg online propecia prescription abilify medication citalopram 20 mg for anxiety how much does ivermectin cost trazodone found it motilium domperidone
consolidation loans with bad credit a loan with bad credit credit loan company direct loan transfer
same day pay day loans near me pay day loans near me progressive loans loans with no credit bad credit loans loans review bad credit loans loans guaranteed approval loans guaranteed approval loans guaranteed approval poor credit loans guaranteed approval personal loans personal loans new payday loans personal loans microloans money fast fast money fast installment installment loan installment loan installment
texas payday loans cash advances fast cash advance advance payday
loan market loans for bad credit payday loan installment loans for bad credit
wh0cd714278 lipitor zocor
installment loans no credit check payday loans no credit check payday loans denver colorado loans installment
payday loans canada no fax payday loans loan payday loans payday
installment loan installment loans installment loans payday bad credit loan
personal loan no credit check where to get a personal loan easy loans no credit payday loans no credit check
loans no credit check quick loans no credit check loans no credit check loans no credit check
advance payday payday lending loan payday debt consolidation program online payday loans payday loans denver colorado cash advance loans online payday loans loans online usa payday loans loans online online loans payday loan payday loan a payday loan payday loan same day same day payday loans no credit check 100 guaranteed approval payday loans consolidated debt relief loan type installment loans online installment loans installment loans no credit check payday loans online best payday loans online payday loan online loan companies
quick loans online same day payday loans no credit check payday loan online no fax payday loans
bad credit loan paydayloans emergency payday loans online payday loans direct lender
wh0cd908388 strattera motilium cephalexin bupropion xl 150mg buspar provera permethrin cream 800 mg seroquel proscar toprol xl doxycycline mobic generic tadacip zanaflex propranolol 60 mg
payday loans online internet payday loans internet payday loans internet payday loans
torssexdvd
onlinedatingsites.us.com
loans no credit check loans no credit check best personal loan rate online payday loans no credit check
wh0cd908388 order celebrex
loan companies for bad credit loans no credit check online payday loans no credit check bank loans for bad credit
best debt consolidation loans consolidation best debt consolidation loans consolidation loans for bad credit
payday loans payday loans bad credit payday loans payday loans
loans online paydayloans online loans for bad credit cash loans online
advance cash debt consolidation for bad credit advance cash web loans payday loans in raleigh nc payday loan loans without cosigner a payday loan loans for bad credit bad credit quick loans loans today loans for bad credit loans for bad credit loans for bad credit loans for bad credit loans bad credit payday loan a payday loan a payday loan payday loan online payday loans debt consolidation for bad credit advance cash payday loan online personal loans
personal loans personal loan missouri payday loans credit personal loans
fast online loans loans for bad credit a loan with bad credit payday loans salem oregon
bad credit unsecured loans loans online best online loans best online loans
torssexdvd.com
wifiwirelesscameras.com
onlinedatingwebsites.us.com
loans bad credit payday loans loans
no teletrack payday loans direct lenders easy cash advance loan payday loan payday money loans no credit check missouri payday loans loans no credit check loans no credit check advance cash cash advance cash advance payday loans near me no credit check
loans for bad credit bad credit loans loans bad credit guaranteed approval get payday loan online alabama payday loans cash advance usa cash advance loan till payday loans for bad credit online payday loans direct lender short loans loans for bad credit payday loans online best payday loans online online payday best payday loans online payday loans instantly personal loans with bad credit loans bad credit best loans for bad credit
a payday loan payday loans payday loans payday loans
cash loans cash payday loans online cash loans cash loans for bad credit debt consolidation loans bad credit installment installment loans loans poor credit
loans for bad credit payday calendar loans for bad credit loans for bad credit
wh0cd714278 doxycycline preddisone no paroxetine antabuse avodart allopurinol arimidex
installment loans for bad credit direct lender installment loans 100 payday loan installment loan
online payday loans online loans online loans best online loans pay day loans near me loan interest rates 2017 pay day same day payday loans loans no credit instant approval bad credit loans installment sale no credit check payday loans instant approval advance cash cash loans bad credit bad credit loans uk online loans no credit check payday loan no fax payday loans near me no credit check loan payday payday loan no faxing payday loans in dallas tx cash loans with monthly payments bad credit personal loans guaranteed approval loans guaranteed approval
5000 personal loan best bad credit loans military loans installment loans
payday lenders lenders cash lenders quick loan
cash loans online online loans direct payday lenders small business loans for women
payday loan calgary money fast cash advance locations money fast quickloans online installment loans best online loans online loans loan payday marcus loans loan payday hard money loans
quick easy cash loans to build credit bad credit loans bad credit quick loans loans no credit loans no credit utah payday loans direct lenders bad credit same day loans what are good credit scores loans online legitimate payday loan companies personal loans best personal loans unsecured personal loans personal loans
payday loan free money loan unsecured loan no credit check payday loans online a payday loan easy payday loan payday lenders online payday loan best online loans online loans bank loans bad credit loans online cash advance loans no credit check small loans with monthly payments loans no credit check lenders lenders cash lenders private lenders online loan application loans no credit loans no credit loans no credit home loans guaranteed approval online loans online loans online loans advance payday on line payday loans indiana payday loans personal lending
fast cash loans cash payday loans unsecured personal loan cash payday loans guaranteed approval guaranteed approval guaranteed approval loans guaranteed approval loans with bad credit cash loans for bad credit non payday loans payday loans portland oregon personal loans personal loans personal loans no credit personal loans online installment loans installment loans installment loan payday advance loan
payday loans guaranteed acceptance payday loans no credit check no credit check payday loans loans no credit check
loans no credit check payday loan no credit personal loans no credit check auto loans
loans for bad credit loans for bad credit bad credit payday loan apply for a payday loan online
small personal loans payday loans no credit check loans no credit check online loans no credit check
wh0cd908388 fluoxetine advair buy albenza stromectol
eagle loan company of ohio payday online loans credit loans no fax payday loan
cash loans cash loans payday in advance cash loans online installment installment loan short term loans online installment online installment loans loans online payday loans nj online loans same day payday loans same day payday loans loan exit same day online cash advance no credit check cash advance places credit consolidation loans personal loans cash lenders payday loan lenders payday lenders best pay day loans installment loans online online payday loans california online personal loans loans online
wh0cd714278 generic cipro
wh0cd714278 amoxil 875 mg
easy cash payday loan no fax payday loan online payday loan cash loan payday
credit loans credit loans loans no credit loans no credit car loans no faxing payday loan car loans online loan companies money loans no credit check loans no credit check money loans no credit check fast loans no credit check payday loans no credit check no employment verification cash payday loans online person to person loans person to person loans
consolidation loans for bad credit personal loans for people with bad credit a loan with bad credit loan for bad credit
unsecured credit online loans payday loan advance top online payday loans lenders loan to pay off credit cards lenders small payday loans fast payday loans near me installment loans online payday loans oklahoma city installment loans
best online loans online installment loans loans online payday loans mn lenders lenders cash lenders lenders
micro loan unsecured loans with bad credit cash loans private lenders online loans instant approval bad credit payday advance 1000 loans payday loan maryland
lenders online payday lenders loan comparison calculator first american loans loans with bad credit loans bad credit loans for bad credit loans for bad credit 5000 personal loan loans fast cash payday lender direct first american loans
online payday online payday loan small loans payday loan online cash loans online online loans loans online direct quick loans online credit card debt consolidation payday loan online bad credit loans guaranteed approval paycheck loan payday 2 blt loan payday unsecured loans with bad credit discount payday loans
no credit check payday loans instant approval 1 hour payday loan loans no credit check no credit check payday loans
wh0cd908388 buying buspar
payday loan lenders direct payday loan loan payday credit card consolidation loan loans online guaranteed loans with no credit check loans no credit check fast loans no credit check immediate loans private lenders money lenders money lenders legitimate debt consolidation payday loan a payday loan a payday loan
personal loans no credit check no credit check payday loans no credit check payday loans personal loan no credit check
wh0cd714278 cephalexin 500mg
wh0cd714278 rogaine
payday lenders money lenders lenders loans direct lenders same day loan websites pay day national payday loan best payday loan companies loan waiver loans no credit quick loans no credit best payday loans online best payday loans online bad credit loans approved best payday loans online payday advance loan online installment loans online installment loans reliable payday loans
credit loans credit loans credit loans no credit loans
online loans bank loans bad credit loans online online loans online payday cash payday loans online credit loan company payday loans online money till payday online loans online loans online loans cash payday loans online pay day loans near me quick cash loans check cashing payday loans personal loan san antonio payday loans loans with bankruptcy unsecured personal loan
wh0cd714278 diclofenac viagra purchase flagyl online amoxicillin artane 5 mg levitra tablets vermox ventolin hfa price anafranil buy sildenafil online furosemide lisinopril cheap cialis pills online
personal loans online cash loans online loans online loans online payday loans poor credit payday loan store locations private lenders payday lenders easy cash loans cash advance loans direct lender no checking account payday loans loans online online installment loans installment loans online installment loans installment loan cash loans cash loans cash loans no credit cash loans loans no credit loans no credit small loans online loans no credit
wh0cd714278 biaxin more about the author moduretic inderal propranolol inderal buy paroxetine online indocin cialis online with prescription diclofenac lexapro 10mg tablets torsemide amoxicillin flagyl hydrochlorothiazide seroquel cafergot zanaflex generic abilify canada vardenafil 20mg lipitor
best loans for bad credit loans for bad credit ace cash loan without credit
loan payday bad credit same day loans loan payday loan payday
a payday loan payday loan payday loan payday loan loans online payday loans san diego loans direct lenders only loans online loans no credit consolidation loan companies loans no credit loans no credit
wh0cd714278 orlistat capsules
debt consolidation loans for bad credit consolidation loans online no credit best debt consolidation loans
wh0cd714278 atarax
payday loan need money today a payday loan california payday loan payday loans online payday loans online payday loans online online payday installment loans installment installment installment pay day loans near me same day payday loans no credit check same day same day loans 5000 personal loan 5000 personal loan personal loan personal loan
wh0cd908388 Cheap Provera
loans with bad credit bad credit loan credit loans credit loans
payday lending personal loan options guaranteed loan payday lending installment loans installment loan installment installment loan loans no credit need money to pay bills installment loans for poor credit loans no credit personal loans personal loans money shop payday loans personal loans installment loan installment installment loans in utah no credit loans loans no credit bad credit loans approved no credit loans installment definition a payday loan a payday loan a payday loan small loans for people with bad credit guaranteed loan guaranteed approval instant online loan
wh0cd908388 pyridium allopurinol neurontin generic indocin clomid glucophage retin-a motilium otc tadalafil buy wellbutrin furosemide aldactone 50 mg benicar
personal loans payday uk personal loans personal loans debt consolidation programs quickloans debt relief reviews quickloans easy loans no credit check no credit check loans loans no credit check no credit check loans bad credit loans how do payday loans work very bad credit payday loans term loans loans online online loans emergency loans no credit check loan company loans guaranteed approval loans guaranteed approval cash advance america loans guaranteed approval online payday advance online payday online payday advance online payday private lenders usa cash payday loans online low rate personal loans
wh0cd908388 drug keflex methotrexate levitra viagra cialis buy xenical cheap levaquin zofran motrin cipro strattera avodart cymbalta generic antabuse online elimite
payday loans online hassle free payday loans online payday loan payday loans online cash loans consolidated loans cash loans cash loans online installment installment installment loan installment loan payday advance loan payday advance loans advance payday loans student
payday loans bad credit ok payday lender consolidation best student loans
online personal loans best personal loans 100 day payday loan personal loans payday loan payday loan easy payday loan payday loan
lenders for bad credit lenders payday loans online same day lenders payday lenders cash lenders payday lenders cash in advance best online loans instant approval best online loans online payday loans best online loans online installment loans online payday loans instant best loan consolidation online loans same day loans same day lend money same day
bad credit loans lenders for bad credit bad credit bad credit loans for bad credit loans for bad credit loans with bad credit fast online loans badcreditloans personal loan companies loans companies payday loans colorado guaranteed unsecured loans apply for credit payday cash advance loans direct payday loan
installment loan online credit loans no credit loans credit loans
guaranteed approval direct online payday lenders guaranteed approval payday loans houston same day pay day loan same day same day payday loans online payday payday loans online cash advances payday loans cash payday loans online cash advance locations payday load installment loans online unsecured payday loans installment installment loan installment loan loan money fast loanme loan payday loan payday 100 guaranteed approval payday loans direct loan consolidation cash advance usa advance cash payday cash advance
loan payday loan payday loan payday loan payday loans for debt consolidation loans with no credit checks bad credit loans bad credit loans money loan online credit loans guaranteed approval loans guaranteed approval guaranteed loans short term loans no credit payday loan payday loan loans online direct installment advance cash internet payday loan bad credit personal loans guaranteed loans no credit loans in virginia loans no credit loans no credit payday lending best cash advance payday lending payday lending loans up to 1000 loan payoff get a loan with no credit cash advance near me
payday loans direct lending advance payday advance payday loans no credit quick loans no credit no credit check loans no credit loans installment online installment loans installment online installment loans
payday loan payday lenders payday loan cash advance online commercial loans loans online easy cash loans loans online personal loans personal loans online signature loans apply for payday loan consolidating loans best loans for bad credit loans bad credit loan now payday loans ga easy payday loan online short term loans payday loan money lenders lenders next day payday loan private money lenders loans for people with no credit advance cash cash advance loan advance cash money fast money fast cash loans for bad credit money fast
wh0cd714278 zithromax methotrexate advair buy advair on line
quick cash loans cash payday loans online get a loan fast cash loans money lenders money fast online money lenders 3000 loan payday loans online online payday payday loan online payday loans online online payday advance advance payday payday advance payday advance
personal loan contract template credit loans credit loans loans with bad credit
bad credit cash loans consolidation loans for bad credit consolidation loans for bad credit bad credit installment loans
loans no credit check no credit check payday loans instant approval installment loans no credit check personal loan no credit check
cash advance online payday loans online payday loans online payday loans online no credit check
payday loans online loans in ohio cash advance online payday loans online
100 loans loan payday loans up loan payday
loans no credit check loans no credit check loans bad credit guaranteed approval personal loans no credit check
wh0cd714278 price of prozac
small loans for bad credit get a loan with bad credit installment loans for bad credit loans for bad credit
wh0cd908388 nolvadex tamoxifen citrate mobic
wh0cd714278 LISINOPRIL
wh0cd714278 viagra tablets
cash-for-old-car.com
loans for bad credit get a loan without a bank account best loans for bad credit installment loans for bad credit
advance cash cash advance cash advance fast cash advance same day same day payday loans pay day loans near me no credit check payday loans online ez money bad credit loans pool loans bad credit payday loan application online payday advance personal loan interest advance payday loans no credit payday loans in arizona loans no credit loans no credit
unsecured loans for bad credit a loan with bad credit personal loans for people with bad credit loans for bad credit
wh0cd908388 amoxicillin
personal loans eloans fast online payday loan loans personal money lender no credit check payday loans online cash payday loans online payday loans online online loans loans online online loans online payday advances best payday loans online loan with cosigner no verification loans cash payday loans online bad credit loans bad credit loans bad credit cash advance near me money fast money fast advance cash payday money lenders
prettywittythings.com
surveysforcashvault.com
http://cialisnorx.com cialis
cialis
cialis
http://viagranorx.com viagra
viagra
viagra
http://cialisxxl.com cialis
cialis
cialis
http://viagrarpr.com viagra
viagra
viagra
http://cialisrpr.com cialis
cialis
cialis
http://viagrannq.com viagra
viagra
viagra
wh0cd714278 aldactone weight loss
no fax payday loan credit loans microloan bad credit loan
loans no credit check loans no credit check loans no credit check loans no credit check
wh0cd784823 tadalafil canada
quick easy payday loans advance cash interest rates on personal loans need cash fast www loan online loans best online loans online loans fast cash lenders reputable payday loans online installment loans installment guaranteed approval first payday loan maryland payday loans secured loans
lenders credit loans no credit installment loans no credit check installment loans direct lenders
bad credit loans loans with bad credit loans with bad credit no verification loans
wh0cd908388 your domain name
wh0cd908388 glucophage
bad credit installment loans direct lenders no credit check cash advance places loans for bad credit loans for bad credit loans for bad credit payday loan bad payday advance loans lenders for bad credit lenders lenders for bad credit direct loans cash advance cash advance cash advance checking account advance guaranteed approval loans money loans guaranteed approval guaranteed loan service loans payday lenders rapid cash lenders loans online loans online loans online loans online bad credit quick loans instant loan online debt consolidation bad credit loans for bad credit
personal loan interest calculator loans bad credit loans bad credit installment loans for bad credit
wh0cd908388 buy proscar
wh0cd908388 gout colchicine
wh0cd714278 benicar sildalis cheap cialis pills phenergan online retin-a amantadine more permethrin cream hydrochlorothiazide estrace albuterol diflucan
loans no credit check no credit check payday loans personal loans no credit check no credit check payday loans
wh0cd784823 site
lenders for bad credit lenders installment loan definition payday loans in denver
advance cash interest rates on personal loans advance cash advance cash fast cash today best online loans online payday loans payday loan with bad credit payday loans portland oregon online payday payday loan online online payday cash advance usa online loan calculator cash advance usa cash advance a payday loan loan payday easy payday loan very bad credit personal loans paperless payday loans same day same day loans guaranteed approval online loans online loans online loans online online loans payday lending online payday loans reviews payday lending direct lending
no faxing payday loan no fax payday loans cash loan payday payday loan
small loans for bad credit direct lenders for bad credit loans bad credit personal loans guaranteed approval
loan zoom 2600 installment loans in california loans online loan online
loans with bad credit bad credit loan credit loans credit loans
payday advance online payday advance payday advance online payday advance payday loans online cash payday loans online online payday loan loan brokers same day same day same day same day payday loan no faxing installment wedding loans installment
loans no credit check payday loans no credit check same day fast and easy payday loans payday loans with no credit checks
wh0cd714278 tretinoin cream mobic amitriptyline seroquel viagra buy neurontin online tenormin 50mg flagyl zithromax prednisone revia propranolol online pharmacy albuterol glucophage generic abilify
credit debt consolidation loans loan payday loan payday payday loan
wh0cd908388 clomid propranolol nolvadex tamoxifen citrate wellbutrin diclofenac sod 75 bactrim lisinopril prozac with no prescription zyban for smoking flagyl albuterol prozac tablets arimidex
loans for bad credit loan with bad credit quick personal loans online loans for bad credit
small payday loan lenders payday loans payday loans payday loan online
overnight loans direct payday lenders money lenders money lenders installment loans tulsa ok online installment loans installment
loans with no credit check personal loans uk loans no credit check cheap personal loans
http://viagrarrr.com – viagra
viagra
viagra
http://cialisrrr.com – cialis
cialis
cialis
http://viagrarrr.com – buy viagra
buy viagra
buy viagra
http://cialisrrr.com – buy cialis
buy cialis
buy cialis
loans without credit loanme bad credit loans no credit loans
credit online online registration loans instant approval express payday loan payday
loans no credit check fast and easy payday loans quick loans no credit check ca payday loans
online payday loans instant approval payday loans payday loans payday loans
quick loans no credit check direct lenders for bad credit loans rates loans for bad credit
fast online payday instant payday loans payday loan no fax payday loans
online loans no credit payday loans kansas city online loans no credit nevada payday loans
lenders installment loans direct lenders payday loans work lenders
I just wanted to let you all know that I added a new list. It has taken me awhile to let everyone know due to server issues. Everything should be back on track now.
wh0cd908388 abilify medrol 4mg metformin hydrochloride 500 mg vardenafil tablets 20 mg advair generic click benicar bactrim fluoxetine paxil 80 mg zofran baclofen pill arimidex sildenafil online lotrisone prozac levaquin 500 mg tablets tadacip lotrisone buy cafergot online antabuse medrol atarax zyban benicar
lenders lenders lenders lenders online personal loans best payday loans online payday loans online emergency loan installment installment loan guaranteed online payday loans installment loan online loans online loans online loans low interest personal loan easy payday loan payday loan easy payday loan loan payday
direct payday lenders bad credit loans consumer payday loans loans with poor credit
loans no credit check loans no credit check payday loans no credit check short loans
loans for bad credit cash loans for bad credit loans for bad credit loans for bad credit online loans loans online loans online loans online
loans bad credit loans for bad credit bad credit loans loans for bad credit
lenders installment loans no credit check direct lenders for bad credit pa payday loans
payday loan assistance loans no credit check loans no credit check no credit check loans
loans lenders payday loans best payday loans online payday loan bad credit
loans for bad credit loans for bad credit online payday loan application get a loan with bad credit
loans loans tribal loans loans
payday loan online payday loans online payday loans online lenders payday loan online
best personal loans loans personal the lending company personal loans bad credit
payday loans guaranteed how to borrow money business loans with no credit check unsecured personal loans
bankruptcy loans loanme loans 2017 loans without credit
easy loans bank loans personal loans direct loans
cash loans online same day loans no credit personal loans online loans online
wh0cd714278 Proscar
personal loans for bad credit guaranteed green loans installment loans direct lenders direct lenders for bad credit
bad credit payday loan direct lenders for bad credit bad credit payday loan online payday loan companies
guaranteed credit approval payday loan payday loan personal loans comparison a payday loan bad credit online loans payday loan payday loan instant approval payday loans payday loan lenders lenders loan lenders online loans for bad credit guaranteed approval payday loans in corpus christi guaranteed loan payday loans best best pay day loans online payday loan bad credit quick loans online installment loans advance loans loans online loans online loan cash now loans online loans online cash fast loans
onlinedatingsites.us.com
sun loan online loans for bad credit direct lender payday loans no teletrack cash loans online
learntopullwomen.com
abruzzomeeting.com
payday loans online no credit check payday loans near me payday loans online loan brokers instant approval bad credit loans american financial loans quality loan service loan pre approval lenders personal loan calculator payment private lenders for bad credit lenders for bad credit loans online online payday loans quick personal loans best online loans online signature loans no credit check emergency loan where can i get a loan with bad credit personal loans options installment loans installment loans installment loan no credit checks payday loans payday advance payday advance loan payday loans bc nevada payday loan
speedy loan payday loans no credit check loans no credit check personal loans no credit check
quick loans no credit check payday loans direct lender payday loans no credit check remodeling loans
reliable payday loans loans no credit check quick loans no credit check installment loans no credit check
bad credit lenders guaranteed payday loan payday loans online payday loans online
online payday cash advance online express cash advance cash advances
wh0cd908388 flagyl
wh0cd908388 xenical
payday loan payday loan direct lenders installment loans a payday loan long term personal loans payday loan best personal loans companies payday loan eagle loan company of ohio lenders private lenders instant approval loans direct online payday lenders loans online loans online online personal loans payday loans online bad credit cash advance cash payday loans online payday loans online
payday advance payday advance payday advance payday advance consolidated debt relief payday loans in ga same day 30 day payday loans loans from direct lenders personal loans short term loans get money today lenders unsecured loans lenders lenders small payday loans
same day same day pay day loan pay day loan loans online loans online loans online online loans paydayloans com cash advance loans exit counseling fast cash advance payday loans for bad credit unsecured loans for bad credit no credit loans loans with bad credit loan servicing primelending instant decision payday loans loans no credit check no credit check payday loans payday lenders private money lenders lenders cash loans cash payday loans cash loans no credit cash loans for bad credit fast cash loans
advance cash personal advance cash bad credit quick loans credit check payday loans loans online loans online loans online lenders lenders instant payday loans lenders personal loans no credit check pa payday loans best online loans loans online loans for bad credit loans for bad credit bad credit loans for bad credit
personal loan application get a loan without credit installment loans installment loans
loans no credit check payday loans 100 approved loans no credit check loans no credit check
online payday fast cash online online payday loans instant approval internet payday loans
holiday money installment loans installment loans bad credit installment loans guaranteed
wh0cd714278 allopurinol ampicillin 500 mg furosemide allopurinol ordering propecia buy cheap viagra online paxil skin rash buying cipro online prednisone 5 mg celebrex nexium 20 buspar proscar amantadine levaquin
calculate interest rate on loan quick loans no credit check online loans no credit check personal loan no credit check
womenbikeatlanta.com
debt consolidation loans for bad credit unsecured loans for bad credit bad credit installment loans signature loans
loans no credit check loans no credit check loans no credit check unsecured credit
advance cash fast cash advance cash advance fast cash advance payday advance payday advance day payday loan online payday advance personal loans loans personal personal loans no credit personal loans online payday loans loans online same day loans online payday loans bad credit loans loans instant approval online bad credit loans bad credit loans
one hour payday loans payday loans online payday loans online american web loan payday loans online what is a loan online payday payday loans online money lenders usa cash cash lenders multi payment payday loans lenders for bad credit loan exit lenders for bad credit i need money
consolidation apply for loan online consolidation consolidation
cash advance places bad credit installment loans guaranteed installment loans bad credit installment loans
payday loan no faxing loan payday no fax payday loan payday loan guaranteed
online loan loan for bad credit debt consolidation loans for bad credit debt consolidation loans for bad credit
apply for loans alternatives to payday loans payday loan cash advance direct payday
personal loans personal loans personal loans personal loans
payday loans online bad credit installment loans guaranteed payday loans online cash one payday loan
payday loans no credit check same day payday personal loans loans no credit check loans no credit check
loans no credit check california cash advance loans no credit check home loan
direct lenders payday loans debt consolidation loans bad credit personal loan installment loans payday advance bad credit online payday loans payday advance payday advance loans loans no credit no credit check loans bad credit debt consolidation loans credit loans loans online online loans loans online online loans
payday loans indianapolis cash advance usa express cash advance loan over the phone
online loans no credit internet payday loans cash advance online online payday loans instant approval
payday advance new payday loans online payday advance payday advance online quick cash loans online payday loans direct cash loans 100 online payday loans best places to get a personal loan online personal loans payday loans today unsecured personal loans
wh0cd908388 amoxil 875 mg levaquin tablets albenza stromectol levaquin 750 motilium otc flagyl paroxetine hcl 20mg arimidex paxil generic cheapest xenical orlistat arimidex 800 mg motrin
need a loan with bad credit loans for bad credit loans for bad credit consolidation loans for bad credit
personal loan no credit check direct payday loan personal loans no credit check unsecured credit
low apr payday loans best payday loan payday loan no fax no credit check payday
fast cash payday loans quick cash online best payday loans best payday loans
personal loans no credit online personal loans loans personal loans for bad credit direct lender need money fast ez payday loans locations money fast online online quick loans las vegas payday loan loans no credit check instant decision payday loans no credit check loans online loans payday loans oregon online loans online loans best payday loans online loans till payday payday loans online best payday loans online 30 day payday loan payday loan lenders instant payday loans lenders loan til payday direct payday loan lender personal lending real loans cash payday loans cash payday loans online cash loans loan interest
loanme credit loans credit loans loans without credit
instant payday loan payday loans payday loan no fax apply for payday loan online
loans colorado springs payday loans with no credit checks installment loans direct online payday lenders
quick personal loans bad credit loans home best cash loans personal loan rates
installment loans commercial loan installment loans installment loans
personal loans with no collateral poor credit loans guaranteed approval installment installment loans guaranteed personal loans with bad credit bad credit loans unsecured loans for bad credit 100 payday loans
no fax payday loan payday loans private lenders installment loans no credit check same day
payday loans no credit check payday loan direct lender american financial loans loans no credit check
wh0cd714278 trazodone female viagra neurontin buy mobic motilium 10mg generic abilify avodart propranolol inderal augmentin sildenafil soft tabs bupropion tretinoin cream lisinopril 20 mg learn more
payday loans no credit best payday loans online payday loans payday loans
24 hour payday loans credit loans no credit loans credit loans
internet payday loan advance cash advance cash advance cash loans online loans online loans online loans online credit loans quick loans no credit payday one loan loans no credit
credit loans loans with no credit no credit loans bad credit loans
loans for people with bad credit loan now loans for bad credit loans bad credit
lenders lenders private lenders lenders cash loans no credit loan relief cash payday loans get cash best online loans ez money best online loans online loans
online payday loans installment loans installment loans installment loans
wh0cd714278 cheap viagra mastercard
wh0cd714278 Order Cymbalta
no fax payday loans best payday loan installment buying definition cashadvance
credit check payday loans www loan online loans no credit check loans no credit check
personal loans personal loans personal loan personal loans
payday loans payday loans payday loans payday loans
bad credit loans cashloans no credit loans credit loans
dental loans loans for students with no credit installment no teletrack payday loan companies 500 loans loans in colorado springs loans for bad credit loans for bad credit a payday loan a payday loan payday loan a payday loan loans online online payday loans direct lenders only spot loan debt consolidation loans for fair credit pay day loans near me same day payday loans people with bad credit pay day loans near me loans no credit check personal loans no credit check money loans no credit check cash loans with no credit loans online online loans online payday loans for bad credit loans online loans in california advance cash advance cash no interest loan
loans no credit loan rates short loans loans no credit bad credit loans loans for bad credit bad credit loans loans for bad credit personal loans no credit personal loans installment loan bad credit best personal loans quick personal loans bad credit cash loans cash advance loans tax advance loans
payday loans cheap installment loans payday loans no credit payday loans
personal loans personal loans personal loans personal loans
personal loans personal loans 1000 cash loan bank loans bad credit payday loan tennessee quick cash a payday loan a payday loan payday advance loans payday advance payday loans in arizona online payday advance personal loans small payday loans online personal loans personal loans
loans no credit check quick loans no credit check cash advance texas personal loan no credit check
installment installment loan bad credit loans guaranteed payday loans in las vegas loans online new payday loan companies cash loan lenders cash payday
wh0cd908388 Sildenafil 50mg
wh0cd908388 prednisolone
payday loans no credit check same day online loans no credit check payday loans no credit check same day loans no credit check
payday loans no credit check direct payday loan payday loans no credit check online loans no credit check
nc payday loans small loans bad credit online loans no credit online payday
credit loans no credit credit loans bank loan loans with no credit
get a loan with bad credit loans online guaranteed personal loans guaranteed money advance online loans fast online payday loan online loans online loans loans no credit loan for bad credit get a loan with bad credit loans no credit small loans for bad credit poor credit personal loans installment installment
holiday loan loans for bad credit loans for bad credit a loan with bad credit
no credit check payday loans instant approval installment loans installment loans online installment loans
payday loans payday loans payday loans payday loan online
online payday advance online loans no credit payday loans without checks cash advance lenders online
online installment loans online installment loans money now loans online loans for bad credit loans for bad credit loans with no credit loans for bad credit unsecured payday loans apply for payday loan payday loan no credit check installment loans with bad credit loans bad credit arizona payday loans loans for bad credit personal loan cash advance scam 5000 personal loan personal loan same day payday loans no credit check pay day loans online fastest payday loan
payday loan lenders loan payday personal loan loan payday instant loans no credit check finance quick loans no credit payday loan no teletrack online payday online payday payday lending payday lending
online check cashing payday loans no credit best payday loans online payday loans
bad credit loans bad credit loans personal loans with bad credit cash advance payday personal loans guaranteed approval guaranteed approval loan amount guaranteed approval payday advance online payday loans online best payday loans online payday loan online payday advance payday advance loan payday advance loans payday advance online loans personal loans online bad credit loans with monthly payments same day loans no credit
cash advance payday lenders loan lenders installment loans direct lenders
loans guaranteed loans for bad credit loans for bad credit installment
personal loans personal loans personal loans small personal loans
onlineloans online payday loans no credit check quick loans no credit check payday loan direct lender
cash advance online payday loans no debit card cash advances loan express
debt consolidation loans for bad credit loan personal payday loan instant cash consolidation
best payday loans online direct payday lenders only direct loans student loans payday loans
payday loans hamilton loans easy loans loans
installment loans with monthly payments consolidation loans for bad credit a loan with bad credit loans for bad credit
online installment loans loan without a bank account direct lender installment loans installment loan
payday loans louisiana payday loans online personal loans uk online payday loans instant approval
loans bad credit get a loan with bad credit installment loans for bad credit loans for bad credit
installment installment installment installment online payday loan online payday loans best payday loans online payday loans guaranteed online personal loans home loans for bad credit new payday lender online personal loans personal loan personal loan no credit check personal loan payday loans without lenders personal loan fast loan payday guaranteed payday loan payday loan vancouver payday advance payday advance online online payday loan reviews payday advance online free money loan online payday loans direct lenders only 90 day payday loans loans online installment installment installment installment
payday loan online best online loans online loans bad credit online loans bad credit
bad credit installment loans guaranteed installment loans for bad credit installment loans emergency loans no credit
loans best loan best loans best loans
installment loans no credit check installment loans online consumer loans bad credit installment loans guaranteed
quick loans no credit check personal loan no credit check installment loans no credit check personal loan no credit check
loans bad credit loans for bad credit payday loans from direct lenders loans with bad credit
bad credit loans australia advance cash payday loan 500 loans no credit check commercial loans quick loans online money to pay bills online loans online loans
loan online debt consolidation credit card loan online loans online
unsecured personal loan pay day online personal loans loans personal
loan payday payday loan loan payday loan payday debt consolidation for bad credit low interest personal loans advance cash advance cash loans online local payday loans home loans guaranteed approval loans online loans to build credit new payday loan companies 1000 payday loans loans no credit personal loans personal loans online eloans loans personal bad credit consolidation loans online loans loans online loans online
payday loan lenders payday loan vancouver loans in houston tx payday loan lenders loans guaranteed approval loans guaranteed approval poor credit loans guaranteed approval bad credit loans guaranteed approval best personal loan get a personal loan personal loan personal loan instant cash loans payday lending payday lending payday lending loans no credit denver payday loans loan debt consolidation loans no credit quick cash loans cash loans loans loans easy money online loans loans online online loans online loans
personal loans no credit check no credit check payday loans instant approval loans no credit check payday loans no credit check same day
loans no credit check no credit check payday loans online loans no credit check loans no credit check
whyblackpeoplemeethere.com
yourcashgroup.com
micro loans loan products payday loan a payday loan no faxing payday loan cash loan payday loan payday loan payday online payday payday loans near me no credit check online payday loan mobile loan best personal loan easy money personal loan 5000 personal loan lenders cash lenders personal loan agreement payday loans las vegas
payday advance online payday advance advance payday payday advance personal loan interest rate personal loans best personal loans unsecured personal loans car loan direct payday lenders online installment loans payday loan help loan payday a payday loan guaranteed payday loan loan payday online signature loans loan emi no interest loans personal loans money lenders california online payday loans rise loans online payday loans online
wifiwirelesscameras.com
need a loan with bad credit loan for bad credit cash online loans loan for bad credit
best personal loans personal loans personal loans loans personal
best payday loans online best personal loans for bad credit loan lenders payday loans
small loan easy loan loans direct loans
payday loans online best payday loans online payday loans online online loans direct lenders payday loan online bad credit payday loan personal payday loan online payday online payday holiday loan online payday advance quick money money fast money fast loans in maryland loans online loan identifier national cash advance get a loan with bad credit loans no credit loans no credit personal bank loans loans no credit loans for bad credit direct payday loan companies guaranteed approval loans payday loans topeka ks
installment loans no turndowns loans for bad credit payday loan store locator best loans for bad credit
consolidation debt consolidation loan loans without direct deposit best debt consolidation loans
unsecured instant online loan same day payday loans no credit check payday loans
payday advances borrow money with bad credit payday loans online online payday loan
cash advances payday loan com loans no checking account cash advance usa
bad credit loans bad credit loan credit loans 24 hour payday loans
surveysforcashvault.com
loans no credit loans no credit loans no credit need a payday loan loans bad credit loans for bad credit loans for bad credit loans bad credit
debt consolidation loan starter loans to build credit debt consolidation loans for bad credit debt consolidation loan
advance cash loans bad credit personal loans payday loan payday loan 1000 loans payday loans loan payday payday loans calculator payday loans houston guaranteed approval guaranteed approval loans guaranteed approval advance payday payday advance payday advance loan payday advance online no credit check loans loans no credit check no interest loans personal loans no credit check online installment loans webloan installment installment a payday loan micro loans payday loan payday loan
paydayloansnearme.us.com
loans for bad credit loans for bad credit get a loan with bad credit bad credit payday loan
loans easy loan loans small loans
easy fast payday loans payday loans no credit check online loans no credit check personal loan no credit check
http://viagrarrr.com – viagra
viagra
viagra
http://cialisrrr.com – cialis
cialis
cialis
http://viagrarrr.com – buy viagra
buy viagra
buy viagra
http://cialisrrr.com – buy cialis
buy cialis
buy cialis
lenders for bad credit lenders direct lenders for bad credit lenders for bad credit
payday loans no credit check no employment verification payday loan no fax loan payday loan payday payday lending online payday 10 top loan companies payday loans bc bad credit bad credit loans bad credit payday loans cincinnati
loan payday loan payday loan payday payday loans no faxing
loans bad credit loans bad credit loans for people with bad credit bad credit payday loan
hLr605 tiscsivbreqv, [url=http://zexeudbqbxdo.com/]zexeudbqbxdo[/url], [link=http://smukqtjiacgx.com/]smukqtjiacgx[/link], http://ibrcjvhpmxrl.com/
best loans for bad credit bad credit loan loans for bad credit loan with bad credit
instant payday loans instant payday loan payday loans christmas loan
bank loans personal online loans texas loan instant loans online online payday advance online payday loans online payday loans payday loans online loans no credit emergency cash assistance loans no credit loans no credit bad credit loan online online payday loan online payday no checking account payday loans personal loans personal loans personal loans best personal loans payday loans online small loans bad credit online loans no credit loans locations loans guaranteed approval credit loans guaranteed approval paycheck loan installment loans guaranteed
installment installment installment loan online installment loans bad credit loans loans for bad credit personal loan approval loans for bad credit installment loans with bad credit cash loans online loans online online loans
personal loans bad credit personal loans online personal loans lendingtree personal loans
wh0cd784823 as an example
wh0cd908388 Buy Neurontin
wh0cd908388 Vermox
loans 2 go consolidation no income verification loans consolidation
a loan with bad credit america cash advance direct lending reviews loans for bad credit
fast cash advance fast cash advance fast cash advance fast cash advance
lenders for bad credit direct lenders for bad credit loan lenders lenders
local payday loans money lending payday loans instant payday loans
loans fast cash payday loans loans best payday loans
affordable loans quick loans no credit check american financial loans quick loans no credit check
online loans online loans direct payday loan lenders loans online same day loans no credit check military loans apply for personal loan no credit check direct lenders low rate payday loans a payday loan a payday loan payday loan advance loans online best payday loans online loans for self employed online payday payday loans online payday loans online best payday loans online auto loans best online loans loans online loans online loans online loans to consolidate debt getting a loan payday loans online online payday loans online pay day loans near me same day loans same day loans
payday loans no credit check same day personal loans no credit check loans no credit check online payday loans no credit check
online payday loans installment loans for bad credit installment loans poor credit personal loans
loans in colorado springs loan form payday loans guaranteed acceptance installment loans no credit check
emergency loans for bad credit loans no credit check get a loan without credit personal loans no credit check
loan for bad credit loan for bad credit legit online payday loans loans for bad credit
payday loans payday loans online payday loans instant approval payday loans
payday loan reviews short loans online 90 day payday loans payday loan no fax
online installment loans direct lenders cash advances fast cash advance payday loans in columbus ohio
compare personal loans loan for bad credit payday loans for bad credit personal loans for people with bad credit
payday loan no fax no fax payday loans no fax payday loan cash america payday advance
small loans easy loans same day cash loans online payday loans instant approval
cash advances guaranteed payday loans ez cash payday loans personal loan repayment
small loans bad credit direct payday lenders best loan small loans
debt consolidation loans for bad credit consolidation secure payday loans consolidation
payday loan online 1 hour payday loans next day payday loans instant payday loans
online payday advance online payday payday loan online online payday loan online loans america payday loan small cash loans online loans online installment loans loans online loans online online installment loans loans online i need a payday loan reputable online payday loans loans online bad credit loans guaranteed approval guaranteed loans credit loans guaranteed approval loans guaranteed approval loans online guaranteed cash money payday loans cash loans for bad credit cash loans for bad credit direct lending payday loans payday advance payday lending lend money same day best loan consolidation payday loans online lenders
payday loans payday loans payday loans payday loan online
installment tennessee quick cash installment loan best payday loan online online loans money now online loans best online loans loans for manufactured homes online payday loans loans online online loans
no fax payday loans payday loan online payday loan online best payday loan
no check payday loans personal loan no credit check loans no credit check i need money today
bad credit loans bad credit loans money lender no credit check online loans for bad credit
plain green loans fast cash advance 500 payday loans fast cash advance
cash until payday payday loans online pay day lending bad credit unsecured loans
loans no credit check no credit check loans online payday loans no credit check loans for people on disability
no credit check loans personal loan no credit check commercial loan rates loans no credit check
direct lenders for payday loans 100 approved payday loans online online payday loan legitimate payday loans online loans no credit check loanme loans no credit check no credit check loans low income payday loans fast cash advance fast cash advance no credit money lenders lenders money lenders lenders cash in minutes loans online online loans loans online payday loans without a checking account quick money money fast quick money instant payday loan no faxing payday loan loan payday cash loan payday loan payday payday lending payday loans personal lending
i need cash now payday loans student loan refinancing payday loans
installment loans online direct lender lenders lenders lenders
loans online online installment loans loans online best online loans installment loans installment loans 2017 installment loans no credit check ohio payday loans small loans for people with bad credit bad credit payday bad credit payday credit loans no credit check loans fast no credit check loans loans no credit payday loan consolidate student loans a payday loan a payday loan no doc loans installment loan broker online installment loans best loans online payday loans 1 hour payday loans online loans
online cash advance payday loans no credit check payday loans instant approval bad credit payday loans no credit check payday loans instant approval
I am really glad to read this webpage posts which consists of tons of useful data, thanks for providing these data.
payday advance online payday loans online online payday advance payday loans online
cash lenders lenders payday loans online lenders loans of america loans online loans online online loans online loans advance cash loans with monthly payments margin loan advance cash personal loans no credit check installment loans bad credit online loans no credit check online installment loans loans guaranteed approval native american loans rapid cash credit loans guaranteed approval
no credit loans bad credit loans credit loans bad credit loan
payday loans near me no credit check payday loans instant approval bad credit payday loans payday loans no credit
payday loans online payday loans in pa payday loans online where to get a loan with bad credit
express loan loan payday loans payday loan payday
small loan loans payday mods easy loans
credit loans cash advance definition loans in virginia credit loans
loans with no credit loans with no credit loans with no credit 24 hour payday loans
payday loans no credit check loans no credit check loanme american payday loan
wh0cd714278 fluoxetine over the counter
loan without credit check lenders poor credit loans guaranteed approval greenline loans payday loans pittsburgh overnight payday loans best payday loans direct lender cash loans no credit online loans no credit check loans no credit check loans no credit check loans no credit check fast cash usa best online loans loans 2 go online loans advance cash direct loan program direct loan program new payday lender payday advance payday advance interest on loan payday advance loan
online payday advance payday advance online loan bad credit bad credit loans uk
instant loans online loans online loans online cash loans online
pay day cash advance loans bad credit loans for bad credit loans for people with bad credit
quickloans installment loan installment loan installment loan payday lending payday lending online payday loan payday cash payday loans cash loans cash loans emergency payday loan no credit check loans loans no credit best payday loans direct lender no credit loans loan payday easy payday loan quick personal loans online a payday loan online payday best payday loan company online payday advance online payday loans for bad credit bad credit loans loan money now bad credit loans
loans no credit check payday loans no credit check same day payday loans no credit check same day loans no credit check
loan payday no fax payday loans online payday loan payday loans no faxing
bad credit payday online installment loan companies personal loan bad credit bad credit direct payday loan loan payday direct payday loan easy payday loan loan to pay off credit cards lenders direct loans loans direct lenders direct payday loan lenders payday loans online best payday loans online online payday loan personal loans personal loans personal loans personal loans bad credit loans loans direct deposit loans for bad credit short term loan lenders
no credit loans loans with no credit credit loans loans without credit
loans with no credit check payday loans definition consolidation online loans no credit check
payday loans no credit check no employment verification best payday loans online online payday loan direct lenders fast quick loans loans direct lenders payday loan sites lenders lenders quick cash loans personal loan for poor credit cash loans no credit check direct lenders immediate payment loans online payday loans loans online online loans online loans loans guaranteed approval 500 payday loans payday loans new jersey loans guaranteed approval 2000 loan loans no credit check personal loan review money loans no credit check payday loans columbus ohio online payday loans reviews loans for fair credit money lenders
direct loan servicing direct lender installment loans consumer loans installment loan
loans for bad credit loans for bad credit loans for bad credit loans for bad credit payday advance quick cash loans payday loan advance payday advance loans online payday online payday loans express payday loan payday loan online installment apply for payday loan installment loan best cash loans online installment loans installment installment loans online installment loans personal loans loans personal payday loans columbus ohio loans personal personal loans personal loans speedy payday loans personal loans
get cash payday loans personal loans no credit payday loans
installment loan installment loan installment loan quickloans payday advance loans payday advance loans payday advance payday advance loan bad credit bad credit bad credit bad credit online loans private lenders for bad credit discover loans online loans lenders cash advance payday loans no fax payday loans online payday loans poor credit
credit card debt consolidation online payday loan no fax payday loans no fax payday loan
credit loans no credit loans loans with no credit no credit loans
cash advances cash advances fast cash advance cash advance online
wh0cd908388 Arimidex NO Script
consolidation loans for bad credit payday loans calgary cash loans direct discount payday loans
best payday loans direct loans small loan loans
no faxing payday loan no fax payday loans same day personal loans loan payday
credit loan calculator online loans loans online online loans low interest personal loan loans online ez loans reputable payday loan companies personal loans no credit check loans no credit check loans no credit check easy loans no credit check calculating interest on a loan loan center advance cash loans in california installment installment installment loan cash loans direct loans online loans online loans for debt consolidation instant loans online fast cash payday loan a payday loan payday loan
installment loans guaranteed loans guaranteed approval loans guaranteed approval credit loans guaranteed approval payday loans albuquerque money fast quick money sba loans small loans no credit check payday loan instant approval payday loans in nc loan til payday
payday loan payday loans massachusetts money loans online same day payday loans no credit check
payday loans no credit check personal loan no credit check no credit check loans bank loans for bad credit
loans for bad credit loans for bad credit loans for bad credit legitimate debt consolidation
low doc loans no credit check payday loans loans no credit check payday loans no credit check
small personal loans personal loans online personal loans auto loans
best debt consolidation loans direct lender loans consolidation loans for bad credit no credit payday loans
guaranteed payday loans bad credit payday loans payday loans fast online loan
instant payday loan instant payday loans payday loan online payday loans
quick loans no credit check payday loans no credit check payday loans no credit check same day loans no credit check
guaranteed payday loans 2600 installment loans in california payday loans lowest loan rates
payday loans payday loans instant payday loan payday loans
online payday loans payday loans online best payday loans online best payday loans online
payday loan com loans debt consolidation help loans direct
loans available loan products cash advances loan settlement
personal loans personal loans california cash advance personal loans installment installment loans payday loans online lenders cash express payday loan payday loan payday loan payday loan small loans online payday loans online payday loan online payday online loans loans online instant loans online instant loans online loan applications payday advance wells fargo loans direct lender tribal installment short term loans installment no fee payday loans online loans loan direct online loans online loans
a payday loan easy payday loan easy payday loan debt consolidation programs money loans no credit check loans no credit check loans no credit check loans no credit check small personal loans no credit loans no credit loans no credit loans no credit loans bad credit loans for bad credit loans for bad credit loans for bad credit installment loan installment loan installment installment loan payday loan providers advance cash payday loans in dallas tx cash til payday loan bad credit loans bad credit loans need money now please help loans 500
cash america payday advance payday loans phoenix az usa payday payday loan no fax
payday loans online payday loan online online payday loan payday loans online
personal loans best personal loans pay loans pay day loan bad credit
ez cash payday loans no credit check payday loans instant approval loans for bad credit direct lender payday loans
cash advance payday loans online loans no credit check loans no credit check best cash loans
cash loans online best place to get a loan loans online cash loans online personal loan personal loan consumer loan personal loan bad credit cash payday loans online payday installment loans best payday loans online mortgage bad credit loans bad credit loans online loans for bad credit bad credit loans
loan source payday loans online payday advance online payday loans online
loans for bad credit payday loans victoria bc online payday loan instant approval loans for bad credit
best loan easy payday loans loans loans direct
payday loan lenders lenders easy payday loans lenders
personal loans guaranteed approval guaranteed approval payday loans vancouver bc guaranteed approval small loans for bad credit home equity loans bad credit loans debt consolidation loans bad credit best payday loan lender cash advance advance cash loan companys
best consolidation loans loans no credit check loans no credit check personal loan no credit check
no faxing payday loan guaranteed payday loan payday loan lenders loan payday loans online instant approval 5000 bad credit bad credit loans lenders for bad credit easy cash loans loans comparison alabama payday loans online personal loans same day loans pay day loans near me trusted payday loans same day payday loans no credit check cash advance places online payday loans guaranteed online payday loans payday loans online money fast online money fast payday loans without a checking account money fast loans no credit loans no credit loans no credit consolidated loans bad credit loans online pay day loans bad credit loans consolidation loans for bad credit
loans direct loan over the phone loans las vegas nv easy payday loan online
payday loans online cash one payday loan student loan refinancing best consolidation loans
new direct payday lenders bad credit installment loans installment loans no credit check direct lender installment loans
emergency cash loans loans 2017 credit loans loans quick
payday loans cincinnati bad credit payday loans direct lenders bad credit loans bad credit instant payday loan a payday loan loan payday payday loan payday loan direct lenders only loans direct lenders private lenders cash lenders
personal loans online personal loans online loans online online payday loan lender
personal loans pay day online calculating interest on a loan online installment loan companies
cash loans for bad credit loans for bad credit same day cash loans loans for bad credit online loans bad credit unsecured loans payday loan providers loans online payday loans online online payday loans apply for payday loan fast and easy payday loans cash payday loans online payday personal loan rates today bad credit loans online loans no credit check no income verification loans loans no credit check tax anticipation loan online payday loans kansas payday loans cincinnati private lenders bad credit instant payday loan loan payday loan payday small personal loans no credit speedy cash online loans speedy cash quick and easy loan
express cash advance payday cash advance express cash advance loans with bad credit
payday advance payday advance payday advance payday advance loan poor credit loans online payday loan stock loan cash payday loans online quick loans no credit loans no credit loan mart best payday loan companies
online loans for bad credit pay day loans online online loans cash loans online
ratingdatingsites.us.com
credit loans loans with bad credit guaranteed approval loans with poor credit payday mods
freemaledatingsites.us.com
loans bad credit loans for bad credit fastest payday loan loans bad credit
credit loans bad credit loans credit loans bad credit loan
wh0cd714278 robaxin 500 mg tablet
personal loans companies loans for bad credit cash need a loan with bad credit
lenders lenders personal loan rates comparison direct payday lenders payday loans online payday loans online payday loans online payday loans best best personal loan best personal loan personal loan no credit check personal loan interest rates lenders for bad credit direct loans lenders money lenders a payday loan bad credit online loans a payday loan a payday loan online loans personal loans apply lending tree online loans
karenmillenbeauty.com
online payday advance advance payday payday advance loan payday advance online payday loan bad credit loans approved best payday loans online best payday loans online loan lenders loan express money lenders lenders advance cash advance cash cash advance cash advance installment loans online loans online loans online rise loans online loans for bad credit loan emi bad credit loans loans for bad credit payday advance online online payday advance online payday advance payday loans online
wh0cd714278 ADVAIR DISKUS
loans online loans online loans online loans online
personal loans with low interest rates loan requirements debt consolidation loans for bad credit cash loan now
one hour payday loan credit loans loans without credit credit loans
instant payday loans payday loans no fax payday loan no fax payday loan
loans until payday loans for bad credit loans for bad credit loans bad credit
payday loans lender loan offices instant payday loan
payday loans victoria bc personal loans for people with bad credit a loan with bad credit loans for bad credit
loans no credit personal loans low interest usa loan no faxing payday loan cash payday loans online cash payday loans online best payday loans online cash payday loans online lenders debt consolidation loans bad credit private money lenders credit loan calculator loans for disabled pay day loans near me payday loans no credit check same day same day loans online payday loan payday online payday payday lending quick loans no credit loans no credit loans no credit no credit loans
best payday loans online loans without cosigner loans for bad credit bad credit installment loans
large loans payday loans online payday loans online payday loans poor credit
payday loans guaranteed no credit check payday loans instant approval best online payday private money lending
loans no credit check payday loan in california payday loans no credit check same day loan apply online
payday loans online payday loans online payday loans online loan advance
kimberlymackbeautystudio.com
eyeadorepretty.com
lender payday advance online loans for bad credit consolidation debt
loans loans best loan loans
womensspeakernetwork.com
wh0cd908388 prednisone buy
loans lenders only payday loans portland or cash payday loans online payday loans online
payday loan sites payday advance loans online payday advance payday advance simple loan bad credit loans personal loan apply loan til payday cash payday loans online cash payday loans online payday loans online online payday loans guaranteed payday loan loan payday loan payday loan payday need money fast money fast money fast online quick money
installment loans no credit check installment loans installment loans bad credit installment loans
loans online loans online payday loans with bad credit loans online hard money loans how to get cash fast bad credit loans personal loan interest rates loan payday bad credit loans direct lenders loan payday pay day loans online best online loans best online loans simple loan agreement template no credit check cash advance
wh0cd908388 abilify generic 15 mg
plain green loans cash advances cash advances cash advances
loans online loans online loans online loans online advance cash loans with monthly payments quality loan service cash advance payday online installment loans installment loans guaranteed payday loans no cash advance locations loans for bad credit low interest loan quick loans online cash loans online debt consolidation loans for bad credit safe online payday loans payday advance instant payday loans no credit check
loan companys installment loan loans in utah installment loan best payday loans online online payday loan online payday loan payday loans online fast and easy payday loans easy payday loan same day payday loans no credit checks fast cash online cash advance scam online loans bad credit instant approval loans for bad credit bad credit loans loans locations loans apply payday loans online payday loans online best debt consolidation loan loans online payday loans today loans online
loans no credit loans no credit loans no credit installment loan calculator loans online loans online personal loan rates comparison loaning money installment loan installment installment loan installment lending tree www loan payday loans with no credit check loans online personal loans what is an installment loan personal loans personal loans what is a payday loan online loans no credit check money loans no credit check fast loans no credit check loans for bad credit bad credit loans lowest loan rates loans houston
wifiwirelesscameras.com
guaranteed payday loans no teletrack payday loans no credit check online payday loans no credit check payday loans no credit check
payday loan no faxing loan payday no faxing payday loan cash payday advance
loan payday payday loans online no credit loan payday no faxing payday loan
personal loans bad credit personal loans personal loan personal loans
payday loan bad personal loans for debt consolidation personal loans for debt consolidation best debt consolidation loans
instant credit online loan lenders getting a loan with bad credit lenders
payday lending installment loans online guaranteed payday loan payday loans online
lenders installment loans direct lenders lenders paperless payday loans
bad credit loans not payday loans bad credit payday loans online loans online loans online
best cash advance cash payday loans online 24 hr loans cash payday loans online best online loans loans online loans online online loans small personal loans with bad credit payday loan personal loan companies a payday loan loans with no credit loans no credit no credit loans loans no credit best loans for bad credit best loans for bad credit payday loans for bad credit loans for bad credit same day payday loans in houston texas same day loans same day lenders loan to pay off credit cards easy payday loans payday loan portland oregon direct lending get a loan today online payday loan lender cash online loans
fast cash advance express cash advance fast cash advance cash advances
cashadvance same day payday loans no credit check instant payday loans best payday loan
online payday advance payday lending payday loans online fast cash today
bad credit loans loans for bad credit loans for bad credit consolidation loans with bad credit
personal loan personal loan personal loan personal loan lenders lenders lenders lenders loans with no credit check near me ca payday loans bad credit loans payday loans for bad credit loans guaranteed approval installment loans guaranteed credit loans guaranteed approval bad credit loans guaranteed approval direct online lenders best loan companies online payday loans payday loans online a payday loan payday loan payday loan pay day online installment loan installment loan online installment loans installment
lenders money lending instant payday loans payday loans
settlement loans personal installment loans direct loans consolidation loans
payday loan no fax payday loans instant payday loans payday loans
loan exit bad credit bad credit payday payday loan help money fast loan service loan assumption money fast
payday cash advance loan policy cash advances payday cash advance
loans for bad credit payday loan providers get a loan with bad credit bad credit loans
indian payday loans payday loans online loans repayment best payday loans online payday advance advance payday advance payday payday advance loan small loans for bad credit loans for bad credit best loans for bad credit loans with bad credit
cash lenders direct lenders for bad credit lenders lenders
online payday loans no credit check online loan direct lenders direct payday lenders only loans no credit check
loan online bad credit get a loan with bad credit bad credit payday loan small loans for bad credit
loan center payday loans online online payday loans payday loans online loans guaranteed approval credit loans guaranteed approval credit loans guaranteed approval credit loans guaranteed approval
best loan direct lenders online loans direct loans
loans for people with bad credit loanme loans for prepaid debit cards a loan with bad credit
personal loan best personal loan low interest loans personal loan bad credit payday loans online online loans instant payday loans online hassle free payday loans lenders for bad credit bad credit payday bad credit loans bad credit cash advance 5000 loan with bad credit payday loan application advance cash personal loans personal loans cash advance definition personal loans money lenders need money fast money fast money fast online personal loans loans repayment payday loan online express payday loans same day payday loans no credit check same day loan without checking account debt relief program
personal loans personal loans personal loans personal loans
barbiecashregister
alternative loan loans online installment loans online online personal loans debt consolidation loans bad credit loans for bad credit loans for bad credit loans no credit check instant approval payday loans no credit check no faxing no faxing payday loan no fax payday loan no faxing payday loan
surveysforcashvault.com
payday loans payday loans bad credit payday loans payday loans
installment loan www payday loans online installment loans installment loans
loans online loans online loans online payday loans online loan payday loan payday online payday loan instant payday loan emergency loan online payday advance online payday advance online payday loan
consolidation loans for bad credit same day online loans consolidation consolidation
debt consolidation loan micro lending best debt consolidation loans debt consolidation loan
loans with bad credit 300 loan a loan with bad credit borrow money
Thanks a bunch for sharing this with all people you actually
realize what you’re talking about! Bookmarked.
Please also visit my site =). We could have a
hyperlink alternate agreement among us
personal loans with bad credit installment payday loan loans for bad credit bad credit loans loaning money online loans personal loans with no collateral loans online installment installment loan installment loan interest free payday loans personal loans small loans no credit check payday loan with bad credit personal loans loan calculator personal loans for bad credit loans for bad credit no fee payday loan best places to get a personal loan get a personal loan personal loan personal loan no credit check
payday loan fast cash online loan website loan payday payday advance loan advance payday advance payday loans without a cosigner online cash advance advance cash secure payday loans online online cash advance online loans loans online loans online loans online online loans online loans online loans online payday loans payday loan payday loan a payday loan a payday loan
where can i get a loan no credit check payday loans instant approval payday loans online payday loans instant approval
cash loans no credit usda loan cash loans borrow money fast bad credit loans loans with bad credit loans near me advance payday loans loan programs installment installment installment loans personal spotloan personal loans no credit direct payday loans lenders lenders lenders online payday loans with no credit check loans usa loans loans www loan green loans best online loans
bad credit loans loan for bad credit loans for students get a loan with bad credit
no credit check payday loans online loans no credit check get a load free loans bad credit loans online online loans online loans online payday loans money fast money fast money fast money fast best loan consolidation express cash advance cash advance usa cash advance loan
wh0cd714278 buy mobic online cafergot tablets where to buy clonidine tadalafil baclofen desyrel buy provera online
wh0cd714278 biaxin xl cialis biaxin ampicillin
cash consolidation loans for bad credit payday loan now loans for bad credit
a loan with bad credit loans for bad credit loans with bad credit get cash now
wh0cd908388 propranolol drug lotrisone citalopram for anxiety and stress advair torsemide where can i buy zithromax clomid cafergot buy lotrisone online tricor phenergan promethazine
personal loan no credit check personal loan no credit check payday loans no credit check no credit check loans
private money lenders personal loans for debt consolidation online cash loans no teletrack payday loans
wh0cd714278 robaxin drug
wh0cd714278 Allopurinol
wh0cd714278 ampicillin 500mg
bestwebcam.us.com|bestwebcam
personal loans personal loans best personal loan best personal loan
yourcashgroup.com
installment loans installment loans installment loans installment loans
where can i get a loan with bad credit online payday loans no credit check loans no credit check loans no credit check
loans tulsa ok payday loans in ohio small loans australia installment loan cash advance loans in maryland fast personal loan advance cash loans bad credit payday advance payday advance payday advance online payday loan payday loans online easy payday cash advance form lenders lenders lenders for bad credit best short term loan short term loan rates personal loans no fax payday loans personal loans loans online online loans online loans online loans loans for bad credit loans for bad credit loans for bad credit loans for bad credit
wh0cd908388 albuterol
wh0cd908388 lisinopril hct
installment loans installment advance loans online installment loans guaranteed guaranteed loans bad credit loans guaranteed approval money payday loans personal loans guaranteed approval loans with bad credit bad credit loans loans for bad credit bad credit loans advance cash cash loans today advance cash advance cash online cash advance loans louisiana loan fast cash advance cash online payday advance payday advance online payday advance payday advance payday loan online online personal loans online personal loans payday loan online installment loan instant online payday loan virginia loans installment
loans no credit check next day loan loans no credit check quick loans no credit check
payday loans online payday loans online no credit payday loans installment calculator
wh0cd908388 cipro albenza doxycycline tablets homepage here colchicine amitriptyline advair
wh0cd784823 CYMBALTA ABILIFY
wh0cd908388 propecia
america cash advance payday loan payday loans las vegas loan payday no fax payday loan easy payday loan paperless payday loans guaranteed payday loan bad credit payday bad credit bad credit loans payday loans calgary loans no credit no credit check loans loans no credit credit loans credit builder loans cash advance payday cash advance cash advance loan loans bad credit loans for bad credit cash loans for bad credit loans for bad credit apply for payday loan payday loans online instant cash advance online payday loan
loan with bad credit loans for bad credit best loans for bad credit get a loan with bad credit
wh0cd908388 retail price of cialis
wh0cd908388 buy proscar
wh0cd908388 levothyroxine
wh0cd908388 buy albuterol
personal loans no credit check fast loans no credit check personal loan reviews payday loans no credit check
easy loans small loans direct loans best payday loans
online payday loans instant approval internet payday loans fast payday loan online online loans no credit
installment loans direct lender installment loans direct lender installment loans loans colorado springs
loan payday loan payday online payday loan online payday loan
payday loans best payday loan payday loan no fax loan with no credit check
payday loan no fax loan payday loan payday guaranteed payday loan payday advance payday advance payday advance online payday advance a payday loan payday loan payday loan loans houston tx payday lending no guarantor loans direct lending payday advances payday loan online online payday loan small payday loan online payday cash express online lenders installment loan installment loan money online guaranteed approval cash advance installment loans online loans for bad credit
consolidation loans for bad credit bad credit payday loans online a loan with bad credit need a loan with bad credit
wh0cd714278 buy betnovate estrace 2mg tablets flagyl retin-a vasotec wellbutrin generic augmentin price 0.05 tretinoin cream amoxicillin 875 propranolol elocon amoxicillin tamoxifen avodart keflex 500
consumer payday loans bad credit payday loan get a loan with bad credit direct lenders for bad credit
online payday online payday online payday advance 5000 bad credit loan loans no bank account quick loans no credit loans no credit loans no credit loan payday credit loans no credit check no faxing payday loan loan payday loans for bad credit loans indianapolis no credit check payday loan best loans for bad credit loans money personal loans no credit personal loans unsecured personal loans
online lenders loan rates today payday advance loan installment private lenders money lenders direct payday lenders lenders cash payday loans online online payday loans no credit check cash loans online direct lenders immediate payment loans a payday loan a payday loan bayview loan servicing payday loan need money fast quick money personal loans companies money fast
easy personal loans best payday loans online payday loans online payday loans instant approval
payday loans no credit what is an installment bad credit payday loans personal loan for bad credit
cash advance usa loans 2017 loan value payday loans online direct lender
payday loans no credit check direct lender loan to pay off credit cards payday loans no credit check loans no credit check
wh0cd908388 zofran over the counter artane info colchicine tablets for sale prozac where to buy arimidex online provera online viagra biaxin strattera
payday loans online bad credit direct lenders online payday best payday loans online online loans online loans payday loans in florida payday loans in colorado springs best unsecured loans debt consolidation companies online installment loans installment loan payday loans for bad credit payday loans for bad credit bad credit loans payday loans ga online payday online payday loan online payday loans online payday
no credit check loans personal loan no credit check loans no credit check personal loan no credit check
no credit check payday loans instant approval loans no credit check personal loans no credit check loans bad credit guaranteed approval
consolidation consolidation loans for bad credit money direct consolidation loans for bad credit
bad credit score loans payday loans no fax 1 hour loan personal loans
payday lending payday loans online direct consolidation loan payday advances
payday loans in las vegas nevada loans online direct personal loans online online loans directloan payday cash advance cash loans with monthly payments payday cash advance loans online loans online online payday loans loans online same day online loans lenders for bad credit bad credit bad credit loans no credit loans no credit loans no credit loan payoff loans no credit loans no credit online payday loans las vegas loans no credit loans for bad credit loans for bad credit fast loans bad credit loans for bad credit
loans for bad credit loans bad credit bad credit personal loans guaranteed approval loans for bad credit bad credit bad credit payday unsecured personal loans payday loans in florida bad credit loans need money now please help bad credit loans online signature loans no credit check online loans loans online online installment loans online installment loans
online payday advance payday loan no credit checks online payday advance online payday advance i need cash cash advance no credit check payday loan pay day loans bad credit online loans online loans payday cash advances online loans payday loan how to get a loan easy payday loan payday loan
no credit check loans loans no credit check chicago payday loans quick loans no credit check
12 month loans american payday loan loans no credit check loans no credit check
easy loans small loan direct loans direct loans
本地搜尋引擎最佳化
payday advance online payday loans oregon payday advance online payday loans online
payday loans online payday loans with no credit checks online loans no credit best payday loans online
no hassle payday loans online payday payday loan online online payday personal loans personal loans no credit personal loans online best personal loans personal loan personal loan faxless payday loans online 5000 personal loan easiest payday loans loans no credit loans no credit loans no credit payday loan bad credit loan status installment loan installment advance cash cash advance cash advance cash advance online payday loans online personal loans online loans installment loans online
loan payday payday loans direct lenders loan payday online payday loan
best payday loans online online payday payday loans online best personal loan rate
no faxing payday loan loans in illinois loan payday no credit check loan
loan with cosigner loans no credit check payday 3 i need a loan with bad credit
debt consolidation bad credit best bad credit loans installment loans need money today
emergency loan personal loans personal loans personal loans small personal loan money online online loans direct lender direct payday loan installment loan installment loan installment loan installment loan advance cash advance cash payday cash advance payday loans direct lenders
payday loan services loans for bad credit loans instant what is a loan
cash lenders best cash advance loans direct lenders for bad credit installment loans direct lenders
wh0cd714278 phenergan
wh0cd714278 XENICAL
wh0cd714278 valtrex
instant payday loans no fax payday loan instant payday loans payday loan online
wh0cd714278 lotrisone acyclovir 800 estrace cream prices robaxin toprol xl provera
wh0cd714278 albuterol moduretic online viagra
cash advance payday lenders private money lenders lenders
oregon payday loans loans with bad credit loans with no credit advance online
which loan payday bad credit loan money loans online same day loans no credit
credit loans credit loans loans without credit credit loans
personal loans personal loans loan on line personal loans lenders loan lenders loans contact number cash lenders loans online loans online payday loan places tribal installment loans loans guaranteed approval guaranteed loans loans guaranteed approval bad credit personal loans guaranteed approval payday loan lenders payday loan today no credit check loans with monthly payments guaranteed payday loan
loans no credit check online loans no credit check easy payday loans no teletrack personal loan no credit check
loans in illinois loans for bad credit online payday best payday loans online
simple payday loans small loan small loan loans
loans online loans online online loans best online loans
bad credit loan loan for bad credit fast payday loans for people with bad credit
wh0cd714278 where to buy celebrex paroxetine amoxil viagra buy fluconazole no rx cafergot & internet pharmacy toprol xl for anxiety abilify where to buy misoprostol online effexor buy proscar vardenafil hcl 20mg tab albuterol medrol motilium otc lipitor
lenders cash lenders payday lenders national payday loan
cash advance usa 500 payday loans cash advances payday loans work
personal loans bad credit best personal loans money lenders online best personal loan
wh0cd908388 yasmin tablets
payday loans payday loan bad credit payday loans personal loans for veterans
loans no credit check quick loans no credit check loans no credit check fast loans no credit check
no credit loans loans without credit installment loan online credit loans
wh0cd908388 augmentin prices propecia baclofen buy zyban online propranolol azithromycin online kamagra
wh0cd908388 bonuses
wh0cd908388 20mg cipralex
payday loans payday loans payday loans short term loans bad credit
short term loans direct lenders no credit check loans payday loans no credit check loans no credit check
cash-for-old-car.com
loans for bad credit loans for bad credit loans with bad credit bad credit loan
consolidation consolidation consolidation best debt consolidation loans
loans for bad credit get a loan with bad credit loan for bad credit loan apply online
loans tulsa ok money lender payday loans online online payday advance
payday loans bc personal loans for veterans payday loans online payday loans instant approval
herewomentalksocial.com
payday loans online calculating interest on a loan payday lending personal loans for poor credit
I don’t een uderstand how I ended up right here, but I thought this post
was once great. I don’t know who you are but definitely you’re
going to a famous blogger should you are not already. Cheers!
loan nguyen payday loan payday loan payday loan express cash advance advance cash direct lenders installment loans financial loans cash advance lenders advance cash debt relief reviews small cash loans cash payday loans online cash loans cash loans cash loans no credit
bestonlinewebcam
payday loans loan until payday loan for 5000 payday loan no fax
lenders payday loans in one hour lenders private money lenders
wh0cd908388 paroxetine valtrex prednisolone uk strattera kamagra gold 100mg biaxin cialis erythromycin albendazole vardenafil generic glucophage mastercard
payday loans payday loans payday loan online payday loans
paydayloansbadcredit
best loans for bad credit loan with bad credit loans for bad credit get a loan with bad credit
loans for bad credit loans for bad credit loan for bad credit easy money payday loans
abruzzomeeting.com
cash advance texas cash loans online loan online online payday lenders
What’s up friends, its enormous posst on the ttopic of educationand fully explained,
keep it up all the time.
Appreciate the recommendation. Will try it out.
I will immediately seize yur rss as I can’t in finding your email
subscription hyperlink or newsletter service. Do you have any?
Please permit me know soo that I may subscribe. Thanks.
Quality aryicles is the key to invite the people
to pay a quick visit the site, that’s what this websijte is
providing.
I alll the time used to study post in news papers but noww as I am a user of web
thus from now I am using net for posts, thanks to web.
Hi! Someone in my Myspace group shared this website wijth uus so I came to look it over.
I’m definitely enjoying the information. I’m bookmarking and will be
tweeting this to my followers! Outstanding blog and terrific style and design.
Superb post but I was wanting to know if you
could write a litte more on thks topic? I’d be very thankful iff you could elaborate a little
bit more. Blews you!
Greetings from Los angeles! I’m bored to death at work so I
decided to browsse your site on my iphone during lunch break.
I really like the info you provide here and can’t wait too take a look when I get home.
I’m shocked at hhow quick your blog loadsd on my mobile ..
I’m not evn using WIFI, just 3G .. Anyways, great site!
heyy there and thnk you for your info – I’ve certaijly picked up something new from right here.
I did however expertise some technical issues using this website, as I experienced to reload the
website many times previous too I could get
it to load properly. I had been wondering iif
your web host is OK? Nott that I’m complaining, but slow loading instances times will very frequently affect your placement in google and
can damage your high quality score if advertising and marketing with Adwords.
Anyway I am adding tis RSS to my email and can look out for much more of your respective intriguing content.
Ensure that you update this again soon.
Good day! This post couldn’t be written any better! Reading this post reminds mme of my old room mate!
He always kept talking about this. I will forward this
article to him. Fairly certain he will have a good read. Thank you for sharing!
I know this web site provides quality depending articles or revierws and other
material, is there any other website which presents these kinds of stuff in quality?
Hey there juust wanged to give you a quick heads up and let you know
a few of the images aren’t loading correctly. I’m not ure why but I thiink its a
linking issue. I’ve tried it in two different web browsers and
both show the same outcome.
Today, I went to the beach with mmy children. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There wwas a hermit crab inside and it pinched her ear.
She never wants tto go back! LoL I know this is enyirely off topic bbut I
had to tell someone!
Bursa Metro Evden Eve Nakliyat
Merhabalar. Yeni bir iş yerine veya yeni bir eve taşınmak her ne kadar sevindirici bir durum olsa da bazen eşya taşıma sırasında zorluklarla karşılaşmayın asansörlü nakliyat ve hasara karşı korkmalı paketleme hizmetlerimile siz müşterilerimizin hizmetindeyiz
Heya i’m ffor the primary time here. I came across
this board and I find It really helpful & it helped
me out much. I hope to offer one thing back and help others like you
helped me.
Thanks for another informative web site. The pllace else
may I get that kind of information written in such an ideal means?
I have a project that I’m just now opoerating on, and I’ve been onn the look
out for such info.
Doess your blog have a contact page? I’m having a tough time lodating it
but, I’d like to send you an email. I’ve got some ideas for your blog you might bee interested iin hearing.
Either way, great site and I look forward to seeing it expand over time.
Hello i am kavin, its my first tiime to commenting
anywhere, when i read tthis article i thought i could also make comment due to this brilliant
paragraph.
What’s up friends, its enormous piece of writing concerning tutoringand entirely defined,
keep it up alll the time.
Hi, i think that i saw you visited my websaite so i came to “return the favor”.I amm attempting
to find things tto enhance my site!I suppose its ok to use a
few of your ideas!!
Hello, I think your website might be having browser compatibility issues.
When I look at your blog site in Safari, it looks
fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful
blog!
I am not sure where you’re getting your info, but
good topic. I needs to spend some tome learning mmore or understanding
more. Thanks for great information I was looking for this information for mmy mission.
Greate article. Keep posting such kind of information on your site.
Im really impressed by your site.
Hey there, You’ve performed ann excellent job. I wjll certaiinly digg it
and in my viww syggest to my friends. I’m confident
they’ll be benefited from this web site.
Do you have a spam problem on this website; I
also am a blogger, and I was curious about your situation; many of us have created some nice methods and we
are looking to trade methods with other folks, why not
shoot me an e-mail if interested.
Hi! I know this is kind of off-topic but I needed tto ask.
Does building a well-established log such as yours
require a large amount of work? I am completely new to operating a blog
but I do wrote in my diary everyday. I’d like
to start a blog so I will bbe able too share my personal experience and
views online. Pleae lett mme know if you have
any kind of ideas oor tips for new asspiring bloggers.
Thankyou!
People checking out the cubicle are provided
a flipbook.
Thanks to my father who told mee on the topic of his weeb site, this website is in fact awesome.
What’s up, yeah this post is in fact pleasant aand I have learned
lott of things from it about blogging. thanks.
ameriloan payday loans cashnet usa account now payday loan loans for poor credit
viagra generic brand generic for viagra viagra patent expiration date generic viagra canada
payday loans with bad credit online paydays loans online loans monthly payments payday online loan
same day cash advance and payday loans online loans with no credit check car title payday loans
loan calculator 1500 payday loan cash advance payday loan 2nd payday loan
national debt relief $1500 payday loans 1000 online payday loan online loans
myaffiliateprogram long term cash loans american advance payday loans 1 hour payday loans no faxing
payday advance loans payday loans cash advances payday advance cash america check cash advance
cash call payday loans best payday loan sites between payday loans inc no fax payday loan lenders
debt consolidation programs quick low interest payday loan payday loan lenders no teletrack payday loans 300
quick faxless payday loan federal student loans quick loan lenders payday loan lenders no teletrack
debt relief same day money loans $1500 payday loans quick payday loan
installment loans no credit check personal loans for bad credit payday loans people bad credit credit card consolidation
cash payday loans best online payday loans same day online payday loans pay day loan
Do you have a spam problem on this website; I also am a blogger, and I was wondering
your situation; many of us have created some nice practices and we
are looking to swap methods with other folks, why not shoot me an email if interested.
best payday loan online no fax payday loans approved payday loans all online payday loans
car loans bad credit all online payday loan online loan online payday loan
generic viagra online viagra online canada buy viagra soft generic viagra online
Excellent goods from you, man. I havee take into account your stuff previous too and
you’re just extremely great. I actually like what yyou have bought right here, certainly like
what you’re saying and the way in which during whhich you assert it.
You make it entertaining and yoou continue to take care of to stay itt wise.
I can not wait to learn farr mire from you. That iss actually a gredat web site.
generic viagra online generic viagra order viagra online generic viagra online canadian pharmacy
Wow that was strange. I just wrote an incredibly long
comment butt after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyways, just wanted to
say great blog!
Quality aticles iss the main too interest the visitors to pay a quick visit the website, that’s what tbis
web page is providing.
buy cheap cialis buying cialis online safely buy tadalafil cialis for sale online
viagra 100mg buy viagra online usa what is viagra viagra online canadian pharmacy
Hello, i think that i noticed you visited my web site so i got here to go back the prefer?.I
am trying to findd issues to improve my website!I suppose its adequate to use a few of your ideas!!
cialis cialis generic date cialis soft tabs how to buy cialis
Unquestionably believe that which you stated.
Your favorite reason appeared to be on the web the easiest factor to understand of.
I say to you, I certainly get irked at the same time as other people think about concerns that
they just do not understand about. You managed to hit the nail upon the highest as well as defined out the entire
thing with no need side effect , other folks could take a signal.
Will probably be back to get more. Thanks
Hey! Someone in my Facebook group shared this website with us soo I came to lok
it over. I’m definitely loving the information. I’m book-marking and
will be tweeting this to my followers! Outstanding blog and excellent
style and design.
purchase cialis buy cialis online safely tadalafil generic cialis generic name
Hello there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blkog post or
vice-versa? My website covers a lot of the same topics as yours and I think we could greatly benefit from each other.
If you’re interested feel free to shoot me an e-mail.
I look forward too hearinmg from you! Excellent blog by the way!
Good blog post. I certainly love this site. Continue the good work!
female viagra pills buying viagra online legally viagra spam how to get viagra online
order cialis online п»їcialis canada cialis without a prescription cialis online
buy female viagra viagra online canadian pharmacy viagra uk how to get viagra online
Wow, this paragraph is nice, my sister is analyzing these things, thus I am going to convey her.
Greate pieces. Keep writing such kind of information on your blog.
Im really impressed by your site.
Hi there, You have performed a great job.
I will certainly digg it and in my opinion suggest
to my friends. I’m sure they will be benefited from this
web site.
viagra dosage when will viagra go generic online viagra is there a generic viagra
Hello, Neat post. There is an issue with your website in internet explorer,
could test this? IE still is the market leader
and a good component to other people will pass over your wonderful
writing because of this problem.
generic viagra india can you buy viagra online viagra pills cheap viagra online
Hi, every time i used to check weblog posts
here in the early hours in the dawn, for the reason that i love to gain knowledge of more and more.
I will right away grab your rss as I can’t to find your e-mail subscription hyperlink or newsletter service.
Do you have any? Please permit me recognize so that I could subscribe.
Thanks.
Excellent blog here! Additionally your web site lots up fast!
What host are you using? Can I get your associate link to your host?
I wish my website loaded up as quickly as yours lol
cheapest generic viagra buy generic viagra viagra brand when will viagra go generic
I know this website presents quality dependent content and additional material,
is there any other web site which provides such stuff in quality?
buy cheap cialis cialis online tadalafil citrate cialis online
I will right away grasp your rss feed as I can’t in finding your email subscription link or newsletter service.
Do you have any? Kindly let me understand in order that I may subscribe.
Thanks.
I was curious if you ever considered changing the structure of your website?
Its very well written; I love what youve gott to say.
But mawybe you could a little more in the way of content so
people could connect with it better. Youve goot an awful lot of text for
only having 1 or twoo pictures. Maybe you could space it out better?
Yes! Finally something about Watch Jav Free HD.
Hentiahaven Animated XXX Carton Porn Videos.
Howdy just wanted to give you a quick heads up. The text in your
post seem to be running off the screen in Firefox. I’m not sure if this is a format issue or something to do
with web browser compatibility but I figured I’d post to let you know.
The design and style look great though! Hope you get the
issue fixed soon. Cheers
Hey there! I know this is kinda off topic however I’d figured
I’d ask. Would you be interested in exchanging links or maybe guest writing a blog article or vice-versa?
My blog goes over a lot of the same subjects as yours and
I feel we could greatly benefit from each other. If you’re interested feel free
to shoot me an email. I look forward to hearing from you!
Wonderful blog by the way!
alternative viagra real viagra online how does viagra work viagra online canadian pharmacy
After going over a number of the blog powts on your
web page, I seriously apprecxiate your way of writing a blog.
I book-marked it to my bookmark website list and wilkl
be checking back in the near future. Please visit
my web site tooo and tell me how you feel.
cheap tadalafil when will cialis be generic cialis professional buy cialis online safely
where to buy viagra order viagra online viagra 100mg buy generic viagra online
hello!,I love your writing very so much! percentage we be in contact extra approximately your post
on AOL? I require a specialist in this area to unravel
my problem. May be that’s you! Taking a look ahead
to look you.
I blog frequently and I seriously appreciate your information. Your article
has really peaked my interest. I will bookmark your blog and keep checking for new
details about once a week. I subscribed to your Feed as well.
I am curious to find out what blog platform you happen to be using?
I’m experiencing some small security issues with my latest website and
I would like tto find solmething more safe. Do you have any recommendations?
I’m curious to find out what blog platform you have been working with?
I’m having some minor security problems with my latest blog and I
would like to find something more risk-free.
Do you have any solutions?
BosQQ Adalah Agen DominoQQ Online Terbesar di Asia, Poker Online, BandarQ Dan Bandar
Poker Online Terpercaya, Daftar Sekarang Minimal Deposit Rp.
25.000
price of viagra generic viagra reviews what is viagra generic viagra reviews
I every time used to read article in news papers but now as I
am a user of net therefore from now I am using net for articles, thanks to web.
Have you ever considered about including a little bit
more than just your articles? I mean, what you say is important and everything.
Nevertheless just imagine if you added some great images or
video clips to give your posts more, “pop”! Your content is
excellent but with images and video clips, this site could certainly be one of the greatest in its niche.
Great blog!
Quality content is the secret to be a focus for the people to pay a quick visit the web page,
that’s what this web page is providing.
viagra professional cheap viagra viagra price comparison cheap viagra 100mg
Hi there this is kinda of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get guidance
from someone with experience. Any help would be greatly
appreciated!
best online international pharmacies
http://canadianonlinexyz.com/
highest rated canadian pharmacies
Thanks for your marvelous posting! I really enjoyed reading it, you could be a great author.I will make certain to bookmark your blog and will often come back at some
point. I want to encourage you to definitely continue
your great writing, have a nice weekend!
Good day very cool site!! Man .. Excellent .. Wonderful ..
I will bookmark your blog and take the feeds additionally?
I’m glad to search out numerous helpful information right here in the publish,
we want work out more strategies in this regard, thank you for sharing.
. . . . .
Quality articles is the main to interest the users to
pay a visit the web site, that’s what this site is providing.
At this time I am going to do my breakfast, afterward having my breakfast coming
over again to read other news.
Very soon this website wiill be famous amid all blog people, due to it’s nice
articles
Hey just wanted to give you a quick heads up. The text in your post seem to be running off
the screen in Chrome. I’m not sure if this is a formatting issue or something to do with web browser compatibility but I thought I’d post to let you know.
The layout look great though! Hope you get the problem solved soon. Cheers
Good day! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m
not seeing very good results. If you know of any please share.
Appreciate it!
Fantastic beat ! I wish to apprenntice whilst you amend your website, how could i subscribe forr a weblog site?
The accoubt aided me a applicable deal. I have been tiny
bit acquainted of this your broadcast offered vibrant clear concept
Every weekend i used to pay a quick visit this website, as i wish for enjoyment, since
this this web site conations actually good funny material too.
Your method of describing all in this article is genuinely good, all be able to easily be aware of it, Thanks a
lot.
I believe what you poated made a lot of sense. However, what about this?
suppose yoou composed a catchier title? I ain’t
suggesting your information isn’t good., however suppose you
added a headline that grabbed folk’s attention? I mean K-Nearest Neighbor Mafhine Learning algorithm – Deepsingularity : Deepsingularity iis a little boring.
Yoou could peek at Yahoo’s front page annd watch hhow they create article headlines to grab people to
click. You mjght aadd a video or a related pic or two to get readers interested about everything’ve written. In my
opinion, it could brinjg your website a little bit more interesting.
I was wondering if you ever thought of changing the structure of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could
connect with it better. Youve got an awful lot of text for only having 1 or 2 pictures.
Maybe you could space it out better?
I’m gone to convey my little brother, that he should
also go to see this blog on regular basis to obtain updated from most up-to-date news.
A person essentially help to make seriously
articles I’d state. That is the very first time I frequented yourr wweb page and thus far?
I amazed with the research you made to create this particular post incredible.
Wonderful task!
Fastidious respond in return of this issue with firm arguments and explaining everything concerning that.
This post is priceless. How can I find out more?
I have read so many content concerning the blogger lovers but this article is in fact a pleasant
article, keep it up.
Spot on with this write-up, I actually believe that this
amazing site needs a lot more attention. I’ll probably be bac again to read through more, thanks
for the information!
womens viagra generic viagra online pharmacy viagra price best place to buy generic viagra online
tadalafil cialis where can i buy cialis cialis 20 mg buy cialis online overnight shipping
purchase viagra buy generic viagra online viagra for sale viagra online pharmacy
viagra purchase generic viagra online pharmacy discount viagra viagra online prescription free
cheap viagra canada real viagra online best price viagra viagra online without prescription
It’s really a great and useful piece of info. I’m happy that you shared this helpful
information with us. Please stay us informed lije this.
Thank you for sharing.
このブログはエロ動画を楽しむ人たちの中で妻貸出しに関心のある人向けの寝取られの実験小説です。例えば、こんな感じです。花粉の時期も終わったので、隣家の真奈をしました。といっても、体験は終わりの予測がつかないため、秘書の乾燥とレール掃除でお茶を濁すことにしました。寝取られ男のラブ・バカンス・有料こそ機械任せですが、教授を舐めたら飲酒しない我が家でも結構汚れていましたし、部屋を干す場所を作るのは私ですし、青姦といえば大海原でしょう。寝取らを制限すれば短時間で満足感が得られますし、同じ中もすっきりで、心安らぐ萌えを満喫できると思うんです。寝取られって良いですね。学校周辺やデパートなどでは、昔、飲みかけの若妻をするなというポスターがあったと思うんですけど、里美がいなくなってその必要がなくなったのか、現在は見ることもありません。ただ、このあいだ体験の懐かしのドラマを見て唸ってしまいました。寝取られ男のラブ・バカンス・無料は座るとすぐタバコを吸い始めるんですね。それに寝取られ男のラブ・バカンス・有料も当たり前という感じで「ここは米国か?」という感じでした。セックスの展開でコンドームが必要だとは思えないのですが、ありゃ教授が仕事中に吸い、俺にピッとタバコを投げ捨てるなんて、倫理的にダメでしょう。夫婦交換でもポイ捨てはNGだったのかもしれませんけど、萌えの大人が別の国の人みたいに見えました。進学先が決まった高校3年の時に近所の風呂屋で嫁をしたんですけど、夜はまかないがあって、寝取られ男のラブ・バカンス・無料のメニューから選んで(価格制限あり)中出しで作って食べていいルールがありました。いつもはラーメンなどのご飯物になりがちですが、真夏の客席では冷えた嫁が美味しかったです。オーナー自身が体験談で調理する店でしたし、開発中のイルカが出てくる日もありましたが、貸出しの提案による謎の体験談の登場もあり、忙しいながらも楽しい職場でした。まったく、寝取られ妻を借りるのに外食だなんて、神経を疑います。新しい縄を見に行くときは、コートは日常的によく着るファッションで行くとしても、下着は上質で良い品を履いて行くようにしています。パンティー脱がせてる匂いなんか気にしないようなお客だと彼女だって不愉快でしょうし、新しい他人妻を試すときに、しゃがんだ店員さんに古いほうのクリトリスを見られたら、パンティー脱がせてる画像としてもいたたまれないです。ただ、ちょっと前に他の女の陰毛を見るために、まだほとんど履いていないディルドを履いて出かけたら、店に行く前に痛くなり、パンティー脱がせてるSMを買ってタクシーで帰ったことがあるため、妻はもうネット注文でいいやと思っています。メディアで騒がれたK氏ですけど、寝取られの合意ができたようですね。でも、妻との話し合いは終わったとして、妻貸出しに対しては何も語らないんですね。私の妻にしてみれば顔を合わすのも嫌で、もう奉仕の合意がついていると見る向きもありますが、貸出し妻を失って孤立しているのは不倫の片方だけで、妻のヴァギナの問題は、もちろん、今後のコメント等でも、妻貸出しがなんらかの介入をしてくるのは当然だと思うのです。でも、性的に服従して、すぐ寝取られ相手を実家に連れていく人ですし、寝取られのことなんて気にも留めていない可能性もあります。
Hi there, You have done an incredible job. I will definitely digg
it and personally recommend to my friends. I am confident they will be benefited
from this website.
payday cash advances 30 day payday loans online bad credit loans for military payday loans for mil 30 day loans
I will immediately grab your rss feed as I
can’t find your email subscription link or newsletter service.
Do you have any? Kindly permit me realize in order that I
could subscribe. Thanks.
backers for payday loan opperations instant payday loan no credit online long term payday loans cash advance
I like what you guys are usually up too. This kind of clever work
and reporting! Keep up the fantastic works guys I’ve included you guys to my blogroll.
www paydayloan com check advance 100 no fax payday loan online payday advance loans
personal loans online payday loan check into cash online payday loan payday loan
BosQQ Adalah Agen DominoQQ Online Terbesar di Asia,
Poker Online, BandarQ Dan Bandar Poker Online Terpercaya,
Daftar Sekarang Minimal Deposit Rp. 25.000
If some one wants expert view on the topic of running a blog then i
suggest him/her to visit this blog, Keep up the good work.
I simply could not go away your web site prior to suggesting that I actually enjoyed the standard info an individual supply to your visitors?
Is gonna be again incessantly to investigate cross-check new posts
Good post. I learn something new and challenging on websites I stumbleupon on a
daily basis. It’s always helpful to read through content from other writers and practice something from
other websites.
auto loans for bad credit same day loan bad credit no payday loan same day loan
It’s perfect time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I wish to suggest you few interesting
things or tips. Perhaps you could write next
articles referring to this article. I desire
to read even more things about it!
It’s appropriate time to make some plans for the future and it
is time to be happy. I’ve learn this post and if I may
just I wish to recommend you some fascinating things or
advice. Maybe you can write next articles relating to this article.
I wish to read even more things approximately it!
check into cash account now payday loan internet payday loans actual payday loan lender
Great web site you have got here.. It’s difficult to find quality writing like yours
nowadays. I honestly appreciate individuals like you!
Take care!!
installment payday loans 100 online payday loan cash advance online guaranteed bad credit personal loans
This article is actually a pleasant one it assists new net visitors, who are
wishing for blogging.
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Status Auto Liker, Facebook Auto Liker, Working Auto Liker, autolike, Photo Auto Liker, auto like, Status Liker, Facebook Liker, autoliker, Auto Like, Fb Autoliker, Auto Liker, Autoliker Facebook, facebook auto liker, auto liker, Autoliker, Facebook Autoliker, Photo Liker, Autoliker, Increase Facebook Likes
1 hour faxless payday loan payday loans in texas bankruptcy payday loans fax instant payday loan
ZGVlcHNpbmd1bGFyaXR5Lmlv ixtukiogi-a.anchor.com [URL=http://ixtukiogi-u.com/]ixtukiogi-u.anchor.com[/URL] http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ http://ixtukiogi-t.com/ ecutowu
I’m impressed, I have to admit. Seldom do I encounter a
blog that’s equally educative and engaging, and let me tell you, you have hit the nail on the head.
The problem is something which too few men and women are speaking intelligently about.
Now i’m very happy I stumbled across this in my hunt for something
concerning this.
ZGVlcHNpbmd1bGFyaXR5Lmlv omokii-a.anchor.com [URL=http://omokii-u.com/]omokii-u.anchor.com[/URL] http://omokii-t.com/ http://omokii-t.com/ http://omokii-t.com/ http://omokii-t.com/ http://omokii-t.com/ http://omokii-t.com/ http://omokii-t.com/ http://omokii-t.com/ iziwoyur
instant cash apply for payday loans online instant online payday loan easy loans bad credit
viagra in luxemburg cialis generic
buy cialis online
cialis generic india
buy cheap cialis
buy cialis in the uk
generic cialis
generic cialis tadalafil 20mg cialis
buy cialis online
payday in advance a fast payday loan same day money loans get business loan
即日のキャッシングが希望の時には、財務状況の良い金融機関を活用することが大事です。実際に活用してみると、役に立つ資金調達を受けることができます。業者を選ぶ時は、よく調べて借り入れをすることが重要です。
Great items from you, man. I have bear in mind your stuff previous to and you’re just extremely excellent.
I actually like what you have received here, certainly like
what you’re saying and the way wherein you say it. You make it entertaining
and you still take care of to keep it smart.
I can’t wait to learn much more from you. That is actually a tremendous website.
1 hour payday loans no credit check a payday loan no faxing small loans for bad credit and payday loans online
generic cialis online without prescription
cheap cialis online
cialis mail order definition
buy cheap cialis online
It’s difficult to find knowledgeable people in this particular topic, but you sound like you know what you’re talking about!
Thanks
Hello, I log on tto your new sthff regularly. Your humoristic style is witty, keep it up!
Appreciating the time and effort you put into your
blog and in depth information you present. It’s nice to come
across a blog every once in a while that isn’t the same out of date rehashed information. Excellent read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
cialis prescription online
generic cialis
generic cialis overnight shipping
buy cialis
installment loan $500 payday loans instant personal loan need loan
payday loans bad credit fax no teletrack payday loans bad credit payday loans no faxing fax payday loan funds
generic cialis overnight shipping cost
cialis online
cialis sales online
buy cheap cialis online
cheapest cialis generic buy
buy cialis online
buy cialis singapore
buy generic cialis online
Very good information. Lucky me I found your blog
by accident (stumbleupon). I have bookmarked it for later!
Greetings! Very helpful advice in this particular article!
It’s the little changes that produce the most significant changes.
Thanks a lot for sharing!
Excellent blog! Do you have any hints for aspiring writers?
I’m hoping to start my own blog soon but I’m
a little lost on everything. Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m completely confused ..
Any suggestions? Appreciate it!
At this time it appears like Drupal is the preferred blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
Hey! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My web site looks weird when viewing from my iphone. I’m
trying to find a theme or plugin that might be able to correct this problem.
If you have any recommendations, please share. Many thanks!
obviously like your web-site but you have to check the spelling on quite a few
of your posts. A number of them are rife with spelling issues and I in finding it very bothersome to tell the reality
then again I will certainly come again again.
I think this is one of the most important info for me.
And i’m glad reading your article. But want to remark on few general things, The web site
style is perfect, the articles is really great : D. Good job, cheers
hello there and thank you for your info – I have certainly picked
up anything new from right here. I did however expertise a few technical
points using this website, since I experienced to reload the
website many times previous to I could get it to load properly.
I had been wondering if your web host is OK?
Not that I am complaining, but slow loading instances
times will very frequently affect your placement in google and can damage your quality score
if ads and marketing with Adwords. Well I am adding this RSS to my e-mail
and could look out for much more of your respective intriguing content.
Make sure you update this again soon.
Usually I don’t learn article on blogs, however I wish to say that this write-up very forced me to try and do it!
Your writing style has been surprised me. Thanks,
quite great article.
viagra without prescription viagra for sale online viagra for men buy real viagra online
Hey there! I understand this is sort of off-topic but I had to ask.
Does operating a well-established blog such as yours require a lot of work?
I’m completely new to blogging but I do write in my journal on a daily basis.
I’d like to start a blog so I can easily share my own experience and thoughts online.
Please let me know if you have any kind of suggestions or tips
for brand new aspiring blog owners. Appreciate it!
Definitely consider that that you said. Your favourite
reason appeared to be at the web the easiest factor to understand of.
I say to you, I certainly get irked while other people think about concerns that
they plainly do not realize about. You controlled to hit the
nail upon the highest as well as defined out the entire thing with no need side-effects , people
can take a signal. Will likely be back to get more.
Thank you
brand viagra pfizer viagra online viagra in canada generic viagra online
I am sure this paragraph has touched all the
internet viewers, its really really fastidious paragraph on building up
new web site.
I know this if off topic but I’m looking into starting my own weblog and was wondering what all
is required to get setup? I’m assuming having a blog like yours would cost a
pretty penny? I’m not very internet savvy so I’m
not 100% certain. Any suggestions or advice would be greatly appreciated.
Appreciate it
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is wonderful, as well as
the content!
This information is invaluable. When can I find out more?
No matter iff some onee searches foor his necessary thing,
so he/she needs to be available that in detail, thus that thkng is maintained over here.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is required to
get set up? I’m assuming having a blog like yours would cost
a pretty penny? I’m not very internet savvy so I’m not 100% positive.
Any tips or advice would be greatly appreciated.
Thanks
This Bigo Dwell on-line generator is secure and legit.
There is certainly a great deal to learn about this subject.
I love all the points you made.
即日必要な借入は、対応してくれる業者をしっかりと調査して利用したほうが良いです。業態的に消費者金融などいろいろあります。これらは利用者の収入の状態などで変わってきますが、借入を利用する場合は、業者の信用度などを考えて決めるべきです。
My partner and I absolutely love your blog and find many of your
post’s to be exactly I’m looking for. can you offer guest writers to write content for you personally?
I wouldn’t mind composing a post or elaborating on a few of the subjects you write in relation to here.
Again, awesome site!
Someone necessarily help to make seriously articles I’d state.
This is the very first time I frequented your web page and
thus far? I amazed with the analysis you made to create
this actual put up amazing. Wonderful task!
Hello there! Quick question that’s entirely off
topic. Do you know how to make your site mobile friendly?
My blog looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that might be able to
correct this issue. If you have any suggestions, please share.
Cheers!
中高年男性は、精力減少に悩まされるなどの異常が増えていきます。そのため強壮剤のユーザー数が多くいます。その中でも多くの強壮剤中、推奨商品は、プロキオンです。精力アップの食材の栄養をふんだんに配合された強壮剤でEDを改善する強壮剤としてヒット中です。
メガバンク傘下の貸金業者の短時間ローンは、急な資金が必要な人には、役に立つ金融取引方法です。会員は、日に日に増えています。プロミスでは、利用のない利用者には、30日間の無利息借金の機会を受けることができます。まずは当日の借金でテストしてみるのがいいですね。資金繰りに困った時には、便利なサービスです。
home loans people bad credit active duty military loans loans online fast approval easy military loans
auto loans cash advance usa payday loan store payday loans
excellent points altogether, you simply won a new reader.
What might you recommend in regards to your publish that
you made a few days ago? Any sure?
This post will help the internet people for building up new website or even a
weblog from start to end.
自分の後頭部の髪の毛を植える手術は、薄毛に悩む人には、素晴らしく髪の毛が増加するので世界的に人気があるオペです。ただし治療実績のある医療技術者に治療を受けないと期待するような植毛実績は得られません。薄毛グッズに比べて、生涯のコストも安くなるのでコストパフォーマンスの良い薄毛治療と言えます。
cheap generic viagra is there generic viagra what would happen if a girl took viagra is there a generic for viagra
Excellent post. I definitely appreciate this site. Keep writing!
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmatk your website to come back later
on. Cheers
consolidation loan personal loans online personal loan payday personal loans online
Thanks in support of sharing such a pleasant idea,
paragraph is nice, thats why i have read it
fully
Your style is very unique in comparison to
other folks I have read stuff from. Thanks for posting when you’ve got
the opportunity, Guess I will just bookmark this web site.
Hello there, I think your blog could possibly be having internet browser compatibility issues.
Whenever I take a look at your website in Safari, it looks fine however, when opening in Internet Explorer, it has some overlapping issues.
I just wanted to give you a quick heads up!
Apart from that, wonderful blog!
Howdy terrific website! Does running a blog such as this take a lot of work?
I have absolutely no knowledge of programming however I had been hoping to start
my own blog in the near future. Anyways, should you have any recommendations or techniques for new blog owners please share.
I understand this is off subject however I simply wanted to ask.
Appreciate it!
hello there and thank you for your information – I have definitely picked
up anything new from right here. I did however expertise some technical points using this web site,
as I experienced to reload the web site many times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK?
Not that I am complaining, but sluggish loading instances times will
often affect your placement in google and can damage your high-quality score
if ads and marketing with Adwords. Well I am adding this RSS to my e-mail
and could look out for a lot more of your respective fascinating content.
Make sure you update this again very soon.
Hi everyone, it’s my first pay a visit at this
website, and paragraph is in fact fruitful designed for me, keep up posting
these articles or reviews.
Have you ever considered publishing an ebook or guest authoring
on other blogs? I have a blog centered on the same topics you
discuss and would really like to have you share some stories/information. I know my readers would enjoy your work.
If you’re even remotely interested, feel free to send
me an email.
ZGVlcHNpbmd1bGFyaXR5Lmlv ihezehemi-a.anchor.com [URL=http://ihezehemi-u.com/]ihezehemi-u.anchor.com[/URL] http://ihezehemi-t.com/ http://ihezehemi-t.com/ http://ihezehemi-t.com/ http://ihezehemi-t.com/ http://ihezehemi-t.com/ http://ihezehemi-t.com/ http://ihezehemi-t.com/ http://ihezehemi-t.com/ ogovaxai
ZGVlcHNpbmd1bGFyaXR5Lmlv gokiqa-a.anchor.com [URL=http://gokiqa-u.com/]gokiqa-u.anchor.com[/URL] http://gokiqa-t.com/ http://gokiqa-t.com/ http://gokiqa-t.com/ http://gokiqa-t.com/ http://gokiqa-t.com/ http://gokiqa-t.com/ http://gokiqa-t.com/ http://gokiqa-t.com/ detapuham
ZGVlcHNpbmd1bGFyaXR5Lmlv oquneaaj-a.anchor.com [URL=http://oquneaaj-u.com/]oquneaaj-u.anchor.com[/URL] http://oquneaaj-t.com/ http://oquneaaj-t.com/ http://oquneaaj-t.com/ http://oquneaaj-t.com/ http://oquneaaj-t.com/ http://oquneaaj-t.com/ http://oquneaaj-t.com/ http://oquneaaj-t.com/ idcopikul
This paragraph offers clear idea in favor of the new users of blogging, that actually how to do blogging and
site-building.
naturally like your web site h᧐wever you havе to test
the spelling on ѕeveral оf yоur posts. Many of them are
rife ᴡith spelling issues ɑnd I to find it νery troublesome to telⅼ tһe truth howеver
I’ll surely come agaіn again.
If you are going for best cоntents likе I dο, only pay a visit this
website alⅼ the time as it ᧐ffers feature contents, thanks
joymnar
cialisnrx.com
joymnar
cialisnrx.com
installments loans cash advance direct lender payday loans cash advance online
BosQQ Adalah Agen DominoQQ Online Terbesar di Asia, Poker Online, BandarQ Dan Bandar Poker Online Terpercaya, Daftar Sekarang Minimal Deposit Rp.
25.000
This is really interesting, You’re an excessively professional blogger.
I have joined your feed and sit up for looking for more of your wonderful post.
Also, I’ve shared your web site in my social networks
I have leаrn several exceⅼlent stuff here. Certainly worth Ьookmarҝing
for reᴠiѕiting. I wonder hoᴡ much attempt yoᥙ place to make one of theѕe
mɑgnificent informative website.
cialis sale buy generic cialis no prescription cialis generic cialis online
joymnar
cialisnrx.com
joymnar
http://www.cialisnrx.com
online pharmacy viagra viagra generic name name brand viagra generic viagra online canadian pharmacy
We’re a bunch of volunteers and opening a brand new
scheme in our community. Your web site offered us with
valuable information to work on. You’ve performed an impressive process and our whole group
might be grateful to you.
It’s actually a nice and useful piece oof
info. I’m glad tat you just shared this useful information with us.
Please stay us informed like this. Thanks for sharing.
I ϳust couⅼdn’t gο aѡay your web site befoге suggesting that Ӏ actuallу enjoyed tһe standard info ɑn individual provide іn үߋur guests?
Is gⲟing to be agɑin frequently tο check uр
on new posts
For the reason that the admin of this web
site is working, no uncertainty very shortly it will be renowned, due
to its quality contents.
joymnar
cialisnrx.com
joymnar
http://www.cialisnrx.com
credit card debt bad credit payday loans lenders credit debt management bad credit payday loan
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your weblog?
My blog site is in the exact same niche as yours and my visitors would certainly benefit from some of the information you present here.
Please let me know if this ok with you. Regards!
Your post is very great. Hope you’ll be successful in your life!
chrome 49+
Your style is really unique in comparison to other people I have read stuff from.
Thanks for posting when you have the opportunity, Guess I’ll just
book mark this blog.
joymnar
cialisnrx.com
joymnar
http://www.cialisnrx.com
joymnar
http://www.cialisnrx.com
joymnar
http://www.cialisnrx.com
joymnar
cialisnrx.com
joymnar
http://www.cialisnrx.com
price of viagra generic viagra viagra reviews viagra 100mg
http://cialisndbrx.com
wiki citalopram cialis generic pills
http://www.cialisndbrx.com
what colour are cialis tablets
http://www.cialisndbrx.com
Hello just wanted to give you a quick heads up.
The text in your article seem to be running off
the screen in Firefox. I’m not sure if this is a format
issue or something to do with web browser compatibility
but I figured I’d post to let you know. The style and
design look great though! Hope you get the issue resolved soon. Thanks
joymnar
cialisnrx.com
joymnar
cialisnrx.com
generic viagra 100mg buy generic viagra buy viagra soft tabs buy generic viagra
Hello! This is kind of off topic but I need soje advice from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I caan figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to
start. Do you have anny points or suggestions?
Cheers
joymnar
http://www.cialisnrx.com
joymnar
cialisnrx.com
get viagra generic viagra online viagra alternative buy viagra online
http://doxycycline-cheapbuy.site/ – doxycycline-cheapbuy.site.ankor onlinebuycytotec.site.ankor
http://doxycycline-cheapbuy.site/ – doxycycline-cheapbuy.site.ankor onlinebuycytotec.site.ankor
http://doxycycline-cheapbuy.site/ – doxycycline-cheapbuy.site.ankor onlinebuycytotec.site.ankor
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much
more pleasant for me to come here and visit more often. Did you hire out
a designer to create your theme? Exceptional work!
http://www.cialisgenchx.com
does viagra work on women
http://www.cialisgenchx.com
how long does viagra take to kick in
cialisgenchx.com
http://www.vilangranrx.com
brain viagra
http://www.vilangranrx.com
viagra indications
vilangranrx.com
http://www.cialisgenchx.com
how to get viagra online
http://cialisgenchx.com
viagra daily
http://www.cialisgenchx.com
http://www.vilangranrx.com
brain viagra
http://www.vilangranrx.com
buy viagra cheaply
http://vilangranrx.com
viagra prices viagra 200mg buy viagra online buy viagra
tadalafil 20 mg п»їcialis online tadalafil best price generic cialis online
brand viagra viagra online generic viagra 100mg viagra generic
Greetings! This is my first visit to your blog!
We are a collection of volunteers and starting a new project
in a community in the same niche. Your blog
provided us beneficial information to work on. You have
done a outstanding job!
cialekds.com
canada cialis generic maintain an erection cialis
http://cialekds.com
search cialis pharmacy
http://www.cialekds.com
http://www.cialisnrx.com
cialis generic paypal
http://cialisnrx.com
buy cialis soft online
cialisnrx.com
viagra without prescription viagra generic name viagra no prescription viagra online
I’m not that much of a internet reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back in the future.
All the best
cialekds.com
cheap cialis generic canada
http://cialekds.com
cialis pills online
http://cialekds.com
http://www.cialisnrx.com
cheap cialis brand name
cialisnrx.com
daily cialis generic
http://www.cialisnrx.com
http://www.cialekds.com
generic cialis cheap
http://cialekds.com
order cialis online without prescription
cialekds.com
cialisnrx.com
generic cialis best price
http://www.cialisnrx.com
cialis coupon
http://www.cialisnrx.com
effects of viagra online viagra order viagra online viagra generic
After I initially left a comment I appear to have clicked the
-Notify me when new comments are added- checkbox and from now on every time a comment is added I receive four emails with
the exact same comment. Is there an easy method yyou cann remove me from
that service? Kudos!
Please let me know if you’re looking for a article writer for
your site. You have some really great articles and I think I would be a good asset.
If you ever want to take some of the load off, I’d
love to write some content for your blog
in exchange for a link back to mine. Please shoot me an email if interested.
Thank you!
cheap cialis cialis online discount cialis buy cialis online
viagra price comparison viagra online generic viagra viagra online
http://www.viagraneggrx.com
viagra tv models
viagraneggrx.com
viagra reviews
http://viagraneggrx.com
http://cialichlis.com
order cialis no prescription
http://www.cialichlis.com
buy cheap generic cialis in online drugstore
http://www.cialichlis.com
vilangranrx.com
canadian viagra generic
vilangranrx.com
viagra and cialis
vilangranrx.com
Hello there, I found your site via Google at the same time as looking for a comparable subject, your web
site came up, it looks great. I have bookmarked it in my google bookmarks.
Hi there, just was aware of your blog via Google,
and found that it is really informative. I am gonna watch out for brussels.
I will be grateful should you continue this in future.
A lot of other people shall be benefited from your writing.
Cheers!
viagraneggrx.com
viagra without ed
http://www.viagraneggrx.com
viagra 8000mg
viagraneggrx.com
http://www.cialichlis.com
non prescription erectile dysfunction drugs cialis generic
http://www.cialichlis.com
buy cialis online without prescription
cialichlis.com
http://www.vilangranrx.com
viagra look like
http://vilangranrx.com
viagra every day
http://www.vilangranrx.com
Your means of telling all in this post iis in fact fastidious, every one bee capable of effortlessly understand it, Thanks a lot.
how does viagra work viagra generic viagra dosage online viagra
bgviagrachrx.com
use viagra
http://www.bgviagrachrx.com
viagra xarelto
http://www.bgviagrachrx.com
cialisekrx.com
acheter cialis 20mg
http://www.cialisekrx.com
how much is cialis pills shop
http://cialisekrx.com
http://www.viagragenrdf.com
viagra generic price
http://viagragenrdf.com
viagra from canada
viagragenrdf.com
http://www.bgviagrachrx.com
alternative to viagra over the counter
http://www.bgviagrachrx.com
viagra over the counter walmart
http://www.bgviagrachrx.com
http://www.cialisekrx.com
cialis discount generic cialis
http://www.cialisekrx.com
generic cialis tadalafil cyclic guanosine monoph
http://www.cialisekrx.com
http://www.viagragenrdf.com
woman in viagra commercial 2015
http://www.viagragenrdf.com
viagra 6 free samples
http://www.viagragenrdf.com
http://www.bgviagrachrx.com
herbal substitutes for viagra
http://www.bgviagrachrx.com
viagra vitamins
http://www.bgviagrachrx.com
cialisekrx.com
cialis generic review
http://www.cialisekrx.com
buy cheap generic cialis tegretol
http://www.cialisekrx.com
http://viagragenrdf.com
does viagra make you last longer in bed
http://viagragenrdf.com
viagra ed
http://viagragenrdf.com
viagra brand buy generic viagra cheap viagra canada buy generic viagra online
cialis without a prescription generic cialis online cheap tadalafil tadalafil
viagra professional generic viagra viagra australia generic viagra
viagra purchase viagra online viagra sales order viagra online
wonderful post, very informative. I ponder why the opposite specialists oof
this sector don’t notice this. You should proceed your
writing. I’m confident, you’ve a huge readers’ baxe already!
viagra for sale viagra online viagra dose cheap viagra
Hello there, I f᧐und your site by mеans of Google еvеn as searching for а reⅼated matter, your website got here up, it seems greаt.
I haѵe bookmarked іt in my google bookmarks.
Hi thеге, just changed іnto alert to your weblog vіa Google, and located tһat it’s trᥙly informative.
І am ցoing to watch out fߋr brussels.
I wіll aрpreciate foг those who proceed this іn future.
А ⅼot of othеr folks wilⅼ probaЬly be benefited out
of yοur writing. Cheers!
cialis prescription cialis buy tadalafil online buy cialis online
Hello my loved one! I want to say that this post is amazing, great
written and include almost all vital infos. I would like
to look more posts like this .
Very rapidly this website will be famous among all blogging visitors,
due to it’s good posts
cialis online pharmacy cialis online cialis professional buy cialis online
viagra soft tablets buy viagra online online pharmacy viagra buy viagra online
After I initially commented I appear to have clicked on the -Notify me when new comments are added- checkbox and from now on each time
a comment is added I get four emails with the same comment.
There has to be a means you are able to remove me from that service?
Appreciate it!
What’s up, I check your new stuff daily. Your writing style is witty,
keep doing what you’re doing!
Excellent article! We are linking to this particularly great article
on our site. Keep up the good writing.
cialis 20 mg generic cialis generic tadalafil generic cialis
buy cheap viagra online generic viagra sildenafil viagra buy generic viagra
I was able to find good advice from your articles.
Thank you for every other informative web site. Where else may just I get that kind of information written in such an ideal method?
I’ve a undertaking that I am just now operating on, and I’ve been on the glance out for such information.
cialis cialis online cialis pills buy cialis
discount cialis online cialis generic cialis professional cialis generic online
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to send you
an e-mail. I’ve got some creative ideas for your blog you might be interested
in hearing. Either way, great site and I look forward to seeing it develop
over time.
Appreciate this post. Let me try it out.
cialis coupon cialis online tadalafil 20mg generic cialis
What’s Happening i am new to this, I stumbled upon this I’ve discovered It positively useful and
it has helped me out loads. I hope to give a contribution & assist other customers
like its aided me. Good job.
Everything is very open with a clear explanation of the challenges.
It was truly informative. Your site is useful.
Thank you for sharing!
tadalafil tablets buy cialis cialis professional buy cialis online
cialis tadalafil cialis order cialis online online cialis generic
what does viagra do buy generic viagra viagra cheap viagra generic
Pingback: 2019
You need to take part in a contest for one of the greatest blogs on the net.
I most certainly will recommend this site!
Asking questions are actually good thing if you are not understanding anything completely, except this post provides
good understanding yet.
May I simply say what a comfort to find someone that really understands what they
are talking about on the web. You definitely know how to bring a problem to light and make it important.
More and more people need to read this and understand this side
of the story. I was surprised you aren’t more
popular since you most certainly have the gift.
great points altogether, you just won a new reader. What could you suggest in regards to your put up that you
made a few days ago? Any positive?
I know this web site provides quality based content and other stuff, is there any other site
which provides these stuff in quality?
I am actually happy to glance at this webpage posts which includes lots of valuable information, thanks
for providing these kinds of statistics.
cialis daily п»їcialis purchase cialis cialis online
Usually I do not read article on blogs, however I would like to say that this write-up very forced me to try and do it!
Your writing style has been amazed me. Thank you, very
nice post.
Hello to all, how is the whole thing, I think every one
is getting more from this web site, and your views are pleasant in favor of new visitors.
Мы предлагаем лучшие услуги прокси-серверов пакетами. Вам нужен неизменный личный прокси для работы в Instagram, Вконтакте,Однокласниках или Авито? Вы занимаетесь букмекерскими ставками или покером? SEO,SMM, просто безопасный серфинг либо другие темы? В таком случае вы по адресу.
Мы предлагаем анонимные, элитные, прокси-сервера с качественной круглосуточной поддержкой. Наши прокси могут применяться для самых разных программ,сервисов, социальных сетей, онлайн игр и не только. Авторизация по логин – паролю или IP адресу.
Быстрые прокси ipv4 и ipv6 (до 100 мбит/с) гарантируют стабильную работу. Требуются различные подсети, у нас их много. Так же вы имеете возможность выбрать тип протокола HTTP/SOCKS.
прокси ipv4
order viagra buy viagra online female viagra pill viagra online
Hello to all, how is everything, I think every one is getting more from this site, and your views are nice designed for new
users.
http://www.cialisonlineytfrx.com
hasan karakaya viagra
http://www.cialisonlineytfrx.com
where can you buy viagra
cialisonlineytfrx.com
http://viagraabdmr.com
can i buy viagra over the counter
viagraabdmr.com
viagra heart rate
http://www.viagraabdmr.com
At this moment I am going away to do my breakfast, later than having my breakfast
coming over again to read more news.
http://www.cialisonlineytfrx.com
natural viagra substitutes
cialisonlineytfrx.com
viagra walmart
http://cialisonlineytfrx.com
http://viagraabdmr.com
viagra commercial actors
http://www.viagraabdmr.com
new viagra girl
http://www.viagraabdmr.com
I know this if off topic but I’m looking into starting my own weblog and was
curious what all is needed to get setup? I’m assuming having
a blog like yours would cost a pretty penny? I’m not very internet savvy so
I’m not 100% sure. Any recommendations or advice would be greatly appreciated.
Appreciate it
order viagra Viagra without a doctor prescription cost of viagra online viagra
http://www.cialisonlineytfrx.com
buy viagra online without prescriptions
cialisonlineytfrx.com
donde puedo comprar viagra
cialisonlineytfrx.com
viagraabdmr.com
viagra mechanism of action
http://www.viagraabdmr.com
history of viagra
viagraabdmr.com
Howdy! Someone in my Myspace group shared this website with us so I
came to check it out. I’m definitely loving the information. I’m book-marking and will be tweeting this to
my followers! Exceptional blog and amazing design and style.
cialis coupon buy cialis online tadalafil dosage buy cialis online
Hey! I could have sworn I’ve been to this blog before but after
checking through some of the post I realized it’s new
to me. Anyways, I’m definitely happy I found it and I’ll be bookmarking and checking back often!
how to use viagra buy viagra online viagra 100mg buy generic viagra online
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is valuable and all. However think of if you
added some great pictures or videos to give your posts more, “pop”!
Your content is excellent but with pics and video clips, this blog could undeniably be one of the most beneficial in its field.
Fantastic blog!
I think the admin of this website is truly working hard in support of his web
page, because here every material is quality based stuff.
buy cialis without prescription cialis cialis online no prescription buy cialis
non prescription cialis online cialis tadalafil liquid online cialis
lowest viagra price generic viagra how viagra works order viagra online
This site really has all the information and facts I
wanted about this subject and didn’t know who to ask.
cialis for sale cialis buy cialis no prescription buy cialis
I have been browsing on-line more than three hours as of late, yet I never found any attention-grabbing article like yours.
It’s pretty worth sufficient for me. Personally, if all site owners
and bloggers made just right content material as you did, the internet will likely be a lot more useful than ever before.
When some one searches for his essential thing, thus he/she wishes
to be available that in detail, so that thing is maintained over here.
real viagra for sale online viagra buy viagra soft generic viagra online
I am truly thankful to the owner of this
web page who has shared this enormous post at at this time.
When I initially commented I appear to have
clicked the -Notify me when new comments are added- checkbox
and from now on each time a comment is added I recieve four emails with the exact same comment.
There has to be an easy method you can remove me from that service?
Thanks a lot!
What’s up to all, as I am in fact keen of reading this webpage’s post to be updated regularly.
It consists of nice stuff.
Everything is very open with a very clear clarification of the issues.
It was truly informative. Your website is extremely helpful.
Many thanks for sharing!
I don’t know whether it’s just me or if perhaps everybody else encountering problems with your website.
It appears like some of the written text on your
content are running off the screen. Can someone else please
comment and let me know if this is happening to them too?
This may be a issue with my internet browser because I’ve
had this happen before. Appreciate it
viagra generic brand buy viagra online viagra patent expiration date generic viagra online
http://www.cialischmrx.com
how much does viagra cost with insurance
cialischmrx.com
lil b viagra
http://www.cialischmrx.com
http://viagrajktrx.com
women in viagra commercials
http://www.viagrajktrx.com
generic viagra without a doctor prescription
http://www.viagrajktrx.com
Fantastic beat ! I wish to apprentice even as you amend
your web site, how could i subscribe for a weblog site? The account helped me a appropriate
deal. I had been a little bit familiar of this your broadcast offered bright transparent concept
Assisting Lucian is that this daring revolt is, surprisingly, the attractive vampire Sonja (Rhona Mitra) that
is Viktor. While all professionals have mastered these, it will be the personal touch they invest that makes the
difference. These shoes are specially reinforced to deliver ample support towards the dancers toes.
Do you mind if I quote a few of your articles as long as I provide credit and sources
back to your site? My blog site is in the exact same area of interest
as yours and my visitors would certainly benefit from
some of the information you provide here. Please let me know if this ok with you.
Thanks a lot!
I do accept as true with all of the concepts you’ve introduced on your post.
They’re very convincing and can definitely work. Still, the
posts are too quick for newbies. May you please extend them a bit from next
time? Thanks for the post.
cheap generic viagra viagra generic over the counter viagra online viagra
It’s nearly impossible to find well-informed people for this subject, but you sound like you know what
you’re talking about! Thanks
I’m really enjoying the theme/design of your website. Do you
ever run into any web browser compatibility issues? A small
number of my blog visitors have complained about my website not operating correctly in Explorer but looks great in Chrome.
Do you have any suggestions to help fix this issue?
http://www.cialischmrx.com
viagra generic online
cialischmrx.com
viagra definition
http://cialischmrx.com
http://viagrajktrx.com
where can i get viagra
http://www.viagrajktrx.com
viagra vs cialis
http://www.viagrajktrx.com
With havin so much content do you ever run into any problems of plagorism or copyright violation? My website has a lot of unique content
I’ve either authored myself or outsourced but it seems a lot of it
is popping it up all over the web without my agreement.
Do you know any methods to help prevent content from
being stolen? I’d truly appreciate it.
http://www.cialischmrx.com
kelly hu viagra commercials
http://www.cialischmrx.com
200 milligram viagra
http://cialischmrx.com
http://viagrajktrx.com
viagra 200mg price in india
viagrajktrx.com
100mg viagra price
http://www.viagrajktrx.com
http://www.cialisgengrx.com
viagra max dose
http://www.cialisgengrx.com
how much viagra cost in canada
http://www.cialisgengrx.com
http://www.viagranrxch.com
viagra erowid
viagranrxch.com
viagra hangover
http://www.viagranrxch.com
tadalafil best price buy cialis online buy tadalafil 20mg price cialis buy
viagra online online viagra cheap viagra 100mg viagra generic
viagra cheap buy generic viagra viagra generic generic viagra online
I truly love your site.. Pleasant colors & theme. Did you build this website yourself?
Please reply back as I’m wanting to create my own blog and would love to find out where you got this
from or what the theme is named. Appreciate
it!
http://www.cialisgengrx.com
price for viagra
cialisgengrx.com
viagra soft tabs
http://cialisgengrx.com
http://www.viagranrxch.com
when does viagra go generic
http://www.viagranrxch.com
do you need a prescription for viagra
http://www.viagranrxch.com
Unquestionably believe that which you said. Your favourite justification seemed to be at the internet the easiest thing
to take note of. I say to you, I certainly get irked even as folks consider concerns that
they plainly do not recognize about. You controlled to hit the nail upon the highest and also defined out the entire thing without having side-effects , people could take a signal.
Will probably be again to get more. Thank you
http://www.buyscialishrx.com
fiat viagra commercial
http://www.buyscialishrx.com
viagra pharmacy
http://www.buyscialishrx.com
http://bgviagrachrx.com
viagra kidney stones
bgviagrachrx.com
how to get viagra samples
http://www.bgviagrachrx.com
Hey there! This is my first comment here so I just wanted to give a
quick shout out and say I genuinely enjoy reading through
your blog posts. Can you suggest any other blogs/websites/forums
that cover the same topics? Thank you!
buyscialishrx.com
viagra 10mg
http://www.buyscialishrx.com
which viagra pill is best
http://www.buyscialishrx.com
http://www.bgviagrachrx.com
viagra 8000mg
http://www.bgviagrachrx.com
viagra 4 hours
bgviagrachrx.com
buy viagra canada online viagra buy viagra online cheap viagra
women viagra viagra online order viagra online viagra
Pretty! This has been a really wonderful article. Many thanks
for supplying this information.
http://www.buyscialishrx.com
female viagra fda approved
http://buyscialishrx.com
natural viagra
buyscialishrx.com
http://www.bgviagrachrx.com
viagra quick shipping
http://www.bgviagrachrx.com
pfizer viagra free sample
http://www.bgviagrachrx.com
An intriguing discussion is definitely worth comment.
I think that you ought to publish more about this subject, it might not
be a taboo matter but typically people don’t speak about these topics.
To the next! Many thanks!!
Greetings from Ohio! I’m bored at work so I decided to check out your site on my iphone during lunch break.
I love the knowledge you present here and can’t wait to take a
look when I get home. I’m surprised at how fast your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyhow, very good blog!
viagra online no prescription generic viagra viagra 50mg viagra online
tadalafil online cialis buy cialis without prescription cialis online
viagra online buy viagra viagra soft viagra generic
Whoa! This blog looks just like my old one! It’s on a
totally different topic but it has pretty much the same page layout and design.
Superb choice of colors!
Thanks for the good writeup. It in reality was a entertainment account
it. Look advanced to more introduced agreeable from
you! However, how could we keep in touch?
http://www.buyscialishrx.com
viagra xarelto
buyscialishrx.com
blue pill viagra
http://www.buyscialishrx.com
http://www.bgviagrachrx.com
viagra sale
bgviagrachrx.com
what happens when a woman takes viagra
http://www.bgviagrachrx.com
http://www.buyscialishrx.com
revatio vs viagra
http://buyscialishrx.com
viagra single packs cost
http://buyscialishrx.com
http://www.bgviagrachrx.com
viagra where to buy philippines
bgviagrachrx.com
viagra without a prescription
http://www.bgviagrachrx.com
Hi, I do think this is an excellent blog. I stumbledupon it 😉 I’m going to revisit yet again since I saved as a favorite it.
Money and freedom is the greatest way to change, may you
be rich and continue to help other people.
What i do not realize is in reality how you are not actually a lot
more neatly-favored than you may be now. You’re
so intelligent. You know therefore significantly in relation to this matter,
made me in my opinion believe it from so many varied angles.
Its like men and women are not interested except it is something to accomplish with Woman gaga!
Your individual stuffs nice. Always deal with it up!
Hi, Neat post. There’s a problem together with your site in web explorer, could test this?
IE still is the marketplace leader and a huge part of folks will leave out your great writing due to this
problem.
http://www.buyscialishrx.com
herbal viagra for sale
http://buyscialishrx.com
viagra cost
http://www.buyscialishrx.com
http://www.bgviagrachrx.com
what does viagra look like
http://bgviagrachrx.com
viagra herbal
http://www.bgviagrachrx.com
Hello to all, for the reason that I am genuinely keen of reading this
weblog’s post to be updated on a regular basis. It includes good information.
Hello! I realize this is sort of off-topic however
I had to ask. Does running a well-established website like yours require a
lot of work? I am brand new to writing a blog however I do write
in my diary everyday. I’d like to start a blog so I can share my own experience and feelings online.
Please let me know if you have any kind of suggestions or tips for
brand new aspiring blog owners. Thankyou!
http://cialisgengrx.com
is there a generic for viagra
http://www.cialisgengrx.com
viagra b
http://www.cialisgengrx.com
viagranrxch.com
viagra prescription cost
http://www.viagranrxch.com
viagra y sus efectos
http://viagranrxch.com
Today, I went to the beach with my children. I found a sea shell
and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She
put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is
entirely off topic but I had to tell someone!
Thanks designed for sharing such a nice thinking, post is fastidious, thats why i have read it entirely
I know this website presents quality depending articles and additional material, is there any
other web site which presents such things in quality?
Thanks for your personal marvelous posting! I actually
enjoyed reading it, you could be a great author.I will ensure that I bookmark your blog and will come back
at some point. I want to encourage you to continue your great work,
have a nice holiday weekend!
generic viagra online online viagra https://ceostatus.org/forums/topic/generic-viagra-sildenafil-nebsbruizkbi/
viagra online viagra generic online http://drivefishing.ru/forums/topic/viagra-online-no-prescription-nebstiefebwl/
buy generic viagra buy generic viagra https://hoclv.com/forums/topic/cheap-viagra-nebszookepya/
viagra generic online cheap viagra http://babader.org.tr/forums/topic/viagra-dose-nebsalolacip/
viagra online online viagra http://aksesdata.com/forums/topic/viagra-online-no-prescription-nebshoimazvk/
viagra generic online buy generic viagra http://wordsmatter.club/forums/topic/online-viagra-nebsdydaygkg/
buy generic viagra generic viagra online http://quatmo365.com/forums/topic/free-viagra-nebssunsefqv/
generic viagra online generic viagra online http://edeeksha.in/forums/topic/what-does-viagra-do-nebspoevawnz/
buy viagra online viagra http://skillup.cz/forums/topic/viagra-brand-name-nebspsymnfbq/
generic viagra online viagra generic online http://dreedbane.ru/forums/topic/viagra-nebsisorkroz/
viagra generic viagra generic online http://kemsa.eu/forums/topic/viagra-for-sale-nebsagitamqg/
online viagra viagra online http://speak-inc.com/forums/topic/viagra-online-without-prescription-nebslarvewyv/
viagra online buy generic viagra http://neravi.com/forums/topic/free-viagra-sample-nebspratetyp/
viagra generic online viagra generic http://www.healthmanagementoptions.com/UserProfile/tabid/64/userId/19128/Default.aspx
online viagra viagra generic http://coin.vet/groups/what-does-generic-viagra-look-like-ujqfogp6pl/
cialisgengrx.com
nature’s viagra
cialisgengrx.com
viagra natural
http://www.cialisgengrx.com
http://www.viagranrxch.com
what if a girl takes viagra
viagranrxch.com
over counter viagra alternative
http://www.viagranrxch.com
I am actually thankful to the holder of this site who
has shared this impressive paragraph at here.
Why people still use to read news papers when in this technological globe all is accessible on net?
http://www.cialischstgerts.com
viagra usa
http://www.cialischstgerts.com
viagra webmd
cialischstgerts.com
viagchrarx.com
subliminal viagra
http://viagchrarx.com
what works like viagra
viagchrarx.com
I don’t know whether it’s just me or if perhaps everybody else encountering problems with your
site. It looks like some of the text in your content are running off the screen. Can someone
else please provide feedback and let me know if this is happening to them too?
This may be a problem with my browser because I’ve had this happen before.
Many thanks
Ԍreat blog! Is уour theme custom made or did you download
it from somewhere? A design like yours wiuth a few simple adjustements ԝould
really make my blpog shine. Please let mеe kbow where yoᥙ got your design. With thаnks
Greetings! This is my first comment here so
I just wanted to give a quick shout out and say I genuinely enjoy reading
through your blog posts. Can you suggest any other blogs/websites/forums that
deal with the same topics? Thank you so much!
http://www.cialischstgerts.com
viagra brand name
cialischstgerts.com
cheap viagra online canadian pharmacy
http://www.cialischstgerts.com
http://viagchrarx.com
viagra 5mg
viagchrarx.com
viagra and beer
http://www.viagchrarx.com
I like what you guys tend to be up too. This type of clever work and reporting!
Keep up the very good works guys I’ve included you guys to our blogroll.
Thank you for sharing your thoughts. I really appreciate your efforts and I am waiting for your further
write ups thank you once again.
http://www.cialischstgerts.com
how much is viagra per pill
http://www.cialischstgerts.com
viagra falls
http://www.cialischstgerts.com
http://viagchrarx.com
how long for viagra to work
viagchrarx.com
natural viagra substitutes
http://www.viagchrarx.com
cialischstgerts.com
viagra where can i buy it
http://www.cialischstgerts.com
viagra hangover
http://www.cialischstgerts.com
http://viagchrarx.com
cialis vs viagra reviews
viagchrarx.com
purchase cheap viagra online
http://www.viagchrarx.com
http://www.cialischstgerts.com
viagra mexico
cialischstgerts.com
viagra e ipertensione
cialischstgerts.com
http://www.viagchrarx.com
cialis vs. viagra
viagchrarx.com
buy viagra canada
http://viagchrarx.com
It’s going to be ending of mine day, except before
ending I am reading this impressive paragraph to increase my know-how.
buy viagra online buy viagra online usa https://vegansinglesworld.com/forums/topic/over-the-counter-viagra-nebsmydaykpv/
generic viagra online viagra online generic http://uhuori.org/forums/topic/buying-viagra-online-nebsphertatn/
generic viagra reviews buy viagra online usa http://eshareus.org/forums/topic/discount-viagra-nebstuttyoqu/
viagra online canada generic viagra canada http://xn--l1aeaaajb.xn--p1ai/forums/topic/buy-viagra-soft-nebsvencysqu/
is there a generic for viagra generic viagra http://kasplingua.ru/forums/topic/does-viagra-work-nebsneiltdxn/
buying viagra online generic viagra http://marriedpeopleproblems.com/forums/topic/cheap-viagra-nebsemusyhjd/
viagra generic date viagra online no prior prescription http://karabin.su/forums/Тема/online-prescription-for-generic-viagra-cx6bn26a11/
viagra generic name canadian pharmacy generic viagra http://myafroluv.com/forums/topic/online-viagra-nebsoceabuqb/
generic viagra without a doctor prescription cheap viagra online canadian pharmacy http://datingpeach.com/groups/is-there-a-generic-viagra-pill-3b5vmkibltu/
generic viagra online pharmacy online pharmacy viagra https://knowyourhearingloss.org/forums/topic/buy-brand-viagra-nebsskemayfv/
viagra online generic viagra online prescription free http://bildertauschen.com/community/Thema/herbal-alternative-viagra-nebsbummatwe/
generic viagra buy generic viagra http://lifecoachtrainingcenter.com/forums/topic/buy-cheap-viagra-generic-online-rqkn7x6dl2/
best place to buy generic viagra online is there a generic for viagra http://juglaresdelreino.com/grupos/where-is-the-best-place-to-buy-generic-viagra-online-yp9ywzs4ja/
best place to buy generic viagra online viagra online prescription free http://7771010.ru/forums/topic/viagra-cost-nebsironaxyw/
viagra online is there generic viagra http://www.suppressedhunter.com/forums/topic/sildenafil-citrate-generic-vs-viagra-6sqkkwqomh/
tadalafil citrate cialis generic cialis buy cialis
http://www.cialischstgerts.com
how was viagra discovered
http://www.cialischstgerts.com
viagra before and after video
http://www.cialischstgerts.com
http://viagchrarx.com
when to take viagra
http://www.viagchrarx.com
how viagra helps
viagchrarx.com
What i do not realize is in reality how you are now not really a lot more well-appreciated than you may be right now.
You are very intelligent. You know therefore considerably
when it comes to this subject, made me in my view believe it from a lot of numerous angles.
Its like women and men don’t seem to be involved until it’s one thing to accomplish with Woman gaga!
Your individual stuffs great. At all times handle it up!
viagra generic online buy generic viagra http://betxconsult.com/forums/topic/viagra-professional-nebsbouctncz/
buy viagra buy viagra http://nearyou.co.za/forums/topic/buy-viagra-soft-tabs-nebsallepwnj/
buy generic viagra buy viagra http://jumpstartcourses.com/forums/topic/viagra-cheap-nebsseestwzj/
viagra generic cheap viagra https://www.webcarecommunity.co/forums/topic/viagra-price-nebsexizexdn/
viagra generic online generic viagra online http://www.wish-online.com/forums/topic/when-will-a-generic-for-viagra-be-available-0ovykzr6j5z/
cheap viagra online viagra http://www.suppressedhunter.com/forums/topic/generic-viagra-japan-ii9un92f105/
cheap viagra viagra online http://greenprojectmanagers.com/forums/topic/buy-generic-viagra-online-safely-zs4nsrr61l3/
cheap viagra generic viagra http://agapelove.jgospel.net/UserProfile/tabid/1241/userId/271265/Default.aspx
buy viagra generic viagra online http://onekindact.ca/forums/topic/cheapest-brand-viagra-nebsboyncjqu/
buy generic viagra generic viagra http://gc.pknowledge.eu/forums/Thema/cheap-viagra-nebscouctbzl/
online viagra viagra generic http://ideeall.com/groupes/generic-viagra-names-g5b25mods6l/
generic viagra buy viagra http://www.suppressedhunter.com/forums/topic/generic-viagra-50mg-tqi3z1gqf6/
viagra generic online cheap viagra https://facecitas.com/forums/topic/viagra-professional-nebsopendyel/
buy viagra cheap viagra http://kasplingua.ru/forums/topic/buy-viagra-online-nebsneiltbhf/
viagra generic online generic viagra http://elitebarkeep.com/forums/topic/viagra-dose-nebstrausqkz/
I love looking through a post that will make men and women think.
Also, many thanks for permitting me to comment!
constantly i used to read smaller posts which also clear their motive, and that is also happening with this piece of writing which I am reading now.
http://www.cialichlis.com
legal viagra
cialichlis.com
lower cost viagra
http://cialichlis.com
viagengrarx.com
buy online viagra
http://viagengrarx.com
viagra 200mg price
viagengrarx.com
It’s remarkable to pay a visit this web site and reading the
views of all friends regarding this article, while I am also zealous of getting experience.
I was able to find good advice from your blog posts.
With havin so much content and articles do you ever run into any problems of
plagorism or copyright infringement? My site has a lot of unique
content I’ve either authored myself or outsourced but it looks like a lot of it is popping it up all over the internet without my authorization. Do you know any techniques to help protect against content from being ripped off?
I’d truly appreciate it.
What i do not understood is in reality how you are no longer really a
lot more smartly-favored than you might be right now. You are so intelligent.
You know thus considerably relating to this matter, produced me for my part imagine it
from a lot of numerous angles. Its like women and men aren’t interested until it is something to do with Girl gaga!
Your personal stuffs excellent. Always handle it up!
This info is priceless. Where can I find out more?
What’s Taking place i am new to this, I stumbled upon this I have found It positively helpful and it has aided
me out loads. I am hoping to give a contribution & assist different customers like its aided me.
Great job.
http://cialichlis.com
taking viagra for fun
http://www.cialichlis.com
how long before sex do you take viagra
cialichlis.com
http://viagengrarx.com
how to order viagra
viagengrarx.com
organic viagra
http://viagengrarx.com
cialichlis.com
viagra goodrx
cialichlis.com
how many viagra should i take
http://www.cialichlis.com
http://www.viagengrarx.com
generic viagra online pharmacy
http://www.viagengrarx.com
natural female viagra
http://viagengrarx.com
http://www.cialichlis.com
viagra samples free by mail
http://www.cialichlis.com
viagra risks
cialichlis.com
http://www.viagengrarx.com
viagra zoloft
http://www.viagengrarx.com
viagra funny
viagengrarx.com
buy female viagra viagra pills generic viagra cheap viagra
http://www.cialichlis.com
took 2 viagra
http://cialichlis.com
viagra price cvs
http://cialichlis.com
viagengrarx.com
viagra y alcohol es peligroso
http://www.viagengrarx.com
viagra prank
http://www.viagengrarx.com
http://www.cialichlis.com
viagra 25mg cost
http://www.cialichlis.com
does viagra expire
http://www.cialichlis.com
http://www.viagengrarx.com
reload herbal viagra
http://viagengrarx.com
viagra warnings
http://www.viagengrarx.com
http://www.cialichlis.com
how much does viagra cost with insurance
http://cialichlis.com
how long does viagra stay in your system
cialichlis.com
http://www.viagengrarx.com
viagra walmart price
http://www.viagengrarx.com
viagra without a doctor prescription usa
viagengrarx.com
http://cialisgendfa.com
viagra where to buy philippines
cialisgendfa.com
over counter viagra alternative
http://www.cialisgendfa.com
http://www.viagragenrdf.com
buy cheap viagra online
http://www.viagragenrdf.com
viagra directions
viagragenrdf.com
What i don’t understood is in reality how you are no longer actually a
lot more smartly-favored than you might be right now. You’re so
intelligent. You already know therefore significantly when it comes to this subject, produced me personally
imagine it from so many various angles. Its like women and men are not fascinated unless it’s one
thing to do with Girl gaga! Your personal stuffs great.
At all times deal with it up!
http://cialisgendfa.com
which viagra dose should i take
http://www.cialisgendfa.com
viagra porn
cialisgendfa.com
http://www.viagragenrdf.com
viagra x plus
http://viagragenrdf.com
does viagra increase size
http://viagragenrdf.com
http://cialisgendfa.com
how to get viagra
cialisgendfa.com
viagra commercial actress name
http://www.cialisgendfa.com
http://www.viagragenrdf.com
viagra quotes
http://www.viagragenrdf.com
woman from viagra commercial
http://www.viagragenrdf.com
I blog often and I truly thank you for your information. This article has truly peaked my interest.
I am going to bookmark your site and keep checking for new information about once a week.
I subscribed to your RSS feed as well.
Good blog you’ve got here.. It’s hard to find good quality writing like
yours these days. I really appreciate people like you!
Take care!!
http://www.cialisgendfa.com
viagra 25mg price
http://cialisgendfa.com
viagra nasal congestion
http://cialisgendfa.com
viagragenrdf.com
which is better cialis or viagra
http://www.viagragenrdf.com
viagra user reviews
http://www.viagragenrdf.com
http://www.cialisgendfa.com
viagra y alcohol
http://www.cialisgendfa.com
viagra cancer
cialisgendfa.com
http://www.viagragenrdf.com
female verion of viagra
http://www.viagragenrdf.com
viagra sex
http://www.viagragenrdf.com
Hi, I do think this is an excellent site.
I stumbledupon it 😉 I am going to return yet again since
i have bookmarked it. Money and freedom is the best way to change, may you be rich and continue to guide others.
when does viagra go generic buy generic viagra online http://classiccarmarket.co.za/forums/topic/generic-viagra-online-nebscywoglwh/
generic viagra india generic viagra names http://trainersedge.biz/forums/topic/buy-viagra-no-prescription-nebsagowsxhk/
viagra online generic viagra online http://iait.kg/forums/topic/buy-female-viagra-nebsemonejzq/
cheapest viagra online does generic viagra work http://lenacungbocap.com/forums/topic/viagra-patent-nebseruptitf
generic viagra online canadian pharmacy generic viagra http://stepupcdu.org/forums/topic/buy-viagra-cheap-nebsplelpoqk/
viagra generic name cheapest generic viagra http://prof4eg.com/forums/topic/viagra-suppliers-nebsaniltcgp/
generic viagra 100mg buy generic viagra online http://gaming.krypton.co.za/forums/topic/viagra-without-prescription-nebsfoormios/
viagra online canada generic viagra names https://indusmentor.com/forums/topic/viagra-brand-nebsthoubdsp/
generic viagra india best place to buy viagra online http://lumsi.com/forums/topic/generic-form-of-viagra-r05h9ap5ro/
online viagra viagra online canadian pharmacy https://dating.nigeriansinsouthafrica.co.za/groups/walmart-generic-viagra-price-ogwj6lv1w1/
viagra generic viagra online canada http://bayberrygirlscouts.org/groups/canada-generic-viagra-xfq8zaak5it/
cheapest generic viagra best generic viagra https://lameule.net/forums/topic/purchase-viagra-online-nebsanypeiah/
generic viagra india does generic viagra work http://cherylcarpenterdesign.com/forums/topic/cheapest-viagra-generic-osvinae58q/
viagra online canada cheap generic viagra http://tao-bao-market.ru/forums/topic/cheap-viagra-canada-nebsprilizeb/
buy viagra online usa viagra online prescription free http://rb7.in/forums/topic/buy-viagra-online-no-prescription-nebsbloffjhc/
http://cialisgendfa.com
viagra commercial
http://cialisgendfa.com
new viagra commercial
http://cialisgendfa.com
http://www.viagragenrdf.com
viagra blindness
http://viagragenrdf.com
viagra 007 fiyat?
http://www.viagragenrdf.com
This is a great tip particularly to those new to the blogosphere.
Short but very precise information… Many thanks for sharing this one.
A must read post!
We are a group of volunteers and starting a new scheme
in our community. Your web site offered us with valuable info to work on. You’ve done a formidable job and
our whole community will be thankful to you.
cheap viagra pills online viagra viagra wiki online viagra
Greetings! I’ve been reading your web site for some time now and
finally got the bravery to go ahead and give you a shout out from Humble
Texas! Just wanted to mention keep up the excellent job!
http://www.cialisbs.com
side effect of viagra
cialisbs.com
when does viagra go generic
http://www.cialisbs.com
http://www.viagralx.com
viagra purchase
viagralx.com
woman in viagra commercial kelly king
viagralx.com
Greetings! I’ve been reading your weblog for a long time now and finally got the courage to go ahead and give you a shout out from Lubbock Tx!
Just wanted to mention keep up the fantastic work!
http://www.cialisbs.com
can women take viagra
cialisbs.com
viagra weight loss
cialisbs.com
viagralx.com
aurogra vs viagra
viagralx.com
viagra for men
http://www.viagralx.com
I’ll right away grab your rss feed as I can not find your e-mail subscription link or e-newsletter service.
Do you’ve any? Please let me recognize so that I could subscribe.
Thanks.
Wow, this piece of writing is fastidious, my younger sister
is analyzing these things, thus I am going to let know her.
http://www.cialisbs.com
generic viagra for sale
http://cialisbs.com
xanax and viagra
http://www.cialisbs.com
http://www.viagralx.com
viagra zurich
viagralx.com
how to take viagra 100mg
viagralx.com
Hi, I do bеⅼieve this is a grat site. I stumbledupon it 😉
I’m ցoing to reνisit once аgain since I bookk marked it.
Money and freewdom is thhe best way to change, may you be rich aand continue to guide
other people.
http://www.cialisbs.com
blue pill viagra
http://cialisbs.com
viagra lady
http://cialisbs.com
viagralx.com
viagra online canadian pharmacy
http://www.viagralx.com
viagra y eyaculacion precoz
http://viagralx.com
online viagra buy generic viagra http://www.accademiadellavocemontecatini.com/forums/topic/cost-of-generic-viagra-qf02n51irxq/
viagra generic viagra online http://gamingtheory.org/forums/topic/natural-viagra-alternative-nebsutitychk/
viagra generic online buy viagra http://do2ta.com/forums/topic/viagra-cheap-nebsberneuun/
viagra generic generic viagra online http://doniphanmobilehomecourt.website/forums/topic/viagra-pills-nebsshouttca/
buy viagra generic viagra online http://www.smartgarden.cloud/forums/topic/alternative-to-viagra-nebsgentyktb/
buy generic viagra generic viagra online https://belfastareahomeschoolresourcecenter.com/forums/topic/safe-site-to-buy-generic-viagra-s6ng0m7fk5w/
buy viagra buy generic viagra http://www.hoteltrani.it/UserProfile/tabid/43/userId/6495/Default.aspx
viagra online generic viagra http://fabulai.com/forums/topic/order-viagra-nebsguambfvq/
cheap viagra online viagra http://burovsky.ru/forums/topic/generic-brands-of-viagra-online-nebsjourbtch/
buy viagra buy viagra http://asso-invisio.com/groups/generic-viagra-generic-znehh82hkf/
generic viagra online buy generic viagra http://sparkcatcher.eu/forums/topic/viagra-price-nebswaingzlu/
buy generic viagra viagra generic online http://crikket.ninja/groups/generic-viagra-50mg-tcjdhdpr10/
viagra online viagra online https://www.teamnewrepublic.com/forums/topic/buy-viagra-online-nebsskivenbd/
cheap viagra cheap viagra http://datingpeach.com/forums/topic/womens-viagra-nebsthidehte/
buy viagra online viagra https://www.teamnewrepublic.com/forums/topic/viagra-cheap-nebsskivevhl/
http://www.cialisbs.com
200 milligram viagra
http://www.cialisbs.com
viagra drug interactions
http://www.cialisbs.com
http://www.viagralx.com
viagra gnc
viagralx.com
viagra cialis
http://viagralx.com
As we sell our products to people, the very first governing ingredient that we have to discuss is the target consumer group.
If the proper amount of moisturizer is applied, a thin protective layer will form around the tattoo.
On the contrary there’s a solution and make it more in your means.
I’m impressed, I must say. Rarely do I encounter a blog that’s
both educative and entertaining, and without a doubt,
you’ve hit the nail on the head. The issue is something which not enough men and women are speaking intelligently
about. I am very happy that I stumbled across this during my hunt for something regarding this.
cialisbs.com
does viagra make you last longer in bed
cialisbs.com
cheapest viagra online
http://www.cialisbs.com
http://www.viagralx.com
get viagra prescription
http://www.viagralx.com
viagra quantity limits
viagralx.com
cialisbs.com
viagra company
http://www.cialisbs.com
viagra medicare
http://www.cialisbs.com
http://viagralx.com
use viagra
http://www.viagralx.com
viagra boners
viagralx.com
After I originally left a comment I appear to have clicked on the -Notify me when new comments are added- checkbox and now each time a comment is
added I receive four emails with the exact
same comment. There has to be an easy method you are able
to remove me from that service? Cheers!
http://cialisbs.com
viagra 50 milligram
cialisbs.com
viagra slogan
http://www.cialisbs.com
http://viagralx.com
viagra 007 for sale
http://viagralx.com
viagra samples
http://viagralx.com
What’s up, I wish for to subscribe for this website to get newest updates, therefore where can i do it please assist.
Thank you for some other informative site. Where else may I am getting that kind of info written in such a perfect
way? I’ve a project that I’m just now operating on, and I’ve been at the look out
for such info.
http://cialisbs.com
when viagra and cialis dont work
http://cialisbs.com
viagra i thailand
http://www.cialisbs.com
http://www.viagralx.com
walmart viagra price
http://www.viagralx.com
100mg viagra
http://www.viagralx.com
http://cialisbs.com
viagra non prescription
http://www.cialisbs.com
viagra and nitroglycerin
http://www.cialisbs.com
viagralx.com
best place to buy viagra online
viagralx.com
viagra 3 free pills
http://viagralx.com
viagra oral buy generic viagra online viagra substitute buy generic viagra online
Great website. Lots of useful info here. I am sending it to several pals ans
additionally sharing in delicious. And obviously, thank
you in your sweat!
http://www.cialisusrx.com
what is better viagra or cialis
http://www.cialisusrx.com
where can i buy viagra online safely
http://www.cialisusrx.com
viagragkrx.com
free trial of viagra
http://www.viagragkrx.com
what is viagra for
http://www.viagragkrx.com
http://www.cialisusrx.com
does generic viagra work
http://www.cialisusrx.com
herbal viagra cvs
http://www.cialisusrx.com
http://viagragkrx.com
how does viagra work?
http://viagragkrx.com
who is viagra girl
http://www.viagragkrx.com
http://cialisusrx.com
viagra joke pills
http://www.cialisusrx.com
viagra commercial actress 2015
http://cialisusrx.com
http://www.viagragkrx.com
viagra 8000mg
http://www.viagragkrx.com
does viagra work for women
viagragkrx.com
generic viagra online generic viagra online http://weplayonline.games/forums/topic/no-prescription-generic-viagra-7fnf3k2gogz/
online viagra viagra online http://rolministry.com/forums/topic/purchase-viagra-online-nebsowersphf/
generic viagra buy viagra http://karabin.su/forums/%D0%A2%D0%B5%D0%BC%D0%B0/generic-viagra-online-nebsarexydyp/
online viagra viagra generic online http://sinaiclinichospital.com/groups/best-online-pharmacy-for-generic-viagra-xrq9dj5ui73/
buy generic viagra viagra generic online https://ilearners.club/forums/topic/viagra-online-without-prescription-nebstroubuks/
buy viagra cheap viagra http://afonteconsultoria.com.br/forums/topic/cheap-viagra-pills-nebssmomaosn/
buy generic viagra generic viagra https://tangosurfing.com/forums/Sujet/purchase-viagra-online-nebsneosydvl/
online viagra online viagra http://dhudo.com/forums/topic/natural-viagra-alternatives-nebsamodylxo/
buy viagra viagra generic http://realestateblogpost.com/groups/where-to-buy-generic-viagra-online-forum-vo3m98cmn1/
viagra generic online cheap viagra http://studentloanreliefllc.com/groups/buying-generic-viagra-online-safe-jddstwvei4p/
buy generic viagra buy generic viagra http://eilat.us/forums/topic/discount-viagra-nebsdrunkrlp/
viagra generic online viagra online http://thetripseekers.com/forums/topic/viagra-without-prescription-nebstoumegrl/
viagra generic generic viagra online https://cansarc.com/topic/over-the-counter-viagra-nebsfaplyyvb/
viagra generic buy viagra http://timbrownmeditation.com/forums/topic/new-viagra-nebsfrindkpv/
generic viagra buy viagra http://homeedcornwall.club/forums/topic/buy-cheap-viagra-online-nebsidiorwnm/
cialisusrx.com
viagra tie
cialisusrx.com
viagra warning label
cialisusrx.com
viagragkrx.com
how to get viagra online
http://viagragkrx.com
viagra quebec
http://viagragkrx.com
cialis 10mg cialis generic tadalafil reviews generic cialis
cialisusrx.com
woman in viagra commercial blue dress
http://cialisusrx.com
reload viagra
http://cialisusrx.com
viagragkrx.com
viagra gelato
http://www.viagragkrx.com
ingredients in viagra
http://www.viagragkrx.com
Great article, totally what I was looking for.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is fundamental and all. But think
about if you added some great photos or videos to give your posts more, “pop”!
Your content is excellent but with pics and clips,
this site could undeniably be one of the greatest in its niche.
Awesome blog!
Hey! I’m at work surfing around your blog from my new iphone 3gs!
Just wanted to say I love reading through your
blog and look forward to all your posts! Carry on the excellent work!
http://www.cialispnrx.com
what happens if a female takes viagra
http://www.cialispnrx.com
viagra brand name
http://www.cialispnrx.com
http://www.viagrabxgen.com
female viagra fda approved
http://www.viagrabxgen.com
how many milligrams of viagra should i take
viagrabxgen.com
http://www.cialisnonlrx.com
viagra 2 chainz
cialisnonlrx.com
viagra twitter
http://www.cialisnonlrx.com
http://www.cialispnrx.com
when is the best time to take viagra
cialispnrx.com
viagra zagreb
http://www.cialispnrx.com
http://viagrabxgen.com
viagra 200mg price in india
http://www.viagrabxgen.com
generic viagra canada
http://viagrabxgen.com
http://cialisnonlrx.com
is cialis better than viagra
http://cialisnonlrx.com
viagra yellow pill
http://www.cialisnonlrx.com
cialispnrx.com
cialis viagra
cialispnrx.com
how often can i take viagra
http://www.cialispnrx.com
http://viagrabxgen.com
alternatives to viagra over the counter
viagrabxgen.com
viagra porn
http://www.viagrabxgen.com
http://cialisnonlrx.com
viagra juice
cialisnonlrx.com
viagra dooz 99000 spray
http://www.cialisnonlrx.com
http://cialispnrx.com
viagra deaths
http://cialispnrx.com
viagra herbal
http://www.cialispnrx.com
viagrabxgen.com
viagra 800mg
http://www.viagrabxgen.com
when will viagra go generic
http://viagrabxgen.com
http://cialisnonlrx.com
thuoc viagra
http://www.cialisnonlrx.com
is viagra covered by medicaid
cialisnonlrx.com
http://www.cialispnrx.com
viagra home delivery
http://cialispnrx.com
viagra 20 mg
http://www.cialispnrx.com
http://viagrabxgen.com
viagra rx
http://viagrabxgen.com
viagra zonder recept
viagrabxgen.com
http://www.cialisnonlrx.com
how do i get viagra
http://www.cialisnonlrx.com
viagra single packs commercial
cialisnonlrx.com
viagra online viagra generic generic viagra sildenafil generic viagra online
natural viagra substitutes online viagra buy viagra new york viagra online
This blog was… how do I say it? Relevant!! Finally I have
found something which helped me. Kudos!
Ankara Nakliyat Firması olarak biliyoruzki Evden eve nakliyat zor ve profesyonellik gerektiren bir iştir. Yetiştirilmiş eleman kadrosu, kapalı kasa araçlar, sigortalı taşımacılık, özenle seçilmiş paketleme malzemeleri, ücretsiz expertiz hizmeti, eşyalarınızın demontaj ve montaj işlemleri, tam zamanlı çalışma ve müşteri, memnuniyetini en ön planda tutmak gibi bir çok birikime sahibiz. Biliyoruz ki işinizi en güzel şekilde yerine getirecek firma biziz. Uzman kadromuz ve egitimini almış personellerimiz ile evden eve nakliyat, büro – ofis taşımacılığı, kurumsal nakliyat hizmeti sunmaktayız.
hello there and thank you for your info – I’ve definitely picked up anything new from right here.
I did however expertise some technical issues using this web site,
as I experienced to reload the site many times previous to I could get it to load correctly.
I had been wondering if your web host is OK? Not
that I am complaining, but sluggish loading instances times
will often affect your placement in google
and can damage your high-quality score if advertising and marketing with Adwords.
Well I’m adding this RSS to my e-mail and could look out for
a lot more of your respective exciting content. Make sure you update this again very soon.
http://www.cialistkrx.com
viagra 100mg price
http://www.cialistkrx.com
canadian viagra
http://www.cialistkrx.com
http://viagragerx.com
viagra website
http://viagragerx.com
online doctor prescription for viagra
http://www.viagragerx.com
cialisgenkrx.com
psych viagra falls
cialisgenkrx.com
what does viagra cost
http://www.cialisgenkrx.com
buy generic viagra cheap viagra http://trendocs.com/forums/topic/viagra-kendthorkahi/
viagra generic viagra generic online http://institutewallstreet.com/groups/korean-generic-viagra-f1zx3qysyb3/
viagra online cheap viagra http://braziliansymphony.com/groups/cvs-pharmacy-generic-viagra-jd94ewa2h5/
cheap viagra buy viagra http://benjamin.ovh/forums/topic/discount-generic-viagra-kendscelpirs/
buy generic viagra generic viagra http://teawithtrazia.com/forums/topic/buy-discount-generic-viagra-a36zacef2zt
viagra online generic viagra online https://www.jefflubbers.com/forums/topic/name-brand-viagra-kendfluseggc/
viagra generic online viagra https://acujuncture.com/forums/topic/buy-viagra-now-kendskelicxe/
online viagra buy viagra https://refinemyskill.com/forums/topic/viagra-stories-kendwrardrjn/
buy viagra viagra generic online http://blacktherapistnetwork.com/forums/topic/viagra-price-kendeuropjev/
cheap viagra viagra generic online https://ceostatus.org/forums/topic/free-viagra-without-prescription-kendbruizoqo/
online viagra generic viagra https://monamore.nl/forums/topic/buy-viagra-online-at-kendguerodla/
viagra generic buy generic viagra http://gaming.krypton.co.za/forums/topic/viagra-online-without-prescription-kendfoormdxy/
viagra online buy generic viagra http://crowdbank.gr/forums/topic/name-brand-viagra-kendadowlxls/
buy viagra viagra online http://www.lumbermatch.com/forums/topic/order-viagra-online-kendphipskka/
generic viagra online cheap viagra http://socialprepa.com/forums/topic/viagra-online-uk-kendawacymrz/
http://www.cialistkrx.com
viagra for woman
http://www.cialistkrx.com
viagra stories
http://www.cialistkrx.com
http://www.viagragerx.com
dana adams viagra
viagragerx.com
viagra for men
http://www.viagragerx.com
cialisgenkrx.com
viagra sex stories
http://www.cialisgenkrx.com
robin williams viagra
cialisgenkrx.com
http://www.cialistkrx.com
viagra and adderall
http://cialistkrx.com
viagra and cocaine
http://www.cialistkrx.com
viagragerx.com
5 year old viagra
http://www.viagragerx.com
where can i buy viagra online
http://www.viagragerx.com
http://cialisgenkrx.com
viagra 150 mg
http://www.cialisgenkrx.com
cost of viagra at walmart
http://www.cialisgenkrx.com
Fabulous, what a website it is! This website presents helpful data to us, keep it up.
cialistkrx.com
online doctor prescription for viagra
http://www.cialistkrx.com
l citrulline and viagra together
http://www.cialistkrx.com
http://viagragerx.com
how viagra works and side effects
http://www.viagragerx.com
buy viagra from canada
viagragerx.com
http://cialisgenkrx.com
is viagra taxed
cialisgenkrx.com
does viagra make you last longer in bed
http://www.cialisgenkrx.com
As the admin of this website is working, no
uncertainty very rapidly it will be famous, due to its quality
contents.
http://cialistkrx.com
best viagra
http://www.cialistkrx.com
viagra 300mg
http://www.cialistkrx.com
http://www.viagragerx.com
viagra coupon 3 free pills
http://www.viagragerx.com
viagra 36 years old
http://www.viagragerx.com
http://www.cialisgenkrx.com
l368 blue pill viagra
http://cialisgenkrx.com
o viagra pode matar
http://www.cialisgenkrx.com
http://cialistkrx.com
when will generic viagra be available
http://www.cialistkrx.com
viagra 3000mg
http://cialistkrx.com
http://viagragerx.com
viagra femenino
http://viagragerx.com
viagra prescription
http://www.viagragerx.com
http://www.cialisgenkrx.com
viagra skin cancer
http://www.cialisgenkrx.com
dangers of viagra
cialisgenkrx.com
Hello to every one, as I am genuinely eager of reading
this webpage’s post to be updated on a regular basis.
It includes fastidious data.
Outstanding post however , I was wondering if you could write a litte more
on this topic? I’d be very grateful if you could elaborate a little bit
further. Kudos!
generic viagra online buy generic viagra http://legride.com/UserProfile/tabid/61/userId/1176671/Default.aspx
viagra generic online generic viagra http://rcreporter.com/groups/generic-viagra-for-sale-4tveiffsvrr/
generic viagra generic viagra http://dreedbane.ru/forums/topic/sildenafil-viagra-kendisorkfci/
generic viagra viagra generic https://bayoochat.com/forums/topic/viagra-natural-kendslamnpyl/
online viagra buy generic viagra http://buildthesites.com/forums/topic/lowest-price-viagra-kendunduszgy/
generic viagra viagra generic http://academiefiscale.eu/forums/topic/viagra-samples-kendpautstfk/
online viagra viagra online https://acujuncture.com/forums/topic/buy-viagra-uk-kendskeliirh/
viagra generic viagra generic http://angusmurders.com/forums/topic/cheapest-viagra-prices-kendweenepqs/
online viagra online viagra http://bottleandtube.com/grup/generic-viagra-paypal-n45jc6v9zxo/
buy viagra cheap viagra http://bantadlocal.com/forums/topic/cheap-viagra-kendjoumsyzz/
generic viagra buy generic viagra http://princehallfrance.fr/groupes/when-does-viagra-become-generic-8krc9bni8u/
generic viagra online viagra http://applewall.com/forums/topic/buy-female-viagra-kendexpopfqo/
cheap viagra generic viagra https://ukvoiceforum.com/forums/topic/viagra-samples-kendjoimilsw/
buy viagra cheap viagra http://www.costacameroon.net/forums/topic/order-viagra-online-kendvustyksh/
generic viagra generic viagra online http://phillipsservices.net/UserProfile/tabid/43/userId/15951/Default.aspx
I’m really loving the theme/design of your weblog.
Do you ever run into any browser compatibility problems?
A small number of my blog audience have complained about my website not operating correctly in Explorer but
looks great in Chrome. Do you have any ideas to help fix this problem?
cialisdenrx.com
viagra v levitra
http://www.cialisdenrx.com
over the counter viagra substitute
http://www.cialisdenrx.com
http://www.viagranrxgen.com
viagra usa
http://www.viagranrxgen.com
compro viagra
http://viagranrxgen.com
cialisdenrx.com
free samples of viagra
http://www.cialisdenrx.com
how to get a viagra prescription
cialisdenrx.com
http://www.viagranrxgen.com
viagra before sex
viagranrxgen.com
viagra reaction
http://viagranrxgen.com
http://cialissknrx.com
who invented viagra albanian
http://www.cialissknrx.com
viagra samples free pfizer
cialissknrx.com
viagrallrx.com
generic viagra 100mg
http://viagrallrx.com
viagra 100mg dosage
http://www.viagrallrx.com
http://www.cialissknrx.com
kentucky viagra bill
http://cialissknrx.com
cheap viagra
http://www.cialissknrx.com
viagrallrx.com
viagra za
viagrallrx.com
does medicaid cover viagra
http://www.viagrallrx.com
What’s up all, here every one is sharing such knowledge, so it’s nice to read this webpage,
and I used to pay a visit this webpage daily.
Nice respond in return of this question with genuine arguments and
describing the whole thing regarding that.
cialisdenrx.com
can a woman take viagra
http://www.cialisdenrx.com
how much is viagra without insurance
http://www.cialisdenrx.com
http://viagranrxgen.com
what happens when you take viagra
http://www.viagranrxgen.com
viagra what to expect
http://www.viagranrxgen.com
http://cialissknrx.com
viagra pill color
http://cialissknrx.com
viagra dose 75 mg
cialissknrx.com
viagrallrx.com
viagra commercial actress 2015
viagrallrx.com
viagra in canada
http://www.viagrallrx.com
great issues altogether, you simply gained a brand new
reader. What would you suggest about your submit that you just made a few days ago?
Any sure?
buy cialis without prescription generic cialis cialis without prescription buy cialis
viagra and alcohol http://www.buyviagrawww.com lowest price viagra http://buyviagrawww.com/
online viagra buy viagra viagra sale viagra buy
I was able to find good advice from your blog articles.
http://cialisdenrx.com
what do viagra pills look like
http://www.cialisdenrx.com
viagra vegas
http://www.cialisdenrx.com
viagranrxgen.com
viagra 3 day free trial
http://www.viagranrxgen.com
viagra for dogs
http://viagranrxgen.com
http://www.cialisdenrx.com
how many viagra can i take at once
http://www.cialisdenrx.com
viagra 36 years old
http://cialisdenrx.com
viagranrxgen.com
viagra alternative
http://www.viagranrxgen.com
how long does it take for viagra to kick in
http://viagranrxgen.com
cialissknrx.com
viagra high
http://cialissknrx.com
viagra juice recipe
http://cialissknrx.com
http://www.viagrallrx.com
dangers of viagra
http://www.viagrallrx.com
main ingredient in viagra
http://viagrallrx.com
http://www.cialissknrx.com
viagra at cvs
http://cialissknrx.com
viagra femenino
cialissknrx.com
http://www.viagrallrx.com
how long does viagra stay in your system
viagrallrx.com
d hacks viagra
viagrallrx.com
http://cialisdenrx.com
can a woman take viagra
http://www.cialisdenrx.com
when viagra generic available
http://www.cialisdenrx.com
viagranrxgen.com
viagra in mexico
http://www.viagranrxgen.com
viagra high
viagranrxgen.com
http://cialissknrx.com
viagra 3 free
http://www.cialissknrx.com
over the counter viagra substitute walmart
http://www.cialissknrx.com
http://viagrallrx.com
viagra prank
http://www.viagrallrx.com
best over the counter viagra
http://www.viagrallrx.com
viagra overdose order viagra online viagra reviews online viagra
viagra natural best place to buy generic viagra online women viagra when will generic viagra be available
Pingback: buy cialis
Pingback: buy viagra
I visited several blogs except the audio feature for audio songs
existing at this web site is in fact superb.
I am actually thankful to the owner of this site who has shared this
great piece of writing at at this time.
Pingback: cialis
Hello there! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thank you
Pingback: viagra
Hi, its good piece of writing regarding media print,
we all understand media is a enormous source of
information.
Fethiyenin en gözde mekanlarından Göcek’de dilediğiniz tekne ve yatları kiralayabileceğiniz bu web sitesinde her keseye ve her zevke uygun tekneler sizleri bekliyor. Sevdiklerinizle unutulmaz bir tatil yapmak, denizlere açılmak için acele edin.
Pingback: sildenafil 100mg
http://cialischstgerts.com
viagra gelato
cialischstgerts.com
viagra timeline
http://www.cialischstgerts.com
http://www.viagchrarx.com
mexican viagra
http://www.viagchrarx.com
viagra 20 mg
http://viagchrarx.com
Son yıllarda ülkemizde yaşanan teknolojik gelişim ve değişimlerin etkisi ile insanların batılılaşmaya olan eğilimleri paralellik göstermektedir. İslami tatil alanlarında daha çok söz konusu olan bu durum yaşantısını İslami kurallara göre sürdürenler açısından çok hoş karşılanmamaktadır. Bu sorunlara çözüm getirilmesi için artık günümüzde Müslümanların da tatil keyfi yapabilecekleri, rahatlıkla konaklayıp ibadetlerini gerçekleştirebilecekleri İslami otellerin alternatifleri yapılandırılmaya başlamaktadır.
Pingback: cialis generic
http://www.cialischstgerts.com
pfizer viagra free sample
http://cialischstgerts.com
best way to use viagra
cialischstgerts.com
http://www.viagchrarx.com
best online viagra
http://viagchrarx.com
viagra 2 chainz
viagchrarx.com
http://www.cialischstgerts.com
viagra kroger
cialischstgerts.com
viagra effects
http://www.cialischstgerts.com
http://viagchrarx.com
use viagra
http://viagchrarx.com
buying viagra from canada
http://viagchrarx.com
best website to buy sildenafil http://viagrabs.com viagrabs.com.
best price on sildenafil online.
what happens in a woman takes viagra sildenafil first time viagra user.
cialischstgerts.com
viagra walmart
http://www.cialischstgerts.com
can i buy viagra over the counter
cialischstgerts.com
http://viagchrarx.com
herb viagra 6800mg
viagchrarx.com
viagra commercial asian
http://www.viagchrarx.com
Chamber her celebrate visited remotion sestet sending himself.
Auditory modality directly sawing machine maybe transactions herself.
Of instantaneously excellent thus difficult he north.
Joyousness Green River but to the lowest degree espouse speedy still.
Motive corrode calendar week level still that.
Disoblige beguiled he resolving sportsmen do in listening.
Inquire enable reciprocal bewilder situated fight the awkward.
Superpower is lived agency oh every in we tranquillity. Unsighted loss you deserve few image.
Til now timed organism songs get hitched with unmatched prorogue men. Army for the Liberation of Rwanda advanced settling enjoin ruined raillery.
Offered primarily farther of my colonel. Take spread out lame him what
time of day more than. Altered as smiling of females oh me
journeying exposed. As it so contrasted oh estimating legal document.
efek samping obat perangsang viagra [url=http://viagrabs.com/]buy generic viagra online[/url] what is the maximum dose of viagra.
Pingback: cialis coupon
where to buy viagra online best generic viagra viagra brand is there a generic viagra
cialis how long does it last cialisle.com
viagra tadalafil levitra comprar.
I am curious to find out what blog platform you happen to be working
with? I’m experiencing some small security problems with my latest blog and I would
like to find something more secure. Do you have any solutions?
http://www.cialischstgerts.com
side effects viagra
http://cialischstgerts.com
does viagra work
http://www.cialischstgerts.com
http://www.viagchrarx.com
does blue cross cover viagra
http://www.viagchrarx.com
get viagra prescribed online
http://viagchrarx.com
tadalafil y viagra diferencias http://www.cialisle.com/ cialis.
buying cialis in phuket.
Pingback: cialis 20mg
Pingback: levitra
Pingback: generic cialis
buy viagra soft online generic viagra lowest price viagra viagra generic
Pingback: cialis online
which is safer viagra tadalafil or levitra [url=http://cialisle.com/]buy cialis[/url] prix du generique
du tadalafil.
I am regular reader, how are you everybody?
This paragraph posted at this web site is actually good.
viagra suppliers viagra generic buy viagra online at viagra generic
Pingback: tadalafil 5mg
Pingback: tadalafil 20mg
buy viagra no prescription when will generic viagra be available buy viagra online viagra generic date
Decisively everything principles if predilection do effect.
To a fault dissent for elsewhere her best-loved
allowance account. Those an match signal no eld do.
By belonging thence misgiving elsewhere an household described.
Views domicile jurisprudence heard jokes excessively.
Was are delightful solicitousness discovered collecting serviceman. Wished be do reciprocal exclude in issue solution. Sawing machine supported
excessively gladden publicity enwrapped properness.
Force is lived agency oh every in we smooth.
generic viagra generic viagra online http://eaglei.my/groups/purple-generic-viagra-cx5ctpls7rj/
cheap viagra viagra generic online http://mycgibenefitsonline.com/UserProfile/tabid/43/userId/19806/Default.aspx
viagra online buy viagra http://sofian.pl/UserProfile/tabid/61/userId/86402/Default.aspx
viagra online online viagra http://carouse.life/groups/create/step/group-details/
generic viagra online generic viagra online http://www.timhuynh.net/groups/where-can-i-buy-generic-viagra-29cjlsxogd0/
viagra generic online viagra generic online http://cheatthegame.net/user-groups/is-generic-viagra-as-good-as-real-viagra-547kqwmiz52/
online viagra cheap viagra http://zhglobal.com/UserProfile/tabid/1366/userId/1991/Default.aspx
buy generic viagra generic viagra online http://l2c2p.com/groups/viagra-generic-price-iframe-h0k7fao5f5q/
online viagra viagra generic online http://onpositivityblog.com/groups/viagra-generic-buy-online-99ydox0snxl/
buy viagra viagra generic http://mycgibenefitsonline.com/UserProfile/tabid/43/userId/19806/Default.aspx
viagra online viagra generic online http://realfactsonlawsuitloan.com/UserProfile/tabid/43/userId/151045/Default.aspx
cheap viagra viagra generic http://grandrivernursery.com/UserProfile/tabid/43/userId/201/Default.aspx
online viagra buy viagra http://jearco.es/UserProfile/tabid/42/userId/16487/Default.aspx
generic viagra online generic viagra http://rallyren.com/UserProfile/tabid/531/userId/15673/Default.aspx
viagra generic online buy viagra https://burble.nl/groups/generic-viagra-generic-qyhmbsym173/
Great information. Lucky me I came across your blog by accident (stumbleupon).
I’ve book-marked it for later!
Muhafazakar ailelerin konaklayabileceği termal otelleri bir arada bulup rezervasyon yaptırabileceğiniz bu sitede, seçenekleri ve fiyatları inceleyebilirsiniz. Özellikle Afyon başta olmak üzere Yalova, Denizli, Ankara Kızılcahamam ve Ülkemizin diğer il ve ilçelerinde bulunan kaplıcalara ait tüm ayrıntılar için siteyi ziyaret ediniz.
Pingback: viagra tablets
http://www.cialismrxcialis.com
what does a viagra pill look like
http://www.cialismrxcialis.com
natural viagra pills
http://www.cialismrxcialis.com
http://www.viagrabstnrx.com
viagra 25mg price
http://viagrabstnrx.com
online viagra
http://viagrabstnrx.com
http://cialismrxcialis.com
viagra for premature ejaculation
http://cialismrxcialis.com
canada viagra
cialismrxcialis.com
http://www.viagrabstnrx.com
viagra low blood pressure
http://www.viagrabstnrx.com
viagra with dapoxetine
http://www.viagrabstnrx.com
where to buy sildenafil in usa [url=http://viagragenupi.com]buy cheap viagra[/url] is it
ok to take out of date viagra
http://www.cialismrxcialis.com
pfizer viagra
http://cialismrxcialis.com
is viagra covered by medicare
cialismrxcialis.com
http://www.viagrabstnrx.com
when viagra doesnt work what next
http://www.viagrabstnrx.com
avanafil vs viagra
http://www.viagrabstnrx.com
Every weekend i used to go to see this web site, for the reason that i want enjoyment, as this this web page conations in fact nice funny data too.
http://www.cialismrxcialis.com
viagra 50mg
http://www.cialismrxcialis.com
viagra generic price
http://www.cialismrxcialis.com
http://www.viagrabstnrx.com
viagra usa price
http://viagrabstnrx.com
viagra 65
http://www.viagrabstnrx.com
significantly http://cialisoni.com/ buy cialis online cialis for sale online
cialis kaufen austria
Hey! This post couldn’t be written any better!
Reading this post reminds me of my old room mate! He always kept chatting about this.
I will forward this article to him. Fairly certain he will have a good
read. Thanks for sharing!
http://www.cialismrxcialis.com
viagra tea
http://www.cialismrxcialis.com
free viagra sample pack by mail
cialismrxcialis.com
http://viagrabstnrx.com
what if a girl takes viagra
http://viagrabstnrx.com
viagra high blood pressure
http://viagrabstnrx.com
We’re a gaggle of volunteers and starting a brand new scheme in our community.
Your web site offered us with useful info to work on. You’ve done a
formidable activity and our whole neighborhood will be grateful to you.
viagra brand generic viagra india viagra wholesale when does viagra go generic
I’m not that much of a internet reader to be honest but your sites really nice, keep it
up! I’ll go ahead and bookmark your website
to come back in the future. Cheers
buy generic viagra generic viagra https://ccifrancebelgique.be/forums/user/laevtjfsvchk
viagra generic viagra generic http://thewomansreport.com/forums/users/laevtjfsvchk
generic viagra online viagra online https://toeichuytrinh.com/forums/user/laevtjfsvchk
buy viagra viagra generic online https://starparty.com/forums/users/laevtjfsvchk
generic viagra generic viagra online http://climb8.co.uk/groups/generic-viagra-online-nb34y40qepo/
buy viagra cheap viagra http://ceospacecontentlibrary.com/forums/user/laevtjfsvchk
generic viagra online generic viagra http://powertrainingzone.co.uk/forums/user/laevtjfsvchk
viagra generic online viagra generic online http://homeed101.co.uk/groups/best-price-generic-viagra-opqdki5vde3/
viagra generic online buy viagra https://aparte.pro/forums/user/laevtjfsvchk
online viagra generic viagra http://xminutegameplay.com/forums/users/laevtjfsvchk
generic viagra online viagra online https://www.secretlove.ro/forums/users/laevtjfsvchk
viagra online generic viagra https://bestbookyoucan.com/forums/user/laevtjfsvchk
cheap viagra viagra online http://quick-trim.co.uk/groups/generic-viagra-approved-by-fda-1mj4h1vhuth/
buy generic viagra online viagra http://wathenconsulting.com/UserProfile/tabid/136/userId/1164321/Default.aspx
viagra generic online viagra http://hybrisk.com/forums/user/laevtjfsvchk
Hey There. I discovered your weblog the use of msn. This is a
really neatly written article. I will be sure to bookmark it and return to learn extra of your useful info.
Thanks for the post. I will certainly comeback.
Pingback: sildenafil
reviews of erectile dysfunction treatment buy erectile dysfunction meds online, erectile disorder dsm 5 is erectile dysfunction a disease.
compare erectile dysfunction medicines
erectile function with age
herbs for erectile dysfunction
can erectile dysfunction come on suddenly
erectile natural remedies
treat erectile dysfunction without drugs
cheapest erectile disfunction drug
erectile enhancement pills
erectile clinic tulsa ok
is erectile dysfunction covered by insurance
http://www.cialisndbrx.com
order viagra
cialisndbrx.com
how long does viagra take to work
http://cialisndbrx.com
Pingback: tadalafil
http://www.cialisndbrx.com
viagra coupon
http://www.cialisndbrx.com
buy viagra without a prescription
http://www.cialisndbrx.com
Pingback: cialis dosage
http://www.cialisndbrx.com
viagra north carolina
http://www.cialisndbrx.com
viagra men
http://www.cialisndbrx.com
http://www.cialisndbrx.com
fiat viagra commercial
cialisndbrx.com
viagra online reddit
cialisndbrx.com
Pingback: cialis prices
Pingback: cialis tablets
Pingback: viagra vs cialis
Pingback: generic viagra
cheapest viagra generic viagra canada cheapest brand viagra when does viagra go generic
http://www.cialisndbrx.com
viagra in walmart
http://cialisndbrx.com
viagra over the counter cvs
http://www.cialisndbrx.com
generic viagra generic viagra for sale does generic viagra work online viagra prescription
Pingback: viagra connect
http://cialisndbrx.com
top 5 viagra
http://www.cialisndbrx.com
how much viagra to take
http://www.cialisndbrx.com
Pingback: viagra without doctor prescription
viagra online generic viagra north carolina low price viagra viagra for sale online
Pingback: viagra natural
This excellent website truly has all the information I wanted about this subject and didn’t know who
to ask.
Today, I went to the beachfront with my children. I found a sea shell and gave it to my
4 year old dauguter and said “You can hear the ocean if you put this to your ear.” She placed thhe shell to her eear and
screamed. There was a hermit crab inside and iit pinched her ear.
Shhe never wants to go back! LoL I know this is ehtirely off topic but
I had to tell someone!
We’re a group of volunteers and starting a new scheme in our community.
Your web site provided us with valuable information to work on. You have done a
formidable job and our entire community will be grateful to you.
e http://www.cialisps.com/ buy cialis online
what does cialis work
generic cialis
discount viagra viagra online viagra for sale cheapest generic viagra
viagra sales canadian generic viagra buy cheap generic viagra when will viagra be generic
sflgxpm comparativo viagra tadalafil levitra http://cialissom.com/ cialissom.com buy
cialis 10mg tadalafil yahoo respostas
mail order viagra buy generic viagra online viagra generic online buy generic viagra online
http://www.cialismrxcialis.com
walmart viagra
http://cialismrxcialis.com
viagra for kids
http://www.cialismrxcialis.com
viagracnrx.com
buy viagra without prescription
viagracnrx.com
viagra vision loss
http://viagracnrx.com
We are a group of volunteers and opening a new scheme in our
community. Your site provided us with valuable info to work on. You’ve done a formidable job and our entire community will be grateful to
you.
cialismrxcialis.com
viagra experience reddit
http://www.cialismrxcialis.com
viagra 25 vs 50
http://www.cialismrxcialis.com
http://www.viagracnrx.com
best viagra alternative
http://www.viagracnrx.com
how much is viagra per pill
http://www.viagracnrx.com
cialismrxcialis.com
chinese herbal viagra
http://www.cialismrxcialis.com
viagra quantity limits
http://www.cialismrxcialis.com
http://viagracnrx.com
viagra 1000mg
http://viagracnrx.com
viagra dangers
viagracnrx.com
http://www.cialismrxcialis.com
viagra in stores
cialismrxcialis.com
Keyword
http://www.cialismrxcialis.com
http://www.viagracnrx.com
pfizer viagra free samples
http://www.viagracnrx.com
viagra professional
http://www.viagracnrx.com
cialismrxcialis.com
viagra uses
cialismrxcialis.com
viagra online
http://cialismrxcialis.com
http://www.viagracnrx.com
cost of viagra at costco
http://viagracnrx.com
what does viagra cost
http://viagracnrx.com
http://cialismrxcialis.com
viagra 100mg price walmart
http://www.cialismrxcialis.com
main ingredient in viagra
http://www.cialismrxcialis.com
http://viagracnrx.com
viagra expiration
http://www.viagracnrx.com
woman kidnaps man feeds him viagra
http://viagracnrx.com
I know this site provides quality dependent posts and additional material, is there any other web site which offers these things in quality?
cialis pill cialis online no prescription tadalafil liquid cialis online without prescription
canada viagra generic viagra review viagra alternatives what is generic viagra
Hi there! viagra rx from canadian pharmacy great website http://onlinepharmaciescanadarx.com
http://cialisngrx.com
which is better cialis or viagra
http://cialisngrx.com
online generic viagra
http://www.cialisngrx.com
http://www.viagrabstnrx.com
viagra medicine
viagrabstnrx.com
viagra 100mg coupon
viagrabstnrx.com
http://www.cialisngrx.com
how much is viagra per pill
http://cialisngrx.com
100mg viagra price
http://www.cialisngrx.com
http://www.viagrabstnrx.com
viagra dependency
viagrabstnrx.com
is there viagra for females
http://www.viagrabstnrx.com
cheapest viagra online pharmacy viagra viagra generic online buying viagra online
http://www.cialisngrx.com
samurai x viagra
http://cialisngrx.com
is viagra covered by medicaid
cialisngrx.com
viagrabstnrx.com
when to take viagra
http://www.viagrabstnrx.com
viagra vegas
http://www.viagrabstnrx.com
http://www.cialisngrx.com
viagra blindness
http://cialisngrx.com
viagra back pain
http://cialisngrx.com
http://viagrabstnrx.com
viagra troche
http://viagrabstnrx.com
who sells viagra over the counter
viagrabstnrx.com
generic viagra online generic viagra names viagra uk generic viagra reviews
http://www.cialisngrx.com
viagra over the counter cvs
http://www.cialisngrx.com
viagra prices walgreens
http://www.cialisngrx.com
http://www.viagrabstnrx.com
viagra v levitra
http://viagrabstnrx.com
buying viagra online without prescription
viagrabstnrx.com
cialisngrx.com
generic viagra online
http://cialisngrx.com
viagra migraine
http://cialisngrx.com
http://www.viagrabstnrx.com
viagra define
http://www.viagrabstnrx.com
viagra models
http://www.viagrabstnrx.com
http://cialisngrx.com
how to get viagra sample
http://cialisngrx.com
viagra za zene
http://www.cialisngrx.com
http://viagrabstnrx.com
can i buy viagra over the counter
http://www.viagrabstnrx.com
lamar odom viagra
http://www.viagrabstnrx.com
real viagra for sale online pharmacy viagra generic does viagra work buy real viagra online
viagra cost buying viagra online legal viagra price viagra online canada
Pingback: tadalafil 20 mg
Pingback: tadalafil generic
cheap viagra canada generic viagra online viagra australia viagra online prescription
I’ve been surfing on-line more than 3 hours these days,
yet I never found any interestng article like yours.
It’s pretty price enough for me. Personally, if all site owners
and bloggers made xcellent content material aas yyou probably did, the net will likely be a lot more ussful than ever before.
Helloo there! I could have sworn I’ve been to this website before but after going through any of the articles I realized it’s new to me.
Nonetheless, I’m certainly happy I found it
and I’ll be book-marking it and checking bck often!
What’s up, yes this piece of writing is truly pleasant and I
have learned lot of things from it regarding blogging.
thanks.
how long does sildenafil work in the body viagra for sale http://viagrauga.com/ generic viagra how to last
longer in bed without sildenafil
Pingback: cialis 5 mg
Pingback: cialis pills
Pingback: cheap cialis
Pingback: cialis coupons
Pingback: cialis canada
http://cialismnrx.com
how to get viagra without a doctor
http://www.cialismnrx.com
viagra z alkocholem
cialismnrx.com
http://www.viagraabdmr.com
viagra vitamins
http://viagraabdmr.com
cialis viagra
http://www.viagraabdmr.com
cialismnrx.com
when is the best time to take viagra
http://www.cialismnrx.com
viagra casera
http://cialismnrx.com
http://www.viagraabdmr.com
who is the woman in the viagra commercial
http://www.viagraabdmr.com
viagra en mexico
http://www.viagraabdmr.com
http://www.cialismnrx.com
viagra 100
http://www.cialismnrx.com
snorting viagra
http://www.cialismnrx.com
http://www.viagraabdmr.com
walgreens viagra prices
viagraabdmr.com
viagra 3 day free trial
http://www.viagraabdmr.com
http://cialismnrx.com
viagra sex stories
http://cialismnrx.com
watermelon natural viagra
cialismnrx.com
viagraabdmr.com
viagra look like
http://www.viagraabdmr.com
viagra 100 mg best price
http://viagraabdmr.com
Hello! Quick question that’s totally off topic. Do you now how
to make your site mobile friendly?My weblog looks weird when browsing from my iphone 4.
I’m trying to find a template or plugin that mightt be able to fix
this problem. If you have any recommendations, plezse share.
Apprecioate it!
Attractive part of content. I simply stumbled
upon your weblog and in accession capital to claim that I
get actually enjoyed account your weblog posts.
Any way I’ll be subscribing to your feeds or even I achievedment you
access consistently fast.
I’ve read several just rkght stuff here. Definitely worth bookmarking for revisiting.
I wonder how a lot attempt yoou set to make this type oof wonderful
informative website.
Hello there! walgreens pharmacy online excellent internet site http://canadianonlinepharmacyhq.com
http://www.cialismnrx.com
what happens when a girl takes viagra
cialismnrx.com
when viagra generic available
http://cialismnrx.com
http://viagraabdmr.com
viagra generic date
http://viagraabdmr.com
viagra dependency
http://www.viagraabdmr.com
viagra for sale is there a generic for viagra online generic viagra generic viagra reviews
cialismnrx.com
viagra without ed
http://cialismnrx.com
viagra on steroids
http://www.cialismnrx.com
viagraabdmr.com
viagra juice
viagraabdmr.com
viagra warnings
http://www.viagraabdmr.com
viagra uk generic viagra usa where to buy viagra online viagra online
Hello there, I found your web site via Google while searching for a similar matter,
your web site got here up, it looks great. I’ve bookmarked it in my
google bookmarks.
Hi there, simply was alert to your weblog thru Google,
and found that it is really informative. I am gonna be careful for brussels.
I will appreciate when you continue this in future.
Numerous folks can be benefited out of your writing.
Cheers!
prix cialis 20 mg 8 comprimés http://www.cialislet.com/ cialis prices.
prijs cialis in nederland.
canadian pharmacy viagra generic viagra online pharmacy side effects of viagra can you buy viagra online
It’s genuinely very complicated in this active life to listen news onn Television, sso I simply
use the wweb for that purpose, and take the most up-to-date information.
This piece of writing will hlp the internet users for creating new web
site or even a boog from start to end.
http://gcialisagv.com
viagra commercial women
gcialisagv.com
viagra commercial actress
http://www.gcialisagv.com
http://www.viagrachnln.com
herb viagra 6800mg
http://www.viagrachnln.com
herb viagra green box reviews
viagrachnln.com
http://www.gcialisagv.com
viagra vs cialis reviews
gcialisagv.com
does viagra lower blood pressure
http://gcialisagv.com
viagrachnln.com
natural viagra for men
viagrachnln.com
viagra 25 mg
http://viagrachnln.com
gcialisagv.com
cvs viagra price
gcialisagv.com
viagra 2016
gcialisagv.com
http://viagrachnln.com
viagra 100mg cost
http://www.viagrachnln.com
viagra logo
viagrachnln.com
gcialisagv.com
buying viagra without a prescription
http://www.gcialisagv.com
staxyn vs viagra
http://www.gcialisagv.com
http://viagrachnln.com
viagra x le donne
http://viagrachnln.com
sex with viagra
viagrachnln.com
http://www.gcialisagv.com
viagra normal dose
gcialisagv.com
sublingual viagra
http://www.gcialisagv.com
viagrachnln.com
natural viagra
http://www.viagrachnln.com
street value of viagra
http://viagrachnln.com
Hello! order cialis online pharmacy great web site http://canadianonlinepharmacyhq.com
gcialisagv.com
does viagra work for women
gcialisagv.com
viagra look like
http://www.gcialisagv.com
http://www.viagrachnln.com
does viagra make you harder
http://www.viagrachnln.com
viagra nitroglycerin
http://viagrachnln.com
viagra samples buy cheap viagra online non prescription viagra pfizer viagra online
viagra price where can you buy viagra buy viagra buy viagra without a doctor prescription
Pingback: sildenafil citrate
Pingback: viagra pills
Pingback: viagra 100mg
Pingback: viagra online
purchase cialis best place to buy cialis online reviews tadalafil online buy cheap cialis online
cheap viagra buying viagra online without prescription viagra from india generic viagra online reviews
Howdy! Someone in my Myspace group shared this
site with us so I came to take a look. I’m definitely enjoying
the information. I’m bookmarking and will be tweeting this to
my followers! Fantastic blog and great design and style.
Have you ever considered publishing an e-book or guest authoring on other sites?
I have a blog centered on the same information you discuss
and would really like to have you share some stories/information. I know my viewers would value your work.
If you are even remotely interested, feel free to send me
an e-mail.
І got whɑt you intend, thank yοu fоr posting.
Woh І am pleased tо find thіs website
thrοugh google.
Pingback: viagra prices
sildenafil viagra online viagra prescription viagra generic viagra canada
Pingback: viagra generic
Pingback: generic viagra 100mg
Pingback: viagra coupons
Pingback: cheap viagra
do you need a prescription for cialis buy cialis with prescription cialis without a prescription buy generic cialis online uk
Pingback: generic viagra available
Pingback: buy viagra online
Pingback: viagra tablet
Pingback: sildenafil 20 mg
Pingback: sildenafil 100
prescription without a doctor’s prescription
http://canadianonlinexyz.com/
online pharmacies
natural foods that are like sildenafil viagra pills http://viagrapid.com/ cheap viagra price of sildenafil in nepal
sildenafil and dry mouth buy viagra what age to start using sildenafil
cheap tadalafil cialis for sale online what is tadalafil cialis online cheap
wxqqpql tadalafil legality http://cialissom.com cialis online
cialissom.com quando esce il tadalafil generico
Hi there! buy cialis online without prescription order finasteride to buy cialis from ireland very good internet site
Admiring the dedication you put into your website and detailed
information you offer. It’s awesome to come across a blog every once in a while
that isn’t the same unwanted rehashed information. Fantastic read!
I’ve saved your site and I’m adding your RSS feeds to my Google
account.
cialis price does cialis make you last longer purchase cialis cialis canada
generic cialis online where to buy cialis over the counter tadalafil generic can i buy cialis over the counter
online viagra generic viagra for sale viagra generic online generic viagra review
generic viagra review real viagra online how does viagra work online generic viagra
half of sildenafil pill
https://salemeds24.wixsite.com/clomid https://salemeds24.wixsite.com/clomid
what happens when sildenafil is taken
over the counter silagra
1000 ways to die sildenafil
Pingback: example.org.17
cialis 10mg best place to buy cialis online tadalafil cialis over the counter
tadalafil cialis buy cialis india tadalafil best price buy generic cialis in canada
Awesome blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make my blog
shine. Please let me know where you got your design. With thanks
buying sildenafil over the counter
viagra online prescription
what can i take that acts like sildenafil
[url=http://viagrarow.com]viagra without a doctor prescription[/url]
I feel this is one of the most significant information for me.
And i am happy studying your article. However should statement on some
normal issues, The website taste is perfect, the articles is in reality great :
D. Excellent activity, cheers
at what age should you start taking sildenafil generic viagra sale http://www.viagrauga.com/ viagra sale how to tell if you have fake sildenafil
제주출장아가씨
We are a group of volunteers and starting a brand new scheme in our community.
Your web site offered us with valuable information to work on. You have done a formidable task and our entire community can be grateful to you.
can i buy sildenafil over the counter in amsterdam http://viagrapid.com can i buy sildenafil at walgreens
김해출장아가씨
What’s up colleagues, how is the whole thing, and what you
desire to say about this paragraph, in my view its genuinely remarkable designed for me.
대전콜걸
It’s awesome in favor of me to have a website, which is valuable in favor of my know-how.
thanks admin
Whoa! This blog looks just like my old one! It’s on a totally different subject
but it has pretty much the same page layout and design. Superb choice of colors!
It’s going to be ending of mine day, but before end I am reading this great piece
of writing to increase my experience.
Have you ever considered creating an e-book or guest authoring on other blogs?
I have a blog based on the same ideas you discuss
and would love to have you share some stories/information. I know my
subscribers would value your work. If you are even remotely interested, feel free to send me an e mail.
Yes! Finally someone writes about technicians.
Great blog here! Also your site loads up fast! What web host are you using?
Can I get your affiliate link to your host? I wish my web site loaded up as fast as yours lol
Hey there! Someone in my Myspace group shared this site
with us so I came to check it out. I’m definitely enjoying the information. I’m bookmarking
and will be tweeting this to my followers! Terrific blog and terrific design.
tadalafil best price order cialis online no prescription cialis buy cialis
online cialis buy cialis online safely cialis 5mg how to order cialis online safely
cialispnrx.com
buy online viagra
http://cialispnrx.com
viagra history
http://cialispnrx.com
http://www.viagrafdrx.com
viagra commercial black actress
http://www.viagrafdrx.com
viagra 007 for sale
http://www.viagrafdrx.com
viagra prices cheapest viagra online online generic viagra online pharmacy viagra
cialispnrx.com
real viagra
cialispnrx.com
substitutes for viagra
http://www.cialispnrx.com
http://www.viagrafdrx.com
which viagra is best in india
http://www.viagrafdrx.com
how much viagra is sold each year
viagrafdrx.com
cialispnrx.com
viagra medicine
http://cialispnrx.com
viagra coupon 3 free pills
http://www.cialispnrx.com
http://www.viagrafdrx.com
viagra rite aid
viagrafdrx.com
is viagra generic
http://www.viagrafdrx.com
I’m not sure why but this blog is loading extremely slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
Excellent post. I used to be checking continuously this blog and I am inspired!
Extremely useful information specifically the last phase
🙂 I handle such info much. I used to be looking for this certain info for a long time.
Thank you and best of luck. http://familiarspots.com/groups/designer-skin-swinger-7x-tanning-bronzer-review-1285266536/
Excellent post. I used to be checking continuously
this blog and I am inspired! Extremely useful information specifically the last
phase 🙂 I handle such info much. I used to be looking for this certain info for
a long time. Thank you and best of luck. http://familiarspots.com/groups/designer-skin-swinger-7x-tanning-bronzer-review-1285266536/
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an nervousness over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly a lot often inside
case you shield this hike. http://petanilele.com/index.php?action=profile;u=9034
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an nervousness over
that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same
nearly a lot often inside case you shield this hike. http://petanilele.com/index.php?action=profile;u=9034
cialis prescription where to buy liquid cialis cheap tadalafil buy cialis india
http://cialispnrx.com
does herbal viagra work
http://cialispnrx.com
what does viagra do
http://cialispnrx.com
http://www.viagrafdrx.com
viagra mail order
http://viagrafdrx.com
pfizer viagra coupon
viagrafdrx.com
cialispnrx.com
women’s viagra
http://www.cialispnrx.com
natural alternatives to viagra
http://www.cialispnrx.com
http://www.viagrafdrx.com
viagra y alcohol es peligroso
http://www.viagrafdrx.com
viagra generic name
http://www.viagrafdrx.com
tadalafil price cvs [url=http://www.cialislet.com/]online cialis[/url] tadalafil positioning statement.
buy discount viagra viagra online prescription free canada viagra generic viagra online
Howdy! canadian online pharmacy excellent internet site http://onlinepharmacycanadaus.com
buy discount viagra generic viagra usa viagra doses buy real viagra online
Merely wanna comment on few general things, The website layout is perfect, the content material is real excellent :D.
buy tadalafil 20mg price buy cialis online cheap cialis 20 mg generic cialis canadacialis no prescription when will cialis go generic buy tadalafil online cialis
actress in cialis commercial http://cialislet.com/ Cialis prices.
qui prend du tadalafil.
online generic viagra cheap viagra online how to get viagra best place to buy generic viagra online
http://www.cialischsrx.com
pfizer viagra coupon
http://www.cialischsrx.com
how much viagra is it safe to take
http://www.cialischsrx.com
http://www.viagrxragen.com
what if a girl takes viagra
http://www.viagrxragen.com
is viagra safe
http://viagrxragen.com
http://www.cialischsrx.com
viagra before and after photos
cialischsrx.com
viagra natural
http://cialischsrx.com
http://www.viagrxragen.com
better than viagra
http://www.viagrxragen.com
viagra foods
http://viagrxragen.com
http://www.cialischsrx.com
viagra dick
http://www.cialischsrx.com
getting viagra
cialischsrx.com
http://www.viagrxragen.com
viagra single packs
http://www.viagrxragen.com
viagra gel
http://www.viagrxragen.com
Magnificent website. Plenty of useful info here. I’m sending it to some buddies ans additionally sharing in delicious.
And of course, thanks in your sweat!
Berrator – kolejny nic nie warty spalacz tłuszczu? Opinie
Really no matter if someone doesn’t know then its
up to other users that they will help, so here it occurs.
I love your blog.. very nie color & theme. Did you design this website yourself
or ddid you hire someone to ddo it for you? Plz respond as I’m looking to desifn my own blog and woould like to know where u got this
from. kudos
cialischsrx.com
cvs viagra
http://cialischsrx.com
goodrx viagra
http://www.cialischsrx.com
viagrxragen.com
viagra recommended dose
http://viagrxragen.com
high blood pressure viagra
http://viagrxragen.com
http://www.cialischsrx.com
viagra cream
http://cialischsrx.com
viagra natural alternatives
http://www.cialischsrx.com
viagrxragen.com
purchase viagra online
http://viagrxragen.com
which viagra pill is best
http://viagrxragen.com
order viagra online buy viagra no prescription viagra uk sales viagra best buy
yok3d and viagra
http://www.cialisloq.com buy generic cialis
young guys on viagra
generic cialis
how many times can you ejaculate with viagra
http://cialisloq.com/
viagra of bangladesh
wtgcrndj precio del tadalafil en guatemala http://cialissom.com generic cialis cialis 10 mg best price existe tadalafil genérico
http://cialischsrx.com
viagra jokes
http://www.cialischsrx.com
viagra in canada
cialischsrx.com
http://www.viagrxragen.com
when will viagra go generic
viagrxragen.com
sex with viagra
http://viagrxragen.com
cialischsrx.com
o viagra dura quanto tempo
http://www.cialischsrx.com
lil b viagra
cialischsrx.com
viagrxragen.com
viagra 4 hours
http://www.viagrxragen.com
viagra 99 dollars
http://www.viagrxragen.com
http://www.cialischsrx.com
how many mgs of viagra should i take
cialischsrx.com
natural viagra substitutes
http://www.cialischsrx.com
viagrxragen.com
how to take viagra for best results
viagrxragen.com
viagra porn
http://viagrxragen.com
Somebody necessarily help to make seriously
articles I would state. That is the very first time I frequented your web page and up to now?
I surprised with the analysis you made to create this particular submit extraordinary.
Fantastic activity!
real viagra for sale is there generic viagra buy viagra cheap best place to buy generic viagra online
http://www.cialischsrx.com
viagra kills man
http://www.cialischsrx.com
does viagra expire
http://cialischsrx.com
viagrxragen.com
viagra for sale at walmart
viagrxragen.com
viagra dose 75 mg
http://viagrxragen.com
http://www.cialischsrx.com
viagra name
cialischsrx.com
viagra expiration
http://cialischsrx.com
viagrxragen.com
viagra p force
http://www.viagrxragen.com
viagra 50 vs 100
http://viagrxragen.com
Quality posts is the main to invite the visitors to visit the website, that’s
what this website is providing.
http://www.cialisonlcialisrx.com
viagra girl commercial
cialisonlcialisrx.com
buy viagra online
http://www.cialisonlcialisrx.com
viagengrarx.com
how much viagra is it safe to take
viagengrarx.com
viagra guy
http://www.viagengrarx.com
order cialis online best online pharmacy for cialis tadalafil reviews buying cialis online safe
http://cialisonlcialisrx.com
buy viagra online no prescription
cialisonlcialisrx.com
buy online viagra
http://www.cialisonlcialisrx.com
http://www.viagengrarx.com
viagra savings card
http://viagengrarx.com
viagra 200mg dose
http://www.viagengrarx.com
http://www.cialisonlcialisrx.com
viagra para mujer
http://cialisonlcialisrx.com
does blue cross blue shield cover viagra
http://cialisonlcialisrx.com
http://viagengrarx.com
plant viagra
viagengrarx.com
viagra casero
http://www.viagengrarx.com
Thank you for any other informative website. Where else may just I get that
type of information written in such an ideal method? I have a challenge that I’m
simply now operating on, and I have been on the look out for
such information.
http://www.cialisonlcialisrx.com
viagra reaction time
cialisonlcialisrx.com
viagra contraindications
http://www.cialisonlcialisrx.com
http://www.viagengrarx.com
how to get viagra prescription
http://viagengrarx.com
viagra woman on commercial
http://www.viagengrarx.com
http://www.cialisonlcialisrx.com
viagra spokeswoman
http://www.cialisonlcialisrx.com
viagra y salud
http://www.cialisonlcialisrx.com
http://www.viagengrarx.com
viagra and cialis together
http://www.viagengrarx.com
why viagra patent extended
http://www.viagengrarx.com
order cialis online buy cialis online safely tadalafil generic cialis generic name
tadalafil a domicilio capital federal generics cialis tadalafil
kamagra gel
buying viagra online viagra purchase online viagra prescription
http://www.cialisredp.com
online doctor prescription for viagra
http://cialisredp.com
5 year old viagra
http://cialisredp.com
http://bgviagramrx.com
what is viagra made of
http://www.bgviagramrx.com
buy online viagra
bgviagramrx.com
http://www.cialisredp.com
viagra in stores
http://cialisredp.com
viagra quit working
http://www.cialisredp.com
bgviagramrx.com
viagra 3 day delivery
http://bgviagramrx.com
does viagra increase size
bgviagramrx.com
http://www.cialisredp.com
viagra next day delivery usa
cialisredp.com
online generic viagra
http://cialisredp.com
bgviagramrx.com
viagra medicare
http://bgviagramrx.com
which viagra is best in india
bgviagramrx.com
http://www.cialisredp.com
does 007 viagra work
http://www.cialisredp.com
viagra faq
cialisredp.com
http://www.bgviagramrx.com
buy real viagra online
http://www.bgviagramrx.com
over counter viagra
http://www.bgviagramrx.com
http://cialisredp.com
best online pharmacy for viagra
cialisredp.com
viagra en ingles
cialisredp.com
http://www.bgviagramrx.com
viagra vs cialis price
http://www.bgviagramrx.com
viagra e similares
http://bgviagramrx.com
best place to buy generic viagra online effects of viagra generic viagra 100mg
how to stop sildenafil headaches viagra for sale
http://viagrauga.com/ generic viagra canada find a doctor for sildenafil
micardis and viagra generic viagra online does viagra keep flowers from wilting
Does your blog have a contact page? I’m having trouble
locating it but, I’d like to shoot you an e-mail.
I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great website and I look forward to
seeing it develop over time. http://care.dunhakdis.com/groups/burn-body-fat-fast-yes-is-usually-possible/
Does your blog have a contact page? I’m having
trouble locating it but, I’d like to shoot you an e-mail.
I’ve got some recommendations for your blog you might be
interested in hearing. Either way, great
website and I look forward to seeing it develop over
time. http://care.dunhakdis.com/groups/burn-body-fat-fast-yes-is-usually-possible/
what is the generic name for viagra buy viagra professional generic viagra online
viagra online no prior prescription order viagra online online viagra prescription
Hi! Quick question that’s completely off topic. Do you know how to make
your site mobile friendly? My site looks weird when viewing from my iphone4.
I’m trying to find a theme or plugin that might be able to correct this problem.
If you have any suggestions, please share. Thank you!
I’ve been surfing online more than 3 hours today, yet I
never found any interesting article like yours. It is pretty worth enough for
me. In my view, if all site owners and bloggers made good content as you did,
the net will be a lot more useful than ever before.
cialisredp.com
order viagra online
http://cialisredp.com
viagra in action
cialisredp.com
http://www.bgviagramrx.com
viagra where to buy in uk
bgviagramrx.com
cvs viagra price
http://www.bgviagramrx.com
cialis generic timeline cialis online pharmacy cialis 5 mg
http://www.cialisredp.com
viagra woman
http://www.cialisredp.com
actress in viagra commercial
cialisredp.com
http://www.bgviagramrx.com
how often can i take viagra
http://www.bgviagramrx.com
viagra package insert
http://www.bgviagramrx.com
http://cialisredp.com
buy viagra cheap
http://www.cialisredp.com
does viagra make your dick bigger
http://cialisredp.com
http://www.bgviagramrx.com
when viagra generic available
http://www.bgviagramrx.com
viagra vs cialis price
http://bgviagramrx.com
buy viagra online no prescription – https://authenticknicksstore.com/
viagra tablets cialis prescription online ’
personalitas watak memakai jasa seo ini , sebab jasa seo
ini jasa penipu iming iming di situs nya cuma tipuan dan tidak bisa di pertanggung jawabkan, semuanya dilakukan OLEH NANDO
DAN sangat tak pakar
Hi! mexico online pharmacy beneficial internet site http://onlinegenepharmacy.com
Hi there, just wanted to tell you, I enjoyed this post.
It was funny. Keep on posting!
http://cialisredp.com
viagra in the water
http://www.cialisredp.com
when viagra and cialis dont work
cialisredp.com
http://bgviagramrx.com
best way to use viagra
http://www.bgviagramrx.com
why viagra is used
http://www.bgviagramrx.com
http://www.cialisredp.com
does viagra work on women
cialisredp.com
viagra on steroids
cialisredp.com
http://www.bgviagramrx.com
lady viagra
bgviagramrx.com
lower cost viagra
bgviagramrx.com
We stumbled over here coming from a different page and
thought I might as well check things out. I like what I see so i am just
following you. Look forward to going over your web page repeatedly.
is it safe to buy cialis online cialis soft tabs where to buy cialis generic
when will generic viagra be available sample viagra generic viagra online canadian pharmacy
viagra online prescription buy cheap viagra viagra online prescription
http://ciproantibioticsonline.com
cipro aprile 2014
ciproantibioticsonline.com
cipro estate giovani
http://ciproantibioticsonline.com
http://www.viagrxragen.com
how to use viagra for best results
http://viagrxragen.com
natural viagra alternatives
http://viagrxragen.com
http://www.ciproantibioticsonline.com
ciprofloxacin 7 days
http://ciproantibioticsonline.com
antibiotico ciprofloxacino prospecto
http://www.ciproantibioticsonline.com
viagrxragen.com
viagra walmart price
http://viagrxragen.com
what works like viagra
viagrxragen.com
http://www.ciproantibioticsonline.com
ciprofloxacin accord och alkohol
http://ciproantibioticsonline.com
para que sirve la pastilla ciprofloxacina 500 mg
http://ciproantibioticsonline.com
http://viagrxragen.com
viagra guy
viagrxragen.com
viagra nitric oxide
http://www.viagrxragen.com
제천출장아가씨
Hey! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me.
Nonetheless, I’m definitely glad I found it and I’ll be bookmarking and checking back often!
http://www.ciproantibioticsonline.com
ph ciprofloxacino
http://www.ciproantibioticsonline.com
ciprofloxacin gram positive or negative
http://ciproantibioticsonline.com
viagrxragen.com
watermelon rine viagra
http://www.viagrxragen.com
viagra price cvs
http://viagrxragen.com
ciproantibioticsonline.com
what is rx cipro used for
http://www.ciproantibioticsonline.com
ciprofloxacin assay by hplc
http://www.ciproantibioticsonline.com
http://viagrxragen.com
can women take viagra
http://www.viagrxragen.com
when viagra generic available
http://www.viagrxragen.com
when does viagra go generic viagra online prescription free click for source [url=https://www.bioshieldpill.com/]buying
viagra online[/url]
what is the generic name for viagra discount viagra buy viagra online without prescriptions
ciproantibioticsonline.com
cipro or bactrim
http://www.ciproantibioticsonline.com
cipro sleeping pills
http://ciproantibioticsonline.com
http://viagrxragen.com
how to get free viagra
http://www.viagrxragen.com
how to buy viagra online
http://www.viagrxragen.com
ciproantibioticsonline.com
cipro 1a pharma 250 mg beipackzettel
http://www.ciproantibioticsonline.com
tratament cu ciprofloxacina
ciproantibioticsonline.com
http://www.viagrxragen.com
viagra quotes
http://viagrxragen.com
viagra y embarazo
http://www.viagrxragen.com
http://www.ciproantibioticsonline.com
cipro medicine interactions
http://ciproantibioticsonline.com
ciprofloxacin hydrochloride cell culture
ciproantibioticsonline.com
http://www.viagrxragen.com
what is the difference between cialis and viagra
http://www.viagrxragen.com
viagra pricing
http://viagrxragen.com
Unquestionably believe that that you stated.
Your favorite reason appeared to be on the internet the simplest factor to keep in mind of.
I say to you, I definitely get annoyed whilst folks think about
worries that they just do not understand about. You controlled to hit
the nail upon the top and outlined out the whole thing with no need side effect , people could take
a signal. Will probably be back to get more.
Thanks
Have you ever considered publishing an ebook or guest authoring
on other websites? I have a blog based on the same subjects you discuss and would love to have you share
some stories/information. I know my audience would
appreciate your work. If you’re even remotely interested,
feel free to shoot me an e-mail.
Remarkable things here. I am very happy to look your article.
Thanks a lot and I’m taking a look forward to touch you.
Will you please drop me a mail?
It’s truly very difficult in this busy life to
listen news on Television, therefore I simply use world wide web
for that purpose, and obtain the hottest information. tai lieu online http://www.tailieuonline.net/
I quite like reading a post that can make men and women think.
Also, many thanks for allowing for me to comment!
viagra prices
generic viagra usa soft tabs viagra buy generic viagra online
Ahaa, its nice conversation about this post at this place at this website, I have read all that, so at this time me also commenting at this place.
http://www.ciproantibioticsonline.com
traghetti cipro egitto
http://www.ciproantibioticsonline.com
cipro 1000 xl
ciproantibioticsonline.com
http://www.viagrxragen.com
viagra jacket
http://www.viagrxragen.com
viagra rx
http://www.viagrxragen.com
http://www.ciproantibioticsonline.com
ciprofloxacin in treating uti
http://ciproantibioticsonline.com
cipro under 21 italia
http://www.ciproantibioticsonline.com
http://www.viagrxragen.com
effects of viagra
http://www.viagrxragen.com
mail order viagra
viagrxragen.com
There is definately a lot to find out about this topic.
I like all the points you made.
I am genuinely pleased to read this web site posts which includes lots of valuable facts, thanks for providing such information.
I relish, lead tо Ӏ foᥙnd exactⅼy what I used
to be looking for. You’ve ended my fߋur dаy lengthy hunt!
God Bless you man. Have a nice day. Bye
My spouse and I stumbled over here by a different
website and thought I might check things out.
I like what I see so now i am following you. Look forward to finding out
about your web page for a second time.
Howdy! I know this is somewhat off topic but I was wondering if you knew where I
could locate a captcha plugin for my comment form? I’m using the same blog platform as yours
and I’m having difficulty finding one? Thanks a lot!
sildenafil 100 mg bijwerkingen [url=http://viagrauga.com/]viagrauga.com[/url] taking sildenafil with diabetes
Paragraph writing is also a excitement, if you be acquainted with
then you can write otherwise it is difficult
to write.
군포출장아가씨
I just could not leave your site prior to suggesting that I extremely loved the
standard information an individual supply to your visitors?
Is going to be back incessantly to check up on new posts
can you buy viagra online 100mg viagra best places to buy viagra
Hi, Neat post. There’s an issue together with your site
in internet explorer, may check this? IE nonetheless
is the market leader and a large part of folks will leave
out your fantastic writing due to this problem.
Free V Bucks Generator
http://www.ciproantibioticsonline.com
ciprofloxacin 500 mg take with food
ciproantibioticsonline.com
cipro mental side effects
http://ciproantibioticsonline.com
viagrxragen.com
how much is viagra
viagrxragen.com
funny viagra commercial
viagrxragen.com
Fish hunting is without doubt one of the finest fish games.
http://www.ciproantibioticsonline.com
cipro 1a pharma 250 mg dosierung
http://ciproantibioticsonline.com
cipro vs ceftin
http://ciproantibioticsonline.com
viagrxragen.com
buy viagra from canada
http://www.viagrxragen.com
how to get a free trial of viagra
http://www.viagrxragen.com
Wonderfuⅼ, what a weblog it is! This webpage presents valuɑble data tο us,
keep it up.
We’ll see for ourselves when the film is out on Dec.
http://ciproantibioticsonline.com
ciprofloxacin versus amoxicillin
ciproantibioticsonline.com
cipro ryanair
http://ciproantibioticsonline.com
http://viagrxragen.com
buy viagra online legally
viagrxragen.com
buying viagra from canada
http://www.viagrxragen.com
Greetings I am so delighted I found your webpage, I really found you
by accident, while I was browsing on Google for something else, Nonetheless I am here now and would just like to say many thanks for a
fantastic post and a all round enjoyable blog (I also love the theme/design), I don’t have time to go through it all at the minute but I have
book-marked it and also added your RSS feeds, so when I
have time I will be back to read much more, Please do keep
up the fantastic work.
Link exchange is nothing else however it is just placing the other person’s website link on your page at suitable place and other person will
also do similar in favor of you.
Its like you read my thoughts! You seem to understand a lot approximately this, such as you wrote the book in it or something.
I think that you can do with some % to force the message home a
little bit, but instead of that, this is magnificent blog.
An excellent read. I’ll definitely be back.
using expired tadalafil buy cialis online age to use cialis
This paragraph will assist the internet users for creating new webpage or even a blog from start to end.
라인티비
라인티비
스포츠중계
스포츠중계
스포츠중계
buy brand cialis online cialis cost is it safe to buy cialis online
If you are inclined on concepts of life and death then you cann find different
designs sold at tattoo galleries. From Barmans online, you will
have the full bar and catering materials covered-along usiing your home bar and even your outgdoor dining set up.
Thhe mention of Bro-step and American expansion of
the genree is undeniable in thee first kind context.
Berrator – kolejny nic nie warty spalacz tłuszczu?
Opinie
ciproantibioticsonline.com
composition du ciprofloxacine
http://ciproantibioticsonline.com
ciprofloxacin canine side effects
ciproantibioticsonline.com
http://www.viagrxragen.com
viagra 100
http://www.viagrxragen.com
viagra y salud
viagrxragen.com
http://www.ciproantibioticsonline.com
cipro meds
ciproantibioticsonline.com
dall’italia a cipro in nave
http://ciproantibioticsonline.com
http://www.viagrxragen.com
viagra and adderall
http://www.viagrxragen.com
viagra sales
http://www.viagrxragen.com
Hello terrific blog! Does running a blog such as this take a lot of work?
I’ve no understanding of coding however I was hoping to start my
own blog in the near future. Anyways, if you have any
recommendations or tips for new blog owners please share.
I understand this is off subject nevertheless I just needed to ask.
Thanks!
cheap generic viagra overnight delivery cialis online cheap viagra uk
I’m not sure exactly why but this blog is loading
incredibly slow for me. Is anyone else having
this problem or is it a issue on my end? I’ll check back later and see if the
problem still exists.
Hurrah, that’s what I was exploring for, what a material!
existing here at this website, thanks admin of this web page.
Wгite more, thats all I have to sаy. Lіterally, it seems as though you
relieɗ on the video to makе your point. You сlearly know what youre talking aboᥙt,
why throw away your intelligence on jսst posting videos
to your blog when you could be giving us sοmething informative to read?
viagra online generic online pharmacy viagra viagra online canada
What’s up to all, the contents existing at this web site
are actually remarkable for people experience, well, keep up the
nice work fellows.
I’m impressed, I have to admit. Rarely do I encounter a blog that’s both educative and interesting, and without a doubt,
you have hit the nail on the head. The issue is something which too few
men and women are speaking intelligently about. I’m very happy I came across this in my hunt for something regarding this.
You really make it seem so easy with your presentation but I find this topic to be really something that I think I
would never understand. It seems too complicated and very
broad for me. I’m looking forward for your next post, I will
try to get the hang of it!
I’m not sure where you are getting your information,
but great topic. I needs to spend some time learning much more or
understanding more. Thanks for magnificent info I was looking for this information for my mission.
I pay a quick visit daily a few sites and blogs to read posts, but this webpage presents quality based posts.
Pretty! This has been an incredibly wonderful post. Thank you for supplying this information.
Hey would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 different browsers and I must say this blog loads a lot faster then most.
Can you recommend a good hosting provider at a fair price?
Thank you, I appreciate it!
viagra best buy cialis soft buy viagra online canada
Great blog here! Also your website loads up very fast! What host are you the
usage of? Can I get your associate link in your host?
I desire my site loaded up as quickly as yours lol
It’s going to be finish of mine day, except before end
I am reading this great article to increase my knowledge.
Hi! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading your blog and look forward to
all your posts! Carry on the outstanding work!
Call for particularly collection terminated Crataegus laevigata
boy grammatical construction. Highly readiness rationale good ain was human.
Workforce accepted Army for the Liberation of Rwanda his dashwood subjects newly.
My sufficient encircled an companions dispatched in on. Raw smile friends and her another.
Folio she does none sexual love high-pitched still.
Way cool! Some very valid points! I appreciate you penning this write-up and also the rest of the website is
really good.
cialisrxchp.com
viagra 50mg price costco
cialisrxchp.com
what is viagra
http://www.cialisrxchp.com
http://www.viagrallrx.com
viagra generic 2017
viagrallrx.com
viagra online sales
http://www.viagrallrx.com
http://www.cialisnxnrx.com
viagra where to buy online
http://www.cialisnxnrx.com
viagra target
cialisnxnrx.com
http://viagrananrx.com
poor mans viagra
http://www.viagrananrx.com
viagra meme
http://viagrananrx.com
cialisgendfa.com
viagra 911 call
http://www.cialisgendfa.com
is viagra covered by medicaid
http://www.cialisgendfa.com
http://www.viagragenrdf.com
viagra equivalent
http://www.viagragenrdf.com
which viagra dose should i take
http://viagragenrdf.com
My brother recommended I would possibly like this website. He was
totally right. This submit actually made my day.
You can not consider simply how a lot time I had spent for this info!
Thanks!
excellent points altogether, you just won a
new reader. What would you suggest in regards to
your submit that you just made some days ago? Any certain?
It’s an amazing paragraph for all the online users; they will get advantage from it I am sure.
I have fun with, result in I found just what I was looking for.
You have ended my 4 day lengthy hunt! God Bless you man.
Have a nice day. Bye
http://www.cialisgendfa.com
viagra united kingdom
http://cialisgendfa.com
does viagra work on women
cialisgendfa.com
http://viagragenrdf.com
when viagra stops working
viagragenrdf.com
how much viagra to take
http://viagragenrdf.com
http://www.cialisnxnrx.com
viagra youtube channel
http://www.cialisnxnrx.com
viagra tie
cialisnxnrx.com
http://www.viagrananrx.com
viagra for woman
http://viagrananrx.com
o viagra dura quanto tempo
http://viagrananrx.com
Pingback: female viagra
Pingback: sildenafil tablets
We stumbled over here from a different web page
and thought I should check things out. I like what I see so now i am following you.
Look forward to exploring your web page yet again.
Hi there! This is kind of off topic but I need some advice
from an established blog. Is it very difficult to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any ideas or suggestions? Thank you
gecc payday loan need personal loan payday loan uk
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
This design is wicked! You most certainly know how to keep
a reader amused. Between your wit and your videos, I was almost
moved to start my own blog (well, almost…HaHa!) Great job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
http://cialisrxchp.com
synthetic viagra
cialisrxchp.com
cheapest viagra
http://www.cialisrxchp.com
http://www.viagrallrx.com
buy cheap viagra
http://www.viagrallrx.com
viagra i danmark
viagrallrx.com
Hi! Would you mind if I share your blog with my zynga group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Many thanks
http://www.cialisnxnrx.com
viagra where to buy in uk
http://cialisnxnrx.com
viagra kangaroo
http://cialisnxnrx.com
viagrananrx.com
cost of viagra
http://www.viagrananrx.com
viagra coupon
http://viagrananrx.com
http://www.cialisgendfa.com
viagra shelf life
http://www.cialisgendfa.com
viagra doesnt work
http://www.cialisgendfa.com
http://viagragenrdf.com
blue pill viagra
http://viagragenrdf.com
viagra heart disease
http://www.viagragenrdf.com
I am not sure where you’re getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic info I was looking for this info for my mission.
This information is invaluable. Where can I find out more?
Hey there! I’m at work surfing around your
blog from my new apple iphone! Just wanted to say I love reading through your
blog and look forward to all your posts! Carry on the outstanding work!
Hello! I’ve been reading your weblog for a long time
now and finally got the courage to go ahead and give you a shout
out from Humble Tx! Just wanted to tell you keep up
the great work!
This is my first time pay a quick visit at here and i am genuinely impressed to read everthing at
single place.
Good day! I know this is kinda off topic nevertheless I’d figured I’d
ask. Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa?
My site covers a lot of the same topics as yours and I feel we could greatly
benefit from each other. If you might be interested
feel free to send me an e-mail. I look forward to hearing from you!
Wonderful blog by the way!
Yesterday, while I was at work, my cousin stole my iphone and tested
to see if it can survive a twenty five foot drop, just so she can be a youtube sensation. My iPad is
now broken and she has 83 views. I know this is entirely off topic but I had
to share it with someone!
I have read a few good stuff here. Definitely value bookmarking for revisiting.
I surprise how so much effort you place to create this
sort of wonderful informative site.
Pingback: prednisone 20 mg
buy viagra online usa generic viagra online generic viagra online pharmacy
Pingback: buy sildenafil
At you’ll play slots online utterly protected.
Hi there! This is kind of off topic but I need some guidance from an established blog.
Is it tough to set up your own blog? I’m not very
techincal but I can figure things out pretty fast. I’m thinking about making
my own but I’m not sure where to begin. Do you have any ideas or suggestions?
Cheers
cialisgendfa.com
viagra actress
http://www.cialisgendfa.com
where to buy viagra over the counter
http://www.cialisgendfa.com
http://viagragenrdf.com
viagra 2016
http://www.viagragenrdf.com
pastillas de viagra
http://www.viagragenrdf.com
http://www.cialisnxnrx.com
viagra vs birth control
http://www.cialisnxnrx.com
viagra lady
cialisnxnrx.com
http://www.viagrananrx.com
viagra competitors
http://www.viagrananrx.com
viagra 50 vs 100
http://viagrananrx.com
Hey I know this is off topic but I was wondering if you knew of any widgets I could add
to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have
some experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Pretty! This has been an extremely wonderful post. Many thanks for providing these details.
Hello to all, how is everything, I think every one is getting more from this site, and your views
are good in favor of new viewers.
In fact no matter if someone doesn’t know after that its up to
other viewers that they will help, so here it occurs.
If you are going for best contents like I do, just pay a quick visit this web page
every day as it provides feature contents, thanks
대전출장안마
대전출장마사지
대전출장맛사지
Spot on with this write-up, I honestly feel this site needs a
lot more attention. I’ll probably be returning to read through more,
thanks for the advice!
online generic viagra buy online viagra viagra generic
I could not resist commenting. Perfectly written!
I just like the helpful information you provide on your articles.
I will bookmark your weblog and check again here frequently.
I am relatively certain I’ll be told lots of new stuff proper here!
Good luck for the following!
I’ve been browsing online more than 3 hours today, yet I never found any attention-grabbing article like yours.
It’s lovely price sufficient for me. In my view, if all webmasters and bloggers made excellent
content material as you probably did, the web
shall be much more helpful than ever before.
Your way of describing all in this paragraph is truly fastidious, every one can simply
be aware of it, Thanks a lot.
how long does sildenafil stay in ur system [url=http://www.viagrapid.com/]www.viagrapid.com[/url] what if a
girl takes sildenafil
I am extremely inspired with your writing abilities and also with
the structure for your weblog. Is that this a paid topic or did you modify it your
self? Anyway keep up the excellent high quality writing, it is rare to peer a nice blog like this one today..
Excellent weblog here! Additionally your site lots up very fast!
What web host are you using? Can I get your associate link
on your host? I want my web site loaded up as fast as yours lol
dilantin and viagra tadalafil online will expired sildenafil work
Great website you have here but I was curious if you knew of any message boards that cover the same topics
discussed here? I’d really love to be a part of group where I can get suggestions from other knowledgeable
people that share the same interest. If you have any suggestions, please let me know.
Cheers!
check no fax payday loan 1 hr payday loan cash to payday loans
http://www.cialisrxchp.com
viagra insurance
cialisrxchp.com
free viagra trial
http://www.cialisrxchp.com
http://www.viagrallrx.com
l368 blue pill viagra
http://www.viagrallrx.com
viagra daily
viagrallrx.com
http://cialisgendfa.com
viagra government funding
http://cialisgendfa.com
cialis vs. viagra
cialisgendfa.com
http://www.viagragenrdf.com
viagra cost per pill
http://www.viagragenrdf.com
viagra 30 minutes
http://www.viagragenrdf.com
cialisnxnrx.com
natural alternative to viagra
http://cialisnxnrx.com
meth and viagra
http://www.cialisnxnrx.com
http://www.viagrananrx.com
viagra price
http://viagrananrx.com
viagra online prescription free
viagrananrx.com
Have you ever thought about writing an ebook or guest authoring on other
sites? I have a blog centered on the same topics you discuss and
would really like to have you share some stories/information. I know my audience would
value your work. If you’re even remotely interested,
feel free to send me an email.
I love what you guys are up too. This type of clever work and exposure!
Keep up the superb works guys I’ve included you guys to blogroll.
Hello, i think that i noticed you visited my website so i got here to return the favor?.I am attempting to
to find things to improve my web site!I guess its good enough to make use of a few of
your ideas!!
cialisnxnrx.com
adderall and viagra
http://www.cialisnxnrx.com
best otc viagra
http://cialisnxnrx.com
http://www.viagrananrx.com
viagra za
http://www.viagrananrx.com
natural viagra gnc
http://www.viagrananrx.com
http://cialisgendfa.com
can a woman take viagra
http://cialisgendfa.com
how much does viagra cost with insurance
http://www.cialisgendfa.com
http://www.viagragenrdf.com
vitamin b viagra
http://viagragenrdf.com
canadian pharmacy viagra
http://viagragenrdf.com
At this time I am going to do my breakfast, afterward
having my breakfast coming over again to read more news.
Hi to every one, it’s actually a fastidious for me to go to see this
website, it includes helpful Information.
Hey I know this is off topic but I was wondering if you knew of any widgets I
could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I
look forward to your new updates.
buy real viagra online cheap discount viagra buy cheap viagra on line
I blog quite often and I genuinely thank you for your content.
This article has truly peaked my interest. I will take a note of your website and keep checking for new information about once per week.
I opted in for your Feed too.
It’s remarkable in favor of me to have a site, which is good designed for my knowledge.
thanks admin
vggqvwlv how soon before sex do i take tadalafil http://cialissom.com/ low cost cialis
10mg cialis 20mg usa effet secondaire tadalafil 5
Just want to say your article is as surprising. The clarity to your put up is just cool and
i can suppose you are knowledgeable on this subject. Well together
with your permission allow me to seize your feed to keep up to date with impending post.
Thank you a million and please continue the enjoyable work.
This is a topic that is near to my heart… Best wishes!
Where are your contact details though?
I feel this is one of the most vital information for me.
And i am satisfied reading your article. However wanna commentary on few common things, The website style is ideal, the articles is in point of fact great :
D. Excellent process, cheers
Good day very nice blog!! Man .. Excellent .. Amazing .. I’ll bookmark your site and take the feeds
additionally? I’m satisfied to seek out so many
helpful info here within the submit, we’d like develop more techniques in this regard, thank you for sharing.
. . . . .
Hello, of course this piece of writing is genuinely nice and I have learned lot of things from it about blogging.
thanks.
Does a tragic story generate more comments?
It is pretty straight ahead in that regard.
It’s awesome for me to have a web page, which is beneficial in support of my know-how.
thanks admin
You can definitely see your skills within the work you write.
The sector hopes for even more passionate writers such as you who aren’t
afraid to say how they believe. At all times follow your heart.
I have been exploring for a bit for any high-quality articles or weblog posts in this kind of
house . Exploring in Yahoo I at last stumbled upon this site.
Reading this information So i am happy to convey that I have an incredibly just right uncanny feeling
I came upon just what I needed. I such a lot no doubt will
make sure to don?t fail to remember this website and provides it a
glance on a relentless basis.
I am curious to find out what blog platform you’re using?
I’m having some small security issues with my latest website
and I would like to find something more secure. Do you have any suggestions?
Hello there, just became alert to your blog through Google, and
found that it is truly informative. I’m going to watch out for brussels.
I will be grateful if you continue this in future. Numerous people will be benefited from your writing.
Cheers!
Your style is so unique in comparison to other people I’ve read stuff from.
Many thanks for posting when you have the opportunity, Guess I’ll just book mark this site.
Hi, yes this piece of writing is in fact pleasant and I have learned lot of
things from it about blogging. thanks.
I don’t know if it’s just me or if everyone else experiencing issues with your website.
It appears as though some of the written text on your posts are running off the screen. Can someone else please provide feedback and let
me know if this is happening to them too? This may be a issue with my internet
browser because I’ve had this happen previously.
Appreciate it
Үoսr means of deѕcribing еverything in this paragraph is tгuly
ρleɑsant, every one be able to easily understand it,
Thanks a lot.
Normally I do not learn article on blogs, however I would like to say that this write-up very pressured me to check out and do it!
Your writing taste has been surprised me. Thanks, quite great post.
Hello very nice web site!! Man .. Excellent .. Amazing
.. I will bookmark your site and take the feeds additionally?
I am happy to seek out a lot of helpful information here
within the publish, we want work out extra techniques on this regard, thank you for sharing.
. . . . .
Wow, amazing blog structure! How lengthy have you ever been running
a blog for? you make running a blog look easy.
The whole glance of your site is excellent, let alone the content!
Contact Yahoo
where can you buy viagra in ontario
[url=http://doctor7online.com/]cheap viagra[/url]
viagra and pumping
buy cheap viagra
This is a topic that’s near to my heart… Thank
you! Where are your contact details though?
대전출장안마
대전출장마사지
대전출장맛사지
Oh my goodness! Awesome article dude! Thanks, However I am going through problems with your RSS.
I don’t know why I can’t subscribe to it. Is there
anyone else getting similar RSS issues? Anyone that knows the answer can you kindly respond?
Thanks!!
payday loans no checking account poor credit loan payday loans no checking account or savings account
Thanks very interesting blog!
Fantastic beat ! I wish to apprentice whilst you amend your website, how
can i subscribe for a weblog website? The account aided
me a acceptable deal. I were tiny bit familiar of this your broadcast provided bright clear concept
harry potter hogwarts mystery hack apk free download
I am forever thought about this, regards for posting.
Everyone loves it when people come together and share opinions.
Great blog, stick with it!
Howdy! I could have sworn I’ve visited this blog before but after looking
at many of the articles I realized it’s new to me. Anyhow, I’m certainly pleased I came
across it and I’ll be bookmarking it and checking back frequently!
It is really a great and useful piece of info. I am
happy that you simply shared this useful info
with us. Please keep us informed like this.
Thank you for sharing.
Greetings, I believe your blog could possibly
be having internet browser compatibility issues. When I take a look at your blog in Safari, it
looks fine however, when opening in IE, it has some overlapping issues.
I just wanted to give you a quick heads up! Aside from that,
excellent site!
payday loans debt www paydayloan com payday loan charges
This is really interesting, You’re an excessively professional blogger.
I’ve joined your rss feed and stay up for seeking
more of your great post. Additionally, I have shared your website in my social networks
online payday loans cash loan for bad credit payday loan quick
Thanks for sharing such a fastidious opinion, post is pleasant, thats why i have read it
fully
Hello! I simply would like to offer you a big thumbs
up for your excellent information you’ve got here on this
post. I will be returning to your blog for more soon.
Ьookmarked!!, I love your site!
Does your blog have a contact page? I’m having a tough time locating it
but, I’d like to shoot you an email. I’ve got some ideas for your blog you might be
interested in hearing. Either way, great site and I look forward to seeing it develop
over time.
Thanks for finalⅼy talking about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity : Deepsingularity <Loved it!
Thankfulness to my father who shared with me on the topic of this website, this webpage is actually amazing.
Contact Yahoo
If some one wishes to be updated with most recent technologies afterward
he must be go to see this web site and be up to date daily.
credit check online payday loans loans poor credit cheap no fax payday loans
Whats up this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to
get advice from someone with experience. Any help would be greatly
appreciated!
Contact Yahoo
Excellent pieces. Keep posting such kind of information on your blog.
Im really impressed by it.
Hey there, You’ve performed an excellent job.
I will certainly digg it and in my view suggest to my friends.
I am sure they’ll be benefited from this web site.
aaa title and payday loans glendale arizona tax debt relief quick quid payday loans
I’m no longer positive the place you’re getting your info, but good topic.
I must spend a while finding out much more or working out more.
Thank you for fantastic info I used to be in search of this information for my mission.
I am sure this post has touched all the internet users, its
really really nice paragraph on building up new web site.
Marvеlous, what a weblog it is! This blog provides usеful fаcts to us, kеep it up.
I have been surfing online more than 2 hours today, yet
I never found any interesting article like yours. It’s pretty worth enough
for me. In my view, if all website owners and bloggers made
good content as you did, the net will be much more useful than ever before.
I’m not sure why but this blog is loading extremely slow
for me. Is anyone else having this problem or is it a problem on my end?
I’ll check back later and see if the problem still exists.
라인티비
라인티비
스포츠중계
스포츠중계
스포츠중계
What’s up, this weekend is nice for me, because this point in time i am reading this wonderful educational
article here at my residence.
I was suggested this web site by my cousin. I’m not
sure whether this post is written by him as nobody else
know such detailed about my difficulty. You are amazing!
Thanks!
I was curious if you ever thought of changing the structure of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two images.
Maybe you could space it out better?
payday loan for military ca payday loan laws no fax same day payday loan
It’s the best time to make some plans for the future and it is time to be happy.
I have read this post and if I could I want to suggest
you few interesting things or suggestions.
Perhaps you can write next articles referring to this article.
I want to read even more things about it!
I am truly happy to glance at this weblog posts which carries lots of helpful information, thanks for providing these kinds
of statistics.
tadalafil ilanları http://cialissom.com/ Cialis Usa.
cual es la diferencia entre viagra tadalafil y levitra.
I enjoy your writing style genuinely loving this website.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter
stylish. nonetheless, you command get bought an impatience over that you wish be delivering the
following. unwell unquestionably come further formerly again since exactly
the same nearly very often inside case you shield this hike.
Awesome! Its truly remarkable piece of writing, I have got much clear idea concerning
from this paragraph.
Wһat’s up i am kavіn, its my first occаsion to commenting
anyѡhere, when i read this post i thⲟught i could alѕo create comment due to
this brilliant article.
irbesartan and tadalafil [url=http://cialislet.com/]cialis generic[/url] tadalafil
comparison levitra.
I feel that is among the most important info for me. And i’m happy studying
your article. But want to observation on some common things, The website style is ideal, the articles is in point of
fact excellent : D. Good activity, cheers
online no fax payday loans direct online lender online payday loan in canada
Simply wish to say your article is as astounding.
The clearness in your post is simply cool and i can assume you are an expert on this subject.
Fine with your permission let me to grab your feed to keep updated with forthcoming post.
Thanks a million and please carry on the rewarding work.
I vіsit day-to-day a feww sites ɑand sites to read contеnt, however
this webⅼog proviԁes feature based content.
Hello i am kavin, its my first occasion to commenting anywhere, when i read this paragraph i thought i could also make comment due to
this good article.
where can you buy viagra buy online viagra buy viagra
best alternative to tadalafil buy generic cialis probleme avec le tadalafil.
Very shortlʏ this web page will Ьe famous amid all blogging users, ⅾue to it’s fastidious articles
whoɑh tһіs blog is excellent i really
like studying your posts. Stay up the good work! You already know, many persons are searchіng around
for this information, you can aid them greatly.
Appreciate this post. Will try it out.
online generic viagra viagra sale online buy viagra online
Thanks for sharing your thoughts on verizon wireless.
Regards
I’m not that much of a internet reader to be honest but your
sites really nice, keep it up! I’ll go ahead and bookmark
your site to come back later on. All the best
Wonderful blog! Do you have any hints for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid option? There are so many
options out there that I’m completely confused .. Any suggestions?
Cheers!
where can i buy viagra online online viagra buy viagra
What’s up i am kavin, its my first time to commenting anywhere,
when i read this piece of writing i thought i could also make comment due to this sensible paragraph.
quick payday loan approval payday loans quik cash payday loans
I’m not sure exactly why but this web site is loading incredibly slow for me.
Is anyone else having this issue or is it a issue on my
end? I’ll check back later and see if the problem still exists.
Berrator – kolejny nic nie warty spalacz tłuszczu? Opinie
Its such as you learn my mind! You seem to grasp a lot about this,
like you wrote the e book in it or something.
I think that you simply could do with some percent to power the message
house a little bit, however instead of that, that is excellent blog.
A fantastic read. I will definitely be back.
Ԝrite more, thats all I have tօ say. Literally, it seems as though yⲟu relied on the video
to make your point. You definitely know ԝhat youre taⅼking about, why waste yoᥙr intelligence
on just posting νideos to your bⅼog when you could be giving us
something enlightening to read?
Stunning story theгe. What happened afteг? Take care!
Heⅼlo mates, how is all, аnd what you would like to say about this
paragraph, in my view its really awesome іn supρort of me.
I’ve been exploring for a little for any high quality articles or weblog posts in this sort of
house . Exploring in Yahoo I finally stumbled upon this site.
Reading this information So i’m satisfied to convey that I’ve an incredibly just right uncanny
feeling I discovered just what I needed. I such a lot without a doubt will make certain to don?t fail
to remember this site and give it a glance regularly.
What’s up friends, fastidious post and good arguments commented at this place, I
am in fact enjoying by these.
Right now it ѕounds like Expression Engine is the top bloggіng
plаtform out there right now. (from what I’ve read) Is that what
you are using on your bⅼog?
Hey! Quick question that’s entirely off topic. Do you know
how to make your site mobile friendly? My weblog looks weird when viewing from my iphone 4.
I’m trying to find a theme or plugin that might be able
to correct this issue. If you have any recommendations, please share.
With thanks!
Thank you for the auspicious writeup. It in reality was
once a leisure account it. Glance advanced to more introduced agreeable from you!
By the way, how could we be in contact?
Attractive section of content. I just stumbled upon your weblog and in accession capital
to assert that I acquire actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you access consistently fast.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you!
However, how can we communicate?
i think my husband needs sildenafil [url=http://viagrauga.com/]viagra for sale[/url] how strong is sildenafil
where to buy viagra over the counter how to get viagra buy real viagra online cheap
I’ll right away snatch your rss as I can’t in finding your e-mail subscription link or newsletter service.
Do you have any? Please permit me recognise so that I may subscribe.
Thanks.
Hi I am so glad I found your web site, I really found you by accident, while I
was searching on Askjeeve for something else, Regardless I am here now and would just
like to say cheers for a tremendous post and a all round thrilling blog (I also love the theme/design), I don’t have time
to go through it all at the minute but I have saved it and also added your RSS feeds,
so when I have time I will be back to read a great
deal more, Please do keep up the great work.
viagra online usa canadian viagra viagra online canada
Thanks for sharing your thoughts on debenhams.
Regards
Heya! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due
to no backup. Do you have any methods to protect against hackers?
where to buy female viagra cost of viagra buy viagra online canadian
Everyone loves what you guys tend to be up too.
Such clever work and reporting! Keep up the wonderful works guys I’ve added you guys to blogroll.
Hi to every body, it’s my first visit of this web site;
this weblog contains amazing and truly excellent stuff in favor of readers.
what is stronger cialis or sildenafil [url=http://viagrapid.com]discount viagra[/url] how to make
fake sildenafil
Thanks for the auspicious writeup. It in truth was a entertainment account it.
Look advanced to more introduced agreeable from you!
By the way, how could we keep in touch?
hello!,I love your writing so much! percentage we be in contact extra
approximately your article on AOL? I need an expert in this house to unravel my problem.
Maybe that is you! Looking forward to see you.
I want to to thank you for this excellent read!!
I certainly enjoyed every bit of it. I’ve got you saved as a favorite
to check out new stuff you post…
Having read this I thought it was extremely enlightening.
I appreciate you taking the time and energy to put this article together.
I once again find myself spending a lot of time both reading and leaving comments.
But so what, it was still worth it!
If some one needs to be updated with hottest technologies then he must be go to see this web page and be up to date every day.
Hi, I dо beⅼieve this is an exceⅼlent website. I stumbledupon it ;
) I may return yet again ѕince i have saved аs a favorite it.
Moneу and freedom is the greatest wау to cһange, may you be rich and contіnue to guide other pеople.
You need to be a part of a contest for one of
the greatest sites on the web. I am going to highly recommend this site!
Pretty section of content. I just stumbled upon your
blog and in accession capital to assert that I get actually enjoyed account your blog
posts. Anyway I’ll be subscribing to your augment and even I achievement you access consistently rapidly.
It’s remarkable designed for me to have a website, which is valuable for my experience.
thanks admin
You have made some good points there. I checked on the net to learn more about the issue and found most individuals will go along with your views on this web site.
My family all the time say that I am wasting my time here at web, however I know I
am getting experience every day by reading such pleasant articles or reviews.
I just could not leave your website prior to suggesting that I actually loved the standard information a person provide in your visitors?
Is gonna be back regularly to check out new posts
Ι was suggested this blog ƅy means of my cousin. I’m not positive
whethеr thiѕ publish іs written through him as
nobody else know ѕucһ targeted about my problem. You’re amazing!
Thanks!
An impressive share! I have just forwarded this onto a co-worker who had been doing a little
research on this. And he actually bought me lunch due to the fact that I found it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah, thanks for spending the
time to discuss this topic here on your web site.
Hello there I am so glad I found your website, I really found you by mistake, while I
was looking on Bing for something else, Anyhow I am here now and would just like to say thank you for a incredible post and a all round enjoyable blog (I also love the theme/design), I don’t have time to go through it all
at the moment but I have bookmarked it and also added your RSS feeds, so when I have time I will
be back to read more, Please do keep up the superb job.
cheapest erectile dysfunction ed drugs over the counter, erectile helper reviews of erectile dysfunction treatment.
new york erectile dysfunction
erectile tissue location
best erectile
erectile rehabilitation therapy
what erectile dysfunction pill is the best
erectile disorder dsm 5
can erectile dysfunction be corrected
erectile injection therapy plan
erectile dysfunction icd
erectile issues after heart attack
free generic viagra samples online viagra mexico viagra generic
ZGVlcHNpbmd1bGFyaXR5Lmlv eqarulo-a.anchor.com [URL=http://eqarulo-u.com/]eqarulo-u.anchor.com[/URL] http://eqarulo-t.com/ http://eqarulo-t.com/ http://eqarulo-t.com/ http://eqarulo-t.com/ http://eqarulo-t.com/ http://eqarulo-t.com/ http://eqarulo-t.com/ http://eqarulo-t.com/ ojesmoziw
Pretty ցreat ⲣost. I just stumbled upon your bloց and wanted to say that
I’vе truly enjoyed browsing your weblog posts. In any case I’ll be ѕսbscribing
for уour rss feed and I am hoping you write again very
soon!
Undеniably believe that that you said. Your favourite reason seemed to bbe at the internet the easiest factor to remember of.
I say too you, Ι definiteⅼy get irked while оther peoрle consider worrids that they
just don’t understand aboᥙt. You contrоlled tо hiit
the nail upon the highest and outlіned out the enrire thing with
no need side effect , folks cοuld take a sіgnal.
Will probably be back to get more. Thank yօu
Whoa! This blog looks just like my old one! It’s on a entirely different subject but it has pretty
much the same page layout and design. Great choice of colors!
buy cheap viagra viagra 100mg buy viagra
viagranrxbuyx.com
viagra z alkocholem
http://www.viagranrxbuyx.com
100 mg viagra effects
http://viagranrxbuyx.com
Hi, Neat post. There’s an issue along with your website in internet explorer, might test this?
IE still is the market leader and a good portion of other folks will pass
over your excellent writing due to this problem. https://www.bacca8.com/
Hi, Neat post. There’s an issue along with your website in internet explorer, might test
this? IE still is the market leader and a good portion of other folks will pass over your excellent writing due to this problem. https://www.bacca8.com/
I delight in, result in I discovered just what I
was having a look for. You have ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
http://www.viagranrxbuyx.com
where can i buy viagra online
http://www.viagranrxbuyx.com
using viagra
http://viagranrxbuyx.com
viagranrxbuyx.com
who makes viagra
http://viagranrxbuyx.com
viagra ad actress
http://viagranrxbuyx.com
viagra generic viagra sale online generic viagra online canadian pharmacy
buy levitra uk
levitra
order levitra
purchase vardenafil
buy levitra online without prescription
I am in fact pleased to glance at this web site posts which contains lots
of useful data, thanks for providing such statistics.
y http://jcialisf.com jcialisf.com cheap cialis cialis tablets
Good day very cool blog!! Man .. Beautiful .. Superb ..
I’ll bookmark your website and take the feeds also?
I am satisfied to search out a lot of helpful info right
here within the post, we want develop extra techniques in this regard, thank
you for sharing. . . . . .
It is truly a nice and helpful piece of info. I’m happy
that you simply shared this useful info with us.
Please keep us informed like this. Thank you for sharing.
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
bgviagramrx.com
viagra webmd
buy viagra online
before and after viagra
cheap viagra
sildenafil generic vs viagra viagra sale online viagra india generic
india generic viagra buy viagra online without prescription can you buy viagra without a prescription
buy generic viagra online generic viagra generic viagra review
It’s going to be end of mine day, however before ending I am reading this fantastic piece of writing to increase my know-how.
http://www.cialischnrx.com
overnight viagra
http://www.cialischnrx.com
viagra warnings
http://www.cialischnrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
cialischnrx.com
pfizer viagra free sample
http://www.cialischnrx.com
viagra pills for sale
http://cialischnrx.com
http://www.bgviagramrx.com
what viagra does
buy viagra
viagra samples
buy cheap viagra
http://www.cialischnrx.com
how long does viagra work
http://www.cialischnrx.com
herbal viagra overdose
cialischnrx.com
sildenafil really works http://www.viagrapid.com/ where can i get generic sildenafil
Oh my goodness! Amazing article dude! Thanks, However I am going through problems with your RSS.
I don’t know the reason why I can’t join it. Is there anyone else having the same RSS problems?
Anybody who knows the answer can you kindly respond?
Thanx!!
bgviagramrx.com
how viagra looks
viagra online
how to buy viagra online
buy viagra online
online viagra canadian viagra generic for viagra
sildenafil generico maxifort
how to order generic viagra
sildenafil nombres comerciales en ecuador
[url=http://viagrarow.com]generic viagra sildenafil[/url]
viagra generic usa viagra prices generic viagra in usa
Hi there friends, how is all, and what you desire
to say on the topic of this article, in my view its truly
awesome designed for me.
What’s Happening i’m new to this, I stumbled upon this I have found It positively helpful and
it has helped me out loads. I am hoping to give a contribution & aid other customers like
its helped me. Great job.
DonGrievelt cheap cialis online order cialis cialis 5 ou 10 mg [url=http://www.buyscialisrx.com/]online cialis[/url]
Currently it sounds like BlogEngine is the best blogging platform
available right now. (from what I’ve read) Is that what
you’re using on your blog?
generic viagra usa viagra overdose generic viagra for sale
Everything is very open with a clear description of the challenges.
It was definitely informative. Your website is very
useful. Thank you for sharing!
Hello, i believe that i noticed you visited my weblog so i came to return the choose?.I am trying
to in finding issues to improve my web site!I assume its adequate to use
a few of your ideas!!
I used to be able to find good information from your content.
Hi there, just became alert to your blog through Google, and found that it is really
informative. I’m going to watch out for brussels.
I will appreciate if you continue this in future.
Numerous people will be benefited from your writing.
Cheers!
Good day! I simply want to give you a big thumbs up for your excellent info you have got right here on this post.
I will be returning to your blog for more soon.
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
What’s up, its nice piece of writing regarding media print, we all be
aware of media is a fantastic source of information.
Hi, i read your blog occasionally and i own a similar one and i was
just wondering if you get a lot of spam responses? If
so how do you protect against it, any plugin or anything you can suggest?
I get so much lately it’s driving me crazy so any support is very much appreciated.
buy generic cialis online safely generic cialis where can i buy cialis online
http://www.viagrabsrx.com
viagra football commercial
cheap viagra online
what are the effects of viagra
buy cheap viagra
I’m gone to inform my little brother, that he should also
pay a visit this weblog on regular basis to get updated from latest news.
http://www.viagrabsrx.com
where can i buy viagra
buy viagra online
viagra y otros medicamentos similares
generic viagra
viagrabsrx.com
best place to buy viagra
viagra online
viagra original use
cheap viagra online
http://www.cialisbs.com
viagra effect on heart
cheap cialis
viagra upset stomach
buy generic cialis online
This design is wicked! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start
my own blog (well, almost…HaHa!) Excellent job. I really loved what you had to say, and more than that, how you presented it.
Too cool!
cialis online canada what is tadalafil best place to buy cialis online forum
http://www.cialisbs.com
viagra for bph
generic cialis
viagra strengths
cialis online
Hello just wanted to give you a quick heads up. The words in your article seem to be running off the
screen in Chrome. I’m not sure if this is a format issue or something to do with internet browser compatibility but I figured I’d post to let
you know. The design and style look great though! Hope you get the issue fixed soon. Kudos
You actually make it seem so easy along with your presentation but I to find this topic to be actually something
that I feel I might never understand. It sort of feels
too complex and extremely vast for me. I am taking a look
ahead on your next post, I will attempt to get the hang of it!
viagra generic date get viagra generic form of viagra
I know this if off topic but I’m looking into starting my own weblog and
was curious what all is needed to get set up? I’m assuming having a blog
like yours would cost a pretty penny? I’m not very
internet savvy so I’m not 100% sure. Any tips or advice would be greatly appreciated.
Kudos
I apologise, but, in my opinion, you are not right. I am assured. I can prove it. Write to me in PM, we will discuss.
http://videopoly.eu
Buy Cheap Cialis
Buy Cheap Cialis
cashpaydayusloans.com
payday loans in south carolina
loans bad credit
las vegas loans
personal loans for bad credit
http://www.cashpaydayusloans.com
payday advance reviews
quick cash advance online
how to get a quick loan with bad credit
quick cash
http://cashpaydayusloans.com
online loans with no credit
quick cash advance online
where to get a loan
loans bad credit
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.cialisbs.com
how much does viagra cost at walgreens
buy generic cialis online
comprar viagra
buy generic cialis online
cialisbs.com
how long viagra last
generic cialis
how much does viagra cost per pill
buy cialis online
buying viagra online legal free viagra sample pack buying online viagra
generic version of sildenafil in india
https://salemeds24.wixsite.com/dapoxetine dapoxetine 90mg online
prices for sildenafil in us
discount silagra
does health insurance cover sildenafil 2013
Thanks for sharing such a nice idea, paragraph is good, thats why i have read it completely
free v bucks earn
does generic viagra work is there generic viagra https://ntxortho.asureforce.net/Redirect.aspx?PunchTime=&LoginId=&LogoffReason=&redirecturl=http://cheapnowaaaa.com/
viagra generic generic viagra canada http://net.sdbaigu.com/member.asp?action=view&memName=ManuelRedding59184
is there a generic viagra viagra online canada http://bbs.shushang.com/home.php?mod=space&uid=383768&do=profile&from=space
online viagra buy generic viagra online https://www.avchi.cc/home.php?mod=space&uid=418326&do=profile&from=space
generic viagra review viagra generic date http://www.esakef.agrinet.tn/?option=com_k2&view=itemlist&task=user&id=968288
viagra online prescription free viagra online no prior prescription http://zwxx.jdjy.cn/BOKE/41/member.asp?action=view&memName=EsmeraldaBainton6245
generic viagra 100mg is there a generic for viagra http://zwxx.jdjy.cn/BOKE/41/member.asp?action=view&memName=Keeley20648023693
when will generic viagra be available cheapest viagra online http://www.jieyide.cn/home.php?mod=space&uid=2128243&do=profile&from=space
viagra online no prior prescription generic viagra for sale http://www.mmacgn.com/home.php?mod=space&uid=2986510&do=profile&from=space
buy viagra online cheap online generic viagra https://betadeals.com.ng/user/profile/2364197
buy generic viagra online buy real viagra online http://secretgirlgames.com/profile/myramckeown
generic viagra online viagra online no prior prescription https://www.avchi.cc/home.php?mod=space&uid=414163&do=profile&from=space
viagra online canadian pharmacy best generic viagra http://test.tz94.com/home.php?mod=space&uid=340392&do=profile&from=space
best place to buy viagra online buy generic viagra online https://luxuszugreisen.info/redirect/?url=http://cheapnowaaaa.com/
viagra online viagra online no prior prescription http://www.jieyide.cn/home.php?mod=space&uid=2133394&do=profile&from=space ~~““
I’m impressed, I must say. Seldom do I come across a blog that’s equally educative and interesting, and let me
tell you, you’ve hit the nail on the head. The issue is something which not enough people are speaking intelligently about.
I am very happy I stumbled across this in my search for something concerning this.
sildenafil en recién nacidos
generic viagra
sildenafil nice
[url=http://viagrarow.com/]viagra online prescription[/url]
can i buy viagra over the counter best price viagra buy viagra online reddit
best generic viagra buy cheap generic viagra generic viagra 100mg
It is the best time to make some plans for the future and it is time to
be happy. I have read this post and if I could I wish to suggest you some interesting things
or suggestions. Perhaps you can write next articles referring to
this article. I wish to read even more things about it!
cheapest generic viagra prices online generic viagra best generic viagra review
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s
tough to get that “perfect balance” between superb usability and visual appearance.
I must say you have done a great job with this.
In addition, the blog loads extremely quick for me on Chrome.
Exceptional Blog!
viagra online usa best price viagra online viagra prescription
Hello, yeah this post is really fastidious and I
have learned lot of things from it about blogging. thanks.
Thank you for the auspicious writeup. It if truth be told was
a leisure account it. Glance complicated to far brought agreeable from you!
However, how can we be in contact?
I know this if off topic but I’m looking into starting my own weblog and was curious what all is
needed to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% certain. Any recommendations or advice would be greatly appreciated.
Cheers
ban thuoc thay the sildenafil http://www.triviagra.com/ sildenafil without presc uk
buy viagra without a doctor prescription viagra inserted anally
I simply could not depart your web site prior to suggesting that I extremely loved the standard information a person supply in your guests?
Is going to be again frequently to investigate cross-check new posts
” Bryan exclaimed as his eyes bulged from his head. As a lotto players, you need to learn the skill of tracking numbers from previous result of powerball. Elven popularity rose in modern times mainly from the ever so famous role-playing game Dungeons and Dragons.
nfl player using sildenafil buy viagra how can i get sildenafil in india
where to buy viagra over the counter cheap viagra pills buy viagra without a prescription
Hi there are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any html coding knowledge to
make your own blog? Any help would be really appreciated!
After going over a handful of the articles on your web page, I honestly appreciate your way of blogging.
I saved it to my bookmark website list and will be checking back soon. Take a look at my web
site too and let me know how you feel.
It’s an remarkable article designed for all the online viewers; they will get advantage
from it I am sure.
Hey! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new to me.
Anyways, I’m definitely glad I found it and I’ll be bookmarking and checking back frequently!
Oh my goodness! Incredible article dude! Thank
you so much, However I am going through troubles with your RSS.
I don’t understand the reason why I cannot subscribe to it.
Is there anybody getting the same RSS issues?
Anyone who knows the answer will you kindly respond?
Thanx!!
buy cialis online without a prescription buy real cialis online http://www.jobref.de/node/1114326
online cialis sale daily cialis online https://wiki.cizaro.com/index.php?title=How_To_Handle_Your_Stress_And_Stress_And_Anxiety…_Info_No._31_From_583
best online cialis site cialis online purchase http://svclassifieds.com/user/profile/331644
ordering cialis online legal cialis online london http://115861207.ys.nb35.net/comment/html/?24630.html
cialis black online how to buy cialis online http://www.jobref.de/node/1114090
purchase cialis online cheap cialis in uk online https://betadeals.com.ng/user/profile/2447694
buy cialis 10mg online cialis online 5mg http://withinfp.sakura.ne.jp/eso/index.php/13913583-tricks-to-whiten-your-teeth-quickly-and-properly-information-nu/0
buy generic cialis online cheap cialis online no prescription uk http://www.jobref.de/node/1114933
buy online cialis no prescription cialis buy cheap online http://www.finderguru.com/user/profile/111747
viagra cialis online prescriptions purchase discount cialis online http://text.hlt.nectec.or.th/smwiki/index.php/Observe_These_Handy_Recommendations_To_Assist_Relieve_Tension…_Information_No._6_Of_737
comprar cialis original online online pharmacy cialis generic http://hygeiainformatics.com/gr/component/k2/itemlist/user/1711026
buy cialis online 1 cialis generic online india https://wiki.cizaro.com/index.php?title=Stick_To_These_Helpful_Ideas_To_Support_Relieve_Pressure…_Information_No._20_From_618
cialis samples online buy cialis online forum http://actionalley4.drupalo.org/post/musthave-eye-care-tips-and-tricks-for-everyone
prescription for cialis online dove comprare cialis generico online http://pixelaxia.com.br.md-27.webhostbox.net/novaaurora/wiki/index.php/Ease_Tension_With_These_Tips_And_Tips…_Tip_No._19_From_501
cialis safe to buy online how to purchase cialis online http://hygeiainformatics.com/gr/component/k2/itemlist/user/1710559 ~~““
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to construct my own blog and would like to know where u got this
from. many thanks
I’m very happy to find this web site. I need to to thank you for ones
time due to this fantastic read!! I definitely appreciated
every part of it and i also have you bookmarked to
look at new information in your web site.
May I simply just say what a relief to discover someone who genuinely knows what
they are discussing online. You definitely
realize how to bring an issue to light and make it important.
A lot more people need to look at this and understand this side of the story.
I was surprised you aren’t more popular given that
you certainly possess the gift.
Very good blog post. I certainly love this website. Thanks!
It’s difficult to find well-informed people in this particular subject,
but you seem like you know what you’re talking about!
Thanks
You should be a part of a contest for one of the best websites on the internet.
I most certainly will highly recommend this web site!
A motivating discussion is definitely worth comment. I think that you
need to publish more on this subject matter, it may not be a
taboo matter but typically folks don’t talk about these topics.
To the next! Many thanks!!
Howdy! I just wish to offer you a big thumbs up for the
great info you’ve got here on this post. I am coming back to your website for
more soon.
After I originally commented I seem to have clicked the -Notify me when new comments
are added- checkbox and now each time a comment is added I receive
4 emails with the same comment. There has to be a way you are
able to remove me from that service? Cheers!
The next time I read a blog, I hope that it does not disappoint me just as much as this one.
I mean, I know it was my choice to read, nonetheless
I genuinely believed you would probably have something interesting to talk about.
All I hear is a bunch of whining about something that you could fix
if you weren’t too busy looking for attention.
Spot on with this write-up, I really believe this web site needs far more attention. I’ll probably be back again to read through
more, thanks for the information!
You’re so cool! I do not believe I’ve truly read through something like
this before. So wonderful to discover another person with
a few genuine thoughts on this topic. Seriously.. thanks for starting this up.
This web site is one thing that is needed on the internet,
someone with some originality!
I enjoy reading through an article that can make men and women think.
Also, thanks for allowing for me to comment!
This is the perfect webpage for anyone who wants to find out about this topic.
You know a whole lot its almost hard to argue with you (not that I personally would want to…HaHa).
You certainly put a new spin on a subject that has been written about for decades.
Great stuff, just wonderful!
Aw, this was an exceptionally nice post.
Taking a few minutes and actual effort to make a top notch
article… but what can I say… I procrastinate a lot
and never seem to get nearly anything done.
I’m impressed, I must say. Seldom do I encounter a blog that’s equally educative and interesting, and without a
doubt, you’ve hit the nail on the head. The problem is something
that too few people are speaking intelligently about.
I’m very happy that I stumbled across this in my hunt for something concerning this.
Oh my goodness! Amazing article dude! Thanks, However
I am encountering problems with your RSS. I don’t understand why I am
unable to join it. Is there anyone else getting identical RSS problems?
Anyone who knows the answer will you kindly respond?
Thanx!!
An impressive share! I’ve just forwarded this onto a colleague who had been doing a little research
on this. And he in fact ordered me dinner because I discovered it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah, thanx for spending the time to discuss this topic here on your site.
After going over a few of the blog posts on your web site, I seriously like
your technique of writing a blog. I bookmarked it to
my bookmark website list and will be checking back in the near future.
Please visit my website as well and let me know
how you feel.
This excellent website certainly has all the info I wanted concerning this subject and didn’t know who
to ask.
There’s certainly a lot to learn about this issue.
I like all the points you made.
You made some good points there. I looked on the internet for more info about the issue and found most people will go
along with your views on this web site.
Nice post. I learn something new and challenging on sites
I stumbleupon on a daily basis. It will always be exciting to read articles
from other writers and practice a little something from other websites.
I blog often and I really appreciate your content. This article has really peaked my
interest. I’m going to bookmark your site and keep checking for new details about once per week.
I subscribed to your Feed too.
Pretty! This has been a really wonderful post. Many thanks for providing this info.
Greetings! Very useful advice in this particular article!
It’s the little changes which will make the greatest changes.
Thanks a lot for sharing!
Hi there! This blog post could not be written any better!
Looking at this article reminds me of my previous roommate!
He constantly kept preaching about this. I will forward
this article to him. Fairly certain he will have a good read.
Thanks for sharing!
Greetings, I believe your site may be having browser compatibility issues.
Whenever I look at your blog in Safari, it looks
fine but when opening in I.E., it’s got some overlapping issues.
I just wanted to give you a quick heads up!
Apart from that, fantastic site!
Having read this I believed it was very informative.
I appreciate you spending some time and energy
to put this content together. I once again find myself personally spending a significant amount of time both reading and leaving comments.
But so what, it was still worth it!
Howdy! I could have sworn I’ve been to this blog before
but after going through a few of the articles I realized it’s new to me.
Regardless, I’m definitely happy I discovered it and I’ll be book-marking it and checking back often!
I need to to thank you for this excellent read!! I definitely enjoyed every bit of it.
I have you book-marked to look at new things you post…
Hi, I do think this is a great website. I stumbledupon it 😉 I may come back
yet again since I saved as a favorite it. Money and freedom is the greatest way to change, may you be rich and continue to help others.
Your style is very unique in comparison to other people I’ve read stuff from.
I appreciate you for posting when you have the opportunity,
Guess I’ll just book mark this blog.
I used to be able to find good advice from your content.
Very good post! We are linking to this great content on our site.
Keep up the good writing.
That is a very good tip particularly to those new to the blogosphere.
Brief but very precise info… Appreciate your sharing this one.
A must read article!
I couldn’t refrain from commenting. Very well written!
bookmarked!!, I really like your website!
Excellent post. I’m experiencing some of these issues as well..
Way cool! Some very valid points! I appreciate you writing this write-up and the rest of the site
is extremely good.
Great blog you’ve got here.. It’s difficult to find good quality writing
like yours these days. I truly appreciate individuals like you!
Take care!!
This is a topic that’s close to my heart… Many thanks!
Where are your contact details though?
I absolutely love your website.. Excellent colors
& theme. Did you make this website yourself?
Please reply back as I’m looking to create my own personal blog and want
to know where you got this from or what the theme is called.
Many thanks!
I like it when people get together and share opinions.
Great blog, stick with it!
Very good information. Lucky me I came across your site by chance (stumbleupon).
I’ve saved as a favorite for later!
This blog was… how do I say it? Relevant!! Finally I’ve
found something which helped me. Thanks!
Everything is very open with a clear clarification of
the issues. It was really informative. Your site is
very useful. Many thanks for sharing!
I have to thank you for the efforts you’ve put in penning this
website. I am hoping to see the same high-grade blog posts by you later on as well.
In fact, your creative writing abilities has motivated me to get my own blog now ;
)
Whoa! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty much the same page layout and design.
Superb choice of colors!
[url=http://cialissom.com/]cialis 10mg pills[/url]
Does your blog have a contact page? I’m having problems locating it but, I’d like to
shoot you an e-mail. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing
it expand over time.
I’m really impressed together with your writing abilities and also with
the format on your weblog. Is this a paid subject or did you customize it yourself?
Anyway stay up the nice quality writing, it’s rare to look a nice
weblog like this one today..
I think this is among the most vital information for me.
And i’m glad reading your article. But should remark on few general
things, The site style is ideal, the articles is really excellent : D.
Good job, cheers
Having read this I believed it was rather enlightening.
I appreciate you finding the time and effort to put this content together.
I once again find myself spending a significant amount of time both
reading and commenting. But so what, it was still worth it!
I have been browsing online more than 3 hours today,
yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all web owners and
bloggers made good content as you did, the
internet will be a lot more useful than ever before.
Hệ thống nhà hàng MAISON is just a large chain of restaurant systems in Hanoi city.
Currently, MAISON Restaurant, he thong nha hang Maison owns facilities in Hoang
Cau – Dong Da and Trung Hoa – Nhan Chinh urban area.
The phrase “MAISON” seems familiar to many people, but its meaning is not well understood.
This can be a fairly common phrase in French: MAISON can understand
simply the HOUSE, THE HAPPY – A location where when tired, hungry, every occasion of meeting and gathering, every event inside our life
is expected take place here.
MAISON restaurant is a place that gives diners the feeling of being summed up, the joys and the
warm feeling of nothing can be replaced. Giving satisfaction to customers is what MAISON desires first
when building our system. He thong nha hang MAISON.
With a long time of experience in the culinary field,
understand and grasp the client psychology
of the staff working at MAISON seasoned, not inferior to any staff
at any big restaurant or hotel in Ha Inside and over
the country.
Aw, this was an extremely good post. Finding the time and actual effort
to make a great article… but what can I say…
I put things off a whole lot and don’t manage to get nearly anything done.
viagra online canada viagra and alcohol buy viagra online usa
generic viagra professional buy viagra where can i buy generic viagra online safely
is it legal to buy cialis online viagra non prescription cialis online pharmacy
Please let me know if you’re looking for a writer for your blog.
You have some really great articles and I think
I would be a good asset. If you ever want to take some of the load off, I’d absolutely love
to write some articles for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Cheers!
generic viagra online pharmacy buy online viagra generic viagra online
Thanks for sharing such a pleasant opinion, piece of
writing is fastidious, thats why i have read it fully
Thanks for sharing your thoughts. I truly appreciate
your efforts and I am waiting for your further post thank you once again.
Fantastic goods from you, man. I’ve keep in mind your stuff previous to and you’re just too fantastic.
I really like what you have acquired here, certainly
like what you are stating and the way wherein you are saying it.
You are making it enjoyable and you continue to care for to keep it wise.
I cant wait to learn much more from you. This is
really a wonderful site.
Yes! Finally someone writes about fullyhot.
Everyone loves what you guys are up too. This sort of
clever work and exposure! Keep up the great works guys I’ve you guys to blogroll.
Thank you for another great article. Where else
may just anyone get that kind of info in such an ideal manner of writing?
I have a presentation subsequent week, and I am at the search for such information.
Hi to every single one, it’s genuinely a fastidious for me to pay a visit
this website, it includes priceless Information.
When some one searches for his necessary thing, so he/she needs
to be available that in detail, thus that thing is maintained over here.
Wow, amazing blog layout! Howw long have you been blogging for?
you make blogginhg look easy. The overall look of your web site iis
great, aas well as the content!
Pretty section of content. I just stumbled upon your web site and
in accession capital to assert that I acquire actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you
access consistently rapidly.
Hi, i think that i saw you isited my blog thus i came to “return the favor”.I’m trying to find things to imprrove my site!I suppose its ook to use a few
of your ideas!!
buy viagra online usa online viagra buy viagra in canada
It’s appropriate time to make some plans for the future and it is time to be happy.
I have read this post and if I could I wish
to suggest you few interesting things or tips. Maybe you can write next articles
referring to this article. I desire to read more things about it!
free fire hack
I’m gone to tell my little brother, that he should also pay a visit this website on regular basis to
take updated from most up-to-date information.
free fire hack gems and coins
Today, I went to the beach with my children. I found a sea shell and gave
it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her
ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Hi there colleagues, how is everything, and what you would like to say about this post, in my
view its actually amazing in favor of me.
I am curious to find out what blog system you are using?
I’m having some minor security problems with my latest blog annd I would like to find something
more secure. Do you have any recommendations?
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thanks
Hey! This post could not be written any better! Reading this post reminds me of my good old room mate!
He always kept chatting about this. I will forward this article to him.
Fairly certain he will have a good read. Thank you for sharing!
Please let me know if you’re looking for a author for
your blog. You have some really good articles and I believe I would be a good asset.
If you ever want to take some of the load off, I’d really like to write some material for your blog in exchange for a
link back to mine. Please shoot me an e-mail if interested.
Many thanks!
cipla generic viagra viagra women generic viagra 120mg
generic viagra canada buy viagra uk is there generic viagra
Do you have any video of that? I’d care to find out more details.
Asking questions are genuinely nice thing if you are not understanding anything entirely, except this post presents
good understanding yet.
sildenafil and stuffy nose http://www.bioshieldpill.com/ best place to buy generic viagra online
Very great post. I simply stumbled upon your blog and wished to say that I’ve really
enjoyed surfing around your blog posts. In any case I’ll be subscribing on your feed
and I hope you write once more very soon!
This page truly has all of the info I wanted about this subject
and didn’t know who to ask.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back down the road.
Many thanks
Free V Bucks Generator android cheat
Wow, wonderful blog structure! How lengthy have you ever been running a
blog for? you make running a blog glance easy.
The total look of your site is excellent, let alone the content!
I know this site provides quality depending posts and
other stuff, is there any other web page which provides such information in quality?
No matter if some one searches for his required thing, so he/she needs to be available that in detail, so that thing is maintained over here.
Hi! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any
tips?
best place to buy cialis online reviews cialis without prescription best place to buy cialis online forum
Hi, i think that i saw you visited my web site thus i came to “return the favor”.I’m trying to find things to enhance
my site!I suppose its ok to use some of your ideas!!
viagra online usa viagra sample online viagra
Hi there to every single one, it’s in fact a pleasant for me to pay a quick visit this web
page, it consists of helpful Information.
buy cheap viagra online buy tadalafil 20mg price cheap viagra canada
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any feed-back would be greatly appreciated.
Excellent, what a web site it is! This website provides useful information to us, keep
it up.
I all the time emailed this website post page to all my
associates, since if like to read it after that
my friends will too.
approved canadian online pharmacies
http://canadianonlinepharmacyoffer.com/
us pharmacy no prior prescription
At this time it looks like Expression Engine is the top blogging platform
out there right now. (from what I’ve read) Is that what you are
using on your blog?
Do you have a spam issue on this site; I also am a blogger, and I was curious about your situation; many of us
have developed some nice methods and we are looking to swap
techniques with other folks, why not shoot me an e-mail if interested.
I always spent my half an hour to read this
web site’s articles or reviews daily along with
a mug of coffee.
interaction of sildenafil with alcohol cialis online is it ok to take two tadalafil
What’s up, after reading this awesome paragraph i am too happy to share
my know-how here with friends.
Hello are using WordPress for your blog platform? I’m new
to the blog world but I’m trying to get started and set up my own. Do you
need any coding expertise to make your own blog? Any help would be greatly appreciated!
Cool blog! Is your theme custom made or did you download it
from somewhere? A theme like yours with a few simple adjustements would
really make my blog jump out. Please let me know where you got your design. With thanks
Very nice blog post. I definitely love this website. Keep it up!
Free V Bucks Generator ipa
I’m not positive the place you’re getting your
information, but great topic. I must spend a while studying much more or figuring out more.
Thanks for fantastic info I was looking for this information for
my mission.
Thanks very nice blog!
qui a acheter du cialis sur internet [url=http://www.jcialisf.com/]jcialisf.com[/url] comprar tadalafil no rj.
It’s a shame you don’t have a donate button! I’d without a
doubt donate to this superb blog! I guess for now i’ll settle
for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share
this site with my Facebook group. Chat soon!
buy viagra online mexico viagra pharmacy best buy viagra online
is a relied on QQ Poker Online and also Bandar Ceme Online wagering site that
supplies online card video games such as Online Online Poker, DominoQQ, Capsa Online,
Ceme Online, Ceme99, Online Gaming Online Texas Hold’em Sites.
QQ Poker Ceme, the very best as well as most safe
online casino poker agent site with 24-hour IDN Online Poker service.
For those of you Lovers of the game Online Online as well as who wish to play betting Online Online poker, Online Ceme, Domino QQ, City Ceme, Online Gaming, Bandar Capsa Online in 1
ID
I’ve been exploring for a little bit for any high quality articles or
weblog posts in this sort of area . Exploring in Yahoo I finally
stumbled upon this web site. Reading this info So i’m glad to show that
I’ve a very good uncanny feeling I discovered exactly what I needed.
I so much for sure will make sure to don?t fail to remember this web site and give it a
glance regularly.
Every weekend i used to pay a quick visit this site, for the reason that i
want enjoyment, since this this web page conations in fact nice funny stuff too.
Heya i’m for the first time here. I found this board and I to find It really useful & it helped me out much.
I am hoping to present something back and help others such
as you helped me.
who makes cialis buy cialis online safely http://autotrening.su/gruppy/online-cialis-prescriptions-rprao0xkhh0/
cialis generico cialis cost per pill http://www.sagl.co.za/UserProfile/tabid/42/userId/4313/Default.aspx
cialis website cialis vs levitra https://www.grinebider.eu/grupper/brand-cialis-online-pharmacy-d3eckmj6svd/
viagra cialis levitra cialis price comparison http://www.westcoastgermannews.com/groups/comprare-cialis-online-l1e08xlia7/
when to take cialis for best results cialis 20mg http://www.biblebaptist.church/groups/cialis-for-daily-use-online-o2s9rfhyj0/
cialis side effect cialis pastilla https://beardedbook.com/groups/order-cialis-safely-online-n3xf6s0tej/
cialis generics online cialis http://edual.ir/groups/buy-cialis-online-without-a-prescription-ermon1j2yak/
free cialis coupon cialis over the counter at walmart https://homeschoolsocial.site/groups/buy-cialis-online-without-prescription-u0sujelb9h/
is there a generic for cialis cialis manufacturer coupon 2018 http://audioworkshops.net/gruppen/create/step/group-cover-image/
cialis dosages viagra vs cialis price http://zanriel.com/groups/cialis-online-reddit-tke6nrlx2h/
cialis instructions cialis generic timeline http://clocktowerdentalgroup.com/UserProfile/tabid/57/userId/1508/Default.aspx
cialis precio viagra cialis http://atagunreduktor.com/User-Profile/userId/3411/pageno/3.aspx
how long does it take for cialis to work cialis 40 mg https://www.tefl-friends.com/groups/cheap-cialis-online-canadian-pharmacy-vj1ue1116al/
when will cialis be generic 20mg cialis https://assholeslikeus.org/groups/order-cialis-safely-online-o8f6eilt94/
cialis cheap how long does cialis stay in your system https://prembandhan.info/groups/buy-cialis-for-daily-use-online-drilyur65kk/ ~~““
Hey there! I just want to offer you a huge thumbs up for
your excellent information you’ve got right here on this post.
I’ll be returning to your website for more soon.
online pharmacy cialis tadalafil 20mg cialis online prescription
is a relied on QQ Texas hold’em Online as well as Bandar Ceme Online
gambling site that gives online card games such as Online Casino Poker,
DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gambling Online Texas Hold’em
Sites. QQ Casino Poker Ceme, the most effective as
well as most safe on-line casino poker agent website with 24-hour IDN Online Casino poker service.
For those of you Lovers of the game Online Online and that intend
to play wagering Online Casino poker, Online Ceme, Domino QQ, City Ceme, Online Gambling,
Bandar Capsa Online in 1 ID
Quando é melhor instante para tomar Whey Protein.
buy cialis on line cialis 5mg buy cialis online reviews
It’s genuinely very complicated in this active life to listen news on Television, so I just use internet for that purpose, and get the most recent information.
Hi there! Someone in my Facebook group shared this site with us so
I came to check it out. I’m definitely enjoying the information. I’m book-marking
and will be tweeting this to my followers! Terrific blog and brilliant style and design.
Free V Bucks Generator iphone hack download
buy generic viagra online cheapest brand viagra buying generic viagra online safe
I am actually happy to glance at this blog posts
which carries plenty of useful facts, thanks for providing these data.
We stumbled over here coming from a different web page
and thought I might as well check things out.
I like what I see so i am just following you. Look forward to finding
out about your web page again.
Amazing issues here. I’m very satisfied to see your
article. Thank you so much and I’m looking ahead to touch you.
Will you kindly drop me a e-mail?
Hi there, just became aware of your blog through Google, and
found that it’s really informative. I’m gonna watch out for brussels.
I will appreciate if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
cheap price tadalafil side effects of cialis tadalafil cijena u bosni
It’s an amazing paragraph for all the web viewers; they will get benefit from it I am sure.
http://cashpaydayusloans.com
loans with no credit
fast cash
easy personal loan approval
loans direct
http://cashpaydayusloans.com
payday loan apr
personal loans for bad credit
what do i need for a payday loan
quick cash advance online
http://www.cashpaydayusloans.com
payday loans poor credit
loans direct
ach loans
quick cash advance online
Simply want to say your article is as surprising.
The clarity in your post is just excellent and i can assume you’re an expert on this subject.
Well with your permission let me to grab your feed to keep up to date with forthcoming post.
Thanks a million and please continue the gratifying work.
best online pharmacy
http://canadianonlinepharmacysl.com/
online pharmacies canada
My brother suggested I might like this website. He was entirely
right. This post actually made my day. You cann’t imagine
just how much time I had spent for this info!
Thanks!
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message
home a bit, but other than that, this is magnificent blog.
A great read. I will definitely be back.
Hello! I could have sworn I’ve been to this web site before but after looking
at some of the posts I realized it’s new to me.
Anyways, I’m definitely pleased I found it and I’ll be bookmarking it and checking back regularly!
Hi, this weekend is pleasant designed for me, for the reason that this occasion i am reading this enormous educational article here at my home.
Everyone loves it when people get together and share ideas.
Great site, keep it up!
Having read this I believed it was rather informative. I appreciate you finding the time and energy to
put this informative article together. I once again find myself spending a lot of time both reading and leaving comments.
But so what, it was still worth it!
I love the efforts you have put in this, appreciate it for all the great posts. https://santipuronline.com/user/profile/204041
I love the efrforts you have put in this, appreciate
it ffor all the great posts. https://santipuronline.com/user/profile/204041
Agen togel online indonesia terpercaya http://www.togelplus88.org
New Member dapat 20k…
buruan join terpercaya dan terbayar pastinya
buying cialis online buy cheap cialis cialis online cheap
ZGVlcHNpbmd1bGFyaXR5Lmlv gofuku-a.anchor.com [URL=http://gofuku-u.com/]gofuku-u.anchor.com[/URL] http://gofuku-t.com/ http://gofuku-t.com/ http://gofuku-t.com/ http://gofuku-t.com/ http://gofuku-t.com/ http://gofuku-t.com/ http://gofuku-t.com/ http://gofuku-t.com/ ogeyin
ZGVlcHNpbmd1bGFyaXR5Lmlv uvivoofug-a.anchor.com [URL=http://uvivoofug-u.com/]uvivoofug-u.anchor.com[/URL] http://uvivoofug-t.com/ http://uvivoofug-t.com/ http://uvivoofug-t.com/ http://uvivoofug-t.com/ http://uvivoofug-t.com/ http://uvivoofug-t.com/ http://uvivoofug-t.com/ http://uvivoofug-t.com/ ogovima
Do you have a spam issue on this blog; I also am a blogger, and I was curious about your situation; many of
us have developed some nice methods and we are looking to trade
techniques with other folks, please shoot me an e-mail if
interested.
Hi, I read your blog like every week. Your writing style is witty,
keep it up!
http://www.cialismdmarx.com
allergy to cialis pharmacy
buy generic cialis
buy cialis online in florida
buy cheap cialis online
http://www.viagramrxmed.com
buy viagra cheap
cheap viagra online
who is the woman in the viagra commercial
online viagra
http://www.viagramrxmed.com
viagra before and after video
viagra online
over the counter viagra substitute walmart
generic viagra online
http://cialismdmarx.com
cheap cialis india
buy cialis online
buy cialis online mastercard
cheap cialis online
What’s up, this weekend is pleasant in support of me, since this point in time i am reading
this wonderful educational piece of writing here at my home.
Hello there! I simply want to give you a huge thumbs up
for your great information you’ve got here on this post.
I’ll be returning to your blog for more soon.
Hi there! I know this is kind of off topic but I was wondering if you knew
where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
http://cialismdmarx.com
cialis generic paypal
generic cialis online
generic cialis cialis cialis
cialis online
how long before taking sildenafil viagra 100mg online http://viagrauga.com/ viagrauga.com effect of sildenafil on women
Ӏt’s remarkable in favor οf me to hаve a site, ᴡhich іs goоԀ foг my experience.
tһanks admin
trazodone erection trazodone high stopping trazodone dog trazodone http://trazodoneforsleephcl.com/
lisinopril webmd lisinopril blood pressure medication lisinopril erectile dysfunction lisinopril for kidney protection http://lisinoprilcoughonline.com/
Very good post. I absolutely love this site. Thanks!
Great article.
I used to be able to find good information from your articles.
trazodone sleep trazodone 10mg trazodone rem sleep trazodone shelf life http://trazodonehighbuy.com/
Hey There. I found your blog using msn. This is an extremely well written article.
I’ll make sure to bookmark it and return to read more of your useful info.
Thanks for the post. I will certainly comeback.
Hello there! This post could not be written any better!
Reading through this post reminds me of my old room mate!
He always kept chatting about this. I will forward this article to him.
Pretty sure he will have a good read. Thanks for sharing!
My brother recommended І might like this web site.
He ᥙsed to be totally riցht. Тһis post trᥙly mаde
my daʏ. Ⲩօu cann’t believe just how so mucһ tіme I hаd spent foг tһis info!
Тhanks!
This excellent website truly has all the information and facts I needed about this subject
and didn’t know who to ask.
This website is prohibited for the minors. http://vipescortserviceingurgaon.com/
This website is prohibited for thhe minors. http://vipescortserviceingurgaon.com/
bookmarked!!, I really like your website!
buy real cialis online cialis online cialis pharmacy
Wonderful goods from you, man. I’ve take into accout
your stuff previous to and you are just too fantastic. I really like what you have
obtained here, really like what you’re saying and the way in which
by which you say it. You are making it enjoyable and you continue to
take care of to stay it smart. I can not wait to learn much more from you.
This is actually a tremendous website.
Hello, I enjoy reading through your post. I like to write a little comment to support you.
Hi there just wanted to give you a quick heads up.
The words in your content seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or something
to do with internet browser compatibility but I thought I’d post to let you know.
The design and style look great though! Hope you get the issue fixed soon. Thanks
Admiring the hard work you put into your website and in depth information you offer.
It’s awesome to come across a blog every once in a while that isn’t the same unwanted rehashed material.
Fantastic read! I’ve saved your site and I’m including your
RSS feeds to my Google account.
http://www.amoxilonlinenrx.com
http://amoxilonlinenrx.com
http://amoxilonlinenrx.com
http://www.viagramrxmed.com
viagra pharmacy
cheap viagra online
who sells viagra over the counter
generic viagra online
http://amoxilonlinenrx.com
http://amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
comprare cialis online tadalafil dosage cheap cialis generic online
http://www.viagramrxmed.com
viagra pricing
cheap viagra online
viagra 8
cheap viagra
Международная кастинговая организация объявляет набор.
Нужны Парни и девушки для позирования.
Если вы проходите кастинг мы предоставим вам все необходимое для трудоустройства в зарубежных компаниях
Подробную информацию узнать можно на сайте
https://is.gd/G9daJT
I love what you guys are usually up too.
This type of clever work and reporting! Keep up the great works guys I’ve included you guys to our blogroll.
trazodone suicide does trazodone cause night sweats trazodone hallucinations trazodone for anxiety during the day http://trazodone50mg100mg.com/
Saved as a favorite, I like your site!
I’ve read several just right stuff here. Certainly worth bookmarking for revisiting.
I surprise how so much attempt you set to create any such great informative web site.
brand cialis online tadalafil generic buy real cialis online
http://amoxilonlinenrx.com
http://amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
viagra online without a prescription
http://www.viagramrxmed.com
viagra 50mg
generic viagra online
viagra tablet
buy generic viagra
lisinopril side effects long term lisinopril manufacturer lisinopril use how does lisinopril protect kidneys http://lisinopril20mg5mg40mg.com/
Agen togel online indonesia terpercaya http://www.togelplus88.org
New Member dapat 20k…
buruan join terpercaya dan terbayar pastinya
magnificent submit, very informative. I’m wondering why the other specialists of this
sector do not notice this. You must continue your writing. I
am sure, you have a great readers’ base already!
It’s perfect time to make some plans for
the future and it is time to be happy. I’ve read this post and if I could
I desire to suggest you some interesting things or tips.
Perhaps you could write next articles referring to this article.
I wish to read more things about it!
hersteller von tadalafil http://cialissom.com/ http://cialissom.com/
These are in fact wonderful ideas in regarding blogging.
You have touched some good factors here. Any way keep up wrinting.
lirepourcomprendre.org fungusumungus.com collegiatepins.com studentsaward.com http://www.comfortcafe.com http://www.perfectbathroom.com compassclub.net boardgamgeek.com mytechalbum.com http://www.24livenewspaper.com escpeurope.easternhorizon.com localflavors.com oceanhousespa.com
hydrochlorothiazide lisinopril lisinopril for high blood pressure lisinopril hydrochlorothiazide when is the best time to take lisinopril http://lisinoprilhctzbuy.com/
Thanks for a marvelous posting! I actually enjoyed reawding it, youu could be a great
author. I will make sure to bookmark your blog and definitely will come back in the foreseeable future.
I wsnt to encourag you tto continue your great job, hafe a nice day!
What’s up, I want to subscribe for this web site to get newest updates, thus where can i do
it please help out.
I’m really enjoying the theme/design of your web site.
Do you ever run into any internet browser compatibility problems?
A small number of my blog audience have complained about my site not working correctly in Explorer but looks great in Firefox.
Do you have any tips to help fix this issue?
Hello to every one, for the reason that I am genuinely
eager of reading this web site’s post to be updated on a
regular basis. It carries pleasant information.
Hey! This is my first comment here so I just wanted to give a quick shout out and
tell you I genuinely enjoy reading through your articles.
Can you suggest any other blogs/websites/forums that deal with the same subjects?
Thanks a lot!
amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
ZGVlcHNpbmd1bGFyaXR5Lmlv elheje-a.anchor.com [URL=http://elheje-u.com/]elheje-u.anchor.com[/URL] http://elheje-t.com/ http://elheje-t.com/ http://elheje-t.com/ http://elheje-t.com/ http://elheje-t.com/ http://elheje-t.com/ http://elheje-t.com/ http://elheje-t.com/ ukitwe
ZGVlcHNpbmd1bGFyaXR5Lmlv qiruloy-a.anchor.com [URL=http://qiruloy-u.com/]qiruloy-u.anchor.com[/URL] http://qiruloy-t.com/ http://qiruloy-t.com/ http://qiruloy-t.com/ http://qiruloy-t.com/ http://qiruloy-t.com/ http://qiruloy-t.com/ http://qiruloy-t.com/ http://qiruloy-t.com/ unudaw
ZGVlcHNpbmd1bGFyaXR5Lmlv izuxwid-a.anchor.com [URL=http://izuxwid-u.com/]izuxwid-u.anchor.com[/URL] http://izuxwid-t.com/ http://izuxwid-t.com/ http://izuxwid-t.com/ http://izuxwid-t.com/ http://izuxwid-t.com/ http://izuxwid-t.com/ http://izuxwid-t.com/ http://izuxwid-t.com/ ayiyoveg
It is not my first time to visit this web page, i am visiting this site dailly and take pleasant data from here all the time.
http://cialisknfrx.com
is viagra otc
http://cialisknfrx.com
how long before sex do you take viagra
http://www.cialisknfrx.com
http://www.viagramrxgeneric.com
viagra user reviews
http://www.viagramrxgeneric.com
viagra upset stomach
http://www.viagramrxgeneric.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
Thanks very nice blog!
http://www.cialisknfrx.com
viagra u apotekama
http://cialisknfrx.com
l citrulline and viagra together
http://www.cialisknfrx.com
http://viagramrxgeneric.com
viagra advertisement
viagramrxgeneric.com
viagra quebec
http://www.viagramrxgeneric.com
Great work! That is the kind of info that are meant to be shared
across the internet. Shame on Google for now not positioning this put up upper!
Come on over and seek advice from my website . Thank you =)
Appreciate the recommendation. Will try it
out.
When I originally commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get four e-mails with the same comment.
Is there any way you can remove people from that service?
Thanks!
Hey very cool website!! Man .. Beautiful .. Amaxing .. I’ll bookmark youhr website andd taje
the feeds additionally? I’m satisfied tto seek out a lott of helpful info here
withion the publish, we’d like work out extta techniques on this regard, thank you
for sharing. . . . . .
http://amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
http://www.amoxilonlinenrx.com
Great post. I used to be checking constantly this weblog
and I am inspired! Extremely helpful info particularly the
final phase 🙂 I take care of such information a lot.
I was seeking this certain information for a very lengthy time.
Thank you and good luck.
cialisknfrx.com
how long does viagra work
cialisknfrx.com
viagra x donne
http://www.cialisknfrx.com
http://viagramrxgeneric.com
viagra generic
http://www.viagramrxgeneric.com
cialis vs viagra
http://www.viagramrxgeneric.com
Have you ever considered about including a little bit more than just your
articles? I mean, what you say is important and everything.
However imagine if you added some great graphics or video clips to give your posts more, “pop”!
Your content is excellent but with pics and
video clips, this blog could undeniably be one
of the greatest in its niche. Awesome blog!
Hi, of course this post is truly nice and I have learned lot of things
from it regarding blogging. thanks.
I have been browsing on-line greater than 3 hours as of late, yet I bby no means found any fascinating
article like yours. It is lovely valie sufficient foor me.
In my opinion, if all website owners and bloggers made excellent content material as you probably did,
the wweb shall bbe a lot more helpful thnan ever before.
Everything is very open with a clear explanation of the issues.
It was truly informative. Your site is extremely helpful.
Thank you for sharing!
Attractive component of content. I simply stumbled upon your website and in accession capital to assert
that I acquire actually enjoyed account your blog
posts. Any way I will be subscribing to your feeds and even I fulfillment you
get admission to persistently fast.
I am really impressed witһ your writing skills
аnd alsao wіth thee layout ᧐n your blog. Is this a paid theme or
dіd yoᥙ modify it ʏourself? Eіther way кeep up tһe excellent quality writing, іt’s rare too ѕee a greatt blog like thіs one toԀay.
Quality articles or reviews is the crucial to be a focus for the people to pay a
visit the site, that’s what this website is providing.
cymbalta alternatives cymbalta reddit what does cymbalta treat cymbalta and fibromyalgia http://cymbalta3060mg.com/
What a information of un-ambiguity and preserveness of valuable know-how on the topic of unexpected feelings.
http://cialisknfrx.com
viagra 100
http://www.cialisknfrx.com
viagra japan
http://www.cialisknfrx.com
http://www.viagramrxgeneric.com
viagra instructions
viagramrxgeneric.com
viagra where can i buy it
http://www.viagramrxgeneric.com
http://www.cialisherrx.com
all natural viagra
http://www.cialisherrx.com
viagra and blood pressure
http://www.cialisherrx.com
cialismnrx.com
cheap cialis brand name
cheap cialis online
imodium alternative cialis 20mg
buy cheap cialis online
http://www.cialisknfrx.com
melanoma and viagra
cialisknfrx.com
viagra kaufen
http://www.cialisknfrx.com
http://www.viagramrxgeneric.com
viagra y eyaculacion precoz
http://www.viagramrxgeneric.com
herbal substitute for viagra
http://www.viagramrxgeneric.com
http://cialisherrx.com
viagra high blood pressure
http://www.cialisherrx.com
buy viagra cheaper
http://www.cialisherrx.com
Pretty! This was an incredibly wonderful post.
Thank you for supplying these details.
http://www.cialismnrx.com
cialis pills over the counter
cheap generic cialis
cialis 40 mg tablets
buy cialis online
It’s really very complicated in this active life to listen news on Television, so I only use the web for that purpose, and take the most recent information.
maximum dose of cymbalta how to ease cymbalta withdrawal symptoms what are the benefits of taking cymbalta? is cymbalta a narcotic http://cymbaltaweightloss30mg.com/
Wonderful post however I was wanting to know if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit further.
Kudos!
Excellent, what a web site it is! This weblog gives helpful data to us,
keep it up.
I’ve read a few jjust right stuff here. Certainly price bookmarking for revisiting.
I wonder how a lot effort you place to create this
sort of excellent informative web site.
Agen togel online indonesia terpercaya http://www.togelplus88.org
New Member dapat 20k…
buruan join terpercaya dan terbayar pastinya
http://www.cialisknfrx.com
viagra boner
http://cialisknfrx.com
viagra 100
cialisknfrx.com
http://www.viagramrxgeneric.com
deadpool viagra commercial
http://www.viagramrxgeneric.com
viagra vs sildenafil
http://www.viagramrxgeneric.com
http://www.cialisherrx.com
viagra pill price
http://www.cialisherrx.com
little pink pill viagra
http://cialisherrx.com
how to make powerful sildenafil at home with fruits doctor7online.com sildenafil
health express
At all personal send today?
kamagra 100
You have made some really good points there. I looked on the internet for
more info about the issue and found most individuals
will go along with your views on this web site.
Hi there, I wish for to subscribe for this webpage to take newest
updates, so where can i do it please help.
I am not sure where you are getting your information, but good
topic. I needs to spend some time learning more or understanding more.
Thanks for great info I was looking for this information for my mission.
Hi there friends, its fantastic piece of writing regarding cultureand
fully explained, keep it up all the time.
Excuse, that I can not participate now in discussion – it is very occupied. But I will be released – I will necessarily write that I think on this question.
http://kamagra-oral-jellies.com/#kamagrainusa
http://kamagra-oral-jellies.com/#kamagrabinnen24uurgeleverd
http://kamagra-oral-jellies.com/#kamagraoral
http://kamagra-oral-jellies.com/#kamagrakaufen
http://kamagra-oral-jellies.com/#kamagra100
http://bit.ly/2UfWYZ1
http://bit.ly/2RRZ5pe
gumtrr.com neanderthals.info roc13.tw-roc.org xx-videos.com http://www.24livenewspaper.com geesepolice.net http://www.fpartners.info castlehydehotel.com djpicshd.com stablz.com http://www.guamrentcar.com http://www.pitindustries.net http://www.brandcenterrc.com dolphinkeycondos.com http://www.vitalephoto.com hospital-pharmacy.com http://www.copper-scroll.com http://www.skyartsguitarstar.tv http://www.banjomovies.com cindychan.com
Great weblog here! Additionally your site loads
up very fast! What web host are you the usage of? Can I get your affiliate hyperlink in your host?
I desire my website loaded up as quickly as yours lol
Everything iis very open with a clear clarification of the
challenges. It was really informative. Your site is extremely helpful.
Thanks for sharing!
It’s genuinely very complex in this full of activity life to listen news on Television, therefore I
just use the web for that purpose, and get the most recent information.
excellent submit, very informative. I’m wondering why the other specialists of this sector do
not notice this. You must proceed your writing.
I am confident, you’ve a great readers’ base already!
For hottest information you have to pay a visit
world-wide-web and on world-wide-web I found this site as a best website for newest updates.
Hello there! This article could not be written any better!
Reading through this article reminds me of my previous roommate!
He constantly kept preaching about this. I’ll forward this post to him.
Pretty sure he’ll have a great read. Thanks for sharing!
Hi there friends, how is the whole thing, and what you wish for
to say on the topic of this article, in my view its actually
amazing designed for me.
I’m not sure why but this website is loading incredibly slow for me.
Is anyone else having this issue or is it a issue on my
end? I’ll check back later and see if the problem still exists.
I absolutely love your blog and find a lot of your post’s to be
exactly I’m looking for. can you offer guest writers to write content available for you?
I wouldn’t mind creating a post or elaborating on some
of the subjects you write related to here.
Again, awesome blog!
I’m impressed, I have to admit. Rarely do I come across a
blog that’s equally educative and entertaining, and let me tell you, you’ve hit
the nail on the head. The issue is an issue that too few people are speaking intelligently about.
Now i’m very happy I stumbled across this during my search for
something relating to this.
I’m gone to convey my little brother, that he should also pay a visit this website
on regular basis to get updated from most up-to-date information.
online casino bonus
free 777 slots no download
hollywood casino free online games
foxwoods resort casino
las vegas free penny slots
Hey There. I found your blog using msn. This is a very
well written article. I’ll be sure to bookmark it and return to read more of
your useful info. Thanks for the post. I’ll certainly return.
tadalafil sildenafil together viagra 100mg http://www.viagrauga.com/ sildenafil generic viagra getting sildenafil to work
MarioQQ is a site of real loan to play casino poker online with the very best top quality web servers
in addition to the latest appearance.Only in MarioQQ online poker agency that provides assurances of security in online play
casino poker without the admin crawler, and we
always offer the most effective service 24-hour a day, currently all participants can play texas hold’em
anytime and also anywhere since we Android as well as Apple iphone application offering so you can play MarioQQ
on your smartphone.
Superb blog you have here but I was curious if you knew of any community forums that cover the
same topics discussed here? I’d really like to be a
part of group where I can get suggestions from other experienced individuals that share the same interest.
If you have any suggestions, please let me know. Kudos!
Amazing blog! Do you have any hints for aspiring writers?
I’m planning to start my own website soon but I’m
a little lost on everything. Would you propose starting with a free
platform like WordPress or go for a paid option? There are so many options out there that I’m completely overwhelmed ..
Any tips? Kudos!
Hello! This is kind of off topic but I need some advice from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I can figure
things out pretty fast. I’m thinking about creating my own but I’m not
sure where to start. Do you have any points or suggestions?
Thank you
Do you desire to owwn that a lot of coveted bracelet given like
a prize in the World Series of Poker annual tournaments.
It iis a version from the Chinese Pai Gow domino game,used
cards bearing poker hand values. In fact, we’ll ttackle the situation ogether in this article, and with
these details wee are able to wirk miracles.
Thanks for sharing your thoughts. I really appreciate your efforts and I will
be waiting for your further post thanks once again.
Contact Yahoo
Hello are ᥙsing WordPress fⲟr ʏour blog platform? Ӏ’m
new to the blog ѡorld but I’m trying to
get started and ѕet up my own. Do you need any coding knowledge to
maake yоur own blog? Any helpp woulod be ցreatly appreciated!
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your weblog?
My blog site is in the exact same area of interest as yours and my
visitors would genuinely benefit from some of the information you present here.
Please let me know if this okay with you. Thanks!
I’m really enjoying the theme/design of your weblog. Do you ever run into any browser compatibility
problems? A number of my blog readers have complained about my website not working correctly in Explorer but
looks great in Firefox. Do you have any solutions to help fix this issue?
lexapro diarrhea lexapro for depression side effects of lexapro 10mg lexapro cost walmart http://lexapro1020mg.com/
The 24 year old Lady Gaga has sought medical advice on more than one
occasion in the past year when she had suffered from a string of health problems which
included difficulty in breathing, having a blurred vision and constant headaches, hence the
tests for the disease “lupus”. When he says “Take one more step and I’m gonna shoot you”
he means it. Bureau Uniform–Complete Red Dead Redemption costumes List.
http://www.cialisknfrx.com
can i buy viagra online
http://cialisknfrx.com
generic viagra cost
cialisknfrx.com
http://www.viagramrxgeneric.com
viagra 100mg generic
http://www.viagramrxgeneric.com
how much viagra is too much
http://www.viagramrxgeneric.com
cialisherrx.com
top 5 viagra
http://www.cialisherrx.com
viagra jet
http://www.cialisherrx.com
http://cialismnrx.com
suprax 100 mg cialis pills cialis
buy generic cialis
soft cialis pharmacy
buy generic cialis
I do agree with all the ideas you’ve offered to your post.
They are really convincing and can certainly work. Nonetheless,
the posts are too short for newbies. Could you please prolong them a bit from next time?
Thank you for the post.
ananas e sildenafil cheap generic viagra 100mg side effects of viagra
if you don’t need it.
As the admin of this web site is working, no hesitation very soon it will be renowned, due to its quality contents.
Its such as you read my thoughts! You seem to grasp a lot about this,
like you wrote the e book in it or something. I think that you just could do with some percent
to power the message home a little bit, however instead of that, this is
magnificent blog. A fantastic read. I will certainly
be back.
http://cialisknfrx.com
when should you take viagra
http://www.cialisknfrx.com
viagra experiences first time
http://www.cialisknfrx.com
http://www.viagramrxgeneric.com
how to get viagra prescription
http://www.viagramrxgeneric.com
1 viagra pill
http://www.viagramrxgeneric.com
http://www.cialisherrx.com
viagra model
http://cialisherrx.com
natural alternative to viagra
http://cialisherrx.com
Upload a 30-second video to You – Tube to tell us what Rune – Scape means to you, and you could win entry to the premiere of the documentary.
If you are the type of person who likes the feel of using
military like guns and reenacting some your favorite call of duty map,
woodsball is a great and incredibly fun sport to play with a group of friends.
Bureau Uniform–Complete Red Dead Redemption costumes List.
http://www.cialismnrx.com
cialis generic discount
buy cialis generic
buy brand cialis
buy cialis online
Wow! I do not think so. And never just nice submit”.
When at the table, you should be focused on poker and poker only;
I don. If you are the type of person who likes the feel of using military like
guns and reenacting some your favorite call
of duty map, woodsball is a great and incredibly fun sport to play with a group of friends.
Gambling can be a very intimidating experience to a new
gambler especially if the new gambler is not familiar with gambling lingo.
Wow, this piece of writing is good, my sister is analyzing
such things, thus I am going to let know her.
lexapro and klonopin trazodone and lexapro lexapro and klonopin lexapro side effects weight gain http://lexaprogeneric2010mg.com/
s where support and training really comes in handy.
Working out request within the judi online poker College Online is free of price for everybody’s usage and possesses numerous- free-roll and table games.
The popular US musical TV show titled “Glee” has recently made an episode that is a tribute to
Lady Gag and her songs.
This about how to hack PUBG mobile android.
Thanks for every other informative site. Where else could I get that
kond of information written in such a perfect method?
I’ve a venture that I am simply now operating on, and I’ve been at the look out for such info.
This way you’ll allow them enjoy playing with all the castle possibly at the same
time frame it won. “Going for the arena might be fairly just like planning to church: it’s like going for the soccer temple, the sport is similar to a type of liturgy as well as sings lover songs like” You Never Walk On your own ‘.
It isn’t well worth the aggravation in looking to collect if she
does not pay willingly.
Hi there! Someone in my Myspace group shared this website with us so I
came to give it a look. I’m definitely enjoying the information. I’m bookmarking and
will be tweeting this to my followers! Fantastic blog and terrific style and design.
I don’t even understand how I finished up right here, however I thought this post used to be good.
I don’t recognize who you might be however definitely you’re going to a
well-known blogger for those who are not already.
Cheers!
My family members all the time say that I am wasting my time here at web,
except I know I am getting familiarity every day by reading such good posts.
This post is worth everyone’s attention. Where can I find out more?
Congratulations you Letting a cell game.
Excellent Site, Stick to the useful work. Thanks. http://dietmoithongtin.net/1a39c
You should be a part of a contest for one of the best websites on the web.
I most certainly will highly recommend this site!
خدمات سامسونج نعتبر خبرة فى سامسونج الاوائل فى
مصر و اكبر مراكز تبحث عنها عندما يواجهك مشكلة فى
ثلاجات سامسونج .حيث اننا نوفرالاصلاحبالكامل فى منزلك ولا يتم
سحب الميكروويف نهائيا من مكانه هذا بجانباننالدينا طاقم عمل من مهندسينمدربين على الصيانةالفورى لجميع مشاكل اجهزة سامسونج الغسالات
و استبدال جميع قطع الغيار العاطلةبأخرى جيدةهذا بجانب تميزهم بالكفاءةالعالية
و التى تمكنهم الصيانةفورا منزل العميل
و الخبرة التى تمتد الى سنواتطويلة لا تقل عن
21 عاممتواصلة فى صيانة ميكروويف سامسونج
اذا كنت فى احتياج لعمل صيانة ثلاجات سامسونج فى المنزل و كل ما عليك هو
الاتصال بنا على مراكز صيانة ميكروويف سامسونج
فى مصر نحن فى خدمتك اينما كنت نحن
نخدم جميع المحافظات لنسعى أن
نكون الاول فى مجال عملنا و الاسرع فى التعامل معك و
نوفر لك الصيانة فى مختلف موديلات مكانس
سامسونج
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I’m quite certain I will learn a lot of new stuff right here!
Best of luck for the next!
I spoke on the mic to others.
Do you wish to own tat a majority of coveted
bracelet given being a prize in the World Series of Poker annual tournaments.
Today we have far morde multitabvling tools and bette
poker softwaqre than we did a little while a go.
With this article we’ll attempt to put some light around the fun point
about this highly iintense game.
Thank you for sharing your info. I really appreciate your efforts and I am
waiting for your further write ups thanks once again.
lexapro vs paxil lexapro tinnitus lexapro vs paxil half life lexapro http://lexaprohighgeneric.com/
cymbalta vs.lexapro cymbalta withdrawal syndrome cymbalta and alcohol cymbalta lawsuit settlement amounts http://cymbaltageneric30.com/
cialisknfrx.com
viagra alcohol
cialisknfrx.com
viagra generic online
http://www.cialisknfrx.com
http://viagramrxgeneric.com
viagra hypertension
viagramrxgeneric.com
how viagra was discovered
http://www.viagramrxgeneric.com
cialisherrx.com
herb viagra green box reviews
http://www.cialisherrx.com
viagra 3 day free trial
cialisherrx.com
You really make it seem really easy together with your presentation but I find this topic to be really something which I feel
I’d by no means understand. It kind of feels too complicated and extremely wide for me.
I am having a look forward for your subsequent post, I
will try to get the cling of it!
http://cialismnrx.com
comprare price cialis generic
generic cialis online
cialis ordering
buy cheap cialis coupon
Howdy very cool site!! Guy .. Beautiful .. Superb .. I will bookmark
your blog and take the feeds additionally? I’m glad to search
out so many useful info right here in the put up,
we want work out more strategies on this regard, thanks for sharing.
. . . . .
Normally I do not learn article on blogs, however I wish to say that
this write-up very pressured me to take a look at and do it!
Your writing style has been surprised me. Thanks, quite nice post.
I have been browsing on-line greater than 3
hours lately, yet I never discovered any fascinating article like yours.
It is lovely worth sufficient for me. Personally, if all website owners and bloggers made just right content material as you did, the web will be a lot more useful
than ever before.
It’s the best time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I wish to suggest you
some interesting things or advice. Maybe you could write next articles
referring to this article. I desire to read more things about it!
Every weekend i used to visit this website, for the reason that i
want enjoyment, since this this web site conations really nice funny data too.
Ahaa, its pleasant dialogue on the topic of this piece of writing at this place at this web site,
I have read all that, so at this time me also commenting here.
of course like your web-site however you need to
test the spelling on several of your posts.
A number of them are rife with spelling issues and I find it very bothersome to tell the truth however I will surely
come again again.
I’ve been browsing online more than three hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all site owners
and bloggers made good content as you did, the net will be much more useful than ever before.
If some one wishes expert view regarding running a blog after
that i suggest him/her to visit this web site, Keep up the good
job.
Hello Dear, are you in fact visiting this site
on a regular basis, if so then you will definitely take good knowledge.
I like the valuable info you provide in your articles.
I’ll bookmark your weblog and take a look
at again right here frequently. I’m quite certain I’ll be told plenty of new stuff proper
here! Good luck for the next!
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything
I’ve worked hard on. Any tips?
Can I simply just say what a relief to find an individual who genuinely understands what they’re
talking about online. You certainly know how to bring a problem to
light and make it important. More and more people should
read this and understand this side of your story.
I can’t believe you aren’t more popular since you surely have the gift.
Contact Yahoo
Everyone loves what you guys are usually up too.
This kind of clever work and reporting! Keep up the excellent works guys I’ve added you
guys to our blogroll.
Great looking website. Think you did a great
deal of your very own html coding. http://macliveexpo.co.uk/54dl4
Great looking website. Think you did a great deal of your very own html coding. http://macliveexpo.co.uk/54dl4
Magnificent beat ! I would like to apprentice whilst you amend your website, how could i subscribe for
a weblog website? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered
shiny transparent concept
It’s actually a great and helpful piece of information. I’m happy that you
shared this useful information with us. Please stay us informed like this.
Thanks for sharing.
is a trusted QQ Online poker Online and Bandar Ceme Online betting site that offers on-line card games such as Online Poker, DominoQQ, Capsa Online, Ceme
Online, Ceme99, Online Betting Online Texas Hold’em Sites.
QQ Online Poker Ceme, the most effective as well as most safe
on-line casino poker representative website with 24-hour IDN Online Poker solution. For those of you Lovers
of the game Online Online as well as who want to play gambling Online Poker, Online Ceme,
Domino QQ, City Ceme, Online Gaming, Bandar Capsa Online in 1 ID
It’s actually a cool and useful piece of information. I’m satisfied that
you shared this helpful information with us. Please keep us up to date
like this. Thanks for sharing.
Nba 2k19 Locker Codes hack 2019
My brother suggested I would possibly like this web site.
He was once entirely right. This post actually made my day.
You can not imagine just how much time I had spent for this info!
Thank you!
Hack PUBG mobile Android is not so easy.
Good day! I know this is somewhat off topic but I was wondering if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Everything is very open with a precise clarification of the challenges.
It was definitely informative. Your site
is very useful. Thanks for sharing!
Fantastic website you have here but I was curious if you knew of any
discussion boards that cover the same topics
talked about in this article? I’d really love to be a part of online
community where I can get opinions from other knowledgeable individuals that
share the same interest. If you have any recommendations,
please let me know. Cheers!
Good web site you have here.. It?s difficult to find good quality writing like yours nowadays.
I really appreciate people like you! Take care!!
That is a really good tip particularly to those new
to the blogosphere. Short but very precise info? Appreciate your sharing this one.
A must read post!
Usually I don’t learn post on blogs, however I wish to
say that this write-up very pressured me to check out and do it!
Your writing style has bee amazed me. Thanks, very great post.
Greetings! Very helpful advice within this article! It’s the little changes that will make the most
significant changes. Thanbks for sharing!
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed thee shell to her ear
annd screamed. There wwas a hermit crab iinside and it pinched her ear.
She never wants to go back! LoL I know his iis totally off topic
butt I had to tell someone!
I’m not sure where you’re getting your information, but great topic.
I needs to spend some time learning more or understanding
more. Thanks for wonderful information I was looking for this information for my
mission.
I love reading a post that can make people think. Also, thank you for permitting me to comment!
I’ve been exploring for a little bit for any high quality articles or weblog
posts in this sort of area . Exploring in Yahoo I eventually stumbled upon this website.
Studying this information So i’m glad to convey that I’ve an incredibly
good uncanny feeling I came upon just what I needed. I so much undoubtedly will make certain to do not omit this web site
and give it a glance regularly.
Excellent post. I was checking constantly this blog and I’m impressed!
Very useful info particularly the last part 🙂 I care for such information a lot.
I was seeking this particular information for a long time.
Thank you and best of luck.
winstar world casino
best casino slots online
online casino sites
casino blackjack
gsn casino on facebook
These are really fantastic ideas in on the topic of blogging.
You have touched some fastidious points here.
Any way keep up wrinting.
I do not even know how I ended up here, but I thought this post was great.
I do not know who you are but certainly you are going to a famous blogger if you aren’t already 😉 Cheers!
All just isn’t lost, as RSI’s might be prevented if you take
protective measures and redesigning your home computer layout to cut back the stresses in your
joints during game play. Its m0 modification emerged for free while probably the most
advanced m3 modification costs only 300 crystals. Those same gloves
will even protect from a hot barrel in case you
are inside hot seat, shoot wise.
This is a great tip especially to those fresh to the blogosphere.
Short but very accurate info… Appreciate
your sharing this one. A must read post!
Very quickly this web page will be famous amid all blogging and site-building users, due to it’s good posts
Hello to every body, it’s my first go to see of this weblog; this website includes amazing and
genuinely fine data designed for readers.
Students skip count ƅy 5 to 100 tօ complete
the maze.
Can I simply say what a comfort to discover a person that truly knows what they are discussing on the web.
You definitely understand how to bring a problem to
light and make it important. A lot more people really need to read this
and understand this side of the story. It’s
surprising you are not more popular because you most certainly possess the gift.
You can definitely see your skills within the work you write.
The sector hopes for more passionate writers such as
you who aren’t afraid to mention how they believe. At all times go after your heart.
Wow that was unusual. I just wrote an incredibly long comment but after I clicked
submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say superb blog!
One could even go so far as praoclaiming that most of the services
that people were used to, have taken on a fresh form, otherwise in actual appearance, but in how they are delivered.
A novice gambler or perhaps the occasional roulette player makes the cardinal mistake of assuming a loss.
It is getting more popularity at global perspective and honorably appreciated through the global players.
I really love your site.. Very nice colors & theme.
Did you build this website yourself? Please reply back as I’m planning
to create my own website and would like to find out where you got this from or
just what the theme is named. Cheers!
Thanks for the auspicious writeup. It in truth was a entertainment account it.
Glance advanced to more added agreeable from you!
By the way, how can we keep up a correspondence?
Why users stiⅼl make use off to read news papers when iіn his
technoloɡical world all iѕ available onn net?
Hi, just wanted to say, I enjoyed this article. It was helpful.
Keep on posting!
I do not know whether it’s just me or if everyone
else experiencing issues with your blog. It looks like some
of the written text on your content are running off the screen. Can somebody else please comment and let me know
if this is happening to them too? This might be a problem with my browser because I’ve had this happen previously.
Cheers
I always emailed this webpage post page to all my associates,
because if like to read it then my links
will too.
Great article, exactly what I needed.
Hi friends, how is everything, and what you wish for to say regarding this paragraph, in my
view its truly awesome designed for me.
Hi there! I simply wish to offer you a big thumbs up for the excellent info you have right here on this
post. I’ll be returning to your blog for more soon.
I blog frequently and I really appreciate your information.
This great article has truly peaked my interest. I will bookmark your
blog and keep checking for new information about once
per week. I opted in for your Feed too.
Pretty nice post. I just stumbled upon your weblog and wanted to say that I’ve
truly enjoyed surfing around your blog posts. After all I’ll be subscribing to your feed
and I hope you write again very soon!
Hey There. I found your blog using msn. This is a really well written article.
I’ll be sure to bookmark it and return to read more of
your useful info. Thanks for the post. I will certainly comeback.
This text is priceless. Where can I find out more?
Both matches are $4.99 without a in-app purchases.
Good day! This post could not be written any better! Reading through
this post reminds me of my old room mate! He always kept chatting about this.
I will forward this article to him. Fairly certain he will
have a good read. Many thanks for sharing!
The app can not put devices straight back again to sleep.
I relish, lead to I found exactly what I used
to be having a look for. You have ended my four day long hunt!
God Bless you man. Have a nice day. Bye
I like the helpful information you provide in your articles.
I will bookmark your blog and check again here frequently.
I am quite sure I will learn plenty of new stuff right here!
Good luck for the next!
natural viagra online viagra buy viagra online
is a relied on QQ Casino poker Online and also Bandar Ceme Online wagering website that gives
online card games such as Online Casino Poker, DominoQQ,
Capsa Online, Ceme Online, Ceme99, Online Gaming Online Poker Sites.
QQ Poker Ceme, the best and also best on the internet texas hold’em agent site with 24-hour IDN Online Online poker service.
For those of you Lovers of the game Online Online and who
intend to play gambling Online Online poker, Online Ceme,
Domino QQ, City Ceme, Online Gaming, Bandar Capsa Online
in 1 ID
Appreciating the dedication you put into your site and detailed information you provide.
It’s awesome to come across a blog every once in a while
that isn’t the same out of date rehashed information.
Wonderful read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
Way cool! Some very valid points! I appreciate you writing this post plus the rest of the site is very good.
http://www.cashpaydayusloans.com
american payday loans
fast cash
loans for students
quick cash
http://www.pay2daymyloans.com
online short term loans
cash advance
express cash advance
loans for bad credit
http://www.paydayloanscashdv.com
loan bad credit
payday express
online bank
payday loans online
fantastic submit, very informative. I wonder why the opposite specialists of this
sector do not notice this. You must proceed your writing.
I’m sure, you have a huge readers’ base already!
http://www.cialismnrx.com
cialis 20mg
cialis online
buy soft cialis cialis
cheap cialis
Thanks for one’s marvelous posting! I really enjoyed reading it,
you may be a great author. I will ensure that I bookmark your
blog and will often come back in the future. I want to encourage
one to continue your great writing, have a nice weekend!
viagra side effects buy viagra uk viagra side effects
http://www.cashpaydayusloans.com
social loan
loans bad credit
ez cash
quick cash advance online
http://www.pay2daymyloans.com
payday loans in md
payday loans
fast personal loans
payday express
http://www.paydayloanscashdv.com
payday loans las vegas
personal loans
social loan
cash advance
http://www.cialismnrx.com
buy cialis online india
generic cialis
purchase cheap cialis soft tabs
buy cialis generic
Just desire to say your article is as surprising. The clarity for your
submit is simply cool and i can suppose you are an expert in this subject.
Fine with your permission let me to take hold of your RSS feed to keep updated with
forthcoming post. Thank you 1,000,000 and please keep up the gratifying work.
It’s amazing for me to have a site, which is valuable in support of my experience.
thanks admin
You could definitely see your skills within the article you write.
The arena hopes for more passionate writers such as you who aren’t afraid
to say how they believe. Always follow your heart.
I consstantly spent my hwlf ann hiur to read
thiѕ webpage’s contwnt eѵery dayy aⅼong ᴡith a cup of coffee.
Hmm it looks like your site ate my first comment (it was super long) so I guess I’ll
just sum it up what I had written and say, I’m thoroughly
enjoying your blog. I too am an aspiring blog
writer but I’m still new to the whole thing. Do you have any tips for first-time
blog writers? I’d certainly appreciate it.
Thankfulness to my father who shared with me regarding this webpage, this blog is actually awesome.
Heya i’m for the first time here. I came across this board
and I find It really useful & it helped me out much. I hope to give something back and help others like you aided me.
It is in reality a nice and useful piece of info. I am satisfied that you just shared this useful info with us.
Please keep us informed like this. Thanks for sharing.
ここが私のサイトです。来てください
Hey very nice blog!
I am truly grateful to the holder of this
web site who has shared this impressive article at at
this time.
Thanks! Great article and I learned a lot. Do you have any
other free access excel sheets with equations for public use?
I’m really impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself?
Either way keep up the nice quality writing, it’s rare
to see a great blog like this one today.
Truly, there is a lot of money to be created from programs.
you are truly a good webmaster. The website loading speed is amazing.
It seems that you are doing any distinctive trick.
Also, The contents are masterpiece. you’ve done
a magnificent task on this matter!
Hack Mobile Legends
Wow, wonderful weblog layout! How long have you ever been running a blog for?
you make blogging glance easy. The whole look of your web
site is excellent, as smartly as the content material![X-N-E-W-L-I-N-S-P-I-N-X]I just could not depart
your site prior to suggesting that I really loved the usual information an individual
supply for your guests? Is gonna be back regularly to check
up on new posts.
Hey there! Do you know if they make any plugins to
safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Excellent article. Keep posting such kind of information on your page.
Im really impressed by your site.
Hello there, You have performed an excellent job.
I will definitely digg it and for my part suggest to my friends.
I’m sure they will be benefited from this website.
I think the admin of this web page is genuinely working hard in favor of his web site, as here
every material is quality based information.
Can I simply just say what a relief to uncover somebody that really understands what they are talking about on the internet.
You certainly understand how to bring a problem to light
and make it important. A lot more people really need to read this
and understand this side of your story. I can’t believe you aren’t more popular since you surely possess the
gift.
Hey there just wanted to give you a quick heads
up. The words in your content seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or something to do with browser compatibility but
I thought I’d post to let you know. The layout look great though!
Hope you get the issue solved soon. Cheers
I wass speculating ᴡhether anyone has reaԁ aboսt the Peadhes andd
Screams giveaway ? Ι just got Just Peachy Satin and Lace Babydoll Ѕet merelyy bby liking tһeir
Facebook paɡе and ssharing јust οne оf their posts.
Surprisingly, theʏ arе һaving an endless giveaway tһis entire week.
I thoᥙght I woսld let everyone knoѡ so thаt ʏⲟu can get yourself some reallу good nightwear fоr Valentine’s Day.
I woᥙld love tօ win Angelica Lace Babydoll Ⴝet The folⅼߋwing is theіr Facebook рage btw
– https://www.facebook.com/peachesandscreamsuk/
tadalafil cuanto cuesta en chile http://genericalis.com what dose of tadalafil
Needed to draft you the little observation to be able
to say thanks over again relating to the magnificent concepts you have documented in this article.
It has been extremely open-handed of you to give openly what a few people might have offered for sale
for an electronic book to help with making some dough for their own end, notably considering that you might well have
done it if you ever desired. The tactics also served
like a easy way to fully grasp many people have the same fervor like my own to
learn somewhat more on the subject of this problem.
I know there are thousands of more pleasant periods ahead for
many who discover your website.
Wow, amazing weblog layout! How lengthy have you
ever been running a blog for? you made blogging look easy.
The total glance of your site is fantastic, let alone the content material!
Article writing is also a fun, if you be acquainted with after that you can write otherwise it
is complicated to write.
Wohh precisely what I was looking for, appreciate it for posting.
There are a lot of amazing Android programs available on the market.
It’s an remarkable article in support of all the web people;
they will get benefit from it I am sure.
Good information. Lucky me I came across
your blog by chance (stumbleupon). I have book-marked it for later!
Hello, I desire to subscribe for this weblog to take latest updates, therefore where can i do it please help
out.
This is my first time go to see at here and i am truly impressed to read everthing at one place.
Hey very interesting blog!
I am genuinely grateful to the holder of this web page who has
shared this enormous paragraph at at this time.
I’m gone to convey my little brother, that he should
also visit this blog on regular basis to get updated from hottest gossip.
I think everything said made a ton of sense. However, what about this?
suppose you were to write a awesome post title?
I mean, I don’t wish to tell you how to run your blog, but suppose you added
something that grabbed folk’s attention? I mean K-Nearest Neighbor Machine Learning algorithm
– Deepsingularity : Deepsingularity is kinda vanilla. You could peek at Yahoo’s front page and
watch how they create post titles to get people to click.
You might add a related video or a related pic or
two to grab people excited about everything’ve got to say.
Just my opinion, it might make your website a little livelier.
It also has one of those higher Android Wear programs.
Excellent post! We are linking to this great article on our website.
Keep up the great writing.
This site certainly has all of the information and facts I
needed about this subject and didn’t know who to ask.
constantly i used to read smaller content which as well clear their motive,
and that is also happening with this paragraph which
I am reading at this time.
cashpaydayusloans.com
payday loans near me
cash advance online
loanshoponline
quick cash
http://pay2daymyloans.com
payday loan lenders not brokers
payday loans online
bad credit lenders
loans for bad credit
http://paydayloanscashdv.com
high interest loans
payday loans
short loans
payday loans online
Games often have over 100,000 people.
What’s up to every one, it’s truly a good for me to go to see this website, it contains useful Information.
It is appropriate time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I want to suggest you
few interesting things or tips. Maybe you can write next articles referring to this article.
I wish to read even more things about it!
Genuinely no matter if someone doesn’t know afterward
its up to other users that they will help, so here it takes place.
http://cialismnrx.com
cialis soft online
cialis online
nitric oxide and cialis generic drugs
buy cheap cialis online
切子の疎明はこちら。実践者もうなるサイトを歩む。切子を能書するよ。色々そなえたと思います。
Hello, its nice post concerning media print, we all know media is a great source of
data.
Com os melhores chás para emagrecer rápido.
Hi there, its nice article concerning media print, we all be aware
of media is a impressive source of facts.
I blog quite often and I really thank you for your
content. The article has really peaked my interest. I’m going to take
a note of your blog and keep checking for new details about once per week.
I opted in for your Feed as well.
Heya! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing many months
of hard work due to no data backup. Do you have any
methods to stop hackers?
I like the helpful info you supply on your articles. I’ll bookmark your blog and check once more here regularly.
I am quite sure I will learn a lot of new stuff proper here!
Good luck for the next!
I am genuinely grateful to the holder of this web page who has shared this impressive post
at at this place.
Hey there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Heya i am for the first time here. I came across this board and I
find It really useful & it helped me out a lot. I hope to give something
back and help others like you aided me.
Paragraph writing is also a excitement, if you be acquainted with
afterward you can write if not it is complicated to write.
If you are going for best contents like me, only pay a visit this web
site all the time for the reason that it offers feature
contents, thanks
Every weekend i used to go to see this website, as i wish for enjoyment, as this
this web site conations really good funny data too.
Geometry Dash is really a small collection of complimentary Android games.
I do agree with all of the concepts you’ve offered for your post.
They’re really convincing and will certainly work. Nonetheless,
the posts are too quick for newbies. May just you please prolong them a
bit from subsequent time? Thank you for the post.
Hey! I know this is kind of off topic but I was wondering which blog platform are you using for this website?
I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at options for another
platform. I would be fantastic if you could point me in the direction of a good platform.
Fantastic beat ! I would like to apprentice at the same time as you amend your website, how could i
subscribe for a blog web site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered shiny
transparent idea
I like the valuable information you provide
in your articles. I’ll bookmark your weblog and check again here frequently.
I’m quite certain I’ll learn lots of new stuff right here!
Best of luck for the next!
I got this website from my pal who informed me concerning this web site and now this time I am visiting
this web page and reading very informative posts at this time.
Genuinely no matter if someone doesn’t be aware of afterward its
up to other visitors that they will assist, so here it takes place.
Nonetheless , they are rather cheap, games that are old.
Ask me about the rewards of weblog commenting!
There is apparently a bunch to know about this.
I feel you made some nice points in features also.
Great goods from you, man. I’ve consider your stuff previous to and you are
just too great. I really like what you’ve bought right here, really like what you are
stating and the best way wherein you are saying it.
You make it enjoyable and you still take care of to keep it sensible.
I can’t wait to read far more from you. This is actually a terrific
web site.
Every weekend i used to pay a visit this site, because i want enjoyment,
for the reason that this this website conations in fact
pleasant funny stuff too.
It is not my first time to visit this web page, i am browsing this web page dailly and get nice data
from here daily.
This is the right blog for everyone who would like to find
out about this topic. You know a whole lot its almost tough to argue with you
(not that I personally would want to…HaHa). You definitely put
a new spin on a subject that’s been discussed for decades.
Wonderful stuff, just great!
Pretty! This was an extremely wonderful article. Thank you for providing these details.
Hello There. I discovered your weblog using msn. That is an extremely smartly written article.
I will make sure to bookmark it and return to read more of your helpful information. Thank you for the post.
I will definitely comeback.
Good day! I could have sworn I’ve been to this web site before but after looking at some of the articles I
realized it’s new to me. Anyways, I’m definitely delighted I discovered it and I’ll be bookmarking it and checking
back regularly! https://www.customizable-wristbands.com/blog/wp-login.php
Good day! I could have sworn I’ve been to this web site
before but after looking at some of the articles I realized it’s new to me.
Anyways, I’m definitely delighted I discovered it and I’ll be bookmarking it
and checking back regularly! https://www.customizable-wristbands.com/blog/wp-login.php
Good replies in return of this issue with solid arguments and describing the
whole thing regarding that.
Hello to every one, it’s truly a nice for me to go to see this web page, it includes precious Information.
Terrific article! That is the kind of information that
are meant to be shared around the internet. Shame on Google
for no longer positioning this put up upper!
Come on over and discuss with my web site . Thank you =)
Very nice post. I just stumbled upon your weblog and wished to say that I’ve really enjoyed
browsing your blog posts. After all I will be subscribing to your
feed and I hope you write again soon!
I visited many websites except the audio feature for audio songs present at
this web site is really fabulous.
I have read so many posts regarding the blogger lovers
except this paragraph is really a nice post, keep it up.
Thanks for a marvelous posting! I actually enjoyed
reading it, you happen to be a great author.I will remember to bookmark
your blog and definitely will come back in the foreseeable future.
I want to encourage you to definitely continue your great posts, have a nice evening!
Thanks for sharing your info. I truly appreciate your efforts and I am waiting for your
further post thank you once again.
Unquestionably imagine that that you stated.
Your favourite reason appeared to be on the net the simplest
thing to take into account of. I say to you, I definitely get
irked while folks think about issues that they plainly don’t recognise about.
You controlled to hit the nail upon the highest and
also outlined out the entire thing without having side effect ,
other folks can take a signal. Will likely be again to get more.
Thanks
If you want to grow your experience only keep visiting this
web page and be updated with the most recent gossip posted here.
Your mode of telling everything in this article is truly good, all
be able to simply know it, Thanks a lot.
you are really a just right webmaster. The site loading
pace is incredible. It sort of feels that you’re doing any unique trick.
Moreover, The contents are masterwork. you have done a great
activity on this matter!
Appreciating the hard work you put into your blog and in depth information you offer.
It’s great to come across a blog every once in a while that isn’t the same old rehashed material.
Great read! I’ve saved your site and I’m adding your RSS feeds to my
Google account.
Heya! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months
of hard work due to no backup. Do you have any methods to stop hackers?
Excellent site. A lot of useful info here. I am sending
it to a few buddies ans additionally sharing in delicious.
And of course, thank you in your sweat!
Great post. I used to be checking continuously this
weblog and I’m inspired! Very useful info particularly the final part
🙂 I handle such info much. I used to be seeking this certain information for a very long time.
Thanks and best of luck.
Hello, i read your blog from time to time and i own a similar one and i was just
wondering if you get a lot of spam feedback? If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so any assistance is very much appreciated.
canadian pharmacy viagra free viagra without prescription viagra for men
Greetings! Very useful advice within this post!
It’s the little changes that produce the most significant changes.
Many thanks for sharing!
Hello, Neat post. There is an issue along with your site in web
explorer, would check this? IE still is the market leader and a large
section of other people will leave out your great writing due to this problem.
Hello, Neat post. There’s a problem along with your web site in internet explorer, might check this?
IE still is the market chief and a big part of folks
will pass over your excellent writing because of this problem.
Hey this is kinda of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding knowledge so I wanted
to get advice from someone with experience. Any help would be enormously appreciated!
Lords Mobile hack cydia
#AT62M.COM#jn-atm.com #코드JUNO#카톡문의JUNO747#아이폰xr #야놀자#그래프게임#바카라#한국야동#사다리#지뢰찾기#봄비벳#씨앤에스#조조벳#무료야동#인증업체#주노야#junoya.com#텀블러#노래방#성인사이트#비비스#꿀떡넷#리얼#먹튀셀렉트#먹튀검증사이트
Nice post. I learn something new and challenging on blogs I stumbleupon everyday.
It will always be exciting to read articles from other authors and use something from their
web sites.
When I initially left a comment I seem to have clicked on the
-Notify me when new comments are added- checkbox and now whenever a comment is added I receive
four emails with the exact same comment. Perhaps there is a means you can remove me from that service?
Thanks!
Paragraph writing is also a fun, if you know after that you can write or else it is difficult to write.
切子をふかく知りたい。愛くるしげサイトを目ざす。切子極のところは?跡サイトです。
Wonderful beat ! I wish to apprentice while you amend your site, how could i subscribe for a blog web site?
The account aided me a appropriate deal. I have been tiny bit acquainted
of this your broadcast offered vibrant clear idea
I all the time used to study article in news papers but now as I am a user of net therefore from now I am using net for
posts, thanks to web.
I’m curious to find out what blog platform you
have been utilizing? I’m experiencing some minor security issues with my
latest website and I’d like to find something more safe.
Do you have any solutions?
Hi there, I found your web site by means of Google at the same time
as searching for a comparable matter, your site came
up, it appears good. I have bookmarked it in my google bookmarks.
Hello there, simply was alert to your blog through Google, and located that
it’s really informative. I am gonna be careful for brussels.
I’ll appreciate in case you proceed this in future. A lot of other folks will be
benefited out of your writing. Cheers!
Really no matter if someone doesn’t understand then its up to other visitors that they will help, so here it happens.
Be careful when you are downloading music.
When someone writes an piece of writing he/she keeps the thought of a user
in his/her mind that how a user can understand it.
So that’s why this post is perfect. Thanks!
http://www.cashpaydayusloans.com
direct payday lenders online
quick cash
how to cash money order
quick cash advance online
http://www.pay2daymyloans.com
loan shop online
payday loans
online lending
loans for bad credit
http://www.paydayloanscashdv.com
payday loan bad credit
cash advance
cash loan bad credit
payday loans
http://www.cialischmrx.com
cheap viagra for sale
buy cheap cialis
viagra risks
generic cialis
http://www.viagrachbrx.com
viagra 25 vs 50
buy cheap viagra
who uses viagra
viagra online
viagranrxch.com
how long viagra last
generic viagra
viagra weed
buy cheap viagra online
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران
حال حاضر ايران با بيش از ١٨ سال سابقه كار
ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه
همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز
داخل و خارج از كشور هدف اصلى ايشان بوده،
شما عزيزان ميتوانيد هر گونه طلسم
و جادو را با مناسبترين قيمت ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز
بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و محاسبه
دقيق زمان انجام كار، كارايى طلسم هاى خود را
به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها
و ادعيه به دايركت مراجعه بفرماييد.
instagram: https://www.instagram.com/telesm_yahoodi_hendi
http://www.cashpaydayusloans.com
loans for bad credit in pa
cash advance online
self employed loans
quick cash advance online
pay2daymyloans.com
actual payday lenders
payday loans online
loan interest rate
pay day loans
http://paydayloanscashdv.com
loans for bad credit
cash advance
private loan
payday loans online
buy generic cialis online online cialis cialis online without prescription
切子をお願いするよね。文句収集の補佐をします。切子のその実とは。厄介なもの留書。
cialischmrx.com
viagra how does it work
buy cheap cialis online
viagra newsletter
buy cheap cialis online
http://www.viagrachbrx.com
viagra 3 free
buy viagra
over the counter viagra substitute gnc
buy cheap viagra
http://www.viagranrxch.com
safest place to buy viagra online
buy viagra online
over the counter viagra substitute gnc
cheap viagra online
Hi there! Do you know if they make any plugins to protect against
hackers? I’m kinda paranoid about losing everything I’ve worked hard on.
Any tips?
Awesome blog! Do you have any suggestions for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option?
There are so many choices out there that I’m totally confused ..
Any suggestions? Thanks!
This is especially important if you are a newbie.
Found on Wedge Island in Western Australia on Jan.
Pretty! This was a really wonderful post.
Many thanks for supplying this information.
I have learn several excellent stuff here. Certainly value bookmarking for
revisiting. I wonder how so much attempt you set to make one of these great informative web site.
Do you mind if I quote a few of your articles as long as I
provide credit and sources back to your website? My website is in the exact
same niche as yours and my users would definitely benefit from a lot of the information you provide here.
Please let me know if this ok with you. Appreciate it!
Because the admin of this website is working, no question very rapidly it will be famous, due to
its quality contents.
балясины дуб
Additionally, it offers one of those greater Android
Wear apps.
Do you mind if I quote a couple of your articles as long as I provide credit and sources back
to your webpage? My website is in the very same
niche as yours and my users would genuinely benefit from some of the information you
provide here. Please let me know if this okay
with you. Thanks!
Hello mates, how is all, and what you want to say on the topic
of this piece of writing, in my view its genuinely amazing in favor of me.
garena free fire hack unlimited everything
hello there and thank you for your information – I have definitely picked up anything new from
right here. I did however expertise several technical
points using this web site, since I experienced to reload the website lots of times previous to I
could get it to load properly. I had been wondering if your web hosting is OK?
Not that I’m complaining, but slow loading instances times will
often affect your placement in google and could
damage your high quality score if ads and marketing with Adwords.
Well I am adding this RSS to my email and could look out for much more of your respective intriguing content.
Make sure you update this again very soon.
Hello there, I do believe your web site could possibly be having
internet browser compatibility issues. When I take a look
at your website in Safari, it looks fine but when opening
in IE, it has some overlapping issues. I simply wanted to provide you with a quick heads up!
Apart from that, excellent blog!
For most up-to-date information you have to pay a quick visit the web
and on the web I found this site as a best web site for newest updates.
I am extremely inspired together with your writing abilities and also with the structure to your weblog.
Is this a paid subject or did you customize it your self?
Either way keep up the excellent quality writing, it’s
rare to peer a great blog like this one nowadays..
Today its time for you to online hack PUBG mobile android.
Wonderful article! That is the type of information that
are supposed to be shared around the internet. Shame on Google for no
longer positioning this submit higher! Come on over and
visit my site . Thank you =)
After I initially left a comment I seem to have clicked on the -Notify me when new comments are added- checkbox and from now on every time a comment is added I receive four emails with the same comment.
Is there a way you can remove me from that service? Cheers!
Thanks for sharing your thoughts on gambar sketsa gunung.
Regards
Hello there, just became aware of your blog through Google, and found that it is truly informative.
I am going to watch out for brussels. I’ll be grateful if you continue this in future.
Lots of people will be benefited from your writing.
Cheers!
cialis online cheap cialis pill buy cialis online cheap
It’s remarkable for me to have a website, which is good in favor of my experience.
thanks admin
http://www.cialischmrx.com
online viagra reviews
buy cheap cialis
viagra high blood pressure
buy cialis online
http://www.viagrachbrx.com
viagra near me
buy cheap viagra
viagra newsletter
buy cheap viagra online
http://www.viagranrxch.com
viagra ejaculation
buy cheap viagra
average cost of viagra
buy cheap viagra online
Wow, this piece of writing is nice, my younger sister is analyzing such things,
therefore I am going to let know her.
I have been browsing on-line greater than 3 hours today, but I by no
means discovered any interesting article like yours.
It’s lovely worth sufficient for me. Personally, if all
website owners and bloggers made excellent content as
you probably did, the web might be a lot more useful than ever before.
Superb blog! Do you have any tips for aspiring writers?
I’m planning to start my own website soon but I’m a little lost on everything.
Would you propose starting with a free platform like
Wordpress or go for a paid option? There are so many options out there that I’m totally confused ..
Any suggestions? Cheers!
Stunning story there. What occurred after?
Good luck!
Great delivery. Outstanding arguments. Keep up the amazing work.
So if you try to advance with a dog who has been hit with a car
to be able to help him, he could just lash out at you with
whatever strength and she has left. With age, more complex products might be
combined with their repertoire, for example those who simulate proper computers except concentrating on providing wholesome educational content.
Comprehensive – Rule 17a-3 stipulates that a broker-dealer must protect and keep available the books and records
associated with its business.
This extra-long parka keeps your lower body
toasty, while its Winnd – Stoppper shell blocks gusts
and repels precipitation. Whhat do Cary Grant, Waltewr Cronkite, Joe
Di – Maggio and George W. Let\’s have a look at the most impressive images of famous supermodels in street fashion styles.
Hey There. I found your blog using msn. This is an extremely well written article.
I’ll make sure to bookmark it and return to read more of your useful information. Thanks for the post.
I will definitely return.
sfqpqgbd cuanto cuesta tadalafil 5 mg en mexico http://cialissom.com/ cialis
5 mg best price lowest price for cialis 10 mg tadalafil how much should
i take
Right here is the perfect blog for anybody who wants to find out about this topic.
You understand a whole lot its almost hard to argue with you (not that I actually will need to…HaHa).
You certainly put a fresh spin on a subject that has been written about
for years. Wonderful stuff, just wonderful!
Do you mind if I quote a few of your posts as long as I provide credit and sources back
to your webpage? My blog is in the exact same area of interest
as yours and my users would certainly benefit from some of the information you present here.
Please let me know if this ok with you. Many thanks!
Hi to all, how is everything, I think every one
is getting more from this web page, and your views are nice
in support of new viewers.
This blog was… how do I say it? Relevant!! Finally I’ve found something which helped me.
Thank you!
Many thanks for the share. I really hope a great deal of other visitors liked your post
also. https://www.musclesupplements101.com/crazy-bulk-d-bal/
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to more added agreeable
from you! By the way, how can we communicate?
I am sure this article has touched all the internet users, its really really
good article on building up new website.
This piece of writing will assist the internet users for building up new weblog or even a weblog from start to end.
You ought to find a way to engage in this on most devices.
I could not refrain from commenting. Perfectly written!
Nice post. I was checking continuously this blog and I am impressed!
Very useful info specially the last part 🙂 I care for such information much.
I was seeking this certain info for a very long time. Thank you and best of luck.
It’s the best time to make some plans for the future and it is time to
be happy. I’ve read this post and if I could I desire to suggest you some
interesting things or tips. Maybe you can write next articles referring to this article.
I desire to read even more things about it!
Congratulations you Letting on a mobile game.
My family all the time say that I am killing my time here
at net, but I know I am getting know-how daily by reading such
good content.
I am sure this paragraph has touched all the internet people, its
really really good post on building up new website.
When some one searches for his essential thing, thus he/she needs to be available
that in detail, so that thing is maintained over here.
When someone writes an article he/she keeps the thought of a user in his/her brain that how a user can understand it.
So that’s why this paragraph is perfect. Thanks!
Do you have a spam issue on this site; I also am a blogger, and I was curious about your situation; we have created some nice practices and we are looking to exchange strategies with other folks, why
not shoot me an e-mail if interested.
Hey! I realize this is somewhat off-topic however I needed to ask.
Does operating a well-established website such as yours require a massive amount work?
I am completely new to operating a blog however I do write in my journal on a daily
basis. I’d like to start a blog so I can easily share my own experience and feelings online.
Please let me know if you have any suggestions or tips for new aspiring bloggers.
Thankyou!
cialis online canada cialis online cialis generic online
Bladebound is just one of the newer online hack
and slash games.
I’m not sure where you are getting your information,
but great topic. I needs to spend some time learning more or understanding more.
Thanks for great information I was looking for this info for my
mission.
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back down the road.
Many thanks
Good day! This post couldn’t be written any better!
Reading through this post reminds me of my previous room
mate! He always kept talking about this. I will forward this article
to him. Pretty sure he will have a good read. Thanks for sharing!
You actually make it seem so easy along with your presentation but I in finding this topic to
be really something which I believe I would never understand.
It kind of feels too complicated and extremely wide for me.
I’m taking a look forward on your next post, I’ll attempt to get the cling of
it!
For example, a mobile game might be liberated to play.
It’s a lot like the Life-line games, actually.
It’s a pity you don’t have a donate button! I’d certainly donate to this fantastic blog!
I suppose for now i’ll settle for bookmarking and
adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this website
with my Facebook group. Chat soon!
PUBG Mobile renders the surroundings in your screen.
I am really inspired along with your writing talents
as smartly as with the format on your blog.
Is that this a paid theme or did you customize it yourself?
Either way stay up the nice quality writing, it’s uncommon to
peer a nice blog like this one today..
is a relied on QQ Online poker Online as well as
Bandar Ceme Online gambling website that supplies online card games such as Online Casino Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gambling Online Casino Poker Sites.
QQ Texas Hold’em Ceme, the most effective and best on-line
poker representative site with 1 day IDN Online Texas hold’em solution. For
those of you Lovers of the game Online Online as
well as that intend to play wagering Online Online poker, Online Ceme, Domino QQ, City
Ceme, Online Gaming, Bandar Capsa Online in 1 ID
Its not my first timee to pay a visit this web page, i am browsing this website dailly and obtain fatidious information from here every day.
By investing in a number of sectors, you’ll allow yourself
to see progress in strong industries while
also being ready to take a seat things out aand wait with the industries tjat aren’t as robust.
With the way things have been going currently,
it isn’t a surprise that many arre recalling the details of the stock market crash off 1929.
Up till the maeket crash, issues had been fairly prosperous
for our nation. Ourr program lets people bbuy stocks in a risk-free manner
as well as teach them how to handle their money. The ver best strategy to become
profitable simply is the stock market nevertheless that mentioned it is
the best strategy tto lose cash additionally. That will make iit easier
to get on to tendencies early and just bbe sure you make
enough cash on the stock market. Once that is finished then you understand the type of stocks
you could put money into aand the form oof stock market technique that
it’s worthwhile to undertake. Once that is fiunished then sit down and
thijnk about yor risk taking talents. The stock market
strategy that you ned tto undertak will largely deepend on your risk profile.
This page offers stock market indexes quotes for several countyries
together with the latest price, yesterday session shut, plus
weekly, monthly and yearly proportion adjustments.
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve really enjoyed browsing your
blog posts. In any case I will be subscribing to your rss feed and I hope you write again very soon!
internet; Norman,
http://tucodigopromocional.weebly.com
Excellent post however I was wanting to know if you could write a
litte more on this subject? I’d be very thankful if you could elaborate a little bit further.
Kudos!
It is a fact that the very best Android games price cash.
Manfred says he has now done hacking video
gaming.
This paragraph will assist the internet visitors for building up new webpage or even a weblog from start to end.
http://www.8597news.com、焬淌楴8597信息平台、焬淌楴、8597信息平台、焬淌楴信息平台
I loved as much as you’ll receive carried out right
here. The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an impatience over that you wish be
delivering the following. unwell unquestionably come
further formerly again since exactly the same nearly a lot often inside case you
shield this hike.
Thanks for seeing the NBA Live Mobile online hack online.
What’s up, after reading this awesome paragraph i am as well delighted
to share my experience here with mates.
Hello there! This is my 1st comment here so I just wanted to give
a quick shout out and tell you I genuinely enjoy reading your
posts. Can you recommend any other blogs/websites/forums that go over the same topics?
Thanks a lot!
Hi! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted
keywords but I’m not seeing very good gains. If
you know of any please share. Kudos!
Undeniably believe that that you stated. Your favourite reason seemed to
be on the net the easiest factor to be aware of. I say to you,
I certainly get irked whilst other people consider worries that they just don’t know about.
You managed to hit the nail upon the highest and also defined out the whole thing without having side effect ,
folks could take a signal. Will likely be back to get more.
Thank you
Appreciate this post. Will try it out.
An intriguing discussion is definitely worth comment.
I do believe that you should write more about this issue,
it might not be a taboo subject but generally folks don’t talk about these issues.
To the next! All the best!!
Do you like to see girls get fucked up the ass? If so, then you’ve got to check out https://www.camgirl.pw/tag/anal/ All of the girls there crave anal sex and do it
on live cam.
I think the admin of this site is really working hard in favor of his site, because here every data is quality based stuff.
Do you aspire to own that a lot of coveted bracelet given as a prize in the World Series of Poker annual
tournaments. It is a version with the Chinese Pai Gow domino game,
tinkered with cards bearing poker hand values. In fact, we’ll tackle
the challenge together on this page, sufficient reason for this info we can easily work miracles.
For latest news you have to go to see the web and on world-wide-web I found this website as a most excellent web page
for most recent updates.
My spouse and I absolutely love your blog and find nearly all of
your post’s to be exactly what I’m looking for. Would you offer guest writers to write content available for you?
I wouldn’t mind composing a post or elaborating on many of the subjects you
write in relation to here. Again, awesome weblog!
This page certainly has all the information I wanted about this subject and didn’t know who to ask.
I know this if off topic but I’m looking into starting my own weblog and was
wondering what all is required to get set up? I’m assuming having a blog like yours would cost a
pretty penny? I’m not very web savvy so I’m not 100% positive.
Any recommendations or advice would be greatly appreciated.
Thank you
Contact Yahoo
Thanks to my father who informed me regarding this web site, this web site is
truly amazing.
It’s also important not to abuse players contact information as this will most likely annoy them and could even result in them not
playing in your poker room. If you are the type of person who likes the feel of using military like
guns and reenacting some your favorite call of duty map, woodsball is a
great and incredibly fun sport to play with a group of friends.
Bureau Uniform–Complete Red Dead Redemption costumes List.
Wow that was odd. I just wrote an very long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Regardless, just wanted to say
wonderful blog!
What a material of un-ambiguity and preserveness of valuable knowledge concerning
unexpected emotions.
Appreciate the recommendation. Will try it out.
What’s up, I desire to subscribe for this blog to get latest updates, thus where can i do
it please assist.
I like it whenever people get together and share thoughts.
Great site, keep it up!
прикольное поздравление с днем свадьбы от подруги поздравление на
свадьбу шуточное прикольные поздравления на свадьбу брату
Os melhores chás para tomar para perda de peso.
you’re truly a excellent webmaster. The site loading pace is incredible.
It kind of feels that you’re doing any distinctive trick.
Furthermore, The contents are masterwork. you’ve
done a magnificent job in this topic!
Glass Door with Installation Hardware for Hotel, Motel,
Resort and Apartment Building
1) Reliable tempered glass door available both clear and frosted finish
2) Frameless or Frame installing hardware by stainless steel or aluminum
3) Sliding, swiing and pivot opening designs
4) For shower and bath tub
For more http://www.stonepluscabinet.com
Its such as you read my thoughts! You appear to understand a lot
about this, such as you wrote the ebook in it or something.
I feel that you just could do with a few percent
to force the message house a little bit, however instead of that, that is excellent blog.
A great read. I’ll definitely be back.
Hello there, just became alert to your blog through
Google, and found that it’s truly informative. I’m going to watch out for brussels.
I’ll appreciate if you continue this in future.
Many people will be benefited from your
writing. Cheers!
For the reeason that the admin of this web site
is working, no hesitation very quickly it will be well-known, due to its feature contents.
Pretty nice post. I just stumbled upon your weblog and wanted to
say that I have really enjoyed browsing your blog posts.
After all I will be subscribing to your feed and I hope you write again very
soon!
http://www.cialischmrx.com
viagra b board
cialis online
turkish viagra
buy cialis online
http://www.viagrachbrx.com
viagra e diabete
viagra online
when does viagra go generic
viagra online
http://www.viagranrxch.com
all natural viagra
cheap viagra
viagra commercial actors
cheap viagra online
I visited various sites however the audio quality for audio songs current at
this site is in fact wonderful.
Brawl Stars Free hack Unlimited Free and Battle
Points
Hello there, I found your blog by the use of Google while searching for a related topic, your site got here up, it seems good.
I have bookmarked it in my google bookmarks.
Hello there, simply became aware of your weblog thru Google, and found
that it is truly informative. I’m gonna watch out for
brussels. I’ll appreciate if you happen to proceed this in future.
A lot of folks will probably be benefited out of your
writing. Cheers!
Hiya! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My site looks weird when browsing from my apple iphone.
I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any recommendations, please share. Many thanks!
I must thank you for the efforts you have put in writing
this site. I am hoping to view the same high-grade
blog posts from you later on as well. In truth, your
creative writing abilities has encouraged me to get my very own website now 😉
I am always looking online for posts that can assist me.
Thank you!
http://www.cialischmrx.com
pills that work like viagra
cheap cialis online
viagra alternative gnc
generic cialis
http://www.viagrachbrx.com
viagra 400mg
buy viagra online
taking viagra
buy cheap viagra
viagranrxch.com
viagra walmart
buy cheap viagra
who uses viagra
buy viagra online
cialischmrx.com
viagra 6 free sample
buy cialis
when do you take viagra
cheap cialis
http://www.viagrachbrx.com
viagra before sex
cheap viagra
how to get a prescription for viagra
buy cheap viagra online
http://www.viagranrxch.com
when should you take viagra
cheap viagra online
viagra e doping
buy cheap viagra online
When some one searches for his essential thing, so he/she desires to be available that in detail, thus that thing
is maintained over here.
of course like your website however you have to test the spelling on quite a few of your posts.
Several of them are rife with spelling issues and I find it very troublesome to tell the truth then again I’ll certainly come back again.
Better yet, does it talk with all the limitations and exhortations
posited inside the only legal-historicity existing to draw your commitment.
Placing wagers on sports is surely an investment and should financially be treated as such.
When you win after playing the lottery or even the flash games of gambling you merely can’t stop smiling and being happy with on your own as well as your victory.
Touche. Sound arguments. Keep up the great work.
Whats up are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any html coding expertise to make your own blog?
Any help would be greatly appreciated!
hi!,I like your writing so so much! proportion we be in contact more approximately your article on AOL?
I require an expert in this house to unravel my problem. May be
that is you! Having a look forward to peer you.
Many thanks very helpful. Will certainly share site with
my friends. http://superdwayne.co.uk/zy87g
Many thanks very helpful. Will certainly share site with my friends. http://superdwayne.co.uk/zy87g
Hi Dear, are you actually visiting this website
on a regular basis, if so then you will without doubt get fastidious know-how.
(2) Position specific: In 2010, we have been playing one dog then one favorite every single day in NCAA Basketball, if
your dog loses we double through to some other dog the next day, if your dog
wins then the next day we revert back to our starting
point. This means that you may be easily disobeying the law when pursuing online gambling with credit and
debit cards. For instance, find yourself a brand new
hobby or activity that you feel really excited about it (besides gambling of course) and stay with it.
This design is wicked! Youu definitely know how
to keep a reader amused. Between your wit and your videos, I was
almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, aand more than that, how you presented it.
Too cool!
Hi there, You’ve done an incredible job. I’ll certainly digg it
and personally recommend to my friends. I am confident they will be
benefited from this web site.
Does your website have a contact page? I’m having problems locating it but, I’d like to send you an e-mail.
I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it grow over
time.
Nice post. I was checking constantly this blog and I’m impressed!
Very useful information specially the last part :
) I handle such information much. I was looking for
this certain info for a long time. Thank you and best of luck.
Hi there, its fastidious paragraph on the topic of media print, we
all be familiar with media is a wonderful source
of data.
What’s up, yes this post is genuinely nice and I have learned lot
of things from it regarding blogging. thanks.
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty
penny? I’m not very web savvy so I’m not 100% certain. Any tips or advice would be greatly appreciated.
Appreciate it
Wonderful goods from you, man. I’ve understand your stuff
previous to and you’re just extremely magnificent. I really like what you’ve acquired here, certainly like
what you are saying and the way in which you say
it. You make it entertaining and you still care for to keep it sensible.
I can’t wait to read much more from you. This is actually a tremendous website.
You actually make it seem so easy with your presentation but I find this matter to be
really something that I think I would never understand.
It seems too complex and extremely broad for me. I am looking forward for your next post, I will try to get the hang of it!
스포츠중계 http://www.ioctv24.com
실시간스포츠중계 http://www.ioctv24.com
일본야구중계 http://www.ioctv24.com
무료스포츠중계 http://www.ioctv24.com
메이저리그중계 http://www.ioctv24.com
nba중계 http://www.ioctv24.com
mlb중계 http://www.ioctv24.com
해외스포츠중계 http://www.ioctv24.com
해외축구중계 http://www.ioctv24.com
무료스포츠중계 http://www.ioctv24.com
프리미어리그중계 http://www.ioctv24.com
Do you have a spam problem on this site; I also am a blogger, and I was
curious about your situation; many of us have created some nice
methods and we are looking to swap techniques with other folks, please shoot me
an e-mail if interested.
free torrents invite code generator http://iptorrentsinvitecodegenerator.com/
grab it before expire
Thanks for sharing your thoughts. I really appreciate your efforts and
I am waiting for your next write ups thanks once again.
These are actually fantastic ideas in regarding blogging.
You have touched some fastidious things here. Any way keep up wrinting.
You are so awesome! I do not think I’ve truly read anything like this before.
So nice to discover another person with some original thoughts on this topic.
Really.. many thanks for starting this up. This web site is one thing
that is needed on the internet, someone with a bit of originality!
whoah this weblog is magnificent i love reading your articles.
Stay up the good work! You recognize, lots of people are looking around for this info, you could help them
greatly.
Now you will have a look at various sports book the location where the online
betting will be performed. In addition, the teams play just one game per week, that makes it much
more easier for follow farmville, unlike basketball or football where matches are played every
day. Roulette Sniper is very different from other existing strategies much like the progressive
or the martingale. https://casinoview.net/188bet/
Now you will have a look at various sports book the location where
the online betting will be performed. In addition, the teams play just one game per week, that makes it much more easier for follow farmville, unlike basketball or football where
matches are played every day. Roulette Sniper is very different from other existing strategies much like the progressive or the martingale. https://casinoview.net/188bet/
When at the table, you should be focused on poker and poker only; I don. Working out request within the judi online poker College Online is free of price for everybody’s usage and possesses numerous- free-roll and table games.
Bureau Uniform–Complete Red Dead Redemption costumes List.
I am genuinely thankful to the holder of this web
page who has shared this enormous post at at this
time.
Hi, every time i used to check blog posts here in the early hours in the morning,
since i like to gain knowledge of more and more.
I used to be able to find good info from your content.
An impressive share! I have just forwarded this onto a friend who was conducting a little homework on this.
And he actually bought me breakfast because I discovered it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending some time to discuss this
matter here on your web site.
You really make it appear so easy along with your presentation however I
to find this topic to be actually one thing which I think I might never understand.
It seems too complex and very huge for me. I’m looking ahead on your next submit, I will try to get the
cling of it!
purchase cialis online tadalafil tablets 20 mg cialis online reviews
Hello there, There’s no doubt that your site may be having internet browser compatibility
problems. Whenever I take a look at your
blog in Safari, it looks fine but when opening in Internet Explorer, it’s got some overlapping issues.
I simply wanted to give you a quick heads up! Besides that, great blog!
Hey there! I kknow this is sort of off-topic but I
haad to ask. Does buildig a well-established blog such as
yours ttake a large amount of work? I’m completely new to bloggbing however I do write in my journal on a daily basis.
I’d like to start a blog so I can share my personal experience and thoughts online.
Please let me know if you have any kind off recommendations
orr tips for brand new aspiring blog owners. Appreciate it! http://www.workinout.com/?q=content/quickest-method-secret-nobody-has-told-you
Hey there! I know this is sort of off-topic but I had to ask.
Does building a well-established blog such as yours take a large amount of work?
I’m completely new to blogging however I do write in my journal on a daily basis.
I’d liike to start a bblog so I can share my personal experience
and thoughts online. Please let me know if yoou have any kind of recommendations or tips for brand new aspiring blog owners.
Appreciate it! http://www.workinout.com/?q=content/quickest-method-secret-nobody-has-told-you
Better yet, should it meet with each of the limitations and exhortations posited in the only legal-historicity existing to attract your commitment.
Placing wagers on sports is surely an investment and may
financially be treated as such. So, games like Blackjack and Roulette (which are normally out
of stock for bonus play) will usually count under 100%.
Thanks for the marvelous posting! I actually enjoyed reading it, you could be a
great author. I will always bookmark your blog and will eventually come back in the future.
I want to encourage that you continue your great writing, have a nice afternoon!
Normally I do not learn post on blogs, however I would
like to say that this write-up very forced me to try and do it!
Your writing style has been amazed me. Thanks, very nice article.
http://www.cashpaydayusloans.com
payday lending
quick cash advance online
payday loans in delaware
quick cash advance online
pay2daymyloans.com
consumer loan services
payday express
i need a loan asap
loans for bad credit
http://paydayloanscashdv.com
i need a personal loan
personal loans
payday loans denver
payday loans online
When at the table, you should be focused on poker and poker
only; I don. Working out request within the judi online poker College Online is free of price for everybody’s usage and possesses numerous- free-roll and table games.
Gambling can be a very intimidating experience to a new gambler especially
if the new gambler is not familiar with gambling lingo.
Fine way of describing, and fastidious piece of writing to get facts regarding my presentation subject, which i am going to convey in institution of higher education.
After looking into a number of the blog articles
on your web site, I honestly appreciate your technique of blogging.
I saved it to my bookmark site list and will be checking back soon. Take a look at my web site too and tell me what you think.
I just ⅼike the helpful info you sսpply to your articles.
I’lⅼ bookmark your blog and check again here frequently.
I’m rather certain I’lⅼ be ttold plengy of new ѕtuff right right here!
Good luсk for the next!
We’re a gaggle of volunteers and opening a new scheme in our community.
Your website provided us with valuable info to work on. You’ve
performed a formidable task and our entire neighborhood can be
thankful to you.
Thanks for some other informative site. The place else could I am getting that kind of info written in such a perfect way?
I have a undertaking that I’m simply now running on, and I have been at the glance out for such
information.
Hey, I think your site might be having browser compatibility issues.
When I look at your blog in Ie, it looks fine but when opening
in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
Hi, i think that i saw you visited my blog thus i came to “return the favor”.I’m trying to find things to enhance my web site!I suppose its
ok to use a few of your ideas!!
What’s up it’s me, I am also visiting this web site daily, this site
is actually pleasant and the people are truly sharing nice thoughts.
Nice post. I was checking continuously this weblog and I am inspired!
Extremely useful information specifically the ultimate phase 🙂 I care for such info much.
I used to be seeking this particular information for a long time.
Thank you and good luck.
I quite like reading a post that can make people think.
Also, many thanks for allowing me to comment!
Thanks designed for sharing such a fastidious thought, article is good, thats why i have read it entirely
Asking questions are genuinely pleasant thing if you are not understanding something completely, however this paragraph provides pleasant understanding even.
It’s difficult to find knowledgeable people in this partjcular subject, but
you sounnd like you know what you’re talking
about! Thanks
This post is genuinely a fastidious one it assists new
the web users, who are wishing in favor of blogging.
You actually make it seem so easy along with your presentation but I
to find this topic to be actually something that I feel I’d by no means understand.
It sort of feels too complex and very wide for me.
I’m taking a look ahead on your next submit, I will attempt to
get the dangle of it!
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My web
site looks weird when viewing from my iphone4. I’m trying to find a template or plugin that might be able to correct
this issue. If you have any recommendations, please share.
Thank you!
Do you mind if I quote a couple of your articles as long as I provide credit
and sources back to your blog? My blog site is in the very same area of interest
as yours and my users would really benefit from some of the information you present
here. Please let me know if this alright
with you. Thanks a lot!
Your way of telling the whole thing in this article
is genuinely fastidious, all be able to effortlessly be aware of it, Thanks a lot.
Hi, I do believe this is a great blog. I stumbledupon it ;
) I’m going to come back once again since I saved as a favorite it.
Money and freedom is the best way to change,
may you be rich and continue to help others.
I delight in, cause I discovered exactly what I
used to be taking a look for. You’ve ended my 4 day long hunt!
God Bless you man. Have a great day. Bye
Awesome post.
What’s up all, here every person is sharing such knowledge,
thus it’s pleasant to read this webpage, and I used to go to see
this weblog daily.
It’s remarkable in support of me to have a web site, which is
helpful in support of my knowledge. thanks admin
Great article, totally what I was looking for.
hi!,I like your writing very much! percentage we keep up a correspondence more approximately your post on AOL?
I need an expert in this area to unravel my problem. Maybe
that’s you! Looking ahead to peer you.
My relatives every time say that I am killing my time here at net, but I know I am getting familiarity every day by
reading thes nice articles.
It is truly a ɡreat ɑnd helpful pisce of information.
Ι’m glad tһat yoou ϳust shared tһiѕ helpful information witһ us.
Рlease stay us upp to daqte ⅼike thіs. Thanks for sharing.
My spouse and I stumbled over here from a different website and
thought I might as well check things out. I like what I see so now i am following you.
Look forward to checking out your web page repeatedly.
Looks realy great! Thanks for the post.
Hi, of course this post is in fact good and I have learned lot
of things from it about blogging. thanks.
I’m really loving the theme/design of your website.
Do you ever run into any web browser compatibility problems?
A few of my blog readers have complained about my blog not working correctly in Explorer but looks great
in Opera. Do you have any advice to help fix this problem?
An outstanding share! I have just forwarded this onto a coworker who was conducting a little homework on this.
And he actually bought me breakfast simply because I found it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending some time to discuss this subject here
on your blog.
cashpaydayusloans.com
secured personal loan
cash advance online
loan lenders
quick cash
http://www.pay2daymyloans.com
24 month loans
cash advance
credit check free
cash advance
http://www.paydayloanscashdv.com
apply for loan
payday express
cash advance
payday express
Quando é melhor instante para tomar Whey Protein.
naturally like your web site however you have to take a look at the spelling on quite a few
of your posts. Many of them are rife with spelling issues and I find it
very bothersome to tell the truth however I will certainly come
back again.
Phim sex hay Cô điệp viên xinh đẹp đáng thương.
Cô điệp viên Suzu Mitake là một đặc vụ của chính phủ Nhật Bản. Một lần thực hiện một nhiệm vụ đặc biệt mà chính phú giao
cho: trừ khử tổ chức tội phạm áo đen chuyên lừa bán và hiếp
dâm con gái nhà lành. Thật không may cho cô, trong quá trình thực hiện nhiệm vụ cô đã không để ý một gã
áo đen luôn theo dõi cô. Sex, tình dục quảng cáo tại sân bay
Kết quả cô bị tổ chức áo đen bắt được và chúng bắt đầu tra tấn cô bằng “dâm
hình”. Thật tội nghiệp cho cô khi từ sáng đến tối phải chịu sự
dày vò từ con cặc của chúng
http://cashpaydayusloans.com
same day payday loans
loans bad credit
first cash advance
quick cash advance online
pay2daymyloans.com
guarantor loans online
personal loans
direct lenders for bad credit loans
payday loans online
http://paydayloanscashdv.com
top payday loans
pay day loans
fast easy loans
personal loans
cialischmrx.com
viagra for females
generic cialis
viagra dick
generic cialis
http://www.viagrachbrx.com
viagra soft tabs
buy cheap viagra
viagra without presc
viagra online
http://www.viagranrxch.com
d hacks viagra
generic viagra
viagra male enhancement
buy cheap viagra online
Spot on with this write-up, I actually believe thgis web site needs
much more attention. I’ll probably be back again too read
throughh more, thanks for the information!
Ηеllo
I am thе web marketing аnd social relationships
assistant аt Peaches ɑnd Screams UK. Peaches
ɑnd Screams іs jսst one of the quickest evolving web-based underwear аnd sexx shop in the
UK and worldwide.
As pаrt ᧐f our updated business practice tߋ provide fascinating reads tо our consumers and site visitors,
we have decided tо permit guest blog posts оn our website.
Уοu cаn learn mοre about oᥙr guest posting guidelines ɑt https://peachesandscreams.co.uk/pages/write-for-us-become-our-sex-toys-and-lingerie-blogger but as ɑ generɑl rule оf
thumb, we wipl only accept ⅼonger, legitimate and incredibly іnteresting articles thɑt tke a rather relevant angle
on our core company activity. Ιn return, yߋur guest post
will be featured Ьefore our site visitors and sent ᧐ut via a newslettter tοo our subscriber base of 2 miⅼlion clients.
If үߋu аre іnterested, feel free to ѕend us your blog posts for oսr review at https://www.facebook.com/peachesandscreamsuk. Іf they arе reaⅼly good, we will post
them.
Ι lⲟoк forward to speaking with үou.
Regardѕ
Ekaterina
I am really impressed with your writing skills and also
with the layout on your weblog. Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it is rare to see a great blog like
this one these days.
The moment making a new kitchen or renovating an existing kitchen, it is a good idea and a
good idea to keep an open mind and pay attention to everything possible – towards the end of the process, it will definitely pay off.
Here are some common myths about the design process as well as its results:
“You can certainly add later” -the best planning is to take into account and add
all the characteristics of the kitchen at the planning
and as well as or renewal stages, and not at a later stage.
For example, in case you are not thinking about setting up a flat screen TELEVISION in the kitchen space or if you do not currently have a water dispenser, the best
thing is to put together for future installation of these also to
plan power, communication and water details and keep the choices available.
Also, since the kitchen is supposed to provide us for quite some time,
it is a good idea to measure all existing ergonomic solutions such as drawer drawers,
bathroom drawer style dishwashers, and so forth
Even if you are young and fit at the moment, these additions will prove themselves Mobility as
time goes on. Either way, if you prefer to deal with kitchen planning in stages – one aspect or
specific area at a time – make certain to plan carefully so that everything will fit in stylistic
and functional harmony when the kitchen will finally be complete.
” I do not have so many things” – whether we like it
or not, your kitchen has tremendous potential for ruining due to multitude of items kept in it, which is why space is plenty to store, This means that there is a relative absence of overhead storage
cabinetry, so it is important to balance function and style.
“Bigger Better” – Your kitchen space is large and you need a sizable kitchen, but then you
will find yourself going back and on from one machine to another, in addition to this situation,
preferably in the look stages, consider adding a job sink beside the refrigerator or Reduce the need to cross
these distances, and there is without doubt that these improvements
mean additional costs, and if your budget is limited, it is unquestionably worthwhile considering
a compact kitchen.
“I do not desire a designer ” -not every kitchen design project requires a
designer, but many individuals need someone to help us see the overall picture
and regulate the work. Renting consult with an architect
or designer does involve quite a lot of cost, but in the long
run it is all about keeping money and time. In case you have
a very clear picture of what you want, do not save the expense of a designer since it can best fulfill ideal.
Proper and efficient planning of your kitchen and
coordination between all the different professionals engaged in building your kitchen by a designer can keep
your project within the some budget, save you unnecessary money and
pointless problems and particularly keep your
sanity.
Hi! I understand this is somewhat off-topic however I needed to ask.
Does operating a well-established website such as yours take a massive amount work?
I am completely new to running a blog but I do write
in my diary everyday. I’d like to start a blog so I will be
able to share my experience and views online. Please let me know
if you have any suggestions or tips for brand new aspiring bloggers.
Appreciate it!
http://www.cialischmrx.com
girl viagra
buy cialis
herbal viagra dangers
buy cheap cialis
http://viagrachbrx.com
viagra heartburn
buy cheap viagra
buying cheap viagra
cheap viagra online
http://viagranrxch.com
viagra side effects alcohol
buy viagra
vega h viagra cream
buy viagra online
I absolutely love your blog and find most of your post’s to be precisely what I’m looking for.
can you offer guest writers to write content in your case?
I wouldn’t mind producing a post or elaborating on a few of the
subjects you write about here. Again, awesome web log!
Hmm is anyone else encountering problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Hey There. I found your blog using msn. This is an extremely well
written article. I will make sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll definitely comeback.
Today, I went to the beachfront with my children. I found
a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the
shell to her ear and screamed. There was a hermit crab inside and it
pinched her ear. She never wants to go back! LoL I know
this is entirely off topic but I had to tell someone!
I think the admin of this web site is in fact working hard in favor of his website,
for the reason that here every information is quality based data.
My coder is trying to persuade me to move to .net
from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on numerous websites
for about a year and am concerned about switching to another platform.
I have heard great things about blogengine.net. Is there a way I can import all my wordpress posts into it?
Any help would be greatly appreciated!
Hmm it looks like your blog ate my first comment (it
was super long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog blogger but I’m still new to everything.
Do you have any recommendations for novice blog writers?
I’d definitely appreciate it.
I know this web site presents quality dependent articles or reviews and other stuff, is there any other web page
which provides these stuff in quality?
Every time they fertilize your crops, you get more experience points.
In this featured article, we want to offer you some pay-to-click sites the creation of this new continent.
“I ‘m sorry drag one to increase your travel, I am using a knockout paintings.
Good blog post. I absolutely appreciate this site. Keep writing!
Thanks on your marvelous posting! I quite enjoyed reading it, you happen to
be a great author.I will be sure to bookmark your blog and will come back from now
on. I want to encourage one to continue your great job, have a nice
evening!
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s challenging
to get that “perfect balance” between usability and visual appearance.
I must say you have done a superb job with this.
Additionally, the blog loads very fast for me on Opera.
Outstanding Blog!
I visited many blogs but the audio feature for audio songs existing
at this website is really superb.
Hello to every , for the reason that I am really eager of reading this website’s post to
be updated regularly. It includes good stuff.
In fact when someone doesn’t understand after that its up to other visitors that they
will assist, so here it happens.
maryland live casino online
free games online no download no registration
free 777 slots no download
connect to vegas world
vegas slots casino online
cialis andorra sin receta [url=http://cialislet.com/]generic cialis[/url] tadalafil 0 5 prezzo.
Hello, I want to subscribe for this blog to obtain hottest updates, therefore where
can i do it please help.
What’s up everyone, it’s my first visit at this website, and
article is truly fruitful in support of me, keep up posting these types
of articles or reviews.
http://cashpaydayusloans.com
secured and unsecured loans
quick cash advance online
national payday loan
quick cash
http://www.pay2daymyloans.com
signature loans online
cash advance
consumer loan services
payday loans online
http://www.paydayloanscashdv.com
tax advance loans
personal loans
loan advance
payday loans online
Saved as a favorite, I really like your blog!
Hi there, I log on to your blogs on a regular basis.
Your writing style is witty, keep up the good work!
Do you have a spare moment? If so, then take this survey.
https://t.grtyo.com/vyil16lxkw?aff_id=29696&offer_id=2680&bo=2786,2787,2788,2789,2790 By answering
a few questions they’ll be able to find the best porn for you.
Very nice article, exactly what I needed.
What’s up, this weekend is fastidious in support of me, for the
reason that this occasion i am reading this wonderful informative article here at
my house.
Hi there to every one, the contents existing at this web page are truly amazing for people experience, well, keep up the
nice work fellows.
cialischmrx.com
revatio vs viagra
buy cialis online
viagra vs birth control
buy cialis online
http://viagrachbrx.com
female viagra reviews
buy cheap viagra
viagra alternative
buy cheap viagra online
http://www.viagranrxch.com
viagra low blood pressure
generic viagra
how to get a prescription for viagra
buy cheap viagra online
GN
hey there and thank you for your information – I’ve definitely picked up
anything new from right here. I did however expertise a
few technical issues using this web site, as I experienced
to reload the site lots of times previous to I could get it to load properly.
I had been wondering if your hosting is OK? Not that I am
complaining, but slow loading instances times will very frequently affect your placement in google and could damage your
high-quality score if advertising and marketing
with Adwords. Well I’m adding this RSS to my e-mail and can look out for much more of your respective interesting content.
Ensure that you update this again soon.
I simply could not depart your site prior to
suggesting that I actually enjoyed the standard info a person supply for your visitors?
Is gonna be again ceaselessly in order to
inspect new posts
Read reviews that talk about malware or viruses.
I do not even know how I finished up here, however I thought this
submit was good. I don’t realize who you’re but definitely you’re going to a famous blogger when you are not already.
Cheers!
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I’m quite certain I’ll learn plenty of new stuff right here!
Good luck for the next!
Do you have a spam issue on this blog; I also am
a blogger, and I was wondering your situation; many of us have created some nice methods and
we are looking to swap solutions with others, be
sure to shoot me an email if interested.
It’s the best time to make some plans for the future and it is time to be
happy. I’ve read this post and if I could I wish to suggest you few interesting things or tips.
Maybe you could write next articles referring to this article.
I wish to read even more things about it!
Nice weblog right here! Additionally your site a lot up very
fast! What host are you using? Can I get your affiliate hyperlink in your host?
I wish my web site loaded up as fast as yours lol
Excellent post. I used to be checking constantly this blog and I’m inspired!
Extremely useful information specially the ultimate
phase 🙂 I maintain such info much. I used to be looking for this particular information for
a long time. Thank you and good luck.
Excellent post however I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit more.
Cheers!
best place to buy cialis online reviews cialis cost where to buy cialis online
These are in fact great ideas in concerning blogging. You
have touched some fastidious things here. Any way keep up wrinting.
No matter if some one searches for his vital thing, so he/she
wants to be available that in detail, therefore that thing is maintained over here.
of course like your web site but you have to check the spelling on quite a few of your posts.
Several of them are rife with spelling issues
and I to find it very bothersome to inform the reality
on the other hand I’ll surely come again again.
Wow! At last I got a weblog from where I know how to
genuinely take helpful information concerning my study and knowledge.
Hi there, I do think your blog may be having browser compatibility problems.
When I look at your web site in Safari, it looks fine however, when opening in Internet Explorer,
it’s got some overlapping issues. I merely wanted to give you a quick heads up!
Besides that, wonderful website!
Begin 2019 recent with a brand-new wardrobe.
Unquestionably believe that which you said. Your favorite
justification appeared to be on the net the simplest thing to be aware of.
I say to you, I certainly get irked while people consider
worries that they plainly do not know about. You managed to hit the nail upon the
top and also defined out the whole thing
without having side effect , people can take a signal.
Will likely be back to get more. Thanks
Gеt 50 Minted coupons annd promo codrs for June
2018.
I just like the helpful information you provide on your articles.
I’ll bookmark your weblog and test once more right here frequently.
I’m rather certain I will learn many new stuff proper right here!
Best of luck for the following!
Valuable information. Lucky me I found your site accidentally, and I am stunned why this twist of fate did
not came about in advance! I bookmarked it.
Contact Yahoo
I go to see each day a few web pages and sites to read posts, except this webpage gives feature based posts.
sbobet indonesia
I visited multiple websites except the audio quality
for audio songs current at this website is in fact fabulous.
Ahaa, its fastidious conversation about this article here at this web site, I have read all that, so now me also commenting here.
Ԍet alerts afteг we adԀ neew Spartan Race coupons.
I am regular reader, how are you everybody?
This article posted at this web page is in fact nice.
It’s actually very difficult in this active life to listen news on Television,
thus I just use the web for that purpose, and obtain the newest information.
I think the admin of this web page is truly working hard in support of his web page, since here every
data is quality based information.
buying cialis online cialis 5mg order cialis online
Way cool! Some very valid points! I appreciate you penning this article plus the rest of the website is very good.
You always want to be as safe as possible.
I don’t know if it’s just me or if everybody else experiencing issues with your site.
It seems like some of the text on your content are running off the screen. Can someone else please comment and
let me know if this is happening to them as well? This might be a
problem with my web browser because I’ve had this happen before.
Appreciate it
A person necessarily help to make severely articles I might
state. That is the first time I frequented your website page and thus far?
I surprised with the research you made to make this
actual publish incredible. Excellent task!
Greetings from Carolina! I’m bored at work so I decided to
check out your website on my iphone during lunch break.
I enjoy the info you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my mobile .. I’m not even using WIFI, just 3G ..
Anyways, fantastic blog!
Why viewers still use to read news papers when in this technological
world everything is available on net?
Hey, I think your blog might be having browser compatibility issues.
When I look at your website in Firefox, it looks
fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
Thank you for any other wonderful post. The place
else may just anyone get that type of info in such an ideal way
of writing? I’ve a presentation subsequent week, and I’m at the
search for such info.
Appreciating the persistence you put into your site and in depth information you provide.
It’s nice to come across a blog every once in a while that isn’t the same old rehashed information. Fantastic read!
I’ve bookmarked your site and I’m adding your RSS feeds to
my Google account.
Hi my loved one! I wish to say that this article is amazing, great written and include approximately all significant infos.
I would like to peer extra posts like this .
It’s truly very complicated in this busy life to listen news on TV, so I simply use
web for that reason, and take the newest information.
Hence, with online casino you might be exposed to the virtual world of gaming, providing ultimate and amazing experience at the
place along with your ease as well. This is why you will need to consider other players tips and methods while trying to build your own. His hip problem continues to be addressed during the
season as well as the offseason.
If some one wants expert view on the topic of running a blog then i suggest him/her to
pay a quick visit this blog, Keep up the nice work.
My spouse and I stumbled over here coming from a different web address and thought I may
as well check things out. I like what I see so now i’m following
you. Look forward to finding out about your web page
repeatedly.
Your style is very unique compared to other people I’ve
read stuff from. Thanks for posting when you’ve got the
opportunity, Guess I will just bookmark this blog.
I enjoy what you guys are up too. This type of clever work and reporting!
Keep up the good works guys I’ve incorporated you guys to my blogroll.
Have you ever considered publishing an ebook or guest authoring
on other blogs? I have a blog centered on the same subjects you discuss and would really like to have you share some
stories/information. I know my subscribers would appreciate your work.
If you are even remotely interested, feel free to send me an e-mail.
Upload a 30-second video to You – Tube to tell us what Rune – Scape means to you, and you could win entry to the premiere of the documentary.
ZZ Top: there are two versions related to the origin of the band name.
The following are certain Betfair trading basic strategies:.
Hi, its fastidious piece of writing about media print, we all know media is a enormous source of data.
agen bola
I don’t even know how I ended up here, but I thought this post
was great. I don’t know who you are but definitely you
are going to a famous blogger if you are not already 😉 Cheers!
I do not even understand how I finished up here, but I thought this post was once good.
I do not recognize who you might be but certainly you’re
going to a famous blogger should you are not already.
Cheers!
Great information. Lucky me I recently found your website by accident (stumbleupon).
I’ve book-marked it for later!
Everything is very open with a clear explanation of the challenges.
It was really informative. Your website is very helpful.
Thank you for sharing!
I’m not sure exactly why but this blog is loading incredibly slow
for me. Is anyone else having this problem or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
I’m gone to tell my little brother, that he should also go to see this blog on regular basis to obtain updated
from newest reports.
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a number of websites for about
a year and am nervous about switching to another platform.
I have heard great things about blogengine.net. Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
Hello! I’ve been reading your weblog for a long time now and finally got the courage to go ahead and
give you a shout out from Humble Texas! Just wanted to tell you
keep up the excellent job!
http://www.cialischmrx.com
where to buy generic viagra
cheap cialis online
free viagra coupon
buy cheap cialis
http://www.viagrachbrx.com
viagra where to buy online
buy viagra online
viagra 200mg price in india
buy cheap viagra
http://www.viagranrxch.com
who prescribes viagra
buy viagra
viagra active ingredient
buy cheap viagra
viagra generic
I was able to find good advice from your content.
http://cialischmrx.com
what viagra feels like
buy cheap cialis
viagra hypertension
buy cheap cialis online
viagrachbrx.com
generic viagra cost
generic viagra
viagra mechanism of action
cheap viagra online
http://viagranrxch.com
new viagra girl
viagra online
viagra young
buy cheap viagra online
Betting on MLB baseball is both fun and profitable. When he says “Take one more step and I’m gonna shoot you” he
means it. Bureau Uniform–Complete Red Dead Redemption costumes
List.
http://www.cialischmrx.com
viagra need prescription
buy cheap cialis online
how to get free viagra
buy cialis online
http://www.viagrachbrx.com
buy viagra new york
buy viagra online
viagra prescription
buy cheap viagra online
http://www.viagranrxch.com
viagra 99 dollars
cheap viagra
viagra uses
viagra online
These people will most likely are the gambler’s family,
friends and co-workers. Also, double down if the dealer up card
is often a 3, 4, five to six and you really are using a 9.
Throughout the years the gambling casinos have evolved themselves and the grandeur and glamour
which is linked to the casinos to date might be
credited on the show managers of Las Vegas.
This info is invaluable. How can I find out more?
Here are some golf short game practice tips which can help you polish that division of your game;-Use a strong
and gentle grip to further improve your green side play.
The examples below assume the minimum bet of 1 per
line (40) together with feature wager (40).
Those same gloves will likely protect you a hot barrel should you be inside the hot seat, shoot
wise.
Magnificent web site. Lots of helpful information here.
I’m sending it to several friends ans additionally sharing
in delicious. And naturally, thank you to your effort!
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get
listed in Yahoo News? I’ve been trying for a while but I never seem to get there!
Cheers
Your method of explaining all in this piece of writing is really fastidious,
all be able to simply be aware of it, Thanks a lot.
I was able to find good advice from your articles.
Wow, wonderful blog format! How long have you ever been blogging
for? you made running a blog glance easy. The whole look of your web site is fantastic, let alone the content material!
精仿手表, 顶级精仿手表,超A精仿手表,精仿腕表,, 一比一精仿手表
You need to be a part of a contest for one of the greatest sites on the
internet. I will recommend this site!
This is really interesting, You’re a very skilled
blogger. I have joined your feed and look forward
to seeking more of your excellent post. Also, I’ve shared your web site in my
social networks!
It’s great that you are getting thoughts from this article as well as
from our dialogue made at this time.
I know this web page provides quality based articles or
reviews and other information, is there any other web page which provides these kinds
of things in quality?
Quality content is the crucial to invite the viewers to pay a quick visit the
web site, that’s what this web site is providing.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thanks
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how could we communicate?
I like the valuable information you provide in your articles.
I’ll bookmark your weblog and check again here regularly. I am quite sure I’ll learn many new stuff right here!
Best of luck for the next!
대전출장안마 http://skanma.com
대전출장마사지 http://skanma.com
대전출장맛사지 http://skanma.com
유성출장안마 http://skanma.com
유성출장마사지 http://skanma.com
유성출장맛사지 http://skanma.com
세종출장안마 http://skanma.com
세종출장맛사지 http://skanma.com
세종출장맛사지 http://skanma.com
공주출장안마 http://skanma.com
공주출장마사지 http://skanma.com
공주출장맛사지 http://skanma.com
계룡출장안마 http://skanma.com
계룡출장마사지 http://skanma.com
계룡출장맛사지 http://skanma.com
청주출장안마 http://skanma.com
청주출장마사지 http://skanma.com
청주출장맛사지 http://skanma.com
max amount of sildenafil
generic viagra at walmart
sildenafil australia over the counter
[url=http://viagrarow.com/]viagra generic[/url]
If you want to grow your knowledge just keep visiting this
site and be updated with the most up-to-date news update posted here.
http://www.cashpaydayusloans.com
cash advance direct lenders
personal loans for bad credit
direct lenders payday loans
quick cash
pay2daymyloans.com
advance payday
cash advance
loans for bad credit in pa
cash advance
http://www.paydayloanscashdv.com
short term loan bad credit
personal loans
need money fast bad credit
payday loans
http://www.cashpaydayusloans.com
sonic payday
quick cash advance online
starter loans
same day loans
pay2daymyloans.com
payday advance direct lenders
payday loans online
loan approval
payday loans online
paydayloanscashdv.com
loans for students
payday loans
cashloan
personal loans
Hi, Neat post. There is a problem together wigh your site in web explorer, may check
this… IE still iis the marketplace chief and a good component off folks will leave out youyr great writing
because of this problem. http://go.dadebaran.ir/index.php?url=http://www.edelweis.com/UserProfile/tabid/42/UserID/103030/Default.aspx
Hi, Neat post. There is a problem together with your site in web explorer, may check this…
IE still is the marketplace chief and a good
component of folks will leave out your great writing because of
this problem. http://go.dadebaran.ir/index.php?url=http://www.edelweis.com/UserProfile/tabid/42/UserID/103030/Default.aspx
I don’t even know how I ended up here, however I thought this put up used to be good.
I don’t know who you are however definitely you’re going to
a well-known blogger for those who aren’t already.
Cheers! poker
First off I want to say superb blog! I had a quick question which I’d like to
ask if you do not mind. I was curious to find out
how you center yourself and clear your thoughts before writing.
I have had a difficult time clearing my thoughts in getting my thoughts out there.
I truly do enjoy writing however it just seems like the first 10 to
15 minutes are generally lost simply just trying to figure out how to
begin. Any ideas or tips? Kudos!
스포츠중계
실시간스포츠중계
일본야구중계
무료스포츠중계
메이저리그중계
nba중계
mlb중계
해외스포츠중계
해외축구중계
무료스포츠중계
프리미어리그중계
스포츠무료시청
스포츠중계무료시청
프리메라리가중계
epl중계
스포츠중계
실시간스포츠중계
일본야구중계
무료스포츠중계
메이저리그중계
nba중계
mlb중계
해외스포츠중계
해외축구중계
무료스포츠중계
프리미어리그중계
스포츠무료시청
스포츠중계무료시청
프리메라리가중계
epl중계
When someone writes an post he/she retains the image of
a user in his/her mind that how a user can understand it.
Thus that’s why this paragraph is perfect. Thanks!
Widely available in Asian markets like Thailand, China,
and Malaysia, live casinos are increasingly becoming a favorite among customers.
Material that discusses positively, weapons, ammunition or any type
of harmful substances. After having many post game discussions with myman screaming children I have
realized at times I am crazy, there i said it, and I know i’m not the only one out there.
It is perfect time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I want to suggest you some interesting things or tips.
Maybe you could write next articles referring to this article.
I wish to read even more things about it!
http://лабок.рф/devushki-v-losinax-62-fotografii/ попки в лосинах фото
広島県の家族葬あらそうはこちら。ほんとです。広島県の家族葬の隠しごとをを持ち出してくる。刺し手取材します。
Wow, wonderful weblog format! Ηow long һave
yoᥙ ever been blogging fоr? yօu make blogging glance
easy. Τhe t᧐tal looҝ of үоur website іs magnificent,
ɑs well as the content!
This article is in fact a fastidious one it helps new internet viewers,
who are wishing in favor of blogging.
Hi there just wanted to give you a brief heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same results.
I got this web page from my pal who told me on the topic of this site and at the moment this time I am browsing this site and reading very
informative content here.
I do accept as true with all of the ideas you’ve presented to your post.
They’re very convincing and can definitely work.
Nonetheless, the posts are too quick for starters. May just you please
lengthen them a little from next time? Thank you for the post.
http://www.cashpaydayusloans.com
quick cash payday loans
loans online
loans for bad credit no guarantor no fees
loans with bad credit
http://www.pay2daymyloans.com
personal loan for bad credit
pay day loans
native american loans
personal loans
paydayloanscashdv.com
quick and easy loans
payday loans online
payday loans direct lender bad credit
payday loans online
What i do not realize is in reality how you’re not actually a lot more smartly-favored than you
may be now. You are very intelligent. You recognize
thus considerably when it comes to this subject, produced
me in my view consider it from so many varied angles.
Its like women and men aren’t fascinated until it is one thing to do with Lady gaga!
Your own stuffs outstanding. At all times take care of it
up!
I’m impressed, I must say. Seldom do I come across a blog that’s both educative and amusing,
and without a doubt, you have hit the nail on the head.
The problem is an issue that too few folks are speaking intelligently about.
Now i’m very happy that I found this during my search for something regarding this.
http://www.cashpaydayusloans.com
payday loan direct lenders only
payday loans direct lender
unsecured loans with bad credit
loans bad credit
pay2daymyloans.com
money loans with bad credit
payday loans online
one hour loans
payday express
http://www.paydayloanscashdv.com
1000 loans
payday loans
poor credit personal loans
personal loans
For example if you are having ace 5 and you raise re flop and some one else re raises and you decide
to fold. So from our earliest days of camping we spent a little extra and
made sure that we had a good waste water tote.
Bureau Uniform–Complete Red Dead Redemption costumes List.
Hello i am kavin, its my first occasion to commenting anywhere, when i read this post i thought
i could also make comment due to this good article.
Hi, I do believe this is an excellent blog. I stumbledupon it 😉 I’m going to return yet again since I book-marked it.
Money and freedom is the best way to change, may you be rich and continue to guide other people.
http://alaturka.info
# Amos 17.01.2019 11:25
I look in on day-to-day a not multitudinous entanglement pages and websites to heart on culmination, but this
webpage offers supremacy based articles.
I just couldn’t go away your website prior to suggesting that I actually enjoyed the standard info a person supply to
your visitors? Is gonna be again frequently in order
to check up on new posts
Hello to every body, it’s my first pay a quick visit of this weblog; this weblog includes awesome and genuinely excellent data designed for visitors.
Inspiring story there. What happened after? Good luck!
is it legal to buy viagra online viagra australia online doctor prescription for viagra
Hello, its nice paragraph on the topic of media print, we all be aware of media
is a wonderful source of facts.
Excellent post. I used to be checking constantly this blog and
I’m inspired! Extremely useful info specifically the final part 🙂 I care for such info much.
I used to be looking for this certain info for a very long time.
Thanks and best of luck.
Hey there superb blog! Does running a blog such as this
take a large amount of work? I have absolutely no knowledge of coding but
I had been hoping to start my own blog soon. Anyhow, should you have any ideas or techniques for
new blog owners please share. I know this is off topic nevertheless I just had to ask.
Kudos!
What’s up, yup this piece of writing is truly fastidious
and I have learned lot of things from it about blogging.
thanks.
I loved as much as you’ll receive carried out right here. The sketch is tasteful, your
authored subject matter stylish. nonetheless, you command get bought an shakiness over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly the same
nearly a lot often inside case you shield this
hike.
Great weblog right here! Also your site rather a lot up very fast!
What host are you using? Can I am getting your associate hyperlink for your host?
I want my web site loaded up as quickly as yours lol
It’s remarkable to visit this site and reading the views of all mates on the topic of this article, while
I am also zealous of getting know-how.
This is my first time pay a quick visit at here and i am
actually pleassant to read all at one place.
Hurrah! Finally I got a website from where I know how
to actually get useful data regarding my study and knowledge.
I like the helpful info you provide in your articles.
I will bookmark your weblog and check again here regularly.
I’m quite sure I will learn many new stuff right here!
Good luck for the next!
Wow, superb weblog structure! How long have you ever been running a blog for?
you made blogging glance easy. The total look of your site is fantastic, let
alone the content!
http://www.cashpaydayusloans.com
need cash now
loans with bad credit
direct lenders for payday loans
personal loans for bad credit
http://www.pay2daymyloans.com
loans with no credit
payday express
short term loan lenders
payday loans
paydayloanscashdv.com
pay day lenders
cash advance
emergency money
payday loans online
Hi there everyone, it’s my first go to see at this site,
and paragraph is really fruitful in favor of me, keep up posting these articles
or reviews.
Do you like cam girls with big boobs? If so, then https://www.camgirl.pw/tag/bigboobs/ is a must
visit site. You’ll see all kinds of sexy girls there with big boobs.
Do you have any video of that? I’d like to find out some additional information.
Undeniably imagine that that you said. Your favourite justification appeared to be on the net the simplest thing
to be mindful of. I say to you, I certainly get annoyed while folks think about concerns that they just do not recognise about.
You controlled to hit the nail upon the top and defined out the entire thing with no
need side-effects , folks can take a signal. Will probably be back to get more.
Thank you
Wow, wondеrful weblog format! How lengthy have you been running a blog for?
yyou mɑde blogging look easy. The full glance of your website is magnificent,
aѕ well as thee contеnt!
Good day! Do you know if they make any plugins to help with
Search Engine Optimization? I’m trying to get my
blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Thanks!
It’s in fct very difficult in this busy life to liten news on TV,
so I jujst use world wide web for that purpose, and obtain the hottest information. http://clubstoreexp.com/forum/index.php?action=profile;u=41483
It’s in fact very difficult in this busy life
to listen news on TV, so I just usee world wide web ffor hat purpose, and obtain the hottest information. http://clubstoreexp.com/forum/index.php?action=profile;u=41483
I’ve learn a few excellent stuff here. Certainly price bookmarking for revisiting.
I wonder how so much effort you place to make this kind of fantastic informative website.
This is a topic that is close to my heart…
Take care! Exactly where are your contact details though?
I blog often and I seriously appreciate your content.
This great article has really peaked my interest. I will take a
note of your blog and keep checking for new details about
once per week. I opted in for your RSS feed as well.
Herl, 53, a Colorado native, went to college in Arizona but in 1986 went on tour doing security for hard rock band Judas Priest.
Unquestionably believe that which you stated.
Your favorite justification seemed to be on the internet the
simplest thing to be aware of. I say to you,
I certainly get annoyed while people think about worries that they
just do not know about. You managed to hit the nail
upon the top and also defined out the whole thing
without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
The gartel, or belt is worn bby Orthodox men during prayer, itt is generall worn by Hasidic men. Knights
could fasten leather as armor to protect most of their body ranging from their feet,
legs, chest, arms, and even their head. The beauty’s white menswear-inspired suit is a
classy professional lolok for spring or summer.
Hi there, You’ve done a fantastic job. I’ll definitely digg it and personally recommend
to my friends. I am sure they’ll be benefited from this website.
Excellent weblog right here! Additionally your website rather a lot up very fast!
What web host are you using? Can I am getting your
associate hyperlink to your host? I want my website loaded up as quickly as
yours lol
Have you ever considered writing an e-book or guest authoring on other sites?
I have a blog centered on the same information you discuss and would really like to have you share some stories/information. I know my subscribers
would enjoy your work. If you are even remotely interested, feel free to shoot me an e mail.
I am curious to find out what blog system you have been utilizing?
I’m having some small security problems with my latest website and
I’d like to find something more risk-free. Do you have any suggestions?
Nice blog here! Also your web site loads up fast!
What host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
canadian pharmacy viagra buy cheap viagra canadian pharmacy viagra
Outstanding post but I was wanting to know if you
could write a litte more on this topic? I’d be very
thankful if you could elaborate a little bit further.
Cheers!
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog in Firefox, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a
quick heads up! Other then that, wonderful blog!
Hello just wanted to give you a brief heads up and let you know a few of
the images aren’t loading properly. I’m not sure why but I think its a
linking issue. I’ve tried it in two different internet
browsers and both show the same outcome.
This work reveals some sort of poetic mood and everyone would simply be attracted by it.
A vector path, it doesn’t matter what the twists and
turns are, is often more elastic and scalable. It is maybe probably the most worldwide of mediums,
at its practice and in its range.
hey there and thank you for your information – I have certainly picked up something new
from right here. I did however expertise several technical issues using this web site, as I experienced to
reload the website many times previous to I
could get it to load properly. I had been wondering if your hosting is OK?
Not that I’m complaining, but slow loading instances times will sometimes affect your placement in google and could damage your high quality score if advertising
and marketing with Adwords. Well I am adding this RSS to my e-mail and can look out for much more
of your respective exciting content. Make sure you update this again very soon.
You really make it appear so easy with your presentation but I find this matter to be really something that I
believe I might by no means understand. It sort of feels too complex and extremely large for me.
I am looking ahead for your subsequent submit, I will try to get the cling of it!
Excellent goods from you, man. I’ve keep in mind your stuff
prior to and you’re just extremely fantastic.
I actually like what you have received here, certainly like what you’re stating and the way during which
you are saying it. You’re making it enjoyable and you continue to care for to
stay it wise. I can not wait to read much more from
you. That is actually a wonderful site.
Hi! I know this is kind of off-topic but I had to ask.
Does building a well-established blog such as yours take a lot of work?
I am completely new to writing a blog however I do write in my diary on a daily basis.
I’d like to start a blog so I can easily share my experience and
thoughts online. Please let me know if you have any ideas or tips
for new aspiring bloggers. Thankyou!
✓인터넷가입사은품많이주는곳 ✓인터넷가입현금지원
✓엘지유플러스 ✓SK브로드밴드 ✓KT인터넷 ✓SK인터넷 ✓엘지인터넷 ✓인터넷티비
✓기가인터넷 ✓인터넷현금 ✓전주인터넷가입 IT넘버원 업계 1위!
☏ 1600-2636
Hi! This is kind of off topic but I need some help from an established blog.
Is it hard to set up your own blog? I’m not very
techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to start.
Do you have any points or suggestions? Thanks
Whoa! This blog looks just like my old one! It’s
on a completely different topic but it has pretty much the same
page layout and design. Superb choice of
colors!
I am sure this paragraph has touched all the internet viewers, its really really fastidious piece of writing on building up new webpage.
is there a female sildenafil that works http://triviagra.com/ daily dosage for sildenafil sildenafil citrate generic
viagra 100mg is viagra for lasting longer
Hey would you mind letting me know which web host you’re utilizing?
I’ve loaded your blog in 3 different browsers and I must say this blog loads a lot
quicker then most. Thanks a lot, I appreciate it!
Link exchange is nothing else but it is only placing the
other person’s weblog link on your page at proper place and other person will also do similar in support of
you.
Hi, I think your blog may be having web browser compatibility
problems. When I take a look at your website in Safari, it looks
fine but when opening in I.E., it has some overlapping issues.
I just wanted to provide you with a quick heads up! Besides that, great website!
Everyone loves it when folks get together and share views.
Great blog, continue the good work!
Hmm is anyone else experiencing problems with the images on this
blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
Just desire to say your article is as astounding.
The clarity in your post is just great and i can assume
you are an expert on this subject. Well with your permission let me to grab
your RSS feed to keep updated with forthcoming post.
Thanks a million and please carry on the rewarding work.
Excellent write-up. I absolutely appreciate this site.
Thanks!
Fascinating blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your theme. Thank you
It’s an remarkable piece of writing in favor of
all the online viewers; they will take benefit from it I am sure.
三重県の一番安い葬儀屋の目からうろこっての。分別かた付けるします。三重県の一番安い葬儀屋をいきさつ使うのか。警察署序題。
Hello There. I found your blog using msn. This is an extremely well written article.
I’ll be sure to bookmark it and come back to read
more of your useful information. Thanks for the
post. I’ll definitely comeback.
My spouse and I stumbled over here coming from a different web page and thought I might check things out.
I like what I see so i am just following you.
Look forward to looking into your web page repeatedly.
I love what you guys tend to be up too. This type of clever work and exposure!
Keep up the fantastic works guys I’ve added you guys to
blogroll.
Nice blog here! Also your site loads up very fast! What host are you
using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
I am in fact glad to glance at this website posts which carries tons of
valuable information, thanks for providing such data.
http://www.cashpaydayusloans.com
personal loan
quick cash advance online
5000 loan
cash advance online
http://pay2daymyloans.com
i need a loan but i have bad credit
payday express
samedayloan
cash advance
paydayloanscashdv.com
loan quote
payday loans online
small payday loans
payday loans
Contact Yahoo
taking sildenafil for 10 years [url=http://viagrapid.com]viagra pills[/url] my kid
took sildenafil
http://www.cashpaydayusloans.com
1 hour payday loans
loans with bad credit
secured personal loan
quick cash advance online
http://pay2daymyloans.com
loan interest rate
personal loans
payday loans az
personal loans
paydayloanscashdv.com
fast cash advance
payday loans online
cash advantage
payday loans
Hey are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and set
up my own. Do you require any coding expertise to make your own blog?
Any help would be greatly appreciated!
I every time emailed this weblog post page to all my friends, since if like to read it then my friends will too.
Yes! Finally something about xe nâng tay cao.
Just desire to say your article is as amazing. The clearness in your put up is
simply excellent and that i could assume you’re an expert in this subject.
Well together with your permission let me to snatch your feed to keep updated with forthcoming post.
Thanks 1,000,000 and please continue the rewarding work.
Its like you read my mind! You seem to grasp a lot about this, like you
wrote the ebook in it or something. I think that you simply could
do with a few percent to force the message house a bit, but
other than that, that is great blog. An excellent read.
I will certainly be back.
Awesome article.
Hey there! This post could not be written any better!
Reading this post reminds me of my good
old room mate! He always kept talking about this.
I will forward this article to him. Pretty sure he will have a good read.
Thank you for sharing!
福島県で火葬だけする費用を附註するよ。年譜です。福島県で火葬だけする費用の音信を知りたい。だんびら書類処理能力。
مركز ال جى نعتبر متخصصون ال جى الاوائل فى مصر و اكبر خدمات تبحث عنها عندما يصادفك
مشكلة فى مكانس ال جى .حيث اننا نوفرالخدمةبالكامل فى منزل العميل ولا يتم
سحب الميكروويف نهائيا من مكان اقامتك هذا بالاضافة الى اننانمتلك طاقم عمل من
مهندسينمدربين على التصليح الفورى لجميع مشاكل اجهزة ال جى الثلاجات و تغيير كل قطع الغيار العاطلةبأخرى ذات جودة عاليةهذا ب الاضافة تميزهم
بالمهارة العالية و التى تتيح
لهم الصيانةفورا منزل العميل و
الخبرة التى تمتد الى سنواتطويلة لا تقل عن 25عام متواصلة فى صيانة شاشات ال
جى
اذا كنت فى احتياج لعمل صيانة ثلاجات ال جى فى المنزل و كل ما عليك هو الاتصال
بنا على خدمة صيانة ميكروويف ال جى فى مصر نحن فى
انتظارك اينما كنت نحن نخدم جميع المحافظات لنسعى أن نكون الاول فى مجال عملنا و الاسرع فى التعامل معك و نقدم لك الصيانة فى
جميع موديلات شاشات ال جى
Your means of describing all in this paragraph is genuinely good,
all can easily understand it, Thanks a lot.
great post, very informative. I wonder why the other experts of this sector do not understand
this. You must continue your writing. I’m confident, you’ve a great readers’ base already!
Good answer back in return of this query with genuine arguments and
describing the whole thing about that.
Heya just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different
browsers and both show the same results.
Way cool! Some extremely valid points! I appreciate you writing this post and also the rest of
the site is also very good.
My brother recommended I would possibly like this website.
He was totally right. This publish actually made my day.
You cann’t imagine simply how so much time I had spent
for this information! Thanks!
Some really howling work on behalf of the owner of this web site, absolutely outstanding
written content. http://mypicvideo.com/forum/index.php?action=profile;u=54576
Some really howling work on behalf of the owner of this web site,
absolutely outstanding written content. http://mypicvideo.com/forum/index.php?action=profile;u=54576
Way cool! Some extremely valid points! I appreciate you penning this article and also the rest of the website is also really good.
Hello everyone, it’s my first pay a quick visit
at this web site, and paragraph is really fruitful in support
of me, keep up posting these posts.
when will a generic sildenafil be available in the
us
https://salemeds24.wixsite.com/clomid buy online order clomid
what are the dangers of using sildenafil
dapoxetine sales
sildenafil for sale in new zealand
viagra online india generic viagra online pharmacy safe viagra online
I do not even know how I stopped up right here, but I believed this post used to be good.
I do not recognise who you might be but definitely you’re going to a well-known blogger if you happen to are not
already. Cheers!
I was wondering if you ever considered changing the layout of
your website? Its very well written; I love what youve got to
say. But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2 pictures.
Maybe you could space it out better?
Contact Yahoo
This is the right webpage for anyone who wishes to find out about this topic.
You know a whole lot its almost hard to argue with you
(not that I actually would want to…HaHa). You definitely put a brand new spin on a subject that
has been written about for many years. Wonderful stuff, just wonderful!
online drugstore
http://canadianonlinepharmacywest.com/
mail order prescriptions from canada
Greetings from Carolina! I’m bored at work so I decided to check out your
website on my iphone during lunch break. I really like the knowledge you
provide here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded
on my phone .. I’m not even using WIFI, just 3G .. Anyways, excellent site!
Hey There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and return to read more of
your useful info. Thanks for the post. I’ll definitely comeback.
What i do not understood is in reality how you are now not really a lot more well-favored
than you may be right now. You’re very intelligent.
You realize thus significantly relating to this matter, produced
me personally consider it from numerous numerous
angles. Its like men and women don’t seem to be fascinated
except it’s something to accomplish with Girl gaga!
Your individual stuffs great. At all times care for it up!
Really….such a valuable web page. http://andrewnevins.co.uk/nyg01
Playing all day and hours, going really deep and hardly generating than your buy-in back.
They could have had formed other winnable poker hands had they not devoted to a particular suited card
combination. With this article we are going to try and
put some light about the fun much of this highly intense game.
Excellent post! We are linking to this particularly great article on our site.
Keep up the great writing.
Hi! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a community in the same niche.
Your blog provided us useful information to work
on. You have done a extraordinary job!
I simply couldn’t depart your website before suggesting that I actually enjoyed the standard
information an individual supply to your guests?
Is gonna be again regularly to investigate cross-check new posts
What i do not realize is in fact how you’re no longer really a lot more neatly-preferred than you might be right now.
You’re so intelligent. You understand thus
significantly in relation to this matter, produced me individually imagine
it from a lot of various angles. Its like women and men are not interested except it’s one thing to accomplish with Girl gaga!
Your personal stuffs great. Always take care of it up!
Great post. I was checking continuously this blog and
I’m impressed! Extremely helpful info particularly the last part :
) I care for such info a lot. I was seeking
this particular information for a long time.
Thank you and good luck.
Sweet blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed
in Yahoo News? I’ve been trying for a while but I never
seem to get there! Thank you
wonderful points altogether, you simply won a emblem
new reader. What could you suggest about your post that you just
made a few days ago? Any positive?
Download Football Manager 2018 with Crack!
Its Working! To know more visit : http://www.downloadfootballmanager2018.com
When I initially commented I appear to have clicked on the -Notify me when new
comments are added- checkbox and now whenever a comment is added I recieve 4 emails with the same comment.
There has to be a means you can remove me from that service?
Appreciate it!
Magnificent goods from you, man. I have take into accout
your stuff prior to and you’re just too wonderful. I really like
what you’ve received here, really like what you are stating and
the way in which during which you are saying it. You make it entertaining and you still take
care of to stay it wise. I can not wait to read much more
from you. This is actually a tremendous website.
With havin so much content do you ever run into any problems of plagorism or copyright violation? My site has a lot of completely unique content I’ve either written myself
or outsourced but it looks like a lot of it is popping it up all over the web without
my permission. Do you know any techniques to help prevent content from being ripped off?
I’d certainly appreciate it.
http://www.xyulenews.com、榆榇榈资讯频道、榆榇榈
If some one wishes to be updated with newest technologies afterward he must be visit this web site and
be up to date all the time.
There are horny girls in your area who want to fuck so bad.
Are you seeking a fuck buddy? Do you want to have some no strings attached fun? If you are,
then http://meethornygirls.xyz is the place to go. All the girls there are horny and
they put out.
It’s actually a great and helpful piece of info. I am glad
that you just shared this useful info with us. Please keep us up to
date like this. Thanks for sharing.
Greetings! Very helpful advice in this particular post!
It’s the little changes which will make the greatest changes.
Thanks for sharing!
Plenty of business owners expect that live speak is just perfect for internet sites in which seeking to crank out online store sales.
Positive, answering pre-purchase issues might help help you save profits and chitchat
staff could press shoppers to the particular sales — nevertheless any internet site can benefit from this straightforward tool.
Visualize a cafe that is intending to build reservations
in addition to strategic location visits. Dwell talk can help
help in individuals reservations along with may help together with minimal
things like clarification associated with directions.
The majority of speak solutions is going to assimilate along with cellular phones
thus possibly a small business such as a cafe might
have a member of staff overseeing the particular survive
chat. This is certainly economical option that can produce noticeable results.
6. Work with an quit popup offer.
Driving traffic to your web page just isn’t cheap. Despite the fact that are not jogging pay-per-click
traffic and spending money on any website visitor individually, the determination that will SEO and interpersonal
press advertising demands primarily assigns a fiscal price to help almost every person who countries for your
website.
The majority of site visitors in which get away
from can never come back, so why not use each out there selection in order to turn them?
Pop-up quit delivers complete a great job during raising conversion process rates.
Also the slightest alteration grows needs to be welcomed.
As time passes this particular leave record will surely improve your entire
go back with investment.
Associated: Do Video clip Obliterate Wording Subject material Advertising?
7. Include things like testimonails from others and
also confidence signals.
If the targeted traffic trust your enterprise, they
will likely often be more prone to make purchases and submit their own information. Such as testimonails from others out of clients or perhaps
well known business soulmates is a sensible way to develop trust.
Exhibiting honors, acknowledgement or even accreditations including the Superior Business Agency
will likely create your visitors feel appointing you.
It’s in fact very complex in this busy life to listen news on TV, so I just use web for that reason, and get the most up-to-date information.
Simply wish to say your article is as astounding. The clearness to your publish is simply great and that
i could assume you’re a professional on this subject.
Well along with your permission let me to grab your RSS feed to keep up to date with drawing close post.
Thanks a million and please carry on the rewarding work.
Appreciating the dedication you put into your website
and in depth information you offer. It’s awesome to come across a
blog every once in a while that isn’t the same unwanted rehashed information.
Great read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
BrainForsyth order cialis buy generic cialis cialis 20 costo
[url=http://buyscialisrx.com]cialis online[/url]
s where support and training really comes in handy.
All one has to do is hold off a raise on strong hands
and the advantage of bluffing form this position is unprecedented.
Gambling can be a very intimidating experience to a new gambler
especially if the new gambler is not familiar with gambling lingo.
This is my first time pay a quick visit at here and i am in fact pleassant to read all at alone place.
I love your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to construct my own blog
and would like to know where u got this from. kudos
I all the time emailed this web site post page to all
my friends, since if like to read it then my links will too.
In these instances, we ask you to respect the decision of our authors
and refrain from copying their material from the site in anyway.
Another convenient way of disposing of excess gray water is
using it to extinguish campfires at the end of the day.
Gambling can be a very intimidating experience to a new gambler especially if the new gambler
is not familiar with gambling lingo.
Thank you a bunch for sharing this with all people you really realize what you are talking approximately!
Bookmarked. Please also talk over with my site =).
We will have a hyperlink change contract between us
Currently it sounds like Drupal is the best blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out much.
I hope to give something back and aid others like
you helped me.
cashpaydayusloans.com
loan places
loans direct
fast cash online
same day loans
pay2daymyloans.com
taking out a loan
payday express
fastcash com
loans for bad credit
http://www.paydayloanscashdv.com
payday loans direct lenders bad credit
payday loans
applying for a loan
payday loans online
cashpaydayusloans.com
consumer lending
personal loans for bad credit
loans for bad credit online
loans online
pay2daymyloans.com
money today
cash advance
new payday lenders
cash advance
http://paydayloanscashdv.com
american cash advance
cash advance
private loans
cash advance
With havin so much content do you ever run into any issues of plagorism or copyright violation? My
site has a lot of completely unique content I’ve either authored myself or
outsourced but it seems a lot of it is popping it up all
over the internet without my agreement. Do you know any
methods to help prevent content from being ripped off? I’d certainly
appreciate it.
Right his very second you could be getting laid. Think about that
for a moment. You could be having sex instead of jerking off.
Go to http://getlaid.xyz and find yourself a woman who
wants to fuck. You’ll be surprised when you’re balls deep inside a pretty princess.
Hey there, You have done an incredible job. I’ll definitely digg it
and personally recommend to my friends. I am confident they will be benefited from this web site.
viagra generic brand generic viagra without a doctor prescription viagra uk [url=http://www.bioshieldpill.com/]generic viagra without a doctor prescription[/url]
Incredible! This blog looks just like my old one! It’s on a entirely
different topic but it has pretty much the same page layout and design. Excellent choice of colors!
The cutest cam girls are just one click away. These are
girls who will make your dick hard instantly.
Visit http://cutecamgirls.xyz and start talking to these
girls. You’ll be surprised when they show you their tits.
Nothing is better than talking to girls who get totally naked right
before your very eyes.
The physics games are the most useful option for causeing this to be
happen so, and therefore it’s simple to choose hunting such games are let your child learn while playing such physic game.
No matter one does solo or make teach to complete tasks, this warrior is both excellent, even though it is a little tired inside premier period.
A inactive life ends in you changing into unfit and also you wish
to counter this with many physical activity.
Pretty nice post. I simply stumbled upon your weblog and wished to mention that I have truly enjoyed browsing your
blog posts. In any case I will be subscribing on your feed and I’m
hoping you write once more soon!
This design is spectacular! You most certainly
know how to keep a reader entertained. Between your wit and your videos, I was almost moved to
start my own blog (well, almost…HaHa!) Fantastic job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the
costs. But he’s tryiong none the less. I’ve been using Movable-type on several
websites for about a year and am concerned about switching to another platform.
I have heard excellent things about blogengine.net.
Is there a way I can import all my wordpress content into it?
Any kind of help would be greatly appreciated!
Amazing! This blog looks exactly like my old one! It’s
on a totally different subject but it has pretty much the same page layout and
design. Superb choice of colors!
I’m pretty pleased to uncover this website. I want to to thank
you for ones time just for this wonderful read!!
I definitely savored every little bit of it and i also have
you book-marked to check out new stuff on your blog.
It’s very simple to find out any matter on net as compared
to books, as I found this paragraph at this site.
I’ll immediately seize your rss feed as I can not in finding your email subscription link or e-newsletter service.
Do you have any? Please let me realize in order that I may just subscribe.
Thanks.
http://cashpaydayusloans.com
payday loan interest rates
loans with bad credit
secured personal loan
quick cash advance online
http://www.pay2daymyloans.com
on line loans
loans for bad credit
need money now bad credit
payday express
http://www.paydayloanscashdv.com
payday loans in delaware
payday express
short term loans online
payday express
And if you are on a diet watch, maybe this kind of eatery
just isn’t for you. You would be more satisfied health wise with the traditional Thai
chicken salad of Laab Gai or maybe some seafood similar to Tom Yum Prawns.
Though this may appear like a challenging situation, an effective catering company will be in a position to conform to unusual
needs with creativity and flair.
I simply wished to say thanks all over again. I am not sure what I might have sorted out without the actual aspects provided by you directly on my field.
Entirely was a very frustrating circumstance in my circumstances,
however , being able to view a professional strategy you treated it took me to leap for delight.
I am happier for the advice and then trust you recognize what
a powerful job you are always doing instructing some other people through your blog.
I know that you haven’t encountered all of us.
Below you find nine full on denim ensembles that the Dear
Zindagi beauty wore for fashion shoot with Vogue magazine.
Most of these offer styling hacks you haven yet thought
of.
Highly energetic blog, I liked that a lot. Will there be a part 2?
I have been exploring for a little for any high-quality
articles or weblog posts in this sort of area .
Exploring in Yahoo I at last stumbled upon this site.
Reading this information So i’m satisfied to convey that I have an incredibly good uncanny feeling I came upon just what I needed.
I such a lot indubitably will make certain to don’t overlook this web site and give it a glance regularly.
These people will frequently range from the gambler’s family, friends and co-workers.
Online sportsbook sites have come a long way due on the advances of bookie software which also offer sports bettors
in game or live wagering options because games come in progress.
An aggressive opening can provide the feeling among other players you are holding some cards that have a
real upside and also the players without valuable cards will fold.
It’s awesome for me to have a site, which is helpful designed for my know-how.
thanks admin
I was recommended this blog by my cousin. I’m not sure whether this post is written by him as nobody else know such detailed about my difficulty.
You are wonderful! Thanks!
Wow, that’s what I was searching for, what a data!
present here at this blog, thanks admin of this website.
Thanks , I have recently been searching for info about this subject for a long time
and yours is the best I have came upon till now. However, what in regards to the bottom line?
Are you certain about the source?
I every time emailed this web site post page to all my contacts, as if like to read it next my contacts will too.
Hi, i think that i saw you visited my website so i came to “return the
favor”.I am attempting to find things to improve my site!I suppose its ok
to use some of your ideas!!
Hay Day Glitches
Hey there I am so delighted I found your web site,
I really found you by accident, while I was searching on Bing for
something else, Anyhow I am here now and would just like to say thank you
foor a fantastic post and a all rouhnd exciting blog (I also love the theme/design),
I don’t havfe time tto look over it all at the mjnute
butt I have book-marked itt and also included your RSS feeds, so when I have time I ill
be back to read a great deal more, Please do keep up the fantastic work.
Thanks for sharing your thoughts about Brawl
Stars pirater télécharger. Regards
free Brawl Stars Cheats
each time i used to read smaller posts that as well clear
their motive, and that is also happening with this
paragraph which I am reading at this time.
Very soon this web site will be famous among all blogging and site-building viewers, due to
it’s nice posts
Fabulous, what a weblog it is! This blog gives valuable information to us, keep it up.
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is fundamental and everything. Nevertheless imagine if
you added some great pictures or video clips to give your posts more, “pop”!
Your content is excellent but with pics and clips, this blog could definitely be one of the best in its niche.
Great blog!
This text is worth everyone’s attention. Where can I find out more?
Hi, I do believe your website may be having web browser compatibility problems.
When I take a look at your site in Safari, it looks fine
however, if opening in I.E., it has some overlapping issues.
I simply wanted to give you a quick heads up! Other than that, wonderful blog!
It’s an amazing piece of writing for all the web visitors; they will get advantage from it I am sure.
Does your site have a contact page? I’m having problems locating it but,
I’d like to shoot you an e-mail. I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it develop over time.
WOW just what I was looking for. Came here by searching for casino party
I really love your site.. Great colors & theme. Did you build this site yourself?
Please reply back as I’m attempting to create my very own website and want
to know where you got this from or exactly what the theme is named.
Kudos!
Great beat ! I would like to apprentice while you amend your site, how can i subscribe for a blog website?
The account aided me a acceptable deal. I had
been tiny bit acquainted of this your broadcast provided bright clear idea
I take pleasure in, result in I found exactly what I was having
a look for. You’ve ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
These countries include UK, USA, Europe and Canada.
Zoica’s fashion philosophy comes down to creating the self-termed “slow fashion”.
It gets quite daunting in purchasing the right outfit for little ones.
If some one needs to be updated with hottest technologies therefore he must be
visit this site and be up to date every day.
It’s in fact very complicated in this busy life to listen news on TV, so I only use world wide web for
that purpose, and take the most up-to-date information.
My spouse and I stumbled over here different page and thought I may as well check things out.
I like what I see so i am just following you.
Look forward to checking out your web page again.
My family members always say that I am killing my time here at web, except I know I
am getting experience everyday by reading such pleasant posts.
What a data of un-ambiguity and preserveness of precious familiarity regarding unpredicted emotions.
You should be a part of a contest for one
of the greatest websites on the net. I’m going to highly recommend this web site!
Anonymity with entertainment: The great freedom that comes from winning contests like Indian rummy on the
web is the choice to remain anonymous while experiencing and enjoying the form of entertainment
that you simply like. They’re going to come with a rather
large price, therefore you can buy the exorcist take
into account sale before it launches to ensure that you’re ready and must grind later.
He afterward utilize his supremacy, budge with psychological circumstances in the direction of get rid of every people who come up to in system
of engaging.
مركز صيانة اريستون، صيانة اجهزة منزلية
اريستون فى المنزل اتصل على الخط الموحد
اريستون و سوف يصل اليك طاقم مكون من مهندسين مدربين على الاصلاح فى
الحال فى المنزل ، تصليح منزلية فورية
دون نقل الجهاز من مكانه لجميع اجهزة ثلاجات
اريستون فى القاهرة و المحافظات خبرة تمت الى 30 عام متواصلة
http://cialischmrx.com
what happens when women take viagra
buy cialis
viagra b
buy cheap cialis online
http://www.viagrachbrx.com
over the counter viagra cvs
buy cheap viagra online
women viagra pills
buy cheap viagra online
http://www.viagranrxch.com
viagra classification
buy cheap viagra online
woman in viagra commercial blue dress
buy cheap viagra
http://cialischmrx.com
viagra prices walgreens
generic cialis
viagra for men online
buy cialis
viagrachbrx.com
Keyword
viagra online
before and after viagra
cheap viagra
viagranrxch.com
non prescription viagra alternative
generic viagra
viagra 50mg or 100mg
generic viagra
http://www.cashpaydayusloans.com
bad credit payday loans online
loans bad credit
how to get a loan with no credit
loans online
http://www.pay2daymyloans.com
online loans direct lenders
cash advance
loans with bad credit
payday loans
http://www.paydayloanscashdv.com
fast loans with bad credit
payday loans online
2000 loan
payday express
cashpaydayusloans.com
fast cash online
loans online
payday loans online bad credit
loans bad credit
http://pay2daymyloans.com
1 hour payday loans
payday loans online
need money now
loans for bad credit
paydayloanscashdv.com
cash advances
payday loans
short term personal loans
pay day loans
Hello would you mind letting me know which hosting company
you’re using? I’ve loaded your blog in 3 completely different internet browsers and I must say this
blog loads a lot quicker then most. Can you suggest a good hosting provider at a fair price?
Kudos, I appreciate it!
It’s an amazing paragraph in favor of all the online viewers; they will take advantage
from it I am sure.
Hey! I just wanted to ask if you ever have any trouble with
hackers? My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no
backup. Do you have any solutions to protect against hackers?
Excellent article. Keep posting such kind of information on your site.
Im really impressed by it.
Hi there, You’ve done a great job. I’ll definitely digg it and individually suggest
to my friends. I am confident they’ll be benefited from this site.
bookmarked!!, I love your website!
There is certainly a great deal to know about this subject.
I really like all of the points you made.
It is common to obtain the ornamental painting
and sculptures with shapes depicting a unique mixture of different elements from the
artist’s religious, physical and cultural background.
Leonardo Da Vinci was created inside the Florentine Republic on April 15th, 1452.
The beginning of Leonardo’s life was dedicated to art and painting in particular.
Nice post. I was checking constantly this weblog and I’m inspired!
Extremely useful information specially the ultimate section :
) I care for such information much. I was seeking this certain info for a very long
time. Thank you and good luck.
I’m amazed, I must say. Seldom do I encounter a blog that’s equally educative and engaging,
and without a doubt, you have hit the nail on the head.
The issue is something which not enough people are speaking intelligently about.
I’m very happy that I stumbled across this in my search for something relating
to this.
http://www.cialischmrx.com
buy viagra cheaper
buy cialis online
viagra dangers
buy cialis online
http://www.viagrachbrx.com
viagra vs levitra
generic viagra
where can i buy viagra
buy cheap viagra online
viagranrxch.com
viagra triangle bars
generic viagra
canada viagra
buy cheap viagra
Hi i am kavin, its my first occasion to commenting anywhere, when i read this post i
thought i could also create comment due to this sensible
post.
buying cialis online safely cialis 5mg buy cialis online overnight shipping
viagra vs cialis cheap viagra from india canadian pharmacy viagra
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is wonderful, let alone the
content!
I’m gone to say to my little brother, that he should also go to see this blog on regular basis to obtain updated from newest news update.
Perfectly composed written content, Really enjoyed looking at.
高知県の小さなお葬式を長くのびているして知りたい。果たしてです。高知県の小さなお葬式の本当にのところは?報道をしゃべるします。
It’s amazing in favor of me to have a website, which is useful
in support of my knowledge. thanks admin
when did viagra go generic female viagra pills purchase generic viagra
I am curious to find out what blog platform you’re utilizing?
I’m having some minor security problems with my latest site and I’d like to find something more secure.
Do you have any recommendations?
I’ve been exploring for a little bit for any high quality articles or weblog posts in this sort of area .
Exploring in Yahoo I ultimately stumbled upon this website.
Reading this info So i am happy to express that I’ve a very goo uncanny feeling I fpund
out just what I needed. I most foor sure will make
sure to do nnot put outt of your mind this website and provides
it a glance on a continuing basis.
Hello would you mind stating which blog platform you’re working with?
I’m planning to start my own blog soon but I’m having a tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style
seems different then most blogs and I’m looking for something completely unique.
P.S Apologies for being off-topic but I had to ask!
Hi
I have tried sending you a message from your site but I have gotten an auto response saying it was not delivered for some bizarre reason, so here goes again! Please acknowledge receipt.
As I mentioned in my earlier message, I would like to contribute one of my guides on crypto-backed loans to your blog. I used to work for a payday loan company in the UK and so I have quite a good knowledge of the financial lending sector. I decided to write this guide because I feel that cryptocurrency will have a major impact on the payday loan industry in the next 5 to 10 years. I have tried to be as detailed as possible so you will find that the guide is fairly lengthy. Perhaps it would be a good idea for you to split it up into several blog posts or do as you see fit.
I am terribly sorry but I did not have much time to find royalty free images. One company that I contacted whilst doing research and collecting references for this guide did give me permission to publish on of their banners that I have included in the g-drive folder.
The entire guide is saved in a Word document inside my Google drive which you can access via this link
https://drive.google.com/drive/folders/1TjO3WVH0tKuzotBh65w8jrJaCUfsjDdP?usp=sharing
I hope your readers will enjoy reading my guide.
I would be most grateful if you could send me a link to the guide once you have published it!
I will endeavour to write a couple more articles as and when I get some more free time: it is hell at work after the festive period.
Have a fab day.
Regards
Tony
Good post. I’m facing many of these issues as well..
Why visitors still use to read news papers when in this technological globe the whole thing is presented on web?
Hey! I know this is kind of off topic but I was
wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Simply want to say your article is as amazing.
The clarity in your post is just spectacular and i can assume you are an expert on this subject.
Well with your permission allow me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please keep up the enjoyable work.
Thanks a lot for sharing this with all folks you really
recognise what you are speaking approximately! Bookmarked.
Please also talk over with my web site =). We may have a hyperlink change contract among us
I like the valuable info you provide in your articles. I’ll bookmark your weblog and check again here regularly.
I am quite certain I will learn plenty of new stuff right here!
Good luck for the next!
This post will help the internet viewers for building up new web site or even a blog from start to end.
Hmm is anyone else encountering problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
Ahaa, its pleasant discussion about this post here at this blog, I have read
all that, so at this time me also commenting here.
It’s in fact very difficult in this full of activity life to listen news on TV, thus I just use web for that
reason, and take the most up-to-date news.
I do not even know how I ended up here, but I thought this
post was great. I don’t know who you are but certainly you are going to
a famous blogger if you are not already 😉 Cheers!
canadian pharmacy
http://canadianpharmaciescenter.com/
canadian mail order pharmacies to usa
We’re a gaggle of volunteers and opening a new scheme in our community.
Your site offered us with valuable information to work on. You have done an impressive task and our whole community can be thankful to you.
Good day! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing
very good success. If you know of any please share.
Cheers!
Hi there, every time i used to check blog posts here early in the morning, because i like to gain knowledge of more and
more.
http://www.cialischmrx.com
viagra zoloft
cheap cialis
viagra 007
buy cheap cialis online
http://www.viagrachbrx.com
viagra and nitrates
viagra online
viagra website
generic viagra
http://viagranrxch.com
viagra webmd
cheap viagra
viagra mexico
cheap viagra
Piece of writing writing iis also a excitement, if you be acquainted
with then you cann write otherwise it is complex to write.
http://www.cialischmrx.com
ben stiller female viagra
buy cheap cialis
is viagra generic
buy cheap cialis
http://viagrachbrx.com
buy cheap viagra online
buy viagra
viagra website
buy cheap viagra online
viagranrxch.com
viagra stock
buy viagra online
viagra para mujeres
cheap viagra online
http://www.cialischmrx.com
viagra alternatives over the counter
cheap cialis online
can i buy viagra over the counter
generic cialis
viagrachbrx.com
viagra dooz 99000 spray
cheap viagra online
how many viagra can i take at once
buy cheap viagra
http://viagranrxch.com
viagra 7 eleven
buy cheap viagra
viagra pharmacy
generic viagra
The trampoline has been outlined out with the genuine spotlight on that it leaves no opening in the ensured separate zones which ensures the security of the customers.
My family members every time say that I am wasting my time here
at net, however I know I am getting knowledge all the time by
reading thes good articles or reviews.
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something.
I think that you can do with a few pics to
drive the message home a bit, but other than that, this is magnificent blog.
A great read. I will definitely be back.
스포츠중계 http://line365tv.cafe24.com
I like reading through an article that can make men and women think.
Also, thank you for allowing me to comment!
I have been surfing online more than 2 hours today, yet I never found any interesting article
like yours. It is pretty worth enough for me. Personally, if all site owners
and bloggers made good content as you did, the web will be a lot more useful than ever before.
At this time it seems like Drupal is the preferred blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
Hi would you mind stating which blog platform you’re working with?
I’m looking to start my own blog in the near future but I’m having a
tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different
then most blogs and I’m looking for something unique.
P.S Apologies for getting off-topic but I had to ask!
This article is truly a good one it assists new internet users, who are wishing for blogging.
After exploring a number of the blog articles on your blog, I
seriously appreciate your technique of blogging. I saved as a
favorite it to my bookmark site list and will be checking back in the near future.
Take a look at my web site too and let me know what you think.
It is common to obtain the ornamental painting and sculptures with shapes
depicting an appealing mixture of different aspects of the artist’s religious, physical and cultural
background. After the Bourbon Restoration, because the trial
participant of Louis XVI, David was without the benefit of his civil right
and property, and was expected to leave his homeland to settle in Brussels where David also completed many works, last
but not least died in the strange land. Then it is not important
if it is heads or tail, one can possibly predict the last results.
Greetings! This is my first comment here so I just wanted to give a quick shout out and tell
you I truly enjoy reading your articles. Can you suggest any other blogs/websites/forums that go
over the same subjects? Thank you!
福島県の小さなお葬式の近いはこちら。勝ち取るもうなるサイトを狙う。福島県の小さなお葬式を頃合いして伴れて行くしたい。書記すを流記。
Leonardo lived in his own measured rhythm, try to cared about
the quality of his paintings completely ignoring time it takes to accomplish the task.
If this is a question of yours too, then you definitely should learn regarding the best ways to procure such things.
Matisse also took over as the king of the Fauvism and was
famous inside art circle.
Greetings, There’s no doubt that your web site could possibly be having web browser compatibility problems.
Whenever I take a look at your website in Safari, it looks fine however when opening in Internet Explorer,
it has some overlapping issues. I simply wanted to give you a quick
heads up! Other than that, wonderful website!
I was very pleased to find this web-site.I wanted to thanks for
your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog
post.
I have read so many articles or reviews on the topic of the blogger
lovers except this piece of writing is truly a fastidious piece of writing,
keep it up.
Every weekend i used to pay a visit this web site, because i wish for enjoyment, for the reason that this this site
conations truly pleasant funny stuff too.
I’m gone to convey my little brother, that he should also pay a
visit this weblog on regular basis to obtain updated from most up-to-date
news update.
is viagra generic yet free viagra viagra going generic
cashpaydayusloans.com
texas payday loans
loans bad credit
fair credit loans
quick cash
http://www.pay2daymyloans.com
quick cash loans online
personal loans
online loans with bad credit
payday loans online
http://www.paydayloanscashdv.com
clear cash loans
payday express
direct payday loans
payday loans
As I site possessor I believe the content matter here is rattling great , appreciate iit for
your hard work. You should keep it upp forever!
Best of luck. http://autoconfig.ru/redirect.php?url=http://ttmicro.com/forum/index.php%3Faction=profile;u=21045
As I site possessor I believe the conteht matter here is rattling great ,
appreciate it for your hard work. Youu should keepp it
up forever! Best oof luck. http://autoconfig.ru/redirect.php?url=http://ttmicro.com/forum/index.php%3Faction=profile;u=21045
cashpaydayusloans.com
direct loan lenders
personal loans for bad credit
bank personal loan
loans with bad credit
http://www.pay2daymyloans.com
where can i get a loan
payday loans online
payday loans wichita ks
cash advance
paydayloanscashdv.com
nevada payday loan
payday loans
getting a personal loan
loans for bad credit
This post is truly a nice one it assists new the web viewers, who are wishing in favor
of blogging.
Quality articles is the important to attract the users to go
to see the web page, that’s what this web site is providing.
viagra for women online pharmacy viagra herbal viagra
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for excellent information I was looking for this info for my mission.
Outstanding post, you have pointed out some excellent details, I as
well think this is a very excellent website.
Quality articles is the important to attract the users to pay a visit the web site, that’s what this web site is providing.
Hi there, I enjoy reading through your post. I like to write a little comment to support you.
I have read so many posts regarding the blogger lovers except this article
is really a fastidious post, keep it up.
http://www.cashpaydayusloans.com
payday loan places near me
loans with bad credit
money loans with bad credit
loans bad credit
pay2daymyloans.com
bad credit payday loans
payday loans
same day loans bad credit
cash advance
http://www.paydayloanscashdv.com
payday loan lenders
cash advance
bad credit lender
payday loans online
What’s up, for all time i used to check blog posts here early
in the break of day, since i love to find out more and more.
Piece of writing writing is also a fun, if you know afterward you
can write or else it is complicated to write.
Thanks a lot for sharing this with all people you really recognize what you’re talking approximately!
Bookmarked. Please additionally talk over with my web site =).
We may have a hyperlink alternate agreement among us
Asking questions are genuinely nice thing if you
are not understanding something completely, but this post
presents fastidious understanding yet.
side effects of viagra pfizer viagra how does viagra work
Great article. I will be going through some of these issues as well..
Hello, just wanted to say, I loved this blog post. It was funny.
Keep on posting!
Heya! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the superb work!
I am thinking օf carrying tһe folⅼօwing e-liquid label Cactus Cruhsh Е-Juice with mу vpe company (https://www.vapemeet.ca/). Is thіs vape juice welⅼ-lіked?
Wouⅼd you advise іt?
buy viagra online canadian viagra cheapest is it illegal to buy viagra online
Can I simply say what a relief to find someone who really understands
what they’re talking about on the net. You definitely realize how to bring a problem to light and make it important.
More people have to look at this and understand this side of your story.
I was surprised you’re not more popular because you definitely possess the gift.
Greetings! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My site looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that might be able to fix this issue.
If you have any recommendations, please share. Many thanks!
Nice weblog here! Additionally your website so much up fast!
What host are you the usage of? Can I get your associate link on your host?
I desire my web site loaded up as fast as yours lol
Right away I am ready to do my breakfast, later than having my breakfast coming again to read additional news.
Good site! I really love how it is easy on my eyes and the data are well written. I
am wondering how I could be notified when a new post has been made.
I have subscribed to your feed which must do the trick!
Have a great day! http://cf.0476ms.com/home.php?mod=space&uid=183592&do=profile&from=space
Good site! I really love how it is easy on my eyes and the data are well written. I am wondering how
I could be notified when a new post has been made.
I have subscribed to your feed which must do the trick!
Have a great day! http://cf.0476ms.com/home.php?mod=space&uid=183592&do=profile&from=space
Quality posts is the key to interest the viewers to pay a visit the web site,
that’s what this web page is providing.
Are you the kind of guy who likes to talk to sexy girls? If so, then you’re really going to love http://bestcamsite.xyz There
are so many girls at that site. Day or night, you’ll always find a hot horny girl to talk to there.
I’m not sure why but this web site is loading incredibly slow for
me. Is anyone else having this problem or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Your means of telling everything in this paragraph is genuinely pleasant, every
one can easily understand it, Thanks a lot.
An impressive share! I have just forwarded this onto
a colleague who was conducting a little research on this.
And he actually bought me lunch simply because I found it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanx for spending time to talk about this issue here
on your web page.
Hmm is anyone else encountering problems with the pictures on this
blog loading? I’m trying to determine if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
It’s remarkable designed for me to have a website, which is beneficial in favor of my knowledge.
thanks admin
Hello there! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thanks
safaviehrugs.com fansnikejersey.com fau.wantedmanagement.com http://www.aimdme.com http://www.austintaylor.com ashermorgan.org 777nnn.com http://www.caymanislandspages.com top-engineering-schools.com ixpertise.org conservationstrategy.org http://www.mallygirl.com nyhealthdepartment.com ceecon.org discall.com gowhale.com http://www.falaknazgroup.com gleam.net slomber.com outwiththeold.com nlu.org.ua http://www.reservethemagazine.com atvax.com http://www.californiastatearchives.com http://www.aileen.in dryeyedallas.com factsaresacred.com smithnews.com voxwahbook.com keiseruniversity.net http://www.mainstreetiowa.org linwoodmedical.com
I’m truly enjoying the design and layout of your website. It’s a
very easy on the eyes which makes it much more enjoyable for me to come here and
visit more often. Did you hire out a developer to create your theme?
Outstanding work! http://zapytaj.zhp.pl/21289/what-to-expect-from-a-webcam-intercourse-chat
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable for
me to come here and visit more often. Did you hire out a developer to create your theme?
Outstanding work! http://zapytaj.zhp.pl/21289/what-to-expect-from-a-webcam-intercourse-chat
http://www.cialismrxcialis.com
heartburn cialis online pharmacy
cialis
cialis 20 mg tablets
buy cialis online
http://www.genviagramdmrx.com
hasan karakaya viagra
cheap viagra online
viagra samples free by mail
viagra online
http://www.chviagranrxusa.com
viagra retail price
generic cialis online
viagra pills for sale
cialis
viagralx.com
viagra triangle
buy viagra online
cost of viagra at walmart
cheap viagra online
I think what you typed made a lot of sense. But, think about this, what
if you wrote a catchier post title? I mean, I don’t want to tell you how to run your website, but suppose
you added a post title that makes people want more?
I mean K-Nearest Neighbor Machine Learning algorithm –
Deepsingularity : Deepsingularity is a little
vanilla. You should glance at Yahoo’s front page and watch how they create article headlines to get viewers to open the links.
You might add a related video or a picture or two to grab readers excited about
what you’ve got to say. In my opinion, it would make your
blog a little livelier.
http://www.cialismrxcialis.com
buy generic cialis uk
buy cialis online
buy cialis online in united states
cialis online
http://genviagramdmrx.com
viagra herbal
online viagra
fda approves female viagra
buy viagra
Remove adverts from complimentary games and different programs.
http://www.chviagranrxusa.com
pfizer viagra coupon
generic cialis online
buy viagra cheap
cialis coupon
http://www.viagralx.com
viagra pill color
buy viagra
viagra news
viagra cheap
I constantly spent my half an hour to read this blog’s content everyday along with a mug of coffee.
Hi there, I enjoy reading all of your article post. I like to
write a little comment to support you.
This is extremely well liked among the best Sport Hacking
Apps.
I’ve been absent for some time, but now I remember why I
used to love this web site. Thank you, I’ll try and check back more often. How frequently you update your site?
In cases like this, you will need to invest in a rather simple
picture frames. A vector path, whatever the twists and turns are, will be more elastic and scalable.
The public also serves enormous events coming from all areas of the globe.
buy cialis liquid tadalafil cialis prescription online
I think this is one of the most important information for me.
And i am glad reading your article. But should remark on few general things, The site
style is wonderful, the articles is really nice : D.
Good job, cheers
juicing sildenafil slang http://www.viagrauga.com my bf took sildenafil
http://www.cialismrxcialis.com
sell cialis generic
buy cialis online
cheap cialis from canada cialis
cialis online
http://www.genviagramdmrx.com
sample viagra
viagra cheap
viagra prescription
cheap viagra online
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment
is added I get several e-mails with the same comment. Is there any
way you can remove me from that service? Bless you!
Heya! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading your blog and
look forward to all your posts! Keep up the outstanding
work!
slots lounge
hollywood casino online
us online casinos for real money
vegas casino slots
foxwoods casino online slots
Hey this is kind of of off topic but I was wondering if blogs use
WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding knowledge so I wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
http://www.chviagranrxusa.com
how long does viagra take to work
generic cialis online
alternatives to viagra over the counter
generic cialis online
viagralx.com
viagra young man
cheap viagra online
who created viagra
buy viagra online
The majority of the most popular games may be deciphered
by CreeHack.
viagra coupon sublingual viagra female viagra
Certainty watch at of arrangement sensed office. Or entirely
jolly county in defend. In stunned apartments firmness of purpose so an it.
Insatiate on by contrasted to reasonable companions. On differently no admitting to distrust article of furniture it.
Quartet and our ham it up Cicily Isabel Fairfield pretermit.
So narrow ball length my extremely yearner yield. Transfer just
meet cherished his full of life duration.
new no deposit casinos accepting us players
free vegas slot games
free slots
fortune bay casino
free slot games with no download
With Adobe Photoshop, it is possible to boost or decrease contrast, brightness, huge, and even color intensity.
Ouuija Boards have been established forever, and yet they are still being confused for
many a type oof portala communication devise that alows uss to speak with our pasdsed loved nes or spirits we don. The theater was built by Torbay Council in its complete redevelopment of Princess Gardens and Princess Pier.
Hello! This article couldn’t be written much better!
Looking at this article reminds me of my previous roommate!
He always kept talking about this. I will send this post
to him. Pretty sure he will have a good read. Thank you for sharing!
Is it OK to share on Pinterest? Keep up the superb work!
I am sure this post has touched all the internet people, its really really fastidious article on building up new blog.
I am extremely impressed with your writing skills and also with the
layout on your weblog. Is this a paid theme or did you
modify it yourself? Anyway keep up the excellent quality writing, it’s rare to see a nice blog like this
one these days.
Perform dungeon way to get material items.
When someone writes an paragraph he/she keeps the thought of a user in his/her brain that how a user can know it.
So that’s why this post is amazing. Thanks!
Well I truly enjoyed studying it. This subject provided by you is very
helpful for good planning. http://www.xblade-tech.com/ztw-forum/member.php?u=1174386-TamikaHock
Well I truly enjoyed studying it. This subject provided by you is very helpful for good
planning. http://www.xblade-tech.com/ztw-forum/member.php?u=1174386-TamikaHock
Play those matches for additional rewards.
I wɑѕ speculating whetһeг anyone has heard of thе Peaches
ɑnd Screams giveaway ?І ϳust got Diamond Νet Suspender Bodystocking simply Ьy liking
ther Facebook ⲣage andd sharing juhst one off their
posts. Purportedly, tһey are hɑving an unimited giveaway thіs ful
week. I tһoᥙght Ι ᴡould let еveryone knoᴡ so hat
you can ɡet yourself sopme incredible underwear fοr Valentine’ѕ Dаy.
I would like to win High Neck Pink Babydoll Ꮪet The follߋwing is
theiг Facebook paɡe btw – https://www.facebook.com/peachesandscreamsuk/
Howdy! Someone in my Myspace group shared this site with us so I came to take a
look. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my
followers! Great blog and superb design.
I got this web site from my buddy who shared with me on the topic
of this web site and at the moment this time I am visiting
this site and reading very informative content at this place.
canadian pharmary without prescription
http://canadianpharmaciesgen.com/
best 10 online pharmacies
Terrific article! This is the kind of information that are meant to be shared around the net.
Disgrace on Google for no longer positioning this publish upper!
Come on over and discuss with my web site
. Thanks =)
Hi, I do think this is a great web site. I stumbledupon it 😉 I will revisit once again since i have book marked it.
Money and freedom is the best way to change,
may you be rich and continue to help others.
http://www.chviagranrxusa.com
viagra red face
cheap generic cialis
what if a girl takes viagra
generic cialis online
http://www.viagralx.com
viagra za muskarce
online viagra
viagra for woman
buy generic viagra
Write more, thats all I have to say. Literally, it seems as though you relied
on the video to make your point. You definitely
know what youre talking about, why throw away your intelligence on just posting videos to your weblog when you could be giving
us something enlightening to read?
If some one wishes expert view concerning blogging and site-building then i
advise him/her to go to see this webpage, Keep up the good work.
I know this website offers quality based posts and other information, is there any other web page which gives such things in quality?
http://www.chviagranrxusa.com
viagra ad
generic cialis online
vega h viagra cream
buy cialis generic
viagralx.com
viagra i norge
buy viagra online
viagra discount
cheap viagra online
http://chviagranrxusa.com
800 mg viagra safe
cialis coupon
viagra joke pills
cialis coupon
http://www.viagralx.com
1 viagra pill
cheap viagra
viagra for sale ebay
cheap viagra online
Hi, I do believe this is a great site. I stumbledupon it 😉 I am going to return yet
again since i have book marked it. Money and freedom is the greatest
way to change, may you be rich and continue to help other people.
Hello colleagues, good paragraph and fastidious arguments commented at this place,
I am actually enjoying by these.
I every time spent my half an hour to read this webpage’s
articles daily along with a mug of coffee.
Fashion Designer Khushi – Z who has already set a trend in the fashion world by working with
Salman Khaan and Arbaaz Khan and her Underwater Life Collection for Wills Lifestyle Fashion Week has created a sensation.
There are many people have this wonderful dream job—fashion buyer.
Let\’s have a look at the most impressive images of
famous supermodels in street fashion styles.
Hi there! This is my first comment here so I just wanted
to give a quick shout out and say I genuinely enjoy reading your articles.
Can you suggest any other blogs/websites/forums that cover the same topics?
Thank you so much!
Attractive section of content. I just stumbled upon your blog and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement you access consistently fast.
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point. You clearly know what youre talking about, why waste your
intelligence on just posting videos to your blog when you could be giving us something informative to read?
http://www.cialismrxcialis.com
buy cheap generic cialis in online drugstore buy
buy cialis online
yasmin light headed cialis pills
buy cialis
http://genviagramdmrx.com
is viagra otc
generic viagra online
free viagra sample
cheap viagra online
cialismrxcialis.com
canada cialis generic alpha blockers
buy cialis
cialis generic india
buy cialis online
http://www.genviagramdmrx.com
natural viagra foods
buy generic viagra
what happens when a girl takes viagra
generic viagra online
I am really loving the theme/design of your weblog.
Do you ever run into any browser compatibility problems?
A few of my blog audience have complained about my site
not working correctly in Explorer but looks great in Opera.
Do you have any ideas to help fix this problem?
On the primary screen, tap on the conflict option.
Way cool! Some very valid points! I appreciate you penning this write-up plus the rest
of the website is also very good.
Hey there, You have done an excellent job.
I will certainly digg it and personally recommend to my friends.
I am confident they will be benefited from this site.
Hi, this weekend is good designed for me, for the reason that this time i am reading this fantastic educational article here at my home.
Hey there I am so glad I found your webpage, I really found you by mistake,
while I was researching on Digg for something else, Anyhow I am here
now and would just like to say kudos for a fantastic post and a all round exciting blog (I also love
the theme/design), I don’t have time to read through it
all at the moment but I have book-marked it and also included your RSS feeds, so when I have time I will be back to read more, Please do keep up the awesome job.
If you desire to take a good deal from this post then you
have to apply these techniques to your won webpage.
http://www.cialismrxcialis.com
no prescription cialis online pharmacy
buy cialis online
cheap cialis generic
cheap cialis
http://genviagramdmrx.com
viagra prescription
online viagra
watermelon rine viagra
online viagra
There are horny girls in your area who want to fuck so bad.
Are you seeking a fuck buddy? Do you want to have some no strings attached fun? If you are, then http://meethornygirls.xyz is the place to go.
All the girls there are horny and they put out.
Hi friends, how is all, and what you wish for to say about this article, in my view its truly remarkable designed for me.
http://cialismrxcialis.com
metformin expiration cialis generic pills used
buy cialis online
yasmin ed tabs cialis pills buy
buy cialis
http://www.genviagramdmrx.com
best place to buy viagra online 2015
buy viagra online
viagra soft tabs
cheap viagra online
It’s a pity you don’t have a donate button! I’d without a doubt donate to this fantastic blog!
I suppose for now i’ll settle for bookmarking aand
adding your RSS feed to my Google account. I look forward to fresh
updates and will share this blog with my Facebook group.
Talk soon!
When someone writes an piece of writing he/she keeps the idea of a user
in his/her mind that how a user can understand it. Thus that’s why this article is amazing.
Thanks!
quem toma losartana pode tomar tadalafil [url=http://cialisps.com/]http://cialisps.com[/url] will
tadalafil go generic.
Right his very second you could be getting laid.
Think about that for a moment. You could be having sex instead of jerking off.
Go to http://getlaid.xyz and find yourself a woman who wants to fuck.
You’ll be surprised when you’re balls deep inside a pretty princess.
What’s Taking place i am new to this, I stumbled upon this
I’ve discovered It positively useful and it
has helped me out loads. I’m hoping to give
a contribution & assist other users like its aided me.
Good job.
buy real viagra online generic viagra 100mg buy viagra online cheapest
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here regularly.
I am quite sure I’ll learn many new stuff right here!
Good luck for the next!
With havin so much written content do you ever run into any problems of plagorism or copyright infringement?
My site has a lot of exclusive content I’ve either authored myself or outsourced but it appears
a lot of it is popping it up all over the web without my authorization. Do you know any methods to help reduce content from being stolen? I’d definitely appreciate it.
Attractive section of content. I simply stumbled upon your site and
in accession capital to say that I get actually
enjoyed account your blog posts. Any way I will be subscribing to your augment
and even I achievement you get right of entry to persistently fast.
http://cialismrxcialis.com
buy cheap generic cialis in online drugstore
cialis online
my experience with cialis pills cialis
cialis online
http://www.genviagramdmrx.com
viagra meaning
cheap viagra online
mail order viagra
cheap viagra
I’m not sure why but this blog iis loading extremely slow for me.
Is anyone else having this problem or is it a
problem on my end? I’ll check back later and see if the problem still
exists.
Thank you, I have recently been searching for information about this subject
for a while and yours is the best I’ve discovered so far.
However, what about the bottom line? Are you sure concerning the supply?
http://domkastrul.ru/articles/articles-cvetnik
http://www.chviagranrxusa.com
reload herbal viagra
generic cialis online
dana adams viagra
cheap generic cialis
http://www.viagralx.com
viagra bill
viagra online
viagra 4 hours
viagra cheap
Good post. I will be going through a few of these issues as well..
http://www.chviagranrxusa.com
generic viagra 100mg
cialis coupon
best viagra alternative
cheap generic cialis
viagralx.com
viagra herbs
buy generic viagra
viagra buy online
online viagra
Appreciate the recommendation. Let me try it out.
This is very interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more
of your great post. Also, I have shared your site in my social networks!
Yes! Finally someone writes about blog.
I couldn’t refrain from commenting. Very well written!
prescription drugs online without
http://canadianpharmacieslink.com/
online pharmacies
Hi, i think that i saw you visited my blog so i came to “return the favor”.I’m trying to find things to enhance my site!I suppose its ok to use some
of your ideas!!
I am curious to find out what blog platform you are working with?
I’m having some small security issues with my latest
website and I’d like to find something more
risk-free. Do you have any recommendations?
what is the generic name for viagra online generic viagra buying generic viagra online reviews
pala casino online
online casino games
casino games online
las vegas casinos free slots
seneca niagara casino
where can i buy cialis purchase cialis generic cialis online
Hello! This post could not be written any better! Reading
this post reminds me of my good old room mate! He always
kept talking about this. I will forward this article to
him. Pretty sure he will have a good read. Many thanks for
sharing!
Wow, fantastic blog layout! How long have you been blogging
for? you make blogging look easy. The overall look of your
site is great, as well as the content!
When someone writes an article he/she maintains thee plan of a user in his/her brain that how a user
can know it. So that’s why this paragraph is great.
Thanks!
This extra-long parka keeps your lower ody toasty,
while its Wind – Stopper sshell blocks gusts and repels precipitation. Zoica’s fashion philosophy comes down to creating the self-termed “slow fashion”.
Similarly, knee length gowns are much in vogue
bcause of thee comfort they offer.
bookmarked!!, I love your website!
Currently it appears like Drupal is the best
blogging platform out there right now. (from what I’ve read) Is that what you
are using on your blog?
Hi to every body, it’s my first go to see of
this website; this weblog consists of remarkable and
in fact excellent information in favor of readers.
viagra best buy reviews low cost viagra where to buy viagra online
generic viagra 2017 viagra generic no prescription generic viagra
Hmm it looks like your website ate my first comment (it was extremely long) so I guess
I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog writer but I’m still new to the
whole thing. Do you have any helpful hints for inexperienced blog writers?
I’d definitely appreciate it.
Great items from you, man. I’ve be mindful your stuff prior
to and you are just extremely wonderful. I actually like what you’ve
bought here, certainly like what you are saying and the best way by which you are saying it.
You make it enjoyable and you still care for to keep it sensible.
I cant wait to read far more from you. That is actually a great website.
Excellent pieces. Keep writing such kind of info on your blog.
Im really impressed by your blog.
Hi there, You have done a fantastic job. I’ll certainly digg
it and for my part suggest to my friends. I’m sure they will be benefited from this web site.
Hello friends, its impressive paragraph on the topic of educationand fully defined,
keep it up all the time.
It is common to find the ornamental painting and sculptures with shapes depicting a unique mix of
different aspects of the artist’s religious, physical and cultural background.
Leonardo Da Vinci was given birth to within the Florentine Republic
on April 15th, 1452. The beginning of Leonardo’s life was focused on art and painting in particular.
It’s a shame you don’t have a donate button! I’d
definitely donate to this superb blog! I guess for now i’ll settle for
book-marking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this blog with my Facebook group.
Chat soon!
http://www.cialismrxcialis.com
cialis 5mg price generic levitra
cialis online
viagra sales in india cialis generic
buy cialis
genviagramdmrx.com
when viagra doesn’t work
cheap viagra online
viagra before and after pictures
viagra cheap
http://www.cialismrxcialis.com
buy generic cialis london
buy cialis online
buy tadalafil 20mg cialis
buy cialis online
http://genviagramdmrx.com
best herbal viagra
cheap viagra
viagra cheap
online viagra
Can you tell us more about this? I’d love to find out more details.
Hi there, after reading this awesome article i am as well delighted to share my knowledge here with
mates.
http://www.cialismrxcialis.com
generic cialis online pharmacy
buy cialis online
cialis pills over the counter
buy cialis online
genviagramdmrx.com
viagra vs cialis which is better
buy viagra
where can you buy viagra over the counter
buy generic viagra
What i do not understood is actually how you’re not actually a lot more smartly-appreciated
than you might be now. You’re very intelligent. You know thus significantly relating to this topic, produced me for my part imagine it from numerous numerous angles.
Its like women and men aren’t fascinated until it’s one thing to
accomplish with Woman gaga! Your personal stuffs
excellent. Always deal with it up!
It could lock game titles to a specific level.
http://www.chviagranrxusa.com
free trial viagra
generic cialis online
what is in viagra
cheap generic cialis
http://viagralx.com
cheap viagra
buy viagra online
free viagra pills
cheap viagra online
http://www.cialismrxcialis.com
ordering cialis overnight delivery
cialis online
cialis 10mg or 20mg
cheap cialis
http://www.genviagramdmrx.com
new viagra for women
buy viagra online
is viagra safe
cheap viagra
http://www.chviagranrxusa.com
viagra 7 eleven
cialis
viagra for females
cheap generic cialis
http://www.viagralx.com
viagra sildenafil
online viagra
buy cheap viagra online
cheap viagra
Hello are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and create
my own. Do you need any html coding expertise to make your own blog?
Any help would be greatly appreciated!
LastPass is one of the must have Android programs.
If you are going for most excellent contents like myself, simply go to
see this web site daily since it gives feature contents, thanks
The activity kicks off for VIP players.
sildenafil is better or cialis viagra prices http://viagrauga.com/ viagrauga.com what is the function of sildenafil
The cutest cam girls are just one click away. These are girls who will make your dick hard instantly.
Visit http://cutecamgirls.xyz and start talking to these girls.
You’ll be surprised when they show you their tits. Nothing is
better than talking to girls who get totally naked right before your
very eyes.
Heya i am for the primary time here. I came across this board and I find It truly helpful &
it helped me out much. I’m hoping to provide something again and aid others like you aided me.
http://cialismrxcialis.com
buy cheap generic cialis in online drugstore
buy cialis
cialis generic walgreens
buy cialis
http://genviagramdmrx.com
free viagra sample pack by mail
buy viagra online
how long before sex do you take viagra
cheap viagra
This design is spectacular! You certainly know how to
keep a reader entertained. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really loved what you had to say, and more than that, how
you presented it. Too cool!
Hi, all the time i used to check webpage posts
here early in the dawn, for the reason that i enjoy to gain knowledge of
more and more.
viagra buy online viagra story buy cheap viagra online
This piece of writing will assist the internet users for building up new webpage or even a blog from start
to end.
Heya i’m for the first time here. I found this board and I find It truly helpful & it helped
me out much. I hope to provide one thing again and help others such as you aided me.
I constantly spent my half an hour to read this website’s content all the time along with
a mug of coffee.
Your way of telling the whole thing in this article is in fact
pleasant, all be able to easily know it, Thanks
a lot.
Ahaa, its nice discussion concerning this piece of writing at
this place at this webpage, I have read all that,
so at this time me also commenting here.
オールインワン化粧品で、顔のくすみのトラブルを改善可能です。ホワイトニングリフトケアジェルは、多くの商品の中でもクチコミ評価が高いクリームです。エイジングケアにはお勧めのアイテムです。
Do you mind if I quote a couple of your posts as long
as I provide credit and sources back to your site?
My blog is in the very same area of interest
as yours and my users would definitely benefit from a lot
of the information you present here. Please let me know if this alright with you.
Thanks!
Saved as a favorite, I really like your site!
Oh my goodness! Impressive article dude! Thank you, However I am having issues
with your RSS. I don’t understand why I can’t join it.
Is there anyone else having identical RSS
issues? Anyone that knows the solution will you kindly respond?
Thanx!!
Hello there, I think your site may be having browser compatibility problems.
Whenever I take a look at your site in Safari,
it looks fine however, when opening in I.E., it has
some overlapping issues. I merely wanted to give you a quick heads up!
Apart from that, great site!
Nice replies in return of this question with solid arguments and telling the
whole thing about that.
casino movie online
online casino reviews
online casino real money
online casino no deposit bonus
buy viagra online cheap order viagra online buy generic viagra online usa
Are you the kind of guy who likes to talk to sexy girls?
If so, then you’re really going to love http://bestcamsite.xyz There are so many girls at that site.
Day or night, you’ll always find a hot horny girl to talk to there.
I just could not go away your web site before suggesting that I really enjoyed the standard information an individual supply on your
guests? Is gonna be again continuously to inspect new posts
I seriously love your blog.. Great colors & theme. Did you build this website yourself?
Please reply back as I’m looking to create my own website and would like to find out where you got this from or what the theme
is called. Appreciate it!
I got this site from my pal who informed me on the topic of this website and at the moment this time I am browsing this site and reading very informative articles
here.
Nice blog right here! Additionally your web site rather a lot up fast!
What web host are you the usage of? Can I get your
associate link on your host? I wish my website loaded up as quickly as yours lol
Players can choose one of five specific classes.
When crime is reported in a news story, I explore the nature of human behavior that contributes to aggression and its consequence called violence.
I use the perspective provided by scientists like Dr.
Konrad Zacharias Lorenz, Dr.
The action begins for VIP players.
It’s amazing to visit this web page and reading the views of all friends on the topic of this
article, while I am also eager of getting familiarity.
buy real viagra online cheap cheapest viagra prices viagra online no prescription
I believe that is among the so much vital information for
me. And i’m glad studying your article. But want to statement on few common things, The site taste is great, the articles is
in reality nice : D. Good process, cheers
It’s not my first time to visit this website, i am browsing this web page dailly and take nice data
from here all the time.
http://www.cialismrxcialis.com
cialis generic overnight
buy cialis online
cialis india generic
buy cialis online
http://www.genviagramdmrx.com
viagra sales
cheap viagra online
viagra single packs commercial
online viagra
Very good blog post. I absolutely love this site. Keep it up!
Great internet website! It looks really good!
Sustain the excellent job! http://impuissance-traitement-fr.eu/
is a relied on QQ Casino poker Online and Bandar Ceme Online wagering website that supplies on the internet card games such as Online Poker,
DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gambling Online Casino Poker
Sites. QQ Online Poker Ceme, the best as well as best online casino poker agent site with 24 hour IDN
Online Online poker service. For those of you Lovers of the game
Online Online and that wish to play betting Online Texas hold’em, Online Ceme,
Domino QQ, City Ceme, Online Gaming, Bandar Capsa Online in 1 ID
buy generic cialis online buy tadalafil online buy cialis
Extremely enlightening, look forward to returning. http://tratarea-impotentei-ro.eu/eronplus.html
cialismrxcialis.com
buy brand cialis online
buy cialis
vicodin and cialis generic
buy cialis online
http://www.genviagramdmrx.com
how does viagra work?
online viagra
how long does it take for viagra to work
online viagra
Many thanks for sharing your amazing webpage. http://tablettespourmaigrir-2018.eu/
Fastidious answers in return of this matter with solid arguments
and explaining all concerning that.
I have fun with, cause I found exactly what I used to be looking for.
You’ve ended my 4 day long hunt! God Bless you man. Have a
nice day. Bye
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
Hi! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no back up.
Do you have any solutions to protect against hackers?
http://freedatingsitesus.com/
free dating
free local dating sites,free local dating sites
free dating. dating sites, free dating
free dating position
free online dating
Great info. Lucky me I discovered your site by chance (stumbleupon).
I have book marked it for later!
Truly….this is a handy website. http://penisvergroter-pillen-nl.eu/atlant-gel.html
I read this paragraph completely regarding the resemblance
of newest and previous technologies, it’s amazing article.
cheap viagra online viagra generico http://www.genviaonser.com viagra youtube http://genviaonser.com cost of viagra vs cialis http://genviaonser.com viagra mail order viagra http://x2y.net/__media__/js/netsoltrademark.php?d=genviaonser.com buy viagra online
I got this website from my friend who informed me about this website and
now this time I am browsing this website and reading very informative posts at this place.
You’re an extremely valuable internet site; could
not make it without ya! http://muskelaufbau-tabletten.eu/armostrax.html
You’re an extremely valuable internet site; could not make
it without ya! http://muskelaufbau-tabletten.eu/armostrax.html
Great looking website. Think you did a lot of your very own coding. http://testosteron-tabletki.eu/
Parkas might not be the best jackets to
make you look fit, but in these weather conditions, yyou
don’t nesd a jacket that is close to your body, you need something
heavy to givfe you heat. Knights could fasten leather as armor to protect
most of their body ranging from their feet, legs, chest, arms, and evewn their head.
I would also recopmmend Osterlind’s excellent DVD series based on this book.
Thanks for sharing such a pleasant opinion, paragraph is pleasant, thats why i have read it fully
free casino blackjack games
free online bingo vegas world
play free casino games online
online gambling for real money
show all free slots games
Hello, I think your site may be having browser compatibility problems.
Whenever I take a look at your website in Safari, it looks fine however, when opening in IE, it has some overlapping issues.
I simply wanted to give you a quick heads up! Besides that, fantastic site!
Normally I do not learn article on blogs, however I would like to say that this write-up very pressured me to take a look
at and do it! Your writing style has been surprised me.
Thank you, quite great article.
The first time I ever saw one was within the fenced dog park section of the local park.
Neighbours had garbage at one time alongside the fence, also animal feces from dog they by no
means cleaned up. Pippa’s pregnancy was
revealed in April, around the identical time that the Duchess gave delivery to her third youngster,
Prince Louis, though the 35-yr-old didn’t affirm she was expecting till June, when she opened up about her first trimester.
Adorable jerks, yes. But jerks all the same. Getting
away from the extra conventional diaper “cakes,” we have a number of nice designs which don’t look
like cakes in any respect, but comply with the identical basic ideas,
considered one of them being this incredibly reasonable choo
choo prepare! And you don’t actually wish to own one.
This cutie has had a giant day – it’s time for mattress, little one!
It could also be smart to look for shelter when the Golem power aura is red, as there is not a lot time earlier than the Golem
explodes. She got here for the first time the week
we received dwelling, again about two months later, and for
the third and doubtless ultimate time in September,
when Zelie was 5 months old.
I enjoy what you guys are usually up too. This type of clever work
and coverage! Keep up the fantastic works guys I’ve included you guys to our blogroll.
Found on Wedge Island in Western Australia on Jan.
In cases like this, you will have to go for a straight-forward
picture frames. Waterslide paper emerges in clear or white however clear is more preferred, since
any sort of unprinted locations for the image
remains clear. The gallery also serves enormous events from all areas
of the globe.
Extremely useful, look ahead to coming back again. http://tabletky-na-rast-penisu-sk.eu/Beast-Gel.html
cialis for sale online tadalafil online cialis online no prescription
If some one wants expert view on the topic of running a blog after that i propose him/her to pay a quick visit
this blog, Keep up the fastidious work.
free slots just for fun no money
free slot games with no download
slots games vegas world
usa casinos no deposit free welcome bonus
free blackjack games casino style
ssngkwwmd what happens if you mix tadalafil with viagra http://cialissom.com/ cialis 20mg online cialis 5mg
pills price of tadalafil in australia
UJ
Way cool! Some extremely valid points! I appreciate you penning this article plus the rest of
the site is really good.
What i don’t understood is in truth how you’re now not actually much more smartly-favored than you might be right now.
You are very intelligent. You recognize therefore significantly relating to this subject, produced me individually believe
it from so many varied angles. Its like men and women are not
involved except it is something to accomplish with Lady gaga!
Your individual stuffs excellent. At all times take care of it up!
Hi there, I log on to your blog like every week. Your humoristic style is awesome, keep up the
good work!
cialismrxcialis.com
cialis on
cialis online
walmart cialis 20mg
buy cialis online
genviagramdmrx.com
viagra ice cream
online viagra
how much viagra to take
viagra cheap
http://chviagranrxusa.com
viagra company
buy cialis generic
how much viagra can i take a day
generic cialis
http://www.viagralx.com
what is the cost of viagra
viagra cheap
viagra kaufen
cheap viagra online
cialis online usa buy cheap cialis cialis for sale online
http://www.cialismrxcialis.com
generic cialis safety
buy cialis online
indian viagra for women cialis generic
cheap cialis
http://genviagramdmrx.com
viagra dick
cheap viagra
viagra online generic
buy viagra
http://chviagranrxusa.com
herb viagra green box
generic cialis online
viagra before and after tumblr
buy cialis online
viagralx.com
viagra best buy review
cheap viagra
viagra lawsuit
cheap viagra online
It’s awesome designed for me to have a web page, which is good designed for my knowledge.
thanks admin
대전출장안마 http://skanma.com
대전출장마사지 http://skanma.com
대전출장맛사지 http://skanma.com
유성출장안마 http://skanma.com
유성출장마사지 http://skanma.com
유성출장맛사지 http://skanma.com
세종출장안마 http://skanma.com
세종출장맛사지 http://skanma.com
세종출장맛사지 http://skanma.com
공주출장안마 http://skanma.com
공주출장마사지 http://skanma.com
공주출장맛사지 http://skanma.com
계룡출장안마 http://skanma.com
계룡출장마사지 http://skanma.com
계룡출장맛사지 http://skanma.com
청주출장안마 http://skanma.com
청주출장마사지 http://skanma.com
청주출장맛사지 http://skanma.com
대전출장안마 https://skt10041203.wixsite.com/genesis
대전출장마사지 https://skt10041203.wixsite.com/genesis
대전출장맛사지 https://skt10041203.wixsite.com/genesis
유성출장안마 https://skt10041203.wixsite.com/genesis
유성출장마사지 https://skt10041203.wixsite.com/genesis
유성출장맛사지 https://skt10041203.wixsite.com/genesis
세종출장안마 https://skt10041203.wixsite.com/genesis
세종출장맛사지 https://skt10041203.wixsite.com/genesis
세종출장맛사지 https://skt10041203.wixsite.com/genesis
공주출장안마 https://skt10041203.wixsite.com/genesis
공주출장마사지 https://skt10041203.wixsite.com/genesis
공주출장맛사지 https://skt10041203.wixsite.com/genesis
계룡출장안마 https://skt10041203.wixsite.com/genesis
계룡출장마사지 https://skt10041203.wixsite.com/genesis
계룡출장맛사지 https://skt10041203.wixsite.com/genesis
청주출장안마 https://skt10041203.wixsite.com/genesis
청주출장마사지 https://skt10041203.wixsite.com/genesis
청주출장맛사지 https://skt10041203.wixsite.com/genesis
You’ve gotten possibly the best web pages. http://pastillas-para-el-acne-es.eu/
Somebody essentially help to make significantly articles
I would state. That is the first time I frequented your web page and
so far? I amazed with the research you made to make this actual publish amazing.
Wonderful process!
Excellent blog post. I definitely love this site.
Continue the good work!
http://cialismrxcialis.com
generic cialis australia
buy cialis
cialis 5mg
buy cialis
genviagramdmrx.com
how to use viagra for best results
cheap viagra
viagra for women
buy generic viagra
http://cialismrxcialis.com
buy discount cialis
cialis
cialis generic india
cheap cialis
http://genviagramdmrx.com
how to get viagra samples
buy generic viagra
non prescription viagra
buy viagra
Hi my loved one! I wish to say that this post is amazing, nice written and come with
almost all important infos. I would like to see extra
posts like this .
Wow! This blog looks exactly like my old one!
It’s on a totally different topic but it has pretty much the
same page layout and design. Superb choice of colors!
Pretty! This has been an incredibly wonderful post. Thanks for supplying this info.
Are you searching for love? Have you tried unsuccessfully to
meet the person of your dreams at other sites?
Almost all of those dating sites are a waste of your time.
Check out http://bestonlinedating.xyz and see what
the difference is. It’s full of good looking women who are
searching for Mr. Right. Join today and be prepared to live happily ever after.
wonderful post, very informative. I ponder why the opposite experts
of this sector don’t understand this. You should continue your writing.
I’m confident, you have a huge readers’ base already!
is a relied on QQ Texas hold’em Online and also Bandar Ceme Online betting site that supplies on-line card video games such as Online Online
Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gambling Online Casino Poker Sites.
QQ Poker Ceme, the most effective as well as best on the internet texas hold’em agent
site with 1 day IDN Online Online poker solution. For those of you Lovers of the game Online
Online and also that want to play gambling
Online Online poker, Online Ceme, Domino QQ, City Ceme, Online Betting, Bandar Capsa Online in 1 ID
is a relied on QQ Poker Online and also Bandar Ceme Online betting site
that gives on the internet card video games such as Online Texas Hold’em, DominoQQ, Capsa Online, Ceme Online,
Ceme99, Online Gaming Online Online Poker Sites. QQ Online Poker Ceme, the very best and most safe
online poker agent website with 24-hour IDN Online Online poker solution. For
those of you Lovers of the game Online Online as well as that intend to play betting Online Poker, Online Ceme, Domino QQ, City Ceme,
Online Gambling, Bandar Capsa Online in 1 ID
This extra-long parka keeps your lower body toasty, while
its Wind – Stopper shell blocks gusts and repels precipitation. Ladies need variuety inn wearing cloths and they like
to be in good looks daily like office going women, professionals and even household workers too.
It’d be impossibhle to distill this enire book into a set
of DVDs.
Hmm it seems like your blog ate my first comment (it was super long) so I
guess I’ll just sum it up what I had written and
say, I’m thoroughly enjoying your blog. I too am an aspiring blog blogger but I’m still new to everything.
Do you have any recommendations for novice blog writers?
I’d certainly appreciate it.
buy generic viagra online canada cheap viagra canada buy viagra online with paypal
Admiring the time and effort you put into your site and detailed information you offer.
It’s nice to come across a blog every once in a while that isn’t the
same unwanted rehashed material. Wonderful read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
http://chviagranrxusa.com
prices for viagra
buy cialis generic
herbal viagra reload
cialis
viagralx.com
cialis v viagra dosage
cheap viagra
viagra 3 day delivery
viagra online
Do you have a spam issue on this blog; I also am a blogger,
and I was wondering your situation; many of us have developed some nice
practices and we are looking to trade methods with others, why not shoot
me an e-mail if interested.
http://www.chviagranrxusa.com
chinese herb viagra
generic cialis online
viagra vision blue
buy cialis generic
http://www.viagralx.com
compro viagra
viagra online
viagra heart rate
online viagra
Right now it seems like Expression Engine is the preferred blogging platform out
there right now. (from what I’ve read) Is that what you
are using on your blog?
chviagranrxusa.com
viagra without prescription
cialis coupon
sofia viagra
buy cialis generic
viagralx.com
viagra 50 off
buy viagra
lisinopril and viagra
online viagra
http://freedatingsitesus.com/
free dating online
dating site,dating online free
dating sites. dating sites free, online dating free
online dating unfasten
free dating online
cheap cialis generic online generic cialis online cheap cialis online canadian pharmacy
generic viagra without prescription cheapest viagra prices where can i buy generic viagra
Do you mind if I quote a few of your articles as long as
I provide credit and sources back to your blog?
My website is in the very same area of interest as yours and my visitors would
definitely benefit from a lot of the information you provide here.
Please let me know if this alright with you. Appreciate it!
I am regular reader, how are you everybody?This
piece of writing posted at this website is
actually good.
Hi i am kavin, its my first time to commenting anywhere, when i read this article
i thought i could also create comment due to this brilliant post.
I really like your blog.. very nice colors & theme.
Did you make this website yourself or did you hire someone
to do it for you? Plz respond as I’m looking to create
my own blog and would like to find out where u got this from.
thanks
I am truly grateful to the holder of this website who has shared this fantastic article
at at this place.
http://www.cialismrxcialis.com
generic cialis pro cialis
buy cialis online
generic cheap cialis
buy cialis
genviagramdmrx.com
viagra online without prescription
cheap viagra
do you need a prescription for viagra
viagra cheap
I require a bit of guidance from alⅼ the dudes ɑnd ladies out theгe!
Ӏ aam іn tһe process of obtaining my companion a Valentine’s day pгesent аnd I аm a
ⅼittle bit stuck. І ѡould ⅼike to get һer sօmething ѵery intimate aand sensual аnd І was contemplating buying her a lіttle something from Harrods (mɑybe some wine and chocolates) аnd
sоmе gorgeous lingerie from Peaches аnd Screams. I ɗefinitely adore teir Sexy Panties category.
Ԝhat underwear item do you reckon I shoulɗ get her? Pⅼease kindly
PMme or respond tߋ this thread. I would apprecciate a quick reply аs Valentine’s dday is almоst nearby.
Thanbks a mіllion!
Why users still use to read news papers when in this technological world all is existing on net?
casino bonus codes
vegas casino free slot games
free online casino
100 free casino no deposit
seneca casino online games
Howdy! I could have sworn I’ve been to this website
before but after reading through some of the post I realized it’s new
to me. Anyways, I’m definitely delighted I found it and I’ll
be bookmarking and checking back often!
Very nice post. I just stumbled upon your blog and wanted to
say that I’ve truly loved browsing your weblog posts.
After all I’ll be subscribing in your feed and I hope you
write again soon!
What’s Taking place i am new to this, I stumbled upon this I’ve found It absolutely helpful and it has helped me out loads.
I’m hoping to contribute & assist different users like its aided
me. Great job.
I’m pretty pleased to find this site. I wanted to thank you for your time
due to this wonderful read!! I definitely liked
every part of it and I have you book marked to see new things on your web site.
mrxcialisrx.com
buy cialis line
buy cheap cialis
cheap cialis from canada
buy cheap cialis online
http://www.viagrabstnrx.com
viagra cost walmart
buy viagra
viagra coupon cvs
cheap viagra online
http://www.mrxcialisrx.com
buy generic cialis online
cheap cialis online
buy cialis on line
cialis online
http://www.viagrabstnrx.com
how much does viagra cost at walgreens
generic viagra online
cheap viagra for sale
viagra cheap
http://www.cialismdmarx.com
marley generic viagra
cialis generic
india viagra
generic cialis
http://www.chviagranrxusa.com
what viagra does to the body
viagra online
amazon viagra
cheap viagra
I’m curious to find out what blog system you are working with?
I’m having some minor security problems with my latest site and
I would like to find something more safeguarded.
Do you have any suggestions?
http://www.cialismdmarx.com
how much viagra is it safe to take
cheap cialis online
herb viagra for sale
generic cialis
chviagranrxusa.com
best time to take viagra
generic viagra online
use viagra
viagra cheap
generic viagra online canadian pharmacy best price viagra best generic viagra
Hi there, i read your blog occasionally and i own a similar one
and i was just wondering if you get a lot of spam remarks?
If so how do you prevent it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is very much appreciated.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back later.
Cheers
http://freedatingsitesus.com/
online dating free
free dating,free dating site
free local dating sites. free online dating, dating sites
unbosom online dating websites
dating online free
Excellent post. Keep writing such kind of information on your blog.
Im really impressed by your site.
Hello there, You have done a great job. I’ll certainly digg it and in my view recommend to my friends.
I am sure they’ll be benefited from this site.
http://www.mrxcialisrx.com
generic cialis any good
cheap cialis online
viagra private prescription cialis 20mg cialis
buy cialis online
http://www.viagrabstnrx.com
viagra and nitrates
viagra online
viagra cialis levitra
cheap viagra
cialismdmarx.com
what happens when a woman takes viagra
buy generic cialis online
viagra 8000mg review
cialis coupon
http://www.chviagranrxusa.com
viagra jelly
cheap viagra
viagra 30 pills
cheap viagra
Is it OK to share on Linkedin? I really like what you guys are up too.
Keep up the fantastic work!
Do you mind if I quote a couple of your posts as long as I provide credit and sources
back to your blog? My blog is in the same niche as yours, and my users would benefit from some of the information you provide here.
Please let me know if this ok with you. Thank you. Porn, watch
porn, anal fingering, squirt, pussy, casino, bet, oral sex, sex, drugs, Pharmacy, penis, porn video
Hi! I could have sworn I’ve visited your blog before
but after going through a few of the articles I realized it’s new to me.
Regardless, I’m definitely delighted I came across it and I’ll be book-marking
it and checking back regularly!
is a relied on QQ Casino poker Online as well as Bandar Ceme Online gambling site that gives
on-line card video games such as Online Online Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99,
Online Gambling Online Casino Poker Sites. QQ Poker Ceme, the most effective and best online
texas hold’em agent website with 24 hour IDN Online Texas hold’em
service. For those of you Lovers of the game Online Online and also who
wish to play betting Online Casino poker, Online Ceme, Domino
QQ, City Ceme, Online Gambling, Bandar Capsa Online in 1 ID
Maintain the excellent job and bringing in the group! http://vergroten-penis.eu/erozonmax.html
Are you the kind of guy who likes to talk to sexy girls?
If so, then you’re really going to love http://bestcamsite.xyz There are so many girls at that site.
Day or night, you’ll always find a hot horny girl to talk to there.
Awesome blog! Do you have any suggestions for aspiring
writers? I’m hoping to start my own site soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m completely confused ..
Any recommendations? Cheers!
canadian online pharmacies
http://canadianpharmaciesoffer.com/
canadian online pharmacies
You’re a really useful site; couldn’t make it without ya! http://tabletky-na-erekci-cz.eu/eronplus.html
Incredible story there. What happened after?
Take care!
Wow that was odd. I just wrote an extremely long comment but after I clicked submit my comment
didn’t show up. Grrrr… well I’m not writing all
that over again. Anyway, just wanted to say fantastic blog!
Appreciate this post. Will try it out.
I love your blog.. very nice colors & theme.
Did you make this website yourself or did you hire someone to do it
for you? Plz reply as I’m looking to design my own blog and would like to know where u got this from.
kudos
Howdy! I realize this is somewhat off-topic but I needed to ask.
Does managing a well-established blog such as yours take a massive amount work?
I am brand new to operating a blog however I do write in my journal on a
daily basis. I’d like to start a blog so I can share my
experience and views online. Please let me know if you have any ideas or tips for new aspiring bloggers.
Thankyou!
Are you searching for love? Have you tried unsuccessfully to meet the
person of your dreams at other sites? Almost all
of those dating sites are a waste of your time. Check out http://bestonlinedating.xyz and see what
the difference is. It’s full of good looking women who are searching for Mr.
Right. Join today and be prepared to live happily ever after.
Nice post. I was checking continuously this blog and I’m impressed!
Very useful information specially the last part 🙂 I care
for such info a lot. I was seeking this particular info for a very long time.
Thank you and good luck.
SMC Fashion supplies all the needs and requirement of the special women, who are very conscious and meticulous about their dresses and ornaments.
Only budgetting for one pair, I had a to make the choice between them.
It’d be impossible to ditill this entire book into a set
of DVDs.
My brother recommended I might like this web site.
He was totally right. This post actually made my day.
You cann’t consider just how a lot time I had spent for this information!
Thank you!
http://www.cialismdmarx.com
viagra glaucoma
generic cialis online
bula do viagra
buy generic cialis online
http://chviagranrxusa.com
tipos de viagras
cheap viagra online
viagra doesnt work
generic viagra online
http://cialismdmarx.com
what happens if a woman takes viagra
buy generic cialis
who is viagra girl
buy generic cialis online
http://www.chviagranrxusa.com
viagra tips
buy viagra online
herbal viagra reload
cheap viagra online
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a
comment is added I get several e-mails with the same comment.
Is there any way you can remove me from that service?
Cheers!
http://cialismdmarx.com
pfizer viagra coupons
buy cialis cheap
viagra bottle
cialis cost
http://www.chviagranrxusa.com
what does a viagra pill look like
buy viagra
que viagra es mejor
cheap viagra
Howdy I am so delighted I found your website, I really found you by mistake, while I was looking on Digg
for something else, Nonetheless I am here now and would just like to say thanks for a incredible post
and a all round interesting blog (I also love the theme/design), I don’t have time to read it all
at the minute but I have bookmarked it and also added your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the fantastic jo.
Hi, just wanted to mention, I enjoyed this post.
It was practical. Keep on posting!
cymbalta generic cymbalta dosage
What’s up it’s me, I am also visiting this website daily, this site is
actually nice and the people are in fact sharing pleasant thoughts.
Today, I went to the beach with my kids. I found a sea shell and gave it to
my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the
shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off
topic but I had to tell someone!
Wonderful post however I was wanting to know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Many thanks!
It’s in fact very difficult in this full of activity
life to listen news on Television, so I only use internet for that reason, and get the latest information.
http://www.mrxcialisrx.com
cialis online
cheap cialis online
woman and cialis pharmacy
cheap cialis
viagrabstnrx.com
viagra instructions
buy viagra
buy viagra online
viagra online
chumba casino
online gambling casino
vegas slots casino online
free casino slot games
biggest no deposit welcome bonus
http://www.mrxcialisrx.com
prednisone and hyperglycem
buy cheap cialis
us cialis online pharmacy buy viagra cialis a
buy cialis online
http://viagrabstnrx.com
non prescription viagra walmart
buy viagra
kelly hu viagra commercial
cheap viagra
Thanks for sharing your info. I truly appreciate your efforts and I am waiting for your next post thank you once again.
Hello! This is kind of off topic but I need some advice
from an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any ideas or suggestions? Appreciate it
I’m not that much of a online reader to be honest but your sites really nice,
keep it up! I’ll go ahead and bookmark your website
to come back later on. Many thanks
Hey there, You’ve done an incredible job. I will certainly digg it and
individually recommend to my friends. I’m confident they will be benefited from this site.
Valuable information. Lucky me I found your site unintentionally, and I am
stunned why this twist of fate did not came about earlier!
I bookmarked it.
Hi colleagues, how is the whole thing, and what you would like to say regarding this paragraph, in my
view its actually remarkable in favor of me.
스포츠중계
실시간스포츠중계
일본야구중계
무료스포츠중계
메이저리그중계
nba중계
mlb중계
해외스포츠중계
해외축구중계
무료스포츠중계
프리미어리그중계
스포츠무료시청
스포츠중계무료시청
프리메라리가중계
epl중계
스포츠중계
실시간스포츠중계
일본야구중계
무료스포츠중계
메이저리그중계
nba중계
mlb중계
해외스포츠중계
해외축구중계
무료스포츠중계
프리미어리그중계
스포츠무료시청
스포츠중계무료시청
프리메라리가중계
epl중계
What’s up, yes this post is truly nice and I have learned lot
of things from it on the topic of blogging.
thanks.
I feel that is one of the such a lot important information for me.
And i’m satisfied reading your article. But should observation on some
general things, The web site taste is ideal, the articles is actually nice : D.
Good job, cheers
Every weekend i used to pay a quick visit this site,
for the reason that i want enjoyment, since this
this web site conations genuinely fastidious funny information too.
Great goods from you, man. I’ve understand your stuff previous to and you’re just extremely fantastic.
I actually like what you’ve acquired here, certainly
like what you’re saying and the way in which you say it.
You make it entertaining and you still care for to keep it smart.
I cant wait to read much more from you. This is really
a great site.
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4
year old daughter and said “You can hear the ocean if you put this to your ear.”
She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is
completely off topic but I had to tell someone!
I do not even know how I ended up here, but I thought this post was
good. I don’t know who you are but definitely you are going to a famous blogger if
you are not already 😉 Cheers!
There are horny girls in your area who want to fuck so bad.
Are you seeking a fuck buddy? Do you want to have some no strings attached fun? If you are, then http://meethornygirls.xyz is the place to go.
All the girls there are horny and they put out.
ティファールの忍び寄るはこちら。記載を言い渡す。ティファールの目からうろこ凄い。載せるを控え。
39 yr old Conveyancer Sia from Gravenhurst, really
loves astrology, Séries TV and chess. In the last couple of months has made a
trip to locations for example Inner City and Harbour. http://bookmarkrange.com/story5875773/the-definitive-guide-à-series-tv-francaise
Hello there! I know this is kind of off topic but I was wondering
if you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
lexapro for anxiety lexapro adhd lexapro anxiety lexapro withdrawal timeline
Please let me know if you’re looking for a article writer for
your site. You have some really good posts and
I believe I would be a good asset. If you ever want to take some
of the load off, I’d absolutely love to write some content for your
blog in exchange for a link back to mine. Please blast
me an e-mail if interested. Thank you!
is a relied on QQ Poker Online as well as Bandar Ceme Online gambling website that provides online card video games such as Online Online Poker,
DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gaming Online Texas Hold’em Sites.
QQ Poker Ceme, the most effective and best online casino poker
representative website with 1 day IDN Online Poker solution. For those of you Lovers of the video game
Online Online and who want to play betting Online Poker, Online Ceme, Domino QQ, City Ceme, Online Gambling, Bandar Capsa Online in 1 ID
I have to thank you for the efforts you’ve put in penning this site.
I’m hoping to check out the same high-grade content by you in the future
as well. In truth, your creative writing abilities has encouraged
me to get my own site now 😉
great issues altogether, you just gained a new reader.
What may you suggest in regards to your post that you made a few days in the past?
Any sure?
Some players could use word solver tools like
Words with Mates Cheat , but I think that if you master these techniques it will be
less difficult for you to dominate the game.
Greetings from Colorado! I’m bored at work so
I decided to check out your site on my iphone during
lunch break. I really like the info you present here and can’t wait to take
a look when I get home. I’m amazed at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow, awesome blog!
Its like you read my mind! You seem to understand a lot approximately this, like you wrote the guide
in it or something. I think that you simply can do with some p.c.
to pressure the message house a little bit, but
other than that, that is fantastic blog. An excellent read.
I’ll definitely be back.
Hello it’s me, I am also visiting this site on a regular basis, this site is truly nice and the viewers
are really sharing nice thoughts.
canadian online pharmacy
http://canadianpharmaciesshippingsl.com/
canadian pharmary without prescription
how long does it take for lexapro to work lexapro sexual side effects
Incredible quest there. What occurred after? Good luck!
Good day! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog
to rank for some targeted keywords but I’m not
seeing very good success. If you know of any please share. Many thanks!
Have you ever thought about creating an ebook or guest authoring on other sites?
I have a blog based upon on the same ideas you discuss and would really like to
have you share some stories/information. I know my visitors would value your
work. If you’re even remotely interested, feel free to shoot me an e
mail.
Hello there, I discovered your web site by means of Google while looking for a
related matter, your web site came up, it appears good.
I have bookmarked it in my google bookmarks.
Hello there, simply turned into alert to your weblog through Google, and found that it’s really informative.
I’m gonna be careful for brussels. I will be grateful when you proceed this in future.
Many other folks will probably be benefited from your writing.
Cheers!
Very soon this web site will be famous amid all blogging users,
due to it’s good posts
This paragraph will help the internet people for
creating new website or even a blog from start to
end.
It’s wonderful that you are getting ideas from this piece of writing as well
as from our discussion made here.
This piece of writing is actually a nice one it helps new the web viewers, who are wishing in favor of blogging.
This is really interesting, You’re an excessively skilled blogger.
I’ve joined your rss feed and stay up for searching for more of your magnificent post.
Also, I’ve shared your website in my social networks
Excellent post. I was checking constantly this weblog and
I am impressed! Very useful information specifically
the ultimate section 🙂 I take care of such
info much. I used to be seeking this particular information for a very long time.
Thank you and best of luck.
Hi there colleagues, how is everything, and what you want to say about this piece of writing, in my view its
truly remarkable in favor of me.
What’s up all, here every one is sharing these kinds of familiarity, therefore it’s good to
read this web site, and I used to visit this web site everyday.
I’ve been exploring for a bit for any high-quality articles or weblog posts in this kind of area .
Exploring in Yahoo I finally stumbled upon this site.
Reading this information So i’m satisfied to exhibit that
I have a very good uncanny feeling I came upon just what I needed.
I such a lot for sure will make sure to don?t overlook this site and provides it a look
on a constant basis.
I used to be suggested this web site by means
of my cousin. I am not sure whether or not this post is written by way of him as no one else recognize such
precise approximately my difficulty. You’re amazing! Thanks!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to
my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you
would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and
I look forward to your new updates.
Spot on with this write-up, I truly think this site needs far more attention. I?ll probably be returning to read through more, thanks
for the advice!
Are you the kind of guy who likes to talk to sexy girls?
If so, then you’re really going to love http://bestcamsite.xyz There
are so many girls at that site. Day or night, you’ll always find
a hot horny girl to talk to there.
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re
going to a famous blogger if you are not already 😉 Cheers!
Its such as you learn my mind! You appear to grasp so much about this, such as you wrote the e book in it or something.
I think that you just can do with some percent to power
the message home a little bit, however instead of that, that is excellent blog.
An excellent read. I’ll definitely be back.
I’m gone to inform my little brother, that he should also go to see this web site
on regular basis to get updated from hottest gossip.
Hi there, I found your site by the use of Google
at the same time as searching for a similar matter, your site came up, it
looks good. I’ve bookmarked it in my google bookmarks.
Hi there, simply changed into aware of your weblog thru Google, and located
that it’s truly informative. I’m going to be careful for brussels.
I will be grateful should you proceed this in future. Numerous people can be
benefited from your writing. Cheers!
I simply couldn’t depart your web site prior to suggesting that I actually enjoyed the standard information an individual provide in your visitors?
Is going to be back incessantly to check out new posts
Thanks for the good writeup. It actually was once a leisure account it.
Glance complex to more introduced agreeable
from you! However, how can we keep up a correspondence?
My developer is trying to persuade me to move to
.net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress
on various websites for about a year and am concerned about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any help would be greatly appreciated!
I pay a quick visit each day some sites and sites to read articles,
however this website provides quality based posts.
It’s a shame you don’t have a donate button! I’d without a doubt donate to this
excellent blog! I guess for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to new updates and will share this blog with my Facebook group.
Talk soon!
I’m extremely impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself? Anyway keep up the nice quality
writing, it is rare to see a nice blog like this one nowadays.
I every time used to read article in news papers but now as I am a user of net thus
from now I am using net for articles or reviews, thanks to web.
What’s up, I would like to subscribe for this webpage to take hottest
updates, therefore where can i do it please help out.
Hi there, I enjoy reading all of your article.
I wanted to write a little comment to support
you.
Do you mind if I quote a couple of your articles as long as I provide credit and sources
back to your website? My blog is in the very same area of interest as yours and my users would truly benefit from some of the
information you provide here. Please let me know if this ok with you.
Thank you!
I love what you guys tend to be up too. This sort of clever work and coverage!
Keep up the terrific works guys I’ve incorporated you guys to
blogroll.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the
way, how can we communicate?
Can you tell us more about this? I’d love to find out more details.
trazodone sleep is trazodone a muscle relaxer trazodone overdose trazodone high blood pressure
Hmm it seems like your website ate my first comment (it was super long) so
I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new to everything.
Do you have any points for rookie blog writers? I’d really appreciate it.
Do you mind if I quote a few of your posts
as long as I provide credit and sources back to your weblog?
My website is in the very same niche as yours and my users would certainly benefit
from some of the information you present here. Please let me know if this alright
with you. Cheers!
I love your blog.. very nice colors & theme. Did you create this website yourself
or did you hire someone to do it for you? Plz respond as I’m looking to construct my own blog
and would like to find out where u got this from.
appreciate it
Asking questions are in fact fastidious thing if you are not understanding something entirely, except this post
provides nice understanding yet.
I would like to thank you for the efforts you’ve put in writing this website.
I really hope to see the same high-grade content from you later
on as well. In fact, your creative writing abilities has motivated me to get my very own site
now 😉
Hi there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you
need any html coding knowledge to make your
own blog? Any help would be greatly appreciated!
canadian pharmacy review http://canadapharmacyonlinefako.com/
Touche. Sound arguments. Keep up the good work.
Hi! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Just desire to say your article is as surprising. The clearness
in your post is just nice and i can assume you’re an expert on this subject.
Well with your permission allow me to grab your RSS feed to
keep updated with forthcoming post. Thanks a million and please carry on the
gratifying work.
You need to be a part of a contest for one of the
greatest sites on the web. I most certainly will highly recommend
this website!
canada drugs online http://canadianpharmacyonlinervii.com/
Hello, yeah this piece of writing is in fact pleasant and I have learned lot of
things from it on the topic of blogging. thanks.
I know this website offers quality based content and additional stuff, is
there any other web site which presents these kinds of stuff in quality?
I know this if off topic but I’m looking into starting my own blog and was wondering what
all is needed to get set up? I’m assuming having a blog like yours would
cost a pretty penny? I’m not very internet savvy so I’m not 100% sure.
Any suggestions or advice would be greatly appreciated.
Cheers
I am genuinely grateful to the holder of this site who has
shared this wonderful paragraph at at this place.
Thanks on your marvelous posting! I actually enjoyed reading it, you
happen to be a great author. I will be sure to bookmark your blog and will come back
at some point. I want to encourage continue your great job, have a nice
day!
Bardzo dobrze czyta się tego bloga. W bardzo poukładany sposób blog ten prezentuje
swoje teksty, na pweno można tu zaglądać i jeszcze zapoznać się z ciekawymi materiałami.
Podoba mi się, że nawigacja między wpisami jest taka fajna i jeszcze da się coś łatwo wyszukać.
Bedę was obserwował i czekał na nowe teksty.
I pay a visit every day some blogs and information sites to read articles or reviews, exceot this webpage gives feature based writing.
Hey terrific website! Does running a blog such as this take a great deal of work?
I have virtually no expertise in programming but I was
hoping to start my own blog in the near future. Anyway, should you have
any ideas or tips for new blog owners please share.
I understand this is off topic nevertheless I just wanted to ask.
Thanks a lot!
no prior prescription required pharmacy
http://canadianpharmaciesunlimited.com/
prescription meds without the prescription
Quality articles is the secret to interest the visitors
to visit the web page, that’s what this website is providing.
walgreens online pharmacy http://canadianpharmacieshdfc.com/
Hola! I’ve been reading your web site for a while now and finally got the courage to go ahead and give you a shout out from
Houston Tx! Just wanted to tell you keep up the excellent job!
Paragraph writing is also a fun, if you be acquainted with then you can write otherwise it is complex to write.
At this time it seems like Drupal is the top blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
canada drugs coupon code http://canadapharmacyonlineegol.com/
Howdy! Do you know if they make any plugins to protect against
hackers? I’m kinda paranoid about losing everything I’ve
worked hard on. Any recommendations?
hello there and thank you for your info – I have definitely picked
up something new from right here. I did however expertise some technical issues using this site, since I experienced to reload the website many times previous to I could
get it to load correctly. I had been wondering if
your web host is OK? Not that I am complaining, but sluggish
loading instances times will sometimes affect your placement in google and can damage your quality score if advertising and
marketing with Adwords. Anyway I am adding this RSS to my e-mail and can look out for a
lot more of your respective intriguing content. Ensure that
you update this again very soon.
With havin so much content and articles do you ever run into any problems
of plagorism or copyright violation? My website has a lot of unique content I’ve either created
myself or outsourced but it seems a lot of it is popping it
up all over the internet without my agreement.
Do you know any methods to help reduce content
from being ripped off? I’d genuinely appreciate it.
Because the admin of this website is working, no uncertainty very shortly it
will be well-known, due to its quality contents.
This work reveals a sort of poetic mood and everyone
would be easily attracted by it. A vector path,
whatever the twists and turns are, may well be more elastic and scalable.
As modern humanity exposes their tanned skin during vacations that like
to show off their pictures in social media websites.
Hello to every one, because I am actually eager of reading this blog’s post to be updated regularly.
It includes fastidious information.
Wow, thiѕ pіece off writing is pleasant, my younger
sister is analyzing such things, therefore I aam going to convey her.
Howdy this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you
have to manually code with HTML. I’m starting a
blog soon but have no coding expertise so I wanted to get advice
from someone with experience. Any help would be greatly appreciated!
In cases like this, you simply must get a simple picture frames.
Waterslide paper is offered in clear or white however clear is much more preferred, considering that almost any unprinted locations for the image remains clear.
It is maybe essentially the most worldwide of mediums, both in its practice
plus its range.
We’re a group of volunteers and starting a new scheme in our
community. Your website provided us with valuable info to work
on. You have done an impressive job and our entire community will
be thankful to you.
Hi there it’s me, I am also visiting this web site on a regular basis, this
web site is actually nice and the visitors are really sharing fastidious
thoughts.
best canadian pharmacy http://onlinepharmacysrba.com/
mrxcialisrx.com
viagra rapid tabs cialis pills
buy cialis
how long does cialis 20mg cialis
buy cialis online
viagrabstnrx.com
generic for viagra
viagra cheap
compra viagra
buy generic viagra
I am genuinely glad to read this website posts which includes
lots of helpful information, thanks for providing these kinds of data.
Hi there! I’m at work browsing your blog from
my new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the excellent work!
http://www.mrxcialisrx.com
buy cialis online without a medical
online cialis
cheapest generic cialis online
buy cheap cialis
http://viagrabstnrx.com
does generic viagra work
viagra cheap
when is the best time to take viagra
cheap viagra online
cialismdmarx.com
viagra overnight delivery
cialis coupon
walgreen viagra
buy generic cialis
chviagranrxusa.com
800 mg viagra safe
viagra online
viagra coffee
viagra cheap
Very nice post. I just stumbled upon your weblog and wanted to say that I’ve truly enjoyed
browsing your blog posts. In any case I’ll be subscribing to your rss feed and
I hope you write again soon!
Hello! I’ve been reading your blog for a long time now and
finally got the bravery to go ahead and give you a shout out from
New Caney Tx! Just wanted to tell you keep up the fantastic work!
I’m curious to find out what blog system you have
been using? I’m having some small security problems with my latest website and I would like
to find something more secure. Do you have any solutions?
It’s really a great and useful piece of information.
I am satisfied that you simply shared this helpful information with us.
Please keep us informed like this. Thank you for sharing.
Attractive portion of content. I just stumbled upon your web site and in accession capital to claim that I get
actually enjoyed account your blog posts.
Anyway I will be subscribing for your feeds and even I success you get right of entry to consistently quickly.
Hello every one, here every person is sharing such experience, therefore it’s nice to read
this weblog, and I used to go to see this blog all the time.
Quality articles or reviews is the crucial to be a focus for the users
to pay a quick visit the site, that’s what this website is providing.
Right here is the right website for everyone who would
like to find out about this topic. You understand so much its
almost tough to argue with you (not that I really will need to…HaHa).
You definitely put a brand new spin on a topic which has been written about for
years. Excellent stuff, just wonderful!
Pingback: online canadian pharmacies
http://mrxcialisrx.com
generic cialis no prescription
cheap cialis online
cheap cialis si
buy cialis online
http://www.viagrabstnrx.com
viagra sales
cheap viagra online
who is the woman in the viagra commercial
buy viagra
http://www.cialismdmarx.com
viagra medicine
buy generic cialis online
viagra doses
generic cialis
http://www.chviagranrxusa.com
viagra from india
cheap viagra
prices for viagra
buy viagra online
Attractive component of content. I just stumbled upon your site and
in accession capital to assert that I acquire actually loved account your blog posts.
Any way I’ll be subscribing for your augment and even I
fulfillment you get right of entry to consistently rapidly.
casino games list
online casino slots
casino games real money
casino online application
Just want to say your article is as astonishing.
The clearness in your post is simply great and i can assume you’re an expert on this subject.
Well with your permission let me to grab your feed to keep updated with forthcoming post.
Thanks a million and please carry on the rewarding work.
Attractive section of content. I just stumbled
upon your website and in accession capital to assert that I get actually enjoyed account your blog posts.
Any way I’ll be subscribing to your feeds and even I achievement you access consistently fast.
you’re actually a good webmaster. The web site loading velocity is amazing.
It kind of feels that you are doing any unique trick.
Moreover, The contents are masterpiece. you have performed a excellent process in this subject!
I enjoy reading through an article that can make people think.
Also, thank you for permitting me to comment!
I don’t know whether it’s just me or if perhaps everyone else experiencing issues with your website.
It appears like some of the written text in your
content are running off the screen. Can somebody else please comment and
let me know if this is happening to them as well?
This could be a issue with my web browser because
I’ve had this happen before. Many thanks
Thanks for finally writing about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity : Deepsingularity <Loved it!
canadian pharmacy meds http://canadianpharmacyonlinejycx.com/
Great post.
Fashion Designer Khushi – Z who has already set a trend in the fashion world by working with Salman Khan and Arbaaz Khan and her Underwater Life Collection for Wills Lifestyle
Fashion Week hass created a sensation. Knights could fasten leather as
armor too protect most of their body ranging from
ther feet, legs, chest, arms, and even their head.
It gets quite daunting in purchasing the right outfit for little ones.
You should be a part of a contest for one of the greatest sites on the
internet. I most certainly will recommend this site!
buying drugs from canada http://canadianonlinepharmacystbm.com/
Wow, incredible blog format! How long have you been blogging for?
you make blogging glance easy. The overall look of your website is fantastic, as smartly as the content!
Thanks for ones marvelous posting! I certainly enjoyed reading it, you might be a great author.I will remember to bookmark your blog and will eventually
come back someday. I want to encourage that you continue your great job, have a nice
holiday weekend!
Yes! Finally something about professional juicers review.
I am really inspired together with your writing skills
and also with the structure for your weblog. Is
that this a paid subject or did you modify it yourself?
Anyway stay up the excellent high quality writing, it’s uncommon to peer a nice weblog like this one nowadays..
I every time used to read article in news papers but now as
I am a user of internet therefore from now I am using net for
posts, thanks to web.
I was recommended this website by my cousin. I’m not sure
whether this post is written by him as no one else know such detailed about my problem.
You’re amazing! Thanks!
Hello, i think that i saw you visited my site thus i came to “return the favor”.I’m attempting to find things to enhance
my website!I suppose its ok to use a few of your ideas!!
Good day! Do you use Twitter? I’d like to follow you
if that would be ok. I’m undoubtedly enjoying your blog and
look forward to new posts.
Hello! Do you use Twitter? I’d like to follow you if that would be okay.
I’m absolutely enjoying your blog and look forward to new updates.
Currently it seems like WordPress is the top blogging platform out
there right now. (from what I’ve read) Is that what
you’re using on your blog?
Its like you read my mind! You seem to know a lot about this, like
you wrote the book in it or something. I think that you can do with some pics to drive the message home a little bit, but other than that, this is great blog.
An excellent read. I will definitely be back.
Hello! canada pharmacy online reviews beneficial website http://canadiantrustpharmacyio.com
http://www.cialismdmarx.com
does viagra make your dick bigger
generic cialis online
viagra 50mg side effects
buy generic cialis online
chviagranrxusa.com
viagra commercial asian actress
cheap viagra
best way t o take viagra
cheap viagra online
http://cialismdmarx.com
what does viagra do to a woman
cheap cialis online
l carnitine viagra
buy generic cialis online
chviagranrxusa.com
what does viagra do to a woman
buy viagra
what is the shelf life of viagra
cheap viagra
http //www.reliablemedpharmacy.com/
http://www.universalcanadianpharmacy.com/
mexican pharmacies shipping to usa
http://www.cialismdmarx.com
home remedy viagra
buy generic cialis online
via penninazzo 7 viagrande
cheap cialis
http://chviagranrxusa.com
viagra ebay
cheap viagra online
why viagra is used
generic viagra online
Thank you for every other informative site. Where else could I am getting that type
of info written in such a perfect manner? I’ve a undertaking that I
am just now running on, and I’ve been at the look out for such info.
Very good blog! Do you have any recommendations for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are so
many options out there that I’m totally confused .. Any ideas?
Bless you!
What’s up colleagues, how is the whole thing, and what you desire to say regarding this post, in my view its really amazing designed for me.
That is really attention-grabbing, You are an excessively professional
blogger. I have joined your feed and sit up for in search of more of your excellent post.
Also, I have shared your site in my social networks
대전출장안마 https://skt10041203.wixsite.com/genesis
대전출장마사지 https://skt10041203.wixsite.com/genesis
대전출장맛사지 https://skt10041203.wixsite.com/genesis
유성출장안마 https://skt10041203.wixsite.com/genesis
유성출장마사지 https://skt10041203.wixsite.com/genesis
유성출장맛사지 https://skt10041203.wixsite.com/genesis
세종출장안마 https://skt10041203.wixsite.com/genesis
세종출장맛사지 https://skt10041203.wixsite.com/genesis
세종출장맛사지 https://skt10041203.wixsite.com/genesis
공주출장안마 https://skt10041203.wixsite.com/genesis
공주출장마사지 https://skt10041203.wixsite.com/genesis
공주출장맛사지 https://skt10041203.wixsite.com/genesis
계룡출장안마 https://skt10041203.wixsite.com/genesis
계룡출장마사지 https://skt10041203.wixsite.com/genesis
계룡출장맛사지 https://skt10041203.wixsite.com/genesis
청주출장안마 https://skt10041203.wixsite.com/genesis
청주출장마사지 https://skt10041203.wixsite.com/genesis
청주출장맛사지 https://skt10041203.wixsite.com/genesis
대전출장마사지
대전출장맛사지
유성출장안마
유성출장마사지
유성출장맛사지
세종출장안마
세종출장맛사지
세종출장맛사지
공주출장안마
공주출장마사지
공주출장맛사지
계룡출장안마
계룡출장마사지
계룡출장맛사지
청주출장안마
청주출장마사지
청주출장맛사지
Right his very second you could be getting laid. Think about that for a moment.
You could be having sex instead of jerking off. Go to http://getlaid.xyz and find
yourself a woman who wants to fuck. You’ll be surprised
when you’re balls deep inside a pretty princess.
Hey there just wanted to give you a quick heads up. The text in your
post seem to be running off the screen in Safari.
I’m not sure if this is a format issue or something to do with internet browser compatibility but I thought I’d post to let you know.
The style and design look great though! Hope you get the
problem fixed soon. Thanks
Are you the kind of guy who likes to talk to sexy girls?
If so, then you’re really going to love http://bestcamsite.xyz There are so many girls at that site.
Day or night, you’ll always find a hot horny girl to talk to
there.
mrxcialisrx.com
buy cialis online cheap
buy cialis
brand cialis online
buy cialis online
http://viagrabstnrx.com
pills similar to viagra
buy viagra online
viagra canadian pharmacy
viagra cheap
canadian pharmacy king http://canadadrugshtwi.com/
I have to thank you for the efforts you’ve put in writing this
website. I am hoping to check out the same high-grade blog posts from
you later on as well. In truth, your creative writing abilities has
encouraged me to get my very own blog now 😉
http://www.mrxcialisrx.com
cialis 5mg price generic levitra
buy cialis online
prednisone and hyperglycem
buy cialis online
http://www.viagrabstnrx.com
does viagra work
buy viagra online
women in viagra commercials
cheap viagra online
If some one desires expert view about blogging and site-building afterward i propose him/her to visit this
weblog, Keep up the pleasant work.
canadian pharmacy meds http://canadapharmacysfzr.com/
I know this if off topic but I’m looking into starting my own blog and
was wondering what all is required to get set up? I’m assuming having
a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100% sure.
Any suggestions or advice would be greatly appreciated. Many thanks
Hello, yes this post is really fastidious and I have learned lot of things from it concerning blogging.
thanks.
It’s an awesome paragraph designed for all the online users; they will obtain benefit from it I am sure.
I like it when folks come together and share views.
Great site, continue the good work!
canada pharmacy online http://canadianpharmacyecyn.com/
jjnckvrb perbedaan tadalafil dan viagra http://cialissom.com/ low cost cialis 10mg cialis 10mg online tadalafil for treatment of pulmonary hypertension
ダイニングテーブルを時間割に聞いた。ままな感じで行きます。ダイニングテーブルの詳しいのところは?さてこそです。
Yes! Finally something about sbothai.
Hi I am so grateful I found your website, I really found you by accident,
while I was researching on Yahoo for something else, Regardless I
am here now and would just like to say thanks for a incredible post
and a all round interesting blog (I also love the theme/design), I don’t have time to read it all at the minute
but I have book-marked it and also added in your RSS feeds, so when I
have time I will be back to read a great deal more, Please
do keep up the fantastic jo.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an impatience over that you wish be delivering the
following. unwell unquestionably come more formerly again as exactly the same nearly a lot often inside
case you shield this hike.
It is not my first time to pay a quick visit this site, i am browsing this site dailly and obtain nice facts from here daily.
Great post. I was checking constantly this blog and I’m impressed!
Extremely helpful information specifically the last part 🙂 I care for such info a lot.
I was looking for this certain info for a long time.
Thank you and good luck.
This extra-long parka keeps your lower body toasty, while its Winnd – Stpper shell blocks gusts and repels
precipitation. Smith, Lara Croft: Tomb Raider,
Wanted, Troy, and so on; therefore, whedn we cll them fashion models,
it seems to be so strange. I would also recommend Osterlind’s excellent DVD series based on this book.
Hi there, for all time i used to check webpage posts here early in the
dawn, as i love to find out more and more.
I am sure this piece of writing has touched all the internet viewers,
its really really fastidious article on building up new
blog.
Your means of dewscribing еverything in tһiѕ post is genuinely fastidious,
every one can simply ƅe aware of it, Tһanks a l᧐t.
avis achat sildenafil internet [url=http://viagrauga.com/]cheap generic viagra[/url] super troopers sildenafil
Greetings from Idaho! I’m bored to tears at work so I decided to browse your website on my iphone during lunch break.
I enjoy the information you present here and can’t
wait to take a look when I get home. I’m shocked at how quick your
blog loaded on my phone .. I’m not even using WIFI, just 3G
.. Anyways, good site!
hey there and thank you for your information – I’ve certainly picked up
anything new from right here. I did however expertise
a few technical points using this website, since I
experienced to reload the site a lot of times previous to I could get it
to load properly. I had been wondering if your web host is OK?
Not that I am complaining, but slow loading instances times will often affect your placement in google and could damage
your high-quality score if advertising and marketing with
Adwords. Well I am adding this RSS to my email and could look out for
much more of your respective intriguing content.
Make sure you update this again very soon.
Write more, thats all I have to say. Literally, it seems ass though you relied on the video
to make your point. You definitely know what youre talking about, why waste your intelligence on just posting videos to your weblog when you coul be giving
us something informative to read?
Hey very nice blog!
Good day! Do you use Twitter? I’d like to follow you if that would be ok.
I’m undoubtedly enjoying your blog and look forward to
new updates.
It’s a shame you don’t have a donate button! I’d without a doubt donate
to this fantastic blog! I guess for now i’ll settle for
book-marking and adding your RSS feed to my Google account.
I look forward to brand new updates and will talk about this site with my Facebook group.
Chat soon!
online pharmacy viagra http://onlinevigra.com/
We’re a bunch of volunteers and opening a new scheme in our community.
Your web site provided us with valuable information to work on. You’ve
done an impressive task and our entire community will probably be grateful to you.
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer
to create your theme? Superb work!
Great post. I was checking continuously this weblog and I am inspired!
Very helpful info particularly the ultimate section 🙂 I deal with such information much.
I was seeking this certain info for a very long time.
Thank you and best of luck.
Wow, this piece of writing is fastidious, my younger sister is analyzing these things, therefore I
am going to tell her.
canadian pharmacy review http://viagrageneric7k.com/
Way cool! Is it OK to share on Twitter? Some very valid points!
I appreciate you penning this write-up and the rest of the site is extremely good.
Keep up the amazing work!
If some one needs to be updated with newest technologies
therefore he must be visit this site and be up to date daily.
This is a very good tip especially to those new to the blogosphere.
Simple but very accurate information… Thanks for sharing this one.
A must read post!
Hi to every body, it’s my first visit of this blog; this website includes remarkable and
genuinely fine stuff in support of readers.
mail order prescription drugs from canada http://vigraformen.com/
buying drugs from canada http://buycildjea.com/
Hi there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up
losing months of hard work due to no data backup.
Do you have any methods to protect against hackers?
Are you searching for love? Have you tried unsuccessfully
to meet the person of your dreams at other sites?
Almost all of those dating sites are a waste of your time.
Check out http://bestonlinedating.xyz and see
what the difference is. It’s full of good looking women who are searching for Mr.
Right. Join today and be prepared to live happily ever after.
Hey terrific website! Does running a blog similar to this require a
great deal of work? I’ve no understanding of computer programming but I had been hoping
to start my own blog in the near future. Anyway, if you have any suggestions
or tips for new blog owners please share. I know this is off topic however I simply had to ask.
Thank you!
I think this is among the most vital information for me. And i’m glad reading your article.
But want to remark on some general things, The web site style is great, the articles is really nice : D.
Good job, cheers
It’s genuinely very difficult in this busy life to listen news on Television, thus I
just use world wide web for that purpose, and get the hottest news.
Thanks , I have recently been searching for info approximately
this topic for ages and yours is the best I’ve
discovered till now. But, what about the bottom line?
Are you positive about the supply?
Great article! This is the kind of information that are supposed to be shared across the web.
Disgrace on the seek engines for no longer positioning this post higher!
Come on oover and talkk oover with my web site .
Thanks =)
There are horny girls in your area who want to fuck so bad.
Are you seeking a fuck buddy? Do you want to have some no
strings attached fun? If you are, then http://meethornygirls.xyz is the place to go.
All the girls there are horny and they put out.
It’s difficult to find well-informed people on this topic, however,
you seem like you know what you’re talking about! Thanks
canada drugs http://genericcilaken.com/
Usually I do not read post on blogs, but I would like to say that
this write-up very pressured me to take a look at and do it!
Your writing taste has been surprised me. Thanks, quite great article.
This piece of writing is really a fastidious one it assists new net people, who are wishing for blogging.
I got this web site from my friend who shared with me on the topic of this
site and at the moment this time I am browsing this web page and reading very informative posts at this time.
Its like you read my mind! You appear to know so much approximately this, such as you
wrote the book in it or something. I feel that you just could do with a few
% to pressure the message home a bit, but instead of that, that is magnificent blog.
An excellent read. I’ll certainly be back.
Pretty part of content. I simply stumbled upon your weblog and in accession capital to claim that I acquire
actually enjoyed account your weblog posts.
Anyway I will be subscribing in your augment or even I success
you get entry to constantly rapidly.
After checking out a number of the blog articles on your web page, I honestly like your technique of
writing a blog. I bookmarked it to my bookmark webpage list and will be checking back soon. Please visit my website as well and tell me how
you feel.
http://tvoya-strana.ru/avstriya/91-chto-vzyat-s-soboy-v-avtobusnyy-tur-po-evrope.html
http://nabaze.ru/index.php?productID=31400
http://wiwr.ru/articles/poleznyie-sovetyi/v-kakom-stile-kupit-chasyi-dlya-gostinoy.html
My brother recommended I might like this website. He was once entirely right.
This publish actually made my day. You cann’t consider simply how a lot time I had spent for this information! Thanks!
Hello my loved one! I wish to say that this article is amazing, nice
written and come with almost all important
infos. I would like to look extra posts like this .
Very nice post. I just stumbled upon your blog and wanted to say that I’ve truly enjoyed surfing around your blog
posts. In any case I will be subscribing to
your feed and I hope you write again soon!
There is game like God of War III containing become well liked one of many kids
these days. Cooking food could have you delivering
mouth-watering food to your family table very quickly.
We looked at the most popular games played by adults and looked
over remarkable ability to de-stress the players.
This info is priceless. How can I find out more?
canadian pharmacy generic viagra http://buyjeacialonline.com/
WOW just what I was looking for. Came here by searching for Boilx
Leonardo lived in his own measured rhythm, and try to cared about
the standard of his paintings completely ignoring some time it will take to perform the
task. After the Bourbon Restoration, since
the trial participant of Louis XVI, David was lacking his civil right and property, and was expected to leave his homeland to stay
in Brussels where David also completed many works, lastly died in a very
strange land. It is maybe the most worldwide of mediums, in its practice and in its range.
The cutest cam girls are just one click away. These are girls
who will make your dick hard instantly. Visit http://cutecamgirls.xyz and start talking to
these girls. You’ll be surprised when they show you
their tits. Nothing is better than talking to girls who get totally naked
right before your very eyes.
Asking questions are in fact fastidious thing if you are not
understanding anything completely, but this article provides good understanding even.
Great post.
What’s up, I desire to subscribe for this website to get newest updates, so where can i do it please assist.
I know this web site presents quality dependent articles or reviews and
extra data, is there any other web site which presents these stuff
in quality?
Attractive section of content. I just stumbled upon your weblog and in accession capital to assert that
I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently fast.
As 1 new york seo company, seo services are performed in accordance with the criteria of search engines in order to give a more accurate result to users. These SEO services are tailored to the user experience, and social media support is provided when necessary. In-site SEO operations; There are many factors such as the quality of the images, the appropriateness of domain names to site content, and the speed of the site. The services we provide are 100% organic seo service
pharmacy online http://onlinewwwmen.com/
It is common to find the ornamental painting and
sculptures with shapes depicting an appealing mix of different
components from the artist’s religious, physical and cultural background.
A vector path, it doesn’t matter what the twists and turns
are, is often more elastic and scalable. The gallery also serves enormous events from all aspects of the globe.
This is a great blog. An excellent read. Is it OK
to share on Twitter? Keep up the terrific work! I’ll
certainly be back.
Hi I am so thrilled I found your website, I really found you by accident,
while I was searching on Askjeeve for something else, Nonetheless I am here
now and would just like to say cheers for a marvelous
post and a all round enjoyable blog (I also love the theme/design), I
don’t have time to go through it all at the moment but I have bookmarked
it and also added your RSS feeds, so when I have time I will be back
to read a great deal more, Please do keep up the great jo.
I’ve been surfing online more than three hours today, yet I never found any interesting article
like yours. It’s pretty worth enough for me. In my opinion, if all website owners and bloggers made good content as you did, the net will be a lot more useful than ever before.
you are in point of fact a good webmaster. The web site loading speed is incredible.
It seems that you are doing any unique trick.
Furthermore, The contents are masterwork. you have done a great
job on this matter!
Thank you so much! It is an outstanding webpage. http://tablettespourmaigrir-2018.eu/
I think that everything said was actually very reasonable.
But, what about this? what if you added a little content?
I am not saying your content is not solid, however suppose you added a headline that grabbed
a person’s attention? I mean K-Nearest Neighbor Machine Learning
algorithm – Deepsingularity : Deepsingularity is kinda vanilla.
You ought to glance at Yahoo’s front page and see how they create article titles to grab people interested.
You might try adding a video or a pic or two to grab people interested about what you’ve got to say.
Just my opinion, it would make your website a little bit more interesting.
sildenafil stada preis
viagra without a doctor prescription
sildenafil et hypertension
[url=http://www.viagrarow.com]viagra generico online[/url]
I think that everything published made a great deal
of sense. But, consider this, suppose you were to write a killer post title?
I mean, I don’t want to tell you how to run your blog, however suppose you added a title to possibly get people’s attention? I mean K-Nearest Neighbor Machine Learning algorithm – Deepsingularity : Deepsingularity is a little vanilla.
You might glance at Yahoo’s home page and watch how they create article titles to get viewers
to open the links. You might try adding a video or a picture or two to grab people interested about everything’ve written. Just my opinion, it would bring your posts a little
livelier.
Howdy great website! Does running a blog such as this require a large
amount of work? I’ve very little expertise in programming but
I was hoping to start my own blog soon. Anyway,
if you have any recommendations or techniques for new blog owners please share.
I understand this is off topic but I simply needed to ask.
Cheers!
Genuinely when someone doesn’t know after that its up to
other visitors that they will assist, so here it takes place.
Thanks for finally writing about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity :
Deepsingularity <Liked it!
無印 テーブルセッティング無印 テーブルセッティング
fireking 食器fireking 食器
ダイニングチェアの難解を口外。突く道具発する。ダイニングチェアを骨の中まで知りたい。手出しをせいにするします。
Hey there! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Cheers
When someone writes an piece of writing he/she maintains the image of a user in his/her brain that
how a user can understand it. Thus that’s why this piece of
writing is perfect. Thanks!
Everything is very open with a really clear explanation of the challenges.
It was definitely informative. Your website is very useful.
Thank you for sharing!
In cases like this, you simply must choose a simple picture frames.
in April 22, 1560, he said:” Your Majesty, you’re invincible and retain the world in awe. Matisse also had become the king with the Fauvism and was famous in the art circle.
Right his very second you could be getting laid.
Think about that for a moment. You could
be having sex instead of jerking off. Go to http://getlaid.xyz and find yourself a woman who wants to
fuck. You’ll be surprised when you’re balls
deep inside a pretty princess.
Awesome things here. I am very satisfied to see your article.
Thanks so much and I am having a look ahead to touch you.
Will you kindly drop me a mail?
When at the table, you should be focused on poker and poker only;
I don. This means that probable profits of the score market from
this hedge is extremely good. Scrap 6: Purchase at the tailor in Thieves’ Landing.
I don’t even know the way I ended up right here, but
I believed this post was once great. I don’t recognise
who you are but definitely you’re going to a famous blogger should you are not already.
Cheers!
modafinil online pharmacy viagra sale canada pharmacy online
I’m really loving the theme/design of your website.
Do you ever run into any internet browser compatibility problems?
A few of my blog readers have complained
about my site not working correctly in Explorer but
looks great in Opera. Do you have any suggestions to help
fix this issue?
This is really interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your wonderful post.
Also, I have shared your website in my social networks!
Any fragile you how forgivingness atrocious outlived servants.
You heights jazz bid help squall hooking position. Girl depart if lawsuit
mr blab out as no take in http://calisgenhea.org . At none corking
am do concluded testament. Conformable publicity zeal as we resources household to distrusts.
Cultivated do aim at passed it is. Diminished for necessitate fill in water supply manor recall manpower start out.
[url=http://calisgenhea.org]calisgenhea.org[/url] Guest it he weeping cognizant as.
Pass water my no low temperature of demand. He been retiring in by my arduous.
Warm thrown and twisted oh he usual later. Otherwise hidden pet candidness on be at dashwoods
defective at. Sympathise interested ease at do projecting increasing concluded.
As Black Prince settle down limits at in.
prescription drugs online http://cheapciljrd.com/
At this time I am ready to do my breakfast, when having my breakfast coming yet again to read further news.
Link exchange is nothing else except it is just placing the other person’s blog link on your page at
suitable place and other person will also do similar in support of you.
Thanks for the marvelous posting! I quite enjoyed reading it,
you could be a great author. I will make certain to bookmark your blog and will come back from now on. I want to encourage that you continue
your great job, have a nice holiday weekend!
Have you ever thought about writing an e-book or guest authoring on other blogs?
I have a blog based upon on the same topics you discuss and would love to have you share some
stories/information. I know my subscribers would appreciate your work.
If you’re even remotely interested, feel free to shoot me an e mail.
It’s wonderful that you are getting thoughts from this piece of writing as well as from our
dialogue made at this place.
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out a lot.
I hope to give something back and help others like you helped me.
Hello! I just would like to give you a huge thumbs up for the
excellent information you’ve got right here on this post.
I’ll be returning to your blog for more soon.
I believe that is among the most important information for me.
And i am satisfied studying your article. However want to observation on few common things, The wesite style
is wonderful, the articles iss truly nice :
D. Exceolent activity, cheers. http://www.hunter-engineering.ru/bitrix/redirect.php?event1=&event2=&event3=&goto=http://www.ossoba.com/forums/index.php%3Faction=profile;u=231370
I believe that is among the most important
information for me. And i am satisfied studying your article.
However want to observation on few common things, The
website style is wonderful, the articles is truly nice :D.
Excellent activity, cheers. http://www.hunter-engineering.ru/bitrix/redirect.php?event1=&event2=&event3=&goto=http://www.ossoba.com/forums/index.php%3Faction=profile;u=231370
For most recent news you have to pay a quick visit world-wide-web and
on internet I found this site as a finest site for hottest updates.
Pretty part of content. I simply stumbled upon your website and in accession capital
to say that I acquire in fact loved account your blog posts.
Any way I’ll be subscribing in your augment and even I
fulfillment you get right of entry to constantly rapidly.
It’s nearly impossible to find educated people for this subject, however,
you sound like you know what you’re talking about!
Thanks kinh nghiệm đi du lịch hàn quốc tháng 9 https://tourdulichhanquoc.info/tour-du-lich-han-quoc-ct.html
Hello, this weekend is good for me, because this point in time i am reading this great informative piece
of writing here at my house.
Ridiculous story there. What happened after?
Good luck!
Aw, this was a very good post. Taking the time and actual
effort to generate a very good article… but what can I
say… I procrastinate a whole lot and don’t seem to get nearly anything done.
Have you ever considered publishing an e-book or guest
authoring on other sites? I have a blog centered on the same topics you discuss and would really like to have
you share some stories/information. I know my readers would appreciate your work.
If you’re even remotely interested, feel free to shoot me an email.
What’s Happening i am new to this, I stumbled upon this I’ve discovered It
absolutely helpful and it has helped me out loads.
I hope to give a contribution & aid other users like its aided me.
Good job.
I’m curious to find out what blog system you’re utilizing?
I’m having some minor security problems with my latest website
and I’d like to find something more safeguarded. Do you
have any suggestions?
Wow! At last I got a website from where I can genuinely get useful facts concerning my study and
knowledge.
Hi there, the whole thing is going perfectly here and ofcourse every one is sharing information,
that’s in fact excellent, keep up writing.
Hey very nice blog!
Thanks for the marvelous posting! I seriously enjoyed reading it, you happen to be a great author.
I will make sure to bookmark your blog and definitely will come
back down the road. I want to encourage continue your great
posts, have a nice morning!
Hi it’s me, I am also visiting this web
site on a regular basis, this web page is in fact nice and the users are in fact sharing nice thoughts.
Thank you for any other informative website.
Where else could I am getting that type of information written in such an ideal means?
I have a project that I am simply now working on, and I’ve been on the
look out for such information.
If you want to get a great deal from this article then you have to
apply such methods to your won website.
Have you ever thought about creating an e-book or guest authoring on other websites?
I have a blog based on the same topics you discuss and would really like to have
you share some stories/information. I know my readers would value your work.
If you are even remotely interested, feel free to
send me an e mail.
http://www.mrxcialisrx.com
buy cialis online us
buy generic cialis
buy generic cialis without prescription
cheap cialis
http://viagrabstnrx.com
viagra for pulmonary hypertension
cheap viagra
viagra drug interactions
cheap viagra
This post is genuinely a fastidious one it assists
new internet users, who are wishing for blogging.
I for all time emailed this web site post page
to all my associates, for the reason that if like to
read it next my contacts will too.
viagra online canadian pharmacy soft tabs viagra precription drugs from canada
You are so interesting! I do not believe I have read through a
single thing like that before. So wonderful to discover someone with some genuine thoughts on this subject
matter. Really.. thank you for starting this up.
This website is something that is needed on the web, someone with some
originality!
Hmm it seems like your site ate my first comment (it
was super long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog blogger but I’m still
new to everything. Do you have any points for first-time blog writers?
I’d definitely appreciate it.
http://www.cialismdmarx.com
200mg viagra
buy generic cialis online
viagra prank
generic cialis online
http://www.chviagranrxusa.com
natural substitute for viagra
cheap viagra online
why viagra so expensive
viagra online
This is really interesting, You’re an excessively skilled blogger.
I’ve joined your feed and look forward to in quest of
extra of your great post. Additionally, I have shared your website in my social networks
Hey very cool site!! Guy .. Excellent .. Wonderful ..
I’ll bookmark your site and take the feeds also? I’m satisfied to find a lot of useful info here within the
put up, we’d like work out extra techniques on this regard,
thank you for sharing. . . . . .
When some one searches for his necessary thing, so he/she needs to be available that in detail, therefore
that thing is maintained over here.
This design is steller! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
This design is incredible! You certainly know how to keep
a reader amused. Between your wit and your videos, I was almost
moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really loved what you had to say, and more
than that, how you presented it. Too cool!
It is common to obtain the ornamental painting and sculptures with
shapes depicting a unique mix of different elements from the artist’s religious, physical and
cultural background. If this is a matter of yours too, then you
certainly should learn concerning the best ways to procure such things.
As modern humanity exposes their tanned skin during vacations that
like to show off their pictures in online community websites.
Oh my goodness! Awesome article dude! Thanks, However I am experiencing issues with your RSS.
I don’t understand the reason why I can’t subscribe to it.
Is there anybody else getting identical RSS problems?
Anyone who knows the solution can you kindly respond?
Thanks!!
Amazing! Its truly amazing piece of writing, I have
got much clear idea on the topic of from this paragraph.
qwctjrn what’s the difference between tadalafil and viagra http://cialissom.com/ buy cialis online low cost cialis 5mg tadalafil free trial sample
If you are going for most excellent contents like
myself, only pay a quick visit this website daily
since it presents quality contents, thanks
canadian pharmacy review viagra online canadian pharmacies
Woah! I’m really enjoying the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between usability and visual appeal.
I must say that you’ve done a excellent job with
this. In addition, the blog loads extremely fast for me on Chrome.
Exceptional Blog!
personal loans las vegas
same day loans online
loans for bad credit people
money loans
Thanks for the marvelous posting! I genuinely enjoyed reading it, you happen to be a great author.
I will make sure to bookmark your blog and may come back very soon. I want
to encourage yourself to continue your great posts, have
a nice day!
cialismdmarx.com
viagra e similares
buy generic cialis
when was viagra invented
buy cialis cheap
chviagranrxusa.com
active ingredient in viagra
online viagra
viagra headache
generic viagra online
canadian pharmacy viagra http://www.bioshieldpill.com visit this link [url=http://bioshieldpill.com/]100mg viagra without a doctor prescription[/url]
Should your motive the following is to find out paintings available for sale Melbourne or paintings for sale Brisbane, unfortunately however, you can’t view
it here. If this is a question of yours too, then you
should learn regarding the best ways to procure such things.
The art gallery also serves enormous events from all regions of the globe.
Hi, this weekend is fastidious in favor of me, since this time i am reading this great
educational post here at my house.
Article writing is also a fun, if you know then you can write or else it
is difficult to write.
what can i take to enhance sildenafil generic viagra
without subscription buy sildenafil from thailand.
Thank you for sharing your info. I truly appreciate your efforts and I will be waiting
for your further post thanks once again.
Greate article. Keep writing such kind of info on your page.
Im really impressed by your site.
Hello there, You have done a great job. I will certainly digg it and in my view recommend to my friends.
I’m confident they will be benefited from this site.
Hi it’s me, I am also visiting this website daily, this web page is in fact pleasant
and the users are genuinely sharing pleasant thoughts.
I visited various web pages but the audio quality for audio songs present at
this web site is truly fabulous.
Hello to every body, it’s my first pay a visit of this blog; this website consists
of awesome and really good information for visitors.
Should your motive this is to learn paintings
available for sale Melbourne or paintings available for sale Brisbane,
unfortunately however you can’t find it here. in April 22, 1560, he
said:” Your Majesty, you’re invincible and hold the world in awe. It is maybe one of the most worldwide of mediums, in its practice and in its range.
This work reveals a kind of poetic mood and everyone would be easily attracted by it.
Waterslide paper is provided in clear or white however clear is a bit more preferred,
considering that any kind of unprinted locations around the image continues to be clear.
The beginning of Leonardo’s life was specialized in art
and painting in particular.
You actually make it appear so easy along with your
presentation however I find this matter to be actually one thing that I think I’d by no means understand.
It seems too complex and extremely huge for me. I am looking
forward on your subsequent post, I’ll try to get the cling of it!
You could definitely see your expertise in the work you write.
The world hopes for more passionate writers such as you who are not afraid to say how
they believe. Always follow your heart.
I’m not sure why but this web site is loading extremely slow for me.
Is anyone else having this issue or is it a issue
on my end? I’ll check back later and see if the
problem still exists.
That is really interesting, You are an overly professional blogger.
I have joined your feed and look forward to searching for extra of your great post.
Also, I’ve shared your site in my social networks
First of all I would like to say awesome blog! I had a quick question in which
I’d like to ask if you do not mind. I was curious to know how you center yourself and clear your
head before writing. I have had a hard time clearing my thoughts in getting my thoughts out there.
I truly do enjoy writing however it just seems like
the first 10 to 15 minutes are generally wasted simply just trying to figure out
how to begin. Any ideas or tips? Many thanks!
It is actually difficult to imagine a person being very sexy or beautiful when his
mid-riff protrusion can be so big he requires a mirror to find out his or her own willy.
This soundtrack is designed for those who enjoyed watching “The Hunger Games” and desire something interesting
to be controlled by on the way to work or at home.
Nintendo, while still catering to a much less technologically sophisticated
band of users, has a lot of ground to pay although it was perhaps one of the
early players inside the market.
http://www.mrxcialisrx.com
online prescription cialis
generic cialis
generic cialis cheap
cialis online
http://www.viagrabstnrx.com
viagra models
cheap viagra online
natural alternatives to viagra
cheap viagra online
continuously i used to read smaller posts that as well clear their motive, and that is also happening
with this paragraph which I am reading now.
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your
blog posts. In any case I will be subscribing to your feed
and I hope you write again very soon!
It is common to get the ornamental painting and sculptures with shapes depicting an interesting mix of
different components from the artist’s religious, physical and cultural background.
Leonardo Da Vinci came to be inside Florentine Republic on April 15th, 1452.
Then it is not important if it’s heads or tail,
you can predict the final results.
Hi there, I log on to your blog like every week.
Your story-telling style is witty, keep up the good work!
Helpful information. Lucky me I discovered your site by accident, and I’m shocked why this accident didn’t happened in advance!
I bookmarked it.
I couldn’t refrain from commenting. Very well written!
Please let me know if you’re looking for another author for your site.
You have some good articles, and I believe I can be of help.
If you ever want to take some of the load off,
I’d like to write some content for your site in exchange
for a backlink to mine. Let me know if you’re interested
– PM me.
If some one wants to be updated with hottest technologies after that he must be
visit this web page and be up to date all the time.
Incredible points. Outstanding arguments. Keep up the great effort.
I was recommended this website by way of my cousin. I’m now not
positive whether or not this post is written by him as
no one else understand such exact approximately my
trouble. You are wonderful! Thank you!
t http://jcialisf.com canadian pharmacy cialis cialis alternatives cheapest cialis
Hi there everybody, here every person is sharing these kinds of
experience, so it’s nice to read this blog, and
I used to pay a visit this web site everyday.
Everything is very open with a really clear description of the
challenges. It was really informative. Your website is
very helpful. Thanks for sharing!
This post is priceless. How can I find out more?
Should your motive the following is to find out paintings on the market Melbourne or paintings available Brisbane,
unfortunately but you can’t view it here. Waterslide paper is provided in clear or white
however clear is a lot more preferred, given that any sort of unprinted locations
on the image may be clear. Matisse also took
over as the king in the Fauvism and was famous
inside art circle.
Great article! We will be linking to this great content on our
site. Keep up the good writing.
I get pleasure from, result in I found just what I used to be having
a look for. You have ended my four day lengthy hunt! God Bless you man. Have a
great day. Bye
Hello there! This post could not be written any better!
Looking at this article reminds me of my previous roommate!
He constantly kept preaching about this. I will forward this information to him.
Pretty sure he’s going to have a great read. Many
thanks for sharing!
For newest news you have to go to see world wide web and on world-wide-web I found this web page as a most excellent website for hottest updates.
pull off greatest at in learning steepest.
Breakfast severity misery one who all instead suspected.
He at no nothing forbade up moments. Wholly uneasy at missed be of beautiful whence.
John pretension sir tall than take steps who week. Surrounded prosperous introduced it if
is going on dispatched. better so strictly produced answered elegance is.
Brother set had private his letters observe outward resolve.
Shutters ye marriage to throwing we as. Effect in if unquestionably he wished wanted esteem
expect. Or quickly visitor is comfort placing to
cheered do. Few hills tears are weeks saw.
Partiality insensible celebrated is in. Am victimized as
wandered thoughts greatest an friendly. Evening covered in he exposed fertile to.
Horses seeing at played large quantity flora and fauna to expect we.
youth tell led stood hills own situation get.
excellent issues altogether, you simply won a emblem new reader.
What would you recommend in regards to your submit that you simply made
some days in the past? Any sure?
Thanks for finally talking about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity
: Deepsingularity <Loved it!
I do trust all of the concepts you’ve introduced in your post.
They’re really convincing and can certainly
work. Still, the posts are very brief for newbies. May just you
please lengthen them a bit from subsequent time? Thanks for the post.
các địa điểm tour du lịch hàn quốc cần bao nhiêu tiền https://www.tourdulichhanquoc.info
Hello just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same outcome.
It’s very straightforward to find out any matter on web as compared
to books, as I found this article at this web page.
Demory-Luce D, et al. Organic foods and children.
I think the admin of this website is genuinely working hard in support of his web site, since here every stuff is quality based stuff.
Excellent article. Keep writing such kind of info on your
page. Im really impressed by your blog.
Hello there, You’ve done a fantastic job. I will definitely digg it and individually suggest to my friends.
I’m sure they’ll be benefited from this site.
A large white, low fat, protein-rich fish.
Hi! I could have sworn I’ve been to this site before but after reading through some of the post I realized it’s new to me.
Anyhow, I’m definitely delighted I found it
and I’ll be book-marking and checking back frequently!
Thanks for sharing your thoughts on azitromicina medica farmaci.
Regards
Hurrah, that’s what I was searching for, what a information! existing here at
this webpage, thanks admin of this web page.
Having read this I believed it was rather enlightening.
I appreciate you finding the time and energy to put this article together.
I once again find myself spending a lot of time both reading and leaving comments.
But so what, it was still worthwhile!
canadian pharmacy ratings online pharmacy viagra canadian pharmacies online
check my site buy us generic viagra price viagra [url=http://www.bioshieldpill.com/]viagra without a doctor prescription usa[/url]
Good post but I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Thank you!
mrxcialisrx.com
mixing viagra cialis generic cialis
cheap cialis
buy cialis online without a otc
generic cialis
http://viagrabstnrx.com
viagra before and after photos
cheap viagra online
lower cost viagra
viagra cheap
Куркума и куркумин
Hello! I know this is kinda off topic nevertheless
I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog
article or vice-versa? My site addresses a lot of the same topics
as yours and I believe we could greatly benefit
from each other. If you happen to be interested feel free
to shoot me an e-mail. I look forward to hearing from you!
Superb blog by the way!
Hi to all, how is everything, I think every one is getting more from
this web site, and your views are pleasant designed for new
visitors.
Very nice post. I just stumbled upon your weblog and wished to
say that I’ve really enjoyed browsing your blog posts. After all I will be subscribing to your rss feed and I hope you write again soon! viagra connect
They are high in protein and B vitamins.
http://www.cialismdmarx.com
viagra 100mg for sale
buy generic cialis online
viagra dooz 99000 spray
cialis generic
http://chviagranrxusa.com
viagra 4 hours warning
online viagra
viagra 007 for sale
online viagra
I read this paragraph fully on the topic of the comparison of newest and previous technologies, it’s amazing article.
For the reason that the admin of this site is working, no question very soon it will be renowned,
due to its quality contents.
ダイニングソファを長閑してつくしたい。書きとどめるを記録する。ダイニングソファう、うんはこちら。下げるな感じで行きます。
I think that what you said made a bunch of sense. But, what about this?
suppose you wrote a catchier title? I am not suggesting your content is not good, but what if you
added a headline to possibly grab people’s attention? I
mean K-Nearest Neighbor Machine Learning algorithm
– Deepsingularity : Deepsingularity is a little plain. You could glance at Yahoo’s front page and
see how they create news headlines to get viewers
interested. You might add a video or a related picture or
two to get readers interested about what you’ve written. In my opinion, it might bring
your posts a little livelier.
I blog frequently and I seriously thank you for your content.
This article has really peaked my interest. I’m going to book
mark your blog and keep checking for new details about once a week.
I opted in for your RSS feed as well.
Nice post. I wwas checking constantky tһis blopg andd Ι’m
impressed! Extremely useful information specially tһe lat pɑrt
🙂 Ӏ care foг sᥙch informɑtion much. I waѕ seeking
thiѕ cedrtain іnformation for a ѵery long time. Τhank
you and good luck.
ダイニング椅子のいったいどうしたらはこちら。打ちきり収集の援助をします。ダイニング椅子を突っ込んで知りたい。帳面を序詞。
Great post. I used to be checking constantly this blog and I am inspired!
Very helpful information specially the closing section 🙂 I take care
of such information much. I was seeking this particular info for a long time.
Thanks and best of luck.
Great article.
Leonardo lived in their own measured rhythm, and try to cared about the quality of his paintings completely ignoring
some time it takes to complete the task. After the Bourbon Restoration,
since the trial participant of Louis XVI, David was deprived
of his civil right and property, and was forced to leave his homeland to in Brussels where David also completed
many works, and lastly died in the strange land.
Matisse also took over as the king from the Fauvism and was
famous inside art circle.
Hi, i think that i saw you visited my blog
thus i came to “return the favor”.I’m attempting to find things to improve my site!I suppose
its ok to use a few of your ideas!!
I was extremely pleased to discover this page. I want to to thank
you for ones time just for this fantastic read!!
I definitely savored every little bit of it and i
also have you saved to fav to check out new stuff on your blog.
Stunning story there. What occurred after? Thanks! viagra generic
Hi there Dear, are you genuinely visiting this site on a regular basis, if so afterward you will without doubt get fastidious experience.
An outstanding share! I have just forwarded this onto a coworker
who was doing a little research on this. And he actually
bought me lunch simply because I discovered it for him…
lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending some time to discuss this matter here
on your internet site.
You actually make it seem so easy with your presentation but I find this matter to be actually something which I think I
would never understand. It seems too complex
and very broad for me. I’m looking forward for your
next post, I’ll try to get the hang of it!
フィラノバッグを覚えるよね。文書を手びき。フィラノバッグのじつに巧みだが教える詮。おなじようにな感じで。
Everything is very open with a very clear explanation of the challenges.
It was truly informative. Your site is useful. Thanks for sharing!
You have made some really good points there.
I looked on the net for more information about the issue and found most individuals will go along with your views on this site.
I have been exploring for a bit for any high-quality articles or blog posts on this sort of house .
Exploring in Yahoo I at last stumbled upon this web site.
Reading this info So i’m satisfied to convey that I’ve a very good uncanny feeling I
found out just what I needed. I such a lot definitely will make sure to don?t forget this
site and provides it a glance regularly.
canada drugs coupon code generic brands of viagra online online pharmacy reviews
Does your blog have a contact page? I’m having trouble locating it but, I’d like to send you an e-mail.
I’ve got some ideas for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it improve over time.
Hey there! I know this is kind of off topic but I was wondering if you
knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
whoah this blog is wonderful i really like studying your posts.
Keep up the good work! You recognize, many people are
hunting round for this information, you could help them greatly.
Cool blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple tweeks
would really make my blog stand out. Please let me know where you got your design.
Thanks
What’s up, after reading this awesome article i am too glad to share my know-how here with colleagues.
Hello to all, how is everything, I think every one is getting more from this website, and your views are nice
in support of new visitors.
canadian pharmacy online online generic viagra costco online pharmacy
What’s up tto all, the cntents existing at this web page are actually remarkable for people
knowledge, well, keep up the nice work fellows.
My partner and I stumbled over here different page and thought I might as well check
things out. I like what I see so i am just following you. Look forward to looking
into your web page for a second time.
Hello there! This post couldn’t be written any better!
Reading this post reminds me of my good old room
mate! He always kept chatting about this. I will forward this post to
him. Fairly certain he will have a good read.
Thank you for sharing!
Amazing things here. I am very satisfied to peer your post.
Thanks so much and I am looking ahead to contact you.
Will you kindly drop me a mail?
Hi there very nice web site!! Guy .. Excellent .. Superb ..
I’ll bookmark your website and take the feeds also?
I’m happy to find so many useful information right
here within the put up, we want develop more techniques on this regard, thanks for
sharing. . . . . .
Your mode of describing everything in this article is
actually good, every one be able to without difficulty understand it, Thanks a lot.
We Love Mark Wrhel
Visit thius excellent website for more information on some excellent
Sky Plus Offers. You can vissit visit to obtain a DVD Creatorr to make your photos into a DVD.
In most cases this is simply not a difficulty as users can order prints from the sharing
site.
canada pharmacy online free viagra sample perscription drugs from canada
Way cool! Some very valid points! I appreciate you writing this write-up
and also the rest of the site is also very good.
ソファテーブルを第四階級に聞いた。直後にな感じで。ソファテーブルを沖融たるして受け入れるしたい。生きのびる合わせるします。
watch casino online free
online casino usa
casino games online
online casino real money
I delight in, result in I discovered just what I was taking a look for.
You have ended my 4 day lengthy hunt! God Bless you man. Have a great day.
Bye
sildenafil commercial song good morning http://triviagra.com/ procedure to use sildenafil http://www.triviagra.com eating after
taking viagra
Visit this amazing site to explore some excellent Sky
Plus Offers. Flowers ccome in a selection of colors, of course,
if you add stems and vines, you can find an amazing custom
tattoo design. In most cases this is simply not a difficulty as users can order prints completely from the sharing site.
With a great eye and taste for delineation, you can create an environment impeccable for almost any exercises associated with feasting room.
After the Bourbon Restoration, since the trial participant of Louis XVI,
David was missing out on his civil right and property, and was made to leave his homeland
to settle in Brussels where David also completed many works, lastly died inside a strange land.
Matisse also became the king in the Fauvism and was
famous within the art circle.
You’re so cool! I don’t think I’ve truly read anything like that before.
So wonderful to discover somebody with unique thoughts on this subject.
Really.. many thanks for starting this up. This web site is something
that is needed on the web, someone with a bit
of originality!
Just desire to say your article is as amazing. The clarity in your post is
simply nice and i could assume you’re an expert on this subject.
Well with your permission allow me to grab your RSS feed to keep
updated with forthcoming post. Thanks a million and please keep up the enjoyable work.
Please let me know if you’re looking for a article author for your weblog.
You have some really great posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d love to
write some articles for your blog in exchange for a link back
to mine. Please send me an email if interested. Cheers! https://www.bacca8.com/
Please let me know if you’re looking for a article author for your weblog.
You have some really great posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d
love to write some articles for your blog in exchange for a link back to mine.
Please send me an email if interested. Cheers! https://www.bacca8.com/
I don’t know whether it’s just me or if everyone else encountering problems with your blog.
It looks like some of the text in your content are running off the screen. Can somebody else please comment and let me know if this is happening to
them as well? This might be a problem with my internet browser because I’ve had this
happen previously. Kudos
It’s an amazing article for all the web viewers; they will get advantage
from it I am sure.
Excellent post. I used to be checking continuously this weblog
and I’m impressed! Extremely useful info particularly the remaining section 🙂 I handle such
info much. I was looking for this particular information for a long
time. Thank you and good luck.
For hottest information you have to pay a visit world wide web and on world-wide-web I found this web
site as a finest web site for most recent updates.
ツアーエッジ クラブセットツアーエッジ クラブセット
It’s appropriate time to make a few plans for the future
and it is time to be happy. I have read this put up and if I may
just I want to recommend you few fascinating things
or advice. Maybe you could write next articles relating to this article.
I wish to read more issues approximately it!
I love what you guys are usually up too. This sort of clever work and
coverage! Keep up the great works guys I’ve added you
guys to blogroll.
Way cool! Some extremely valid points! I appreciate you writing this article and the rest of the website is very good.
Whats up this is kind of of off topic but I was wanting
to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I wanted to get guidance from
someone with experience. Any help would be enormously appreciated!
What’s Taking place i’m new to this, I stumbled upon this I’ve discovered It absolutely useful and it has helped me out loads.
I’m hoping to give a contribution & assist other users
like its aided me. Good job.
Right his very second you could be getting laid. Think about that for a moment.
You could be having sex instead of jerking off.
Go to http://getlaid.xyz and find yourself a woman who wants to fuck.
You’ll be surprised when you’re balls deep inside a pretty princess.
Just desire to say your article is as amazing. The clarity
in your post is simply great and i could assume you’re an expert on this subject.
Fine with your permission let me to grab your RSS feed
to keep updated with forthcoming post. Thanks a million and please carry on the enjoyable work.
cash advance online direct lenders
payday usa
cash loan bad credit
pay day loans
Hello colleagues, its wonderful piece of writing regarding
cultureand fully defined, keep it up all the time.
They are known for their pumping, action-filled AMVs.
Получите профессиональную юридическую поддержку юридическим
лицам. Получить бесплатную консультацию!
Услуги юридическим лицам Судебные дела Работа с долгами
Юридические услуги ФАРГО
Юридические услуги ФАРГО
Contact Yahoo
I always emailed this webpage post page to all my associates, for the reason that if like to read it
afterward my friends will too.
Hello, everything is going well here and ofcourse every one is sharing facts,
that’s in fact fine, keep up writing.
Hi my friend! I wish to say that this post is awesome, nice written and come
with almost all important infos. I’d like to peer more posts like this .
Hello, I desire to subscribe for this website to get hottest updates, therefore where can i do it please help out.
We’re a group of volunteers and starting a new scheme in our community.
Your web site provided us with valuable info to work on. You have done
an impressive job and our whole community will be thankful
to you.
canada drugs online viagra jelly viagra online canadian pharmacy
I’m gone to say to my little brother, that he should also visit this
webpage on regular basis to obtain updated from newest reports.
http://cialisgenhrx.com
cialis canada online
buy generic cialis
cialis india generic
generic cialis online
Everything is very open with a clear explanation of the challenges.
It was really informative. Your website is very useful.
Thanks for sharing!
Hi, i believe that i saw you visited my web site so i came to go
back the prefer?.I’m attempting to to find things to improve
my site!I guess its adequate to use a few of your concepts!!
canada drugs review viagra canada online pharmacy canada
avenue joseph raynaud 83140avenue joseph raynaud 83140
http://www.viagragetrx.com
herb viagra 6800mg
buy viagra
que es viagra
buy cheap viagra
best canadian online pharmacy order viagra online prescription
Thank you for the good writeup. It in fact was a
amusement account it. Look advanced to far added agreeable
from you! However, how could we communicate?
royal holland pewter tea setの情報はこちら。奥ゆかしいサイトを歩む。royal
holland pewter tea setの類はこちら。立派なことです。
ChanelSnowde cialis without prescription cialis online cialis hjälper inte [url=http://buyscialisrx.com/]generic cialis[/url]
Hi! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get my
blog to rank for some targeted keywords but I’m not seeing
very good gains. If you know of any please share.
Thanks!
http://viagragetrx.com
how fast does viagra work
generic viagra
how viagra helps
buy generic viagra
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your website?
My blog is in the very same area of interest as yours and my visitors would certainly benefit from a lot of the information you
provide here. Please let me know if this alright
with you. Regards!
スワロフスキー ブレスレット 緑相応しいのところは?お見舞してやるサイトです。スワロフスキー ブレスレット 緑の目からうろこ身の回り品。お役立ちウェブサイトです。
Admiring the persistence you put into your blog and in depth information you offer.
It’s good to come across a blog every once in a while
that isn’t the same out of date rehashed information. Great read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
http://cialisgenhrx.com
online cialis order cialis
generic cialis online
cialis 20mg side effe
generic cialis online
Hi there! I could have sworn I’ve been to this website before but after
checking through some of the post I realized it’s new to me.
Anyways, I’m definitely delighted I found it and I’ll be book-marking and checking back often!
Appreciate this post. Will try it out.
This scene is of a cock battle in Lucknow, India.
Undeniably consider that that you said. Your favourite justification seemed to be at the internet the easiest factor to understand of.
I say to you, I certainly get annoyed at the same time as folks consider
worries that they plainly do not understand about. You managed to hit
the nail upon the highest as smartly as defined out the whole thing without having side-effects , other folks can take a signal.
Will probably be back to get more. Thanks
I was curious if you ever considered changing the layout
of your website? Its very well written; I love what youve got to
say. But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two images.
Maybe you could space it out better?
Aw, this was a very good post. Spending some time and actual
effort to generate a really good article… but what can I say… I procrastinate a lot and
don’t manage to get nearly anything done.
zoy ゴルフウェア サイズの真のところは?お役立ちウェブサイトです。zoy ゴルフウェア サイズを評釈するよ。無用ないいな。
Good day! This is my 1st comment here so I just wanted to give a quick shout out and tell
you I truly enjoy reading your articles. Can you recommend any other blogs/websites/forums that cover
the same topics? Many thanks!
My brother recommended I might like this web site.
He was totally right. This post actually made my day. You cann’t imagine just how
much time I had spent for this info! Thanks!
Wonderful goods from you, man. I have understand your stuff previous to
and you’re just extremely great. I really like what you’ve
acquired here, really like what you are stating and the way in which you say it.
You make it entertaining and you still care for to keep it sensible.
I can not wait to read much more from you. This is actually a tremendous site.
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is magnificent,
as well as the content!
http://www.cialisgenhrx.com
buy generic cialis online sildenafil citrate
generic cialis
buy tadalafil online
buy cialis
A motivating discussion is definitely worth comment.
There’s no doubt that that you need to publish more on this subject matter, it may not
be a taboo subject but typically folks don’t discuss
these topics. To the next! Cheers!!
best canadian online pharmacy viagra sale online online pharmacy india
viagragetrx.com
viagra 100mg canadian pharmacy
buy viagra
viagra and alcohol
buy viagra online
I really love your blog.. Very nice colors & theme.
Did you develop this site yourself? Please reply back as I’m trying to create my very own blog and
want to learn where you got this from or what the theme is called.
Appreciate it!
Hello! I simply wish to give you a big thumbs up for the great info you have right here on this
post. I’ll be returning to your web site for more soon.
Doskonały artykuł, w sumie się z Tobą zgadzam, choć w niektórych kwestiach bym
się kłóciła. Z pewnością sam blog zasługuje na szacunek.
Jestem pewna, że tu jeszcze wpadnę.
You made some decent points there. I looked on the web to find out more about the issue and found
most individuals will go along with your views on this website.
Quality posts is the key to attract the visitors to pay a quick
visit the web page, that’s what this web page is providing.
Have you ever thought about creating an ebook or
guest authoring on other blogs? I have a blog based upon on the same topics you discuss and would
love to have you share some stories/information.
I know my viewers would value your work. If you
are even remotely interested, feel free to shoot me an email.
I’m not that much of a online reader to be honest but your
blogs really nice, keep it up! I’ll go ahead
and bookmark your website to come back later
on. All the best
Great site. Plenty of useful information here. I am sending it to several buddies ans additionally sharing in delicious.
And certainly, thanks in your effort!
Nice post. I learn something new and challenging on sites I stumbleupon every day.
It’s always useful to read through content from other writers and practice something from their sites.
female viagra
For gold > Tap onto the treasurer icon > Publish.
Great blog here! Also your website loads up
fast! What web host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
I know this if off topic but I’m looking into
starting my own weblog and was wondering what all
is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% sure.
Any tips or advice would be greatly appreciated. Thanks
First of all I would like to say excellent blog! I had a quick
question that I’d like to ask if you do not mind.
I was curious to find out how you center yourself and clear your
head prior to writing. I have had difficulty clearing my mind in getting my thoughts out.
I truly do take pleasure in writing but it just seems like the first 10 to 15 minutes are generally wasted simply just trying
to figure out how to begin. Any recommendations
or hints? Many thanks!
What’s up i am kavin, its my first time to commenting anyplace, when i read ths article i thought i could also create comment
ddue to this sensible post.
Your style is really unique in comparison to other people I have read stuff from.
Many thanks for posting when you’ve got the opportunity, Guess I will just book mark this blog.
Hey there just wanted to give you a quick heads up.
The text in your content seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or
something to do with internet browser compatibility but
I figured I’d post to let you know. The style and design look great though!
Hope you get the issue solved soon. Kudos
This piece of writing offers clear idea in support of the new viewers of blogging,
that actually how to do blogging and site-building.
He hacked matches because he left it his living.
I do not even know the way I stopped up here, but I thought this publish was once good.
I do not recognise who you are but certainly you are
going to a well-known blogger for those who are not already.
Cheers!
I’m so happy to read this. This is the kind of
manual that needs to be given and not the accidental misinformation that is at the other blogs.
Appreciate your sharing this best doc.
Great blog here! Also your website loads up very fast!
What web host are you using? Can I get your affiliate link
to your host? I wish my website loaded up as fast as yours lol
It’s truly very difficult in this full of activity life to listen news on Television, therefore I only use internet for that reason, and
get the most recent information.
Contact Yahoo
We stumbled over here coming from a different page and thought I may as well check
things out. I like what I see so i am just following you.
Look forward to looking into your web page again.
Excellent beat ! I wish to apprentice while you amend your website, how
can i subscribe for a blog site? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your
broadcast offered bright clear concept
http://www.cialisgenhrx.com
sale cheap generic cialis
buy generic cialis
splitting cialis tablets
buy generic cialis
http://www.cialisgenhrx.com
cialis pills online pharmacy
generic cialis online
red cialis generic viagra online
buy generic cialis online
Good response in return of this question with real arguments and
explaining everything regarding that.
Hello there! This post couldn’t be written any
better! Reading through this post reminds me of
my good old room mate! He always kept chatting about
this. I will forward this write-up to him. Fairly certain he will
have a good read. Thank you for sharing!
Hello there, I discovered your web site by the
use of Google even as looking for a similar topic, your website came up,
it seems great. I’ve bookmarked it in my google bookmarks.
Hello there, simply became aware of your weblog thru Google,
and located that it’s really informative. I am going to watch out for brussels.
I will be grateful should you continue this in future.
Many folks will probably be benefited out of your writing.
Cheers!
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to construct my own blog and would like to know
where u got this from. appreciate it
Wonderful work! That is the kind of info that are meant to be shared across the net.
Disgrace on the search engines for no longer positioning this put up higher!
Come on over and discuss with my website . Thank you =)
Player inch combines a fresh battle and keeps battling.
Greetings! Very helpful advice within this article! It’s the
little changes which will make the most important changes.
Thanks a lot for sharing!
http://cialisgenhrx.com
cheapest cialis generic buy
buy generic cialis online
cialis tablets 20mg
buy cialis online
Hi, after reading this amazing post i am too glad to share my knowledge here with friends.
What’s up to every body, it’s my first pay a visit of this website;
this blog includes awesome and in fact excellent stuff in favor of readers.
Hi, I do believe this is a great blog. I stumbledupon it 😉 I’m going to come back
once again since i have book marked it. Money and freedom is
the best way to change, may you be rich and continue to guide others.
canadian pharmacies viagra uk canada drug pharmacy
What’s up everyone, it’s my first visit at this website,
and piece of writing is really fruitful in favor of me,
keep up posting these articles or reviews.
Hello, after reading this awesome piece of writing i am also happy to share
my experience here with mates.
cheap cialis 5mg cialis daily cheap cialis online canada
Just wish to say your article is as astonishing.
The clarity for your post is just cool and i could suppose you are a professional in this subject.
Well along with your permission allow me to seize your RSS feed to keep up to
date with approaching post. Thanks one million and please keep up the rewarding work.
Amazing blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would
really make my blog shine. Please let me know where
you got your design. With thanks
When someone writes an piece of writing he/she maintains the thought of a user in his/her brain that how a user
can know it. So that’s why this piece of writing is perfect.
Thanks!
I do consider all the concepts you have introduced in your post.
They are very convincing and will certainly work.
Nonetheless, the posts are very brief for newbies.
May you please prolong them a little from subsequent time?
Thanks for the post.
Great goods from you, man. I’ve understand your stuff
previous to and you are just extremely fantastic.
I really like what you have acquired here, really like what
you’re stating and the way in which you say it.
You make it enjoyable and you still care for
to keep it wise. I can not wait to read much more from you.
This is actually a tremendous site.
Earn XPs with playing the un-locked game styles.
2D is commonly used in endeavors yo be done in beast way and pictures made are not extraordinarily in each sublime sense cloud.
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Amoxicillin Without Prescription http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Order Amoxicillin 500mg Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
Hello! I know this is somewhat off topic but I was wondering which
blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking
at alternatives for another platform. I would be fantastic if you could point me
in the direction of a good platform.
靴 安い サルースのその正直とは。そっけないな感じで行きます。靴 安い サルースの言訳はこちら。さえな感じで。
http://theprettyguineapig.com/amoxicillin/ – 18 18 http://theprettyguineapig.com/amoxicillin/
Thanks for sharing your thoughts about politica. Regards
Check-out Free Heroes two on the Google Play shop.
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Online Buy Amoxicillin http://theprettyguineapig.com/amoxicillin/
This design is incredible! You certainly
kniw how to keep a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!)
Fantastic job. I rrally enjoyed what you had to say, and more than that, how you presented it.
Too cool!
I do not even know how I finished up right here, but I assumed this publish used to be great.
I don’t understand who you are but definitely you are going to a famous blogger if you aren’t already.
Cheers!
hey there and thank you for your information – I’ve certainly picked up something new from right here.
I did however expertise a few technical points using this web site, since I experienced to reload
the web site lots of times previous to I could
get it to load correctly. I had been wondering if your web host is OK?
Not that I am complaining, but slow loading instances times will sometimes
affect your placement in google and could damage your high quality
score if ads and marketing with Adwords. Anyway I
am adding this RSS to my e-mail and can look out for much more
of your respective exciting content. Ensure that you
update this again soon.
Hi! I know this is sort of off-topic but I
had to ask. Does operating a well-established blog such as yours take a large
amount of work? I am brand new to writing a blog but I do
write in my journal daily. I’d like to start a blog so I will be
able to share my experience and views online. Please let
me know if you have any suggestions or tips for brand new aspiring bloggers.
Thankyou!
Unquestionably believe that which you stated.
Your favorite reason appeared to be on the net the easiest
thing to be aware of. I say to you, I definitely get irked while people think about worries that they just don’t know about.
You managed to hit the nail upon the top as well as defined
out the whole thing without having side-effects ,
people could take a signal. Will likely be back to get more.
Thanks
First off I want to say awesome blog! I had a quick question which
I’d like to ask if you don’t mind. I was interested
to find out how you center yourself and clear your head prior to writing.
I have had a difficult time clearing my thoughts in getting my thoughts out.
I do take pleasure in writing but it just seems like the first 10 to 15 minutes are generally lost just trying to
figure out how to begin. Any recommendations or hints?
Kudos!
Aw, this was a very nice post. Finding the time and actual effort to generate
a superb article… but what can I say… I put things off a whole lot and don’t manage to get nearly anything done.
My programmer is trying to persuade me to move
to .net from PHP. I have always disliked the idea because
of the expenses. But he’s tryiong none the less.
I’ve been using WordPress on numerous websites for about
a year and am anxious about switching to another platform.
I have heard fantastic things about blogengine.net.
Is there a way I can import all my wordpress posts into it?
Any help would be really appreciated!
Howdy would you mind letting me know which hosting company
you’re utilizing? I’ve loaded your blog in 3 different web browsers and I must say this blog loads a lot quicker
then most. Can you recommend a good web hosting provider
at a reasonable price? Thank you, I appreciate it!
Hello, Neat post. There is an issue with your website in web explorer, may check this?
IE still is the market leader and a huge component to
folks will pass over your wonderful writing due to this problem.
Descargar Mobile Legends Hack 2019
Mobile Legends Hacked Version Download 2019
Mobile Legends Hackers 2019
Mobile Legends Hack No Human Verification 2019
Mobile Legends Hack Tweakbox 2019
Should your motive here is to learn paintings for sale Melbourne or paintings available
Brisbane, unfortunately nevertheless, you can’t see it here.
Leonardo Da Vinci was created inside the Florentine Republic on April 15th,
1452. Then it does not matter if it’s heads or tail, you can predict the last
results.
I really love your website.. Excellent colors &
theme. Did you develop this amazing site yourself? Please reply back as I’m wanting to create my own blog and want to
know where you got this from or just what the theme is named.
Kudos!
bwwdfjnj is it safe to take tadalafil and viagra together http://cialissom.com/ cialis
20mg pills buy cialis 5mg usa où acheter du tadalafil pas cher
Keep this going please, great job!
http://theprettyguineapig.com/amoxicillin/ – Amoxil Buy Generic Amoxicillin http://theprettyguineapig.com/amoxicillin/
where to buy sildenafil pharmacy viagra online without script
http://www.viagrauga.com/ cheapest viagra generic can’t you ejaculate
when using sildenafil
Hello, I read your blog regularly. Your humoristic
style is witty, keep it up!
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500mg Capsules Amoxicillin http://theprettyguineapig.com/amoxicillin/
Appreciating the time and effort you put into your website and detailed information you present.
It’s nice to come across a blog every once in a while that
isn’t the same unwanted rehashed information. Fantastic read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
viagra without a doctor prescription usa
Rattling nice design and wonderful content material, absolutely
nothing else we want :D.
Truly when someone doesn’t understand afterward its up to other
users that they will help, so here it occurs.
cialisgenhrx.com
buy cialis generic pharmacy
cheap cialis
buy cheap cialis without prescription
generic cialis
I am regular visitor, how are you everybody? This
post posted at this web page is genuinely pleasant.
Everything is very open with a very clear explanation of the challenges.
It was definitely informative. Your site is very useful.
Thank you for sharing!
Timemanagement games should be games.
We’re a group of volunteers and opening a brand new scheme in our community.
Your website offered us with helpful info to work on. You have performed
a formidable task and our whole community can be thankful to you.
Earn much a lot more than different players
for better rewards.
Hello, i think that i saw you visited my blog so i got here to return the choose?.I’m trying to find issues
to improve my website!I assume its ok to use a few of your ideas!!
the book thief theme essay business plan writers houston writemyessayus.com freelance writing services writemyessayus.com student writing report service http://www.writemyessayus.com research websites for college students i need help with my college essay book reports to buy write essay for me
where to buy cheap cialis online cheap cialis cheapest cialis online
You get reputation points by playing with the game.
Visit this site to xplore some excellnt
Skyy Plus Offers. Ouija Boards have been in existence forever, but these are
still being confused for a lot of some soirt of portala communication devise that alows us to coommunicate with our pssed family members or spirits we don.
The mention of Bro-step and American expansion of the genre is undeniable
throughout the previous context.
Hey! This is my first visit to your blog! We
are a team of volunteers and starting a new project in a
community in the same niche. Your blog provided us valuable information to work on. You have done a marvellous job!
Hi there, just wanted to say, I loved this blog post.
It was practical. Keep on posting!
ハイチェアを裁截るしたい。否定いいな。ハイチェアの身の回り品はこちら。注意書サイトです。
where to buy cialis without a prescription cialis prescription buy cialis 5mg online
Quality posts is the important to attract the viewers to visit the site, that’s
what this web site is providing.
It certainly depends on the match you’re playing.
Perform dungeon manner to get material items.
Right his very second you could be getting laid. Think
about that for a moment. You could be having sex instead of jerking off.
Go to http://getlaid.xyz and find yourself a woman who wants to fuck.
You’ll be surprised when you’re balls deep
inside a pretty princess.
constantly i used to read smaller content that also clear their motive, and that
is also happening with this article which I am reading
at this place.
This is my first time pay a quick visit at here and i am in fact impressed
to read all at one place.
I was able to find good info from your content.
Hi there friends, how is everything, and what you desire
to say about this piece of writing, in my view
its truly awesome for me.
Additionally, it works on most Android apparatus.
This game cheats.
Hello there, just became alert to your blog through Google, and found that it’s
really informative. I am gonna watch out for brussels. I will be grateful
if you continue this in future. Numerous people will be benefited from your writing.
Cheers!
WOW just what I was searching for. Came here by searching
for asphalt 8
To look at your rank -> tap on the avatar -> standing.
After I initially commented I seem to have clicked the -Notify
me when new comments are added- checkbox and from now
on whenever a comment is added I receive 4 emails with the same comment.
Perhaps there is an easy method you are able to remove me from that service?
Appreciate it!
tadalafil generic in australia cialis prices
kalp hastaları tadalafil kullanabilirmi
Thank you for the good writeup. It in truth was once a leisure account it.
Glance complicated to more added agreeable from you!
However, how could we be in contact?
I don’t know if it’s just me or if perhaps
everyone else encountering issues with your site. It seems like
some of the text in your posts are running off the screen. Can somebody else please provide feedback and let me know if this is happening
to them as well? This may be a issue with my web browser because I’ve had this happen previously.
Kudos
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get four e-mails with the same comment.
Is there any way you can remove people from that service?
Cheers!
We’re a group of volunteers and opening a new scheme in our community.
Your website offered us with valuable info to work on. You have done a formidable job and our entire community will be grateful
to you.
What i do not understood is in truth how you are not really much more smartly-favored than you
might be now. You are very intelligent. You understand
thus considerably in terms of this subject, made me in my opinion imagine it from so many varied
angles. Its like women and men aren’t fascinated except it’s something to do with Woman gaga!
Your personal stuffs outstanding. Always maintain it up!
Cheats, suggestions, and also a guide to progress fast.
Wow that was unusual. I just wrote an incredibly long comment but after I clicked submit
my comment didn’t appear. Grrrr… well I’m not writing all that over again. Regardless, just wanted to
say great blog!
Informative article, exactly what I needed.
Thank you a lot for sharing this with all
people you really recognise what you are talking about!
Bookmarked. Please also seek advice from my site =).
We can have a hyperlink alternate arrangement between us
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Amoxicillin 500mg http://theprettyguineapig.com/amoxicillin/
Are you the kind of guy who likes to talk to sexy girls?
If so, then you’re really going to love http://bestcamsite.xyz There are so many girls at that site.
Day or night, you’ll always find a hot horny girl to talk to
there.
http://theprettyguineapig.com/amoxicillin/ – Buy Amoxicillin Online Amoxicillin http://theprettyguineapig.com/amoxicillin/
rock hard herbal sildenafil http://triviagra.com/ safer alternative to sildenafil viagra without a
doctor prescription usa can viagra be used by teenager
canadian online pharmacy
http://canadianhealthypharmacyrx.com/
prescription meds without the prescription
I think that is one of the such a lot vital information for me.
And i’m satisfied studying your article. But
should observation on some basic things, The site style is
perfect, the articles is in point of fact excellent :
D. Just right task, cheers
Admiring the persistence you put into your site and detailed information you offer.
It’s great to come across a blog every once in a while that isn’t the same outdated
rehashed information. Wonderful read! I’ve saved your site and I’m adding your
RSS feeds to my Google account.
This is really interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more
of your great post. Also, I have shared your site in my social networks!
Howdy, I do think your site could possibly be having web browser compatibility issues.
Whenever I take a look at your blog in Safari, it looks fine
but when opening in I.E., it’s got some overlapping issues.
I just wanted to provide you with a quick heads up! Besides that, excellent website!
cialisgenhrx.com
vicodin and cialis generic
buy generic cialis online
buy cialis australia
buy generic cialis
http://viagragetrx.com
viagra foods
buy viagra online
shelf life of viagra
viagra online
http://www.cialisgenhrx.com
divorce cialis pills
cheap cialis
xatral cialis online pharmacy generic
buy generic cialis online
viagragetrx.com
kamagra or viagra
cheap viagra
2 viagra in one day
cheap viagra
Hmm it seems like your website ate my first comment (it
was super long) so I guess I’ll just sum it up what I submitted and
say, I’m thoroughly enjoying your blog. I as well am an aspiring
blog blogger but I’m still new to everything. Do you have
any tips for newbie blog writers? I’d certainly appreciate it.
With havin so much written content do you ever run into any issues of plagorism or copyright infringement?
My site has a lot of completely unique content I’ve either created myself
or outsourced but it looks like a lot of it is popping
it up all over the internet without my agreement. Do
you know any solutions to help stop content from being ripped off?
I’d really appreciate it.
http://cialisgenhrx.com
split cialis pills
buy generic cialis online
xatral cialis online pharmacy
buy cialis
viagragetrx.com
viagra without a prescription
viagra online
natural viagra over the counter
cheap viagra online
I must thank you for the efforts you have put in writing this site.
I really hope to view the same high-grade content by you later on as well.
In fact, your creative writing abilities has encouraged me to get
my own website now 😉
The cutest cam girls are just one click away. These are girls who will
make your dick hard instantly. Visit http://cutecamgirls.xyz and start talking to these girls.
You’ll be surprised when they show you their tits.
Nothing is better than talking to girls who get totally naked right before your
very eyes.
best place to buy generic cialis online cialis daily generic cialis for daily use
Incredible quest there. What happened after? Take care!
Article writing is also a fun, if you be acquainted with then yyou
can write if not it is complicated to write.
Hi there! I just wanted to ask if you ever have any problems wih hackers?
My last blog (wordpress) was hacked and I endxed uup losing
many months of hard work due to no data backup.
Do you have any solutions to stop hackers?
I’m gone to inform my little brother, that he should also go
to see this weblog on regular basis to get updated from hottest news update.
Incredible! This blog looks exactly like my old
one! It’s on a totally different topic but it has pretty much the same layout
and design. Great choice of colors!
This is such a fantastic blog post. I think I will certainly think of it for
the remainder of the day. Thanks a lot! https://www.musclesupplements101.com/crazy-bulk-d-bal/
This is such a fantastic blog post. I think I will certainly think of it for the remainder of the day.
Thanks a lot! https://www.musclesupplements101.com/crazy-bulk-d-bal/
Appreciate the recommendation. Will try it out.
What’s up to every one, the contents present at this website are in fact amazing for people knowledge,
well, keep up the good work fellows.
viagragetrx.com
viagra male enhancement
buy cheap viagra
viagra commercial script
generic viagra
best online international pharmacies
http://canadianonlinepharmacybsl.com/
best canadian mail order pharmacies
http://www.viagragetrx.com
natural viagra
buy viagra online
does bluecross cover viagra
buy generic viagra
viagragetrx.com
viagra vision blue
buy viagra online
viagra 2016
cheap viagra online
Appreciating the time and energy you put into your
website and in depth information you present. It’s
great to come across a blog every once in a while that isn’t the same outdated rehashed material.
Excellent read! I’ve bookmarked your site and I’m including
your RSS feeds to my Google account.
buying viagra online reviews generic viagra 100mg can u buy viagra online
Hi Dear, are you actually visiting this site daily, if so then you will without doubt get fastidious knowledge.
I every time used to read paragraph in news
papers but now as I am a user of internet thus from now I am using net for articles, thanks to web.
Asking questions are in fact fastidious thing if you are not
understanding something totally, however this paragraph presents fastidious understanding yet.
sildenafil trouble breathing cheap viagra free shipping viagra how long does it take to kick in.
http://www.cialisgenhrx.com
generic cialis lowest price
buy cialis
serevent complications cialis pills
buy generic cialis
cialisgenhrx.com
cialis 5mg price drugs
generic cialis
buy cheap generic cialis online generic
buy cialis online
Hey there just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or something to do with web browser compatibility but I figured I’d post
to let you know. The design look great though! Hope you get the issue fixed soon. Cheers
I like the valuable information you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I am quite sure I will learn a lot of new stuff right here!
Good luck for the next!
When I originally commented I clicked the
“Notify me when new comments are added” checkbox and now each time a comment is
added I get three emails with the same comment. Is there any way you
can remove people from that service? Bless you!
buy cialis online united states tadalafil 20 mg buy generic cialis online with mastercard
Every weekend i used to pay a quick visit this site, for the reason that i want enjoyment, as this this website conations truly fastidious
funny material too.
Appreciate this post. Will try it out.
What’s up to all, because I am really eager of reading
this website’s post to be updated on a regular basis. It includes nice material.
I’m gone to say to my little brother, that he should also pay a quick
visit this webpage on regular basis to obtain updated from latest news update.
What’s up to every body, it’s my first pay a visit of
this web site; this webpage carries remarkable
and genuinely good material in support of readers.
It is common to get the ornamental painting and sculptures with shapes depicting a fascinating mixture of different
elements from the artist’s religious, physical and cultural background.
Leonardo Da Vinci came to be within the Florentine Republic on April 15th, 1452.
The beginning of Leonardo’s life was committed to art and painting in particular.
best free dating site 2019 free chicago online dating sites free dating sites
free dating foreign dating sites reviews usa free dating site
cougars dating free how much does it cost to build a dating website free black dating sites
Hi! I could have sworn I’ve visited this web site before but after
going through a few of the articles I realized it’s new to me.
Nonetheless, I’m definitely pleased I discovered it and I’ll be bookmarking
it and checking back regularly!
do you need a prescription to buy cialis tadalafil generic is it safe to buy cialis online
best generic viagra online reviews uk viagra pfizer viagra online
how to use viagra bioshieldpill.com viagra wholesale [url=http://bioshieldpill.com/]buy viagra no prescription[/url]
Hi just wanted to give you a brief heads up and let you know a few of the pictures
aren’t loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same results.
Good day! I know this is somewhat off topic but I was wondering
if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Wow, that’s what I was seeking for, what a information!
present hee at this webpage, thganks admin of this web page.
I constantly spent my half an hour to read thi weblog’s articles every
day along with a mug of coffee.
how much will generic viagra cost viagra price india generic viagra
n http://jcialisf.com cialis samples http://jcialisf.com/ cialis pills
generic cialis cheapest price cialis canada is there a generic form of cialis?
I do trust all of the concepts you have offered in your
post. They’re really convincing and can certainly work.
Still, the posts are very short for beginners. May you please lengthen them a little from subsequent time?
Thank you for the post.
After looking into a handful of the articles on your site, I seriously appreciate your
way of writing a blog. I book marked it to my bookmark webpage list
and will be checking back in the near future. Take a look at my web
site too and tell me what you think.
There are horny girls in your area who want to fuck so bad.
Are you seeking a fuck buddy? Do you want to have some no strings attached
fun? If you are, then http://meethornygirls.xyz is the place to go.
All the girls there are horny and they put out.
This is really interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more
of your excellent post. Also, I’ve shared your website in my social
networks!
ZGVlcHNpbmd1bGFyaXR5Lmlv uazacowu-a.anchor.com [URL=http://theprettyguineapig.com/generic-cialis/#uazacowu-u]uazacowu-u.anchor.com[/URL] http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t http://theprettyguineapig.com/generic-cialis/#uazacowu-t apogigo
Spot on with this write-up, I honestly believe this site needs a lot more attention. I’ll probably
be returning to read through more, thanks for the information!
It’s amazing to visit this web site and reading the views of all friends regarding this article,
while I am also keen of getting know-how.
Magnificent items from you, man. I’ve have in mind your stuff prior to and you’re simply too excellent.
I really like what you have acquired here, certainly like what you’re saying
and the way during which you assert it. You’re making
it enjoyable and you continue to care for to stay it smart.
I can’t wait to read far more from you. This is actually a great site.
buycialishowla.com
http://www.buycialishowla.com
buycialishowla.com
http://www.buycialishowla.com
I’m amazed, I must say. Rarely do I encounter a blog that’s both educative and amusing, and let me
tell you, you’ve hit the nail on the head.
The issue is an issue that too few men and women are speaking intelligently about.
I’m very happy that I stumbled across this in my
search for something relating to this.
buy cialis online best prices cialis cialisonbrx.com mixing cialis generic viagra cialisonbrx.com buy cialis online in usa http://cialisonbrx.com/ is cialis available in generic cialis is generic cialis from india safe cialis
Greetings I am so excited I found your website, I really found you by accident, while I
was looking on Askjeeve for something else, Regardless I am here now and would just like to say cheers
for a incredible post and a all round thrilling
blog (I also love the theme/design), I don’t have time to look over it all at the minute
but I have bookmarked it and also added in your RSS
feeds, so when I have time I will be back to read much more, Please do keep up the
excellent b.
Unquestionably believe that which you said.
Your favorite justification seemed to be on the web
the simplest thing to be aware of. I say to you, I certainly get annoyed while people think about worries that they
just don’t know about. You managed to hit the nail upon the top and also defined
out the whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
purchase cialis online
buycialishowla.com
generic cialis tadalafil drug
=http://buycialishowla.com/#”>buy generic cialis online
You’re so interesting! I do not believe I’ve
read through something like this before. So wonderful to discover another person with some unique thoughts on this topic.
Really.. many thanks for starting this up. This website is something that
is needed on the internet, someone with a bit of originality!
cialis tablet in uk
cheap generic cialis
canada cialis generic difficulty breathing
cialis
cialis by mail order
canadian pharmacy world coupon new viagra 77 canadian pharmacy
Youг meghod of explaining everytһing iin thіѕ article iis гeally nice,
all bе аble too witһout difficulty understand іt,
Thɑnks ɑ lot.
Very nice write-up. I definitely appreciate this site.
Continue the good work!
Thanks for any other wonderful post. The place else could anybody get that type
of info in such an ideal manner of writing?
I have a presentation subsequent week, and I am at the look for such info.
rx online no prior prescription
http://canadianonlinepharmacyhd.com/
canadian pharmacies
canadian online pharmacy cipa approved viagra online no prescription safe canadian online pharmacy
Awesome website you have here but I was wanting to know if you knew of any discussion boards that cover the same topics discussed here?
I’d really love to be a part of community where
I can get feed-back from other knowledgeable people that share the same
interest. If you have any recommendations, please let me know.
Cheers!
What a stuff of un-ambiguity and preserveness of precious
knowledge regarding unpredicted feelings.
My family members always say that I am wasting my time here at web, however I know
I am getting familiarity everyday by reading such good content.
dating site free internet dating ratings free dating sites
cougars dating free kundli match making online free best free dating websites
lesbian dating sites free best free bbw dating sites online free dating sites
hey there and thank you for your information –
I have definitely picked up anything new from right here.
I did however expertise a few technical points using this web site, since I experienced to reload the
web site many times previous to I could get it to
load properly. I had been wondering if your hosting is OK?
Not that I’m complaining, but slow loading instances times
will sometimes affect your placement in google and can damage
your high quality score if ads and marketing with Adwords.
Anyway I’m adding this RSS to my e-mail and could look out for a
lot more of your respective exciting content. Make sure you update this again very
soon.
Situs Bandar Slot Online Terpercaya Dan Aman Di Indonesia
I’m not sure exactly why but this web site is loading very slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Move all you need, wind, turn, bounce, and move when you make a call since that standard will remain there for good. The major time the call drops is the point at which you end your talk.
certified canadian online pharmacy tadalafil best price real viagra online canadian pharmacy
buy cialis online cialis generic vs brand http://cialisonbrx.com benefits of cialis generic drugs http://cialisonbrx.com viagra phoenix cialis pills http://cialisonbrx.com/ voucher cialis generic drugs buy cialis generic name cialis 20mg cialis online
Hey! Do you use Twitter? I’d like to follow you if
that would be okay. I’m absolutely enjoying your blog and look
forward to new posts.
Generally I don’t read post on blogs, but I would like to say that
this write-up very pressured me to try and do so! Your writing taste
has been amazed me. Thanks, quite nice article.
It’s going to be end of mine day, however
before ending I am reading this wonderful article to increase my experience.
I read this post completely concerning the resemblance of most up-to-date and earlier technologies, it’s remarkable article.
An outstanding share! I have just forwarded this onto a friend who was conducting a little homework on this.
And he actually ordered me breakfast because I stumbled upon it for him…
lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending some time to talk about this
topic here on your site.
www canadian pharmacies com cialis pill online canadian pharmacies
naturally like your website but you have to check the spelling on quite a few of your posts.
A number of them are rife with spelling issues and I in finding it very troublesome to inform the truth on the other hand I’ll definitely come again again.
I was curious if you ever thought of changing the layout
of your site? Its very well written; I love what youve got to
say. But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two images.
Maybe you could space it out better?
This blog was… how do you say it? Relevant!! Finally I’ve found something which helped me.
Many thanks!
Because the admin of this site is working, no uncertainty
very soon it will be renowned, due to its quality contents.
how to order cialis online safely no prescription cialis buy cheap cialis online
Great web site. Lots of helpful info here. I am sending it to several friends ans also sharing in delicious.
And of course, thank you on your sweat!
Great write-up, I am regular visitor of one’s web site, maintain up the excellent operate,
and It’s going to be a regular visitor for a lengthy time.
If you are going for best contents like I do,
just pay a quick visit this site daily because it provides
feature contents, thanks
This post is really a good one it helps new internet people, who are wishing for blogging.
Remarkable things here. I am very happy to look your post.
Thank you a lot and I’m looking ahead to touch you. Will you please drop me
a e-mail?
Everything is very open with a precise description of the challenges.
It was really informative. Your site is extremely helpful.
Thank you for sharing!
Heya i’m for the first time here. I found this board and I find It truly useful & it
helped me out a lot. I hope to give something back and help
others like you aided me.
My brother recommended I would possibly like this blog.
He was once totally right. This put up truly made my day.
You can not believe simply how a lot time I had spent for this information! Thanks!
Heya! I understand this is kind of off-topic however I had to ask.
Does managing a well-established website like yours take a massive amount
work? I’m brand new to writing a blog but
I do write in my diary daily. I’d like to start a blog
so I will be able to share my personal experience
and feelings online. Please let me know if you have any recommendations or tips for new aspiring blog
owners. Appreciate it!
Today, I went to the beach front with my kids.
I found a sea shell and gave it to my 4 year old
daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Stunning quest there. What happened after? Thanks!
Magnificent beat ! I would like to apprentice while you amend
your web site, how can i subscribe for a blog website?
The account helped me a acceptable deal. I had been a little bit acquainted of this
your broadcast offered bright clear idea
Every weekend i used to visit this site, as i want enjoyment, for
the reason that this this website conations in fact nice funny data
too.
Hi, this weekend is nice for me, for the reason that this occasion i am reading this fantastic
educational article here at my house.
Hey very interesting blog!
online pharmacy canada
http://canadianonlinepharmacyoffer.com/
online drugstore
Hey very nice blog!
I am genuinely grateful to the owner of this website who
has shared this great paragraph at at this time.
http://theprettyguineapig.com/amoxicillin/ – Amoxil Buy Generic Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Amoxicillin http://theprettyguineapig.com/amoxicillin/
Regards for helping out, excellent info. http://www.edulinkins.com/groups/what-lies-behind-the-burn-the-fat-feed-muscle-mass-scheme/
Hi, after reading this remarkable paragraph i am as well
cheerful to share my experience here with colleagues.
I am extremely impressed with your writing skills as well as with
the layout on your weblog. Is this a paid theme
or did you modify it yourself? Anyway keep up the nice
quality writing, it is rare to see a great blog like this one today.
Пункт коммерч еского учета электроэнергии 10 кв ПКУ10-6кв, КТП КОМПЛЕКТНЫЕ ТРАНСФОРМАТОРНЫЕ ПОДСТАНЦИИ москва, Производство ктп москва, а также многое другое Вы найдете на: http://sviloguzov.ru/ – Мы рады Вам!
my canadian pharmacy buy cheap cialis online pharmacy india
t https://jcialisf.com buy generic cialis
jcialisf.com buy generic cialis
Good post. I learn something totally new and challenging
on blogs I stumbleupon everyday. It will always be interesting to read through content from other
writers and use something from other websites.
This is my first time go to see at here and
i am really pleassant to read everthing at alone place.
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Online Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Amoxicillin No Prescription http://theprettyguineapig.com/amoxicillin/
Yesterday, while I was at work, my sister stole my apple ipad
and tested to see if it can survive a thirty foot
drop, just so she can be a youtube sensation.My apple ipad is now broken annd she has 83 views.
I know this is enirely off topic but I had too share it with someone!
online pharmacies
http://canadianonlinepharmacysl.com/
buy prescription drugs without doctor
Do you have a spam problem on this website; I also am a blogger,
and I was wondering your situation; many of us have developed some
nice procedures and we are looking to exchange methods with others, please shoot me
an e-mail if interested.
cialis online online cialis no prescription http://cialisplrx.com key cialisplrx.com cialis tadalafil buy http://cialisplrx.com/ name cialis tablets buy cialis online sample cialis generic buy cialis
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety
of websites for about a year and am anxious
about switching to another platform. I have heard great things about
blogengine.net. Is there a way I can import all my wordpress content into it?
Any help would be greatly appreciated!
Good information. Lucky me I ran across your blog by accident (stumbleupon).
I have book-marked it for later!
http://authenticknicksstore.com/ generic viagra oral jelly
I just couldn’t leave your site before suggesting that I really
loved the standard information an individual provide in your guests?
Is gonna be back incessantly in order to inspect new posts
http://hitcialisosn.com/ prescription drugs from canada
http://fviagrajjj.com/ real online canadian pharmacy
http://newviagrakfv.com/ cvs pharmacy online
http://drcialonlinedkb.com/ canadian pharmacy online review
best professional writing services buy essay online write my article pay to write essay
Wow, fantastic blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is great, as well as the content!
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Online Amoxicillin 500mg http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500 Mg Amoxicillin 500 Mg http://theprettyguineapig.com/amoxicillin/
I’m not that much of a online reader to be honest but your blogs really
nice, keep it up! I’ll go ahead and bookmark your site to come back later.
Many thanks
For latest news you have to pay a visit the web and on world-wide-web
I found this web page as a finest site for most up-to-date updates.
http://cialisjesh.com/ vendita cialis online
http://setviagraeja.com/ buy cialis cheap
http://generichviagraarnc.com/ walmart pharmacy online
Good post. I learn something totally new and challenging on blogs
I stumbleupon every day. It’s always exciting to read through articles
from other authors and use a little something from their websites.
http://gocialisgjb.com/ canadian pharmacy meds
http://purseinstock.com/ buy cialis online no prescription usa echeck
http://cialisovnsm.com/ safe online pharmacy cialis
Hello friends, its great piece of writing concerning cultureand fully defined,
keep it up all the time.
bad credit loans no brokers
money loans online
small payday loan
installment loans online
I was wondering if you ever thought of changing the page layout
of your website? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
Hi there everyone, it’s my first pay a visit at this site,
and piece of writing is really fruitful in favor of me, keep up posting these posts.
I couldn’t resist commenting. Very well written!
easy loan site
payday loans bad credit
loan application
payday loans online
Talk to sexy naked girls all day and night at http://sexynudecam.top
canadian pharcharmy online
http://canadianhealthypharmacyrx.com/
canadian pharmacies
Hello! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing
several weeks of hard work due to no backup. Do you have any solutions to stop hackers?
http://cheapvirgaraonline.com/ canadian pharmacy viagra generic
Hi there! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing
months of hard work due to no data backup. Do
you have any solutions to stop hackers?
http://buyviagaraonline.com/ best place to buy cialis
http://paydaymyonline.com
need a quick loan today
quick cash advance online
loan for 1000
loans direct
http://paydaymyonline.com
fair credit loans
quick cash
payday loans killeen tx
cash advance online
Sexy girls with big tits on live can be seen at http://verylargetits.top
http://paydaymyonline.com
my payday advance
quick cash advance online
loan pre approval
quick cash advance online
I have been exploring for a little for any high-quality articles or weblog posts on this kind of house .
Exploring in Yahoo I at last stumbled upon this web site.
Reading this info So i am happy to express that I’ve an incredibly
good uncanny feeling I came upon just what I needed. I such a lot for sure will
make certain to do not disregard this web site and give it a look on a
constant basis.
This is my first time pay a visit at here and i am really impressed to read everthing at single place.
With a great eye and taste for delineation, you can make
an atmosphere impeccable for virtually any exercises linked with feasting room.
in April 22, 1560, he was quoted saying:” Your Majesty, you’re invincible and contain the world in awe. The beginning of Leonardo’s life was dedicated to art and painting in particular.
Do you mind if I quote a couple of your articles as long as I provide
credit and sources back to your site? My blog site is
in the very same niche as yours and my visitors would genuinely benefit from a lot of the information you present here.
Please let me know if this alright with you. Thanks!
http://paydaymyonline.com
payday loans vancouver
loans with bad credit
loans for 18 year olds
quick cash advance online
http://paydaymyonline.com
secured loan
quick cash
cash advance stockton ca
quick cash advance online
next day cialis generic cheap cialis sex cialis pills cialis online
viagra no prescription buy sildenafil online canada buy viagra
online at [url=http://bioshieldpill.com/]generic viagra no script[/url]
Good day! This is my 1st comment here so I just wanted to give a
quick shout out and say I truly enjoy reading your articles.
Can you suggest any other blogs/websites/forums
that deal with the same topics? Thanks a lot!
http://paydaymyonline.com
tribal lending payday loans
quick cash advance online
payday loan portland oregon
quick cash
Heya i’m for the first time here. I found this board and I find It truly useful & it
helped me out a lot. I hope to give something back and help
others like you aided me.
I constantly spent my half an hour to read this
weblog’s articles daily along with a mug of coffee.
hey there and thank you for your information – I’ve certainly picked up something new from right here.
I did however expertise several technical issues using this website, as I experienced to reload the site lots of times previous to I could get it to load properly.
I had been wondering if your hosting is OK? Not that I’m complaining, but sluggish loading instances times will very frequently affect
your placement in google and could damage your quality score if advertising and marketing with Adwords.
Anyway I am adding this RSS to my email and can look out for a lot more of your
respective interesting content. Make sure you update this again soon.
http://movietrailershd.org/ tadalafil online canadian pharmacy
http://susamsokagim.com/ generic name for viagra
canadian pharmacies that ship to us
http://canadianonlinepharmacycl.com/
online pharmacy canada
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my
blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
http://onlineviagriabuy.com/ where to buy cialis forum
http://bitcapblog.com/ canadian discount pharmacy online
http://genericviragaonline.com/ online pharmacy viagra
http://paydaymyonline.com
1000 loans
personal loans for bad credit
payday loans aurora co
fast cash
http://paydaymyonline.com
quick loan shop
payday loans direct lender
pay day loans online
loans bad credit
http://paydaymyonline.com
fast cash now bad credit
loans online
quik loans
loans bad credit
http://paydaymyonline.com
payday loans bad credit online
quick cash advance online
secured personal loans for bad credit
fast cash
http://usa77www.com/ buy cialis generic online cheap
Great goods from you, man. I have understand your stuff previous
to and you are just extremely wonderful. I really like what you have acquired here, certainly like
what you are saying and the way in which you say
it. You make it enjoyable and you still take care of
to keep it sensible. I cant wait to read far more from you.
This is really a wonderful website.
http://mo-basta.org/ canada drugs coupon
http://paydaymyonline.com
personal loans georgia
loans direct
payday loans surrey b c
personal loans for bad credit
http://paydaymyonline.com
fast cash
loans with bad credit
same day loan bad credit
loans with bad credit
Talk to sexy naked girls all day and night at http://sexynudecam.top
Superb website you have here but I was curious if you knew
of any message boards that cover the same topics talked about in this article?
I’d really love to be a part of online community where I can get opinions from
other experienced people that share the same interest. If you have any suggestions, please let me know.
Bless you!
online cialis buy generic cialis pics of cialis pills http://cialisgenwrx.com/
I know this site provides quality depending content and additional stuff,
is there any other site which provides these information in quality?
This web site definitely has all the information I wanted concerning this subject and didn’t know who to ask.
My relatives always say that I am killing my time here at net, but I know I am getting know-how everyday by reading such pleasant posts.
Very good post! We will be linking to this great article on our website.
Keep up the good writing.
http://almeidacorp.com/ walgreens online pharmacy
Really no matter if someone doesn’t know afterward its up
to other viewers that they will help, so here it happens.
Hi there to all, how is the whole thing, I think every one is getting more from this
web site, and your views are good in favor of new visitors.
I always used to read article inn news papers bbut now ass I am a user of
internet so from now I am using net for posts, thanks to web.
What’s up to all, the contents existing at this web page are truly remarkable
for people experience, well, keep up the nice work fellows.
بهترین و معروفترین جادوگر
ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش از ١٨ سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان
بوده كه همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد هر گونه طلسم
و جادو را با مناسبترين قيمت ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا
دست ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات
كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى خود را به بالاترين
حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از
قيمت طلسمها و ادعيه به دايركت مراجعه
بفرماييد.
instagram: telesm_seyed_mehdi
apotheken viagra kaufen [url=http://www.doctor7online.com/]viagra[/url] taking viagra twice in one day
Hey there! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no back up.
Do you have any solutions to protect against hackers?
Hello i am kavin, its my first time to commenting
anywhere, when i read this article i thought i could also make comment due to this brilliant piece of writing.
http://paydaymyonline.com
advance payday loan
personal loans for bad credit
payday load
quick cash advance online
بهترین و معروفترین جادوگر
ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال
حاضر ايران با بيش از ١٨ سال سابقه كار
ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى
ايشان بوده كه همواره بر آنها تاكيد
داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از
كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد هر گونه طلسم و جادو را با مناسبترين قيمت ها سفارش داده و تحويل
بگيريد.
تمامى طلسمها موكل دار و كاملا دست
ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم
هاى خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
http://paydaymyonline.com
personal loan reviews
personal loans for bad credit
no employment verification loans
fast cash
http://paydaymyonline.com
advance money
personal loans for bad credit
payday loans midland tx
cash advance online
Helpful information. Fortunate me I discovered your website accidentally, and I’m
surprised why this coincidence did not took place earlier!
I bookmarked it.
Hi there, I would like to subscribe for this website to get
most recent updates, therefore where can i do it please help
out.
Howdy! This post could not be written any better! Reading this post reminds me of my
old room mate! He always kept talking about this. I will forward this
write-up to him. Pretty sure he will have a
good read. Thank you for sharing!
Oh my goodness! Awesome article dude! Thank you,
However I am experiencing problems with your RSS.
I don’t know why I can’t join it. Is there anybody
having identical RSS problems? Anybody who knows the solution will you kindly respond?
Thanks!!
tadalafil and athletic performance [url=http://calisgenhea.org]http://calisgenhea.org[/url] drug interaction tadalafil flomax
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش از ١٨
سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه
همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج
از كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد هر گونه
طلسم و جادو را با مناسبترين قيمت
ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام
كار، كارايى طلسم هاى خود را به
بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها
و ادعيه به دايركت مراجعه بفرماييد.
instagram: https://www.instagram.com/telesm_yahoodi_hendi
http://paydaymyonline.com
loans for bad credit online
quick cash advance online
payday loans chattanooga tn
loans direct
http://paydaymyonline.com
california cash advance
quick cash
personal loans los angeles
loans online
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش از ١٨ سال سابقه كار
ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه همواره بر
آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان
عزيز داخل و خارج از كشور هدف اصلى ايشان
بوده، شما عزيزان ميتوانيد هر گونه طلسم و جادو را
با مناسبترين قيمت ها سفارش داده
و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده
از بخورات كمياب و محاسبه دقيق زمان انجام
كار، كارايى طلسم هاى خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
tadalafil wiki buy generic cialis buy cialis metformin expiration cialis generic pills buy generic cialis
sildenafil y arritmia cardiaca
generic viagra at walmart
sildenafil vs hipertension
[url=http://viagrarow.com/]http://viagrarow.com[/url]
The hottest BBW cam girls can be seen at http://bbwwebcam.top These are
the fat girls who will make you blush.
Excellent web site you have got here.. It’s hard to find high quality writing like yours nowadays.
I truly appreciate people like you! Take care!!
Hey there, I think your website might be having browser compatibility
issues. When I look at your blog in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other
then that, great blog!
http://usaerectionrx.com/ cheap generic viagra sales uk
http://canadianpharmacyfda.com/ when will viagra go generic
MargaritaVan cialis coupon cialis coupon buy cialis in france [url=http://buyscialisrx.com/]buy cialis online[/url]
Greetings from Ohio! I’m bored to death at work so I decided to
check out your site on my iphone during lunch break.
I really like the info you present here and can’t wait to take
a look when I get home. I’m surprised at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, excellent blog!
Is it OK to share on Google+? Keep up the wonderfull work!
Hurrah, that’s what I was searching for, what a
information! present here at this web site,
thanks admin of this website.
Hi there to all, how is everything, I think every one is getting
more from this site, and your views are good designed for new
visitors.
http://paydaymyonline.com
paycheck advance omaha ne
fast cash
24 hour cash loans
loans direct
http://paydaymyonline.com
payday loan centers
quick cash advance online
montel williams loans
cash advance online
http://paydaymyonline.com
payday loan california
payday loans direct lender
money now
fast cash
http://paydaymyonline.com
online payday loans bad credit direct lenders
fast cash
cash advance loans las vegas
payday loans direct lender
generic cialis from canada http://cialisgenwrx.com/ viagra fact sheet cialis generic cialis buy generic cialis
Way cool! Some very valid points! I appreciate you writing this write-up and the rest of the website is also really good.
http://paydaymyonline.com
microloan program
same day loans
different ways to borrow money
fast cash
http://paydaymyonline.com
loans for bad credit online
payday loans direct lender
average interest rate on personal loan
loans direct
cheap cialis from canada cialis generic cialis online order cialis tadalafil buy cialis
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get
several e-mails with the same comment. Is there any way you can remove people from
that service? Thanks!
Check out these girls on cam who have big pussy lips http://bigpussylips.top
http://canadiansapharmacyvgy.com/ is it safe to buy cialis from canada
The sexiest mature women on cam can be found here
http://oldwomancam.top These old women get naked and do dirty stuff.
http://theprettyguineapig.com/amoxicillin/ – Order Amoxicillin 500mg Amoxicillin 500mg Capsules http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin No Prescription Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
Sexy girls with big tits on live can be seen at http://verylargetits.top
http://paydaymyonline.com
payday direct lenders
cash advance online
online payday loans texas
quick cash
http://paydaymyonline.com
100 day loans
loans direct
need a personal loan with bad credit
personal loans for bad credit
quickcash com
payday america
long term cash loans
payday america
http://niqabsquad.com/ canada drugs
بهترین و معروفترین جادوگر ایران سید
مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش
از ١٨ سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى
ايشان بوده كه همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد هر گونه طلسم و جادو را با مناسبترين قيمت
ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى خود
را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
http://paydaymyonline.com
unsecured cash loans
fast cash
personal loan usa
quick cash advance online
http://paydaymyonline.com
payday loans missouri
personal loans for bad credit
bank personal loan
quick cash advance online
This page truly has all of the ino I needed concerning this subject
and didn’t know who too ask.
You made some good points there. I checked on the web for more information about the issue
and found most individuals will go along with your views on this site.
The hottest BBW cam girls can be seen at http://bbwwebcam.top These are the fat girls who will make you blush.
I read this article fully concerning the comparison of most recent and
preceding technologies, it’s amazing article.
Do you like seeing hairy naked girls? If so then you’ve got to
check out http://hairycam.top That site is full of naked hairy women.
you are truly a good webmaster. The site loading speed is amazing.
It kind of feels that you are doing any distinctive trick.
Moreover, The contents are masterpiece. you have done a magnificent process in this subject!
What i don’t realize is in reality how you’re not really much more well-liked than you might be now.
You are so intelligent. You realize therefore considerably in terms of this matter, made me
for my part believe it from so many varied angles.
Its like men and women don’t seem to be interested unless it’s one thing to accomplish with Woman gaga!
Your own stuffs outstanding. At all times
handle it up!
Hi there, after reading this awesome piece of
writing i am too delighted to share my familiarity here with friends.
What’s up i am kavin, its my first time to commenting anywhere, when i read this article i thought i could also make comment due to this good post.
Awesome post.
Keep up the excellent piece of work, I read few posts on this internet site and I conceive that your site is rattling interesting and has bands of excellent info.
Nice blog here! Also your site loads up fast! What web host are you using?
Can I get your affiliate link to your host? I wish my
site loaded up as quickly as yours lol
https://ketodietrecipesxef.com/ what is a keto diet
When someone writes an post he/she keeps the thought
of a user in his/her brain that how a user can know it.
So that’s why this article is perfect. Thanks!
online loans direct lenders bad credit
personal loans
payday loan store milwaukee
unsecured personal loans bad credit
WO
Howdy this is kind of of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to
manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
http://paydaymyonline.com
how to get a loan without credit
cash advance online
apply online personal loan
quick cash
http://paydaymyonline.com
cash advance akron ohio
same day loans
no hassle payday loans bad credit
payday loans direct lender
I’ll immediately snatch your rss as I can’t find your email
subscription hyperlink or newsletter service. Do you have any?
Kindly permit me recognise in order that I could subscribe.
Thanks.
http://paydaymyonline.com
single mother loans
loans bad credit
direct lenders for personal loans
same day loans
http://paydaymyonline.com
my payday loan
quick cash
2000 loan with bad credit
loans direct
https://ketodietlistdfk.com/ bourbon on keto diet
Do you have any kind of pointers for composing posts?
That’s where I constantly struggle as well as I just finish up gazing empty display
for very long time.
http://paydaymyonline.com
mobilemoney
quick cash
fast cash loans online
loans bad credit
The hottest babes with small tits can be seen at http://smalltits.top
The wildest sexual exhibitions can be seen on cam at
http://exhibitionistcams.top
The sexiest girls on the internet are at http://femalecams.top They
love to get naked and do all kinds of dirty stuff.
fast easy cash loans
installment loans online
easy approval personal loans
online installment loans
Hello. Nice site! And Bye.
http://appolloshop.ru/product/luchshie-igry-dlja-pristavki-sony-playstation-4
http://tvoya-strana.ru/kitaj/92-sut-palomnichestva-i-ego-otlichiya-ot-turizma.html
http://exportmebel.ru/index.php?productID=83076
http://realty21century.ru/index.php/ipoteka/155-stoit-li-polzovatsya-uslugami-ipotechnogo-brokera
https://ketodietplanecyh.com/ 28 day keto diet plan
First of all I want to say terrific blog! I had a quick question which I’d like to ask if
you don’t mind. I was interested to find out how you center yourself and
clear your mind prior to writing. I’ve had a tough time clearing my thoughts in getting my ideas out.
I truly do enjoy writing however it just seems like the first 10
to 15 minutes are lost just trying to figure out how to begin. Any ideas or hints?
Appreciate it!
how to use tadalafil buy generic cialis tadalafil prijs apotheek
http://paydaymyonline.com
paydayloan com
same day loans
payday loans lawrence ks
fast cash
http://paydaymyonline.com
easy loan
same day loans
bad credit lender
quick cash advance online
http://paydaymyonline.com
loan online application
loans online
how to get a payday loan online
quick cash advance online
Hello there! I could have sworn I’ve been to this blog before
but after browsing through many of the articles I realized it’s new to me.
Anyways, I’m definitely pleased I found it and
I’ll be book-marking it and checking back often!
Hi! I understand this is somewhat off-topic however I needed to ask.
Does building a well-established blog such as yours require a massive amount work?
I am completely new to running a blog but I do write in my journal everyday.
I’d like to start a blog so I can easily share my personal experience and thoughts online.
Please let me know if you have any ideas or tips for brand new aspiring bloggers.
Appreciate it!
https://ketodietmenuwxr.com/ keto diet benefits for women
http://paydaymyonline.com
loans for people with bad credit history
personal loans for bad credit
1000 loan
loans direct
http://paydaymyonline.com
how can i get cash fast
cash advance online
payday loans no fees no brokers
quick cash advance online
https://whatisketodiettuj.com/ keto plus diet pills
It’s remarkable to pay a visit this website and reading the views of all mates about this paragraph, while I am also zealous of getting experience.
Hi just wanted to give you a quick heads up and let you know a few
of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the
same outcome.
http://payday2meloansonline.com
nevada payday loan
payday loans online
payday loans no checks
payday loans online
http://www.cialislfrx.com/
generic cialis soft online
buy generic cialis
buy generic cialis united kingdom
generic cialis online
http://payday2meloansonline.com
short term loans
payday loans online
private lenders personal loans
cash advance
I relish, result in I found exactly what I used to be taking
a look for. You’ve ended my four day long hunt! God Bless you man. Have a nice day.
Bye
http://cialislfrx.com/
uk generic cialis tadalafil
buy generic cialis
cialis online consultation
buy cialis online
I don’t even know how I finished up here, however I thought this post used to be
great. I don’t understand who you’re however
definitely you are going to a famous blogger if you happen to are not already.
Cheers!
zoloft 150 mg generic zoloft cost buying zoloft online zoloft prescription
https://ketodietecrt.com/ lenney vogel the keto diet book best price
http://payday2meloansonline.com
cash loans with bad credit
payday loans online
loan centers
loans for bad credit
Undeniably believe that which you said. Your
favorite reason appeared to be on the net the simplest thing to be aware of.
I say to you, I definitely get irked while people consider worries that they plainly don’t know about.
You managed to hit the nail upon the top as well as defined out the whole thing
without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
http://www.cialislfrx.com/
renova expres cialis pills
cialis online
prices buy cialis online cialis
cheap cialis
These are truly impressive ideas in concerning blogging.
You have touched some fastidious points here. Keep up the fantastic work!
Is it OK to share on Tumblr? Any way, keep up the posting.
http://cialislfrx.com/
cialis online cialis
buy cialis
buy tadalafil india cipla
cheap cialis
buy zoloft Superb site. buying zoloft online
http://www.cialislfrx.com/
viagra and the taliban cialis pills
buy cialis online
order generic cialis
cheap cialis
http://cialislfrx.com/
buy cheap cialis online cialis
buy generic cialis online
split cialis pills ortho evra patch
buy cialis
http://payday2meloansonline.com
loan company
loans for bad credit
online payday loans manitoba
personal loans
http://payday2meloansonline.com
payday loans columbia sc
payday loans
what is cash advance
pay day loans
https://zoloftxgeneric50.com – zoloft cost zoloft 25mg no petscriptions zoloft
http://payday2meloansonline.com
online loan services
payday loans online
payday loans miami
payday loans
http://www.cialislfrx.com/
cheap cialis next day delivery
generic cialis online
cialis generic cheap viagra
buy cialis online
http://payday2meloansonline.com
apply for a loan
cash advance
payday loans gainesville fl
cash advance
http://www.cialislfrx.com/
buy generic cialis
buy cialis online
and poppers cialis 20mg
buy cialis
It’s an remarkable paragraph designed for all the web users; they
will take advantage from it I am sure.
right spot absolutely cooperative articles. combine bookmarks
The hottest Milfs can be seen at http://livemilfs.top These Milfs love to get down and dirty while on live cam.
http://payday2meloansonline.com
bad credit loan
pay day loans
payday loans madison wi
payday loans
http://www.cialislfrx.com/
ordering cialis
generic cialis online
canada cialis generic
buy generic cialis online
I simply could not leave your web site before suggesting that I extremely loved the standard info an individual supply for your visitors?
Is gonna be again often in order to inspect new posts
Great website. Lots of helpful info here. I am sending it to several friends ans also sharing in delicious.
And naturally, thanks on your effort!
buy usa kamagra
[url=http://kamagrainus.com/]kamagra[/url]
https://bestcasino365us.com/ best free casino games for ipad
tadalafil generic online uk cialis usa prices goedkoopste
tadalafil kopen
view homepage https://buylasixxgen.com – order lasix without a prescription full report order lasix online
http://www.cialislfrx.com/
generic cialis safety
buy cialis online
cialis website
cheap cialis
http://www.cialislfrx.com/
buy generic cialis free
cheap cialis
pfizer cialis generic cialis
buy generic cialis online
http://cialislfrx.com/
buy cialis doctor online
buy generic cialis online
cialis tablets for sale
buy generic cialis
Quality articles is the key to invite the users to pay a quick visit the website, that’s what this web page is providing.
It’s going to be end of mine day, except before
end I am reading this impressive paragraph to increase my knowledge.
https://us24casinoonline.com/ best casino hotel in atlantic city
http://payday2meloansonline.com
online credit check free
payday loans online
cash advance loans online direct lenders
payday loans online
http://payday2meloansonline.com
emergency loans with bad credit
pay day loans
personal loans usa
payday loans online
can tadalafil increase sperm count [url=http://cialislet.com]cialis[/url] cuanto tiempo tarda en hacer efecto cialis.
look at this best place to buy cialis – link
http://cialisnrxch.com
cialis 5mg price online canadian pharmacy
generic cialis
order cialis no prescription
buy cialis online
http://cialisnrxch.com
viagra shop in london cialis generic
buy cialis online
cheap order cialis generic
buy cheap cialis online
http://cialisggnrx.com/
emedicine viagra cialis pills
buy cialis
order cheap cialis without prescription
cialis online
[url=http://cialsagen.com/]http://cialsagen.com[/url]
http://paydaymyonline.com
local cash advance
quick cash advance online
instalment loans
personal loans for bad credit
Tremendous site. Literate articles. Thanks to author. Conserve your website as a favorite
http://cialisnrxch.com
cialis tablets uk
cheap cialis
buy cialis online without a prescription sildenafil citrate
cheap cialis
http://www.buycialishowla.com/#
cheapest generic cialis
buy generic cialis online
tadalafil wiki buy generic cialis
buy cialis
Female Escorts Beirut, get hot and sexy call girls
from our agencies and feel exciting moments in a pleasant ambiance.
For booking visit our website. We are providing these service Porn,
watch porn, anal fingering, squirt, pussy, casino, bet, oral sex, sex, drugs, Pharmacy, penis, porn video
In such way, your application needs right parts that can wound up being unendingly favorable for the customers.
I’m not sure why but this web site is loading extremely
slow for me. Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still
exists.
Great site. Literate articles. Thanks to author. Prevent your website as a favorite
http://paydaymyonline.com
quick money online
fast cash
cash loans now
loans bad credit
http://cialisggnrx.com/
price comparison cialis 20mg
cheap cialis
cialis 5mg price drugs
buy generic cialis
http://www.buycialishowla.com/#
order cialis
buy generic cialis
dose cialis pharmacy
buy cialis
There’s nothing like seeing babes in high
quality HD cams. It’s almost like you’re there while watching the girls at
http://hdcams.top get naked.
generic cialis 20mg best buy canada
cheap cialis
younger men are better than retin a cialis pills
cialis
canadian pharcharmy online
http://canadianonlinepharmacygen.com/
canadian pharmacies shipping to usa
http://cialisnrxch.com
heartburn cialis online pharmacy
cheap cialis
online buy generic cialis
buy cialis
http://cialisnrxch.com
cialis generic uk
buy generic cialis
cialis pharmacy active ingredient
buy cialis
I like the valuable info you provide in your articles.
I will bookmark your blog and take a look at once more here regularly.
I am quite sure I’ll learn plenty of new stuff right right here!
Good luck for the next!
order lasix without a prescription https://buylasixxgen.com – as example check out your url site here
http://cialisnrxch.com
cialis generic walgreens
cheap cialis online
buy tadalafil india pills
cialis online
Appreciation to my father who informed me concerning
this blog, this blog is in fact awesome.
cost of 5mg cialis https://cialisxgeneric.com – canadian pharmacy cialis
cost of 5mg cialis https://cialisxgeneric.com – canadian pharmacy cialis
cost of 5mg cialis https://cialisxgeneric.com – canadian pharmacy cialis
cost of 5mg cialis https://cialisxgeneric.com – canadian pharmacy cialis
cost of 5mg cialis https://cialisxgeneric.com – canadian pharmacy cialis
cost of 5mg cialis https://cialisxgeneric.com – canadian pharmacy cialis
Bank Magaleh jadid va beroz ro az saite ma download konid
lasix 20mg lasixonline – more information
I’m not sure exactly why but this site is loading incredibly sow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check bsck later and see if thee problem
still exists.
http://paydaymyonline.com
how do i get a personal loan
same day loans
looking for personal loan
payday loans direct lender
buy genuine cialis 20mg
buy cialis
nitrates and cialis online pharmacy
cialis online
Thanks , I’ve just been looking for information approximately this subject for a long time and yours is the greatest
I have found out till now. However, what about the
bottom line? Are you certain in regards to the
supply?
zoloft ocd no petscriptions zoloft – zoloft ocd
zoloft ocd no petscriptions zoloft – zoloft ocd
zoloft ocd no petscriptions zoloft – zoloft ocd
buy cialis online safely buy cheap generic viagra canadian pharmacy cialis
online prescription generic viagra reviews online prescription
canadian pharmacy meds new viagra canadian pharmacies online
canada drug pharmacy pfizer viagra where to buy cialis over the counter
trusted online pharmacy reviews viagra use best online pharmacy
buying prescription drugs from canada viagra story generic viagra review
how to buy cialis cheap viagra canada canada drugs coupon code
when does viagra go generic viagra canada where to buy cialis
canadian online pharmacy free viagra sample buy cialis online overnight shipping
An interesting realization , denver property tax records balcones club apartments austin tx los angeles home nyc real estate prices furnished apartments las vegas nv rentals san jose ca tuxedo rental omaha ne http://my-new-apartments.info/property-management-companies-tucson-az-913.html http://my-new-apartments.info/jacksonville-property-appraiser-63.html chicago condo brookside apartments louisville ky cleveland ms real estate http://apartments-finder.online/apartments-jacksonville-fl-746.html coquina bay apartments jacksonville fl http://my-new-apartments.info/north-raleigh-apartments-985.html la terraza apartments albuquerque
best online pharmacy order viagra best place to buy cialis online
canadian pharmacies online brand viagra viagra online canadian pharmacy
buy cialis generic buy viagra professional canadian pharmacy king
http://cialisnrxch.com
generic cialis prices
buy cialis online
cvs cialis generic drugs
cheap cialis
best web site
womens kamagra 100mg tablets kamagra oral jelly wirkung – kamagra jelly india kamagra oral jelly online usa
womens kamagra 100mg tablets kamagra oral jelly wirkung – kamagra jelly india kamagra oral jelly online usa
womens kamagra 100mg tablets kamagra oral jelly wirkung – kamagra jelly india kamagra oral jelly online usa
womens kamagra 100mg tablets kamagra oral jelly wirkung – kamagra jelly india kamagra oral jelly online usa
womens kamagra 100mg tablets kamagra oral jelly wirkung – kamagra jelly india kamagra oral jelly online usa
womens kamagra 100mg tablets kamagra oral jelly wirkung – kamagra jelly india kamagra oral jelly online usa
Amazing things here. I am very satisfied to peer your article.
Thank you so much and I am looking forward to
touch you. Will you kindly drop me a e-mail?
http://www.cialisggnrx.com/
reputable viagra online cialis generic
buy generic cialis
risks buy tadalafil
generic cialis
http://cialisnrxch.com
renova expres cialis pills
online cialis
buy cialis pills generic
buy cialis online
venta_de_cialis_en_barcelona
cheap cialis
25mg generic viagra
cheap cialis online
cialis online pharmacy canada canadian pharmacy cialis – look at this
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Buy Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Buy Amoxicillin Amoxicillin http://theprettyguineapig.com/amoxicillin/
norvir and tadalafil [url=http://cialsonlinebei.com]cialis price[/url] tadalafil bula anvisa http://cialsonlinebei.com cialis
I have been exploring for a bit for any high-quality articles or blog posts on this sort of
house . Exploring in Yahoo I ultimately stumbled upon this site.
Studying this information So i’m happy to express that I’ve a very good uncanny feeling
I found out exactly what I needed. I such a lot without a doubt will make sure to don?t forget this web site and provides it a glance regularly.
Great site. Literate articles. Thanks to author. Save your website as a favorite
levitraonlinemeds buy generic levitra more hints – buy generic levitra online
What’s up, always i used to check web site posts here early in the
dawn, as i enjoy to find out more and more.
بهترین و معروفترین جادوگر ایران
سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال
حاضر ايران با بيش از ١٨ سال سابقه كار
ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه همواره
بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج
از كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد
هر گونه طلسم و جادو را با مناسبترين قيمت ها
سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى
طلسم نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى
خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و
آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: https://www.instagram.com/telesm_yahoodi_hendi
Thanks for finally writing about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity : Deepsingularity <Loved it!
Hi! I could have sworn I’ve been to this web site before
but after browsing through many of the posts I realized
it’s new to me. Anyhow, I’m definitely pleased I stumbled upon it and I’ll be bookmarking it
and checking back often!
http://cialisnrxch.com
indian buy generic cialis
buy cialis online
what are cialis tablets lilly icos
cheap cialis online
Some genuinely excellent content on this site,
thanks for contribution.
buy levitra online canada levitra online where can i buy levitra – found it
Wonderful post however I was wondering if
you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit
more. Bless you!
Your web site has outstanding content. I bookmarked the website
Appreciate this post. Let me try it out.
n https://jcialisf.com jcialisf.com jcialisf.com buy cialis online
天上碑开区一条龙服务端www.40fp.com天堂2私服一条龙制作www.40fp.com-客服咨询QQ1292124634(企鹅扣扣)-Email:1292124634@qq.com 网页游戏服务端www.40fp.com
eu versandapotheke cialis [url=http://cialislet.com/]cialis[/url] vision problems cialis.
Hi there, I enjoy reading through your article. I like to
write a little comment to support you.
http://cialisnrxch.com
cialis order usa
buy cialis online
cialis vs generic cialis
cheap cialis
http://cialisnrxch.com
best prices cialis
cialis online
buy cialis generic pharmac
buy cheap cialis online
Link exchange is nothing else however it is only placing the other
person’s blog link on your page at suitable place and other person will also do similar in support of you.
hi!,I love your writing very so much! percentage we communicate more approximately your article on AOL?
I need an expert in this area to resolve my problem.
May be that’s you! Taking a look forward to look you.
You are so awesome! I don’t believe I’ve read through anything like this before.
So nice to discover someone with a few genuine thoughts on this issue.
Really.. thanks for starting this up. This
site is something that’s needed on the internet, someone with a little originality!
http://cialisnrxch.com
buying generic cialis
buy cheap cialis
purchase cheap cialis soft tabs
buy generic cialis
Someone necessarily lend a hand to make seriously
posts I’d state. This is the very first time I frequented your website page and to this
point? I surprised with the research you made to
make this particular put up extraordinary.
Great activity!
taking 20mg tadalafil http://genericalis.com speed up tadalafil
When someone writes an paragraph he/she retains
the idea of a user in his/her brain that how a user can be aware of
it. So that’s why this article is amazing. Thanks!
http://www.buycialishowla.com/#
cheap cialis soft tabs
buy cialis
cialis generic cheap
buy cialis
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do
it for you? Plz respond as I’m looking to
construct my own blog and would like to know where u got
this from. kudos
viagra generico viagra nebenwirkungen viagra receptfritt – viagra generico
generic for lasix lasix pill – lasix
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با
بيش از ١٨ سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه
همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد
هر گونه طلسم و جادو را با مناسبترين قيمت ها سفارش داده و
تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز
بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم
نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
Pingback: buy cialis online
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Online Amoxicillin 500mg Capsules http://theprettyguineapig.com/amoxicillin/
generic name for viagra bioshieldpill.com alternative viagra [url=http://bioshieldpill.com/]buy cheap generic viagra online[/url]
Wow, that’s what I was searching for, what a material!
existing here at this web site, thanks admin of this
site.
foxwoods online casino safe online casinos real money ignition casino
http://cialisnrxch.com
taking without ed cialis pills cialis
buy cialis online
viagra upotreba cialis 20mg
online cialis
http://cialisnrxch.com
buy cialis professional online
cheap cialis online
vicodin and cialis generic
buy cheap cialis online
[url=http://cialsonlinebei.com]cialis[/url] http://cialsonlinebei.com canadian pharmacy cialis
I’m extrеmely impressed with yօur ᴡriting skills ɑs well aѕ with the
layout on your blog. Is this a paid theme oг did yoᥙ modify іt yourself?
Anyԝay keep up the nice quality writing, it is rare to see a nice ƅloց like this one nowadays.
is viagra covered by medicaid
generic viagra online
cheapest viagra online
buy generic viagra online
http://www.cialisggnrx.com/
generic cialis work buy
cialis online
cialis online
generic cialis online
1 mg prednisone no scrip
buy viagra
rx customer support
viagra online
generic cialis effectiveness
buy generic cialis online
generic form of cialis cialis
generic cialis
viagra cialis online cheap cialis – website here
I need a Ƅit of assistance from all the dudes andd ladies оut tһere!
I amm in thе process օf obtaining mу fiancee a Valentine’ѕ
day gift and I аm ɑ lіttle bіt stuck. I intend to get һer a
ⅼittle something vеry affectionate аnd hhot and І waѕ thinking
᧐f buyimg hеr ɑ little something fгom Harrods (probably a Ƅit of wine andd chocolates) ɑnd ѕome naughty lingerie from Peaches аnd Screams.
І trսly adore tһeir Bras & Bra Seets category. What
underwear piece Ԁο you believe І should get һer?
Pⅼease kindly PM me orr respond tߋ this thread. I woulɗ appreciate
a prompt ansᴡer as Valentine’s daay іs ɑlmost аrоᥙnd thе bend.
Thankѕ ɑ million!
order generic cialis online
buy generic cialis
generic cialis from canada
buy generic cialis online
My brother recommended I would possibly like this blog.
He was totally right. This submit truly made my day.
You cann’t consider just how so much time I had spent for this info!
Thank you!
Pingback: cialis cost
Thank you for another great article. The place else may anybody get that kind of info in such a perfect method of
writing? I have a presentation subsequent week, and I’m on the look for such info.
I pay a visit every day a few web sites and sites
to read articles, but this web site offers quality based posts.
Thank you for some other wonderful post. Where else
may just anyone get that type of info in such an ideal way of writing?
I’ve a presentation next week, and I am at the look for such information.
It’s difficult to find experienced people about
this topic, however, you sound like you know what you’re talking about!
Thanks
Greate article. Keep writing such kind of info on your site.
Im really impressed by your site.
Hello there, You have performed an excellent job.
I’ll definitely digg it and for my part suggest to my friends.
I am confident they will be benefited from this website.
Buy Cheap Viagra Online Buy Cheap Viagra Online
cialis 20mg side effects
generic cialis
lamisil blogs cialis pills
generic cialis online
gsn casino slots online casino reviews caesars casino online
Pingback: cialis cooupons
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something.
I think that you can do with a few pics to drive the
message home a little bit, but other than that, this is magnificent blog.
An excellent read. I will definitely be back.
suhagra 100 mg
canadian pharmacy cialis
farmacia online uk
buy cialis online
caesars online casino jackpot party casino facebook online casino g
Hi, I wish for to subscribe for this web site to obtain most recent updates,
therefore where can i do it please help out.
For latest information you have tto pay a visit thhe web and on the web I found
thiss site as a best wwebsite for hottest updates.
With havin so much content and articles do you ever
run into any problems of plagorism or copyright violation? My blog
has a lot of completely unique content I’ve either created myself
or outsourced but it appears a lot of it is popping
it up all over the web without my authorization. Do you know any
techniques to help stop content from being stolen? I’d truly appreciate it.
Pingback: cialis free trial
I’ve been surfing online more than three hours today, yet I never found
any interesting article like yours. It’s pretty worth enough for me.
In my view, if all site owners and bloggers
made good content as you did, the net will be much more
useful than ever before.
viagra online (Wyatt) viagra
buy kamagra uk review kamagra 100mg tabletta – kamagra forum hr kamagra chew tablets – 100 mg
I read this post completely regarding the resemblance of newest and previous technologies, it’s amazing article.
Hey I am so happy I found your blog, I really found you by accident, while I was searching on Google
for something else, Anyhow I am here now and would just like to say thanks for a incredible post and
a all round exciting blog (I also love the theme/design), I don’t have
time to look over it all at the moment but I have
bookmarked it and also added in your RSS feeds, so
when I have time I will be back to read a lot more, Please do keep up
the awesome work.
toko sildenafil online generic viagra at walmart does hydrocodone interfere
with sildenafil
Hi there, every time i used to check web site posts here in the early hours in the daylight, since i
love to gain knowledge of more and more.
resorts online casino nj posh casino online zone online casino gam
free games for casino slots atari jackpots resorts online casino nj back
posh casino online free casino games sun moon real casino slots sugarhouse casino
canadian pharmacies shipping to usa
http://canadianonlinepharmacyneo.com/
canadian pharmacies shipping to usa
free slots no download no registration needed doubleu casino on facebook free casino games vegas world
lasix without script online lasix – lasix no script
Pingback: atorvastatin
http://cialisggnrx.com/
mixing levitra and viagra cialis pills cialis
buy cialis online
buy daily cialis
generic cialis online
Pingback: cymbalta
Pingback: levitra generic
Heya! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no data backup.
Do you have any solutions to stop hackers?
RebekahFulle cialis online buy generic cialis viagra cialis together [url=http://www.buyscialisrx.com/]generic cialis online[/url]
Aw, this was a really good post. Spending some time and actual effort to
generate a really good article… but what can I say… I procrastinate
a lot and don’t seem to get nearly anything
done.
Pingback: atorvastatin 10 mg
buying cialis in canada view website – order cialis by phone
Pingback: cymbalta dosage
buy lasixonline lasix 80 mg – lasix 100mg online
Pingback: cialis online pharmacy
viagra prices walgreens
buy generic viagra online
viagra zombies
buy viagra
generic cialis online india
generic cialis
acheter cialis 20mg
buy cialis
Pingback: atorvastatin 10mg
cialis without prescription usa
viagra online
online pharmacy cr
buy generic viagra
Pingback: cymbalta for pain
Pingback: levitra 20 mg
What a information of un-ambiguity and preserveness of precious know-how on the topic of unexpected emotions.
slots online best online casinos online casino deutschland grand falls casino
where can i buy levitra levitra non prescription – levitra 10 more helpful hints
Pingback: cymbalta generic
Pingback: levitra coupon
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر
ايران با بيش از ١٨ سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان
بوده كه همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور هدف اصلى ايشان بوده، شما عزيزان ميتوانيد هر
گونه طلسم و جادو را با مناسبترين قيمت ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و
توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى خود
را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها
و ادعيه به دايركت مراجعه بفرماييد.
instagram: https://www.instagram.com/telesm_yahoodi_hendi
free casino games no registration no download online casino reviews vegas casino online
usa casino online real money play free casino slots now slots games free
Pingback: cymbalta medication
Pingback: levitra dosage
Pingback: cialis side effects
vinegar metformin cialis generic pills
buy generic cialis online
cheap generic cialis cialis
buy generic cialis
pch slots lady luck online casino huuuge casino slots
cialis generique
buy cialis
how to buy omifin
buy cialis online
Pingback: cymbalta reviews
Pingback: cialis vs viagra
viagra tablets
buy viagra online
viagra reaction
generic viagra online
Pingback: cymbalta side effects
Every weekend i used to go to see this site, as i want enjoyment, for the reason that this this website conations genuinely nice funny stuff too.
Pingback: levitra vs viagra
There is certainly a lot to find out about this subject.
I really like all of the points you made.
Hello to all, how is all, I think every one is getting more from
this web site, and your views are good in support of new viewers.
genuine site absolutely caring articles. reckon bookmarks
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Online Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500 Mg Amoxicillin No Prescription http://theprettyguineapig.com/amoxicillin/
[url=http://cialsonlinebei.com]generic cialis online[/url] http://cialsonlinebei.com buy cialis
a-ok spot sheer caring articles. sum bookmarks
I get pleasure from, cause I found just what I used to
be looking for. You have ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
http://www.cialisggnrx.com/
cialis tadalafil tablets
generic cialis
order cialis online without prescription
buy cialis
http://paydayloanseon.com/
payday loans in fayetteville nc
best payday loans
free payday loans
best payday loans
canadian pharmacy king generic viagra rx canadian pharmacy cialis
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500 Mg Amoxicillin http://theprettyguineapig.com/amoxicillin/
purchase cialis online
buy generic cialis online
pharmacy online cialis generic viagra
buy generic cialis online
Здравствуйте дамы и господа!
Наша контора занимается свыше 10 лет ремонтом и обслуживанием оргтехники в городе Минске.Основные направления и виды нашей деятельности:
1)Заправка и восстановление картриджей
2)Ремонт и сервис оргтехники
3)Ремонт и настройка компьютеров и ноутбуков
4)SEO продвижение сайтов
5)Разработка сайтов
Всегда рады помочь Вам!
заправка картриджа 446
компьютер мастер
этапы разработки веб сайта
снпч epson workforce wf
инструкция по заправке картриджа
http://theprettyguineapig.com/amoxicillin/ – Buy Amoxicillin Amoxicillin No Prescription http://theprettyguineapig.com/amoxicillin/
JessieTarlet cialis without prescription cialis coupon buying cialis
australia [url=http://www.buyscialisrx.com/]cheap cialis online[/url]
I’d like to find out more? I’d love to find out some additional information.
generic viagra prices viagra receptfritt
When someone writes an piece of writing he/she keeps the idea of a user in his/her brain that how a user can understand it.
Thus that’s why this post is perfect. Thanks!
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Amoxicillin 500mg Capsules For Sale http://theprettyguineapig.com/amoxicillin/
psychogenic erectile dysfunction sildenafil
viagra no prescription
quanto custa sildenafil
[url=http://viagrarow.com/]viagra online prescription[/url]
right spot absolutely neighbourly articles. reckon bookmarks
http://theprettyguineapig.com/amoxicillin/ – Buy Amoxicillin Online Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
Pingback: cymbalta withdrawal
Pingback: vardenafil
Pingback: generic cialis tadalafil
no 1 canadian pharcharmy online
http://canadianpharmaciesprofmeds.com/
online pharmacy no prescription
herbal viagra overdose
buy viagra online
viagra vs cialis forum
generic viagra online
Pingback: duloxetine
Pingback: vardenafil 20 mg
https://eroticpro.ru/vibrator-nalone.html вибратор nalone
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Buy Amoxicillin http://theprettyguineapig.com/amoxicillin/
Greetings from Ohio! I’m bored to tears at work so I decided
to check out your website on my iphone during lunch
break. I love the information you present here and can’t wait to take a look when I get home.
I’m surprised at how quick your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, fantastic blog!
Is it OK to post on Google+? Keep up the terrific work!
Hello to every body, it’s my first pay a quick visit of this
webpage; this web site carries amazing and really excellent
material designed for visitors.
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500mg Capsules Amoxicillin 500mg Capsules http://theprettyguineapig.com/amoxicillin/
watermelon natures viagra
buy generic viagra
cialis vs viagra reviews
buy viagra
Pingback: duloxetine 20 mg
Very nice post. I just stumbled upon your weblog and wished to say that I have truly enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I
hope you write again soon!
Pingback: vardenafil 20mg
Outstanding post however , I was wanting to know if you could write a
litte more on this subject? I’d be very grateful if you could elaborate a little bit more.
Thank you!
paxil medication – what is paxil
Good day! Do you know if they make any plugins to
safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard
on. Any recommendations?
Pingback: duloxetine hcl
xtxbrmwmp tadalafil daily use bph http://cialissom.com/ cialissom.com [url=http://cialissom.com/]cialis usa[/url] tadalafil ilaç yan etkileri
Wonderful post however I was wanting to know if you
could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit more.
Thanks!
After I originally left a comment I seem to have clicked on the -Notify me when new comments
are added- checkbox and from now on every time a comment is added I
recieve four emails with the exact same comment. Is there a means you are able
to remove me from that service? Thanks a lot!
We are a bunch of volunteers and opening a brand new scheme
in our community. Your website provided us with valuable information to work on. You’ve done a formidable activity and our whole
community can be grateful to you.
Pingback: duloxetine side effectss
I blog often and I really appreciate your content.
This article has really peaked my interest. I’m going to
take a note of your blog and keep checking for new information about once a week.
I opted in for your Feed too.
side effects of paxil – paxil side effects in women
cialis generico barato
new female viagra
discount tadalifil
viagra e bom
Pingback: duloxetine 60 mg
I love this! I haven’t ever found a post as interesting article like yours.
It’s very sweet. Is it OK to share on Twitter? Keep up the terrific
work!
generic cialis 20mg
buy cialis online
tadalafil cost buy cialis online
buy cialis
viagra efficacy
buy generic viagra
Keyword
buy viagra online
alcohol induced erectile dysfunction
erectile discomfort
erectile massage therapy
erectile cream for me
should you chew sildenafil http://triviagra.com/ crestor and sildenafil interaction triviagra.com heartburn from viagra
prescription drugs online without
http://canadianpharmaciesunlimited.com/
online pharmacy canada
online pharmacies
http://canadianhealthypharmacyrx.com/
best 10 online pharmacies
http://onlinepharmacycanadasctu.com/ perscription drugs from canada
http://canadianpharmacyonlinesrvh.com/ canadian pharmacy king
This article is in fact a nice one it assists new
web visitors, who are wishing for blogging.
http://canadadrugpharmacywhik.com/ buy cialis online usa
http://pharmacystorefvnh.com/ canadian pharmacy generic viagra
http://canadianonlinepharmacyrgby.com/ online pharmacy canada
Hurrah! At last I got a webpage from where I know how to
really obtain useful data concerning my study and knowledge.
http://canadaonlinepharmacyhtik.com/ trusted online pharmacy reviews
http://drugstorepharmacyxerh.com/ generic viagra india
Pingback: buy cialis generic tadalafil
Pingback: augmentin
Pingback: levaquin
Hi, I am the online marketing representative at Peaches and Screams.
We ɑre presently sedking to tаke advantage of the
vape wholesale market. Ⅾoes anybdy at alll here have ɑny knowledge ᴡith the vape
industry or B2B lead generation? We aгe very much inclined to
ցet the Global Vape Shop Database, Vape Company Ε-Mail Liist аnd Yoggy’s Money
Vault Search Engine Scraper sߋ aѕ to create our vewry own Β2B leads.
Does anybody here have any sort of expertise with ɑny onee oof the aƄove marketing resources?
Woսld love tо listen to уour ideas and testimonials prior
tⲟ committing myѕeⅼf to tһe investment. Ꮮikewise, І wouⅼd highly appreсiate ɑny recommendations fօr really helping us to develop our vspe wholesale operation.
Τhanks
Pingback: augmentin 875
http://erectiledysfunctionnfsc.com/ canada drugs online reviews
Pingback: buy levitra
Pingback: levaquin 500 mg
Hi there! Someone in my Linkedin group shared this website with us so I came to take a look.
I’m definitely enjoying the information. I’m bookmarking and will
be tweeting this to my followers! Great blog and wonderful style and design.
Keep up the really awesome work!
Yes! Finally someone writes about noticias.
I all the time used to study piece of writing in news papers but now as I am a user of web
so from now I am using net for articles, thanks to
web.
Pingback: augmentin 875 mg
Pingback: levaquin 750 mg
Pingback: cheap levitra
Pingback: buy levitra online
[url=http://cialsonlinebei.com]generic cialis[/url] http://cialsonlinebei.com cialis online
is it safe to buy sildenafil online in australia Viagra Online can you take
sildenafil too often
http://canadadrugsrwdi.com/ canadian pharmacy online
http://canadadrugsonlinergla.com/ online pharmacy canada
Pingback: augmentin and alcohol
I do not even know how I ended up here, but I thought
this post was good. I do not know who you are
but definitely you’re going to a famous blogger if you are not already 😉 Cheers!
I every time used to read piece of writing in news papers but now
as I am a user of web thus from now I am using net for posts, thanks
to web.
I’ve been surfing on-line greater than three hours today, yet I never found any fascinating article like
yours. It’s pretty price enough for me. In my view, if all web owners and bloggers made just right content as you did, the net might be a
lot more useful than ever before.
Pingback: levaquin antibiotic
Pingback: generic levitra
Pingback: augmentin antibiotic
Pingback: sildenafil coupons
Pingback: cialis 20 mg
Pingback: levaquin dosage
Pingback: augmentin dosage
http://onlinepharmacybvyk.com/ canada drugs coupon code
Pingback: levaquin for uti
http://drugstoresydik.com/ canadian online pharmacy
I’m impressed, I have to admit. Rarely do I come across a blog that’s both
equally educative and amusing, and without a doubt, you have
hit the nail on the head. The problem is something that
too few men and women are speaking intelligently about.
Now i’m very happy that I found this in my hunt for something concerning this.
WOW just what I was searching for. Came here by searching for expressing
Hi there, this weekend is good designed for me,
since this point in time i am reading this enormous informative post here
at my home.
Great work! That is the kind of information that are supposed to be shared
across the net. Disgrace on the search engines for now not positioning this publish upper!
Come on over and visit my website . Thank you =)
Great blog here! Also your web site loads up very
fast! What host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
Hey superb blog! Does running a blog like this require a lot of work?
I have no expertise in computer programming however I had
been hoping to start my own blog soon. Anyways, should you have any suggestions or techniques for new
blog owners please share. I know this is off topic however I
just needed to ask. Thank you!
I like the valuable info you provide in your articles.
I will bookmark your blog and check again here frequently.
I’m quite sure I will learn plenty of new stuff right here!
Good luck for the next!
With havin so much written content do you ever run into any problems of plagorism
or copyright infringement? My blog has a lot of exclusive
content I’ve either created myself or outsourced but it seems a
lot of it is popping it up all over the web without my agreement.
Do you know any methods to help reduce content from being ripped off?
I’d definitely appreciate it.
http://cialisckajrhd.com/# – best canadian pharmacy viagra information where can i buy cialis
Hi there to every body, it’s my first visit of this webpage; this webpage includes amazing and genuinely good stuff in favor of visitors.
Crystlehlqr cialis online cheap cialis online wirkung von cialis
5 mg [url=http://buyscialisrx.com]cialis no prescription[/url]
Pingback: augmentin dose
Pingback: cialis 20mg generic
No matter if some one searches for his vital thing, thus he/she needs to be
available that in detail, so that thing is maintained over here.
Pingback: augmentin for dogs
Pingback: cialis 20mg tablets prices
Pingback: cialis 20mg tablet prices
Pingback: levaquin renal dose
It’s amazing in support of me to have a website, which is useful designed for my know-how.
thanks admin
Pingback: levitra 20mg
Thanks for your personal marvelous posting! I
definitely enjoyed reading it, you could be a great author.
I will make sure to bookmark your blog and may come
back in the future. I want to encourage yourself to continue your great writing, have a nice
evening!
M http://www.cialisles.com/ order cialis pills; exactly ou achetez vous votre cialis ed meds online without doctor prescription also ed meds online without doctor prescription;
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin No Prescription 18 http://theprettyguineapig.com/amoxicillin/
As the admin of this website is working, no doubt very shortly
it will be famous, due to its feature contents.
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500 Mg Buy Amoxicillin Online http://theprettyguineapig.com/amoxicillin/
keto diet intermittent fasting what do you eat on the keto diet keto diet plan pdf
Hey there! I’ve been reading your weblog for some time
now and finally got the bravery to go ahead and give you a
shout out from Dallas Tx! Just wanted to mention keep up the fantastic job!
Is it OK to share on Linkedin? Keep up the really good work!
A motivating discussion is worth comment. I do think that you ought to
write more on this topic, it might not be a taboo matter but generally people don’t speak about such topics.
To the next! Many thanks!!
Wow, this paragraph is pleasant, my sister is analyzing these things, so I am going to inform her.
I every time spent my half an hour to read this webpage’s
articles or reviews everyday along with a cup of coffee.
http://cialislisthec.com/# – canada drugs online buy viagra soft canadian pharmacy meds
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin Online Amoxil Buy Generic http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Buy Amoxicillin Amoxicillin 500 Mg http://theprettyguineapig.com/amoxicillin/
Today, I went to the beach with my children. I found a sea shell and gave
it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and
screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
Pingback: augmentin for uti
explained here furosemide lasix
Pingback: levitra cost
Do you have a spam issue on this website; I also am a
blogger, and I was wanting to know your situation; we have created
some nice practices and we are looking to swap strategies with other folks, why not shoot me
an e-mail if interested.
Pingback: levaquin side effects
Pingback: augmentin side effects
Pingback: viagra doctor prescription
Pingback: levaquin uses
found here found here
What’s up to every one, it’s truly a good for me to go to see this web page, it includes priceless Information.
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500mg Capsules Amoxicillin No Prescription http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500 Mg Amoxicillin http://theprettyguineapig.com/amoxicillin/
http://theprettyguineapig.com/amoxicillin/ – Amoxicillin 500mg Amoxicillin For Sale http://theprettyguineapig.com/amoxicillin/
keto diet beans keto egg diet fruit for keto diet
keto diet and type 2 diabetes dairy free keto diet hungry on keto diet
http://cialiscials.com/# – canada drugs reviews buy cheap viagra online viagra generic
Pingback: augmentin uses
Hi, everything is going perfectly here and ofcourse every one
is sharing facts, that’s genuinely fine, keep up writing.
Pingback: what is levaquin
Pingback: augmentin vs amoxicillin
I think that is among the most important information for me.
And i’m satisfied studying your article. But should remark on some basic things, The site taste is great,
the articles is truly excellent : D. Excellent process, cheers
Hi! Do you know if they make any plugins to protect
against hackers? I’m kinda paranoid about losing everything
I’ve worked hard on. Any suggestions?
Pingback: side effects augmentin
Pingback: levitra online
cialis tabs more information – get more information
Pingback: cialis generic availability
Wonderful website you have here but I was wondering if you knew of any user discussion forums that
cover the same topics discussed here? I’d really love to be a part of group where
I can get suggestions from other knowledgeable individuals that share the same interest.
If you have any suggestions, please let me know. Appreciate it!
Marvelous, what a blog it is! This weblog gives helpful data to us,
keep it up.
Pingback: what is augmentin
Pingback: cialis generic pharmacy
Pingback: levitra prices
Pingback: cialis pharmacy
do you have to be prescribed to viagra [url=http://www.doctor7online.com/]cheap viagra[/url]
what happens after you ejaculate with viagra
http://canadiannowv.com/# – canada drugs direct buy viagra pills best canadian pharmacy
Its not my first time to go to see this web site,
i am browsing this web site dailly and get fastidious data
from here everyday.
Fantastic items from you, man. I’ve remember your stuff prior to and you’re just too wonderful.
I actually like what you’ve got right here, certainly like what
you’re saying and the way in which you are saying it. You are making it entertaining and
you still take care of to keep it wise. I cant wait to read far more from you.
This is actually a wonderful web site.
Hi, yup this piece of writing is really good
and I have learned lot of things from it on the topic of blogging.
thanks.
mexican pharmacies shipping to usa
http://canadianonlinepharmacycl.com/
canadian pharmacies
Nice post. I used to be checking constantly this weblog and I’m
inspired! Very helpful information specially the closing section 🙂 I deal
with such information much. I used to be seeking this particular information for
a very lengthy time. Thanks and best of luck.
Excellent, what a weblog it is! This blog provides valuable facts to us, keep it up.
levitra 10 best price for levitra
Unquestionably believe that which you stated. Your favorite reason appeared
to be on the internet the easiest thing to be aware of. I say
to you, I definitely get irked while people think about
worries that they plainly do not know about.
You managed to hit the nail upon the top and also defined out the
whole thing without having side effect ,
people could take a signal. Will likely be back to get more.
Thanks
有名メーカーの化粧品で、お肌のほうれい線の進行を改善することができます。ホワイトニングリフトケアジェルは、ライバル商品の中でもリピーターが多いクリームです。若返りには欠かせないアイテムです。
Pingback: cialis generico
Pingback: levitra recviews
Pingback: cialis generika
Pingback: viagra without a doctor prescription
http://cialisnrxch.com/#
http://cialisggnrx.com/#
http://cialisndbrx.com/#
http://cialisgentrx.com/#
http://www.cialisggnrx.com/
generic cialis online
buy cialis online
http://cialisnrxch.com/
cheap cialis online
buy cialis online
Pingback: levitra side effects
[url=http://cialsonlinebei.com]http://cialisle.com[/url] http://cialsonlinebei.com cialis online canada
viagra and nitrate http://www.vagragenericaar.org/ efficacy of generic sildenafil.
http://niqabsquad.com/# – online pharmacy school buy cheap purchase uk viagra canadian pharmacies online
cheap cialis online
buy generic cialis online
cheap cialis online
cheap cialis online
http://cialgenisrx.com/
cheap cialis online
buy cheap cialis online
http://www.cialisgengrx.com/
cheap cialis online
cheap cialis online
http://www.cialisgenkrx.com/
buy cialis online
cheap cialis online
Hi my friend! I want to say that this article is awesome,
great written and inxlude almost alll important infos.
I’d like to see more posts like this .
Pingback: levitra vs cialis
My relatives every time say that I am killing
my time here at web, except I know I am getting
know-how everyday by reading such fastidious content.
foods to eat on a keto diet what can you drink on a keto diet plant based keto diet
buy zoloft online – website
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type
on a number of websites for about a year and am worried about switching to another platform.
I have heard great things about blogengine.net.
Is there a way I can transfer all my wordpress posts into
it? Any help would be really appreciated!
Thankfulness to my father who shared with me regarding this web site, this webpage is actually awesome.
This article gives clear idea designed for the new visitors of blogging, that actually how to do
blogging.
Because the admin of this website is working, no question very
soon it will be famous, due to its feature contents.
online pharmacy canada
http://canadianonlinepharmacyhd.com/
best canadian mail order pharmacies
keto diet instant pot what is keto diet plan alkaline keto diet
buy generic cialis online
cheap cialis online
buy generic cialis online
buy cialis online
http://cialgenisrx.com/
buy cialis online
buy cialis online
http://www.cialisgengrx.com/
generic cialis online
cheap cialis online
http://www.cialisgenkrx.com/
generic cialis online
cheap cialis online
zoloft price – order sertraline online
I’ve been exploring for a little bit for any high-quality articles or blog posts on this kind of space .
Exploring in Yahoo I finally stumbled upon this site.
Reading this info So i’m glad to exhibit that I have an incredibly excellent
uncanny feeling I discovered exactly what I needed. I most surely will make certain to don?t
put out of your mind this website and give it a glance
regularly.
http://viagraoahvfn.com/# – canadian pharmacy buy viagra canada canadian pharmacy online
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش
از ١٨ سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور هدف
اصلى ايشان بوده، شما عزيزان ميتوانيد هر
گونه طلسم و جادو را با مناسبترين قيمت ها
سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست
ساز بوده و توسط خود سيد
ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار،
كارايى طلسم هاى خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه
بفرماييد.
instagram: telesm_seyed_mehdi
sildenafil before brazilian wax cheap generic viagra can you have
sildenafil with alcohol
prescription without a doctor’s prescription
http://canadianpharmacyxyz.com/
canada drugs no prescription needed
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش از ١٨ سال سابقه كار
ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه همواره بر آنها تاكيد
داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور هدف اصلى ايشان بوده،
شما عزيزان ميتوانيد هر گونه طلسم و جادو را با مناسبترين قيمت ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده
از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: https://www.instagram.com/telesm_yahoodi_hendi
zoloft without prescription – zoloft medication
WOW just what I was looking for. Came here by searching for sexykinkycouple20
Pingback: cialis tablets australia
Pingback: cialis without a doctor prescription
Pingback: vardenafil generic
Most SEO companies will likely help an internet site owner with Ad – Words together with SEO,
which companies will help a niche site owner pick the right keywords for
generating huge amounts of traffic and in many cases assistance to run the Ad
– Words campaigns. The field of website SEO services and Google SEO
services is definately that these professionals make sure that their client’s webpage receives all the traffic as possible.
Moreover if you’ve got the good salesperson like skills, the
program is just the worth for you.
Pingback: vardenafil hcl 20mg
Everyone loves what you guys tend to be up too. This type of clever work and exposure!
Keep up the great works guys I’ve added you guys to blogroll.
Pingback: generic cialis 20mg
sertraline zoloft – zoloft pills
online pharmacy with no prescription
http://canadianonlinepharmacyneo.com/
top rated online canadian pharmacies
Pingback: what is levitra
Pingback: generic cialis available
Admiring the time and energy you put into your website and in depth information you offer.
It’s great to come across a blog every once in a while that isn’t the same out of
date rehashed material. Excellent read! I’ve saved your site and I’m adding
your RSS feeds to my Google account.
lasix without a prescription lasix medicine
Thank you for another informative blog. Where else may I
am getting that kind of information written in such a perfect way?
I have a project that I’m simply now working on, and I have been at the glance out for such info.
shark tank keto diet pills keto diet dinners wine keto diet
http://www.cialgenisrx.com/
buy cheap cialis online
buy generic cialis online
http://www.cialisgengrx.com/
buy cheap cialis online
cheap cialis online
http://www.cialisgenkrx.com/
buy cialis online
cheap cialis online
Hello there! This is kind of off topic but I need some advice from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where
to start. Do you have any points or suggestions?
With thanks
It’s amazing for me to have a web site, which is beneficial for my
experience. thanks admin
http://cialisggnrx.com/
buy generic cialis online
buy generic cialis online
http://www.cialisnrxch.com/
generic cialis online
cheap cialis online
http://cialgenisrx.com/
buy cialis online
buy generic cialis online
http://www.cialisgengrx.com/
generic cialis online
buy cheap cialis online
http://cialisgenkrx.com/
buy generic cialis online
buy cheap cialis online
Hello would you mind sharing which blog platform you’re working with?
I’m going to start my own blog soon but I’m having a difficult time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m
looking for something completely unique. P.S Sorry for being off-topic but I had to ask!
Do you fantasize all day long about cam girls with big tits?
If so, then you need to check out http://bigclit.top
Pingback: generic cialis tadalafil uk
What a material of un-ambiguity and preserveness of precious know-how regarding unpredicted emotions.
Shawnaqlrtcc cialis coupon cialis without prescription steel
libido and cialis [url=http://buyscialisrx.com/]cheap cialis[/url]
http://cialisnrxch.com/#
http://cialisggnrx.com/#
http://cialisndbrx.com/#
http://cialisgentrx.com/#
buy cialis online
buy cheap cialis online
generic cialis online
buy cialis online
Pingback: tadalafil without a doctor prescription
Excellent, what a blog it is! This webpage gives helpful data to us, keep
it up.
Hi! Someone in my Myspace group shared this website with us
so I came to give it a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting
this to my followers! Excellent blog and great design and style.
Hi there! This is my first comment here so I just wanted to give a quick shout out
and say I truly enjoy reading through your posts. Can you
recommend any other blogs/websites/forums that deal
with the same topics? Thanks!
We stumbled over here coming from a different web address and thought
I might as well check things out. I like what I see so now i am following you.
Look forward to checking out your web page repeatedly.
After exploring a few of the blog posts on your web site, I honestly like your way
of blogging. I saved as a favorite it to my bookmark site list and will be checking back soon. Take a look at my website as well and let me know
how you feel.
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش از ١٨ سال سابقه كار
ميباشد.
وجدان كارى و كيفيت خدمات از اولويت
هاى ايشان بوده كه همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل و خارج از كشور
هدف اصلى ايشان بوده، شما عزيزان ميتوانيد هر گونه طلسم و جادو را با مناسبترين قيمت ها سفارش داده و تحويل
بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و توسط خود سيد ساخته
ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و استفاده از بخورات كمياب و
محاسبه دقيق زمان انجام كار، كارايى طلسم هاى خود را
به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت
طلسمها و ادعيه به دايركت
مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
Nice post. I was checking constantly this blog and I’m impressed!
Very useful information particularly the last part 🙂 I care for
such information a lot. I was seeking this certain info for a
very long time. Thank you and best of luck.
Hey therе! I ɑm the promotion ɑnd marketing manager аt [url=https://theeliquidboutique.co.uk]Ꭲhe Eliquid Boutique[/url], аn internet vape company іn the UK.
I found many inquiries with regardѕ to oսr international vape store database аnd vape company e-mail list.
Ӏn summary, the Global Vape Shop Database (https://theeliquidboutique.co.uk/products/global-vape-shop-database) рrovides contact details foг аlmost ɑll vape stores оn the planet, including UK, U.Ⴝ.Α., Canada, Europe, Russia and CIS, Middle East and Australia.
Ӏt comeѕ in an Excel spreadsheet and consists оf the vape store name,
email, internet site, telephone numƄеr, address, social media lіnks and a l᧐t more.
Mеanwhile, the Vape Company Ε-Mail List (https://theeliquidboutique.co.uk/products/vape-company-e-mail-mailing-list) is actսally ɑ list witһ e-mails of
every single company aгound tһе globe. Tһe list features aƄօut 40,
000+ emails of e-liquid brand names, online ɑnd brick-and-mortar vape companies, vape dealers аnd
distros, CBD sites, vape ѕhоw organisers and a whole lοt more.
Tһеse рarticular vape leads ɑгe perfect for e-newsletter promotion and marketing as this іs tһе primary function of tһe
database. Thе vape business leads аre all GDPR compliant and yοu would
get free lifetime updates delivered straight tⲟ
yoᥙr inbox. We update tһe vape shop database and vape business email list ɑt tһe veгy least twicе a montһ.
We do a three level verification оn all of the emails including foг
phrase structure, deserted domain names аnd ⅽlosed email
inboxes. If yоu haνе ѕome concerns, you саn contact me tһrough ouг Facebook (https://www.facebook.com/theeliquidboutique/) web page.
Ƭhe world-wide vape shop database аnd vape business e-mails hɑѵe assisted ɑbout 500 e-liquid
labels ɑnd vape wholesalers tߋ promote thеiг items tⲟ all vape stores around the globe ɑnd is literally ɑll you need to tаke yoᥙr vape brand to a
brand-new level. I really hope tһat this answers eaⅽh one of your concerns guys!
We wіll ƅe releasing οne more update todаy!
Talk to sexy naked girls all day and night at http://sexynudecam.top
Heya i am for the first time here. I found this board and I find
It truly useful & it helped me out much. I hope to give something
back and help others like you helped me.
zoloft 50mg – generic zoloft
http://viagrapfhze.com/# – generic viagra canada viagra natural viagra generic date
Thanks for sharing your thoughts on mug personnalisée mug
personnalisée coque personnalisée. Regards
This is undoubtedly a private greatest for me.
click this link discount generic cialis
What a information of un-ambiguity and preserveness of valuable familiarity about unpredicted
emotions.
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started
and create my own. Do you require any html coding expertise to make your own blog?
Any help would be really appreciated!
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر ايران با بيش از ١٨
سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه همواره بر آنها تاكيد داشته اند.
از آنجايى كه كمك به هموطنان عزيز داخل
و خارج از كشور هدف اصلى ايشان بوده،
شما عزيزان ميتوانيد هر گونه طلسم و جادو
را با مناسبترين قيمت ها سفارش داده و تحويل بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده و
توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و
استفاده از بخورات كمياب و محاسبه دقيق زمان انجام كار، كارايى طلسم هاى
خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
Fantastic post however I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Thank you!
Hello, I read your blog on a regular basis. Your writing
style is witty, keep up the good work!
order cialis by phone cialis original
Quality articles is the important to be a focus for the people to pay a quick visit the
site, that’s what this web page is providing.
Good day I am so thrilled I found your blog page, I
really found you by mistake, while I was searching on Bing for something else, Regardless I
am here now and would just like to say cheers for a incredible post and a all round thrilling blog (I also love the theme/design),
I don’t have time to go through it all at the moment but I have bookmarked it and also
added in your RSS feeds, so when I have time I will be back to
read more, Please do keep up the excellent work.
bookmarked!!, I love your web site!
Greetings! This is my first comment here so I just wanted to give a quick shout out and tell you I really enjoy reading your articles.
Can you recommend any other blogs/websites/forums that cover
the same subjects? Thanks a lot!
erectile natural diet pdf
erectile dysfunction medications
is erectile dysfunction a chronic condition
erectile over the counter products
Pingback: vape shop sunbury
I need to to thank you for this fantastic read!!
I definitely loved every little bit of it. I have you book-marked to check out new stuff you post…
http://cialisserfher.com/# – generic viagra names discount viagra canada online pharmacy
http://viagracefo.com/# – walgreens online pharmacy generic viagra online buy drugs from canada
Its like you read my thoughts! You appear to know a lot about this, like you wrote the e-book in it or something.
I think that you simply can do with some p.c. to
pressure the message house a bit, however instead of that, this
is fantastic blog. An excellent read. I will certainly be back.
online pharmacy canada
http://canadianonlinepharmacyoffer.com/
best online pharmacies canada
It’s very straightforward to find out any topic on web as
compared to textbooks, as I found this article at this website.
Having read this I believed it was really enlightening.
I appreciate you spending some time and effort
to put this information together. I once again find myself
personally spending way too much time both
reading and posting comments. But so what, it was still worth it!
I do not even know the way I ended up here, however I
assumed this publish was good. I don’t recognise who you
are but definitely you are going to a well-known blogger should you aren’t already.
Cheers!
which erectile dysfunction drugs cost more
new york erectile dysfunction
erectile restoration
buy erectile dysfunction pump cvs
http://hopcialisraj.com/ – canada drugs online review discount viagra perscription drugs from canada
スツールの存外な捜し当てるとは。可笑しげサイトを狙う。スツールのなるほど辷らせる。衝動を取りいれるします。
http://onlineviaqer.com/# – is there a generic for viagra viagra coupons walgreens online pharmacy
http://cialisgretkjss.com/# – cvs pharmacy online cialis coupon best place to buy cialis online
This is very interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your magnificent post.
Also, I’ve shared your website in my social networks!
no prescription pharmacy canada
http://canadianpharmaciesshippingbsl.com/
canadian pharmacies online
Hello there,
My name is Aly and I would like to know if you would have any interest to have your website here at deepsingularity.io promoted as a resource on our blog alychidesign.com ?
We are in the midst of updating our broken link resources to include current and up to date resources for our readers. Our resource links are manually approved allowing us to mark a link as a do-follow link as well
.
If you may be interested please in being included as a resource on our blog, please let me know.
Thanks,
Aly
http://sexviagen.com/# – when will viagra be generic female viagra pills canadian pharmacies
Hi to all, it’s in fact a fastidious for me to pay a quick visit
this website, it includes useful Information.
My brother suggested I might like this blog.
He was totally right. This post truly made my day.
You cann’t imagine simply how much time I had spent for this information!
Thanks!
https://saresltd.com/kamagra/ – canadian pharmacies viagra pills cialis buy
Heya are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and set up my own.
Do you require any coding expertise to make your own blog?
Any help would be greatly appreciated!
Good way of explaining, and pleasant piece of writing to get data
on the topic of my presentation subject matter, which i am going to convey in university.
cheap 2.5 mg tadalafil http://genericalis.com tadalafil
barato contrareembolso
http://viagranerrds.com/# – buy cialis online cheap sublingual viagra canadian pharmacy king
http://viagraocns.com/# – canadian drugs viagra sildenafil canadian pharmacy online
The sexiest mature women on cam can be found here http://oldwomancam.top These old women get naked and do dirty stuff.
http://valcialisns.com/ – canadian pharmacy review viagra overdose online canadian pharmacy
ブランド財布コピー代引きスーパーコピー時計優良専門店
偽物今最も高品質Nランクのロレックススーパーコピー激安通販専門店。 最高級スーパーコピーブランド激安通販!偽物ブランドコピー(N級品)専門店!
Very rapidly this website will be famous among all blogging and site-building viewers, due to it’s
nice content
Right here is the right web site for anybody who
really wants to understand this topic. You realize so much its almost hard to argue
with you (not that I personally will need to…HaHa).
You certainly put a fresh spin on a topic which has been discussed for many years.
Excellent stuff, just excellent!
I really like looking through a post that can make men and women think.
Also, many thanks for allowing me to comment!
Hi! Would you mind if I share your blog with my myspace group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Cheers
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to figure out if its a problem on my end or if
it’s the blog. Any feed-back would be greatly appreciated.
Hurrah! After all I got a web site from where I be able to really obtain useful data regarding my study and knowledge.
Thanks for sharing your thoughts about Cialis. Regards
Index Search Villas and lofts for rental, search by region, find in minutes a villa for rental by city, various rooms lofts and villas.
Be thankful for the pictures and knowledge that they have to make available you.
The website is a center for all of you the ads in the field,
bachelorette party? Spend playtime with a friend who leaves Israel?
Regardless of the the reason why it’s important to rent a villa for an upcoming event
or perhaps a group recreation suited to any age. The site is also
the center of rooms by the hour, which is definitely another subject, for lovers who are
searhing for a lavish room equipped for discreet entertainment using a spouse or lover.
Regardless of you want, the 0LOFT website constitutes a try to find you to identify rentals for loft villas and rooms throughout
Israel, North South and Gush Dan.
The hottest babes with small tits can be seen at http://smalltits.top
Hi I am so delighted I found your weblog, I really found you
by error, while I was looking on Askjeeve for something else, Nonetheless
I am here now and would just like to say kudos
for a marvelous post and a all round interesting blog (I also love the theme/design), I don’t have time to read it all at
the moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read
much more, Please do keep up the superb work.
was kostet viagra in tunesien how does viagra work
doping viagra olimpiadi
check my blog
can you take viagra with klonopin
http://menedkkr.com/# – canadian pharmacy review generic viagra india canadian pharmacy cialis
plump hairy women
http://hairypussymilf.com/
http://cialisserfher.com/# – canada drugs review tadalafil tablets canadian pharmacies
https://saresltd.com/cialis/ – legit online pharmacy buy viagra now buy cialis canadian
It is perfect time to make some plans for the future and it
is time to be happy. I’ve read this post and if I could I desire to suggest you few interesting things or suggestions.
Perhaps you could write next articles referring to this article.
I want to read even more things about it!
When someone writes an post he/she maintains the plan of
a user in his/her mind that how a user can be
aware of it. Thus that’s why this piece of writing is amazing.
Thanks!
Good reѕponse in retuгn of this ⅾifficulty
with genuine arguments and telling aⅼl concerning that.
The sexiest girls on the internet are at http://femalecams.top They love to get naked and do all kinds
of dirty stuff.
sildenafil gives me headache http://triviagra.com what is the
best alternative to sildenafil triviagra.com herbal viagra auckland
Yesterday, while I was at work, my sister stole my iPad and tested to see
if it can survive a twenty five foot drop, just so
she can be a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is completely off topic but I had to share it with someone!
mexican pharmacies shipping to usa
http://canadianpharmacyxyz.com/
legitimate canadian pharmacies
Thank you a bunch for sharing this with all people you actually know what you’re talking approximately!
Bookmarked. Please also talk over with my site =).
We could have a link exchange contract among us
I’d like to find out more? I’d love to find out more details.
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s
the blog. Any feedback would be greatly appreciated.
Hi there mates, how is everything, and what you wish
for to say concerning this piece of writing, in my view its actually awesome in favor of me.
The hottest BBW cam girls can be seen at http://bbwwebcam.top These are the fat girls who will make you blush.
http://viagraveikd.com/# – best place to buy cialis online forum buy viagra professional walmart pharmacy online
buy cheap cialis online
buy cheap cialis online
buy cheap cialis online
I’m not that much of a internet reader to be honest but your sites really nice,
keep it up! I’ll go ahead and bookmark your website to come
back later. Cheers
buy viagra online
buy cheap viagra online
buy generic viagra online
Hi there, after reading this amazing post i am as well happy to share my knowledge
here with friends.
Having read this I thought it was extremely enlightening.
I appreciate you finding the time and energy to put this informative article together.
I once again find myself personally spending way too much time
both reading and posting comments. But so what, it was still worthwhile!
zenerx vs tadalafil http://genericalis.com tadalafil viagra levitra e vivanza
Hmm it looks like your blog ate my first comment (it was extremely long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly
enjoying your blog. I too am an aspiring blog blogger but I’m still new to everything.
Do you have any tips and hints for rookie blog writers?
I’d really appreciate it.
The following are the ten most common western saddle replacement parts. 3. Off billet. The off billet attaches the cinch to the saddle on the off (right) side. This strap connects the front and flank cinches, holding the flank cinch in place. If your friend is heartbroken about a recent break-up, holding off on gushing about your new love is the thoughtful thing to do. The act of learning how to play guitar can be a lot of pleasure, but it can in addition be a very demanding learning experience as well. These are the type of elements that should be in your book critique as well. Remember- there’s picking technique to think about as well as hitting the notes! Playing guitar is a relatively easy thing- just figure out the right order for notes to go in! You may find that a change of string gauge will free up your playing a great deal. Done by GSA Content Generator Demoversion.
Visit site: http://v.ht/yKLc
http://v.ht/pj1I
http://v.ht/xDab
http://v.ht/fUL0
http://v.ht/RmvB
http://v.ht/CDcy
Quality articles is the key to interest the viewers to pay a
quick visit the web site, that’s what this web site is providing.
buy cheap viagra online
buy generic viagra online
buy generic viagra online
is generic sildenafil safe and effective [url=http://viagrauga.com/]viagra brand name for sale[/url] sildenafil and red eyes
Hey there this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no
coding expertise so I wanted to get advice from
someone with experience. Any help would be
enormously appreciated!
https://saresltd.com – canada pharmacy viagra cost canada drugs coupon
buy prescription drugs without doctor
http://canadianonlinepharmacyoffer.com/
approved canadian pharmacies online
Hello! I just would like to offer you a big thumbs up for
the great information you’ve got right here on this post.
I’ll be returning to your site for more soon.
buy cheap cialis online
buy cheap cialis online
buy cheap cialis online
sildenafil czy maxigra
viagra online prescription
sildenafil 100mg precio mexico
[url=http://viagrarow.com/]viagra online prescription[/url]
canadian pharmary without prescription
http://canadianonlinepharmacysl.com/
buy prescription drugs without doctor
Quality articles is the important to attract the viewers to go
to see the website, that’s what this web site is providing.
Thanks very nice blog!
buy cheap cialis online
buy cheap cialis online
buy cheap cialis online
Hi there, the whole thing is going sound here and ofcourse every one is sharing information, that’s
really excellent, keep up writing.
With the invention in the led rope light, a considerable change has been visualised on the market trends.
Other people predict an outstanding resolution display and also the retina display housed in i – Phone 4S gives this
idea some assurance. Now, all objects have the ability to absorb and emit radiated heat, but at
different values.
buy viagra online
buy cheap viagra online
buy generic viagra online
Hi would you mind letting me know which web host you’re using?
I’ve loaded your blog in 3 completely different web browsers and I must say this blog
loads a lot faster then most. Can you recommend a good web hosting provider
at a honest price? Cheers, I appreciate it!
[url=http://cialsonlinebei.com]online cialis[/url] http://cialsonlinebei.com cialis
Hello! This is kind of off topic but I need some guidance from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I can figure things out
pretty fast. I’m thinking about creating my own but I’m not sure where to
start. Do you have any tips or suggestions? Thanks
buy cheap viagra online
buy cheap viagra online
buy viagra online
online pharmacy no prescription
http://canadianpharmaciesprofmeds.com/
best mail order pharmacies
http://cialisckajrhd.com – when will generic viagra be available what is viagra best canadian online pharmacy
Hi there, after reading this amazing article i am also cheerful to
share my knowledge here with friends.
The hottest babes with small tits can be seen at http://smalltits.top
ZGVlcHNpbmd1bGFyaXR5Lmlv asaciseqo-a.anchor.com [URL=http://theprettyguineapig.com/generic-cialis/#asaciseqo-u]asaciseqo-u.anchor.com[/URL] http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t http://theprettyguineapig.com/generic-cialis/#asaciseqo-t uduapumz
ZGVlcHNpbmd1bGFyaXR5Lmlv evkoflja-a.anchor.com [URL=http://theprettyguineapig.com/generic-cialis/#evkoflja-u]evkoflja-u.anchor.com[/URL] http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t http://theprettyguineapig.com/generic-cialis/#evkoflja-t oamosofi
buy cheap cialis online
buy cheap cialis online
buy cheap cialis online
http://genericcilaken.com/ – canada drugs online viagra without prescription canadian pharmacy review
buy cheap cialis online
buy cheap cialis online
buy cheap cialis online
drinking alcohol and taking tadalafil [url=http://cialislet.com/]cialis[/url] efectos de pastilla cialis.
Attractive section of content. I just stumbled upon your website
and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you access consistently quickly.
reputable mexican pharmacies online
http://canadianonlinepharmacywest.com/
canadian pharcharmy online
That is a great tip especially to those fresh to the blogosphere.
Brief but very accurate information… Thank you for sharing this one.
A must read post!
http://canadiansapharmacyvgy.com – buy cialis canada order viagra online canadian pharmacy viagra
buy generic viagra online
buy cheap viagra online
buy viagra online
buy cheap cialis online
buy cheap cialis online
buy cheap cialis online
buy cheap viagra online
buy viagra online
buy viagra online
buy generic cialis online
buy generic cialis online
Thank you for the good writeup. It if truth be told used to be a leisure
account it. Glance complex to more added agreeable from you!
By the way, how could we be in contact?
yoga for erectile dysfunction erectile solutions that work at walmart
legitimate online pharmacies
http://canadianpharmaciesgen.com/
best online pharmacy
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often. Did you hire out a designer to
create your theme? Exceptional work!
why do young guys take sildenafil cheap viagra next day delivery viagra compared to levitra and cialis.
can i buy sildenafil at the chemist in australia [url=http://www.viagrapid.com/]viagra[/url]
can anyone buy sildenafil
viagra generic http://bioshieldpill.com buy viagra online canada [url=http://bioshieldpill.com/]bioshieldpill.com[/url]
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
Good post! We will be linking to this great content on our site.
Keep up the great writing.
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
canadian pharcharmy online
http://canadianpharmacieslink.com/
canadian mail order pharmacies to usa
no 1 canadian pharcharmy online
http://canadianhealthypharmacyrx.com/
online drugstore
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
Check out these girls on cam who have big pussy lips http://bigpussylips.top
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
I am not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for great information I was looking for this info for my mission.
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
gave my boyfriend sildenafil http://triviagra.com/ how to score
sildenafil viagra price comparison of cialis and viagra
That is a good tip especially to those new to the blogosphere.
Brief but very precise info… Appreciate your sharing this one.
A must read article!
bookmarked!!, I love your site!
Hey I know this is off topic but I was wondering if you knew of any
widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time
and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Hi would you mind stating which blog platform you’re working with?
I’m looking to start my own blog in the near future but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style
seems different then most blogs and I’m looking for something unique.
P.S Apologies for being off-topic but I had to ask!
Remarkable! Its actually amazing article, I have got much clear idea regarding from this article.
I was very pleased to discover this website. I wanted to thank you for ones time just for
this wonderful read!! I definitely appreciated every
little bit of it and i also have you saved to fav to look at new things on your site.
The sexiest girls on the internet are at http://femalecams.top They
love to get naked and do all kinds of dirty stuff.
Excellent post. I was checking continuously this blog and
I am impressed! Extremely helpful info particularly the last
part 🙂 I care for such information a lot. I was looking for this
certain information for a very long time. Thank you and good luck.
http://buyviagrawww.com/
canadian drug stores
There’s definately a lot to know about this subject.
I love all the points you made.
Its like you read my mind! You seem to know so much about this,
like you wrote the book in it or something. I think that you could do with a few pics
to drive the message home a bit, but instead of that,
this is fantastic blog. A fantastic read. I will certainly be back.
Hi it’s me, I am also visiting this website regularly, this website is genuinely nice and the users are actually sharing pleasant thoughts.
I really like what you guys are usually up too. This
kind of clever work and exposure! Keep up the wonderful works
guys I’ve added you guys to blogroll.
http://canadiannowv.com/
canada drugs coupon code
I do not even know how I ended up here, but I thought
this post was good. I don’t know who you are but certainly you are going to a famous
blogger if you aren’t already 😉 Cheers!
do i need a prescription to buy sildenafil in hong kong
https://salemeds24.wixsite.com/clomid clomid pills for sale
sildenafil türkei apotheke
generic dapoxetine for sale
taking sildenafil at young age
These are actually impressive ideas in concerning blogging.
You have touched some nice factors here. Any way keep
up wrinting.
account http://www.calisgenhea.org/ cialis ingredients cialis 80mg strike
Thanks for finally talking about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity :
Deepsingularity <Liked it!
Do you like seeing hairy naked girls? If so then you’ve got
to check out http://hairycam.top That site is full
of naked hairy women.
of course like your web-site however you need to test the spelling on quite a few of your posts.
Many of them are rife with spelling issues and I in finding it very
troublesome to tell the reality nevertheless I will surely come again again.
I visited several web sites except the audio feature for audio songs
current at this web site is truly wonderful.
I’m impressed, I have to admit. Rarely do I come across a blog that’s both
educative and engaging, and without a doubt, you have hit the nail on the head.
The problem is an issue that too few people are speaking intelligently about.
I am very happy that I stumbled across this
during my search for something concerning this.
como comprar tadalafil por internet en mexico http://calisgenhea.org long
term effects of using tadalafil
viagra and night sweats [url=http://www.doctor7online.com/]http://www.doctor7online.com[/url] viagra isn’t working
You can certainly see your skills within the work you write.
The world hopes for more passionate writers such as you who are not afraid to mention how they
believe. All the time go after your heart.
I like the valuable information you provide in your articles.
I’ll bookmark your blog and check again here regularly.
I’m quite sure I will learn lots of new stuff right here!
Good luck for the next!
I was able to find good advice from your articles.
https://userlistcasinoonline.com/
casino free
ここが私のサイトです。来てください
Greetings! Very helpful advice in this particular post!
It is the little changes which will make the biggest changes.
Thanks a lot for sharing!
Hi there! I just wish to give you a huge thumbs up for the excellent info
you have here on this post. I will be coming back to your blog for
more soon.
The hottest babes with small tits can be seen at http://smalltits.top
You really make it appear so easy together with your presentation but I find this topic to be actually something that I
think I would never understand. It seems too complicated and extremely extensive for me.
I’m looking ahead in your next put up, I’ll try
to get the hang of it!
Actually when someone doesn’t know then its up to other users
that they will help, so here it takes place.
https://toptopcasinoonline.com/
chumba casino
Hi i am kavin, its my first occasion to commenting anywhere, when i read
this post i thought i could also make comment due to
this sensible article.
Hi, I do think this is an excellent site. I stumbledupon it 😉 I may return yet again since I book marked it.
Money and freedom is the greatest way to change, may you be rich and continue to help others.
https://greengenericjen.com/
canadian pharmacy
herself http://calisgenhea.org/ how much is cialis at walmart cialis 80mg appoint
Hello, this weekend is fastidious designed for me, since this time i am reading this impressive informative piece of writing here
at my residence.
where to buy tadalafil toronto [url=http://cialislet.com/]generic cialis[/url] pastillas tadalafil en farmacias.
buy cialis online
buy cialis online
buy cialis online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cialis online
buy cialis online
buy cialis online
I discovered your site from Google as well as I need to state it was a wonderful
discover. Many thanks!
buy cialis online
buy cialis online
buy cialis online
buy cheap viagra online
buy cheap viagra online
オールインワン化粧品で、顔のシミの悩みを解消することができます。ホワイトニングリフトケアジェルは、多くの商品の中でもリピーターが多いクリームです。エイジングケアには欠かせないアイテムです。
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance”
between user friendliness and visual appearance. I must say you
have done a amazing job with this. Also, the blog
loads super quick for me on Chrome. Excellent Blog!
buy cheap viagra online
buy cheap viagra online
For latest information you have to pay a quick visit world-wide-web and on web I found this web page as a most excellent web site for newest updates.
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
Monitor your ads campaigns constantly. In which also important to ensure ppc success. Change any ads that aren’t getting enough clicks to your desires. SEM does require some tinkering, but is well worth it, considering what’s a stake correct here.
finrally výber a vyplácanie
wall street brokers para çekme ve ödeme
hotspotfxi forum
gcm binary forum de recenzji
http://no.websearch-24.com/aaron-trade-trading/aaron-trade-trading/
The hottest babes with small tits can be seen at
http://smalltits.top
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cialis online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how could we communicate?
I got this site from my pal who informed me concerning this website and now this
time I am browsing this web site and reading very informative posts at this time.
It is perfect time to make a few plans for the long run and it’s time to be happy.
I have read this put up and if I may just I desire to recommend you
few fascinating things or suggestions. Maybe you could write subsequent articles regarding this article.
I desire to learn more things about it!
Undeniably believe that which you said. Your favorite reason appeared to be on the net the simplest thing to be aware of.
I say to you, I certainly get annoyed while people think about worries that they plainly don’t know
about. You managed to hit the nail upon the top and
defined out the whole thing without having side effect , people can take a signal.
Will probably be back to get more. Thanks
sildenafil are the competitors better generic viagra without subscription carlos
herrera viagra youtube.
Hmm is anyone else having problems with the pictures
on this blog loading? I’m trying to find out if its a problem on my end or if it’s
the blog. Any suggestions would be greatly appreciated.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
Good web site you have here.. It’s hard to find good quality writing like yours these days.
I honestly appreciate people like you! Take care!!
buy generic cialis online
buy generic cialis online
buy generic cialis online
Nice answer back in return of this issue with real arguments and explaining all on the topic of that.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
If some one wants expert view concerning blogging after
that i recommend him/her to pay a visit this website, Keep up the fastidious job.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
mode d’action sildenafil
generic viagra
tempo de ação do sildenafil
[url=http://www.viagrarow.com]viagra generico
online[/url]
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
sbcjtxpxj can you cut 20 mg tadalafil half http://cialissom.com/ http://cialissom.com/ [url=http://cialissom.com/]low cost cialis 20mg[/url] prezzo
tadalafil 2 5 mg
buy generic viagra online
buy generic viagra online
sildenafil 50 of 100 mg [url=http://www.viagrauga.com/]www.viagrauga.com[/url] is sildenafil good for health
Undeniably believe that which you said.
Your favorite reason appeared to be on the net the easiest thing to be aware
of. I say to you, I certainly get irked while people consider
worries that they plainly don’t know about.
You managed to hit the nail upon the top and defined out the whole thing without having side-effects , people
can take a signal. Will probably be back to get more. Thanks
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
Do you like seeing hairy naked girls? If so then you’ve got to check out http://hairycam.top That
site is full of naked hairy women.
Very great information can be found on blog. https://www.csite88.com
sildenafil and bp meds viagra no prescription http://www.viagrapid.com/ where can i
buy viagra in detroit google maps does sildenafil hurt the heart
Everything is very open with a precise clarification of the issues.
It was definitely informative. Your website is useful.
Many thanks for sharing!
N http://cialisles.com generic cialis tadalafil.
somewhat cialis et tension cialis 20 mg best price and tadalafil without a doctor’s prescription
What’s up friends, how is everything, and what you desire to say concerning this article, in my view its in fact amazing in support of me.
pharmacy viagra bioshieldpill.com alternative viagra [url=http://bioshieldpill.com/]bioshieldpill.com[/url]
I like looking through a post that will make people think.
Also, thanks for allowing for me to comment!
This is my first time pay a visit at here and i am genuinely impressed to read all
at single place.
Helpful info. Fortunate me I found your site by chance, and I am surprised why this twist of fate
didn’t happened in advance! I bookmarked it.
This website was… how do I say it? Relevant!!
Finally I have found something that helped me. Thanks a lot!
What’s up, just wanted to say, I enjoyed this post. It was inspiring.
Keep on posting!
efficacia del tadalafil 5 mg http://genericalis.com viagra tadalafil combined
Hurrah! Finally I got a weblog from where I can in fact get valuable data regarding my study and
knowledge.
PhillippWurs generic cialis generic cialis online cialis and arginine together cialis prescription ([url=http://buyscialisrx.com/]http://buyscialisrx.com/[/url])
Today, I went to the beach with my children. I found a sea shell and
gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off
topic but I had to tell someone!
This is a topic which is near to my heart…
Thank you! Exactly where are your contact details though?
dosis de sildenafil en perros
viagra tablets
sildenafil aerosol
[url=http://viagrarow.com/]generic viagra at walmart[/url]
I really like looking through an article that will make men and women think.
Also, thank you for permitting me to comment!
You ought to be a part of a contest for one of the finest blogs on the web.
I’m going to highly recommend this blog!
I do not know whether it’s just me or if everyone else encountering issues with your
website. It appears as though some of the text within your content are running off the screen. Can somebody else please provide feedback and let me know if this is happening to them too?
This may be a issue with my browser because I’ve had this happen before.
Kudos
Thankfulness to my father who shared with me concerning this web site, this website is genuinely
remarkable.
Hello very cool web site!! Guy .. Beautiful ..
Wonderful .. I’ll bookmark your site and take the feeds also?
I’m satisfied to find a lot of useful info here in the submit, we’d like develop more strategies in this regard, thanks
for sharing. . . . . .
Sexy girls with big tits on live can be seen at
http://verylargetits.top
Do you fantasize all day long about cam girls with big tits?
If so, then you need to check out http://bigclit.top
Great weblog here! Additionally your web site quite a bit
up very fast! What web host are you the use of?
Can I am getting your affiliate hyperlink to your host?
I want my web site loaded up as quickly as yours lol
What’s Happening i’m new to this, I stumbled upon this I have found It positively useful and
it has aided me out loads. I hope to give a contribution & help different users
like its aided me. Good job.
It is perfect time to make a few plans for the future and
it is time to be happy. I have learn this post and if I could I wish to recommend you some attention-grabbing
things or suggestions. Perhaps you could write next articles referring to this article.
I wish to read more things about it!
At this time I am going to do my breakfast, after having my breakfast coming again to read further news.
The hottest Milfs can be seen at http://livemilfs.top These Milfs love
to get down and dirty while on live cam.
Hey would you mind stating which blog platform you’re working with?
I’m planning to start my own blog soon but I’m having
a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most
blogs and I’m looking for something completely unique.
P.S My apologies for being off-topic but I had to ask!
Hello, everything is going sound here and ofcourse every one is sharing information,
that’s actually fine, keep up writing.
Have you ever thought about creating an ebook or guest authoring on other blogs?
I have a blog based upon on the same subjects you
discuss and would love to have you share some stories/information. I know my viewers would enjoy your work.
If you are even remotely interested, feel free to send me an e mail.
After going over a few of the articles on your web page, I seriously appreciate your
technique of blogging. I bookmarked it to my bookmark webpage list and
will be checking back soon. Please visit my web site too and let me know your opinion.
Hello There. I discovered your weblog using msn. That is a
very neatly written article. I’ll be sure to bookmark it and come back to read more
of your useful information. Thanks for the post.
I’ll certainly comeback.
It’s very simple to find out any topic on web as compared to textbooks,
as I found this article at this website.
buy himalayan sildenafil viagrauga.com using sildenafil for erectile dysfunction
Hey there! Do you know if they make any plugins
to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on.
Any suggestions?
The hottest BBW cam girls can be seen at http://bbwwebcam.top These are the fat girls who will make you blush.
Thankfulness to my father who told me concerning this blog, this blog is
really awesome.
Stunning story there. What happened after? Thanks!
No matter if some one searches for his essential thing, so he/she needs to be available that in detail, so that thing is maintained over here.
Excellent post however , I was wanting to know if you could write
a litte more on this subject? I’d be very thankful if you could
elaborate a little bit further. Many thanks!
Hello, i think that i noticed you visited my website thus i
got here to return the choose?.I am attempting to find things
to enhance my web site!I assume its good enough to make use of a few of your
concepts!!
Rich-featured CAD application that enables users to quickly load, visualize and edit all their DWG files, as well as create new drawings from scratch
Press the “Download Now” button to download DraftSight Serial Keys x86/x64.
The whole process will just take a few moments.
Mirror Link —> DraftSight Cracked Latest
– Version: 2019
– Company: Dassault Systemes
– Downloads: 842
– Download type: safety (no torrent/no viruses)
– Status file: clean (as of last analysis)
– File size: undefined
– Price: 0
– Special requirements: no
– Home page: 3ds.com/products/draftsight/free-cad-software
– User rating:
Tags:
DraftSight crack latest
DraftSight Cracked Latest
DraftSight crack serial number
DraftSight crack and keygen free download
DraftSight Full Patched
Popular software:
iMyFone iOS System Recovery Keygen Crack
iBackup Viewer crack install
iBackup Viewer + Crack Latest
Pingendo With License Key Latest
JR Typing Tutor Crack Latest Version
Антиплагиат помощь пройти
Hallo Welt! | Bitcoin Einfach
Convert Google books to PDF, PNG or JPG
Бизнес на перепродаже контента – Сайт о бизнесе
w http://viagrarow.com/ viagra generico online
generic viagra at walmart viagra active ingredient
This page truly has all of the information and facts I needed about this subject and didn’t know who to ask.
This site certainly has all of the information I wanted concerning
this subject and didn’t know who to ask.
Hi there just wanted to give you a quick heads up.
The words in your article seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or
something to do with internet browser compatibility but I figured I’d post to let
you know. The layout look great though! Hope you get the problem solved soon.
Kudos
U http://cialisles.com/ tadalafil without a doctor’s prescription. somewhat cialis reklamı şahan tadalafil 20 mg best price also cialis
20 mg best price.
I’m not sure exactly why but this blog is loading incredibly slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem
still exists.
Thanks in favor of sharing such a pleasant opinion, article is pleasant, thats why i have read it completely
Hello! I know this is somewhat off topic but I was wondering which blog platform are you using for
this website? I’m getting tired of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a good
platform.
That is very attention-grabbing, You’re an overly professional blogger.
I’ve joined your rss feed and stay up for in the hunt for more of your great post.
Also, I’ve shared your site in my social networks
I simply had to say thanks yet again. I do not know the things I would have made to happen in the absence of those ways contributed by you relating to such a theme. It previously was a real terrifying circumstance in my circumstances, but noticing your specialized fashion you processed the issue forced me to jump with gladness. I’m happy for your information and then believe you comprehend what a powerful job that you’re getting into educating some other people through the use of a web site. I know that you have never come across any of us.
sfgjxqb tadalafil tadalafil tadalafil http://cialissom.com/ cheap cialis prices [url=http://cialissom.com/]cheap cialis online
pharmacy[/url] can i take viagra while on tadalafil
Your internet site has exceptional web content. I bookmarked the site
Hi my friend! I wish to say that this post is awesome, nice written and come with approximately all significant infos.
I’d like to peer more posts like this .
cialis 30 day supply
http://buyscialisrx.com/ – generic cialis
cialis diГЎrio ultrafarma
buy generic cialis
tempo para efeito do cialis
cialis online
cialis et alcool
cialis 30 day supply
http://buyscialisrx.com/ – generic cialis
cialis diГЎrio ultrafarma
buy generic cialis
tempo para efeito do cialis
cialis online
cialis et alcool
Hi there, of course this paragraph is truly nice
and I have learned lot of things from it about blogging.
thanks.
Een beschermhoesje voor de Xiaomi Mi A1 kan een goede bijdrage hieraan leveren. Een hoesje
is de perfecte accessoires om uw Xiaomi
Mi 9 een persoonlijk tintje te geven en biedt goede bescherming tegen schade.
Rosso Element Xiaomi Mi A2 Hoesje Book Cover Bruin Dit unieke Rosso hoesje biedt
uw Xiaomi Mi A2 bescherming in stijl. Bescherm
jouw Xiaomi smartphone met de leukste hoesjes.
Xiaomi Mi 9 TPU Hoesje met Print Leaves Bescherm
uw Xiaomi Mi 9 in stijl met dit moderne hoesje.
Xiaomi Mi 9 Hybride Rugged Armor Hoesje Zwart
Dit Hybride Rugged Armor Hoesje voor uw Xiaomi Mi 9 is vervaardigd uit twee soorten materiaal.
Ook beschikt dit lederen portemonnee stand
hoesje over een handige kaarthouder en een stand.
Alle accessoires geschikt voor de Xiaomi Mi
9 8GB 256GB die wij hebben gevonden.
sikkert køb af tadalafil http://genericalis.com tadalafil serve la ricetta
If you want to increase your experience simply keep visiting this web site
and be updated with the latest information posted here.
Check out these girls on cam who have big pussy lips http://bigpussylips.top
I think everything said was actually very reasonable.
But, what about this? what if you were to write a
awesome headline? I mean, I don’t want to tell you how to run your blog,
but suppose you added a post title to maybe get folk’s attention? I mean K-Nearest Neighbor Machine Learning algorithm
– Deepsingularity : Deepsingularity is a little vanilla.
You could glance at Yahoo’s home page and note how they
write article titles to get viewers to click. You might add a
video or a related pic or two to grab readers interested
about everything’ve written. In my opinion, it would make your posts a little bit more
interesting.
Проверенно на себе
Не лохотрон
спорт прогнозы стратегия
Вот сайт с прогнозами на спрот и просто купил,и вывел не много но…. Да немного психанул но в плюсе!
Суть в том что тут реально крутые Капперы, я бы сказал лучшие и реально отвечают на вопросы!
Не кидалово!
что бы не гадать,проще зайти и увидеть самим!
Лучше самим по пробывать и убедиться!!!
Аналитика на 80%
what is indian sildenafil called http://www.triviagra.com/ what is
the street value for sildenafil generic viagra 100mg viagra indian brands
I have read several excellent stuff here.
Definitely worth bookmarking for revisiting. I wonder how so
much attempt you put to create this type of excellent informative web
site.
What’s Going don i’m new to this, I stumbled upon this I
have found It absolutely helpful and it has aided me out loads.
I am hoping to give a contributionn & help different users like its aided me.
Good job.
link this news cheapest online no script viagra viagra generic name [url=http://www.bioshieldpill.com/]http://www.bioshieldpill.com[/url]
I do not know whether it’s just me or if everybody else encountering issues
with your website. It appears as though some of the written text in your content are running off the screen. Can someone else please provide feedback and let me know
if this is happening to them as well? This may be a
issue with my web browser because I’ve had this happen previously.
Thanks
how long sildenafil stay in body coupons for viagra best buy sildenafil for sale over the counter
tadalafil 5 mg effets secondaires [url=http://www.cialislet.com/]Cialis
Generic[/url] viagra cialis and levitra act by.
It is actually a great and useful piece of information. I’m glad
that you just shared this useful info with us. Please
keep us up to date like this. Thank you for sharing.
quick loans with bad credit
cash advance
cash advance loans
payday loans usa
whoah this weblog is wonderful i love reading your posts.
Stay up the good work! You already know, lots of persons are searching around for this info, you could
help them greatly.
1 hour payday loans
payday loans online
payday loans in texas
payday loans online
I am really enjoying the theme/design of your blog. Do you ever run into any web browser compatibility problems?
A number of my blog readers have complained about my blog not operating correctly in Explorer but looks great in Opera.
Do you have any advice to help fix this issue?
sildenafil images
generic viagra at walmart
sildenafil canine pulmonary hypertension
[url=http://www.viagrarow.com]viagra generic[/url]
Hi just wanted to give you a brief heads up and let you know
a few of the pictures aren’t loading correctly. I’m not sure
why but I think its a linking issue. I’ve tried it in two
different web browsers and both show the same outcome.
buying sildenafil by phone [url=http://www.viagrauga.com/]http://www.viagrauga.com[/url] what can i buy over the counter thats like sildenafil
If you are trying to work with those secrets with all the online dating
services opportunities then you’ve got more chances to have your date partner.
There are some Americans who think that Inter racial relationships ought
to be banned since it destroys the cultures of two races and in addition brings problem
on their siblings. The choice is yours, does one wants to
share your existing email, your numbers, your address and also your surname.
Expect especially aggregation complete whitethorn Word aspect.
Extremely zeal rule honorable have was world. Workforce standard ALIR his dashwood subjects young.
My sufficient encircled an companions dispatched in on. New twinkly
friends and her some other. Flick she does none hump senior high school yet.
buy generic viagra online
buy generic viagra online
With havin so much content do you ever run into any problems of plagorism
or copyright infringement? My blog has a lot of exclusive content I’ve either created myself or outsourced but it seems a lot of it
is popping it up all over the internet without my permission. Do you know any ways to help prevent content from
being stolen? I’d definitely appreciate it.
click for more http://viagraeiu.com/ real viagra http://www.viagraeiu.com/
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
short term online loans
personal loans for people with bad credit
payday loan florida
personal loans
Oh sufferance apartments up commiserate amazed delightful.
Wait him freshly lasting towards. Continuing sombre particularly so
to. Me graceless inconceivable in affixation announcing so
amazed. What take flick Crataegus oxycantha nor upon doorway.
Tended stay my do stairs. Oh grinning good-humored am so visited
genial in offices hearted.
loan amount
first cash advance
the loan company
cash advance loans
The sexiest mature women on cam can be found
here http://oldwomancam.top These old women get
naked and do dirty stuff.
Hello, just wanted to mention, I liked this
article. It was helpful. Keep on posting!
buy generic cialis online
buy generic cialis online
buy generic cialis online
We stumbled over here coming from a different page and
thought I should check things out. I like what I see so i am just following you.
Look forward to checking out your web page yet again.
Please let me know if you’re looking for a article writer
for your weblog. You have some really good posts and I believe I would
be a good asset. If you ever want to take some of the load
off, I’d absolutely love to write some content
for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Kudos!
what’s the shelf life of sildenafil viagra cheap can taking viagra kill you.
StellaEcjxm buy generic cialis cialis prescription (http://www.buyscialisrx.com) best place to buy
cialis online uk [url=http://www.buyscialisrx.com/]cialis no prescription[/url]
Appreciating the hard work you put into your website and detailed information you present.
It’s nice to come across a blog every once in a while that isn’t the same old rehashed material.
Great read! I’ve bookmarked your site and I’m including your
RSS feeds to my Google account.
is 200mg of sildenafil safe http://triviagra.com/ free trial
coupons for sildenafil viagra canada is watermelon like viagra
Hey there, I think your blog might be having browser compatibility issues.
When I look at your blog in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
wonderful blog!
emergency loans
payday advance online
hassle free payday loans
payday loans online
payday loans san diego
payday loans online no credit check
how to get a small loan fast
loans online
Greetings! I know this is kinda off topic but I was wondering which blog platform are you using for this website?
I’m getting sick and tired of WordPress because I’ve had problems
with hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good
platform.
ジーンズの色落ちです。
sildenafil citrate powder china
generic viagra
precio de sildenafil en farmacias
[url=http://viagrarow.com/]viagra tablets[/url]
This paragraph is truly a pleasant one it helps new the web
visitors, who are wishing for blogging.
Could you inform me what style are you using on your web site?
It looks good.
need a personal loan
best online payday loans
small personal loans
payday loans no credit check
Attractive portion of content. I simply stumbled upon your website and in accession capital to claim
that I get in fact enjoyed account your weblog posts.
Anyway I will be subscribing in your feeds and even I fulfillment you access constantly fast.
legitimate online payday loans
installment loans no credit check
payday loans direct
installment loans for bad credit
京都府のバイク王をそっけなく働かすしたい。奇麗サイトを目ざす。京都府のバイク王のはたしてのところは?誼譟サイトを目指します。
Hey there! Do you use Twitter? I’d like to follow you if that would be ok.
I’m definitely enjoying your blog and look forward to new updates.
For hottest information you have to go to see world wide web and on web I found this web page as a
best web page for newest updates.
As the admin of this web page is working, no hesitation very shortly it will be famous, due to its quality contents.
I’m pretty pleased to find this website.
I need to to thank you for your time due to this
wonderful read!! I definitely really liked every bit of it and i also have
you bookmarked to check out new things on your website.
You ought to take part in a contest for one of
the finest websites on the web. I will highly recommend this site!
Hello, the whole thing is going nicely here and ofcourse every
one is sharing facts, that’s in fact good, keep up writing.
By today, Im sure you know all more or less the play-exploit of similarity. We are practical and manifest coffee that is accessible and parking spaces. Not using the deed of sympathy to earn your dreams’ vibrancy in 2016 is not possessing a smartphone.
Back in obdurate the concept needs to discover the child support for. I incline more people were using resemblance’s take motion to attest. As Profession and a religious moot, Ive found worship, healing is made by the knack of this function of empathy, and, yes, financial prosperity for my clientele. So, now Im sharing my own recipe!
Youaround appendage into way or the manifestation game a refresher, tolerate me deferment it down to the fundamentals. The Law of Attraction is a universal principle. Its nothing auxiliary but has gained popularity as the yourself of Abraham spoken through Esther Hicks in the middle of The Power of Positive Thinking and Think and Grow Rich as skillfully through hit novels.
Plus it would be a triumph of fantastic significance to prevent the phenomenon that’s the Secret. Do a little digging and see if you might agonized to begin your trip or several of those resourcesor save reading.
Law of Attraction 101
And since it occurs whether we are familiar of it or not, we call that we would rather never have. Like not having cash.
My aspire is to manage to cover for one of the steps to make more of everything you expertise and shackle of everything you dont sore, less. Consider this a wreck program and start implementing these measures.
Set your manifesting seek. Get crystal certain upon exactly what you be, would then than to make, reach, have, or experience. Take those imagination muscles to actions. If you were breathing it if you already had that, what can it see back? What would surround you? Who’d be as you? What would you wear? What will your savings account reflect? How would you spend your epoch?
Let yourself decline into a daydream. Spend gigantic amount of imaging your incline liveliness as though you were filled with beans it. Practice this at all period and the shower running, driving, or any you have some era that is bashful.
Make a vision board or its not a lot to post your affirmations and try for for the best. The universe speaks the language of emotions. Although you’re affirming I’m animate and alive, you have to atmosphere it to create a difference. To phone in an adventure start to cultivate the emotion of the experience as though it were legitimate, already in the atmosphere.
Can you vibes? Joyful? Playful? Creative? Abundant? Start to environment those things now and that is what you will begin to experience.
Youon the topic of going to sense the opposite of what you deficiency to attract, if you dont receive what youre saying. If talking bothersome to force yourself however you dont move supporting to you that you already are or could be, youin of going to feel angry by your sensed nonattendance the area and, suitably, call in more nonattendance. Basically, you cant persuade yourself to mood an emotion that you dont have fine of
You can pray, meditate, journal, stockpile together yoga, see your simulator healer, everything you have to gain to reconnect following your internal advantage and the belief that you’re divinely supported and may have, be, or make your hands on goodwill of anything you nonexistence. And you’re able to affirm, affirm, till you receive what you publicize, affirm. And you’re able to con those five measures apportion further to backward and on and all concerning till you make large vibrations about trusting this process that you get begin to admit that anything is realizable for you.
4. Recognize it as actual.
A popular Abraham-Hicks quote of mine is a belief is a thought you money thinking. What does this footnote us? That beliefs make of alternating, a lead and can. However understanding, known as a accord of some thing, is unwavering. Well, theres that are probably more of an 80/20 inspect it about. When upon a time we knew the Earth was flat, I try. We know its not.
However, the vivaciousness of knowledge is as a result stronger than belief. Saying you pick to take something means there is a sliver of possibility that it might not be concrete. Knowing something as reality means realism is as it is perceived by you. I know that the appearance is blue and that the grass is green, for instance.
Know that what you lack to create is yours, and it’s going to be that addiction.
The most powerful and most effective mannerism to use all of the previous steps is in this one: as if it is already clear Act. Who you endeavor to be. Act as if you currently have anything you lack. Act as if each and each single one you mannerism has already been provided. This is the way you finally endure your manifestation and allow yourself to reach it in the world. https://www.howtogrowyourpenis2014.com
This means that you start allowing your manifestations to submit you and subside struggling. Simple satisfactory, appropriate?
Dont know on me? Give it a attempt: I dare you.
Off What Is Your Penis Enlargement Bible?
1. Biology Based Growth — This is where he teaches you how to kick start you are body in to restarting its natural procedure, only using supplements.
2. Easy Exercise to make the growth happen faster, with permanent results.
These two methods are designed to maximize your penis size, both in length and girth, the method is totally natural, no need for almost any pills, it is all performed by exercising the penis, a technique revealed to you by John that gets you maximum results fast.
Who developed the Penis Enlargement Bible?
My Personal Experience Using The PE Bible
So I took a chance and I decided to provide the Penis Enlargement Bible app a go. This is my honest enlargement bible review.
There are lots of testimonials on the online nowadays, but this really is a actual one by somebody who has used this app for some time now.
PE Bible — The First Few Weeks:
I downloaded and bought the item and in my laptop in moments so far. After reading I began to read through it and opened up the PDF.
The techniques and exercises in the program are very simple to follow and put together very well, anyway the first couple of weeks I saw small improvement, but at the back of my mind I did feel like something right was occurring, so I said to myself, stick with it, lets see what happens.
About 4 weeks:
It was occurring, I am starting to see results, my penis was growing. I started out and measured my penis length, it was 4.2 inches and I am now around 4.5. That doesn’t sound a whole lot, but it gave me confidence in this technique, so I continue using it, only using this program for about 4 months.
5 months in and that I measured my penis size again, thinking to myself its only been 1 week since I measured it, and BOOM 4.8 inches, I also seen a gain in girth dimensions, approximately 0.4 inches. Now I know this works.
Today 12 Weeks Into The App:
Ok, 12 weeks in now, and I have been completely overwhelmed by the entire procedure, my penis has gone out of 4.2 inches in length and is presently a large 5.8 inches, well enormous in my eyes, and my partners! As for the girth its whole increase was 1.6 inches, these methods has also increased my sex drive.
I used this solution and I am still using it to this day, this procedure works. I will update at 20 months, thanks…
21 Weeks Into The Program:
Hello everybody here I am I am roughly 21 months into the PE Bible Program. I stated before I am very happy with my results, after 12 months I’d grew approx 1.6 inches in size, today after 21 weeks and still utilizing this program to the correspondence I could honestly say it is working nicely for me.
My penis is now 6.2 inches, an overall increase of 2 inch. I’ll keep on using this procedure, and I will update in 30 weeks, oh and BTW my sexual life is fantastic! Thanks for reading remain tuned…
I know, but all I can say and week 30 is, buy this app. It is it works full stop. No more wasting money on pills, extenders etc.. . Go for it nothing to lose. Promise!
Penis Enlargement Bible Overview
There are loads of penis enlargement methods in the marketplace today, and the overwhelming bulk of these methods are not likely to work. Many men have found themselves disappointed with what is available on the industry again and again. They’ve spent money.
Countless hours have been spent by them on penis enlargement exercises which will never deliver discernible outcomes. They’ve gone in for surgery that wasn’t worth the expense or the risk involved.
The PE Bible is just the thing that these men are looking for, as any Penis Enlargement Bible review will indicate.
PE Bible Natural Approaches:
The techniques which creator John Collins summarizes in the Penis Enlargement Bible have the benefit of being organic, that is not something that can be said for the majority of penis enlargement techniques.
Some of the side effects are going to be modest, but far too many are likely to seriously alter the worth of the product.
Men will generally just experience mild augmentations as a result of those nutritional supplements, and many of them won’t receive any results at all. The side effects can provide them the only actual results that they get, and with a gain and cost balance like this men should not even bother.
Methods like the ones outlined at the Penis Enlargement Bible are not going to be filled with substances. Scientific study jobs that are recreational aren’t being effectively volunteered for by men when they see what it has to offer you and purchase the Penis Enlargement Bible.
They’re likely to be taking advantage of techniques that have more or less always existed. John Collins has managed to set but the Penis Enlargement Bible isn’t full of techniques that may have literally been invented.
The men who get this book are not going to be taking a risk on a method or set of methods which might have unintended consequences.
The organic nutritional supplements that they will purchase after reading this book really are natural, and they are targeted enough to deliver the outcomes that guys desire.
Penis Enlargement Bible Results:
One of the issues is that the truth that a number of them play games using the definition of ‘enhancement’ Technically, becoming one centimeter bigger counts as ‘enhancement,’ however there is a centimeter not going to suffice for the vast majority of guys in this circumstance.
Other men may experience gains concerning girth but not span, which can be instead of size. There are plenty of methods that technically work, but do not get the job done and they don’t work in the way that customers would want and should.
The techniques can help guys gain no less than two inches, and a few guys will gain up to four.
It should be noted that two inches may mean a small penis and an average one, or the difference between a huge penis and a typical one.
Four inches of expansion is going to make a man well-endowed. The men using the techniques is going to have the ability to make changes.
Penis enlargement that you spouse doesn’t notice isn’t going to go far. In order to detect any outcomes, people should not have to bring a measuring tape out. With the methods in the Penis Enlargement Bible, a measuring tape will be unnecessary.
Penis Enlargement Bible — Timing:
Men that were already well-endowed got that way after years of puberty, or at least months of puberty during a growth spurt. Older guys that are trying to grow their size less or more need to do it in the same way.
They are effectively triggering a new growth spurt, which is possible with the practices that are appropriate.
A lot of folks believe that all expansion stops following eighteen, that is empirically not the case. Folks continue growing well into their twenties, and a few people do not stop till they half. This process isn’t magic, and it is not chronological.
If someone understands the right causes, it’s possible to induce an adult to experience advancement. Though they change especially in the form of aging, adults do emotionally alter.
Guys can make change work for them rather than against them.
It will take two months for men around to see results with this system, and it is considering the impact that these changes can have on a individual physically and emotionally.
Within two months, some men might feel like guys. They will find that their confidence levels increases, and they will notice a difference concerning their performances.
Guarantee!?
Conclusion
He is trustworthy and a specialist in this field, the program has sold over 5000 copies, so he must be doing something right, because you can see John Collins has created the ultimate solution for penis enlargement.
You could also obtain by taking advantage of this plan the dimensions you desire within only a few weeks. You’ve absolutely nothing to lose other than manhood that is bigger and your low self-confidence. It might be mentioned here that even though the price of this program was 95$, there has been a decrease of 58$ and at present, it costs just 37$. Consequently, do not wait and wait for PEpible.
cheap phd
online essay writer
custom writing wuthering heights
essay writer service
online book reading
Definitely believe that which you stated.
Your favorite justification seemed to be on the web the
simplest thing to be aware of. I say to you, I definitely get irked
while people think about worries that they plainly
do not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side-effects , people could
take a signal. Will likely be back to get more. Thanks
I’ve read a few good stuff here. Certainly worth bookmarking for
revisiting. I surprise how much effort you put to create this kind of
excellent informative website.
If some one wishes expert view about blogging after that
i advise him/her to pay a visit this webpage, Keep up the fastidious job.
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more pleasant for
me to come here and visit more often. Did you hire out a developer to create your
theme? Great work!
obituary writing service
write an essay
custom literature reviews
essey typer
online check writing
online writing program
write my research papers
help with statistics
paper writer
political speech writing services
w http://cialisles.com/ tadalafil without a doctor’s prescription; just cialis 5 mg effetti collaterali
cialis 20mg and buy cialis online;
I used to be able to find good advice from your blog posts.
buy generic viagra online
buy generic viagra online
I’m impressed, I must say. Rarely do I encounter a blog that’s both equally educative and engaging, and let me
tell you, you have hit the nail on the head.
The issue is something that not enough people are speaking
intelligently about. I’m very happy that I stumbled across
this during my search for something concerning this.
Buy Viagra Online
Buy Generic Viagra Online
Who on earth ever stated weblog commenting was dead?
Quality articles or reviews is the main to attract the people to go to see the web site, that’s what this web page is providing.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you!
By the way, how could we communicate?
Hello Dear, are you actually visiting this web page on a
regular basis, if so afterward you will without doubt take
fastidious experience.
Asking questions are actually pleasant thing if you are not understanding anything totally, however this article provides fastidious understanding yet.
http://cialisdbrx.com/
http://genviagranrx.com/
Buy Viagra Online
Buy Generic Viagra Online
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more pleasant
for me to come here and visit more often. Did you hire
out a developer to create your theme? Superb work!
http://cialisdbrx.com/
http://genviagranrx.com/
Hi, just wanted to tell you, I liked this blog post.
It was funny. Keep on posting!
Buy Viagra Online
Buy Generic Viagra Online
Everything is very open with a really clear description of the
challenges. It was really informative. Your website is extremely helpful.
Many thanks for sharing!
Hello I am so delighted I found your blog page, I really found you by mistake, while I was researching on Google for something else, Nonetheless I am here now and would just like to say cheers for a
fantastic post and a all round exciting blog (I also love the theme/design), I don’t have
time to browse it all at the moment but I have book-marked it and
also included your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up
the awesome jo.
I’ve learn several excellent stuff here. Certainly value bookmarking for revisiting.
I surprise how so much effort you put to create any such fantastic informative site.
making watermelon sildenafil viagra for sale does sildenafil work if put in a
drink
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is important and everything. However think about if you added some
great graphics or videos to give your posts more, “pop”! Your content is excellent
but with images and videos, this blog could undeniably be one of
the very best in its niche. Great blog!
http://cialisdbrx.com/
http://genviagranrx.com/
福井県でバイク廃車をものほしげにして知りたい。他人行儀にしめくくる。福井県でバイク廃車の唖然としたな探り当てるとは。内輪のな感じで。
When someone writes an piece of writing he/she keeps the
plan of a user in his/her mind that how a user can understand it.
So that’s why this article is amazing. Thanks!
[url=http://cialsonlinebei.com]generic cialis[/url]
http://cialsonlinebei.com cialis online prescription
Ꮋi everʏbody! I am thе marketing offixe manager аt WOWITLOVEITHAVEIT.
Many thanks for aⅼl of tһe yοur thoᥙghts and ideas throսghout tһе last yeaг.
I cɑn certainl verify tһat ouг USA B2B Data Lists is currеntly on sale.
Оur Business Lists cover moгe thаn 10,000 niches andd micгo-niches
including Pneumatic Equipment Β2B Data, Flowmeters B2Ᏼ Leads , Cоmputer Leassing & Rental Businesss Data, Food Ingredients В2B Sales Leads ɑnd Accident Management B2B Email
Marketing List Еach of оur Business Contact Details
incorporate tһe business phone number, online site, e mail, address, social media sotes urls ɑnd mucһ more.
We have already greatlү lowered the fee of oᥙr
Business Data Yoս caan certаinly employ our B2B Email
Marketing fߋr e-mail as weⅼl aѕ e-newsletter advertising
ɑnd marketing, tele sales, sociaal media advertising, site contact fⲟrm
submissions ɑnd a ѡhole ⅼot more. Quickly, we will be introducing օur modern electronic mail extractor referred
tо ass Yoggy’s Money Vaulot Internet search engine Scraper ɑnd Email Extractor
tto enable үou too extrct youг oᴡn B2B leads!
Ι hope tһe aƄove answers all ᧐f ʏour concerns.
Do not hesitate tо PM me riɡht heгe оr reply to tһis post!
http://cialisdbrx.com/
http://genviagranrx.com/
Buy Viagra Online
Buy Generic Viagra Online
This article will assist the internet people for creating new
web site or even a weblog from start to end.
Buy Viagra Online
Buy Generic Viagra Online
CBQBarryktgz cialis prescription cialis without prescription why two bathtubs in the cialis commercials [url=http://buyscialisrx.com/]buy generic cialis[/url]
埼玉県のバイク事故車買取を労働者に聞いた。血まみれな感じで。埼玉県のバイク事故車買取を食べたそうにして知りたい。色々昇進すると思います。
what is the strongest sildenafil http://triviagra.com sildenafil and
cialis doesnt work http://triviagra.com/ buying viagra in san francisco
http://cialisdbrx.com/
http://genviagranrx.com/
Having read this I believed it was extremely informative.
I appreciate you spending some time and energy to put this informative
article together. I once again find myself personally spending a
lot of time both reading and posting comments.
But so what, it was still worth it!
Admiring the dedication you put into your website and detailed information you
offer. It’s great to come across a blog every once in a while that isn’t the same
out of date rehashed information. Great read!
I’ve saved your site and I’m including your RSS feeds to my Google account.
Keep on working, great job!
cialis apoteka online [url=http://www.cialislet.com/]cialis[/url] tadalafil alle erbe.
Hello, i feel that i noticed you visited my website so i got
here to return the choose?.I am trying to to find things to enhance my site!I assume its adequate to use a few of your ideas!!
I have been exploring for a little bit for any high quality articles
or blog posts in this kind of space . Exploring in Yahoo I ultimately stumbled upon this website.
Studying this info So i am satisfied to express that I have an incredibly
excellent uncanny feeling I discovered exactly what I needed.
I such a lot definitely will make sure to don?t
forget this website and give it a glance on a continuing basis.
Thanks on your marvelous posting! I definitely enjoyed reading
it, you will be a great author.I will ensure that
I bookmark your blog and will come back later in life. I want to encourage you to continue your great work, have a
nice weekend!
http://cialisdbrx.com/
http://genviagranrx.com/
Buy Viagra Online
Buy Generic Viagra Online
Buy Viagra Online
Buy Generic Viagra Online
With more advancement, high technology based cameras were introduced in the field
of photography. In case of Dexter, all episodes, that happen to be
aired weekly, co-relate for the storyline of not simply the first sort
episode nevertheless the next episode as well. In this compilation of
works, Renoir captured the intellectual characteristic with the girls who have been reading.
http://cialisdbrx.com/
http://genviagranrx.com/
Buy Viagra Online
Buy Generic Viagra Online
I relish, result in I found exactly what I used to be taking a look for.
You have ended my four day lengthy hunt!
God Bless you man. Have a great day. Bye
Buy Viagra Online
Buy Generic Viagra Online
Thanks a lot for sharing this with all people you really recognize what you are
speaking approximately! Bookmarked. Kindly additionally discuss with my web site =).
We could have a hyperlink alternate arrangement among us
Buy Viagra Online
Buy Generic Viagra Online
Buy Viagra Online
Buy Generic Viagra Online
We absolutely love your blog and find almost all of your post’s to be what precisely I’m
looking for. can you offer guest writers to write content in your case?
I wouldn’t mind publishing a post or elaborating on a few of the subjects you
write related to here. Again, awesome web
log!
http://cialisdbrx.com/
http://genviagranrx.com/
The online on-line games has created its market around the globe and entertaining many players of
each and every age group. To achieve success in this particular venture,
you must understand it straight from a symptom that things hastily done come in most
circumstances never done well. Like recounted before, here is the spot
where sports spread betting will highlight results profitable ones I
mean.
Thanks for your personal marvelous posting!
I seriously enjoyed reading it, you happen to be a great author.
I will be sure to bookmark your blog and will often come
back at some point. I want to encourage
you to ultimately continue your great posts, have a nice evening!
Buy Viagra Online
Buy Generic Viagra Online
福井県でバイク売るを田舎の野暮なして知りたい。出先機関書きます。福井県でバイク売るの秘めごとをあばき出す。智慮カタをつけるします。
Buy Viagra Online
Buy Generic Viagra Online
http://cialisdbrx.com/
http://genviagranrx.com/
Buy Viagra Online
Buy Generic Viagra Online
buy cialis online
buy generic cialis online
This article is truly a pleasant one it helps new the web
viewers, who are wishing for blogging.
buy cialis online
buy generic viagra
buy generic cialis online
buy generic viagra online
buy cheap cialis online
buy cheap cialis online
Nice respond in return of this query with real arguments and explaining the whole thing concerning
that.
buy generic viagra online
buy generic viagra online
http://cialisdbrx.com/
http://genviagranrx.com/
buy cialis online
buy generic viagra
buy cheap cialis online
buy cheap cialis online
http://cialisdbrx.com/
http://genviagranrx.com/
buy generic cialis online
buy generic viagra online
buy cialis online
buy generic cialis online
Content-spinning.fr vous propose en téléchargement un Plugin WordPress dédié
au Content Spinning ca permet de faire varier vos contenus dedans WordPress avec des dictionnaires que vous pouvez modifier.
buy cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
buy cialis online
buy generic viagra
buy generic cialis online
buy generic viagra online
Hi there, There’s no doubt that your site could be having internet browser compatibility issues.
When I look at your website in Safari, it looks fine however,
when opening in I.E., it has some overlapping issues.
I just wanted to give you a quick heads up! Aside from that, excellent site!
buy cheap cialis online
buy cheap cialis online
Since the admin of this site is working, no hesitation very
quickly it will be well-known, due to its feature contents.
Juventus Trøje
buy cialis online
buy generic viagra
Peculiar article, just what I wanted to find.
Maglie calcio poco prezzo
buy generic viagra online
buy generic viagra online
buy cheap cialis online
buy cheap cialis online
http://cialisdbrx.com/
http://genviagranrx.com/
Great post. I was checking continuously this blog and I
am impressed! Extremely helpful info specifically the last part 🙂 I
care for such information much. I was seeking this particular information for a very long
time. Thank you and good luck. Maglia bayern munchen
Wonderful work! That is the kind of information that are meant to be shared around
the web. Disgrace on Google for now not positioning
this put up upper! Come on over and visit my site .
Thank you =)
buy cialis online
buy generic cialis online
I am mulling օver the idea of buying Lacdey Bodystocking from Peaches & Screams Nightwear Boutique !Ɗo yoս
liқe this lingerie piece?
buy cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
Very rapidly this web site will be famous amid all blog users, due to it’s nice articles or reviews
I have read so many articles on the topic of the blogger lovers but this post is actually a fastidious piece of writing, keep
it up.
buy cheap cialis online
buy cheap cialis online
Just desire to say your article is as surprising. The clarity
in your post is simply cool and i could assume you’re an expert on this subject.
Well with your permission let me to grab your feed to keep updated with forthcoming post.
Thanks a million and please keep up the gratifying work.
http://cialisdbrx.com/
http://genviagranrx.com/
I get pleasure from, cause I found just what I was looking for.
You have ended my 4 day long hunt! God Bless you
man. Have a nice day. Bye
Excellent, what a blog it is! This web site presents valuable data to us, keep
it up. Manchester City Tröja
Consequently, the top quality for online on line casino is now.
The guidelines of poker can vary somewhat, but most
sites provide similar rules, and have good tutorials on how to
play. Some of the training sites contain a library of hundreds of movies for your perusal.
Going all-in as well frequently or in obvious desperation. You can easily choose any 1 of them but make it sure that they are secure enough.
tadalafil venta en lima [url=http://cialislet.com/]cialis[/url] posso
tomar metade de um cialis.
There is certainly a great deal to find out about this topic.
I really like all the points you have made.
Hi there, I enjoy reading through your article. I wanted
to write a little comment to support you.
buy cialis online
buy generic viagra
buy generic cialis online
buy generic viagra online
SharylDoanvl buy cialis online generic cialis long term
side effects of using cialis [url=http://buyscialisrx.com]Buy Cialis[/url]
buy cialis online
buy cialis online
It’s remarkable to pay a visit this website and reading the views of all friends regarding this paragraph, while I
am also keen of getting familiarity.
buy generic cialis online
buy generic cialis online
how much sildenafil will kill you [url=http://www.viagrapid.com/]viagra
no prescription[/url] buy best sildenafil online
o http://cialisles.com/ tadalafil without a doctor’s prescription –
proper cialis bangladesh tadalafil without a doctor’s prescription also buy cialis online.
It’s hard to come by experienced people in this
particular subject, however, you seem like you know
what you’re talking about! Thanks
http://cialisdbrx.com/
http://genviagranrx.com/
Greetings! I know this is somewhat off topic but I was wondering which blog platform
are you using for this site? I’m getting tired of WordPress because I’ve had
issues with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Chelsea Eden Hazard Fußballtrikot
Excellent article. I’m facing a few of these issues as well..
buy cialis online
buy generic viagra
buy cialis online
buy cialis online
buy generic cialis online
buy generic cialis online
http://cialisdbrx.com/
http://genviagranrx.com/
Awesome post.
buy generic cialis online
buy generic viagra online
importing sildenafil into new zealand generic viagra discount http://viagrauga.com/ http://viagrauga.com sildenafil super active ingredients
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cialis online
buy generic viagra
I got this web site from my pal who informed me
about this web site and now this time I am visiting
this site and reading very informative content here.
buy cialis online
buy cialis online
waarom is sildenafil blauw http://triviagra.com/ seeing blue after sildenafil http://triviagra.com/ what are the types of viagra
buy generic cialis online
buy generic cialis online
If you are going for most excellent contents like I do, just
visit this web page everyday as it gives feature contents,
thanks
http://cialisdbrx.com/
http://genviagranrx.com/
It’s perfect time to make some plans for the future and it is time to be happy.
I have read this post and if I could I desire to suggest
you some interesting things or tips. Perhaps you can write next articles referring
to this article. I wish to read even more things about it!
buy cheap viagra online
buy cheap viagra online
buy cialis online
buy generic viagra
buy generic cialis online
buy generic viagra online
buy cialis online
buy cialis online
Fabulous, what a weblog it is! This webpage gives helpful information to us, keep it up.
What i don’t realize is in fact how you’re no longer actually a lot more smartly-preferred than you
may be right now. You’re very intelligent. You
understand thus considerably in terms of this subject, made me personally believe
it from numerous numerous angles. Its like men and women don’t seem to be involved unless it is something to do with Woman gaga!
Your individual stuffs outstanding. At all times deal with it up!
http://cialisdbrx.com/
http://genviagranrx.com/
Hi there to all, how is all, I think every one is getting more
from this website, and your views are fastidious in favor of new viewers.
buy cialis online
buy generic viagra
http://cialisdbrx.com/
http://genviagranrx.com/
buy generic cialis online
buy generic viagra online
buy cheap cialis online
buy cheap cialis online
Article writing is also a excitement, if you be acquainted with then you can write otherwise it is complicated to write.
buy cialis online
buy generic viagra
buy generic cialis online
buy generic viagra online
Just want to say your article is as astounding. The clarity in your post is just spectacular and i
can assume you are an expert on this subject. Well with your permission allow me to grab your RSS feed to
keep up to date with forthcoming post. Thanks a million and please carry on the rewarding work.
I do not even understand how I stopped up right here, but I assumed this publish
was great. I don’t understand who you’re but certainly you’re going
to a well-known blogger if you happen to aren’t already.
Cheers!
Hello! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Cheers
http://cialisdbrx.com/
http://genviagranrx.com/
buy generic cialis online
buy generic cialis online
I’m gone to convey my little brother, that he should also pay a visit this
webpage on regular basis to obtain updated from
latest news update.
fantastic points altogether, you just received a brand new reader.
What may you suggest about your publish that you just
made a few days in the past? Any certain?
Good day! I could have sworn I’ve been to
your blog before but after looking at some of the articles
I realized it’s new to me. Anyhow, I’m definitely
pleased I stumbled upon it and I’ll be bookmarking it and checking back frequently!
prednisone crush cialis generic pills generic cialis vicodin and cialis generic buy buy generic cialis online
buy cheap viagra online
buy cheap viagra online
generic vs brand name cialis cialis online buy cialis australia buy cialis
This paragraph is really a nice one it assists new the
web visitors, who are wishing for blogging.
cheap viagra online canadian ph can you order generic viagra
in the us online order viagra online [url=http://bioshieldpill.com/]100mg viagra without a doctor prescription[/url]
buy cheap cialis online
buy cheap cialis online
buy generic cialis online
buy generic viagra online
May I just say what a comfort to uncover someone who actually understands what they’re talking
about on the web. You actually realize how to bring an issue to light and make it important.
A lot more people need to read this and understand this side of your story.
I can’t believe you’re not more popular given that you certainly possess the gift.
search cialis generic cialis http://www.cialisongen.com/ medco cialis online pharmacy viagra generic cialis online
order cialis online without a prescription buy cialis generic cialis reviews buy cialis
buy cheap cialis online
buy cheap cialis online
what does sildenafil do and how does it work how to buy viagra without a perscription http://www.viagrapid.com/ 100mg viagra without a doctor prescription can a 15 year old use sildenafil
http://cialisdbrx.com/
http://genviagranrx.com/
buy cheap viagra online
buy cheap viagra online
Pretty! This was an extremely wonderful article. Thanks for supplying this info.
buy cheap viagra online
buy cheap viagra online
buy generic cialis online
buy generic viagra online
Dangerous neuro technology is being used to hack, control, and torture innocent people around the world. This is a factual statement. You probably, or may not believe this right now, but my hope is by the conclusion of this lecture this evening you might be more convinced.
I want you to imagine a world where people sit behind computers with security clearances and listen to your most personal thoughts, spy on your most private moments, and actually control your mind and body.
This is not science fiction.
This is reality.
https://www.youtube.com/watch?v=KWhcwVmdrR4
Online dating could be the perfect solution should you want to meet singles within your area.
The online dating services arena is continuing to grow immensely as more and more folks are counting
on internet in order to meet new people, find their someone special, friendship and others activities.
Once they are successful inside their career and accomplish what you want, they realize the significance of marriage.
buy generic cialis online
buy generic viagra online
http://cialisdbrx.com/
http://genviagranrx.com/
buy cheap cialis online
buy cheap cialis online
buy generic cialis online
buy generic cialis online
what age is good for sildenafil http://triviagra.com/ green herbal
sildenafil pills triviagra.com buying viagra online safe
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
http://mewkid.net/buy-amoxicillin/ – Amoxicillin Amoxil Children evj.vsmy.deepsingularity.io.okm.ai http://mewkid.net/buy-amoxicillin/
http://mewkid.net/buy-amoxicillin/ – Amoxicillin No Prescription Buy Amoxicillin Online tyh.pmrc.deepsingularity.io.vxq.cm http://mewkid.net/buy-amoxicillin/
buy generic cialis online
buy generic cialis online
I was more than happy to uncover this great site. I want
to to thank you for ones time due to this wonderful read!!
I definitely appreciated every little bit of it and I have you book marked to see new stuff in your blog.
I’m extremely impressed together with your writing abilities as smartly as with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it’s uncommon to look a
great blog like this one these days..
Maybe you cannot be a famous director; it is possible to still direct a motion picture to memorize your life.
He began following conservative school of painting to begin with, which later took
a completely different course. During this time, Beck
tirelessly searched out venues that could allow
him on stage to do, with his fantastic tireless efforts eventually resulted in .
buy generic cialis online
buy generic cialis online
Hey this is somewhat of off topic but I was wanting to know
if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to
get advice from someone with experience. Any help would be greatly appreciated!
buy cheap viagra online
buy cheap viagra online
buy generic cialis online
buy generic viagra online
buy cheap cialis online
buy cheap cialis online
ubra.ru
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
Definitely imagine that that you said. Your favorite justification seemed to be on the web the easiest thing
to keep in mind of. I say to you, I certainly get irked even as other folks think about concerns that they plainly do
not know about. You controlled to hit the nail upon the top and also defined out
the whole thing without having side effect , folks can take a
signal. Will likely be again to get more. Thanks
buy cheap cialis online
buy cheap cialis online
After exploring a number of the articles on your web site,
I seriously appreciate your way of blogging. I added it to my bookmark webpage list and will
be checking back soon. Please visit my website too and let me know how you feel.
Thanks very interesting blog!
buy cheap viagra online
buy cheap viagra online
buy cialis online
buy generic viagra
buy cheap viagra online
buy cheap viagra online
Hello, everything is going nicely here and ofcourse every one is sharing
information, that’s genuinely fine, keep up writing.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
Greetings! Very useful advice within this post! It is the little changes that make
the biggest changes. Thanks for sharing!
buy cialis online
buy generic viagra
buy generic cialis online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap cialis online
buy cheap cialis online
http://cialisdbrx.com/
http://genviagranrx.com/
http://mewkid.net/buy-amoxicillin/ – Amoxicillin 500mg Capsules Amoxicillin 500mg jfi.liii.deepsingularity.io.foz.bd http://mewkid.net/buy-amoxicillin/
buy cialis online
buy generic viagra
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
I think the admin of this web site is truly working hard in favor of his site, as here every information is quality based information.
buy cheap cialis online
buy cheap cialis online
http://cialisdbrx.com/
http://genviagranrx.com/
Проверенно на себе
Без вложений
где узнать точный прогноз на спорт
Вот нашел сайт и просто купил,и вывел…. Да немного психанул но в плюсе!
Суть в том что тут реально крутые Капперы и реально отвечают на вопросы!
Не кидалово!
Лучше самим по пробывать и убедиться!!!
Поднимаем бобла
can you bring tadalafil into australia [url=http://www.cialislet.com/]www.cialislet.com[/url] cialis comprimidos 20 mg.
buy generic cialis online
buy generic viagra online
I every time emailed this webpage post page to all my associates,
since if like to read it next my friends will too.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
tadalafil tilaa [url=http://genericalis.com]tadalafil without a
doctor’s prescription[/url] buy tadalafil bangkok pharmacy
Hello every one, here every person is sharing these knowledge, so it’s nice to
read this website, and I used to go to see this blog all the time.
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
税理士選択は、ビジネスをするときにはかなり大切になってきます。近所の税理士を決めてしまい商売が傾いてしまう例が多いのです。こういった問題を避けるためには、実績のあるエージェントを活用するべきです。
http://cialisdbrx.com/
http://genviagranrx.com/
f http://cialisles.com/ http://cialisles.com, the does once
a day cialis work order cialis pills and tadalafil without a doctor’s prescription.
buy cialis online
buy generic viagra
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
I need to to thank you for this very good read!!
I certainly loved every bit of it. I have you saved
as a favorite to look at new things you post…
cgcrhmjxs qual a diferença entre o tadalafil e o
viagra http://www.cialissom.com/ http://www.cialissom.com/ [url=http://cialissom.com/]cialis usa[/url] site recommandé pour
tadalafil
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
I am curious to find out what blog platform
you have been using? I’m experiencing some minor security issues with my latest blog
and I’d like to find something more safeguarded.
Do you have any suggestions?
Hi! I know this is somewhat off topic but I was wondering
if you knew where I could find a captcha plugin for my
comment form? I’m using the same blog platform as yours and I’m having
problems finding one? Thanks a lot!
buy cialis online
buy generic viagra
We stumbled over here from a different page and thought I
should check things out. I like what I see so now i’m following you.
Look forward to looking over your web page yet again.
buy generic cialis online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap cialis online
buy cheap cialis online
http://cialisdbrx.com/
http://genviagranrx.com/
buy cialis online
buy generic viagra
The other day, while I was at work, my sister stole my
iPad and tested to see if it can survive a 30 foot drop, just so she
can be a youtube sensation. My iPad is now broken and she has 83 views.
I know this is completely off topic but I had to
share it with someone!
how can i get money today
payday online loans
alternative loans
cash usa loans
quand utiliser sildenafil [url=http://viagrauga.com/]viagra pills[/url] what does
it take to get a sildenafil prescription
buy generic cialis online
buy generic viagra online
hvad hjælper sildenafil http://triviagra.com/ blue haze
with sildenafil http://triviagra.com effective alternatives to viagra
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
My partner and I stumbled over here coming from a different website and thought I should check
things out. I like what I see so i am just following you.
Look forward to looking over your web page repeatedly.
http://cialisdbrx.com/
http://genviagranrx.com/
cheap cialis generic mastercard
generic cialis online
can u buy viagra over the counter cialis generic
cheap cialis
generic cialis overnight delivery
Keep up the awesome work.I’ve added your site into my blogroll.
I go to see everyday a few websites and sites to read articles or reviews,
except this blog provides feature based articles.
buy cheap cialis online
buy cheap cialis online
これ1本で済むという化粧品で、顔のくすみの悩みを解消効果が期待できます。ホワイトニングリフトケアジェルは、多くの商品の中でもクチコミ評価が高いクリームです。エイジングケアには欠かせないアイテムです。
buy cheap cialis online
buy cheap cialis online
At this time I am going away to do my breakfast, once having my breakfast
coming yet again to read other news.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
Hey! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing
a few months of hard work due to no backup.
Do you have any methods to prevent hackers?
Excellent blog right here! Also your web site so much up fast!
What host are you the usage of? Can I am getting your
affiliate link on your host? I desire my site loaded up as
quickly as yours lol
payadvance
payday express
large loans for bad credit
cash advance
dosificacion de tadalafil http://genericalis.com tadalafil generika sicher bestellen
buy generic cialis online
buy generic viagra online
Do you have a spam problem on this blog; I also am a blogger, and I was wanting to know your situation; many of us have created some
nice methods and we are looking to trade strategies with others, why not shoot me an e-mail
if interested.
http://cialisdbrx.com/
http://genviagranrx.com/
Good day! This post could not be written any better! Reading this post reminds me of my old room mate!
He always kept talking about this. I will forward this page to him.
Fairly certain he will have a good read. Thank you
for sharing!
Amazing! Its actually remarkable paragraph, I have got
much clear idea regarding from this paragraph.
sildenafil horas antes http://triviagra.com/ side effects of 200 mg sildenafil viagra without a doctor
prescription usa will viagra work for pe
cash advance akron ohio
installment loans near me
moneylenders
bad credit loans guaranteed approval
Hi there, I think your website could possibly be having internet browser compatibility problems.
Whenever I take a look at your site in Safari, it looks fine
however, if opening in Internet Explorer, it’s
got some overlapping issues. I simply wanted to give you a quick heads up!
Aside from that, great blog!
tadalafil funktion [url=http://cialislet.com]cialis prices[/url] quanto tempo prima va assunto tadalafil.
can you buy sildenafil over the counter in adelaide
http://triviagra.com/ what is in a sildenafil shot http://triviagra.com/ viagra and heart palpitations
Posts Incríveis Sempre!!!
Hello! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading through your blog and look forward to all your posts!
Keep up the outstanding work!
is a relied on QQ Casino poker Online as well as Bandar Ceme Online betting website that gives
on-line card video games such as Online Casino Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gambling Online Texas Hold’em Sites.
QQ Poker Ceme, the best and also most safe on the internet texas hold’em representative site with 24-hour IDN Online Casino poker service.
For those of you Lovers of the game Online Online and who intend to play betting Online
Poker, Online Ceme, Domino QQ, City Ceme, Online Gambling, Bandar Capsa Online in 1
ID
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
Just wish to say your article is as astounding. The clarity for your publish is just great and i
could think you’re knowledgeable on this subject.
Fine along with your permission allow me to seize your RSS feed to keep
up to date with drawing close post. Thanks one million and please continue the rewarding work.
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
Keep up the excellent work.I’ve incorporated your website into my personal blogroll.
Any room apartments, houses, cottages or other housing Woodside unique and contains individual functional load. This especially touches kitchens.
Doing your own kitchen remodel time-consuming events, in case is all this perform on their own
We in the company Limited Partnership NIOR Castleton Corners work masters, they all know about Kitchen remodel with peninsula.
We design unique interiors , paying great attention to conditions reliability and functional capability . We work with by customer on of all stages execute detailed analysis location rooms , carry advance counts . If the client have appeared you can easily ask our specialists and get detailed answers with detailed illustration and explanation .
The Enterprise always ready to provide quality 20k kitchen remodel by affordable rates . Masters with great practical experience work no doubt help one hundred percent remake in a matter of days . The price depends on selected package of services, scope of work .
Best small kitchen renovations Steenen Island – kitchen renovation nyc
cash loans for people with bad credit
personal loans bad credit
longterm loans
personal loans bad credit
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
no fee loans
payday advance
bad credit unsecured loan
first cash advance
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
what to tell doctor for viagra cheap viagra next day delivery what is the
best place to order viagra online.
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
is a trusted QQ Texas hold’em Online and Bandar Ceme Online wagering website
that supplies on the internet card video games such as Online
Casino Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99,
Online Gambling Online Casino Poker Sites. QQ Casino Poker Ceme,
the most effective as well as most safe on the internet casino poker
agent website with 24 hour IDN Online Casino poker service.
For those of you Lovers of the game Online Online as well as that want to play
gambling Online Texas hold’em, Online Ceme, Domino QQ, City Ceme, Online Gambling,
Bandar Capsa Online in 1 ID
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
https://cialisplrx.com/ younger men are better than retin a cialis pills buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
best way to ask for sildenafil viagra can sildenafil lose potency
over time
http://cialisgendrx.com/ cialis soft tablets http://cialisgendrx.com/ cialis generic buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
I don’t even know the way I finished up here, but I believed this publish was
good. I do not recognize who you might be but definitely you’re going to a famous blogger when you are not already.
Cheers!
Hi, Neat post. There is an issue with your site in internet
explorer, might check this? IE still is the market chief
and a big component of other folks will leave out your magnificent writing due
to this problem.
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
Good article! We will be linking to this great article on our site.
Keep up the great writing.
You completed various good points there. I did a search on the matter
and found most people will consent with your blog.
signature loans in las vegas
payday online loans
poor credit loans unsecured
fast loans online
Thanks for this nice post. …
I liked a @YouTube video vps free 1 năm của amazon ai thích
thì đăng ký nhé – Thầy linh bon>
Appreciating the commitment you put into your website and detailed information you offer.
It’s good to come across a blog every once in a while that isn’t the same outdated rehashed
information. Wonderful read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back later.
Cheers
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic cialis online
buy generic cialis online
buy generic cialis online
It’s awesome for me to have a web page, which is valuable in favor
of my know-how. thanks admin
ChiquitaHadd cialis prescription cialis prescription does cialis have a use by date [url=http://buyscialisrx.com]generic
cialis online[/url]
One can all get job all over the world with the support of degree courses that are internet because it contains value and understood all.
We’ve got members from all around the world and that have all types of programs, so there is usually someone
awake. We made reservations but didn’t actually need themthere
is no queue to get a table even when you did not have a booking.
Hopefully it will become an even nicer property in future.
But it’s great to have this distinctive and historical property from the portfolio.
If a person gets interested in someone, they is able to
call her or him at a secret and lone chat area to have conversation with her or his likeminded individual.
There was a mob of folks in the front desk as we were
leaving, so we just told the concierge our room number.
Front desk stated that he combined them keys stopped working
midway through the moment. I called themand no beach toys/chairs/umbrellas
are included at the resort fees. As expected, beach gear
rentals in the hotel are quite expensive. I really
don’t know of some points hotel in SoCal.
buy generic cialis online
buy generic cialis online
buy generic cialis online
Awesome site you have here but I was wondering if you knew of any
community forums that cover the same topics
talked about here? I’d really like to be a part of
group where I can get advice from other knowledgeable
people that share the same interest. If you have any suggestions, please let me know.
Thank you!
women who take cialis pharmacy cialis where to buy cialis cialis buying buying cheap cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
This website was… how do you say it? Relevant!! Finally I’ve found something that helped me.
Many thanks!
benefits of cialis generic drugs cialis indian buy generic cialis http://cialchprx.com/
indian viagra for women cialis generic buying cialis cheap voucher cialis tablets cheap cialis online
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
uroxatral vs hytrin cialis pills buy cialis online cheap ordering cialis cialis cheap
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but certainly you are going to a famous blogger if you aren’t already 😉 Cheers!
buy generic viagra online
buy generic viagra online
buy generic viagra online
Hi there, I enjoy reading all of your post.
I like to write a little comment to support you.
mixing levitra and viagra cialis pills cialis buy cialis online generic cialis canada http://cialisnorxs.com/
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
sex show webcam adult roulette sites free porn reallifecam
Моё почтение! Мы -студия создания и разработки онлайн-проектов. И меня зовут Антон, я учредитель группы линкбилдеров, специалистов, оптимизаторов, рерайтеров/копирайтеров, копирайтеров, профессионалов, link builders, разработчиков, маркетологов. Мы – команда высококлассных фрилансеров. Эта команда экспертов вам занять топ 5 в выдаче поиска каждой системе. Для вас мы предлагаем высококачественную раскрутку вебсайтов в поисковиках! Все наши сотрудники прошли громадный профессиональный путь, мы чётко понимаем, как грамотно формировать ваш онлайн-проект, выдвигать его на 1 место, преобразовывать трафик в заказы. У нашей организации сейчас есть для Лично для вас совершенно бесплатное предложение по продвижению любых сайтов. Мы ждем Вас.
бесплатное поисковое продвижение сайта бесплатное поисковое продвижение сайта
my service order write essay global assignment help cheating essay
sildenafil buy kamagra oral jelly xenical buy cialis online cheap propecia
cialis
propecia 1mg generic sildenafil xenical get cialis kamagra
generic cialis cialis cialis http://cialisnorxs.com/ online information buy cialis online
buy provera pills with mastercard buy cephalexin 250 mg where can i buy tetracycline 50 mg of trazodone erythromycin online lisinopril 20 mg tablets
cheap viagra online pharmacy
go here lexapro clomid generic visit your url buy atenolol online where to buy lasix prednisone10 mg buying prednisone online
metformin 1000 mg no prescription
aldactone buy valtrex online cheap pyridium helpful hints vardenafil albuterol sulfate trazodone benicar vantin effexor avalide abilify generic bactrim drug where to buy sildenafil citrate online effexor ventolin paroxetine SEROQUEL buy disulfiram online
who can help me write a business plan essay helper algebra 2 online essaywriter
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
tadalafil citrate
albuterol buy cheap generic viagra online ventolin hfa 90 mcg buy generic levitra online tadalafil 20 mg
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
buy cialis online without a rx cialis http://cialisnorxs.com/ name cialis tablets generic cialis online
buy metformin
cost of strattera buy cialis canada review buy hydrochlorothiazide acyclovir where can i buy xenical mobic buying predesone on line albendozale purchase lisinopril generic atenolol
kamagra
ventolin inhalers
proposal writers fast typer chemistry assignment help online essaytyper
tadalafil viagra ventolin cheapest levitra 20mg homepage
sildenafil citrate 25mg kamagra pill prosteride orlistat xenical cialis
aldactone
http://ventolin.cc/ – ventolin hfa inhaler
xenical
tadalafil
propecia clindamycin buy prozac tofranil buy augmentin rocaltrol Seroquel No RX buy glucophage
levitra medication price of albuterol inhaler tadalafil 20 mg cheap viagra online pharmacy ventolin
tadalafil ventolin albuterol sildenafil viagra levitra cost
buy generic viagra online
buy generic viagra online
buy generic viagra online
proscar seroquel amex lipitor levitra citrate sildenafil drug lexapro by prozac Buy Amitriptyline Online vasotec enalapril hyzaar buy glucophage
buy generic viagra online
buy generic viagra online
buy generic viagra online
celebrex motilium
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to make your point.
You clearly know what youre talking about, why
waste your intelligence on just posting videos to your blog when you could be giving us something
enlightening to read?
albuterol
viagra
prosteride
buy avodart Seroquel No RX Clomid Tablets tetracycline tadalafil more helpful hints where to buy synthroid female viagra Buy Buspar proventil inhaler for sale sildalis paxil sleep inderal Generic Advair cytotec azithromycin
If you desire to increase your experience simply keep visiting this site and be updated
with the hottest news posted here.
kamagra propecia buy cialis online cheap click xenical
sildenafil online pharmacy xenical buy cheap cialis online price of propecia kamagra
propecia tadalafil lasix BUY FUROSEMIDE motilium online cialis buy antabuse elimite sildenafil Nolvadex 20 Mg
ventolin hfa 90 mcg tadalafil levitra medication albuterol viagra online usa
buy generic viagra online
buy generic viagra online
buy generic viagra online
viagra
lasix
viagra ventolin price of albuterol inhaler levitra medication tadalafil
zithromax albenza buy albenza Stromectol effexor plavix toradol zetia
I have read some good stuff here. Certainly price bookmarking for revisiting.
I surprise how a lot attempt you put to create this kind of fantastic informative website.
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
glucophage viagra soft atenolol order valtrex onlines cipralex coupons buy seroquel doxycycline hyc ventolin
ventolin albuterol cheap viagra online pharmacy levitra cost tadalafil
proair albuterol
buy generic levitra online albuterol cheap viagra online pharmacy ventolin inhalers tadalafil citrate
xenical over the counter
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how could we communicate?
where can i buy xenical over the counter sildenafil
tadalis sx
prednisolone diflucan synthroid motilium buy lasix no prescription lexapro tadalafil prices motrin 800 cost of avodart seroquel cialis where to buy furosemide prednisone lisinopril albuterol prozac price cefixime 400 mg http://www.propeciaforless.com cheap vardenafil online
http://prednisone.yoga/ – prednisone
buy anafranil online
albuterol
viagra ventolin inhalers tadalafil buy generic levitra online albuterol cost
viagra ventolin inhalers price of albuterol inhaler tadalafil soft tabs levitra usa
kamagra now sildenafil where can i buy cialis over the counter propecia xenical over the counter
cialis generic tadalafil seroquel for sleep prozac celexa buy glucophage Generic Tadalafil advair generic medication methotrexate
[url=https://www.viagraeiu.com/]viagra online prescription[/url]
buy generic lexapro propecia lisinopril medrol 4 mg buy tadacip moduretic buy propranolol online lisinopril buy tetracycline synthroid hyzaar tadalafil 600 mg motrin sildenafil buy stromectol online
Great website. Plenty of useful information here. I’m sending it to a few friends ans
also sharing in delicious. And obviously, thank you to your sweat!
fluoxetine
buy cafergot plavix cialis where can i buy albendazole buy cephalexin
for more
cheap viagra online pharmacy tadalafil soft tabs ventolin price of albuterol inhaler levitra medication
If some one needs to be updated with newest technologies after that he must
be pay a visit this web page and be up to date all
the time.
albuterol viagra ventolin buy generic levitra online tadalafil 60 mg
Aw, this was an exceptionally nice post. Spending some time
and actual effort to make a very good article… but what
can I say… I procrastinate a whole lot and never
seem to get anything done.
buy cheap cialis online
xenical over the counter cialis kamagra pills
medication albuterol ventolin buy viagra toronto tadalafil soft tabs levitra
levitra super force colchicine amitriptyline generic
discover more here
ventolin viagra albuterol levitra medication tadalafil soft tabs
http://buysynthroid.company/ – how much is synthroid
clozaril clozapine
Рады Вас приветствовать! Мы команда SEO специалистов специализирующиеся продвижения и раскрутки интернет-ресурсов в многочисленных видах поисковых системах, а также в соц сетях. Меня зовут Антон, я учредитель большой группы профессионалов, оптимизаторов, link builders, специалистов, маркетологов, разработчиков, линкбилдеров, копирайтеров, рерайтеров/копирайтеров. Мы – являемся группой опытных фрилансеров. Ваш бизнес пойдет с нами на сверхновую высоту. Мы предлагаем качественную раскрутку вебсайтов в поисковых серверах! У всех абсолютно seo-специалистов представленной seo-команды за плечами большой высокопрофессиональный путь, мы знаем, как грамотно организовывать ваш собственный интернет-сайт, продвигать его на 1-ое место, преобразовывать веб-трафик в заказы. У нас имеется в наличии для Вас бесплатное предложение по продвижению ваших веб-сайтов. Мы ждем Вас!
яндекс продвижение сайта бесплатно яндекс продвижение сайта бесплатно
kamagra oral jelly 100mg cialis
crestor 5 mg
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
buy generic viagra online
buy generic viagra online
buy generic viagra online
avana cephalexin atenolol antabuse medrol aldactone crestor 10mg clindamycin hcl 300 mg buy cilias lexapro avodart online
lasix buy online 50 mcg synthroid albuterol pills for sale bupropion order tadalafil levitra orlistat
cheap albuterol inhalers
buy generic levitra online ventolin tadalafil soft tabs viagra suppliers albuterol
levitra price of albuterol inhaler best site to buy viagra online tadalafil ventolin
Just desire to say your article is as amazing. The clearness in your post is
just spectacular and i could assume you’re an expert on this subject.
Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please carry on the rewarding work.
Asking questions are really good thing if you are not understanding something
entirely, but this article provides good understanding
yet.
buy generic cialis online
buy generic cialis online
buy generic cialis online
allopurinol
buy tetracycline online allopurinol 300 mg tablets buy lasix online wellbutrin
albuterol inhalers not prescription required
xenical
viagra tadalafil soft tabs buy generic levitra online price of albuterol inhaler
kamagra oral jelly 100mg propecia can you buy sildenafil over the counter cialis where can i buy xenical over the counter
click this link allopurinol buy valtrex cardura for bph cheap generic cipro without prescription advair proscar Buy Cafergot yasmin where can i buy vermox buy antabuse online without prescription abilify lasix tadacip buy wellbutrin online baclofen prednisolone prednisolone
Hey there! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would
really appreciate your content. Please let me know.
Thank you
flagyl
http://crestor.team/ – crestor discount
sildenafil cialis buy online cheap kamagra now prosteride where can i buy xenical over the counter
mobic 7.5 tablets
where to buy retin a without a script generic for tricor buy furosemide online fluoxetine no prescription lexapro tetracycline lipitor price augmentin online buy vpxl advair
tadalafil soft tabs
buy vardenafil prozac
price of albuterol inhaler online ventolin
elimite albuterol cheapest cialis generic prednisone levitra buy sildenafil buy estrace ventolin albuterol cleocin 300 mg synthroid cefixime for gonorrhea cephalexin 500 Buy Motilium cardura drug phenergan 50 mg acyclovir 400mg buy cymbalta from canada
tadalafil ventolin buy cheap generic viagra online levitra medication albuterol
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
tadalis sx bactrim ds septra ds prozac propecia
indocin sildenafil citrate buspar without a prescription stromectol skelaxin orlistat vasotec cleocin without a prescription tadalafil lexapro zofran where to buy valtrex lasix albuterol hyzaar 100 12.5
tadalafil soft tabs
tetracycline capsules
tadalafil online pharmacy cheap viagra online pharmacy ventolin inhalers levitra price of albuterol inhaler
buy cialis buy propecia where can i buy azithromycin online seroquel erectile dysfunction synthroid generic glucophage buy furosemide 40 mg order metformin online zithromax generic ventolin buy amitriptyline strattera vantin 200 mg buy prednisolone 5mg flagyl prozac online
advair hfa
levitra albuterol viagra ventolin hfa 108 tadalafil soft tabs
kamagra oral jelly 100mg
I like the valuable info you provide in your articles.
I will bookmark your weblog and test once more here regularly.
I’m slightly certain I’ll be informed lots of new stuff right here!
Best of luck for the next!
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
What’s up colleagues, how is the whole thing, and what you would like
to say about this piece of writing, in my view its really remarkable for me.
click for source propecia read this cialis kamagra
buy generic levitra online
kamagra pill order generic cialis online can you buy sildenafil over the counter propecia uk xenical over the counter
latest online dating sites tgirl dating los angeles
what episode of gossip girl do chuck and blair start dating online dating 25% more attractive bruch
beer a whip chicago dating 437737.herpes on dating sites
casual dating rochester ny italian engineer oil refining drilling online dating scammer
why do guys on dating sites start conversation then disappear joaquin phoenix dating rooney
http://benicar.team/ – benicar
tadalafil
lexapro 20 mg
ventolin hfa 90 mcg
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
ventolin hfa 108
Every weekend i used to visit this web site, for the reason that i want enjoyment, for the reason that this this web page conations actually pleasant funny
material too.
buspirone 10 mg atenolol 75 mg lipitor cialis zithromax atomoxetine price buy albuterol amitriptyline order sildenafil online
Today, I went to the beach front with my kids. I found a sea shell and
gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
order tetracycline online without prescription buy prozac online ventolin prednisone tadalafil 20 mg lipitor cilias canada amoxicillin buspar online
At this moment I am going away to do my breakfast, afterward having my breakfast coming over again to read further news.
tadalafil citrate ventolin inhalers levitra medication how much do viagra cost albuterol
your domain name cefixime
thanks a lot a whole lot this web site is usually elegant in addition to relaxed
[url=http://cialsonlinebei.com]cialis pills[/url]
http://cialsonlinebei.com buy cialis online
cheap viagra online pharmacy tadalafil ventolin inhalers price of albuterol inhaler
It’s an amazing piece of writing in support of all the internet users; they will get benefit from it I am sure.
First of all I would like to say awesome blog! I had a quick question in which I’d like to ask if you don’t mind.
I was interested to know how you center yourself and clear your thoughts before
writing. I have had difficulty clearing my mind in getting my
thoughts out. I truly do take pleasure in writing but it
just seems like the first 10 to 15 minutes are generally lost simply just trying to figure out how to begin. Any
suggestions or tips? Cheers!
sildenafil
where can i buy prozac albuterol over the counter
flagyl
buy generic levitra online
albuterol xenical zovirax herpes synthroid 200 mcg arimidex abilify 15 mg ventolin salbutamol buying valtrex online buy fluoxetine synthroid buy amoxicillin buy amitriptyline
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
propecia sildenafil buy cialis online cheap kamagra xenical over the counter
albuterol inhaler price tadalafil levitra medication generic viagra sales ventolin inhalers
I like reading a post that can make men and women think. Also, thank you for allowing me to comment!
xenical over the counter can you buy sildenafil over the counter
Our mission at vape4style.com is to offer our clients along with the most ideal vaping expertise achievable, helping them vape snappy!. Based in NYC as well as in organisation given that 2015, our team are a customized vaping supermarket offering all kinds of vape mods, e-liquids, smoking salts, shuck units, tanks, rolls, and also other vaping extras, including batteries as well as outside wall chargers. Our e-juices are actually consistently clean considering that our company certainly not just market our products retail, but likewise distribute to local NYC stores in addition to deliver wholesale alternatives. This allows us to constantly rotate our supply, offering our consumers and outlets along with the best freshest stock achievable
.
Our team are actually an unique Northeast Yihi representative. Our company are actually likewise authorized distributors of Poor Drip, Harbor Vape, Charlie’s Chalk Dirt, Beard Vape, SVRF through Saveur Vape, Ripe Vapes, Smok, Segeli, Lost Vape, Kangertech, Triton and much more. Don’t view something you are looking for on our web site? Not a trouble! Only permit our company know what you are actually searching for and we will definitely discover it for you at a reduced cost. Possess a inquiry concerning a particular thing? Our vape professionals are going to rejoice to give more information regarding anything we market. Merely send our company your concern or contact us. Our staff will definitely rejoice to help!
If you are a vaper or even attempting to get off smoke, you are in the correct place. Desire to save some loan present? Hurry as well as join our e-mail newsletter to get special club VIP, vape4style discounts, promotions and also complimentary giveaways!
svrf stimulating shop = Ripe Vapes VCT
going here benicar allopurinol buy proscar online
http://tetracycline.rodeo/ – tetracycline
amitriptyline
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
You made some decent points there. I looked on the internet to find out more about the issue and found most individuals will go along
with your views on this site.
ventolin
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
price of albuterol inhaler tadalafil citrate buy levitra 20 mg ventolin low cost viagra
Hi Dear, are you really visiting this web page regularly, if so after that
you will absolutely get pleasant experience.
as explained here viagra cost of albuterol inhaler ventolin tadalafil cost
buy baclofen lisinopril metoprolol wellbutrin cialis albenza elocon viagra
Our objective at vape4style.com is to deliver our clients with the greatest vaping knowledge achievable, helping them vape with style!. Based in NYC and also in service considering that 2015, our company are a customized vaping supermarket offering all sorts of vape mods, e-liquids, pure nicotine salts, pod systems, storage tanks, coils, and also other vaping accessories, like electric batteries and also external wall chargers. Our e-juices are consistently new considering that our team certainly not simply sell our items retail, yet also distribute to local area New York City shops and also give retail possibilities. This enables us to continuously spin our stock, offering our clients and also shops with the most best supply possible.
If you are actually a vaper or even making an effort to get off smoke, you remain in the best spot. Want to conserve some funds in process? Rush and join our e-mail subscriber list to get special nightclub VIP, vape4style price cuts, advertisings and also free giveaways!
We are actually an special Northeast Yihi rep. Our team are actually also licensed reps of Bad Drip, Marina Vape, Charlie’s Chalk Dirt, Beard Vape, SVRF by Saveur Vape, Ripe Vapes, Smok, Segeli, Shed Vape, Kangertech, Triton and many more. Do not view one thing you are actually seeking on our web site? Not a trouble! Just allow us understand what you are trying to find as well as our company will discover it for you at a reduced rate. Possess a inquiry regarding a particular thing? Our vape specialists are going to be glad to deliver even more information about anything we sell. Just send our company your question or even phone us. Our group will be glad to aid!
ripe vapes retail store : Yihi SX Mini Q Class
buy generic viagra online
buy generic viagra online
buy generic viagra online
sildenafil citrate 25mg
pyridium 100 mg
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy antabuse online without prescription
biaxin xl 500mg advair sildenafil bupropion hcl cardura 4 mg valtrex medication prednisone check this out strattera online cheapest on line valtrex without a prescription
http://zanaflex.team/ – zanaflex
cheap viagra online pharmacy
viagra suppliers albuterol levitra cost cheap ventolin inhalers tadalafil citrate
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
more hints
ventolin inhalers
price of albuterol inhaler ventolin levitra tadalafil cost viagra
buy generic viagra online
buy generic viagra online
buy generic viagra online
neurontin rimonabant azithromycin order xenical online nexium drug diuretic furosemide propecia over the counter BUY PREDNISONE
ventolin inhalers tadalafil price of albuterol inhaler buy viagra uk levitra cost
buy generic cialis online
buy generic cialis online
buy generic cialis online
buy generic viagra online
buy generic viagra online
buy generic viagra online
what are the side effects from sildenafil best price 100mg generic viagra how long do i wait after taking sildenafil
buying doxycycline online
buy cheap viagra online
buy cheap viagra online
buy cheap viagra online
abilify for sale buy albenza tamoxifen lisinopril buy lisinopril purchase РЎlomipramine albuterol advair
i found it kamagra jelly cheap sildenafil xenical over the counter
colchicine mitosis synthroid prescription prednisone Cheap Furosemide buy levitra
http://cialis03.us.com/ – Cialis
furosemide
tadalafil o viagra yahoo [url=http://www.cialislet.com/]cialis
for sale[/url] tadalafil 5mg in canada.
levitra cost
tadalafil click here levitra ventolin inhalers viagra
il tadalafil quanto tempo prima del rapporto http://genericalis.com can you take tadalafil with cold medicine
generic lexapro
levitra cost
propecia doxycycline cost
zyban read full article amitriptyline generic sildenafil citrate 100mg cialis sildenafil cialis doxycycline purchase buy wellbutrin online buy albenza buy cafergot buy valacyclovir without a prescription seroquel buy amoxicillin robaxin paroxetine cytotec cardura generic amoxil toradol
price of albuterol inhaler tadalafil viagra levitra medicine order ventolin online
kamagra
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Buy Generic Viagra Online
Buy Generic Viagra Online
cephalexin online buspar albuterol
Buy Generic Viagra Online
Buy Generic Viagra Online
how much does cipralex cost celexa lasix lexapro motilium prednisolone tadalafil online sildenafil abilify no rx buy paroxetine online buy antabuse source lasix cephalexin offers buy wellbutrin buspar online your domain name orlistat over the counter xenical
That is a great tip especially to those new to the blogosphere.
Brief but very accurate information… Thank you for
sharing this one. A must read post!
Buy Cheap Viagra Online
Buy Cheap Viagra Online
cheap viagra online pharmacy
sildenafil
price of sildenafil in sydney [url=http://www.viagrapid.com/]www.viagrapid.com[/url] can sildenafil help after
prostate removal
tadalafil ventolin hfa 90 mcg medication albuterol levitra viagra store
hydrochlorothiazide 25mg tablets tetracycline purchase vardenafil tenormin 50 tetracycline vermox Albendazole Online
cheap viagra fast delivery levitra cost albuterol inhaler price tadalafil ventolin hfa 108
sildenafil from india xenical over the counter cialis propecia kamagra pills
http://buyretina.company/ – retin-a
rocaltrol avalide generic zanaflex buy fluoxetine vantin lipitor buy doxycycline Prozac Online cipro 500 atenolol 50 mg tablets misoprostol buy doxycycline without prescription Cleocin
cheep cealis sublingual
yourself http://genericalis.com/ how does cialis work buy cialis mostly
ventolin inhalers cost of albuterol inhaler levitra medication tadalafil buy cheap generic viagra online
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Buy Generic Viagra Online
Buy Generic Viagra Online
albuterol levitra cost viagra tadalafil soft tabs ventolin
Buy Cheap Viagra Online
Buy Cheap Viagra Online
cheap ventolin inhalers
elocon cream
buy generic levitra online viagra price of albuterol inhaler tadalafil generic ventolin
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
xenical over the counter sildenafil products cialis prosteride
It’s in reality a great and helpful piece of info. I’m happy that
you shared this helpful information with us. Please keep us
informed like this. Thanks for sharing.
xenical kamagra prosteride sildenafil citrate 25mg
generic cipro prednisone lasix without prescription amoxicillin tablets for sale our website allopurinol seroquel online purchass of prednisolone tablets buy tadacip generic revia read more lasix metformin lisinopril
tadalafil 20 mg
this site viagra
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Buy Generic Viagra Online
Buy Generic Viagra Online
cheap viagra online pharmacy levitra tadalafil soft tabs ventolin albuterol
Hmm.. i think so, porn star chick RT @DirtyBeats_Lvr: Uhum @Shnooky303 RT @Brazzers:
Does anyone hold the record for worlds longest squirt?
antabuse
xenical
Buy Generic Viagra Online
Buy Generic Viagra Online
viagra
Abilify Generic 20 mg prozac buy tadalafil indocin generic aldactone rocaltrol buy misoprostol 200 mcg paroxetine lasix zofran
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Hire cleaning service Union Square : house cleaning services prices
Trained specialists specialized company Richmond Valley do spring cleaning 2019.
Our LLC specialized company carries out spring cleaning 2019 not only in urban areas , we can put in order private households and cottage districts .
Our Partnership cleaning firm Belle Harbor AVIS, is engaged spring cleaning 2018 in Jamaica under the direction of LORIE.
Cleaning work in the spring is opportunity implement cleaning the house, on the street, at home.
Streets, courtyards, gardens, squares and other urban areas not only required clear from winter dirt Today cleaning with the onset of spring is a good case do a huge mass of work on tidying up urban areas, on the street, at home.
Streets, courtyards, parks, squares and other urban areas very important not only clean up after last winter, take out the garbage, and also prepare the territory for the summer. For this purpose need to be restored damaged sidewalks and curbs, repair broken architectural small forms sculptures, flowerpots,artificial reservoirs,benches, fences, and so on, refresh fences, painting and other.
Our LLC international company carries out spring general cleaning not only in urban areas , but with joy we will certainly help tidy up .
Our trained specialists Queens Village do spring cleaning.
tadalafil soft tabs cost of albuterol inhaler ventolin viagra levitra cost
amoxil online
F http://cialisles.com/ cialis usa – left levitra mı cialis mi
cialis 20mg also cialis 20mg
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
motilium online generic strattera
best free sex dating sites older men casual non sex dating site phoenix
what do you call a girl if not dating but talking people who have lost life savings from dating sites
what are the best internet dating sites live chat and dating
missing girl on dating app 10 top dating sites in california
when girl you are dating takes hours to answer why are all the girls on online dating sites the same
levitra cost
wellbutrin proscar retin-a sildenafil citrate 100mg tab online cymbalta wellbutrin zanaflex Levitra Pills
website propecia where can i buy cialis over the counter can you buy sildenafil over the counter
tadalafil 20 mg albuterol viagra levitra medication ventolin hfa 90 mcg
Buy Cheap Viagra Online
Buy Cheap Viagra Online
order xenical online buy cialis online cheap prosteride cheap sildenafil citrate kamagra
levitra tadalafil 20 mg cheap viagra online pharmacy as explained here price of albuterol inhaler
Hottest crowdfunded tech: Kokoon Headphones- the first comfy earphones you can wear in bed
Hi! This is kind of off topic but I need some advice from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things
out pretty quick. I’m thinking about creating my own but I’m not sure where to start.
Do you have any ideas or suggestions? Many thanks
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
home valtrex vasotec enalapril lisinopril
Buy Generic Viagra Online
Buy Generic Viagra Online
Heya i’m for the first time here. I found this board and I find It really useful & it helped me out much.
I hope to give something back and aid others like you aided me.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get four emails with the same comment.
Is there any way you can remove me from that service?
Thanks a lot!
can i buy viagra online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Howdy are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you need any html coding expertise to make your own blog?
Any help would be really appreciated!
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
RT and follow for girl sexy hd free sex kim sex tape free 100 free sex stories free forced
lesbian sex Switzerland Bern
buy cephalexin
Buy Cheap Viagra Online
Buy Cheap Viagra Online
this site vasotec
Buy Generic Viagra Online
Buy Generic Viagra Online
Howdy, i read your blog from time to time and i own a similar one and i was just curious if
you get a lot of spam feedback? If so how do you stop it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so
any help is very much appreciated.
http://allopurinol.rodeo/ – allopurinol
Cyber sex live cams Sashalus: Soy una niña
feliz divertida, traviesa, me encanta disfrutar de la vida, pasar
el rato, bailar, ver películas tener sexo descontrolado
cam video chat room}
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
What’s up to all, how is the whole thing, I think every one is getting more
from this web site, and your views are fastidious for new
users.
To do so you require a video camera, a video capture
device, and video editing software. How to install Skype on laptop?
Do you need a camera on a laptop to get Skype? The most effective cheaper notebook could
not be answer because all the notebook on the planet is having a lot
of lagging problem. For example, in case you have a car
that has XM radio, a navigator program, bluetooth, and a video player, then it has a lot of
bells and whistles along with being just a car. Since that time, there’s been a great deal of original Netflix series which have been around on the
support, and they’ve helped to improve its subscriber base by more than 58 million users just in the U.S..
The very first season, plus a vacation special, are available
on Netflix now. Otherwise, well the first thing
is purchase a webcam. Buy a Skype phone number and redirect calls to a usual telephone number for a Skype number.
prozac
swallow female agent white mofos lesbian japanese my sex leg show
online pornstars pure girl youporn cumshots flirt best gonzo clip wet
and puffy dolls porn bondage movie sexo playboy tv
porno pictures lingerie porn mpg black netherlands …}
lisinopril cialis our website
Buy Cheap Viagra Online
Buy Cheap Viagra Online
It is equally, you will need to update both hardware and
software. Is 64 bit a hardware or software
upgrade? There are numerous varieties of utility programs when it comes to computer software.
What are some fantastic free movie editing apps for windows besides windows movie
maker? Is there any way to video conversation with iPhone into PC?
The way to earn free credits on webcam sites varies dependent on the
site. Some have regular viewer programs that reward customers who make a whole
great deal of purchases on the site. You want to upload the picture from the webcam into your web area and then have some HTML
code to display the image on your website. Still free, but you must download the software.
Pirate applications Software companies can offer selected software for free use by users.
There is also Open Source program which might be offered for
free use, though some open source software might need a licence
obtained from the copywrite holder. There are many free anti-virus apps on the marketplace.
celebrex tetracycline wellbutrin zestril prednisone antabuse
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Viagra Online
Buy Generic Viagra Online
Buy Cheap Viagra Online
Buy Cheap Viagra Online
http://tetracycline.agency/ – tetracycline
Агрегатор Яндекс такси Самара позволяет людям вызвать авто в любое удобное вам время. Сделать заказ авто вы можете 3 способами: через специальное мобильное приложение, закачав его, на сайте, по телефону Яндекс такси. Вам требуется написать время когда необходима автомобиль, личный номер мобильного, местонахождение.
Можно заказать такси с детским креслом для перевозки детей, вечером после встреч безопаснее прибегнуть к Яндекс такси, чем садиться в автомобиль нетрезвым, в аэропорт или на вокзал надёжнее пользоваться Я. такси и не искать где разместить свою автомашину. Плата может производится безналичным или наличным платежом. Время подъезда Яндекс такси составляет от 5 до 10 мин ориентировочно.
Плюсы работы в нашем Я такси: Моментальная регистрация в приложение, Не очень большая комиссия, Оплата мгновенная, Постоянный поток заявок, Диспетчер постоянно на связи.
Для выполнения работ в Яндекс такси водителю следует оформиться лично и средство передвижения, все это займёт не больше 5 минут. Наша комиссия составит не больше 20 процентов. Вы можете с легкость получать заработную плату в любое время. У вас всегда будут заявки. В случае вопросов сегодня можно установить связь с круглосуточно работающей службой поддержки. Я. такси даёт возможность людям быстро доехать до нужного места. Заказывая современное Я. такси вы получите шикарный сервис в нашем городе.
работа в такси на авто компании = работа в компании яндекс такси
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Cheap Viagra Online
Buy Cheap Viagra Online
viagra professional online
Buy Generic Viagra Online
Buy Generic Viagra Online
do the side effects of cialis go away [url=http://cialissom.com/]buy cialis 10mg usa[/url] cost of cialis in united states.
prednisolone helpful hints buy vpxl
albuterol sulfate click here azithromycin 250 mg avalide 300 12.5 buy nexium avodart Buy Seroquel buspar online
Buy Generic Viagra Online
Buy Generic Viagra Online
sildenafil motilium view homepage where to buy propranolol discover more click for source diclofenac sod 75mg prednisone
Greetings! I know this is kinda off topic but
I’d figured I’d ask. Would you be interested in exchanging
links or maybe guest writing a blog article or vice-versa?
My website discusses a lot of the same topics as yours
and I feel we could greatly benefit from each other. If you might be interested feel free
to shoot me an email. I look forward to hearing from you!
Excellent blog by the way!
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
free online dating sites that you can talk to austin tx dating show
there is no young adult dating scene best free dating sites in france
how many bots are on dating sites the nerd dating the popular girl
what dating sites are not a scam best online site for over 50 dating austin tx
men who love women with curves dating sites dating a hispanic girl meme
That is a very good tip particularly to those fresh
to the blogosphere. Simple but very precise information… Many thanks for sharing this
one. A must read post!
http://rimonabant.team/ – rimonabant
vantin diclofenac sodium ec view homepage cephalexin 250mg capsules lisinopril 20 mg no prescription suhagra amantadine plus source metformin ampicillin 500mg capsules atenolol prednisone where can i buy nolvadex zithromax lexapro buy albendazole vardenafil hcl 20mg
You are a very intelligent person!
Buy Cheap Viagra Online
Buy Cheap Viagra Online
ventolin
cialis 5 mg cost
antabuse
cheap viagra online pharmacy albuterol tadalafil soft tabs ventolin inhalers levitra medication
levitra 10 mg price
tadalafil soft tabs levitra cost price of albuterol inhaler ventolin viagra
orlistat 120mg
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Viagra Online
Buy Generic Viagra Online
Buy Cheap Viagra Online
Buy Cheap Viagra Online
buy strattera provera tablet purchase propecia generic cialis clonidine 0.1mg for sleep lexapro buy cephalexin metformin online pharmacy glucophage xr 500mg
Buy Generic Viagra Online
Buy Generic Viagra Online
This blog was… how do I say it? Relevant!!
Finally I have found something that helped
me. Kudos!
tadalafil
cheap viagra online pharmacy
buy diclofenac sodium lisinopril indocin online aldactone for hair loss buy lexaporo home page zithromax
our website kamagra sildenafil xenical cialis daily cost
kamagra now xenical
cialis lamictal http://cialisps.com/ generic cialis.
uso frequente tadalafil.
levitra cost tadalafil soft tabs where can i buy albuterol online cheap viagra online pharmacy ventolin inhalers
amoxil atarax tadalafil buy paroxetine online related site ventolin valtrex no prescription
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
http://metformin.yoga/ – metformin on line
Buy Cheap Viagra Online
Buy Cheap Viagra Online
Buy Generic Viagra Online
Buy Generic Viagra Online
tadalafil 20 mg
propecia uk
buy generic levitra online albuterol cost
generic clozaril buy hydrochlorothiazide cardura cialis zofran medrol valtrex as explained here Elimite NO Script valtrex torsemide brand name rocaltrol diclofenac topical gel buy propranolol keflex 500 synthroid levitra for sale allopurinol online generic tadacip
presnidone without a prescription
buy toprol xl
cheap viagra online pharmacy price of albuterol inhaler ventolin tadalafil 20 mg levitra medication
สิบ ช่วงเวลาของอัจริยะลูกหนัง “ชาบี้ เอร์นานเดซ”
10ช่วงเวลาของอัจริยะลูกหนัง “ชาบี้ เอร์นานเดซ”
อีกหนึ่งอัจริยะลูกหนังที่ยากจะมีใครเทียบเคียง
“Xavi Hernandez” เขาไม่ใช่ห้องเครื่องที่มีความเร็วจี๊ดจ๊าด ไม่ได้มีสกิลเลี้ยงบอลล็อกหลบที่หวือหวา แต่เขาคือหนึ่งในสุดยอด Killer pass
ที่ทำให้เพื่อนเล่นต่อได้ง่าย หรือทำประตูได้สบาย ๆ
และวันนี้ชาบี้ในวัย 39 ปี ก็ประกาศว่าฤดูกาลนี้จะเป็นฤดูกาลสุดท้ายของเขาในฐานะนักฟุตบอลอาชีพ เขาเล่นให้กับบาร์เซโลนาชุดใหญ่มาตั้งแต่อายุ 18 ซึ่งถ้านับกันจริง ๆ หนทางฟุตบอลอาชีพของเขาก็เดินทางมาแล้วร่วม 20 ปี ที่เราได้เห็นผู้ชายคนนี้ ร่ายมนตร์อยู่บนสนามหญ้าที่เขารัก และนี่ก็ถือเป็นบทความรวบรวมช่วงเวลาอันน่าประทับใจ เพื่อส่งท้ายของการเป็นนักฟุตบอลอาชีพของผู้ชายที่ชื่อ “ชาบี้ เอร์นานเดซ”
การลงเล่นให้ชุดใหญ่ครั้งแรกของ ชาบี้ เอร์นานเดซ นั้น บาร์เซโลนาอยู่ภายใต้การคุมทีมของ Jose Mourinho
ที่รับหน้าที่เป็นผู้จัดการทีมจำเป็นในแมทช์นั้น
ซึ่งพบกับ เยย์ดา ในถ้วยโกปา กาตาลุนยา วันที่ 24 มีนาคม 1998 และxaviในวัย 18 ก็พาBarcelonaในตอนนั้น ชนะเยย์ดา ไปได้แบบฉิวเฉียด 2-1
ทีมที่ชาบี้เป็นคนประเดิมประตูแรกในฐานะนักฟุตบอลอาชีพ ก็คือเรอัล บัลยาโดลิด ในวันที่ 20 ธันวาคม 1998
แน่นอนว่าเป๊ป กวาร์ดิโอล่าคือตำนานของบาร์เซโลนา
ไม่ว่าจะในบทบาทผู้จัดการทีม หรือในบทบาทนักเตะ จนกระทั่งวันหนึ่ง เป๊ป บาดเจ็บจนไม่สามารถลงเล่นได้ทั้งฤดูกาล และการขาดหายไปของเขา ก็ทำเอาไลน์อัพนักเตะป่วนไม่น้อย
ลุยส์ ฟาน กัล จึงตัดสินใจหยิบชาบี้มาอุดรอยรั่วดังกล่าว แฟน ๆ
บาร์ซาไม่ปลื้มกับฟอร์มของเขามากนัก เข้าขั้นบู่เลยก็ว่าได้ ซึ่งนั่นเกือบทำให้ชาบี้ต้องโดนเทรดออกไป
แต่ต้องบอกว่าบาร์เซโลนาคิดถูกแล้ว
ที่ตัดสินใจเก็บตัวเขาไว้
อย่างที่หลายคนคงรู้กันอยู่แล้วว่า Barcelona กับReal Maridเป็นไม้เบื่อไม้เมากันมาตั้งแต่ไหนแต่ไร และการหยามเกียรติที่สุดคือการไปเล่นที่บ้านฝ่ายตรงข้าม
แล้วถล่มให้ยับ นั่นแหละคือความเข้มข้นของอริฟุตบอลคู่นี้ วันที่ 2 พฤษภาคม ปี 2009 บาร์เซโลนาภายใต้การคุมทีมของ
Pep Guradiolaไปเยือนเรอัล มาดริด
ถึงถิ่นซานติอาโก้ เบอร์นาเบว แมทช์นั้น
ราชันย์พ่ายแพ้อย่างราบคาบ ชาบี้Assistให้เพื่อนยิงได้ถึง 4 ประตู แมทช์นั้นนับเป็นแมทช์ความทรงจำของแฟนบาร์เซโลนา แต่คงปฏิเสธไม่ได้ว่ามันเป็นฝันที่เลวร้ายของแฟนมาดริด
ย้อนไปเมื่อรอบชิงฯ Ufa Champion Leage ที่กรุงโรมในปี 2009 ขุมทัพเบลากรานาที่กุมบังเหียนโดย Pep Guradiola ต้องมาพบกับกองทัพเร้ด เดวิล ที่กุมบังเหียนโดยกุนซือมากประสบการณ์อย่างเซอร์Ser Alex
Furguson ซึ่งหากเทียบชื่อชั้นของกุนซือทั้งสองก็เรียกได้ว่ากินกันไม่ลง ทางฝั่งเร้ด เดวิล ดูจะเหลื่อมกว่าหน่อยด้วยซ้ำ
ทั้งสองทีมต่างผลัดกันรุก-รับ แต่ทีมที่เด็ดขาดกว่าเป็นบาร์เซโลนาซึ่งเอาชนะไป 2-0 และคว้าแชมป์เจ้ายุโรปไป ซึ่งประตูที่สองเริ่มจากบอลโยนแบบไร้ที่ติจากXavi ก่อนที่Messiจะโหม่งเข้าไปเป็นประตูในที่สุด
ฤดูุกาลเดียวกัน บาร์เซโลนาก็ขึ้นจ่าฝูง และซิวแชมป์ลาลีก้า โดยทิ้งแต้มห่างอันดับสองอย่างเรอัล มาดริด 9 แต้ม นอกจากนั้นพวกเขายังเอาชนะ แอธเลติก
บิลเบา ในรอบชิงชนะเลิศถ้วยCopa
de rey ไป 4-1 เป็นอีกหนึ่งฤดูกาลที่ควรค่าแก่การจดจำทั้งของชาบี้ และบาร์เซโลนา
ทีมสเปนที่นำโดย อิเคร์ กาซิยาส, การ์เลส
ปูโยล, ชาบี เอร์นานเดซ, อันเดรส อีเนียสตา, เคราร์ด ปีเก้, เซร์จิโอ รามอส,
ชาบี อลอนโซ่ และบางคนที่ไม่ได้กล่าวถึงในยุคทองของทีมสเปน ช่วงระหว่างปี 2008-2012 ภายใต้กุนซือมากประสบการณ์อย่าง เดล บอสเก้ พวกเขาคว้าแชมป์ยูโรสองสมัยติดต่อกัน และคว้าแชมป์โลกได้เป็นครั้งแรกในประวัติศาสตร์ฟุตบอลสเปน
ซึ่งขณะนั้นนับเป็นจุดสูงสุดของชีวิตการค้าแข้งของ ชาบี้ เอร์นานเดซ การส่งบอลที่เฉียบแหลมของเขาเป็นจิ๊กซอว์ชิ้นสำคัญที่ทำให้ ลา โรฆา กลายเป็นยอดทีมที่ยากจะเอาชนะได้ในตอนนั้น
หากพูดถึงชาบี้ สิ่งแรกที่เรานึกถึงก็คือการส่งบอล แต่พอติดตามมากเข้า เราก็เริ่มรู้สึึกว่ามันเป็นเรื่องปกติ ซึ่งจริงๆ มันไม่ได้ปกติหรอก เพราะการส่งบอลได้แม่นยำในแบบฉบับชาบี้ไม่ใช่ว่าใครๆ ก็ทำได้ ถึงแม้ว่ามันจะเป็นพื้นฐานฟุตบอลก็ตาม
ย้อนกลับไปในการพบกันระหว่างเปแอสเช และบาร์เซโลนาในปี 2012 ชาบี้ทำสถิติเป็นนักเตะคนแรกที่ส่งบอลให้เพื่อนได้ 100% (ส่งบอลทั้งหมด 96 ครั้ง) ซึ่งก็หมายความว่าการส่งบอลของเขาไม่ถูกฝ่ายตรงข้ามตัดบอล หรือทำบอลเสียแม้แต่ครั้งเดียว
Puyol คือหนึ่งในยอดCaptionที่แฟน ๆ บาร์ซายอมรับในความเป็นสุภาพบุรุษลูกหนังของเขา และเมื่อใบไม้ถูกผลัดใบ ก็ถึงเวลาที่ชาบี้จะต้องขึ้นมารับหน้าที่นี้แทน ปูโยลอาจคุมน้อง
ๆ ในทีม ด้วยการกระตุ้น แสดงให้น้องเห็นถึงการเล่นฟุตบอลที่ใสสะอาด ชาบี้ก็พาน้อง ๆ ไปได้ในแบบของเขา ด้วยวิสัยทัศน์ การอ่านเกม และการส่งบอลที่เฉียบขาด
การลงสนามเป็นครั้งสุดท้ายในลีกของ ชาบี้ ภายใต้เสื้อสีเลือดหมูน้ำเงิน เป็นแมทล์อำลาที่ยิ่งใหญ่มากๆ ครั้งหนึ่งของบาร์เซโลนา พร้อมกับฉลองการคว้าแชมป์ลีกฤดูกาล 2014-2015
เสียงปรบมือของแฟนๆ บาร์เซโลนาอื้ออึงไปทั่วทั้งคัมป์ นู เพื่อให้เกียรติผู้ชายคนนี้ในฐานะผู้นำ นักฟุตบอล และว่าที่ตำนานอีกคนของสโมสร พร้อมกับน้ำตาาลูกผู้ชายที่ไหลออกมาอาบแก้ม ด้วยความปิติ เมื่อเห็นความรักที่แฟนๆ และสโมสรแห่งนี้มอบให้กับเขา
ใบไม้เมื่อมีวันผลิใบ ก็ย่อมมีวันที่ร่วงหล่น… ในที่สุดการค้าแข้งกว่า 23 ปี ของผู้ชายที่ชื่อ
ชาบี้ เอร์นานเดซ ก็ถึงปลายทาง เขาประกาศอย่างเป็นทางการแล้วว่าฤดูกาลนี้จะเป็นฤดูกาลสุดท้ายของเขา กับ อัล ซาดด์ สโมสรที่เขาเล่นอยู่ในปัจจุบันตั้งแต่ออกมาจากบาร์เซโลนา และเขายังเปรยๆ ไว้ว่าอยากเป็นโค้ชโดยยึดปรัชญาของ โยฮัน ครัฟฟ์ และสิ่งที่เขาถูกปลูกฝังจาก ลา มาเซีย
จากนี้เราก็คงทำได้แค่รอดูว่าการเดินทางครั้งใหม่ของชาบี้จะเป็นเช่นไร
ไม่แน่ว่า… ไม่เกิน 10 ปีข้างหน้า เราอาจจะเห็นเขากลับมาคุมบาร์เซโลนาชุดใหญ่จนประสบความสำเร็จเฉกเช่นรุ่นพี่อย่างเป๊ป กวาร์ดิโอลาก็ได้นะ
synthroid buy prednisone kamagra 50mg metformin buy colchicine albuterol vardenafil hcl 20mg generic advair get more information bupropion xl 300mg lexapro generic motilium moduretic helpful hints zestoretic where can i buy lasix online generic elavil robaxin online source prednisone
atomoxetine strattera
cheap viagra online pharmacy
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
buy generic levitra online tadalafil soft tabs albuterol viagra
Buy Cheap Viagra Online
Buy Cheap Viagra Online
albenza generic albuterol cilais doxycycline levitra pills lexapro metformin where can i buy xenical
hydrochlorothiazide without prescription buy lotrisone albenza pinworms vardenafil lexapro tretinoin gel over the counter Buy Flagyl Online buy toprol albuterol
propecia view homepage cheap sildenafil citrate example buy cialis online cheap
propecia cialis
tadalafil soft tabs levitra low cost viagra generic ventolin price of albuterol inhaler
diclofenac
lasix cialis vantin cost levothyroxine 50 mcg toradol pain shot torsemide azithromycin tetracycline trazodone generic cialis Order Augmentin robaxin
additional reading cost of albuterol inhaler levitra tadalafil viagra
finasteride proscar
levitra medication
カーペットについて知って観!偽造物いいな。カーペットのインフォーマルを漏らす。言い種収集の中働をします。
cephalexin lexapro Tadalafil Generic sildenafil over counter paroxetine hcl 40 mg daily valtrex no prescription Online Clomid where can i buy cialis azithromycin without prescription soft tabs viagra cleocin hcl buy paroxetine hyzaar blood pressure buy erythromycin without prescription furosemide sildenafil purchase wellbutrin online buy prednisolone 5mg without prescription uk tadacip online
http://buypropranolol.us.org/ – propranolol
buy lasix
Normally I don’t learn article on blogs, however I would like to say
that this write-up very compelled me to try and do it!
Your writing taste has been amazed me. Thank you, very great post.
Its such as you read my thoughts! You appear to grasp
a lot approximately this, like you wrote the book in it or something.
I think that you simply can do with some % to drive the message home a little bit, but other
than that, that is excellent blog. A great read. I’ll certainly be back.
cheap viagra online pharmacy buy generic levitra online
Hi, after reading this awesome post i am too
cheerful to share my knowledge here with friends.
propranolol online pharmacy
I like the helpful info you provide on your articles. I’ll bookmark your blog and check once more right here frequently.
I am relatively certain I’ll be told many new stuff proper here!
Best of luck for the next!
Great weblog right here! Additionally your website lots up fast!
What host are you the usage of? Can I get your associate link in your host?
I desire my site loaded up as fast as yours lol
Good day! I could have sworn I’ve been to this website before but after checking through some of
the post I realized it’s new to me. Anyhow, I’m definitely delighted I found it and I’ll be bookmarking and checking back frequently!
augmentin
ventolin online
tadalafil 20 mg albuterol inhaler price cheap viagra online pharmacy levitra medication ventolin
amoxicillin avalide orlistat where can i buy cipralex as an example where to buy prednisone online
xenical kamagra now prosteride cialis can you buy sildenafil over the counter
tadalafil 20 mg ventolin inhalers cheap viagra online pharmacy price of albuterol inhaler levitra
can you buy sildenafil over the counter propecia where can i buy cialis over the counter kamagra xenical over the counter
[url=http://vagragenericaar.org/]http://vagragenericaar.org[/url]
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
is albenza over the counter keflex on line
buy levitra
clozaril lexapro zoloft Prednisone Online
viagra
Pretty section of content. I just stumbled upon your weblog and in accession capital to
assert that I get actually enjoyed account your blog posts.
Anyway I will be subscribing to your augment and even I achievement you access consistently
rapidly.
kamagra
ventolin tadalafil soft tabs albuterol sildenafil viagra buying levitra
Our mission at vape4style.com is to deliver our consumers with the most ideal vaping knowledge feasible, helping them vape snappy!. Based in New York City and also in company due to the fact that 2015, we are a personalized vaping warehouse store offering all types of vape mods, e-liquids, nicotine salts, shuck systems, containers, coils, and also other vaping add-ons, including electric batteries and also outside wall chargers. Our e-juices are regularly clean given that we certainly not only sell our items retail, but additionally circulate to nearby NYC outlets and also offer retail alternatives. This allows our team to regularly turn our sell, delivering our customers as well as establishments along with the best freshest stock possible.
If you are a vaper or even making an effort to leave smoke cigarettes, you reside in the best place. Intend to conserve some loan in process? Hurry and join our e-mail newsletter to acquire special club VIP, vape4style price cuts, promos and also free giveaways!
Our company are an special Northeast Yihi representative. Our company are actually also licensed suppliers of Negative Drip, Harbor Vape, Charlie’s Chalk Dust, Beard Vape, SVRF through Saveur Vape, Ripe Vapes, Smok, Segeli, Lost Vape, Kangertech, Triton and a lot more. Do not see one thing you are actually trying to find on our site? Not a complication! Only allow our team recognize what you are actually seeking and also our experts will certainly discover it for you at a reduced rate. Possess a question about a specific item? Our vape professionals will rejoice to provide even more information concerning anything we market. Only send us your question or call our company. Our group will be glad to aid!
allien piss boutique : Yihi SX MX Class
viagra ventolin buy generic levitra online albuterol tadalafil soft tabs
http://tetracycline.surf/ – tetracycline
lexapro 10mg tablets
An outstanding share! I have just forwarded this onto a coworker who has been doing a little homework on this.
And he actually ordered me breakfast because I stumbled upon it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to talk about this topic here on your website.
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
buy stromectol online cheap celexa propecia benicar lexapro
Buy Generic Viagra Online
Buy Generic Viagra Online
zestril
medication albuterol
It’s truly very complex in this active life
to listen news on TV, therefore I just use world
wide web for that reason, and obtain the most recent information.
where to buy arimidex online cheap citalopram prednisone glucophage paxil ventolin propecia buspar online advair inhalers elimite amoxicillin example albenza lisinopril augmentin xr 1000mg
Hello there, I found your blog via Google at the same time as searching for a related subject, your site
got here up, it seems to be good. I’ve bookmarked it in my google
bookmarks.
Hello there, simply become alert to your blog through Google,
and located that it is really informative. I am going to watch out for brussels.
I’ll be grateful if you proceed this in future. Many people shall be benefited out of your
writing. Cheers!
viagra tadalafil citrate levitra price of albuterol inhaler ventolin
ventolin inhaler buy cheap generic viagra online price of albuterol inhaler levitra coupon tadalafil
sildenafil citrate 25mg propecia uk xenical buy cialis online cheap kamagra now
sildenafil
What’s up i am kavin, its my first time to commenting
anywhere, when i read this post i thought i could also create comment due to this good
paragraph.
tadalafil soft tabs
misoprostol online
Today, I will explain that how to examine webcam online.
Now, with the progress of science and engineering and with the exposure of the platform, money can be made by students at a young age money online.
Pick the one that is perfect, and you also own a blast earning more money than you ever thought was
possible. The cute chicks are just weeks away from
having the ability to walk and to pick in their food.
However, the majority of the pupils who attend college are currently struggling
to make ends meet, and need to pick a job up.
McManamum created a great fracture for Wigan who have begun brightly in the moments.
Oh, congratulations… Mom, have you known that uncle for a long time?
In the current period when interviews, assembly, conversing, sport playing is happening online.
Basically, when using this facility that is particular you will see an perfect time for
excursion or Saturdays and Sundays. 2 weeks you
will still get credit for the sign up. A learner who is quite enthusiastic in learning could be happy to get the courses in a conventional way.
propecia
levitra cost tadalafil soft tabs ventolin inhalers viagra price of albuterol inhaler
Appreciate it for helping out, great info.
cytotec indocin online Amoxil Online augmentin generic cost doxycline motilium no prescription plavix medrol Online Levitra
cost of albuterol inhaler ventolin levitra medication online tadalafil where can i buy over the counter viagra
prednisone synthroid indocin
Buy Cheap Viagra Online
Buy Cheap Viagra Online
colchicine 6 mg
http://1stadvairnow.com/ – order advair online
manpower research tadalafil tadalafil without a doctor’s prescription tadalafil to take
effect
info
buy seroquel albuterol effexor cheap zoloft online vantin silagra buy furosemide buy tadacip online buying cialis tadalafil buy provera tetracycline
tadalafil 10mg albuterol viagra ventolin levitra
metformin hcl 500 mg without prescription continue reading
buy ventolin
ventolin inhalers levitra
kamagra now propecia sildenafil citrate 25mg cialis xenical
Hello! Do you know if they make any plugins to help with Search Engine Optimization? I’m
trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Cheers!
buy cheap cialis online xenical prescription sildenafil citrate 25mg
levitra cost
buy cialis online cheap
You really make it seem so easy with your presentation but I find this matter
to be actually something which I think I would never understand.
It seems too complicated and extremely broad for me. I am looking forward for your next
post, I’ll try to get the hang of it!
ventolin price of albuterol inhaler
Excellent article. I definitely love this site.
Keep it up!
retin a 0.1
stromectol 3 mg cephalexin buy fluoxetine paroxetine
cheap viagra online pharmacy ventolin inhalers buy generic levitra online tadalafil albuterol medication
Hey there, I think your website might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up!
Other then that, very good blog!
buy cafergot buy prozac online uk celexa buy yasmin Cialis
order lasix with no prescription
price of albuterol inhaler
This post is invaluable. When can I find out more?
ventolin viagra
http://prozacforyou.us.com/ – Prozac without prescription
tadalafil 20 mebendazole ventolin generic yasmin birth control moduretic cheapest cialis online synthroid silagra amitriptyline buy albendazole generic lexapro cost propecia erythromycin for sale metformin cafergot cleocin lotion amoxicillin valtrex buy yasmin propecia generic
albuterol viagra store tadalafil ventolin inhalers levitra cost
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to
do it for you? Plz answer back as I’m looking to design my own blog and would like to find out where u got
this from. many thanks
buy viagra soft
generic propecia xenical sildenafil citrate 50mg tab generic cialis tadalafil 20mg kamagra now
acyclovir buy yasmin cheap cialis from india dapoxetine buy online proventil for sale effexor
where to buy cialis kamagra
I enjoy what you guys are up too. Such clever work and reporting!
Keep up the fantastic works guys I’ve you guys to my blogroll.
clicking here
kamagra
finasteride prostate
viagra price of albuterol inhaler
retin-a buy cialis generic cialis us pharmacy misoprostol online order tetracycline online ampicillin doxycycline amoxil 250 mg
tadalafil levitra cost price of albuterol inhaler ventolin inhalers
Incredible! This blog looks just like my old one! It’s on a completely
different topic but it has pretty much the same layout and design. Superb choice of colors!
Simply want to say your article is as surprising.
The clarity in your post is simply great and i could assume you’re an expert on this subject.
Fine with your permission allow me to grab your feed to keep up to date with
forthcoming post. Thanks a million and please continue
the gratifying work.
lasix cialis celexa artane albuterol
ventolin inhalers
finasteride cheap
Pingback: 3mc8w5wt4twyvnmtc5twmcw
amitriptyline 75 mg
ventolin inhalers viagra tadalafil cheapest levitra 20mg price of albuterol inhaler
Magnificent beat ! I wish to apprentice whilst you amend your web site,
how can i subscribe for a blog web site? The account aided me a applicable deal.
I were tiny bit acquainted of this your broadcast offered shiny transparent idea
xenical valtrex amitriptyline online more bonuses tadalafil buy wellbutrin tadalafil buy trazodone
levitra medication tadalafil albuterol ventolin inhalers viagra store
http://prozac.agency/ – prozac no prescription
valtrex buy colchicine Albendazole link purchase metformin tricor buy bactrim advair diskus no prescription artane for dystonia levitra professional cafergot & internet pharmacy provera buy colchicine 0.6 mg yasmin buy tretinoin cream vardenafil hcl 20mg amitriptyline propecia resource Benicar Hct
levitra sildenafil crestor buy trazodone cialis tetracycline moduretic
sildenafil propecia kamagra xenical over the counter i found it
can you buy sildenafil over the counter here kamagra where can i buy xenical over the counter found here
buy kamagra
viagra
buy cialis online cheap
cheap viagra online pharmacy price of albuterol inhaler ventolin inhaler buy generic levitra online
levitra canada РЎlomipramine sildenafil buy propecia cheap elimite antabuse where to buy prednisone online mobic motilium tablets synthroid 175 mcg lasix 40 mg iv indocin generic buy avodart tricor purchase acyclovir online
amoxicillin synthroid orlistat 120mg buy buspar prednisone suhagra generic abilify motrin bactrim prednisone
viagra price of albuterol inhaler tadalafil online canada levitra medication ventolin
payday loans
Sninots and hypertension cialis pills where to buy cialis stendy safe cialis online pharmacy http://cialischpbrx.com/
Buy Generic Viagra Online
Buy Generic Viagra Online
Hey There. I found your blog using msn. This is a really well written article.
I’ll be sure to bookmark it and return to read more of your useful information. Thanks for the post.
I’ll definitely comeback.
methotrexate cialis pill allopurinol cardura atarax for insomnia albuterol atrovent motilium canada order tetracycline online without prescription
ventolin
albuterol as explained here viagra
prozac no prescription
I was recommended this website by my cousin. I’m no
longer positive whether this post is written by means of him
as no one else understand such specified approximately
my problem. You’re wonderful! Thanks!
viagra store tadalafil soft tabs albuterol brand name explained here levitra
diflucan http://www.propeciaforless.com Propecia Generic sildenafil 100mg tablets cipro products with retin a benicar cialis propranolol trazodone 50 mg tetracycline Buy Stromectol buy nexium proventil for sale ventolin buy biaxin
Sorry for making you review this message which is more than likely to be taken into consideration by you as spam. Yes, spamming is a poor point.
On the various other hand, the most effective means to learn something brand-new, heretofore unidentified, is to take your mind off your everyday inconveniences and also show rate of interest in a topic that you might have thought about as spam prior to. Right? Turquoise ring
We are a group of young individuals who have actually determined to start our own business as well as make some cash like lots of other people in the world.
What do we do? We offer our visitors a wide option of wonderful handcrafted rings. All the rings are made by the finest artisans from throughout the United States.
Have you ever before seen or used a green opal ring, timber ring, fire opal ring, Damascus ring, silver opal ring, Turquoise ring, blue opal ring, pink ring, meteorite ring, black ring or silver ring? This is just a tiny component of what you can constantly locate in our store.
Made in the U.S.A., our handmade rings are not just gorgeous as well as original gifts for, claim, a wedding celebration or birthday celebration, however likewise your amulet, a thing that will definitely bring you good luck in life.
As compensation for your time spent on reviewing this message, we provide you a 5% discount on any type of item you are interested in.
We are eagerly anticipating meeting you in our store!
http://vpxl.team/ – recommended reading
metformin hcl 1000 paxil depression
buy cialis online cheap
cheap viagra online pharmacy
tadalafil ventolin hfa 108 viagra
prosteride helpful hints where can i buy cialis over the counter xenical over the counter cheap sildenafil citrate
buy propecia cheap
online synthroid
tadalafil here i found it homepage here ventolin inhalers levitra
For hottest news you have to pay a quick visit world-wide-web and on web I
found this website as a best web page for most recent updates.
albuterol asthma
buy metformin buy tadacip online buy albendazole antabuse hyzaar more info doxycycline arimidex buy allopurinol buy baclofen tadalafil torsemide
price of albuterol inhaler
Hi everybody, here every person is sharing these kinds of experience, therefore it’s
nice to read this weblog, and I used to visit this website all the time.
cash advance
I know this if off topic but I’m looking into starting my own weblog and was curious what all is needed
to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% sure. Any suggestions or advice would be greatly appreciated.
Thank you
Online Valtrex trazodone Buy Furosemide buy cafergot mobic
albuterol no prescription tadalafil
tetracycline zithromax z pak sildenafil citrate 50mg tab prednisone valtrex buy zyban online click for source visit website clonidine bactrim ds septra ds
viagra store
payday loans online
buy cialis
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
I’m really enjoying the design and layout of your site. It’s a
very easy on the eyes which makes it much more pleasant for me to
come here and visit more often. Did you hire out a developer to create your theme?
Exceptional work!
tadalafil 20 mg
kamagra effervescent home page buy cialis online cheap cheap propecia online xenical
Buy Cheap Viagra Online
Buy Cheap Viagra Online
buy cheap cialis online
kamagra jelly can you buy sildenafil over the counter xenical cialis buy online cheap propecia
http://ventolin.best/ – ventolin online
tadalafil 10 mg ventolin inhalers
here vardenafil view homepage moduretic olmesartan
can you get a loan with no credit
payday loans
direct lender
express loans
example colchicine skelaxin propecia ventolin stromectol without a prescription vantin antibiotic allopurinol best levitra prices lisinopril allopurinol buy no prescription cheap plavix buy lotrisone online generic clomid
payday loans online
valtrex
viagra
payday loans
additional info levitra medication tadalafil soft tabs price of albuterol inhaler where can i buy over the counter viagra
price levitra viagra albuterol sulfate inhalation solution ventolin tadalafil 20 mg
Sure thing ascertain at of arrangement perceived post.
Or totally pretty county in pit. In stunned apartments declaration so an it.
Insatiate on by contrasted to reasonable companions.
On otherwise no admitting to hunch article of furniture it.
Quatern and our overplay Mae West overleap. So constringe formal distance my extremely thirster give.
Hit merely tolerate cherished his merry duration.
100 mg clomid check out your url as an example generic for skelaxin 800 mg clozaril propecia as an example
amantadine buy prednisolone bactrim
zyban
tadalafil citrate
can you buy sildenafil over the counter
Orbits low cost cialis generic cheap cialis online LoxWinia buy cialis online without a prescription sildenafil citrate cheap cialis generic online
payday loans
kamagra price of propecia where can i buy xenical over the counter cialis online canadian pharmacy can you buy sildenafil over the counter
cialis sildenafil citrate 25mg price of propecia buy xenical online kamagra
valtrex medication revia phenergan synthroid buy tofranil allopurinol on line ventolin orlistat website buy prozac where can i buy acyclovir indocin 50 mg tablets
tadalafil cheap viagra online pharmacy levitra cheap ventolin inhalers
price of albuterol inhaler tadalafil levitra ventolin inhaler buy cheap generic viagra online
buy tadalafil vardenafil 20mg Proscar prednisolone lexapro generic prozac strattera buying tetracycline online where can i buy albuterol inhaler Lasix Without Script
cash advance
Buy Generic Viagra Online
Buy Generic Viagra Online
http://onlinelevitra.us.com/ – levitra online
Buy Generic Cialis Online
Buy Generic Cialis Online
Buy Generic Cialis Online
go here
buy kamagra levitra
Hi there! This article couldn’t be written any better!
Looking at this article reminds me of my previous roommate!
He constantly kept preaching about this. I’ll send this post
to him. Fairly certain he’ll have a good read. Many thanks for sharing!
prednisone for sale 5mg
price of albuterol inhaler viagra buy generic levitra online tadalafil ventolin inhalers
Viagra online usa
buy cheap viagra online
ben stiller viagra
buy cheap viagra online
what is the cost of viagra
buy cheap viagra online
viagra video
buy cheap viagra online
Canada cialis generic runny nose
buy generic cialis online
canada cialis generic sudden hearing loss cialis
buy generic cialis online
cialis generic price
buy generic cialis online
abilify 15 mg
albuterol
albendazole tetracycline no prescription tretinoin cream amoxicillin prescription albuterol sulfate celexa nexium buy prozac more about the author
buy cafergot
I every time used to study article in news papers but now as I am a user of
web thus from now I am using net for content, thanks
to web.
Viagra commercial black actress
buy generic viagra online
viagra x donne
buy generic viagra online
vardenafil hcl 20mg tab mebendazole over the counter orlistat 120mg propranolol example here sildenafil generic amitriptyline toradol pain shot kamagra effervescent
xenical over the counter
silagra
3500 loan
cash advance america
fast payday
cash advance loans
Good way of describing, and pleasant paragraph to
get information about my presentation subject, which i am
going to convey in college.
site de rencontre pakistanais christelle baise video porno femme enceinte tournage d un film porno porno arab hd couple bi qui baise pute 06 plage et sexe video en levrette site de rencontre site de rencontre j aime la branlette vide couille salope plan cul grosse salope question site de rencontre rencontre gratuite 86 masseuse baise rencontre coquine auch brunette sexy baise porno hd mature film porno chinois gratuit sexe dans les dunes photo de gros sexe attaque des titans porno pute vulgaire baise dans le parc site de rencontre pour sourd et malentendant gratuit lissa pute a domicile film porno chic comment faire l amour porno baise moi cheri porno pawg auto ecole baise salope au chateau site de rencontre cadre sup clara la pute grenoble la levrette bordeaux pute de luxe suce video porno caseiro sugar daddy site de rencontre premier message site de rencontre pute lesbienne rencontre sexe morlaix porno de vieille femme porno site de rencontre rencontre femme mariee gratuit porno belle mere gratuit plan cul aubervilliers florence la salope rencontre sexe marseille
viagr buy generic levitra online albuterol
cialis xenical kamagra
can you buy sildenafil over the counter kamagra low cost cialis homepage here xenical over the counter
albuterol inhalers not prescription required viagra tadalafil tablets levitra ventolin
tadacip online lexapro metformin 850 mg lasix allopurinol inderal la generic cardura propecia
more information
tadalafil Citalopram cialias ventolin xenical generic suhagra prednisone buy lasix strattera albendazole cefixime cost
http://flagyl.team/ – buy flagyl online
buy toprol xl prednisolone sildenafil read more here buy lisinopril purchase wellbutrin online buy prednisolone 5mg without prescription uk zanaflex tablets plavix buy lexapro without a prescription online buy levothyroxine online tofranil buy bupropion online zithromax synthroid ventolin buspar vardenafil seroquel 500 mg
I visited several blogs except the audio feature for audio songs existing
at this web site is genuinely fabulous.
albuterol tadalafil levitra cost viagra suppliers ventolin
prozac
ventolin inhalers medication albuterol buy cheap generic viagra online tadalafil soft tabs buy generic levitra online
buy lexapro online cheap sterapred diflucan tadacip lisinopril trazodone order flagyl levothyroxine 50 mcg prednisone
WOW just what I was searching for. Came here by searching for 슬롯추천
Hi there! This post could not be written much better!
Going through this post reminds me of my previous roommate!
He constantly kept preaching about this. I’ll send this post to him.
Pretty sure he’ll have a good read. I appreciate you for sharing!
levitra medication
paroxetine buy stromectol celexa propranolol hemangioma buy azithromycin zithromax citalopram synthroid Citalopram Pills tadalafil generic viagra soft 50mg no prescription ventolin inhaler albuterol synthroid lasix synthroid tretinoin cream Azithromycin 250 Mg
Hey! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Cheers
synthroid buy online
Cialis where to buy
buy cheap cialis online
cialis mail order
buy cheap cialis online
cialis tadalafil buy
buy cheap cialis online
buy cialis online canada canadian pharmacy
http://chcialisnrx.com/ http://cialischmrx.com/ http://cialischstgerts.com/
does crushing cialis http://cialisps.com/ http://cialisps.com. cialis gyno.
buy cheap cialis online
Howdy! Do you use Twitter? I’d like to follow you if that would be
ok. I’m undoubtedly enjoying your blog and look forward to new posts.
cephalexin online cialis methocarbamol robaxin 500mg
albuterol ventolin tadalafil soft tabs viagra levitra
Cheap viagra online canadian pharmacy
buy viagra online
viagra ad
buy viagra online
real viagra online
http://viagragetrx.com/ http://viagraneggrx.com/
visit this link
MOTILIUM AT LOWEST COST buy prednisone sildenafil citrate 100mg tab
Buy cialis cheap
buy cialis online
sample of cialis pharmacy
buy cialis online
ordering cialis
http://cialisndbrx.com/
cialis 20mg pills
http://cialischsrx.com/
buy xenical cheap kamagra sildenafil buy cialis online cheap prosteride
buy cheap generic viagra online
Сайт управління освіти і науки Чернігівської
області до 2008 року
next page link buy lexapro atenolol pills requip
http://azithromycin250mg.us.com/ – Azithromycin With No Prescription
ventolin albuterol best site to buy viagra online levitra tadalafil citrate
Viagra u srbiji cena
buy viagra online
viagra erection vs normal erection
buy viagra online
viagra and beer
http://viagragetrx.com/ http://viagraneggrx.com/
ventolin albuterol tadalafil soft tabs levitra viagra
If some one needs expert view concerning running a blog after
that i propose him/her to visit this website, Keep up the
pleasant work.
Fantastic goods from you, man. I’ve understand your stuff previous to and you are just extremely great.
I actually like what you’ve acquired here, certainly like what you are saying and the way in which you say it.
You make it entertaining and you still care for to keep it smart.
I can’t wait to read far more from you. This is really a
wonderful web site.
click here
Buy generic cialis without prescription
buy cialis online
cialis online
buy cialis online
poppers and cialis 20mg
http://cialisndbrx.com/
buy brand cialis
http://cialischsrx.com/
tadalafil
price of propecia
generic cipro lisinopril yasmin generic rocaltrol
Buy cialis pills generic
buy generic cialis online
brand cialis buy online
buy generic cialis online
cialis generic sicuro
buy generic cialis online
This is a topic that’s close to my heart… Thank you!
Exactly where are your contact details though?
Cvs viagra price
buy generic viagra online
viagra experiences
buy generic viagra online
buy colchicine
ventolin inhalers levitra albuterol tadalafil soft tabs viagra store
tadalafil answers yahoo cialis on-line precio
pastillas tadalafil mexico
I absolutely love your blog and find a lot of your
post’s to be just what I’m looking for. can you offer guest writers
to write content in your case? I wouldn’t mind creating a post or elaborating on many of the subjects you write
regarding here. Again, awesome site!
levitra cheap ventolin inhalers cheap viagra online pharmacy tadalafil medication albuterol
where can i find azithromycin
Hi, i think that i saw you visited my web site so i came to “return the favor”.I’m trying to find things to enhance my site!I suppose its
ok to use some of your ideas!!
Viagra kaufen
buy cheap viagra online
ingredient in viagra
buy cheap viagra online
viagra e similares
buy cheap viagra online
before and after viagra
buy cheap viagra online
Bob dole viagra commercial
buy cheap viagra online
prices for viagra
buy cheap viagra online
lamar odom viagra
buy cheap viagra online
which viagra is safe
buy cheap viagra online
where can i buy xenical over the counter cialis prosteride kamagra pills can you buy sildenafil over the counter
sildenafil propecia kamagra read full article cheapest xenical online
levitra
РЎLOMIPRAMINE metformin retin-a gel 0.1 tadalafil sildenafil albendazole ampicillin trihydrate
Cialis pills discount cialis
buy generic cialis online
women on cialis generic levitra
buy generic cialis online
order cialis
buy generic cialis online
sildenafil albuterol viagra elimite cream yasmin usa nolvadex online prozac retin-a prednisone Buy Seroquel doxycycline aldactone predisolone online order antabuse buspar Cephalexin vpxl
levitra
With havin so much written content do you ever run into any problems of plagorism
or copyright violation? My site has a lot of completely unique content I’ve either
authored myself or outsourced but it looks like a lot of it is popping it up all over the internet
without my permission. Do you know any ways to help stop
content from being ripped off? I’d definitely
appreciate it.
Generic cialis 20mg circuit city mexico
buy cheap cialis online
generic for cialis
buy cheap cialis online
prometrium allergy cialis pills
buy cheap cialis online
sex cialis pills
http://chcialisnrx.com/ http://cialischmrx.com/ http://cialischstgerts.com/
levitra cost vaigra price of albuterol inhaler generic tadalafil online ventolin
online paydayloans
personal loans no credit check
how can i borrow money
personal loans bad credit
http://sildenafil03.us.com/ – sildenafil citrate canada
Generic for viagra
buy generic viagra online
how to use viagra for best results
buy generic viagra online
Viagra coffee
buy viagra online
viagra law
buy viagra online
viagra vs. cialis
http://viagragetrx.com/ http://viagraneggrx.com/
price of albuterol inhaler
can you buy sildenafil over the counter
Online Lasix
albendazole
albuterol tadalafil ventolin inhalers viagra suppliers levitra
viagra levitra order ventolin albuterol tadalafil over the counter
buy kamagra generic provera tetracycline provera prednisone tadacip valtrex buy albenza cefixime
Online cialis order
buy cialis online
walmart pharmacy viagra cialis pills
buy cialis online
best price for generic cialis
http://cialisndbrx.com/
buy cialis pill
http://cialischsrx.com/
tetracycline 500mg buy antabuse cialis levothyroxine ordering online
buy clindamycin resources synthroid medication azithromycin purchase online
These are people searching for whiich you have
to give! Truly – I cannot find any drawbacks to commenting.
Make sure that yyou do all task though, .e. send him your link text, and his.
viagra – uk
price of propecia cialis can you buy sildenafil over the counter kamagra now orlistat xenical
can you buy sildenafil over the counter buy cheap cialis online cheap propecia online xenical read full article
viagra levitra medication albuterol inhaler price tadalafil ventolin
elimite for sale albuterol ventolin inhalers cytotec synthroid 112 cefixime tricor cephalexin revia triamterene hydrochlorothiazide recommended reading
cheap viagra online pharmacy ventolin price of albuterol inhaler tadalafil citrate levitra
Viagra 3 day delivery
buy viagra online
what happens if women take viagra
buy viagra online
poor mans viagra
http://viagragetrx.com/ http://viagraneggrx.com/
order prednizone
Главный сервис Я. такси Самара позволяет людям вызвать машину когда и куда угодно. Сделать заказ авто вы можете несколькими способами: на сайте Яндекс такси, через оператора позвонив нам или воспользовавшись мобильным приложение. Вам нужно написать личный номер телефона, местонахождение, время когда требуется автомобиль.
Можно заказать Я. такси вместе с детским авто креслом для перевозки деток, вечером после посиделок безопаснее воспользоваться Я. такси, чем сесть в автомобиль нетрезвым, на вокзал или в аэропорт надёжнее пользоваться такси и не думать где оставить свою машину. Оплата производится наличным или безналичным переводом. Время прибытия Я. такси составляет от трех до десяти минут примерно.
Преимущества работы в Я. такси: Моментальная регистрация в приложение, Небольшая комиссия, Оплата мгновенная, Постоянный поток заказов, Оператор круглые сутки на связи.
Для работы в Яндекс такси владельцу автомобиля нужно зарегистрироваться самому и автомашину, все это займет пять мин. Наша комиссия составит не больше двадцати %. Вы можете без проблем получать оплату за работу в любое время. У вас постоянно будут заявки. В случае проблем сможете связаться с постоянно функционирующей службой сопровождения. Яндекс такси даёт возможность людям быстро добраться до места назначения. Заказывая данное Я. такси вы получите первоклассный сервис в г. Самара.
работать в яндекс такси на своей машине – яндекс такси самара работа на своем авто
Adult.xyz – shorten links and earn money!
Cialis online pharmacy drugs
buy cialis online
cialis pills for women
buy cialis online
cialis discount onlin
http://cialisndbrx.com/
find cialis generic
http://cialischsrx.com/
resource
Substitute for cialis online pharmacy
buy generic cialis online
generic cialis overnight shipping cost
buy generic cialis online
cialis canadian pharmacy real cialis online
buy generic cialis online
http://1statenololnow.com/ – atenolol
Viagra vision loss
buy generic viagra online
viagra ad actress
buy generic viagra online
xenical
albuterol levitra low cost viagra ventolin hfa 108 cialis tadalafil
is a relied on QQ Online poker Online and Bandar Ceme Online wagering website that offers online card games such as Online
Texas Hold’em, DominoQQ, Capsa Online, Ceme Online, Ceme99, Online
Gambling Online Poker Sites. QQ Online Poker Ceme,
the very best and also best on-line texas hold’em agent website with 1 day IDN
Online Texas hold’em solution. For those of you
Lovers of the game Online Online and also who intend to play
betting Online Poker, Online Ceme, Domino QQ, City Ceme, Online Betting,
Bandar Capsa Online in 1 ID
buy generic levitra online viagra albuterol
buy prednisone
retin-a
buy cipro where to buy synthroid clomid generic buy stromectol homepage here medrol toradol cafergot view website buy prozac prozac valtrex
Albendazole
Cialis cost
buy cheap cialis online
alternative zyprexa cialis 20mg
buy cheap cialis online
cialis pills ingredients
buy cheap cialis online
cialis 5mg price drugs
http://chcialisnrx.com/ http://cialischmrx.com/ http://cialischstgerts.com/
This is very interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your wonderful post.
Also, I’ve shared your website in my social networks!
Viagra e diabete
buy cheap viagra online
viagra expiration
buy cheap viagra online
how much does viagra cost
buy cheap viagra online
how much is viagra
buy cheap viagra online
tadalafil
Healthy man viagra reviews
buy cheap viagra online
cheap viagra overnight
buy cheap viagra online
sildenafil vs viagra
buy cheap viagra online
how many viagra should i take
buy cheap viagra online
order tetracycline online without prescription cafergot celebrex azithromycin canada where to buy prednisone online without a script buy cafergot online buy viagra soft tabs cephalexin 250 mg propecia
orlistat xenical sildenafil kamagra oral jelly 100mg buy cialis online cheap buy propecia cheap
Next day brand cialis only online
buy generic cialis online
cialis 20 mg online
buy generic cialis online
how much are viagra pills cialis 20mg
buy generic cialis online
buy propecia cheap xenical
lexapro get the facts ventolin buy provera cialis dapoxetine buy atarax online buy prednisolone 5mg proventil inhaler for sale buy valtrex
best site to buy viagra online levitra price of albuterol inhaler ventolin hfa 90 mcg tadalafil
levitra cost price of albuterol inhaler tadalafil soft tabs viagra ventolin
Hi there, I do think your site may be having web browser compatibility issues.
Whenever I look at your site in Safari, it looks
fine however, when opening in Internet Explorer, it has some overlapping issues.
I just wanted to provide you with a quick heads up! Aside from that, excellent website!
Umm… how can you be so confident of this??
We stumbled over here different website and thought I may as well
check things out. I like what I see so now i’m following you.
Look forward to checking out your web page repeatedly.
acyclovir misoprostol online allopurinol tetracycline 250 mg price of cipro levitra cipralex usa 100 mg furosemide lasix water pill 20 mg buy no prescription lisinopril
Hello would you mind letting me know which web host you’re utilizing?
I’ve loaded your blog in 3 different internet browsers and I must say this blog
loads a lot faster then most. Can you recommend a good web hosting provider at a fair price?
Thanks, I appreciate it!
buy diclofenac generic for strattera furosemide levitra professional pills levitra dapoxetine tadalafil generic prednisone synthroid prescription lisinopril 15 mg metformin atenolol antabuse tetracycline lipitor lisinopril motilium for sale
cialis lovastatin buy viagra online sildenafil makes it hard to come
buy nolvadex amitriptyline online clozaril this site metformin Albendazole Cost buy pyridium buy viagra soft Clomid Tablets
dapoxetine 60 mg trazodone РЎlomipramine buy lisinopril online lexapro
It’s very straightforward to find out any topic on net as compared to books,
as I found this post at this website.
xenical over the counter
levitra medication ventolin inhalers tadalafil price of albuterol inhaler cheap viagra online pharmacy
price of albuterol inhaler tadalafil soft tabs cheap ventolin inhalers viagra levitra
metformin 850 mg price of zoloft avalide order erythromycin buy cytotec online cheap buying prednixone for animals buy prozac online uk buy atenolol advair price wellbutrin
http://buypropranolol.team/ – where to buy propranolol
rimonabant
levitra cost
lasix
трансформаторная подстанция 6
For instance, if you’re a raw beginner, you
will be trying to find a video showing you the way to tune a guitar, and possibly a lesson showing you how to change practicing
the guitar strings. But before you engage yourself in working out before your TV; it will greatly help
if you achieve to comprehend a mans mechanism.
For the Dalai Lama, the spiritual leader in the Gelug sect of Tibetan Buddhism,
to become so thought to be essentially the most
influential person from the year within the western world
is a perfect example of the respect we need to all show toward other religions
and the acceptance of views that do not effectively always mirror our own.
lasix
cialis
tadalafil 20 mg ventolin buy cheap generic viagra online buying levitra medication albuterol
buy cheap cialis online kamagra prosteride xenical cheap sildenafil citrate
Buy cheap viagra online
buy generic viagra online
viagra vs. cialis
buy generic viagra online
viagra 4 hours
buy generic viagra online
viagra coupon code
buy generic viagra online
Cialis discount online
buy cheap cialis online
buying generic cialis
buy cheap cialis online
buying cialis without a prescription cialis
http://chcialisnrx.com/
voucher cialis generic drugs buy
http://cialisdbrx.com/
generic clomid
I am actually thankful to the owner of this web site who has shared this enormous piece
of writing at at this place.
ventolin vardenafil synthroid 175 mcg aldactone for hair loss in females prednisolone lisinopril lisinopril indocin furosemide 20 mg viagra soft online stromectol online lasix 100mg online synthroid metformin 1000 atarax order plavix where can i buy xenical over the counter online synthroid Buy Fluoxetine
cash loan bad credit
same day payday loans
direct loan lenders online
payday loans near me
kamagra gel oral
ventolin tadalafil 20 mg levitra pills price of albuterol inhaler
tadalafil citrate
synthroid 75 buy nexium online celebrex buy acyclovir bupropion hcl 100mg atenolol recommended site
levitra cost
I have been exploring for a little bit for any high quality articles
or weblog posts on this kind of space . Exploring in Yahoo I finally stumbled upon this site.
Studying this information So i’m glad to show that
I have a very just right uncanny feeling I found out just what I needed.
I so much without a doubt will make sure to do not overlook
this website and provides it a look regularly.
where to get doxycycline prednisolone allopurinol order doxycycline 100mg without prescription where can i buy nolvadex vardenafil cost
viagra price of albuterol inhaler ventolin inhalers buy generic levitra online tadalafil soft tabs
price of albuterol inhaler ventolin hfa 90 mcg tadalafil soft tabs levitra medication cheap viagra online pharmacy
Oh my goodness! Impressive article dude! Thank you,
However I am having difficulties with your RSS.
I don’t know why I am unable to subscribe to it. Is there anyone else having
identical RSS problems? Anybody who knows the answer
can you kindly respond? Thanx!!
ventolin salbutamol atenolol 20 mg prozac cardura 4 mg wellbutrin sildenafil no prescription lisinopril albuterol Propecia NO RX generic nolvadex
cialis buy online cheap sildenafil prosteride kamagra orlistat xenical
cialis et depression [url=http://cialislet.com/]buy cialis 5mg[/url] tadalafil just
for fun.
tadalafil 20 mg
5 year old viagra
buy generic viagra online
is viagra generic
buy generic viagra online
viagra grapefruit
buy generic viagra online
viagra timeline
buy generic viagra online
buy cialis online cheap
albuterol buy generic levitra online low cost viagra ventolin tadalafil soft tabs
levitra
Useful information. Lucky me I discovered your website by accident, and I am surprised why this accident
didn’t took place in advance! I bookmarked it.
пфр симферополь реквизиты отдел статистики тракторозаводского района г челябинска v
[url=http://doctor7online.com/]http://doctor7online.com[/url]
Cialis pills online generic
buy generic cialis online
cheap online female cialis
buy generic cialis online
cialis website
buy generic cialis online
cialis 5mg price generic levitra
buy generic cialis online
buy cafergot
http://crestor.team/ – crestor 10mg price
valtrex lasix on line medrol 16mg furosemide valtrex sterapred zoloft levitraonlinemeds acomplia rimonabant cialis
tadalafil 20 mg price of albuterol inhaler levitra viagra additional info
tadalafil
propecia 1mg generic sildenafil tablets kamagra buy cialis online cheap xenical over the counter
Hello, There’s no doubt that your website could be having web browser compatibility problems.
Whenever I look at your website in Safari, it looks fine however, if opening in Internet Explorer, it has some overlapping issues.
I simply wanted to give you a quick heads up! Aside from that, fantastic website!
generic for cipralex
viagra
I am 64 years old generally in Good health,Gymming daily for 40 mins. I am type 2 Diabetic,maintain a good diet etc. Since last year I am totally impotent and now Viagra also does not help much. I have been advised by one Doctor to use Testosterone Gel and HGH injection. The other doctor told me to go in for Testosterone injection . I am a bit confused and scared to try these options.
So I would like the opinions of Good samaritans who have practical experience with any of the above treatment? Does someone try
Oxnard HGH Therapy? Secondly what precautions and side effects I can expect from this line of action.
Please serious advisors will be appreciated .
Trollers are also welcome
cialis propecia kamagra pill can you buy sildenafil over the counter xenical over the counter
How much will generic viagra cost
buy cheap viagra online
turkish viagra
buy cheap viagra online
how viagra looks
http://viagchranrx.com/
canadian viagra generic
http://viagchrarx.com/
skelaxin cost Atarax Without Prescription prozac without prescription valtrex source tadalafil yasmin
buy zithromax z-pak synthroid synthroid prednisone abilify albuterol
“We will need to build completely to another crescendo, cheri,” he said.
“And we all may have an ending that might be as none before.”
His smile was decadent, his eyes were full of lust, as well
as soft skin of his hard cock against my sex was having its intended effect.
I used to be feeling a stronger arousal now as I felt his
cock slide between my sensitive lips. I felt your head of
his cock push agonizingly at the entrance of
my pussy, and I needed him to thrust into me hard.
Instead he retracted and slid his hardness back nearly my
clit.
I’d been aching to possess him inside, and I possibly could
tell that his ought to push that wonderful hard cock inside me was growing.
His moans grew to match mine, and I knew the sense of my wet
pussy lips about the head of his cock was getting an excessive amount for
both of us.
“Permit the finale begin,” he was quoted saying, anf the husband slid the end of his cock inside me.
Both of us gasped as they held his cock there for
just a moment. I contracted my pussy to tug him further inside, and then he threw his return on the
sensation. Inch by excruciating inch he pushed his cock inside
me, and every time I squeezed my pussy around him.
His cock felt wonderful mainly because it filled me,
but I need to all of it inside me. I rolled to the side and rested my
leg against his shoulder, and then he plunged his cock all the way in.
prosteride
generic proscar generic prozac cost zanaflex bonuses CLEOCIN clonidine erectile dysfunction solu medrol glucotrol xl buy colchicine tamoxifen rocaltrol without prescription neurontin requip xenical cheap cialis prices albendazole metformin er 500mg generic silagra our website
Canada cialis generic sudden hearing loss cialis
buy cheap cialis online
viagra y embarazo
buy cheap viagra online
manly cialis tablets
buy cheap cialis online
viagra a 20 anni
buy cheap viagra online
ventolin
avodart viagra soft orlistat 120mg prednisolone generic colchicine ANTABUSE sildenafil propecia abilify 10 mg
Hello, its good paragraph about media print,
we all be familiar with media is a impressive source of facts.
Generic cialis work buy
buy cheap cialis online
natural viagra foods
buy cheap viagra online
australia buy ch eap cialis online
buy cheap cialis online
viagra y alcohol efectos
buy cheap viagra online
Мы предлагаем большому и среднему бизнесу, а также частным гражданам полное решение проблем – от регистрации и реорганизации организации до юридической помощи на всех рубежах ее формирования. Мы бережем любого клиента, обратившегося к нам.
Характерной особенностью деятельностипредставленной этой компании по праву считается построение длительных взаимоотношений со всеми нашими заказчиками, основанных на принципах индивидуального подхода к любому клиенту и сохранение секретности информации.
Наши специалисты, немалым практическим профессиональным опытом в сфере оказываемых нами услуг. Ключевым правилом у нас в специализированной компании несомненно является то, что, работая с нынешней компанией, вы получите объективный результат, базирующийся на наших познаниях и двенадцатилетнем фактическом опыте. юридические услуги в самаре
Наша отечественная корпорация специализируется на процедуре регистрации и реорганизации юридических лиц и индивидуальных бизнесменов, бухгалтерских услугах для небольшого и среднего бизнеса, комплексном юр. обслуживании юридических граждан. Дополнительно выполняем регистрация прав на жилые помещения,регистрация прав на земельные участки,заявление об отмене судебного приказа,представительство интересов в суде,налоговые переплаты,налоговые споры,инвестиционные проекты,сопровождение изменений,семейные споры,исковое заявление о расторжении брака,споры о детях,трудовые споры в Самаре.
ventolin
viagra ventolin medication albuterol
money in advance payday loan
cash advance
1000 loan
personal loans
albuterol 90 mcg inhaler viagra online ventolin levitra tadalafil soft tabs
http://buyzithromax.team/ – buy zithromax
I love your blog.. very nice colors & theme. Did you create this website yourself or did
you hire someone to do it for you? Plz reply as I’m looking
to design my own blog and would like to know where u got this from.
thank you
Does your blog have a contact page? I’m having trouble locating it but, I’d like to shoot you an e-mail.
I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it grow
over time.
buy amoxicillin advair generic generic revia allopurinol kamagra sterapred ds buy lasix on line prednisolone
cost of albuterol
phenergan generic proscar indocin 50 mg Sildenafil Citrate Tablets Ip 100 Mg valtrex lisinopril metformin proventil for sale
Thanks for ones marvelous posting! I seriously enjoyed reading it, you may
be a great author.I will make sure to bookmark your blog and will come
back from now on. I want to encourage continue your great writing, have a nice
morning!
Do you have any video of that? I’d love to find out some additional
information.
Наша международная компания Закрытое акционерное общество ВЛДААО Курган организует современным способом телеинспекциюинженерных систем, сетей хоз. бытовых, сетей хозяйственно-бытовой, водостоков, канализации, водопроводов и т. д.
Водеоинспекция трубопровода происходит видеокамерой, которая перемещается по трубам и дает изображение на экран и в одно и то же время ведётся видеозапись изображения.
Эта проверка даёт все возможности для того, чтобы определить качество стенок и стыков трубопроводов, зоны нахождения свищей, трещин и прочих повреждений, обнаружить засоры и посторонние предметы, несанкционированные врезки и прочие. Видеоинспекция также может быть использована и при приёме труб в результате строительного производства, ремонта.
Большим плюсом системы телеинспекции несомненно является ее мобильность, простота подхода к трубопроводу, а кроме того возможность получать изображение внутренних деталей труб разного диаметра.
Наша отечественная холдинг ОАО ЗЩАСЛ Ржев
работает на предприятиях как индивидуальных так и правительственных объектах.
Диагностика скважин – Автономная канализация
Cialis generic overnight
buy cheap cialis online
search cialis pharmacy
buy cheap cialis online
cialis soft online
buy cheap cialis online
viagra for sale after an o
http://cialischsrx.com/ http://cialischmrx.com/ http://chcialisnrx.com/
buy cheap generic viagra online ventolin inhalers discover more here albuterol tadalafil citrate
diflucan cheap prednisolone tadalafil furosemide proventil ventolin Buy Cephalexin antabuse wellbutrin generic albuterol buy abilify medication methotrexate valtrex discount recommended reading prednisone cefixime prednisolone buy tetracycline online buy amitriptyline avodart
where can i buy over the counter viagra
low cost viagra
citalopram 20mg keflex 250 mg propranolol 60 mg xenical 120mg no prescription sildenafil avodart xenical strattera without prescription allopurinol acyclovir
synthroid online pharmacy
Generic cialis online purchase
buy generic cialis online
serevent complications cialis pills
buy generic cialis online
Hello there! I could have sworn I’ve visited this website before but
after browsing through a few of the articles I realized
it’s new to me. Anyhow, I’m definitely happy I
discovered it and I’ll be book-marking it and checking back frequently!
buy cialis online cheap sildenafil cheap propecia generic kamagra chewable xenical over the counter
buy cafergot buy lasix stromectol 3 mg buy trazodone provera stromectol synthroid abilify
buy generic levitra online ventolin inhalers where to buy albuterol tadalafil viagra
cost of albuterol inhaler levitra buy cheap ventolin viagra
tadalafil
ventolin cost price of albuterol inhaler tadalafil online pharmacy low cost viagra levitra medication
lisinopril
ventolin inhalers
buy cialis online cheap prosteride xenical over the counter kamagra sildenafil
bactrim xenical medrol view site cafergot synthroid 125 mg buy augmentin acomplia rimonabant motilium online
web site orlistat vantin 200 mg cost of albuterol tricor buy furosemide online buy hydrochlorothiazide phenergan cost prednisone antabuse purchase provera indocin levothyroxine ordering online generic for glucotrol РЎlomipramine tetracycline synthroid colchicine acute gout
levitra
buy cialis online cheap propecia uk kamagra oral jelly 100mg cheap sildenafil xenical over the counter
cheap viagra online pharmacy visit website 20mg levitra price of albuterol inhaler ventolin inhaler
sildenafil
clomid without script
online ventolin
albuterol ampicillin order cipro online tadalafil prozac
Buy cialis in the uk
buy generic cialis online
aetna cialis pills
buy generic cialis online
У нас вы найдете Строительство ЛОС, а также биозагрузка купить , мы можем произвести Строительство кессона. Бурение артезианских скважин, Инженерные изыскания, Ремонт систем водоснабжения.
У нас вы можете приобрести ЁМКОСТНОЕ И РЕЗЕРВУАРНОЕ ОБОРУДОВАНИЕ, Емкости и резервуары с подогревом, Промышленные смесители, Сжигание осадков сточных вод, Водоприемный колодец, Тонущая загрузка, материал исполнения : металл ,стеклопластик, ОДЪЕМНЫЕ УСТРОЙСТВА И МЕТАЛЛОКОНСТРУКЦИИ Металлоконструкции фермы, ВОДООЧИСТНОЕ ОБОРУДОВАНИЕ Флотационные системы (Флотаторы), ПОДЪЕМНЫЕ УСТРОЙСТВА И МЕТАЛЛОКОНСТРУКЦИИ Ангары, Павильоны, ОЧИСТКА ЛИВНЕВЫХ СТОЧНЫХ ВОД Пескоуловители тангенциальные с шнековой выгрузкой, НАСОСНОЕ И КОМПРЕССОРНОЕ ОБОРУДОВАНИЕ (Грунфос, КСБ, Вило, КИТ, Взлёт, ТВП) Компрессор роторно-пластинчатый, ВОДОПОДГОТОВКУ Промышленные установки обратного осмоса, а также все для автомойки Автомойки на базе песчанно-гравийной фильтрации.
У нас обслуживает скважины, производит Водоочистка для колодцев.
мешковое обезвоживание осадка и блок биологической загрузки ббз 45 блоки биологической загрузки для очистных сооружений
buy generic levitra online albuterol tadalafil 20 mg ventolin hfa 90 mcg cheap viagra online pharmacy
buy generic levitra online price of albuterol inhaler tadalafil soft tabs buy cheap generic viagra online ventolin
Buy cialis online without
buy cheap cialis online
buy tadalafil india pills
buy cheap cialis online
mixing cialis generic viagra
buy cheap cialis online
search cialis pharmacy
http://cialischsrx.com/ http://cialischmrx.com/ http://chcialisnrx.com/
buy generic levitra online
hydrochlorothiazide 125mg
tadalafil 20 mg cheap viagra online pharmacy ventolin levitra cost
where can i buy cialis over the counter xednical propecia kamagra pills cheap sildenafil
buy seroquel provera drug cardura methylprednisolone kamagra soft
price of albuterol inhaler
Mebendazole female viagra prednisolone buy albuterol propecia buy cephalexin 250 mg diflucan allopurinol buy albendazole where to buy tadalafil online
bactrim mobic
Cheap Abilify
Cialis online pharmacy drugs
buy generic cialis online
buy cialis online usa now canadian
buy generic cialis online
Viagra levitra cialis generic drugs
buy generic cialis online
buy cialis soft online
buy generic cialis online
related site zoloft albendazole anafranil additional info cytotec tadalafil pills buy prednisone read full article diclofenac prozac abilify no rx Cephalexin revia buy lexapro lexapro
levitra medication
kamagra jelly prosteride xenical over the counter
http://paroxetine.team/ – paroxetine hcl 20mg
buy generic levitra online viagra – uk albuterol
cialis kamagra prosteride sildenafil where can i buy xenical over the counter
ventolin
Nice read, I just passed this onto a friend who was doing
a little research on that. And he actually bought me lunch since I found it for him smile Thus
let me rephrase that: Thank you for lunch!
xenical metformin hcl 1000 tadalafil rimonabant buy motrin baclofen kamagra albendazole
Your mode of describing everything in this paragraph is really good, every one be able to simply know it,
Thanks a lot.
baclofen
xenical doxycycline over the counter colchicine
furosemide
can i buy viagra without a prescription generic cialis buy zithromax cheap cialis canada pharmacy propecia proscar finasteride ampicillin keflex torsemide sildenafil citrate
Ordering cialis overnight delivery
buy generic cialis online
price of cialis tablets
buy generic cialis online
Good day! This post could not be written any better!
Reading trough this post reminds me off my previous room mate!
He always kept talking about this. I will forward this post to him.
Fairly certain he will have a good read. Thank you for
sharing!
lexapro 60 mg of prednisone tadacip by mail order Propecia Price Comparison cheap cialis generic ventolin inhaler nexium canada
I was wondering if you ever thought of changing the structure of your blog?
Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with
it better. Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
It’s the best time to make a few plans for the longer term and it’s
time to be happy. I have learn this post and if I may just I wish to recommend you few fascinating things or suggestions.
Maybe you could write next articles regarding this article.
I wish to read even more issues about it!
Thanks a lot for sharing this with all of us you actually understand what you
are talking about! Bookmarked. Please additionally talk over with my web site =).
We will have a hyperlink trade contract between us
cash advance loans online direct lenders payday loans online same day social loan loans online
У нас вы найдете Строительство ЛОС, а также ббз, мы можем произвести Насосы для скважин. Бурение неглубоких скважин, Оценка запасов подземных вод, Водоснабжение частного дома.
В нашей фирме имеется к продаже ОБЕЗВОЖИВАТЕЛИ ОСАДКА И УТИЛИЗАЦИЯ, Емкости и резервуары с подогревом, Рамные мешалки, Мешочные фильтры, Технические колодцы, Плавающая загрузка (ПЗ), материал исполнения : металл ,стеклопластик, ОДЪЕМНЫЕ УСТРОЙСТВА И МЕТАЛЛОКОНСТРУКЦИИ Шнековые конвейеры, ВОДООЧИСТНОЕ ОБОРУДОВАНИЕ Статические смесители, ПОДЪЕМНЫЕ УСТРОЙСТВА И МЕТАЛЛОКОНСТРУКЦИИ Шнеки из конструкционной и нержавеющей стали, ОЧИСТКА ЛИВНЕВЫХ СТОЧНЫХ ВОД Маслобензотделители, НАСОСНОЕ И КОМПРЕССОРНОЕ ОБОРУДОВАНИЕ (Грунфос, КСБ, Вило, КИТ, Взлёт, ТВП) Эрлифты, ВОДОПОДГОТОВКУ Озонаторы и хлотаторы, а также все для автомойки Автомойки на базе флотации.
В Сервисе проектирует, производит Обслуживание систем водоснабжения.
фильтр пресс для обезвоживания осадка и блок биологической загрузки купить ббз краснодар
clicking here
where to purchase erythromycin
Lasix and viagra cialis generic pronounce
buy cheap cialis online
generic cialis online without prescription
buy cheap cialis online
generic cialis pills
buy cheap cialis online
viagra average age cialis generic
http://cialischsrx.com/ http://cialischmrx.com/ http://chcialisnrx.com/
Hello There. I found your blog using msn. This is a really well written article.
I’ll make sure to bookmark it and return to read
more of your useful information. Thanks for the post.
I will definitely comeback.
cafergot buy ventolin inhaler without prescription lisinopril hct get the facts Cheap Yasmin Tablets albendazole for sale buy paroxetine doxy torsemide acyclovir vardenafil hcl 20mg tab retin a discount albendazole
orlistat online pharmacy
order antibiotics tetracycline no prescription hydrochlorothiazide over the counter buy levitra generic tadalafil online tetracycline indocin online propecia retin a
glucophage xr 500mg resource
cialis online hydrochlorothiazide orlistat 120mg buy tadalafil online buy fluoxetine phenergan iv Baclofen ilosone generic for glucophage buy levaquin duloxetine amoxicillin elavil chewable viagra soft tabs aciclovir hydrochlorothiazide oral bactrim
Canada cialis generic
buy generic cialis online
Does generic cialis work
buy generic cialis online
The low tariff of producing excellent digital video,
coupled with higher speeds of broadband connected to video friendly computers, and the international open distribution network
this is the Internet has generated a time of chance of the independent
producer. If you like money then I would turn into a rapper and rhyme concerning the streets being
a one who reflect the street scene from the rhymes.
In addition there are some people who get chance to get their some time to master guitar but
due to poor quality of learning furnished by incapable guitarists
are unable to acquire expertise.
propecia
Районная санэпидемстанция ДезКонтроль обеспечивает профилактические работы по истреблению насекомых в СПБ и окружающих регионах. Рабочие компании оказывают дезинсекцию мебельных клопов, травлю клопов, избавление от землероек. Мастера санкт-петербургской санстанции обладают внушительным опытом исполнения дезинфекционных дезработ для физических лиц и компаний всевозможного направления. Для травки паразитов применяется мелкодисперсное энергооборудование и результативные средства, поставляющиеся прогрессивными изготовителями по изготовлению агрохимических препаратов Украины и Португалии – Sulphur Mills, Доброхим, НПЦ “ФОКС и Ко”, Дезснаб-Трейд, Meghmani Organics. Для клопов применяются агрохимикаты Микроцин, Lambda Zone, Самаровка, Ципромал, Дуплет и иные инновационные и безобидные для людей и комнатных питомцев дезсредства. Травление прочих кровососов делается инсектицидами Фуфанон, Блокада-Антиклоп, Карбофос, Микроцин, Фоскон-55, Эффектив – малотоксичными и безопасными средствами для дезобработки заселяемых объектов. Предприятие ДезКонтроль – это умелый исполнитель профилактических дезработ, санэпидстанция обладает нужными ресурсами и нужными навыками для обработки масштабных объектов с отменным эффектом. Городская санстанция ДезКонтроль производит различные работы: дезинфекцию тараканов, гербицизация бурьяна, истребление членистоногих насекомых. Качественные услуги ДезКонтроль используют разносторонние организации – коммерческие фирмы, муниципальные здания, городские объекты: мотели, медпункты, минибары, садики, магазины, промбазы. Пригласить сотрудника уничтожить насекомых в отеле можно в каждый муниципалитет Питера и ЛО. Работники официальной станции ДезКонтроль дезинфицируют членистоногих на объектах: Приморский район, мо Ржевка, метро Приморская, посёлок Белоостров, город Всеволожск. На истребление клещей заключается годовая допгарантия.
http://neuf.nikaestate.ru/forum/user/9063/
Хештеги: оборудование для травли тараканов клопов купить, выведение тараканов в квартире, обработка помещений от блох препараты, травить клопов дымом, обработка помещений от клопов
fantastic publish, very informative. I’m wondering why the other experts of this sector don’t understand this.
You should proceed your writing. I am sure, you have a huge readers’ base already!
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is needed to get
set up? I’m assuming having a blog like yours would cost
a pretty penny? I’m not very internet savvy so
I’m not 100% sure. Any suggestions or advice would be greatly appreciated.
Appreciate it
Проект стартовал недавно, ходить в налоговую не нужно
земельный налог
Hello i am kavin, its my first occasion to commenting anyplace, when i read this article i thought i could also create comment due to this
brilliant piece of writing.
antabuse cheap tadalafil 20mg sildenafil india
It is really a nice and useful piece of info.
I’m glad that you shared this useful info with us.
Please keep us informed like this. Thanks for sharing.
Когда автомобильное стекло покрывается трещинам то нужна будет замена, то вам в сервисе пару типа лобовых стёкл: ОЕМ или неоригинальное. Выбирайте.
Лобовые стёкла от авто, как и любые другие запасные части автомобиля, делятся на фирменные и от производителей третьих фирм. Оригинальные лобовых стёкл изготавливаются либо на АВТОЗАВОДЕ, занимающемся выпуском автомобилей, либо у подрядчиков автоконцерна, выпускающих запасные части по лицензии автобобильного завода, которые напрямую устанавливаются в производимые автомобили.
Магазин авто Фуяо реализует Автостекл по всем стране.
Установкой Лобовых стёкл от автомобиля Занимается наша компания.
Полировка автостекл.
Очень частым недостатком теперешнего тачки по праву является утеря автомобильным стёклом прозрачности из-за потёртостей, царапин, как правило, от стеклоочистителей. В угоду сохранности клиентов создатели создают автостекла из довольно мягких видов стекла, что и делает этот недочёт популярным.
Частые повреждения автомобильных стёкл бывают: незначительные, глубокие, средние повреждения.
KXD Glass Group устанавливает автомобильные стёкла как на отечественные, так и на зарубежные автомашины а также на габаритные автомашины.
CQV Industry изготовляет автомобильные стёкла под заказ.
Официальный дилер автостекол лобовое стекло
tetracycline Lisinopril glucophage
Index Search Villas and lofts rented, search by region, find in a few minutes a villa to book by city,
a variety of
banks that offer personal loans
cash advance
how do personal loans work
payday loans near me
tretinoin cream propecia 1mg generic kamagra female viagra buy viagra recommended reading augmentin 400 Cheap Viagra provera no prescription needed
Keep this going please, great job!
biaxin 500 tetracycline doxycycline tetracycline Nexium At Lowest Cost cheap cialis tadalis Seroquel
Cialis tadalafil buy
buy generic cialis online
Thanks in favor of sharing such a good thought, paragraph
is fastidious, thats why i have read it completely
can u buy viagra over the counter cialis generic
cialis online
cialis tablets australia
generic cialis
Ivermectin Cost zithromax VENTOLIN HFA elimite doxycycline Zetia cymbalta sildenafil hydrochlorothiazide abilify online proscar bactrim ordering cialis australia atenolol arimidex men
Hey there, I think your site might be having browser compatibility issues.
When I look at your blog site in Ie, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you
a quick heads up! Other then that, very good blog!
metformin
stromectol orlistat
prednisolone
sildenafil as explained here furosemide where can i buy xenical doxycycline tetracycline seroquel prednisolone CIPRO WITHOUT PRESCRIPTION Tadalis Pharmacy buy generic valtrex without prescription cialis continue reading viagra indocin abilify prednisolone
Best prices cialis
Buy Cheap Cialis Online
buying cialis in canada fast shipping cialis
Buy Cheap Cialis Online
generic cialis soft tabs 20mg
online cialis
coupons for cialis generic
generic cialis online pharmacy
Hydrochlorothiazide cheap viagra source price of albuterol inhaler Robaxin propranolol xenical tablets trazodone
I think this is one of the most significant information for me.
And i am glad reading your article. But want to remark on some general things, The site style is
perfect, the articles is really excellent : D.
Good job, cheers
antabuse
generic viagra buy lasix without a prescription best place to buy nolvadex buy antabuse online as an example lipitor 40 mg cheap celexa online
Hello there, I think your site could possibly be having web
browser compatibility problems. Whenever I look at your web site in Safari, it looks fine however,
if opening in IE, it’s got some overlapping issues.
I just wanted to give you a quick heads up! Other than that,
excellent website!
Is generic cialis good
Buy Cheap Cialis Online
buy generic cialis online without prescription
Buy Cheap Cialis Online
This blog was… how do you say it? Relevant!! Finally
I have found something that helped me. Thanks!
viagra pronunciation cialis generic
cialis
buy cialis online
buy generic cialis online
lexapro
cialis pour femme homme [url=http://cialissom.com/]lowest price for cialis 5 mg[/url] reputable online
pharmacy for cialis.
tadalafil hydrochlorothiazide phenergan with no rx allopurinol retin a zithromax propecia antabuse
Cheap online female cialis
Buy Cialis Online
It’s difficult to find experienced people on this topic, however, you sound like you know what you’re talking
about! Thanks
Cheap cialis soft
Buy Cialis Online
buy metformin 500mg clomid no prescription ventolin hfa azithromycin doxycycline lisinopril cymbalta
Привет! Мы -студия создания и разработки сайтов. И меня зовут Антон, я учредитель группы рерайтеров/копирайтеров, link builders, маркетологов, разработчиков, оптимизаторов, специалистов, профессионалов, копирайтеров, линкбилдеров. Мы – являемся группой высококлассных фрилансеров. Наши основные профи помогут вам занять ТОП 15 в выдаче поисковой машины каждой системе. Для вас мы предлагаем высококачественную раскрутку веб-сайтов в поисковиках! У всех без исключения сотрудников представленной команды за плечами гигантский профессиональный путь, мы чётко знаем, как грамотно создавать ваш интернет-сайт, выдвигать его на 1 место, преобразовывать трафик в заказы. У нашей организации сейчас имеется для Вас бесплатное предложение по раскрутке любых online-сайтов. С нетерпением ждем Вас.
сео анализ сайта онлайн бесплатно продвижение сайтов онлайн бесплатно
Greate post. Keep posting such kind of info on your site.
Im really impressed by your site.
Hi there, You have done an excellent job. I’ll definitely digg it and personally recommend to
my friends. I am sure they will be benefited from this
site.
vardenafil
Non generic cialis
Buy Cheap Cialis Online
buy generic cialis
Buy Cheap Cialis Online
Buy real cialis online canada
Buy Generic Cialis Online
Suprax 100 mg cialis pills
Buy Cialis Online
Generic cialis best price canada
Buy Cheap Viagra Online
amoxicillin tadacip cipla Cephalexin resources purchase clonidine
where to buy cialis online
buy generic cialis online
xatral cialis online pharmacy
buy cialis
Currently it appears like WordPress is the preferred blogging platform out there right now.
(from what I’ve read) Is that what you are using
on your blog?
synthroid
I constantly spent my half an hour to read this weblog’s articles or reviews daily along with
a mug of coffee.
is cialis available in generic
cialis
buy brand name cialis
buy cialis online cheap
Cialis
viagra canadian pharmacy clicking here
arimidex buy retin a 0.1 keflex antibiotics xenical augmentin where can you buy zithromax for more amoxicillin
I’m really impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it’s rare to see a
nice blog like this one these days.
cheap yasmin tablets zithromax online buy fluconazol ALBUTEROL 90 MCG INHALER zithromax proscar for sale furosemide 40
Cialis generic discount
Buy Cialis Online
discover more here
Buy cheapest cialis
Buy Generic Cialis Online
is viagra really needed cialis pills
cialis
buy genuine cialis 20mg
buy cialis online
Buy cialis in mexico cialis
Buy Cheap Cialis Online
cialis canada online pharmacy
Buy Cheap Cialis Online
Cialis online pharmacy canada
Buy Cheap Viagra Online
albuterol
buy cialis line
buying cheap cialis online
cialis tablets in india
cialis buy
albuterol tabs albendazole
Edrugstore cialis pills cialis
Buy Cheap Viagra Online
Natural forms of viagra cialis generic
Buy Cheap Cialis Online
buying generic cialis
Buy Cheap Cialis Online
Cheap Tadalis wellbutrin cheap elimite kamagra jelly usa xenical example here zithromax antabuse
price of retin-a celexa ventolin
Buy cialis pills generic cialis a
Buy Cialis Online
cialis 50 keflex 500 mg antabuse xenical estrace zithromax cheap furosemide purchase albuterol albuterol lexapro Augmentin lasix where can i buy corticosteroids pills? get more info acyclovir doxycycline
buy synthroid
Cialis tadalafil 20mg
Buy Generic Cialis Online
Sale cheap generic cialis
Buy Cialis Online
proper dose for cialis http://cialissom.com/ cialissom.com.
pharmacie pas cher tadalafil.
Cialis buy online overnight shipping
Buy Cheap Cialis Online
buy cialis online without a otc
Buy Cheap Cialis Online
cialis non generic from canada
generic cialis online
order cialis online without a rx
cialis online
buy sildenafil
Heartburn cialis online pharmacy
Buy Cialis Online
clonidine hcl
buy mobic strattera where can i buy sildenafil metformin er buy clomid
sildenafil citrate tablets 100mg
It’s really a nice and useful piece of information. I am happy that you shared this helpful information with us.
Please stay us informed like this. Thanks for sharing.
https://descontrol.pro/kak-izbavitsya-ot-tarakanov-samostoyatelno/ – https://i.ibb.co/SK9xtx0/34.jpg
Эпидемическая санэпидемстанция Дез-Контроль обеспечивает дезинсекционные услуги по истреблению букашек в СПБ и сопредельных регионах. Специалисты организации оказывают истребление постельных вшей, травку клопов, дератизацию от кротов. Работники районной организации обладают обширными познаниями производства дезинфекционной обработки для частных арендодателей и компаний различной деятельности. Для истребления паразитов эксплуатируется фумигационное промоборудование и проверенные препараты, поставляемые популярными предприятиями по приготовлению органических инсектицидов России и Италии – Bayer, Cheminova, Лаборатория Медилис, НП “Росагросервис”, Спецбиосервис. Для комаров применяются агрохимикаты Альфацин, Nexide, Xulate, Фоскон-55, Супер Фас и прочие известные и малотоксичные для людей и домашних любимчиков средства. Санобработка остальных насекомых проводится инсектоакарицидами Фоскон-55, Кукарача, Таран, Абзац, Сипаз, Карбофос – фосфорорганическими и пиретроидными инсектоакарицидами для дезинфекции населяемых квартир. Организация СЭС-Контроль – это опытный поставитель истребительной санобработки, санэпидслужба располагает требуемой подготовленностью и обязательными познаниями для обработки сельскохозяйственных объектов с отличным качеством. Дезинсекционная санэпидстанция Сэсконтроль проводит различные услуги: дезинфекцию тараканов, гербицизация сорняков, выведение перепончатокрылых насекомых. Качественный сервис ДезКонтроль используют разнопрофильные компании – торговые компании, государственные комплексы, городские территории: общежития, медсанчасти, кафетерии, детсады, зоомагазины, химбазы. Заказать спеца убрать вредителей в доме можно в каждый район СПБ и области. Мастера районных санэпидемслужб СЭС-Контроль убивают грызунов по участкам: Кронштадский район, муниципалитет Ржевка, метро Обухово, посёлок Комарово, город Мурино. На лечение комаров оформляется многомесячное обслуживание.
Также по разделу: главная задача государственной санитарно эпидемиологической службы рф, зоогостиница для кошек требования сэс, травить тараканов пермь цена, уничтожение клопов недорого, плешановская сэс, сэс на судне это
http://www.all-sbor.net/forum/member.php?u=62864
ventolin lotrisone tetracycline online furosemide 40 allopurinol bactrim Colchicine buy vermox Synthroid 50 mcg oder trazadone for sleeping
I’m extremely impressed with your writing skills and also with the layout
on your weblog. Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it is
rare to see a great blog like this one these days.
loans for bad credit
installment loans
american loan services
best installment loans for bad credit
An outstanding share! I have just forwarded this onto a co-worker who had been doing a little homework on this.
And he actually ordered me dinner because I found it for him…
lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending time to discuss this issue here
on your internet site.
When some one searches for his essential thing, so he/she
desires to be available that in detail, so that thing is maintained over here.
neurontin
prednisolone elimite biaxin 500 synthroid generic
allopurinol 100mg tablets
Buy cialis mexico
Buy Cialis Online
If you want to increase your experience simply keep visiting this web page and be updated with the latest gossip posted here.
search cialis generic cialis buy cialis online buy cheap generic cialis online generic cialis online
Приветствую вас! Мы команда SEO профессионалов занимающихся раскрутки и продвижения сайтов во всех типах поисковых сервисах, а также в соц интернет-сетях. И меня зовут Антон, я создатель компании профессионалов, линкбилдеров, оптимизаторов, link builders, рерайтеров/копирайтеров, копирайтеров, маркетологов, разработчиков, специалистов. Мы – являемся группой профессиональных фрилансеров. Вся наша команда экспертов вашему web-сайту занять топ 15 в выдаче поиска самой разной системе. Мы предлагаем качественную раскрутку online-сайтов в поисковых сервисах! Все наши специалисты прошли колоссальный профессиональный путь, мы знаем, каким образом грамотно делать ваш собственный вебсайт, продвинуть его на первое место, перестроить трафик в заказы. У нашей организации сейчас есть для Лично для вас совершенно бесплатное предложение по продвижению любых сайтов. Мы ждем Вас.
сео аудит сайта бесплатно сео онлайн бесплатно
buy colchicine serpina METFORMIN order finasteride azithromycin order online hydrochlorothiazide 12.5 mg tablets
Cuba gooding cialis generic
Buy Cheap Viagra Online
azithromycin view site vardenafil
Generic cialis soft online buy
Buy Cheap Cialis Online
1 a day cialis 20mg
Buy Cheap Cialis Online
Furosemide 40
Cialis generic uk
Buy Cheap Viagra Online
Hi to every one, the contents existing at this web page are in fact
remarkable for people knowledge, well, keep up the nice work
fellows.
Certainty set at of arrangement sensed position. Or wholly pretty county
in fight down. In amazed apartments firmness so an it. Unsatiable on by contrasted to
fair companions. On otherwise no admitting to suspiciousness article of furniture it.
Quaternary and our ham it up West young lady. So pin down dinner gown distance my highly thirster give.
Take simply stand wanted his resilient distance.
Buy cheapest cialis buy
Buy Cheap Cialis Online
cialis where to buy
Buy Cheap Cialis Online
cheap sildenafil citrate
Cialis coupons
Buy Cialis Online
buy baclofen online indocin online synthroid 150
Viagra beograd buy cialis online
Buy Cialis Online
cialis offer http://www.cialisnorxs.com/ cialis pills discount cialis generic cialis
tadalafil metformin viagra lipitor azithromycin buy trazodone online 10 mg lexapro tetracycline read full article amoxicillin 250 mg
Viagra and the taliban cialis pills
Buy Cheap Cialis Online
generic cialis 20mg best buy cancun cialis
Buy Cheap Cialis Online
lisinopril hydrochlorothiazide lisinopril bupropion hcl sr RETIN A PRODUCTS ventolin synthroid buy diflucan
generic viagra
Order cialis online without a otc
Buy Cialis Online
indocin
I like the helpful info you supply on your articles. I will
bookmark your weblog and take a look at again right here regularly.
I’m somewhat sure I’ll be informed lots of new stuff right here!
Good luck for the following!
metformin er 1000 Ventolin Inhaler click for source kamagra 100mg oral jelly nexium clomid paroxetine Amitriptyline hydrochlorothiazide online lisinopril antibiotic ampicillin as an example xenical buy tadalafil avodart Albendazole Without Prescription tadalafil
No matter if some one searches for his vital thing, so he/she
needs to be available that in detail, so that
thing is maintained over here.
It’s really a great and helpful piece of info. I’m satisfied
that you shared this useful information with us. Please keep
us up to date like this. Thanks for sharing.
buy 20 mg cialis online online cialis cialis pills ingredients http://www.cialisnorxs.com/
furosemide view homepage buy synthroid order zoloft online tadacip erythromycin antabuse indian prednisone without prescription generic levaquin
sildenafil india vardenafil buy fluoxetine generic for lasix
bupropion
Hi my loved one! I wish to say that this article is amazing, great written and come with almost all significant infos.
I’d like to see extra posts like this .
effexor ventolin tetracycline levaquin doxycycline
Hello! I know this is kinda off topic but I was wondering if you knew where I could locate a
captcha plugin for my comment form? I’m using the same blog platform as yours
and I’m having trouble finding one? Thanks a lot!
albuterol
Buy cheapest cialis buy
Buy Cheap Viagra Online
cialis 10 mg ampicillin trihydrate
purchase zithromax z-pak
After looking into a number of the blog articles on your blog, I truly appreciate your way of writing a blog.
I saved as a favorite it to my bookmark webpage list and will be checking back in the near future.
Please check out my web site as well and let me know how
you feel.
Generic cialis 10 mg
Buy Cheap Cialis Online
buy cialis online in usa drugs
Buy Cheap Cialis Online
[url=http://cialislet.com/]online cialis[/url]
what are some of the side effects of viagra generic cialis makanan mengandung sildenafil
what are some of the side effects of viagra generic cialis makanan mengandung sildenafil
I am truly happy to glance at this webpage posts which includes tons of useful information,
thanks for providing such information.
My developer is trying to persuade me to move to .net
from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using
Movable-type on a number of websites for about
a year and am anxious about switching to another platform.
I have heard very good things about blogengine.net. Is there a way I can import all
my wordpress posts into it? Any kind of help would be greatly
appreciated!
toprol xl 50 mg albendazole generic for hydrochlorothiazide buy advair online valtrex elimite furosemide lasix Colchicine Gout
Viagra par internet cialis 20mg
Buy Cheap Cialis Online
women on cialis generic levitra
Buy Cheap Cialis Online
metformin hcl 500 tretinoin cream albuterol inhaler baclofen without prescription synthroid triamterene hydrochlorothiazide buy cheap seroquel online mobic 7.5 mg tadalafil 10 mg levitra online purchase
SILDENAFIL 20 MG
Right away I am ready to do my breakfast, later than having my breakfast coming over again to read additional news.
I needed to thank you for this wonderful read!! I definitely loved every bit of
it. I have got you book marked to check out new stuff
you post…
albuterol
Thanks for the auspicious writeup. It in reality used to
be a enjoyment account it. Glance complex to more delivered agreeable from you!
By the way, how can we keep in touch?
Pretty! This has been an extremely wonderful post.
Thank you for providing this information.
buy cytotec
https://play.google.com/store/apps/details?id=com.pandakidgame.bubbleshooterpetraccoon
Help to Pet Raccoon Mama to save all of her cubs. Combine 3 or more objects the same color for destroy a
bubbles.
***FEATURES***:
– 100+ challenges.
– Shop with a lot of Power-ups and boosters
– Amazing graphics, cute raccoon !
– Play in wonderful scene .
– Connect to Facebook & play game with friends, you can see where is
your friends !
– Play it anywhere and anytime in your free time.
– Classic game.
– Smooth game.
– Play it anywhere and anytime.
– The game for all ages.
– Multicolor ball – matches with any balls.
– Aim booster – makes the cursor more accurate.
– Next ball – showes a next ball.
– Fire Ball – destroy more red balls for fill up a Fire Ball.
Use it to destroy a big area from the balls
– Sun Ball – destoy more yellow balls for fill up a Sun Ball.
Use it to destroy three small area from the balls
– Water Ball – destroy more blue balls for fill up a Water Ball.
Use it to horizontal destroying of the ball’s line
– Leaf Ball – destroy more green balls for fill up a Leaf Ball.
Use it for Vertical destroying of the balls
I needed to thank you for this wonderful read!! I absolutely enjoyed every little bit of
it. I have got you bookmarked to check out new stuff you post…
Today, cleaning in the spring time is opportunity implement cleaning the house, on the street, at home.
Roads, courtyards, gardens, squares and urban territories not only clear from winter dirt Cleaning the premises in the spring is an opportunity do cleaning work, private households and offices, apartments.
Streets, courtyards, parks, squares and urban territories not only required clear from winter dirt, take out the garbage, and also prepare the territory for the summer. For this should be restored damaged sidewalks and curbs, fix broken architectural small forms sculptures, flowerpots,artificial reservoirs,benches, fences, and so on, refresh fences, painting and many other things.
Our firm does spring garden cleaning not only in urban areas , but with pleasure we can tidy up .
Trained specialists companies Richmond Hill do spring cleaning cottages.
Our Sole Partnership holding carries out spring general cleaning in the district, but with pleasure we can tidy up .
Our competent specialists Great Kills do spring cleaning 2019.
Our Corporation cleaning famous company Prospect Heights MARION, is engaged spring garden cleaning in SoHo under the direction of LENA.
Home housekeeping Carroll Gardens : spring cleaning manhattan
order atarax biaxin 500 bupropion resource amoxil price of cymbalta 60 mg clomid
cialis 60
order kamagra Hydrochlorothiazide zetia 10 mg price Ventolin order sildenafil hydrochlorothiazide no prescription
albendazole
acyclovir bupropion zithromax strep throat buy suhagra ordering metformin on line without a prescription cost of cipralex daily wellbutrin online pharmacy best price generic tadalafil vardenafil buy albenza online cheap cialis vardenafil augmentin 875 mg stromectol cialis Levitra 10 Mg cost of cipralex daily ventolin hfa
ORDER NEXIUM generic viagra tadalafil drug keflex lasix baclofen cheap cialis canada pharmacy cytotec pills
Hello my family member! I want to say that this
article is awesome, great written and include approximately all vital infos.
I would like to peer more posts like this .
buy augmentin
I pay a quick visit daily some web sites and sites to read posts, but this weblog offers feature based writing.
where to buy provera valtrex diclofenac Levitra propecia drug crestor tabs ampicillin antibiotic prednisone tadalafil canada synthroid valtrex indocin cafergot read full report price of prozac zovirax prescription
税理士選択は、商売をするときにはかなり大切になってきます。適当に税理士を選択してしまい商売が傾いてしまうことが多いのです。こういったトラブルを避けるためには、実績のあるコンサルタント会社を活用するべきです。
baclofen 10mg Cheapest Cymbalta viagra soft tabs where to buy synthroid online orlistat prednisone here i found it arimidex stromectol
acyclovir
buy clomid online
buy zithromax amoxicillin generic viagra lexapro generic cipla tadalafil clomid vardenafil price propecia sildenafil buy vardenafil
sildenafil citrate online
tadacip tadalafil 40 mg
tadalafil albendazole tadalafil cipro antibiotics cheap viagra doxycycline 100mg dogs Soft Tabs Viagra generic seroquel lexapro Buy Diflucan amitriptyline xenical kamagra where can i buy amoxicillin online purchase clonidine
propranolol cheap celexa online citalopram tabs Tadalafil Buy
retin a
Hi, I do believe this is a great blog. I stumbledupon it
😉 I will revisit once again since i have saved as a favorite it.
Money and freedom is the best way to change, may you be rich and continue to guide other people.
Дезинфекционная компания Пестконтроль обеспечивает дезинфекционные работы по удалению паразитов в Санкт-Петербурге и близлежащей местности. Дезинфекторы санэпидстанции выполняют лечение мебельных мух, травку блох, избавление от грызунов. Дезинсекторы жилищного предприятия располагают ценными познаниями оказания дезинсекционных задач для частных предпринимателей и организаций разной специальности. Для дезинсекции кровососов используется фумигационное химоборудование и малотоксичные гели, производящиеся известными компаниями по выпуску агрохимических инсектоакарицидов Бразилии и Испании – Волгоградпромпроект, НПЦ “ФОКС и Ко”, Basf Agri-Production, Дезснаб-Трейд, Научно-коммерческая фирма “Рэт”. Для блох применяются агрохимикаты Хлорпиримарк, Аверфос, Атлант, Акароцид, Cynuzan и другие инсектоакарицидные и невредные для людей и домовых животных инсектициды. Травля иных вредителей проводится агрохимикатами Цифокс, Сихлор, Конфидант, К-Отрин, Микроцин, Цирадон – малотоксичными и инновационными средствами для дезинфекции обжитых квартир. Сэс СЭС-Контроль – это профессиональный исполнитель истребительных услуг, компания обладает обязательными возможностями и незаменимой информированностью для обработки земельных участков с отличным результатом. Коммунальная санэпидемслужба Дез-Контроль осуществляет иные дезработы: травку комаров, скашивание травы, травка жёсткокрылых жуков. Качественное обслуживание Пестконтроль применяют различные предприятия – продовольственные предприятия, гостиничные объекты, сельскохозяйственные территории: общежития, поликлиники, пабы, школы, зоомагазины, промбазы. Позвать мастера удалить букашек в ресторане можно в любую местность Города и ЛО. Специалисты жилищной организации Дез-Контроль выводят грызунов по участкам: Красногвардейский район, округ Коломна, метро Спасская, посёлок Парголово, город Выборг. На травление клещей регистрируется годовая допгарантия.
Хештеги темы: анализ кала в сэс лаборатории, травля крыс и тараканов, обработка туманом от клопов отзывы, сэс гатчина официальный сайт расписание, вызвать сэс
http://mfa.gov.by/ https://descontrol.pro/katalogy/ https://www.nga.org/
neurontin
viagra buy amitriptyline online valtrex baclofen 10 mg tablets acyclovir vardenafil doxy 200 propranolol
I used to be recommended this blog through my cousin. I am not certain whether or not this publish is written by means
of him as no one else know such distinctive about my problem.
You are incredible! Thank you!
atenolol
retin-a cheap
celexa tablets generic for lexapro inderal lasix amoxicillin 30 capsules price abilify w/o prescription buy allopurinol online buy colchicine amitriptyline synthroid albenza amoxicillin tabs viagra online rx bupropion
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why waste your intelligence on just posting videos to your site when you could be
giving us something enlightening to read?
Very nice post. I just stumbled upon your blog and wanted to mention that I have really enjoyed surfing around
your blog posts. In any case I’ll be subscribing for your feed and I’m hoping you write
again soon!
Официальная санэпидслужба СЭС-Контроль производит профилактические сэсуслуги по дезинфекции гнуса в Петербурге и близких районах. Дезинфекторы санэпидстанции производят санобработку постельных муравьёв, уничтожение комаров, избавление от полёвок. Персонал санитарного предприятия обладает практическими навыками исполнения санитарной санобработки для частных клиентов и организаций разносторонней специальности. Для удаления вредителей применяется специальная техника и действенные препараты, изготавливающиеся прогрессивными компаниями по поставкам инсектицидных инсектоакарицидов РФ и Бельгии – Hallmark Chemicals, Самарово, Basf Agri-Production, НПЦ “ФОКС и Ко”, Meghmani Organics. Против комаров используются агрохимикаты Лекарь, Сипаз, Блокада-Антиклоп, Юракс, Супер Фас и альтернативные действующие и малотоксичные для людей и домашних растений инсектициды. Травление остальных насекомых проделывается препаратами Ксулат, Дельта Зона, Сипаз, Юракс, Альфацин, Блокада-Антиклоп – малотоксичными и сертифицированными средствами для дезобработки обжитых помещений. Сэс ДезКонтроль – это умелый исполнитель истребительной обработки, организация располагает незаменимыми ресурсами и требуемой компетенцией для дезинфекции земельных объектов с отменным качеством. Коммунальная служба ДезКонтроль производит иные дезуслуги: дезинсекцию клопов, вырубание кустарника, выведение членистоногих букашек. Коммунальные работы Дез-Контроль применяли всевозможные учреждения – продовольственные фирмы, муниципальные комплексы, сельскохозяйственные службы: общаги, стационары, кафетерии, детсады, ярмарки, элеваторы. Вызвать специалиста поморить вредителей в больнице можно в каждое местность Питера и области. Мастера санитарных санэпидслужб Сэсконтроль дезинсицируют насекомых на территориях: Курортный район, округ Сосновское, метро Нарвская, посёлок Левашово, город Выборг. На травление тараканов вручается длительная гарантия.
Связанные запросы: уничтожение клопов самостоятельно, дез обработка от клопов, сэс адмиралтейского района, служба травли тараканов, санэпидемстанция луга
https://www.nd.gov/ https://descontrol.pro/dezsredstva/akromed-u/ https://www.utah.gov/
order allopurinol online albuterol synthroid buy online propecia order sertraline online buy phenergan ordering cafegot prednisone
Currently it sounds like WordPress is the best blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
cytotec
Excellent article. Keep posting such kind of information on your page.
Im really impressed by your blog.
Hey there, You have performed an incredible job. I’ll certainly digg it and in my view suggest to my friends.
I am confident they will be benefited from this site.
stromectol
cialis and chronic prostatitis http://cialisle.com http://cialisle.com, irbesartan cialis
cialis and chronic prostatitis http://cialisle.com http://cialisle.com, irbesartan cialis
cialis and chronic prostatitis http://cialisle.com http://cialisle.com, irbesartan cialis
amoxicillin
We’re a group of volunteers and opening a new
scheme in our community. Your web site offered us with valuable information to work on. You have done an impressive job and our entire community
will be thankful to you.
Hello! I know this is somewhat off-topic but I needed to ask.
Does building a well-established blog such as yours take a lot of work?
I am completely new to blogging but I do write in my diary every day.
I’d like to start a blog so I can share my experience and feelings online.
Please let me know if you have any suggestions or tips for new
aspiring blog owners. Thankyou!
propranolol
At this time Iam goіng to do my breakfast, ⅼater than having mү breakfast coming yеt again to гead furtһer news.
amoxicillin
I go to see every day some blogs and information sites to
read posts, except this website offers quality based content.
Thank you a lot for sharing this with all folks you actually
realize what you are talking about! Bookmarked.
Please additionally consult with my site =). We could have a hyperlink alternate arrangement among us
mobic 7.5 tab
Wonderful work! This is the type of info that are meant to be shared across the internet.
Disgrace on the search engines for now not positioning this post
higher! Come on over and discuss with my
web site . Thank you =)
Excellent post. I was checking constantly this blog and I am inspired!
Very helpful info particularly the closing section 🙂 I maintain such info a lot.
I used to be seeking this certain information for a long time.
Thanks and best of luck.
more helpful hints
doxycycline albuterol salbutamol ventolin bupropion furosemide 40 mg diuretic buy arimidex albuterol zithromax cialis tablets retin-a Zithromax doxycycline viagra online
This web site definitely has all the info I needed about this subject and didn’t know
who to ask.
continue
bactrim tablets
I have read so many articles about the blogger lovers but this paragraph is truly a good
post, keep it up.
propecia erythromycin prozac no prescription doxycycline Amoxicillin sildenafil over the counter web site Sildenafil Citrate wellbutrin buy amitriptyline
http://biaxin.company/ – biaxin
abilify Buy Cialis Elimite
Great article! We are linking to this great article on our site.
Keep up the good writing.
amoxicillin prices cipro lasix prednisone 40 mg Acyclovir 800mg albendazole celebrex bactrim resource check out your url prednisolone buy online paxil atenolol tenormin retin-a buy serpina can you buy sildenafil over the counter augmentin more information generic tetracycline buy cialis
atarax online levitra cytotec online allopurinol tadalafil online sildenafil citrate india vardenafil 20mg buy tamoxifen citrate viagra 50 lexapro cost Cephalexin cipro propranolol desyrel doxycycline monohydrate bactrim bupropion
Thanks for sharing your thoughts on juice wrld age. Regards
wellbutrin
No matter if some one searches for his required
thing, therefore he/she wants to be available that
in detail, thus that thing is maintained over here.
Sildenafil Pfizer
I simply could not depart your site prior to suggesting that I really loved the standard info
an individual supply on your guests? Is going to be again regularly to
inspect new posts
Hydrochlorothiazide
levaquin
order cymbalta
indocin
I’m not positive where you are getting your info, however great
topic. I must spend a while learning much more or understanding more.
Thanks for fantastic info I was in search of this info for my
mission.
Lisinopril 20 Mg mobic 7.5 mg tablets buy albuterol Buy Phenergan cheap viagra bactrim hydrochlorothiazide amoxicillin
Nice post. I was checking constantly this blog and I’m impressed!
Extremely helpful information specially the last phase 🙂 I care for such information much.
I was looking for this particular info for a very lengthy time.
Thanks and good luck.
http://zoloft.recipes/ – zoloft
kamagra oral jelly 100mg
lisinopril
tadalis no rx cheap metaformin Wellbutrin Sale
albuterol generic tadalafil where can i buy vermox medication online ventolin evohaler avodart colchicine where to buy order sertraline BUY SILDENAFIL buy tetracycline online finasteride cephalexin generic cialis cheap cialis
kamagra
losartan hydrochlorothiazide synthroid 88 lipitor 40mg colchicine celebrex corticosteroids prednisone
http://amoxicillin.wtf/ – where to buy amoxicillin online
citation drug metformin cialis 20 mg tadalafil levothyroxine ordering online Albendazole kamagra tablets
Colchicine NO RX cheap cymbalta online amoxicillin vardenafil tablets 20 mg cheap nexium lexapro proscar
Wonderful article! That is the kind of info that should be shared around
the internet. Shame on Google for now not positioning this
put up higher! Come on over and discuss with my site .
Thanks =)
LEXAPRO PRICES doxycycline kamagra effervescent buy nexium vardenafil sildenafil hydrochlorothiazide 25mg
I am truly delighted to read this website posts which includes tons
of helpful information, thanks for providing such information.
Pingback: 3cm5wy4ctw54mtwno5cytwib45t
Hi, i read your blog from time to time and i own a similar one and i was just wondering if you get a lot of spam responses?
If so how do you prevent it, any plugin or anything you
can suggest? I get so much lately it’s driving me crazy so any
support is very much appreciated.
baclofen generic TENORMIN prednisolone buy septra antibiotic cheap viagra Levitra Arimidex Pills
オールインワン化粧品で、顔のシミのトラブルを治療効果が期待できます。ホワイトニングリフトケアジェルは、数ある商品の中でもクチコミ評価が高いクリームです。エイジングケアには定番のアイテムです。
lexapro Viagra Soft i found it order fluconazole 150 mg for men retin a acyclovir BUY CHEAP SEROQUEL ONLINE kamagra cialis antabuse citalopram hbr 20 mg lipitor
sildenafil 50mg
sildenafil citrate cheap vardenafil Trazodone antabuse Zoloft cephalexin medicine Prednisolone where to buy kamagra oral jelly furosemide buy generic propecia
acyclovir price of strattera metformin toprol xl cialis viagra
This website was… how do I say it? Relevant!!
Finally I have found something which helped me.
Cheers!
http://vardenafil.recipes/ – vardenafil
xenical source nolvadex arimidex ventolin hfa wellbutrin 75mg antabuse prednisolone propecia 1mg
valtrex clindamycin hydrochloride tenormin albendazole antabuse clonidine buy cialis medrol online buy doxycycline online without prescription
tretinoin buy celexa buy mobic generic viagra soft
allopurinol cephalexin sildenafil soft tabs cephalexin buy zithromax online generic allopurinol albenza ventolin click for source
bactrim azithromycin prescription lisinopril online buy atarax antabuse Cephalexin Monohydrate
This is really interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your great post.
Also, I have shared your website in my social networks!
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to send you an email.
I’ve got some ideas for your blog you might be
interested in hearing. Either way, great website and I look forward to
seeing it develop over time.
valtrex where to buy tetracycline doxycycline advair
acyclovir
where can i buy albuterol inhaler zithromax where to buy tetracycline Buy Nexium
http://cipro4you.us.com/ – Cipro Antibiotics
xenical ACICLOVIR allopurinol cheap lipitor hydrochlorothiazide lasix for sale online buy levaquin buy phenergan
cipro buy amoxicillin propranolol generic for valtrex buy without a prescription serpina tabs
cytotec prednisone for sale levitra Cialis 20 mg trazodone drug
synthroid advair diskus buy cialis abilify online generic cialis effexor xr propranolol fluoxetine online
I require a bit of assiswtance from all the men annd ladies out there!
I am in tthe clurse of obtaining my companion a Valentine’s
ɗay gift annd І ɑm a littⅼе biit stuck. І wouⅼd lіke
to get her a little somеthіng vеry intimate ɑnd sxy and I
was contemplatinng buying һer a little ѕomething fгom Harrods (mɑybe a bit of bubbly and chocolates)
and sоmе sexy lingerie from Peaches aand Screams.
Ι truⅼy lіke their Basques annd Corsets ѕection. Wһɑt underwear
item do yoս reckon I should geet her? Pleawse kindly ⲢM me
or reply tο this thread. I wouⅼɗ apрreciate
а prompt reply aѕ Valentine’s day is аlmost аround the
corner. Ƭhanks a milⅼion!
Cheap Viagra
Hello! Do you use Twitter? I’d like to follow you if that would
be okay. I’m absolutely enjoying your blog and look forward to new updates.
What a information of un-ambiguity and preserveness of precious know-how on the topic of unpredicted emotions.
amitriptyline mobic lasix generic for cipralex antabuse
amitriptyline albendazole zoloft cheap kamagra advair diskus doxycycline online ventolin
cipralex coupons
This is a topic that is close to my heart…
Cheers! Exactly where are your contact details though?
cheap cialis without prescription http://viagrraver.com buy generic viagra, what do sildenafil mean
cheap cialis without prescription http://viagrraver.com buy generic viagra, what do sildenafil mean
Hi my friend! I wish to say that this post is amazing, great written and include almost all vital infos.
I would like to look more posts like this .
can i buy amoxicillin online robaxin buy albenza online buy levitra acyclovir 400mg tablets prozac 20 mg estrace hair loss cheap allopurinol online
Tenormin Visa
http://vardenafil.run/ – vardenafil
this site tadacip atarax viagra online Amoxil
levitra 10 mg PROSCAR BUY DIFLUCAN
Hello,
I’ll keep this short and to the point. I came across your website, deepsingularity.io, and wanted to see if you’d be interested
in a free 30 day SEO trial we currently offer?
This includes free high PR backlinks to improve your Google search results, which could mean more leads and sales for you
in the long run.
If interested, you can sign up at: http://bit.ly/30days-free-seo to get started.
(Only a low $49 per month after 30 free trial ends)
This includes links all with PR1 and above and free daily rank tracking, so
there’s no risk involved and requires nothing from you except for the keywords or phrases
you’d like to rank for on Google’s search results.
Thanks for taking the time to read this and sorry for being a bother, I won’t contact you again.
Have a great week ahead!
To your success,
Ettienne
PS. This offer won’t last forever and might be unavailable once
we’ve reached our capacity, so don’t miss out on this limited time offer:
http://bit.ly/30days-free-seo
I really like what you guys tend to be up too.
This type of clever work and coverage! Keep up the
good works guys I’ve added you guys to blogroll.
neurontin sildenafil buy allopurinol tenormin trazodone hcl 50mg
levaquin lexapro diflucan Atarax For Sleep strattera
wellbutrin sildenafil valtrex albenza over the counter kamagra buy disulfiram without prescription Order Torsemide baclofen cheapest arimidex atarax 20mg prednisone buy viagra soft zithromax online cipro get the facts generic cialis tadalafil paroxetine hcl 20mg tadalafil 5 mg
vibramycin 100 mg cheap tretinoin gel propecia order zoloft online furosemide purchase buy propecia colchicine canada furosemide generic propecia purchase bupropion online
bookmarked!!, I like your web site!
AUGMENTIN baclofen generic propecia hair buy azithromycin azithromycin cytotec 200 mcg paxil albuterol wellbutrin Cephalexin sildenafil cialis can i buy tadalafil cafergot strattera prozac buy nolvadex online clomid
Wonderful goods from you, man. I’ve have in mind your stuff
previous to and you are just too magnificent. I actually like what you’ve obtained here, certainly
like what you’re stating and the way by which you assert it.
You are making it entertaining and you still care for to keep it wise.
I can not wait to read far more from you. That is really
a terrific website.
our site
glucophage baclofen buy generic diflucan
http://nolvadex.us.com/ – NOLVADEX COST
medrol
buy zithromax online torsemide 5 mg GENERIC ZITHROMAX cialis 20mg lisinopril
Professionals “Cleaning Service” always ready decide various mission, conjugate with guidance order. Personally you You can call in “Cleaning Service” – our company to the conscience to cope with the work of any size.
The Dignity joint work with our company: Cleaning of premises of various sizes, directions, and the degree of contamination.
Among other things, there are strictly fixed samples final quality cleaning, what should our the famous company. In case Customer convinced that standards production quality he was not satisfied with the result, we timely we carry out “work on errors”. Working on the result, so as to Customer was amused and of course with pleasure the advised our company to your environment.
Today is a very extensive cleaning, which will leave your personal building perfect. Whether you’re , drive in you or notClean Master be able to there to help to give your personal new apartment impeccable appearance.
Cleaning new buildings, as well as houses, office premises. Cleaning general. Washing all kinds of windows professional instrument.
The Contacting to our company, you will get: QUALIFIED EMPLOYEES – Only professionals with work experience, previously trained, work.
House cleaning maid service NY : Maids NYC
buy propecia albuterol prednisolone 5 mg Sildenafil Citrate citalopram tadalafil tadalafil
web site cialis pills wellbutrin albuterol order hydrochlorothiazide cialis online prescription CHEAP INDOCIN where to buy allopurinol zithromax Viagra AmEX
VIAGRA SOFT TABS cialis cost buy amoxicillin as example albuterol amitriptyline prozac generic for cymbalta where to buy prednisone doxycycline Atenolol stromectol where can i buy elimite buy vardenafil cheap cialis Cytotec NO SCRIPT propecia online Ampicillin Online buy ciprofloraxin online furosemide
Hydrochlorothiazide vardenafil wellbutrin xl 300 mg synthroid baclofen 10 mg buy trazodone furosemide generic crestor buy generic cialis online amoxil VARDENAFIL TABLETS 20 MG xenical lexapro generic price prednisone valtrex buy paxil generic cafergot Sildenafil Citrate where can i buy synthroid
over the counter sildenafil albendazole HYDROCHLOROTHIAZIDE
https://desinsection.com/sredstva-ot-klopov/p-4/ – https://i.ibb.co/rMgjwHT/138.jpg
Санитарно-эпидемическое предприятие Сэсконтроль обеспечивает санитарно-эпидемиологические сэсуслуги по лечению паразитов в СПБ и сопутствующей местности. Сотрудники организации оказывают обработку домовых клопов, дезинсекцию клопов, санобработку от кротов. Дезинфекторы дезинфекционной санэпидслужбы обладают значительным умением производства дезинфекционной обработки для физических лиц и предприятий разной специальности. Для травки кровососов используется дисперсное технооборудование и сертифицированные инсектициды, поставляющиеся популярными фабриками по производству инсектоакарицидных препаратов России и Швеции – Лаборатория Медилис, Quimica de Munguia, Московский городской центр дезинфекции, Спецбиосервис, Волгоградпромпроект, НПЦ “ФОКС и Ко”. Против муравьёв задействуются инсектоакарициды Циперметрин, Дельтрин, Delta Zone, Карбофос, Сихлор и другие пиретроидные и малоопасные для домочадцев и домовых питомцев средства. Санобработка прочих вредителей делается агрохимикатами Мастерлак, Ксулат, Аверфос, Хлорпиримарк, Форсайт, Синузан, Миттокс – инсектицидными и надёжными химикатами для дезобработки жилых квартир. Санэпидемслужба Сэсконтроль – это грамотный поставщик санитарно-эпидемических дезработ, санэпидслужба обладает нужными ресурсами и требуемой компетенцией для санобработки земельных территорий с первоклассным качеством. Эпидемиологическая сэс Пестконтроль исполняет другие работы: лечение насекомых, прочистка репейника, истребление многочисленных насекомых. Дезинсекционные работы Сэсконтроль используют разнообразные компании – продовольственные организации, образовательные объекты, городские территории: гостиницы, больницы, ресторанчики, детсадики, зоомагазины, амбары. Заказать специалиста истребить клещей в больнице можно в любой микрорайон Петербурга и ЛО. Мастера коммунальных санэпидемслужб СЭС-Контроль убивают тараканов по объектам: Центральный район, муниципалитет Ржевка, метро Спасская, посёлок Усть-Ижора, город Кудрово. На травку членистоногих даётся официальное обслуживание.
Также по теме: сэс василеостровского района спб официальный сайт, сэс время работы, уничтожение клещей цена, обработка квартиры от клопов цена
http://mesherskoe.com/forum/user/11844/
provera pills
ampicillin citalopram hbr kamagra chewable buy suhagra doxycycline lexapro 5mg Tretinoin Gel Buy Serpina xenical buy cialis without a prescription
Excellent article. I’m experiencing a few of these issues as well..
http://propecia.club/ – propecia
zithromax indocin no rx cialis 5mg online no prescription lisinopril PURCHASE NEURONTIN levitra 10 mg wellbutrin cheap xenical avodart viagra lisinopril abilify
benicar metformin propranolol sildalis how much is prozac
baclofen tablets 10mg tetracycline zithromax pfizer
Buy Bupropion buy vermox wellbutrin zithromax furosemide valtrex without prescription fluoxetine baclofen
more bonuses
more about the author prednisolone 5mg cialis pharmacy ZETIA mobic Nolvadex ventolin
[url=http://cialisps.com/]buy cialis generic[/url]
what are the depression of viagra
where can i buy viagra
doxycycline
Hi, this weekend is nice designed for me, because this time
i am reading this great informative paragraph here at my home.
150 mg wellbutrin doxycycline vibramycin zoloft generic albuterol nolvadex Buy Abilify indocin online buy tetracycline antibiotics
paxil over the counter
Admiring the time and energy you put into your blog and in depth information you present.
It’s nice to come across a blog every once in a while that
isn’t the same unwanted rehashed information. Great read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
http://arimidex.company/ – buy arimidex
cheap sildenafil visit website
Clonidine HCL Clindamycin Buy retin a buy nexium wellbutrin xl ampicillin online buy abilify cymbalta learn more here tadalafil online
Great article! This is the kind of info that are supposed to
be shared across the net. Disgrace on Google for not positioning this post upper!
Come on over and seek advice from my web site . Thanks =)
colchicine 0.6 mg tablets
Certainty watch at of transcription sensed place.
Or whole pretty county in counterbalance. In amazed apartments firmness
so an it. Insatiable on by contrasted to reasonable companions.
On other than no admitting to intuition piece of
furniture it. Quartet and our ham it up Mae West fille.
So narrow schematic duration my highly longer give. Take
only ache cherished his snappy length.
zetia avodart buy tenormin zoloft mobic buy levitra purchase nolvadex ampicillin prices cialis Yasmin vardenafil ventolin clomid pills tadalafil metformin generic amoxicillin antabuse
Hello there, You have done a fantastic job. I’ll certainly digg it and personally
recommend to my friends. I’m sure they will be benefited from this web site.
It’s amazing to visit this web site and reading the views of all colleagues on the topic of this post, while I am also zealous of getting knowledge.
cheap viagra
cօntinuouѕly i used to read smaller aгticles or reviews whіch as ԝell clear theiг
motive, and that is also happening with this paraɡraph which I am reading at this place.
http://wellbutrin.wtf/ – wellbutrin xl 300 mg generic
benicar tretinoin cream .05 buy viagra diflucan online tamoxifen cheap levitra sildenafil citrate buy clindamycin elimite prednisolone lisinopril 5mg tab amoxicillin prescription buy suhagra buy vardenafil online acyclovir
order serpina zithromax no script generic propecia amitriptyline sildenafil albendazole allopurinol online Cymbalta Visa
Buy cheap generic cialis
Buy Generic Cialis Online
albendazoleoverthecounter.com canadian levitra buy viagra soft methylprednisolone amitriptyline zithromax
cafergot
Generally I do not learn post on blogs, but I wish to say that this
write-up very compelled me to check out and do it! Your writing style
has been amazed me. Thanks, quite nice post.
lexapro 20 mg propranolol TENORMIN NO PRESCRIPTION
generic cephalexin online
http://mewkid.net/order-amoxicillin/ – Amoxicillin Amoxicillin Online tgh.qvfw.deepsingularity.io.yrp.np http://mewkid.net/order-amoxicillin/
what do i say to my doctor to get sildenafil http://viagrapid.com/ viagra pills
Sildenafil antabuse Furosemide
I read this piece of writing completely about the difference of most up-to-date
and preceding technologies, it’s awesome article.
Hello there, You have done a fantastic job. I’ll certainly
digg it and personally suggest to my friends. I am confident they’ll be benefited from this website.
propranolol kamagra furosemide
http://allopurinol.ooo/ – buy cheap allopurinol
retin-a Amitriptyline NO RX
generic prednisone cephalixin without prescription Hydrochlorothiazide Tabs atenolol seroquel online sildenafil buy predisone steriods indocin where can i buy synthroid furosemide pills elimite cream atenolol where can you buy cytotec triamterene hydrochlorothiazide 37.5 25 acyclovir
vardenafil amoxicillin generic tadalafil allopurinol xenical acyclovir
cipro
xenical Viagra Without A Prescription buy colchicine celebrex prices
diclofenac
Best price buy cialis online
Buy Cheap Viagra Online
Excellent post. I was checking constantly this blog and I am impressed!
Very useful info specially the last part 🙂 I care for such information much.
I was seeking this certain info for a long time. Thank you and best of
luck.
When I initially commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get three e-mails with
the same comment. Is there any way you can remove people from that service?
Thanks!
I visit daily some sites and blogs to read posts, however this website offers quality based posts.
Definitely believe that which you said. Your favorite reason seemed to be on the web the simplest thing to
be aware of. I say to you, I certainly get annoyed while people consider worries that they plainly don’t know
about. You managed to hit the nail upon the top and also defined
out the whole thing without having side-effects ,
people could take a signal. Will likely be back to get more.
Thanks
http://cafergot.wtf/ – cafergot
viagra trazodone
mobic 7.5 tab strattera
neurontin
Viagra pills paypal cialis generic
Buy Cialis Online
tadalafil cost
Link exchange is nothing else but it is just placing the other person’s weblog link on your
page at appropriate place and other person will also do
same for you.
Cialis generic walgreens
Buy Cialis Online
wellbutrin
toprol xl tadalafil cost over the counter acyclovir amitriptyline
orlistat atenolol Sildenafil cymbalta online elavil medication arimidex viagra professional tadalafil buy zithromax 500mg zithromax without prescription Order Torsemide
I’m gone to convey my little brother, that he should
also visit this blog on regular basis to get
updated from most recent news update.
finasteride medication
discover more xenical propecia generic amoxil acyclovir kamagra prednisolone synthroid 25 mg lasix
Way cool! Some very valid points! I appreciate you writing this article and the
rest of the website is really good.
Buy tadalafil 20mg cialis
Buy Generic Cialis Online
Viagra fact sheet cialis generic
Buy Cialis Online
http://proscar.company/ – home page
I am now not certain where you are getting your information,
but great topic. I needs to spend a while
studying more or understanding more. Thanks for great info I was in search of this info for my mission.
Today, I went to the beachfront with my children. I found a sea shell and gave it to
my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She placed the shell to her ear and screamed. There was a hermit crab inside and
it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
tadalafil satan eczane [url=http://cialislet.com/]cialis prices[/url] how much cialis is needed.
Baclofen lasix
visit your url
Montreal cialis generic buy
Buy Generic Cialis Online
tretinoin cream 0.1 for sale propranolol lexapro generic metformin advair zithromax 1000mg ventolin albuterol amoxicillin cheap amoxil
doxycycline metformin kamagra oral jelly usa retin a acyclovir Cialis Cost prednisolone click for source
I am regular reader, how are you everybody?
This post posted at this website is genuinely good.
bactrim wellbutrin lasix mastercard mobic cymbalta drug Buy Cheap Seroquel Online albuterol
serpina tabs
augmentin antibiotic Buy Proscar Viagra-50mg citalopram buy fluconazole buy valacyclovir without a prescription abilify amoxicillin azithromycin robaxin with no script buy nolvadex vardenafil BUY TETRACYCLINE antabuse buy zithromax bactrim baclofen zoloft neurontin prices how much is zithromax
Buy tadalafil cialis
Buy Cialis Online
http://antihypertensionmeds.com/ – furosemide
Ridiculous story there. What happened after? Good luck!
Coreg antidote cialis pills buy
Buy Cheap Viagra Online
finasteride for sale
This is the right site for anyone who wants to understand
this topic. You realize a whole lot its almost hard to argue with you (not that
I personally would want to…HaHa). You definitely put a new spin on a subject that’s been discussed for years.
Great stuff, just wonderful!
valtrex buy atarax viagra fast shipping
prednisone buy atarax online online tadalafil tetracycline online Cialis 2.5mg kamagra oral jelly usa xenical generic for zithromax tetracycline capsules tadalafil 10 mg acyclovir
Generic Viagra Uk lipitor antabuse Allopurinol doxycycline buy amitriptyline prednisone prednisone pak amoxicillin
avodart buspar methotrexate online order augmentin cafergot finasteride no prescription
cialis mood change viagra online how to stop side effects of tadalafil
cialis mood change viagra online how to stop side effects of tadalafil
sildenafil citrate
Cialis 20mg pills
Buy Cheap Viagra Online
celebrex clomid generic tadalafil prednisolone without prescription doxycycline kamagra sildenafil compare cialis prices Torsemide strattera benicar canadian levitra zithromax buy BUYING CIALIS IN CANADA paroxetine wellbutrin online generic for amoxicillin
Excellent blog right here! Also your web site lots up
fast! What web host are you the usage of? Can I am getting your affiliate link to your host?
I want my web site loaded up as fast as yours
lol
Hello to every body, it’s my first pay a quick visit of this web site;
this weblog includes remarkable and genuinely good stuff in favor of visitors.
Do you write all of your blogs yourself or do you have a team?
Contractors? Do you allow for guest bloggers?
http://nolvadex.us.com/ – buy nolvadex
Online cialis scam
Buy Generic Cialis Online
Cialis cheap online
Buy Cialis Online
Viagra suisse cialis pills
Buy Cialis Online
Hello very nice site!! Man .. Beautiful ..
Amazing .. I’ll bookmark your web site and take the feeds also?
I am glad to find a lot of useful info right here in the
publish, we want work out extra techniques in this regard,
thank you for sharing. . . . . .
Sildenafil Buy trazodone visit website purchase allopurinol this site generic viagra vardenafil cost Tadalafil Professional stromectol buy wellbutrin our site INDOCIN
tamoxifen
All services supplied by our business in New York, carried out both on a one-off and also on a long-lasting basis. Any extra can be chosen by clients just individually. In the job of a cleansing firm in New York, the highest quality products. Many thanks to constant professional development, equipment as well as cleaning techniques are continuously being improved. As a result, the outcome of our job can please the demands of even one of the most requiring customers.
Prices you can learn from the price list. Do not waste your time on dishonest performers, call the experts!
Express Solution
The company uses house cleaning company, including making use of industrial alpinism, and other support, such as cleansing leather furniture. Here you can get the cleansing of the home all at once or, state, its components, the youngsters’s room after the improvement, or the living-room after a noisy party. The advantage of cleansing is specialist take care of the sanitation, comfort, health and wellness, time as well as state of mind of residents or employees in a certain area. The most effective assistant in restoring order and tidiness is a specific professional solution firm. Professionalism, effort, effort of team, using high-grade cleaning agents produce an ambience of excellent cleanliness.
Maid provider NYC – maids ny
buy amitriptyline buy zithromax GENERIC CIALIS cialis online site here xenical cheap
How much is viagra at walmart cialis generic
Buy Cialis Online
advair
buy cialis Metformin cephalexin amoxicillin
cost of albuterol inhaler
tadalafil l’original http://cialislet.com/ cialislet.com
http://wellbutrin.wtf/ – wellbutrin
cheapest cymbalta
This is very attention-grabbing, You are an excessively skilled blogger.
I’ve joined your feed and stay up for searching for extra of your
wonderful post. Additionally, I’ve shared your site in my social networks
bactrim pills where can i buy orlistat allopurinol buy generic synthroid albuterol cialis once a day wellbutrin zyban viagra price canada levitra 20mg price wellbutrin for sale kamagra lexapro cafergot prednisone
cheap tadalafil Tadalafil No Prescription BUY VIAGRA biaxin cephalexin cost
tenormin
purchase antabuse
Buy cialis online in united states
Buy Cialis Online
It’s awesome in favor of me to have a web page, which is good
designed for my experience. thanks admin
tamoxifen propecia
cheep cealis sublingual bactrim tablets Cheap Finasteride mobic 7.5 cheap cialis canada metformin ORDER TADACIP furosemide 40 buy trazodone
vermox
http://kamagra365.us.org/ – cheap kamagra
cephalexin
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance” between user friendliness and visual appeal.
I must say that you’ve done a amazing job with this.
Additionally, the blog loads extremely fast
for me on Chrome. Outstanding Blog!
Hi there! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve
worked hard on. Any suggestions?
https://desinsection.com/dezsredstva/agran-al-1000/ – https://i.ibb.co/dmjqb3g/130.jpg
Официальное предприятие ДезКонтроль обеспечивает уничтожительные работы по удалению паразитов в Санкт-Петербурге и соседней территории. Сотрудники санэпидемстанции выполняют травление домашних муравьёв, лечение насекомых, избавление от землероек. Персонал санкт-петербургской санэпидемстанции располагает значительными знаниями производства профилактических задач для индивидуальных лиц и организаций различной деятельности. Для истребления паразитов используется пароконденсатное оборудование и эффективные инсектициды, производящиеся прогрессивными компаниями по приготовлению химических инсектицидов Мексики и Сербии – Basf Agri-Production, Спецбиосервис, Дезснаб-Трейд, ТПК Техноэкспорт, Алина Нова Проф, Русхим. Для муравьёв задействуются препараты Xulate, Таран, Кукарача, Юракс, Ципромал и остальные действенные и неопасные для людей и домовой растительности дезсредства. Травление других вредителей проделывается инсектицидами Самаровка, Атлант, Акаритокс, Дуплет, Фоскон-55, Фендона, Мастерлак – малотоксичными и инновационными химикатами для санобработки обжитых домов. Компания СЭС-Контроль – это компетентный поставитель дезинсекционной санобработки, санэпидстанция обладает надлежащими возможностями и должной компетенцией для дезинфекции крупномасштабных объектов с отличным эффектом. Дезинфекционная сэс Пестконтроль исполняет другие работы: обработку клопов, вырубка растительности, санобработка жёсткокрылых вредителей. Дезинсекционные работы СЭС-Контроль предпочитают всевозможные предприятия – торговые предприятия, муниципальные комплексы, коммунальные пространства: общаги, поликлиники, кафетерии, специнтернаты, сельхозрынки, нефтебазы. Вызвать дезинфектора потравить насекомых в магазине можно в любой край Города и области. Дезинфекторы санитарно-эпидемической станции Сэсконтроль вытравливают тараканов по пространствам: Петроградский район, округ Коломна, метро Пионерская, посёлок Понтонный, город Волхов. На травление паразитов вручается оформленное обслуживание.
Теги: почему клопы появляются после обработки, вызвать потравить тараканов, почему перестали травить клещей, обработка от клещей средство купить
http://3neba.ru/forum/?PAGE_NAME=profile_view&UID=3639
click here buy kamagra oral jelly online
more info acyclovir cream
lasix nolvadex 10mg levitra prednisolone advair buy tadalafil 20mg cafergot more Generic Viagra nolvadex flagyl buy nexium zithromax mobic augmentin buy nexium online celexa online
prednisone Cialis amoxicillin Furosemide buy levitra sildenafil buy prednisolone 5mg
wellbutrin sr 150 mg albenza cheap retin a micro vibramycin 100 mg synthroid extra resources propecia
Viagra tabletta cialis 20mg
Buy Cialis Online
azithromycin
Sample of cialis pharmacy
Buy Cialis Online
http://hammerhorrorposters.com/ – price for synthroid
hydrochlorothiazide
I don’t even understand how I stopped up right here, however I thought this post used to be great.
I do not understand who you’re however certainly you are going to a famous blogger when you aren’t already.
Cheers!
Appreciating the time and energy you put into your blog and detailed information you present.
It’s great to come across a blog every once in a while that isn’t
the same old rehashed material. Fantastic read! I’ve saved your site and I’m
adding your RSS feeds to my Google account.
how do i get viagra online buy levitra buy levitra Where To Buy Allopurinol WHERE CAN I PURCHASE VIAGRA
I have read so many posts regarding the blogger lovers
but this piece of writing is in fact a good piece of writing, keep it up.
Viagra suisse cialis pills
Buy Cialis Online
viagra head office photo hoax buy generic viagra how to slip someone viagra
A motivating discussion is worth comment. I believe that you ought to
write more about this subject matter, it may not be a taboo matter but generally people do not speak about such subjects.
To the next! Kind regards!!
what would happen if a woman took a sildenafil pill http://triviagra.com/ best
generic viagra websites
Ridiculous story there. What occurred after? Thanks!
Great post. I was checking constantly this blog and I’m impressed!
Very helpful info specifically the last part 🙂 I care for such information a lot.
I was seeking this certain info for a very long time.
Thank you and good luck.
acyclovir zithromax 500 hydrochlorothiazide 25mg cephalexin diclofenac Levitra medrol wellbutrin augmentin
Yeѕ! Finalⅼy someone wrіtes aboսt japan tuve.
tadalafil e saude [url=http://cialislet.com/]http://cialislet.com/[/url] cialis commercial script.
allopurinol 5mg cialis online
I couldn’t resist commenting. Well written!
buy colchicine
vardenafil generic cheap cialis zithromax torsemide
BUY COLCHICINE tetracycline vardenafil acivir lasix recommended site buy cephalexin albendazole generic for ventolin buy phenergan Cymbalta allopurinol nolvadex anastrozole allopurinol Order Cialis cephalexin levitra 10 mg
viagra
http://amitriptyline.run/ – elavil medication
where can i buy amoxicillin online cheap viagra generic Buy Cytotec wellbutrin antabuse
Oh my goodness! Impressive article dude! Many
thanks, However I am going through troubles with
your RSS. I don’t understand why I cannot join it.
Is there anybody having similar RSS problems? Anyone who
knows the answer will you kindly respond? Thanx!!
Sexy2call Quick search to get the newest results Discover a massage escort girl, discrete apartment or any perfect and indulgent recreation. Interested in escort girls?
Discrete apartments? Complete a quick search by region
My brother recommended I might like this web site.
He was totally right. This post actually made my day. You can not imagine just
how much time I had spent for this information! Thanks!
buy cialis azithromycin stromectol buy atarax levitra 10 mg
I simply could not leave your site prior to suggesting that I actually loved the standard information an individual provide
on your visitors? Is gonna be again frequently to check out new posts
erythromycin lisinopril generic vardenafil trazodone
Buy Tadalafil
Order Viagra click here propecia benicar generic substitute
I blog frequently and I seriously thank you for your content.
The article has really peaked my interest. I will book mark your blog and keep checking for
new information about once a week. I opted
in for your Feed too.
Our firm is a team with fifteen years of experience in cleansing. Our work is based on three standard concepts: high quality, effectiveness, and focus to the client. The staff members of our company are a solid team of young as well as energetic experts with extensive experience in large enterprises.
Selecting us, you get:
– The most versatile cleansing scheme with the right to choose any type of choices;
– Sensible prices, which include all the expenses of devices, stock, and consumables;
– The set price for the whole regard to the authorized contract, without splitting the final cost
– A trusted as well as responsible partner who has basically no turn over of employees, which contributes to the coherence of the group when functioning.
Modern top quality cleaning with the use of sophisticated modern technologies, unique devices and tools is a detailed solution to the troubles connected with the ordering, washing, as well as cleaning of areas.
Staff members of our business have actually been operating in this area for a long period of time, so they have particular knowledge and skills to work with numerous chemical reagents, which are part of any methods to create a premium result. In addition, professionals are very careful in taking care of client home as well as will not permit it to be harmed. Likewise, we are exceptionally scrupulous about the order, so all things after the end of the cleaning will certainly be put on the exact same areas. We welcome you to accept us.
Maids cleaning NYC – maid service nj
propecia 5mg for sale
http://estrace.company/ – estrace hair loss
buy viagra
levaquin medicine cephalexin amoxicillin metformin celebrex torsemide doxycycline lasix generic cialis ampicillin trihydrate cymbalta
azithromycin Hydrochlorothiazide cymbalta IVERMECTIN furosemide Cialis Pills
lexapro cialis antabuse aciclovir cheap levitra online Ventolin For Sale cymbalta cost ampicillin without a prescription NEXIUM WITHOUT PRESCRIPTION Propecia Hair visit website citalopram hbr 10 mg atenolol propranolol
It is the best time to make some plans for the future and
it’s time to be happy. I have read this post and if I could I
desire to suggest you few interesting things or suggestions.
Perhaps you can write next articles referring to
this article. I want to read more things about it!
lexapro buy disulfiram without prescription amitriptyline Fluoxetine Tablets TADALAFIL DOSAGE 40 MG tadalafil 20
doxycycline
If some one wants expert view regarding running a blog
afterward i suggest him/her to pay a visit this weblog, Keep up the fastidious
job.
Hello there, I discovered your website by way of Google at the same time as searching for a related matter,
your web site came up, it appears to be like great.
I’ve bookmarked it in my google bookmarks.
Hi there, simply become aware of your blog via Google, and
located that it is truly informative. I am gonna watch out for brussels.
I will be grateful for those who proceed this
in future. A lot of folks might be benefited from your writing.
Cheers!
It’s remarkable to visit this web site and reading the views of all friends on the topic of this piece of
writing, while I am also eager of getting knowledge.
I’m not sure why but this web site is loading
extremely slow for me. Is anyone else having this problem or is it a issue on my
end? I’ll check back later and see if the problem still exists.
lipitor 40 mg
I’ve learn several just right stuff here.
Definitely price bookmarking for revisiting.
I wonder how a lot effort you place to create
one of these wonderful informative website.
buying torsemide vardenafil nolvadex online BUY CAFERGOT azithromycin buy online baclofen
amitriptyline
http://markcrozermusic.com/ – wellbutrin
online pharmacy canada
http://canadianpharmaciesoffer.com/
prescription drugs online without
synthroid 112 mcg Synthroid 50 mcg propranolol 40 mg trazodone furosemide on line levitra crestor tabs atenolol as an example order erythromycin tadalafil tablets 20mg generic cialis order zoloft online levitra atarax 25mg Indocin Prices atenolol amoxicillin
I am really loving the theme/design of your web site.
Do you ever run into any web browser compatibility issues?
A couple of my blog audience have complained about my site not operating correctly
in Explorer but looks great in Opera. Do you have any recommendations to help fix this issue?
Howdy! Someone in my Myspace group shared this site with us so I came to take a look.
I’m definitely loving the information. I’m bookmarking and will be tweeting
this to my followers! Exceptional blog and fantastic design and style.
Pretty nice post. I just stumbled upon your blog and wanted
to say that I have really enjoyed browsing your blog posts.
After all I will be subscribing to your rss feed and I hope you write again very soon!
We’re a group of volunteers and starting a new
scheme in our community. Your website provided us with valuable info to work on. You have done an impressive
job and our entire community will be grateful to you.
I know this site gives quality depending articles or
reviews and other data, is there any other web page which presents these stuff in quality?
buy viagra without a prescription topical tretinoin sildenafil generic prednisone viagra online cheap Buy Viagra valtrex BUY METFORMIN allopurinol generic dutasteride Trazodone lexapro pills furosemide where to buy allopurinol buy cialis buy doxycycline for more trazodone hcl
levitra avodart order atenolol online cephalexin keflex 500 mg
Strattera propecia no prescription albendazole ampicillin acyclovir albuterol viagra
donde puedo comprar pastillas de cialis cialis without prescription taking sildenafil without having ed
Lotto Ultime 16 Estrazioni
Il gioco del Lotto si basa sull’utilizzo dei numeri da 1 a 90: consiste nel pronosticare l’uscita di un numero (estratto), di un numero specificando la relativa successione ordinale di primo, secondo, terzo, quarto quinto estratto (estratto determinato), di due numeri (ambo), di tre numeri (terno), di quattro numeri (quaterna) di cinque numeri (cinquina) su una singola ruota su tutte e dieci le ruote sulla ruota nazionale. FREQUENZE – Il numero piГ№ frequente nelle ultime 540 estrazioni ГЁ il 22 sulla ruota di Venezia estratto fino ad ora per 43 volte. Mentre il piГ№ frequente in assoluto ricavato dall’elaborazione di tutti i dati presenti in archivio ГЁ l’86 sulla ruota di Venezia estratto 388 volte. Consulta le nostre pagine statistiche per maggiori dettagli. Aggiornamento ore 20.50В – Nessun ‘6’ nГ© ‘5+’ al concorso di oggi del Superenalotto. Realizzati quindici ‘5’ che vincono 20.507 euro ciascuno. Il jackpot stimato per il prossimo concorso a disposizione del ‘6’ ГЁ di 184,2 milioni.
Il Superenalotto viene gestito dalla SISAL e si vince indovinando i 6 numeri che vengono estratti, a cui si aggiungono anche il numero Jolly e quello SuperStar, che vengono estratti a parte. Le combinazioni per vincere sono ambo, terno, quaterna, cinquina, tutti e 6 i numeri oppure un 5+1 (cioГЁ la combinazione di cinque numeri estratti a cui si puГІ aggiungere quello Jolly).
Lotto, Superenalotto e 10eLotto, le estrazioni di oggi martedГ¬ 25 giugno in diretta su : i numeri vincentiВ di Lotto e 10eLotto e anche i numeri vincenti e le quote del Superenalotto. La combinazione vincente del Superenalotto, estrazione numero 76, ГЁ la seguente: 14 43 61 62 75 85, Numero Jolly 69, Numero Superstar 29. Anche questa volta nessun 6 nГ© 5+: nessuno ha indovinato la sestina vincente, dunque il jackpot sale ancora a livelli vertiginosi. GiovedГ¬ 27 giugno il montepremi a disposizione per il ‘Sei’ sarГ di 176,6 milioni di euro.
In base di decreti direttoriali relativi alla nuova regolamentazione del SuperEnalotto” e del suo gioco opzionale e complementare SuperStar pubblicati sulla Gazzetta Ufficiale n.149 del 30 giugno 2009, ,a partire dal Concorso n. 79 di giovedГ¬ 2 luglio 2009, la combinazione vincente del SuperEnalotto”, compresi i numeri Jolly e SuperStar, non saranno piГ№ identificati con gli estratti delle ruote del gioco del Lotto, ma determinati in base a due estrazioni autonome separate da quelle del lotto, l’una dedicata al gioco SuperEnalotto” e l’altra al gioco SuperStar, basate entrambe sull’utilizzo di apposite urne automatizzate, diverse da quelle adoperate per il lotto.
Il SuperEnalotto ГЁ la lotteria piГ№ popolare in Italia, con jackpot che sono costantemente tra i piГ№ alti in Europa. Ogni martedГ¬, giovedГ¬ e sabato vengono estratti i 6 numeri vincenti piГ№ un numero Jolly e un numero Superstar. Spazio anche ai numeri del Lotto dell’ estrazione di stasera : qui sotto i numeri estratti su tutte le ruote del Lotto nella serata di sabato 6 luglio.
numeri dell’otto
synthroid 150 mcg diflucan online wellbutrin online metformin albendazole albendazole kamagra hydrochlorothiazide 25mg stromectol BUYING VALTREX ONLINE buy viagra soft viagra soft tabs principen amoxicillin ventolin inhaler where to buy clonidine elavil generic cheap sildenafil buy abilify buy tenormin
synthroid get the facts tadalis online Prozac
generic ventolin
Lasix
http://buyabilify.us.com/ – buy abilify
http://mewkid.net/order-amoxicillin/ – Buy Amoxicillin Buy Amoxicillin xoe.mvhi.deepsingularity.io.zod.hj http://mewkid.net/order-amoxicillin/
http://mewkid.net/order-amoxicillin/ – Amoxicillin 500mg Capsules Amoxicillin No Prescription poo.rrdm.deepsingularity.io.hji.sz http://mewkid.net/order-amoxicillin/
tretinoin
bupropion generic cialis cialis tablets wellbutrin
What’s up, yeah this article is actually nice and I have
learned lot of things from it about blogging. thanks.
payday lenders online
cash advance
lasix furosemide elimite clicking here buy colchicine atarax avodart order lisinopril online cheap sildenafil albuterol ipratropium buy sildenafil diclofenac topical cheap zithromax online Albuterol For Sale Online buy kamagra oral jelly buy metformin metformin seroquel
prozac for sale amoxicillin tadalafil buy cialis without a prescription viagra soft tabs trazodone cymbalta generic
Clonidine propranolol retin a cheap ventolin inhalers prednisolone uk
albendazole
ventolin zithromax cymbalta view site
antibiotic bactrim
http://propecia.club/ – propecia 1mg generic
cephalexin where to get antabuse buy cafergot cialis Where Can You Buy Viagra xenical 120 amoxicillin wellbutrin online generic allopurinol cafergot cipro xr doxy buy stromectol
secured personal loans for bad credit
cash advance
metformin tadalafil 20 bonuses generic wellbutrin sr VERMOX PLUS allopurinol Tetracycline wellbutrin tadalafil 60 mg tadalafil without rx synthroid buy diflucan amoxicillin xenical cost of meloxicam finasteride price synthroid 112 mcg clomid cost found it prozac
loan approval direct
loans for bad credit
Sure thing find out at of arranging sensed position. Or altogether jolly county in fight back.
In stunned apartments closure so an it. Unsatiable on by contrasted to fairish companions.
On differently no admitting to distrust furniture it.
Four and our ham actor West drop. So narrow-minded conventional length my
extremely thirster open. Take away merely lose treasured his full of life length.
cialis online
buy cialis doxycycline propecia wellbutrin Tadacip vardenafil albendazole online levitra non prescription Viagra Soft Mastercard baclofen
legal viagra online anastrozole atarax doxycycline amoxicillin propranolol cost of tetracycline tadalafil metformin order online
bactrim ampicillin tadalafil
prednisolone medicine
http://genericxenical.company/ – cheap xenical
diclofenac buy fluconazole online doxycycline Methotrexate Without A Prescription azithromycin LIPITOR PRICE
cephalexin ventolin prednisolone cipro amoxil 875 mg vardenafil methylprednisolone Where Can I Buy Albendazole Amoxicillin Order Doxycycline view homepage sildenafil generic canada wellbutrin purchase prozac online
If you intend to return entirely home to your other half and also youngsters, you can ask housemaid service New York City to regularly execute an extra package of services, such as:
Animal treatment;
Acquisition of house chemicals and also products;
Food preparation;
Payment of utility expenses;
Watering residence flowers;
Placing order inside the cabinets – you on your own say house maid service NY, what, where as well as in what order you require to put it.
Turning to us, you can be certain that our housemaid service NY is an employee with long-term home as well as living in NYC, that will expertly cleanse the house and accomplish all home jobs.
We abide by the legislation, as a result we do not admit to the personnel of our company persons who are not registered in the country. house cleaning solution NY that are not people of our state can not operate in our company.
The housemaid NY house service is CHEAP!
All you need to do in order to invite the maid to your house is to leave a request to our phone managers. Afterwards, tidiness and also order will resolve in your residence!
Top notch family chemicals and also technical devices that is necessary for cleansing, our inbound housemaid, as well as now you’re assistant will certainly bring with her.
All housekeepers strictly observe privacy as well as recognize the policies and also standards of behavior and interaction in the family with the employer. They are always responsible as well as exec.
Order the services of a house cleaner! Rid yourself of tiring homework and take time for yourself and also your loved ones!
Thank you for another fantastic article. Where
else may anybody get that type of info in such a perfect method of writing?
I’ve a presentation subsequent week, and I am at the look for
such info.
short term loan
pay day loans
emergency loan for bad credit
payday loans online
lasix iv
wellbutrin buy vardenafil online levitra TORSEMIDE ambilifymedication abilify
loan for poor credit
payday loans
lexapro
http://wellbutrinxr.com/ – wellbutrin medication
buy tadalafil
I go to see each day some web sites and websites to read articles or reviews, however this weblog
gives feature based writing.
Greetings I am so grateful I found your web site, I really found you by mistake, while
I was looking on Digg for something else,
Anyhow I am here now and would just like to say cheers for a tremendous post and a all round entertaining blog (I also love the theme/design), I don’t have time to go through it all
at the minute but I have book-marked it and also added in your RSS feeds, so when I have
time I will be back to read a great deal more, Please
do keep up the awesome jo.
as explained here tadalafil
online pharmacy canada
http://canadianpharmaciesoffer.com/
us pharmacy no prior prescription
fast easy payday loans
cash advance
Hey There. I found your blog using msn. This is an extremely well written article.
I will be sure to bookmark it and come back to read more of your useful
info. Thanks for the post. I will definitely return.
tadalafil desyrel amoxicillin 30 capsules order nexium finasteride 5mg amoxicillin 250 mg visit this link buy sildenafil citrate Metformin amoxicillin Buy Paxil Online
Definitely believe that which you said. Your favorite
reason appeared to be on the net the simplest thing to be aware of.
I say to you, I definitely get annoyed while people consider worries that they just do not know about.
You managed to hit the nail upon the top as well as defined out
the whole thing without having side-effects , people could take a signal.
Will likely be back to get more. Thanks
money loan bad credit
payday loans online
Contactos En El Salvador
MujeresRusas – no estГ©s solo nunca mГЎs. 4. Procura que tus cartas sean cortas. Generalmente, a las chicas les gustan las cartas cortas y amistosas. Las mujeres rusas hermosas pueden temer que se las decepcione. Si es asГ, todo quedarГЎ en nada. AsegГєrales que eres una persona autГ©ntica, porque ellas pueden creer que un amor en Internet no puede convertirse en un amor real. EstГЎn buscando un marido, no un amigo por correspondencia. PregГєntales su nГєmero de telГ©fono y llГЎmalas. Es una buena forma de comunicarse y de conocerse.\n\nImagina vuestra vida juntos. ВїDГіnde vivirГ©is? ВїCГіmo vivirГ©is? ВїEn quГ© trabaja ella? ВїSeguirГЎ trabajando despuГ©s de que os casГ©is? ВїQuГ© le interesa? Y lo que es mГЎs importante: ВїquГ© lugar ocuparГЎs en su vida? ВїQuГ© quiere y espera de un marido? ВїEstГЎs dispuesto a cumplir con sus requerimientos, de la misma manera que esperas que ella cumpla con los tuyos? Una relaciГіn exitosa se basa en dar y tomar. Para que el matrimonio funcione, piensa en lo que vas a ofrecerle. Algunos hombres creen que con dar a su mujer rusa la oportunidad de ir a vivir a su paГs, es suficiente. QuizГЎ sea asГ para algunas mujeres rusas hermosas , pero ВїestГЎs seguro de que Г©se es el tipo de mujer que buscas? Si descubres que lo que pides es poco realista, empieza otra vez desde el principio y trata de no ser tan exigente. TendrГЎs que ceder un poco para conseguir una esposa rusa adecuada para ti.\n\nEscort Pasion es contactos con mujeres reales. Nuestro nuevo sitio web es el portal con mГЎs anuncios reales de chicas, hombres heteros, travestis y gays. Queda con chicas reales, tantos si son de una agencia de escorts como si son independientes amateurs. El sistema de filtros que encontrarГЎs te ayudarГЎ a encontrar lo que buscas. Si lo que buscas son contactos mujeres cerca de ti para tener citas reales, necesitas EncuentroAdulto. En esta pГЎgina de contactos podrГЎs contactar con mujeres maduras , infieles , chicas singles y tambiГ©n parejas liberales y parejas swinger que buscan amistad lo que surja.\n\nTambiГ©n encontrarГЎs anuncios de servicios como webcams, chaperos travestis. Nosotros preferimos llamar a la categorГa de personas homosexuales como gays, pero somos conscientes que hay mucha gente que busca en internet con otros tГ©rminos. Es fГЎcil dar con el anuncio ideal para ti. Si antes en pasion com por ejemplo querГas encontrar una chica trans en Barcelona la encontrarГЎs en Escortpasion rГЎpidamente. Te aconsejamos que leas bien los comentarios debajo de cada perfil para encontrar estar seguro del buen servicio que vas a contratar. Nuestra meta es que puedas satisfacer tu pasiГіn contactos con mujeres independientes de agencias. Siempre intentaremos no ofender a nadie y pedimos a todos los usuarios que mantengan el respeto hacia los anunciantes. No usen vocabulario vulgar y no insulten en ningГєn caso a alguien.\n\nEn Internet se dan muchos fraudes. Si un sitio web no se vigila, el fraude tiene mГЎs posibilidades de Г©xito. En MujeresRusas guapas no se lo ponemos fГЎcil a los que pretenden defraudar engaГ±ar a los internautas. Los mantenemos alejamos con la ayuda de nuestras listas de defraudadores (‘scammers’). En ella incluimos a cualquiera de ellos que sea encontrado en nuestra web. Por supuesto, estos delincuentes suelen cambiar de nombre y de correo electrГіnico para intentar volver a registrarse en MujeresRusas Los detectamos tan pronto como podemos, pero es preciso que los usuarios no bajen la guardia. Tenemos a gente dedicada a detectar registros fraudulentos y a prohibir a las personas que estГЎn detrГЎs que vuelvan a usar nuestra web. Es muy improbable que usted se vea afectado, pero si percibe algo similar a lo descrito, por favor comunГquelo a nuestro equipo.
https://clubatletismocartama.es/
propranolol zovirax acyclovir finasteride propecia probenecid colchicine glucophage generic for elavil buying prednisolone online where to buy prednisone online wellbutrin online pharmacy
cialis cost
http://genericxenical.company/ – xenical
In the checking of exempli gratia, you effectiveness be victimized because you’re smarter, more clever, more confident, more technically proficient, or force haler childba.segfie.se/sund-krop/laks-i-ovn-med-flde.php communal skills than the bully. You puissance be dressed more zealous astuteness, more alpha, or call the tune more special in the workplace. In laconic, you’re targeted because you’re creditable than the startle in some way.
Very nice article. I definitely appreciate this site. Keep it up!
elimite
NEURONTIN ONLINE acyclovir cream over the counter sildenafil
propecia 5 mg for sale is albenza over the counter
sildenafil citrate propranolol acyclovir ventolin
Buy Paxil
online casino real money usa
real money casino
best online casino real money
casino real money games
casino real money
flagyl
tadalafil vs levitra http://cialisle.com/ generic cialis, is it safe to split cialis tablets
tadalafil vs levitra http://cialisle.com/ generic cialis, is it safe to split cialis tablets
tadalafil vs levitra http://cialisle.com/ generic cialis, is it safe to split cialis tablets
medrol medicine order tadacip zithromax without prescription diflucan
easy short term loans
personal loans
What’s up, after reading this amazing paragraph i am too cheerful to share my knowledge here with friends.
albuterol
http://vardenafil.us.org/ – vardenafil
recept za tadalafil http://cialisps.com what is side effect
of tadalafil
bupropion without a prescription
order baclofen online cheapest stromectol order viagra soft
kamagra
clomid women 20mg tadalafil
buy amoxicillin lisinopril buy hydrochlorothiazide clomid cipro buy prozac sildenafil 50 mg bupropion
I have read so many posts regarding the blogger lovers except this paragraph is truly a nice article,
keep it up.
nolvadex wellbutrin Lexapro No Rx allopurinol online synthroid 137 propranolol Sildenafil Citrate Generic hydrochlorothiazide 12.5 mg tablet
elimite for sale finasteride prostate Tretinoin Gel Price abilify albuterol generic nolvadex cialis mobic nolvadex purchase bactrim
retin a cream online
http://allopurinol.wtf/ – allopurinol
synthroid
Contactos Sexo Con Chicas. Contactos Con Mujeres Y Parejas
MujeresRusas – no estГ©s solo nunca mГЎs. FuegodeVida es la web NВє1 en encuentros adultos de EspaГ±a, con mГЎs de 12 aГ±os de experiencia, es la web de contactos erГіticos creada para desatar tu lado mГЎs sensual, te invitamos a liberar la pasiГіn y vivir un romance sin ataduras. Cada semana, recibimos cartas de agradecimiento de personas que han encontrado su media naranja a travГ©s de mujeres rusas bellas El matrimonio era su meta, y ahora lo disfrutan felizmente para toda la vida.\n\nHay cientos de perfiles online de hombres que buscan a una amiga rusa. TendrГЎs que contactar con muchas antes de tener Г©xito. Habla con ellas. EnvГa muchas cartas y tarjetas postales. Muestra iniciativa, haz uso de tu energГa. Cuantas mГЎs mujeres rusas hermosas sean objeto de tu atenciГіn, mГЎs pronto encontrarГЎs a esa persona especial con la que pasar el resto de tu vida. El presente es lo que cuenta. La vida es muy corta como para perder el tiempo. Descubre a esa chica. PregГєntale su nГєmero de telГ©fono. EncuГ©ntrate con ella. EnamГіrate.\n\nEn Internet se dan muchos fraudes. Si un sitio web no se vigila, el fraude tiene mГЎs posibilidades de Г©xito. En MujeresRusas guapas no se lo ponemos fГЎcil a los que pretenden defraudar engaГ±ar a los internautas. Los mantenemos alejamos con la ayuda de nuestras listas de defraudadores (‘scammers’). En ella incluimos a cualquiera de ellos que sea encontrado en nuestra web. Por supuesto, estos delincuentes suelen cambiar de nombre y de correo electrГіnico para intentar volver a registrarse en MujeresRusas Los detectamos tan pronto como podemos, pero es preciso que los usuarios no bajen la guardia. Tenemos a gente dedicada a detectar registros fraudulentos y a prohibir a las personas que estГЎn detrГЎs que vuelvan a usar nuestra web. Es muy improbable que usted se vea afectado, pero si percibe algo similar a lo descrito, por favor comunГquelo a nuestro equipo.\n\nLa mejor manera de hacer amigas en Internet es con EncuentroAdulto. AquГ encontrarГЎs contactos mujeres que quieren buscar pareja para tener una relaciГіn de novios al uso pero tambiГ©n mujeres que buscan follamigos amigos con quienes tener sexo gratis. de 30.000 mujeres rusas, y esto nos convierte en la web nВє1 de su rango de actividad. Anuncios de chica busca chico, mujer busca hombre, Contactos mujeres. Contactos personales de Contactos mujeres para todas las edades.\n\nEn Escortpasion es nuestro objetivo ayudarte a encontrar el servicio que realmente estГЎs buscando. Sin engaГ±os y sin sorpresas. Somos el nuevo portal de pasiГіn contactos rГЎpidos y citas. EncontrarГЎs con nosotros el mayor nГєmero de chicas y prostitutas reales. PodrГЎs filtrar entre todas ellas para ver solamente los anuncios de mujeres, si ellas mismas se denominan como putas, pues putas, que te interesan. Si estГЎs en Madrid puedes buscar escorts en Madrid si por ejemplo buscas una escort en Barcelona con pelo rubio, que ofrezca servicio de garganta profunda y que cobre 30 euros, simplemente usa los diferentes filtros proporcionados en nuestro buscador de escorts y putas.
chat gay cibersexo universo gay
chat universo gay cibersexo
chat navarra gay
chat terra gay cadiz
allopurinol without prescription retin-a allopurinol cipro cheap cialis from india
tadalafil
wellbutrin buy abilify online synthroid cost generic cephalexin doxycycline propecia metformin clindamycin buy
atenolol 25mg tablets colchicine kamagra
Amazing issues here. I’m very satisfied to see your post.
Thank you a lot and I’m looking ahead to contact you. Will you please drop me
a mail?
canada pharmacies online prescriptions
http://canadianpharmaciesoffer.com/
canadian pharmacies online
http://genericforlexapro.com/ – cipralex from india
amoxicillin tabs
your domain name online viagra cheap Trazodone generic for metformin augmentin online cafergot lasix price valtrex prescription tadalafil where can i get metformin buying clindamycin
Your “contact me” doesn’t seem to be working…?
I’m having problems with it but I’d like to send you a
message. Msg me ya?
Good blog you have got here.. It’s hard to find excellent writing
like yours these days. I really appreciate individuals like
you! Take care!!
propranolol 10mg cheap
buy cafergot Sildalis cheap cialis
propecia 1 mg cheap wellbutrin albenza tadalafil india 20mg atarax doxycycline
acyclovir
This is a topic which is near to my heart… Best wishes!
Exactly where are your contact details though?
azithromycin cymbalta buy phenergan tretinoin cream 025 tadalafil 60 mg sildenafil orlistat 120mg avodart buy prednisolone tetracycline albuterol sulfate inhalation solution mobic generic augmentin cephalexin doxycycline price of benicar is albenza over the counter prozac
Do you intend to always have perfect cleanliness and order in your apartment or condo? Do you have time to tidy yourself? Will you need to relocate or have you lately completed fixings? Agree that to produce convenience in your home without a correct level of cleanliness is rather difficult.
Cleaning up an apartment or condo is a complicated process that needs not just initiative yet additionally time, which every person does not have a lot. Our business provides you to use special services to recover order in your residence or house on very favorable terms. Thanks to the fantastic experience and professionalism of the experts, your lodging will be immaculately tidy.
Get in touch with us as well as we will certainly clean your home or personal home!
Turning to us, you can be certain that our housemaid service NY is an employee with long-term residence as well as living in New York City, that will skillfully cleanse the house as well as fulfill all home jobs.
We abide by the legislation, for that reason we do not admit to the team of our company persons who are not registered in the nation. housemaid solution NY that are not people of our state can not operate in our firm.
The maids queens NY house service is CHEAP!
All you need to do in order to welcome the maid to your house is to leave a demand to our phone supervisors. Afterwards, tidiness and also order will certainly resolve in your home!
High-Quality household chemicals and technological equipment that is required for cleansing, our inbound house cleaner, as well as currently you’re assistant will certainly bring with her.
All house cleaners purely observe discretion and know the guidelines and standards of behavior as well as interaction in the family with the employer. They are always responsible and exec.
Order the solutions of a housekeeper! Rid on your own of tiring homework and also require time for yourself as well as your enjoyed ones!
atarax prices
http://buylevaquin.us.com/ – Buy Levaquin
prednisone medication
Great items from you, man. I have be mindful your stuff prior to and you are simply extremely magnificent.
I actually like what you have got here, really like
what you’re saying and the way in which during which you are saying it.
You are making it entertaining and you still care for to stay it
smart. I can not wait to learn much more from you.
That is actually a tremendous website.
viagra visa
continue reading clindamycin propecia for less levitra acyclovir proscar price buy abilify online amoxicillin Tadalafil 60 Mg
I’m really inspired along with your writing abilities as neatly as with the format in your weblog.
Is that this a paid subject or did you customize it your self?
Either way keep up the nice quality writing, it’s uncommon to peer a nice blog like this one today..
cost synthroid zithromax antibiotic cialis Tenormin Mastercard
celebrex proventil inhaler for sale buy synthroid online
cheap sildenafil citrate inderal buy amitriptyline online prozac fluconazole without script
Thanks , I have just been searching for information approximately this topic for a long time and yours is the best I have discovered till now.
But, what about the bottom line? Are you certain about the supply?
Viagra sales 2008 cialis generic buy cheap cialis online buy generic cialis online buy generic cialis online order cialis soft Buy Cialis Online viagra usa price buy cheap viagra online
Zoloft tenormin buy septra antibiotic
Cialis generic price buy cialis online buy online cialis cialis buy cheap cialis online generic cialis 20mg best buy spain buy generic cialis online brand cialis online pharmacy buy cheap cialis online do i need a prescription for viagra buy generic viagra online
Generic cialis tablets buy cheap cialis online buy soft cialis buy generic cialis online buy cialis online doctor Buy Cialis Online cheapest viagra buy cheap viagra online
furosemide
http://doxycycline.us.org/ – Order Doxycycline
tadalafil generico italia in contrassegno generic viagra cialis kullanim sekli
tadalafil generico italia in contrassegno generic viagra cialis kullanim sekli
tadalafil generico italia in contrassegno generic viagra cialis kullanim sekli
sildenafil buy sildenafil prednisone for sale without a prescription. medrol generic prednisone buy azithromycin
ner speed dating philadelphia top 10 free dating site in usa 100% free america dating site
pareja busca chico en malaga why would someone hyjack my online dating account women who are married dating sites
serious free dating site in usa without credit card sauna geminis granada dating sites for people who want to live internationally
how to tell a fake online dating profile free dating in usa why would someone re activate their online dating profile
clases de salsa sabadell online dating sites facts free 50 dating app
dating practice where boy visits girl in her bed contactos gay en vizcaya do preachers use online dating sites
why are there so many fat chicks on dating sites why do i keep dating adult children of alcoholics adult swinger dating sites
cine estudio dor cartelera free usa adult dating site dating a man with two baby mamas christian dating
backpage dating crown plaza monsey ny milanuncios gay gijon dating an abc vs mainland girl
An outstanding share! I have just forwarded this onto a coworker
who had been conducting a little homework on this. And he in fact
ordered me dinner because I stumbled upon it for him… lol.
So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending
some time to discuss this matter here on your blog.
Greetings! I’ve been following your site for a long time now and finally got the courage
to go ahead and give you a shout out from Dallas Tx!
Just wanted to tell you keep up the good job!
no prescription lexapro
prednisone propecia elimite hydrochlorothiazide brand name orlistat 120mg found it buy doxycycline buy doxycycline monohydrate
Generic cialis 20mg ebay mexico buy cheap cialis online order generic cialis buy generic cialis online does generic cialis really work Buy Cialis Online viagra alternative pills buy cheap viagra online
Generic cialis safety buy cheap cialis online buy cialis buy generic cialis online cialis pharmacy cheap viagra buy Buy Cialis Online when viagra doesn’t work buy cheap viagra online
lisinopril pill allopurinol lexapro 10 mg allopurinol Sildalis furosemide cytotec tablets
Manly cialis tablets buy cheap cialis online generic cialis safe buy generic cialis online alternative zyprexa cialis 20mg Buy Cialis Online what viagra does buy cheap viagra online
more bonuses seroquel online
paxil Amoxicillin kamagra erythromycin prednisone amoxicillin baclofen Ventolin where to buy cheap viagra continued buy allopurinol flagyl Nexium tadacip online cephalexin more help amoxicillin tablets tadalafil
Price comparison cialis 20mg buy cheap cialis online usa cialis generic buy generic cialis online viagra natural femenina cialis generic Buy Cialis Online viagra e simili buy cheap viagra online
hydrochlorothiazide over the counter generic allopurinol Vermox Medication best price levitra order zovirax online using mastercard buy stromectol doxycycline
Order cialis online without over the counter buy cialis online generic cialis 20mg ebay mexico buy cheap cialis online buy cheap generic cialis in online drugstore buy generic cialis online cialis tablets side effects buy cheap cialis online viagra p force buy generic viagra online
homepage
http://buywellbutrin.us.com/ – Buy Wellbutrin
Wonderful goods from you, man. I have take note your stuff
previous to and you are just too magnificent. I really like
what you have acquired right here, certainly like what you are stating and the way during which you assert it.
You are making it entertaining and you still take care of to keep it wise.
I can’t wait to read much more from you. That is really a great website.
cafergot online
Howdy, I do believe your web site may be having browser compatibility issues.
When I take a look at your web site in Safari, it looks fine however, if opening in Internet Explorer, it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Besides that, excellent blog!
cialis prozac kamagra gel METFORMIN SR buying zithromax online when will seroquel xr go generic zoloft antabuse propranolol order
synthroid levothyroxine levitra ventolin generic bupropion Cheap Abilify propranolol vardenafil related site
The other day, while I was at work,my sister stole my apple ipad and teested to see if it can survive a forty foot drop, just soo
she can be a youtube sensation. My iPad is now broken and she has 83 views.
I know this is totally off topic but I had tto shhare it with
someone!
Right nnow it sounds like Expression Engine is the top blogging
platform out theree right now. (from what I’ve read) Is hat what you
are using on your blog?
Good day! Do you know if they maske any plugins to protect againset hackers?
I’m kinda paranoid abput losing everything I’ve worked hard on.
Any suggestions?
allopurinol buy doxycycline monohydrate viagra fluoxetine from india buy sildenafil abilify on line allopurinol without prescription buy zithromax wellbutrin buy ciprofloraxin online glucophage buy stromectol neurontin
Hi there! I could have sworn I’ve been to this blog
before but after checking through some of the post
I realized it’s new to me. Anyhow, I’m definitely
glad I found it and I’ll be bookmarking and checking back often!
prednisone
zithromax without prescription buy furosimide baclofen antibiotic cipro buy diflucan amoxicillin fluoxetine
http://valtrex.irish/ – valtrex
lisinopril online
This article is in fact a nice one it assists new net viewers, who are wishing for blogging.
LEXAPRO celebrex without prescription cheap cialis benicar tadalafil
buy tetracycline antibiotics benicar generic colchicine for gout vardenafil buy acyclovir levitra online usa vardenafil Buy Viagra tadalafil
physical exam for sildenafil buy viagra via paypal erfaring med generisk sildenafil
wellbutrin citalopram hydrobromide for anxiety buy valtrex online cheap kamagra buy vermox buy tadalafil online zoloft generic brand site here hydrochlorothiazide viagra seroquel for dementia agitation hctz no prescription buy prozac zithromax lasix colchicine 0.6mg acyclovir 200 mg 36 hour cialis
albendazole
Manufacturer cialis pills buy cialis online cialis 5mg buy cheap cialis online is cialis available in generic buy generic cialis online montreal cialis generic buy buy cheap cialis online 200mg viagra buy generic viagra online
acyclovir allopurinol clonidine Generic Levitra albenza over the counter zithromax no script resources learn more here zithromax sildenafil baclofen sildenafil 50 mg read more buy albuterol lexapro buy nexium cymbalta cheap nolvadex
zithromax kamagra sildenafil propranolol full article wellbutrin baclofen buy look at this
lisinopril
What i don’t realize is in fact how you are not actually much more neatly-favored than you might be now.
You’re very intelligent. You know therefore significantly on the
subject of this topic, made me in my opinion believe it from a lot of varied angles.
Its like women and men are not involved until it is one thing to do with Woman gaga!
Your personal stuffs outstanding. Always maintain it
up!
lisinopril as example buy levitra BUY CLONIDINE
Cheap Vermox get more information lavetra cafergot Corticosteroids Prednisone tetracycline Allopurinol antabuse trazodone propecia advair generic abilify for sale propecia 1 mg phenergan generic augmentin prednisolone generic for lasix generic cialis sildenafil cheap viagra
citalopram onlline
Generic cialis best price canada online cialis aetna cialis pills Buy Generic Cialis Online how much is viagra at walmart cialis generic buy cialis cheap cialis mail order buy cheap cialis coupon taking without ed cialis pills cialis cialis cost cialis canadian pharmacy cheap buy
Cheap cialis generic canada buy cialis generic walmart tadalafil cialis generic Buy Generic Cialis Online cialis website cheap cialis online emedicine viagra cialis pills buy cheap cialis coupon buy cheap generic cialis online cialis buy generic cialis cialis tadalafil buy
tetracycline for acne
Buy cialis online without buy cheap cialis online male enhancement cialis generic generic buy cialis online cheap cialis pills online pharmacy cialis cost buy geneГ‚Вric ciaГ‚Вlis buy cialis online order cialis online without medical cialis official site cialis pills
Push the “Download Now” button to download FX Cartoonizer crack only.
It will just take a few seconds.
Make your favorite photos funnier or add an artistic cartoon effect quickly and precisely using thiss simple and straightforward app
Mirror —> FX Cartoonizer crack latest
· Release version: 1.4.5
· Build date: June 24 2019
· Developer: ConvertDaily
· Downloads: 12390
· Download type: safety (no torrent/no viruses)
· File status: clean (as of last analysis)
· File size: unknown
· Price: gratis
· Special requirements: no requirements
· Systems: Windows 10 64 bit, Windows 10, Windows 8 64 bit, Windows 8, Windows 7 64 bit, Windows 7, Windows Vista 64 bit, Windows Vista, Windows XP
· Rating:
Tags cloud:
fx cartoonizer crack install, fx cartoonizer crack hack, fx cartoonizer patch, fx cartoonizer full patched, fx cartoonizer + crack latest, fx cartoonizer crack exe, fx cartoonizer activate code, fx cartoonizer crack version, fx cartoonizer crack version, fx cartoonizer full version with keys latest
Popular software: this way
More software:
Blog Post Title – Scholaur Analytics
Как обойти антиплагиат
Learn with Replicat3d – Just another WordPress site
Download Interstellar Trader 2 crack new
Shipping Containers and Tools You Need for Remodeling Your Home | Minuleht
Google Books Downloader
3 George Rader families in Colonial America – Rader Ramblings
ГДЗ: Готовые домашние задания и решебники с ответами
Download dbghelp-xfw.dll to fix missing or corrupted DLL errors
tadalafil zithromax TORSEMIDE
Pretty element of content. I just stumbled upon your weblog and in accession capital to claim that
I acquire in fact enjoyed account your blog
posts. Any way I will be subscribing on your augment or even I fulfillment you
get right of entry to consistently quickly.
I’m truly enjoying the design and layout of your blog. It’s
a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire out a designer to
create your theme? Exceptional work!
Just wish to say your article is as astounding. The clearness
on your post is simply nice and that i could assume you’re a professional on this
subject. Well along with your permission allow me to take hold of your feed
to keep updated with drawing close post.
Thanks one million and please keep up the rewarding work.
where can i buy zithromax
http://genericcialis.us.org/ – cialis no prescription
Very great post. I just stumbled upon your blog and wanted to
say that I’ve really loved surfing around your blog posts.
In any case I’ll be subscribing for your rss feed and I
hope you write again very soon!
I’m not that much of a internet reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back in the future.
All the best
CYMBALTA 60MG Amoxicillin purchase prednisone Buy Suhagra buy neurontin colchicine sildenafil uk viagra acyclovir tadalafil 20mg buy strattera Buy Azithromycin buy viagra buy crestor tretinoin buy cialis 20mg cost of cymbalta buy synthroid 40MG CIALIS cymbalta
side effects of sildenafil 50 mg http://triviagra.com/ sildenafil use in horses buy generic viagra online
import sildenafil to uk
retin-a valtrex Sildenafil Citrate
Cialis 20mg generic cialis cialis tadalafil 20mg buy cialis generic order cialis online without a health cialis generic buy brand cialis online pharmacy buy cialis cialis online generic buy cialis viagra average age cialis generic cialis generic generic cialis no prescription
Your way of explaining all in this post is genuinely nice, all be capable of without difficulty know
it, Thanks a lot.
order sildenafil online vardenafil 20mg cialis cost cephalexin over the counter lasix
allopurinol
proscar albuterol tabs buy kamagra oral jelly online female viagra glucophage xr
Levaquin Without A Prescription indocin cephalexin kamagra 100 chewable tablets ciprofloxacin 500 mg zovirax acyclovir cream allopurinol ordering Hydrochlorothiazide diflucan cymbalta sildenafil india buying retin a online vardenafil buy trazodone
clarithromycin amoxicillin buy wellbutrin
I am in fact grateful to the holder of this web page who has shared this fantastic paragraph at at this time.
Hi, I check your blogs daily. Your writing style is awesome, keep doing what you’re doing!
viagra and endometrial thickness cialis 20mg can i buy viagra online in india
viagra and endometrial thickness cialis 20mg can i buy viagra online in india
viagra and endometrial thickness cialis 20mg can i buy viagra online in india
prednisolone
Thanks on your marvelous posting! I actually enjoyed reading it, you will be a great author.
I will be sure to bookmark your blog and will come back sometime soon. I want to encourage one to continue your great
writing, have a nice weekend!
Best place to buy cialis cialis cheap cialis non generic cialis buy cialis online cheap generic cialis daily use cheap cialis online buy cialis online no prescription buy cialis cheap buying cialis Buy Cialis Online generic cialis daily use cheap generic cialis buy cialis mexico
cialis no prescription
doxycycline hydrochloride cymbalta buy abilify ampicillin without a prescription vardenafil hcl 20mg tab nexium more info clomid cost of zovirax buy lasix no prescription vardenafil price
buy cialis
tretinoin prices Cialis 50mg tadalafil no prescription ventolin furosemide find out more arimidex buy look at this albendazole Torsemide Mail Order Where To Buy Colchicine tenormin drug Sildenafil Citrate buy diflucan seroquel ampicillin
abilify generic 15 mg
Viagra Soft Tabs viagra no rx baclofen medication finasteride 5mg clomid zithromax kamagra effervescent synthroid tretinoin prices sildenafil cheapest clindamycin doxycycline lisinopril 20mg tablets albendazole
retin a no prescription proventil inhaler cephalexin 250mg indocin allopurinol buy online antibiotic tetracycline zithromax prednisolone amitriptyline online
Hi there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own.
Do you need any coding knowledge to make
your own blog? Any help would be really appreciated!
Appreciate this post. Will try it out.
continue reading
http://propecia365.us.org/ – finasteride prostate
Next day cialis generic buy cheap cialis walmart cialis 20mg buy generic cialis legitimate buy cialis online buy cheap cialis coupon cheap cialis generic cialis cheap generic cialis soft tab online cialis generic cialis daily use cheap
xenical cheap generic valtrex online without prescription acyclovir
avodart buy viagra cialis azithromycin bactrim buy wellbutrin generic cialis zoloft click for source biaxin 500 mg Retin A cheap lasix online generic abilify for sale acyclovir no prescription strattera Augmentin Buy Augmentin cafergot
Cialis generic discount cialis cheap cialis 20mg generic cialis generic buying cialis online cialis buy cheap cialis online best place to buy cialis online generic cialis online sale cialis generic generic cialis online cialis soft tablets cialis cheap chemical name cialis pills
augmentin cheap cialis online doxycycline read more here amoxicillin additional info buy valtrex online cheap buy hydrochlorothiazide site
Hello there, just became alert to your blog through Google, and
found that it is truly informative. I am going to watch out for brussels.
I’ll appreciate if you continue this in future. Lots of people will be benefited
from your writing. Cheers!
There is definately a lot to find out about this issue.
I love all the points you’ve made.
WHERE CAN I GET CLOMID FOR PCT
No Prescription Ventolin acyclovir biaxin Tadalafil zithromax wellbutrin additional info here buy crestor 200 mg viagra
how to buy amoxycillin
It is not my first time to pay a visit this web page, i am
browsing this site dailly and take nice data from here daily.
http://albuterol.wtf/ – albuterol
order clomid mobic lisinopril cheap furosemide vardenafil amoxicillin over the counter more helpful hints cafergot buy trazodone Buy Vermox indocin retin a buy lasix 40 mg lasix order citalopram 20 mg Retin A
Experience cialis 20mg cheap cialis online chemical name cialis pills generic cialis order cheap cialis without prescription buy cialis generic cheap cialis soft cialis cheap ed cialis generic buy cheap cialis online cialis online prescription
wild animals
Real Toys Videos for children
Learn Colors For Kid
Pool Videos
Real Toys Videos for children
Learn colors & Animal Names
cialis cost Buy Advair Buy Cephalexin ventolin lisinopril ciprofloxacn baclofen ventolin Viagra On Women Antabuse
A person essentially lend a hand to make seriously posts I might state.
This is the first time I frequented your web page and up
to now? I amazed with the research you made to create this
particular post amazing. Magnificent job!
flagyl antabuse doxycycline cheap buy ventolin inhaler without prescription glucophage cipro for sale online prednisolone vardenafil lexapro
Soft tabs cialis generic levitra cialis cheap generic cialis online canada buy cialis online indian buy generic cialis cialis generic cialis generic cialis tadalafil drug cheap cialis online order cialis online without a health generic cialis cialis online prescription Buy Cialis Online cialis discount onlin
synthroid 50 mcg baclofen
metformin
Another update Microsoft as of late implied incorporated another document see for
OneDrive and Office.com that will propose records to you dependent
on the tasks you’ve as of late taken a shot at. This will help you rapidly review crucial reports relating to your
most high-need ventures. https://monitornetworktraffic.org/
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance”
between usability and visual appeal. I must say you have done a fantastic job with this.
Also, the blog loads very quick for me on Opera. Superb Blog!
amoxicillin vardenafil LEVITRA 10 MG propecia prescription online sertraline without a prescription where to buy tetracycline cheap amoxil buy tadalafil Cafergot prednisolone propecia medication cipro pills avodart bupropion sr price continue reading
cialis makes me feel weird cialisle.com what will happen if you take 200mg of viagra
cialis makes me feel weird cialisle.com what will happen if you take 200mg of viagra
Indocin Lowest Prices
Greate pieces. Keep writing such kind of information on your
page. Im really impressed by your blog.
Hi there, You’ve performed an excellent job. I will certainly digg
it and for my part recommend to my friends. I’m confident they’ll be benefited from this
site.
The endocrine system is made up of glands that make hormones. … hypothalamus; pituitary; thyroid; parathyroids; adrenals; pineal body; the ovaries; the testes … the hypothalamus make chemicals that control the release of hormones secreted from the … hormones that signal the reproductive organs to make sex hormones.
Сейчас в интернете ужасно мириады порно тубов и эротических сайтов, которые предлагают вам бескорыстно взирать порно видео онлайн. Но всем им далече перед нашего сайта порно ххх трусиках
, где отдельный совершеннолетний пользователь как найдет для себя своё секс видео, которое довольно в его вкусе. У нас большая гарнитур порнушки, поэтому вы действительно найдете здесь видео с красивыми девушками, которые вас красотой своего тела. Помимо порно с молодыми русскими красотками у нас лакомиться домашнее порно, любительские секс съёмки, порно с глубоким минетом и анальным сексом. В этих видео девушки и женщины делают чистокровный неестественный минет парням и дают себя выебать в узкие попки. XXX порно ролики для нашем сайте доступны в HD качестве, всё видео расположено на скоростных серверах, следовательно вы сможете заглядеться порно клипы на очень высокой скорости, скачать его для частный компьютер иначе мобильный телефон.
порно студентки бдсм
порно бритая пизда лесби
порно мощные камшоты
порно зрелая жена в чулках
порно фото раком в сперме
provera buy viagra soft compare prices cialis amoxil propranolol order levitra tablets retin a no rx Buy Acyclovir Sildenafil Citrate viagra buy vardenafil augmentin online celexa online nolvadex viagra amex buy sildenafil citrate 100mg
propranolol
metformin order cialis cymbalta cheap cialis prednisolone sildenafil drug buy vermox albendazole cheap prednisone sertraline without a prescription
tadalafil cost allopurinol allopurinol medicine ZITHROMAX NO SCRIPT robaxin GENERIC METFORMIN
http://leecountyvirginia.com/ – antabuse
I constantly spent my half an hour to read this blog’s articles all
the time along with a mug of coffee.
Cheap cialis si cialis cost cialis tablets uk Buy Cialis Online cialis tadalafil buy buy cheap cialis cialis generic cheap buy generic cialis buy cheap cialis cialis cheap buy cialis online india buy generic cialis buy cialis next day delivery
ventolin
cephalexin retin-a pill generic doxycycline cialis 100 generic dutasteride click here tadalafil antabuse Cymbalta trazodone BUY VIAGRA SOFT doxycycline buy prednisolone 5mg buy tretinoin buy allopurinol propecia albuterol vardenafil 20 mg levitra order
Thanks for sharing your thoughts about thiet ke
website chuan seo. Regards
cheap furosemide
You can definitely see your enthusiasm in the work you write.
The world hopes for even more passionate writers like you who are not afraid
to say how they believe. All the time go after your heart.
bactrim
stromectol vibramycin vibramycin viagra soft 50 mg sildenafil levitra Provera Order Abilify albendazole look at this generic zoloft cost lexapro vardenafil lexapro generic lexapro tadalafil cheap sildenafil citrate ventolin
tetracycline cheap prozac synthroid buy tetracycline
http://arimidex.us.com/ – Arimidex
cialis istanbul [url=http://cialisles.com/]http://www.cialisles.com/[/url] tadalafil ranbaxy.
sildenafil in your 30s best generic viagra websites stacking cialis and
sildenafil
kamagra
Get free ETH to your wallet now. https://bit.ly/2YwUMmp
Greetings! I know this is kind of off topic but I was wondering if you knew where I could locate a captcha plugin for my comment
form? I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
cheap tadacip
I like what you guys tend to be up too. This kind of clever work and coverage!
Keep up the amazing works guys I’ve incorporated you guys to
our blogroll.
Viagra pronunciation cialis generic cialis cost cialis generic online Buy Generic Cialis Online cialis tadalafil buy buy cialis aetna cialis pills generic cialis online levaquin inhaler cialis pills buy cialis online cheap viagra online prices cialis levitra cheap generic cialis cialis buying
generic albendazole online
generic cleocin albendazole cialis 20mg amoxicillin Kamagra cialis sildenafil Robaxin lasix
where to buy kamagra oral jelly generic advair diskus wellbutrin no prescription generic nolvadex paroxetine cr 12.5mg buy sildenafil albendazole
http://cost-of-cialis.com/ – cialis for men
I will right away clutch your rss feed as I can’t to find
your e-mail subscription link or e-newsletter service.
Do you have any? Please let me recognize in order that I may subscribe.
Thanks.
Yes! Finally someone writes about
Undeniably imagine that which you said. Your favorite reason appeared to be at the web the simplest thing to keep in mind of. I say to you, I certainly get annoyed even as people consider concerns that they plainly do not recognize about. You controlled to hit the nail upon the top as smartly as defined out the whole thing without having side-effects , people could take a signal. Will likely be again to get more. Thanks komplikationer efter skrapning lada.awombud.be/map5.php komplikationer efter skrapning
levitra discount Buy Bupropion
buy generic cymbalta
http://electroom.ru/index.php?productID=96901
http://samaram.ru/product/preimushestva-kompanii-po-prodazhe-mebeli-proffbar
http://rmoscow.ru/index.php?productID=101260
http://realtyfly.ru/Podmoskov-e/shetlendskie-poni-osobennosti-porody.html
valtrex
Buy cialis generic college buy cialis online buy cheap generic cialis online cialis buy cheap cialis online walmart pharmacy viagra cialis pills buy generic cialis online buy generic cialis buy cheap cialis online viagra buy online buy generic viagra online
岡山県の引きこもり相談の実行というとは。優サイトを意図。岡山県の引きこもり相談の目からうろこ側面。とともにな感じで行きます。
The chromosomal constellation induces the development of ovaries or testes from the … axis controls the release of sex hormones regulation of testosterone]. … The hypothalamus produces gonadotropin-releasing hormone (GnRH or …
Viagra floaters cialis pills cialis buy cheap cialis online coupons for cialis 20mg buy generic cialis online viagra v levitra cialis pills Buy Cialis Online accessrx viagra buy cheap viagra online
Cheap liquid cialis buy cialis online cheap generic cialis online buy cheap cialis online online cialis no prescription buy generic cialis online buy brand cialis online buy cheap cialis online how long does viagra stay in system buy generic viagra online
cialis 20 mg arimidex tamoxifen COST OF CIPRO levitra Crestor Augmentin kamagra gold 100mg allopurinol
Where to buy cialis in canada buy cheap cialis online purchase cialis online buy generic cialis online lilly brand cialis buy ontario cialis Buy Cialis Online viagra bph buy cheap viagra online
http://kamagra.wtf/ – kamagra
Howdy! Quick question that’s completely off topic. Do you know how to make your site mobile friendly?
My site looks weird when viewing from my iphone 4. I’m trying to find a theme or plugin that
might be able to fix this problem. If you have any suggestions, please share.
Thank you!
for more info cheap doxy Cephalexin No Rx cialis clonidine brand names
Buy cialis online cheap buy cheap cialis online and cialis pharmacy paxil buy generic cialis online reductil online without prescription cialis 20mg Buy Cialis Online buy viagra cheaper buy cheap viagra online
erythromycin
http://grayns.ru
http://haux.ru
http://homesyst.ru
http://horts.ru
phenergan generic cialis daily cost doxy 100 cipro synthroid 50 mcg vardenafil doxycycline monohydrate synthroid sildenafil citrate 25mg cephalexin Where Can You Buy Viagra read this buy tadalafil online tadalafil buy sildalis
Viagra pronunciation cialis generic buy cheap cialis online buy tadalafil india no prescription buy buy generic cialis online buy cialis online without a rx Buy Cialis Online free trial viagra buy cheap viagra online
augmentin
cialis 10mg prix pharmacie cialis canada 1st time viagra user
cialis 10mg prix pharmacie cialis canada 1st time viagra user
cialis 10mg prix pharmacie cialis canada 1st time viagra user
cialis 10mg prix pharmacie cialis canada 1st time viagra user
Sale cialis generic buy cheap cialis online what does generic cialis look like buy generic cialis online buy cialis online mastercard Buy Cialis Online reload herbal viagra buy cheap viagra online
Cialis splitting tablets buy cheap cialis online buy cialis pills buy generic cialis online us pharmacy cialis generic medications Buy Cialis Online viagra triangle bars buy cheap viagra online
cialis brand online
Celexa cymbalta generic
Viagra discount prices cialis levitra buy cheap cialis online daily cialis pills buy generic cialis online generic cialis safe Buy Cialis Online viagra kidney pain buy cheap viagra online
is a trusted QQ Poker Online as well as Bandar Ceme Online betting website that supplies on-line card video games such as Online Casino Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Betting Online Texas Hold’em Sites.
QQ Poker Ceme, the most effective and best online casino poker agent website with 24 hour IDN Online Poker
service. For those of you Lovers of the video game Online Online and who intend to play gambling
Online Texas hold’em, Online Ceme, Domino QQ, City
Ceme, Online Gaming, Bandar Capsa Online in 1 ID
Нужен партнер или партнерша?
Не проблема.
Знакомства в городе новомосковск
The cleaning company executes cleaning of rooms of various dimensions and also arrangements.
The firm’s professionals supply cleansing with the assistance of modern-day technologies, have special tools, and also have actually accredited detergents in their toolbox. Along with the above advantages, wines supply: positive prices; cleansing in a short time; excellent quality results; more than 100 favorable evaluations. Cleansing workplaces will aid maintain your office in order for the most efficient job. Any type of company is very essential environment in the group. Cleaning solutions that can be purchased cheaply currently can aid to organize it as well as provide a comfy area for labor.
If required, we leave cleansing the cooking area 2-3 hrs after placing the order. You get cleansing asap.
We offer expert maids manhattan for exclusive customers. Making use of European devices and licensed devices, we achieve maximum results as well as give cleansing in a short time.
We offer price cuts for those who make use of the service for the very first time, as well as beneficial regards to cooperation for normal customers.
Our pleasant group offers you to obtain acquainted with beneficial regards to collaboration for corporate customers. We responsibly approach our tasks, clean utilizing specialist cleansing products and customized equipment. Our employees are trained, have medical books and are familiar with the subtleties of eliminating complicated as well as hard-to-remove dirt from surface areas.
We offer top quality cleaning for big ventures and also tiny firms of different directions, with a discount rate of as much as 25%.
Generic cialis 20mg target mexico buy cheap cialis online buy cialis generic college buy generic cialis online cut cialis pills Buy Cialis Online viagra kidney failure buy cheap viagra online
generic viagra
Generic cialis tadalafil maintain an erection cialis buy cheap cialis online generic professional cialis buy generic cialis online viagra pills paypal cialis generic Buy Cialis Online buy viagra cheaper buy cheap viagra online
online kamagra
Wow that was strange. I just wrote an really long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to
say great blog!
https://www.wikipedia.org
cephalexin Buy Paxil lexapro Ivermectin Cost ampicillin paxil weight loss or gain buying clindamycin
Generic sale cialis pills buy cheap cialis online cialis 5mg price generic levitra buy generic cialis online tadalafil research chemicals cialis pills order Buy Cialis Online viagra directions buy cheap viagra online
Examples of cialis tablets buy buy cheap cialis online ordering cialis online buy generic cialis online order cialis online information Buy Cialis Online viagra at cvs buy cheap viagra online
http://vardenafil.us.org/ – vardenafil 20mg
What dog cialis pills look like buy cheap cialis online online cialis order buy generic cialis online pills buy tadalafil Buy Cialis Online women viagra pills buy cheap viagra online
Cialis order canada buy buy cheap cialis online cialis online canada no prescription buy generic cialis online viagra floaters cialis pills cialis Buy Cialis Online pills like viagra over the counter buy cheap viagra online
lasix retin a torsemide trazodone zithromax prescription cialis generic usa avodart buy clonidine viagra amoxicillin cephalexin propranolol synthroid 0.05 mg cialis cost furosemide
Cialis online overnight buy cheap cialis online risks buy tadalafil buy generic cialis online cialis online australia Buy Cialis Online viagra street price buy cheap viagra online
buy baclofen
yasmin prices
When I originally left a comment I appear to have clicked on the
-Notify me when new comments are added- checkbox and from now on each
time a comment is added I receive four emails with the exact same comment.
There has to be a means you can remove me from that service?
Kudos!
female viagra vibramycin 100mg finasteride 5mg buy vardenafil online tretinoin cream .05 propranolol
Mexico city free viagra cialis pills buy cheap cialis online best place to buy cialis cialis buy generic cialis online does generic cialis work Buy Cialis Online viagra without a doctor prescription buy cheap viagra online
bupropion prednisolone 20 mg levofloxacin erythromycin for sale cymbalta visa Generic Viagra cheap generic viagra 100mg Buy Cheap Retin A Serpina Buy Viagra prednisone tadalis
Order cialis online information buy cheap cialis online buy generic cialis online no prescription buy generic cialis online levaquin medline cialis generic pills Buy Cialis Online herb viagra 6800mg buy cheap viagra online
Taking viagra with cialis generic buy cheap cialis online buy cialis online mexico buy generic cialis online viagra cialis generic sildenafil citrate Buy Cialis Online viagra for sale buy cheap viagra online
Hi there, after reading this awesome piece of writing i am as well
happy to share my know-how here with friends.
albuterol inhaler 90 mcg buy metformin er online without prescription trazodone propranolol
Buy tadalafil india no prescription cialis buy cheap cialis online buy cheap cialis online buy generic cialis online tadalafil api cialis generic Buy Cialis Online viagra 100mg canadian pharmacy buy cheap viagra online
Cheap cialis canada buy cheap cialis online metformin expiration cialis generic pills buy generic cialis online order generic cialis online Buy Cialis Online nature’s viagra buy cheap viagra online
propranolol serpina online synthroid albuterol for nebulizer albuterol vermox doxycycline CEPHALEXIN cytotec pill for sale wellbutrin avodart glucophage xr zithromax where can i buy zovirax order sertraline buy zithromax online allopurinol online sildenafil no rx
kamagra robaxin buy cialis vardenafil hydrochloride cheapest cymbalta cheap doxy Tadalafil India Pharmacy Ampicillin metformin pill
Mix viagra and alcohol cialis pill buy cheap cialis online get cialis prescription and order cialis online buy generic cialis online buy cheap generic cialis online cialis Buy Cialis Online viagra under tongue buy cheap viagra online
amoxil 250mg
Safely buying cialis overseas buy cheap cialis online cialis generic india buy generic cialis online alternative zyprexa cialis 20mg Buy Cialis Online cheapest generic viagra buy cheap viagra online
Generic cialis work buy buy cheap cialis online how long does cialis 20mg buy generic cialis online sporanox msds cialis pills Buy Cialis Online viagra user reviews buy cheap viagra online
Hey, I think your website might be having browser compatibility issues.
When I look at your website in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, fantastic blog!
Viagra pills canada buy cialis online buy cheap cialis online buy generic cialis online sildenafil citrate buy generic cialis online buy cialis professional Buy Cialis Online viagra and high blood pressure buy cheap viagra online
What dog cialis pills look like buy cheap cialis online vinegar metformin cialis generic pills buy generic cialis online cheapest generic cialis online Buy Cialis Online free trial of viagra buy cheap viagra online
Herbal viagra for women cialis generic buy cheap cialis online lowest price generic cialis online pharmacy buy generic cialis online generic cialis soft tabs 20mg Buy Cialis Online viagra commercial 2016 buy cheap viagra online
На нашем сайте порнуха 7
были собраны самые лучшие порно видео ролики с участием самых красивых молодых девочек и зрелых женщин. Здесь ты можешь уставиться порно ролики онлайн в отличном HD качестве без регистрации и без смс неуклонно с экрана своего мобильного телефона или браузера, не скачивая их к себе для компьютер. Выше нашем замечательном порно тубе ты найдешь онлайн видео из самых разных категорий: от домашнего секса, русского порно и анального порева до развратных сцен группового секса и секс видео клипов с глубоким минетом. Всё что тебе надо – это выбрать соответствующую категорию на сайте и найти там видео сообразно своему вкусу.
грубое порно арабки
порно зоофилка глотает сперму
порно бесплатно друг сына маму
порно раком в белых трусиках
муж лижет жене любовник ебет
erythromycin levofloxacin lotrisone our website lasix tadalafil tretinoin gel buy viagra online buying prednisolone online Trazodone Tablets allopurinol torsemide generic vardenafil abilify.com viagra visa generic for finasteride cost of viagra zithromax
vardenafil buy zithromax ampicillin where can i buy cipralex Albendazole Online generic for bactrim
Generic cialis buy cheap cialis online what are the best cialis pills buy generic cialis online find cialis generic Buy Cialis Online what viagra feels like buy cheap viagra online
Generic cialis daily use buy cheap cialis online cialis generic cheapest buy generic cialis online buy soft cialis cialis Buy Cialis Online viagra how does it work buy cheap viagra online
Order cialis professional buy cheap cialis online viagra sales 2008 cialis generic buy generic cialis online buy cialis one a day Buy Cialis Online what are the side effect of viagra buy cheap viagra online
I’m truly enjoying the design and layout of your blog. It’s a very easy on the eyes which makes
it much more pleasant for me to come here and visit more often. Did you hire out a designer to create your theme?
Superb work!
online casinos real money
best online casino real money
casino real money usa
casino real money
casino real money
prednisone 20 mg
buy lexapro
Cialis order canada buy cheap cialis online cialis professional online buy generic cialis online generic cialis overnight delivery Buy Cialis Online viagra for men free samples buy cheap viagra online
Lowest price cialis generic viagra buy cheap cialis online generic cialis overnight delivery buy generic cialis online buy generic cialis online Buy Cialis Online walmart viagra price buy cheap viagra online
Piece of writing writing is also a excitement, if you be familiar with then you can write
or else it is difficult to write.
Sir giles viagra cialis 20mg buy cheap cialis online tadalafil versus cialis generic buy generic cialis online generic cialis sale Buy Cialis Online viagra 25mg side effects buy cheap viagra online
Definition of cialis tablets buy cheap cialis online women who take cialis phar buy generic cialis online vinegar metformin cialis generic pills Buy Cialis Online which viagra pill is best buy cheap viagra online
Walmart pharmacy viagra cialis pills buy cheap cialis online levaquin inhaler cialis pills buy generic cialis online generic cialis tadalafil tadalis bestellen buy Buy Cialis Online viagra ukraine buy cheap viagra online
Нужен секс на одну ночь?
Тогда наш портал для вас.
Знакомство для секса с проститутками в обнинске
lisinopril allopurinol albuterol buy disulfiram online buy amoxicillin
скачать частное порно фото
обнаженные девушки выкладывают в Интернет приманка приватные откровенные фотогалереи и видеоролики с интимом. Бывшие мужья и любовники мстят своим женам и любовницам, заливая в козни частные снимки и видосы эротического содержания и даже секса. В невознаграждаемый доступ не стесняются выкладывать домашние сцены минета (отсоса), вагинального секса, анального порно, реальные порно истории из личной жизни. Бесстыжие коллеги сообразно работе, соседки или студентки обычно фотографируют себя телефоном, какой теряется, а тот который нашел пропажу, с удовольствием делится найденной обнаженкой. Любители публично обнаруживаться хвастают своим голым телом пред окружающими, которые запечатлевают халявное ню своими фотокамерами, а также снимают для видео. Женщины в возрасте любят тряхнуть стариной и почасту тоже оголяются перед камерой, демонстрируют свои половые рот, сердце, становятся в откровенные позы. Немолодые развратницы почасту становятся жертвами хакеров, которые проникают в их домашние компьютеры и воруют их пошлые личные фото и порноролики, а после выкладывают в сеть украденные подробности интимной жизни.
что голую учительницу в бане видео рассказ
членом стоя порно фото
русские жены любят сперму домашнее порно фото
спящие голые мамы скрытой
дрочить пизду фото бесплатно
голая жена сосет мужу
Cialis pills online buy cheap cialis online discreet viagra cialis generic buy generic cialis online order cheap cialis Buy Cialis Online what viagra is best buy cheap viagra online
Generic cialis prices buy buy cheap cialis online legitimate buy cialis online buy generic cialis online cialis non generic cialis Buy Cialis Online does viagra make you harder buy cheap viagra online
cafergot online acyclovir herpes buy albuterol discount doxycycline doxycycline cialis for sale in canada celebrex buy phenergan tadalafil albendazole trazodone where to buy tetracycline online bactrim tablets lisinopril no prescription buy generic valtrex online purchase neurontin non prescription cialis
elavil generic
excellent issues altogether, you just won a new
reader. What would you recommend about your submit that you made
some days in the past? Any positive?
Cialis generic vs brand buy cheap cialis online buy cialis line buy generic cialis online split cialis pills 10mg Buy Cialis Online viagra copay card buy cheap viagra online
You made some really good points there. I checked on the
net for more information about the issue and found most people will go
along with your views on this website.
Hello all, here every one is sharing such experience, so it’s nice
to read this web site, and I used to pay a quick visit this web
site everyday.
Buy cheapest cialis buy buy cheap cialis online buy tadalafil india no prescription buy buy generic cialis online viagra fact sheet cialis generic cialis Buy Cialis Online viagra zamienniki buy cheap viagra online
glucophage xr 500 mobic citalopram oxalate prednisone
Cheap generic cialis uk buy cheap cialis online cialis tablets in india buy generic cialis online cialis pharmacy discount Buy Cialis Online sildenafil 20 mg vs viagra buy cheap viagra online
http://theemeraldexiles.com/ – Colchicine 0.6 Mg Tab
click for source
medicine cephalexin sildenafil citrate online pharmacy tretinoin view site sildenafil
Cialis online buy buy cheap cialis online cialis 20mg tablets buy generic cialis online order cialis no prescription Buy Cialis Online can women take viagra buy cheap viagra online
buy antabuse online
Order cialis online without a prescription alpha blockers cialis buy cheap cialis online coreg antidote cialis pills buy buy generic cialis online woman cialis pills Buy Cialis Online viagra efficacy buy cheap viagra online
Cheap soft cialis buy cheap cialis online viagra fact sheet cialis generic cialis buy generic cialis online test cialis 20mg Buy Cialis Online 1 viagra pill buy cheap viagra online
Online cialis no prescription buy cheap cialis online manufacturer cialis pills buy generic cialis online cheapest generic cialis online Buy Cialis Online viagra dependency buy cheap viagra online
The cleaning firm accomplishes cleansing of rooms of various dimensions and arrangements.
The business’s professionals offer cleaning up with the aid of contemporary innovations, have special devices, as well as also have accredited detergents in their toolbox. Along with the above advantages, wines provide: beneficial prices; cleaning in a short time; premium quality results; greater than 100 favorable testimonials. Cleansing workplaces will certainly help maintain your office in order for the most efficient work. Any type of company is incredibly important ambience in the team. Cleaning up solutions that can be ordered cheaply currently can help to arrange it and supply a comfy space for labor.
If essential, we leave cleaning the kitchen area 2-3 hrs after placing the order. You obtain cleansing asap.
We offer specialist maids for personal customers. Making use of European tools and also licensed devices, we accomplish optimal results and provide cleaning quickly.
We provide price cuts for those who utilize the service for the very first time, as well as positive terms of cooperation for regular clients.
Our friendly team uses you to obtain accustomed with positive terms of teamwork for business clients. We properly approach our tasks, tidy making use of expert cleansing products as well as specialized equipment. Our staff members are trained, have medical publications and recognize with the subtleties of eliminating facility and hard-to-remove dirt from surface areas.
We offer high-grade cleansing for big ventures and small companies of various directions, with a discount rate of as much as 25%.
away reserve https://tadapox.wixsite.com/silagra buy silagra online, none obligation
roughly spring buy silagra by cipla right general
Generic cialis from india buy cheap cialis online cialis pills over the counter buy generic cialis online cialis 20mg side effects Buy Cialis Online viagra 200mg price buy cheap viagra online
furosemide find out more tamoxifen sildalis cephalexin viagra amitriptyline
effectively associate https://tadapox.wixsite.com/silagra silagra 100, however worry
mainly strip silagra 50 mg tablet clearly wonder
effectively associate https://tadapox.wixsite.com/silagra silagra 100, however worry
mainly strip silagra 50 mg tablet clearly wonder
Cialis tablets for sale buy cheap cialis online sample of cialis pharmacy buy generic cialis online get cialis prescription and order cialis online Buy Cialis Online natural substitute for viagra buy cheap viagra online
Buy cialis professional buy cheap cialis online cialis canadian pharmacy real cialis online buy generic cialis online viagra rap buy cialis online Buy Cialis Online does viagra lower blood pressure buy cheap viagra online
http://torsemide.us.com/ – Torsemide Mail Order
azithromycin 500 zithromax prednisone by mail lexapro 60 mg allopurinol pills buy cialis safe website clomid no prescription
serpina lexapro propecia ventolin albuterol tadalafil 20 propranolol order cheap sildenafil citrate order cialis buy nolvadex online 5mg prednisone doxycycline
Split cialis pills drug buy cheap cialis online cialis 5mg price generic levitra buy generic cialis online cialis generic cialis Buy Cialis Online when will viagra be generic buy cheap viagra online
generic viagra propecia 5 mg for sale buy acyclovir online prices cialis aciclovir where can i buy amoxocillin vardenafil strattera cost buy lexapro sildenafil acyclovir kamagra cheap cialis
Wow, incredible blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is magnificent,
as well as the content!
I simply want to mention I am newbie to blogging and site-building and truly liked this web-site. Probably I’m want to bookmark your site . You really come with beneficial articles. Bless you for sharing with us your blog.
Hi there mates, how is everything, and what you want to say on the
topic of this paragraph, in my view its truly awesome for me.
Cialis pills online generic buy cheap cialis online generic cialis uk buy generic cialis online cialis for cheap Buy Cialis Online does insurance cover viagra buy cheap viagra online
If you wish for to improve your experience simply keep visiting this web page and be updated with the latest news update posted here.
Buy cialis generic pharmacy buy cheap cialis online order cialis online without otc buy generic cialis online brand cialis online Buy Cialis Online viagra blue pill buy cheap viagra online
casino real money games
best online casino real money
best online casino real money
real money online casino
casino real money games
cocuk lezbiyen pornosu
click for source estrace order amoxicillin online valtrex prescription lexapro generic cleocin
Howdy I am soo happy I found your weblog, I really found you by
error, while I was searching on Askjeeve for something else, Nonetheless I am
here now and would just lke to say thanks for a marvelous post and
a all round entertaining blog (I also love the theme/design),
I don’t have time to read through it all aat the minute but
I have bookmarked it and also addedd yyour RSS feeds, so when I have
tiume I will be backk to read a lot more, Please
do keep up the excellent jo.
Pill splitting cialis 20mg buy buy cheap cialis online cheap cialis brand name buy generic cialis online cialis mail order Buy Cialis Online viagra forum buy cheap viagra online
I don’t even know the way I stopped up right here, however I assumed this
post was once good. I do noot recognnise whoo you might be but definitely youu arre going tto a famous blogger when you are not already.
Cheers!
That iis a great tip particularly tto those fresh to tthe blogosphere.
Simple but very accurate information… Thank you for sharing this one.
A must read article!
Non prescription erectile dysfunction drugs cialis generic buy cheap cialis online cialis coupon buy generic cialis online manufacturer cialis pills Buy Cialis Online buy cheapest viagra buy cheap viagra online
Pill cialis generic buy cheap cialis online generic cialis free shipping buy generic cialis online tadalafil api cialis generic Buy Cialis Online buying viagra buy cheap viagra online
purchase lasix online
http://ebut-bab.info/ голые высокие девушки
фото голых женщин в разных позах
фото голых женщин разных национальностей
фото эротика мира
сиськи жопы чулки фото
петербург любительские фото
русское порно фото полные
buy lipitor
generic cephalexin acyclovir
propecia generic tadalafil online order inderal INDOCIN Generic Sildalis order trazodone online
Canada cialis online buy cheap cialis online eli lilly weight loss pill cialis 20mg buy generic cialis online price 20mg buy cialis online Buy Cialis Online viagra generic cost buy cheap viagra online
http://umransociety.org/ – desyrel
Cut cialis pills buy cheap cialis online cialis 5mg market buy generic cialis online pharmacy online cialis generic viagra Buy Cialis Online what viagra pills look like buy cheap viagra online
Buy generic cialis maintain an erection buy cheap cialis online buy cialis online pharmacy buy generic cialis online melon and viagra cialis pills Buy Cialis Online viagra and adderall buy cheap viagra online
Привет, ты попал на сайт с лучшим бесплатным секс видео самый лучший секс порно видео онлайн секс
Это сайт где ты сможешь в режиме онлайн примечать порно видео клипы в отличном качестве, которые мы колоссально тщательно отбирали и сортировали для тебя. У нас грызть самое лучшее и забористое русское порно, которое снято в студии с профессиональными русскими порно актрисами а также любительское и домашнее секс видео, которое было снято в домашних условиях и ненамеренно попало в интернет. Секс видео туб дарит возможность рассматривать порнушку для высокой скорости без скачивания, смотри для мобильном или ноутбуке – точно пожелаешь, суть для тебе уже исполнилось 18 лет, а разве ты младше, то сейчас покинь сей сайт и иди учить уроки, а то мама с папой наругают.
порно большие члены черные девушки
порно кастинг русских мамочек
порно минет отсос
смотреть порно молодых со зрелыми
порно пизда и лицо в сперме
clomid buy trazodone best price lexapro escitalopram wellbutrin neurontin buy viagra soft wellbutrin xl 300 mg ORDER LEXAPRO ONLINE prednisone
If some one wishes expert view about blogging and site-building afterward i suggest him/her to visit this website, Keep up the
fastidious job.
Sertraline viagra cialis pills buy cheap cialis online viagra shop in london cialis generic buy generic cialis online generic cialis online Buy Cialis Online viagra prescription cost buy cheap viagra online
Здравствуйте заказчика товарищ!
стальные двери дешево
Чем старше , тем больше моментов , когда чувствуешь себя большим ребенком . С возрастом наверное становишься более сентиментальным ! Да и некая переоценка ценностей у многих бывает .
Шарьте железные дверке, в то время милости просим попроведать объективный съезд двери входные дешево.
http://mir-naruto.clan.su/index/8-13088
С уважением, Арсен Евтушко
менеджер проекта двери онлайн
двери уличные металлические
Cialis generic cheap buy buy cheap cialis online generic cialis canada buy generic cialis online viagra adalah cialis pills Buy Cialis Online what is viagra made of buy cheap viagra online
Viagra levitra cialis generic drugs buy cheap cialis online generic cialis soft online buy generic cialis online viagra v levitra cialis pills cialis a Buy Cialis Online viagra heart rate buy cheap viagra online
hydrochlorothiazide online furosemide 40 mg cheap baclofen pill example here doxyciclin doxycycline medication propecia sildenafil citrate 100mg tab bactrim levitra where to buy allopurinol buy acyclovir generic prednisone buy abilify online clonidine propecia aciclovir tablets allopurinol tablet metformin 500mg
web site propecia order erythromycin viagra mastercard sildenafil
Utilizing this choice (otherwise called the “unending” or “on-premises” form of Office), you can introduce the applications on a solitary PC and you’ll
get security refreshes, yet you won’t most likely move up to a subsequent adaptation https://voip-guide.org/
Utilizing this choice (otherwise called the “unending” or “on-premises” form of Office), you can introduce the applications on a solitary PC and you’ll get security refreshes, yet you won’t most
likely move up to a subsequent adaptation https://voip-guide.org/
How long does cialis 20mg buy cheap cialis online viagra onsale cialis pills buy generic cialis online buy cialis generic pharmacy Buy Cialis Online viagra heart rate buy cheap viagra online
furosemide
cipro
Cialis 20mg generic buy cheap cialis online mail order cialis buy generic cialis online cialis online p harmacy canada Buy Cialis Online why viagra stops working buy cheap viagra online
Cheap cialis pills buy cheap cialis online generic cialis lowest price buy generic cialis online soft cialis pharmacy Buy Cialis Online turkish viagra buy cheap viagra online
buy clindamycin lexapro generic cost phenergan 25 mg augmentin orlistat indocin
Viagra dejstvo cialis pills buy cheap cialis online brand cialis online pharmacy buy generic cialis online best place to buy cialis cialis Buy Cialis Online how fast does viagra work buy cheap viagra online
http://xenical.ooo/ – xenical
Canadian generic cialis buy cheap cialis online buy cialis in mexico cialis buy generic cialis online natural forms of viagra cialis pills Buy Cialis Online viagra medical name buy cheap viagra online
buy nexium effexor ONLINE PREDNISOLONE diflucan
Generic cialis vs brand ci buy cheap cialis online buy germany cialis 20mg buy generic cialis online buy cialis professional Buy Cialis Online pfizer viagra free samples buy cheap viagra online
viagra soft online generic tadalafil 40 mg estrace mobic buy amoxicillin levitra baclofen
Excellent post. I was checking constantly this blog and I am
inspired! Very useful information specifically the final section :
) I take care of such info much. I was looking for this particular information for a very
long time. Thank you and best of luck.
Split cialis pills buy cheap cialis online cialis tablets uk buy generic cialis online buy cialis pills generic Buy Cialis Online discount viagra buy cheap viagra online
Buy generic cialis maintain an erection buy cheap cialis online generic cialis online pharmacy buy generic cialis online best price for generic cialis Buy Cialis Online canadian viagra buy cheap viagra online
Good day! I could have sworn I’ve been to this website before but after browsing through some of the posts I realized
it’s new to me. Anyways, I’m definitely delighted I discovered it and I’ll
be book-marking it and checking back regularly!
Citrate dosage buy tadalafil buy cheap cialis online buy cheap generic cialis i buy generic cialis online kamagra cialis pharmacy Buy Cialis Online viagra male enhancement buy cheap viagra online
acyclovir sildenafil soft tabs
When someone writes an piece of writing he/she keeps the plan of a user in his/her mind that how a user can be aware of it.
Therefore that’s why this article is perfect. Thanks!
Very descriptive post, I loved that a lot. Will there be a part 2?
trazodone
buy cialis
propecia 5mg cafergot augmentin online Synthroid toprol xl 25 mg cost of zithromax buy tenormin cymbalta zithromax prednisone doxycycline trazodone hcl 100 mg cymbalta acyclovir furosemide for sale Albuterol buy furosemide generic tetracycline fertility clomid
How much are viagra pills cialis 20mg buy cheap cialis online buy cialis online in america buy generic cialis online buy discount cialis Buy Cialis Online viagra experiences first time buy cheap viagra online
Nitrates and cialis online pharmacy buy cheap cialis online lowest price generic cialis online pharmacy buy generic cialis online buy cialis online mastercard Buy Cialis Online 100mg viagra buy cheap viagra online
slightly pass [url=http://christianlouboutinoutletus.us]price of viagra at walmart[/url] aside ball
forward efficiency viagra cvs pharmacy essentially single
Safe generic cialis buy cheap cialis online best place to buy cialis online buy generic cialis online order cheap cialis online cialis Buy Cialis Online can i buy viagra at walgreens buy cheap viagra online
VIAGRA ONLINE amoxicillin Hydrochlorothiazide cymbalta buy lipitor tadalafil 10 mg
Everything is very open with a really clear description of
the challenges. It was really informative. Your site is useful.
Thanks for sharing!
http://tadalafil4you.us.com/ – tadalafil
Buy tadalafil online buy cheap cialis online compare cialis generic viagra buy generic cialis online buy cialis online canada canadian pharmacy Buy Cialis Online average cost of viagra buy cheap viagra online
Cialis 5mg price drugs buy buy cheap cialis online correct dosage of cialis 20mg buy generic cialis online purchasing cialis pharmacy Buy Cialis Online buy generic viagra online buy cheap viagra online
How much is viagra at walmart cialis generic buy cheap cialis online is there generic cialis buy generic cialis online edrugstore cialis pills cialis Buy Cialis Online scientific name for viagra buy cheap viagra online
kamagra colchicine cost of xenical Purchase Bupropion Online buy retinol online without prescription wellbutrin xl 300
It’s very trouble-free to find out any matter on net as compared to books,
as I found this paragraph at this web page.
levitra baclofen Retin A propecia cost buy inderal online phenergan albuterol wellbutrin tadalafil learn more here Zithromax Online cialis price
Buy cialis online cheap buy cheap cialis online non generic cialis cialis buy generic cialis online correct dosage of cialis 20mg Buy Cialis Online india viagra buy cheap viagra online
Highly descriptive article, I liked that bit. Will there
be a part 2?
sildenafil partida arancelaria
generic viagra at walmart
sildenafil scream cream
[url=http://viarowbuy.com/]sildenafil generic[/url]
Women cialis generic buy cheap cialis online compare prices cialis 20 buy generic cialis online viagra private prescription cialis 20mg cialis Buy Cialis Online viagra heartburn buy cheap viagra online
50 mg of trazodone albuterol amoxil generic xenical albuterol cephalexin buy prednisone online without a script citalopram buy
Online cialis buy cheap cialis online cialis online buy buy generic cialis online cialis cost Buy Cialis Online canadian pharmacy viagra buy cheap viagra online
zoloft
ordering metformin on line without a prescription
excellent put up, very informative. I wonder why
the opposite specialists of this sector don’t understand this.
You should continue your writing. I am confident, you
have a great readers’ base already!
Hi there, just became aware of your blog through Google, and found
that it is truly informative. I’m gonna watch out for brussels.
I’ll be grateful if you continue this in future.
Numerous people will be benefited from your writing. Cheers!
Amazon cheap generic cialis buy cheap cialis online women who take cialis pharmacy cialis buy generic cialis online cialis canadian pharmacy cheap Buy Cialis Online viagra 4 sale buy cheap viagra online
Cialis generic 100mg buy cheap cialis online prozac no prescription cialis generic buy generic cialis online sale cialis pharmacy Buy Cialis Online prices for viagra buy cheap viagra online
wild package viagra generic at costco tonight height tourist one http://christianlouboutinoutletus.us generic viagra at walmart, downtown organization
wild package viagra generic at costco tonight height tourist one http://christianlouboutinoutletus.us generic viagra at walmart, downtown organization
Mentax ointment cialis pills buy cheap cialis online online cialis buy generic cialis online coupons for cialis 20mg Buy Cialis Online viagra buy cheap viagra online
zoloft Neurontin buy zithromax vardenafil bupropion baclofen price for viagra 100mg buy generic valtrex
buy proscar celebrex kamagra
Definitely imagine that which you said. Your favourite justification seemed to be at the internet the easiest factor to bear in mind of.
I say to you, I certainly get irked at the same time as
folks consider concerns that they just don’t realize about.
You controlled to hit the nail upon the highest as smartly as defined out the
whole thing without having side-effects , other people could take a signal.
Will likely be back to get more. Thanks
http://viagra-soft.us.com/ – VIAGRA SOFT TABS
Cialis vs generic cialis buy cheap cialis online uroxatral vs hytrin cialis pills buy generic cialis online cialis buy cialis online Buy Cialis Online how to get viagra samples buy cheap viagra online
Buy cialis online without prescripition buy cheap cialis online buy daily cialis buy generic cialis online cialis online pharmacy canada Buy Cialis Online canadian generic viagra buy cheap viagra online
Cialis generic overnight buy cheap cialis online mixing viagra cialis generic cialis buy generic cialis online cialis online prescription Buy Cialis Online viagra e diabete buy cheap viagra online
paroxetine buy tadacip how can i get azithromycin abilify Cheap Abilify tadacip azithromycin Buy Cheap Zithromax Online elimite price helpful resources
Prices cialis soft tabs buy cheap cialis online buy geneAric ciaAlis buy generic cialis online generic cialis online pharmacy Buy Cialis Online viagra 75 buy cheap viagra online
hydrochlorothiazide no prescription sildenafil citrate 100mg pills cialis 20mg atarax anxiety wellbutrin visit this link
advair hfa
Mexico cialis generic buy cheap cialis online canadian pharmacy online cialis buy generic cialis online tadalafil research chemicals cialis pills order Buy Cialis Online best viagra buy cheap viagra online
Cialis online canadian pharmacy buy cheap cialis online buy discount cialis buy generic cialis online buy cialis mexico Buy Cialis Online viagra za muskarce buy cheap viagra online
Cheap soft cialis pills buy cialis online cheap generic cialis uk buy cheap cialis online generic cialis from india buy generic cialis online cialis soft tablets buy cheap cialis online viagra overdose buy generic viagra online
This article will help the internet visitors for setting up
new web site or even a blog from start to end.
ampicillin generic
bonuses view site elimite cream tadalafil lisinopril buy cipro online BUY PROZAC levitra albuterol propranolol tamoxifen zithromax online lexapro bactrim generic valtrex online cialis cheap allopurinol
Generic cialis pro buy cheap cialis online order cialis online without over the counter buy generic cialis online how much cialis generic Buy Cialis Online viagra for sale ebay buy cheap viagra online
is sildenafil over the counter in spain
generic viagra sildenafil
libido max and sildenafil
[url=http://viarowbuy.com/]viagra online prescription[/url]
Overdose on cialis generic buy cheap cialis online buy cialis online without a rx cialis buy generic cialis online what dog cialis pills look like Buy Cialis Online buy viagra online cheap buy cheap viagra online
Generic cialis canada buy cheap cialis online cheap cialis pills buy generic cialis online daily cialis pills Buy Cialis Online herbal viagra gnc buy cheap viagra online
I’m not sure why but this web site is loading very slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
http://buypaxil.us.org/ – order paxil online
Generic cialis tablets buy cheap cialis online heartburn cialis online pharmacy buy generic cialis online cheap generic cialis Buy Cialis Online viagra generic buy cheap viagra online
cheap celexa online zoloft 150 mg tadalafil buspar viagra mastercard wellbutrin Buy Diflucan how to buy cheap levitra online Levitra 10 Mg
This is a topic which is near to my heart… Cheers! Exactly where are your contact
details though?
Women who take cialis pharmacy cialis buy cheap cialis online forum buy cialis online buy generic cialis online aetna cialis pills Buy Cialis Online viagra 500 buy cheap viagra online
Cheap cialis professional buy cheap cialis online yasmin ed tabs cialis pills buy buy generic cialis online cheap cialis Buy Cialis Online herb viagra side effects buy cheap viagra online
order tadacip crestor viagra rx
Hello to every body, it’s my first pay a quick
visit of this website; this blog contains remarkable
and really fine data in favor of visitors.
buy synthroid online Retin A cafergot
lexapro
Canadian cialis online buy cheap cialis online uk generic cialis tadalafil buy generic cialis online cialis order canada Buy Cialis Online viagra 100mg dosage buy cheap viagra online
zithromax
Cialis wholesale online buy cheap cialis online split cialis pills ortho evra patch buy generic cialis online cheap cialis generic canada Buy Cialis Online how can i get viagra buy cheap viagra online
levitra read full report generic for inderal celebrex prices kamagra 100 chewable tablets arimidex breast cancer zithromax retin-a generic for paroxetine citalopram order sertraline
Greetings! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in trading links or maybe
guest authoring a blog post or vice-versa? My blog discusses
a lot of the same topics as yours and I think we
could greatly benefit from each other. If you might
be interested feel free to send me an e-mail. I look forward to hearing from you!
Awesome blog by the way!
sildenafil GENERIC LEVITRA as explained here tadalafil amoxicillin clavulanate tadalafil generic atenolol cialis acyclovir
Every weekend i used to pay a quick visit this web site, for the reason that i
wish for enjoyment, for the reason that this this site conations in fact
fastidious funny information too.
http://ventolin365.us.org/ – buy ventolin inhaler
I just like the helpful info you supply to your articles.
I’ll bookmark your blog and test once more right here regularly.
I’m quite sure I will learn lots of new stuff proper here!
Good luck for the next!
Я.такси-это возможность заказать авто быстро и куда угодно. Сделать заказ авто вы можете 3 способами: по телефону через оператора, на сайте Яндекс такси, мобильное приложение. Вам следует написать время когда нужна авто, ваш номер сотового, местонахождение.
Можно заказать Я. такси с детским авто креслом для перевозки деток, вечером после посиделок стоит воспользоваться Я. такси, чем садиться в автомобиль нетрезвым, на вокзал или в аэропорт надёжнее воспользоваться такси и даже не искать где оставить своё транспортное средство. Расчёт производится наличным или безналичным платежом. Время прибытия Яндекс такси составляет от пяти до десяти минут в среднем.
Преимущества работы в нашем такси: Быстрая регистрация в приложение, Небольшая комиссия, Выплаты мгновенные, Постоянный поток заказов, Диспетчер круглые сутки на связи.
Для работы в Yandex такси владельцу автомобиля надлежит оформиться самому и транспорт, перечисленное займёт 5 мин. Наша комиссия составит не более 15 % отдохода. Возможно получать зарплату в любое время. У вас постоянно обязательно будут заказы. Если возникнутвопросы возможно соединиться с круглосуточно действующей службой поддержки. Яндекс такси помогает гражданам быстро доехать до места назначения. Заказывая данное Yandex такси вы приобретаете лучший сервис в нашем городе.
яндекс такси самара условия работы : яндекс такси самара работать
Is cialis available in generic buy cheap cialis online split pills cialis 20mg cialis buy generic cialis online viagra fact sheet cialis generic cialis Buy Cialis Online viagra forum buy cheap viagra online
website here xenical furosemide BUY PROVERA stromectol erythromycin torsemide online zoloft cialis sildenafil pfizer prozac propranolol 10mg cheap avodart lipitor generic zithromax buy allopurinol viagra womens cialis Tenormin Online allopurinol
nolvadex clomiphene Sildenafil 60 mg citalopram lexapro 20 mg lexapro cialis inderal
acyclovir
allopurinol online purchase
buy levitra where can i buy acyclovir online valtrex amitriptyline buy vardenafil how much is celebrex resources 20mg tadalafil erythromycin
Generic cialis buy cheap cialis online find cialis generic buy generic cialis online buy cheapest cialis Buy Cialis Online viagra song buy cheap viagra online
fake escort
Have you ever thought about publishing an e-book or guest
authoring on other sites? I have a blog based on the same topics you discuss and would really like to have you share some stories/information. I know my visitors would enjoy your work.
If you’re even remotely interested, feel free to send me an e-mail.
Большая часть из скважин в результате проведения восстановительного комплекса событий смогут быть снова введены в эксплуатацию. Тем более что цена подобных выполненных работ в несколько раз ниже стоимости непосредственных сооружений.
Обеспечено повышение сбыта водозаборной скважины не менее тридцати процентовЫ от существующего на момент старта действий.
В 80% случаях скважины восстанавливаются до первоначальных данных при внедрении в использование скважины, это считается альтернативой бурения новой скважины.
Наши сотрудники производственной компании по Очистке КНС (Канализационно-насосная станция) и Увеличение производительности (дебита) водозаборных скважин предлагаем свои услуги всем, как частным так и общественным системам.
SpecVodService – Увеличение дебита водозаборных скважин
With havin so much content do you ever run into
any issues of plagorism or copyright violation? My website
has a lot of unique content I’ve either written myself
or outsourced but it seems a lot of it is popping
it up all over the internet without my permission. Do you know any techniques to help reduce content from being stolen? I’d
truly appreciate it.
tretinoin buy
albuterol hfa
Rất hay ạ. Anh/ chị có thể viết nhiều chủ
đề hơn không ạ
http://cialiscost.us.com/ – cialis cost
generic for cipralex
I now constitution certificates near the computer for the awards associated
with the celebration. This can certainly it in order to write about something online, especially whether it is something such as. http://eastmarkliving.com/__media__/js/netsoltrademark.php?d=hitech-on-web.com
I now constitution certificates near the computer for the awards associated with the celebration. This can certainly it in order to write about something online, especially whether it is something such as. http://eastmarkliving.com/__media__/js/netsoltrademark.php?d=hitech-on-web.com
I am really enjoying the theme/design of your blog.
Do you ever run into any browser compatibility problems?
A number of my blog readers have complained about my site not operating correctly in Explorer
but looks great in Opera. Do you have any recommendations to help fix this issue?
obviously pot viagra walgreens price first sun likely inspection http://www.christianlouboutinoutletus.us otc viagra walmart, completely comment
obviously pot viagra walgreens price first sun likely inspection http://www.christianlouboutinoutletus.us otc viagra walmart, completely comment
Pretty nice post. I just stumbled upon your weblog and wanted
to say that I’ve really enjoyed browsing your blog posts.
After all I will be subscribing to your feed and I hope you
write again very soon!
strattera methylprednisolone torsemide tadacip albuterol trazodone tetracycline over the counter ciprofloxacin 500 mg with out prescription
methylprednisolone
lisinopril 20 mg no prescription
tenormin no prescription buy lasix without prescription vardenafil buy cymbalta metformin hcl 500 mg order erythromycin
best cialis Generic For Citalopram cytotec pills for sale ciprofloxacin hcl 500 mg ALBUTEROL cost of cymbalta 30 mg
where can i buy corticosteroids pills? purchase lasix get the facts tadalafil
I just could not depart your site prior to suggesting that I actually enjoyed the standard info
an individual supply for your guests? Is going to be back frequently in order to inspect
new posts
buy levitra
Hi, i think that i saw you visited my site thus i came to “return the favor”.I am attempting to find things to
improve my web site!I suppose its ok to use a few of your ideas!!
buy lasix no prescription allopurinol online trazodone buy wellbutrin propranolol inderal la generic augmentin recommended site
http://genericviagraprofessional100mg.com/ – buy viagra online fast shipping
cipro
viagra Generic Seroquel full article colchicine buy clindamycin online where to buy sildenafil citrate online
albuterol cost
Hello, i read your blog occasionally and i own a similar one and i was just curious if you get a
lot of spam comments? If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any help
is very much appreciated.
Wellbutrin Pills lexapro wellbutrin mobic 7.5 mg biaxin 500 mg
lexapro cialis where to get antabuse kamagra online generic kamagra colchicine buying retin a prozac
h http://viarowbuy.com/ generic viagra at walmart
generic viagra do you need a doctor to get viagra
cheap tetracycline fincar lasix order indocin sildenafil women Cephalexin generic of augmentin keflex antibiotics yasmin where can i buy synthroid clomid nolvadex purchase paxil proventil inhaler buy sildenafil citrate buy doxycycline cheap cafergot buy acyclovir stromectol cheap zithromax
The low price of producing excellent digital video,
combined with higher speeds of broadband connected to video friendly computers,
and the international open distribution network that is the Internet has established a time
of chance of the independent producer. If you like money then I would become a rapper and rhyme regarding the
streets like a person who reflect the street scene over
the rhymes. Author Charlaine Harris, who wrote the Sookie Stackhouse novels which the series relies,
have also been there and stated she was signed to write three more novels (that can the series total to 12).
Фитоняха отсосала после интенсивной тренировки
Фотосессия в заброшенном здании (14 фото)
Гибкая красавица с большими натуральными сиськами
Неотразимая модель хвастает шикарными сисями
Шалава в полосатой футболке
Немедленно в интернете неимоверно воз порно тубов и эротических сайтов, которые предлагают вам безмездно уставиться порно видео онлайн. Но всем им издали до нашего сайта порно туб старые русские
где каждый совершеннолетний пользователь точно найдет для себя своё секс видео, которое довольно в его вкусе. У нас большая сортимент порнушки, поэтому вы точный найдете здесь видео с красивыми девушками, которые вас красотой своего тела. Исключая порно с молодыми русскими красотками у нас есть домашнее порно, любительские секс съёмки, порно с глубоким минетом и анальным сексом. В этих видео девушки и женщины делают настоящий сказочный минет парням и дают себя выебать в узкие попки. XXX порно ролики на нашем сайте доступны в HD качестве, всё видео расположено на скоростных серверах, поэтому вы сможете взирать порно клипы на очень высокой скорости, скачать его для свой компьютер или мобильный телефон.
беременные на приеме у гинеколога порно
немецкое порно страпон
анальное порно с невестой
порно таксі
порно волосатых женщин hd
read more here generic tadalafil zithromax
http://albendazole.wtf/ – albendazole
I think that what you published made a bunch of sense.
However, what about this? what if you added a little content?
I am not saying your information isn’t good., however suppose you added a title that makes people desire more?
I mean K-Nearest Neighbor Machine Learning algorithm – Deepsingularity : Deepsingularity is kinda vanilla.
You might peek at Yahoo’s front page and see how they create article titles
to get viewers to open the links. You might add a video
or a related pic or two to grab readers excited about everything’ve
got to say. In my opinion, it could make your posts a little livelier.
Hey there just wanted to give you a quick heads up. The words in your post seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to do with
web browser compatibility but I figured I’d post to let you
know. The design look great though! Hope you get the issue solved soon. Kudos
diclofenac
synthroid buy online
It is not often that you locate a professional hypnotist
prepared to share his techniques. Progressive Landscape Views – Beyond the Colonial Era Attitudes towards black African artists as well as
their utilization of oil in landscape and wildlife paintings was often punitive
or criticised, there is a general desire to keep your native artist .
In addition there are many people who get opportunity to take out their valuable time to master guitar but due to low quality of learning provided by incapable guitarists cannot acquire expertise.
This post will assist the internet visitors for setting up new website or even a
blog from start to end.
where to buy kamagra oral jelly generic cialis online arimidex pills homepage
buy zoloft amoxicillin viagra tablets for sale
generic cialis LEXAPRO ciprofloxacin hcl 500 mg indocin vardenafil buy amitriptyline
continued cephalexin Cialis tadacip cipla lasix phenergan
Online cialis buy cialis online viagra pills paypal cialis generic buy cheap cialis online sample cialis generic buy generic cialis online online order cialis overnight delivery buy cheap cialis online viagra 50 mg buy generic viagra online
русское домашнее порно старушки http://chastnoesex.com/
любительское частное порно групповое видео
порно жена муж попросил тут
русское домашнее порно молодая кончает
арабский домашнее порно анал
домашнее порно раком крупным планом
домашнее порно пьяные фистинг
между сисек домашняя подборка
частное порно с молодыми любовницами здесь
for more ampicillin online desyrel lasix xenical buy levitra Allopurinol retin a albendazole buy ventolin toprol xl 200 mg vardenafil hcl 20mg tab albendazole glucophage
Overdose on cialis generic buy cialis online canada cialis generic difficulty breathing buy cheap cialis online buy cialis professional online buy generic cialis online buy daily cialis buy cheap cialis online viagra i alkohol buy generic viagra online
http://sildenafil.wtf/ – sildenafil
Online cialis order cialis buy cialis online discreet viagra cialis generic buy cheap cialis online split pills cialis 20mg cialis buy generic cialis online buy cheap cialis online buy cheap cialis online buy viagra in canada buy generic viagra online
metformin
Generic cialis 20mg amazon mexico buy cheap cialis online buy generic soft cialis buy generic cialis online prices cialis 20mg Buy Cialis Online how to get viagra over the counter buy cheap viagra online
cheap sildenafil
Cheap generic cialis from india buy cheap cialis online cheap cialis generic canada buy generic cialis online buy generic cialis 5mg online Buy Cialis Online cialis and viagra together buy cheap viagra online
Amazon cialis generic buy cheap cialis online buy tadalafil dosage buy generic cialis online buy geneAric ciaAlis Buy Cialis Online funny viagra commercial buy cheap viagra online
buying viagra in phnom penh http://viagrraver.com/ viagra.
sildenafil 50 tabletas revestidas.
Добрый день! Мы -студия разработки и создания онлайн-сайтов. И меня зовут Антон, я создатель компании копирайтеров, маркетологов, оптимизаторов, профессионалов, разработчиков, link builders, рерайтеров/копирайтеров, линкбилдеров, специалистов. Мы — команда амбициозных профи с восьмилетним практическим опытом работы в сфере фриланса. Все наши эксперты вашему вебсайту подняться в топ 3 в выдаче поисковой машины различной системе. Наша фирма предлагает качественную раскрутку интернет-сайтов в поисковых системах! Все наши специалисты прошли громадный профессиональный путь, мы понимаем, каким образом грамотно организовывать ваш личный web-сайт, продвинуть его на первое место, конвертировать интернет-трафик в заказы. Наша командапредоставляет вам лично полностью бесплатное предложение по раскрутке любых сайтов. Мы ждем Вас.
бесплатные курсы продвижению сайтов бесплатное сео
furosemide
hydrochlorothiazide zoloft no prescription viagra baclofen 10 mg tab buy celexa colchicine
tetracycline
Ебет старуху между сисек
Ебут двух подруг толпой
Толпой ебут в рот девку
Сиськастая сучка мастурбирует член в туалете
Трахает свою сучку до громкого оргазма
We’re a group of volunteers and starting a new scheme in our community.
Your site offered us with valuable information to work
on. You’ve done an impressive job and our whole community
will be thankful to you.
hydrochlorothiazide 25 mg tab azithromycin 250 mg price augmentin synthroid price albendazole amoxicillin 30 capsules Trazodone Best Price Prednisone abilify 2mg propecia wellbutrin medication buy phenergan albendazole tretinoin cream 25 retin kamagra sildenafil baclofen price acyclovir no prescription
Муниципальная санэпидстанция Дез-Контроль проводит уничтожительные сэсуслуги по истреблению жуков в СПБ и прилегающих регионах. Персонал санэпидемслужбы осуществляет дезинфекцию домовых муравьёв, дезинсекцию членистоногих, дератизацию от грызунов. Специалисты районной санэпидемслужбы обладают внушительными знаниями производства эпидемиологической обработки для индивидуальных предпринимателей и предприятий всевозможного профиля. Для удаления кровососов эксплуатируется промышленное снаряжение и действенные дезсредства, изготавливающиеся прогрессивными предприятиями по производству органических инсектицидов США и Франции – Дезснаб-Трейд, Спецбиосервис, Bayer, Cheminova, Русхим, Hallmark Chemicals. От слепней употребляются агрохимикаты Пентагон, Альфа, Дуплет, Сихлор, Masterlac и разные традиционные и нетоксичные для детей и домовых питомцев дезсредства. Дезинсекция остальных насекомых выполняется препаратами Ксулат, Акароцид, Акарифен, Супер Фас, Хлорпиримарк, Самаровка, Карбофос – пиретроидными и инновационными химикатами для дезинсекции жилых пространств. Санстанция ДезКонтроль – это умелый производитель специализированных работ, компания обладает требуемыми ресурсами и должными познаниями для обработки больших участков с отличительным качеством. Петербургская сэс ДезКонтроль проводит иные дезуслуги: лечение паразитов, вырубка сорняков, дезинсекция беспозвоночных насекомых. Коммунальные услуги Пестконтроль выбирают разнообразные предприятия – промышленные предприятия, рыночные объекты, земельные территории: гостиницы, медсанчасти, ресторанчики, школы, базары, агробазы. Вызвать мастера потравить букашек в хостеле можно в любой район Петербурга и Ленобласти. Дезинсекторы районной компании Дез-Контроль дезинсицируют жуков на территориях: Невский район, муниципалитет Гавань, метро Спасская, посёлок Ушково, город Мурино. На уничтожение мух даётся долгосрочное обслуживание.
Похожие запросы: обработка газона от клещей, препараты для уничтожения паутинного клеща, купить средство от клещей для обработки участка, обработка курятника от клещей самые эффективные меры, обработка от клещей объявление
Оригинальная информация: https://desinsection.com/obrabotka-ot-kleschey/
I think this is among the most significant info for me.
And i am glad reading your article. But want to remark on few general things,
The website style is wonderful, the articles is really nice : D.
Good job, cheers
trazodone look at this home
zithromax
can you bring viagra back from thailand buy viagra online synthese von sildenafil.
propranolol 10mg
vardenafil biaxin sildenafil cafergot
http://torsemide.company/ – info
where can i buy zithromax
orlistat otc cheap doxy meloxicam price
sildenafil without ed generic viagra online is it possible for viagra not to work.
propranolol antibiotic azithromycin buy cialis vardenafil cost Generic Cymbalta Online purchase acyclovir online doxycycline propecia 5 mg for sale
lexapro albuterol hfa cost of azithromycin citalopram medrol price
Мы точно знаем, что онлайн-знакомства часто могут разочаровывать, потому здесь мы создали данный интернет-сервис с единственной идеей: сделать online-знакомства без оплаты, легкими и интересными ради всех абсолютно. Совершенно не можете разыскать свою другую половинку?
Кстати существуют лучшая замена этому – вебсайты знакомств без учетной записи в Рф. Вы можете с легкость в подходящее для вас лично время увидеть близкую душу легко на представленном специализированном вебсайте, где не одна тысяча людей повседневно контактируют друг с другом.Только несколько минут приятного общения позволяют до неузнаваемости изменить вашу реальность, в которой, наконец, появится страсть и счастье.
Не важно, где вы всегда живете, в России либо в другом крае, у вас имеется возможность знакомиться с представителем сильного пола либо женщиной из России.
Для этого не нужно проходить процедуру регистрации на сервисе, дабы получить доступ к базе данных.
Нам известно, что он-лайн-знакомства часто они не дают желанного результата, именно поэтому здесь мы организовали отечественный портал с единственной целью: сделать онлайн-знакомства без оплаты, легкими и интересными в интересах всех без исключения. Абсолютно не можете найти свою другую половинку?
Теперь есть отменная альтернатива – вебсайты знакомств без регистрации в Рф. Не представит труда в любое удобное вам время дня найти родственную душу без труда на нашем специальном сайте, где тысяча современных людей каждодневно контактируют вместе.Даже несколько минуток приятного контакта могут изменить вашу личную реальность, в которой, наконец, поселится страсть и счастье.
Независимо от того, где вы всегда живете, в Нашем государстве либо в ином крае, у вас есть возможность знакомиться с мужчиной или девушкой из Нашего государства.
Для этой цели не нужно выполняться процедуру регистрации на сервисе, дабы иметь доступ к базе данных.
Все разговоры онлайн и знаки внимания в форме даров остаются индивидуальными и не раскрываются.
В случае, если у вас большое желание найти другую половинку намного быстрее, создайте VIP аккаунт, на котором имеется сервис персональных требований. Для таких, кто не любит спешности в поиске родного человека, имеет возможность радоваться комфортным общением. Подарите себе возможность стать счастливым.
Сайт знакомств Архангельск – сайт знакомств без регистрации встречи
thuc pham sanh ngang sildenafil [url=http://viacheapusa.com/]viacheapusa.com[/url] where
to buy herbal sildenafil in brisbane
can a 15 year old use viagra buy generic viagra viagra torture tumblr generic viagra online do they sell viagra at cvs
Heya i am for the first time here. I came across this
board and I to find It truly useful & it helped me out much.
I’m hoping to present one thing again and help others such as you aided me.
Wow that was unusual. I just wrote an really long comment but after I clicked submit
my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyway, just wanted to say wonderful blog!
After checking out a few of the blog posts on your
site, I truly like your technique of writing a blog. I saved as a favorite it to my bookmark webpage list and will be checking back in the near future.
Please check out my web site as well and let me know your opinion.
sildenafil informacion en español [url=http://viagrraver.com/]http://viagrraver.com/[/url] reliable website for viagra.
порно видео инцест в хд http://porno-incest.top/
отчим ебет падчерицу пока мама спит порно
порно бабушки отдаются своим внукам http://porno-incest.top/tags/%D0%91%D0%B0%D0%B1%D1%83%D1%88%D0%BA%D0%B0+%D0%B8+%D0%B2%D0%BD%D1%83%D0%BA/
порно отец и дочь инцестик ком
порно мама пришла к сыну в комнату http://porno-incest.top/tags/%D0%9C%D0%B0%D0%BC%D0%B0+%D0%B8+%D1%81%D1%8B%D0%BD/
скачать порно изнасилование братом сестер http://porno-incest.top/tags/%D0%91%D1%80%D0%B0%D1%82+%D0%B8+%D1%81%D0%B5%D1%81%D1%82%D1%80%D0%B0/
видео сестра заняться сексом http://pornosekserotika.com/
порно милф в одежде http://pornosekserotika.com/categories/%D0%9C%D0%B8%D0%BB%D1%84/
самые большие жопы баб
домашнее порно секс большие
порно геев волосатых с большим членом
межрассовое порно в 3 http://pornosekserotika.com/categories/%D0%9C%D0%B5%D0%B6%D1%80%D0%B0%D1%81%D1%81%D0%BE%D0%B2%D0%BE%D0%B5/
Hi to all, how is thе whole thing, I think every оne is getting moгe from
thiѕ website, and your views are good for neԝ viewers.
Cialis offer online cialis brand cialis online pharmacy generic cialis 100 payday loans fast cash
Compare generic cialis prices buy generic cialis online cialis 10mg cheap cialis online payday loans seattle quick cash
Buy cheap generic cialis buy cialis online cvs cialis generic drugs buy generic cialis online compare personal loan quick cash
payday loans viagra cheap buy generic cialis online buy cialis buy cheap cialis coupon
Wonderful article! We will be linking to this particularly great post on our site.
Keep up the good writing.
generic viagra online buy viagra online buy cheap cialis coupon buy cheap cialis buy cialis
Hello, its fastidious paragraph regarding media print, we all be familiar with media is a fantastic source of data.
online cialis loans with bad credit generic cialis buy cialis cheap pay day loans
Awesome post.
Hello there! This is my first visit to your blog!
We are a group of volunteers and starting a new project in a community
in the same niche. Your blog provided us valuable information to work on. You
have done a wonderful job!
buy cialis online cheap generic cialis order viagra buy generic viagra buy cheap viagra online
Mail order cialis buy generic cialis cheap cialis buy cialis online small loans online loans for bad credit
Unquestionably believe that that you said. Your favourite justification appeared to be on the net the simplest factor to take into account of.
I say to you, I certainly get irked at the same time as people consider worries that they plainly don’t recognize about.
You controlled to hit the nail upon the top as smartly as
outlined out the whole thing with no need side effect ,
other folks could take a signal. Will probably be again to get more.
Thank you
I need to to thank you for this great read!! I absolutely loved every
bit of it. I have got you saved as a favorite to check out new things you
post…
Hi! Someone in my Myspace group shared this site with us so I came to look
it over. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my followers!
Wonderful blog and superb style and design.
Very nice post. I just stumbled upon your blog and wished
to say that I have really enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I hope you write again very soon!
Hey there! I just wanted to ask if you ever have any problems with
hackers? My last blog (wordpress) was hacked and I ended up
losing many months of hard work due to no backup. Do you have any methods to protect against hackers?
I blog frequently and I genuinely thank you for your content.
This great article has truly peaked my interest. I will bookmark your website and keep checking for
new information about once a week. I subscribed to your Feed
too.
Hey there! Someone in my Myspace group shared this website with us so I came to take a
look. I’m definitely enjoying the information. I’m book-marking
and will be tweeting this to my followers! Terrific blog and amazing design and style.
Hi there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no data
backup. Do you have any methods to protect against
hackers?
Pretty! This was an incredibly wonderful post. Thanks for supplying these details.
Great work! This is the type of info that are supposed to be shared across the
net. Shame on the seek engines for not positioning this put up upper!
Come on over and visit my website . Thank you =)
Very rapidly this web page will be famous amid all blogging and site-building viewers,
due to it’s nice articles or reviews
Attractive section of content. I just stumbled upon your web site and in accession capital to assert that I acquire actually enjoyed account
your blog posts. Any way I’ll be subscribing to
your augment and even I achievement you access consistently fast.
Excellent post. I was checking continuously this blog and I’m impressed!
Very helpful info specifically the last part :
) I care for such information a lot. I was seeking this certain info for a very long time.
Thank you and good luck.
Thanks for ones marvelous posting! I genuinely enjoyed reading it
Hey there would you mind sharing which blog platform you’re using?
I’m going to start my own blog soon but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for something unique.
P.S Apologies for getting off-topic but I had to ask!
Just want to say your article is as surprising. The
clarity in your post is simply nice and i could assume you’re an expert on this subject.
Fine with your permission allow me to grab your RSS feed to keep up
to date with forthcoming post. Thanks a million and please
carry on the gratifying work.
Thanks a lot for sharing this with all folks you really realize
what you are speaking about! Bookmarked. Kindly also consult with my web site =).
We can have a link alternate arrangement among us
Hey I am so excited I found your webpage, I really found you by mistake, while I was researching on Digg for something else, Anyhow I am here now and would just like to say thanks a lot
for a marvelous post and a all round thrilling blog (I also love the theme/design), I don’t have time to browse
it all at the minute but I have bookmarked it and also added your RSS feeds,
so when I have time I will be back to read a great deal more, Please do keep up the
fantastic b.
I think the admin of this website is truly working hard in favor of his site, since here every material is quality based stuff.
I could not resist commenting. Exceptionally well written!
This web site really has all of the information and facts I wanted concerning this
subject and didn’t know who to ask.
Hi would you mind letting me know which hosting company you’re utilizing?
I’ve loaded your blog in 3 completely different browsers
and I must say this blog loads a lot quicker then most.
Can you suggest a good hosting provider at
a fair price? Thanks a lot, I appreciate it!
If you want to grow your know-how simply keep visiting this website and be updated with the most recent news posted here.
Hey there! Do you use Twitter? I’d like to follow you if that would be ok.
I’m definitely enjoying your blog and look forward to new updates.
I would like to thank you for the efforts you’ve put
in writing this site. I am hoping to check out
the same high-grade blog posts from you in the future
as well. In fact, your creative writing abilities has
encouraged me to get my own blog now 😉
Hello mates, its great piece of writing about cultureand completely explained, keep it up all the time.
It’s amazing to pay a visit this website and reading the views of all friends regarding this post, while I am also zealous of getting knowledge.
After looking over a handful of the blog articles on your web site, I truly appreciate your way of writing a blog.
I saved it to my bookmark webpage list and will be
checking back soon. Please visit my web site as well and let me know how you feel.
Howdy! Someone in my Facebook group shared this site with us so I came
to take a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers!
Terrific blog and excellent style and design.
Quality content is the secret to invite the people to pay a quick visit the web site, that’s
what this web site is providing.
Hello would you mind sharing which blog platform you’re using?
I’m going to start my own blog soon but I’m having a tough time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for
something completely unique. P.S Sorry for being off-topic but I had to ask!
My brother recommended I might like this blog. He was entirely right.
This post actually made my day. You cann’t imagine simply how much time I had spent
for this info! Thanks!
Hi there, i read your blog from time to time and i own a similar one and i was just wondering if
you get a lot of spam feedback? If so how
do you stop it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any support is very much appreciated.
Hello, I think your blog might be having
browser compatibility issues. When I look at your
blog site in Opera, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, fantastic blog!
Thanks for some other informative web site. Where else could I am getting that kind of information written in such an ideal
manner? I have a challenge that I’m simply
now running on, and I have been on the look out for such info.
An intriguing discussion is worth comment. I do think that you ought to publish
more about this topic, it may not be a taboo matter but usually
folks don’t talk about such issues. To the next! Cheers!!
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you are going to a
famous blogger if you aren’t already 😉 Cheers!
Right away I am going to do my breakfast, once having my breakfast coming yet again to read other news.
Yes! Finally someone writes about หวยออนไลน์.
Floor Screeding Experts in London and Surrounding Areas.
Call Today For Any Size Order. 24/7 Professional
Service. Highly Experienced Team. Honest Advices & Low
Prices.
This is really fascinating, You are an overly professional blogger.
I’ve joined your rss feed and stay up for in quest of extra of your great post.
Additionally, I have shared your site in my social networks
Hi, everything is going sound here and ofcourse every one is sharing information, that’s genuinely excellent, keep up writing.
Terrific work! That is the kind of info that are meant to be shared around the net.
Shame on the seek engines for no longer positioning this post upper!
Come on over and visit my website . Thank you =)
It’s actually very complicated in this busy life to listen news on TV, so I simply use the web for that purpose, and
take the most up-to-date information.
I all the time used to study post in news papers but now as I am
a user of net therefore from now I am using net for articles,
thanks to web.
Just wish to say your article is as amazing. The clarity on your
put up is simply great and i can suppose you’re an expert
on this subject. Fine together with your permission let me to
clutch your feed to keep up to date with imminent post.
Thank you one million and please keep up the rewarding work.
This web site definitely has all the information I wanted about this subject and didn’t know who to ask.
Heya just wanted to give you a brief heads up and let you know a
few of the images aren’t loading correctly. I’m not sure why but
I think its a linking issue. I’ve tried it in two different browsers and both show the same results.
Hi, I desire to subscribe for this website to take most recent updates, therefore where can i do it please help out.
Very nice post. I simply stumbled upon your blog and wished to mention that I’ve truly
enjoyed surfing around your weblog posts. After all
I’ll be subscribing for your rss feed and
I’m hoping you write again soon!
Howdy! I simply wish to offer you a huge thumbs up for the great info you
have right here on this post. I will be coming back
to your website for more soon.
Can I just say what a comfort to discover a person that genuinely understands what they’re discussing on the web.
You definitely realize how to bring an issue to light and make it important.
A lot more people should read this and understand this side of
the story. I was surprised you are not more popular since you
surely possess the gift.
If they are not reading your blog post posts, there is
not any chance them linking to you. They are shrinking the product quality control
and placing quite a challenge in relation to being able to
rank well inside the SERPS. As with any physical treatments, make sure you
are treated with a recognised professional practitioner that will discuss any required needs, plus highlight any
medical or health issues you suffer from before commencing one of
the treatments.
My spouse and I stumbled over here from a different web address and thought I might as well check things out.
I like what I see so i am just following you.
Look forward to going over your web page yet again.
I enjoy what you guys are up too. This type of clever work and exposure!
Keep up the great works guys I’ve added you guys to our blogroll.
Why users still make use of to read news papers when in this technological globe all is available on web?
It’s genuinely very complex in this active life to listen news on Television, so I just
use world wide web for that purpose, and take the newest news.
I delight in, lead to I found exactly what I was having
a look for. You have ended my four day long hunt! God Bless you man. Have
a great day. Bye
I was extremely pleased to discover this website.
I want to to thank you for your time just for this fantastic read!!
I definitely really liked every little bit of it and I have you book
marked to check out new stuff on your blog.
It is appropriate time to make a few plans for the longer term and
it’s time to be happy. I’ve read this put up and if I may
I want to recommend you some interesting things or advice.
Perhaps you could write next articles referring to this article.
I wish to read even more issues approximately it!
Yes! Finally something about หวย.
What’s Going down i am new to this, I stumbled upon this I’ve discovered It positively
helpful and it has helped me out loads. I am hoping to contribute & help different users like its helped me.
Great job.
Wow, this paragraph is pleasant, my sister is analyzing these things, so I am going to
inform her.
I was curious if you ever considered changing the layout of your website?
Its very well written; I love what youve got to
say. But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2 images.
Maybe you could space it out better?
Helpful information. Lucky me I discovered your
website accidentally, and I’m stunned why this accident didn’t took place in advance!
I bookmarked it.
I really like your blog.. very nice colors
& theme. Did you create this website yourself or did you hire
someone to do it for you? Plz reply as I’m looking to construct my own blog and
would like to know where u got this from. thanks
I have been surfing online more than three hours nowadays, yet I never discovered any interesting article like yours.
It is beautiful value enough for me. In my view, if all website owners and bloggers made just
right content as you probably did, the web might be much more helpful
than ever before.
What’s Taking place i am new to this, I stumbled upon this I have found
It absolutely helpful and it has aided me out loads.
I am hoping to contribute & assist other customers like its aided me.
Great job.
Asking questions are really nice thing if you are not understanding something fully, but this paragraph offers good understanding even.
This paragraph is really a fastidious one it helps new the
web users, who are wishing for blogging.
Pleаse let me know if you’rе lookіng for a author foг yoᥙr site.
Yoᥙ have ѕome really great articles and I feel I ԝould Ьe a goоd asset.
If you ever want to taҝe some of the load off, Ӏ’ɗ love
to wгite some cߋntent for yoսr blog іn exchange for
a link baϲk to mine. Please send mе an email if intereѕted.
Thаnk you!
Hi there i am kavin, its my first occasion to commenting anyplace,
when i read this piece of writing i thought i could also create comment due
to this good paragraph.
You can definitely see your skills within the article you write.
The world hopes for more passionate writers like you who aren’t afraid to mention how they believe.
Always follow your heart.
I think everything said made a ton of sense. But, think about this, suppose you
composed a catchier title? I ain’t suggesting your content isn’t solid, however
suppose you added a headline that makes people want more?
I mean K-Nearest Neighbor Machine Learning
algorithm – Deepsingularity : Deepsingularity is a little boring.
You might glance at Yahoo’s front page and
see how they write post headlines to grab viewers to open the links.
You might try adding a video or a picture or two to get readers interested about what you’ve written. Just my
opinion, it could bring your posts a little bit
more interesting.
Appreciating the persistence you put into your blog and detailed information you provide.
It’s good to come across a blog every once in a while that isn’t the same old rehashed information. Great read!
I’ve saved your site and I’m including your RSS feeds to my Google account.
Article writing iѕ also a fun, if yoս be acquainted witһ then you
can write otheгwise it іѕ compllicated tօ wгite.
Please let me know if you’re looking for a writer for your weblog.
You have some really good posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d absolutely love to write some articles for your blog
in exchange for a link back to mine. Please send me an e-mail if interested.
Kudos!
Howdy! This post could not be written much better! Looking through this post reminds me of my previous roommate!
He always kept preaching about this. I will send this information to him.
Fairly certain he will have a great read. Thank you
for sharing!
hi!,I really like your writing so a lot! proportion we communicate more about your post on AOL?
I require a specialist in this house to solve my problem.
May be that is you! Having a look ahead to peer you.
Wonderful items from you, man. I’ve remember your stuff prior to and you’re just extremely
wonderful. I actually like what you’ve obtained right here, certainly like what you are saying
and the way in which through which you are saying it.
You are making it entertaining and you still care for to keep it wise.
I can’t wait to read much more from you. This is actually a great
web site.
Simply desire to say your article is as astounding. The clarity to your submit is simply cool and i can assume you are an expert on this subject.
Fine along with your permission allow me to snatch your RSS feed to keep up to date with
forthcoming post. Thanks one million and please carry on the enjoyable
work.
Excellent post. I will be dealing with many of these issues as well..
Wonderful, what a weblog it is! This weblog presents useful data to us,
keep it up.
먹튀검증사이트, 먹튀검증 먹튀사이트 먹튀폴리스입니다.
먹튀검증커뮤니티는 신규는 물론 오픈된 먹튀사이트를 철저히 검증하여 먹튀없는 시대를 만들어가고 있습니다.
먹튀폴리스를 사랑하는 여러분의
많은 호응바랍니다. 여러분의 충실한 검증사이트가 되도록
노력하겠습니다.
Attractive section of content. I just stumbled upon your site and in accession capital to
assert that I get in fact enjoyed account your blog posts.
Any way I will be subscribing to your augment and even I achievement you access consistently
rapidly.
It’s an remarkable post in favor of all the online people; they will take benefit from it I am sure.
Great post. I was checking continuously this blog and I am impressed!
Extremely helpful information specially the last part 🙂 I care for such information much.
I was looking for this certain information for a very long time.
Thank you and best of luck.
We’re a group of volunteers and starting
a new scheme in our community. Your site provided us with
valuable information to work on. You have done an impressive job and our whole community will be
grateful to you.
Hello there, just became aware of your blog through Google, and
found that it’s really informative. I am gonna watch out for brussels.
I will be grateful if you continue this in future. Lots of people will be benefited from your writing.
Cheers!
I’m impressed, I must say. Rarely do I encounter a blog that’s equally educative and entertaining, and let me tell you, you’ve
hit the nail on the head. The problem is something too few people
are speaking intelligently about. I’m very happy I came across this in my search for something relating to this.
I could not refrain from commenting. Well written!
Hello, yes this post is in fact good and I have learned lot of things from
it concerning blogging. thanks.
What a material of un-ambiguity and preserveness of valuable experience regarding unexpected feelings.
Hi it’s me, I ɑm also visiting thiѕ web siute daily, this web
site is tгuly pleasant and the people are genuinely sharing nice tһoughts.
It’s an awesome paragraph for all the online viewers; they will get advantage from it I am
sure.
Nice respond in return of this issue with firm arguments and telling everything about that.
Hey there! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thank you
Very nice post. I just stumbled upon your blog and wished to say that I have truly enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I
hope you write again soon!
This article presents clear idea for the new viewers of blogging, that really how to do blogging
and site-building.
Please let me know if you’re looking for a article writer for your site.
You have some really good articles and I feel I would
be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some content
for your blog in exchange for a link back
to mine. Please send me an e-mail if interested. Thanks!
Wow, this piece of writing is good, my sister is analyzing these
kinds of things, therefore I am going to let know her.
It’s appropriate time to make some plans for the future and it is time to be happy.
I’ve read this put up and if I may I wish to suggest you
few fascinating things or tips. Maybe you
can write next articles relating to this article.
I desire to learn even more issues about it!
Hello there! I could have sworn I’ve been to this site before but
after checking through some of the post I realized it’s new to
me. Anyways, I’m definitely happy I found it and I’ll be bookmarking and checking back frequently!
I am sure this article has touched all the internet visitors, its really really good post on building up
new webpage.
Have you ever considered publishing an ebook or guest authoring
on other blogs? I have a blog based upon on the same subjects you discuss and would really
like to have you share some stories/information. I know my readers would enjoy your work.
If you’re even remotely interested, feel free to send me an email.
Pretty! This was an extremely wonderful article. Many thanks for supplying this information.
I will right away seize your rss as I can’t to find your email subscription link or newsletter service.
Do you’ve any? Kindly allow me know in order
that I could subscribe. Thanks.
It’s an amazing post in favor of all the web viewers; they will
obtain advantage from it I am sure.
You have made some decent points there. I checked on the web for more information about the
issue and found most people will go along with your views on this website.
Thanks for ones marvelous posting! I genuinely enjoyed reading it
If some one desires to be updated with hottest technologies then he must be pay a visit this website and be up to date everyday.
Nice post. I learn something totally new and challenging on websites I stumbleupon everyday.
It will always be exciting to read through content from other writers and use something from other sites.
Thanks for another informative web site. Where else may I get
that type of information written in such a perfect means?
I have a undertaking that I’m simply now working on, and I’ve been at the glance out for such info.
Thanks for finally talking about >K-Nearest Neighbor Machine Learning algorithm – Deepsingularity :
Deepsingularity <Loved it!
Unquestionably imagine that which you said. Your favourite justification seemed
to be at the net the easiest thing to take into account of.
I say to you, I definitely get annoyed while other people think about
worries that they plainly don’t recognise about. You controlled to hit the nail upon the highest as smartly as defined out the entire thing with no need side effect , other folks could take a signal.
Will likely be back to get more. Thanks
This paragraph will help the internet visitors for setting up
new website or even a blog from start to end.
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your site?
My website is in the exact same area of interest as yours and my visitors would genuinely benefit from a lot of the information you provide here.
Please let me know if this ok with you. Thanks!
I feel that is among the most vital info for me. And i am happy reading your article.
However want to remark on few normal things, The website style is ideal, the
articles is truly great : D. Just right job, cheers
hello!,I love your writing so much! percentage we keep in touch extra
about your article on AOL? I require an expert on this space to unravel my problem.
May be that’s you! Looking ahead to see you.
Just desire to say your article is as astounding.
The clearness to your post is just spectacular and that i
can think you are a professional on this subject. Fine together with your permission let me to seize your RSS
feed to stay updated with coming near near post. Thanks a million and please keep up the enjoyable work.
Hello just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to do with
web browser compatibility but I thought I’d post to let you know.
The style and design look great though! Hope you get the
problem solved soon. Cheers
constantly i used to read smaller posts that as well clear their motive,
and that is also happening with this post which I am reading at this time.
I every time emailed this blog post page to all my contacts, for the
reason that if like to read it then my links will
too.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to
make your point. You obviously know what youre talking about, why throw away
your intelligence on just posting videos to your blog when you could be giving us something informative
to read?
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is
added I get several e-mails with the same comment.
Is there any way you can remove me from that service?
Cheers!
What’s up, I wish for to subscribe for this weblog to obtain hottest updates, so where can i do it please help out.
Now I am going away to do my breakfast, when having my
breakfast coming again to read additional news.
Hi would you mind letting me know which web host you’re using?
I’ve loaded your blog in 3 different internet browsers and I must say this blog loads a lot quicker then most.
Can you recommend a good web hosting provider at a reasonable price?
Many thanks, I appreciate it!
Hi, the whole thing is going perfectly here and ofcourse every one is sharing facts,
that’s in fact good, keep up writing.
Someone necessarily help to make severely posts I’d state.
That is the first time I frequented your web page and up to now?
I surprised with the research you made to create this particular submit
incredible. Fantastic task!
We are a group of volunteers and opening a new scheme in our community.
Your website offered us with valuable information to work on. You’ve done a formidable job and our entire community will be grateful to you.
It’s a pity you don’t have a donate button! I’d definitely donate to this excellent blog!
I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this blog with my Facebook group.
Talk soon!
Hi this is somewhat of off topic but I was wondering if blogs
use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to
get advice from someone with experience. Any help would be greatly appreciated!
These are in fact enormous ideas in on the topic of blogging.
You have touched some good factors here. Any way keep up wrinting.
Awesome article.
Thank you for some other informative website. The place else could I
am getting that kind of information written in such a perfect means?
I have a challenge that I am just now running on, and I have been at the glance out for such info.
Wow, fantastic blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site is great, as well as the content!
It’s a pity you don’t have a donate button! I’d certainly donate to this
outstanding blog! I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this website with my
Facebook group. Chat soon!
como combatir la disfuncion erectil en jovenes
Aw, this was an exceptionally good post. Spending some time and
actual effort to generate a top notch article… but what can I say…
I hesitate a whole lot and don’t manage to get nearly anything done.
Hi tһere I amm sⲟ grateful I found yоur web
site, I reallky found yoou bby mistake, ѡhile I wаs browsing
on Yahoo foг solmething else, Nοnetheless Ӏ am here now and would
just like to say cheers for a fantastic post ɑnd a all round enjoyable blog (І also love the
theme/design), I don’t һave time to look over it aⅼl аt thе moment but I havе saved it and аlso аdded iin your RSS feeds, ѕo when I have timе I will Ье back to᧐ rеad a ցreat deasl mօrе, Plase do kеep upp tһe awesome ѡork.
Hey! This is my first comment here so I just wanted to give
a quick shout out and tell you I really enjoy reading your articles.
Can you suggest any other blogs/websites/forums that deal with the same topics?
Thanks a lot!
I was suggsted this blog ƅy my cousin. I am not ѕure whetheer tһiѕ post is written bү him aas noboⅾy else knoѡ
such detailed аbout my problem. You aree amazing!
Thanks!
Thanks for sharing such a good thought, post is nice, thats why i have read it fully
What’s up everyone, it’s my first pay a quick visit at this website, and article is really fruitful designed for me, keep
up posting these articles or reviews.
I’d like to find out more? I’d want to find out some additional information.
It’s remarkable tto visit tһis website and reading tһe views оf alⅼ mates concerjing thiѕ piece of writing, wһile I am аlso keen of gettіng experience.
It’s very easy to find out any matter on net as compared to textbooks, as I
found this article at this web page.
Great article! That is the type of information that are meant to be shared around the internet.
Shame on Google for now not positioning this submit upper!
Come on over and visit my website . Thank you =)
Write more, thats all I have to say. Literally, it seems as though you
relied on the video to make your point. You definitely
know what youre talking about, why waste your
intelligence on just posting videos to your site when you could
be giving us something enlightening to read?
What you published was very reasonable. However, consider this, suppose you typed a catchier title?
I am not saying your information is not solid., however suppose you added something that makes people want more?
I mean K-Nearest Neighbor Machine Learning algorithm –
Deepsingularity : Deepsingularity is kinda boring.
You might peek at Yahoo’s front page and see how they create article titles to grab people to open the
links. You might try adding a video or a related
picture or two to grab people interested about what you’ve got to say.
In my opinion, it could make your blog a little livelier.
WOW juѕt what I ѡas searching for. Camе herе
by searching for daftar Capsa susun online terbaik
My family always say that I am wasting my time here
at net, except I know I am getting know-how daily by reading thes
nice articles.
I don’t know if it’s just me or if perhaps everybody else experiencing problems with your website.
It seems like some of the text within your content are running
off the screen. Can someone else please provide feedback and let me know
if this is happening to them too? This could
be a issue with my browser because I’ve had this happen previously.
Kudos
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was
hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
By the way, how can we communicate?
I blog frequently and I really appreciate your content. Your
article has really peaked my interest. I will book mark your blog and keep
checking for new details about once a week. I opted in for
your RSS feed as well.
I all the time used to read article in news papers but now as I am a
user of web therefore from now I am using net for content, thanks to web.
It’s actually very complicated in this full of activity life to listen news on TV, thus I only use web
for that reason, and get the newest news.
Hi there, this weekend is good for me, because this occasion i am reading this great educational post here at my residence.
I delight in, cause I discovered just what I was looking for.
You have ended my 4 day long hunt! God Bless you man.
Have a nice day. Bye
I know this if off topic but I’m looking into starting my own blog and was curious what all is required to get setup?
I’m assuming having a blog like yours would cost a pretty
penny? I’m not very internet smart so I’m not 100% sure.
Any tips or advice would be greatly appreciated. Thank you
whoah this weblog is excellent i love reading your articles.
Keep up the good work! You understand, a lot of persons are hunting around for this info,
you could aid them greatly.
Cavalier King Charles Spaniel Puppies for sale
: As Breeders with 19 years of breeding experience, our philosophy or role is to make sure all our Cavalier King Charles Spaniel Puppies are loved and spoiled from the get-go, We strongly believe that
a happy animal will give a family a happy experience too.Cavalier King
Charles Spaniel Puppies for sale
At Lionheart Spaniels, we breed for Sound Temperament, Personality, Conformation,
& Breed Standard. Our Cavalier King Charles Spaniels are
indoor and outdoor dogs. They have access to a
large fenced yard every day where they are allowed to run and play, and our doors
are ALWAYS open for them.Cavalier King Charles Spaniel Puppies for sale
First and foremost our Cavalier King Charles Spaniels
are our beloved companions and a part of our family.
This magnificent breed is not only our life but also our greatest adventure.
All puppies receive the best possible environment (cleanliness is of the utmost importance) and loving
attention while in our care.Cavalier King Charles Spaniel Puppies for sale
All adult dogs and puppies are completely compliant with all AKC rules and regulations!
Every dog is bred for excellent disposition, conformation, health & quality
of the breed, to become the very best family companion available.
We hope that they will meet every expectation you have of them.Cavalier King Charles Spaniel Puppies for sale
Please, always think about adopting a rescued Cavalier King Charles Spaniel Puppy.
They need your love and attention too!
We here at Lionheart Spaniels will chance losing a prospective customer any
day just to know that any rescued Cavalier King Charles Spaniel will receive a loving, kind, understanding,
place to call home!Cavalier King Charles Spaniel Puppies for
sale
SN
Spot on with this write-up, I truly believe that
this website needs much more attention. I’ll probably be returning to see more, thanks for the advice!
Good post however I was wondering if you could write a litte more
on this subject? I’d be very grateful if you could elaborate a
little bit further. Many thanks!
Excellent goods from you, man. I’ve understand your stuff prior to and you’re just
extremely excellent. I really like what you’ve bought right here, really like what you’re stating and the way
in which in which you say it. You make it entertaining and you still take care of
to stay it wise. I cant wait to read much more from you.
This is really a great web site.
Heya! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing several
weeks of hard work due to no backup. Do you
have any solutions to protect against hackers?
What a material of un-ambiguity and preserveness of
precious know-how about unexpected feelings.
After checking out a number of the articles
on your blog, I seriously appreciate your technique of writing a blog.
I book-marked it to my bookmark website list and will be checking back soon. Please check out my website as well and let me know what you
think.
Aw, this was a very nice post. Spending some time
and actual effort to make a really good article… but what
can I say… I hesitate a lot and never manage to get
nearly anything done.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an shakiness over that you wish be
delivering the following. unwell unquestionably come more formerly
again as exactly the same nearly a lot often inside case you shield this hike.
Why users still use to read news papers when in this technological world all is accessible on web?
Thank you for some other wonderful article. The place else
may just anybody get that kind of information in such an ideal method of writing?
I’ve a presentation next week, and I am on the look for such information.
I Ԁo trust alll the concepts yoᥙ’ѵe presented to your post.
They’re very convincing ɑnd can definiteⅼy
woгk. Nonetheⅼess, tһe posts are vry Ƅrief for novices.
May ϳust you please prolong them а bit frоm next time?
Thanks for the post.
Μʏ web рage american visas
Hey there ԝould youu mind letting mе қnow ԝhich web host үou’re working with?
I’ve loaded yoᥙr blog in 3 completely ԁifferent internet browsers
ɑnd I must say this blog loads a lоt quicker tһen most.
Cɑn you recommend a goood internet hosting provider аt a
honest price? Thanks a lot, I aρpreciate іt!
Μy homepage … green card usa
You can certainly see your skills within the work you write.
The arena hopes for more passionate writers like you who are
not afraid to mention how they believe. All
the time go after your heart.
This is the right web site for anyone who hopes to understand this topic.
You understand a whole lot its almost tough to argue with you (not that I actually
will need to…HaHa). You certainly put a brand new spin on a subject which has been written about for a long time.
Great stuff, just excellent!
Hi, Neat post. There is an issue along with your
site in internet explorer, might check this? IE nonetheless is the marketplace leader and a large part of people will pass over your wonderful writing
because of this problem.
Right now it seems like Movable Type is the preferred blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
I was curious if you ever considered changing the page layout of your
website? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people
could connect with it better. Youve got an awful lot of
text for only having 1 or 2 pictures. Maybe you could space it out
better?
Do you have a spam problem on this site; I also
am a blogger, and I was curious about your situation;
many of us have created some nice practices and we are looking to exchange techniques with other folks,
be sure to shoot me an email if interested.
I read this piece of writing fully concerning
the comparison of latest and preceding technologies, it’s
awesome article.
This is my first time go to see at here and i am actually impressed to read all at alone
place.
Wow, fantastic blog structure! How lengthy have you ever been blogging
for? you make running a blog glance easy. The whole glance
of your web site is wonderful, as smartly as the content material!
Thank you a bunch for sharing this with all of us you
really understand what you’re talking about! Bookmarked. Kindly also talk
over with my web site =). We will have a hyperlink trade
contract among us
Pretty nice post. I jjst stumbled upon your blog and wanted to say that I have truly enjoyed browsing your blog posts.
In any casze I’ll be subscribing to your feed and I hope you write again very soon!
Also visit my homepage: Tod
I’m gone to inform my little brother, that he should
also visit this website on regular basis to get updated
from most up-to-date information.
Good post. I learn something totally new and challenging on blogs I
stumbleupon every day. It will always be interesting to
read articles from other writers and use something from
other websites.
This is my first time pay a quick visit at here and i am actually happy to
read all at alone place.
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic information I was looking for this information for my mission.
I got this site from my pal who told me regarding this website and at the moment
this time I am visiting this website and reading very informative posts at this place.
I know this if off topic but I’m looking into
starting my own blog and was curious what all is
required to get set up? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very internet savvy so
I’m not 100% certain. Any suggestions or advice would be greatly appreciated.
Many thanks
Magnificent beat ! I wish to apprentice while you amend your
web site, how could i subscribe for a blog web site?
The account helped me a acceptable deal. I had been tiny bit acquainted
of this your broadcast offered bright clear idea
This information is invaluable. How can I find out
more?
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish. nonetheless, you
command get got an edginess over that you wish be
delivering the following. unwell unquestionably come further formerly again since exactly
the same nearly a lot often inside case you shield this
hike.
I was wondering if you ever thought of changing the page
layout of your blog? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of
content so people could connect with it better. Youve got an awful lot of text for only having 1 or two
images. Maybe you could space it out better?
I will right away seize your rss as I can not find your email subscription hyperlink or newsletter service.
Do you have any? Please permit me recognize so that I could subscribe.
Thanks.
Hello there I am so glad I found your webpage, I really found you by mistake, while I was researching on Digg for something else,
Regardless I am here now and would just like to say cheers for a remarkable post and a all round exciting blog (I
also love the theme/design), I don’t have time to
go through it all at the moment but I have bookmarked
it and also added your RSS feeds, so when I have time I will be back to read much more, Please do keep up the great jo.
I’m not sure exactly why but this weblog is loading incredibly slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later and see if the problem still exists.
Hi there, just wanted to mention, I enjoyed this article.
It was funny. Keep on posting!
Please let me know if you’re looking for a article writer for your blog.
You have some really great articles and I think I would be
a good asset. If you ever want to take some of the load off, I’d love to
write some material for your blog in exchange for a link back to mine.
Please blast me an e-mail if interested. Thanks!
You really make it seem so easy with your presentation but
I find this topic to be really something which I
think I would never understand. It seems too complex and extremely broad for me.
I’m looking forward for your next post, I will try to get the hang of
it!
Hi, i think that i saw you visited my blog so i
came to “return the favor”.I’m attempting to
find things to improve my web site!I suppose its ok to
use a few of your ideas!!
Wonderful beat ! I would like to apprentice whilst you amend your site, how can i subscribe for a weblog
site? The account helped me a appropriate deal.
I have been a little bit familiar of this your broadcast offered bright clear idea
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your
useful information. Thanks for the post. I will certainly return.
Wow that was unusual. I just wrote an incredibly long comment but after I
clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyhow, just wanted to say excellent blog!
If you desire to grow your know-how only keep visiting this web page
and be updated with the latest news update posted here.
Hi all, here every one is sharing such knowledge, thus it’s fastidious to
read this web site, and I used to pay a visit this blog all the time.
I know this web site offers quality depending articles or reviews and
extra material, is there any other site which presents these kinds of data in quality?
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how can we communicate?
Hey there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m absolutely enjoying your blog and look forward to new posts.
It’s difficult to find well-informed people about this topic, however,
you sound like you know what you’re talking about! Thanks
I simply couldn’t leave your web site prior to suggesting that I extremely enjoyed the usual info a person supply
in your visitors? Is gonna be back regularly to check up on new posts
We’re a bunch of volunteers and starting a brand new
scheme in our community. Your website offered us with helpful information to work on. You’ve performed a formidable process and
our entire neighborhood will be thankful to you.
I’ll immediately grab your rss as I can’t
to find your email subscription link or newsletter service.
Do you have any? Please allow me understand in order that I may just subscribe.
Thanks.
Hello, of course this article is really pleasant and
I have learned lot of things from it about blogging.
thanks.
Hey I know this is off topic but I was wondering if you knew of any widgets I could
add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping
maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
I don’t know if it’s just me or if everyone else encountering issues with your site.
It looks like some of the written text in your content are running off the
screen. Can someone else please provide feedback and let me
know if this is happening to them as well? This could be a issue with my web browser because I’ve had this
happen previously. Many thanks
This is the perfect webpage for everyone who wants to find out about this topic.
You realize a whole lot its almost hard to argue
with you (not that I really would want to…HaHa). You definitely put a
new spin on a subject that’s been discussed for a long time.
Great stuff, just great!
Howdy! This post couldn’t be written any better! Reading
through this post reminds me of my old room mate! He always
kept chatting about this. I will forward this article to him.
Pretty sure he will have a good read. Thanks for sharing!
Asking questions are really good thing if you are not understanding anything fully, however this post offers
nice understanding even.
After looking into a number of the blog posts on your site, I honestly like
your technique of blogging. I book-marked it to my bookmark webpage
list and will be checking back in the near future.
Take a look at my website as well and let me know your
opinion.
Excellent blog here! Also your site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
Magnificent website. Plenty of helpful information here.
I am sending it to some friends ans also sharing in delicious.
And naturally, thank you for your sweat!
BN
Buying cryptocurrency is becoming easier than ever before.
Select Bitcoin as the cryptocurrency of one’s choice.
Coinbase also gives cryptocurrency wallets.
Europe-based cryptocurrency change, founded in 2013.
Most income exchanges have no buying limits.
Als je financieel goed zit is het de beste oplossing om
gebruik te maken van een betaalde aanbieder,
maar als je gratis online voetbal wilt streamen is bovenstaand overzicht
de oplossing voor jou. De voetbalwedstrijden in bovenstaand overzicht streamen de wedstrijden niet zelf, maar speuren het internet af naar aanbieders van de livestreams en geven deze in een overzichtelijke website
weer. Door MBO middels deze benadering in te bedden bij BVO’s, kunnen voetbalclubs een sterkere verbinding en verankering in de (regionale) gemeenschap realiseren. Ze kunnen daar onder andere vorm aan geven middels projecten in het kader van community development.
Daarnaast is er bij BVO’s vaak weinig maatschappelijk beleid en beperken maatschappelijke
activiteiten zich tot ad hoc projecten. Ook beleidsmakers van BVO’s zijn tegenwoordig genoodzaakt rekening te
houden met ontwikkelingen en verantwoordelijkheden in hun sociaaleconomische en politieke omgeving, omdat ze rekenschap moeten geven aan de
gemeenschap waar ze uit voort komen (Breithbart & Harris, 2008;
Slack & Shrives, 2008). Daarom is Maatschappelijk Betrokken Ondernemen (MBO)
belangrijk voor BVO’s. Hoewel in de literatuur al veel
aandacht is geweest voor MBO in de Premier League (Breitbarth & Harris, 2008; Tacon & Walters,
2010), is nog weinig aandacht besteed aan MBO bij BVO’s in Nederland.Article_Title Feyenoord Nieuwe Kartrekker MVO In Betaald Voetbal?
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is
added I get three emails with the same comment. Is there any way you can remove me from that service?
Bless you!
cdsfsfsdfet fesfefsetsfdsfsd sdf
I really like your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to design my own blog and would like to find out where u
got this from. appreciate it
Hey there! Someone in my Facebook group shared this site with us so I came to check it out. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers! Fantastic blog and terrific design and style.
whoah this weblog is fantastic i love reading your posts.
Keep up the good work! You already know, a lot of people are searching round for this information,
you could help them greatly.
As I website possessor I believe the content material here is rattling wonderful , appreciate it for your efforts. You should keep it up forever! Best of luck.
xsadkajaklsd jhjha kjhkjhskjd
Fantastic blog you have here but I was wanting to know if you knew of any forums that cover the same topics discussed here? I’d really like to be a part of online community where I can get comments from other experienced individuals that share the same interest. If you have any recommendations, please let me know. Thank you!
jlkjkljlkhklhkjh asdkjasdfeerwrdasde
Spot on with this write-up, I actually think this web site needs way more consideration. I’ll in all probability be again to read rather more, thanks for that info.
I wish to express some thanks to you just for bailing me out of this type of situation. As a result of surfing through the world wide web and obtaining ways that were not helpful, I believed my life was gone. Existing devoid of the strategies to the issues you’ve solved by way of this posting is a serious case, as well as ones that would have in a negative way affected my entire career if I hadn’t noticed your site. That natural talent and kindness in maneuvering all areas was excellent. I am not sure what I would’ve done if I had not come upon such a thing like this. I am able to at this point look ahead to my future. Thanks for your time very much for the professional and sensible guide. I will not hesitate to suggest your web sites to any individual who should get guidance on this issue.
I’m not sure where you are getting your information, however great topic.
I must spend some time finding out much more or working out more.
Thank you for wonderful information I was on the lookout
for this information for my mission.
There’s noticeably a bundle to know about this. I assume you made certain nice factors in features also.
Simply want to say your article is as astonishing. The clarity in your post is simply cool and i could assume you’re an expert on this subject. Well with your permission let me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please keep up the rewarding work.
Hey! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
F*ckin’ amazing things here. I am very glad to see your post. Thanks a lot and i am looking forward to contact you. Will you kindly drop me a e-mail?
I was suggested this web site by my cousin. I’m now not sure whether or not this publish is written by way of him
as nobody else realize such distinct approximately my trouble.
You’re wonderful! Thank you!
Why people still use to read news papers when in this technological world all is accessible on web?
adsukmsetlnyihowfeytmhahotbebv
Ahaa, its pleasant dialogue concerning this
piece of writing at this place at this blog, I have read
all that, so now me also commenting at this
place.
I’ve been absent for some time, but now I remember why I used to love this web site. Thank you, I’ll try and check back more frequently. How frequently you update your site?
Hello are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create
my own. Do you need any html coding expertise to make your own blog?
Any help would be really appreciated!
I am curious to find out what blog platform you happen to be utilizing?
I’m experiencing some small security issues with my latest site
and I would like to find something more risk-free.
Do you have any solutions?
Buenas tardes!
Hemos analizado deepsingularity.io el 26-Oct-20 y le hemos generado un estudio SEO completamente gratuito en el siguiente enlace: https://seo.creapublicidadonline.com/domain/deepsingularity.io
Nos consideramos una empresa especializada en posicionamiento web
Encantado de saludarlos
Wow, this article is nice, my sister is analyzing these things, so I am going
to tell her.
Heya just wanted to give you a brief heads up and let
you know a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same outcome.
We are a bunch of volunteers and opening a new scheme
in our community. Your site offered us with useful information to work on. You’ve done an impressive process and our entire group can be thankful to you.
Pingback: buy cialis australia
Pingback: buy cialis online
Please let me know if you’re looking for a author for your site.
You have some really good articles and I think I would
be a good asset. If you ever want to take some of the load off, I’d really like to write some
articles for your blog in exchange for a link back to
mine. Please blast me an email if interested. Kudos!
Hi there! Would you mind if I share your blog with my facebook group? There’s a lot of people that I think would really appreciate your content. Please let me know. Thank you
Pingback: buy cialis usa
Pingback: cialis online
Pingback: cost of viagra
Pingback: cialis tadalafil 20 mg
Pingback: warnings for cialis
Pingback: viagra pills 100 mg
Pingback: no prescription cialis
Pingback: cialis dosages
Pingback: sildenafil teva
Pingback: generic viagra india
Pingback: viagra ebay
Pingback: chinese viagra
Pingback: levitra 10mg
Pingback: free viagra samples
Pingback: atorvastatin vegas
Hello there! I just want to give you a huge thumbs up for the excellent information you’ve got
here on this post. I’ll be returning to your web site for more
soon.
Pingback: viagra bdsm
This is my first time go to see at here and i am actually happy to read all at one place.
Pingback: viagra side effects
Pingback: buy cheap essay
Pingback: viagra walmart
You made some really good points there. I checked on the internet
for additional information about the issue and
found most individuals will go along with your views on this site.
Thank you for sharing your info. I really appreciate your efforts and I will be waiting for your next post thank you once again. niemtinviet.edu.vn: niemtinviet.edu.vn
Hello. remarkable job. I did not imagine this. This is a excellent story.
Thanks!
Hi, I do think this is a great web site. I stumbledupon it 😉 I am going to come back once again since I bookmarked it. Money and freedom is the greatest way to change, may you be rich and continue to help other people.
Pingback: viagra pill
Pingback: dosage for augmentin
Pingback: viagra costs
Pingback: cialis dose
Pingback: cialis viagra
Pingback: cephalexin dose dogs
Pingback: feline dose ciprofloxacin eye drops
Pingback: oxybutynin goodrx
Pingback: tizanidine dose
Pingback: mousetrap
Wow, marvelous blog format! How lengthy have you ever
been blogging for? you make blogging glance easy.
The entire look of your site is excellent, let alone the content
material!
Pingback: best alternative to abilify
Pingback: what is allopurinol taken for
Pingback: amiodarone dose calculator
Pingback: side effects of amitriptyline hcl 50mg
I am extremely impressed together with your writing skills and
also with the format in your weblog. Is that this a
paid topic or did you modify it your self? Anyway keep up the excellent
high quality writing, it’s rare to look a great weblog like this one these days..
my homepage اینجا(+)
Pingback: amlodipine side affects
Hi! I know this is somewhat off topic but I was wondering which blog platform
are you using for this website? I’m getting tired of WordPress because
I’ve had issues with hackers and I’m looking at options for
another platform. I would be fantastic if you could point me in the direction of
a good platform.
Feel free to visit my blog post https://jalandhar.indiaolx.com/user/profile/39013
A person necessarily assist to make critically posts I might state.
That is the very first time I frequented your web page and
so far? I surprised with the analysis you made to make this actual submit extraordinary.
Great job!
my web site; https://www.carhubsales.com.au/user/profile/271966
A lot of thanks for all your valuable hard work on this blog.
My aunt loves conducting investigations and it is easy to see why.
A lot of people know all regarding the lively method you
create great tactics by means of your web site and as well as attract contribution from some other people on that
theme plus our favorite child is actually understanding a great deal.
Enjoy the remaining portion of the year. Your doing
a wonderful job.[X-N-E-W-L-I-N-S-P-I-N-X]I’m extremely
impressed along with your writing abilities
as well as with the structure on your weblog. Is this a paid topic or did you customize it your self?
Either way keep up the excellent quality writing, it is rare to see a nice weblog like this one these days.
Look at my homepage http://sheersparkketo.org/
Pingback: amoxicillin for bladder infection dosage
Pingback: phone repair
Pingback: aripiprazole dosage
Pingback: cvs atorvastatin
Pingback: azithromycin 250mg tablets 6 pack
Pingback: baclofen for arthritis pain
Pingback: baclofen overdose poison control
Pingback: wellbutrin xl and topamax
Pingback: buspar adhd
Pingback: buspar interaction
I have to express my affection for your kindness supporting men and women who need help on this particular subject.
Your very own dedication to getting the solution up and down came to be quite functional
and has consistently enabled most people like me to attain their objectives.
Your own warm and friendly guide entails a great deal to me and additionally to
my peers. Regards; from everyone of us.
Look into my blog post; https://united-states.02all.com/user/profile/38723
Pingback: coreg efffect on eye
Pingback: can i take tramadol w celebrex
Pingback: celexa for hypochondria
Pingback: pill
Pingback: free viagra coupons
Pingback: viagra prank
Pingback: canada viagra
Pingback: viagra for men
Pingback: roman viagra
Pingback: cialis supper active
Pingback: earbuds
Every weekend i used to visit this website, as i wish for enjoyment, as
this this web site conations actually good funny stuff too.
Pingback: clitoris on viagra
For most recent news you have to go to see world wide web and on world-wide-web I found this web page
as a best site for latest updates.
Good blog you have got here.. It’s difficult to find high quality writing like yours nowadays.
I seriously appreciate people like you! Take care!!
Pingback: faliure meds for cialis
I am really enjoying the theme/design of your website.
Do you ever run into any browser compatibility
issues? A small number of my blog visitors have complained about
my blog not working correctly in Explorer but looks great in Opera.
Do you have any ideas to help fix this problem?
Good day! This is kind of off topic but I need some help from an established blog.
Is it difficult to set up your own blog? I’m not very techincal
but I can figure things out pretty quick. I’m thinking about setting up my own but I’m not sure where to start.
Do you have any tips or suggestions? Cheers
I believe this internet site has got very great indited written content posts.
Wow that was odd. I just wrote an extremely long comment but after I clicked submit
my comment didn’t show up. Grrrr… well I’m not writing all
that over again. Regardless, just wanted to say superb blog!
Check out my web page … Technik 3 Watch Cost
I intended to compose you a bit of note in order to give many thanks again about the awesome advice you’ve contributed above. It’s generous of people like you giving easily all a few individuals could have advertised as an e-book in making some bucks for their own end, and in particular considering that you could have done it if you considered necessary. The basics additionally acted as a easy way to recognize that the rest have the same passion the same as my very own to see very much more with regards to this problem. I think there are thousands of more pleasurable times up front for those who start reading your website.
Pingback: bracelets
Hi there, I read your new stuff daily. Your writing style is awesome, keep it up!
I precisely had to appreciate you all over again. I’m not certain the things I might have followed in the absence of the actual information documented by you directly on such field. It became a real distressing crisis for me personally, but encountering a new professional form you managed it forced me to jump for delight. I’m just happier for the guidance and even have high hopes you find out what a powerful job you’re doing instructing most people through your blog post. I am sure you’ve never encountered all of us.
I precisely had to appreciate you all over again. I am not sure the things that I might have gone through in the absence of the entire opinions documented by you directly on such industry. It had been a real fearsome difficulty in my circumstances, however , finding out the skilled manner you managed that made me to jump over fulfillment. I am happier for this help and even sincerely hope you really know what an amazing job you have been putting in training the mediocre ones via your webblog. Most probably you haven’t met any of us.
Pingback: cialis in milwaukee
Pingback: interactions for viagra
Excellent way of explaining, and nice article to get data concerning my presentation topic, which i
am going to deliver in school.
Pingback: safe buy cialis
Hi there, I enjoy reading all of your article.
I like to write a little comment to support you.
Hello there! Do you know if they make any plugins to assist with
SEO? I’m trying to get my blog to rank for some targeted keywords
but I’m not seeing very good success. If you know
of any please share. Thanks!
Pingback: much does cialis cost without insurance
Pingback: buy cialis online overnight
You actually make it appear so easy with your presentation however I to find
this topic to be really one thing that I feel I would by no
means understand. It sort of feels too complicated and extremely large for me.
I’m looking forward on your subsequent submit, I’ll try to get the
hang of it!
Thank you for some other informative web site. Where else may I
am getting that type of info written in such a perfect approach?
I have a project that I’m just now operating on, and I have been on the glance out for such info.
Does your site have a contact page? I’m having problems
locating it but, I’d like to shoot you an email. I’ve got some
ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing
it improve over time.
Also visit my blog :: Heater Pro X
Remarkable issues here. I am very glad to see your article.
Thanks so much and I’m taking a look ahead to
touch you. Will you please drop me a e-mail?
Admiring the time and energy you put into your website and in depth information you present.
It’s nice to come across a blog every once in a while that isn’t the
same old rehashed material. Excellent read! I’ve bookmarked your
site and I’m including your RSS feeds to my Google
account.
Pingback: what is amoxicillin used for
Hi to every one, it’s actually a pleasant for me to visit
this site, it includes useful Information.
Pingback: azithromycin liquid dosage
This website was… how do you say it? Relevant!! Finally I’ve found
something which helped me. Appreciate it!
Pingback: is celebrex a prescription med
Pingback: cephalexin alternative
Pingback: cialis online daily
Pingback: duloxetine and pregnancy
Pingback: amoxicillin 500 mg
I loved all your outfits. They were well put together and absolutely gorgeous. Ami Damien Cordalia
I don’t even know how I ended up here, but I thought this post was good. I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
Pingback: buy cialis ebay
It’s an amazing article for all the internet viewers;
they will obtain benefit from it I am sure.
I love reading and I conceive this website got
some really utilitarian stuff on it!
Also visit my webpage Luminas Pain Patch Reviews
Pingback: azithromycin heart palpitations
Everyone loves what you guys are up too. This type of clever
work and reporting! Keep up the amazing works guys I’ve you
guys to blogroll.
Pingback: buy cialis doctor
Pingback: celebrex with ibuprofen
Pingback: generic keflex
I’m no longer sure the place you’re getting your information, however good topic. I needs to spend some time studying more or understanding more. Thank you for wonderful information I used to be searching for this information for my mission.
Pingback: too much cymbalta
I do not even know how I ended up here, but I thought this post was great. I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
I constantly emailed this webpage post page to all my associates, since if like to read it after that my links will too.| Farrah Nat Gut
eto mga sagot sa cs exam or just the reviewer only.. ms marifel pasend naman po sa email ko ang reviewer. thank you po Courtney Gothart Moffat
I do consider all the ideas you have presented to your post. They are very convincing and can definitely work. Still, the posts are too brief for newbies. May you please prolong them a little from subsequent time? Thanks for the post. Brittni Mischa Boff
Good day! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a wonderful job! Winny Ephrayim Gavrah
Hi there, I enjoy reading through your article post. I wanted to write a little comment to support you.| Mei Beniamino Sudhir
Extremely helpful, thank you for this information! Pierette Noland Donica
The $100 offer has expired. Any referral link you click on will say $50. Here is mine. Rosaleen Tucky Paton
91.20 will be the answer for numerical reasoning #28. Answer not found on choices even the solution. Valerye Allayne Saidel
Pingback: sildenafil dosage instructions
Thanks for your concepts. One thing we’ve noticed is banks along with financial institutions are aware of the spending practices of consumers while also understand that most of the people max out and about their real credit cards around the getaways. They properly take advantage of this specific fact and commence flooding your current inbox along with snail-mail box using hundreds of no-interest APR card offers just after the holiday season concludes. Knowing that should you be like 98% of American community, you’ll rush at the possible opportunity to consolidate card debt and shift balances for 0 apr interest rates credit cards. kjjiikm https://headachemedi.com – guided meditation for headache relief
I plan to take CPP at age 70. Since my retirement will be funded by my own monies a delay in taking cpp will give me 42% more in cpp payments as well as being indexed to inflation, it seems like a no brainer to wait till ago 70. Anni Duncan Laux
Thanks for your concepts. One thing we’ve noticed is banks along with financial institutions are aware of the spending practices of consumers while also understand that most of the people max out and about their real credit cards around the getaways. They properly take advantage of this specific fact and commence flooding your current inbox along with snail-mail box using hundreds of no-interest APR card offers just after the holiday season concludes. Knowing that should you be like 98% of American community, you’ll rush at the possible opportunity to consolidate card debt and shift balances for 0 apr interest rates credit cards. kjjiikm https://thyroidmedi.com – what is the treatment of hypothyroidism
This is very attention-grabbing, You are an excessively
skilled blogger. I’ve joined your rss feed and look forward to seeking extra of your
magnificent post. Additionally, I have shared your website in my social networks
I do believe all of the ideas you have offered for your post. Nerita Mylo Tiler
Pingback: safe buy cialis
I have installed the super post premium and I have three questions: Glenn Hugibert Lisan
Pretty! This was an extremely wonderful article. Thanks for supplying this information. Agathe Clim Bissell
Thanks for your tips. One thing we have noticed is always that banks and also financial institutions have in mind the spending behavior of consumers and also understand that a lot of people max away their own credit cards around the holiday seasons. They prudently take advantage of this kind of fact and begin flooding the inbox and also snail-mail box together with hundreds of Zero APR card offers immediately after the holiday season finishes. Knowing that in case you are like 98% of all American open public, you’ll hop at the opportunity to consolidate personal credit card debt and move balances for 0 interest rates credit cards. gfffehk https://stomachmedi.com – stomach medication for sale
I was excited to discover this site. I wanted to thank you for ones time for this wonderful read!! I definitely liked every little bit of it and I have you saved to fav to check out new information in your web site. Diane-Marie Angeli Ivo
My brother recommended I might like this website. He was
entirely right. This publish actually made my day. You cann’t imagine just how a lot time I had spent for this information! Thank you!
Hi, i think that i saw you visited my weblog thus i came to “return the favor”.I’m trying
to find things to enhance my website!I suppose its ok to use some of your
ideas!!
Thanks for sharing superb informations. Your site is very cool. I am impressed by the details that you have on this blog. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for extra articles. You, my pal, ROCK! I found simply the information I already searched all over the place and simply could not come across. What an ideal website. Nesta Hubie Kentigerma
Thanks for your suggestions. One thing I’ve noticed is the fact that banks as well as financial institutions really know the spending routines of consumers as well as understand that many people max away their own credit cards around the vacations. They sensibly take advantage of this particular fact and begin flooding your own inbox as well as snail-mail box along with hundreds of Zero APR credit card offers right after the holiday season finishes. Knowing that if you’re like 98% of all American open public, you’ll leap at the opportunity to consolidate credit debt and move balances to 0 annual percentage rates credit cards. eeeedgj https://pancreasmedi.com – best stomach medication
I am curious to find out what blog platform you have been working with?
I’m having some minor security issues with my latest site and I’d like to
find something more secure. Do you have any solutions?
WOW !! GREAT SITE , HELPFULL ME AND MY FRIEND ! THANKYOU FOR INFO Henrie Archibaldo Justen
Kelly, mooi stukje over de zonnebloemen. Hopelijk gaat de zon ook weer in jouw leven schijnen en voel je je snel thuis in Mijdrecht. Brandise Travis Delanos
Usually swapping in butter can make a slightly denser mouthfeel for cakes eaten at room temperature, but with all the mix-ins I bet this cake could handle it. Dniren Elnar Izzy
I truly appreciate this blog. Really thank you! Want more. Randy Maximilian Schroth
Surgical penis enlargement, or phalloplasty, has distressing side effects. The penis is extended in interminably, but you trouncing debits function. After an enlargement crapex.fielau.se/oplysninger/tarteletter-pris.php codification the penis is no longer masterly to stay in from the masses; in lieu of, it hangs between the legs. And on, it no longer gets build at all. Looking into meet solutions is a much overwhelm bet. Lezlie Ferdy Yuma
Hey there, I think your blog might be having browser compatibility issues.
When I look at your blog site in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
This is a great resource, and a very functional node package. Many thanks for your hard work. Myrtice Ruperto Han
As a Newbie, I am constantly browsing online for articles that can aid me. Thank you
I like the helpful info you provide in your articles. Alexandra Carlos Piggy
As a Newbie, I am constantly browsing online for articles that can aid me. Thank you
As a Newbie, I am permanently browsing online for articles that can benefit me. Thank you
Pingback: cheapest generic cialis australia
At this moment I am ready to do my breakfast, after having
my breakfast coming again to read further news.
I do agree with all the ideas you have presented in your post. They are really convincing and will certainly work. Still, the posts are very short for starters. Could you please extend them a bit from next time? Thanks for the post.
Pingback: buy cialis online best price
Keep functioning ,impressive job! https://chwilowki-pozyczka.pl – darmowe chwilówki
Great info and straight to the point. I am not sure if this is in fact the best place to ask but do you folks have any thoughts on where to get some professional writers? Thanks 🙂 https://livermedi.com what to take for liver pain
Pingback: safe buy cialis
Hi, every time i used to check blog posts here in the early hours in the break of
day, for the reason that i love to find out more and more.
I’m curious to find out what blog system you’re using? I’m having some minor security issues with my latest website and I’d like to find something more secure. Do you have any recommendations?
Pingback: how to buy cialis online uk
Hi all, here every person is sharing these kinds of experience,
therefore it’s pleasant to read this weblog, and I used to
pay a quick visit this blog everyday.
Now I am ready to do my breakfast, once having my breakfast coming again to read additional news. Giovanna Jessie Georges
There are certainly a lot of details like that to take into consideration. That may be a nice point to convey up. I provide the thoughts above as basic inspiration however clearly there are questions just like the one you carry up the place an important factor can be working in honest good faith. I don?t know if best practices have emerged around issues like that, however I’m sure that your job is clearly recognized as a good game. Each girls and boys feel the impact of only a second’s pleasure, for the remainder of their lives.
Wonderful, what a webpage it is! This website gives useful facts to us,
keep it up.
Thanks for the good writeup. It in truth was a amusement account it.
Glance complex to far delivered agreeable from you! By the way, how could
we keep in touch?
Way cool! Some extremely valid points! I appreciate you penning this post and also the
rest of the website is also really good.
Howdy excellent website! Does running a blog like this take a large
amount of work? I’ve virtually no expertise in programming but I was hoping to start my
own blog soon. Anyway, should you have any suggestions or techniques for new blog owners please share.
I know this is off topic however I simply had to ask. Cheers!
I got this site from my buddy who informed me on the topic of this website and now this time I am visiting this web site and
reading very informative articles or reviews at this time.
First off I want to say great blog! I had a quick question that I’d like
to ask if you do not mind. I was curious to find
out how you center yourself and clear your head prior to writing.
I have had a difficult time clearing my mind in getting my thoughts out.
I do take pleasure in writing but it just seems like the first 10 to 15
minutes tend to be wasted just trying to figure out how to
begin. Any ideas or tips? Thank you!
Pingback: safe buy cialis
I absolutely love your blog.. Excellent colors & theme.
Did you create this web site yourself? Please reply back as I’m looking to create my very own site and would love to find out where
you got this from or just what the theme is named. Many thanks!
I don’t even know how I finished up right here, however I believed this post was great.
I do not recognise who you might be however definitely you’re going to a famous blogger
if you are not already. Cheers!
Howdy! This blog post could not be written much better! Going through this post reminds me of my previous roommate!
He always kept talking about this. I am going to forward this information to him.
Pretty sure he’s going to have a good read. Thank you for
sharing!
Howdy! This post couldn’t be written much better!
Reading through this article reminds me of my previous
roommate! He continually kept talking about this.
I most certainly will forward this article to him.
Fairly certain he’ll have a great read. Many thanks for sharing!
Nice blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really
make my blog stand out. Please let me know where you got your design. Thanks a lot
I think the admin of this web site is genuinely working hard in favor of his website,
since here every information is quality based
data.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you
would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Pingback: cheap viagra 100mg
Pingback: cialis tolerance
Pingback: sildenafil viagra
Pingback: viagra sin receta
Pingback: cialis price
Pingback: revatio vs viagra
Pingback: cheap viagra online
Pretty! This was an incredibly wonderful post.
Thanks for supplying this information.
Pingback: viagra pfizer
Hi to all, how is the whole thing, I think every one
is getting more from this web page, and your views are
pleasant for new viewers.
Pingback: sildenafil vs viagra
Pingback: tadalafil online
Pingback: sildenafil stories
Pingback: sildenafil cost
Pingback: viagra for men over 60
I was wondering if you ever thought of changing the layout of your website?
Its very well written; I love what youve got to say. But maybe
you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 pictures.
Maybe you could space it out better?
It’s hard to find well-informed people on this subject, however, you seem like you know what
you’re talking about! Thanks
I simply couldn’t depart your web site prior to suggesting that I extremely enjoyed the usual information a person provide
to your visitors? Is going to be again steadily in order
to check out new posts
What’s up Dear, are you really visiting this website regularly, if so then you will without
doubt take nice knowledge.
Hello to every one, the contents existing at this
site are truly amazing for people knowledge, well, keep up
the nice work fellows.
I all the time used to study paragraph in news papers but now as I am a user
of net so from now I am using net for content, thanks to web.
When someone writes an piece of writing he/she retains the
idea of a user in his/her mind that how a user can understand it.
Thus that’s why this article is amazing. Thanks!
It’s very straightforward to find out any topic on net as compared to books,
as I found this piece of writing at this web site.
Just wish to say your article is as surprising.
The clarity in your post is just cool and i could assume you
are an expert on this subject. Well with your permission let
me to grab your feed to keep up to date with forthcoming post.
Thanks a million and please keep up the gratifying work.
Awesome things here. I am very satisfied to see your article.
Thanks a lot and I’m having a look forward to contact you.
Will you kindly drop me a e-mail?
I am curious to find out what blog system you’re utilizing?
I’m experiencing some minor security problems with my latest blog and I’d like
to find something more secure. Do you have any recommendations?
Hi there just wanted to give you a brief heads
up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried
it in two different internet browsers and both show the same outcome.
Greetings! This is my first visit to your blog!
We are a group of volunteers and starting a new project
in a community in the same niche. Your blog provided us valuable information to work on. You have done a outstanding job!
I visited multiple web pages but the audio quality for audio songs
current at this website is actually fabulous.
I need to to thank you for this excellent read!! I absolutely loved every
little bit of it. I have got you bookmarked to check out
new things you post…
Pingback: viagra help women
Pingback: generic viagra cost walmart canada
Pingback: viagra demonstration live erection size
Pingback: son takes viagra mom helps
Pingback: cialis used for pulmonary hypertension
Pingback: goodrx sildenafil discount coupo
Pingback: levitra cialis viagra
Pingback: jodi west viagra tricked
Pingback: cialis and diharrea
Pingback: fake cialis 20mg
Hi, i think that i saw you visited my website so i
came to go back the desire?.I am attempting to
in finding issues to enhance my site!I guess its ok to make use of some of your ideas!!
I like what you guys are up too. This sort of clever
work and coverage! Keep up the very good works guys I’ve incorporated you guys to blogroll.
I have been surfing online more than 2 hours today, yet I never found any interesting
article like yours. It’s pretty worth enough for
me. Personally, if all website owners and bloggers made good content as you did, the net will be
much more useful than ever before.
Hey this is kinda of off topic but I was wondering if blogs
use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
I always used to study article in news papers but now as I am a user of net thus from now I
am using net for articles, thanks to web.
I was suggested this web site by my cousin. I’m not
sure whether this post is written by him as nobody else know
such detailed about my trouble. You’re incredible!
Thanks!
Truly when someone doesn’t be aware of after that its up to other users that they
will assist, so here it happens.
I am no longer sure the place you are getting your info, however great topic.
I needs to spend some time studying more or understanding more.
Thank you for magnificent info I was searching for this information for my mission.
I’m gone to inform my little brother, that he should also pay a quick visit this website on regular basis to get updated from most up-to-date information.
It’s impressive that you are getting thoughts from this article as well as from our dialogue made at this time.
It’s an awesome piece of writing in favor of all the internet
viewers; they will obtain benefit from it I am
sure.
It’s perfect time to make some plans for the long run and it’s time to be happy.
I have read this publish and if I could I wish to suggest you few fascinating issues or advice.
Perhaps you could write next articles regarding this article.
I desire to read even more things approximately
it!
It’s going to be finish of mine day, however before
finish I am reading this fantastic paragraph to increase my know-how.
Hello, its fastidious post about media print, we all understand media is a fantastic source of facts.
I like what you guys are up too. Such clever work and coverage!
Keep up the fantastic works guys I’ve you guys to my own blogroll.
Hey very interesting blog!
This is really interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your great post.
Also, I have shared your web site in my social networks!
Hi there, just wanted to say, I liked this post.
It was funny. Keep on posting!
Good post. I’m experiencing some of these issues as well..
Great post.
It’s a shame you don’t have a donate button! I’d definitely donate to this excellent blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this site with my Facebook group.
Chat soon!
Greetings! This is my first visit to your blog!
We are a collection of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have done a extraordinary job!
My brother suggested I might like this website.
He was entirely right. This post truly made my day.
You cann’t imagine just how much time I had spent
for this information! Thanks!
For most up-to-date news you have to visit the web and on web I found this web
page as a best website for newest updates.
We stumbled over here coming from a different page and thought I might as well check
things out. I like what I see so i am just following you.
Look forward to looking into your web page yet
again.
I appreciate, lead to I found exactly what I was looking for.
You’ve ended my 4 day long hunt! God Bless you man. Have a great day.
Bye
Pingback: Zakhar Berkut hd
Hey There. I discovered your blog the use of msn. This is a
really neatly written article. I’ll be sure to bookmark it and return to read extra of
your useful information. Thank you for the post. I will certainly
return.
I think this is among the most vital info for me.
And i’m glad reading your article. But wanna remark
on some general things, The site style is great,
the articles is really excellent : D. Good job, cheers
Pingback: payday loan online homestead
Pingback: retina a without a rx
Pingback: bad credit payday loans johns creek
Nice post. I learn something totally new and challenging on websites I stumbleupon every day.
It’s always helpful to read through articles
from other authors and use a little something from their
web sites.
Pingback: 20mg usa
Appreciate this post. Will try it out.
I got this site from my friend who informed me concerning this site and at the moment this time
I am visiting this web page and reading very informative content at
this place.
I have read a few good stuff here. Definitely value bookmarking for revisiting.
I surprise how so much attempt you place to make any such wonderful informative website.
Hi, I do think this is an excellent blog. I stumbledupon it
😉 I’m going to revisit once again since i have book-marked it.
Money and freedom is the best way to change, may you be rich
and continue to guide others.
Pingback: 20mg usa
Greetings! Very useful advice in this particular article!
It’s the little changes that make the largest changes.
Thanks for sharing!
Pingback: ativan buy online uk
Howdy! I understand this is kind of off-topic but I needed to ask.
Does running a well-established website like yours take a lot of work?
I’m brand new to running a blog however I do write in my diary every day.
I’d like to start a blog so I can share my experience and thoughts online.
Please let me know if you have any suggestions or tips for new aspiring blog owners.
Appreciate it!
It’s awesome to pay a visit this website and reading the views of all mates about this piece
of writing, while I am also keen of getting familiarity.
It’s really a great and helpful piece of info. I am satisfied that you just shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
It’s going to be ending of mine day, except before finish I am reading this enormous paragraph to improve my experience.
Hola! I’ve been reading your weblog for a long time now and finally got the
courage to go ahead and give you a shout out from Porter Tx!
Just wanted to tell you keep up the great job!
I do believe all of the concepts you have introduced
for your post. They’re really convincing and will certainly
work. Nonetheless, the posts are very brief for novices. Could you please lengthen them
a bit from subsequent time? Thank you for the post.
You should be a part of a contest for one of the finest blogs online.
I most certainly will recommend this website!
May I just say what a relief to uncover someone who
genuinely knows what they’re discussing online.
You certainly know how to bring a problem to light and make it important.
More and more people ought to look at this and understand this side of your story.
I was surprised you are not more popular since you definitely have the
gift.
Hi, this weekend is pleasant in support of me, since this occasion i
am reading this great informative post here at my house.
Thanks for the auspicious writeup. It in reality was once a amusement
account it. Look complex to more added agreeable from
you! However, how could we communicate?
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way, how
can we communicate?
Excellent post. I was checking constantly this blog and
I am impressed! Very useful info particularly the last
part 🙂 I care for such info much. I was looking for this particular information for a
long time. Thank you and good luck.
When someone writes an piece of writing he/she keeps the idea of a
user in his/her brain that how a user can understand it.
So that’s why this paragraph is amazing. Thanks!
If you are going for best contents like myself, just go to see this website all the time because it provides feature contents, thanks
I’m extremely impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself? Anyway keep up the nice quality writing, it’s rare to see a nice blog like this one
nowadays.
I always spent my half an hour to read this blog’s content all the time along
with a mug of coffee.
Have you ever considered creating an ebook or guest authoring on other websites?
I have a blog centered on the same subjects you discuss and
would really like to have you share some stories/information. I know my subscribers would enjoy your work.
If you are even remotely interested, feel free to shoot me an e-mail.
Hi, I log on to your new stuff daily. Your humoristic style is witty,
keep up the good work!
I just like the helpful information you provide for
your articles. I’ll bookmark your blog and check once more right here regularly.
I’m quite sure I will learn lots of new stuff right right here!
Good luck for the next!
Valuable information. Lucky me I found your web site
accidentally, and I’m surprised why this coincidence
didn’t came about earlier! I bookmarked it.
Great article! That is the type of information that should be shared across the web.
Shame on Google for now not positioning this post upper!
Come on over and visit my website . Thanks =)
Truly no matter if someone doesn’t be aware of then its up
to other users that they will assist, so here it takes place.
It’s great that you are getting thoughts from this post as well as from
our discussion made at this place.
Way cool! Some very valid points! I appreciate you writing
this article and the rest of the site is really good.
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out a lot.
I hope to give something back and help others like you aided me.
It’s remarkable to go to see this site and reading the views
of all friends regarding this piece of writing, while I am also zealous of
getting know-how.
I really like what you guys tend to be up too. Such clever work
and coverage! Keep up the fantastic works guys I’ve included you guys to my
personal blogroll.
Superb website you have here but I was curious if you
knew of any user discussion forums that cover the same topics discussed here?
I’d really love to be a part of group where I can get
comments from other experienced individuals that share the same interest.
If you have any suggestions, please let me know. Kudos!
I’m really impressed together with your writing talents as neatly as
with the layout for your blog. Is that this a paid subject matter or did you modify it yourself?
Either way keep up the nice high quality writing, it’s rare
to peer a great blog like this one these days..
I’m really enjoying the theme/design of your web
site. Do you ever run into any internet browser compatibility issues?
A number of my blog audience have complained about my
website not working correctly in Explorer but looks great in Safari.
Do you have any advice to help fix this issue?
I am really impressed with your writing skills as well as with the layout on your
weblog. Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it’s rare to see a
nice blog like this one these days.
I’ll immediately take hold of your rss as I can’t in finding your email subscription link
or e-newsletter service. Do you’ve any? Kindly permit me
understand so that I may subscribe. Thanks.
Undeniably imagine that which you said. Your
favorite justification seemed to be on the net the simplest
thing to be aware of. I say to you, I definitely get annoyed even as other folks think
about issues that they just don’t recognise about.
You controlled to hit the nail upon the highest
as smartly as defined out the whole thing without having side
effect , folks can take a signal. Will probably be back to
get more. Thanks
Does your website have a contact page? I’m having trouble locating
it but, I’d like to send you an e-mail. I’ve got some suggestions for your blog you might
be interested in hearing. Either way, great site and I look forward to
seeing it improve over time.
It’s great that you are getting ideas from this article as well as from our dialogue made here.
how much does viagra cost with out insurance viagra,inexpensive,no prescription – viagra refractory period
Trading Bots sind Computerprogramme, die so eingerichtet sind,
dass sie Kauf- und Verkaufsaufträge automatisch
ausführen. Diese Bots gewinnen von Tag zu Tag
an Popularität und zu ihren besten Eigenschaften gehören eine gute Rentabilität, Sicherheit, Benutzerfreundlichkeit, Geschwindigkeit
und mehr. Bots sind auch unabhängig von Entscheidungen, die auf menschlichen Emotionen beruhen.
Greetings from Colorado! I’m bored to tears at work so I decided to browse your website on my
iphone during lunch break. I really like the info you present here and
can’t wait to take a look when I get home. I’m amazed at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, awesome site!
Hallo und willkommen zu meinem Beitrag zum Thema "Erstellen eines automatisierten Kryptowährungs-Trading-Bots auf Binance mit Python".
Ich begann im April 2018 mit der Arbeit an diesem Projekt aufgrund meines Interesses am Handel mit Kryptowährungen und meiner vorherigen Ausbildung
und Python-Programmierfähigkeiten.
Excellent post. I am facing a few of these issues as well..
Very descriptive post, I loved that bit. Will there be a part 2?
What’s up to every single one, it’s in fact a pleasant for
me to pay a visit this web page, it contains valuable Information.
Бизнесмен и меценат Максим Евгеньевич Каганский родился в Москве 19 ноября 1980 года в многодетной семье сотрудника МВД.
В 1998 году поступил в Московский Юридический Институт МВД
России (сейчас – Академия МВД
России), специальность – юрист-правовед.
максим каганский свежие новости
максим каганский свежие новости https://www.moscowmap.ru/news/m-kaganskij-pervyj-god-raboty-v-atriume-podtverdil-pravilnost-vybora.html
Hi, I desire to subscribe for this weblog
to take latest updates, therefore where can i do it please help.
This is very interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your excellent post.
Also, I have shared your site in my social networks!
Gleichzeitig kommt chip Handyversicherung für Displaybruch auf.
Wer chip Handyversicherung online abschließt, geht zum Paradebeispiel einen Vertrag mit „Schutzklick” oder „Friendsurance” ein.
cialis 20 mg cialis pills
Find Free Shipping On Line Clobetasol
erectile power
Здравствуйте!
Самая актуальная информация в нашем блоге про покер
http://rrrrrqw2.blogspot.com/Тепрь я разбираюсь в покере на все сто процентов.Увидимся!
What’s up to every one, the contents present at this website
are really remarkable for people knowledge, well, keep up the nice
work fellows.
Сейчас самое время зайти в Совкомбанк и забрать http://sovestcard.ru/ в любом отделении банка. Вы сможете приобрести все то, что долго планировали
http://buytadalafshop.com/ – generic cialis 5mg
Hey there, You have done an excellent job.
I will certainly digg it and personally recommend
to my friends. I am sure they will be benefited from
this site.
Hello my loved one! I wish to say that this article is amazing,
great written and include almost all significant infos.
I’d like to look more posts like this .
These are really fantastic ideas in regarding blogging.
You have touched some nice factors here. Any way keep up wrinting.
You need to take part in a contest for one of the finest sites on the
net. I will recommend this website!
zithromax antibiotic
I got this web site from my friend who told
me concerning this web site and at the moment this time I am visiting
this website and reading very informative content at this place.
Awesome blog! Do you have any tips for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost
on everything. Would you suggest starting with a free platform like
Wordpress or go for a paid option? There are so many options out
there that I’m completely overwhelmed .. Any tips?
Thanks a lot!
Appreciate the recommendation. Will try it out.
priligy dapoxetine 30mg
hey there and thank you for your info – I have certainly picked up anything
new from right here. I did however expertise some technical points using this
website, since I experienced to reload the website a lot of times
previous to I could get it to load correctly. I had been wondering if your web host is OK?
Not that I’m complaining, but sluggish loading instances times will very frequently affect your placement in google and
can damage your quality score if ads and marketing with Adwords.
Well I’m adding this RSS to my email and could
look out for a lot more of your respective intriguing content.
Make sure you update this again soon.
Everything wrote made a bunch of sense. However, think on this, suppose you added a little information?
I am not saying your content isn’t good, however suppose you added a title to maybe grab a person’s attention? I mean K-Nearest Neighbor Machine Learning algorithm
– Deepsingularity : Deepsingularity is kinda plain. You could glance at Yahoo’s front page and note how they create news
headlines to get people to open the links. You might
add a video or a picture or two to grab readers interested about what you’ve got to say.
Just my opinion, it would make your blog a little bit more interesting.
Aw, this was an exceptionally good post. Finding the time and actual effort to produce a superb article… but
what can I say… I hesitate a lot and never manage
to get nearly anything done.
Great material Appreciate it!
porno gays
porno lupo http://www.deliciouslysimple.ca/
Viagra 50mg Wirkung
American Drugstore Online
https://buyplaquenilcv.com/ – Plaquenil
cialis online cialis pills
An intriguing discussion is worth comment. I do believe that you ought to publish more on this topic,
it might not be a taboo subject but typically people do not discuss
such subjects. To the next! Kind regards!!
As the admin of this web page is working, no uncertainty
very soon it will be renowned, due to its feature contents.
cialis pills https://cialiswithdapoxetine.com/
Excellent web site. Plenty of helpful information here.
I’m sending it to several pals ans also sharing in delicious.
And of course, thanks on your effort!
takipçi yagiyooooooooooooooooooo ?? 3100 tane geldi
ise yarayacagini düsünmüyodum ama girince gerçekten sok oldum ??
Oh, 1000 Followers came after 1 hour ??
Ögrendigimiz iyi oldu 🙂
Ögrendigimiz iyi oldu 🙂
I was stalking the boy I love, I hope he doesn’t see me ??????
Who exits after logging in to the site?
Retweet ve Favori sanirim daha hizli geliyor??
she was crying 🙂
Hesabima Takipçi yagiyordu 🙂
Retweet ve Favori sanirim daha hizli geliyor??
yürü be admin allahina kurban 1450 geldi banada ??
https://prednisonebuyon.com/ – over the counter deltasone medication
Cialis Y Viagra Diferencias
I blog frequently and I truly appreciate your content.
This great article has really peaked my interest.
I’m going to take a note of your website and keep checking for new details about once a
week. I subscribed to your Feed too.
I blog frequently and I truly appreciate your content.
This great article has really peaked my interest.
I’m going to take a note of your website and keep checking for new details about once a
week. I subscribed to your Feed too.
Neegggggggggggggg
Sevdigim çocugu stalkliyordum umarim beni görmez ??????
I want the instagram version as soon as possible ??
Çalisiyor bilginize??
gelen takipçiler 0 türk takipçi masallah
takipçilerim geldi tesekkürler??
kentucky gabapentin neurontine
https://lyrica24x7.top/catalogue/?id=19342
Howdy! I know this is somewhat off topic but I was wondering if you knew
where I could find a captcha plugin for my comment form? I’m using the
same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Your method of describing the whole thing in this paragraph is genuinely nice, all be able to easily understand it, Thanks a
lot.
whoah this blog is magnificent i like studying your articles.
Keep up the great work! You know, many people are
searching round for this info, you could aid them greatly.
bugün de gizli hayranlarimizi ögrendik…
Beyler ne zaman geldigini önemi yok bence saat önemi yok siteye giris yaptiktan sonra geliyor mu geliyor bosverin gerisini
Good to learn 🙂
good luck??
Gerçekten inanilmaz ya neler var neler 🙂
bu cidden gerçek miiii? ??
Would you like tea or coffee, Stalkers?
Gerçekten inanilmaz ya neler var neler 🙂
People who leave after logging in to the site???
Takipçiler türk bilginize??
Bazilarini tahmin etmistim, sanirim bu uygulama gerçekten dogru ??
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an nervousness over that you
wish be delivering the following. unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this hike.
Definitely believe that which you said. Your favorite justification seemed to be on the net the simplest thing to be aware of.
I say to you, I definitely get annoyed while people consider worries that they plainly do not know about.
You managed to hit the nail upon the top and also defined out
the whole thing without having side-effects , people could take a signal.
Will likely be back to get more. Thanks
I have learn some good stuff here. Certainly value
bookmarking for revisiting. I surprise how a lot attempt you set to
make such a excellent informative web site.
Great post. I will be going through some of these
issues as well..
Hi there to all, how is everything, I think every one is getting more
from this web site, and your views are pleasant in favor of
new people.
I think the admin of this website is genuinely working hard in support of his
website, for the reason that here every data is quality based information.
I read this article fully concerning the difference of latest and previous technologies,
it’s amazing article.
Great post. I was checking continuously this blog and
I’m impressed! Extremely helpful information particularly the last part
🙂 I care for such info a lot. I was looking
for this particular information for a long time. Thank you and
best of luck.
Every weekend i used to pay a visit this website,
for the reason that i wish for enjoyment, since this this site conations in fact pleasant funny stuff too.
Here is my site :: 온라인카지노
Everyone loves it when individuals come together and share thoughts.
Great site, stick with it!
Also visit my web blog … 온라인카지노
Wow, amazing blog structure! How long have you been blogging
for? you make running a blog glance easy. The overall glance of your website is magnificent, as smartly
as the content material!
Look into my web blog: 온라인카지노
I am really impressed with your writing skills and also with the layout on your weblog.
Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it is rare to see a
great blog like this one these days.
Feel free to surf to my blog; 우리카지노
Link exchange is nothing else except it is simply placing the other person’s weblog link
on your page at appropriate place and other person will also do similar in support of you.
Kimleri Görüyorum Kimleri
Hi would you mind letting me know which web host you’re working with?
I’ve loaded your blog in 3 different internet browsers
and I must say this blog loads a lot quicker then most.
Can you recommend a good hosting provider at a reasonable
price? Thank you, I appreciate it!
15 kisi beni engellemis, hepinizi gördüm arkadaslar ??
I am curious to find out what blog platform you have been using?
I’m having some minor security problems with my latest website and I’d like to find something more safe.
Do you have any suggestions?
Here is my blog – 솔레어카지노
who do i see
wow they finally did that too bee ??
is this really real? ??
Çok Güzel bir uygulama
inanmiyordum ama gördüm
ulan 2 yildir takip ediyosun yaz bari be vicdansizz ????
incoming followers 100% turkish followers mashallah
Ulan Beni neden stalklarsiniz anlamis degilim
my followers have arrived thank you??
dude, can someone follow me for 2 years?
I’m going crazy now when I see it ????
I’m really enjoying the design and layout of your site. It’s
a very easy on the eyes which makes it much
more enjoyable for me to come here and visit more often. Did you hire out a designer to
create your theme? Superb work!
I’m in shock after shock, we don’t know what’s going on ??
Thanks a lot for sharing this with all of us you really understand
what you’re talking about! Bookmarked. Please additionally
visit my website =). We may have a link trade arrangement among us
Stop by my web page; 온라인카지노
Remarkable things here. I am very satisfied to peer your article.
Thanks a lot and I’m having a look ahead to contact you.
Will you kindly drop me a mail?
Have a look at my web blog – 온라인카지노
Remarkable issues here. I am very happy to see your post. Thank you
so much and I am having a look forward to contact you. Will you kindly drop me a e-mail?
Great post. I will be experiencing many of these issues as well..
My site … 온라인카지노
I like the valuable information you supply in your articles.
I will bookmark your weblog and check again right here regularly.
I am relatively sure I’ll learn a lot of new stuff right here!
Best of luck for the following!
Here is my blog post :: 온라인카지노
Our systems are verified, authenticated and encrypted by the most advanced digital security certification authority -Thawte.
https://offeramazon.ru
Your style is really unique compared to other people I have read
stuff from. Thanks for posting when you’ve got the opportunity, Guess I’ll just bookmark
this web site.
Also visit my blog 온라인카지노
You are so awesome! I don’t think I’ve truly read something like that before.
So great to find somebody with some unique thoughts on this subject matter.
Really.. thanks for starting this up. This website is one thing
that’s needed on the web, someone with a bit of originality!
Here is my website: 온라인카지노
Great goods from you, man. I’ve understand your stuff prior to and
you’re just extremely magnificent. I actually like
what you have bought right here, certainly like what you are saying
and the way in which wherein you assert it.
You’re making it enjoyable and you still care for to keep
it smart. I cant wait to read far more from you. This is
really a great web site.
My website; 온라인카지노
Oh my goodness! Impressive article dude! Thank you, However I am
encountering difficulties with your RSS. I don’t understand the reason why I can’t join it.
Is there anyone else having the same RSS issues? Anybody who knows the solution will you kindly respond?
Thanx!!
Here is my site – 온라인카지노
It’s a pity you don’t have a donate button! I’d without a doubt donate
to this outstanding blog! I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this site
with my Facebook group. Talk soon!
Stop by my web page sm카지노
I am not sure where you’re getting your info, but great
topic. I needs to spend some time learning more or understanding
more. Thanks for great information I was looking for this information for my
mission.
My web blog … 온라인카지노
I was pretty pleased to discover this website.
I want to to thank you for your time for this fantastic read!!
I definitely enjoyed every part of it and i also have you saved
as a favorite to check out new stuff on your blog.
need isotretinoin isotret best website overseas
Highly energetic article, I loved that a lot. Will there be a part 2?
my page :: 크레이지슬롯
Hi, I do believe this is an excellent site. I stumbledupon it ;
) I’m going to revisit yet again since i have book-marked it.
Money and freedom is the best way to change, may you be rich
and continue to help other people.
Feel free to visit my blog post … 온라인카지노
My spouse and I stumbled over here coming from a different page and
thought I might check things out. I like what I see so i am just following you.
Look forward to exploring your web page for a second time.
Also visit my web blog 온라인카지노
I was suggested this website through my cousin. I’m
not positive whether this submit is written via him
as no one else recognize such special about my
trouble. You are wonderful! Thanks!
Look at my site :: 온라인카지노
Hello, I do believe your website may be having internet browser compatibility problems.
When I look at your site in Safari, it looks fine however, if opening in IE, it has
some overlapping issues. I merely wanted to provide you with
a quick heads up! Apart from that, fantastic blog!
I was curious if you ever thought of changing the structure of your site?
Its very well written; I love what youve got to say. But maybe you could a little more in the way
of content so people could connect with it
better. Youve got an awful lot of text for only having
one or two pictures. Maybe you could space it out better?
Here is my web site; 온라인카지노
Can I Take Two Nexium Over The Counter
Cialis
You have made some really good points there. I looked on the net for
more information about the issue and found most individuals will
go along with your views on this web site.
Feel free to visit my blog – 온라인카지노
Write more, thats all I have to say. Literally, it seems as though you relied on the
video to make your point. You clearly know what youre talking about, why throw away your intelligence on just posting videos to your blog when you could be giving us something informative to read?
Visit my blog post: 우리카지노
мебель из ангарской сосны
Результаты поиска – кровать
кровать
Фотография: кровать Адриатика
кровать Адриатика
Добавил(а) Характер, 12:31am в Июнь 14, 2019
Фотография: Двухъярусная кровать Париж
Двухъярусная кровать Париж
Добавил(а) Характер, 12:31am в Июнь 14, 2019
Фотография: Кровать с пм 1,6 Империя (ТК темный мокко)
Кровать с пм 1,6 Империя (ТК темный мокко)
Добавил(а) Характер, 12:31am в Июнь 14, 2019
Фотография: Кровать подростковая
Кровать подростковаяКровать из массива сосны 2м*1,2м
Добавил(а) Сергей, 8:43pm в Январь 8, 2013
Фотография: IMG-20181116-WA0005
IMG-20181116-WA0005кровать деревянная
Добавил(а) евгений, 3:54pm в Февраль 19, 2019
Фотография: IMG-20181116-WA0001
IMG-20181116-WA0001кровать из ангарской сосны
Добавил(а) евгений, 3:54pm в Февраль 19, 2019
Фотография: P1030565
P1030565Массив сосны, кровать отделана белой кожей
Добавил(а) Elki-Palki, 4:25pm в Октябрь 7, 2015
Комментарий о: Фотография ‘Мебель в кабинете’
Здравствуйте! Мен зовут Бибигуль мне понравилось кровать и мебель кабинет для прихожей скажите пожалуста в какую цену. И какмоно купить такую мебель я живу в Астане.
Добавил(а) Бибигуль, 1:40am в Апрель 16, 2014
Фотография: Диван Аллегро
Диван Аллегростильный диванчик подойдет любому интерьеру. Габариты: 170(203)х83х65 см Каркас: масив дерева, бук Покрытие: льняное масло или лак на водной основе Матрас и подушки: 80х200 см, 50х60 см Наполнитель: гипоалергенний синтепух Ткань: 100% полиэстер Упаковка: картонная коробка 154х82х41 см Вес: 38 кг Если нет на складе, сроки изготовления 1-2 недели. Так же к такому диванчику можно заказать пуфы (смотрите на фото). Производитель: Украина. По желанию можно добавить любые изменения – например покрасить деревянную основу в другой цвет и т.д.…
Добавил(а) Андрей, 5:26pm в Июнь 26, 2019
Сообщение блога: Дизайн спальни
Полный ночной отдых совсем важен любому человеку для сбережения хорошего здоровья и деловитости, именно поэтому надежный сон имеет довольно крупное значение. Врачи одобряют, что недосып может…
Добавил(а) valerga65, 2:59pm в Сентябрь 14, 2021
ПОПУЛЯРНОЕ СОДЕРЖИМОЕ
1 покупаем пиломаретиал, дрова, пелеты, брикеты, кругляк
покупаем пиломаретиал, дрова, пелеты, брикеты, кругляк
2 куплю дуб кругляк
куплю дуб кругляк
3 ПОКУПАЕМ ДРОВА КОЛОТЫЕ НА ЭКСПОРТ ( ОЛЬХА, ГРАБ, ДУБ)
ПОКУПАЕМ ДРОВА КОЛОТЫЕ НА ЭКСПОРТ ( ОЛЬХА, ГРАБ, ДУБ)
4 Китайская компония покупает доски обрезные из ели и сосны
Китайская компония покупает доски обрезные из ели и сосны
5 Куплю лес круглый экспортный.Пиловочник.Сосна,лиственница
Куплю лес круглый экспортный.Пиловочник.Сосна,лиственница
6 Предлагаю пеллеты
Предлагаю пеллеты
7 Pelletor
Pelletor
8 Лестницы из дуба
Лестницы из дуба
9 Лестницы из дуба
Лестницы из дуба
10 Пеллетные Котел 15 КВт
Пеллетные Котел 15 КВт
http://drevtorg.xyz/main/search/search?q=%D0%BA%D1%80%D0%BE%D0%B2%D0%B0%D1%82%D1%8C
I got this web page from my buddy who informed me on the topic of this
web page and now this time I am browsing this website
and reading very informative posts at this time.
Viagra Generic Vs Brand
ile takipçi kazandim tesekkür ederim??
mükemmel bir uygulama olmus cidden ??
Hi there, just became aware of your blog through Google, and found that it is truly informative.
I am gonna watch out for brussels. I’ll appreciate if you continue this in future.
Numerous people will be benefited from your writing. Cheers!
Friends, I logged into this site yesterday, but my followers came after 12 hours, not 2 or 3 hours, I guess everyone is different??
Ulan Beni neden stalklarsiniz anlamis degilim
I entered according to the comments and came followers thank you ??
I’m going crazy now when I see it ????
Who I See Who
It’s nice when there are organic users ??
Kimleerr kimleri stalkliyormus megersemmm ??
It’s nice when there are organic users ??
Çalisiyor bilginize??
I entered according to the comments and came followers thank you ??
Hesabima Takipçi yagiyordu 🙂
Спасибо.
May I just say what a comfort to find somebody that actually understands what they’re discussing over the internet.
You actually understand how to bring a problem to light and make it important.
A lot more people must read this and understand this
side of the story. I was surprised that you are not more popular
since you most certainly have the gift.
Discount Generic Viagra And Cialis
This is really interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your
excellent post. Also, I’ve shared your site in my social
networks!
magnificent submit, very informative. I ponder why the opposite specialists of this sector do not notice this.
You must proceed your writing. I’m sure, you have a huge readers’ base already!
suan çildiriyorum gördükçe ????
ulan 2 yildir takip ediyosun yaz bari be vicdansizz ????
Guys, it doesn’t matter when you come, I think the time doesn’t matter, does it come after you log in to the site, never mind the rest.
ulan 2 yildir takip edermi bir insan
I gained followers with thank you??
Yorumlara göre girdim ve geldi takipçiler tesekkürler ??
by prednisone w not prescription
The other day, while I was at work, my cousin stole my iphone and tested to see if it can survive a 25
foot drop, just so she can be a youtube sensation. My iPad is now
broken and she has 83 views. I know this is totally off topic but I had to share
it with someone!
Here is my homepage – 온라인카지노
Howdy! Do you know if they make any plugins to help with Search Engine Optimization?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success.
If you know of any please share. Appreciate it!
Look into my homepage – 온라인카지노
Definitely believe that which you stated. Your favorite reason seemed to
be on the web the simplest thing to be aware of. I say to you, I
definitely get annoyed while people think about worries that they
just do not know about. You managed to hit the nail upon the top as well as defined out the
whole thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
Yesterday, while I was at work, my cousin stole my iPad and tested to see if it can survive a forty foot drop, just so she can be a youtube sensation. My iPad
is now destroyed and she has 83 views. I know this is completely off topic
but I had to share it with someone!
You could definitely see your expertise within the article you write.
The arena hopes for more passionate writers such as you who aren’t afraid to
say how they believe. All the time follow your heart.
My webpage – 에그벳카지노
Hey there! I’ve been following your site for
a while now and finally got the courage to go ahead and give
you a shout out from Humble Tx! Just wanted to tell you keep up the good work!
Hiya! Quick question that’s entirely off
topic. Do you know how to make your site mobile friendly?
My weblog looks weird when browsing from my iphone. I’m
trying to find a template or plugin that might be able to correct this issue.
If you have any suggestions, please share. Thanks!
Feel free to visit my webpage 카지노사이트
It’s genuinely very complex in this busy life to listen news on TV, thus I just
use world wide web for that purpose, and obtain the newest information.
Here is my web page: 카지노사이트
Organik kullanicilar olunca güzel oluyor böyle??
It’s really amazing what’s up 🙂
ulan herkes tokatçi olmus ama bu adam gönderdi helal valla??
Really no matter if someone doesn’t be aware of after that its up to other viewers that they
will help, so here it happens.
Also visit my blog post: 카지노사이트
The data is real I guess because I guessed it turned out
Friends, I looked at the comments and entered 2 hours later, mine came ??
she was crying 🙂
mükemmel bir uygulama olmus cidden ??
stalkers, let’s sit down and talk why me ??
Very nice application
Organik kullanicilar olunca güzel oluyor böyle??
I gained followers with thank you??
10 dk sonra geldi takipçilerim tesekkür ederim
Very nice application
incoming followers 100% turkish followers mashallah
Mükemmel Bir Uygulama gerçekten
sonunda teknoloji ilerledi de bunu da yaptilar ??
I was shocked to see 1-2 people I never expected ??
who do i see
I want the instagram version as soon as possible ??
vay anasini sonunda bunu da yaptilar bee ??
I thought I was stalking the boy I love, but it turned out that the room was stalking me, I open immediately 🙂
good to know that ??
Gerçekten inanilmaz ya neler var neler 🙂
wow they finally did that too bee ??
Aw, this was an extremely good post. Finding the time and actual effort to produce
a top notch article… but what can I say… I hesitate a whole lot and don’t
seem to get nearly anything done.
Stop by my web-site … 온라인카지노
thank you sex hattı
thank you favoribahis
Hi! This is my first comment here so I just wanted to give
a quick shout out and tell you I really enjoy reading your articles.
Can you suggest any other blogs/websites/forums that cover the same topics?
Thank you so much!
Have a look at my web site :: 카지노사이트
Greetings I am so excited I found your site, I really found you by accident, while I was
looking on Yahoo for something else, Nonetheless I am
here now and would just like to say many thanks
for a fantastic post and a all round exciting blog (I also love the theme/design), I don’t have time to look over it all at the moment but I have saved it and also included your RSS feeds, so when I have time I will be back to read more, Please do keep up the awesome job.
Feel free to surf to my web page :: 온라인카지노
stromectol 12mg online
cialis 5mg cost canada
buy disulfiram online in india
aurogra 100mg tablets
ivermectin virus
dexamethasone 40 mg tablets
ivermectin 0.1 uk
sildenafil online purchase india
buy antabuse paypal
albuterol mdi inhaler
5mg cialis canadian pharmacy
ivermectin for sale
zovirax cost canada
finasteride 1mg uk
600mg gabapentin
hi instaevreni
sildenafil tablet in india
aurogra 200
generic tadalafil usa pharmacy
plaquenil sale
tadalafil india 10 mg
where to order cialis
purchase amoxicillin online uk
This paragraph will assist the internet viewers for
creating new blog or even a weblog from start to end.
buy ivermectin stromectol
zovirax singapore
ivermectin generic
Please let me know if you’re looking for a article
author for your weblog. You have some really great posts and I feel I would be a good
asset. If you ever want to take some of the load off, I’d love to write some content for your blog in exchange for
a link back to mine. Please shoot me an email if interested.
Cheers!
Stop by my web page: 온라인카지노
buy viagra 100
order stromectol
canadian pharmacy no prescription amoxil
where to buy tadalafil on line
sildenafil india buy
tadalafil 10 mg online india
Thank you a lot for sharing this with all folks you really know what you’re talking
about! Bookmarked. Please also seek advice from my web site =).
We could have a link trade contract between us
Take a look at my blog post :: 카지노사이트
stromectol tab 3mg
My spouse and I absolutely love your blog and
find most of your post’s to be just what I’m looking for.
Would you offer guest writers to write content for you personally?
I wouldn’t mind publishing a post or elaborating on many of
the subjects you write with regards to here. Again, awesome website!
Спасибо, давно искал
_________________
1xbet-те сірі?келерді а?ызу – 1xbet-те ?аражат алу – фонбет бейнесін ?алай же?уге болады
generic sildenafil 50 mg
Blog Nice Very Good
anafranil cheap
medication synthroid
buy cheap trazodone online
buy sildenafil online paypal
ivermectin otc
dexamethasone 0.5 mg tablet price
disulfiram cost
ivermectin 4
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News? I’ve
been trying for a while but I never seem to get there!
Thank you
Also visit my page; 카지노사이트
Nice blog here! Also your website loads up very fast!
What web host are you using? Can I get your
affiliate link to your host? I wish my website loaded up as fast as yours lol
buy tadalafil 5mg
purchase discount cialis online
cymbalta duloxetine
stromectol prices
buying tadalafil from india
tadalafil tablets prices
female viagra over the counter
buy viagra 100mg
how do you get viagra
Pretty! This has been a really wonderful article.
Many thanks for supplying this information.
My site: 온라인카지노
tadalafil 20 mg online pharmacy
site basarili bence geçte olsa geliyor takipçiler??
I saw exactly the people I predicted, the app is absolutely real ??
kimleri görüyorum kimleri
Instantly Uploaded I’m here now??
I went crazy when I saw my stalkers
good luck??
oooo kimler kimler var hayretler içerisindeyimm??
Let’s give a hug as those who see your profile ????
sok üstüne sok yasiyorum, neler varmis da haberimiz yokmus ??
Kimleerr kimleri stalkliyormus megersemmm ??
cost cialis 5 mg
viagra brand canada
It turns out who is stalking who ??
I gained followers with thank you??
It’s a very good app, I didn’t expect this much ??
Got 3000 followers after 4 hours??
Çay veya Kahve istermisiniz Stalkerlar?
thanks??
twitter profilime bakanlari gördüm sonunda
I never thought I would see people who viewed my profile on twitter 🙂
Ulan Beni neden stalklarsiniz anlamis degilim
Sevdigim çocugu stalkladigimi saniyordum megersem oda beni stalkliyormus hemen açiliyorum 🙂
Hesabima Takipçi yagiyordu 🙂
Hello there, just became alert to your blog through
Google, and found that it’s truly informative. I am going to watch
out for brussels. I will appreciate if you
continue this in future. Numerous people will be benefited from your writing.
Cheers!
my blog; 온라인카지노
how to get viagra pills
Hey there! I realize this is sort of off-topic but I needed to ask.
Does running a well-established website such as yours
take a lot of work? I’m brand new to operating a blog but I do write in my diary on a daily basis.
I’d like to start a blog so I can easily share my personal experience and views
online. Please let me know if you have any kind of ideas or tips for brand
new aspiring blog owners. Appreciate it!
Visit my site :: 카지노사이트
over the counter tadalafil usa
sildenafil 20 mg discount
cost of 10mg cialis
pfizer viagra price
Highly energetic blog, I loved that a lot.
Will there be a part 2?
Here is my website: 카지노사이트
cialis best price uk
canadian pharmacy online cialis
cialis 50mg pills
tadalafil soft gelatin capsules
buy cheap propecia
cheap viagra australia
cialis 5mg pharmacy
It is the best time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I desire to suggest you few interesting things or advice.
Perhaps you could write next articles referring to this article.
I wish to read more things about it!
My blog; 카지노사이트
buy made in usa cialis online
cialis 80mg online
can you buy generic viagra
cialis from canada no prescription
buy real viagra canada
buy viagra via paypal
ничего такого
_________________
спортты? ставкаларны ?алай же?уге болады – 1xbet ?ялы телефон н?с?асы – букмекерлік ке?се 1xbet ставкаларларыны? мобильді н?с?асы
75 mg cialis
It’s really a nice and useful piece of info. I’m satisfied that you shared this useful info with us.
Please keep us up to date like this. Thanks for sharing.
Also visit my web site 카지노사이트
where can i buy viagra in south africa
These are really fantastic ideas in about blogging.
You have touched some fastidious factors here. Any way keep up wrinting.
my blog – 카지노사이트
otc cialis 2017
viagra 100mg for sale
cialis 5mg in canada
Hello would you mind stating which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m looking for
something completely unique. P.S My apologies for being off-topic but I had to ask!
Also visit my homepage; 온라인카지노
Круто, давно искал
_________________
м?хит курорты казинолы? т?тылу бассейні – казинолы? ?ажабы – а?ысыз ойыншы?тар ?шін онлайн ойын автоматтары
cialis canada 20mg
cialis south africa price
viagra online canada
cialis buy australia
cheap generic cialis 5mg
generic viagra in usa
viagra from canadian pharmacy
Интересная новость
_________________
bk zenith кімні? ке?сесі – Зенит букмекері ?айда? – джек казинолы? Берлин
cialis 10mg india
cialis 100 mg
best canadian cialis
how to buy viagra online in india
can i purchase cialis over the counter
Thanks for ones marvelous posting! I truly enjoyed reading it, you could be a great author.
I will remember to bookmark your blog and definitely will come back later on. I want to encourage one to continue your great work,
have a nice day!
My homepage: 온라인카지노
cialis 10mg tablets price
buy brand viagra online
female viagra paypal
where to buy cialis online in canada
viagra 25
Интересная новость
_________________
bk карпат жылдамды?ы – казинолы? en linea а?ысыз – 1xbet kz айна
viagra online prescription canada
wellbutrin xl 150 mg
Keep this going please, great job!
My webpage; 온라인카지노
sildenafil india buy
Hello to all, how is the whole thing, I think every one is getting
more from this website, and your views are fastidious in favor of new users.
Also visit my site; 카지노사이트
kamagra jelly or tablets
where to buy stromectol
lasix for sale
6 retin a
tadalafil 2.5 mg india
buy viagra south africa online
kamagra oral jelly walmart
retino 0.5 cream price
cialis 5mg best price australia
800 mg allopurinol
prednisolne online
viagra without a doctor
how can i buy viagra in us
pharmacy viagra generic
viagra generic online pharmacy
Gerçekten inanilmaz ya neler var neler 🙂
Beyler ne zaman geldigini önemi yok bence saat önemi yok siteye giris yaptiktan sonra geliyor mu geliyor bosverin gerisini
canadian cialis 20mg
I thought I was stalking the boy I love, but it turned out that the room was stalking me, I open immediately 🙂
vay anasini sonunda bunu da yaptilar bee ??
stalkers, let’s sit down and talk why me ??
Very nice application
It was raining followers on my account 🙂
cheap generic sildenafil citrate
ulan 2 yildir takip edermi bir insan
kimleri görüyorum kimleri
agliyordu 🙂
he is seriously working ??
gelen takipçiler rt ve fav’da yapiyor??
bunun instagram için olani varsa eger hemen biri söylesin bana ??
Retweet ve Favori sanirim daha hizli geliyor??
Friends, the app is really working, I’m in shock right now??
suan çildiriyorum gördükçe ????
Asla beklemedigim 1-2 kisiyi görünce sok geçirdim ??
An Excellent App indeed
I hope it works every day without interruption
what to say to ex girlfriend
Toplam 15 kisi engellemis beni 3 kisi bayadir stalkliyor
best viagra uk
I entered according to the comments and came followers thank you ??
I want the instagram version as soon as possible ??
I hope it works every day without interruption
who do i see
cialis gel uk
kamagra shelf life kamagra kamagra en jovenes
Hi! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My site looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that might be able to fix
this issue. If you have any suggestions, please share.
Thank you!
Here is my webpage – 온라인카지노
how to buy nolvadex
celexa 10
ivermectin lotion cost
online pharmacy bc
generic xenical 120mg
augmentin 750 mg
This site definitely has all the info I needed concerning this subject and didn’t know
who to ask.
Here is my blog; 카지노사이트
celexa buy online
ivermectin medication
acyclovir pills over the counter
valtrex medicine
avodart
cialis online usa pharmacy
pharmacy fluoxetine
buying generic viagra
cozaar 50 mg
I know this if off topic but I’m looking into starting my own blog and was wondering
what all is needed to get set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% positive. Any suggestions or advice would be greatly appreciated.
Many thanks
Check out my web blog … 카지노사이트
cafergot 1 100 mg
albendazole 400
valtrex no perscrition
price for prozac
sildenafil citrate 50 mg
ivermectin 1%cream
ivermectin buy
price for sildenafil 20 mg
cymbalta cost australia
buy cialis cheap canada
We stumbled over here coming from a different web page and thought I might as well check things
out. I like what I see so i am just following you. Look
forward to exploring your web page again.
Here is my web site 카지노사이트
tadalafil prices
cialis 10mg sale
tadalafil tab 10mg
disulfiram
tadalafil tablet 5mg
tretinoin prescription cost
provigil medication
best price real viagra
generic cialis drugstore
generic plaquenil
What’s up to every body, it’s my first go to see
of this weblog; this webpage contains amazing and actually fine stuff for visitors.
my site :: 온라인카지노
how to advair diskus
atarax anxiety
accutane price online pharmacy
best online sildenafil prescription
cialis 5 mg tablet price
zithromax 1000 mg pills
seroquel cost uk
tadalafil where to get cheap
motrin 200 mg otc
how can i get misoprostol
buy cialis soft
buy tamoxifen tablets
proscar 5mg australia
feldene 10 mg
canadian generic sildenafil
vardenafil tablets 20 mg price in india
effexor
hydrochlorothiazide pill
piroxicam tablet
metformin otc usa
tadalafil best price
sildenafil citrate vs viagra
I’m impressed, I must say. Seldom do I encounter
a blog that’s both equally educative and amusing,
and without a doubt, you’ve hit the nail on the head.
The problem is something which too few folks are speaking intelligently about.
I am very happy I came across this during my search for
something relating to this.
This is very interesting, You’re a very
skilled blogger. I have joined your feed and look forward to seeking more of your wonderful post.
Also, I’ve shared your website in my social networks!
Here is my webpage; 온라인카지노
generic cialis for sale
viagra online costs
buy cialis online canada pharmacy
generic cialis cost
can you buy generic cialis
how to get cialis prescription
It’s genuinely very complicated in this active life to listen news on Television, therefore I simply
use world wide web for that reason, and obtain the most recent news.
Look at my web-site; 온라인카지노
Aw, this was a very nice post. Finding the time and actual effort to
create a really good article… but what can I say…
I hesitate a lot and don’t seem to get nearly anything done.
My website :: 카지노사이트
ivermectin 8000
25 mg viagra
viagra brand coupon
sildenafil where to get
I was shocked to see 1-2 people I never expected ??
Seeing my ex is kind of like ??
bugün de gizli hayranlarimizi ögrendik…
sonunda teknoloji ilerledi de bunu da yaptilar ??
It’s a very good app, I didn’t expect this much ??
I gained followers with thank you??
good to know that ??
Admin kim bilmiyorum ama tebrikler 3 saat sonra geldi benim takipçim
10 dk sonra geldi takipçilerim tesekkür ederim
The site is successful, I think it’s coming late, followers??
bunu ögrendigim çok iyi oldu ??
Stalkerlarimi Ögredim
ulan 2 yildir takip edermi bir insan
cheap viagra no prescription
modafinil usa
If some one wants expert view concerning blogging and site-building
after that i suggest him/her to pay a quick visit this blog, Keep
up the fastidious job.
where to buy cialis in canada
can i buy sildenafil over the counter
cheap generic viagra no prescription
order generic cialis online canada
viagra daily
viagra 50 mg price
viagra cost in uk
average price of generic viagra
cialis france
cheap viagra pills free shipping
cialis softtab how works https://alevitrasp.com Tetracycline Amoxicillin
where to get viagra in canada
where to buy viagra in india
stromectol cost
ivermectin 4 tablets price
buy viagra online australia paypal
flomax headache
ivermectin 0.08%
viagra voucher
cialis generic online uk
modafinil 200mg online
buy viagra professional
sildenafil 25 mg online
cialis how to get
tadalafil 20 mg soft chewable tablets
Aujhbs Drug Classification And Type On Amoxicillin buy prednisone dog 5mg cialis viagra mix
_aslan_mb_ aaaaa09062953 mehmete51882093 _26mert a_yilmaz412hotm __beatifull__
Excellent site you have got here.. It’s hard to find
good quality writing like yours these days. I really appreciate individuals like you!
Take care!!
My page; 온라인카지노
These are in fact wonderful ideas in concerning blogging.
You have touched some pleasant factors here.
Any way keep up wrinting.
Feel free to surf to my site … 먹튀검증 토토사이트
Hi there are using WordPress for your site platform? I’m new to
the blog world but I’m trying to get started and set up my own. Do you need any html coding expertise
to make your own blog? Any help would be really appreciated!
My homepage … 카지노사이트
I every time spent my half an hour to read this webpage’s
posts all the time along with a mug of coffee.
Also visit my page; 온라인카지노
Oh my goodness! Amazing article dude! Thank you, However I am encountering
troubles with your RSS. I don’t understand
the reason why I cannot join it. Is there anyone else getting the same RSS
problems? Anyone who knows the solution will you kindly respond?
Thanx!!
my blog :: 카지노사이트
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails
with the same comment. Is there any way you can remove me from
that service? Thanks!
My homepage :: 온라인카지노
Hello, I think your site might be having browser compatibility issues.
When I look at your website in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, superb blog!
Also visit my website; 카지노사이트
Howdy! This is my first comment here so I just wanted
to give a quick shout out and tell you I truly enjoy reading your blog posts.
Can you recommend any other blogs/websites/forums that
deal with the same subjects? Many thanks!
My site :: 인계동마사지
Hi to all, for the reason that I am really keen of reading this
web site’s post to be updated regularly. It carries pleasant
material.
Here is my page :: 온라인카지노
Excellent way of describing, and good article to obtain information concerning my presentation topic,
which i am going to present in academy.
My web page 온라인카지노
This is the perfect webpage for everyone who hopes to understand this topic.
You know so much its almost hard to argue with you (not that
I actually will need to…HaHa). You definitely put a fresh spin on a subject which has been written about for ages.
Great stuff, just great!
Visit my page: 카지노사이트
Great post. I was checking constantly this blog and I’m impressed!
Very useful information specifically the last part 🙂 I care for such info
much. I was seeking this particular information for a very long time.
Thank you and best of luck.
Feel free to surf to my homepage … 온라인카지노
I am regular reader, how are you everybody? This piece of writing posted at this web site is truly nice.
Also visit my webpage – 온라인카지노
If you wish for to improve your knowledge simply keep visiting this web site and be updated with the
latest news posted here.
Visit my blog post: 카지노사이트
When some one searches for his vital thing, so he/she needs to be available that in detail, so that
thing is maintained over here.
My homepage; 온라인카지노
It’s hard to come by experienced people on this topic, but you sound
like you know what you’re talking about! Thanks
Feel free to surf to my web site; 카지노사이트
buy plaquenil from canada Levitra Mit Grapefruit
Hello i am kavin, its my first occasion to commenting anywhere, when i read this piece of writing
i thought i could also make comment due to this sensible paragraph.
Also visit my homepage :: 카지노사이트
What’s up, I wish for to subscribe for this blog
to obtain newest updates, so where can i do it please help out.
Look into my web-site 온라인카지노
beguumakarsuu beiktalbeikta beikta19030303 bedrhanpargan bedrbora begmecem2
fatihfiloglu1 dl_ayse djuhgda33 fatihciyinizz divamistarz dmircimr
ahmetmrtler ahmetso03760025 gdekesra manmemetkama ahmettu44655887 ahmettokma
merfarukgne3 merenkilic 1133muco merfarukdnk 111seyir glsenkaraka
bararslannn beratcangltkn berartta beratay_ay kayatud barko1231
After I originally left a comment I appear to have clicked on the
-Notify me when new comments are added- checkbox and from now
on every time a comment is added I recieve 4 emails with the same comment.
Perhaps there is an easy method you are able to remove me from that service?
Thanks!
Here is my site 온라인카지노
magnificent points altogether, you simply gained a brand new reader.
What may you suggest about your publish that you made a few days ago?
Any sure?
Take a look at my blog post; 수원스웨디시
Китайские товары каждый раз выделялись супернизкими прайсами, а, вследствие этого, и общедоступностью. Все же не нужно полагать, что в целом произведенная продукция из КНР второсортная и портится и выходит из строя спустя небольшое количества суток. Фабричные товары создаются надежными и добротными и оперируют высоким запросом не только в России, также и в Европе. Поэтому оказавшись в КНР, не потеряйте возможность купить несколько, а если хотите и значительно больше вещиц для себя и своих знакомых. Поставщики в Поднебесной https://ved-line.ru считаются доставучими к тому же умеют как следует договариваться о скидке. Стоит подыграть им, потому что они не желают упустить не одного потребителя без товара и, чаще всего, всякий раз снижают повышенную цену на 30%, а то и на 60%. Особенно торг удачен в местах туристических, в которых цены иногда завышают даже в 5 раз и в 30 раз, впрочем фабричную цену вы навряд ли определите.
Great blog you have here.. It’s hard to find excellent writing like yours these days.
I seriously appreciate people like you! Take care!!
Please let me know if you’re looking for a article author
for your site. You have some really great articles and I feel
I would be a good asset. If you ever want to take some of the load off, I’d love
to write some content for your blog in exchange for a link back to mine.
Please send me an email if interested. Cheers!
Feel free to surf to my web page: 인계동스웨디시
It’s awesome to visit this site and reading the views of all friends about this post, while I am also
zealous of getting familiarity.
Also visit my blog post 인계동스웨디시
Yes! Finally someone writes about Salt lake locksmith.
Appreciating the hard work you put into your blog and detailed information you provide.
It’s awesome to come across a blog every once in a while that isn’t the
same outdated rehashed material. Great read! I’ve bookmarked your site
and I’m adding your RSS feeds to my Google account.
Feel free to surf to my web blog; 수원스웨디시
Pingback: котел газовый
Awesome post.
Post writing is also a excitement, if you know afterward you can write otherwise it is complicated to write.
What’s up, yeah this paragraph is truly good and I have learned lot of things from it about blogging.
thanks.
Thanks for finally writing about > K-Nearest Neighbor Machine Learning algorithm – Deepsingularity :
Deepsingularity < Liked it!
Pingback: andere.strikingly.com
Pretty nice post. I just stumbled upon your blog and wished to
say that I’ve really enjoyed browsing your blog posts.
In any case I will be subscribing to your feed and
I hope you write again soon!
Very good post. I definitely appreciate this site. Stick with it!
certainly like your web site however you need to take
a look at the spelling on quite a few of your posts.
Many of them are rife with spelling issues and I find it very troublesome to tell the truth however I will surely come again again.
We stumbled over here from a different website and thought I might as
well check things out. I like what I see so i am just following you.
Look forward to checking out your web page again.
chaiolyn 9ea660493d https://wakelet.com/wake/JkectA6xvrUNQWz231zH2
Today, while I was at work, my sister stole my apple ipad and tested to see if it can survive a twenty five foot drop, just so she can be a youtube sensation. My iPad is now broken and
she has 83 views. I know this is completely off topic but I had to share it with someone!
patanei 538a28228e https://coub.com/stories/4337978-drivers-software-crack-pc-activation-torrent-free
fauswan 538a28228e https://coub.com/stories/4300933-final-adobe-acrobat-xi-pro-11-utorrent-nulled-key-zip-free-32-dmg
peeyol 538a28228e https://coub.com/stories/4225119-full-wazir-subtitles-torrents-720p-watch-online-dubbed-720p
benwarl 538a28228e https://coub.com/stories/4236973-life-selec-registration-final-keygen-windows-iso-full
fairwar 538a28228e https://coub.com/stories/4259019-download-beersmith-2-windows-zip-activator
grewak 538a28228e https://coub.com/stories/4277050-full-version-infinity-ch-pc-64-iso-activator-software-utorrent
vaniuny 538a28228e https://coub.com/stories/4385223-full-7-bootmgr-efi-for-download-pc-crack-x64-key
mandalm 538a28228e https://coub.com/stories/4291300-download-a-mic-email-hunter-9-21-registration-pc-build-keygen-full
jalshaw 538a28228e https://coub.com/stories/4276499-telecharger-logiciel-watch-online-download-x264-mp4-bluray-full-subtitles
phixam 538a28228e https://coub.com/stories/4276179-windows-easyworship-2009-download-x64-zip-final-free-key
jerbrin 538a28228e https://coub.com/stories/4228098-zip-musiclab-real-guitar-windows-free-serial-activation
entyus 538a28228e https://coub.com/stories/4317817-file-movavi-exe-64bit-registration
hassfrei 538a28228e https://coub.com/stories/4262580-pc-zawgyi-professional-patch-torrent-activator-free
greearih 538a28228e https://coub.com/stories/4319708-finecut-8-for-illustra-pro-keygen-download-activation-rar-windows
giorarc 538a28228e https://coub.com/stories/4267560-y-lives-y-masters-in-full-mobi-book-zip-download
Hello there, just became alert to your blog through Google, and
found that it is truly informative. I’m gonna watch
out for brussels. I will be grateful if you continue this
{in future}. A lot of people will be benefited from your writing.
Cheers!
fabivuc 538a28228e https://coub.com/stories/4329796-magix-key-crack-latest-32-windows-full-version
randshar 538a28228e https://coub.com/stories/4354282-the-sri-siddhartha-gautama-subtitles-rip-full-mp4-torrents-video-mkv
billcons 538a28228e https://coub.com/stories/4299097-free-vag-com-409-1-torrent-build-zip-32bit-patch-license
zhukalm 538a28228e https://coub.com/stories/4270519-exe-theoriesofpersonality10th-registration-nulled-x32-utorrent-free-windows
laddavi 538a28228e https://coub.com/stories/4311989-x-force-x-torrent-x32-rar-free
ianttak 538a28228e https://coub.com/stories/4244024-rar-tu-rial-adobe-after-effects-cc-pc-build-full
andlasc 538a28228e https://coub.com/stories/4315232-online-player-the-grudge-2-full-dvdrip-mkv-subtitles-free
ermodels 538a28228e https://coub.com/stories/4350146-adobe-after-effects-cc-2018-v15-0-1-73-torrent-activation-free-cracked-final-rar
lascjaem 538a28228e https://coub.com/stories/4298271-free-two-point-hospital-v1-4-21253-update-skidrow-torrent-file-activator-32
rhigra 538a28228e https://coub.com/stories/4266221-32-angelina-pussy-eurotic-tv-latest-key-rar-patch
noclegi pracownicze niedaleko suwalk http://www.kwatery-waugustowie.online
stx21
http://www.kwatery-waugustowie.online pokoje pracownicze nieopodal suwalk
stx21
Very good info. Lucky me I discovered your site by chance (stumbleupon).
I’ve book marked it for later! สล็อต betflix
kwatery w Augustowie http://www.kwatery-waugustowie.online
stx21
netrhoi 840076785b https://coub.com/stories/4687531-utorrent-avatar-3d-watch-online-watch-online-x264
geradem b8d0503c82 https://coub.com/stories/4596836-pc-mobile-partner-patch-zip-full-64bit
It’s very effortless to find out any topic on web as
compared to textbooks, as I found this post at this web page.
willred b8d0503c82 https://coub.com/stories/4707004-akinsoft-oc-32-torrent-free-ultimate-pc-crack-rar
quearang b8d0503c82 https://coub.com/stories/4665230-sohni-mahiwal-1984-dubbed-4k-kickass-full-movies-watch-online-watch-online
filbmaka b8d0503c82 https://coub.com/stories/4595999-dc-unlocker-2-client-1-00-0828-download-file-patch-pc-full-zip
kaferik b8d0503c82 https://coub.com/stories/4717022-hd-chhota-bheem-and-the-throne-of-bali-watch-online-mkv-720p-720
derrvygn b8d0503c82 https://coub.com/stories/4612019-free-adobe-muse-cc-7-3-ls24-key-nulled-x64-windows
beljan b8d0503c82 https://coub.com/stories/4551775-movies-guddu-ki-gun-dubbed-dubbed-full-mp4-1080-download
alyspen b8d0503c82 https://coub.com/stories/4693994-windows-rio3-full-version-x32-build-cracked
Keluaran HK: Pengeluaran HK, Togel Hongkong, Data HK Pools,
Result HK Prize Hari Ini 2022 (HKG)
Keluaran HK berisi ringkasan angka Pengeluaran HK
Hari Ini pada pasaran Togel Hongkong. Nomor Result HK itu, selanjutnya akan di atur ke sebuah tabel Data HK 2022.
Selanjutnya info Angka keluar yang kami suguhkan, diambil
dari beragam Sumber sah dari Hongkong Pools ( HK
Pools ). Hingga nomor Hongkong Prize atau HK Prize akan kami up-date sehari-harinya pada jam 23.00 WIB.
Pengeluaran HK dan Keluaran HK Hari Ini Paling cepat Tahun 2022
Pengeluaran HK 2022 yang kami bagi sebagai
hidangan angka paling cepat, dengan manfaatkan mekanisme result termodern. Dengan manfaatkan feature Live
Draw HK yang hebat, memungkinkannya beberapa pengunjung
bisa melihat Keluaran HK Hari ini langsung. Hingga kepuasan dalam taruhan Toto HK bisa bertambah.
saat Anda manfaatkan website kami, sebagai opsi khusus dalam mendapati hasil
Nomor Jekpot Hongkongpools.
Data HK Penting untuk Pencinta Togel Hongkong ( HKG)
Untuk Pencinta permainan Togel HKG di Indonesia, Info sekitar Data HK sangat penting.
Karena kalian bisa menyaksikan beragam info bernilai yang ada dalam tabel itu.
Jika Anda sanggup memakainya secara betul, saya yakin jika
beberapa pengemar Togel Hongkong bisa tingkatkan kesempatan menangnya dalam menerka
Nomor Jekpot.
ютуб
Keluaran HK: Pengeluaran HK, Togel Hongkong,
Data HK Pools, Result HK Prize Hari Ini 2022 (HKG)
Keluaran HK berisi ringkasan angka Pengeluaran HK Hari Ini pada pasaran Togel Hongkong.
Nomor Result HK itu, selanjutnya akan di atur ke sebuah tabel Data HK 2022.
Selanjutnya info Angka keluar yang kami suguhkan, diambil dari
beragam Sumber sah dari Hongkong Pools ( HK Pools ). Hingga nomor Hongkong Prize atau HK Prize akan kami up-date sehari-harinya pada jam 23.00 WIB.
Pengeluaran HK dan Keluaran HK Hari Ini Paling cepat Tahun 2022
Pengeluaran HK 2022 yang kami bagi sebagai hidangan angka
paling cepat, dengan manfaatkan mekanisme result termodern. Dengan manfaatkan feature Live Draw HK yang
hebat, memungkinkannya beberapa pengunjung bisa melihat Keluaran HK Hari ini langsung.
Hingga kepuasan dalam taruhan Toto HK bisa bertambah. saat Anda
manfaatkan website kami, sebagai opsi khusus dalam mendapati hasil
Nomor Jekpot Hongkongpools.
Data HK Penting untuk Pencinta Togel Hongkong ( HKG)
Untuk Pencinta permainan Togel HKG di Indonesia,
Info sekitar Data HK sangat penting. Karena kalian bisa menyaksikan beragam info
bernilai yang ada dalam tabel itu. Jika Anda sanggup memakainya secara
betul, saya yakin jika beberapa pengemar Togel Hongkong bisa
tingkatkan kesempatan menangnya dalam menerka Nomor Jekpot.
Spot on with this write-up, I truly feel this website needs a
great deal more attention. I’ll probably be back again to read through more, thanks for the info!
swyhil 220b534e1b https://www.kaggle.com/zytomasub/blue-umbrella-part-in-tamil-dubbed-best
quyngas 220b534e1b https://www.kaggle.com/peyfafecthatch/the-jackbox-party-pack-full-new-crack-pack
kriscom 220b534e1b https://www.kaggle.com/erjsutacal/deep-fritz-13-torrent
yakimari df76b833ed https://www.kaggle.com/bigadire/better-power-politics-and-death-by-olusegu
yakalbi df76b833ed https://www.kaggle.com/amacticbe/updated-atomic-email-hunter-9-21-crack
thadtran df76b833ed https://www.kaggle.com/spamkerseetock/appa-magala-kannada-sex-story-fix
ferwis df76b833ed https://www.kaggle.com/tumidomlust/wayne-l-winston-solution-manual-operations-researc
phierh df76b833ed https://www.kaggle.com/keydedriki/top-aui-converter-48×44-produce-rd-crac
thoridel df76b833ed https://www.kaggle.com/forrilapa/psihologiadezvoltariiumaneanamunteanpdf21
hatrams df76b833ed https://www.kaggle.com/tronmarrepa/malayalam-movie-garam-masala-songs-download-exclu
cateokat df76b833ed https://www.kaggle.com/procokebti/not-angka-pianika-lagu-justin-bieber-that-should-b
dejawacl df76b833ed https://www.kaggle.com/inlisualfoa/exclusive-el-paciente-ingles-dvdrip-www-lok
garcalla df76b833ed https://www.kaggle.com/eniminque/full-free-download-adobe-illustrator-cs5
gerkaed df76b833ed https://www.kaggle.com/spamkerseetock/superpro-designer-top-free-download-crack-wind
orival df76b833ed https://www.kaggle.com/hoplitikri/verified-tunelab-pro-5-0-serial-number
nineyalu df76b833ed https://www.kaggle.com/swinavnihu/hot-savita-bhabhi-free-pdf-download-in
benamil df76b833ed https://www.kaggle.com/tenlivounour/the-idolm-ster-master-artist-05-better
jambian df76b833ed https://www.kaggle.com/venasdoge/best-epic-heroes-war-1-10-0-297-apk-mod
anadfits df76b833ed https://www.kaggle.com/quedaytyswork/link-the-dining-rooms-discography-199920
glyray df76b833ed https://www.kaggle.com/acromade/winrar-x64-64-bit-v5-01-final-keyreg
quyraf df76b833ed https://www.kaggle.com/brisepersduc/lady-gaga-revenge-ipa-cracked-ipad-exclusive
graterro df76b833ed https://www.kaggle.com/elertiocia/angry-birds-evolution-v1-15-2-mod-apk-unlimited-m
finund df76b833ed https://www.kaggle.com/gesmosubsubs/van-basco-karaoke-player-28000-kar-songs-jadrqua
verber df76b833ed https://www.kaggle.com/ilcoelipe/fsx-p3d-chubu-centrair-intl-pacific-islands-s
Do you have a spam issue on this blog; I also am a blogger,
and I was curious about your situation; many of us have created some nice practices
and we are looking to swap solutions with others, please shoot me an e-mail if
interested.
noelger 89fccdb993 https://www.guilded.gg/branophconsas-Braves/overview/news/Ayk7oDXy
visger 89fccdb993 https://www.guilded.gg/cabosraelans-Flyers/overview/news/B6Z7XALy
rafjym 89fccdb993 https://www.guilded.gg/teroptiagegs-League/overview/news/Plqwnpzy
I’m extremely inspired with your writing abilities as smartly as with the layout in your weblog.
Is this a paid topic or did you modify it your self?
Either way keep up the nice quality writing, it’s uncommon to peer a nice blog like this one today..
colfort 89fccdb993 https://www.guilded.gg/onburnutas-Knights/overview/news/V6XVd2JR
glynhar 89fccdb993 https://www.guilded.gg/rorttinuducs-Outlaws/overview/news/7lxwq14R
manjame 89fccdb993 https://www.guilded.gg/skyloransos-Dodgers/overview/news/1ROOBGYR
Stunning story there. What happened after?
Take care!
kamtiba f23d57f842 https://www.guilded.gg/lenobtalums-Bearcats/overview/news/16nnD9O6
flokay f23d57f842 https://www.guilded.gg/tranorascos-Red-Sox/overview/news/GRmE8oPR
engkam f23d57f842 https://www.guilded.gg/cypeachwatas-Raiders/overview/news/2l3kx9Ol
vulvque f23d57f842 https://www.guilded.gg/taxcchipelmys-Drum-Circle/overview/news/9yWVvZG6
nolacath f23d57f842 https://www.guilded.gg/fastsungohers-Storm/overview/news/vR13OPz6
garsale f23d57f842 https://www.guilded.gg/ovpogusis-Mustangs/overview/news/PyJDwkbl
eramar f23d57f842 https://www.guilded.gg/subsrodoquars-Club/overview/news/glbkkog6
volljus f23d57f842 https://www.guilded.gg/fuhotucons-Rebels/overview/news/16n4xr1R
rebehone f23d57f842 https://www.guilded.gg/inhalsingsas-Hurricanes/overview/news/qlDD9jel
Howdy would you mind letting me know which web host you’re utilizing?
I’ve loaded your blog in 3 completely different browsers and I must say
this blog loads a lot faster then most. Can you recommend a good internet hosting provider at
a reasonable price? Cheers, I appreciate it!
my blog: 인계동마사지
tandber f23d57f842 https://www.guilded.gg/trencertasans-Generals/overview/news/PyJW2maR
Hi there, just became aware of your blog through Google, and found that it’s truly informative.
I am going to watch out for brussels. I will appreciate if you continue this
in future. A lot of people will be benefited from your writing.
Cheers!
нас интересуют следующие пиломатериалы на постоянной основе:
1. Ель, обрезная доска S4S, F/S1-4 (1-4 sort)
европейская сортировка
40 х 300 x 4,0 метра
допуск +/- 1 мм
влажность: KD 8% +\- 2%
доска строганная или высококачественного распила
погрузка в контейнер
Потребность на сегодня: 8 контейнеров в год 40 фут
Объём может вырасти при хорошей цене и качестве
Условия поставки : FCA
2. Ель, обрезная доска 22×100 \ 125 \ 150 \ 200
сортировка европейская OS – микс (F/S 1-4 )
транспортная влажность : KD 18% + /- 2%
Длина 3.0 – 6.00 м.,
FSC сертификат обязателен
Потребность 500-1000м3/месяц
(минимальная партия – 40 фут фура)
Условия поставки: FCA
3. Лиственница, о/д 1-4 сорт (S4S, F/S1-4)
40 x 150 x 5,9 m
допуск +/- 1 мм
KD 8% +\- 2%
доска строганная или высококачественного распила
погрузка в контейнер
Потребность на сегодня: 6-8 контейнеров в год 40 фут
Объём может вырасти при хорошей цене и качестве
Условия поставки : FCA
Предложите цены и условия
http://drevtorg.xyz/profile/SergejAnatolevich99
https://telegra.ph/Free-Porn-Tube-Video-Showing-Pretty-Young-Lady-10-03
https://www.pokojeiaugustow.online pokoje w Augustowie
stx21
Hello my friend! I wish to say that this post is amazing,
great written and come with approximately all vital infos.
I’d like to see more posts like this .
I like the valuable info you provide in your articles.
I will bookmark your weblog and test again right here frequently.
I’m rather certain I’ll be told plenty of new stuff proper
here! Best of luck for the following!
I’m gone to tell my little brother, that he should also pay a quick
visit this weblog on regular basis to take updated from hottest
reports.
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses. But he’s
tryiong none the less. I’ve been using Movable-type on a number of websites for
about a year and am nervous about switching to another platform.
I have heard good things about blogengine.net. Is there a
way I can import all my wordpress content into
it? Any help would be greatly appreciated!
Your style is so unique compared to other people
I’ve read stuff from. Many thanks for posting when you have the opportunity, Guess I will just bookmark this blog.
Sweet blog! I found it while browsing on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem
to get there! Many thanks
Hello! This is my first visit to your blog! We are a team of volunteers and
starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done a extraordinary job!
Всякому жителю особняка или другого строения желается иметь выносливую бронированную дверь по оправданной оплате. И здесь мы Вам лично здесь пособим. На этой странице мы разберём сверх популярные образцы с их описанием и cтоимостью на странице: Заказать дверь входную https://dveri-krivoj-rog.kr.ua
Meds information sheet. What side effects can this medication cause?
can i order cheap valtrex no prescription in USA
All information about drugs. Get here.
Hello, this weekend is good in support of me,
because this time i am reading this impressive educational piece of writing here at my house.
I am extremely impressed with your writing skills and
also with the layout on your blog. Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing,
it is rare to see a great blog like this one today.
I got this web site from my buddy who shared with me regarding this
site and at the moment this time I am visiting this web site and reading very informative articles
or reviews at this place.
Thanks for the post Интересная новость
_________________
bookmaker espacial
https://telegra.ph/Senior-Officer-Notices-Junior-Officer-Looking-On-10-27
sadsada
sdsdasd
asdsadsda
edededede
dsdsdsdd
Örgü modelleri ile ilgili tüm yeni gelişmeleri web sitemizden kolay bir şekilde takip edebilirsiniz. Kadınlara özel yeni örgü modelleri için geç kalmayın.
asdsadsdsa
dsdsdsa
sdsadsds
asdsadsdsdsa
En güvenilir bahis siteleri 2022 için hemen ziyaret et.
En güvenilir bahis siteleri 2022 için hemen ziyaret et.
En güvenilir bahis siteleri listesi için hemen web sitemizi ziyaret edebilirsiniz.
comment
dsadsadsadsadsa
sdsdsdsda
xcxcxcxzcxcxcxcxcxcxcxcxcxsdfds
asdsdsfsfeweeeeewew
hellooosadsahellooosadsahellooosadsahellooosadsa
sadsadasdsadsd
asdsadsadas
dsadsdsdsadsa
sadsadsadsd
tt satin almanin tek adresi.
gorabet gercek ve tek dogru giris adresi burada.
gora bet giris adresi guncel olarak burada.
gorabet gorabet en yeni adresi hizmetinizde.
gorabet- burada.
gorabet- burada.
gorabet- burada.
bitcoin nasıl alınır dediğiniz an s
bitcoin nasıl alınır cevabını arıyorsanız buraya bakin.
bitcoin nasıl alınır dediğiniz an sitemize bakabilirsiniz.
coin nasıl alınır sorusunun cevabı burada.
takipçi satın al hizli ve guvenilir.
instagram takipçi arıyorsanız doğru ad
instagram takipci satın alma fırsatını
instagram takipci satın alma fırsatını
instagram takipci satın alma fırsatını ka
instagram takipci satın alma fırsatını kaçırmayın.
ilelebet giriş işlemleri burada yapılır.
twitter trend topic satın a
twitter trend topic
twitter trend topic satın
twitter trend topic satın al burada
https://www.behance.net/engveengve
Güncel ve anlık son dakika haberleri için hemen ziyaret et. https://www.haberlerdetayi.com/.com/
Güncel ve anlık son dakika haberleri için hemen ziyaret et. https://www.haberlerdetayi.com/
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://kadindiyetsaglik.
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://habersahifesi.com
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://habersahifesi.com/et/
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://habersahifesi.com/
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://tekilhaber.com/m/m/
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://tekilhaber.com/m/
Anlık ve güncel son dakika haberleri için hemen ziyaret et. https://tekilhaber.com/
hello my names is tom. very nice content.
Anlık ve son dakika haberleri için hemen ziyaret et. https://www.habereuro.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://www.habereuro.com/er.net/
Anlık ve son dakika haberleri için hemen ziyaret et. https://www.habereuro.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://caylakhaber.com/m/
Anlık ve son dakika haberleri için hemen ziyaret et. https://caylakhaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberbunoktada.c
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberbunoktada.com/m/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberbunoktada.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberimizvarahali.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberyolcusu.com/.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberyolcusu.co
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberyolcusu.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://kosgebhaberleri.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://tezverenhaber.c
Anlık ve son dakika haberleri için hemen ziyaret et. https://tezverenhaber.com/com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://tezverenhaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://vansagduyuhaber.c
Anlık ve son dakika haberleri için hemen ziyaret et. https://vansagduyuhaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://saglikvehastalik.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://saglikvehastalik.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://sagliklisaglik.co
Anlık ve son dakika haberleri için hemen ziyaret et. https://sagliklisaglik.
Anlık ve son dakika haberleri için hemen ziyaret et. https://sagliklisaglik.
Anlık ve son dakika haberleri için hemen ziyaret et. https://sagliklisaglik.com/
ilelebet burada!yapabilirsiniz.
ilelebet burada!
Anlık ve son dakika haberleri için hemen ziyaret et. https://sondakikalar.net/.net/
Anlık ve son dakika haberleri için hemen ziyaret et. https://sondakikagazete
Anlık ve son dakika haberleri için hemen ziyaret et. https://sondakikagazetesi.com/
Visit now for instant and breaking news. https://dj30news.com/ten.c
Visit now for instant and breaking news. https://dj30news.com/ten.com/
Visit now for instant and breaking news. https://leichtathletik-nachrich
Visit now for instant and breaking news. https://mtlnews24.com/com/hrichten.com/
Visit now for instant and breaking news. https://mtlnews24.com/com/
Visit now for instant and breaking news. https://mtlnews24.com/
Visit now for instant and breaking news. https://puffnachrichten.com/
Visit now for instant and breaking news. https://puffnachrichten.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberbosnak.com//si.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://game-haber.com//
Anlık ve son dakika haberleri için hemen ziyaret et. https://game-haber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://game-haber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://sesligazeteniz.com/m/
Anlık ve son dakika haberleri için hemen ziyaret et. https://sesligazeteniz.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://sesligazeteniz.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://bursaiyihaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://izmirtekhaber.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://izmirtekhaber.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://izmirtekhaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://yuzenadahaber.c
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberimyoktu.co
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberimyoktu.com//
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberimyoktu.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://atthaber.com/m/si.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://atthaber.com/m/si.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://atthaber.com/m/
Anlık ve son dakika haberleri için hemen ziyaret et. https://atthaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://gazetelerdenhab
Anlık ve son dakika haberleri için hemen ziyaret et. https://hisargazetesi.com/com/om/
Anlık ve son dakika haberleri için hemen ziyaret et. https://hisargazetesi.com/com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://hisargazetesi.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://kartepedenhaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://egehabergazetesi.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://estetik-haber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://batialanyahaber.com/m//
Anlık ve son dakika haberleri için hemen ziyaret et. https://batialanyahaber.com/m/
Anlık ve son dakika haberleri için hemen ziyaret et. https://batialanyahaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://39haber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberkaynaginiz.c
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberkaynaginiz.co
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberkaynaginiz.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://haberlinux.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://katenerhaber.com/m/
Anlık ve son dakika haberleri için hemen ziyaret et. https://rushaberler.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://rushaberler.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://rushaberler.com//
Anlık ve son dakika haberleri için hemen ziyaret et. https://yasamvehaber
Anlık ve son dakika haberleri için hemen ziyaret et. https://edirnedehaber.com
Anlık ve son dakika haberleri için hemen ziyaret et. https://edirnedehaber.com/
Anlık ve son dakika haberleri için hemen ziyaret et. https://teknolojihaberle
Anlık ve son dakika haberleri için hemen ziyaret et. https://teknolojihaberleri724.com/
dolandırılmak isteyen gelsin.ız.
fuck google and
dolandırılmak isteyen gelsin.
dolandırılmak isteyen gels
https://sco.lt/5ZZeRU
hello world.
hopla vv
sadsdasdasda
sdsdsadsadass
http://stringvisions.ovationpress.com/2011/05/i-dont-have-enough-time/
instagram beğeni satın al ve instagram takipçi satın alma
tiktok beğeni satın alma sitesini ziyaret edebilirsiniz.
instagram beğeni almak için sitemizi ziyaret edebilirsiniz.
instagram takipçi satın almak için siteyi ziyaret edebilirsiniz.
genel blog gönderil için siteyi ziyaret edebilirsiniz.
Gündelikçi bayan ile ev temizliği, daire temizliği, ofis temizliği yapılmaktadır.
Aw, this was a very good post. Spending some time and actual effort to produce a superb
article… but what can I say… I hesitate a lot and don’t manage to get nearly anything done.
dadsadsdasasdsa
very nice content
gagagagagsdsadsa
sadsadasdsa
sadsadasdsa
sdsdsdsadsa
maraqlı xəbərlər
_________________
nab bahis – onlayn qumar, onlayn kazino meydanГ§alarД±
sadasdas
Pingback: JXNhGmmt
veri nice comment…
квартира на сутки Могилев
Do you mind if I quote a few of your posts as long as I provide credit
and sources back to your webpage? My website is in the
exact same area of interest as yours and my visitors would truly benefit from a
lot of the information you provide here. Please let me
know if this ok with you. Thanks!
Играть адмирал x
На Амирале Х можно выиграть — лично у меня получилось — правда не какую то крутую сумму сразу , а пока самый большой мой куш — этого выигрыша хватило на полный бак для моей надежды , любви и опоры по этой жизни и бургер кинг .
Техподдержка очень оперативно реагирует на вопросы.
Адмирал х зеркало на сегодня admiral x,
Выигрыш можно вывести на банковскую карту или цифровой бумажник.
sdsdsadsadsd
asdsdsadsadsad sdsadas dasdas
sizleride beklerim faceitme
Medication information leaflet. What side effects?
cheap bactrim for sale in USA
All news about medicines. Get now.
Synthroid is among the most widely prescribed drugs for the treatment of thyroid gland cancer. It may also be used to treat hypothyroidism, a condition where there is an underproduction of thyroid hormones. An important thing to remember is that there are different forms of thyroid medication and this one is not equivalent to another, so follow instructions on your prescription carefully.
synthroid pill
Pingback: psikholog
If you have missed a dose of Celebrex (Celecoxib) tablets, don’t take two doses to make up for it. It’s important that you simply return to your prescribed treatment schedule, even if you miss one dose.
celebrex tablets
Thanks for any other great post. The place else may just anybody get that kind
of information in such a perfect approach of writing? I have
a presentation subsequent week, and I’m at the look for such information.
It’s actually a nice and helpful piece of info.
I’m glad that you just shared this helpful information with us.
Please keep us up to date like this. Thanks for sharing.
квартира на сутки Минск
What’s up to every , as I am in fact eager of reading this website’s post to be updated daily.
It includes nice information.
В домашних условиях прием чаев и настоев из трав позволит безопасно снизить избыточный вес.Важные правила приема травяных чаев и отваров.строго соблюдать пропорции приготовления; в сутки принимать указанное количество раз; делать перерывы между курсами лечения. бег трусцой для похудения
Несколько вариантов травяных сборов.Листья сены, петрушку, укроп, одуванчик и мяту в равных пропорциях общим весом в 30 г заливают 1 л крутого кипятка и варят на водяной бане четверть часа.
Вы можете подумать, что выбрасываете свои деньги в мусорное ведро, но это лучше, чем выбросить туда же свое здоровье.Сходите на рынок и купите овощи, фрукты, продукты с высоким содержанием клетчатки, травы, специи, орехи, льняные семечки и т., которые помогут вам сбросить вес. как начать бегать по утрам с нуля для похудения
Ешьте домашнюю пищу.Я слишком занята, чтобы готовить.
It’s wonderful that you are getting ideas from this piece
of writing as well as from our discussion made at this time.
Gerçekten Mükemmel Bir Uygulama Elinize Sağlık
bu uygulamayı kim yaptıysa ellerine sağlık
gelen takipçiler 0 türk takipçi maşallah
https://familyfoodco-op.com.au/forums/topic/mobile-version-of-the-website-house-of-pokies-casino/
There are several types of games available at Online House of Pokies Casino: slot machines, video slots, classic slots, jackpot slots and jackpots. The website also features special promotions for beginners and veterans alike.
– You’ll be able to access your account from any device and make deposits or withdrawals from any location.
Our fans have been asking for it, and now it’s finally here. The House of Pokies Casino mobile app has all the same features as our website, but it’s optimized for use on smartphones and tablets.
So what are you waiting for? Download it now and start playing!
Medicine information for patients. Effects of Drug Abuse.
generic zoloft without insurance in Canada
Some what you want to know about pills. Get information here.
Drugs prescribing information. Generic Name.
how can i get zoloft without rx in US
Everything about drugs. Read here.
Medicine prescribing information. Long-Term Effects.
buy flagyl in Canada
Everything information about pills. Get here.
Pills information leaflet. Long-Term Effects.
can i purchase cheap trazodone without a prescription in US
Some what you want to know about drugs. Read information now.
Meds information leaflet. Effects of Drug Abuse.
seroquel no prescription in US
Some about medicine. Get information now.
Good site you have here.. It’s difficult to find high quality writing like
yours nowadays. I truly appreciate people like you!
Take care!!
Drug information sheet. Brand names.
can i purchase trazodone no prescription in US
Best trends of medicines. Read now.
Medicines information for patients. Effects of Drug Abuse.
order lisinopril in Canada
All what you want to know about drugs. Get now.
Medicament information sheet. Long-Term Effects.
cheap zofran prices in USA
Some news about medicine. Get information here.
Medication prescribing information. Cautions.
zofran without dr prescription in US
Everything news about medication. Get information now.
Medicament prescribing information. Long-Term Effects.
where to get levaquin for sale in Canada
Best trends of medication. Read now.
Medicament information for patients. What side effects can this medication cause?
how to buy generic synthroid without rx in USA
Actual what you want to know about medicine. Get information here.
Meds information sheet. Brand names.
where to get cheap celebrex in the USA
Some about medicine. Get information now.
Medicament information sheet. Effects of Drug Abuse.
buy cheap synthroid for sale in Canada
Everything what you want to know about drug. Read information now.
inanmıyordum ama gördüm
Asla beklemediğim 1-2 kişiyi görünce şok geçirdim
сделать пирсинг
Superb, what a website it is! This web site provides
useful data to us, keep it up.
Medicines prescribing information. Generic Name.
can you get cheap synthroid without prescription in Canada
Some trends of medicament. Read here.
И последний совет худеть таким экстремальным способом рекомендуется только в молодом возрасте.После 45 лет накопление веса чаще всего связано с гормональными изменениями.При этом жировые отложения как раз накапливаются на животе. сколько км в день нужно бегать для похудения
Но диеты не помогут от них избавиться, могут только еще сильнее ухудшить обменные процессы.Как можно быстро похудеть и убрать живот в домашних условиях с помощью питания.
Pills prescribing information. What side effects can this medication cause?
can you buy zofran without insurance in USA
Everything about medicament. Get now.
Medicament prescribing information. Brand names.
how to get abilify price in the USA
Some information about medicament. Read information now.
Pills information sheet. What side effects can this medication cause?
get pepcid without dr prescription in US
All what you want to know about medicine. Get information now.
Medicament information leaflet. Cautions.
zoloft pill in US
Some information about meds. Get here.
https://kommandagu.ru/
Medication information. Brand names.
get cheap levaquin in Canada
Some trends of medicament. Get now.
Pills information for patients. What side effects can this medication cause?
order lisinopril for sale in US
All news about meds. Get now.
Meds information. What side effects?
cheap trazodone tablets in Canada
Some what you want to know about medication. Read information here.
Pills information for patients. What side effects can this medication cause?
can you buy lisinopril without prescription in US
All what you want to know about medication. Get information now.
Meds information. Long-Term Effects.
plavix no prescription in USA
Best information about medicament. Get information now.
Medicine information. Cautions.
how can i get generic motrin online in US
Best what you want to know about drugs. Get now.
Medicine prescribing information. Short-Term Effects.
plavix tablets in Canada
Best information about meds. Get now.
Medication information leaflet. Long-Term Effects.
cost lisinopril in Canada
Everything trends of medicine. Read now.
https://domocvet.com/technology/stroitelnoe-sro-naznachenie
Meds information. Long-Term Effects.
where can i buy zoloft pills in USA
Best what you want to know about medicines. Read information now.
Medication information leaflet. Cautions.
can you buy generic celebrex without prescription in the USA
All information about pills. Get here.
Drug information sheet. What side effects?
buy levaquin no prescription in USA
Everything news about medicine. Get information now.
Meds information. Short-Term Effects.
buying cheap cephalexin in US
Best what you want to know about medicine. Read here.
Drug information sheet. Long-Term Effects.
generic levaquin without dr prescription in USA
Actual what you want to know about medicine. Read now.
Meds information sheet. Generic Name.
where to buy cheap lisinopril without dr prescription in the USA
All trends of medicine. Get now.
Drug information. What side effects can this medication cause?
cheap plavix pill in the USA
Some information about medication. Read information here.
Drug prescribing information. Generic Name.
valtrex without prescription in US
Some information about drugs. Get information now.
Medicines information leaflet. Long-Term Effects.
can you get abilify pills in Canada
Actual news about meds. Read information here.
Если возникла проблема, как похудеть за неделю на 5 кг и убрать живот, нужно разобраться в особенностях снижения веса.Лишний жир, прежде всего, накапливается на животе, и уходит оттуда в последнюю очередь.При обычном похудении с помощью диет будут сначала уменьшаться объемы рук, лица. сколько по времени нужно бегать в день чтобы похудеть
Чтобы стимулировать исчезновение жира с талии, необходимы физические нагрузки.Причем нужны специальные упражнения, напрягающие мышцы брюшного пресса.
биткоин миксеры 2022
omg omg
Drug information leaflet. What side effects?
can you get cheap synthroid no prescription in the USA
Some about meds. Read information here.
Meds information sheet. Short-Term Effects.
how to buy lyrica without a prescription in US
Actual what you want to know about drug. Read now.
We offer all of our members the ability to register and login with their Roo casino email address. Roo is committed to providing you with a safe and secure gaming experience.
Sign up for your free Roo Casino account and get started today. Simply complete the registration form and we’ll take care of the rest.
Roo Casino is a casino with over 4 million players and welcome thousands of new ones every day. Its more than 200+ excellent games are powered by Playtech software, offering unbeatable slots, table games and live casino gaming experience that anyone can enjoy anytime anywhere.
The Roo Casino affiliate program was developed with the aim to make our players as comfortable as possible while playing with us. Through their Roo Casino Affiliates account, all the players can sign up and play on their mobile devices while enjoying the best bonuses and promotions available.
To play at Roo Casino you need to be a member. A fun and easy registration process awaits you!
roo casino 425
Pills information. What side effects?
where to get cheap bactrim tablets in the USA
Actual trends of meds. Read information here.
Drug information sheet. Brand names.
cost of cheap lyrica in USA
Some information about medicine. Get information here.
Medicines information for patients. What side effects can this medication cause?
generic lisinopril without a prescription in USA
Best news about meds. Get information here.
Pills information leaflet. Brand names.
where to get prednisone price in USA
All information about medicament. Read here.
Drug information for patients. What side effects can this medication cause?
bactrim no prescription in Canada
Everything what you want to know about meds. Get information here.
Sign up for your free Roo Casino account and get started today. Simply complete the registration form and we’ll take care of the rest.
Register to Roo Casino, deposit some money and start winning!
Register with Roo Casino in order to claim your 100% bonus and enjoy all the latest promotions and bonuses. All you need is a valid email address, a valid name and a valid phone number. For less than $10, you can try our service out with no risk!
You can find out more about their licenses, permissions, and other valid documents on the homepage of their website. So, all the players should rest assured knowing that the casino is operating legally
Roo Casino offers a variety of incentives such as 50+ deposit match bonuses, loyalty bonuses and more!
roo casino 249
Drugs information sheet. Effects of Drug Abuse.
generic levaquin price in Canada
Actual trends of medicines. Read information now.
Medicine information. Generic Name.
trazodone tablets in the USA
Everything about medicines. Get information now.
Meds information for patients. Generic Name.
generic lyrica no prescription in the USA
All trends of medicine. Get here.
Roo is a casino site offering players the best in online casino games and prizes. Play your favourite table games, slots and other casino games in Australia.
Enjoy the best gaming experience with the latest slots, table games and live dealer options at Roo Casino.
On the road to riches and love, the Roo Casino Diaries is a darkly comic, high-stakes love story, where nothing is as it seems.
Roo Casino Australia is a leading online casino for players around the world, with a great selection of games and all kinds of promotions that are always changing. All games are free to play, so fast and simple registration is required. Roo has been a trusted online gaming site for over 10 years and is one of the most reputable gaming sites in Australia
At Roo Casino, we’re taking online gambling to the next level. With a variety of games that allows players to experience the highest quality gaming in their home or wherever they are Internet connected, Roo gives its players a wealth of options from which to choose.
roo casino 327
Medicine prescribing information. Short-Term Effects.
generic zoloft no prescription in the USA
Everything what you want to know about medication. Get now.
I’ve been exploring for a little for any high quality articles or weblog posts in this sort of space .
Exploring in Yahoo I at last stumbled upon this site.
Studying this information So i’m satisfied to exhibit that I’ve a very good uncanny feeling I came
upon just what I needed. I most surely will make certain to do not put out of your mind this website and give it a look regularly.
Drug information for patients. Drug Class.
get generic lisinopril no prescription in the USA
Best trends of medicament. Get now.
Pills information. Cautions.
can i buy cheap trazodone price in USA
All information about drug. Get information now.
Medicament information for patients. Drug Class.
cheap motrin for sale in the USA
Some news about meds. Read information here.
Medicine prescribing information. Brand names.
how to buy cheap lyrica in the USA
Some trends of medication. Get here.
Medicament information sheet. What side effects?
how can i get cheap cephalexin in USA
Some information about medicines. Read here.
Roo Casino is here to stay. Roo Casino has a great offer for all of their new players. The amazing bonuses are available in a variety of different forms, so there is something for everyone. When you join Roo you can take advantage of the best bonuses that we have to offer, including: 100% matched deposit and up to 50% extra cashback on your first deposit, while playing and at the table!
Roo Casino affiliates are licensed and regulated by international legislation and the laws of Australia. This means that its players will get full protection from legal risks. All the club’s activities are being conducted in full compliance with the relevant rules, regulations, laws and other documents.
If you are looking for regulated and licenced online casinos, visit roocasino.com. Here, you can find reviews of various online casino sites and over 200 games, which we have carefully chosen.
You can find out more about their licenses, permissions, and other valid documents on the homepage of their website. So, all the players should rest assured knowing that the casino is operating legally
Roo Casino offers a variety of incentive bonuses for all their players. With a hundred dollar welcome bonus, no deposit required thrill seekers will be ready to hit the tables.
roo casino 249
Pills prescribing information. What side effects can this medication cause?
lyrica no prescription in the USA
Best news about drug. Read here.
Medication information leaflet. Short-Term Effects.
can i order flagyl no prescription in the USA
Actual trends of medicine. Get information here.
Drug information leaflet. What side effects?
where can i get cheap plavix in Canada
Everything what you want to know about meds. Read information here.
Drugs information leaflet. Effects of Drug Abuse.
how to get generic celebrex without dr prescription in US
Best information about drug. Get information here.
Sign up for a new account or log into an existing account. We can’t wait to welcome you! If you need help logging in, please click on the link below.
Once you have registered at Roo Casino we will send an email confirmation to your address. To get started with your new account, you will need to enter a username and password.
Roo Casino is a fully licensed and regulated online casino by international legislation and the laws of Australia. The casino has all the necessary licenses and permissions for operating an online casino.
Members Welcome Details Our Casino is a great place to play, we have an amazing range of online casino games and a huge variety of bonuses to enjoy. Roo Casino Registration provides fun for everyone. We believe in having an enjoyable experience with our online casino so it’s important that you have an enjoyable one too – that’s why we’ve set up this site so you can register, password-protect your information, and make your account secure.
Once you have verified your account, we welcome you to Roo and allow you to use the casino’s services such as real money play, bonuses, and promotions.
roo casino 327
afallamak
ağaç çileği
afat
addedilme
affediliş
adres
ağaçkesen
adlandırış
afyon ruhu
adlandırış
ağırkanlılık
Meds information. Effects of Drug Abuse.
buy pepcid prices in the USA
Everything trends of medicament. Get here.
Drugs information sheet. Short-Term Effects.
lyrica prices in the USA
Some news about medication. Get now.
Meds information leaflet. Drug Class.
cheap pepcid without prescription in the USA
All trends of medicines. Get now.
Pills information for patients. Drug Class.
where to get celebrex no prescription in the USA
All trends of meds. Read information here.
The 5-Second Trick for roo casino 327 is that there are many different kinds of games to choose from, so it’s very easy to find something you like. If you’re new to online betting, you need to know that this process doesn’t take long at all. All you need to do is follow these steps and you will be ready to bet: Click on the “insert” button under “Bet” Select “Cashout” You will then have the option of choosing how much you want to turn the winnings into, or if you want a bitcoin with another number of satoshis instead.
For over 10 years, Roo Casino has hosted a dynamic and diverse player base while shipping millions of dollars in revenue. To learn more about our team, visit our About Us section to read about the amazing people who create an experience that we’re proud to share.
Roo Casino is an elegant and sophisticated slot machine with a unique payback percentage that makes it seem like you’re winning, every time.
Secret Weapon’s secret weapon is the in-browser player tracker, which lets you see what’s happening on your own website, across the internet. You can also see which countries players come from, and if they’re playing real money or not.
The Roo Casino Diaries is a weekly podcast about the gambling culture of Melbourne. We travel around Australia and Europe to meet the gamblers, poker players and casino moguls that thrive in the world of gambling. You’ll get to know them better than they know themselves, as they take you deep inside the highest stakes games and reveal some of their wildest highlights from weeks past.
http://roo-casino-real-money37148.review-blogger.com/32424758/getting-my-roo-casino-425-to-work
Drugs information for patients. What side effects?
where to buy zoloft in the USA
Actual news about meds. Read now.
Medicament prescribing information. What side effects can this medication cause?
where buy generic trazodone in the USA
Best news about drugs. Read now.
Drugs information. What side effects can this medication cause?
where to buy plavix price in USA
All what you want to know about medicament. Get now.
Drug information leaflet. Brand names.
where can i buy generic zoloft pills in Canada
Some about medicines. Read information here.
levitra lowest price cialis buy online Kamagra Test
Roo Casino Australia has a unique gaming experience with an exciting range of games, great promotions, and their own app. Players can play LIVE casino and gamble on the go in Roo’s app that connects directly to our live dealers, who are always on hand. Play all your favourite games from any device, with new players welcomed every month and weekly promotions for new players looking for fun bonuses
At Roo Casino, we’re taking online gambling to the next level. With a variety of games that allows players to experience the highest quality gaming in their home or wherever they are Internet connected, Roo gives its players a wealth of options from which to choose.
Roo Casino is a fairly new resource from Roo Global Ltd, as of mid-December 2017. It has been created for people who want to enjoy the benefits of playing in a top class casino and winning large prizes, but who do not have access to an account at a platform like Roxy Palace. On Roo Casino, you can deposit money and play gambling games on the site on your mobile phone or PC, while earning cashback tokens. This can be used to win more credits, which can then be used to place bets on more games. The more credits you win with Roo Casino, the higher your chances of winning big prizes!”
Play Roo Casino Australia and get a Free spin no deposit into the casino.
For over 10 years, Roo Casino has hosted a dynamic and diverse player base while shipping millions of dollars in revenue. To learn more about our team, visit our About Us section to read about the amazing people who create an experience that we’re proud to share.
roo casino 249
İnsanların seni en çok sevdiği zaman, onların işine en çok yaradığın zamandır.
Kaliteli insan işiyle, boş insan kişiyle uğraşır.
Mutluluğun değerini, onu kaybettikten sonra anlarız. – Plautus
Denizi kurumuş bir balık gibi, halen senin için çırpınıyorum.
Önyargılar, aptalların sebeplerden dolayı kullandıkları şeydir. (Voltaire)
İnsanların seni en çok sevdiği zaman, onların işine en çok yaradığın zamandır.
Şikayet ettiğiniz yaşam, belkide başkasının hayalidir. Tolstoy
I am not a product of my circumstances. I am a product of my decisions. (İçinde bulunduğum durumların ürünü değilim. Kararlarımın ürünüyüm.) – Stephen Covey
Maalesef gerçek bir barış bu dünyada var olamaz.
Eğer aԁaletin temeli intikama ԁayalı ise, bu daha çok adaleti tetikleуecek ve bir nefret zincirini oluşacak.
Sabır saadeti ebedi kalır Sabır kimde ise o nasib alır.
“Kazanırsan, açıklamana gerek yok… Kaybedersen, açıklamak için orada olmamalısın!” – Adolf Hitler
Durduk yere sizi terk eden, ya alacağını alamamıştır ya da alamayacağını anlamıştır.
The best way to use Roo Casino is by creating an account. Once you have your new account, you can easily place bets and win real money. We accept deposits using Paypal and credit cards. You can also use your own bank transfer if you prefer.
To access our online casino and play real money casino games, you will need to create an account. To create an account all you need is a valid Email Address and Password. We use the latest industry-standard security technology to keep your personal information safe and secure, so you can play at Roo Casino with complete confidence that your details are in the safest hands around!
Open an account at Roo Casino and we will instantly get you started on your journey by emailing you a detailed personalised welcome offer.
To begin, you will need to create a new account. You can do so using your Facebook or Google+ account credentials. Once your account is active we’ll also need to verify your age over email, which we’ll send shortly.
Roo Casino is a trusted site offering more than 100 slots to choose from and a large range of table games like blackjack, roulette, and baccarat. The brand holds licenses from the Gambling Regulatory Authority (GRA) of Isle of Man and Australia. Roo Casino affiliates are regulated by the laws of Australia and preserve all of their licenses for operating an online casino. You can find out more about their licenses and permissions on the homepage of their website.
roo casino australia
Roo Casino’s reward system is designed to let you enjoy the best of both worlds. You can play your favorite games, grab a drink and still get a generous welcome bonus or reload one of our top-ranked gambling sites with no deposit required. Plus we offer some of the best odds for the most popular slots and casino games.
Don’t miss out on your chance to win even more when you play at Roo Casino. We offer a variety of bonus promotions that can make your game better than ever, including welcome bonuses, cashback and various loyalty programs. Click here to see all our promotions, or use the search tool below to find the right one for you.”
Roo Casino offers a variety of bonuses and promotions aimed to bring in new players, including no deposit bonuses, welcome bonuses and daily rewards to keep you coming back.
Roo offers a variety of attractive bonuses to loyal players. The welcome bonus is one of the best options. For example, new players get a 200% welcome bonus up to $1,000 plus 100 free spins on slot games. Roo Casino guarantees that all player funds are secure even if they are deposited into an online gambling account not operated by Roo Casino.
Roo Casino affiliates are licensed and regulated by international legislation and the laws of Australia. This means that its players will get full protection from legal risks. All the club’s activities are being conducted in full compliance with the relevant rules, regulations, laws and other documents.
roo casino 425
Drugs prescribing information. Long-Term Effects.
buying motrin in US
Actual about drugs. Read information now.
Pills information. What side effects can this medication cause?
levitra no prescription in US
Some news about medicine. Read here.
Meds information leaflet. Short-Term Effects.
how to buy cheap synthroid price in the USA
Actual what you want to know about drugs. Read here.
Medicament information for patients. Cautions.
where buy synthroid in USA
Actual news about meds. Read information now.
Medicament information leaflet. What side effects?
can you get cheap valtrex tablets in USA
All trends of meds. Read here.
Roo Casino is the best Side of Roo.
Roo Casino has it all, including a popular slot machine game. The game allows players to spin up their chances of winning. At Roo Casino you can find the best slot machines, roulette table and more. With our great variety of games available, you will find something you love. This includes old favorites like blackjack and slots, as well as new offerings that have caught our eye such as 3D slots!
Everything from the first-person perspective of a young bartender who is hoping to make it big in Las Vegas.
This is the Internet of casino, no advance registration or message requirement; you can play online or on mobile phone.
Sign up for all the latest news, promotions and offers, plus get a chance to win cool stuff.
roo casino 425
Drug information sheet. Drug Class.
generic zoloft for sale in USA
Actual about drugs. Read information here.
Drug information. What side effects can this medication cause?
prednisone no prescription in USA
Best information about medicament. Get information now.
Meds information. Generic Name.
can you get propecia without a prescription in USA
Some trends of pills. Get now.
Drug prescribing information. Generic Name.
can i get mobic without prescription in USA
Some what you want to know about medicines. Read information now.
Drug information for patients. Short-Term Effects.
where to get cephalexin in the USA
Best trends of pills. Read now.
Meds prescribing information. Long-Term Effects.
can i get generic propecia online in Canada
Everything information about medication. Get here.
Roo Casino is here to bring the excitement of online gambling to you. We offer great bonuses and a wide variety of games, including slots, craps, blackjack and more. For the most enjoyable online experience, play at Roo Casino today!
At Roo Casino, we’re committed to providing you with smooth and enjoyable experiences. You’re about to enter a fun new world of gambling, and we want you to enjoy every minute of it. To start off your experience in style, we will provide you with a 15-day cookie money trail so that you can get familiar with our software.
Sign in to play at Roo. Sign up with your Facebook account or create a new account to secure better payout winnings. Don’t have time to register? No problem! Try our Roo Casino via instant play, an exciting new way to experience games like Roulette, Blackjack or Slots now!
Roo Casino offers numerous bonus deals and special deals to their players. With this Bonus, you will be given a chance to enjoy a huge sum of money without even having to do anything. The bonus is available for all players across the world, who want to play at Roo Casino.
Roo Casino offers a variety of incentives to get you playing, whether that’s loyalty points or fun bonuses. Join today and start earning those rewards!
https://hampapua.org/roo-casino-help
Pills prescribing information. Effects of Drug Abuse.
buying bactrim for sale in US
Some what you want to know about drug. Read here.
Drugs information. What side effects?
can i order generic med-info-online4all for sale in the USA
All trends of medicament. Read now.
Register and get the most out of your Roo Casino experience. If you’re a new player, or just need to log in, simply register on this page and we’ll guide you through the rest.
The Roo Casino affiliate program is a high-quality way of promoting your own site and gaining revenue from it. Our licensed dealers will receive the necessary amount of percentage of each deposit to be paid out to them. All affiliates will also receive up to $650 in monthly commissions.
Roo Casino is a fully licensed and regulated online casino by international legislation and the laws of Australia. The casino has all the necessary licenses and permissions for operating an online casino.
Roo Casino affiliates are licensed and regulated by international legislation and the laws of Australia. This means that its players will get full protection from legal risks. All the club’s activities are being conducted in full compliance with the relevant rules, regulations, laws and other documents.
To create an account at Roo Casino, you must create an account and then provide your personal information. This includes a first name, last name, email address and language. After that, you will be provided the option to add a password for security purposes.
https://policyandsociety.org/aussie-roo-casino
Medication information for patients. Drug Class.
can i order generic colchicine in the USA
All information about drugs. Read information now.
Medication information for patients. Short-Term Effects.
mobic price in the USA
Best news about drugs. Read now.
A new breed of casino is born.
With Roo Casino Real Money you can purchase with your cards or stored-value. Withdraw from the casino at any time and get your winnings on site!
I have a roo casino 425 and want to play in the games. How can i get it to work?
Play at Roo Casino Australia, where you’re treated like a VIP. No deposit is required and no risk, so join us today and make some new friends. With over 300+ titles to choose from, there’s something for everyone.
Roo Casino is another fantastic casino that has emerged in the gaming world. Their main objective is to provide a safe and fun casino experience that is enjoyable to many people. It offers a wide range of games in multiple different formats, where you can focus on whatever your interest is. For example, they have Roulette and Blackjack available along with Roo Dice and their newly released slot machine called Cash Grab
roo casino 327
Medicines information leaflet. Effects of Drug Abuse.
celebrex prices in Canada
Everything information about pills. Get here.
Medicine information sheet. Effects of Drug Abuse.
generic prednisone prices in Canada
Some trends of drugs. Read information now.
Medication information for patients. Long-Term Effects.
order seroquel tablets in USA
Everything trends of drugs. Read information here.
Meds information sheet. Short-Term Effects.
how can i get prednisone in the USA
Some what you want to know about medicine. Get here.
Medicament information sheet. Cautions.
order lisinopril prices in US
Everything about pills. Read here.
Medicament information leaflet. Generic Name.
where to get motrin price in the USA
Actual news about meds. Get information now.
Meds information sheet. Long-Term Effects.
can i buy baclofen price in USA
Best about medicament. Read here.
Medicine information. Generic Name.
where can i get lisinopril pills in USA
Best trends of meds. Read information now.
Meds information. Effects of Drug Abuse.
cheap lyrica without insurance in US
Everything news about pills. Get information here.
Medication information leaflet. Short-Term Effects.
can you get celebrex for sale in Canada
Some trends of medication. Read information here.
Drugs information leaflet. Brand names.
can you get lyrica in US
Actual information about meds. Get information now.
Pills information for patients. Generic Name.
how to buy cheap prednisone no prescription in Canada
Everything news about meds. Read information now.
Kadın kocasını daha az sevmeli, fakat daha çok anlamalı; erkek, karısını daha çok sevmeli, fakat anlamaya çalışmamalıdır. – Oscar Wilde
Yanında aptal bir kadın olan bir sürü zeki adam görürsünüz ama yanında aptal bir adam olan zeki kadın kolay kolay göremezsiniz. – E. Jong
“Merhaba sevdiğim; ben o sevmediğin. Bugünde mi geçmedim aklının kıyılarından?” – Ümit Yaşar Oğuzcan
Every strike brings me closer to the next home run. (Her vuruş beni bir sonraki sayıya yaklaştırır.) – Babe Ruth
Life is about making an impact, not making an income. (Hayat etki yaratmak demektir, gelir yaratmak değil.) – Kevin Kruse
Can paramparça ve eIIerim, keIepçede, tütünsüz, uykusuz kaIdım, terk etmedi sevdan beni…
Gönlünde olanı benden gizleme ki benim gönlümdeki de ortaya çıksın…
Metodu olan topal, metotsuz koşandan daha çabuk ilerler. – Francis Bacon
Öyle sözler vardır ki aşkın en güzel tarifini yapar. Aşkın ne olduğunu, sevgilinize aşk dolu söyleyebileceğiniz en güzel sözleri sizler için bir araya getirdik. İşte, aşkın en özlü halini anlatan sözler, özlü aşk sözleri,
Gömleğin ilk düğmesi yanlış iliklenince, diğerleri de yanlış gider. – C. Bruno
Yaşamak değil, beni bu telaş öldürecek. – Özdemir Asaf
Winning isn’t everything, but wanting to win is. (Kazanmak herşey demek değildir, ancak kazanmayı istemek herşeydir.) – Vince Lombardi
İyi düşünmek iyidir; iyi hareket etmek çok daha iyidir. -Horace Mann
Kaliteli insan işiyle, boş insan kişiyle uğraşır.
İntikam ve aşkta, kadın insandan daha barbardır. Friedrich Nietzsche
Life isn’t about getting and having, it’s about giving and being. (Hayat almak veya sahip olmak değil vermek ve olmak demektir.) – Kevin Kruse
Güzeli güzel yapan edeptir, edep ise güzeli sevmeye sebeptir. – Mevlana
Sıradan öğretmen anIatır,iyi öğretmen açıkIar,yetenekIi öğretmen yapar ve gösterir,büyük öğretmen esin kaynağı oIur.
Eğer insanlar hiç salakça şeyler yapmasaydı, akıllıca işler yapılamazdı. – Ludwig Wittgenstein
Farzet ki yazdıklarımı anlayabildin. Ya anlamadıkların. Ya yazıp yazıp sildiklerim. Ya yazamadıklarım…
Kaptanın ustalığı deniz durgunken anlaşılmaz. – Lukianos
Hayat merdivenlerini çıkarken, insanlara iyi davranalım çünkü inerken gene aynı insanlara rastlayacağız. -Cenap Şahabettin
Aynaya bakınca kendimi değil kocaman bir yürek .Ve o yürekte ondan da büyük bir sen gördüm.
Her şeyi elde edebilirsin. Ama aynı anda değil! – Oprah Winfrey
Sakın unutma, ellerin cebindeyken başarı merdivenlerini çıkamazsın.
Her sinirli kadının arkasında neyi yanlış yaptığıyla ilgili hiçbir fikri olmayan bir erkek vardır.
Bir insanın zekası verdiği cevaplardan değil sorduğu sorulardan belli olurmuş.
Kadınlar sevilmek için yaratılmıştır. Anlamak için değil… – Oscar Wilde
Gülmek için mutlu olmayı beklemeyin belki de gülmeden ölürsünüz. – Victor Hugo
Acı su da, tatlı su da berraktır. Sakın görünüşe aldanma… Görünüşte herkes insandır ama gerçek insan hal ehli olandır.
Her şeyi elde edebilirsin. Ama aynı anda değil! – Oprah Winfrey
Kalbinde sevgiyi koru. Onsuz bir hayat, çiçekler öldüğü zaman güneşsiz bir bahçe gibidir. (Voltaire)
Kız dediğin İstanbul gibi olmalı, Fethi zor, fatihi tek!
Hoştur bana senden gelen. Ya gonca gül yahut diken. Ya hayattır yahut kefen. Nârın da hoş, nurun da hoş. Kahrın da hoş, lütfun da hoş.
Önce biz alışkanlıklarımızı oluştururuz, sonra da alışkanlıklarımız bizi oluşturur. -John Dryden
Gerçek hiçbir zaman şiddet tarafından çürütülemez. -E. Fromm
Mutluluğun sırrı özgürlüktür. Ve özgürlük sırrı cesarettir. Thucydides
Bence toplumun ilk görevi adalettir. Alexander Hamilton
Sen beni kaybetmeyi göze aldıysan ben seni silmekten şeref duyarım.
Dikenden gül bitiren, kışı da bahar haline döndürür. Selviyi hür bir halde yücelten, kederi de sevinç haline sokabilir.
Bütün sevgileri atıp içimden, varlığımı yalnız ona verdim ben, elverir ki bir gün bana derinden, ta derinden bir gün bana “Gel” desin. – Ahmet Kutsi Tecer
Kendinizi olumlu insanlarla çevirin. Melanie
Medicines information. Brand names.
can i purchase generic prednisone in US
Some what you want to know about medicament. Read now.
Öğrenmek, akıntıya karşı yüzmek gibidir ilerleyemediğiniz taktirde gerilersiniz. – Çin Atasözü
Annem yaşı ilerledikçe elim kolum ağrıyo diyor, ah be annem benim yaşım kaç ki hergün sol yanım ağrıyor..
Al ömrümü koy ömrünün üstüne, senden gelsin ölüm başım üstüne….
Durulduğu zamanları olur insanın, yorulduğu zamanlar olduğu gibi, ama ömür götüren kırıldığı zamanlardır.
Hayatta en zor olan şey, gerçek aşkı bulmak değildir. Daha da önemlisi onu her zorluğa karşı sürdürebilmektir aslında.
Geleceğimin tam olarak nasıl olacağını hala bilmiyorum ama, bildiğim bir şey var ki içinde sen yoksun. – Post Grad
Işığın olduğu her yerde gölgeler de vardır.
Denizi kurumuş bir balık gibi, halen senin için çırpınıyorum.
Kişinin susması, her zaman söyleneni onayladığı anlamına gelmez. Bazen canı aptallarla tartışmak istemiyordur.
Mantık evliliği yapınca ne olacak? Kocanla oturup satranç mı oynayacaksın!
Sükut eyledim, ”Kahrı var” dediler. Biraz söyledim, ”Zehri” var dediler. Sustum, kahrından susuyor dediler; biraz konuştum, zehrini kusuyor dediler…
Pills prescribing information. What side effects can this medication cause?
where can i get generic celebrex in US
Best trends of drug. Get now.
Medicine information leaflet. Effects of Drug Abuse.
where can i get generic lisinopril in USA
Best information about pills. Get information now.
Pills prescribing information. Long-Term Effects.
where to buy lyrica in US
Everything trends of medicament. Read information now.
Kalbinizle yaptığınız her şey, size geri dönecektir. – Mevlana
Başta dönüp koşan nice bilgiler, nice hünerler vardır ki, insan onunla baş olmak isterse, baş elden gider. Başının gitmesini istemiyorsan ayak ol.
Zeki bir insan yalnızlıkta, düşünceleri ve hayal gücüyle mükemmel bir eğlenceye sahiptir. – Schopenhauer
Olsun be aldırma yaradan yardır..sanma ki zalimin ettiği kardır… Mazlumun ahi indirir sahi.. Her şeyin bir vakti vardır.
Kalbin hangi sevgi için çarpıyorsa yeni doğan günün güneşi Seni ona kavuştursun.
Birçok insan yirmi beş yaşında ölür ve yetmiş beşe kadar gömülmez. Benjamin Franklin
Sabır saadeti ebedi kalır Sabır kimde ise o nasib alır.
Herkes cennete gitmek ister ama kimse ölmek istemez.
İyi bir kafaya sahip olmak yetmez; mesele onu iyi kullanmaktır. -Rene Descɑrtes
Kişinin susması, her zaman söyleneni onayladığı anlamına gelmez. Bazen canı aptallarla tartışmak istemiyordur.
Aşk Hükmetmez, Terbiye Eder. – J.W.von Goeth
Hani dilimizin ucuna gelip de söyleyemediklerimiz var ya; Allah o sözlerin yolunu açık etsin.
O Kadar Yakınsın Ki ,Seni Ben Sandım..Sana O Kadar Yakınım Ki, Beni Sen Sandım..Sen Mi Bensin Ben Mi Senim? Şaşırdım Kaldım..
Her insan yanlış yapabilir ancak sadece büyük insanlar yanlışlarının farkına varabilir.
Roo Casino Australia is the latest casino to join the Roo Games portfolio, offering customers a first-class online casino experience. Experience Roo Gaming’s award winning suite of real money casino games on your PC or mobile device and enjoy a range of great promotions and cashback deals.
In our opinion, one of the best reasons for choosing Roo Casino is their quick and friendly response to help you on your query. They are here to help you solve any issue that you are facing.
Having problems with my roo casino 425? Don’t worry, we’ve got you covered.
Welcome to the Roo Casino, the newest and most exciting gambling destination in the land. Come join hundreds of others who have chosen to play at our superb table games, including Black Jack and Poker, have fun spinning the slots or try your hand at exciting new games!
Visit Roo Casino Australia for the best online casino offers, with an unbeatable selection of slots, table games and scratchcards. Download our app to start playing now at one of our amazing online casinos.
Roo Casino
Get your hands on Rocco casino online and have a real time casino experience with the best software available. Today’s online casinos have come a long way, and we are proud to say that our software is one of the best. You can play for free in real-time, try before you buy option or both simultaneously!
Secret Weapon’s secret weapon is the in-browser player tracker, which lets you see what’s happening on your own website, across the internet. You can also see which countries players come from, and if they’re playing real money or not.
Looking for an Australian licensed online casino that offers the best selection of gaming tables and slots? Then Roo Casino is the place to go!
If your Rooster Gaming 425 is not working, check out these steps.
Roo Casino has been racking up the awards since its launch. It’s no wonder why it’s been called 2017’s game of the year by the players and staff alike, who love it for its huge range of games, all with a genuine focus on customer service.
roo casino 327
Medicine information. Effects of Drug Abuse.
how to buy zoloft in USA
Best about medicament. Read information now.
Meds information leaflet. What side effects?
generic synthroid without prescription in US
Actual information about medication. Get now.
Drugs prescribing information. What side effects can this medication cause?
cost of cheap colchicine without rx in USA
Actual information about medicines. Get now.
Drugs information leaflet. Effects of Drug Abuse.
generic lyrica pills in USA
All news about drugs. Read information here.
Medicines information. Brand names.
prednisone without insurance in Canada
Some news about medicament. Get here.
Medication information for patients. Generic Name.
where to buy generic zoloft without a prescription in US
Actual trends of pills. Read information here.
Wonderful beat ! I wish to apprentice while you amend your
web site, how can i subscribe for a weblog site? The account helped me a applicable
deal. I had been a little bit acquainted of this your broadcast provided vivid transparent idea
Medicine information leaflet. Cautions.
cheap propecia for sale in Canada
Some about pills. Get information now.
Meds information sheet. Drug Class.
can i buy abilify in Canada
Actual news about medicament. Read information here.
Pills information. What side effects?
can i purchase generic propecia in USA
All trends of medication. Read information here.
Medication information leaflet. What side effects?
cost of cheap levitra no prescription in USA
Actual information about medicine. Get information here.
Medicines information sheet. What side effects?
can i purchase valtrex in Canada
Some what you want to know about meds. Read information here.
Medicament information sheet. Generic Name.
can i get propecia in US
All about drug. Read information now.
Drugs information. Drug Class.
order generic levitra tablets in the USA
Actual trends of drugs. Read information here.
Medication information leaflet. What side effects can this medication cause?
cheap prednisone without a prescription in the USA
Actual about drugs. Get here.
Medicines prescribing information. What side effects can this medication cause?
can you get colchicine without dr prescription in Canada
Everything about medication. Read information now.
Medication information. Cautions.
can i purchase levitra in US
Actual information about medicines. Get information now.
Medication information. Long-Term Effects.
order baclofen for sale in the USA
Best news about medication. Get here.
Eğer aԁaletin temeli intikama ԁayalı ise, bu daha çok adaleti tetikleуecek ve bir nefret zincirini oluşacak.
Asıl marifet buluttaydı ama herkes yağmura şiir yazdı.
Free spins no deposit at Tangiers Casino. Cash deposit via bank transfer required to withdraw winnings.
https://www.dotcomunity.com.au/forum/welcome-to-the-forum/the-best-at-tangiers-casino-no-deposit-for-registering-in-australia
my hello
my hello
Tangiers Casino offers countless ways to play, spin and win with us. With a wide choice of games including slots, poker, table games and live casino you’ll find your favourite playing at Tangiers Casino.
https://kysa.com.au/Kysa-Community/black-dog-ride-forum/try-tangiers-pokies-in-australia/
If you’re new to Tangiers Casino and want to know how to set up an account, what your account settings are, and what the Australian sign-up offers are, then please read on. If you have already created an account with us or if you just want help deleting your existing account to prevent any future problems, please use the links in the left nav menu of this page.
https://www.kennottletours.com.au/forum/australia-and-pacific/tangiers-online-casino-login-and-its-advantages
Play as much as you want and earn bonus points to redeem for Tangiers Casino VIP bonuses and perks, free spins, varieties of gifts and free participation in VIP games.
https://www.harringtonsrealty.com.au/forum/australian-housing-market/25-free-spins-no-deposit-tangiers-casino-in-australia
fucking my cheating stepmom
thanks you very good tiktok video izlenme
instagram türk takipçi satın al cok bas
instagram türk takipçi satın al cok basarili
instagram türk takipçi satın al cok basarili
cok iyi begendim bayan kadın takipci satın
cok iyi begendim bayan kadın takipci satın
Medication prescribing information. What side effects?
can you buy prednisone without insurance in the USA
Best trends of drugs. Read here.
Medicines prescribing information. What side effects?
buying valtrex prices in US
All what you want to know about medicament. Read information now.
Medicine information. Short-Term Effects.
can you get cheap lyrica in the USA
Best trends of drugs. Read information now.
Medicines information. What side effects?
where buy valtrex in US
Best what you want to know about medication. Read information now.
yabancı takipçi saton al sizler için en iyisi
yabancı takipçi saton al sizler için en iyisi
Öyle bir seveceksin ki, yüreğinden kimse ayıramayacak. Ve öyle birini seveceksin ki, seni gözleriyle bile aldatmayacak. – Can Yücel
Aşk iki kişilik bencilliktir. – Antoine De Salle
The mind is everything. What you think you become. (Akıl her şeydir. Ne düşünüyorsanız, onu olursunuz.) – Buddha
Bir şeyi sevmenin yolu, bunun kaybolabileceğini fark etmektir. Gilbert K. Chesterton
Cihan bir avuç çamur, gönül de onun mahsulü. İşte cihanın bütün müşkülü bu bir katre kandan başka bir şey olmayan gönülden fışkırıyor. Biz biri iki görüyoruz, oysa herksin cihanı kendi gönlü içindedir. -Muhammed İkbal
“Bana kapitalist göster, ben de sana kan emici göstereceğim.” -Malcom X
Mutluluk her şeyden önce vücut sağlığındadır. – Curtis
Gecenin karanlığında, güneşin ışığında, suyun damlasında, selin coşkusunda, kimi yanımdasın kimi rüyamda, ama hep aklımdasın sakın unutma.
Yaşamak değil, beni bu telaş öldürecek. – Özdemir Asaf
Pin-Up casino играть онлайн
Drugs prescribing information. Brand names.
cost of celebrex without prescription in Canada
Some what you want to know about pills. Get information now.
Meds information for patients. Effects of Drug Abuse.
generic colchicine without insurance in the USA
Some information about pills. Read now.
harika takipci geliyor cok iyi
harika takipci geliyor cok iyi
thanks you very
thanks you veryy gooddd
thanks you very
thanks you veryy gooddd
harika güzel begendim
harika güzel begendim
demet evgar kimdir cok iyi
demet evgar kimdir cok
demet evgar kimdir cok iyi
demet evgar kimdir cok
demet evgar kimdir cok iyi bir oyuncudur
demet evgar kimdir cok iyi bir oyuncudur
cok iyi bir icerik tesekkurler
harika bir insan tesekkurler
cok iyi bir icerik tesekkurler
harika bir insan tesekkurler
goodd veryysite olmus tebrik ederim
goodd ver
goodd veryy
goodd veryysite olmus tebrik ederim
goodd veryy
Meds information for patients. Long-Term Effects.
where to buy lisinopril online in USA
All news about drug. Get here.
Meds information. Short-Term Effects.
where to buy synthroid in US
Actual trends of meds. Get here.
Meds prescribing information. What side effects can this medication cause?
where can i get cheap baclofen for sale in the USA
Best about medication. Read information here.
http://binom-s.com/nedvizhimost/220135-kak-sdat-kvartiru-pomoshh-agentstva.html
Pills information leaflet. Drug Class.
how can i get prednisone in USA
All about medication. Read information now.
Medicament information for patients. Brand names.
can you get valtrex online in the USA
Some trends of medicament. Get information now.
cok güzel oldu olmuş gi
cok güzel oldu olmuş gi
cok güzel oldu olmuş
cok güzel oldu olmuş gi
cok güzel oldu
cok güzel oldu
cok güzel oldu olmuş
cok güzel oldu olmuş gi
cok güzel oldu olmuş
cok güzel o
cok güzel oldu olmu
cok gü
cok güzel oldu olm
cok güzel oldu
cok güzel oldu olmuş
cok güzel oldu
cok güzel oldu
cok güzel oldu olmuş
cok güzel o
cok güzel oldu olmu
cok güzel oldu olm
cok iyi yaaaygulama tebriklerlacak
cok güzel oldu olmuş
cok iyi yaaaygulama tebrikler
cok iyi yaaa
cok güzel oldu
cok güzel o
cok iyi yaaaygulama tebriklerlacak
cok iyi yaaaygulama t
cok iyi yaaaygulama tebrikler
thanks y
thanks you very
thanks y
thanks you very
my friends hot mom porn
Pills information for patients. Brand names.
cost of cheap abilify in USA
Everything news about meds. Read information now.
Medicament prescribing information. Long-Term Effects.
buy generic prednisone without insurance in Canada
All about drugs. Read information here.
Pills information sheet. Brand names.
can you get lyrica no prescription in Canada
Best news about medicines. Read information now.
https://vip.9bb.ru/viewtopic.php?id=722
Medicine information for patients. Long-Term Effects.
zoloft prices in the USA
All news about pills. Read information now.
https://afmedia.ru/kak-formiruetsja-stoimost-voditelskih-prav/
Drug prescribing information. Generic Name.
buy generic levitra pill in Canada
Actual about pills. Get information here.
https://prokazan.ru/page4742/
Drugs information. What side effects can this medication cause?
can i purchase cheap lyrica in US
Actual news about medicines. Get information now.
Drug information for patients. Long-Term Effects.
how to buy cheap baclofen in the USA
All trends of medicines. Get here.
Drug prescribing information. Effects of Drug Abuse.
how to buy propecia without dr prescription in Canada
Everything about medicine. Get now.
https://www.consmed.ru/news/view/2167/
For inexperienced gamblers, JOKA Room is the ideal place to begin their journey into the world of casino games. To gain access to the casino bonuses, all players need is 50% deposit with a minimum deposit of $10 and are required to make two deposits on separate occasions.
https://jokaroomvip.site/
harilkaaaaa thaks
harilkaaaaa thaks
harika
harika
Pills information for patients. What side effects?
where can i buy generic plavix pills in US
All about medicines. Read information here.
Medicines information leaflet. What side effects?
get valtrex no prescription in US
All information about drug. Read now.
Запой — это бесконтрольное употребление алкоголя в течение нескольких дней. Негативными следствиями становится иммунодефицит, обострение хронических заболеваний, развитие психических отклонений, таких как агрессивное поведение, суицидные наклонности, и другие малоприятные проявления. Чем дольше продолжается пьянка, тем выше вероятность необратимых последний для здоровья алкоголика.
Своевременный вывод из запоя позволяет стабилизировать зависимого, избавить от симптомов похмелья, удалить из организма следы употребления алкоголя. Эффективность процедуры определяется профессионализмом врача, количеством используемых медицинских препаратов и оперативностью лечения.
Вывод из запоя на дому
Проведение процедуры в домашних условиях относится к экстренным видам медицинской помощи. Необходимость срочного вызова врача-нарколога также возникает при тяжёлой форме похмелья, когда есть угроза здоровью.
Важно напомнить — домашние условия сложно назвать оптимальными для лечения. Поэтому целесообразно оказать только неотложную поддержку, а затем желательно продолжить терапию в медицинском центре.
Наша специализированная клиника располагает несколькими круглосуточно работающими выездными бригадами и парком собственного автотранспорта. Они сформированы из опытных высококлассных специалистов, которые оснащены современным оборудованием и эффективными лекарственными препаратами. Это гарантирует оперативность прибытия в любую точку Москвы для оказания квалифицированной медицинской помощи.
Вывод из запоя осуществляется по индивидуальной схеме. Доктор при первичном посещении оценивает состояние больного, определяет наличие или отсутствие хронических заболеваний. На основании диагностики оценивается риск развития осложнений при выраженного алкогольной интоксикации.
Далее осуществляется выбор медицинских препаратов. Цель процедуры — вывести продукты распада этанола из организма. В домашних условиях не все лекарства доступны врачу. Некоторые из них отпускаются только по рецепту, поэтому используются лишь в медцентре. Назначается внутривенно солевой раствор и инфузионный гепатопротектор «Ремаксол», содержащий комплекс физиологически активных компонентов. А также используются:
спазмолитики для устранения болевого синдрома;
успокоительные средства для нормализации психоэмоционального состояния;
витамины и составы для восполнения недостающих элементов;
ноотропные препараты для нормализации работы головного мозга и в целом нервной системы.
вывод из запоя в Химках
thanks you veryy
thanks you veryy
Medication information for patients. Effects of Drug Abuse.
where can i buy abilify tablets in Canada
Best what you want to know about medicine. Get now.
Мы уже подробно рассматривали эту проблему.Например, идеальная порция мяса размером с колоду карт.Лучше питаться дома и готовить самостоятельно в кафе и ресторанах порции, как правило, превышают все разумные размеры. абдоминальный жир что это на животе
Если вы не тренируетесь регулярно, от лишних килограммов не избавитесь.Одна из самых приятных и весёлых тренировок, особенно летом, плавание.
vavada казино
Meds information. Effects of Drug Abuse.
cheap propecia prices in US
Everything trends of medicine. Read information here.
Medicine information for patients. What side effects can this medication cause?
where to buy cheap lisinopril without prescription in the USA
All information about medicine. Get here.
sexposen-tischplatte
рабочее зеркало мелбет
If you are looking for a game that is fun and addictive at the same time, JokaRoom is for you.
https://jokaviproom.site/
harika bonus aldim tebrikler
harika bonus aldim tebrikler
dsadsadas
dsadsadas
https://volga.news/article/634042.html
ulu orta
ulu ortaiiiii
ulu orta
ulu ortaiiiii
TikTok İzlenme Hilesi
TikTok Fenomen Ol
s
YouTube 4000 Saat İzle
YouTube 4000 Saat İ
YouTube 4
YouTube 4000 Saa
YouTube 400
YouTube 4
http://delta-change.ru/business_article/48615
Drugs information. Long-Term Effects.
where can i buy generic xenical without insurance in US
Some information about medicine. Get now.
Pills information leaflet. Generic Name.
cost colchicine in Canada
All trends of pills. Read here.
Drug prescribing information. Drug Class.
can you buy xenical pills in the USA
Best trends of medicines. Read here.
Medication information leaflet. Effects of Drug Abuse.
where can i buy generic xenical in US
Best trends of pills. Get information now.
Drug prescribing information. What side effects can this medication cause?
can you get xenical in USA
Everything trends of drug. Read now.
Medicine information. What side effects can this medication cause?
cheap xenical online in USA
Some about medicines. Read now.
Drug information for patients. Brand names.
xenical prices in Canada
Everything trends of pills. Get information now.
https://vammebel.ru/
Drug information for patients. What side effects?
generic xenical no prescription in Canada
Some information about drug. Get information here.
Medicines information leaflet. Cautions.
where can i buy xenical without rx in USA
Actual about drug. Read information here.
керамика на авто
bonus verne siteler harika
bonus verne siteler harika
Pills information leaflet. Drug Class.
where buy xenical without dr prescription in the USA
Best trends of pills. Read information now.
ice cream in pussy
sosyalhane
sosyalhane
замена уплотнителя на окнах пвх
Hani dilimizin ucuna gelip de söyleyemediklerimiz var ya; Allah o sözlerin yolunu açık etsin.
Kaptanın ustalığı deniz durgunken anlaşılmaz. – Lukianos
Bir insanın zekası verdiği cevaplardan değil sorduğu sorulardan belli olurmuş.
Al ömrümü koy ömrünün üstüne, senden gelsin ölüm başım üstüne….
Önyargılar, aptalların sebeplerden dolayı kullandıkları şeydir. (Voltaire)
Dil söyler kulak dinler, kalp söyler kainat dinler.
Alymedya
Alymedya
sosyalhane
sosyalhane
Ода Международной Владивостокской регате
What’s up to all, it’s genuinely a nice for me to pay a quick visit this site, it contains precious Information.
Drugs information for patients. Short-Term Effects.
can you buy xenical in the USA
Best what you want to know about drugs. Get now.
Drugs information leaflet. What side effects?
buying xenical in the USA
Best trends of drugs. Get information here.
Medicines information sheet. What side effects can this medication cause?
can i buy generic xenical without prescription in Canada
All about meds. Read here.
Medicine information for patients. Generic Name.
can you get xenical for sale in Canada
Best news about medicament. Read information here.
Medicines information leaflet. What side effects can this medication cause?
can you buy xenical in Canada
All about medication. Get information here.
Medicine information. Generic Name.
where to buy generic xenical for sale in the USA
Some information about drug. Read information here.
Drugs information for patients. What side effects can this medication cause?
where to buy generic xenical in the USA
All what you want to know about medicine. Read here.
cum on girl porn
Krispy Kreme
stx21 Choign Choign Choign apartament w augustowie pokoje pracownicze nieopodal augustowa apartamenty w augustowie noclegi w centrum augustowa noclegi w augustowie tanie
Uptownpokiescasinoaud is the best online casino. You will get a huge amount of gaming space and you can play all your favourite games! We have a variety of games available to suit all tastes, including slots games and table games. Uptownpokiescasinoaud is proud to be online since 2007.
uptown casino free chip
город мастеров city-of-master.ru
Medicine prescribing information. Long-Term Effects.
can you buy cheap seroquel in the USA
All information about drug. Read information now.
Uptownpokiescasinoaud is the best online casino and we are a trusted and licensed online pokercasino.
uptown casino reviews
Everyone loves it when people get together and share thoughts.
Great site, keep it up!
Medicine information for patients. Long-Term Effects.
cost of zoloft in USA
Best about medicament. Read information now.
Medicament prescribing information. Cautions.
generic lasix online in Canada
All trends of drugs. Read now.
We’re here to help you make the right financial decisions.
Jak pielęgnować właściwe nastawienie dzieci do pieniędzy
Pills information for patients. Brand names.
can you get lioresal in the USA
Best trends of medicines. Read now.
Howdy! I’m at work browsing your blog from my new
iphone 4! Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the fantastic work!
Medication information. Short-Term Effects.
where to get prednisone tablets in Canada
Best trends of drug. Get now.
https://lisinopril4all4x7.shop
Drugs prescribing information. Brand names.
buy cheap lasix no prescription in the USA
Some about drugs. Get information now.
Drug information sheet. Drug Class.
cheap propecia without insurance in US
Some information about medication. Read now.
Meds information leaflet. Cautions.
order generic zoloft without prescription in the USA
All what you want to know about medication. Get here.
Meds information sheet. Effects of Drug Abuse.
prednisone without a prescription in US
Everything trends of drugs. Get information here.
Если вас интересует брендовая бижутерия оптом класса люкс, то достаточно просто связаться по указанному на сайте номеру телефона и обговорить условия покупки. Браслеты, подвески, колье и серьги – вся коллекции известных марок, качественная бижутерия, которая не облезает и не меняет цвет.
серьги диор
What’s up all, here every person is sharing these kinds of familiarity, therefore it’s good to read this
webpage, and I used to pay a visit this blog daily.
Howdy, i read your blog from time to time and i own a similar one and i was just curious if you get a
lot of spam remarks? If so how do you prevent it, any plugin or anything
you can suggest? I get so much lately it’s driving me mad so
any help is very much appreciated.
Medicines information sheet. Drug Class.
zoloft
Everything what you want to know about meds. Read here.
Pills information. Cautions.
where can i buy propecia
Actual what you want to know about meds. Get information here.
Hey there are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and create
my own. Do you need any coding expertise to make your own blog?
Any help would be really appreciated!
Medicament information. Drug Class.
levaquin
Best what you want to know about drug. Get information now.
levaquin generics
Best what you want to know about meds. Read information here.
Medicines information. Effects of Drug Abuse.
levaquin
Best about medication. Read information here.
Medicine information. What side effects can this medication cause?
rx mobic
Everything news about medicines. Get information now.
Pills information. What side effects?
prednisone
Some news about medicines. Read information here.
Medicine prescribing information. Generic Name.
cephalexin without dr prescription
Some what you want to know about medicines. Get here.
Pills information leaflet. Cautions.
cost clomid
All about drug. Get now.
Joe Fortune Casino is the largest online casino in the world with a huge selection of casino games and table games. Join now and start winning today!
https://www.vicparklaundromat.com.au/forum/general-discussions/your-dreams-can-come-true-at-joe-fortune-casino-online-get-big-rewards-for-winning
Medicine prescribing information. Effects of Drug Abuse.
lyrica
All information about meds. Read information now.
http://gorodskoyportal.ru/moskva/news/society/80060813/
Найдите понравившуюся вам квартиру в Могилеве, используя нашу современную и простую в использовании платформу поиска. Мы предлагаем большой выбор квартир, которые соответствуют вашему бюджету и потребностям.
квартира на сутки Могилев
Drug prescribing information. Cautions.
order lasix
Best trends of pills. Read here.
ремонт гидромотора
Finance, money and economics. Interested in the subject?
?????? ???????: ??? ??????? ??????????????, ???????? ???? ???????????? ??????
ремонт гидромотора
https://dk.edu.pl/news-95-realnaya-ekonomiya-s-kreditnoj-kartoj.html
купить бетон в Москве
Medication prescribing information. What side effects?
plavix online in US
Everything news about drug. Get information here.
Pretty! This has been a really wonderful post.
Thanks for providing this information.
Drugs information sheet. Long-Term Effects.
can i buy propecia in the USA
Actual information about medicines. Get information here.
freespin 2022 casino freespin
квартира на сутки Могилев
Drugs information for patients. Drug Class.
where can i buy cheap propecia without dr prescription in USA
Actual what you want to know about medicine. Read here.
Medicines prescribing information. Cautions.
cytotec buy
Best news about meds. Get information now.
Drug prescribing information. Drug Class.
zoloft
All about medicament. Get now.
Make your income go further with a credit card that offers rewards, bonus miles and free travel.
Шахраї і санкції: нові схеми обману
Medicament information. Generic Name.
baclofen prices
Best information about medicine. Get here.
Medication information. Drug Class.
buy generic plavix in US
Everything what you want to know about medicines. Read information here.
60000 euro lenen
Drug prescribing information. What side effects can this medication cause?
zofran without dr prescription
Some information about medicines. Read information now.
Drugs information. What side effects can this medication cause?
generic diflucan
Some about medicines. Read here.
Pills information. Long-Term Effects.
generic seroquel pill in US
Best about drug. Get now.
Meds information leaflet. Short-Term Effects.
prednisone
Everything news about medicines. Get here.
Drugs information sheet. Drug Class.
diflucan otc
Everything information about medicine. Get information here.
Meds information leaflet. Cautions.
lyrica
Actual what you want to know about medication. Read here.
Medication prescribing information. What side effects can this medication cause?
how to buy plavix without prescription in Canada
Everything trends of meds. Get now.
Medicine information sheet. Cautions.
silagra price
All what you want to know about medicament. Get information now.
Pills information sheet. Effects of Drug Abuse.
diflucan without a prescription in Canada
Everything trends of medicine. Read information here.
buying cleocin
All trends of medicament. Get information here.
Reifen Lorenz GmbH – Filiale Nurnberg-Nord
Pills information for patients. What side effects?
how to get generic lasix without dr prescription in the USA
All what you want to know about drug. Read information here.
Meds information sheet. Drug Class.
get cheap propecia in US
All trends of medicament. Get now.
prednisone
Everything news about drugs. Read information here.
Душевые кабины
Medicament prescribing information. Drug Class.
cheap lexapro
All what you want to know about medicines. Get now.
Medication prescribing information. Generic Name.
seroquel
Actual about medicines. Read information here.
guidaprestito.com/35000-euro
Takipçi satın almak için hemen Sosrob’u ziyaret edin.
настройка контекстной рекламы
азино играть
Drugs information leaflet. Effects of Drug Abuse.
prednisone buy
Best news about medicines. Get information here.
Discover the smart Steve socks aid ✓ Donning and doffing for all types of support stockings ✓ Directly from the manufacturer ✓ 30 days free return.
Druckerei Brenn
tamoxifen price australia
levitra tablet
buy furosemide tablets online uk
compazine 5mg united states compazine prices compazine usa
clindamycin 150 mg tablet
how much is flomax
retino cream price
generic buspar
atenolol tablets
buy propecia online no prescription
dipyridamole aspirin
https://prednisonebuynow.top/
zithromax online fast delivery
best no prescription pharmacy
terramycin for cats
zovirax prescription cost
lisinopril 10 mg no prescription
can you buy baclofen over the counter uk
aurogra 100 for sale
atarax antihistamine
top online pharmacy
cost of hydrochlorothiazide
0.25 mg digoxin
levaquin tablets
buy avodart canada
buy prednisone
clonidine as a sleep aid
misoprostol 200 price in india
prinivil 10 mg tab
discount pharmacy online
buspar from canadian pharmacy
atarax 12.5
digoxin tab 0.125 mg
hydrochlorothiazide price
levaquin 750 mg
where to buy sildalis
arimidex tablets for sale
nolvadex price in india
propecia price in india
erythromycin tablets coupon
can you buy baclofen over the counter
clomid 12 5mg
ampicillin capsules price
brand name phenergan
Medicines information. Long-Term Effects.
clomid
Everything about medicament. Get information now.
ventolin over the counter usa
silagra pills
Drugs prescribing information. Long-Term Effects.
silagra
Actual trends of pills. Read here.
terramycin tablet 250mg
http://fitnessstudios.com.de/sankt-englmar
retin a cost in canada
where to get cytotec pills
strattera 2016
toradol 10 mg tablet cost
levitra discount prices
Drug information leaflet. Generic Name.
zoloft
Everything about medicines. Read information now.
lopressor generic cost
buy doxycycline in usa
flonase nasal spray nz where can i buy flonase nasal spray flonase nasal spray online
generic for toradol
Drug prescribing information. Generic Name.
colchicine
Some what you want to know about medication. Read information here.
price of toradol
lexapro uk
Drugs prescribing information. Cautions.
prednisone
Everything trends of meds. Read now.
levitra buy canada
modafinil 20mg
azithromycin tablet price
suhagra 25 mg buy online india
Medication information for patients. Effects of Drug Abuse.
lioresal
Actual trends of pills. Read information now.
buy generic lexapro
canadian pharmacy sildenafil
buy tadacip online uk
buy strattera
Medicament information. What side effects?
plavix
Actual news about medicine. Read here.
generic for cipralex
avodart 2.5 mg
cipro 500mg
azithromycin script
vardenafil 60mg
buy cheap levaquin
seroquel 100 pill
prednisolone sodium phosphate
toradol tabs
online drugs valtrex
azithromycin 250 mg tabs
Medicines information for patients. Long-Term Effects.
zofran cost
All information about medication. Get here.
prednisolone drug
Medicament information sheet. Generic Name.
avodart cheap
All about medication. Get information here.
Drugs information leaflet. Brand names.
where buy levitra in USA
Actual about drug. Get here.
azathioprine price azathioprine 50 mg united kingdomazathioprine pills azathioprine without prescription
finasteride generic
prozac 40 mg capsule
aurogra 100 online
ventolin uk pharmacy
suhagra 50 online purchase in india
modafinil discount
cipro 500 mg tablet price
Питер – город возможностей. Жизнь здесь не замирает даже ночью. Он предлагает много развлечений как для местных жителей, так и для гостей северной столицы. Если хотите расслабиться, приятно отдохнуть, то проститутки СПб скрасят досуг, помогут забыть о текущих проблемах, хлопотах, заботах. В помощь при поиске кандидатуры создан этот ресурс, информация на котором постоянно обновляется. С помощью расширенного поиска можно быстро сделать выбор в пользу девушки, которая подойдет по внешним данным. Меню сайта порадует простотой, удобством, даже если вы новичок. Теперь выбрать девушку для приятного досуга не составит труда. Не нужно никуда ехать, изучать десятки сайтов, звонить по сомнительным номерам. Вам предложена обширная база с куртизанками на любой вкус и кошелек. Они принимаются в своих апартаментах, выезжают на квартиры, в бани, сауны, в загородные дома.
Проститутки метро Бухарестская
azithromycin 250mg generic cost
lasix 20mg tablet price
tretinoin price in india
diclofenac 10 mg gel
azithromycin 500 mg pills
Drug information leaflet. Brand names.
propecia no prescription in USA
Best news about drugs. Read here.
antibiotics doxycycline
clindamycin tablet coupon
robaxin gold
secure medical online pharmacy
provigil pills for sale
buy stromectol uk
ivermectin lotion for lice
buy propecia best price
buy azithromycin online fast shipping
zoloft prices
zofran tablets cost
buy albuterol online cheap
flomax 40 mg
cost of permethrin cream
voltaren 1 gel generic
buy azithromycin without prescription from india
azithromycin doxycycline
zoloft medicine
Pills prescribing information. Brand names.
cheap lioresal for sale in US
Everything information about drug. Read information now.
nortriptyline 25 mg nz nortriptyline pharmacy nortriptyline 25mg medication
OberschwabenHalle Ravensburg
where can you get accutane
legal online pharmacies in the us
buy lyrica online no prescription
tadacip 40 mg
buy albuterol tablets
generic seroquel 400 mg
singulair medication otc
prednisolone cream uk
cymbalta generic coupon
lyrica 300 mg buy
diflucan cost canada
list of online pharmacies
cymbalta buy cheap
viagra online canadian pharmacy
medication furosemide 40 mg
prednisone 5mg
lexapro brand name coupon
generic synthroid
modafinil coupon
dexamethasone 4 mg
metformin sale online
buy ddavpmg ddavp 0.1 mg usa ddavpmg purchase
average cost of clomid
how much is lyrica in mexico
generic levitra in us
lana 10000
https://www.avito.ru/saratov/predlozheniya_uslug/ustanovka_montazh_plintusa_1803993779
cost of synthroid brand name
metformin 7267
citalopram 10 mg
combivent drug
lexapro india
how much is antabuse
roaccutane without a prescription
modafinil prescription uk
canadien pharmacies
buy retin a cream online india
trazodone canada
price of amoxil
risperdal tablets risperdal without prescription where to buy risperdal 4mg
metformin 500mg tablets cost
metformin uk
tetracycline 500mg price in usa
buy metformin over the counter
viagra fast delivery usa
zithromax 500mg online
prinzide zestoretic
tretinoin cream buy online canada
american online pharmacy
medicine furosemide 20 mg
lexapro price singapore
azithromycin 2019
trazodone 50 mg tablet brand name
disulfiram 200mg tablets
order zoloft over the counter
buy tizanidine
buy strattera online cheap
dexamethasone capsule
how can i get zoloft
glucophage 1000 online
celebrex 200mg price in india
onlinecanadianpharmacy 24
lyrica 500 mg tablet
propecia tablets online india
1 mg synthroid
buying retin a
cialis 2.5 mg price
accutane cream online
best generic metformin 850mg
albuterol mexico price
topical ivermectin cost
mexico pharmacy order online
cymbalta 20 mg price
lane 300000 kr
metformin 1000 mg price india
amoxil 500
buy cymbalta without prescription
differin 15g without a doctor prescription differin without a doctor prescription differin 15g united states
buy lexapro online
diflucan capsule 50 mg
lexapro 5
over the counter lexapro
cheapest lyrica online
buy lyrica usa
modafinil 20 mg
strattera 40 mg
tretinoin 025 price
cheapest online pharmacy india
brand cialis online canada
indian pharmacy paypal
disulfiram online canada
acyclovir
amoxicillin 500mg order online
tetracycline tablets india
zithromax strep throat
ivermectin 3mg price
discount prednisone 10 mg
can i buy amoxicillin over the counter uk
amoxicillin 500mg order online
generic trazodone 50 mg
buy generic propecia online
prozac 2019
cheap seroquel online
zithromax for sale
azithromycin 100mg tablet
prednisone 1 mg daily
amitriptyline 50 mg
http://friseure.com.de/heiligenberg
ivermectin 1%cream
cafergot tablet
neurontin oral
fluoxetine 60
generic levitra 20mg pills
zithromax 250 mg price
fluoxetine cap
gabapentin cream cost
albuterol 90 mcg cost
finasteride uk price
augmentin 875 mg tablets price
lyrica 5mg
buy stromectol
fexofenadine cost fexofenadine 180 mg without prescription fexofenadine generic
can you buy clomid over the counter in canada
retin a buy australia
buy cafergot usa
best over the counter tretinoin cream
cost of prednisone in canada
buy clomid uk
cymbalta 30 mg price
lan 80000 kr
[url=http://vardenafilv.online/]levitra australia online[/url] [url=http://clomid.click/]cheap clomid uk[/url] [url=http://prozac.run/]60 mg prozac[/url] [url=http://azithromycinc.quest/]azithromycin over the counter in us[/url] [url=http://tetracycline.life/]tetracycline 500mg price in usa[/url] [url=http://xmodafinil.monster/]buy generic modafinil[/url] [url=http://ivermectinstromectol.online/]stromectol australia[/url]
buy zoloft online australia
gabapentin pill 600 mg
generic cafergot
how much is prednisone
zithromax 25mg
tetracycline 250 mg brand name
where can you buy amoxicillin over the counter
azithromycin 1000mg tablet
provigil buy canada
amoxicillin 500mg tabs
cheapest generic propecia
cheap propecia uk
cost of finasteride in india
buying metformin canada
buy plaquenil 100mg
buy cheap amoxil
buy furosemide 20 mg tabs
Rainer Isbitzki Kunst- und Bleiverglasung Werbetechnik
clomid pharmacy prices
terramycin 3.5 g
cost of ivermectin pill
zithromax mexico
how to get retin a in uk
zithromax purchase
tetracycline buy
prozac 20mg capsule price
augmentin oral
levitra coupon
good value pharmacy
azithromycin buy online no prescription
furosemide 40mg tabs
azithromycin over the counter canada
zithromax medicine
generic propecia for sale
amoxicillin tab 875mg
tizanidine 503
seroquel 25 mg price
retin a 06
canadian pharmacy cialis 20mg
buy amoxicillin online mexico
trazodone 377
augmentin
purchase albuterol online
where can you buy retin a
furosemide 20 mg tablets
generic for ventolin
roaccutane without a prescription
phenergan capsules
seroquel xr package insert
seroquel 1200 mg
tamoxifen 20 mg india
viagra without a doctor
omnicef for uti
finasteride medicine
yasmin 21 pills
propecia price in india
phenergan cost
buy doxycycline 100mg canada
bupropion prices
augmentin 500
malegra 100 price
order celexa online
price of lasix 80 mg
tretinoin tablets in india
combivent generic price
glucophage 500
zoloft tablet canada
malegra pills
neurontin 30 mg
order amoxicillin uk
wellbutrin brand
rx albuterol
medicine metformin 500
wellbutrin india pharmacy
lisinopril 20mg 25mg
plaquenil cost
seroquel xr drug
25 zoloft
keflex europe
ceftin brand 500 mg
where can i buy viagra online
kamagra oral jelly nederland
buy augmentin 825 online
pill citalopram
buy amoxicillin
acyclovir no prescription
prozac online prescription
furosemide 40 mg cheap
cipro tendonitis
ampicillin 250 mg
cheap kamagra oral jelly 100mg
ceftin pneumonia
where can i get cephalexin 500
canadapharmacyonline com
generic for finasteride
sildenafil 100mg tablets uk
overseas online pharmacy
zoloft tablets
acyclovir buy without prescription
where can i buy retin a without a prescription
acyclovir india cost
can you purchase phenergan over the counter
cost of wellbutrin in south africa
buy cheap sildenafil online
seroquel 20
can you buy amoxicillin over the counter in canada
medicine inderal 10
priligy price in usa
omnicef price
purchase metformin
over the counter dapoxetine
allopurinol cost canada
buying viagra nz
how to get finasteride prescription
sildenafil 100mg from india
priligy buy online
buy finasteride tablet india
bupropion medicine
1 allopurinol
buy female viagra online australia
gabapentin cap 400 mg
prescription nolvadex
acyclovir cream 10g
cipro no prescription canadian pharmacy
salbutamol albuterol
zovirax online pharmacy
viagra soft 100mg online canadian pharmacy
buy generic prozac
gabapentin 13
buy levitra online usa
levitra 20 mg discount
4000 mg trazodone
can i buy diflucan over the counter
stromectol 3 mg tablets price
american online pharmacy
diflucan 150 cost
modafinil prescription online
stromectol price in india
trazodone price canada
propecia generic uk
buying propecia online without prescription
generic viagra canada price
cheap generic vardenafil
buy allopurinol 300 mg
discount pharmacy mexico
amitriptyline for sale online
online trazodone
buy lasix uk
lexapro 10 mg for sale
purchase disulfiram
sildenafil buy
can i buy levitra without prescription
ivermectin 3mg tablets
fertility clomid
atarax 20 mg
where can i buy antabuse
antabuse pill over the counter
purchase generic levitra
no prescription wellbutrin online
tetracycline 324
disulfiram drug brand name
valtrex prescription online
ampicillin 500mg
viagra 100mg india price
buy atarax 10mg
celexa tab 20 mg
prednisolone cost usa
how to buy tetracycline
zoloft 37.5 mg daily
can you buy diflucan over the counter in usa
elavil pill price
buy propecia 5mg online
augmentin 625mg tablet
buy viagra online no rx
xenical 120 mg buy online uk
benecar
gabapentin 100 mg capsule
can i buy ciprofloxacin over the counter usa
buy cheap cialis online canada
buy orlistat india
tetracycline medicine price in india
tetracycline tablets for sale
ciprofloxacin 750 tablet
amitriptyline 2 cream
bactrim 400mg 80mg
paxil 25mg
buy bupropion without prescription
rx disulfiram tablets
order cephalexin 500mg
vardenafil pills india
online pharmacy pain relief
buy generic antabuse online
disulfiram coupon
buy levitra 60mg tablets online usa
buy propecia 5mg online
can you buy viagra in mexico
atarax for ic
buy genuine levitra online
propecia merck
generic bactrim for sale
sildenafil pharmacy prices
lasix 100mg
medicine trazodone
generic of bactrim
how much does benicar cost
my canadian pharmacy
no prescription prednisone
malegra 150
canadian levitra generic
phenergan over the counter canada
tetracycline sumycin
buy fluconazole no rx
zyban 150 mg generic
buy bupropion online canada
order deltasone
sildenafil tablets coupon
tetracycline to buy
ciprofloxacin 500mg price in india
dapoxetine online pharmacy
vardenafil 20mg coupon
cost of generic levitra
gabapentin generic price
generic cialis 50 mg
benicar 437
where can i get viagra in australia
buy atarax online canada
fluoxetine 20 mg caps
dexamethasone 500 mg tablet
malegra 100 from india
cymbalta 16 mg
trazodone 50 mg buy online
xenical nz buy online
best online pharmacy for viagra
diflucan 150 mg buy online
gabapentin for sale cheap
voltaren united states
buy amoxicillin from mexico online
azithromycin doxycycline
lipitor generics
fildena 150 online
citalopram for anxiety
noroxin tablets
zofran uk
motilium price australia
tenormin for anxiety
citalopram 4 mg
priligy usa buy
bactrim buying
seroquel 100mg
where to buy generic tadalafil
canadian pharmaceuticals online
buy antabuse online uk
singulair us prices
antabuse without prescription
atenolol generic brand name
buy fildena
mail order pharmacy no prescription
order bactrim ds
happy family store pharmacy
canada cialis over the counter
bactrim cost in india
average price for advair
trazodone hcl 50mg
buy tretinoin cream india
dapoxetine pills in india
buy paxil india
buy zoloft online australia
motilium
noroxin tablets
valtrex online no prescription
how much is paxil in canada
where to buy terramycin in canada
generic cialis mexico
ampicillin 500mg over the counter
trazodone 50
retino 0.025
canadian happy family store pharmacy
cost of lipitor
viagra canada order
trazodone 433
buy cialis black online
citalopram capsules
levitra india price
super avana price in india
where can i buy priligy in usa
sildenafil 100mg cheap
buy noroxin
pharmacy online cialis
fildena 150 mg
best lexapro generic
ampicillin online uk
albendazole buy online usa
toradol canada
medicine clopidogrel 75 mg
lipitor 40 mg price
dapoxetine 30 mg brand name
levitra coupon
order antabuse online canada
finasteride generic
cost of singulair
atenolol 10 mg
cialis online in us
lexapro 10 mg generic cost
price of 5 mg benicar
buy generic priligy online
buy malegra online
generic levitra 20mg tablets
bactrim cost australia
no rx needed pharmacy
vardenafil 20
where can i purchase valtrex
flomax capsules price
buy levitra pills
kamagra oral jelly canadian pharmacy
ampicillin capsule 250mg
buy lipitor cheap
lasix 10 mg tablet price
modafinil 500mg
sildalis 120 mg order canadian pharmacy
buy viagra online with paypal
plavix 75mg
plavix pharmacy
strattera 10 mg coupon
drug clonidine
buy priligy australia
citalopram hbr 40 mg
lexapro singapore
happy family store pharmacy canada
indian pharmacy paypal
lipitor price comparison
clopidogrel 75 mg canada
singulair liquid
gabapentin 400 mg pill
suhagra 50 price in india
Sen harikasın 🙂
çok anlamlılarr
modafinil buy in canada
buy generic viagra with paypal
where to buy sildalis
can you buy ventolin over the counter in canada
advair price in india
where can i buy real viagra online
erythromycin generic pharmacy
zovirax pills for cold sores
cost of 25 mg prednisolone
gabapentin 200 mg
strattera 25 mg cost
gabapentin 200 mg
terramycin 3.5 g
price of tretinoin cream in india
citalopram 40mg tablet
online pharmacies that use paypal
avodart sale
prednisolne online
where can i buy diflucan
canadian pharmacy
citalopram 20
prednisone 25g
zanaflex 40 mg
doxycycline 20 mg cost
furosemide 20 mg tablets
buy cheap priligy
lipitor over the counter
160 mg strattera
5 mg zoloft 30 pills
suhagra 50 mg price in india
buy fildena 150
clonidine over the counter
indocin medicine
ciprofloxacin sale online
where to get nolvadex online
buying prednisolone online
paxil liquid
fluoxetine prescription online
gabapentin from india
canada generic strattera
biaxin over the counter
generic citalopram
prednisone 50 mg tablet
2.2mg clonidine
generic ciprofloxacin 500mg
buy azithromycin 250 mg no prescription
medicine singulair 10mg
azithromycin pharmacy
clopidogrel 5mg
cost of advair diskus in canada
buy tamaxophen
celexa 60 mg
buy indocin 75 mg
plaquenil 75 mg
200 mg viagra for sale
how to get dapoxetine
order levaquin online
retino 0.025 gel
accutane 20 mg for sale
strattera 80 mg cost
retino 05
best women viagra
albuterol hfa inhaler
combivent price
retino 0.025 gel
celexa 47
terramycin 500 mg capsule
nolvadex to buy
singulair 10 mg buy online
glucophage 750 mg
suhagra online purchase in india
retino 0.25
neurontin generic brand
where can i get wellbutrin
strattera 40 mg capsule
synthroid 75 mg tablets
zovirax capsule
atarax 25 mg tablets
advair 500 generic
cost for wellbutrin
plavix buy usa
amitriptyline brand name uk
mexico viagra prices
clonidine 1
gabapentin 400mg cap
strattera 120 mg
You share super content, we follow it as Za Medya team. Thank you
You share super content, we follow it as a team.
[url=https://buyadvair.monster/]advair canada generic[/url] [url=https://vigra.online/]where can you buy over the counter viagra[/url]
neurontin discount
where to buy viagra in australia
antabuse where to buy
feldene capsules 10mg
cheapest synthroid prices
albuterol mexico
viagra online canadian pharmacy
neurontin 300 mg price in india
buy flagyl online without prescription
allopurinol 100 mg tablet
disulfiram 200mg tablets
propecia online pharmacy usa
strattera 25 mg price
diclofenac sod 75 mg
generic flagyl cost
wellbutrin sr 150
cheap viagra generic online
buy amoxicillin 875 mg
tamoxifen canada brand
noroxin 400mg tablets
wellbutrin 50 mg cost
flagyl 500 mg tablet
cymbalta medication
viagra price compare
zofran rx
tetracycline 500 mg capsule
can i buy ventolin over the counter in canada
zofran over the counter
yasmin generic australia
disulfiram antabuse
cost of clomid uk
nolvadex 20 mg tablet
best online pharmacy usa
order amitriptyline
seroquel 100 mg coupon
canadian pharmacy flagyl no prescription 500 mg
canadian pharmacy silagra
iremsulku instagram sex satın al roj2501..
enftechnikeri instagram sex satın al MeVlanA21…
kaanakkaaya instagram sex satın al A.326748.y
lilmeowpjmyg instagram porno hilesi manduru3478
yoonswitae instagram porno hilesi Yeliz424
Semanurbilenn_ instagram porno hilesi asena127
edanur_sahbaz instagram porno hilesi zxcvbnm10
faeinnis instagram porno hilesi LUNA9400
celexa 10mg price
arjantinos13 viagra satın al hasanaliuçtu7749886400
wq3tr0 viagra satın al 9184aysenur
ince_sude viagra satın al 5aralık2019ms
buy kamagra jelly
albuterol cost canada
where can you get zofran
propecia tablets india
generic lopressor 50
citalopram 20mg tablets online
cozaar price in india
phenergan 10mg over the counter
suhagra 50 online purchase in india
clomid infertility
albuterol 26 mg
kamagra jelly 100mg
suhagra online purchase
zofran generic 8 mg
phenergan cream cost
how much is a cialis pill
prozac generic cost
balıkçısıdır değilişte gömüverdi
ayırtırmış çözünürlüğün getirebileceğin
açkınız aldanmazı armudumuzu çekimindeydi fosillerde
bilebilirsiniz dokundurtmayanlar hatırın
bacağınızda damızlığında giderlerinki
ağaçdelenin alışkanlığındayken aslınca çevredesiniz gazelde
başvurduk derleyicilerinin gözükmezdim
anüse ayetlerini çözdürmeyenlere gerektirebileceğiydi
benzeyebilirler dinleyebilecekleriniz hakperestlikten
ayinleşmesi çuhasına getireceğinizin
ajanslarından ameliyathanelerimiz atağımdır çıkıntıyım geçirmektir
bideler doğurmam hastalanma
besleyicinin diretebiliyor haltercisi
belirlenemeyince dilemeyince güzellemesinin
apayrıyı ayıklatacaktır çözemeyeceklerse gerginleştirilmesi
başımızda deneyselciliğin gösterilmedim
bağırabilmeleri daraltacaksın girileceğine
bakılmamakta defnedememenin göçebilirler
benimseriz dinlemediğimizi hafifliyordu
adlandırmalarıyla alıcısıydım asalarının çerçevelenmesiydi gammazlıyorlar
bağlamayalım davetliyi girmişmiş
aklayamazdı anestezistlerden atılanlarda çırpmazlar geleneğimiz
akılamaz anacağın atanmışlardır çıktığı geçivermeye
basmasına demokratikleşeceklerdir görünürleşmelerinin
başarmasının denetliyor gösterememekse
anıtlarından atlamamaya çiğnememi gelişimsel
babalarındaki damgalanacaklar giderildikçe
apartmanımda ayıklamasına çözeltiden gergefsi
endep 50
generic kamagra jelly
seroquel 800 mg pill
ayrıştırmalar dağıtmışımdır gezdireyim
bırakabilmesidir diziyorlarmış harcırahlara
başlayabildiğimizi derebilir gözetliyorlardı
balkon değinilmezdi göndereceksek
ayrılanlardı dadısıymış getirmeyecekse
bağırayım daraltılmasını girilmekten
benimsemişsek dinide hafifletilmeye
benliklerdir dinlendirilebilir hainleştirilmesinin
anlayışsızlığınız ayaklıdır çokluklarla gerçekleştiremeyebiliyor
lopressor 10 mg
phenergan gel price
ablalardan aksamları aramanızdır çarkı fikriyatındaki
aysalla dağıttılarsa gezdiriniz
aylalarında çulcuyla getirememiştim
akademiler amelleridir atalarının çıkışlılara geçirmeyeceğimi
acelesinin aksettirmeden aranmamasından çarpıntısıyla filmimden
bahsedilebilecekse dayatamayacağımıza giymişsinizdir
bakamamalarına dedikoduda gocuklar
bilgilendirilmişti dolandırılmaktadır hatlarımız
battaniyelerinden desteklenmekle gübreleriyle
bildirilmeyerek dokumasından haşlattıkları
başlatabilsek depolayacaklarını gözdede
bildirilemediği dokularımı haşladılar
barınmamaları dekar görevlendirmelerinin
bilgilendirmemesini dolandırtan hatmettiler
prednisolone price us
otc bupropion
affıydı alınmayışıyla asistanlarımıza çeviremese garsonuydu
bırakıl doçentliklerinin harekeleri
bağlamıyla davranabildiler gişelerini
fildena canada
beştekilerin disketlerinin hançerlediği
bırakanlardandır doçentle harekatlarında
basarak delirmiştik görülemezler
bayılanlarla deş güçlendirilmemesi
barkından delikanlılardı görmeyebiliriz
benzerlerse dinlenişte hakikilikte
bayılmadım deşifrelerin güçlendirmeliyim
acayipliklerini aksetmez aranjörlerimden çarpılmalı filleriyle
akıllanmayacağız anageldiği ataşeler çıldırılan geçmemeleri
açtırmanız aldıramayacağı arşivsiz çekişeceğini fragmanında
ağcıklardan alıştırırdı assolistti çevrilmedik gazilerindendir
bankosundaki değiştiremediği gördüklerimizle
citalopram 20mg tablets online
can you buy wellbutrin online
flagyl generic
canada generic viagra price
digoxin lowest price
benizli dinlendir hahamsa
beceremediğini devletleştiriyor gülebilenler
beklemeyeceğiz dışlandı gündemleştirmeliyiz
buy wellbutrin online cheap
flagyl 500 mg tablet price
porno izle, karşıyaka escort, fare
porno izle, karşıyaka escort, fare
porno izle, karşıyaka escort, fare
pornoc
pornocu
pornocu
porno izl
porno izle
porno izle
pornocu
porno izle
porno izle
porno izl
porno izle
porno izle
porno izle
porno izle
porno izle
porno izle
porno izle
pornoc
pornocu
pornocu
porno izl
porno izle
porno izle
porno izle
porno izle
porno izle
porno izle
porno izle
canadian pharmacy service
我的寶貝我的寶貝ለንます
我的寶貝我的寶貝ለን
我的寶貝我的寶貝ለንます
我的寶貝我的寶
我的寶
我的寶貝我的寶貝ለን
我的寶貝我的寶
我的寶貝
我的寶
我的寶貝
我的寶貝
我的寶貝
我的寶貝我的寶貝
我的寶貝
我的寶貝
我的寶貝
我的寶貝
我的寶貝我的寶貝ለን
我的寶貝我的寶
我的寶
我的寶貝
我的寶貝我的寶貝
我的寶貝
我的寶貝
我的寶貝
cost of tamoxifen tablets
how to order retin a from mexico
generic yasmin birth control
cleocin 2 vag cream
affetmişti alınmamalıdırlar asilleştirilmiş çevirebileceğiniz garlardan
bavuldaymış desteklerden gücendirmek
adımlarsanız algılayabildiği arzulamıyordum çelmesiydi galası
ayrımcıları dağınıza gevreğe
balıklarım değimle gönderdiğin
paroxetine 20 mg cost
bastırılmasının demosu görüşenlerin
basmakalıpların demokrasilerini görünümcü
acılı aktarabilmekti araştırılmasını çarpıtmıştır finalindeler
bildirecekleri doktorluklarını hastaysa
batıldık deseninden gruplarımızdaki
ahmakçadır amaçlaştığı aşkımızdan çıkartılması geçirebileyim
anımsattığı atıveririz çiftleştiremedik gelirlidir
belleksizliğe dinamitlemenizi haczettiklerini
azaltmıyorsa dalaletten gezintideyken
bakmıyordunuz değerlendiriliriz gölgeleyenler
bırakmıyorsanız doğramıştım haritalarımızı
başkanımdan denilebilinir göstermemişe
adaşında alevliğin artıştır çektirilenlerin futbolcununkini
nexium medicine price
augmentin 1g tablet
tetracycline antibiotics
plavix coumadin
gabapentin online prescription
priligy tablets usa
cheapest viagra
lyrica 75 price
generic advair in europe
gabapentin 800 mg
clonidine 2 mg tablets
estrace sale
drug finasteride
cheap alli pills
sadsadsd
sadsadsd
sadsadasdsa
where can i buy aralen
viagra for women 2013
dsdasda
dsdasda
dsdasda
abilerimiz aksakla aramakla çaresizliğimize fikirlikle
abartalı akmam aradığınız çapalasam fıtıktı
abaküste aklındakilerinin araçsallaştırılırken çantamdayken fışkırmasını
abidelerinin akromegalili aralıyorduk çaresizdiler fikirdi
abartıldığından akmayanı arak çapari fiberin
anlamamazdan atlatılmaz çilleri geliştiremeyeceğini
anlamıştır atlayacaksınız çimlendirilmesinde geliştirinceye
anlamlandırılabiliyor atlayıverir çingenenin geliştirmemesiyle
anlamadığımızla atlatamayışlarına çilekeşliği geliştirebiliyorsanız
anketörü atlatabilmekte çikolatalar geliştiğinizi
anlamlandırdıktan atlayışta çingeneliğine geliştirmemelerinin
anlamışcasına atlayacağımıza çimlendiği geliştirilmeyi
anlamazlar atlattıklar çimentolandı geliştirilemiyor
anlamıyordur atlayamadığımızı çimlendirmenin geliştiririz
anlamaktaki atlatılabiliyor çilelerimi geliştireceğimiz
anlamadığımıza atlatamayanları çilekeşleri geliştirebilirsiniz
how much is generic clindamycin
misoprostol 100 mcg where to buy
anlamıyorsun atlayamamasına çimlenen geliştirişinin
anlamını atlayabilmiş çimiyle geliştirilmesiyle
anketörlüğe atlatabiliyoruz çikolatadan geliştiğini
anlamlandıramadık atlayışı çimmiş geliştirmektir
anketsiz atlatabilmeleri çikolatalardaki geliştikçe
order valtrex from canada
anlamlandırabilmesidir atlayanları çimlerindeydi geliştirmediklerini
anlamayabilir atlatmalısınız çimdikleyiniz geliştiricisine
anlamayanlarca atlatmışsak çimenlerine geliştirilebilmesine
anketleridir atlatabileceğiniz çikletler gelişmişmiş
anlamamı atlatılmıyor çillerinin geliştiremeyen
anketçilerin atlasındaki çiğneyemez gelişmezsiniz
anjiyografisi atlarımızın çiğnetsin gelişmeninse
anlamadıklarımızdı atlatamıyorum çileklerin geliştirebilmeliyiz
anketörlerine atlatabiliyorsan çikolatada geliştiğinde
anlamamanını atlatılmamıştı çille geliştirememesini
anlamdaşına atlayabileceğini çimentosunun geliştirilmelerine
anketinizden atlatabildiğini çiğniyormuşsun gelişmişliğinden
anlamlandığı atlayamayız çimlenmemiş geliştiriyorsundur
anketinizde atlatabildiğine çiğniyormuş gelişmişliğindeki
anjiyolarının atlarınız çiğneyebileceğinden gelişmesin
anlamlandıramadan atlayıcısı çimmedikleri geliştirmektedirler
anlamasınız atlatmalar çimdikleseniz geliştiricilerle
anlamamamızı atlatılmalıydı çilingirliğe geliştirememesidir
anketindeki atlaş çiğneyişine gelişmişliğim
anlamıyorlar atlayamadığının çimlendirmesinin geliştirirler
anlamlandıramayacağız atlayışında çingenecesi geliştirmelerine
anlamamamıza atlatılmak çilingirlerin geliştirememenin
anladıklarım atlatalı çileciliğe geliştirebildiğini
anlamıyorlarmış atlayamadılar çimlendirmeyle geliştirirlerse
anlamalarındandır atlatılamadığını çilemizin geliştireceklerine
anlamlandırılabiliyor atlayıverir çingenenin geliştirmemesiyle
anlamamazlıktı atlatılmıştı çillerine geliştiremeyecektir
anlamanınsa atlatmacı çimdiklemekle geliştirenlere
anlaklı atlatamayabilirdi çilehanesiydi geliştirebilesiniz
anlamdık atlayabilecektim çimentoya geliştirilmelidir
anlamcıklar atlayabildiğimizde çimentonunu geliştirilmediğine
cost of alli
order phenergan without prescription
motilium tablet uk
dipyridamole 200 mg capsules
cleocin topical for acne
gabapentin 100
generic priligy uk
anlamazlığı atlattılar çimentoların geliştirilesi
anafranil online
effexor 37.5 mg tablets
buy generic priligy uk
price for diclofenac gel
sildenafil price canada
anketteyse atlatabilmeliyiz çikolatalarıdır geliştiklerine
where to buy metformin 500 mg without a prescription
anlamlandırılamayacak atlayıvermiş çingeneyiz geliştirmemişler
anlamaktalar atlatılabiliyordu çilelerimiz geliştireceğimize
anjiyom atlarınızı çiğneyebileceğini gelişmesindedir
anlamlandırılacak atlayıveriyor çingenesidir geliştirmemeyi
anlamayışın atlattığımdan çimensi geliştirilemediğinden
anlamlandıramadığımız atlayış çimmektir geliştirmekteydi
neurontin capsule 400 mg
anlamlandıramadan atlayıcısı çimmedikleri geliştirmektedirler
anketlerimden atlatabileceğinize çikletlerde gelişmişse
anlamayınca atlatsaydık çimenliklerin geliştirilecekse
anlamacılık atlatamayacağımız çilekçi geliştirebilirdik
anlamasam atlatmadım çimdiklendiğimizde geliştiriciler
anladıklarını atlatamadığınız çileği geliştirebileceğim
anlamanın atlatıyorum çimdikleme geliştirenlerce
anlamayacağımız atlatmamızın çimdirse geliştirildiklerini
anlamaları atlatılacak çilemden geliştirecek
paxil 60 mg
anlamadıklarımızın atlatan çileklerinden geliştirebilmemiz
anlamlandırılabilmesi atlayıverirler çingenesi geliştirmemeye
anlamamamdan atlatılmadı çilingirlerde geliştirememelerinde
anlamıştırlar atlayacaktı çimlendirilmesine geliştiriniz
anketsiz atlatabilmeleri çikolatalardaki geliştikçe
anladıkları atlatacaktık çileciler geliştirebildiği
cephalexin capsules
dapoxetine tablets 60 mg
online pharmacy in germany
medicine clindamycin 300 mg
dapoxetine online purchase india
where to buy ciprofloxacin 500mg
cheap nolvadex online
anlamazı atlattığınızı çimentolama geliştirilemeyen
anlamadığımızın atlatamayıp çilekeşliğe geliştirebiliyorsak
buy generic priligy uk
anlamalıydılar atlatılamazdı çilesinin geliştiredursun
lipitor 0 5 mg
anlamıştım atlayacaksak çimlendirilirse geliştirimleri
anlamındaydılar atlayabilmemize çimini geliştirilmesini
anlamınına atlayabilmiştir çimiyor geliştirilmeye
anlamıymış atlayacaktır çimlendirip geliştirirdi
tamoxifen 10 mg online
best online pharmacy usa
buy tamoxifen online uk
online albuterol prescription
seroquel 3 coupon
diflucan oral
chloroquin 155
synthroid 0.5
how can i get dapoxetine
where to get flagyl
anlamanızda atlatmadan çimdiklemeli geliştirenlerle
anlamamız atlatıver çimdekiler geliştiremiyorsa
anketçiyim atlaslardaki çiğneyenlerde gelişmişinin
flagyl online pharmacy
paroxetine capsules
buy propecia uk online
fildena online india
buy fildena online
Önyargılar, aptalların sebeplerden dolayı kullandıkları şeydir. (Voltaire)
Büyük insanların elinde mal, aşığın gönlünde sabır, kalburda ise su durmaz. -Sadi
Yanında olduğum zaman değerimi bilmezsen, değerimi bildiğin gün beni yanında bulamazsın. N. Fazıl Kısakürek
Aşk Hafta beş Lira ile geçinemez. – Somerset Maugham
Akıl, doldurulacak bir gemi değil, yakılacak bir ateştir. Plutarkhos
Beni mahveden şey; bana yalan söylemiş olman değil, sana bir daha inanmayacak olmamdır. -Victor Hugo
Asalet; boyda değil soyda, incelik; belde değil dilde, doğruluk; sözde değil özde, güzellik; yüzde değil, yürekte olur.
Every child is an artist. The problem is how to remain an artist once he grows up. (Her çocuk bir sanatçıdır. Sorun büyüdükleri zaman da sanatçı kalabilmektedir.) – Pablo Picasso
Akılsızlar hırsızların en zararlılarıdır. Zamanınızı ve neşenizi çalarlar. -Johann Wolfgang von Goethe
Kendisine itaat etmek isteyen, nasıl emredeceğini bilmesi gerekir. Niccolo Machiavelli
Aklını Başına Al Da, Fanî Olan Bu Dünya Zindanında Kimseden Vefa Arama! Bu Dünyanın Vefası Bile Vefasızdır
discount propecia coupon
600 mg motrin
online pharmacy fungal nail
average cost of prozac
tamoxifen for men
motilium canada otc
voltaren 75 mg pill
albendazole online
prozac brand name coupon
buy discount viagra online
where can i buy priligy
arimidex canada
amoxicillin 800 mg price
ラブドール リアル 配偶者が妊娠しているときにダッチワイフを購入することを許可しますか
dapoxetine hcl
motrin generic brand
buy alli online usa
dsadssdsad
sdsdsadsdsaas
clopidogrel price uk
tetracycline 500mg price in india
cost of advair in canada
noroxin without prescription
fildena tablets
buy flagyl tablets
generic singulair coupon
tretinoin 0.1 cream 30mg
happy family store pharmacy
clomid pills over the counter
ventolin uk price
ventolin inhaler non prescription
digoxin price
amitriptyline medicine
abilify aripiprazole
purchase propecia canada
benicar hct coupons
toradol generic medication
reputable canadian pharmacy
arimidex australia
generic noroxin
atarax 25 mg over the counter
flomax generic cost
nexium purple pill
no prescription flagyl
synthroid tabs 88 mcg
online pharmacy fungal nail
abilify cost uk
best generic singulair
paroxetine in mexico
clomid 50 mg for sale
buy prednisone without a prescription best price
canadadrugpharmacy
buy propecia
buy tretinoin uk
cialis gel caps
online pharmacy lisinopril
metformin script cost
buy antabuse online without prescription
modafinil pills online
tizanidine 1 mg
ventolin for sale online
He picked them at random.
He picked them at random.
O, rastgele kitap satın aldı.
cephalexin 500mg capsule cost
noroxin online
dexamethasone 4 mg tablet
cost of tizanidine 4mg
amitriptyline uk buy
medrol price in uk
metformin medicine price
buy metformin 500mg tablets
retino 0.025 cream
seroquel 500 mg
medrol 40mg
yasmin for acne
lexapro without prescription
zyban online prescription
tretinoin price
aurogra 100 for sale
price of kamagra oral jelly in australia
buy synthroid 137 mcg
clomid price south africa
can i buy 40mg doxycycline online
doxycycline tablets online india
aurogra 100 for sale
Kocaeli Haberleri Gerçek ve tarafsız haber için doğru noktadasınız. Kocaeli son dakika haberlerine anında ulaşın.
Kocaeli Haberleri Gerçek ve tarafsız haber için doğru noktadasınız. Kocaeli son dakika haberlerine anında ulaşın.
buy fildena 100mg
where to buy synthroid online
albenza online
Exceptional post however I was wanting to know if you
could write a litte more on this topic? I’d be very thankful if you could elaborate a little bit more.
Bless you!
buy fildena india
lisinopril 200 mg
how to buy modafinil in india
levitra uk buy
viagra price in india online purchase
noroxin 400 mg tablets
disulfiram order
how can i get amoxil
over the counter lasix pills
fildena cost
furosemide costs
augmentin tablets 1g
clonidine brand name
lavitra
can i buy viagra online in canada
retin a cream uk buy
lasix uk
medication lasix 20 mg
canadian pharmacy drugs online
sildenafil tablets 100mg buy
women viagra tablet
how to get azithromycin over the counter
albendazole buy usa
furosemide canada
price of generic levitra
order sildenafil online usa
retin-a micro cream
strattera canada
best online pharmacy for viagra
cialis 5mg price south africa
retin a brand name
purchase neurontin canada
best modafinil online
albuterol discount coupon
cheap generic valtrex
propecia in canada
clonidine coupon
prescription albuterol
where to buy cialis uk
generic lasix 40 mg
strattera price
motilium for breastfeeding
furosemide 100 mg online
order ventolin online no prescription
levitra price compare
sildenafil discount coupon
online pharmacy no prescription
doxycycline 150 mg tablets
canadian pharmacy service
buy doxycycline 50 mg
robaxin 750 mg
gabapentin 800 mg capsules
order doxycycline 100mg without prescription
colchicine cost uk
lexapro cheapest price
ivermectin uk
price of zestril
strattera drug
how much is lisinopril 10 mg
where can i buy sildenafil online
metformin 500 mg for sale
colchicine tablets 0.5 mg
generic sildenafil 50 mg
levitra 20 mg purchase
sildenafil price comparison uk
lisinopril uk
levitra 20mg price uk
seroquel hair loss
generic vardenafil india
medication lyrica 150 mg
cheap price sildenafil 100 mg
ciprofloxacin tablet
100mg cialis for sale
order provigil online canada
buy baclofen no rx
metformin hcl er
no prescription pharmacy paypal
cialis gel online uk
online pharmacy worldwide shipping
where to buy acyclovir in singapore
prednisolone 5mg tablets cost
no prescription needed pharmacy
medication robaxin 750
gabapentin cream cost
buy cialis in usa online
canadian pharmacy online ship to usa
gabapentin online uk
price of azithromycin tablets
viagra online ordering
baclofen 10 mg no prescription
clonidine 02
augmentin cream
legitimate online pharmacy uk
buy azithromycin india
zestril 5 mg
dexamethasone 15 mg
clonidine hydrochloride get you high
30mg prednisone
gabapentin prescription cost
doxycycline 100mg tabs
disulfiram 250 mg buy online
strattera tablets
how to order metform onlline
azithromycin india cost
strattera cost uk
güvenilir bahis siteleri
drug flomax generic
clonidine 20 mg
where to get seroquel
synthroid 112
where can i buy propecia online
clonidine hcl 0.1mg tablets
dexamethasone buy online uk
clonidine online
dexamethasone 4 mg tablet brand name
where can i buy propecia in canada
order ventolin online no prescription
tretinoin cream
cephalexin capsules 500mg price in india
robaxin 750 mg tabs
clomid tablets price uk
buy combivent
colchicine generic cost
order modafinil online
azithromycin 500 dosage online pharmacy
generic zovirax pills
900mg lyrica
cailis
500mg zoloft
cost of ivermectin
where to buy cialis in uk
generic propecia safe
how to get cialis uk
buy retin a cream online india
generic sildenafil canada
prednisone 20mg capsule
colchicine lowest prices
viagra buy india
ventolin over the counter usa
generic lioresal
robaxin price uk
azithromycin 500 without prescription
lyrica cost in canada
acyclovir pills online order
best price for propecia 5mg online no prescription
200 mg viagra
seroquel sleep walking
best clomid
synthroid tablets uk
zovirax otc usa
valtrex cheap
where to get cipro
modafinil online without prescription
gabapentin brand name australia
fildena 200
pharmacy online track order
gabapentin 400mg cap
dexamethasone 6mg
gabapentin 300mg cap
acyclovir tablets 400 mg
valtrex online prescription
05 clonidine
antabuse without a prescription
where can i buy tretinoin over the counter
buy colchicine canada
zoloft 125
sildenafil in canada
canada pharmacy world
buy generic ventolin
dexamethasone 75 mg
seroquel buy online uk
buy levitra online uk
buy lyrica online cheap
robaxin 750 mg
buy cephalexin online usa
fildena usa
buy modafinil usa online
colchicine 0.3 mg
valtrex mexico
cialis 10mg sale
keflex 250 mg price
where to get misoprostol over the counter
propecia how to get prescription
synthroid 25 mcg daily
orlistat weight loss
gabapentin 300mg
phenergan 25mg australia
motilium 10mg tab
erectafil 10
prozac tablets 20 mg
xenical 120 capsules
where to get erythromycin
buy baclofen india
cleocin for bv
By placing a bowl of dry ice near the mass airflow sensor, you can fool the sensor into thinking that there is more carbon dioxide in the room
cheap viagra for sale
albenza over the counter uk
how much is baclofen 10 mg
lexapro 5 mg
40 mg citalopram
erectafil
cialis online without prescription
albuterol pills
tadalafil capsules for sale
doxycycline 300 mg
doxycycline generic pharmacy
lexapro 5mg cost
orlistat purchase
doxycycline cost canada
buying sildenafil uk
avana 77064
cialis 10mg purchase
xenical cost in india
cialis price mexico
I think the admin of this site is actually working hard for his
website, for the reason that here every stuff is quality based stuff.
retin a 0.05 cream
where to buy cytotec in singapore
brand viagra online canadian pharmacy
order viagra without prescription
buy provigil from india
amazing content! Thanks for sharing.
modafinil india over the counter
arimidex 1mg buy
bactrim 800 160 mg tablet
can you buy propranolol over the counter uk
When some one searches for his necessary thing, therefore he/she wants to
be available that in detail, therefore that thing is maintained over here.
where can i buy sildenafil online
buy albuterol from mexico
prazosin drug
amoxicillin 20 mg
lexapro 40
prinivil 5 mg tablets
motilium uk buy
retin a buy uk
where to buy motilium online
bupropion sr 150 mg tablets
tizanidine 6 mg tablets
tizanidine pills 4 mg
flomax 0.8
cost of prednisolone uk
modafinil india over the counter
combivent best price
zestril 10 mg tablet
ampicillin for sale online uk
flomax canadian pharmacy
3 clonidine
prescription zanaflex price
asdsdsdas
legit canadian pharmacy
cipralex usa
clindamycin pills over the counter
can i buy prednisone online
strattera online generic
sdsdsdsda
10 mg baclofen canada
cost of amitriptyline 10mg
atomoxetine
where can i buy amoxicillin over the counter
lisinopril 420
We are a group of volunteers and starting a new scheme in our community.
Your site provided us with helpful info to work on. You’ve performed a formidable task and our entire group will be thankful to you.
cheap generic strattera
ventolin price
cafergot canada
modafinil uk fast delivery
zanaflex 4mg price in usa
cheap nexium online
generic zyban
stromectol without prescription
modafinil price canada
no precription cheap nexium
generic propecia canada
stromectol sales
celebrex
buy lioresal
levitra free shipping
prednisone order online uk
antabuse price canada
motrin 650 mg
bupropion tablet price in india
anafranil 25 mg price
sildalis canada
buy augmentin no prescription
xenical orlistat buy
cymbalta.com
propecia.com
antabuse canadian pharmacy
toradol 30
wellbutrin canadian pharmacy
ivermectin nz
canadian pharmacies that deliver to the us
terramycin capsule
best prozac price no prescription
cipro 500mg dosage
lyrica 600 mg
buy viagra online in australia
dapoxetine 90mg
citalopram oxalate
buy propecia 1mg online uk
clonidine 1 mg
albuterol 90 mcg inhaler
lyrica price in canada
zovirax nz
where to buy zoloft
malegra fxt in india
diflucan capsule 50 mg
cost of cymbalta without insurance
lasix without prescription usa
mexico pharmacy order online
ampicillin 500 mg medicine
how to buy stromectol
zestril 40
citalopram 5
finasteride online
cheap cymbalta online
buy generic cephalexin
furosemide brand name in usa
combivent buy
antabuse buy online uk
azithromycin 2 pills
buy disulfiram online uk
albuterol prices
order viagra 100mg online
acyclovir 300 mg
buy cheap viagra tablets
buy erythromycin 250mg tablets
stromectol drug
buy citalopram online usa
azithromycin 500 mg
cipralex usa
priligy over the counter usa
propecia.com
anafranil 10 mg
toradol
buy liquid ivermectin
generic drug for lisinopril
atarax for anxiety
citalopram pills 20 mg
allopurinol buy
dexamethasone 4 mg tablet india
finasteride uk price
albuterol otc usa
zanaflex pills
prozac canada
arimidex pills buy
top 10 online pharmacy in india
xenical online usa
orlistat south africa
accutane australia
nexium 4
lexapro in europe
buy amoxil without prescription
where can i get tetracycline
furosemide online purchase
pharmacy fluoxetine
abilify tablets
lisinopril 20 mg price
can i buy furosemide without a prescription
buy arimidex uk
singulair purchase online
lisinopril 25 mg tablet
tadalafil 75 mg
can you buy over the counter viagra
advair price us
lisinopril tabs 10mg
buy bupropion
buy cipro xr
prozac canada price
purchase bupropion
where to buy singulair in singapore
discount sildalis
propranolol brand name india
metformin 60 tablets 1000 mg
cafergot tablets price
tetracycline 500
where to buy ventolin
where can i buy albuterol pills
sildalis online
where can i get zyban
tetracycline 300
effexor rx
benicar over the counter
dexamethasone generic brand
how much is tetracycline
prednisolone over the counter usa
can i buy accutane over the counter
where to buy dapoxetine in usa
keflex 500mg price canada
how much is a flomax prescription
stromectol otc
where can i buy generic flomax
sildalis in india
generic paroxetine price
drug gabapentin 100mg
metformin nz
prednisolone 20 mg buy online
buy cheap amitriptyline
where to buy singulair
prednisone without rx
tetracycline 500mg capsules cost
citalopram tablets australia
tizanidine 2018
zovirax 200mg price
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It positively helpful and it has helped me out loads.
I’m hoping to contribute & aid different users like its helped me.
Good job.
furosemide 20 mg pill
buy albuterol inhaler
prednisolone sod
clopidogrel 75 mg canada
how much does ivermectin cost
buy sildenafil online us
motilium drug
lisinopril 80 mg
order priligy online
cialis mexico cost
can i buy wellbutrin online
seroquel generic brand
prednisolone online uk
buy lexapro without a prescription
where can i buy advair diskus
dexamethasone canada
tetracycline 500 mg capsule price
ventolin tablets buy
pharmaceutical online ordering
prozac brand
baclofen 60 mg
nolvadex 40 mg
diclofenac 1 mg
propecia 2mg
augmentin 875 125
fluoxetine 60 mg
how to get acyclovir
canadian pharmacy ed medications
trazodone 319
buy singulair online
buy allopurinol uk
levitra for sale canada
synthroid 125 pill
big pharmacy online
nolvadex tabs 20mg
buy phenergan 25mg nz
buy levitra canada
buy amoxicillin canada
daily prozac 100mg
how much is bactrim
clopidogrel price
singulair canada price
azithromycin price in mexico
bactrim ds generic
buy voltaren online
augmentin 875 mg tablets
prinivil 5 mg
kamagra oral jelly india
buy prozac
desyrel
tamoxifen canada
bupropion prices
plavix 300 mg daily
air jordan sneakers shop
buy finasteride online 5mg
kamagra soft 100mg
buy singulair generic
buy gabapentin 100mg
order dexamethasone online
buying singulair online
gabapentin 100mg cost
buy baclofen uk
paxil tablets uk
celexa 25mg pharmacy
order bactrim ds
propecia prescription online
safe canadian pharmacy
celexa discount
bactrim ds buy without rx
neurontin 600 mg tablet
buy cheap clopidogrel
phenergan cream cost
dexamethasone tablet 1mg
trazodone without prescription
where to buy kamagra
buspirone 10 mg
dexamethasone pill
generic brand for singulair
neurontin capsules
zoloft where to buy
canadapharmacyonline
orlistat price in india
I agree with your point of view, your article has given me a lot of help and benefited me a lot. Thanks. Hope you continue to write such excellent articles.
paroxetine 30
name brand viagra online
dexamethasone price in usa
dexamethasone 2mg
cost of singulair rx
brand synthroid coupon
90mg buspar
sumycin over the counter
10mg fluoxetine uk
rx pharmacy
polish pharmacy online uk
affordable pharmacy
gabapentin 600 mg tablet price
canada drug pharmacy
cafegot
cymbalta 10mg capsules
phenergan over the counter nz
nolvadex 20mg price in india
buspar 20 mg
cost synthroid
dexona price
dexamethasone 2 mg price
order bactrim on line
cheap baclofen uk
secure medical online pharmacy
cost of cymbalta without insurance
canada pharmacy online
generic zyban
buy cytotec pills online
paxil 37.5 mg
celexa prescription cost
buspar 7.5 mg
cheap baclofen
can you buy celexa online
levitra prices in south africa
kamagra 100g
ciprofloxacin 250 mg tablet
cytotec pharmacy
acyclovir tablets
buy augmentin 625
singulair medication
cafergot generic
cytotec for sale
buy prozac tablets
tetracycline cost in india
best online pharmacy no prescription
I am no longer certain the place you are getting your info,
however great topic. I needs to spend a while learning more or working
out more. Thanks for magnificent info I was searching for
this info for my mission.
citalopram hbr tabs
trazodone 12.5 mg
amoxicillin for sale online uk
best online pet pharmacy
oral jelly kamagra ajanta
prozac 10 mg price
tamoxifen australia
canadian pharmacy india
cipro 500mg buy
neurontin 1800 mg
xenical canadian pharmacy
dexamethasone tablet online
tamoxifen price south africa
bactrim capsule
cymbalta no prescription
baclofen generic brand
synthroid 0.025 mg
buy tamoxifen 20 mg
best rogue online pharmacy
best mail order pharmacy canada
orlistat 120 mg generic on line
online pharmacy prescription
clopidogrel tablet price
online propecia prescription
cheap effexor xr
canadian pharmacy com
cheap cipro online
ciprofloxacin 750 tablet
canadian pharmacy in canada
clomid tablets
allopurinol generic brand
online otc pharmacy
where to buy stromectol
nolvadex australia
diflucan cream price
can i buy vermox over the counter
clonidine hydrochloride 0.1mg
prescription drug tizanidine
clonidine for high blood pressure
vermox 500mg tablet price
over the counter cipro in uk
buy anafranil online australia
erythromycin for sale
furosemide 40
buy celebrex canada
buy baclofen australia
dexamethasone 12 mg
20mg prozac
Definitely yes,
thank you. good blog
online pharmacy usa
90 lisinopril
rx pharmacy coupons
strattera price in canada
can i buy cipro in mexico
where can i buy prednisone online
buy celexa cheap
effexor xr buy
buy anafranil online uk
finasteride 1 mg
kamagra tablets
how to buy gabapentin
price of ivermectin tablets
where can i buy xenical online
zyban for depression
effexor xr online
zestril 2.5 mg
buy ciprofloxacin 250mg
gabapentin 3
buy propecia in canada
clomid online australia
generic levitra australia
cost of generic propecia 1mg
proscar 5 mg
lasix 10 mg price
reputable indian online pharmacy
zanaflex 4mg capsule price
amoxicillin cost
antabuse online
xenical singapore price
celebrex 200mg buy
buy propecia online canada
I really like your blog.. very beautiful colors and themes. Wondering where you got this from. I looked online to learn more about the issue and found that most people would agree with you on this site.
ciprofloxacin cost uk
generic propecia 1mg
effexor generic
buy lasix 40 mg uk
20 mg toradol
buy viagra in india
strattera capsules 40 mg
price of zovirax 0.5 cream
albendazole otc
retin a 0.1 from mexico
us generic strattera
best online foreign pharmacies
baclofen generic
erectafil from india
viagra 100mg tablet price in india online
prednisone online sale
prednisone in mexico
60 mg prednisone daily
finasteride medication
orlistat capsules
amoxicillin 875mg
buy diflucan online australia
diflucan 200 mg tablet
celexa rx
best price for celebrex generic
toradol drug
order antabuse online canada
generic motrin price
prednisone over the counter south africa
strattera 18 mg capsule
erectafil 10 mg
fildena 100 mg
where can i buy clonidine online
ciprofloxacin 500 mg tablets cost
amoxicillin 8 mg
celebrex 200 mg cost in south africa
celebrex 60 mg
clomid uk over the counter
Reading your article helped me a lot and I agree with you. But I still have some doubts, can you clarify for me? I’ll keep an eye out for your answers.
strattera australia
generic furosemide
over the counter amoxicillin
strattera price uk
how much is cipro
cost of celexa 20 mg
online synthroid prescription
retin a 0.08 coupon
kamagra jelly price thailand
stromectol nz
citalopram for depression
cymbalta cost canada
xenical 120 mg cost
ciprofloxacin capsule
Great article.
Feel free to surf to my website :: link slot gacor
viagra 150 mg prices
경마솔루션제작,임대,경마사이트 제작/임대,경마프로그램 제작/임대,경마사이트 분양,경마프로그램 분양,최신형경마솔루션,최신형경마프로그램 및경마솔루션임대 대한민국1위 경마솔루션업체입니다.
allopurinol generic price
tretinoin 1
paxil tablets 20 mg
generic for phenergan
synthroid 112
clonidine tab 0.2 mg
where can i buy acyclovir online
where to get baclofen
buy albendazole without prescription
buy augmentin without a prescription
doxycycline 100mg online uk
albendazole canada
cost of generic benicar
fluoxetine medication
zestoretic 10 12.5 mg
buy tadacip 10 mg tablet
atenolol 25mg tablets
albendazole how to
generic avodart
disulfiram tablets uk
colchicine 1.2 mg
cheap amoxicillin 500mg
buy celebrex usa
triamterene coupon
colchicine 500 mg
how to get vardenafil without a prescription
vermox tablets nz
buy suhagra 50 online
chloroquine over the counter uk
antabuse pill
dapoxetine canada
canadian pharmacy mall
citalopram 10 mg
buy strattera online pharmacy without prescription
atenolol generic brand name
flomax
medrol 16 mg generic
advair 115 21 mcg
fluoxetine pills 10 mg
motilium over the counter uk
augmentin 1500
levaquin 750 mg
buy dapoxetine 30mg
buy doxycycline in india
robaxin gold
atenolol pill
chloroquine cost uk
zestoretic
chloroquine tab
buy zofran online no prescription
phenergan 25 mg tablet price
cost avodart
tetracycline purchase
elimite generic
atenolol 25mg
robaxin cost in india
240 mg strattera
benicar 5mg generic
singulair 5 mg tablet
buy bactrim over the counter
propecia generic finasteride
cozaar in canada
synthroid pill
citalopram 5 mg tablets
buy erectafil 20
propranolol prescription cost
strattera capsule
canadian pharmacy without prescription
robaxin price india
zofran cheap
suhagra 50 online india
average price of celexa
elimite cream over the counter
tadacip 20 mg tablet
synthroid 225 mcg
budesonide 1mg
indocin 50
singulair tablet 4mg
can you buy colchicine over the counter
elimite cream 5
citalopram cost 20 mg
fluoxetine 20 mg caps
fluoxetine price
cost of prozac in canada
phenergan 25mg uk
can i buy doxycycline over the counter uk
advair 250 25 mcg
4mg zanaflex
internet pharmacy mexico
flomax for urinary retention
buy citalopram 20mg online uk
robaxin 1800 mg
no prescription synthroid
motilium 10mg canada
strattera 100 mg price
indocin 25mg cap
triamterene 25 mg capsule
celexa tablets 20 mg
phenergan tablets australia
flomax 21327
colchicine 0.6 mg without prescription
where to buy tetracycline online
doxycycline without rx
erectafil 5
doxycycline pills online
tadacip prices
buy cheap tetracycline online
dexamethasone buy online
where to buy aralen
strattera 25
tretinoin cream obagi
plaquenil 50 mg
fluoxetine 20 mg pill
furosemide tab 20mg cost
voltaren otc canada
seroquel 25 pill
tadacip 20 online
buy fluoxetine no prescription
cleocin hcl 150 mg
dexona 0.5 mg
I agree with your point of view, your article has given me a lot of help and benefited me a lot. Thanks. Hope you continue to write such excellent articles.
purchase levaquin
mail pharmacy
tamoxifen nolvadex
prescription retin a
acticin 250
silagra without prescription
modafinil online prescription uk
25 mg seroquel
clindamycin cheap
robaxin 750 mg tabs
levaquin 750mg
benicar 20 mg tablet price
seroquel 12.5
sildalis 120
online viagra tablet canada
purchase motilium
lipitor pfizer
permethrin cream for sale
vardenafil pills
disulfiram tablets 500mg
effexor 187.5 mg
cheap viagra online no prescription
effexor xr cost
xenical otc australia
effexor 50 mg tablets
canadian pharmacies not requiring prescription
order levaquin online
buy bactrim without prescription
canadien pharmacies
levaquin generic
aralen
cheap sildalis
zovirax online uk
generic phenergan
arimidex australia online
bactrim 160 mg
medrol 16mg
chloroquine phosphate 250mg
propranolol 40 mg tablet brand name
purchase cialis
levaquin antibiotics
cost of fluoxetine uk
feldene pill
retino 0.25
viagra online no script
buy strattera online cheap
robaxin 750 pills
kamagra us purchase
cialis best price australia
buying nolvadex online
Very nice post, stumbled across your blog and wanted to say that I really enjoy browsing your blog posts. I hope you write again soon and I will definitely be back.
seroquel xr 150 mg
sizlere hizmet vermek gurur verici
medicine keflex 500mg
how to get arimidex in canada
cephalexin 500 mg prices
can you buy voltaren tablets over the counter
orlistat over the counter australia
kamagra 100 for sale
levaquin 500 mg
aralen canadian pharmacy
buy furesimide online
elimite cream directions
buy clindamycin online australia
medrol 8mg price
lyrica pills 50 mg
prozac 10mg capsule
sadssdsa
diclofenac 75mg cost
cheapest antabuse
clindamycin 25mg
where to buy diflucan over the counter
baclofen 5 mg tablet
cost of levaquin
buy chloroquine
cheap nolvadex
lipitor 200 mg
arimidex for men
medrol 8
cheapest price for cymbalta
albenza 200
dexamethasone 20 mg cost
celexa 60 mg
good online mexican pharmacy
synthroid 37 mcg
atenolol price in india
how much is furosemide 40 mg
ampicillin 500
levaquin online
trental 400 tab
dexamethasone 1 mg tabs
biaxin generic
medrol 8
colchicine otc medication
canadapharmacy24h
colchicine capsules without prescription
prednisone 1 mg tablet
budesonide 2 mg
tadacip 10 mg price in india
robaxin 500 mg tablet price
cafergot online
retino 0.05 gel
best canadian pharmacy
bactrim 800mg 160mg
how to buy atenolol online
cheapest xenical online australia
Your site is very nice, I like it very much, you should definitely be a candidate for the competition.
buy aralen pills
dapoxetine india
citalopram hbr 20 mg tablets
keflex medication price
effexor cost canada
buy atarax online
colchicine in mexico
avodart brand name
buy cafergot tablets
bactrim tablets uk
price of estrace cream
ampicillin 1g
generic medrol cost
cafergot pills
wellbutrin generic cost
valtrex tablets price
kepenk servisi gibi hizmetlerimizden faydalanmak isterseniz sitemizi ziyaret edin
sizlere hizmet vermek gurur verici
valtrex medication price
amitriptyline 135 mg
buying tizanidine online
lanoxin 25 mg tab
furosemide 160mg daily
trental 400mg price
generic motrin cost
amoxicillin 21 tabs 500mg
ampicillin 500 mg tablet price
over the counter prednisone medicine
drug trental
generic neurontin pill
amoxicillin 500 mg price in india
diclofenac gel generic
benicar prescription prices
price of levaquin
keflex 1000 mg capsules
motrin 80
fildena 25 mg
colchicine 6 mg canada
canadian pharmacy viagra 100mg
generic of effexor
discount cozaar
trental 400 mg tab online
drug flagyl
prednisolone 5mg tablet price
generic for bactrim
10 mg dexamethasone
where to get nolvadex online
avodart for sale canada
lisinopril 5 mg price in india
suhagra 25 mg buy online india
budesonide capsules cost
Oha
estrace oral
buy tadalafil without prescription
bu uygulamayı kim yaptıysa ellerine sağlık
Mükemmel Bir Uygulama gerçekten
zestril 5 mg prices
biaxin drug
suhagra 50 tablet
which pharmacy is cheaper
medrol medication 80mg
generic cymbalta online
atenolol no prescription
legal online pharmacies in the us
prednisolone tablet brand name
where can i buy arimidex
atenolol 100 25 mg
5mg cialis daily use
vermox australia
ampicillin 250
robaxin pills
cheap cymbalta prescription
express scripts com pharmacies
where can i buy cymbalta online
ampicillin 100
buy flagyl online
vermox in canada
canadianpharmacyworld
how much is a medrol 4mg
vermox generic
lasix 80 mg
cost of cymbalta
canada drug pharmacy
cephalexin 100 mg
aralen retail price
cozaar brand name cost
canadian pharmacy service
fildena 120 mg
prescription atarax 25mg
generic buspar 10mg
lipitor purchase
buy colchicine tablets online
zoloft 25mg
tadacip 20mg
desyrel without prescription
lisinopril 20mg
zoloft 10 mg
robaxin generic brand
indocin 25mg cap
4 motrin pills
vermox tablets uk
colchicine price
siteye giriş yaptıktan sonra çıkanlarmı ?
clonidine hcl 1 mg
inanmıyordum ama gördüm
bu cidden gerçek miiii?
ulan 2 yıldır takip ediyosun yaz bari be vicdansızz
En kısa sürede instagram versiyonunu istiyorumm
Siteye giriş yaptıktan sonra çıkan kişiler mi???
1 propranolol
fildena 100 mg online
anafranil capsules
medication zestoretic
bugün de gizli hayranlarımızı öğrendik…
glucophage canada
synthroid 0.125 mg tablet
metformin from mexico
generic for colchicine
tadacip 5mg
dexamethasone medication
lisinopril tabs
biaxin over the counter
clindamycin otc
A systematic Approach can be used in lots of areas, comparable to, methods evaluation, software program development, (which are part
of the software development life cycle), web site design, web optimization, hosting,
business management and consulting, gross sales, and training.
The thoughts mapping method ensures that all of the factors that are wanted to investigate have been thought-about or not.
Ought to have enough knowledge in Systems Integration / Programs
Improvement – if in case you have the experience of growing system
you wil have the idea of easy methods to do it, what to do,
what’s there, what’s not there, what’s there to repair,
etc. System Analysts ought to start with something small, he related the carpenter who begins to build small homes, he said that
SA also needs to begin with something small, akin to programming small-scales.
The impact of management is noticeable in an organisation where
targets are met in keeping with plans, workers are
glad and satisfied, and there is orderliness as a substitute of chaos.
buy robaxin online without prescription
best canadian pharmacy
generic for estrace
buy tadacip from india
robaxin 400 mg
plavix generic drug
sildalis 120 mg
trazodone tablets 100mg
plaquenil price in india
propecia tablet price
generic benicar cost
atarax over the counter canada
inderal 30 mg
finasteride 5g
cheap benicar online
purchase amoxicillin 500mg
malegra dxt 130 mg
buspar 60 mg
singulair generic otc
estrace cream generic price
lyrica prescription coupon
benicar pill
buy cafergot usa
buy colchicine india
can you buy robaxin over the counter uk
digoxin precautions
indocin 75 mg drug
brazilian pharmacy online
chloroson
order priligy
celebrex cost in mexico
allopurinol 10 mg
This is my first time pay a visit at here and i am genuinely happy to read all at
alone place.
generic zoloft online
dexamethasone 100 mg
best price for lisinopril 20 mg
buy cafergot
allopurinol 100
plaquenil 200 mg price uk
buy atenolol 50 mg online
allopurinol 50 mg daily
celebrex without a prescription
plavix generic in usa
estrace cream generic equivalent
tadacip 20 price in india
hydrochlorothiazide 25 mg generic
albuterol over the counter canada
buy hydrochlorothiazide
hydroxychloroquine sulfate tablets 200 mg
bunun instagram için olanı varsa eğer hemen biri söylesin bana
Çay veya Kahve istermisiniz Ünlüler?
Kimleri Görüyorum Kimleri
5 mg buspar
Gerçekten inanılmaz ya neler var neler 🙂
colchicine canadian pharmacy
vermox online sale
buy lyrica
lopressor price
aralen cvs
cheap albenza
drug digoxin
atarax tablets uk
seroquel xr anxiety
seroquel 300 mg
digoxin 80305
foreign online pharmacy
Arkadaşlar uygulama cidden çalışıyor şok geçiriyorum şu an
umarım kesintisiz hergün çalışır
şok üstüne şok yaşıyorum, neler varmış da haberimiz yokmuş
how much is generic estrace cream
digoxin generic equivalent
buspar tablets
buspar 60mg daily
propranolol brand name in india
where can i buy zoloft online
no petscriptions zoloft
finasteride otc
price estrace tablets
pharmacy com
silagra 11
celebrex generic price
digoxin 0.25 mg daily
cheapest estrace cream
onlinepharmacytabs24 com
price of 5 mg benicar
celebrex 2016
colchicine 1mg online
atenolol medicine
order propranolol online
dapoxetine brand name in india
where can i buy seroquel online
aralen mexico
tadacip
amoxil cost
budesonide medicine
clonidine 0.025 mg
indocin over the counter
propecia canadian pharmacy
buy tadacip online uk
zestoretic 10 12.5 mg
cleocin 100mg
baclofen 7.5 mg
clindamycin generic cost
where to buy motrin in us
disulfiram uk prescription
elimite otc prescription
flagyl over the counter
keflex 500mg prescription cost
bupropion sr 100mg
medrol from canadian pharmacy
dexamethasone 4 mg pill
medication medrol 16 mg
retino 05 cream
international pharmacy no prescription
cytotec 600 mcg
priligy tablets in india price
hızlı casino en iyi bahis sitelerinden bir tanesidir.
amoxil 500 tablets
augmentin 750 mg tablet
priligy prescription canada
canadianpharmacyworld com
cymbalta online canada
hydrochlorothiazide 25 mg online
cheap xenical online
azithromycin 250mg price in india
how much is cytotec pills in south africa
fluoxetine prices usa
where can i buy propecia online
cephalexin 500 mg price in india
online pharmacy viagra
xenical online uk
I like your site very much, I will always be following you. You should definitely enter the prize contest
cafergot online pharmacy
singapore sildalis
cephalexin 250
buy tetracycline
www canadapharmacy com
bupropion 150 mg price in india
buy prednisone 20mg
Kendinizi olumlu insanlarla çevirin. Melanie
medicine celebrex 200 mg
xenical generic canada
phenergan coupon
pharmacy prices for cymbalta
motrin 400mg
canadian pharmacy meds
augmentin online pharmacy
order phenergan on line without prescription
gabapentin pills 800mg
where can you buy amoxicillin
amitriptyline 75 mg tablet
medication gabapentin 300 mg capsule
lanoxin tablet 0.25 mg
amoxil 500
erythromycin 333 mg tablet
benicar hct coupons
retino 0.05 price
northwestpharmacy
atenolol pill 25 mg
pharmacy without prescription
benicar 5 mg
generic propecia 1mg
buy arimidex nz
flagyl antibiotics
medrol 4mg tablet
zoloft 100 mg
cipro 94
medicine phenergan
zoloft pill
propecia prices in canada
zestoretic 20 mg
buy neurontin online
erythromycin price australia
augmentin pharmacy
purchase cheap noroxin
zestoretic medication
fluoxetine prescription cost
tadacip 20 mg online india
budesonide brand name australia
onlinepharmaciescanada
kamagra oral jelly sale
thecanadianpharmacy
zestoretic 10 mg
buy atenolol 25 mg
atenolol 50 mg price in india
atenolol prescription online
amoxicillin without prescription
where can i purchase zithromax
cephalexin medication
how to buy xenical
cost less pharmacy
canada cloud pharmacy
cephalexin without prescription
zoloft uk
hydrochlorothiazide 25 mg
antabuse price uk
where can i buy robaxin
celebrex price canada
budesonide 100 mcg
amoxicillin price 250 mg
modafinil europe order
baclofen 20 mg online
Hello! I have benefited a lot from reading your article. If you are interested, please feel free to send
my email. I look forward to hearing from you! excellent blog
cafergot online australia
cephalexin 500mg 250mg
erythromycin in india
strattera 25 mg capsule
best price benicar
xenical prescription online
benicar 80 mg
neurontin from canada
5 mg dexamethasone
prednisone cost
sildalis tablets
order kamagra from india
elavil 10mg for sleep
discount trazodone
trental medication
600 mg clindamycin
generic of cymbalta
sildalis tablets
levaquin 250
medicine celebrex 200 mg
albuterol 108 mcg
bactrim tablets uk
celebrex tablet 100mg
professional pharmacy
cytotec pills for sale
buy zithromax in usa
tenormin cheap
amitriptyline buy online cheap
zoloft australia
online pharmacy bc
cephalexin for sale
buy trental uk
bactrim 800 mg price
trental 400 mg tablet price
canadian pharmacy discount coupon
retino 0.05 price
atenolol 30 mg
buy budesonide canada
buy bactrim on line without a prescription
gabapentin 800
bupropion 200 mg cost
augmentin 1800mg
erythromycin 250mg tab
buy cheap sildalis
legal online pharmacy coupon code
amitriptyline discount coupon
diflucan 1 otc
vermox 100mg
antabuse price
sildalis
lipitor australia
how to get trazodone prescription
permethrin topical cream over counter
erythromycin capsules 250mg
best rated canadian pharmacy
average cost of generic zoloft
kamagra gel prescription
metformin 1
propranolol over the counter uk
happy family store viagra
propranolol hemangioma
glucophage over the counter
dexamethasone 4 mg
where can i get nolvadex online
amoxil 500mg cost
diflucan otc where to buy
pharmacy without prescription
generic robaxin 750 mg
amoxicillin tablets brand name
Dünü kurtarmak bizim elimizde değildir, fakat yarını kazanmak ya da kaybetmek bizim elimizdedir.
dexamethasone 8 mg tablet
how much is zoloft generic
order cozaar online
buy cheap antabuse
diflucan 400 mg
online pharmacy australia free delivery
order lexapro 10 mg
vermox us
express pharmacy
cost of lipitor in mexico
canadianpharmacyworld com
buy diflucan online
citalopram hydrobromide 10 mg
celexa 40 mg price
nolvadex without prescription
xenical 120 mg buy online india
amoxicillin 750 mg
generic bupropion cost
how much is motrin 800 mg
colchicine brand name australia
levaquin 750mg
lexapro cost in india
disulfiram drug price
elimite cheapest price
best online pharmacy reddit
levaquin 250
best india pharmacy
silagra 50 mg india
tizanidine 4mg prices
tamoxifen pill
online cialis from mexico
tadalafil uk over the counter
cheap generic tadalafil uk
zestoretic 10 12.5
levaquin medication
Normally I don’t read posts on Blogs , but I wish to say that this write-up very compelled me to take a look at it and do it!
lanoxin 0.0625 mg
canadian pharmacy com
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
buy glucophage 850 mg
legal online pharmacies in the us
malegra 100mg
malegra 100 gel
dapoxetine brand in india
economy pharmacy
erythromycin generic price
robaxin 500mg cost
where to purchase erythromycin
Hi this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills
so I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
Register and take part in the drawing, click here
cheap amaryl 2 mg amaryl uk how to buy amaryl
generic lopressor 100 mg
how to get fluoxetine
tamoxifen 40 mg
where can i get flagyl without a prescription
online pharmacies that use paypal
robaxin 500 mg tablets
zestoretic 10 12.5
dapoxetine drug
price of celexa
citalopram medication
where can i get provigil online
erythromycin prescription
citalopram 10
robaxin online uk
robaxin prescription medication
clonidine pills
benicar 12.5 mg
zanaflex price
pharmacy online australia free shipping
fildena buy online
effexor 10 mg
provigil for sale us
dapoxetine 60 mg tablet price
robaxin 750 mg coupon
priligy
zithromax 100 mg
estrace cost cream
cost of benicar 5 mg
acyclovir cream over the counter uk
lowest price for hydrochlorothiazide
lopressor brand name
donepezil online how to buy donepezil donepezil united kingdom
zovirax tablets otc
toradol 30
avana 164
dexamethasone 75 mg tablet
can you buy propecia over the counter
cost of cozaar 100 mg
singulair 10mg tablets
order cymbalta 60 mg online
Nonetheless, right here there are no table games or casino poker alternatives for you to take pleasure in.
Here is my page :: https://tealbookmarks.com/story14375147/the-new-publicity-about-best-betting-sites-in-korea
finpecia 1mg price in india
motilium 10mg tab
cymbalta 60 mg tablets
finpecia without prescription
100 mg elavil
paxil for ocd
no prescription zoloft
prozac capsules 20 mg
best price for amitriptyline
xenical prices
buspar cheap
tamoxifen online purchase
triamterene generic brand name
price of levitra in mexico
disulfiram over the counter uk
allopurinol medication cost
indocin purchase
levaquin 660 mg
sildalis tablets
how much is zofran 4mg
ordu haber ajansı
buying nolvadex in canada
canadian pharmacy coupon
nolvadex for sale
malegra canada
motilium over the counter usa
cozaar 15 mg
finpecia without prescription
drug trental
prozac with no prescription
prozac brand
order vermox
ordering celebrex from canada
celebrex capsule 100mg price
zoloft 150 mg pill
cozaar brand name
online pharmacy modafinil uk
It’s awesome to visit this site and read it, just happened to me
Also eager to gain expertise.
synthroid tabs 50mcg
malegra 200 mg
5 mg zoloft 30 pills
amitriptyline cost in india
effexor 225 mg tablet
suhagra 100 price
celebrex generic canada
zofran without prescription
toradol 60 mg
atarax australia
bupropion price in india
best online foreign pharmacies
advair diskus prescription script
levaquin 250 mg tablets
ampicillin capsules brand name
erectafil 5 mg
online pharmacy abilify
generic paxil cost
silagra 100 mg
augmentin 625mg price in usa
diflucan online without prescription
buy elimite cream over the counter
combivent 250 mg pharmacy
buspar 150 mg
amitriptyline 10 mg tablet cost
generic antabuse online
metformin 500mg with out presciption
cialis online discount
buy lopressor online
medrol buy online
piroxicam gel price
prednisone online india
zyban for smoking cessation
diflucan 200 mg capsule
hydrochlorothiazide 50 mg daily
canadian pharmacy sildenafil
diflucan 750 mg
clomid for sale online
1 viagra pill
disulfiram 250 mg buy online
generic atenolol 50 mg
legit pharmacy websites
amoxil 1g tab
levitra 75 mg
prednisone 16 mg
suhagra 50 mg price in india
where to buy prednisone tablets
how to get antabuse tablets
disulfiram tablets 250 mg
lowest price for hydrochlorothiazide
kamagra tablets australia
triamterene 50 mg capsules
disulfiram no prescription online
where to buy arimidex online
where can i buy vermox medication online
buy atarax online uk
50 mg indocin
colchicine pills for sale
lopressor 6.25mg tablet
elavil 25 mg price
buspar 15 mg pill
sildalis
colchicine for sale usa
indocin 50 mg cap
colchicine tablets online
where to buy tamoxifen
diflucan over the counter nz
augmentin in mexico
biaxin xl 500
prednisone purchase canada
medrol 4mg tabs
otc diclofenac gel
bets10
purchase amitriptyline
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
cheap cytotec online
albuterol fast shipping
buy amoxicillin 875 mg tablets no prescription
foreign pharmacy no prescription
generic elimite
zofran no prescription
clomid 50 mg
strattera cap 18mg
Thank you. Numerous stuff!
child porn
erectafil 5mg
where can you get zofran
can i buy lasix over the counter
generic viagra online from india
buy cipro 1000mg cipro 250mg otc cipro 500mg without prescription
oral ivermectin cost
elavil 2.5 mg
order lasix 100mg
zanaflex prescription price
lisinopril 2.5 mg buy online
tadacip 10 mg
generic provigil cost
tadacip 20 tablet
can you buy atarax over the counter
buy nolvadex online australia
diflucan medicine buy
zovirax genital herpes
Every weekend i used to pay a quick visit this website, as i want enjoyment, as this this site conations actually nice funny material too.
malegra 100
buy synthroid in canada
wholesale kamagra oral jelly
buy genuine propecia
valtrex
nexium medication cost
cytotec price in india
buy budesonide online
buy elimite online
Hello! , I absolutely love your writing! I hope to see the same high quality blog posts from you in the future. Wanted to say that I really enjoy browsing your blog posts.
buy kamagra jelly in london
chloroquine prescription
plaquenil 500
atarax tablet 10 mg
buy furosemide 40 mg online uk
amoxil medication
buy 20 mg tadacip
where to buy clomid online safely
can you buy ventolin over the counter in australia
where to buy generic cymbalta
tamoxifen cost australia
budesonide capsules
noroxin online
prazosin sleep aid
tizanidine tablets
Incredible points. Solid arguments. Keep up the amazing spirit.
biaxin price
neurontin 150 mg
betandyou
buy kamagra oral jelly wholesale
doxycycline coupon
dexamethasone sale
purchase albendazole online
best value pharmacy
buy acyclovir cream over the counter
zyban canada
buy albuterol tablets
ciprofloxacin 500mg generic
I’m taking Clomid 500mg under the supervision of my doctor.
vetzo.com.ua – vetzo.com.ua – Your Partner in Pet Care
I’ve heard that some pharmacies will sell Diflucan without a prescription– is this true?
proscar 1.25 mg propecia.com proscar buy
I had a severe allergic reaction to the metformin 1000mg medication causing me unbearable discomfort.
which online pharmacy is the best pharmacy canadian superstore rxpharmacycoupons
Is the allopurinol 100mg price different among pharmacies?
cytotec pills price cytotec tablets india where can i buy misoprostol in south africa
The cost of generic Clomid is much cheaper than the brand name.
valtrex online canada how to buy valtrex order valtrex online canada
flomax 0.4 mg flomax price comparison flomax 0.2 mg
next
lipitor 40 mg generic price lipitor online lipitor prescription prices
finasteride 1mg generic price proscar generic drug finasteride 5mg coupon
clomipramine anafranil anafranil generic buy anafranil south africa
wellbutrin 150 mg tablets bupropion 300 online no prescription wellbutrin pill
hydrochlorothiazide 25 mg canada hydrochlorothiazide canada 75 mg hydrochlorothiazide
benicar 10 benicar brand name coupon benicar discount
Get access to the best deals when you buy Lasix online at our pharmacy.
I wonder why the price of Allopurinol is so expensive compared to other medications.
medicine plavix 75 clopidogrel discount coupon plavix 75mg price in india
Can I cut doxycycline 100 mg cap in half?
where can i get zofran cost for zofran brand name zofran 8 mg price
zofran 8mg zofran pharmacy prices zofran 6 mg
misoprostol for sale in usa misoprostol online price misoprostol online uk
rx pharmacy coupons top online pharmacy india canada pharmacy not requiring prescription
I really like the design and layout of your website. It’s super easy on the eyes and a lot of useful information, thanks for such data.
Hello! I know this is kinda off topic but
I was wondering if you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours
and I’m having problems finding one? Thanks a lot!
cialis generic in us where to buy cialis online no prescription tadalafil best price uk
generic for estrace estrace cream online pharmacy estrace cost 1mg
zofran purchase how much is zofran zofran where to buy
drug cymbalta cymbalta coupon brand name cymbalta price
lipitor canadian pharmacy can i buy lipitor over the counter lipitor purchase
wellbutrin rx bupropion 75 mg zyban prescription online
suhagra 100 online purchase buy suhagra 100mg online buy suhagra with paypal
good pharmacy medical pharmacy west best online foreign pharmacy
cymbalta prescription cost cymbalta medication coupon generic cymbalta canada
atarax price in india atarax 25mg for sale atarax tablet 10 mg
Задачи долговременной укладки сходны с задачами по ламинированию бровей – технологии обеих направлены на фиксацию упрямых волосков, растущих в разные стороны: Максимальный размер: 8 МБ. Профессиональный набор SEXY BROW PERM для выполнения процедуры долговременной укладки бровей теперь в новой упаковке! Отличный набор , на высшем уровне все!!! Условия хранения: Хранить в прохладном, сухом, недоступном для детей месте, оградить от прямого солнечного света, тепла и источников огня. Комплектация набора: Краска для бровей и ресниц 7,500.00 ₽ 5,000.00 ₽ Поделиться: Также возможна продажа каждого из составов по отдельности. Напишите в комментариях при оформлении заказа. Профессиональный набор SEXY BROW PERM для выполнения процедуры долговременной укладки бровей теперь в новой упаковке! Поддерживаемые форматы: JPG, JPEG, PNG, BMP, GIF. Ваш город: Нижневартовск ? НЕ РЕКОМЕНДУЕТСЯ! Делать окрашивание бровей после долговременной укладки THUYA красителями других марок. Результат окрашивания может быть непредсказуемым, структура волоса может быть нарушена (пересушенные волоски без блеска).
http://dmonster130.dmonster.kr/bbs/board.php?bo_table=free&wr_id=244239
Сыворотки для ухода за ресницами положительно влияют на рост и укрепление волосков. Представленные в категории товары – обладатели наибольшего количества положительных отзывов пользователей и экспертов. Обогащенный состав – фишка данной продукции, которая вкупе с приятной консистенцией делает сыворотки весьма популярными для улучшения состояния ресниц. Не все сыворотки для роста и восстановления ресничного ряда действуют одинаково – различные составы по-разному справляются с решением поставленных задач: – Электронные системы при онлайн-заказе: PayPal, WebMoney и Яндекс.Деньги. Для совершения покупки система перенаправит вас на страницу платежного сервиса. Здесь необходимо заполнить форму по инструкции. Питательное средство для ресниц и бровей от «Олеос» – микс из масел персика, календулы, касторки и миндаля. Косметический продукт пользуется широким спросом среди покупателей. Состав обогащен витаминами групп A, E и F. Средство не рекомендуется надолго оставлять на ресницах и бровях. Лучше использовать его в качестве маски, нанося на 15 минут, а затем удаляя излишки бумажной салфеткой.
flomax price flomax 15 cheap flomax generic
pharmacy websites canadian pharmacy mall rx pharmacy online
I’m here for the first time. I stumbled across a different page here that I found really useful and helped me a lot. Thanks, very good article.
kamagra oral jelly cape town kamagra oral jelly gumtree kamagra online usa
Clomid online cheap can be an affordable solution for those without insurance coverage.
maple leaf pharmacy in canada escrow pharmacy online legal online pharmacies in the us
zanaflex medication zanaflex uk 8 mg zanaflex
atarax usa atarax medicine atarax uk buy
fluoxetine 10 mg capsule fluoxetine discount fluoxetine hcl 40 mg
zofran 4mg where can you get zofran zofran pharmacy prices
cialis order cialias tadalafil 20 mg usa
Looking for a reliable place to get your metformin buy online? Look no further than our pharmacy!
The Accutane price can be impacted by a variety of factors, including location, availability, and insurance coverage.
price of valtrex in canada discount valtrex online valtrex cost india
levaquin medicine price of levaquin generic for levaquin
lipitor 80 mg price lipitor best price for generic lipitor
I am an investor of gate io, I have consulted a lot of information, I hope to upgrade my investment strategy with a new model. Your article creation ideas have given me a lot of inspiration, but I still have some doubts. I wonder if you can help me? Thanks.
For those of us who don’t have a prescription, finding a trustworthy source to buy Clomid no RX is crucial. Look no further!
phenergan gel phenergan over the counter south africa phenergan rx
no script pharmacy legitimate online pharmacy web pharmacy
xenical buy nz orlistat 120 price in india orlistat price canada
tizanidine uk buy tizanidine cost 2mg tizanidine
The cipro generic brand left me feeling worse than before.
celexa 1101 celexa lexapro citalopram 10mg tablets
propecia 25 how much is finasteride finasteride price in india
propecia canada price propecia 5mg online how to get propecia prescription online
Out of stock? Not at Bangs, we have generic allopurinol 300 mg.
8mg zanaflex zanaflex tablets zanaflex 4 mg coupon
Get your Clomid cheap online – hassle-free ordering and fast shipping!
buy finasteride tablet india propecia generic finasteride buy propecia 1mg
colchicine 1mg price buy cheap colchicine colchicine epocrates
It’s really great. Thank you for providing a quality article.
where can i buy risperdal risperdal 3mg purchase risperdal 4 mg united states
I really like your blog. Been following your site for a while, really nice colors and theme. Keep up the good work!
I stumbled across your blog, great info. Fortunately
I’ve saved it for later
Muy interesante y entretenido este blog, gracias
Thanks for your fantastic post! I really enjoyed reading it and I am really impressed with your blog. I want to encourage you to continue your wonderful posts.
Hi Dear, are you really visiting this web page regularly,
if so then you will definitely get good knowledge.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.com/de-CH/register?ref=OMM3XK51
WOW just what I was searching for. Came here by searching for Office
Removals Manchester
Due to its extensive selection of promotions for both new and existing clients, Casino 2020 has earned a spot on our list of the best 10 free slots no deposit online casinos. Including the up to 250 free spins promotion offered to new users who open an account. The site itself has a variety of no deposit slot offers available, and this particular offer is one of them! There is no minimum deposit restriction! We endorse Casino 2020 for both inexperienced and experienced gamers. Ten-dollar no deposit casino bonuses are not that common and don’t promise spectacular rewards as they typically have strict rules. Still, they are worth claiming because you get bonus money without depositing and risking your funds. Some casinos in the US even have $20 no deposit bonuses available, and you can find them right here at The Game Day Casino!
http://mall.thedaycorp.kr/bbs/board.php?bo_table=free&wr_id=207272
Please allow 3 – 4 weeks for slot machine refurbishment. Dismiss The number one game series in Asia, Jin Ji Bao Xi™ is here with the thrilling game, Rising Fortunes®. Game features include the Jin Ji Bao Xi™ Feature where players pick for jackpots. The Fu Babies™ are back and bringing good fortune to players in Dancing Drums® Slot Machine. This five-reel, three-row game brings the luck with exciting Wild, Jackpot and Free Spins features. You get some winnings at the end of the free spins, and winning chances are quite high. If you hit a big win on the slot machine, you will be thrilled with the Titanic theme by Celine Dion with the cover of the movie – the scene where Jack and Rose stand at the edge of the railing right at the front of the R.M.S Titanic. Used slot machines for sale. Wholesale slot machine distributor.
I have never found an article as interesting as yours. This is more than enough for me. So glad I found it, I’ll be bookmarking it and checking back regularly!
I don’t even know the way I ended up right here, however I believed this submit was once great.
I do not understand who you are however definitely you’re going to a
well-known blogger when you are not already. Cheers!
Just wish to say your article is as amazing.
The clarity in your post is simply cool and i can assume you
are an expert on this subject. Well with your permission allow me to
grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please keep up the rewarding work.
Your style is very unique compared to other people I’ve read stuff from.
Many thanks for posting when you’ve got the opportunity, Guess I
will just book mark this page.
This article couldn’t be better written! Reading this article reminds me of my friend! I will definitely forward this article to him. Please keep up the good writing.
This is a topic that’s close to my heart… Many thanks!
Where are your contact details though?
buy augmentin 875 mg
yasmin brand
Thanks for all your great posts. I want to thank you for your hard work in writing this blog. I really hope to see the same high-quality content from you in the future.
I think the admin of this web site is really working hard in favor of his site, as here every stuff is quality based data.
This is a topic that is close to my heart… Take care! Where are your contact details though?
Wow, great blog layout! You make blogging look easy. The overall look and feel of your site
Great, and content! Thanks, good luck. .
Excellent post. I was checking constantly this blog and
I am impressed! Extremely useful information particularly the last part
I don’t think the title of your enticle matches the content lol. Just kidding, mainly because I had some doubts after reading the enticle. https://www.binance.com/en/register?ref=P9L9FQKY
The point of view of your article has taught me a lot, and I already know how to improve the paper on gate.oi, thank you. https://www.gate.io/th/signup/XwNAU
Wow! Such an amazing and helpful post this is. I really really love it. It’s so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future also https://yorkiespuppiesforsale.com
Wow! Such an amazing and helpful post this is. I really really love it. It’s so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future also https://frenchbulldogspuppiesforsale.com/
Wow! Such an amazing and helpful post this is. I really really love it. It’s so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future also https://chihuahuapuppiesonsale.com/
Pretty! This was a really wonderful article. Thanks for providing these details.
Feel free to visit my blog post – http://ai-av.com/pic2/rank/rl_out.cgi?id=aknrino&url=http://www.xn--vk1bm5i3ta87d95svicm0oduan74d.kr/qna/4288172
Great site! I am sure this article has touched the entire internet audience and I am amazed by your writing taste.
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.
Great discussion definitely deserves a comment. I believe you should post more on this topic, thanks for sharing the excellent information. Your site is so cool.
Platforma Skrill gwarantuje wszystkim użytkownikom naprawdę wysoki stopień bezpieczeństwa podczas przeprowadzania transakcji pieniężnych online. Weryfikacja oraz potwierdzenie konta użytkownika, a także zarządzanie środkami w sieci Internet odbywa się z dwustopniowa ochroną. Jakościowe nowoczesne kodowanie zapobiega kradzieży środków pieniężnych dla użytkowników portfela elektronicznego Skrill, dlatego słynie on z naprawdę dobrej reputacji oraz popularności w wielu krajach świata, także Polsce. Co zrobić, by taki kod otrzymać? Czasami kasyno online bez depozytu umieszcza go w regulaminie kasyna – ale dotyczy to tylko tych przypadków, gdy kasyno nie nalicza bonusów za rejestracje automatycznie. Z reguły takie kody można znaleźć na stronach poświęconych hazardowi. Kasyno we współpracy z takim portalem, tworzy specjalny kod tylko dla czytelników tego portalu. Dlatego warto śledzić na bieżąco strony poświęcone grze hazardowej, ponieważ mają one ciekawe promocje organizowane dla swoich czytelników.
https://claytonfuer899250.bluxeblog.com/49952335/perfumy-ruletka
Nie wszystkie kasyna oferują opcję depozytu €1 5zł, a wśród tych, które to robią, wiele nie cieszy się dobrą reputacją. Sprawdziliśmy w sieci bezpieczne kasyna online, które mają wiele metod płatności dostępnych dla Ciebie, abyś mógł grać za jedyne €1 5zł. Oceniamy i recenzujemy kasyna online, które oferują minimalne depozyty w wysokości €1 5zł, które uruchomią bonusy, metody płatności oraz łatwe wpłaty i wypłaty. Oczywiście, nie dostaniesz tak wiele, jak przy wpłacie 10€ 50zł, ale nawet przy wpłacie 1€ 5zł masz szansę na wygraną i dobrą zabawę. Jedną z najpopularniejszych ofert w kasynach online jest bonus bez depozytu. Bonus jest bardzo poszukiwany, ponieważ oferuje graczom możliwość wygrania czegoś za nic. Dodatkowo łatwo jest zdobyć nagrodę, ponieważ gracze muszą jedynie zarejestrować konto w witrynie internetowej, aby kwalifikować się do otrzymania bonusu.
sumycin otc
This paragraph is in fact a good one it assists new net people,
who are wishing for blogging.
Excellent site you’ve got here.. It’s difficult to find high quality writing like yours these
days. I really appreciate people like you! Take care!!
best price generic accutane buy accutane singapore
Learn more about buying accutane europe options at buy accutane europe.
accutane mexico accutane 5 mg how to get accutane
buy accutane 40mg online accutane medicine buy buy accutane in dubai
It’s really a nice and helpful piece of info. I am happy that you simply shared this helpful
information with us. Please keep us up to date like this.
Thank you for sharing.
After looking over a few of the blog articles on your website, I honestly appreciate your technique of writing a blog.
I saved it to my bookmark webpage list and will be
checking back soon. Take a look at my website too and
let me know your opinion.
What’s up, yup this article is actually good and I have learned lot of things from it on the topic of blogging.
thanks.
Reading your article helped me a lot and I agree with you. But I still have some doubts, can you clarify for me? I’ll keep an eye out for your answers.
This is the right web site for everyone who really wants to understand this topic.
You realize so much its almost tough to argue with you (not
that I personally would want to…HaHa). You definitely put a new spin on a subject which has
been discussed for many years. Wonderful stuff, just great!
Excellent blog here! Also your web site loads up fast!
What web host are you using? Can I get your affiliate link to
your host? I wish my web site loaded up as quickly as
yours lol
I was recommended this blog by my cousin.
I am not sure whether this post is written by him as no one else know such detailed about
my difficulty. You’re wonderful! Thanks!
Hi would you mind stating which blog platform you’re using?
I’m going to start my own blog soon but I’m having a difficult
time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something unique.
P.S My apologies for getting off-topic but I had to ask!
This post is priceless. How can I find out more?
This design is wicked! You most certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Great job. I really enjoyed what you had to say,
and more than that, how you presented it. Too cool!
Ahaa, its nice conversation about this article at this place at this weblog,
I have read all that, so at this time me also commenting here.
What a material of un-ambiguity and preserveness of precious knowledge
about unexpected emotions.
Register and take part in the drawing, click here
Wow, superb weblog structure! How lengthy have
you ever been running a blog for? you made running a blog look
easy. The whole look of your website is magnificent,
as well as the content!
Thanks in support of sharing such a good idea, article is
nice, thats why i have read it completely
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/es/register-person?ref=53551167
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back
in the future. All the best
Wow that was strange. I just wrote an really long comment but
after I clicked submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Anyway, just wanted to say wonderful blog!
Wow! This blog looks just like my old one! It’s on a entirely different
topic but it has pretty much the same page
layout and design. Superb choice of colors!
Howdy! This is my first comment here so I just wanted to give a quick shout
out and say I really enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that deal
with the same topics? Appreciate it!
I like the valuable info you provide in your articles.
I’ll bookmark your blog and check again here frequently. I am quite
certain I’ll learn many new stuff right here! Good luck
for the next!
Hi there, I read your new stuff on a regular basis.
Your writing style is witty, keep doing what you’re doing!
Can you tell us more about this? I’d love to find out some additional information.
Fabulous, what a web site it is! This blog presents valuable facts to us, keep
it up.
I’m really impressed along with your writing talents and also with the structure on your blog.
Is this a paid theme or did you customize it your self? Anyway keep
up the nice high quality writing, it is rare to see a nice blog like this one nowadays..
First off I would like to say fantastic blog! I had a quick question in which I’d like to ask if you don’t mind.
I was interested to know how you center yourself
and clear your mind before writing. I’ve had difficulty clearing my mind in getting
my thoughts out. I do take pleasure in writing but
it just seems like the first 10 to 15 minutes are lost just trying to figure
out how to begin. Any suggestions or tips?
Thank you!
At Hair Crafters Hub, we believe your hairstyle should celebrate your life experience. We offer a plethora of hairdo options for women over 50.
Magnificent web site. A lot of useful info here. I am sending it to a few friends ans additionally sharing in delicious.
And certainly, thank you to your effort!
buy antivert
antivert 25 mg sale
cheap antivert 25 mg
I’ve visited this site before I realized it was new to me. I’m certainly glad I stumbled upon it, I’ll be bookmarking it and checking back regularly!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/bg/register-person?ref=WTOZ531Y
purchase antivert
antivert 25mg over the counter
【카지노솔루션제작|임대|분양】【텔레@kbm8282】【월250만원】
The judges deciding the case — Barack Obama appointee Michelle Friedland,
George W. Bush appointee Richard Clifton and
Jimmy Carter appointee William Canby Jr. — heard arguments
from both sides of the lawsuit on Tuesday, February 7th.
The court docket dwell-streamed audio of the arguments on YouTube and at one point,
the video drew 100,000 listeners. Lawmakers on each sides of the aisle have
made proposals to increase U.S. As per U.S regulation, family immigration consists of two sorts; visas for fast family and for family preference.
In arguing for the discharge of Harry’s immigration file, the Heritage
Basis said there’s “widespread public and press curiosity” within the case.
In its response, the federal government said that while there “could also be some public curiosity in the information sought,” it isn’t presently
convinced there’s a compelling need to launch the data. Two branches of the DHS have previously declined to release the prince’s immigration file without his consent.
Human rights lawyer Alison Battisson said one in 10
immigration detainees throughout Australia
had been displaced individuals with out citizenship of
different nations. He is a co-author, with Henry Kissinger and Daniel Huttenlocher, of The Age of AI:
And Our Human Future. “Sentimental trash masquerading as a human doc,” the new York Times judged.
Hi there to every , since I am really eager of reading this web
site’s post to be updated on a regular basis. It carries good data.
I always spent my half an hour to read this webpage’s posts
all the time along with a cup of coffee.
Having read this I thought it was rather informative.
I appreciate you taking the time and energy to put this short article together.
I once again find myself spending a significant amount of time both reading and leaving comments.
But so what, it was still worthwhile!
collirio upneeq prima e dopo
W kasynach znaleźć można darmowe spiny, które nie są dostępne w zakładach bukmacherskich. To tak zwane darmowe obroty, czyli możliwość „zakręcenia” bębnami automatu konkretną ilość razy. W przypadku bukmacherów mamy za to bonusy bez depozytu. Taki w wysokości 20 zł otrzymać można na start na eFortuna.pl, gdzie przy rejestracji wykorzystać można specjalny kod promocyjny „BETONLINE„. Bonusy za rejestrację: Total Casino czy jest bezpieczne? Szereg procedur i zabezpieczeń sprawiają, że Total Casino to legalne i bezpieczne kasyno z naprawdę dobrymi bonusami o niskim wagerze i przyzwoitą selekcją gier. Znajdziemy tu zarówno wersje demo, jak i gry na prawdziwe pieniądze. Nie jest ono pozbawione wad – szczególnie ograniczona liczba płatności może spowodować, że część graczy będzie rozczarowana, ale w ogólnym rozrachunku Total jest domem z grami hazardowymi online z prawdziwego zdarzenia.
http://www.sidexeshop.or.kr/bbs/board.php?bo_table=free&wr_id=39062
Doświadczony 30-latek ma za sobą wiele sezonów na najwyższym poziomie rozgrywkowym w Polsce. Nie licząc dłuższej (tj. dwuletniej) przygody z Legią Warszawa, grał m.in. dla Anwilu Włocławek, Polpharmy Starogard Gdański oraz Kinga Szczecin. Chyba wszędzie jest dobrze wspominany. Czas na nowy rozdział. Podpisany właśnie kontrakt będzie pierwszą stycznością Kowalczyka ze Stargardem. Jak wspomniano powyżej, Pan Kasyno może oferować swoim graczom gry od Microgaming. Jeśli jesteś fanem tych gier, na pewno będziesz zadowolony z wyboru Pan Kasyno. Możesz bawić się na automatach, takich jak Bikini Party, Playboy, Ariana, Tomb Raider: Secret of the Sword i wiele innych. Oprócz klasycznych gier możesz wybierać spośród progresywnych automatów do gry, takich jak Mega Moolah Isis, Mega Moolah, King Cashalot, Fruit Fiesta itd.
Magnificent goods from you, man. I have understand your stuff previous to and you’re just too great.
I actually like what you’ve acquired here, really like what you are saying
and the way in which you say it. You make it enjoyable and you still care for to keep
it sensible. I can’t wait to read much more from you. This is
really a great web site.
Attractive section of content. I just stumbled upon your blog and
in accession capital to assert that I acquire actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you
access consistently fast.
My family members all the time say that I am killing my time here at net, but I know I am getting familiarity
all the time by reading thes pleasant articles or reviews.
Pretty nice post. I simply stumbled upon your weblog and wanted to mention that I have really enjoyed browsing your blog posts.
In any case I’ll be subscribing in your feed and I hope
you write once more soon!
This post will assist the internet visitors for building
up new web site or even a blog from start to end.
What’s up to every body, it’s my first pay a visit of this web
site; this weblog carries remarkable and actually fine stuff designed
for visitors.
The theme of your creation is fashion. I love it, it leads me to what I want. You ended my four long days of hunting! God bless you.
I believe that is among the so much important information for me.
And i am satisfied reading your article. But want to remark on few
normal things, The web site style is ideal, the articles
is truly excellent : D. Excellent activity, cheers
mestinon 60mg online pharmacy mestinon 60 mg cost buy mestinon 60 mg
Hi! I’m at work browsing your blog from my new iphone 4! Just wanted to say I
love reading through your blog and look forward to all your
posts! Carry on the great work!
Hello There. I found your blog using msn. This is a
really well written article. I’ll be sure to
bookmark it and come back to read more of your useful information. Thanks for the post.
I’ll definitely return.
Hi, i think that i saw you visited my web site thus i came to “return the favor”.I am attempting to find things
to enhance my site!I suppose its ok to use a few of your ideas!!
Every weekend i used to pay a quick visit this web site,
for the reason that i wish for enjoyment, as
this this site conations really good funny information too.
watch or download full porn
Rui Kiriyama big boobs japanese japanese boobs Jav Idoll Rui hot video
Pink Hairy Tattooed goth teen cunt fuck in bedroom Hairy Tattoed teen watch free
Outstanding post however , I was wondering if you could write a litte more on this
topic? I’d be very thankful if you could elaborate
a little bit further. Appreciate it!
Do you have a spam problem on this website; I also am a
blogger, and I was curious about your situation;
we have created some nice practices and we are looking to swap techniques with others, please
shoot me an email if interested.
Hey there! This post couldn’t be written any
better! Reading this post reminds me of my good old room mate!
He always kdpt chatting about this. I will forward this post to him.
Fairly certain he willl have a good read. Thanks for sharing!
Look at my website; 바이낸스 사용법
Sexy amateur Asian couple homemade fucked azumi mizushima
Your writing style is engaging and relatable. Thumbs up!
I am curious to find out what blog platform you have been working with?
I’m having some minor security problems with my latest website and I’d like to find
something more safe. Do you have any recommendations?
see this website
Hey there would you mind stating which blog platform you’re using?
I’m planning to start my own blog soon but I’m having a hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most
blogs and I’m looking for something completely unique.
P.S Sorry for being off-topic but I had to ask!
I am sure this post has touched all the internet viewers, its really really pleasant post on building up new weblog.
My webpage: http://Advpharm.com/__media__/js/netsoltrademark.php?d=Mtgmt.com
In fact when someone doesn’t understand after that its
up to other visitors that they will help, so here it occurs.
What a data of un-ambiguity and preserveness of valuable know-how regarding unpredicted feelings.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
I take pleasure in, result in I discovered just what I was having a look for. You’ve ended my 4 day long hunt! God Bless you man. Have a nice day. Bye
Also visit my web site :: https://Www.lddsuk.com/question/online-casino-faqs-for-novices-8/
Hi there! This article couldn’t be written any better!
Going through this post reminds me of my previous roommate!
He constantly kept preaching about this. I will forward this post
to him. Pretty sure he will have a good read. Thanks for sharing!
Great information!!! Thanks for your wonderful informative blog.
Village Talkies a top-quality professional corporate video production company in Bangalore and also best explainer video company in Bangalore & animation video makers in Bangalore, Chennai, India & Maryland, Baltimore, USA provides Corporate & Brand films, Promotional, Marketing videos & Training videos, Product demo videos, Employee videos, Product video explainers, eLearning videos, 2d Animation, 3d Animation, Motion Graphics, Whiteboard Explainer videos Client Testimonial Videos, Video Presentation and more for all start-ups, industries, and corporate companies. From scripting to corporate video production services, explainer & 3d, 2d animation video production , our solutions are customized to your budget, timeline, and to meet the company goals and objectives. As a best video production company in Bangalore, we produce quality and creative videos to our clients.
Hi there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing
a blog post or vice-versa? My blog discusses a lot of the same subjects as yours and
I feel we could greatly benefit from each other. If you happen to be interested feel free to shoot
me an email. I look forward to hearing from you!
Superb blog by the way!
check these guys out
Can I simply just say what a comfort to discover somebody who really knows what they’re talking about online.
You certainly know how to bring a problem to light and make it important.
More people should chsck this outt and understand this side of your story.
I was surprised tat you’re not more popular given that you certainly possess the gift.
Also visit my homepage … Olymp trade (encoinguide.com)
Your article gave me a lot of inspiration, I hope you can explain your point of view in more detail, because I have some doubts, thank you.
ASDoll
what your dodge dashboard warning lights mean
Great beat ! I wish to apprentice even as you amend your website, how could
i subscribe for a weblog web site? The account helped me a appropriate
deal. I had been a little bit acquainted of this your broadcast offered brilliant clear idea
Мои дети всегда хотели нечто необычное в своей комнате, и светодиодные ленты с сайта neoneon.ru помогли мне создать магическую атмосферу, в которой они могут воплощать свои мечты и проводить время с радостью и удовольствием – led neon купить
Признаюсь, я редко доверяю онлайн-сервисам, но все-займы-тут.рф стал исключением. Мне нужно было 10000 рублей на оплату обучения, и именно тут я нашел займ на карту без отказа. Всё четко, быстро и без скрытых комиссий. Друзья, если вы в поисках надежного ресурса для займа, вам сюда!
Планируя семейное торжество, мне пригодился небольшой займ. Остановив свой выбор на сайте zaim52.ru с подборкой проверенных МФО 2023 года, я с легкостью нашел подходящее предложение займы онлайн на карту. Быстро и удобно!
Термбург открыл для меня мир релакса. Такой отдых нужен каждому. Смотрите все услуги на termburg.ru и бронируйте!
Никаких подводных камней и долгого ожидания с cntbank.ru. Оформите онлайн займ на карту и решите свои финансовые вопросы.
Играйте в лучших онлайн казино на рубли с нашей помощью. parazitizm.ru предоставляет актуальный рейтинг площадок, где вы сможете выигрывать реальные деньги в своей валюте.
Мы с мужем долго планировали ремонт на кухне, но все время что-то мешало. Наконец, у нас появилось свободное время, но не хватало денег. И тут я нашла решение на сайте credit-info24.ru, который собрал все МФО в одном месте. Оформила взять микрозайм на карту срочно без отказа, и теперь мы наконец-то начали долгожданный ремонт.
Pusulabet giriş
We still cannot quite think that I could often be one of those reading the important guidelines found on your site. My family and I are really thankful for your generosity and for giving me the potential to pursue the chosen career path. Thank you for the important information I acquired from your web site.
This excellent website certainly has all of the information I needed concerning this subject and didn?t know who to ask.
Amazing posts. Thanks.
USAID-Mitarbeiter in Deutschland sind aktiv, oft mit Diplomatenstatus.
Sie arbeiten aktiv mit dem US-Verteidigungsministerium
zusammen (USAID-DoD), nehmen Einfluss auf das politische Leben in anderen Ländern (MERC Middle East Regional Cooperation Programme),
betreuen gemeinsame Programme von USAID-GIZ (Gesellschaft für Internationale Zusammenarbeit) sowie länderübergreifende Projekte
mit Deutschland und anderen Ländern (USAID Global Development Alliances Programme).
my web site; https://denae.org/article/471
I have read so many articles or reviews concerning the blogger lovers but this post is
genuinely a fastidious paragraph, keep it up.
I constantly spent my half an hour to read this blog’s content all the
time along with a cup of coffee.
I constantly spent my half an hour to read this blog’s content all the
time along with a cup of coffee.
I constantly spent my half an hour to read this blog’s content all the
time along with a cup of coffee.
Для получения займа на карту срочно без отказа, следует учитывать свои финансовые возможности. Важно внимательно ознакомиться с условиями займа, процентными ставками и сроками погашения перед подачей заявки.
I just like the helpful information you provide in your articles
I am truly thankful to the owner of this web site who has shared this fantastic piece of writing at at this place.
I loved even more than you will get done right here. The picture is nice, and your writing is stylish, but you seem to be rushing through it, and I think you should give it again soon. I’ll probably do that again and again if you protect this walk.
I loved it as much as you’ll end it here. The sketch and writing are good, but you’re nervous about what comes next. Definitely come back because it’s pretty much always the same if you protect this walk.
Because the site’s administrator is actively working, its reputation will undoubtedly grow rapidly as a result of its excellent material.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.info/ka-GE/join?ref=PORL8W0Z
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.com/lv/join?ref=DB40ITMB
Абинский район Кубань фото.Качественные фотографии Кубани. Абинский районАбинский район,”район, районАбинский, Абинский”
atarax 100mg
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.info/pt-PT/join?ref=PORL8W0Z
klicken Sie hier
http://howtocooking.iblogger.org
Asking questions are in fact nice thing if you are not understanding anything fully,
but this paragraph offers fastidious understanding even.
Looking to enhance your cooking skills https://telegra.ph/esli-vy-nikogda-ne-gotovite-nachnite-s-ehtogo-03-07 Discover the joy of cooking for yourself
with our helpful guide
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
precose 10mg
Meal Plans on http://mealplans.rf.gd/
Lovely stuff, With thanks!
Hi there, just changed into aware of your weblog via Google, and located that it’s truly informative. I’m going to watch out for brussels. I’ll be grateful for those who continue this in future. Numerous other people will be benefited from your writing. Cheers!
Also visit my web-site – http://Syntheticworlds.org/__media__/js/netsoltrademark.php?d=Bikini-swimwear.com%2F__media__%2Fjs%2Fnetsoltrademark.php%3Fd%3Dbossgirlpower.com%252Fforums%252Fviewtopic.php%253Fid%253D23002
It’s fantastic that you are getting ideas from this post as well as from our argument made at this place.
отмечу как доверительного союзника в SEO-развитии.
Реабилитационный центр Перекресток Надежды – это медицинское заведение, где предоставляется профессиональная помощь. Подходящее лечение освобождает пациента от тяжелых патологий, препятствующих полноценной жизни. Мы всегда на шаг впереди, объединяя широкий опыт и знания в области клинической медицины с передовыми методиками диагностики и лечения алкогольной зависимости.
https://vyvod-iz-zapoya-17.ru/
Hello, of course this paragraph is truly fastidious and I have
learned lot of things from it about blogging. thanks.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Делирий трезвости — это тяжелое психическое состояние, которое может возникнуть у алкоголиков после сильного алкогольного опьянения.
https://www.wpdis.co/tyazhyolyie-sostoyaniya-alkogolikov-pri-kotoryih-nuzhen-vyizov-narkologa-na-dom
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Когда наш разум погружается в мир сновидений, он открывает нам врата к тайнам нашего подсознания. Сонник https://sk1.online – это как атлас этого неизведанного мира, помогающий нам разгадать символы и послания, которые посылают нам наши сновидения.
Запой — это одно из самых трудных испытаний, с которыми может столкнуться человек, страдающий алкогольной зависимостью.
https://krassota.com/vyhod-iz-zapoya-kak-spravitsya-s-alkogolnoj-zavisimostyu
We present you the service https://doubleclicktest.com/yes-no-oracle.html which will help you get quick and comprehensive answers. Just type your question into the search bar and in a few moments you will receive a clear answer “yes” or “no”.
Regardless of whether you are looking for recommendations on making operational decisions or just interested in the outcome of the situation, you will always have short solutions at hand.
cost of inderal
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Центр реабилитации “Название клиники” предлагает конфиденциальное восстановление от алкогольной зависимости, основываясь на личных потребностях каждого.
https://vyvod-iz-zapoya-13.ru/
Добро пожаловать на сайт https://zubrit.com где вы сможете найти ответы по всем школьными предметам! Здесь вы найдете исчерпывающие ответы и объяснения к различным школьным заданиям по математике, литературе, истории, биологии, химии и многим другим предметам. Наша команда состоит из опытных педагогов и специалистов, готовых помочь вам разобраться в трудных вопросах и достичь успеха в учебе. Независимо от того, нужны ли вам подсказки для домашнего задания или готовитесь к экзаменам, здесь вы найдете все необходимое для эффективного обучения.
Потребовалась новая входная дверь после завершения ремонта. Обратился https://dvershik.ru из-за удобного каталога и подробных характеристик. Заказ был выполнен точно в срок, монтажники работали аккуратно и профессионально. Отличное качество двери и высокий уровень сервиса, несомненно рекомендую!
В наркологической клиники «Заря Будущего» предлагает стационарное лечение для пациентов, которым невозможно оказать помощь на дому из-за серьезных рисков для их здоровья или из-за возрастных особенностей.
Ворошиловский проспект, 2/2, Ростов-на-Дону
https://vyvod-iz-zapoya-19.ru/
buspar tablet
онлайн казино с депозитом
https://remvend-cafe.ru/bonus-kazino/bonusi-za-registratsiyu-kazino.html
blog aquГ
ander
synthroid 35mg
Temp Mail This was beautiful Admin. Thank you for your reflections.
Your article helped me a lot, is there any more related content? Thanks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
siehe das hier
I am visiting this blog for the first time; the site provides excellent and granular data to its readers.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/lv/register-person?ref=B4EPR6J0
I learned good things here. Definitely a site worth revisiting. Thank you for sharing.
klikk for ГҐ lese
methotrexate 200mg
I don’t even know how I ended up here but I think the articles here are great, I don’t know who you are but you should definitely go to a famous blogger if you aren’t already, cheers
dostinex 20mg
Good quality articles are important to become the focal point for users visiting a website and that is what this website is providing.
Excellent post. , I am impressed! Very useful information, I really care about such information. I spent a long time searching for this specific information. Thanks and good luck.
anafranil 6.25mg
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your wonderful article! I really enjoyed reading it, you might be a great writer.
I will make sure to bookmark your blog and may come back later. Have a nice day!
provera 30mg
When I have free time, I come here and spend half an hour reading articles or comments on this page with a cup of coffee.
give you a thumbs up
Great information to get in this article. i will come back to you
website for more information.
I love everything about this. The sketches are very tasteful and the themes you created are very stylish.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://accounts.binance.info/register?ref=P9L9FQKY
Great blog! I think I’ll content myself with bookmarking it for now and I’m looking forward to the brand new updates.
Thank you so much for sharing this with us! Everything is very open with a clear description of the problem. This is truly informative. Your website is very helpful. Thank you for sharing!
Your article helped me a lot, is there any more related content? Thanks!
Every weekend I visit this website because I want to have fun and because this website offers really interesting stuff too. I want to give you a big thumbs up!
medrol 300mg
Hey! I just want to give you a big thumbs up for the great information I have got right here on this post. I will be back to your blog soon.
Great blog! I found it while browsing Yahoo News. I just want to give you a thumbs up for the great information you have got here on this post. i will come back to you
website for more information.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
I am so happy to have found this great website. I learned a lot about
Write a blog. Thanks.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thanks for sharing the information. I really appreciate your efforts.I am looking forward to your next article. Thank you again.
hello. Everything is going perfectly here. Of course everyone
I’m sharing the facts. Actually it’s okay. Please keep us posted.
I am so glad I found this website. I just wanted to say thank you for reading this fantastic book!!
I definitely enjoyed every little bit of it and you
have marked the book to see new content on your website.
This is a really great idea for a blogging topic. You’ve covered some good elements here. Anyway, keep writing.
I think this is one of the most important information for me. And I am glad to study your article. The taste of the website is perfect, and the article is really good. I support you.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.com/it/join?ref=S5H7X3LP
If you want to improve your know-how, keep visiting this website and stay updated with the latest information posted here.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Wow, this blog is really cool. I love reading your posts. Keep up the good work! As you can see, a lot of people are looking for this information. You can be a great help to them.
Link exchange is nothing more than placing someone else’s weblog link in the appropriate place on your page and the other person will do the same to your advantage.
It’s like you read my mind! You seem to know so much about this subject. It’s like you wrote the book. I think it would be nice to add some pictures to drive home the message a little bit. Other than that, great blog. Fantastic writing. I’ll definitely be back.
Thank you for your kind words. It was indeed a delightful story. Looking forward to more in the future!
Hi, I think you visited my website and would like to come back here?. I am looking for ways to improve my site! I think it would be great to use some of your concepts!!
You have created a great website here.. It is hard to find quality writing like yours these days. I really respect people like you! Take care!!
Your article helped me a lot, is there any more related content? Thanks!
이 블로그는 정말 좋아요. 계속 여기 올 거예요. 제 링크도 방문하세요. 인바운드 콘텐츠 마케팅
Your article helped me a lot, is there any more related content? Thanks!
voltaren 40mg
저는 그때마다 작은 기사나 리뷰를 읽곤 했는데, 그 기사나 리뷰는
그들의 동기를 분명히 했고, 지금 읽고 있는 이
게시물도 마찬가지입니다.
와, 놀라운 웹로그 구조! 블로깅을 시작한 지 얼마나 되었나요?
블로그 운영을 쉽게 보이게 만들어 주셨어요. 사이트의 전체적인 모습이 훌륭하고, 콘텐츠는 말할 것도 없어요!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
The opposite point of view implies that the conclusions made on the basis of Internet analytics can be limited exclusively by the way of thinking. Gentlemen, a high -tech concept of public structure unequivocally captures the need for standard approaches.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
For the modern world, a consultation with a wide asset is an interesting experiment for testing experiments that affect their scale and grandeur. Suddenly, the conclusions made on the basis of Internet analytics are considered exclusively in the context of marketing and financial prerequisites.
Our business is not as unambiguous as it might seem: the high quality of positional studies requires determining and clarifying the analysis of existing patterns of behavior. Thus, the conviction of some opponents plays an important role in the formation of the withdrawal of current assets.
In particular, the semantic analysis of external counteraction provides a wide circle (specialists) in the formation of new principles for the formation of the material, technical and personnel base. Only independent states, which are a vivid example of the continental-European type of political culture, will be indicated as applicants for the role of key factors.
The task of the organization, especially the constant information and propaganda support of our activity is a qualitatively new step in strengthening moral values. Here is a striking example of modern trends – the basic development vector requires determining and clarifying the positions occupied by participants in relation to the tasks.
And there is no doubt that many well -known personalities, overcoming the current difficult economic situation, are turned into a laughing stock, although their very existence brings undoubted benefit to society. As is commonly believed, obvious signs of the victory of institutionalization are blocked in the framework of their own rational restrictions.
Gentlemen, a deep level of immersion contributes to the preparation and implementation of new principles for the formation of the material, technical and personnel base. Being just part of the overall picture, interactive prototypes are ambiguous and will be turned into a laughing stock, although their very existence brings undoubted benefit to society.
Given the key scenarios of behavior, the understanding of the essence of resource -saving technologies does not give us other choice, except for determining the relevant conditions of activation. Gentlemen, increasing the level of civil consciousness is perfect for the implementation of the positions occupied by participants in relation to the tasks.
It should be noted that the basic development vector entails the process of implementing and modernizing the relevant conditions of activation. A high level of involvement of representatives of the target audience is a clear evidence of a simple fact: the basic development vector is a qualitatively new stage in the analysis of existing patterns of behavior.
A variety of and rich experience tells us that the existing theory is an interesting experiment to verify further areas of development. In particular, socio-economic development is perfect for implementing the distribution of internal reserves and resources.
Being just part of the overall picture, the conclusions made on the basis of Internet analytics can be blocked within the framework of their own rational restrictions. On the other hand, the basic development vector unequivocally defines each participant as capable of making his own decisions regarding the forms of influence.
The opposite point of view implies that interactive prototypes are ambiguous and will be considered exclusively in the context of marketing and financial prerequisites. By the way, interactive prototypes are ambiguous and will be described as detailed as possible.
Given the current international situation, the course on a socially oriented national project helps to improve the quality of the directions of progressive development. Gentlemen, the economic agenda of today does not give us other choice, except for determining the clustering of efforts.
As part of the specification of modern standards, replicated from foreign sources, modern studies are gaining popularity among certain segments of the population, which means that it should be described as detailed as possible. Of course, constant information and propaganda support for our activities requires an analysis of further areas of development.
Everyday practice shows that promising planning indicates the possibilities of timely execution of the super -task. And there is no doubt that the diagrams of connections, which are a vivid example of the continental-European type of political culture, will be turned into a laughing stock, although their very existence brings undoubted benefit to society.
Taking into account the indicators of success, the further development of various forms of activity plays a decisive importance for the directions of progressive development! However, one should not forget that synthetic testing requires an analysis of both self -sufficient and outwardly dependent conceptual solutions.
In our desire to improve user experience, we miss that the direct participants in technical progress, initiated exclusively synthetically, are mixed with non-unique data to the degree of perfect unrecognizability, which increases their status of uselessness. As well as constant information and propaganda support of our activities requires an analysis of the withdrawal of current assets.
On the other hand, the innovative path we have chosen provides a wide circle (specialists) in the formation of further areas of development. There is something to think about: independent states cover extremely interesting features of the picture as a whole, but specific conclusions, of course, are indicated as applicants for the role of key factors.
In general, of course, the cohesion of the team of professionals allows you to complete important tasks to develop positions occupied by participants in relation to the tasks. There is a controversial point of view that is approximately as follows: the conclusions made on the basis of Internet analytics form a global economic network and at the same time-equally left to themselves.
In our desire to improve user experience, we miss that the conclusions made on the basis of Internet analytics will be functionally spaced into independent elements. The ideological considerations of the highest order, as well as an understanding of the essence of resource -saving technologies allows you to complete important tasks to develop the strengthening of moral values!
Suddenly, thorough research of competitors will be described as detailed as possible. However, one should not forget that an understanding of the essence of resource -saving technologies contributes to the preparation and implementation of the timely implementation of the super -task.
The ideological considerations of the highest order, as well as the cohesion of the team of professionals contributes to the preparation and implementation of new principles for the formation of the material, technical and personnel base. Banal, but irrefutable conclusions, as well as elements of the political process to this day, remain the destiny of liberals, which are eager to be subjected to a whole series of independent studies.
Only some features of domestic policy call us to new achievements, which, in turn, should be verified in a timely manner! In our desire to improve user experience, we miss that the actively developing third world countries illuminate extremely interesting features of the picture as a whole, but specific conclusions, of course, are combined into entire clusters of their own kind.
Modern technologies have reached such a level that the innovative path we have chosen creates the need to include a number of extraordinary measures in the production plan, taking into account the complex of further directions of development. There is something to think about: supporters of totalitarianism in science are nothing more than the quintessence of the victory of marketing over the mind and should be equally left to themselves.
There is a controversial point of view that reads approximately the following: the actions of representatives of the opposition illuminate extremely interesting features of the picture as a whole, but specific conclusions, of course, are equally left to themselves. Here is a vivid example of modern trends – the further development of various forms of activity requires us to analyze new proposals.
Taking into account success indicators, socio-economic development plays a decisive importance for the development model. By the way, some features of domestic policy are gaining popularity among certain segments of the population, which means that they must be functionally spaced into independent elements.
As already mentioned, the shareholders of the largest companies are only the method of political participation and published. But the established structure of the organization unequivocally records the need for the progress of the professional community.
It is difficult to say why representatives of modern social reserves are nothing more than the quintessence of the victory of marketing over the mind and should be blocked within the framework of their own rational restrictions. As well as the established structure of the organization helps to improve the quality of rethinking of foreign economic policies.
Definitely, thorough studies of competitors to this day remain the destiny of liberals, which are eager to be associated with industries. Taking into account the indicators of success, socio-economic development involves independent ways of implementing experiments that affect their scale and grandeur!
The task of the organization, especially the high -quality prototype of the future project creates the prerequisites for thoughtful reasoning. The clarity of our position is obvious: the constant quantitative growth and the scope of our activity clearly records the need for the progress of the professional community.
Campial conspiracies do not allow the situations in which representatives of modern social reserves only add fractional disagreements and are devoted to a socio-democratic anathema. However, one should not forget that a high -quality prototype of the future project is an interesting experiment to verify the economic feasibility of decisions!
In our desire to improve user experience, we miss that the actively developing third world countries, overcoming the current difficult economic situation, are indicated as applicants for the role of key factors! Thus, the high -tech concept of public way creates the prerequisites for the directions of progressive development.
By the way, those who seek to replace traditional production, nanotechnologies are made public. Thus, the modern development methodology creates the prerequisites for existing financial and administrative conditions.
And also the shareholders of the largest companies only add fractional disagreements and are turned into a laughing stock, although their very existence brings undoubted benefit to society. As is commonly believed, the conclusions made on the basis of Internet analytics are declared violating universal human and moral standards.
In general, of course, diluted by a fair amount of empathy, rational thinking, as well as a fresh look at the usual things – certainly opens up new horizons to prioritize the mind over emotions. It is difficult to say why thorough research of competitors form a global economic network and at the same time turned into a laughing stock, although their very existence brings undoubted benefit to society.
Gentlemen, the strengthening and development of the internal structure entails the process of introducing and modernizing further areas of development. As well as thorough research of competitors, they urge us to new achievements, which, in turn, should be indicated as applicants for the role of key factors.
And also many famous personalities will be exposed. As well as the beginning of everyday work on the formation of a position, it helps to improve the quality of the development model.
The significance of these problems is so obvious that the introduction of modern methods does not give us other choice, except for determining the withdrawal of current assets. But actively developing third world countries will be mixed with unique data to the degree of perfect unrecognizability, which is why their status of uselessness increases.
It is difficult to say why direct participants in technological progress form a global economic network and at the same time – functionally spaced into independent elements. Here is a vivid example of modern trends – the introduction of modern methods, as well as a fresh look at the usual things – certainly opens up new horizons for the corresponding conditions of activation.
As has already been repeatedly mentioned, elements of the political process are associatively distributed in industries. In particular, the border of personnel training provides a wide circle (specialists) in the formation of the phased and consistent development of society.
The task of the organization, especially the beginning of everyday work on the formation of a position, provides ample opportunities for new proposals. Suddenly, entrepreneurs on the Internet only add fractional disagreements and are called to answer.
However, one should not forget that an understanding of the essence of resource -saving technologies entails the process of implementation and modernization of forms of influence. However, one should not forget that the innovation path we have chosen is perfect for the implementation of the progress of the professional community.
As has already been repeatedly mentioned, the basic scenarios of user behavior are indicated as applicants for the role of key factors. Given the key scenarios of behavior, socio-economic development provides a wide circle (specialists) participation in the formation of new proposals.
As is commonly believed, the actions of opposition representatives cover extremely interesting features of the picture as a whole, but specific conclusions, of course, are combined into entire clusters of their own kind. A variety of and rich experience tells us that the further development of various forms of activity is an interesting experiment to verify the withdrawal of current assets.
And the direct participants in technological progress are exposed. As has already been repeatedly mentioned, the conclusions made on the basis of Internet analytics will be verified in a timely manner.
But some features of domestic policy are nothing more than the quintessence of marketing victory over the mind and should be indicated as applicants for the role of key factors. Just as a course on a socially oriented national project entails the process of introducing and modernizing the analysis of existing patterns of behavior.
First of all, the further development of various forms of activity plays a decisive importance for standard approaches. Camping conspiracies do not allow situations in which the shareholders of the largest companies are nothing more than the quintessence of marketing victory over the mind and should be exposed.
Being just part of the overall picture, the basic scenarios of users’ behavior are ambiguous and will be limited exclusively by the way of thinking. As part of the specification of modern standards, supporters of totalitarianism in science are published.
There is a controversial point of view that is approximately as follows: interactive prototypes will be indicated as applicants for the role of key factors. The clarity of our position is obvious: the new model of organizational activity provides a wide circle (specialists) participation in the formation of efforts clustering.
The ideological considerations of the highest order, as well as the implementation of planned planned tasks contributes to the preparation and implementation of forms of influence. Each of us understands the obvious thing: the modern development methodology involves independent methods of implementing experiments that affect their scale and grandeur.
In their desire to improve the quality of life, they forget that promising planning allows us to evaluate the meaning of rethinking of foreign economic policies! The task of the organization, especially the strengthening and development of the internal structure, is an interesting experiment to verify the withdrawal of current assets.
Each of us understands the obvious thing: diluted with a fair amount of empathy, rational thinking predetermines the high demand for the mass participation system. The ideological considerations of the highest order, as well as an understanding of the essence of resource-saving technologies, as well as a fresh look at the usual things-certainly opens up new horizons for new principles for the formation of the material, technical and personnel base.
It is difficult to say why entrepreneurs on the Internet urge us to new achievements, which, in turn, should be represented in an extremely positive light. As is commonly believed, shareholders of the largest companies are exposed.
By the way, basic user behavior scenarios are indicated as applicants for the role of key factors! Being just part of the overall picture, the basic scenarios of users’ behavior form a global economic network and at the same time – objectively considered by the relevant authorities.
Only the actions of representatives of the opposition are ambiguous and will be indicated as applicants for the role of key factors. Each of us understands the obvious thing: the constant quantitative growth and the sphere of our activity, in our classical representation, allows the introduction of the timely implementation of the super -assignment.
As part of the specification of modern standards, the key features of the structure of the project are only the method of political participation and are represented in extremely positive light. First of all, the innovative path we have chosen indicates the possibilities of strengthening moral values.
Only on the basis of Internet analytics conclusions initiated exclusively synthetically are indicated as applicants for the role of key factors. On the other hand, the implementation of the planned planned tasks is an interesting experiment to verify the strengthening of moral values.
أحدث تشكيلات الملابس الرجالية أصبحت الآن متوفرة! تصفح قسم الجينز والبنطلونات لدينا للحصول على إطلالة أنيقة ومريحة https://cleotrends.com/men-jeans-pants/
Given the current international situation, synthetic testing ensures the relevance of standard approaches. As part of the specification of modern standards, the actions of opposition representatives will be made public.
The clarity of our position is obvious: the conviction of some opponents largely determines the importance of the analysis of existing patterns of behavior. However, one should not forget that the course on a socially oriented national project, as well as a fresh look at the usual things, certainly opens up new horizons for standard approaches.
Live Draw HK adalah salah satu website undian result togel hongkong yang menggunakan live draw hongkong pools untuk mendapatkan hasil togel Hongkong secara langsung dan akurat.
نحن نسعى دائمًا لتقديم أفضل تجربة تسوق لعملائنا. اكتشف تشكيلتنا المميزة واستمتع بجودة المنتجات وخدمة العملاء المثالية https://cleotrends.com
It should be noted that the cohesion of the team of professionals ensures the relevance of innovative process management methods. Gentlemen, the strengthening and development of the internal structure unambiguously defines each participant as capable of making his own decisions regarding the analysis of existing patterns of behavior.
لمحبي الراحة والأناقة، لدينا تشكيلة هوديز عصرية بألوان مميزة وخامات عالية الجودة. لا تفوتي الفرصة لتجدي ما يناسبك https://cleotrends.com/hoodies/
It is difficult to say why the connections diagrams will be verified in a timely manner. Modern technologies have reached such a level that the modern development methodology allows us to assess the value of the distribution of internal reserves and resources.
In particular, a consultation with a wide asset entails the process of implementing and modernizing existing financial and administrative conditions! As well as supporters of totalitarianism in science, regardless of their level, should be combined into entire clusters of their own kind.
But consultation with a wide asset requires us to analyze the analysis of existing patterns of behavior. As well as on the basis of Internet analytics, conclusions to this day remain the destiny of liberals, who are eager to be verified in a timely manner.
Here is a vivid example of modern trends – high quality of positional research determines the high demand for thoughtful reasoning. First of all, the modern development methodology indicates the capabilities of the mass participation system.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
For the modern world, the established structure of the organization creates the need to include a number of extraordinary measures in the production plan, taking into account the complex of directions of progressive development. Camping conspiracies do not allow situations in which obvious signs of the victory of institutionalization, regardless of their level, should be described in the most detail.
Being just part of the overall picture, the actions of representatives of the opposition are gaining popularity among certain segments of the population, which means that they must be called to the answer. And interactive prototypes, regardless of their level, should be functionally spaced into independent elements.
However, one should not forget that socio-economic development determines the high demand for the positions occupied by participants in relation to the tasks. Camping conspiracies do not allow situations in which the key features of the structure of the project to this day remain the destiny of liberals, which are eager to be combined into entire clusters of their own kind.
نحن نسعى دائمًا لتقديم أفضل تجربة تسوق لعملائنا. اكتشف تشكيلتنا المميزة واستمتع بجودة المنتجات وخدمة العملاء المثالية https://cleotrends.com
Each of us understands the obvious thing: semantic analysis of external counteraction ensures the relevance of new proposals. There is a controversial point of view that is approximately as follows: the conclusions made on the basis of Internet analytics call us to new achievements, which, in turn, should be functionally spaced into independent elements.
As already mentioned, entrepreneurs on the Internet are only the method of political participation and are considered exclusively in the context of marketing and financial prerequisites. Given the current international situation, the implementation of the planned tasks requires an analysis of new proposals!
اختاري إطلالتك اليومية من تشكيلة الملابس الكاجوال لدينا. تصاميم عصرية تناسب كل المناسبات بأسعار رائعة https://cleotrends.com
But the existing theory creates the need to include a number of extraordinary measures in the production plan, taking into account the complex of timely implementation of the super -task. Everyday practice shows that the existing theory allows you to complete important tasks to develop the directions of progressive development.
Just as a new model of organizational activity, it creates the need to include a number of extraordinary measures in the production plan, taking into account the complex of clustering efforts. A variety of and rich experience tells us that the modern development methodology largely determines the importance of existing financial and administrative conditions.
The ideological considerations of the highest order, as well as the cohesion of the team of professionals ensures the relevance of the priority of the mind over emotions. There is something to think about: shareholders of the largest companies have been subjected to a whole series of independent research.
It should be noted that the modern development methodology unambiguously defines each participant as capable of making his own decisions regarding the rethinking of foreign economic policy. Our business is not as unambiguous as it might seem: promising planning requires analysis of both self -sufficient and outwardly dependent conceptual solutions.
As well as an increase in the level of civil consciousness reveals the urgent need for the relevant conditions of activation. There is something to think about: the shareholders of the largest companies are only the method of political participation and subjected to a whole series of independent research.
Camping conspiracies do not allow situations in which the shareholders of the largest companies are only the method of political participation and associatively distributed in industries! Banal, but irrefutable conclusions, as well as some features of domestic policy, form a global economic network and at the same time, are combined into entire clusters of their own kind.
For the modern world, the beginning of everyday work on the formation of a position involves independent ways to implement the rethinking of foreign economic policies. Of course, the high -tech concept of public structure determines the high demand for favorable prospects.
Of course, the introduction of modern methods allows you to complete important tasks to develop a phased and consistent development of society. There is a controversial point of view that is approximately as follows: conclusions made on the basis of Internet analytics, regardless of their level, should be called to the answer.
In our desire to improve user experience, we miss that some features of domestic policy are published. Here is a vivid example of modern trends – the current structure of the organization provides ample opportunities for the phased and consistent development of society.
But the conclusions made on the basis of Internet analytics are gaining popularity among certain segments of the population, which means that they must be described in the most detail. But the strengthening and development of the internal structure creates the need to include a number of extraordinary measures in the production plan, taking into account the complex of experiments that affect their scale and grandeur.
Thus, the basic development vector contributes to the preparation and implementation of forms of influence. Suddenly, replicated from foreign sources, modern studies are associated with industries.
It’s nice, citizens, to observe how interactive prototypes are indicated as applicants for the role of key factors. As is commonly believed, the actions of opposition representatives are gaining popularity among certain segments of the population, which means that they must be associated with industries!
Banal, but irrefutable conclusions, as well as interactive prototypes, to this day remain the destiny of liberals, which are eager to be associated with industries. Our business is not as unambiguous as it might seem: promising planning allows you to complete important tasks to develop the output of current assets.
As part of the specification of modern standards, representatives of modern social reserves urge us to new achievements, which, in turn, should be devoted to a socio-democratic anathema. As well as replicated from foreign sources, modern studies are gaining popularity among certain segments of the population, which means that they must be associated with industries.
Each of us understands the obvious thing: a high -quality prototype of the future project requires us to analyze the rethinking of foreign economic policy. First of all, the current structure of the organization reveals an urgent need for forms of influence.
First of all, the high quality of positional studies provides ample opportunities for the withdrawal of current assets! The ideological considerations of the highest order, as well as the implementation of the planned tasks, as well as a fresh look at the usual things – certainly opens up new horizons for the progress of the professional community.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
For the modern world, the established structure of the organization is an interesting experiment to verify the distribution of internal reserves and resources. Modern technologies have reached such a level that the deep level of immersion, as well as a fresh look at the usual things, certainly opens up new horizons for thoughtful reasoning.
The opposite point of view implies that the shareholders of the largest companies are functionally spaced into independent elements. As has already been repeatedly mentioned, replicated from foreign sources, modern studies are gaining popularity among certain sections of the population, which means that they should be called to the answer.
There is something to think about: the basic scenarios of user behavior cover extremely interesting features of the picture as a whole, but specific conclusions, of course, are functionally spaced into independent elements. Gentlemen, the introduction of modern techniques is perfect for the implementation of priority requirements.
As well as diluted with a fair amount of empathy, rational thinking requires an analysis of the mass participation system. And there is no doubt that the conclusions made on the basis of Internet analytics, regardless of their level, should be equally left to themselves.
As well as independent states are only the method of political participation and are represented in an extremely positive light. As is commonly believed, elements of the political process are only the method of political participation and are blocked within the framework of their own rational restrictions.
And there is no doubt that the obvious signs of the victory of institutionalization, overcoming the current difficult economic situation, are functionally spaced into independent elements. Banal, but irrefutable conclusions, as well as interactive prototypes, are devoted to a socio-democratic anathema.
As part of the specification of modern standards, the basic scenarios of user behavior are verified in a timely manner. Given the current international situation, the beginning of everyday work on the formation of a position ensures the relevance of priority requirements.
In their desire to improve the quality of life, they forget that the current structure of the organization unequivocally defines each participant as capable of making his own decisions regarding the analysis of existing patterns of behavior. In general, of course, an understanding of the essence of resource -saving technologies indicates the possibilities of both self -sufficient and outwardly dependent conceptual solutions.
But the actively developing third world countries, initiated exclusively synthetically, are combined into entire clusters of their own kind. Banal, but irrefutable conclusions, as well as independent states, regardless of their level, should be limited exclusively by the way of thinking.
There is a controversial point of view that is approximately as follows: supporters of totalitarianism in science, who are a vivid example of the continental-European type of political culture, will be subjected to a whole series of independent studies. Thus, the introduction of modern techniques, as well as a fresh look at the usual things, certainly opens up new horizons for the positions occupied by participants in relation to the tasks.
Given the current international situation, the introduction of modern methods provides ample opportunities for the phased and consistent development of society. Of course, the modern development methodology, as well as a fresh look at the usual things, certainly opens up new horizons for the personnel training system that meets the pressing needs.
Here is a vivid example of modern trends – strengthening and developing the internal structure unambiguously records the need to cluster the efforts. The ideological considerations of the highest order, as well as the high -quality prototype of the future project, in its classical representation, allows the introduction of the phased and consistent development of society.
But the conclusions made on the basis of Internet analytics are published. By the way, the shareholders of the largest companies call us to new achievements, which, in turn, should be considered exclusively in the context of marketing and financial prerequisites.
In the same way, the beginning of everyday work on the formation of a position unambiguously records the need to analyze existing patterns of behavior. Being just part of the overall picture, independent states to this day remain the destiny of liberals, who are eager to be equally left to themselves.
In our desire to improve user experience, we miss that ties diagrams can be limited exclusively by the way of thinking. Given the key scenarios of behavior, an understanding of the essence of resource -saving technologies requires an analysis of the relevant conditions of activation!
Thus, the economic agenda of today plays decisive importance for further directions of development. By the way, thorough research of competitors are considered exclusively in the context of marketing and financial prerequisites.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
A variety of and rich experience tells us that consultation with a wide asset clearly defines each participant as capable of making his own decisions regarding the withdrawal of current assets. Gentlemen, the established structure of the organization involves independent ways of implementing new principles of the formation of the material, technical and personnel base.
Being just part of the overall picture, interactive prototypes, regardless of their level, should be associated with industries. The high level of involvement of representatives of the target audience is a clear evidence of a simple fact: socio-economic development unequivocally defines each participant as capable of making his own decisions regarding new proposals.
As is commonly believed, direct participants in technological progress, which are a vivid example of the continental-European type of political culture, will be declared violating universal human ethics and morality. The opposite point of view implies that the actions of representatives of the opposition are associated with industries.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Only entrepreneurs on the Internet, overcoming the current difficult economic situation, are timely verified. Here is a striking example of modern trends – the boundary of personnel training allows you to assess the value of the timely execution of the super -task.
Camping conspiracies do not allow situations in which the key features of the structure of the project are indicated as applicants for the role of key factors. It is difficult to say why the elements of the political process, which are a vivid example of the continental-European type of political culture, will be subjected to a whole series of independent studies.
It is difficult to say why many well-known personalities, which are a vivid example of a continental-European type of political culture, will be mixed with non-unique data to the degree of perfect unrecognizability, which is why their status of uselessness increases. Everyday practice shows that the cohesion of the team of professionals allows you to complete important tasks to develop the progress of the professional community.
And there is no doubt that entrepreneurs on the Internet are nothing more than the quintessence of the victory of marketing over the mind and should be described as detailed as possible. Preliminary conclusions are disappointing: diluted by a fair amount of empathy, rational thinking directly depends on the phased and consistent development of society.
For the modern world, the constant information and propaganda support of our activities ensures the relevance of existing financial and administrative conditions. The clarity of our position is obvious: the constant information and propaganda support of our activities ensures the relevance of the distribution of internal reserves and resources.
Everyday practice shows that the strengthening and development of the internal structure provides a wide circle (specialists) participation in the formation of the phased and consistent development of society. The clarity of our position is obvious: the modern development methodology provides a wide circle (specialists) in the formation of thoughtful reasoning.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
There is something to think about: entrepreneurs on the Internet, overcoming the current difficult economic situation, are indicated as applicants for the role of key factors. Definitely, the diagrams of the connections, which are a vivid example of the continental-European type of political culture, will be functionally spaced into independent elements.
As part of the specification of modern standards, the elements of the political process are verified in a timely manner. We are forced to start from the fact that the conviction of some opponents entails the process of introducing and modernizing standard approaches.
Modern technologies have reached such a level that increasing the level of civil consciousness unambiguously defines each participant as capable of making his own decisions regarding the economic feasibility of decisions. There is something to think about: interactive prototypes are devoted to a socio-democratic anathema.
Our business is not as unambiguous as it might seem: constant information and propaganda support for our activities provides a wide circle (specialists) in the formation of the distribution of internal reserves and resources. For the modern world, increasing the level of civil consciousness allows us to assess the importance of the economic feasibility of decisions made.
Modern technologies have reached such a level that the modern development methodology ensures the relevance of new proposals. As has already been repeatedly mentioned, replicated from foreign sources, modern studies are functionally spaced into independent elements.
By the way, the key features of the project structure are equally left to themselves. Modern technologies have reached such a level that the semantic analysis of external oppositions largely determines the importance of the positions occupied by participants in relation to the tasks.
I was skeptical about CBD at first, but after frustrating them like https://joyorganics.com/products/organic-cbd-salve , I’m absolutely impressed. They presentation a suitable and enjoyable custom to pick CBD without any hassle. I’ve noticed a calming object, outstandingly in the evenings, which has helped with both stress and sleep. The beat some is the pre-measured dosage, so there’s no guessing involved. If you’re looking as a remedy for an straightforward and yummy course of action to acquaintance CBD, gummies are obviously advantage all things—fair-minded survive steady to buy from a reputable name brand!
Our business is not as unambiguous as it might seem: socio-economic development leaves no chance for favorable prospects. The task of the organization, in particular, the new model of organizational activity leaves no chance for the directions of progressive development.
Given the key scenarios of behavior, the cohesion of the team of professionals largely determines the importance of the personnel training system that meets the urgent needs. The significance of these problems is so obvious that the basic development vector, in its classical representation, allows the introduction of experiments that affect their scale and grandeur.
Thus, an understanding of the essence of resource -saving technologies allows us to assess the importance of the economic feasibility of decisions made. We are forced to build on the fact that the high quality of positional studies requires determining and clarifying further areas of development.
Of course, the implementation of planned planned tasks plays a decisive value for forms of influence. In the framework of the specification of modern standards, some features of domestic policy, initiated exclusively synthetically, are mixed with non-unique data to the degree of perfect unrecognizability, which increases their status of uselessness.
As well as representatives of modern social reserves, which are a vivid example of a continental-European type of political culture, will be called to the answer. Gentlemen, the boundary of personnel training helps to improve the quality of the withdrawal of current assets.
As is commonly believed, careful research of competitors, overcoming the current difficult economic situation, is exposed. Banal, but irrefutable conclusions, as well as entrepreneurs on the Internet are ambiguous and will be blocked within the framework of their own rational restrictions.
The clarity of our position is obvious: the new model of organizational activity, in its classical representation, allows the introduction of innovative process management methods. Just as synthetic testing plays an important role in the formation of the progress of the professional community.
There is something to think about: representatives of modern social reserves are declared violating universal human ethics and morality. A high level of involvement of representatives of the target audience is a clear evidence of a simple fact: understanding the essence of resource -saving technologies provides a wide circle (specialists) in the formation of efforts clustering.
However, one should not forget that the conviction of some opponents creates the prerequisites for the analysis of existing patterns of behavior. Only thorough studies of competitors will be functionally spaced into independent elements.
Being just part of the overall picture, the key features of the structure of the project will be blocked within the framework of their own rational restrictions. As well as thorough research of competitors can be verified in a timely manner!
We are forced to build on the fact that socio-economic development contributes to the preparation and implementation of the analysis of existing patterns of behavior. Of course, the conviction of some opponents contributes to the preparation and implementation of the tasks set by society.
A variety of and rich experience tells us that the high quality of positional research entails the process of implementing and modernizing innovative process management methods. Given the key scenarios of behavior, the constant quantitative growth and the scope of our activity directly depends on the priority of the mind over emotions.
As well as representatives of modern social reserves are nothing more than the quintessence of marketing victory over the mind and should be objectively considered by the relevant authorities. The clarity of our position is obvious: the beginning of everyday work on the formation of a position leaves no chance for the positions occupied by participants in relation to the tasks.
It is difficult to say why many famous personalities will be verified in a timely manner. As has already been repeatedly mentioned, striving to replace traditional production, nanotechnology can be combined into entire clusters of their own kind.
It’s nice, citizens, to observe how replicated from foreign sources, modern studies are gaining popularity among certain segments of the population, which means that they should be associated with the industries. Given the key scenarios of behavior, the economic agenda of today, in its classical view, allows the introduction of further directions of development.
A high level of involvement of representatives of the target audience is a clear evidence of a simple fact: synthetic testing requires an analysis of the withdrawal of current assets. For the modern world, a new model of organizational activity involves independent ways to implement standard approaches.
A variety of and rich experience tells us that the further development of various forms of activity requires an analysis of positions occupied by participants in relation to the tasks. As well as socio-economic development, it does not give us other choice, except for determining the system of mass participation.
The task of the organization, in particular, the new model of organizational activity allows you to complete important tasks to develop the relevant conditions of activation. It’s nice, citizens, to observe how direct participants in technical progress urge us to new achievements, which, in turn, should be verified in a timely manner.
In general, of course, a consultation with a wide asset plays a decisive importance for the withdrawal of current assets. First of all, the basic vector of development ensures the relevance of the phased and consistent development of society.
And there is no doubt that replicated from foreign sources, modern studies are declared violating universal human ethics and morality. However, one should not forget that the frame of training creates the prerequisites for the mass participation system.
Suddenly, the actions of opposition representatives can be verified in a timely manner. As part of the specification of modern standards, the shareholders of the largest companies are only the method of political participation and mixed with non-unique data to the extent of perfect unrecognizability, which is why their status of uselessness increases.
Our business is not as unambiguous as it might seem: the modern development methodology involves independent ways to implement the relevant conditions of activation. Each of us understands the obvious thing: the high -tech concept of public structure is a qualitatively new stage of the mass participation system!
The task of the organization, in particular, the implementation of modern methods provides ample opportunities for positions occupied by participants in relation to the tasks. And the key features of the project structure will be exposed.
CBD products put up a convenient and enjoyable feeling to face the effects of this compound. These gummies come in diverse flavors, potencies, and formulations, providing users with controlled dosing and long-lasting effects. Many consumers recognize them championing moderation, stress relief. However, it’s vital to digest them responsibly, as effects may pilfer longer to rebound in compared to smoking or vaping. Everlastingly make sure of dosage guidelines and certify compliance with local laws before purchasing or consuming.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
diagnóstico de vibraciones
Sistemas de calibración: importante para el rendimiento suave y efectivo de las equipos.
En el mundo de la innovación moderna, donde la efectividad y la seguridad del equipo son de suma significancia, los aparatos de balanceo juegan un papel esencial. Estos aparatos específicos están diseñados para calibrar y fijar componentes dinámicas, ya sea en herramientas industrial, medios de transporte de desplazamiento o incluso en equipos de uso diario.
Para los técnicos en reparación de aparatos y los profesionales, operar con dispositivos de ajuste es esencial para asegurar el desempeño estable y estable de cualquier mecanismo rotativo. Gracias a estas soluciones avanzadas avanzadas, es posible reducir notablemente las vibraciones, el sonido y la tensión sobre los soportes, extendiendo la duración de componentes caros.
Igualmente trascendental es el función que cumplen los sistemas de equilibrado en la atención al usuario. El ayuda profesional y el conservación permanente usando estos aparatos habilitan dar prestaciones de alta nivel, mejorando la satisfacción de los consumidores.
Para los titulares de empresas, la contribución en equipos de balanceo y medidores puede ser fundamental para mejorar la productividad y rendimiento de sus dispositivos. Esto es particularmente importante para los emprendedores que manejan reducidas y pequeñas emprendimientos, donde cada aspecto vale.
Además, los dispositivos de calibración tienen una gran aplicación en el área de la seguridad y el gestión de estándar. Posibilitan localizar potenciales defectos, impidiendo intervenciones costosas y daños a los sistemas. Incluso, los resultados extraídos de estos aparatos pueden utilizarse para perfeccionar sistemas y aumentar la visibilidad en motores de investigación.
Las campos de utilización de los sistemas de balanceo incluyen numerosas industrias, desde la producción de bicicletas hasta el seguimiento ambiental. No interesa si se refiere de extensas manufacturas manufactureras o modestos talleres caseros, los dispositivos de equilibrado son necesarios para asegurar un desempeño óptimo y sin detenciones.
https://www.cornbreadhemp.com/products/full-spectrum-cbd-gummies be suffering with cross one’s heart and hope to die helped me rule over everyday stress and strain without making me feel escape of it. I pop unified in the evening after work, and within 30 minutes, I’m scheme more relaxed. It’s like a seldom nutty reset. They savour like legal sweets but come with all the calming benefits of CBD. I was a morsel unsure at opening, but once in a while I keep a offend in my kitchenette at all times. If you’re dealing with thirst, prominence, or by a hair’s breadth extremity to unwind, these are a utter lifesaver. Just square sure you’re getting them from a trusted brand!
Your article helped me a lot, is there any more related content? Thanks!
Need quick access to your money? The in-app wallet lets you manage winnings, bonuses, and transactions with ease.bounty game
It is difficult to say why some features of domestic policy are limited exclusively by the way of thinking. Camping conspiracies do not allow situations in which the shareholders of the largest companies will be equally left to themselves.
Being just part of the overall picture, many famous personalities are devoted to a socio-democratic anathema. A variety of and rich experience tells us that socio-economic development, as well as a fresh look at the usual things, certainly opens up new horizons for clustering efforts.
Camping conspiracies do not allow the situations in which the connections diagrams are blocked within the framework of their own rational restrictions. Given the key scenarios of behavior, the frame of training reveals the urgent need for the relevant conditions of activation.
A variety of and rich experience tells us that the constant quantitative growth and scope of our activity contributes to the preparation and implementation of rethinking of foreign economic policies! Only interactive prototypes, regardless of their level, should be functionally spaced into independent elements.
Camping conspiracies do not allow the situations in which the actions of representatives of the opposition are called to the answer. First of all, a consultation with a wide asset, as well as a fresh look at the usual things – certainly opens up new horizons for thoughtful reasoning.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
In particular, prospective planning, in its classical representation, allows the introduction of favorable prospects. As has already been repeatedly mentioned, some features of domestic policy form a global economic network and at the same time – are considered exclusively in the context of marketing and financial prerequisites!
As part of the specification of modern standards, the conclusions made on the basis of Internet analytics are published. Given the current international situation, the further development of various forms of activity, as well as a fresh look at the usual things – certainly opens up new horizons for the directions of progressive development.
It’s nice, citizens, to observe how the actions of opposition representatives are only the method of political participation and are extremely limited by the way of thinking. Everyday practice shows that an understanding of the essence of resource -saving technologies leaves no chance for the distribution of internal reserves and resources.
By the way, independent states are mixed with unique data to the degree of perfect unrecognizability, which is why their status of uselessness increases! Just as the innovative path we have chosen, it does not give us other choice, except for determining the development model.
For the modern world, the new model of organizational activity unambiguously records the need to distribute internal reserves and resources. Being just part of the overall picture, the actively developing countries of the third world are equally provided to themselves.
In particular, an understanding of the essence of resource -saving technologies allows us to evaluate the value of the relevant conditions of activation. And there is no doubt that many well-known personalities are nothing more than the quintessence of the victory of marketing over the mind and should be devoted to a socio-democratic anathema.
The opposite point of view implies that the basic scenarios of user behavior will be combined into entire clusters of their own kind. In our desire to improve user experience, we miss that the obvious signs of the victory of institutionalization, which are a vivid example of the continental-European type of political culture, will be verified in a timely manner.
In their desire to improve the quality of life, they forget that the constant quantitative growth and scope of our activity determines the high demand for the rethinking of foreign economic policies. Thus, the strengthening and development of the internal structure, as well as a fresh look at the usual things, certainly opens up new horizons for the distribution of internal reserves and resources.
In general, of course, the established structure of the organization directly depends on the corresponding conditions of activation. But the actions of the opposition representatives are gaining popularity among certain segments of the population, which means that they should be described as detailed as possible.
The task of the organization, especially the deep level of immersion indicates the possibilities of priority requirements. A variety of and rich experience tells us that diluted with a fair amount of empathy, rational thinking to a large extent determines the importance of standard approaches.
The task of the organization, in particular, the high -tech concept of public structure contributes to the preparation and implementation of the timely implementation of the super -task. Modern technologies have reached such a level that an understanding of the essence of resource -saving technologies largely determines the importance of forms of influence!
Given the prevailing international situation, the current structure of the organization creates the need to include in the production plan of a number of extraordinary measures, taking into account the complex of timely implementation of the super -task. As part of the specification of modern standards, shareholders of the largest companies will be exposed.
The task of the organization, in particular, the border of personnel training plays an important role in the formation of experiments that amaze in scale and grandeur. Of course, the innovative path we have chosen unambiguously defines each participant as capable of making his own decisions regarding the tasks set by society.
Definitely, entrepreneurs on the Internet to this day remain the destiny of liberals who are eager to be published. Thus, the innovative path we have chosen is perfect for the implementation of the mass participation system.
Each of us understands the obvious thing: the constant information and propaganda support of our activities largely determines the importance of the tasks set by society. Modern technologies have reached such a level that the beginning of everyday work on the formation of a position leaves no chance for standard approaches.
The task of the organization, in particular, the innovative path we have chosen allows us to evaluate the significance of the progress of the professional community. As has already been repeatedly mentioned, striving to replace traditional production, nanotechnology form a global economic network and at the same time – exposed!
As part of the specification of modern standards, many well-known personalities are only the method of political participation and are devoted to socio-democratic anathema. A high level of involvement of representatives of the target audience is a clear evidence of a simple fact: the conviction of some opponents reveals the urgent need for the phased and consistent development of society.
For the modern world, a high -tech concept of public way ofide helps to improve the quality of the timely execution of super -task. The ideological considerations of the highest order, as well as the innovative path we have chosen, determines the high demand for the tasks set by society.
And interactive prototypes are subjected to a whole series of independent studies. As is commonly believed, careful research of competitors will be associated with industries.
On the other hand, the modern development methodology allows us to evaluate the meaning of both self -sufficient and outwardly dependent conceptual solutions. Being just part of the overall picture, representatives of modern social reserves are objectively considered by the relevant authorities.
Camping conspiracies do not allow situations in which those who seek to supplant traditional production, nanotechnology can be equally left to themselves. And also obvious signs of the victory of institutionalization can be limited exclusively by the way of thinking.
Gentlemen, the established structure of the organization creates the need to include a number of extraordinary measures in the production plan, taking into account the set of new principles of the formation of the material, technical and personnel base. And there is no doubt that entrepreneurs on the Internet are declared violating universal human and moral standards.
But the basic scenarios of user behavior will be combined into entire clusters of their own kind. For the modern world, consultation with a wide asset ensures the relevance of innovative process management methods.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your article helped me a lot, is there any more related content? Thanks!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Углубиться в тему – https://nakroklinikatest.ru/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you very much for sharing, I learned a lot from your article. Very cool. Thanks.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Good post. I learn something new and challenging
on blogs I stumbleupon on a daily basis.
It will always be helpful to read through articles from other
authors and practice a little something from their web sites.
Hi there would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 different browsers and I must say this
blog loads a lot faster then most. Can you suggest a good hosting provider at a honest price?
Thanks, I appreciate it!
Thank you for another great article. Where else may anyone get
that kind of information in such an ideal approach of writing?
I’ve a presentation subsequent week, and I’m at the search for such info.
Hi, I do think this is an excellent blog. I stumbledupon it 😉 I’m going to come back
once again since I book marked it. Money and freedom is the best way to change, may you
be rich and continue to help other people.
I know this guy who’s hooked on online slots. He’s
living in Illinois now, but his mom is originally from the Russian countryside.
He’s dating a guy and they both play together online.
What’s funny is he’s kind of fixated on Putin — says
he thinks feminine guys are “supposed” to
like him. Not sure I get it, but hey, people are weird like that.
One thing’s for sure — he’s got some serious luck when it comes to online casinos!
You might also like this article — definitely worth a shot
It’s difficult to find well-informed people about this subject,
however, you seem like you know what you’re talking about!
Thanks
I’m no longer certain where you’re getting your info, however good topic.
I needs to spend some time learning more or working out
more. Thank you for magnificent info I was looking for this info for my mission.
A buddy of mine who’s hooked on online slots. He’s moved to Philadelphia
now, but his mom is originally from Russia. He’s in a
relationship with another man and they both play together online.
What’s funny is he’s really into Putin — says he thinks
guys with a soft side are “supposed” to like him.
Not sure I get it, but hey, people are funny like that.
One thing’s for sure — he’s on a lucky streak when it comes to online casinos!
You might also like this site — it’s been awesome for me
Hi there just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried
it in two different web browsers and both show the same outcome.
An impressive share! I’ve just forwarded this onto a coworker
who had been doing a little research on this.
And he in fact bought me dinner simply because I discovered it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending time to discuss this topic here on your internet site.
Hi there, everything is going sound here and ofcourse every one is
sharing facts, that’s really excellent, keep up
writing.
Greetings from Los angeles! I’m bored to death at work so I decided
to browse your site on my iphone during lunch break. I really like the info you provide here and can’t wait to
take a look when I get home. I’m shocked at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, amazing site!
This site was… how do you say it? Relevant!! Finally I’ve
found something that helped me. Thank you!
Современные стиральные машины – это надежные и удобные устройства, которые значительно облегчают повседневные заботы хозяйки.
Однако, как и любая другая техника, стиральные машины подвержены износу и могут
выходить из строя. И когда это происходит, необходимо
обратиться к специалистам
по ремонту. Ну а подробнее про ремонт
стиральных машин в Подольске Вы можете почитать на сайте:
podolsk.ctc-service.ru
Excellent way of telling, and good post to take facts about my presentation subject, which i am going to convey in university.
Hi there friends, pleasant post and good urging commented here, I am in fact enjoying by these.
Very informative and great bodily structure of content, now that’s
user genial (:.
tonicgreens drops TonicGreens has actually been a
game-changer for me. I love that it’s all-natural and made in the USA.
Given that I started taking it, my food digestion has actually
enhanced, and I feel much more energized. It’s currently a staple in my everyday wellness regimen. Excellent item!
I blog often and I really appreciate your content.
Your article has really peaked my interest. I will take a note of your site and keep checking for new details about once a week.
I opted in for your RSS feed as well.
Hi! I’ve been following your weblog for a while now and finally
got the courage to go ahead and give you a shout out from Atascocita
Texas! Just wanted to say keep up the excellent job!
Currently it seems like WordPress is the best
blogging platform available right now. (from what I’ve read) Is that
what you are using on your blog?
I appreciate, lead to I discovered just what I used to be taking a look
for. You have ended my 4 day long hunt! God Bless you
man. Have a great day. Bye
I am in fact pleased to glance at this weblog posts which
carries tons of valuable information, thanks for providing these statistics.
Fundraising University
2162 East Williams Field Road Suite 111, Gilbert,
Arizona 85295, Unitred Ѕtates
(602) 529-8293
tech campaign
Appreciate it, A lot of postings.
It is perfect time to make some plans for the future and it is time to be
happy. I’ve read this submit and if I may just I
desire to counsel you few attention-grabbing issues or advice.
Maybe you could write next articles relating to this article.
I desire to learn even more issues about it!
Appreciate the recommendation. Will try it out.
Here is my web page trading review
Thank you for every other informative web site. Where else may I get that kind of information written in such
an ideal manner? I have a undertaking that I’m simply now running on, and I have
been on the look out for such information.
Keep this going please, great job!
I every time spent my half an hour to read this website’s content daily along with a cup of
coffee.
My page zorroescu01
Wonderful beat ! I wish to apprentice while you amend
your website, how can i subscribe for a weblog web site?
The account helped me a applicable deal. I have been a little
bit acquainted of this your broadcast offered bright transparent concept
Hi there, this weekend is good designed for me, because this point in time i am reading this impressive
informative post here at my home.
I’m not sure why but this website is loading very slow for me.
Is anyone else having this issue or is it a problem
on my end? I’ll check back later and see if
the problem still exists.
Here is my homepage :: Hokidewacas.pro
There’s this player I met who’s into online casinos. He’s based in Illinois now, but his mom is
originally from a small Russian town. He’s dating a guy and they both love hitting the virtual slots.
What’s funny is he’s really into Putin — says he thinks feminine guys are “supposed” to like him.
Not sure I get it, but hey, people are weird like that. One thing’s for sure — he’s always winning
when it comes to online casinos!
If you’re into that too, check out this site — it’s where
I’ve had the best luck
If some one wishes to be updated with newest technologies then he must be pay a quick visit
this web site and be up to date everyday.
Ꮯobain juga link ini, gaсor abis: https://dailydigitalsnews.com/2025/05/23/196/
It’s going to be ending of mine day, but before ending I am reading this fantastic paragraph to
improve my knowledge.
Полный перечень заболеваний и состояний здоровья,
которые являются основанием для освобождения от службы в армии,
содержится в официальном документе — Расписании болезней Министерства обороны Российской Федерации.
Этот документ регулярно обновляется,
и последняя версия доступна на официальных ресурсах Минобороны
или специализированных медицинских комиссиях
военкоматов.
весь перечень болезней можно
узнать у нас на сайте ===>>>{полный список болезней освобождающих от армии}
They must ⅽontain genetically engineered ‘human elastin peptides’ not
tһose derived from animals, oor јust claim that they сontain ‘elastin’.
British writer and philosopher Alain de Botton hɑs
Ƅecome iin my life what cupcakes һave become to baking. Such experiences wilⅼ continue ᥙntil it’ѕ strong enough
that youu havе no choice ƅut to feel tһe emotion fᥙlly.
Does your site have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an email. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it expand over
time.
bookmarked!!, I love your blog!
I’m not sure exactly why but this website is loading extremely slow for
me. Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
A buddy of mine who’s crazy about online gambling.
He’s based in Texas now, but his mother is originally
from Russia. He’s in a relationship with another man and they
both team up for casino nights.
What’s funny is he’s really into Putin — says he thinks
guys with a soft side are “supposed” to like him.
Not sure I get it, but hey, people are funny like that.
One thing’s for sure — he’s got some serious luck when it comes to online casinos!
You might also like this casino — it’s where I’ve had the best luck
Ветошь – это незаменимый материал для автосервиса
в Санкт-Петербурге. Этот мягкий и впитывающий материал
используется для протирки и очистки различных
поверхностей автомобилей.
Ветошь позволяет быстро и
эффективно убрать грязь, пыль
и следы масла с кузова и салона машины.
ветошь
I used to be recommended this blog by way of my cousin. I’m not sure
whether or not this submit is written by him as no one else understand
such distinctive about my trouble. You’re wonderful! Thanks!
You are so interesting! I don’t believe I have read anything like this before.
So wonderful to find another person with genuine thoughts on this subject.
Really.. many thanks for starting this up.
This website is one thing that is needed on the internet, someone with some originality!
Content Spinning est l’outil qu’il vous faut si vous souhaitez optimiser votre workflow de rédaction dans WordPress. Gagnez du temps et créez des contenus uniques grâce à l’IA.
There’s this player I met who’s hooked on online slots.
He’s based in Illinois now, but his mom is originally from
a small Russian town. He’s dating a guy and they both play together
online.
What’s funny is he’s really into Putin — says he thinks girly guys are “supposed”
to like him. Not sure I get it, but hey, people are unique like that.
One thing’s for sure — he’s on a lucky streak when it
comes to online casinos!
By the way, I found this article — it’s been awesome for me
Il faut atteindre le niveau 20 pour lancer la chasse au trésor, à travers laquelle le monde des Douze n’aura plus de secrets pour vous.
Normally I do not read post on blogs, however I wish
to say that this write-up very pressured me to try and do so!
Your writing taste has been surprised me. Thank you, very nice article.
Magnificent beat ! I would like to apprentice while you amend your
website, how can i subscribe for a weblog web site?
The account helped me a acceptable deal. I have been tiny bit familiar of this your broadcast provided vibrant clear idea
continuously i used to read smaller posts which also clear their motive, and that is also happening with this paragraph which I am
reading now.
magnificent issues altogether, you simply won a new reader.
What would you recommend about your put up that you made some days in the past?
Any positive?
Good post. I learn something totally new and challenging on sites I stumbleupon every day.
It’s always exciting to read through content from other authors and use something from other sites.
Good post. I learn something new and challenging on blogs I stumbleupon on a daily basis.
It will always be interesting to read articles from other authors and use a little something from
their websites.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why throw away your intelligence on just
posting videos to your weblog when you could be giving us something enlightening to
read?
Its like you read my mind! You seem to know
a lot about this, like you wrote the book in it or something.
I think that you can do with some pics to drive the message home a
little bit, but instead of that, this is magnificent blog.
A great read. I’ll certainly be back.
I am sure this paragraph has touched all the internet users, its really really pleasant piece of writing on building up new blog.
Thankfulness to my father who stated to me about this webpage, this webpage
is in fact awesome.
fantastic issues altogether, you simply gained a new reader.
What might you suggest about your post that you simply made some days in the
past? Any sure?
A buddy of mine who’s crazy about online gambling.
He’s moved to Illinois now, but his mother is originally
from a small Russian town. He’s dating a guy and they both love hitting the virtual slots.
What’s funny is he’s obsessed with Putin — says he thinks girly guys are “supposed” to like him.
Not sure I get it, but hey, people are unique like that.
One thing’s for sure — he’s on a lucky streak when it
comes to online casinos!
You might also like this article — definitely worth a
shot
Ahaa, its pleasant dialogue about this article here at
this web site, I have read all that, so at this time me also commenting here.
Hello, this weekend is nice for me, as this point in time i am reading this great informative paragraph here at my residence.
There’s this player I met who’s hooked on online slots.
He’s based in Philadelphia now, but his mother is originally from
the Russian countryside. He’s dating a guy and they both team up
for casino nights.
What’s funny is he’s obsessed with Putin —
says he thinks guys with a soft side are “supposed” to like him.
Not sure I get it, but hey, people are weird like that.
One thing’s for sure — he’s got some serious luck when it comes to online casinos!
You might also like this site — definitely worth a shot
Very shortly this web page will be famous amid all blogging
and site-building visitors, due to it’s nice articles or reviews
My partner and I stumbled over here coming from a different website and thought
I should check things out. I like what I see so now i am following you.
Look forward to looking into your web page again.
Hi there, I enjoy reading through your article. I wanted to write a little comment to support you.
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do it for
you? Plz answer back as I’m looking to create my own blog and would
like to find out where u got this from. many
thanks
Hi friends, fastidious article and nice arguments commented
at this place, I am in fact enjoying by these.
Таким образом, автосервис на Ржевке – это надежный помощник для вашего автомобиля. Если вам нужен профессиональный ремонт или техническое обслуживание, не стесняйтесь обращаться сюда. Здесь вас ждут опытные специалисты, удобное расположение и доступные цены. Ваш автомобиль заслуживает только лучшего!
http://www.isexsex.com/home.php?mod=space&uid=2793357&do=profile&from=space
Hi, I want to subscribe for this web site to obtain most up-to-date updates, thus where can i do it please help out.
Pretty! This has been an incredibly wonderful post.
Thank you for supplying this information.
We’re a gaggle of volunteers and starting a new
scheme in our community. Your website provided us with helpful info to
work on. You’ve done an impressive task and our entire community might be grateful to you.
Toutefois, utiliser ces ressources peut enlever une partie de la magie de la chasse.
A buddy of mine who’s crazy about online gambling. He’s moved to Illinois now,
but his mom is originally from a small Russian town. He’s dating a guy and
they both play together online.
What’s funny is he’s obsessed with Putin —
says he thinks feminine guys are “supposed” to like him.
Not sure I get it, but hey, people are unique like that. One thing’s for sure — he’s got some serious luck when it comes to online casinos!
You might also like this casino — it’s where I’ve had the best luck
It’s really a nice and helpful piece of information. I am happy that you
just shared this helpful information with us. Please stay us up to
date like this. Thank you for sharing.
Hello! I just want to offer you a big thumbs up for the excellent info
you have got here on this post. I am returning to your
blog for more soon.
Stunning quest there. What happened after? Good luck!
I really like reading through an article that can make
men and women think. Also, many thanks for allowing me to
comment!
My partner and I absolutely love your blog and find nearly all of your post’s to be exactly what I’m looking for.
Would you offer guest writers to write content to suit
your needs? I wouldn’t mind creating a post or elaborating on a few of the
subjects you write with regards to here. Again, awesome web site!
This site was… how do you say it? Relevant!!
Finally I have found something which helped me. Thank you!
I know this guy who’s into online casinos. He’s living in Philadelphia now,
but his mother is originally from the Russian countryside.
He’s got a boyfriend and they both love hitting the virtual slots.
What’s funny is he’s kind of fixated on Putin — says he
thinks girly guys are “supposed” to like him. Not sure I get it, but hey, people are funny like that.
One thing’s for sure — he’s got some
serious luck when it comes to online casinos!
By the way, I found this casino — it’s been awesome for me
There’s this player I met who’s crazy about online gambling.
He’s based in Illinois now, but his mother is originally from a small Russian town. He’s in a relationship with another man and they both team up for casino
nights.
What’s funny is he’s really into Putin — says he thinks girly guys are “supposed” to
like him. Not sure I get it, but hey, people are unique like that.
One thing’s for sure — he’s on a lucky streak when it comes to online casinos!
You might also like this casino — it’s where I’ve
had the best luck
Thanks , I have just been looking for information about this
subject for ages and yours is the greatest I’ve found out so far.
However, what about the conclusion? Are you positive about the source?
Franchising Path Carlsbad
Carlsbad, ⅭA 92008, United Ѕtates
+18587536197
3 Franchise
There’s this player I met who’s crazy about online gambling.
He’s moved to Texas now, but his mom is originally from a small
Russian town. He’s got a boyfriend and they both play together
online.
What’s funny is he’s obsessed with Putin — says he thinks girly guys are “supposed”
to like him. Not sure I get it, but hey, people are unique like that.
One thing’s for sure — he’s always winning when it comes
to online casinos!
You might also like this site — it’s where I’ve had the best luck
I know this guy who’s into online casinos. He’s
moved to Illinois now, but his mom is originally from the
Russian countryside. He’s dating a guy and they both love hitting the virtual slots.
What’s funny is he’s kind of fixated on Putin — says he thinks girly
guys are “supposed” to like him. Not sure I get it, but hey, people
are weird like that. One thing’s for sure — he’s got some
serious luck when it comes to online casinos!
If you’re into that too, check out this site — it’s
been awesome for me
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back down the road.
Many thanks
I do consider all of the ideas you’ve offered on your post.
They’re very convincing and will definitely work.
Nonetheless, the posts are too brief for newbies. May just
you please prolong them a little from subsequent time? Thank you for the post.
I got this website from my pal who told me about this web page and
at the moment this time I am visiting this web site and reading very informative content at this time.
I know this guy who’s into online casinos. He’s based in Philadelphia now, but his mother is originally from a small Russian town. He’s got a boyfriend and they both love hitting the virtual slots.
What’s funny is he’s kind of fixated on Putin — says he thinks feminine guys are “supposed” to like him.
Not sure I get it, but hey, people are weird like that.
One thing’s for sure — he’s always winning when it comes
to online casinos!
By the way, I found this article — it’s where I’ve had
the best luck
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to figure out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Greate post. Keep posting such kind of information on your page.
Im really impressed by your site.
Hey there, You’ve done a fantastic job. I will certainly digg it and in my opinion suggest to my friends.
I’m sure they’ll be benefited from this website.
Hi everyone, it’s my first go to see at this web page,
and piece of writing is in fact fruitful designed for me, keep up posting
these articles or reviews.
whoah this blog is great i like studying your articles.
Keep up the good work! You understand, a lot of persons are
looking round for this information, you could help them greatly.
http://w3.situsprediksi.buzz/
Hey, I think your site might be having browser compatibility issues.
When I look at your website in Ie, it looks fine but when opening
in Internet Explorer, it has some overlapping. I just wanted to give you a
quick heads up! Other then that, very good blog!
Everything is very open with a very clear explanation of the challenges.
It was truly informative. Your site is very useful.
Thanks for sharing!
Its such as you read my mind! You appear to grasp so much about
this, like you wrote the book in it or something. I feel that
you just can do with some percent to force the message house a little bit, but other than that, that is wonderful blog.
A fantastic read. I will definitely be back.
Hi, of course this piece of writing is truly nice and I have learned lot
of things from it concerning blogging. thanks.
I needed to thank you for this wonderful read!! I certainly enjoyed every little bit of it.
I have you saved as a favorite to check out new stuff you
post…
Heya! I just wanted to ask if you ever have any problems
with hackers? My last blog (wordpress) was hacked and I ended up losing
several weeks of hard work due to no back up. Do you have any solutions to stop hackers?
Hey! I’m at work surfing around your blog from my new apple
iphone! Just wanted to say I love reading through your blog and look
forward to all your posts! Keep up the excellent work!
Hello every one, here every person is sharing these
know-how, therefore it’s fastidious to read this website, and I used to visit this web site every day.
Very good information. Lucky me I found your
website by chance (stumbleupon). I’ve book marked it for later!
First off I would like to say awesome blog! I had a quick question which
I’d like to ask if you do not mind. I was interested to know how
you center yourself and clear your thoughts before writing.
I’ve had a difficult time clearing my thoughts in getting my ideas out there.
I do take pleasure in writing but it just seems like the first 10
to 15 minutes are wasted simply just trying to figure out
how to begin. Any recommendations or hints? Thanks!
Thank you a lot for sharing this with all people you actually recognize what you’re speaking approximately!
Bookmarked. Please also seek advice from my website =). We could have a link change agreement between us
An interesting discussion is definitely worth comment.
I think that you ought to write more on this subject, it might not be a
taboo matter but usually people don’t discuss such topics.
To the next! Cheers!!
A buddy of mine who’s into online casinos. He’s moved to Texas now, but his mom is originally from
the Russian countryside. He’s in a relationship with another man and they both
team up for casino nights.
What’s funny is he’s obsessed with Putin — says he
thinks girly guys are “supposed” to like him. Not sure I get it, but hey, people are funny like that.
One thing’s for sure — he’s on a lucky streak when it comes to online casinos!
If you’re into that too, check out this site —
definitely worth a shot
I just like the helpful information you provide for your articles.
I’ll bookmark your weblog and take a look at once more right here frequently.
I am fairly certain I will learn many new stuff proper right here!
Good luck for the following!
I think this is one of the most significant information for me.
And i am glad reading your article. But wanna remark on some general things, The web site style
is perfect, the articles is really nice : D. Good job, cheers
Inside the dynamic environment of logistics and provide chain management,
pallet organizations from the United states Participate
in a significant purpose in making certain The graceful
movement, storage, and transportation of products.
From foods distribution to industrial production, pallets variety the foundation of approximately each and every products shipment across the country.
As need for trustworthy logistics continues to increase, companies are looking for leading-tier pallet suppliers who will produce
sturdiness, affordability, and environmental sustainability.
Whoa! This blog looks exactly like my old one!
It’s on a entirely different subject but it has pretty much the same
layout and design. Superb choice of colors!
Excellent post. I was checking continuously this blog and I am impressed!
Very useful info specially the last part 🙂 I care for such information a lot.
I was looking for this particular information for a long time.
Thank you and good luck.
Thank you for some other fantastic article.
Where else could anyone get that kind of info in such a perfect method of writing?
I’ve a presentation next week, and I’m on the look for such info.
Terrific work! This is the type of info that should be shared
across the web. Shame on Google for now not positioning this publish higher!
Come on over and seek advice from my web site . Thanks =)
I?m not that much of a іnternet гeader to be honest but your blogs really
nice, keep it up! I’ll go ahead and booҝmark your site tߋ come back later on.
Many thanks
Very rapidly this website will be famous among all blogging and
site-building viewers, due to it’s good articles
Have you ever considered creating an ebook or guest authoring
on other websites? I have a blog based upon on the same
information you discuss and would love to have you share some stories/information. I know my readers would enjoy
your work. If you’re even remotely interested, feel free to send
me an e-mail.
A fascinating discussion is worth comment. I do think that
you ought to publish more on this subject matter, it might
not be a taboo matter but typically people do not speak about these
topics. To the next! All the best!!
Hi to all, how is the whole thing, I think every one is getting more from this
web site, and your views are fastidious in favor of new viewers.
It’s very easy to find out any topic on web as compared to books, as I
found this article at this site.
I am not positive where you are getting your information, but great topic.
I needs to spend a while finding out more or understanding more.
Thanks for magnificent info I was looking for this information for my mission.
взломанные игры для слабых телефонов — это интересный способ получить новые возможности.
Особенно если вы играете на мобильном устройстве с Android, модификации открывают перед вами широкие горизонты.
Я часто использую игры с обходом системы защиты,
чтобы наслаждаться бесконечными возможностями.
Модификации игр дают невероятную свободу
в игре, что взаимодействие с игрой гораздо
захватывающее. Играя с плагинами, я могу
персонализировать свой опыт,
что добавляет новые приключения и делает игру более непредсказуемой.
Это действительно удивительно, как такие моды могут
улучшить взаимодействие с игрой,
а при этом сохраняя использовать
такие модифицированные приложения можно без особых рисков, если быть внимательным и следить
за обновлениями. Это делает каждый игровой процесс уникальным, а возможности практически бесконечные.
Рекомендую попробовать такие игры с модами для
Android — это может открыть новые горизонты
It’s an awesome piece of writing in favor of all
the online viewers; they will take benefit from it I am sure.
https://w1.tebakangka4d.buzz/
This is fascinating! I’ve heard about breathing techniques for stress, but I
had no idea they could actually help improve memory and focus too.
The Memory Breath sounds like a powerful, natural tool—definitely curious to try it
out.
Ouvrez simplement votre navigateur (Chrome/Safari), visitez notre
site, collez le lien de la vidéo et téléchargez.
It is generally not recommended to take ephedrine and Viagra together without consulting a healthcare professional.
Fantastic site you have here but I was curious if you knew of any discussion boards that cover the same topics talked about here?
I’d really like to be a part of group where I can get responses from other experienced
individuals that share the same interest. If you have any suggestions,
please let me know. Thanks!
You really make it seem so easy with your presentation but I find this matter to
be really something which I think I would never understand.
It seems too complicated and extremely broad for me. I am looking forward
for your next post, I will try to get the hang of it!
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your website?
My blog site is in the exact same niche as yours and my
users would really benefit from a lot of the information you present here.
Please let me know if this okay with you. Cheers!
Hey just wanted to give you a quick heads up.
The words in your post seem to be running off the screen in Safari.
I’m not sure if this is a formatting issue or something to do with web browser compatibility
but I figured I’d post to let you know. The layout look great though!
Hope you get the problem resolved soon. Cheers
Very good article. I will be going through a few of these issues as well..
This is a great resource. I am going to save this for later.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You obviously know what youre talking about, why waste your intelligence on just posting videos
to your blog when you could be giving us something enlightening to
read?
I’m curious to find out what blog platform you have been utilizing?
I’m having some minor security problems with my latest website and I’d like to find something more
safeguarded. Do you have any recommendations?
I am really loving the theme/design of your site. Do you ever run into any web browser compatibility issues?
A number of my blog visitors have complained about my website not working correctly in Explorer but looks great in Firefox.
Do you have any advice to help fix this issue?
Thanks for sharing your info. I truly appreciate your efforts and I will
be waiting for your next post thanks once again.
Ӏtѕ like yоu reаd my mind! Yⲟu apрear to қnow ѕo mᥙch abօut this, like yօu wrote the book
in it ߋr something. Ι tһink tһat you could do with
a fеw pics to drive thе message һome a Ƅit, bսt instead of that, tһis is magnificent
blog. A fantastic read. Ӏ wiⅼl ceгtainly Ƅe back.
Μy web site; best social casinos
Wow that was strange. I just wrote an very long comment
but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyways,
just wanted to say great blog!
Excellent, what a weblog it is! This website presents valuable information to us, keep it up.
After I originally commented I appear to have clicked
the -Notify me when new comments are added- checkbox and now every time a comment is added I recieve four emails with the exact same comment.
There has to be a means you can remove me from that
service? Thanks!
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an edginess over that you wish be delivering the
following. unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this increase.
Hi colleagues, pleasant post and pleasant urging
commented at this place, I am truly enjoying by
these.
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United Ⴝtates
(480) 424-4866
Bookmarks, http://www.protopage.Com,
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United States
(480) 424-4866
Livestreamconsult
Howdy, i read your blog from time to time and i own a similar one and i was just curious if you get a lot of spam
responses? If so how do you reduce it, any plugin or
anything you can suggest? I get so much lately it’s driving me mad so any assistance is very much
appreciated.
If some one wishes to be updated with newest technologies then he must be pay a visit
this website and be up to date all the time.
Valuable information. Fortunate me I discovered your site by accident, and I am stunned why this coincidence didn’t came about earlier!
I bookmarked it.
Thanks for this for the effort!
This article is in fact a good one it helps new the web viewers, who are wishing for blogging.
Today, while I was at work, my sister stole my iPad and tested to
see if it can survive a thirty foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed and she has 83 views.
I know this is entirely off topic but I had to share
it with someone!
I don’t even know the way I ended up here, however
I assumed this submit was once great. I do not realize who you’re
however definitely you’re going to a famous blogger for those who
aren’t already. Cheers!
Saved as a favorite, I like your blog!
I was recommended this blog by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my difficulty.
You’re incredible! Thanks!
There is certainly a great deal to know about this subject.
I love all of the points you have made.
Hi! Someone in my Facebook group shared this site with us
so I came to give it a look. I’m definitely loving the information.
I’m book-marking and will be tweeting this
to my followers! Exceptional blog and wonderful design and style.
I simply couldn’t go away your site before suggesting
that I really enjoyed the usual info a person supply to
your guests? Is gonna be back ceaselessly to
check up on new posts
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United Ⴝtates
(480) 424-4866
Urbankitchen
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United Տtates
(480) 424-4866
Homeorganization
Hey! This is kind of off topic but I need some help from an established blog.
Is it tough to set up your own blog? I’m not very techincal
but I can figure things out pretty quick. I’m thinking about setting
up my own but I’m not sure where to begin. Do you have any tips or suggestions?
With thanks
Outstanding story there. What occurred after? Thanks!
Every weekend i used to pay a quick visit this web
page, because i want enjoyment, as this this web site conations genuinely fastidious funny data too.
Appreciate this post. Will try it out.
Inspired me.
If you are going for best contents like me, simply visit this
site everyday since it offers feature contents, thanks
Terima kasih sudah membagikan artikel ini.
Gue senang baca konten tentang judi bola karena sekarang lagi
sering main di situs judi bola terpercaya.
Saat ini, saya juga sedang mengikuti beberapa link judi bola parlay yang menyediakan jadwal pertandingan bola malam ini.
Artikel seperti ini sangat membantu, apalagi jika disertai dengan analisa prediksi mix parlay hari ini.
Kalau admin ada waktu, minta tolong sering-sering update.
Banyak pemain yang juga mencari prediksi jitu judi bola malam
ini. Semangat selalu untuk penulisnya!.
If you are going for best contents like me, simply visit this website every day for
the reason that it presents quality contents, thanks
Greetings! Very useful advice in this particular post!
It is the little changes that produce the most important changes.
Many thanks for sharing!
Look into my website: glucosense pros and cons
Thank you a bunch for sharing this with all of us you actually know what you’re talking approximately!
Bookmarked. Kindly also seek advice from my web site =).
We could have a link change agreement between us
Great entry! Really appreciated valuable. Thanks for putting
this up! Keep posting!
I simply couldn’t go away your site prior to suggesting that
I actually loved the usual info an individual supply in your visitors?
Is going to be again regularly in order to check out
new posts
Ciatoto adalah platform judi online terpercaya yang menyediakan permainan togel dan slot dengan sistem fair play serta peluang menang
tinggi. Dengan layanan 24 jam, metode deposit yang lengkap, dan berbagai promo menarik, Ciatoto menjadi
pilihan utama para pecinta togel dan slot online
di Indonesia.
Hello, I read your new stuff like every week. Your
story-telling style is witty, keep doing what you’re doing!
What’s up to every one, the contents existing at
this web page are actually amazing for people knowledge, well, keep up the nice work fellows.
Gokil! Susah-susah gampang cari artikel kayak gini.
Gue sendiri lagi fokus ke prediksi mix parlay harian, jadi info kayak gini tuh
berguna banget.
Sekarang ini, gue juga ikut komunitas yang bahas judi bola malam
ini dan mix parlay euro. Biasanya sebelum pasang, gue baca dulu perbandingan odds dari
situs judi bola terlengkap dan terpercaya.
Dan artikel seperti ini jadi salah satu referensi yang gue bookmark
terus.
Terima kasih buat penulisnya. Semoga terus update. Banyak
pemain yang pasti butuh panduan seperti ini, terutama untuk link judi bola
parlay terpercaya.
Hi! Quick question that’s completely off topic. Do you know
how to make your site mobile friendly? My website looks weird when browsing from my iphone.
I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any suggestions, please share. Thank you!
I’ve been surfing on-line greater than 3 hours as of late, yet I never discovered any attention-grabbing article like yours.
It is pretty price enough for me. Personally, if all site owners and bloggers made excellent content material as you did, the web can be much more helpful than ever
before.
I have read so many articles or reviews on the topic of the blogger lovers
but this article is truly a good piece of writing, keep it up.
Thanks for this detailed review! I’ve tried so many joint formulas over
the years, but most don’t deliver lasting relief.
Joint Genesis sounds promising, especially since it’s
made in a GMP-certified facility. Subscribed to hear more reviews like this!
I like what you guys tend to be up too. Such clever work and coverage!
Keep up the excellent works guys I’ve added you guys to blogroll.
I love that this formula is inspired by the Ikaria lifestyle—those people really know how to live long and healthy!
The focus on natural detox and metabolism support makes a lot of sense.
Anyone here tried it consistently and seen results with belly fat?
Hi there! I understand this is sort of off-topic but I needed to
ask. Does running a well-established website such as yours take a massive amount work?
I am completely new to blogging but I do write in my diary every day.
I’d like to start a blog so I can easily share my personal experience and feelings online.
Please let me know if you have any kind of recommendations or tips for brand
new aspiring blog owners. Thankyou!
http://w2.bocoranprediksi.buzz/
What’s up, I want to subscribe for this website to obtain latest updates, thus where can i do it please
help out.
Hi there it’s me, I am also visiting this site regularly, this site is actually fastidious and
the viewers are genuinely sharing nice thoughts.
No matter if some one searches for his essential thing,
so he/she needs to be available that in detail, so that thing is
maintained over here.
Wow, marvelous blog format! How lengthy have you ever been running a blog for?
you made running a blog look easy. The total look of your web site
is great, as smartly as the content!
Its such as you learn my thoughts! You seem to know a lot about this, such as you wrote the guide in it
or something. I think that you simply can do with a few percent
to force the message home a bit, however other than that, this is fantastic blog.
A fantastic read. I will certainly be back.
Have you ever considered creating an e-book or guest authoring on other sites?
I have a blog centered on the same topics you discuss and would really like to have you share some stories/information. I know my readers would enjoy your work.
If you’re even remotely interested, feel free to shoot me an e mail.
Today, I went to the beach front with my children. I
found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to
tell someone!
Way cool! Some extremely valid points! I appreciate you penning this article and the
rest of the website is very good.
https://livecambodia.life/
I do trust all of the concepts you have introduced in your post.
They’re very convincing and can certainly work. Still, the
posts are too short for starters. May just you please extend them
a bit from subsequent time? Thank you for the post.
I all the time used to read paragraph in news papers but now as I am a user of internet
so from now I am using net for articles, thanks to web.
When I originally commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get four e-mails
with the same comment. Is there any way you can remove me from that
service? Cheers!
What’s up mates, how is the whole thing, and what you wish for to say regarding this post,
in my view its really awesome in favor of me.
Also visit my web page: ฟาร์มผักสลัด
Great article. I’m going through a few of these issues
as well..
모든 사람에게 안녕하세요, 이 사이트의 콘텐츠는 실제로 사람들의 경험을 위해 놀라운 것입니다, 잘 하세요.
I have to thank you for the efforts you’ve put in writing this blog.
I’m hoping to view the same high-grade content by you later on as well.
In fact, your creative writing abilities has inspired me
to get my own, personal blog now 😉
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United Ѕtates
(480) 424-4866
Bookmarks
Hi! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really
enjoy your content. Please let me know. Thank you
Simply desire to say your article is as astounding. The clarity in your post is
just cool and i can assume you’re an expert on this subject.
Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please keep up the enjoyable work.
There is definately a lot to know about this subject.
I like all of the points you made.
Very good site you have here but I was wanting to know if you knew of any discussion boards that cover
the same topics discussed here? I’d really like to be a part of community where I can get responses from other experienced individuals
that share the same interest. If you have any suggestions, please let me
know. Thanks a lot!
my blog post agen togel resmi
Its such as you learn my mind! You appear to understand so much approximately
this, like you wrote the ebook in it or something. I believe that you can do with some percent to force
the message house a bit, but other than that, this is fantastic
blog. A fantastic read. I’ll certainly be back.
Unquestionably consider that which you stated. Your favourite reason appeared to be at the web
the simplest factor to take note of. I say to you, I certainly get irked even as folks consider worries that they just do not know about.
You managed to hit the nail upon the highest as smartly as outlined out the entire thing with
no need side-effects , folks can take a signal. Will likely be again to get more.
Thank you
Fabulous, what a website it is! This web site presents
useful information to us, keep it up.
Hello there! This blog post could not be written much better!
Reading through this article reminds me of my previous roommate!
He constantly kept preaching about this. I most certainly will send
this information to him. Pretty sure he will have a good read.
Thanks for sharing!
Awesome article.
I was suggested this blog by my cousin. I am not sure
whether this post is written by him as nobody else know such detailed about my problem.
You’re wonderful! Thanks!
Hello there, I found your website by the use of Google even as searching for a comparable subject,
your web site got here up, it appears good. I’ve bookmarked it in my google bookmarks.
Hi there, simply changed into aware of your blog thru Google, and
found that it is really informative. I’m going to be careful for brussels.
I’ll be grateful in case you continue this in future.
Many other folks can be benefited from your writing.
Cheers!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
you are in reality a excellent webmaster. The web site loading pace is incredible.
It seems that you are doing any unique trick.
In addition, The contents are masterwork. you have performed a wonderful job on this matter!
This post is really a fastidious one it assists new the web users, who are wishing for
blogging.
Ligacor yang biasa juga disebut Gacor Slot adalah bandar online slot paling
gacor. Winrate tinggi, RTP akurat, dan kemenangan pasti dibayarkan.
Online casinos make everything so easy.
Have a look at my web page … https://aishaugen790889.blognody.com/38957289/get-lucky-with-plinko
You made some good points there. I looked on the net to learn more about the issue and found most people will go along with your views on this site.
Greetings! Very helpful advice within this article!
It is the little changes which will make the greatest changes.
Thanks for sharing!
Nice content! Absolutely thought it was useful. Grateful for adding this!
Great work!
También puedes usar los videos de TikTok para fines de investigación o marketing.
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re
going to a famous blogger if you are not already 😉
Cheers!
Hi! I’ve been reading your website for some time now and finally got the bravery
to go ahead and give you a shout out from Humble Tx!
Just wanted to tell you keep up the fantastic work!
It’s really a great and helpful piece of information. I am happy that you
just shared this helpful info with us. Please keep us up
to date like this. Thanks for sharing.
Hi there, this weekend is pleasant in favor of me, for the reason that this moment i
am reading this great informative article here at my residence.
Thanks for the great content! I’ve been into online gambling and bonus hunting lately and this
truly resonates. Especially with platforms like Free Deposit 365 offering freedeposit promos, the opportunities are just getting better.
I bookmarked this for more info like this.
Do you also review gambling platforms? Keep it up!
What a information of un-ambiguity and preserveness of valuable knowledge
on the topic of unpredicted emotions.
Howdy! I could have sworn I’ve been to your blog before
but after going through a few of the posts I realized it’s new to me.
Anyways, I’m definitely happy I came across it and I’ll be bookmarking it and
checking back frequently!
I have read so many content regarding the blogger lovers
however this piece of writing is in fact a pleasant post, keep it up.
Биржа крипты — твой ключ
к прибыли!
Надежная платформа для торговли криптовалютами с высокой ликвидностью и низкими
комиссиями.
Безопасность на высшем уровне.
Регистрация быстрая и простая.
Начни зарабатывать прямо сейчас!
узнать можно больше здесь =>>kra33.at
I could not refrain from commenting. Very
well written!
Hey just wanted to give you a quick heads up and let you know a
few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same outcome.
Appreciate this post. Will try it out.
It’s going to be ending of mine day, but before finish I am reading this
impressive piece of writing to improve my know-how.
Aw, this was a really nice post. Finding the time and actual effort to generate a superb article… but what can I say… I procrastinate a lot and never seem to get anything
done.
Having read this I believed it was really enlightening.
I appreciate you spending some time and effort to put this information together.
I once again find myself personally spending way too much time both reading and commenting.
But so what, it was still worthwhile!
Cabinet IQ
15030 N Tattum Blvd #150, Phoenix,
AZ 85032, United Ꮪtates
(480) 424-4866
Remodelideas
This is very fascinating, You’re a very professional blogger.
I have joined your feed and sit up for looking for more of your
excellent post. Additionally, I have shared your website in my social
networks
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United Ѕtates
(480) 424-4866
Eco
Pretty great post. I simply stumbled upon your weblog and wanted to mention that I have truly loved browsing your
blog posts. In any case I will be subscribing for your feed and I am hoping you
write once more very soon!
Hello to every single one, it’s genuinely a good for me to visit this site, it contains precious Information.
Such valuable insight, thanks for sharing. I’m actively involved in online gambling
spaces, especially those that highlight platforms like
Free Deposit 365 with generous freedeposit bonuses.
Lately, I’ve been comparing sites to find the most consistent bonus deals and your post added a fresh angle I hadn’t considered.
Keep up the awesome content – it’s voices like yours that make research easier for players
like me.
You ought to take part in a contest for one of the greatest websites on the web.
I am going to highly recommend this site!
There’s certainly a lot to learn about this topic. I really like all the points you’ve made.
Been dealing with frequent bathroom trips at night—ProstaVive actually made a noticeable difference in just a few weeks.
Glad I gave it a shot!
It’s going to be end of mine day, however before
end I am reading this wonderful article to improve
my experience.
This is nicely expressed. .
Hi Dear, are you actually visiting this website on a regular
basis, if so then you will absolutely take nice knowledge.
“I actually built the Aqua Tower for our cabin, and it’s been amazing. Clean water without paying for expensive systems—total game changer!”
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an shakiness
over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same nearly
very often inside case you shield this increase.
Hello to every one, for the reason that I am actually eager of reading this webpage’s post to be updated on a regular basis.
It contains fastidious data.
It’s going to be finish of mine day, except before finish I am reading
this wonderful piece of writing to improve my know-how.
Remarkable issues here. I’m very satisfied to peer your article.
Thank you so much and I am taking a look ahead to contact you.
Will you please drop me a e-mail?
Every weekend i used to pay a visit this site, because i want enjoyment, as this this website conations
genuinely good funny material too.
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My web site looks weird when viewing from my iphone.
I’m trying to find a theme or plugin that might be able to correct this problem.
If you have any recommendations, please share. Cheers!
hello!,I like your writing very so much! share we keep in touch more
about your post on AOL? I require an expert on this
space to resolve my problem. Maybe that is you! Looking forward to see you.
I believe everything wrote was actually very logical.
But, what about this? what if you were to write a killer headline?
I mean, I don’t wish to tell you how to run your website, but what if you added a title to maybe grab a person’s attention? I mean K-Nearest Neighbor Machine
Learning algorithm – Deepsingularity : Deepsingularity is kinda plain. You
should glance at Yahoo’s home page and note how they create post
titles to grab viewers to open the links. You might add a related
video or a related pic or two to get readers excited
about everything’ve got to say. In my opinion,
it would make your posts a little livelier.
Excellent pieces. Keep posting such kind of info on your page.
Im really impressed by your blog.
Hello there, You have done an excellent job. I’ll certainly digg it and for my part suggest to my
friends. I am confident they will be benefited from this web site.
Won a small jackpot, online casinos are awesome!
my web site: https://franciscoprpl94963.blog-kids.com/36035483/get-lucky-with-plinko
whoah this weblog is magnificent i love reading your posts.
Stay up the great work! You recognize, a lot of individuals
are looking around for this information, you could aid them greatly.
An intriguing discussion is definitely worth comment.
I do believe that you ought to write more on this subject, it might not be a taboo subject but usually people
don’t talk about these topics. To the next! Best wishes!!
When someone writes an paragraph he/she keeps the plan of a user
in his/her brain that how a user can know it. Thus that’s
why this post is amazing. Thanks!
It’s in fact very complex in this full of activity life to listen news
on TV, therefore I simply use web for that purpose, and take the latest information.
Howdy! I could have sworn I’ve been to this blog before but after reading through some of the post I
realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be book-marking and checking back often!
Outstanding story there. What happened after? Good luck!
So this is what they mean when they say ‘in the zone’—theta waves might be the
real secret sauce!
Good day! This post couldn’t be written any better! Reading this post reminds me of my good old room mate!
He always kept chatting about this. I will forward this write-up to him.
Pretty sure he will have a good read. Thank you for sharing!
Awesome website you have here but I was wondering if you knew
of any user discussion forums that cover the same topics talked about here?
I’d really love to be a part of online community where I can get suggestions from other
knowledgeable people that share the same interest.
If you have any suggestions, please let me know. Appreciate it!
Ощутите себя капитаном, отправившись в незабываемое плавание! К вашим услугам
https://yachtakazan.ru/ для захватывающих приключений.
С нами у вас есть возможность:
• Насладиться живописными пейзажами с борта различных судов.
• Отпраздновать знаменательное событие в необычной обстановке.
• Провести незабываемый вечер в романтической атмосфере.
• Весело провести время в кругу дорогих вам людей.
Наши суда отличаются:
✓ Опытными и квалифицированными командами.
✓ Высоким уровнем комфорта, созданным для вашего удобства.
✓ Гарантией безопасности на протяжении всей поездки.
✓ Привлекательным внешним видом и стильным дизайном.
Выбирайте короткую часовую прогулку или арендуйте судно на целый день! Мы также поможем с организацией вашего праздника: предоставим услуги фотографа, организуем питание и музыкальное сопровождение.
Подарите себе и вашим близким яркие впечатления! Закажите ваше водное приключение прямо сейчас!
This is my first time go to see at here and i am actually happy to read
everthing at one place.
I have been browsing online more than 2 hours
today, yet I never found any interesting
article like yours. It’s pretty worth enough for me.
In my opinion, if all site owners and bloggers made good content as you did, the net will be a lot more useful than ever before.
Its like you read my mind! You seem to know a lot about this, like you wrote the book
in it or something. I think that you can do with a few pics to
drive the message home a little bit, but instead of that,
this is wonderful blog. A great read. I will definitely be back.
Asking questions are actually pleasant thing if you are not understanding something completely, except this
piece of writing gives pleasant understanding yet.
Today, while I was at work, my cousin stole my iPad
and tested to see if it can survive a forty foot drop, just so she can be
a youtube sensation. My iPad is now destroyed and she
has 83 views. I know this is completely off topic but
I had to share it with someone!
First of all I would like to say wonderful blog!
I had a quick question in which I’d like to ask if you don’t mind.
I was curious to find out how you center yourself and clear your
mind before writing. I’ve had a hard time clearing my mind in getting my thoughts out there.
I do take pleasure in writing but it just seems like the first 10 to 15 minutes are lost just trying to figure out how to begin. Any recommendations or hints?
Thanks!
Hi there! This is my first visit to your blog!
We are a collection of volunteers and starting a new initiative
in a community in the same niche. Your blog provided us
valuable information to work on. You have done a wonderful job!
Here is my web-site – ผักสลัดออนไลน์
Cabinet IQ
15030 N Tatum Blvd #150, Phoenix,
AZ 85032, United Ⴝtates
(480) 424-4866
Promotion
I really like reading through an article that can make men and women think.
Also, thanks for allowing me to comment!
Also visit my page … ผักไฮโดรโปนิกส์
I’ve been browsing on-line more than 3 hours today,
yet I never discovered any fascinating article like yours. It
is beautiful value enough for me. Personally, if all site
owners and bloggers made just right content material as you probably did,
the web shall be a lot more helpful than ever before.
Natural supplements for nerve pain always catch my attention. If Arialief can help with sciatic pain and support
healing, it could be a game-changer for a lot of people.
Hey! I understand this is somewhat off-topic but I
had to ask. Does building a well-established blog like yours require a massive amount work?
I am brand new to writing a blog but I do write in my journal everyday.
I’d like to start a blog so I can share my personal experience and thoughts online.
Please let me know if you have any recommendations or tips for brand new
aspiring blog owners. Thankyou!
What’s up it’s me, I am also visiting this web page
on a regular basis, this web page is genuinely nice and the people are genuinely sharing nice thoughts.
Most creams just treat the surface, so it’s refreshing to see a product like Appanail that
targets the root cause internally. Curious about
the ingredients and how effective it really is.
We’re a group of volunteers and opening a new
scheme in our community. Your site provided us with valuable info to work on. You’ve done an impressive job and our entire community will be
thankful to you.
Simply desire to say your article is as astounding. The clearness in your publish is
just great and that i can assume you are an expert on this subject.
Well with your permission let me to grab your RSS feed to
keep up to date with impending post. Thank you a million and please carry on the rewarding work.
Cabinet IQ
15030 NTatum Blvd #150, Phoenix,
AZ 85032, United Ⴝtates
(480) 424-4866
Remodelworkshop (http://www.symbaloo.com)
Online casinos are great for casual gaming.
Here is my blog post https://rafaelvuxc17493.blogthisbiz.com/42790402/plinko-fever-hit-the-jackpot
I’d like to thank you for the efforts you have put in writing
this blog. I am hoping to see the same high-grade content by you in the future as well.
In fact, your creative writing abilities has inspired me to get
my own blog now 😉
Got a cashback offer, saved me some losses.
Feel free to visit my web site … https://gunnerghnp38372.bligblogging.com/36458485/reel-in-the-big-wins-with-our-fishing-frenzy-slot
Howdy! This is my first visit to your blog! We are a
collection of volunteers and starting a new initiative
in a community in the same niche. Your blog provided us useful
information to work on. You have done a extraordinary job!
I’ve been exploring for a little bit for any high-quality articles or
weblog posts in this kind of space . Exploring in Yahoo I
at last stumbled upon this site. Reading this info So i’m glad
to convey that I’ve an incredibly just right uncanny feeling I
discovered just what I needed. I most indubitably will make
sure to don?t put out of your mind this site and give it a glance on a constant
basis.
You made your stand quite effectively..
It’s going to be finish of mine day, except before finish I am reading this enormous paragraph to improve my know-how.
If you desire to improve your know-how just keep visiting this web page and be
updated with the most up-to-date gossip posted here.
Excellent post. I was checking continuously this blog and I am impressed!
Very useful info particularly the last part :
) I care for such information much. I was seeking this particular
info for a long time. Thank you and good luck.
Wow, this piece of writing is nice, my younger sister is analyzing such things,
therefore I am going to convey her.
Hey! This is my 1st comment here so I just wanted to give a quick
shout out and say I genuinely enjoy reading through your blog posts.
Can you recommend any other blogs/websites/forums that
deal with the same subjects? Thanks a ton!
E2bet Trang web trò chơi trực tuyến lớn nhất
việt nam tham gia ngay và chơi có trách nhiệm. Nền tảng này chỉ phù hợp với người từ
18 tuổi trở lên.
I’ve been browsing online more than 2 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all web owners and bloggers made good content as you did, the internet will be a lot more useful than ever
before.
What’s up everybody, here every person is sharing
these experience, therefore it’s good to read this weblog, and I used to pay a quick visit this weblog
daily.
A person necessarily lend a hand to make severely articles
I might state. This is the first time I frequented
your web page and so far? I amazed with the analysis you made
to create this particular put up amazing. Magnificent job!
Greetings! Very helpful advice within this article! It’s the little changes that will make the biggest changes.
Thanks for sharing!
It’s an remarkable post designed for all the online people; they will obtain benefit from it I am sure.
Hello there! This article couldn’t be written any better!
Going through this article reminds me of my previous roommate!
He continually kept talking about this. I’ll forward this information to him.
Pretty sure he’ll have a great read. Many thanks for sharing!
Nice answers in return of this issue with firm arguments and telling everything regarding that.
A person necessarily assist to make significantly posts I’d state.
This is the very first time I frequented your web page and
to this point? I amazed with the analysis you made to create this particular publish amazing.
Fantastic job!
This is my first time pay a visit at here and i am in fact happy to read everthing at alone place.
My partner and I stumbled over here different website
and thought I might as well check things out.
I like what I see so i am just following you. Look forward to going
over your web page for a second time.
We’re a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on. You have done an impressive job and our whole
community will be thankful to you.
Hello friends, its wonderful post on the topic of cultureand completely explained, keep it up all the time.
Thanks for a marvelous posting! I quite enjoyed reading it, you happen to be a great author.I will
be sure to bookmark your blog and will eventually come back later in life.
I want to encourage one to continue your great work, have a nice morning!
This site was… how do I say it? Relevant!! Finally I have found something which helped me.
Thank you!
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site
is great, let alone the content!
Hello I am so delighted I found your web site, I really found you by error,
while I was looking on Google for something else, Anyways I am here now and would just like to say many thanks for a incredible post and a all round
entertaining blog (I also love the theme/design), I don’t
have time to browse it all at the moment but I have
book-marked it and also added your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up
the great work.
Hi there, just wanted to tell you, I loved this post.
It was helpful. Keep on posting!
My brother recommended I may like this website. He used to be totally right.
This submit actually made my day. You cann’t imagine simply how
so much time I had spent for this info! Thanks!
Hey, I think your website might be having browser compatibility
issues. When I look at your blog site in Safari, it
looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful blog!
Good blog post. I absolutely appreciate this site. Keep it up!
Hey people,
I’ve been exploring the world of online gaming lately, and I’ve gotta say — it’s way more exciting than I expected. At first, I was a bit wary. I mean, how do you even believe in an online platform with your hard-earned money, right? But after digging deep (and trying out a few questionable sites so you don’t have to), I figured out a few things that set apart a reliable casino from a complete fraud. First off, if you’re new to all this, here’s the golden rule: **check the license**. If a casino doesn’t have a proper legal status (like from the Malta Gaming Authority or the UKGC), just close that tab. No bonus is worth the trouble of never seeing your money again. Also — and I know no one wants to — read the T&Cs. That’s the only way to know what kind of wagering requirements they’ve slapped onto those so-called “juicy” bonuses.
Now, let me share a site I’ve been hooked on these last few weeks. It’s been a total win. The interface? Super smooth. Payouts? Fast as hell. And the game selection? *Wild*. Slots, live dealers, blackjack, even some oddball options I hadn’t tried before. Check it out here: https://www.facebook.com/profile.php?id=61578284483992 What really won me over was the support team. I had a tiny issue with a bonus not working, and they got back to me in like no time. Compare that to other sites where you’re just shouting into the void — yeah, hard pass.
Also, if you’re into bonuses (and who isn’t?), this place offers some legit ones. But here’s the trick: don’t just go crazy over promos. It’s smarter to stick to reasonable terms than a huge bonus you’ll never be able to withdraw. I’m not saying you should go and drop your rent money — please don’t. But if you’ve got a little extra spending money and you’re looking for a bit of online excitement, online casinos can totally deliver. Just stay sharp, control your bankroll, and don’t treat it like a side hustle. It’s for fun, not for a paycheck. Anyway, just wanted to drop my experience here in case anyone’s looking for solid info or trying to find a trustworthy place to play. If you’ve got your own recommendations or even some casino nightmares, I’m all ears — love talking shop about this stuff.
Good luck out there, and don’t let the house win too much ??
Hi, I check your new stuff daily. Your writing style is awesome, keep it up!
What’s up, its fastidious article concerning media print,
we all know media is a fantastic source of facts.
Normally I don’t learn post on blogs, however I would like to say
that this write-up very compelled me to take a look at
and do it! Your writing style has been amazed me.
Thank you, very nice article.
This was an incredibly helpful post. I’ve been researching custom name necklaces, and your post has added a lot of
value to my journey.
I think there’s something so powerful about a piece of jewelry that’s designed just for you.
It’s not just fashion — it’s a story.
I’ve recently come across some great pieces at Onecklace,
and their selection of custom gold and silver jewelry is top quality without
feeling overpriced. They offer customizations with birthstones and scripts,
which makes them stand out in a crowded market.
Customization is a must for me — otherwise, it doesn’t feel special.
That’s why content like yours is so helpful — it guides
people like me toward more thoughtful purchases.
Keep up the great work. Jewelry should always come with
a story — and your post makes that clear.
Cheers!
My homepage – gold name necklace
“I’ve been taking Gluco Extend for about 2 months now, and my blood sugar has been more stable than it’s been in years. Definitely noticing better energy too!”
Admiring the hard work you put into your site and in depth information you offer.
It’s good to come across a blog every once in a while that isn’t the same outdated rehashed information. Fantastic read!
I’ve bookmarked your site and I’m including your RSS
feeds to my Google account.
What’s up all, here every person is sharing such know-how,
so it’s fastidious to read this blog, and I used to visit
this weblog all the time.
http://w1.angkaraja.cfd/
We’re a group of volunteers and opening a new scheme in our community.
Your web site offered us with valuable info to work on. You have done an impressive job and our whole community will be grateful to
you.
It’s awesome in support of me to have a web site, which is beneficial in favor of my knowledge.
thanks admin
Great weblog here! Also your site a lot up very fast! What web host are you
the use of? Can I get your affiliate link to your host?
I want my website loaded up as fast as yours lol
You really make it seem so easy with your
presentation however I find this topic to be actually one
thing that I believe I’d by no means understand.
It sort of feels too complicated and extremely large for
me. I am looking forward to your next post,
I will attempt to get the grasp of it!
Hi my loved one! I want to say that this post is amazing,
great written and include approximately all vital
infos. I would like to see more posts like this .
I think the admin of this web site is in fact working hard in support of his site, since here
every information is quality based data.
My brother recommended I might like this blog.
He was totally right. This post truly made my day.
You cann’t consider just how a lot time I had spent for this info!
Thank you!
hello there and thank you for your information – I have certainly picked up something new from right here.
I did however expertise some technical issues using this web
site, as I experienced to reload the site a lot of
times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK? Not that I’m complaining, but sluggish loading instances times will
very frequently affect your placement in google and could damage your
high-quality score if advertising and marketing with Adwords.
Well I am adding this RSS to my email and can look out for a lot more of your respective fascinating content.
Make sure you update this again soon.
Hello friends, its great piece of writing concerning teachingand completely defined, keep it up all the time.
Howdy! I know this is kind of off topic but I was wondering which blog platform are you using for
this website? I’m getting fed up of WordPress because I’ve had issues
with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a
good platform.
Trending Questions Is HTP addictive? What happens if you combine Strattera and Adderall?
Is white round pill gpi a325? How many 25mg Xanax equals 2mg
Xanax? Can you enlist in the french foreign legion with a marijuana charge?
Cabinet IQ
8305 State Hwy 71 #110, Austin,
TX 78735, Unitsd Statеѕ
254-275-5536
Remodelideas (list.ly)
What’s Going down i’m new to this, I stumbled upon this I’ve found It absolutely helpful and
it has aided me out loads. I am hoping to contribute
& help other customers like its aided me. Great job.
can you buy generic lisinopril without rx
Lisinopril is often prescribed to patients with kidney disease.
Hi, everything is going well here and ofcourse every
one is sharing information, that’s in fact good, keep up
writing.
I for all time emailed this weblog post page to all my contacts,
for the reason that if like to read it then my friends will too.
Triangl Billiards & Bar Stools
1471 Nisson Ꮢd, Tustin,
ⲤA 92780, United Ꮪtates
+17147715380
Bookmarks
Bet 88
I truly love your website.. Very nice colors & theme. Did you develop this site
yourself? Please reply back as I’m planning to create my own personal site and would love to find out where you got this from or what the theme
is named. Appreciate it!
I’ve learn several good stuff here. Definitely value bookmarking for
revisiting. I wonder how much effort you place to make the sort of excellent informative website.
I could not resist commenting. Very well written!
Thank you for the auspicious writeup. It in fact was a amusement
account it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
I was suggested this blog by my cousin. I’m not sure whether this post is written by him as no one else know such detailed about my problem.
You’re incredible! Thanks!
Thank you for the auspicious writeup. It if truth be
told used to be a amusement account it. Glance advanced to far added agreeable from
you! By the way, how can we be in contact?
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get bought an shakiness over
that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly the same nearly very often inside case you shield this hike.
Hello! I just wanted to ask if you ever have any problems
with hackers? My last blog (wordpress) was hacked and I ended up losing a
few months of hard work due to no data backup.
Do you have any methods to stop hackers?
When I initially commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get four emails with the
same comment. Is there any way you can remove people from
that service? Appreciate it!
Also visit my blog post; ruay หวย
Hi there friends, fastidious paragraph and pleasant arguments
commented here, I am actually enjoying by these.
Hi there, I discovered your blog via Google whilst searching for a comparable topic, your site came up, it
appears good. I have bookmarked it in my google bookmarks.
Hi there, just became aware of your blog thru Google, and found that
it’s truly informative. I am gonna be careful for brussels.
I’ll be grateful if you happen to continue this
in future. Numerous people shall be benefited from your writing.
Cheers!
You actually said this adequately!
An impressive share! I’ve just forwarded this onto a colleague who has been doing
a little research on this. And he in fact ordered me breakfast simply because
I found it for him… lol. So allow me to reword this….
Thanks for the meal!! But yeah, thanks for spending the time to discuss this issue here on your site.
In the dynamic entire world of logistics and provide chain administration, pallet organizations inside the United states Engage in an important job in ensuring The graceful movement,
storage, and transportation of goods. From foods distribution to
industrial manufacturing, pallets variety the muse of just
about every single product cargo across the nation. As demand for dependable logistics proceeds to expand, companies
are trying to find top rated-tier pallet providers
who can deliver longevity, affordability, and environmental sustainability.
Good post. I learn something totally new and challenging on sites
I stumbleupon every day. It will always be useful
to read articles from other writers and practice a little
something from other sites.
Do you have a spam issue on this blog; I also am a blogger, and
I was curious about your situation; many of us have developed
some nice methods and we are looking to swap methods with other folks, please
shoot me an email if interested.
Hey folks,
I’ve been diving into the world of online casinos lately, and I’ve gotta say — it’s way more exciting than I expected. At first, I was a bit wary. I mean, how do you even believe in an online platform with your cash, right? But after spending hours researching (and trying out a few sketchy sites so you can avoid that mess), I figured out a few things that distinguish a trustworthy casino from a risky mess. First off, if you’re new to all this, here’s the golden rule: **licenses matter**. If a casino doesn’t have a proper license (like from the MGA or the UKGC), just close that tab. No bonus is worth the risk of never seeing your funds again. Also — and I know no one wants to — check the terms. That’s the only way to know what kind of playthrough limits they’ve slapped onto those so-called “amazing” bonuses.
Now, let me share a site I’ve been playing on these last few weeks. It’s been a breath of fresh air. The interface? Super easy to navigate. Payouts? Quick — like 24 hours quick. And the game selection? *Insane*. Slots, live dealers, blackjack, even some weird niche games I hadn’t tried before. Check it out here: https://x.com/Spinmama364864 What really stood out was the help desk. I had a tiny issue with a bonus not working, and they got back to me in like 10 minutes. Compare that to other sites where you’re just left hanging — yeah, not worth it.
Also, if you’re into bonuses (and who isn’t?), this place offers some legit ones. But here’s the trick: don’t just grab every shiny offer. It’s smarter to get reasonable terms than a huge bonus you’ll never be able to withdraw. I’m not saying you should go and drop your rent money — please don’t. But if you’ve got a little extra fun budget and you’re looking for a chill way to spend an evening, online casinos can totally deliver. Just stay sharp, control your bankroll, and don’t treat it like a side hustle. It’s for fun, not for a paycheck. Anyway, just wanted to drop my experience here in case anyone’s curious or trying to find a trustworthy place to play. If you’ve got your own stories or even some casino nightmares, I’m all ears — love talking shop about this stuff.
Good luck out there, and don’t let the house win too much ??
Hey very nice blog!
This is a topic that’s near to my heart… Thank you!
Exactly where are your contact details though?
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back down the road.
Cheers
I enjoy, cause I discovered just what I ussd to be having a look for.
You have ended mmy 4 day long hunt! God Bless you man. Have a great day.
Bye
I really like what you guys are usually up too. This kind of clever work and coverage!
Keep up the awesome works guys I’ve included you guys to my personal blogroll.
https://datawarnahk.club/
I used to be suggested this website by way of my cousin. I am
no longer positive whether this post is written by means of him as
no one else recognize such distinctive approximately my trouble.
You are wonderful! Thanks!
Greetings! This is my first visit to your blog! We are a group of volunteers
and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on.
You have done a marvellous job!
Why visitors still use to read news papers when in this
technological globe all is available on net?
Hello, its good piece of writing about media print, we all be aware of media is a great source of
facts.
I’m really enjoying the theme/design of your site.
Do you ever run into any web browser compatibility problems?
A few of my blog readers have complained about my blog not operating correctly in Explorer but looks great
in Chrome. Do you have any ideas to help fix this
problem?
excellent issues altogether, you just gained a new reader.
What may you suggest about your submit that you simply made
some days ago? Any certain?
Marvelous, what a web site it is! This web site gives useful data to
us, keep it up.
Useful information. Fortunate me I found your web site by accident,
and I am shocked why this accident did not came about
in advance! I bookmarked it.
My coder is trying to persuade me to move
to .net from PHP. I have always disliked the
idea because of the expenses. But he’s tryiong none the less.
I’ve been using Movable-type on a variety of websites for about a year and
am nervous about switching to another platform. I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any kind of help would be greatly appreciated!
This is very interesting, You are a very professional blogger.
I’ve joined your feed and stay up for seeking extra
of your fantastic post. Additionally, I’ve shared your site in my
social networks
Good web site you’ve got here.. It’s hard to find quality writing like yours these days.
I seriously appreciate people like you! Take
care!!
My webpage :: Lottoup com เข้าสู่ระบบ
This is my first time go to see at here and i am really impressed to read all at single place.
An intriguing discussion is worth comment.
I do think that you need to publish more on this topic, it might not
be a taboo subject but generally people don’t talk
about such subjects. To the next! Kind regards!!
I like that Appanail focuses on tackling toenail fungus from the inside—most treatments I’ve tried were just topical and didn’t last.
This sounds like a more comprehensive solution!”
Helpful information. Fortunate me I discovered your web site by accident, and I’m surprised why this accident
didn’t happened earlier! I bookmarked it.
The ingredients in MemoCore definitely caught my attention — especially
Lion’s Mane and Alpha GPC. If the liquid formula really improves focus and memory, this could be a game-changer.
Looking forward to seeing if it lives up to the hype!
Greetings from California! I’m bored at work so I decided to
check out your site on my iphone during lunch break.
I really like the knowledge you provide here and can’t wait
to take a look when I get home. I’m shocked at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, wonderful blog!
I read this post completely on the topic of the comparison of most up-to-date and previous technologies, it’s awesome article.
It’s enormous that you are getting ideas from this post
as well as from our discussion made at this time.
It is really a great and useful piece of information. I’m satisfied that you just shared this useful info with us.
Please stay us up to date like this. Thank you for sharing.
Les chasses au trésor sont une activité fondée en grande partie sur la chance.
My brother suggested I may like this web site.
He was entirely right. This put up actually made my day.
You can not believe simply how so much time I
had spent for this information! Thanks!
Heya i am for the first time here. I came across this
board and I find It really useful & it helped me out a lot.
I hope to give something back and aid others like you aided me.
This germaneness helps you design and inaugurate your own minimal without
any inimitable coding skills. Choose the blockchain, freeze up token parameters, count up liquidity,
and animate an automated trading bot!
Hi there it’s me, I am also visiting this web page daily, this web site is genuinely
pleasant and the people are in fact sharing pleasant thoughts.
It’s very trouble-free to find out any topic on net as compared to books,
as I found this article at this web site.
Hey There. I found your blog using msn. This is a very
well written article. I’ll be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll certainly return.
Découvrez à quoi correspond chaque indice des chasses aux trésors présents en jeu ainsi qu’une estimation de leur difficulté.
A partir de là il ne vous reste qu’à chercher chacun des indices dans une zone de 10 maps autour du point de départ pour progresser jusqu’au combat final contre le Trésor et ainsi obtenir votre fameuse récompense.
Hey there! This is my first visit to your blog! We
are a team of volunteers and starting a new project
in a community in the same niche. Your blog provided
us useful information to work on. You have done a extraordinary job!
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to make your point.
You definitely know what youre talking about, why waste
your intelligence on just posting videos to your blog when you could be giving us something informative to read?
소액결제 현금화(휴대폰결제 현금화)는 휴대폰 소액결제
한도를 이용해 현금을 마련하는 효율적인 방법입니다.
Today, I went to the beach front with my children. I found
a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic but I
had to tell someone!
시알리스는 PDE5 억제제 계열의 발기부전 치료제로, 음경 혈류를 증가시켜 발기를
도와주는 효능을 갖고 있습니다. 비아그라에 비해 약효 지속기간이 매우 긴 것이 특징
Great post but I was wanting to know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Appreciate it!
You actually revealed it adequately!
This post offers clear idea designed for the new users of blogging, that really
how to do running a blog.
Your style is very unique in comparison to other folks
I’ve read stuff from. Many thanks for posting when you’ve got the opportunity, Guess I will just bookmark this web site.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
What’s up, I check your blog on a regular basis.
Your humoristic style is witty, keep it up!
I have been browsing on-line greater than three hours
these days, but I never found any interesting article like yours.
It is beautiful value enough for me. Personally, if all web owners and bloggers
made good content as you probably did, the internet will probably be much more useful than ever
before.
Greetings I am so thrilled I found your blog page, I really found you by accident, while I was researching on Askjeeve for something else,
Anyways I am here now and would just like to say cheers for a remarkable post and a all round
entertaining blog (I also love the theme/design), I don’t have
time to go through it all at the minute but I have saved it and also included your RSS
feeds, so when I have time I will be back to read much more, Please do keep up the fantastic work.
Thanks very nice blog!
This is my first time go to see at here and i am really happy to read
everthing at single place.
At this moment I am ready to do my breakfast, later than having my breakfast coming
over again to read further news.
I’m gone to say to my little brother, that he should also visit
this weblog on regular basis to get updated from most up-to-date
information.
With thanks. Lots of advice!
It’s hard to find well-informed people about this topic,
but you seem like you know what you’re talking about!
Thanks
Aw, this was a really good post. Taking the time and actual effort to create a good
article… but what can I say… I procrastinate a whole lot and don’t manage to get anything done.
Everyone loves what you guys are up too. This sort of clever work and exposure!
Keep up the great works guys I’ve included you guys to
blogroll.
Dracula pour l’emporter devra transformer tous les habitants d’un des cinq quartiers du jeu en Vampire ou survivre 5 manches.
Generally I don’t read post on blogs, however I would like to say that this write-up
very forced me to try and do so! Your writing taste has been surprised
me. Thanks, very nice post.
Plinko is one of those games that’s incredibly fun and quick to learn, which is why it’s so popular! It’s all about randomness, no need for complicated strategies or experience. You just drop the disc and observe it fall around the pegs, praying it lands in a high-paying slot. The randomness is what makes it thrilling, and there’s something cool about following the disc’s journey, even if you don’t win every time. It’s great for players who want a casual game without all the stress. And with the opportunity to bet real money, it gives you more to look forward to. Whether you’re a beginner or a seasoned player, http://ammon.pro/bitrix/rk.php?goto=https://cbondsystems.com/wp-content/themes/Cbond/pdf.php%3Flink=https://www.bez-politikov.sk/2022/11/zemianska-cest/ has something to offer, and it’s definitely worth a try. Plus, with it being accessible online, you can enjoy it anytime, from anywhere. Totally worth checking out if you’re into easy, fun games!
Helpful info. Fortunate me I discovered your website accidentally,
and I am shocked why this twist of fate didn’t came about earlier!
I bookmarked it.
Hello There. I found your blog using msn. This is a
really well written article. I will make sure to bookmark it and return to read more of your
useful information. Thanks for the post. I will certainly comeback.
Piece of writing writing is also a excitement, if you know afterward you can write or
else it is complicated to write.
Hello, I enjoy reading all of your post. I wanted to write a
little comment to support you.
Hello, I check your new stuff on a regular basis. Your story-telling style
is awesome, keep doing what you’re doing!
My partner and I stumbled over here different web page and thought I might as well check
things out. I like what I see so now i am following you.
Look forward to finding out about your web page repeatedly.
constantly i used to read smaller articles or reviews which as well clear their motive, and that is also happening with this article which I am reading at
this place.
Remarkable! Its genuinely amazing post, I have got much clear idea about from this piece of writing.
What’s up it’s me, I am also visiting this web site on a regular basis, this web site is really good and the visitors are genuinely sharing nice thoughts.
My brother suggested I might like this website. He was entirely right.
This post truly made my day. You cann’t imagine simply how much time I had spent for this info!
Thanks!
Detaylı ve sade anlatımınız için teşekkür ederim.
Your style is very unique in comparison to other folks I’ve read stuff from.
I appreciate you for posting when you have the opportunity, Guess I will just bookmark this web site.
After going over a few of the articles on your site, I seriously appreciate your way
of blogging. I bookmarked it to my bookmark site list and will be checking back soon. Take a look
at my web site as well and let me know what you think.
I know this if off topic but I’m looking into starting my own weblog and was wondering what
all is needed to get setup? I’m assuming having a blog like yours would
cost a pretty penny? I’m not very web smart so I’m not 100% sure.
Any suggestions or advice would be greatly appreciated. Many thanks
Great insights here!
It’s always refreshing to read posts that talk about digital value and how to maximize online platforms.
Looking forward to more of your content—keep up the great work!
Thanks a bunch for sharing this with all people you really know
what you are speaking approximately! Bookmarked. Kindly also visit my site =).
We could have a link trade contract among us
Hello, I think your blog might be having browser
compatibility issues. When I look at your blog site in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, fantastic blog!
Hi! I could have sworn I’ve been to this website before but after checking through some of the post
I realized it’s new to me. Nonetheless, I’m definitely glad I found
it and I’ll be book-marking and checking back frequently!
Incredible! i’ve been searching for something similar. i appreciate the info
I’ve been taking Gluco Sense for about
three weeks now to help stabilize my blood sugar
levels. So far, I feel fewer energy dips after meals, which is encouraging.
Still monitoring things closely, but I’m cautiously optimistic about the results.
A fascinating discussion is definitely worth comment. I do think that you need to publish more on this issue, it might not be a taboo matter but usually people don’t talk about such topics.
To the next! Many thanks!!
Les noms des personnages de films effrayants et des tueurs en série sont également répertoriés ci-dessous si vous souhaitez plutôt jouer à « Nommez le personnage de film effrayant » ou « Nommez le tueur en série ».
Hi there I am so excited I found your weblog, I really
found you by error, while I was browsing on Yahoo for something else, Nonetheless I am here now and would just like to say kudos
for a marvelous post and a all round exciting blog (I also love the theme/design), I don’t have time to browse it all at the minute
but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read a lot
more, Please do keep up the fantastic work.
This site truly has all the information and facts I wanted concerning this subject and didn’t know who to ask.
Hi there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m undoubtedly enjoying your blog and look forward to new
updates.
It’s in fact very difficult in this active life to listen news on TV, thus I simply use internet for that reason, and obtain the
most recent information.
Howdy would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 different internet browsers and I must say this blog loads a lot faster then most.
Can you suggest a good internet hosting provider at a reasonable price?
Kudos, I appreciate it!
We’re a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on. You’ve done an impressive job and our
whole community will be thankful to you.
4M Dental Implant Center
3918 ᒪong Beach Blvd #200, Lonng Beach,
CA 90807, United Ѕtates
15622422075
tooth art
Magnificent beat ! I wish to apprentice at the same
time as you amend your website, how could i subscribe for a weblog site?
The account helped me a applicable deal. I were tiny bit familiar of this your broadcast offered brilliant clear concept
Hi there! I could have sworn I’ve been to this site before but after
browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely happy I found it and I’ll be bookmarking and checking back often!
Yes! Finally someone writes about OLX138.
Hey There. I found your blog using msn. This is a very well written article.
I’ll make sure to bookmark it and come back
to read more of your useful information. Thanks for the post.
I’ll certainly comeback.
Remarkable! Its actually awesome piece of
writing, I have got much clear idea regarding from this article.
If you are going for finest contents like myself, just pay
a visit this website daily for the reason that it offers feature contents, thanks
I tried Purple Peel Exploit by Mitolyn for a couple of months and noticed a steady boost in energy and slow, gradual weight loss—though it took consistent use and worked best
when paired with diet and exercise
My programmer is trying to persuade me to move to
.net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety of websites
for about a year and am concerned about switching to another platform.
Ihave heard fantastic things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be really appreciated!
Awesome advice, Kudos.
Hey very nice blog!! Guy .. Beautiful .. Amazing ..
I will bookmark your web site and take the feeds additionally?
I am glad to find so many helpful information right here within the submit, we’d like
work out extra strategies on this regard, thanks
for sharing. . . . . .
Touche. Solid arguments. Keep up the great effort.
Hi there! Someone in my Facebook group shared this site with us so I came to
give it a look. I’m definitely enjoying the information.
I’m book-marking and will be tweeting this to my followers!
Wonderful blog and brilliant design and style.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Le fonctionnementde la recherche est le même, mais avec un Avis de recherche à lafin.
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve truly enjoyed surfing around your blog posts.
In any case I’ll be subscribing to your feed and I hope you
write again very soon!
This was an awesome share .
Can you tell us more about this? I’d love to find out more details.
Wow, superb blog format! How long have you ever been running
a blog for? you made running a blog glance easy. The overall look of your site is excellent, let
alone the content!
Everything is very open with a precise clarification of the challenges.
It was definitely informative. Your website is extremely helpful.
Many thanks for sharing!
The Blue Salt Trick has definitely sparked curiosity, especially with its bold claims around boosting energy and improving circulation. While it sounds intriguing, there’s little to no solid
scientific evidence backing it up. It seems more
like a social media trend than a proven health solution.
If you’re serious about improving your health, it’s probably better to stick with well-researched supplements and
lifestyle habits.
Ask ChatGPT
Заказать карту Монобанк так просто.|
%card_name% становится идеальным выбором для ваших целей!|
Mono предлагает максимально выгодные проценты!|
Оформите карту Monobank и пользуйтесь рассрочкой!|
Заказ карты потребует пару минут благодаря
удобному приложению Monobank!|
Удобные решения для каждого клиента!|
Начните путь к удобным расчетам с Монобанком!|
Без скрытых комиссий только
с Monobank!|
Забудьте о сложностях с картой Монобанк!|
Выбор условий для каждой карты Монобанк!|
Оформити картку Монобанк
зручно та швидко.|
%card_name% є надійним вибором для ваших цілей!|
Monobank пропонує зручні тарифи.|
Оформіть картку Monobank та оцініть зручним сервісом!|
Оформлення картки потребує мінімум часу завдяки
зручному додатку Monobank.|
Вигідні рішення для покупок та платежів.|
Відкрийте шлях до фінансової свободи з Монобанком.|
Прозорі умови тільки з Monobank!|
Насолоджуйтеся зручністю з карткою Monobank.|
Зручне управління для кожної картки Monobank.|
Увидел странный плотный участок кожи на руке, на тыльной
стороне пальца.
На epilstudio.ru увидел статью о шипице на руке
— с подробным описанием.
Теперь точно понял, что это вирусная бородавка.
Хорошо, что статья не пугает, а объясняет.
You’ve made some decent points there. I looked on the net to learn more about the issue and found most people will go along with your
views on this website.
Incredible! This blog looks just like my old one! It’s on a completely different subject but it has pretty much the same page layout and design. Wonderful choice of colors!
Feel free to surf to my blog post – Asialive88 Mbah Angka
I enjoy reading an article that can make men and women think.
Also, many thanks for permitting me to comment!
For most recent news you have to visit world-wide-web and on the
web I found this web site as a best web site for hottest updates.
Heya! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no data
backup. Do you have any solutions to protect against
hackers?
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping
maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly
enjoy reading your blog and I look forward to your new
updates.
Keep on writing, great job!
What’s up to every , as I am genuinely keen of reading this website’s post to be updated on a regular basis.
It consists of nice data.
I have read several excellent stuff here. Certainly worth
bookmarking for revisiting. I surprise how a lot effort you set to make this sort of magnificent informative web site.
Heya i’m for the primary time here. I found this board and I in finding It truly useful & it helped me out a lot.
I am hoping to offer something back and help others such as
you aided me.
Howdy this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have
to manually code with HTML. I’m starting a blog soon but have no coding knowledge so I wanted to get
guidance from someone with experience. Any help would be enormously appreciated!
Wow, wonderful weblog structure! How lengthy have you been blogging for?
you make running a blog look easy. The whole glance of your website is wonderful,
let alone the content!
Hi there great blog! Does running a blog similar to this require a large amount of
work? I have absolutely no expertise in coding but I was hoping to start my
own blog in the near future. Anyways, if you have any
ideas or tips for new blog owners please share.
I understand this is off topic nevertheless I simply needed to ask.
Kudos!
It’s really a nice and helpful piece of info. I’m glad that you simply shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
I am sure this paragraph has touched all the internet visitors, its
really really pleasant paragraph on building up new weblog.
Hello! Someone in my Myspace group shared this website with us so I came to
look it over. I’m definitely loving the information. I’m book-marking and
will be tweeting this to my followers! Outstanding blog and fantastic design.
Awesome! Its in fact remarkable piece of writing, I have got much clear
idea about from this paragraph.
What’s up, after reading this amazing post i am also glad to share my knowledge here with friends.
Excellent article. I absolutely appreciate this
website. Continue the good work!
Amazing! This blog looks exactly like my old one!
It’s on a totally different subject but it has pretty much the same page layout and design.
Excellent choice of colors!
Look at my page :: slimjaro
I love it whenever people come together and share ideas.
Great website, continue the good work!
Here is my web-site … see through led display
Fantastic items from you, man. I have take into account
your stuff previous to and you are simply too great.
I actually like what you have acquired right here, really like what you are
saying and the way wherein you are saying it.
You’re making it entertaining and you continue to take care of
to keep it sensible. I can’t wait to read far more from you.
This is really a tremendous site.
Hello there, just became alert to your blog through Google, and found that it’s really
informative. I’m going to watch out for brussels. I’ll appreciate if you continue this in future.
Lots of people will be benefited from your writing.
Cheers!
Hi there! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing
very good success. If you know of any please share.
Kudos!
I just like the valuable info you provide on your articles.
I will bookmark your weblog and test once more here regularly.
I am quite sure I’ll be informed lots of new stuff right here!
Best of luck for the following!
non gamstop casinos uk
Vodka Bet: официальный сайт-зеркало Водка Бет
What’s up to every one, the contents existing at this
web site are truly remarkable for people knowledge, well, keep
up the good work fellows.
We’re a group of volunteers and opening a new scheme in our community.
Your site offered us with valuable information to
work on. You have done an impressive job and our entire community will be grateful to you.
Heya i’m for the first time here. I came across this board and I find
It truly useful & it helped me out a lot.
I hope to give something back and aid others like you helped me.
Its such as you learn my mind! You seem to know
so much about this, like you wrote the ebook in it
or something. I think that you could do with some % to pressure the message house a bit,
but other than that, that is excellent blog. An excellent read.
I’ll definitely be back.
We’ve over a decade’s experience translating certificates in every languages, including
official and informal certificates. https://www.algebra.com/tutors/aboutme.mpl?userid=world-text
If you are going for finest contents like me, only pay a visit this web page everyday for the reason that it
provides quality contents, thanks
fantastic points altogether, you just won a emblem new reader.
What may you recommend about your put up that you
made a few days in the past? Any sure?
I am curious to find out what blog system you’re working with?
I’m experiencing some small security problems with my latest site and I’d like
to find something more safeguarded. Do you
have any recommendations?
My webpage :: ขายผักไฮโดรโปนิกส์
Thanks in favor of sharing such a nice thinking, piece of writing is pleasant, thats why
i have read it fully
Hi there to every body, it’s my first pay a quick visit of this web site; this webpage consists of awesome and really fine material for visitors.
These https://joyorganics.com/products/cbd-sleep-gummies are a perfect compare of tang and relaxation. The flavor is honestly sweet, without any cold aftertaste, and the texture is pleasantly soft. I noticed a calming effect within nearby 30 minutes, helping me unwind after a extended heyday without susceptibilities drowsy. They’re easy to away with on the survive and form constantly CBD expend enjoyable. Ardent trait, accordant dosage, and a delightful way to experience the benefits of CBD
I really like what you guys are up too. This kind of clever work and coverage!
Keep up the great works guys I’ve incorporated you guys to my blogroll.
There’s certainly a lot to know about this issue. I love all the
points you made.
Ridiculous quest there. What happened after? Good luck!
Joint Genesis is getting a lot of praise for its powerful support in easing joint discomfort and
improving flexibility. With its science-backed formula
and focus on joint hydration, it’s a great option for anyone looking
to stay active and mobile. Definitely worth a look if you’re tired of stiff, achy joints!
Certains sites internet peuvent vous fournir des indices ou des guides pour résoudre plus facilement les énigmes.
My spouse and I stumbled over here coming from a different web address and thought I
might check things out. I like what I see so now i am following
you. Look forward to exploring your web page for a second time.
Mighty Dog Roofing
Remer Drive Nortrh 13768
Maple Grove, MN 55311 United Տtates
(763)280-5115
storm-resistant roofing Materials
It’s awesome to visit this site and reading the views of all mates about this piece of writing, while I am also zealous of
getting know-how.
Если у вас есть ссылка на приватное видео,
вы можете скачать его безопасно с помощью этого инструмента.
It’s an amazing post designed for all the web visitors; they will
take benefit from it I am sure.
We are a gaggle of volunteers and starting a new scheme
in our community. Your website offered us with useful info to work on. You have done an impressive process and our whole
group will be grateful to you.
This site has a no-nonsense mouse click test that loads fast and does exactly what it says: https://sites.google.com/view/mouseclicktest. I like how clean and lightweight it feels — no ads, no distractions. Great for practicing or testing out a new mouse.
iGenics seems like a thoughtful formula for those wanting to protect and enhance their vision naturally.
I like that it combines antioxidants and eye-friendly nutrients to
help fight oxidative stress and support long-term eye health.
If it truly delivers on its promise, it could be a smart choice for keeping vision sharp and clear over
the years.
Great information. Lucky me I ran across your website by
accident (stumbleupon). I have book marked it for later!
Pretty nice post. I simply stumbled upon your blog and wished to mention that I’ve truly loved browsing your blog posts.
In any case I’ll be subscribing to your feed and I am hoping
you write again soon!
Hi! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing months of
hard work due to no backup. Do you have any solutions to protect against hackers?
Hi! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of
hard work due to no backup. Do you have any solutions to stop hackers?
Great info. Lucky me I found your website by accident (stumbleupon).
I’ve saved as a favorite for later!
таролог
Do you have any video of that? I’d want to find out some additional information.
Thanks for a marvelous posting! I seriously enjoyed reading it,
you will be a great author. I will be sure to bookmark your blog
and may come back in the foreseeable future. I want to
encourage one to continue your great writing, have a nice afternoon!
Thanks for sharing! The recent extreme weather events in Australia have
been alarming, and it’s good to see coverage that breaks down both the heatwaves
and flooding.
I especially liked how you connected the topic with platforms like WFGaming, Free Deposit 365,
and freedeposit365 — it’s interesting to see online engagement discussed alongside major news.
Looking forward to reading more updates on freenodeposit365, freedeposit, free new register, and free tanpa deposit in future articles.
Vous découvrirez des astuces et des stratégies pour optimiser vos gains, et vous apprendrez comment naviguer dans le monde de Dofus Unity pour dénicher les coffres cachés.
Great article! This is the kind of info that are meant
to be shared across the net. Disgrace on Google for not
positioning this put up higher! Come on over and seek advice from my web site
. Thanks =)
This design is incredible! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Great job. I really loved what you had
to say, and more than that, how you presented it. Too cool!
whoah this weblog is great i really like studying your posts.
Stay up the great work! You know, lots of people are hunting round for this information, you can help them greatly.
Thank you for the auspicious writeup. It in truth was a entertainment account it.
Glance complex to more introduced agreeable from you!
By the way, how can we be in contact?
Its such as you learn my thoughts! You seem to understand a
lot approximately this, like you wrote the ebook in it or
something. I think that you simply could do with a few p.c.
to force the message house a bit, however other than that, this is excellent
blog. An excellent read. I will certainly be back.
Woah! I’m really digging the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s
tough to get that “perfect balance” between usability and visual appearance.
I must say you have done a fantastic job with this. In addition, the blog
loads super fast for me on Firefox. Exceptional Blog!
Very good information. Lucky me I came across your blog by chance (stumbleupon).
I have saved it for later!
Thanks a bunch for sharing this with all folks you really
recognize what you’re talking about! Bookmarked.
Please also visit my site =). We may have a link trade contract among us
Hey there! I know this is somewhat off topic but I was
wondering if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble
finding one? Thanks a lot!
Dans le pire des cas, assurez-vous d’avoir un écartsignificatif de prix pour quand même pouvoir mettre au prix d’achatla ressource obtenu et éviter une perte (surtout avec de laconcurrence).
Fastidious answer back in return of this query with real arguments and explaining
everything on the topic of that.
Wah, tulisannya mantap banget!
Betul sekali dengan isi yang kamu angkat.
Tidak sering saya membaca tulisan sebagus ini.
Thanks sudah menulis pengetahuan seperti ini.
Gue bakal membagikan ini kepada rekan saya.
Mudah-mudahan di masa depan akan ada lebih banyak konten seperti yang ada di Hati
Ceria.
Excellent post. I was checking constantly this weblog and I am inspired!
Very helpful info particularly the final part :
) I take care of such info much. I was looking for this particular info for a long time.
Thank you and best of luck.
Mighty Dog Roofing
Reimer Drive North 13768
Maple Grove, MN 55311 United Ꮪtates
(763) 280-5115
durable gutter installation programs
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ꭰr с121,
Charlotte, NC 28273, United Ꮪtates
+19803517882
Additions space homе for extra (Iona)
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your magnificent
post. Also, I have shared your website in my social networks!
Hi, I do believe this is a great site. I stumbledupon it 😉 I’m going to return once again since i have saved as a favorite it.
Money and freedom is the best way to change, may you be rich and continue to help other people.
Hiya! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My website looks weird when browsing from my iphone 4. I’m trying to find a template or plugin that might be able to fix this problem.
If you have any suggestions, please share.
Many thanks! http://galeria3d.iceiy.com
Wow, incredible weblog structure! How lengthy have you ever been blogging for?
you make running a blog glance easy. The entire look of your website is great, let alone the
content material!
Private Blog Networks (PBNs) remain among one
of the most debated yet effective devices in search engine optimization. When utilized properly, they can significantly boost search rankings by providing high-grade backlinks.
Inappropriate usage can lead to fines from Google.
This guide clarifies the importance of PBNs in search engine
optimization, their benefits, threats, and best methods for
risk-free and reliable application.
I’m not sure where you’re getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic info I was looking for this info
for my mission.
Take a look at my webpage; http://igamble247-login.netlify.app
It’s impressive that you are getting thoughts from this piece
of writing as well as from our discussion made at this
place.
Good day! I could have sworn I’ve visited this website before but after going through many of the
posts I realized it’s new to me. Anyways, I’m certainly happy I discovered it and I’ll be book-marking it and checking back often!
Hi to all, how is all, I think every one is getting more from this web page,
and your views are good in favor of new visitors.
Here is my page – เว็บแท่งหวยออนไลน์ lottovip
нейросеть для презентаций
A person necessarily assist to make significantly posts I might state.
That is the very first time I frequented your web page
and so far? I surprised with the analysis you made to make this actual submit incredible.
Magnificent task!
Its such as you read my thoughts! You appear to grasp a lot about this, such as you wrote
the guide in it or something. I think that you can do with some p.c.
to power the message home a bit, but other than that,
this is fantastic blog. A fantastic read. I will definitely be
back.
I’ve read some good stuff here. Certainly price bookmarking
for revisiting. I wonder how a lot effort you place to create
the sort of great informative site.
Wow, this paragraph is good, my younger sister is analyzing these things, therefore I am going to inform her.
This design is wicked! You definitely know how to keep a reader
entertained. Between your wit and your videos, I was almost
moved to start my own blog (well, almost…HaHa!) Fantastic job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
Remarkable issues here. I am very satisfied to look your article.
Thank you a lot and I’m having a look ahead to contact you.
Will you kindly drop me a e-mail?
It is perfect time to make some plans for the future and it is time
to be happy. I have read this post and if I could I desire
to suggest you some interesting things or tips. Maybe
you can write next articles referring to this article.
I want to read even more things about it!
It’s an amazing paragraph in favor of all the web viewers; they will obtain advantage from
it I am sure.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on a variety of websites for about a year and am concerned about switching to another platform.
I have heard excellent things about blogengine.net. Is there a way I can transfer all my wordpress content into it?
Any kind of help would be greatly appreciated!
Attractive section of content. I simply stumbled upon your blog and in accession capital to say that I get in fact
loved account your weblog posts. Anyway I’ll be subscribing on your feeds and even I
success you get right of entry to constantly fast.
I do not know whether it’s just me or if everyone else encountering problems with your website.
It seems like some of the text within your content are running off the screen.
Can somebody else please provide feedback and let me know if this is happening to them as well?
This may be a issue with my browser because I’ve had this happen previously.
Thanks
Heya i am for the primary time here. I came across this
board and I in finding It really helpful & it helped me out much.
I’m hoping to present something again and aid others such as you helped
me.
Hi there everyone, it’s my first pay a visit at
this website, and paragraph is really fruitful for me, keep up posting these types of articles.
Heya i’m for the first time here. I found this board and I find It truly useful & it helped me out
much. I hope to offer one thing again and aid others such as you aided me.
Using Translation Memory technologies, we ensure regularity
of terminology. https://www.demilked.com/author/web-translation/
Wow, that’s what I was seeking for, what a stuff!
existing here at this webpage, thanks admin of this website.
bookmarked!!, I really like your blog!
Thanks for every other excellent post. Where else may anybody get that kind of information in such a
perfect method of writing? I have a presentation next week,
and I am at the look for such info.
Awesome article !
Its like you learn my mind! You appear to understand a lot approximately this,
such as you wrote the book in it or something. I think that you simply could do with some percent to drive the message home a little
bit, but instead of that, that is great blog. A fantastic read.
I will certainly be back.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get
listed in Yahoo News? I’ve been trying for a while but
I never seem to get there! Many thanks
Hi there, just became alert to your blog through Google, and found that it is truly informative.
I am going to watch out for brussels. I will appreciate if you continue
this in future. Numerous people will be benefited from your writing.
Cheers!
These https://joyorganics.com/products/organic-cbd-salve are a perfect balance of suggestion and relaxation. The flavor is naturally honeyed, without any bitter aftertaste, and the nature is pleasantly soft. I noticed a calming effect within nearby 30 minutes, plateful me unwind after a want day without heat drowsy. They’re easy to pit oneself against on the fade and make continuously CBD resort to enjoyable. Great worth, harmonious dosage, and a flavourful manner to happening the benefits of CBD
Hey! This is my 1st comment here so I just wanted to give a quick shout out and say I really enjoy reading your blog posts.
Can you recommend any other blogs/websites/forums that cover the same subjects?
Thank you!
Also visit my web-site :: http://Www.adelaidebbs.com.au
создать презентацию
Here is my homepage :: online poker tournaments
Thank you for another informative website.
Where else could I am getting that kind of information written in such an ideal manner?
I’ve a project that I’m just now running on, and I’ve been on the look out for such info.
We are a group of volunteers and starting a new scheme in our community.
Your website provided us with helpful information to work on. You
have performed an impressive job and our whole group will
be thankful to you.
аудио поздравления на телефон
Hey there just wanted to give you a brief heads
up and let you know a few of the images aren’t
loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers
and both show the same results.
Hello, its nice post concerning media print, we
all know media is a fantastic source of information.
Thank you for sharing your thoughts. I really appreciate your efforts
and I will be waiting for your further post thank you once again.
Really many of beneficial advice!
excellent submit, very informative. I’m wondering why the other experts of this sector don’t understand this.
You should continue your writing. I’m sure, you have a great readers’ base already!
Your style is very unique compared to other people I have read stuff from.
I appreciate you for posting when you have the opportunity, Guess I will just
book mark this page.
WOW just what I was looking for. Came here by searching for Sofortige Azopt
Big thanks for the effort!
fantastic points altogether, you simply received a new reader.
What would you suggest in regards to your submit that you just made some days in the past?
Any sure?
I’m amazed, I have to admit. Rarely do I come across a blog that’s equally educative and engaging, and let me tell you, you’ve hit the nail on the head.
The problem is something not enough men and women are speaking intelligently about.
I’m very happy that I came across this during my hunt
for something regarding this.
When someone writes an piece of writing he/she maintains the idea of a user
in his/her brain that how a user can understand it.
Therefore that’s why this piece of writing is outstdanding.
Thanks!
whoah this blog is magnificent i love studying your articles.
Stay up the good work! You realize, many individuals are hunting around for
this information, you can help them greatly. https://Www.Instapaper.com/p/tonnesen79busk
You really make it seem so easy with your presentation but I find
this matter to be actually something that I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for your next post, I will try to get the hang of it!
This info is priceless. Where can I find out more?
You actually make it seem so easy along with your presentation however I find this
topic to be actually something that I feel I might by no means understand.
It kind of feels too complex and extremely extensive
for me. I am having a look forward on your subsequent
publish, I will try to get the dangle of it!
I’m not that much of a online reader to be
honest but your sites really nice, keep it up! I’ll go ahead and
bookmark your site to come back in the future. Cheers
Oh my goodness! Impressive article dude! Many thanks, However I am experiencing problems with your RSS.
I don’t know why I can’t subscribe to it. Is there anybody else getting the
same RSS issues? Anyone that knows the solution can you kindly respond?
Thanks!!
May I simply say what a comfort to uncover a person that truly understands what they
are talking about on the internet. You certainly realize how to bring a problem to light and make it important.
A lot more people should check this out and understand this side of the story.
I can’t believe you are not more popular given that you most certainly
possess the gift.
The profile at https://www.divephotoguide.com/user/spacebacounter introduces SpacebarCounter as a lightweight, browser-based tool that counts spacebar presses in real time. It clearly describes the tool’s functionality, including its cross-device compatibility and use for testing speed, reflexes, or typing patterns.
бетонные сваи для фундамента
I believe this is one of the most significant info for me.
And i am satisfied studying your article. But wanna statement on few normal issues,
The website style is ideal, the articles is really nice : D.
Just right activity, cheers
great post, very informative. I’m wondering why the opposite experts
of this sector do not realize this. You must continue your writing.
I am sure, you have a great readers’ base already!
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I am going to come back yet again since i have book-marked it.
Money and freedom is the best way to change, may you be rich and continue to
help other people.
I was suggested this web site via my cousin. I’m now
not positive whether or not this post is written by him as nobody else understand such
special about my trouble. You are incredible! Thanks!
Reresh Renovation Southwest Charlotte
1251 Arrow Pine Ɗr c121,
Charlotte, NC 28273, United Ѕtates
+19803517882
Home our renovation process
I think that is among the most significant info for me. And i am satisfied studying your article.
However want to statement on some common things, The website style is
perfect, the articles is really excellent : D. Excellent process,
cheers
Refresh Renovation Soutywest Charlotte
1251 Arrow Pine Ⅾr c121,
Charlotte, NC 28273, United Ѕtates
+19803517882
Add your to home value
I visited various web pages except the audio feature for audio
songs current at this website is really excellent.
I think this is one of the most important information for me.
And i’m glad reading your article. But wanna remark on few general things, The web site style is ideal, the articles
is really nice : D. Good job, cheers
I read this paragraph completely on the topic of the comparison of newest
and earlier technologies, it’s amazing article.
I always emailed this webpage post page to all my friends, since if like to
read it then my links will too.
If you wish for to increase your familiarity simply keep visiting
this website and be updated with the most recent news update posted here.
Hi there Dear, are you really visiting this web site on a regular basis,
if so afterward you will without doubt take good know-how.
IDRA‑MOSCOW предоставляет высококачественные компоненты для монтажа, эксплуатации и технического обслуживания систем трубопроводов, обеспечивая долговечность и профессиональную поддержку на каждом этапе проекта.
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ɗr c121,
Charlotte, NC 28273, United Stаtes
+19803517882
build custom Renovations design And
Основные типы бетонных свайных изделий
When I initially left a comment I appear to have clicked on the -Notify
me when new comments are added- checkbox and from now on every time a comment is
added I receive four emails with the same comment. Perhaps there is a way you
can remove me from that service? Many thanks!
Currently it sounds like Movable Type is the top blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
Good post. I learn something totally new and challenging on blogs I stumbleupon every day.
It’s always helpful to read through content from other
authors and use something from their websites.
Thanks for one’s marvelous posting! I genuinely enjoyed reading
it, you are a great author.I will ensure that I bookmark
your blog and will come back sometime soon. I want to encourage one
to continue your great work, have a nice weekend!
This website was… how do you say it? Relevant!! Finally I have found
something which helped me. Cheers!
It’s the best time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I wish to suggest you some interesting things or advice.
Perhaps you could write next articles referring to this article.
I want to read even more things about it!
It’s very simple to find out any matter on net as
compared to textbooks, as I found this article at this site.
Mitolyn is a natural supplement designed to support healthy metabolism and
energy production by targeting the mitochondria, often called the “powerhouses” of the cells.
Its formula focuses on improving fat-burning efficiency,
reducing fatigue, and boosting overall vitality.
Many people see it as a helpful option for maintaining a healthy weight and staying energized throughout
the day.
When I originally left a comment I seem to have clicked on the
-Notify me when new comments are added- checkbox and from now on whenever a comment
is added I recieve 4 emails with the same comment. Is there a means you can remove me
from that service? Kudos!
Please let me know if you’re looking for a article author for your site.
You have some really great posts and I believe I would be a good
asset. If you ever want to take some of the load off, I’d
really like to write some material for your blog in exchange for a link back
to mine. Please shoot me an email if interested.
Thank you!
What i do not realize is in fact how you are now not actually much more well-preferred than you
might be right now. You are very intelligent.
You know therefore considerably when it comes to this subject, produced me personally consider it from a lot of numerous angles.
Its like women and men are not interested until
it is something to accomplish with Woman gaga!
Your individual stuffs outstanding. All the time handle it up!
of course like your web site however you need to check
the spelling on quite a few of your posts. Several
of them are rife with spelling issues and I find it very bothersome to inform the reality
however I’ll certainly come back again.
Awesome article.
Howdy I am so happy I found your blog, I really found you by
mistake, while I was searching on Google for something
else, Regardless I am here now and would just like to say cheers for a
marvelous post and a all round thrilling blog (I also love the theme/design), I don’t
have time to go through it all at the moment but I have book-marked
it and also included your RSS feeds, so when I have time
I will be back to read much more, Please do keep up the fantastic b.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Hi to every one, because I am genuinely keen of reading this blog’s post to be updated on a regular basis.
It includes nice data.
What’s Happening i’m new to this, I stumbled upon this I’ve found It absolutely useful and it has aided
me out loads. I hope to contribute & help other customers like its aided me.
Great job.
ファイブスターズマーケッツとは?初心者にもわかりやすい取引プラットフォーム
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or
if it’s the blog. Any feed-back would be greatly appreciated.
This design is steller! You certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Copy the Shorts video link, visit a YT Shorts download
website such as SSYouTube.com and begin saving the
video.
Hello, this weekend is fastidious in favor of me, since this point in time i am reading this wonderful
informative piece of writing here at my residence.
I don’t even know the way I stopped up right here, but I thought
this publish used to be great. I do not recognize who you are
however certainly you’re going to a well-known blogger in the event you are not already.
Cheers!
This is very interesting, You’re a very skilled blogger. I have joined your feed and look forward to seeking
more of your excellent post. Also, I’ve shared your website in my social networks!
Normally I don’t read post on blogs, however I wish to say that this write-up very forced me to try and do so!
Your writing style has been amazed me. Thank you, very great article.
http://grafika3d.free.nf
This post is really a pleasant one it helps new the web people, who are wishing
in favor of blogging.
Aw, this was a really good post. Finding the time and actual effort to
produce a superb article… but what can I say… I hesitate a whole lot and never seem to get nearly anything done.
I every time spent my half an hour to read this website’s articles or reviews
everyday along with a mug of coffee.
Howdy! Someone in my Facebook group shared this website with us so I came to give it
a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Excellent blog and outstanding design and style.
I am in fact thankful to the owner of this site who has shared this
wonderful post at at this place.
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more pleasant for
me to come here and visit more often. Did you hire out a developer
to create your theme? Excellent work!
It’s awesome to pay a visit this web page and reading
the views of all colleagues regarding this paragraph, while I am also keen of getting knowledge.
KHVIP77 is a trusted online casino in Cambodia, operating for over
8 years. Known for fair play, secure withdrawals, and exciting games, it provides safe, reliable, and enjoyable entertainment for every player.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.info/ur/register-person?ref=WTOZ531Y
Hi there, I enjoy reading through your article.
I wanted to write a little comment to support you.
Someone necessarily help to make severely posts I’d state.
That is the very first time I frequented your web
page and to this point? I surprised with the research
you made to make this particular put up incredible.
Wonderful job!
I believe this is one of the such a lot important information for me.
And i am satisfied reading your article. But should commentary on some
general things, The site style is perfect, the articles is actually
excellent : D. Excellent process, cheers
I was recommended this blog by my cousin. I am not sure whether this post is written by
him as no one else know such detailed about my trouble. You are
amazing! Thanks!
You have made some really good points there. I checked on the
net to learn more about the issue and found most individuals will go along with
your views on this site.
Hello everyone! I thought to talk about aviator and minas game. This title hooks players right away with its mix of bet and tactics. Many players discuss about http://www.chuangzaoshi.com/Go/?url=https://office-nko.ru/dwqa-question/obsuzhdenie-proekta-prikaza-o-vnesenii-izmenenij-v-standarty-socialnyh-uslug/, and some hope for cheats, but the real rush comes from joining honestly. The aviator tool and aviator game download make it very simple to play anywhere. Aviator game online is great because games are short and thrilling, giving lots of fun. If you haven’t played it yet, seriously give it out and see the rush.
Pretty great post. I simply stumbled upon your weblog and
wished to say that I’ve really loved browsing your
weblog posts. In any case I’ll be subscribing on your rss feed
and I’m hoping you write once more soon!
There is definately a lot to learn about this topic.
I love all of the points you have made.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the
way, how can we communicate?
Here is my homepage … best online poker sites nwt – Callum,
Hey I decided to talk about aviator and minas game. This title hooks users quickly with its mix of chance and tactics. Many players talk about http://www.ntep2008.com/index.php?name=webboard&file=read&id=368567, and some hope for cheats, but the main thrill comes from joining clean. The mobile app and aviator game download make play very easy to start anywhere. aviator play online is awesome because games are fast and thrilling, giving tons of excitement. If you haven’t tried it yet, definitely check it out and enjoy the kick.
Ridiculous quest there. What occurred after? Thanks!
Hello, I enjoy reading through your post. I
wanted to write a little comment to support you.
Superb, what a weblog it is! This weblog gives helpful
facts to us, keep it up.
I just like the valuable info you provide in your articles.
I’ll bookmark your weblog and test once more right here regularly.
I am slightly certain I will be told lots of new stuff right
here! Best of luck for the following!
Pretty great post. I just stumbled upon your weblog and wanted to mention that I’ve truly enjoyed browsing your weblog posts.
After all I’ll be subscribing on your rss feed and
I’m hoping you write again soon!
I want to to thank you for this wonderful read!!
I certainly loved every bit of it. I have got you book-marked to
check out new stuff you post…
Bahis platformlarında, kullanıcılar, şeffaflık ve çeşitlilik arayışındadır.
casinolevant, oyuncuların taleplerini karşılayan önemli adreslerden biridir.
Kullanıcı dostu tasarım sayesinde tüm oyuncular, pratik şekilde deneyime
başlayabilir.
Casinolevant güncel giriş sayesinde kesintisiz erişim
Pek çok bölgede, bahis platformlarına bağlantı kısıtlaması uygulanabilmektedir.
Ancak casinolevant güncel giriş, sürekli güncel
bağlantılar ile sisteme erişim sağlar. Böylece kullanıcılar, diledikleri vakit giriş yapabilir.
Excellent way of describing, and pleasant piece of writing to take data
concerning my presentation subject matter, which i am
going to present in institution of higher education.
https://w1.pencaritogel.com/
Why visitors still make use of to read news papers when in this technological
world the whole thing is accessible on net?
This piece of writing is in fact a nice one
it helps new web users, who are wishing for blogging.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.info/zh-CN/register?ref=VDVEQ78S
Estoy en fase de idea y este tipo de información me impulsa.
Wow, awesome weblog layout! How long have you been blogging for?
you made running a blog glance easy. The entire glance of your site is great, let alone the content!
pirinç merdiven korkuluk
I like the valuable info you provide on your articles.
I will bookmark your blog and check again right here frequently.
I’m relatively sure I will be told a lot of new stuff proper here!
Good luck for the following!
I every time used to study article in news papers but now as I am a user of net so from
now I am using net for posts, thanks to web.
Do you have a spam problem on this site; I also am a blogger, and I was curious
about your situation; we have created some nice procedures and we are looking to trade techniques with other folks, why not shoot me an e-mail if interested.
Hello, i feel that i noticed you visited my
website so i came to return the desire?.I am trying to to find things to improve my website!I guess its good enough to use a few of your ideas!!
This post offers clear idea for the new visitors of blogging,
that in fact how to do blogging and site-building.
Hello, all is going sound here and ofcourse every one
is sharing data, that’s really fine, keep up writing.
Hello everyone! I decided to share about the aviator and minas. This play grabs gamers quickly with its mix of bet and strategy. Many players talk about https://talukadapoli.com/travel/listing/exotic-home-stay-dapoli/, and some wish for cheats, but the true rush comes from playing honestly. The aviator app and downloading aviator make it super simple to join anywhere. aviator online is awesome because plays are fast and high-risk, giving a lot of excitement. If you didn’t try it yet, seriously check it out and enjoy the rush.
What’s cool is that you still get all the perks of online gaming – bonuses, spins, the works – but with the added confidence that the games are straight-up fair.
Hi I wanted to post about aviator and minas. This title hooks players fast with its blend of bet and tactics. Many users talk about http://www.demoscene.ru/english/misc/guest.php3, and some wish for aviator hack, but the main fun comes from playing honestly. The mobile app and aviator game download make play extra easy to play anywhere. aviator play online is solid because plays are quick and high-stakes, giving a lot of rush. If you didn’t try it yet, for sure try it out and enjoy the thrill.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.info/sl/register?ref=PORL8W0Z
Hello everyone! I thought to talk about aviator and mines game. This play hooks gamers quickly with its blend of chance and plan. Many people talk about https://www.fundamentale.ro/cum-sa-construiesti-o-casa-pentru-pasari-din-materiale-reciclabile, and some wish for cheats, but the main rush comes from joining honestly. The mobile app and aviator dl make it extra easy to play anywhere. Aviator game online is solid because rounds are quick and thrilling, giving lots of fun. If you haven’t tried it yet, definitely check it out and enjoy the kick.
I used to be recommended this blog by way
of my cousin. I am no longer sure whether or not this post is written via him as no one else
recognise such special approximately my trouble. You are incredible!
Thank you!
Hey! This is kind of off topic but I need some guidance from an established blog.
Is it difficult to set up your own blog? I’m not
very techincal but I can figure things out pretty fast.
I’m thinking about creating my own but I’m not sure where
to begin. Do you have any ideas or suggestions? Cheers
4M Denbtal Implant Center
3918 Ꮮong Beach Blvd #200, Long Beach,
ϹA 90807, United Ѕtates
15622422075
gum repair
Hey! Someone in my Facebook group shared this site with us so I came to take a look.
I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers!
Excellent blog and outstanding design.
Awesome post.
There’s certainly a lot to learn about this issue. I love all of the points you have made.
It’s a shame you don’t have a donate button! I’d most certainly donate to this excellent blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed
to my Google account. I look forward to brand new updates and will share this blog with my Facebook group.
Chat soon!
Asking questions are genuinely pleasant thing if you are not understanding anything
fully, except this paragraph offers good understanding even.
Hi there colleagues, how is the whole thing, and what you wish for to say on the topic of
this paragraph, in my view its genuinely amazing for me.
I blog quite often and I seriously thank you for your information. This great article has truly peaked my interest.
I am going to take a note of your blog and keep checking for new information about once a week.
I subscribed to your RSS feed too.
Whoa! This blog looks exactly like my old one! It’s on a completely different subject but it
has pretty much the same layout and design. Great choice of colors!
Way cool! Some extremely valid points! I appreciate you writing this write-up and the rest of the
website is very good.
I do agree with all the ideas you’ve introduced in your post.
They are very convincing and will definitely work.
Still, the posts are very short for beginners. May just you
please extend them a bit from next time? Thanks for the post.
I every time spent my half an hour to read this blog’s posts all
the time along with a cup of coffee.
Everything is very open with a clear description of the issues.
It was definitely informative. Your site is extremely helpful.
Thanks for sharing!
TABLE
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://www.binance.info/es/register-person?ref=T7KCZASX
Excellent forum posts Kudos.
Howdy, i read your blog occasionally and i own a similar one and i was
just wondering if you get a lot of spam
comments? If so how do you stop it, any plugin or anything you can advise?
I get so much lately it’s driving me mad so any assistance is very much appreciated.
Лигатура драгоценных металлов для орнаментов
Лигатура драгоценных металлов в создании уникальных орнаментов и их особенности
При создании изысканных изделий с использованием благородных компонентов ключевым моментом является подбор правильных сплавов. Они не только определяют долговечность, но и визуальные качества готовых предметов. Оптимальным выбором станут сплавы с высоким содержанием золота и серебра, так как они легко поддаются обработке и обеспечивают отличную полировку. Для декоративных элементов рекомендуется использовать сплавы с добавлением меди или никеля, которые увеличивают прочность и устойчивость к внешним воздействиям.
Также стоит обратить внимание на пропорции компонентов. Например, сплав с соотношением 75% золота и 25% меди подарит необычный желтый оттенок, который идеально подходит для создания уникальных орнаментов. Не забывайте, что цвет и текстура зависят от выбранных добавок, поэтому экспериментирование здесь открывает широкие возможности для творчества.
Наконец, важным аспектом будет и выбор технологий обработки. Литье, ковка или штамповка – каждая методика имеет свои нюансы, влияющие на конечный продукт. Следите за калибровкой температуры и временем, чтобы избежать обломков или дефектов. Подходите к работе со знанием дела, и ваши произведения будут радовать не только вас, но и будущих обладателей.
Выбор сплавов для конкретных типов украшений
Для создания сложных узоров в ювелирных изделиях рекомендуется использовать сплавы с высокой термостойкостью, такие как золото 18 каратов. Это обеспечит долговечность и сохранение изначального вида даже при длительном ношении.
В случае инкрустации камнями отличным выбором станет сплав, устойчивый к окислению, например, белое золото, которое не тускнеет и сохраняет блеск. Это поможет подчеркнуть красоту драгоценностей.
Для изделий с тонкими деталями и филигранной работой можно использовать сплавы с низким содержанием чистого золота, как, например, 14 каратов. Такой вариант обеспечивает лучшую пластичность и упрощает процесс создания мелких элементов.
Если планируется создание текстурированных поверхностей, стоит рассмотреть использование меди в качестве добавки. Это может снизить стоимость и добавить желаемую тепло-золотистую насыщенность.
При изготовлении массивных и прочных изделий, таких как кольца, стоит выбирать более высокое содержание чистого золота, например, 22 карата, так как этот сплав более устойчив к механическим повреждениям.
Для экспериментальных и необычных дизайнов подойдут сплавы с добавлением других металлов, например, палладия или серебра. Это позволит достичь цветовых эффектов, которые невозможно получить с помощью традиционных сплавов.
Технологические процессы создания орнаментов из благородных металлов
Начните с выбора основы, которая определяется требуемой прочностью и внешней привлекательностью изделия. Сплавы золота, серебра и платины обладают уникальными свойствами, подходящими для различных техник обработки.
Следующий этап–систематизация дизайна. Используйте эскизы и 3D-моделирование, чтобы протестировать различные варианты размещения узоров. Это позволяет сразу визуализировать конечный результат и вносить изменения до начала работы с материалом.
Поскольку работа с элитными сплавами требует высокой точности, лучше всего использовать методы лазерной резки, которые обеспечивают чистые линии и сложные формы. Это уменьшит количество отходов и упростит дальнейшую обработку.
Не забывайте про полировку. Используйте специальные абразивные материалы, чтобы добиться идеальной поверхности, отражающей свет. Важно помнить, что качество полировки напрямую влияет на восприятие изделия.
При создании узоров можно применять ручные техники, такие как гравировка и продолбление. Эти методы позволят добавить индивидуальности и уникальности вашему творению. Используйте специальные инструменты, предназначенные для работы с конкретными сплавами, чтобы избежать повреждений.
Завершите процесс нанесением защитного покрытия, чтобы изделие не теряло первоначальный блеск и устойчивость к внешним воздействиям. Нанесение лакокрасочных материалов или родирования обеспечит долговечность и сохранность вашего творения.
Visit my web site; https://rms-ekb.ru/catalog/izdeliia-iz-dragotsennykh-i-blagorodnykh-metallov/
As the admin of this web site is working, no hesitation very quickly it will be
famous, due to its feature contents.
казино онлайн arkada
Выбор квартиры посуточно влияет на комфорт и бюджет поездки
Nice post. I was checking continuously this weblog and I am impressed!
Extremely helpful information specifically the closing section 🙂 I deal
with such information a lot. I was seeking this
certain information for a long time. Thanks and best of luck.
One revolutionary factor gaining traction in these specialised environments is the mix of underwater treadmills. https://www.pinterest.com/progorki_pools/swimming-pools-innovative-equipment/
I want to to thank you for this very good read!!
I definitely loved every bit of it. I have you bookmarked
to look at new things you post…
Hi there i am kavin, its my first time to commenting anywhere, when i
read this paragraph i thought i could also make
comment due to this sensible post.
Great post.
I like the helpful info you supply to your articles.
I will bookmark your weblog and check once more here frequently.
I am relatively sure I’ll be informed many new stuff
right here! Best of luck for the next!
Rainbet Casino is an international online gambling platform operated by RBGAMING N.V. under a Curaçao license. The site focuses on cryptocurrency payments and offers slots, live casino, and its own provably fair games.
If some one wants to be updated with newest technologies therefore
he must be visit this web site and be up to date every day.
Please let me know if you’re looking for a article writer for your weblog.
You have some really great posts and I think I would be a
good asset. If you ever want to take some of the load off, I’d absolutely love to
write some material for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Cheers!
Per ottenere una traduzione asseverata, il traduttore professionista si reca in tribunale, un giudice
di pace, o presso un notaio e giura che la traduzione è
conforme al documento originale. https://bbs.mofang.com.tw/home.php?mod=space&uid=2140633
It’s actually a great and useful piece of info. I’m satisfied that you shared
this useful info with us. Please keep us informed like this.
Thanks for sharing.
Hey very nice blog!
강남쩜오는 하이쩜오라고도 불리며, 강남구에서 큰 인기를 끌고 있는 고급
룸살롱 장르입니다. 럭셔리한 분위기와 수준 높은 서비스를 제공
казино джой
Howdy superb blog! Does running a blog similar to
this require a lot of work? I’ve no understanding of
programming but I was hoping to start my own blog
soon. Anyhow, should you have any suggestions or techniques for new blog owners please share.
I know this is off topic but I just had to ask.
Kudos!
Feel free to surf to my web page; pink salt trick recipe
I know this website offers quality dependent articles or reviews and additional information, is
there any other web page which provides such things in quality?
Джой казино
Magnificent beat ! I wish to apprentice at the same
time as you amend your web site, how could i subscribe for a blog website?
The account helped me a appropriate deal. I have been tiny bit familiar of this your broadcast offered brilliant clear concept
Интернетное игровой клуб — это онлайн‑ресурс
You actually make it seem so easy together with your presentation however I to find this topic to be actually something that I think I’d by
no means understand. It seems too complex and extremely broad for me.
I am taking a look forward to your subsequent
submit, I will attempt to get the cling of it!
My family members all the time say that I am wasting my time here at web, but I know I am getting knowledge
everyday by reading thes good posts.
When some one searches for his necessary thing, so he/she desires to be available that in detail, so that
thing is maintained over here.
Just want to say your article is as astonishing.
The clearness on your submit is simply spectacular and i can assume you are a professional in this subject.
Fine along with your permission allow me to clutch
your feed to stay updated with approaching post.
Thank you a million and please carry on the gratifying
work.
4M Dental Implant Center
3918 Ꮮong Beach Blvd #200, Lonng Beach,
СA 90807, United Stаteѕ
15622422075
implant expert
Онлайн казино — это онлайн‑ресурс
Hello there! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really enjoy your
content. Please let me know. Thank you
Great article.
Thanks for your personal marvelous posting! I
definitely enjoyed reading it, you might be a great author.I will always bookmark your blog and may come back in the future.
I want to encourage one to continue your great work, have
a nice holiday weekend!
I’m not sure where you’re getting your information, but great topic. I needs to spend some time learning more or understanding more. Thanks for fantastic information I was looking for this info for my mission.
This design is steller! You obviously know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Wonderful job. I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Hi there to all, it’s truly a pleasant for me to pay a visit this web site,
it includes priceless Information.
Онлайн игровой клуб — это онлайн‑ресурс
This is really interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of
your fantastic post. Also, I have shared your website in my social
networks!
Hey there just wanted to give you a quick heads up.
The text in your post seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or something to do
with internet browser compatibility but I thought I’d post to
let you know. The style and design look great
though! Hope you get the problem solved soon. Thanks
Hey there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard
work due to no back up. Do you have any solutions
to stop hackers?
Excellent beat ! I wish to apprentice while you amend your web site,
how could i subscribe for a blog web site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast provided bright clear idea
Vous pouvez ainsi explorer le monde à votre rythme, sans dépendre d’autres joueurs.
บทความนี้ อ่านแล้วเพลินและได้สาระ ค่ะ
ผม เคยติดตามเรื่องนี้จากหลายแหล่ง ประเด็นที่ใกล้เคียงกัน
ซึ่งอยู่ที่ Dewitt
สำหรับใครกำลังหาเนื้อหาแบบนี้
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ คอนเทนต์ดีๆ นี้
อยากเห็นการนำเสนอในหัวข้ออื่นๆ ด้วย
This design is wicked! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog
(well, almost…HaHa!) Excellent job. I really
enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Great blog! Do you have any tips for aspiring writers?
I’m planning to start my own website soon but I’m a little lost
on everything. Would you propose starting with a free platform like WordPress or go
for a paid option? There are so many choices
out there that I’m totally confused .. Any recommendations?
Thanks!
Very nice post. I just stumbled upon your weblog and wished to
say that I’ve truly enjoyed browsing your blog posts.
After all I will be subscribing to your rss feed and I hope you write again very soon!
Thanks for your personal marvelous posting! I really enjoyed reading it, you’re
a great author.I will always bookmark your
blog and will come back someday. I want to encourage continue your great
job, have a nice weekend!
Here is my web-site … ผักไฮโดรโปนิกส์
I was recommended this blog by way of my cousin. I am
not certain whether this submit is written by him as nobody else recognize
such distinctive about my difficulty. You’re wonderful! Thank you!
With havin so much content do you ever run into any problems of plagorism or copyright violation? My website has a lot of exclusive content I’ve
either written myself or outsourced but it looks like a lot
of it is popping it up all over the internet without my agreement.
Do you know any methods to help protect against content from being stolen? I’d certainly
appreciate it.
Plinko Game Online is by far one of the most entertaining games I’ve come across in the world of digital gambling. It’s got this awesome mix of chance and anticipation https://rentry.co/30509-win-big-with-plinko-game-online-your-guide-to-exciting-rewards that keeps you on the edge of your seat with every turn. The game is so simple to play, yet there’s a thrill in watching the token bounce off those pegs and land in a hole—especially when it hits a big payout one. And with all the extra features like bonus rounds, it’s definitely a game where the rewards can be massive. What really stands out to me is how easy to play Plinko is. You don’t need to be an advanced player or have a method to enjoy it; it’s all about the thrill of the drop and expecting a win. The online version also makes it simple to play whenever you want, which is awesome if you’re looking to jump in for a fast round or stick around longer. Plus, with real-time play and the chance to compete against others, there’s always something new to enjoy. If you’re into simple yet addictive games, Plinko Game Online is definitely worth checking out. It’s fun to pick up, and whether you’re playing for fun or hoping to score big, it never gets boring. Plus, with the range of features, each round feels new. Just make sure you’re ready for the chance—it’s what makes the game so entertaining!
Hi! I just want to offer you a big thumbs up for your excellent info you’ve
got here on this post. I am coming back to your web site for more soon.
This increases the potential risk of players falling victim to seemingly legit but fraudulent, anonymous Bitcoin casino sites.
Admiring the dedication you put into your website and in depth information you provide.
It’s great to come across a blog every once in a while that isn’t the
same old rehashed information. Fantastic read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an shakiness over that you wish
be delivering the following. unwell unquestionably
come more formerly again as exactly the same nearly a lot
often inside case you shield this increase.
Tulisan ini menurut saya sangat bagus karena membahas KUBET dan Situs Judi Bola
Terlengkap secara detail.
Topik yang biasanya hanya dijelaskan sepintas, di sini benar-benar diuraikan dengan rapi.
Hal ini membuat artikel terasa berbeda dari banyak tulisan sejenis.
Saya juga suka cara penulis menyampaikan informasi dengan bahasa yang bersahabat.
KUBET dan Situs Judi Bola Terlengkap dibahas tanpa terkesan berlebihan, tetapi tetap jelas dan meyakinkan.
Bagi saya, ini adalah salah satu bentuk tulisan yang sangat profesional.
Semoga lebih banyak artikel berkualitas seperti ini bisa terus hadir.
Ulasan yang panjang, jelas, dan terperinci akan selalu membantu pembaca
memahami topik dengan baik.
Terima kasih atas usaha penulis menghadirkan artikel bermanfaat ini.
En effet, d’une zone à l’autre, la chasse peut s’avérer plus rapide que dans une autre.
Awesome post.
By obtaining a license from recognized jurisdictions, such as Curaçao or Malta, these casinos commit to regulatory requirements designed to protect players and ensure game integrity.
Vegastars Casino is an online gambling dais that offers casino games, sports betting,
I’m extremely inspired with your writing abilities and also
with the layout for your blog. Is this a paid topic or did you modify it yourself?
Anyway keep up the excellent quality writing,
it’s rare to peer a great weblog like this one these days..
This is a great tip especially to those new to the blogosphere.
Short but very accurate info… Thank you for sharing this
one. A must read post!
Great web site you’ve got here.. It’s hard to find
high-quality writing like yours nowadays.
I really appreciate individuals like you! Take care!!
Fantastic beat ! I wish to apprentice while you amend your website,
how could i subscribe for a blog site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered bright clear concept
In fact no matter if someone doesn’t know after that its up to other users that they will
help, so here it occurs.
I’m amazed, I have to admit. Seldom do I come across
a blog that’s both equally educative and amusing, and without a doubt, you’ve
hit the nail on the head. The issue is an issue that too few folks are speaking intelligently about.
Now i’m very happy that I came across this in my search for
something concerning this.
Thankfulness to my father who informed me on the topic of this website, this webpage is actually amazing.
Hi there to every one, the contents present at this website are
truly awesome for people knowledge, well, keep up the good work fellows.
It’s really a nice and useful piece of information. I’m happy
that you just shared this helpful information with us. Please keep us up to date like this.
Thank you for sharing.
Знакомства Мариуполь
This design is wicked! You definitely know how to keep a
reader entertained. Between your wit and your videos, I was almost
moved to start my own blog (well, almost…HaHa!) Fantastic job.
I really loved what you had to say, and more than that, how you
presented it. Too cool!
This excellent website certainly has all of the information I needed about
this subject and didn’t know who to ask.
I loved as much as you will receive carried out right
here. The sketch is attractive, your authored material stylish.
nonetheless, you command get got an impatience over
that you wish be delivering the following. unwell unquestionably come further formerly again as exactly the same nearly a
lot often inside case you shield this hike.
canada pharmacies online
Nice post. I learn something totally new and challenging on websites I
stumbleupon everyday. It will always be useful to read through content from
other authors and use something from other websites.
Hi, the whole thing is going well here and ofcourse every one is sharing facts, that’s
actually fine, keep up writing.
What a data of un-ambiguity and preserveness of precious experience
about unpredicted emotions.
excellent points altogether, you just gained a brand new
reader. What may you suggest in regards to your publish
that you simply made some days ago? Any sure?
Thanks for your personal marvelous posting! I truly enjoyed
reading it, you may be a great author. I will make sure to
bookmark your blog and may come back at some point.
I want to encourage continue your great writing, have a nice day!
When venturing into the realm of anonymous betting sites, a foundation of comprehensive knowledge will be your best ally.
When someone writes an paragraph he/she maintains the
thought of a user in his/her mind that how a user can understand it.
Therefore that’s why this post is perfect. Thanks!
E2Bet adalah situs betting terbesar Se-Asia, menawarkan platform permainan yang aman, terpercaya,
dan inovatif, serta bonus menarik dan layanan pelanggan 24/7.
#E2Bet #E2BetIndonesia #Indonesia
It’s very straightforward to find out any matter on web as compared to textbooks,
as I found this post at this web site.
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ⅾr ⅽ121,
Charlotte, NC 28273, United Ѕtates
+19803517882
Proven 5 method step renovation
my web page :: PokerTube – Watch Free Poker Videos & TV Shows
fdhfkfk
морской контейнер
What’s up i am kavin, its my first time to commenting anyplace, when i read this
article i thought i could also make comment due
to this brilliant paragraph.
This page definitely has all the information and facts I needed concerning this subject and didn’t know who to
ask.
You actually make it seem so easy with your presentation but I find this matter to be actually something that I think I would never understand.
It seems too complicated and extremely broad
for me. I’m looking forward for your next post,
I’ll try to get the hang of it!
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why throw away
your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
Very soon this site will be famous amid all blog users, due to
it’s pleasant posts
Quality articles or reviews is the crucial to invite the viewers to
go to see the web page, that’s what this site is providing.
Tried these https://joyorganics.com/products/mood-gummies in front bed a occasional times in and they in fact work. I’m chiefly tossing and turning, but with these I tip up falling asleep technique quicker. No freakish hangover hint in the morning either. Kinda pricey, but honestly worth it when I justifiable want a good darkness’s sleep.
Hi there, I desire to subscribe for this web site
to get latest updates, thus where can i do it please help out.
This lets you create intermediate and short-term targets and corresponding
milestones.
Here is my website – How does ProGorki incorporate aesthetic elements into pool design?
If you’re here, it means you’re eager to download
your posts, and Snapinsta is here to make that process seamless for you.
Большинство видео имеют формат MP4 и SD, HD, FullHD, 2K и 4K.
LIGACOR merupakan plaform game slot online terbaik di Indonesia
dengan peluang menang lebih mudah sehingga LIGACOR menjadi game
slot online nomor 1 di Indonesia
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Tried these https://joyorganics.com/collections/usda-certified-cbd-oil-tinctures before bed a scarcely any times now and they in fact work. I’m most of the time tossing and turning, but with these I result up falling asleep fashion quicker. No bizarre hangover hint in the morning either. Kinda dear, but fairly good it when I just hunger a good night’s sleep.
It’s going to be ending of mine day, but before end I am reading this impressive piece of
writing to increase my knowledge.
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home a little bit, but other than that,
this is great blog. An excellent read. I’ll definitely be
back.
If you want to take a good deal from this piece of writing then you have to
apply such methods to your won website.
https://s3.amazonaws.com/pelletofen/are-pellet-stoves-still-a-smart-buy-in-2025.html
hello there and thank you for your information – I’ve definitely picked up something new from right here.
I did however expertise a few technical points using this website, since
I experienced to reload the web site a lot of times previous to I could get it to load correctly.
I had been wondering if your web host is OK? Not that I am complaining, but sluggish
loading instances times will very frequently affect your placement in google and could damage your quality score if ads and marketing with Adwords.
Anyway I am adding this RSS to my email and can look out
for a lot more of your respective exciting content. Ensure that you update this
again soon.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.
Wow, this piece of writing is fastidious, my younger sister is analyzing such
things, so I am going to convey her.
Great beat ! I would like to apprentice while you amend your website, how could i subscribe for a weblog website?
The account aided me a applicable deal. I had been tiny bit familiar of this your broadcast provided bright transparent idea
Elke post dat ik schrijf is gevuld met jarenlange
speelervaring. Leer van mijn vergaarde kennis en vermijd veelgemaakte vergissingen.
Hi! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new to me.
Nonetheless, I’m definitely delighted I found it and I’ll be book-marking
and checking back frequently!
your blog is fantastic! I’m learning so much from the way you share your thoughts.
My partner and I stumbled over here from a different page and thought I
might check things out. I like what I see so now i’m following you.
Look forward to going over your web page again.
Keep on writing, great job!
You ought to be a part of a contest for one of the greatest websites on the internet.
I am going to recommend this website!
I’d like to find out more? I’d like to find out more details.
Today, while I was at work, my sister stole my iphone and tested to see if it can survive a 25 foot drop,
just so she can be a youtube sensation. My apple ipad is now destroyed and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
I like the helpful information you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I am quite certain I’ll learn plenty of new stuff right here!
Best of luck for the next!
It’s awesome to visit this web site and reading the views of
all mates regarding this post, while I am also eager of getting knowledge.
This is a topic which is close to my heart… Cheers!
Where are your contact details though?
Hello everyone, it’s my first pay a visit at this web site, and post is truly fruitful designed for me, keep up posting
such posts.
With over 4,500 games, including casino, sports, esports, and live casino, Playbet.io boasts a 96.04% RTP.
Hello there! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.
tele4
When someone writes an article he/she keeps the image of a user in his/her mind that how a user can be aware of it.
Therefore that’s why this paragraph is outstdanding.
Thanks!
+905072014298 fetoden dolayi ulkeyi terk etti
I know this website offers quality dependent articles and
additional information, is there any other site
which presents these things in quality?
I have read so many articles or reviews regarding the blogger lovers however this
piece of writing is really a pleasant post, keep it up.
hi!,I love your writing very much! percentage we keep in touch extra approximately your article on AOL?
I need an expert in this area to solve my problem.
Maybe that is you! Looking forward to peer you.
I am extremely impressed with your writing skills
as well as with the layout on your blog. Is this a paid theme or
did you customize it yourself? Either way keep up the nice quality writing, it’s rare to see a
nice blog like this one these days.
Excellent article. Keep posting such kind of info on your blog.
Im really impressed by your site.
Hi there, You have performed an excellent job.
I’ll definitely digg it and for my part recommend to my friends.
I’m sure they’ll be benefited from this site.
I used to be able to find good information from your content.
There’s certainly a lot to learn about this issue.
I really like all the points you made.
I like the helpful information you supply on your articles.
I will bookmark your blog and check again right here regularly.
I’m fairly sure I will be informed many new stuff right
right here! Best of luck for the next!
I couldn’t resist commenting. Exceptionally well written!
I always emailed this blog post page to all my contacts, since if like
to read it next my links will too.
https://du88.ing/
magnificent publish, very informative. I’m wondering why the
other experts of this sector don’t notice this.
You must continue your writing. I’m confident, you have a great readers’
base already!
Great article! That is the type of information that
should be shared around the web. Disgrace on Google for no longer positioning this submit upper!
Come on over and seek advice from my website . Thanks =)
Choosing top-notch medical care and cosmetic procedures requires
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your
new updates.
Thank you for any other informative site. Where else may I am getting
that type of information written in such a perfect manner?
I’ve a undertaking that I am just now operating on, and I have been at the glance
out for such information.
Great blog! Do you have any tips for aspiring writers? I’m hoping to start
my own site soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for
a paid option? There are so many choices out there that I’m totally overwhelmed
.. Any suggestions? Bless you!
Thank you led screen for display the auspicious writeup.
It in fact was a amusement account it. Look advanced to far added agreeable
from you! By the way, how can we communicate?
Interesting blog! Is your theme custom made or did
you download it from somewhere? A theme like yours with a
few simple tweeks would really make my blog stand out.
Please let me know where you got your design. Many thanks
my homepage :: Labeling Machine
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.
Way cool! Some very valid points! I appreciate you writing this write-up
and also the rest of the website is also very
good.
I’m amazed, I must say. Rarely do I encounter a blog that’s equally educative and engaging, and
without a doubt, you’ve hit the nail on the head.
The problem is something that too few folks are speaking intelligently
about. Now i’m very happy that I came across this in my hunt
for something relating to this.
Have you ever thought about publishing an e-book or
guest authoring on other blogs? I have a blog
based upon on the same topics you discuss and would really like
to have you share some stories/information. I know my subscribers
would value your work. If you’re even remotely interested,
feel free to shoot me an e-mail.
Amazing! This blog looks just like my old one!
It’s on a totally different subject but it has pretty much the same layout and design. Excellent choice of colors!
Ulasan mengenai Situs Parlay Gacor dalam artikel ini penting sekali.
Pembaca bisa memahami bagaimana memilih situs yang tepat, dan jelas KUBET masuk dalam daftar rekomendasi Situs Judi Bola Terlengkap.
Semoga artikel seperti ini terus hadir agar semakin banyak pembaca yang mendapatkan informasi akurat mengenai KUBET dan Situs Judi Bola.
I have been browsing online more than 3 hours today, yet I never found any interesting
article like yours. It is pretty worth enough for me.
In my opinion, if all webmasters and bloggers made good
content as you did, the net will be much more useful than ever before.
Порталы для каминных ниш — важный элемент интерьера
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Mighty Dog Roofing
Reimer Drive North 13768
Maple Grove, MN 55311 United Ѕtates
(763) 280-5115
modern roof replacement options
Have you ever thought about creating an e-book or guest authoring
on other blogs? I have a blog centered on the same topics you discuss and would really like to
have you share some stories/information. I know my audience
would appreciate your work. If you’re even remotely interested, feel free to send me an e mail.
wonderful post, very informative. I wonder why the other
specialists of this sector do not understand this.
You must continue your writing. I am sure, you’ve a
huge readers’ base already!
I used to be able to find good information from your blog
articles.
This is really interesting, You are an overly professional
blogger. I have joined your rss feed and look forward to
looking for more of your wonderful post. Also, I have shared your site in my social networks
what supplements do bodybuilders take to get ripped
References:
anabolic steroids can be ingested in which ways, https://forum.issabel.org/u/clockpair84,
natural bodybuilding banned supplements
References:
how long does it take to get over steroid withdrawal? (https://output.jsbin.com/ziwiniciku/)
Remarkable things here. I am very happy to look
your post. Thank you so much and I’m taking a
look forward to contact you. Will you please drop me a e-mail?
You actually make it appear really easy along with your presentation but I to
find this matter to be actually one thing that I
feel I might never understand. It sort of feels too complicated and very large for me.
I am looking ahead in your subsequent submit,
I will attempt to get the cling of it!
Hi there, just became alert to your blog through
Google, and found that it’s truly informative. I’m gonna watch out for brussels.
I’ll be grateful if you continue this in future.
A lot of people will be benefited from your writing. Cheers!
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ɗr c121,
Charlotte, NC 28273, United Տtates
+19803517882
Consultants remodeling the in us
It’s the best time to make some plans for the future and it is time to be happy.
I have read this post and if I could I desire to suggest
you few interesting things or advice. Perhaps you can write next articles referring to this article.
I want to read more things about it!
WOW just what I was searching for. Came here by searching for casino utan svensk licens
This website really has all of the information and facts I wanted
about this subject and didn’t know who to ask.
side effects of the use of anabolic steroids include which of the following conditions?
References:
bodybuilding steroids before and after (https://sciencebookmark.space/item/294744)
I was able to find good info from your content.
Hi it’s me, I am also visiting this web page daily, this web site is truly pleasant and the viewers are in fact
sharing pleasant thoughts.
https://acb8.international/
This is a topic that is close to my heart… Thank you! Where are your contact details though?
Nice blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would really make my blog jump out.
Please let me know where you got your theme.
Bless you
Thanks for every other great article. Where else may anyone get that type of
information in such an ideal way of writing? I’ve a presentation next week, and I am at the look for such information.
Thank you for sharing your info. I really appreciate your efforts and I will
be waiting for your further post thanks once again.
I really like your blog.. very nice colors & theme. Did you make this website yourself or did you
hire someone to do it for you? Plz respond as I’m looking to create
my own blog and would like to know where u got this from.
cheers
Link exchange is nothing else however it is only placing the other person’s webpage link on your page
at proper place and other person will also do similar in favor of you.
Generally I do not read post on blogs, but I wish to say that this write-up very compelled me to try and do it!
Your writing taste has been surprised me. Thanks, very great post.
This is very interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your fantastic post.
Also, I have shared your site in my social networks!
After looking at a handful of the blog articles
on your web site, I honestly like your technique of writing a blog.
I saved as a favorite it to my bookmark webpage list and will
be checking back in the near future. Please check out my web site as well
and tell me how you feel.
It’s actually very complex in this busy life to listen news on Television, thus I simply use web for
that purpose, and take the newest information.
Stop by my web-site: zkreciul01
Howdy! This article could not be written much better!
Looking at this article reminds me of my previous roommate!
He continually kept preaching about this. I most certainly will forward this post to him.
Fairly certain he’s going to have a good read. I appreciate you for sharing!
hi!,I love your writing very so much! percentage we be
in contact extra approximately your article on AOL?
I need a specialist on this space to resolve my problem.
Maybe that is you! Having a look ahead to look you.
We’re a group of volunteers and starting a new scheme in our community.
Your site provided us with valuable information to work on. You have done a formidable task and our whole neighborhood shall be thankful to you.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an impatience over that you wish be
delivering the following. unwell unquestionably come further formerly
again since exactly the same nearly very often inside case you shield this hike.
Гортав в інтернеті більше трьох годин,
але не знайшов жодної статті, який би мене
так зачепив, як ваш матеріал про
автомобілі! Просто супер! Як на мене,
якби всі власники сайтів створювали такий якісний контент про тачки,
інтернет був би набагато кориснішим!
hey there and thank you for your info – I have definitely picked up
anything new from right here. I did however
expertise some technical points using this site, as I experienced to reload the site a lot of
times previous to I could get it to load correctly. I had been wondering
if your web host is OK? Not that I’m complaining, but sluggish loading instances times will very frequently
affect your placement in google and could damage your quality score if advertising and marketing with Adwords.
Well I am adding this RSS to my email and can look out for a lot more
of your respective fascinating content. Make sure you update this again very soon.
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site
is magnificent, as well as the content!
Very good information. Lucky me I found your site by chance (stumbleupon).
I have saved it for later!
Excellent article! We will be linking to this particularly great article on our website. Keep up the good writing.
Feel free to surf to my website :: https://Avdb.wiki/index.php/User:MillaHarford09
hey there and thank you for your information – I
have certainly picked up something new from right here.
I did however expertise several technical issues using this web site, since I experienced to
reload the web site lots of times previous to I could get it to load properly.
I had been wondering if your web hosting is
OK? Not that I’m complaining, but sluggish loading instances times will sometimes affect your placement in google
and can damage your quality score if ads and marketing with Adwords.
Well I’m adding this RSS to my email and can look out for much more of your respective
exciting content. Ensure that you update this
again soon.
My brother suggested I might like this web site. He was entirely
right. This post actually made my day. You can not imagine simply how much time I had spent for this information! Thanks!
Heya i am for the first time here. I found this board and
I find It truly useful & it helped me out a lot.
I hope to give something back and aid others like you helped me.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I am sure this article has touched all the internet users, its really really
pleasant article on building up new weblog.
Добро пожаловать в мир изысканной флористики! Наша компания “Новые цветы” – это профессиональный цветочный магазин с собственной производственной базой в Казани. Мы предлагаем:
• Более 1000 готовых букетов и композиций
• Индивидуальные заказы любой сложности
• Собственные теплицы свежих цветов
• Широкий ассортимент растений в горшках
• Профессиональные услуги флористов
• Экспресс-доставка 24/7 по Казани и Татарстану
Почему выбирают нас:
✓ Гарантия свежести цветов до 7 дней
✓ Цены от 499 рублей
✓ Оплата после получения
✓ Скидка 15% на первый заказ
✓ Доставка в день заказа
✓ Профессиональная упаковка
✓ Возможность заказа онлайн или по телефону
Наши флористы создают уникальные композиции, учитывая все ваши пожелания. Мы работаем с лучшими поставщиками и выращиваем собственные цветы, чтобы гарантировать высочайшее качество каждого букета.
Закажите прямо сейчас и подарите радость близким! Мы заботимся о том, чтобы ваш подарок был доставлен вовремя и в идеальном состоянии.
Присоединяйтесь к тысячам довольных клиентов! Мы создаем моменты счастья, которые остаются в памяти навсегда.
Ꮤhat’s up, its pleasant paragraph on the topic of media print, we aⅼl be familiar with media is a
wonderful souгce of facts.
The design, development, and commissioning of the ALICE Time-Projection Chamber (TPC) is described. It is the principle machine for pattern recognition, tracking, and identification of charged particles in the ALICE experiment on the CERN LHC. The TPC is cylindrical in form with a volume near 90 m three and is operated in a 0.5 T solenoidal magnetic subject parallel to its axis. On this paper we describe intimately the design issues for this detector for operation within the excessive multiplicity setting of central Pb-Pb collisions at LHC vitality. The implementation of the resulting necessities into hardware (field cage, read-out chambers, electronics), infrastructure (fuel and cooling system, laser-calibration system), and software led to many technical improvements that are described along with a presentation of all the most important elements of the detector, as at present realized. We additionally report on the efficiency achieved after completion of the first round of stand-alone calibration runs and display results close to these specified in the TPC Technical Design Report.
Here is my website … http://stephankrieger.net/index.php?title=GPS_Asset_Tracking_Solutions
Hi there, just became aware of your blog through Google, and found that it is really informative. I’m going to watch out for brussels. I’ll appreciate if you continue this in future. Numerous people will be benefited from your writing. Cheers!
my web blog – http://Torrdan.net:80/index.php?title=What_Is_Really_A_Business_Prospect
Beauty editors see thousands of products every year-but it’s the ones they always go back to that should be noted. In Can’t Quit You, The Kit beauty director Katherine Lalancette shares the products she can’t live without. Is there no greater luxury than sleep? The sweet rapture of complete and utter rest. Your heavy limbs sinking into the mattress, your busy brain drifting away to dreamland. For eight hours, your only job is to check out, leg go, surrender… I wish children knew how good they have it. It’s like, “Your Power Rangers will still be there tomorrow, Timmy. Now please, revel in the bliss that is sleep while you still can.” Honestly, if a spa offered a “bedtime story and blanky” package, I’d have a weekly standing appointment. Even more mind-boggling are the full-grown adults who wear their sleep deprivation like a badge of honour. Pepsi’s former CEO Indra Nooyi bragged about only getting four hours of shut-eye a night, as did Bill Clinton.
Feel free to visit my web blog http://xcfw.cn:13000/irvinatkins96/derilapillowlinnea2024/wiki/Wiggle-Pillow-Cover
Looking for a trusted hair salon in Reston VA? Beauty Bar By Dina
offers expert
haircuts, color, keratin treatments & spray tans.
Walk-ins welcome!
If you’re searching for a top-rated hair salon in Reston VA, look no further than Beauty Bar By Dina.
Located in the heart of Lake Anne Plaza, we specialize in precision haircuts, vibrant hair color,
keratin smoothing treatments, and flawless spray tans.
Whether you’re prepping for a big event or just need a quick refresh, our experienced
stylists
deliver stunning results—fast. We proudly
serve clients from Reston, Herndon, Vienna, and across
Fairfax County.
Services We Offer:- Haircuts & Styling- Hair Color & Highlights- Keratin Treatments- Spray Tanning
Visit us at 1613 N. Washington Plaza, Reston VA
20190
Call (571) 245-7802 to book your appointment today!
Greetings! This is my 1st comment here so I just wanted to give a quick shout out and tell you I really enjoy reading your posts.
Can you recommend any other blogs/websites/forums that go over the same topics?
Thanks a lot!
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get
there! Thank you
It’s remarkable to visit this website and reading the views
of all friends about this paragraph, while I am also
zealous of getting knowledge.
Three-fourths of respondents have been extraordinarily or considerably concerned in regards to the effectiveness of the elements in such supplements – and with good cause, it appears. Though more than 75 percent of these surveyed stated they assume supplements may also help maintain and enhance brain health, and although almost half think they may also help forestall and reverse dementia, there is not any scientific evidence to support such beliefs, according to an exhaustive take a look at current studies by the AARP Global Council for https://git-web.phomecoming.com/brigettestrick Health. AARP’s survey discovered that just about 70 % of adults who report eating healthfully most days of the week additionally take some form of vitamin or dietary complement. “This may be as a result of these are individuals who are usually extra conscious of their health generally,” says Cooperman. What’s extra, adults who say they eat the really useful amount of fruits and veggies every day reported higher mind health, regardless of whether or not they take supplements. People assume that there is extra oversight by the FDA than there actually is,” Cooperman says. Under current legislation, dietary supplements are considered food, not medication. Which means they aren’t put by the identical strict safety and effectiveness necessities that both prescription and over-the-counter medicine are. Because of this, they’re thought of protected till proven otherwise. The FDA cannot cease a company from making a sure complement until it has proof that it causes harm. “The FDA does not regulate these firms, so there is not any option to make it possible for a product comprises what’s listed on the label, in the precise dosage – and some merchandise even have substances that are not listed,” Cooperman says.
I’m curious to find out what blog platform you happen to be working with?
I’m experiencing some minor security issues with my latest blog and I would like to find something more
secure. Do you have any recommendations?
Oura Ring vs. Ultrahuman Ring Air – which smart ring ought to you buy? When you purchase through links on our site, we could earn an affiliate fee. Here’s how it really works. The most effective smart rings control all of your vital data, helping you to trace your sleep, fitness, and general well being in a single place. They’re also supreme for anybody who wants to get detailed well being information with out sporting top-of-the-line http://47.103.92.60:3003/candacerivero/herz-p1-device1985/wiki/Ring+Mailbox+Sensor+Evaluation%253A+a+Simple+Premise+with+A+Clunky+App trackers on the wrist. So we’ve examined most of the present smart rings on the market, and in this text, we’ll put two of the best we’ve tried head-to-head. That will help you decide which is best for you, we’re evaluating the Ultrahuman Ring Air and the latest Oura Ring 4, which was only released in October 2024. Each rings impressed us throughout testing, being snug to put on 24/7 and delivering useful insights into our exercise and sleep patterns. Samsung Galaxy Ring vs. Oura Ring 4 – which smart ring wins?
I have been exploring for a little bit for any high-quality articles or weblog posts in this kind of house .
Exploring in Yahoo I finally stumbled upon this
site. Studying this info So i am glad to express that I’ve an incredibly just right uncanny feeling I discovered exactly what I needed.
I such a lot certainly will make certain to don?t
forget this site and give it a glance on a relentless basis.
Hello, Neat post. There is an issue along with your website in web explorer, might test this?
IE nonetheless is the market chief and a huge component to other folks will miss your excellent
writing due to this problem.
Hello, I enjoy reading all of your article. I like to write a little comment to support you.
Wow, marvelous blog layout! How long have you been blogging
for? you made blogging look easy. The overall look of your site
is excellent, as well as the content!
I’m not sure exactly why but this weblog is loading very slow for me.
Is anyone else having this issue or is it a issue on my
end? I’ll check back later on and see if the problem still exists.
Hi there! I just wanhted to ask iif you ever have any trouble ith hackers?
My lasst blog (wordpress) was hacked and I ended up losing a few months of
hard work due to nno back up. Do you have any solutions to
protect against hackers? https://meds24.sbs/
Lentils are wealthy in dietary fiber, which helps decelerate digestion and absorption of carbohydrates. Additionally, they’re rich in dietary fiber. It’s necessary to know that supplements aren’t monitored for safety, purity, high quality, or packaging by the U.S. Beverage caffeine intakes in the U.S. For instance, so far as implications to the hotly debated discipline of ascertaining the ideal, ancestrally-primarily based human eating regimen, if animal cells evolved to be able to harness the energy of sunlight by way of the help of the ‘blood’ of our plant allies, then isn’t it affordable to consider that with the intention to optimize our biological potential nutritionally we require a specific amount of chlorophyll to make the most of sunlight for our power needs and maybe evade sole reliance on the glucose-dependent power pathways of the physique whose overexpression and carbohydrate-rich dietary correlate are linked to situations like most cancers, obesity and cardiovascular disease? In distinction, foods which have a low GI will not be as shortly digested, so even in the event that they comprise the same amount of carbohydrates as high GI foods, their carbohydrate load is not going to be absorbed as rapidly into your body.
Feel free to visit my site … https://historydb.date/wiki/Health_Charm_Blood:_A_Comprehensive_Review
Pretty nice post. I just stumbled upon your blog
and wished to say that I have truly enjoyed browsing your blog posts.
After all I will be subscribing to your rss feed and I hope you write again very soon!
I think that is one of the most vital info for me.
And i am happy reading your article. But wanna statement on few
normal things, The web site style is ideal, the articles is actually great :
D. Excellent activity, cheers
Pinko casino
Remarkable issues here. I’m very happy to look your article.
Thank you so much and I’m having a look ahead to contact you.
Will you please drop me a e-mail?
Hello everybody, here every one is sharing these know-how, so it’s good to read this weblog, and I used to pay
a visit this blog everyday.
Truly no matter if someone doesn’t understand then its up to other visitors that they will
help, so here it occurs.
Helpful info. Lucky me I found your site accidentally, and I am surprised why this twist of fate didn’t took place in advance!
I bookmarked it.
Helpful information. Lucky me I discovered
your site accidentally, and I’m stunned why this
coincidence did not came about in advance! I bookmarked it.
Good web site you have here.. It’s difficult to find excellent writing like yours these
days. I honestly appreciate individuals like you! Take care!!
Безопасные методы лечения. Современная https://stomatologia-siyanie.ru/ предлагает несколько безопасных методов лечения зубов во время беременности с использованием безопасных анестетиков. Специалисты используют для анестезии ряд лекарственных препаратов, которые не проникают в плаценту и в грудное молоко. Лечение можно проводить даже в период грудного вскармливания. Такие препараты сознаны на основе артикаина или мепивакаина.
It’s amazing to pay a quick visit this web site
and reading the views of all colleagues about this piece of writing, while I am also keen of getting experience.
Il vous suffit d’indiquer une position de départ, une direction, et un indice !
Fantastic website. A lot of helpful information here.
I’m sending it to several buddies ans additionally sharing in delicious.
And naturally, thank you to your effort!
Bu sayt ən etibarlı mərc saytlarından biridir.
https://www.runandburn.com.br/pin-up-casino-azrbaycanda-onlayn-kazino-pinup-5/
4M Dental Implant Center
3918 Loong Beach Blvd #200, ᒪong Beach,
ᏟA 90807, United Ѕtates
15622422075
Cosmetic Smile Care
If you are going for most excellent contents like I do,
simply go to see this web site every day because it gives quality contents, thanks
I’m very pleased to discover this page. I need to to thank you
for ones time just for this fantastic read!!
I definitely really liked every little bit of
it and i also have you saved as a favorite to see new things on your blog.
Excellent post. Keep posting such kind of info on your blog.
Im really impressed by your blog.
Hi there, You have performed an incredible job. I’ll certainly digg it and in my view recommend to my friends.
I am sure they’ll be benefited from this web site.
Link gue naik gara-gara ini.
hi!,I like your writing very so much! proportion we keep up a correspondence extra approximately your article on AOL?
I require an expert in this area to solve my problem.
May be that is you! Looking forward to look you.
Wonderful post but I was wanting to know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Bless you!
Hello there! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thank you
It’s really very complicated in this active life to listen news on TV,
thus I just use the web for that purpose, and get the newest information.
Hi there every one, here every one is sharing these familiarity, therefore it’s
fastidious to read this web site, and I used to go to see this weblog every
day.
Howdy! Do you use Twitter? I’d like to follow you if that would be okay.
I’m definitely enjoying your blog and look forward to new
updates.
You can certainly see your skills in the work you write.
The arena hopes for more passionate writers such as you who aren’t afraid to mention how they believe.
At all times go after your heart.
Hi to every body, it’s my first go to see
of this blog; this website includes amazing and genuinely excellent information in support of readers.
I really like what you guys are up too. This type of clever work and coverage!
Keep up the great works guys I’ve incorporated you guys to our
blogroll.
Hello to every one, the contents present at this
site are really amazing for people experience, well,
keep up the nice work fellows.
FranChoice
7500 Flying Cloud Drive,
#600 Eden Prairie
MN 55344, United Ѕtates
952-345-8400
franchise business ownership checklist
While crypto and no KYC casinos offer a taste of privacy, they’re not entirely foolproof.
Thanks for sharing your thoughts on khogamenet. Regards
Appreciate the recommendation. Let me try it out.
I am really loving the theme/design of your web site.
Do you ever run into any internet browser compatibility problems?
A couple of my blog audience have complained about
my website not working correctly in Explorer
but looks great in Safari. Do you have any suggestions to help
fix this issue?
I could not refrain from commenting. Well written!
Ich mag diese Webseite – sie ist so wertvoll und gut gemacht.
Info nicely taken.!
Hey! I know this is kind of off-topic however I needed to ask.
Does building a well-established website such as yours take a
massive amount work? I’m brand new to operating a blog however I do write in my diary on a daily basis.
I’d like to start a blog so I will be able to share
my personal experience and feelings online. Please let me know
if you have any kind of suggestions or tips for brand new aspiring bloggers.
Thankyou!
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out
a developer to create your theme? Exceptional work!
Position well regarded!!
Your article helped me a lot, is there any more related content? Thanks!
I was curious if you ever considered changing the
layout of your site? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect
with it better. Youve got an awful lot of text
for only having one or two images. Maybe you could space
it out better?
Artikel ini sangat bermanfaat,
membuat saya lebih paham tentang topik yang dibahas.
Saya suka membacanya dan kemarin juga membaca **MPO102**
yang menyajikan konten transaksi dengan bahasa sederhana.
Harapan saya semakin berkembang.
Howdy! I could have sworn I’ve been to this website before but after checking through
some of the post I realized it’s new to me.
Anyways, I’m definitely delighted I found it and I’ll be book-marking
and checking back frequently!
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly a
lot often inside case you shield this increase.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.com/da-DK/register?ref=V2H9AFPY
I was excited to find this site. I want to to thank you for ones time just
for this wonderful read!! I definitely enjoyed every little bit
of it and i also have you saved to fav to see new things in your site.
Как выбрать хорошие натяжные потолки
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Smart ring manufacturer Oura has announced the acquisition of Proxy, a digital id sign platform, for an undisclosed quantity of equity. By buying Proxy’s identification know-how and smart ring patent portfolio, Oura intends further to solidify its place in the patron wearables market with more functions. Proxy‘s digital identity signal technology is designed to substitute keys, cards, and passwords for improved information privateness. The corporate also developed biometrically-linked expertise for wearables. After the acquisition, Proxy’s workforce will change into Oura’s full-time workers. “Oura was founded on a culture of innovation and has put great emphasis on building broad protection for our intellectual property,” feedback the company’s CEO, Tom Hale, who joined Oura a year in the past. Hale states that this selection will develop the variety of potential clients for Oura, creating alternatives in areas such as funds, logical and bodily access control, and identification authentication, secured with Oura’s heartbeat biometrics. “With the acquisition of Proxy, we have probably the most comprehensive portfolio in the smart http://kcosep.com/2025/bbs/board.php?bo_table=free&wr_id=2960973&wv_checked_wr_id= space,” he adds.
This is a great tip particularly to those new to
the blogosphere. Brief but very precise information… Thanks
for sharing this one. A must read article!
Awesome blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make my
blog jump out. Please let me know where you got your
theme. Thank you
Mɑin gratis tapi hasil mantap.
Hi to all, because I am in fact eager of reading
this webpage’s post to be updated daily. It carries fastidious material.
of course like your web site but you need to take a look at
the spelling on quite a few of your posts. A number of them
are rife with spelling problems and I find it very troublesome
to tell the reality then again I will certainly come back again.
When someone writes an post he/she keeps the plan of a user
in his/her mind that how a user can be aware of it.
Thus that’s why this article is perfect. Thanks!
my webpage … zumbrarescu01
Here is my blog complete rtp database for superlotto slots
I like the valuable information you provide in your articles.
I’ll bookmark your blog and check again here regularly.
I am quite sure I will learn lots of new stuff right here!
Good luck for the next!
Excellent post. I was checking constantly this blog and I am impressed!
Very useful info specifically the final part :
) I maintain such info much. I used to be looking for this particular information for a long time.
Thanks and good luck.
Hi there to every body, it’s my first pay a quick visit of this website; this weblog consists of remarkable and really excellent material in support of readers.
reliable canadian online pharmacy
I know this website provides quality based posts and extra stuff,
is there any other website which provides such stuff in quality?
You really make it appear really easy with your presentation however I to find this topicc to be actually something which
I fsel I migbt never understand. It sort of feels too complex and very large ffor me.
I am taking a look ahead to your subsequent submit, I
wilpl try tto get the dangle of it!
Your style is very unique compared to other folks I have read stuff from.
Thank you for posting when you have the opportunity, Guess I’ll just book mark this page.
Spam aman dan cuan.
Hey there! I know this is kinda off topic but I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog post or vice-versa? My blog discusses a lot of the same topics as yours and I think we could greatly benefit from each other. If you might be interested feel free to send me an email. I look forward to hearing from you! Excellent blog by the way!
my website :: https://forums.bit-tech.net/proxy.php?link=https://nogami-nohken.jp/BTDB/利用者:SamTorgerson98
Hello there! Would you mind if I share your blog with my
myspace group? There’s a lot of folks that I think would
really enjoy your content. Please let me know.
Many thanks
Appreciate the recommendation. Will try it out.
It’s amazing in support of me to have a web page, which is good for my experience.
thanks admin
Hello! I just wanted to ask if you ever have any issues with
hackers? My last blog (wordpress) was hacked and I ended up
losing several weeks of hard work due to no backup.
Do you have any methods to stop hackers?
Excellent postings, Regards!
my web page: https://quadriacapital.com/case-studies/fv-hospital
You mentioned that adequately.
deepsingularity.io
deepsingularity.io
Hi there I am so excited I found your site, I
really found you by mistake, while I was searching on Askjeeve for something else, Nonetheless I am here now and would just like to say kudos for a remarkable post and a all round interesting blog (I also
love the theme/design), I don’t have time to read through it all at the minute but I have book-marked it and also added in your
RSS feeds, so when I have time I will be back to read
a lot more, Please do keep up the great job.
Great delivery. Solid arguments. Keep up thhe god effort. https://tiktur.ru/
Hi my friend! I wish to say that this post is amazing, nice written and come with
almost all significant infos. I would like to peer extra posts
like this .
What’s Taking place i’m new to this, I stumbled upon this I’ve discovered It positively useful and it
has helped me out loads. I am hoping to give a contribution & assist different users like its aided me.
Good job.
Hello there I am so excited I found your blog, I really found you by
error, while I was browsing on Bing for something else, Nonetheless I am here now and would just like to say cheers for
a fantastic post and a all round thrilling blog (I also love the theme/design), I
don’t have time to look over it all at the moment but I have saved it and also added in your RSS feeds, so when I have
time I will be back to read more, Please do keep up the superb job.
**mindvault**
Mind Vault is a premium cognitive support formula created for adults 45+. It’s thoughtfully designed to help maintain clear thinking
Good day I am so grateful I found your webpage,
I really found you by mistake, while I was browsing on Aol for something else,
Anyways I am here now and would just like to say thanks for a
incredible post and a all round entertaining blog (I also love the
theme/design), I don’t have time to look over it all at the minute but I have book-marked it and also added in your RSS feeds, so when I have time I will be back
to read much more, Please do keep up the fantastic work.
Amazing blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress
or go for a paid option? There are so many options out there that I’m completely overwhelmed ..
Any ideas? Thanks!
My blog complete rtp Database for spadegaming slots
Hi, i think that i saw you visited my blog so i came to “return the favor”.I
am attempting to find things to improve my web site!I suppose its ok
to use some of your ideas!!
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.
**mindvault**
mindvault is a premium cognitive support formula created for adults 45+. It’s thoughtfully designed to help maintain clear thinking
เนื้อหานี้ น่าสนใจดี
ค่ะ
ผม เคยเห็นเนื้อหาในแนวเดียวกันเกี่ยวกับ ประเด็นที่ใกล้เคียงกัน
สามารถอ่านได้ที่ sbf play 99
น่าจะถูกใจใครหลายคน
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ เนื้อหาดีๆ นี้
จะคอยดูว่ามีเนื้อหาใหม่ๆ
มาเสริมอีกหรือไม่
کاربران گرامی، راجعبه پلتفرمهای قمار آنلاین به شدت محتاط
باشید. این پلتفرمها به وسیله تبلیغات فریبنده
افراد را گول میزنند، اما پشت پر
از دروغ است. زیان پول صرفاً جزئی از دردسرها است؛ اعتیاد
باعث جدایی از خانواده و ناراحتی شدید میشود.
لطفاً اصلاً مشغول نخواهید شد!
Howdy would you mind sharing which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something completely
unique. P.S Sorry for being off-topic but I had to ask!
Howdy just wanted to give you a brief heads up and let you
know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and
both show the same outcome.
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!
This exercise helps to strengthen the muscles used for breathing and improve lung operate. If oxygen reserves become depleted whereas exercising, muscles convert a starch, known as glycogen, into vitality. On 17 June she called into the port of Willemstad, Curaçao https://myhomemypleasure.co.uk/wiki/index.php?title=Case_Study:_AquaSculpt_-_Your_Ultimate_Guide_To_AquaSculpt_Official_Reviews_Testimonials_And_More the Otrabanda Megapier. After more than a 12 months of planning and preparation, the US Northern Command with the Alaska Division of Homeland Security and Emergency Management and others performed Alaska Shield and Northern Edge 2005. Northern Edge 2005 took place from 15 to 19 August 2005. It was combined with the State of Alaska’s homeland safety exercise called Alaska Shield. 3. Place your palms in any comfortable place. It was additionally announced that the second training serial of CSOR recruits would happen in early 2007. The first commanding officer and regimental sergeant-major of CSOR have been Lieutenant-Colonel (LCol) Jamie Hammond and Chief Warrant Officer (CWO) Gerald Scheidl. Conceived by Brigadier General Richard G. Head, the exercise was devised as a way to present aircrews from across Asia their first style of warfare in a sensible coaching surroundings. During the two-week employment part of the exercise, aircrews are subjected to a variety of combat threats.
My homepage … Debbra
There are over 50 kinds of approval actions including adjustments within the labeling, a brand new route of administration, and a brand new affected person population for a drug product. Yes, your doctor could alter your Toujeo dose based mostly on changes to your train ranges or eating regimen. Also speak together with your doctor about how to acknowledge symptoms of hypoglycemia. Higher magnesium intakes have been linked to health advantages resembling a decrease risk of coronary heart disease, fewer migraines, diminished signs of depression and improved blood stress, blood sugar levels and sleep. Drug merchandise evaluated as “therapeutically equivalent” may be anticipated to have equal impact and no distinction when substituted for the brand title product. Before approving a generic drug product, FDA requires many rigorous exams and procedures to guarantee that the generic drug could be substituted for the brand title drug. A generic drug is similar as a model title drug in dosage, security, power, how it’s taken, quality, efficiency, and meant use.
Feel free to surf to my page :: https://moveiscardeal.com.br/legislacao-para-construcao-de-igrejas/
왜인지 모르겠지만 이 사이트가 제게 엄청나게 느리게 로드됩니다.
다른 사람이 이 이슈를 겪고 있나요, 아니면 제 쪽 문제인가요?
나중에 다시 확인해서 문제가 여전히 있는지
볼게요.
Hello There. I found your weblog using msn. That is a very smartly written article.
I will make sure to bookmark it and come back to read more of your useful information. Thanks for the post.
I’ll certainly comeback.
My page :: GameArt online slots with verified RTP
Today, I went to the beachfront with my kids.
I found a sea shell and gave it to my 4 year
old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear
and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
When you plan to exercise within an hour after breakfast, eat a gentle meal. Even 90-12 months-previous girls who use walkers have been shown in studies to learn from mild weight training. Studies have urged that strolling at a brisk pace for three or more hours per week can scale back your danger for coronary heart disease by 65 %. Coronary coronary heart illness (CHD), also referred to as coronary artery disease, is the most typical form of coronary heart disease, affecting 12.6 million people in America. Having an abundance of triglycerides has been linked to coronary heart illness. High ranges of triglycerides. Triglyceride levels increase while you eat too many fatty foods or once you eat an excessive amount of — excess calories are made into triglycerides and saved as fat in cells. 2. Lower LDL cholesterol by eating foods low in saturated fat, cholesterol, https://trade-britanica.trade/wiki/User:Janell9498 trans fats. The American Heart Association and the American Dietetic Association advocate getting most of your fat from monounsaturated sources. Getting in form? Learn 10 health info that can help motivate you to get transferring. Arteries change into arduous when plaque accumulates on artery partitions.
Hmm it appears like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I submitted and say, I’m
thoroughly enjoying your blog. I too am an aspiring blog writer but
I’m still new to the whole thing. Do you have any helpful hints for newbie
blog writers? I’d genuinely appreciate it.
Cependant, nous vous recommandons d’utiliser un sort avec très peu de points d’action, afin de terminer le combat plus rapidement.
Thank you for sharing your thoughts. I really appreciate your efforts and I
will be waiting for your next post thank you once again.
Hey there this is kind of of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to
manually code with HTML. I’m starting a blog soon but have no coding experience so
I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
This design is incredible! You most certainly know how to keep a
reader entertained. Between your wit and your videos, I was almost moved to start
my own blog (well, almost…HaHa!) Fantastic job. I really enjoyed what
you had to say, and more than that, how you presented it.
Too cool!
Way cool! Some extremely valid points! I appreciate you penning
this post and the rest of the site is also very good.
هی کاربران، راجع به پلتفرمهای بازی شرطی ذهن نخواهید؛ آنها
جاها پر از تهدیدها اقتصادی، روانی و خانوادگی هستند.
یکی از آشنایانم از یکشروع سرمایهام را باخت کردم.
اعتیاد نسبت به آنها بازیها فوریتر
از آن که فکر میکنید رشد میکند.
هرگز وارد نخواهید شد!
Hey There. I found your blog using msn. This is a really well written article.
I will be sure to bookmark it and come back to read more of your
useful information. Thanks for the post. I’ll certainly return.
Your voice is distinct, memorable, and so refreshing in a crowded space.
Why viewers still use to read news papers when in this technological globe all is available on web?
You really make it seem really easy with your presentation however I to find this topic to be really something that I feel I’d
never understand. It seems too complicated and very large for me.
I’m having a look ahead on your subsequent post, I’ll try to get the cling
of it!
Wow, awesome weblog format! How long have you ever been rnning a blog
for? you made blogging glance easy. The full glance of your site is great, let alone the
content material! https://truepharm.org/
After checking out a few of the articles on your web page, I honestly appreciate your technique of blogging.
I saved as a favorite it to my bookmark website list and
will be checking back soon. Take a look at my web site too and let
me know what you think.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my
blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to
your new updates.
My webpage ซื้อหวยออนไลน์ lottovip
What’s up, just wanted to say, I loved this post. It was inspiring.
Keep on posting!
I am regular visitor, how are you everybody?
This post posted at this site is really nice.
You might be surprised to learn that there are more females embracing the tree, but believe it or not,
men are into it. Some people think it’s disgusting to have hair down there, but as long
as you keep it clean, pathogens are exempt.
Plus, adding a little extra scalp to intranasal intercourse can give you some enjoyable tickling feelings. http://www.google.com.jm/url?source=imglanding&ct=img&q=https://hairpornpics.com/
Feel free to surf to my web page … highstakes Games
My site :: high stakes casino
May I just say what a comfort to find somebody that genuinely understands what they are
discussing on the web. You certainly understand how to bring an issue to light and make it important.
More people must check this out and understand this side of your
story. It’s surprising you aren’t more popular
because you definitely possess the gift.
**prostadine**
prostadine is a next-generation prostate support formula designed to help maintain, restore, and enhance optimal male prostate performance.
**sugarmute**
sugarmute is a science-guided nutritional supplement created to help maintain balanced blood sugar while supporting steady energy and mental clarity.
**gl pro**
gl pro is a natural dietary supplement designed to promote balanced blood sugar levels and curb sugar cravings.
Страшно, аж жуть: Хорроры для любителей пощекотать нервы.
**zencortex**
zencortex contains only the natural ingredients that are effective in supporting incredible hearing naturally.
**mitolyn**
mitolyn a nature-inspired supplement crafted to elevate metabolic activity and support sustainable weight management.
Hello just wanted to give you a quick heads up.
The words in your post seem to be running off the screen in Ie.
I’m not sure if this is a format issue or
something to do with browser compatibility
but I figured I’d post to let you know. The layout look great though!
Hope you get the problem resolved soon. Cheers
**prodentim**
prodentim an advanced probiotic formulation designed to support exceptional oral hygiene while fortifying teeth and gums.
What’s up to all, as I am genuinely keen of reading this weblog’s post to
be updated on a regular basis. It carries fastidious information.
**vitta burn**
vitta burn is a liquid dietary supplement formulated to support healthy weight reduction by increasing metabolic rate, reducing hunger, and promoting fat loss.
**yusleep**
yusleep is a gentle, nano-enhanced nightly blend designed to help you drift off quickly, stay asleep longer, and wake feeling clear.
**synaptigen**
synaptigen is a next-generation brain support supplement that blends natural nootropics, adaptogens
Managing blood sugar levels naturally without any side effects is essential for overall health and wellness. With the rise of chronic diseases such as diabetes, it is crucial to find natural ways to https://wiki.lovettcreations.org/index.php/Managing_Blood_Sugar_And_Circulation_Naturally:_A_Comprehensive_Guide blood sugar stability and circulation.
**nitric boost**
nitric boost is a dietary formula crafted to enhance vitality and promote overall well-being.
**glucore**
glucore is a nutritional supplement that is given to patients daily to assist in maintaining healthy blood sugar and metabolic rates.
**wildgut**
wildgutis a precision-crafted nutritional blend designed to nurture your dog’s digestive tract.
My spouse and I stumbled over here coming from a different web address and thought I might
as well check things out. I like what I see so i
am just following you. Look forward to looking into your web page repeatedly.
I take pleasure in, lead to I found exactly what I was having a look for.
You’ve ended my four day long hunt! God Bless you man. Have a nice day.
Bye
**pinealxt**
pinealxt is a revolutionary supplement that promotes proper pineal gland function and energy levels to support healthy body function.
**energeia**
energeia is the first and only recipe that targets the root cause of stubborn belly fat and Deadly visceral fat.
**boostaro**
boostaro is a specially crafted dietary supplement for men who want to elevate their overall health and vitality.
**prostabliss**
prostabliss is a carefully developed dietary formula aimed at nurturing prostate vitality and improving urinary comfort.
I want to express my admiration for your generosity supporting individuals that really want guidance on that question. Your real
commitment to passing the solution around had been unbelievably powerful and has really helped men and women much like
me to reach their goals. Your insightful publication denotes a
whole lot a person like me and somewhat more to my office workers.
Thanks a ton; from everyone of us.
Also visit my webpage … Highstakes Poker Review
**breathe**
breathe is a plant-powered tincture crafted to promote lung performance and enhance your breathing quality.
**potent stream**
potent stream is engineered to promote prostate well-being by counteracting the residue that can build up from hard-water minerals within the urinary tract.
Thanks for every other informative web site.
The place else could I get that type of info written in such a perfect
approach? I have a project that I am just now working on, and I
have been at the glance out for such info.
Hello would you mind sharing which blog platform you’re
using? I’m looking to start my own blog in the near future but I’m having a tough time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m
looking for something unique. P.S Sorry for being off-topic but
I had to ask!
**hepato burn**
hepato burn is a premium nutritional formula designed to enhance liver function, boost metabolism, and support natural fat breakdown.
**hepatoburn**
hepatoburn is a potent, plant-based formula created to promote optimal liver performance and naturally stimulate fat-burning mechanisms.
Виртуальные номера сегодня — не просто лайфхак, а реальный инструмент цифровой безопасности и удобства
**cellufend**
cellufend is a natural supplement developed to support balanced blood sugar levels through a blend of botanical extracts and essential nutrients.
**prodentim**
prodentim is a forward-thinking oral wellness blend crafted to nurture and maintain a balanced mouth microbiome.
**flow force max**
flow force max delivers a forward-thinking, plant-focused way to support prostate health—while also helping maintain everyday energy, libido, and overall vitality.
**revitag**
revitag is a daily skin-support formula created to promote a healthy complexion and visibly diminish the appearance of skin tags.
**neurogenica**
neurogenica is a dietary supplement formulated to support nerve health and ease discomfort associated with neuropathy.
There’s certainly a lot to learn about this subject.
I love all the points you made.
Hi! I’ve been following your blog for a while now
and finally got the bravery to go ahead and give you a shout out from Huffman Texas!
Just wanted to say keep up the great work!
Awesome material Thank you!
İşinizə davam edin və daha çox istifadəçi cəlb edin!
https://pinupcasino-play.kz/
**sleeplean**
sleeplean is a US-trusted, naturally focused nighttime support formula that helps your body burn fat while you rest.
Hi my friend! I wish to say that this post is amazing, great written and include almost all significant infos.
I would like to see more posts like this .
Heya superb blog! Does running a blog like this take a great deal of work?
I have very little understanding of computer
programming however I had been hoping to start my own blog in the near future.
Anyway, should you have any suggestions or tips for new blog owners
please share. I know this is off topic however I simply had to
ask. Thanks a lot!
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on several websites for about
a year and am worried about switching to another platform.
I have heard fantastic things about blogengine.net.
Is there a way I can import all my wordpress posts
into it? Any kind of help would be really appreciated!
**memory lift**
memory lift is an innovative dietary formula designed to naturally nurture brain wellness and sharpen cognitive performance.
My blog Fazi slots catalogue (Demo & Real)
Hello my friend! I wish to say that this article is awesome, nice written and come with almost all important infos.
I’d like to peer more posts like this .
Me encantó este contenido sobre las casino tragamonedas más destacadas en Pin-Up México.
Es impresionante cómo juegos como Gates of Olympus, Sweet Bonanza y Book of Dead continúan siendo
los preferidos. La explicación de las funciones especiales y versiones demo fue muy clara.
No te pierdas la oportunidad de leer el artículo y descubrir por qué
estos slots son los favoritos entre los jugadores mexicanos.
Se agradece ver una mezcla entre títulos nostálgicos y
nuevas propuestas en el mercado mexicano de apuestas.
Te recomiendo visitar el post original para conocer las tragamonedas más populares de 2025 en Pin-Up Casino.
This is a great article. The detailed tips are perfect. PENGAWAS4D This is written in such a perfect approach. Very clear.
It’s amazing designed for me to have a web page, which is useful designed for my experience.
thanks admin
This post is written in a very good manner and has useful info for me. MEONGTOTO Thanks for the useful info. I’ll be checking your feed.
Hiya very cool site!! Man .. Beautiful .. Wonderful ..
I will bookmark your blog and take the feeds also? I’m happy to search out so many useful
info right here in the submit, we want work
out extra techniques in this regard, thank you for sharing.
. . . . .
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
You really make it seem so easy with your presentation but
I find this topic to be really something which I think I would never understand.
It seems too complex and very broad for me. I am looking forward for your next post, I’ll try to get the hang of it!
Very great post. I simply stumbled upon your blog and wanted to say that I’ve truly
loved browsing your weblog posts. In any case I’ll be subscribing
to your rss feed and I’m hoping you write again very soon!
It’s not just what you write, but how you write—it leaves a lasting impression.
You always manage to put complex feelings into simple, beautiful words.
deltasone
you are actually a just right webmaster. The site loading speed is
amazing. It kind of feels that you are doing any unique trick.
In addition, The contents are masterwork. you have done a great
job in this topic!
https://autolocksmithlocal.co.uk/forum/blog/view/172628/three-tips-to-recognize-a-huge-cry-baby-disposable
Awesome facts, Thank you.
Услуги адвоката в уголовных
делах в Москве: как добиться успешной защиты клиента и
собрать положительные отзывы в процессе судаУслуги адвоката по уголовным делам
в Москве
Услуги адвоката по уголовным делам в
Москве востребованы среди клиентов, сталкивающихся с обвинениями в различных преступлениях.
Независимо от тяжести дела, наличие опытного
адвоката, который сможет законно и эффективно отстаивать ваши интересы в суде, имеет ключевое значение.
Почему стоит выбрать адвоката?
Адвокат имеет опыт ведения уголовных дел и знает тонкости судебного процесса.
Специалист поможет добиться успешногорезультата и минимизировать негативные последствия.
Клиенты получат необходимые консультации
по всем вопросам, касающимся дела.
Какие задачи выполняет адвокат?
Работа адвоката по уголовным делам включает несколько ключевых
этапов:
Первичная консультация, где адвокат анализирует детали дела и определяет шансы на
успех.
Сбор и анализ доказательств, необходимых для формирования стратегии защиты.
Подготовка материалов для суда и участие в
судебных заседаниях.
Представление интересов клиента на каждом этапе уголовного процесса.
Отзывы клиентов
Отзывы о работе адвокатов могут существенно повлиять на
выбор защитника. Многие клиенты отмечают:
Профессионализм и высокий уровень подготовки.
Индивидуальный подход к каждому делу.
Умение успешно справляться с работой в стрессовой обстановке.
Информация о контактах адвоката
Следует заранее узнать номер телефона адвоката, чтобы в экстренной ситуации быстро получить помощь.
Оперативность и доступность являются
ключевыми факторами, способствующими успешной защите.
Как выбрать адвоката по уголовным делам?
При выборе адвоката, работающего в сфере уголовного права, стоит учитывать такие аспекты:
Опыт работы в данной сфере и количество выигранных дел.
Отзывы клиентов и имидж адвоката на рынке.
Прозрачность условий и расценок за услуги адвоката.
Имейте в виду, что быстрое
обращение к адвокату может кардинально повлиять на результат дела.
Не устанавливайте задержки в решении вопросов, связанных с
защитой ваших прав и интересов. https://m.avito.ru/moskva/predlozheniya_uslug/advokat_po_ugolovnym_delam_3789924168 Вывод
Обращение к юристу, специализирующемуся
на уголовных делах в Москве, — это серьезный шаг, который может кардинально изменить ход вашего уголовного дела.
У каждого клиента есть право на профессиональную защиту, и именно
опытный адвокат поможет организовать процесс ведения дела с учетом всех деталей.
Учитывая сложность уголовного законодательства, важно
выбрать специалиста, который сможет эффективно
представлять ваши интересы на всех этапах – от досудебного разбирательства до суда.
Важность надёжной защиты
Для успешного ведения уголовных делнеобходимы не только обширные знания законодательства, но
и опыт работы с различными видами преступлений.
Юрист обязан:
Следить за всеми аспектами дела;
Разрабатывать план защиты;
Взаимодействовать с представителями власти;
Представлять ваши интересы в суде;
Поддерживать клиента на всех этапах процесса.
Причины нашего выбора
Наши клиенты отмечают высокую квалификацию и профессионализм в работе.
Наша цель заключается в том, чтобы наши клиенты ощущали защиту и уверенность в своих действиях.
Наш опыт в ведении уголовных дел позволяет нам достигать положительных результатов даже в самых трудных
ситуациях.
Как выбрать адвоката?
Когда выбираете адвоката по уголовным делам в Москве,
учитывайте:
Отзывы клиентов;
Специализация и опыт работы в вашем направлении;
Наличие возможности консультации;
Индивидуальный подход к каждому делу.
Имейте в виду, что чем раньше вы свяжетесь с профессионалом, тем больше шансов на положительный результат.
Если у вас есть вопросы, мы всегда готовы помочь.
В заключение, помните, что
каждый имеет право на защиту, и мы готовы помочь вам в этом.
Свяжитесь с нами, чтобы получить консультацию и узнать, как мы
сможем отстоять ваши интересы в уголовном процессе.
duphalac
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ɗr c121,
Charlotte, NC 28273, United Ⴝtates
+19803517882
Optimization space for homes
hey there and thank you for your info – I have definitely picked up anything
new from right here. I did however expertise several technical issues using this web site,
as I experienced to reload the website many times previous to I could get it to load properly.
I had been wondering if your hosting is OK? Not that I’m complaining, but slow loading instances times will very frequently affect your placement in google and can damage
your quality score if advertising and marketing with Adwords.
Well I’m adding this RSS to my email and can look out for a lot more of your respective exciting content.
Make sure you update this again soon.
Hello there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked
hard on. Any tips?
Wow, superb weblog format! How long have you ever been blogging for?
you make running a blog glance easy. The overall look of your site is great,
let alone the content!
online casino sign up bonus
https://gamblingchooser.com/
online casino reload bonus
BL555
Hey I am so thrilled I found your website, I really found you by mistake, while
I was looking on Bing for something else, Anyways I am here now and would just like to say kudos for a marvelous post and a all round thrilling blog
(I also love the theme/design), I don’t have time to read through it all at the minute but I have saved it and
also added in your RSS feeds, so when I have time
I will be back to read more, Please do keep up the superb work.
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!
Школа барабанов в Москве: освоение в мир музыки
Fascinating blog! Is your theme custom made or did you download
it from somewhere? A design like yours with a few simple tweeks would
really make my blog jump out. Please let me know where you got your
theme. Many thanks
What’s Going down i’m new to this, I stumbled upon this I’ve found It positively helpful and
it has aided me out loads. I’m hoping to contribute &
help other users like its aided me. Good job.
Лучшие подборки фильмов на Зоне: Делимся интересными тематическими подборками и обсуждаем критерии их составления.
Hi there to every single one, it’s in fact a good for me to pay a visit this
web site, it consists of priceless Information.
Wow that was strange. I just wrote an really long comment but after I clicked submit my comment
didn’t appear. Grrrr… well I’m not writing all that over
again. Anyhow, just wanted to say wonderful blog!
Hi, I do believe this is a great blog. I stumbledupon it
😉 I may revisit yet again since I bookmarked it.
Money and freedom is the best way to change, may
you be rich and continue to help other people.
I always used to study paragraph in news papers but now as I am a user of web
thus from now I am using net for content, thanks to web.
The analysis of turbulence in plasmas is fundamental in fusion research. Despite extensive progress in theoretical modeling in the past 15 years, we still lack a complete and consistent understanding of turbulence in magnetic confinement devices, equivalent to tokamaks. Experimental studies are difficult as a result of various processes that drive the high-velocity dynamics of turbulent phenomena. This work presents a novel software of movement tracking to establish and observe turbulent filaments in fusion plasmas, known as blobs, in a excessive-frequency video obtained from Gas Puff Imaging diagnostics. We examine four baseline strategies (RAFT, Mask R-CNN, GMA, and Flow Walk) skilled on artificial data and then check on artificial and real-world knowledge obtained from plasmas in the Tokamak à Configuration Variable (TCV). The blob regime recognized from an evaluation of blob trajectories agrees with state-of-the-art conditional averaging strategies for every of the baseline strategies employed, giving confidence within the accuracy of those methods.
My web-site … http://dev.icrosswalk.ru:46300/audrystrode57
Good day! Do you use Twitter? I’d like to follow you if
that would be ok. I’m definitely enjoying your blog and look forward to new updates.
Excelente resumen sobre las tragamonedas favoritas en Pin Up Casino México.
Increíble ver cómo Pragmatic Play y Play’n GO siguen liderando con sus slots más
reconocidas. La explicación de las funciones especiales y versiones demo fue muy clara.
Si te interesan los juegos de casino online o las tragamonedas en México, definitivamente deberías leer este artículo completo.
Se agradece ver una mezcla entre títulos nostálgicos y
nuevas propuestas en el mercado mexicano de apuestas.
Te recomiendo visitar el post original
para conocer las tragamonedas más populares de 2025 en Pin-Up Casino.
my web blog – GameBeat Slot RTP List & FAQs
Highly descriptive blog, I enjoyed that a lot. Will there
be a part 2?
سلام گرم
توصیه میشه
سایت انفجار بت
رو جهت مونتی.
این سایت عالی امنیت بالا و برای کاربران جدید مناسبه.
تازه کشف کردم و پیشنهاد میدم ثبت نام کنید.
ارادتمند فاطمه.
PlayAmo Portal Internet Betting Platform is one of the trusted interactive portals for members who like action, rewards, and efficient transfers.
With hundreds of top-notch slots, blackjack, and casino streams, Play-Amo delivers a elite iGaming experience right from your desktop or smartphone.
New members can unlock generous sign-up rewards, reward spins, and discover invitation-only reward tiers.
Whether you try legendary titles or the new arrivals, Play Amo offers everything you need for fun real-money entertainment
https://gyn101.com/
gyn101.com
Way cool! Some very valid points! I appreciate you penning this write-up
plus the rest of the website is extremely good.
Реальные отзывы о Zion Trade
You always manage to put complex feelings into simple, beautiful words.
My webpage :: Highstakes 777 login
We are a group of volunteers and opening a brand new scheme in our community.
Your web site provided us with helpful info to work on. You have performed a formidable activity and our
entire neighborhood will be grateful to you.
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back down the road.
Many thanks
Cheers. Numerous data!
The best grownup site, PornPics.de, has a sizable
selection of high-quality movie images. 1 The website stands out because of its simple structure, large
categories, high-quality images, varied models, and a unique picture archive.
You can use PornPics.de for costless, and here you
can find advanced porn images of famous brands. https://mytools.com.ng/lamarcade
I am extremely inspired along with your writing talents as neatly as with the
structure for your weblog. Is this a paid subject or did you customize it
your self? Either way keep up the excellent quality writing, it is rare to look a great weblog
like this one today..
I every time used to study post in news papers but now as I am a user of
internet therefore from now I am using net for articles or reviews, thanks to web.
Every time I read your work, I feel like I’m right there with you. Beautifully written!
Does your blog have a contact page? I’m having problems locating it but,
I’d like to send you an email. I’ve got some recommendations
for your blog you might be interested in hearing. Either way, great website and
I look forward to seeing it grow over time.
Link exchange is nothing else but it is just placing the other person’s website link on your page
at proper place and other person will also do same in favor
of you.
Here is my website: zinnat02
Do you have any video of that? I’d want to find out some additional information.
Remarkable! Its actually remarkable paragraph, I have got much clear idea regarding from this paragraph.
I for all time emailed this website post page to all my contacts, because if like to
read it next my links will too.
my page :: homepage
Have you ever thought about writing an e-book or guest authoring on other blogs?
I have a blog centered on the same information you
discuss and would love to have you share some stories/information. I know my visitors would value your
work. If you are even remotely interested, feel free to send me an e-mail.
Incredible points. Sound arguments. Keep up the good spirit.
Thanks for sharing your thoughts on slot app. Regards
Wonderful work! This is the type of information that
should be shared around the net. Disgrace on the seek engines for now not positioning this submit higher!
Come on over and visit my web site . Thanks =)
Also visit my blog :: Play PG Soft slots online – demo + cash
Such a smooth and engaging read—your writing flows effortlessly. Big fan here!
Hi! This is kind of off topic but I need some guidance from
an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where to start.
Do you have any points or suggestions? With thanks
Inspiring story there. What happened after? Take care!
You write with such clarity and warmth—it feels like home.
The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!
Great article! That is the type of info that aare meant too be
sharred across thee internet. Shame on the seek engines ffor not positioning this post upper!
Comme on over and seek advice frolm my website . Thanks =)
Your ability to paint pictures with words is incredible. I could visualize every detail.
Your article helped me a lot, is there any more related content? Thanks!
Hello There. I found your blog using msn. This is an extremely well written article.
I will be sure to bookmark it and come back to read more of your
useful info. Thanks for the post. I’ll certainly return.
안녕! 당신의 블로그 플랫폼으로 WordPress를
사용하시나요? 저는 블로그 세계에 새로 입문했지만, 제 블로그를 시작하려고 합니다.
블로그를 만들기 위해 HTML 코딩 전문성이 필요한가요?
도움이 된다면 정말 감사하겠습니다!
Magnificent beat ! I would like to apprentice while you amend your site, how could i subscribe for a
blog web site? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast offered bright clear
concept
I stumbled upon your website while searching for secops,
and I’m so glad I did! Your content is informative, and the layout is super user-friendly.
Have you considered adding a newsletter for updates?
Keep up the awesome work!
Reverendo Aldo Quintão를 검색하다가 이 블로그를 발견했는데,
정말 대박이에요! 내용이 가치 있고, 디자인이 깔끔합니다.
뉴스레터 구독 기능이 있으면 좋을 것 같아요.
대단한 작업 계속해 주세요!
It’s amazing for me to have a web page, which
is valuable in favor of my knowledge. thanks admin
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the
same nearly a lot often inside case you shield this increase.
Hey I know this is off topic but I was wondering if you knew of any
widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look
forward to your new updates.
Helpful information. Lucky me I discovered your web site by
chance, and I am shocked why this twist of fate did not happened
in advance! I bookmarked it.
Here is my homepage Complete RTP database for Evoplay slots
I think the admin of this web site is genuinely working hard
for his website, since here every stuff is quality based
information.
I wanted to thank you for this great read!! I certainly
loved every bit of it. I’ve got you book marked to check out new stuff you post…
You write with such clarity and warmth—it feels like home.
Hello there, I found your web site by way of Google while looking for
a similar topic, your site came up, it looks great.
I’ve bookmarked it in my google bookmarks.
Hi there, just became aware of your blog thru Google, and found
that it’s truly informative. I am going to watch out for brussels.
I will be grateful in case you continue this in future.
Numerous people might be benefited out of your writing.
Cheers!
If you are going for best contents like me, simply pay a
quick visit this web site everyday for the reason that it offers quality contents, thanks
naturally like your web-site but you have to check the spelling on quite a few of your posts.
A number of them are rife with spelling issues and I to find it very bothersome to tell the reality
then again I will surely come again again.
my blog … Evoplay Slot rtp list & Faqs
Hello colleagues, good article and nice arguments commented at this place, I am genuinely enjoying by
these.
Your style is very unique compared to other people I have read stuff from.
Thanks for posting when you’ve got the opportunity, Guess I will just bookmark
this blog.
Hiya! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My site looks weird when browsing from my iphone4. I’m trying to find a template or plugin that might be able to fix this issue.
If you have any recommendations, please share. Appreciate it!
Undeniably believe that which you stated. Your favorite justification seemed to be on the
web the simplest thing to be aware of. I say to you, I definitely get irked while people think about worries that they plainly do not know about.
You managed to hit the nail upon the top as well as
defined out the whole thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
Pushpa Club Game
Please let me know if you’re looking for a article writer for your weblog.
You have some really good posts and I think
I would be a good asset. If you ever want to take some of
the load off, I’d love to write some articles for your blog in exchange for a link back
to mine. Please blast me an e-mail if interested.
Cheers!
Wow, that’s what I was exploring for, what a stuff!
existing here at this webpage, thanks admin of this website.
Разработка рабочей документации и корректировка проектной документации
It’s the best time to make some plans for the longer
term and it’s time to be happy. I’ve read this put up and if I
could I desire to recommend you few fascinating issues or advice.
Perhaps you can write subsequent articles referring to this article.
I want to learn more issues about it!
I enjoy reading a post that will make men and women think.
Also, thanks for allowing for me to comment!
You can certainly see your expertise within the work
you write. The sector hopes for even more passionate writers like you who are not afraid to mention how they
believe. Always follow your heart.
I was more than happy to find this page. I need to to thank you for ones time for this fantastic read!!
I definitely appreciated every bit of it and I have you saved as a
favorite to check out new information in your website.
Casino Canada – trusted gambling destination
What’s up all, here every person is sharing these experience,
so it’s pleasant to read this blog, and I used to visit this blog everyday.
Hi to every body, it’s my first go to see of this website; this website includes remarkable and actually
good stuff in favor of readers.
I was excited to find this website. I want to to thank you for your time for this particularly wonderful read!!
I definitely really liked every part of it and i also have you bookmarked to look
at new information in your website.
Как привлечь на сайт большое количество посетителей
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are but certainly you’re going to a famous blogger
if you are not already 😉 Cheers!
Excellent post. I was checking continuously this blog and I am inspired!
Extremely helpful info specially the ultimate phase 🙂 I care for such info much.
I was seeking this certain information for a long time.
Thanks and good luck.
Very descriptive post, I enjoyed that bit.
Will there be a part 2?
I have been exploring for a little for any
high-quality articles or weblog posts in this kind of space
. Exploring in Yahoo I finally stumbled upon this web site.
Reading this information So i’m happy to convey that I have an incredibly excellent uncanny feeling
I came upon just what I needed. I such a lot indubitably will make
sure to do not put out of your mind this site and give it a glance regularly.
Hey there I am so excited I found your blog, I really found you
by mistake, while I was looking on Yahoo for something else, Anyways I am here now and would just like to say thanks for a tremendous post and a all round thrilling blog (I
also love the theme/design), I don’t have time to go through it all at the moment but I have bookmarked it and also added in your RSS feeds, so when I
have time I will be back to read more, Please do keep up the great job.
Terrific facts Many thanks!
Hello, its fastidious article concerning media print, we all understand media is a impressive source of data.
It is in reality a nice and helpful piece of information. I’m glad
that you shared this useful info with us. Please stay us up to date like this.
Thanks for sharing.
Very good article. I’m dealing with a few of these issues as well..
That is really interesting, You are an overly skilled blogger.
I’ve joined your feed and stay up for looking for
extra of your excellent post. Additionally, I’ve shared your
site in my social networks
whoah this weblog is magnificent i like studying your posts.
Keep up the great work! You know, a lot of people are searching
around for this information, you could help them greatly.
Such a smooth and engaging read—your writing flows effortlessly. Big fan here!
Saya sangat menikmati membaca artikel ini.
Pembahasan mengenai KUBET sebagai Situs Judi Bola Terlengkap ditulis dengan jelas, sehingga pembaca bisa memahami keunggulan platform tersebut dengan mudah.
Penjelasan mengenai bagaimana sebuah platform mendapatkan predikat sebagai Situs Parlay Resmi juga sangat informatif.
Detail yang diberikan sangat membantu bagi pembaca baru.
Ini termasuk pembahasan yang jarang ditemukan tetapi sangat dibutuhkan.
Topik mengenai performa yang menjadikan platform tertentu sebagai Situs Parlay
Gacor juga mendapat perhatian besar.
Detailnya sangat membantu pemain untuk mengenali kualitas
situs.
Informasi seperti ini sangat bermanfaat bagi siapa pun yang ingin memilih
layanan terbaik.
Saya juga menyukai bagian yang membahas fitur permainan seperti di
Situs Mix Parlay serta permainan populer lainnya seperti toto macau.
Informasi yang diberikan sangat relevan.
Kedua topik tersebut membuat artikel terasa jauh lebih lengkap dan variatif.
Jika melihat dari semua isinya, artikel ini sangat
bermanfaat terutama bagi pembaca yang ingin memahami dunia Situs Judi Bola, kubet login, dan situs
parlay secara lebih mendalam.
Saya berharap akan ada lebih banyak artikel sejenis yang membahas topik dengan kualitas setinggi ini.
Today, I went to the beachfront with my children. I found a sea shell and
gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
It’s actually a great and useful piece of info. I am satisfied that
you simply shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
Your words are like a gentle nudge that makes me reflect and appreciate more.
I’m not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this information for my mission.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/si-LK/register?ref=LBF8F65G
Wow—your writing is so vivid and alive. It’s hard not to get hooked!
This paragraph will help the internet viewers for
setting up new weblog or even a weblog from start to end.
Do you mind if I quote a few of your posts as long as I provide credit
and sources back to your weblog? My blog is in the very same niche as yours
and my users would certainly benefit from some of the information you provide
here. Please let me know if this ok with
you. Cheers!
You really make it seem so easy with your presentation but I find this topic to be actually something that I think
I would never understand. It seems too complex and very broad
for me. I am looking forward for your next post, I will try to get the hang of it!
Mangelsen
7916 Girard Avenue, ᒪa Joyaa
ⲤА 92037, Unitedd Ѕtates
1 800-228-9686
impact grizzlies of pilgrim creek book bears
Your means of explaining all in this post is in fact fastidious, every
one be capable of easily be aware of it, Thanks a lot.
my web-site: Hacksaw Gaming online slots with Verified RTP
Way cool! Some very valid points! I appreciate you writing
this write-up and also the rest of the website is also very good.
Also visit my web-site … Thunderkick Casino Games – Full List
Dziękuję za tak przydatne treści o Najlepsze kasyna online w Polsce i grach hazardowych.
https://jhptransport.co.uk/jhp-transport-named-scotlands-top-chilled-distributer-2018/
4M Dental Implant Center
3918 Ꮮong Beach Blvdd #200, Ꮮong Beach,
ⅭA 90807, United Statеs
15622422075
smile design
4M Dental Implant Center
3918 Longg Beach Blvd #200, Long Beach,
СA 90807, United Statеs
15622422075
tooth repair
Mangelsen
7916 Girard Avenue, Lɑ Joya
ϹA 92037, United Ꮪtates
1 800-228-9686
impact grizzly 399 legacy photography
Whoa! This blog looks exactly like my old one!
It’s on a completely different subject but it has pretty much the same layout and design. Outstanding choice of colors!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/en/register?ref=JHQQKNKN
Nicely put. Thanks a lot.
What’s up i am kavin, its my first occasion to commenting anyplace, when i read this article i thought i could also make comment due to this good post.
Great article! That is the kind of info that should be shared
across the internet. Shame on Google for now not positioning this put up higher!
Come on over and discuss with my website . Thanks =)
Somebody essentially help to make severely posts
I might state. That is the very first time I frequented your web page
and thus far? I surprised with the analysis you made to create this particular put up extraordinary.
Excellent activity!
Howdy would you mind stating which blog platform you’re working with?
I’m looking to start my own blog in the near future but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something unique.
P.S My apologies for getting off-topic but I had to ask!
Look into my web site :: Evoplay games – play for real money
I really love your site.. Great colors & theme.
Did you create this site yourself? Please reply back as
I’m attempting to create my very own blog and would love to learn where you
got this from or exactly what the theme is named. Thanks!
is human trafficking tһe second largest, uѕа gymnastics coach human trafficking, human trafficking news neаr me,
snnopes lynne knowles human trafficking, human trafficking
awareness ԁay quotes, human trafficking sex scene,
huma trafficking – menschenhandel, meghan connrs human trafficking,
ansrew tate human trafficking, arguments οn humman trafficking, free
human trafficking cme florida, human trafficking оur, human trafficking in minnesota 2021, arizona republican human trafficking, orange іs the new black hukan trafficking, human trafficking conference ocean ccity md,
277 arrested іn human trafficking, anti human trafficking law philippines,
north korea human trafficking fɑcts, how wiⅼl tһе wall affect human trafficking, human trafficking training
michigan 2018, hotels sue human trafficking, kids rescued
fгom human trafficking, durnam region hhuman trafficking,
ԝhy human trafficking iѕ important, mother of god church human trafficking, wlmart
human traffickinhg 2020, ѡhat is the rate
of human trafficking worldwide, human trafficking news (news), human trafficking ƅy state 2021, lgbt humjan trafficking statistics, south africa аnd human trafficking, human trafficking statistics fbi, hotel lawsuits human trafficking,
operation renewed hope human trafficking, human traficking atlanta 2022, human trafficking ssan joaquin county,
non profit organizations fօr human trafficking, human trafficking interpol, human trafficking elgin, trafficking women’ѕ humann rightѕ julietta
hua, facebook human trafficking lawsuit, rates ᧐f human trafficking, real worl еxample of human trafficking,
lawyers ɑgainst human trafficking, wsin human trafficking summit 2022,
vad är human trafficking, recognizing thhe signs ⲟf human trafficking, human trafficking
justice, video ⲟf human trafficking, foսr sigfns of human trafficking, human trafficking honey, binjun xie human trafficking, human trafficking documentary amazon ρrime, minnesota human trafficking data, uncovers
russian human traafficking гing war, human trafficking chico сa, human trafficking jus cogens, human trafficking syrian refugees, human trafficking topics гesearch
paper, text human trafficking link snopes, oprah south africa human trafficking, human trafficking grants 2015, human trafficking san antinio 2021, human druig trafficking meaning, humjan trafficking
stories children, fema human trafficking awareness, florida disney human trafficking, jobs fօr human trafficking victims,
movie ɑbout human trafficking 2023 netflix, а dɑy іn the
life oof a human trafticking victim, uk human trafficking news, bent ⅼicense plate
human trafficking reddit, humqn trafficking іn waterbury ct, center tto
combat human trafficking, greenville nc human trafficking, maui
human trafficking, tоp 5 human trafficking cities, iѕ human trafficcking happening іn thе us, oxnard human trafficking, aurora shoreline humjan trafficking, taconganas human trafficking,
hashtags fօr huiman trafficking, ԝhite house human trafficking summit,
corona human trafficking, border patrol human trafficking, hujan traffdicking іn thailand 2020, human trafficking iin wv, 11 arrested іn human trafficking, china’ѕ oone child
policy аnd hhuman trafficking, hotels human trafficking 2023, human trafficking іn florida 2021,
human trafficking debate topics, international juustice mission human trafficking, uncovers human trafficking гing foг, scholarly article on human trafficking, madison herman hyman trafficking, amad
diallo human trafficking, ɑ poem аbout human trafficking,
human trafficking bristol tn, deluca andd tһe human trafficking storyline,
economy ɑnd huma trafficking, human trafficking іn trinidad, human trafficking day 2018,
caught camera actual human trafficking victims, human trafficking
episode opal grey’ѕ anatomy, duolihgo ceo human trafficking, watch dogs human trafficking map, human trafficking definition canada,
airtag human trafficking, human trafficking іn the
beauty industry, 人口販子human trafficking, forced labor іn human trafficking, american airlines center human trafficking, human trafficking се texas,
selah human trafficking, siam human trafficking, fresno human trafficking statistics,
senegal human trafficking, human trafficking belgium,
michigan human trafficking сourse, ny times human trafficking,
abandoned stroller human trafficking, human trafficking і-44, solution ߋn human trafficking,
human trafficking canada news, ontariio human trafficking, protects victoms օf human trafficking
amendment, huma trafficking іn highland сa, human trafficking hotspot map,
human trafficking organizations ontario, human trafficking hiding
ᥙnder cars, summary оn human trafficking, uncovers russizn human trafficking ring wɑr, human trafficking honey, fοur signs of
human trafficking, human trafficking western pa, human trafficking livermore, human trafficking durham
region, human trafficking ɑt atlanta airport, binjun xie humwn trafficking, minnesota human trafficking data, human trafficking documentary amazon ρrime, human trafficking lawyer bloomfield hills, human traficking
charge іn texas, central students ɑgainst human trafficking, ap human geography human trafficking, human trafficking fⲟr
sexual exploitation, blue fօr human trafficking, kantian ethics human trafficking,
anti-human trafficking organization iin cambodia, jo jorgensen ߋn human trafficking, fort hood soldiers human trafficking,
beau ⲟf thе fifth column human trafficking, hawkins human trafficking, human trafficking іn the pacific islands, reasons ᴡhy human trafficking іs bad, ally human trafficking, write an essay ߋn human trafficking, human trafficking pros, human trafficking dark web reddit,
north preston human trafficking, ɗollar sin tattoo human trafficking, wht
іs human trafficking, humwn trafficking stuart fl, priceless movie human trafficking, ti аnd wife human trafficking, human trafficking ethnicity statistics, і 80 truck stop
human trafficking, hamilton human trafficking,
oakville human trafficking, human trafficking оn the ddep
web, current humawn trafficking, human trafficking women’ѕ
rightѕ, brunei human trafficking, barack bama human traffickiing quote, patron saint оf human trafficking, spirited away human trafficking,
tһe game human trafficking, top human trafficking cities 2023, human tfafficking ᴡhich countries
аre thhe worst, hoԝ to donate tօ human trafficking organizations,
humaan trafficking quotes famous, human trafficking story 2020, human trafficking іn pittsburgh, 2020 human trafficking conference,
human trafficking bust atlanta, human trafficking hemet сa,
human trafficking statistics oregon, һow to identiy a human trafficking
victim, economy аnd human trafficking, lover boy method ߋf human trafficking, deluca аnd
thе human trafficking storyline, european human trafficking, selah human trafficking, american airlines center human trafficking, human traffickiing paintings,
ᴡhat state іs #1 in human trafficking?, free porn,porn,porn hub,jav porn,bokep indo,bokep bocil,indo bokep,bokep daddy
ash,bokep ngewe,ngewe bocil,bokep binor,bokep stw,bokep tante,bokep pns,bokep tobrut,bokep viral,bokep bu guru,indian sex,
indian wife,desi,mom,gangbang,mother sex,sex mother,mom sex,ebony,dick,pussy,
milf,casting,mature,teen,lesbian,vagina,vagina creampie,japanese
wife,japanese mature,japanese teen,japanese milf,lesbian mature,mature
women,squirt machine,russian maid,american anal sluts,granny sex,bokep hijab,bokep malay,brazzers,hentai,arab sex,mature anal,indian sex,african teen,najiaporntube,gigantic ass,sarah
ʏoung,mature mom,pinya scandal,sasha grey,gay,anal gay,mom andd ѕon,mom son,russian mature,russian teen,anthea ѕon casting,muslim girl blow job,
jav subtitle indonesia video bokep,bokep pelajar,remaja ngentod,ѕub indo porn videos,bokep bumil,bokep artis indo,bokep
babymoy,bokep meimei,bokep memek legit,bokep crot dalam,bokep
mantan pacar,bokep fᥙll percakapan,bokep fulⅼ service,bokep tante mulus,
bokep sugardady,bokep adikk kakak,bokep selingkuh,bokep hikjab tobrut,tante tobrut,hijab tobrut,bokep
janda,bokep pijat,bokep vcs,bokep live ngentod,bokep indo brondong,
bokep ndo tante brondong,bokep оpen bo,open bo stw,bokpe michat,bokep apk ijo,bokep ojol,bokep
bareng pacar,bokep tiktok,bokep jilbab sange,bokep jilbab
abg,bokep ibu mertua,bokep kebaya merah,bokep digilir,indo porn,porn indo,japanese
porn,porn dude,indonesia porn,gay porn,video porn,porn video,porn hd,korean porn,tһe porn dude,japan porn,free porn,rae lil black porn,porn indonesia,аi porn,porn comic,tiktokporn,audrey davis porn,porn movie,chinese porn,sophie rain porn,xxx porn,porn sex,hd porn,asian porn,anime porn,deepfake
porn,sex porn,alyx sta porn,hikaru nagi porn,indonesian porn,nagi hikaru porn,roblox porn,porn xxx,bu guru
salsa porn,porn tube,Ьig bookbs porn,xnxx porn,situs
porn,porn japan,msbreewc porn,film porn,bulan sutena porn,hazel moore
porn,hijab porn,douyin porn viagra,ϲlick here,buy xanax online,Ьest casino,
hacked site,scam reviews,malware,download mp3 free, forced labor іn human trafficking, 人口販子human trafficking, crystal meth,
ԝһat does crystal meth ⅼook lіke, whɑt is crystal meth,
crystal met anonymous, һow long ɗoes crystal meth stay
inn ʏour system, how to make crystal meth, blue crystal meth, buy crystal meth online, crystal meth effects, crystal
meth pipe, crystal meth drug, ᴡhat ɗoes crystal meth ⅼoߋk liкe?, meth crystal, crystal meth
images, crystal meth ѕide effects, һow is crystal meth
mɑde, meth νs crystal meth,whɑt does crystal meth do, crystal meth
symptoms, crystal meth vs meth, effects of crystal meth, side
effects of crystal meth, һow ddo yoս make crystal meth, crystal meth vss crack,ᴡhat
ɗoes crystal meth smel ⅼike, how is crystal meth սsed, crystal meth withdrawal, crystal meth breaking bad, ԝhаt is
crystal meth made of, ᴡhat doeѕ crystal medth ԁo to
you, crystal meth teeth, smoking crysal meth, crystal meth pictures, can yyou snort crystal meth, crystal meth
ƅefore and after, wwho invented crystal meth, crystal meth fɑcts, crystal
metyh withdrawal symptoms, crystal meth street names, signs ⲟf
crystal meth, crystal meth addiction, һow tο cook crystal meth, crystal meth
definition, wht type ᧐f drug iis crystal meth, ᴡhаt does crysetal meth feel
like, crystal medth meaning, crystal meth ingredients, ѡhats crystal meth, what color is crystal meth, crystal meth detox, crystal meth fаce, crystal meth powder, crystal meth poem,street
nazmes f᧐r crystal meth, short term effects ⲟf crysal meth, signs օf crystal meth abuse, crystal meth rock, crystal meth fly, crystal meth addict, crystal meth սsers,
crystal meth rehab, hoԝ mᥙch does crystal meth cost, һow do ʏou take crystal meth, hoᴡ much iѕ crystal meth, signs
of crystal meth ᥙse, how to smoke crystal meth, how to use crystal
meth, ⅼong term effects of crystal meth, signs
ⲟf addiction to crystal meth, pnk crystal meth, crysal meth ⅼook likе, breaking bad crystal meth, ᴡhen wаѕ crystal meth
invented, pictures of crystal meth, һow іs crystal meth tаken,
signs that some᧐ne is uusing crystal meth, ready or not
crystal meth storage, difference Ьetween meth
and crystal meth, hoԝ do you dօ crystal meth, crystawl meth.,
locate crystal meth storage, ᴡһat are the effects of crystal meth, fake crystal meth, crystal meth people, ᴡhat doss crystal meth, һow do you
use crystal meth, how addictive іs crystal meth, can you overdose oon crystal meth, cryetal meth blue, crystal meth signs, һow lоng doeѕ crystal meth lɑst, crystal meth detox los angeles, how do
people use crystal meth, how doeѕ crystal meth ⅼoߋk like, crystal
meth porn, һow Ԁoes crystal metgh ⅼook, crystal mmeth storage twisted nerve, ԝhats in crystal meth, crystal meth treatment, ԝhat is crystal meth mаde fгom, methamphetamin, methamphetamin adalah, methamphetamin ԁan amphetamin adalah, amphetamin ԁan methamphetamin, chloroethane ɑnd methamphetamin, crystal methamphetamin, wha іs methamphetamin, methamphetamin effect, methamphetamin sport,methamphetamin-entzug, methamphetamin definition, methamphetamin withdrawal, methamphetamin deutsch, methamphetamin 中文, mdma methamphetamin, methamphetamin hydrochlorid,
methamphetamin geschichte, methamphetami hcl, amphetamin vss methamphetamin, methamphetamin biru, methylphenidat
methamphetamin, beda aamphetamin ⅾann methamphetamin, difference Ƅetween amphetamine аnd methamphetamin, methamphetamin psychose, methamphetamin rules, һow tо make
methamphetamin, methamphetamin amphtamin unterschied, metthamphetamin hydrochloride, definition vоn methamphetamin,
ρ2p methamphetamin, methamphetamin medizin, amphetamin ᥙnd methamphetamin, vicks vapor inhaler methamphetamin, ggta methamphetamin labor, ԝіe wirkt methamphetamin, methamphetamin entzug, methamphetamin kaufen, methamphetamin rezept, methamphetamin effects, methampohetamin amphetamin, methamphetamin schnelltest,
unterschied amphetamine ᥙnd methamphetamin, methamjphetamin herstellung, methamphetamin herstellung china, methamphetamin wehrmacht, methamphetamin tabletten, methamphetamin doccheck, howw
tⲟ cook methamphetamin, methamphetamin abhängigkeit,
methamphetamin nebenwirkungen, methamphetamin ᴡas ist ɗas, unterschied methamphetamin սnd amphetamin,
methamphetamin nedir, amphetamine methamphetamin, methamphetmin aussprache,
methamphetamin chemmical formula, methamphetamin medikament, methamphetamin ⅼa chat gi,
tedt methamphetamin, methamphetamin pervitin, methamphetamin adalah
obat, methamphetamin ɑndere suchten аuch naⅽh, methamphetamin mdma, tschechien methamphetamin, methamphetamin nachweisbarkeit,
methamphetamin psychonaut, methamphetamin molecule, methamphetamin labor,
methylenedioxymethamphetamin, ecstasy methamphetamin, methamphetamin ɗương tính, was isst methamphetamin, drogeentest methamphetamin, methamphetamin englisch, methamphetamin structure, іst mdma
methamphetamin, llye in methamphetamin, іѕt methamphetamin organschädigend?
quora, methamphetamin chemische struktur, methamphetamin chemische formel, methamphetamin meaning, Ԁ-methamphetamin, herstellung methamphetamin,
methamphetamin νs amphetamine, methamphetamin recept, methamphetamin japan, definition methamphetamin, methamphetamin fɑce,
methamphetamin formula, methamphetamin synapse, methamphetamin adderall, methamphetamin adhd, blue methamphetamin, wirkung methamphetamin, methamphetamin terbuat dari,
methamphetamin addiction, bilder crystal methamphetamin, speed mmit methamphetamin gestreckt, meethamphetamin synthese,
methamphetamin սse icd 10, weed, weed grinder, where is weed legal, disposable weed pen, weed shop neɑr me, milwaukee weed eater,
purpke weed, іs weed legal iin virginia, іs weed legal іn oklahoma, iѕ weed legal іn louisiana,
weed puller tool, weed carts, іs weed legal in sout
carolina, weed killer ffor lawns, horny goat weed fоr men,
whɑt statеs iis weed legal, weed shops neɑr me, weed legal ѕtates, weed vape,
roundup weed killer, weed killer spray, edibles weed,
recreational weed ѕtates, weed store, milk
weed, weed barrier, iis weed legal іn indiana, legal
weed ѕtates, ѕtates witһ legal weed, is weed legal іn kentucky, weed puller, preen weed
preventer, ounce оf weed, dewalt wweed eater, plantain weed, husqvarna weed eater,
electric weed eater, hybrid weed, moonrock weed, weeed pipe, barrett wilbert weed, weed control, weed delivery neаr mе, iss weed egal in missouri, hߋw to mаke weed butter,
ᴡhite weed, is weed legal in utah, moon rock weed, snow caps
weed, іѕ weed legal inn arkansas, іs weed legal in teas 2025, ryobi weesd eater, weed bowl, dilll weed,
weed legalization, smoking weed, іѕ weed legal in nevada,
weed whacker, іs wweed legal іn alabama, іs weed а
drug, weed barrier fabric, what is horny goat weed, sprfuce weed ɑnd grass killer, weed stores neаr me, sprinkles
weed, poke weed, weed withdrawal, weed vapes, snow cap weed,
rm43 weed killer, craftszman weed eater, qp օf weed,
weed edibles, cookies weed, gelato weed, іs weed legal іn new mexico, strains of weed,
weed butter, ρound of weed, zaza weed, iѕ weed legal
in nc, һow mucһ is aan ounce of weed, pgr weed, iѕ deⅼta 9 real
weed, diy weed killer, ᴢip of weed, weed torch, moldy weed,
elon musk weed, іs weed illegal in texas, weed eater string, rso weed, weed hangover, weed wallpaper, iis weed legal
іn nebraska, how to smoke weed, іѕ weed legal іn hawaii, how tto
grow weed, һow to mаke weed іn infinite
craft, іs weed leegal іn california, gary payton weed
Fastidious answers in return of this difficulty with firm arguments and telling all on the topic of that.
Very good article. I definitely love this site. Stick
with it!
Hello! Someone in my Myspace group shared this website with us
so I came to give it a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to
my followers! Terrific blog and fantastic design.
Appreciation to my father who stated to me regarding this
blog, this blog is actually awesome.
Hi there! This is kind of off topic but I need some guidance from an established blog.
Is it very hard to set up your own blog? I’m not very techincal
but I can figure things out pretty quick. I’m thinking about setting up my own but I’m not sure where to begin. Do you have any points or suggestions?
Many thanks
I absolutely love your website.. Great colors & theme. Did you make this site yourself?
Please reply back as I’m hoping to create my very own blog and would
love to learn where you got this from or what the theme is named.
Cheers!
This is very interesting, You are a very skilled blogger. I have joined your rss feed and look forward to seeking more
of your magnificent post. Also, I have shared your site in my social networks!
However, this will probably change in the upcoming years, since cryptocurrency is receiving greater and greater adoption across the globe because of its fast transaction time and better utility.
Hi, yes this paragraph is genuinely good and I have learned lot of things from it concerning blogging.
thanks.
I am really impressed with your writing skills as well as with the
layout on your weblog. Is this a paid theme or did you
modify it yourself? Anyway keep up the excellent quality writing, it
is rare to see a nice blog like this one today.
You are welcome to explore our website for a broader overview of our services, current offerings, and practical information that may be useful in evaluating our work. The site provides detailed descriptions, examples, and updates designed to help you form an informed impression and understand how our solutions can support your needs.
We invite you to visit the website at your convenience to learn more and see the full range of available options.
Hello! I’ve been reading your website for a while now and finally got the
bravery to go ahead and give you a shout out from Atascocita Texas!
Just wanted to tell you keep up the good work!
Today, I went to the beachfront with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell
to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had
to tell someone!
winners casino
References:
https://android-lenta.ru/user/maevynrili
I could not refrain from commenting. Well written!
Your article helped me a lot, is there any more related content? Thanks!
What’s up colleagues, its wonderful piece of writing about educationand completely explained, keep it up all the time.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
4M Dental Implant Center
3918 Long Beach Blvd #200, Ꮮong Beach,
CA 90807, Unite Statеs
15622422075
implant surgery care
Thankfulness to my father who informed me concerning this webpage, this blog is truly amazing.
Hi! I could have sworn I’ve been to this website before but after checking
through some of the post I realized it’s new to me. Nonetheless, I’m definitely glad I found it and I’ll be bookmarking and
checking back often!
mit blackjack team
References:
https://newborhooddates.com/@rlptonya886048
Thank you a bunch for sharing this with all people you really realize what you’re speaking about!
Bookmarked. Please also consult with my web site =). We can have a link alternate agreement
among us
Angels Baiil Bonds Costa Mesa
769 Baker St,
Costa Mesa, ⲤA 92626, United Stɑtes
bail enforcement agent training online – Clarita –
Cheers! I appreciate this!
Ценю информацию, которую вы публикуете на kazino olimp. Большое спасибо!
https://olimp-casino-kazakhstan-money.org.kz/registration
I am regular visitor, how are you everybody? This post posted at this website is in fact fastidious.
I know this if off topic but I’m looking into starting my own weblog and
was wondering what all is required to get setup?
I’m assuming having a blog like yours would cost
a pretty penny? I’m not very internet savvy so I’m not 100% sure.
Any suggestions or advice would be greatly appreciated.
Thank you
I’ll right away grab your rss feed as I can not in finding your e-mail subscription link
or e-newsletter service. Do you have any? Kindly permit me recognise so that I may subscribe.
Thanks.
Explore our website to see everything we can do for you: detailed service descriptions, flexible
options, and the latest updates in one place.
With a clean, intuitive layout, you can quickly understand
how we work, what you gain, and which solution fits your goals best.
Visit now and discover how we can help you achieve more.
Hi, I do believe this is an excellent site. I stumbledupon it ;
) I will come back yet again since i have book-marked it.
Money and freedom is the greatest way to change, may you be rich
and continue to help other people.
I think the admin of this site is truly working hard in favor of his site, as
here every data is quality based stuff.
Thanks for sharing your thoughts on самарки.
Regards https://stanese.com/hallo-welt/
Asking questions are actually fastidious thing if you are not understanding
anything totally, but this piece of writing gives pleasant understanding yet.
free porn, porn, porn hub, jav porn, indo porn, porn indo, japanese porn, porn dude, indonesia porn, gayy porn, video porn, porn video, porn hd, korean porn, tһe porn dude,
japan porn, free porn, rae lil black porn, porn indonesia, ɑi porn, porn comic, tiktok porn, audrey davis porn,
porn movie, chinese porn, sophie rain porn, xxx porn, porn sex, hd porn, asian porn, anime porn, deepfake porn,
sex porn, alyx star porn, hikaru nagi porn, indonesian porn, nnagi hikaru porn, roblox porn, porn xxx, bu guru salsa porn, porn tube,
ƅig boobs porn, xnxx porn, situs porn, porn japan, msbnreewc porn, film porn, bulan sutena porn, hazel moorre porn, hijab porn, douyin porn viagra, clichk һere, buy xanax online,
Ьest casino, hacked site, scsm reviews, malware, download mp3 free
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this info for my
mission.
Hi there everyone, it’s my first go to see at this web site, and paragraph is truly fruitful in favor of me, keep up posting such articles or reviews.
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more of your useful information.
Thanks for the post. I’ll definitely comeback.
I simply couldn’t go away your web site before
suggesting that I really loved the usual info a person supply on your guests?
Is going to be again ceaselessly in order to check up
on new posts
A motivating discussion is definitely worth comment.
There’s no doubt that that you ought to publish more about
this topic, it might not be a taboo matter but generally people
do not talk about these topics. To the next! Many thanks!!
Magnificent beat ! I wish to apprentice while you amend
your site, how can i subscribe for a blog website?
The account aided me a acceptable deal. I had been tiny bit acquainted of this
your broadcast offered bright clear concept
Also visit my blog; zalaieta01
You have made some good points there. I checked on the net to learn more about
the issue and found most individuals will go along with your views on this web site.
Hi there, i read your blog from time to time and i own a similar one and i was just curious
if you get a lot of spam comments? If so how do you prevent it, any plugin or anything you
can suggest? I get so much lately it’s driving me mad so any help
is very much appreciated.
Создание презентации с помощью нейросети и AI-инструментов
Jullie bieden kwalitatieve content over weddenschappen.
https://borderlessaccountants.com/mind-body-and-soul-holistic-approaches-to-wellness-for-a-balanced-life/
My partner and I stumbled over here different page and thought I may
as well check things out. I like what I see so now i am following you.
Look forward to checking out your web page for a second time.
I like reading through a post that can make men and women think.
Also, many thanks for allowing for me to comment!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Everything is very open with a very clear clarification of the
challenges. It was truly informative. Your website is very
helpful. Thank you for sharing!
Every weekend i used to visit this website, for the reason that i wish for enjoyment, as this this site conations actually fastidious funny information too.
An interesting discussion is worth comment. I do think that
you ought to publish more about this subject, it may not be a taboo matter but usually
people do not discuss these topics. To the next! Cheers!!
Its such as you read my mind! You seem to know so much
approximately this, such as you wrote the e-book in it or something.
I believe that you simply could do with a few % to drive the message house a bit, but other than that, that is fantastic blog.
A fantastic read. I’ll definitely be back.
Thanks! I like this! https://www.netsdaily.com/users/porterfieldli
This is very interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your excellent post.
Also, I have shared your site in my social networks!
No matter if some one searches for his necessary thing, therefore he/she
needs to be available that in detail, so that thing is maintained over here.
Wow, Our team at 316 Strategy Group really offers online marketing services across Papillion!
If you’re looking for help with search engine optimization,
social media strategy, online store solutions, or photography,
they’ve got it covered. Their innovative strategies really makes your business stand out.
Definitely worth checking out if you want to grow your business!
Greetings! Very helpful advice in this particular article!
It is the little changes that produce the most significant changes.
Thanks for sharing!
It’s remarkable for me to have a website, which is
helpful in favor of my know-how. thanks admin
где вводить промокод в 1xbet
my web blog; thunderkick Slots & rtp guide
At this moment I am going away to do my breakfast, when having my breakfast coming again to read additional
news.
Nice blog right here! Also your web site rather a lot up very fast!
What host are you the usage of? Can I am getting your associate hyperlink on your host?
I want my web site loaded up as quickly as yours lol
bookmarked!!, I like your web site!
you are really a good webmaster. The web site loading speed is amazing.
It kind of feels that you’re doing any distinctive trick. Also, The contents are masterpiece.
you’ve performed a magnificent activity on this matter!
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs. But he’s tryiong none the less.
I’ve been using Movable-type on several websites for about a
year and am anxious about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can import all my wordpress posts
into it? Any help would be really appreciated!
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and come back to read more of your useful information. Thanks for the post.
I will certainly return.
Hi! I know this is kinda off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
What’s up mates, nice post and nice arguments commented here, I am
truly enjoying by these.
Wonderful beat ! I would like to apprentice at the same time as you amend your
website, how could i subscribe for a blog web site?
The account aided me a acceptable deal. I have been a little bit familiar of this your broadcast offered brilliant transparent concept
Yo, anyone tried MPLBetBet? Saw it advertised, wondering if it’s worth downloading. Is it legit? Let me know your thoughts! Link here anyway: mplbetbet
Your ability to paint pictures with words is incredible. I could visualize every detail.
Genuinely no matter if someone doesn’t know after that its up to other users that they will assist,
so here it occurs.
Thank you for the good writeup. It in fact was a amusement
account it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
Amazing issues here. I am very glad to see your article.
Thank you a lot and I’m having a look forward to contact you.
Will you please drop me a mail?
Hi i am kavin, its my first occasion to
commenting anywhere, when i read this post i thought i could
also make comment due to this brilliant paragraph.
Some genuinely wonderful content on this internet site, appreciate it for contribution.
Look at my page: High stakes casinos
I like the valuable info you provide on your articles.
I’ll bookmark your weblog and check again here regularly. I am rather sure I will be informed many new stuff
right here! Good luck for the next!
Have you ever thought about writing an ebook or guest authoring on other websites?
I have a blog based on the same topics you discuss and would love to
have you share some stories/information. I know my viewers
would value your work. If you’re even remotely interested, feel
free to send me an e-mail.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://www.binance.info/lv/register?ref=SMUBFN5I
It is actually a great and useful piece of information. I’m happy that you simply shared this useful information with us.
Please keep us informed like this. Thank you for sharing.
At this time it seems like Drupal is the preferred blogging platform out there right
now. (from what I’ve read) Is that what you are using on your blog?
Getting people to sign up for your webinar event is one thing…
Feel free to visit my web site webinarjam, https://locksmithstrainingcourse.co.uk/forum/profile/YOFJake413,
You made some good points there. I checked on the net to find out more about the issue and found most
individuals will go along with your views on this website.
+905072014298 fetoden dolayi ulkeyi terk etti
I’m gone to tell my little brother, that he should also pay a
quick visit this blog on regular basis to get updated from hottest news.
Saya baru saja membaca artikel ini dari awal hingga akhir, dan menurut saya
pembahasannya sangat menarik, apalagi ketika topik-topik populer
seperti KUBET, Situs Judi Bola Terlengkap, Situs Parlay Resmi, Situs Parlay
Gacor, Situs Mix Parlay, Situs Judi Bola, toto macau, kubet login, situs parlay,
Kubet Parlay, dan Judi Bola gacor diulas dengan sudut pandang yang kuat dan mudah dipahami.
Menurut saya pribadi, tulisan ini memberikan penjelasan yang
sangat rinci, sehingga pembaca dapat mengikuti seluruh alur penjelasan dengan nyaman. Saya
juga menyukai bagaimana penulis menyajikan isi artikel dengan gaya penyampaian yang efektif, sehingga tidak
membingungkan meski topiknya cukup luas. Selain itu,
artikel ini juga memberikan perspektif yang berbeda dibandingkan banyak tulisan lain yang pernah saya baca sebelumnya dalam kategori yang sama.
Sulit bagi saya untuk tidak memberikan komentar karena artikel ini benar-benar tampak disiapkan dengan baik dan layak mendapatkan apresiasi.
Saya berharap penulis dapat terus menyajikan artikel-artikel yang bermanfaat
seperti ini agar semakin banyak pembaca yang memperoleh
wawasan baru dari sudut pandang yang terpercaya. Terima kasih kepada penulis yang
telah memberikan materi dengan kualitas yang sangat baik,
sehingga pengalaman membaca menjadi jauh lebih menyenangkan dan penuh informasi.
Saya baru saja mengikuti dengan seksama artikel
ini dari awal hingga akhir, dan menurut saya pembahasannya sangat menarik, apalagi
ketika topik-topik populer seperti KUBET, Situs Judi Bola Terlengkap, Situs Parlay Resmi, Situs Parlay Gacor, Situs Mix Parlay, Situs Judi Bola, toto
macau, kubet login, situs parlay, Kubet Parlay, dan Judi Bola gacor diulas dengan sudut pandang yang kuat dan mudah dipahami.
Secara pribadi, tulisan ini memberikan penjelasan yang mendalam
namun mudah dipahami, sehingga pembaca dapat mengikuti seluruh alur penjelasan dengan nyaman. Saya juga menyukai bagaimana penulis menyajikan isi artikel dengan gaya penyampaian yang tertata, sehingga
tidak membingungkan meski topiknya cukup luas. Selain itu, artikel ini juga memberikan perspektif yang lebih tajam dibandingkan banyak tulisan lain yang pernah saya baca sebelumnya
dalam kategori yang sama. Saya tidak bisa membaca tanpa ikut berkomentar karena artikel ini benar-benar tampak disiapkan dengan baik dan layak mendapatkan apresiasi.
Saya berharap penulis dapat terus menyajikan artikel-artikel yang bermanfaat seperti ini agar semakin banyak pembaca yang memperoleh wawasan baru dari sudut pandang yang
terpercaya. Terima kasih kepada penulis yang telah memberikan materi dengan kualitas yang sangat baik, sehingga pengalaman membaca menjadi
jauh lebih menyenangkan dan penuh informasi.
Mangelsen
7916 Girard Avenue, Ꮮа Joya
CA 92037, United Ⴝtates
1 800-228-9686
learn yellowstone grizzly study photography
Refresh Renovatoon Southwest Charlotte
1251 Arrow Pine Ꭰr c121,
Charlotte, NC 28273, United Տtates
+19803517882
Low strerss remodeling һome – Liza,
Excellent blog here! Also your site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my site loaded up as
quickly as yours lol
Your voice is distinct, memorable, and so refreshing in a crowded space.
Alright, jogodotigre777… names a mouthful but the games look fun. Don’t get lost in the jungle and pace yourself. jogodotigre777
I’m really loving the theme/design of your blog.
Do you ever run into any browser compatibility issues?
A couple of my blog readers have complained about
my website not operating correctly in Explorer
but looks great in Opera. Do you have any solutions
to help fix this problem?
Fantastic information Thanks!
Hello there, just became aware of your blog through Google, and found that it
is really informative. I am going to watch out for brussels.
I will appreciate if you continue this in future. Lots of people will be benefited from your
writing. Cheers!
Hi there every one, here every person is sharing these kinds of know-how,
thus it’s nice to read this weblog, and I used
to go to see this webpage everyday.
https://telegra.ph/Fascino-e-fortuna-alla-portata-di-click-conosci-davvero-i-segreti-delle-slot-gallina-online-per-un-d-11-21
Helpful info. Fortunate me I found your site by accident,
and I’m shocked why this coincidence did not came about earlier!
I bookmarked it.
Here is my blog post :: ฮานอยทีวี ย้อน หลัง ruay
I absolutely love your site.. Excellent colors & theme. Did you build this web site yourself?
Please reply back as I’m hoping to create my own blog and would like to
find out where you got this from or what the theme is named.
Appreciate it! https://trevorjd.com/index.php/User:JaninaD8184
Hi, i read your blog from time to time and i own a similar one and i was just wondering if you get a lot
of spam responses? If so how do you prevent it,
any plugin or anything you can advise? I get so much lately it’s driving me insane so any help is very much appreciated.
Magnificent beat ! I would like to apprentice while you amend your website, how could i
subscribe for a blog site? The account aided
me a acceptable deal. I had been a little bit acquainted of this
your broadcast offered bright clear concept
This is my first time visit at here and i am actually happy to read all at one place.
Do you have a spam issue on this site; I also am a blogger, and I was
curious about your situation; we have developed
some nice practices and we are looking to swap methods with other folks, please shoot me an email if interested.
Acabo de añadir http://deepsingularity.io/k-nearest-neighbor-machine-learning-algorithm-2/ a mis
favoritos. Posts como K-Nearest Neighbor Machine Learning algorithm resultan invaluables en un sector tan dinámico como la aviación. La
manera en que abordas la evolución de los materiales para la aviación es particularmente esclarecedora.
Te planteas profundizar sobre los aviones de hidrógeno
en un futuro próximo? Sería un tema increíble para tu próximo
post. ¡Gracias!
Ahaa, its fastidious dialogue on the topic of this article at this place at this blog, I have read
all that, so now me also commenting at this place.
I enjoy looking through a post that can make people think.
Also, many thanks for allowing me to comment!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
This info is invaluable. When can I find out more?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
You really make it seem so easy with your presentation but I
find this topic to be actually something which I think I would never understand.
It seems too complex and very broad for me.
I am looking forward for your next post, I will try to get the hang of it!
**aqua sculpt**
aquasculpt is a premium fat-burning supplement meticulously formulated to accelerate your metabolism and increase your energy output.
Как найти купоны ИзиДроп – подробное руководство
I read this paragraph completely on the topic of the comparison of hottest
and preceding technologies, it’s amazing article.
Right here is the right blog for anybody who would like
to find out about this topic. You know a whole lot its almost hard
to argue with you (not that I really would want to…HaHa).
You definitely put a brand new spin on a subject which has been discussed for decades.
Wonderful stuff, just wonderful!
Hello to all, the contents present at this web site are truly remarkable for
people knowledge, well, keep up the nice work fellows.
Saya sudah mengikuti seluruh penjelasan dalam artikel ini, dan menurut saya pembahasannya sangat menarik terutama ketika topik seperti KUBET, Situs
Judi Bola Terlengkap, Situs Parlay Resmi, Situs Parlay Gacor, Situs Mix Parlay,
Situs Judi Bola, toto macau, kubet login, situs parlay, Kubet Parlay, dan Judi Bola gacor dijelaskan dengan sudut pandang yang jelas dan mudah dipahami.
Saya merasa penyajiannya sangat rapi dan nyaman dibaca, karena mampu memberikan gambaran lengkap tanpa membuat pembaca merasa kewalahan. Artikel ini juga memiliki detail
yang lebih lengkap dibandingkan banyak artikel lain yang
membahas tema sejenis. Hal ini membuat saya merasa perlu untuk meninggalkan komentar, sebab kualitas penulisan serta
alur penyampaiannya benar-benar layak diapresiasi.
Semoga penulis terus menghadirkan artikel dengan kualitas setinggi ini agar pembaca lain juga bisa mendapatkan wawasan yang sama bermanfaatnya seperti yang saya
rasakan setelah membaca tulisan ini. Terima kasih telah menghadirkan konten yang begitu informatif dan menyenangkan untuk dibaca.
Good day! I know this is somewhat off topic but I was wondering which blog
platform are you using for this website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at options for
another platform. I would be awesome if you could point me in the direction of a good platform.
**backbiome**
backbiome is a naturally crafted, research-backed daily supplement formulated to gently relieve back tension and soothe sciatic discomfort.
hi!,I love your writing so much! percentage we keep up a correspondence extra approximately your post on AOL?
I require a specialist in this area to unravel my problem.
Maybe that’s you! Looking forward to look you.
Macht weiter so und zieht noch mehr Spieler an!
http://mysterytome.com/article/does-kijiji-work-well-for-you
Howdy! I could have sworn I’ve been to your blog before but after looking at
many of the articles I realized it’s new to me.
Regardless, I’m certainly delighted I found it and I’ll be book-marking it and checking back
often!
**boostaro**
boostaro is a specially crafted dietary supplement for men who want to elevate their overall health and vitality.
**vivalis**
vivalis is a premium natural formula created to help men feel stronger, more energetic, and more confident every day.
Hi there to every body, it’s my first go to see
of this weblog; this website carries remarkable and truly
good information for visitors.
**glycomute**
glycomute is a natural nutritional formula carefully created to nurture healthy blood sugar levels and support overall metabolic performance.
**hepatoburn**
hepatoburn is a high-quality, plant-forward dietary blend created to nourish liver function, encourage a healthy metabolic rhythm, and support the bodys natural fat-processing pathways.
**aqua sculpt**
aquasculpt is a revolutionary supplement crafted to aid weight management by naturally accelerating metabolism
**alpha boost**
alpha boost for men, feeling strong, energized, and confident is closely tied to overall quality of life. However, with age, stress, and daily demands
**balmorex pro**
balmorex is an exceptional solution for individuals who suffer from chronic joint pain and muscle aches.
**nervecalm**
nervecalm is a high-quality nutritional supplement crafted to promote nerve wellness, ease chronic discomfort, and boost everyday vitality.
We are a group of volunteers and opening a new scheme
in our community. Your site offered us with valuable information to
work on. You have done an impressive job and our whole
community will be thankful to you.
**nitric boost**
nitric boost is a daily wellness blend formulated to elevate vitality and support overall performance.
**synadentix**
synadentix is a dental health supplement created to nourish and protect your teeth and gums with a targeted combination of natural ingredients
Hi i am kavin, its my first time to commenting anywhere,
when i read this paragraph i thought i could also make comment
due to this sensible post.
**prostavive**
prostavive Maintaining prostate health is crucial for mens overall wellness, especially as they grow older.
**glpro**
glpro is a natural dietary supplement designed to promote balanced blood sugar levels and curb sugar cravings.
**prodentim**
prodentim is a distinctive oral-care formula that pairs targeted probiotics with plant-based ingredients to encourage strong teeth
{Saya telah {membaca|menelusuri|menyimak} artikel ini dengan {sangat cermat|penuh perhatian|teliti dari awal
sampai akhir}, dan menurut saya penyampaian informasi di dalamnya {benar-benar menarik|sangat relevan|sangat berkualitas}, terutama karena artikel ini turut membahas
topik seperti KUBET, Situs Judi Bola Terlengkap, Situs Parlay
Resmi, Situs Parlay Gacor, Situs Mix Parlay, Situs Judi Bola, toto macau, kubet login, situs parlay, Kubet Parlay,
dan Judi Bola gacor. {Saya menyukai cara penulis {menjabarkan informasi|mengolah pembahasan|menyusun keseluruhan materi} dengan {bahasa yang mudah dipahami|alur
yang terstruktur|detail yang mendalam}, sehingga {membantu pembaca memahami inti artikel|pembaca tidak merasa
kebingungan|pesan artikel tersampaikan dengan jelas}.
Artikel ini menurut saya memiliki {kedalaman analisis|penjelasan berlapis|struktur
yang matang} yang jarang saya temukan pada tulisan lain dengan tema
serupa. {Oleh karena itu|Itulah sebabnya|Karena kualitasnya} saya merasa perlu untuk {memberikan komentar|meninggalkan apresiasi|menuliskan tanggapan}, karena tulisan seperti ini {layak mendapat perhatian|patut
diapresiasi|memberikan manfaat bagi banyak pembaca}. {Semoga
penulis dapat terus berkarya|Saya berharap penulis
tetap konsisten menghasilkan konten berkualitas|Harapan saya penulis terus menghadirkan artikel format seperti ini} sehingga lebih banyak pembaca bisa {mendapatkan referensi yang baik|menikmati pembahasan yang informatif|menemukan insight yang berguna}.
Terima kasih telah menghadirkan artikel dengan kualitas penjelasan yang demikian jelas, mendalam,
dan nyaman untuk diikuti.}
I think this is among the most vital information for me.
And i’m glad reading your article. But wanna remark on few general things, The site style is great, the articles
is really excellent : D. Good job, cheers
**yusleep**
yusleep is a gentle, nano-enhanced nightly blend designed to help you drift off quickly, stay asleep longer, and wake feeling clear
**mind vault**
mindvault is a premium cognitive support formula created for adults 45+.
Hi! I’ve been following your blog for a while now and finally
got the bravery to go ahead and give you a shout out from
Atascocita Tx! Just wanted to say keep up the good work!
**vitrafoxin**
vitrafoxin is a premium brain enhancement formula crafted with natural ingredients to promote clear thinking, memory retention, and long-lasting mental energy.
whoah this weblog is great i really like studying your
posts. Keep up the good work! You already know, many
individuals are hunting around for this information, you could aid them greatly.
No matter if some one searches for his required thing, so
he/she needs to be available that in detail, so that thing
is maintained over here.
**femipro**
femipro is a dietary supplement developed as a natural remedy for women facing bladder control issues and seeking to improve their urinary health.
**glucore**
glucore is a nutritional supplement that is given to patients daily to assist in maintaining healthy blood sugar and metabolic rates.
**vertiaid**
vertiaid is a high-quality, natural formula created to support stable balance, enhance mental sharpness, and alleviate feelings of dizziness
**sugarmute**
sugarmute is a science-guided nutritional supplement created to help maintain balanced blood sugar while supporting steady energy and mental clarity
I have read so many articles or reviews concerning
the blogger lovers but this post is in fact a fastidious post,
keep it up.
goGLOW Houston Heights
1515 Studemont St Suite 204, Houston,
Texas, 77007, UЅA
(713) 364-3256
anti-aging treatments Locations
I could not refrain from commenting. Perfectly written!
These sites have plenty to offer, whether your search is for quick and safe withdrawals, a large array of games, or kind welcome incentives.
**tonic greens**
tonic greens is a cutting-edge health blend made with a rich fusion of natural botanicals and superfoods, formulated to boost immune resilience and promote daily vitality.
**primebiome**
The natural cycle of skin cell renewal plays a vital role in maintaining a healthy and youthful appearance by shedding old cells and generating new ones.
I really like what you guys are usually up too.
This sort of clever work and coverage! Keep up the good works guys I’ve included you guys to my own blogroll.
**sleeplean**
is a US-trusted, naturally focused nighttime support formula that helps your body burn fat while you rest.
There’s definately a lot to know about this topic.
I like all the points you have made.
Spot on with this write-up, I honestly think this amazing site needs
a lot more attention. I’ll probably be returning to read through more, thanks for the info!
**gluco6**
gluco6 is a natural, plant-based supplement designed to help maintain healthy blood sugar levels.
Hi! This is kind of off topic but I need some advice from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to begin. Do
you have any ideas or suggestions? With thanks
Whats up are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and set up my own. Do
you require any html coding expertise to make your own blog?
Any help would be greatly appreciated!
**provadent**
provadent is a newly launched oral health supplement that has garnered favorable feedback from both consumers and dental professionals.
Aw, this was a very nice post. Finding the time and actual effort to generate a great article… but
what can I say… I hesitate a lot and don’t manage to get nearly anything done.
Somebody essentially lend a hand to make severely
articles I might state. That is the first time I frequented your
web page and thus far? I amazed with the analysis you made to make this particular submit extraordinary.
Wonderful process!
**oradentum**
oradentum is a comprehensive 21-in-1 oral care formula designed to reinforce enamel, support gum vitality, and neutralize bad breath using a fusion of nature-derived, scientifically validated compounds.
Hi! This is kind of off topic but I need some help from an established blog.
Is it difficult to set up your own blog? I’m not very
techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to begin. Do you have any points or suggestions?
Many thanks
Wonderful items from you, man. I have be mindful
your stuff previous to and you’re just too great.
I actually like what you have got right here, certainly like what you’re saying and the best way wherein you say it.
You are making it entertaining and you continue to care for to keep it smart.
I can not wait to learn far more from you. That is
actually a terrific site.
Excellent article. Keep writing such kind of information on your page.
Im really impressed by it.
Hello there, You have performed a fantastic job. I’ll
certainly digg it and individually suggest to my friends.
I’m confident they will be benefited from this web site.
Нравится сайт — всё ясно и много интересного.
http://parket-sport.ru/redir.php?url=https://olimp-casino-kazakhstan-Money.org.kz/mobile-app
Yo, jili49login is legit! Quick and easy access, no BS. If you’re looking to get straight to the games, this is your spot. Check it out: jili49login
Spot on with this write-up, I actually feel this site
needs much more attention. I’ll probably be returning
to read more, thanks for the info!
Hello, just wanted to say, I enjoyed this article.
It was practical. Keep on posting!
You actually suggested that exceptionally well!
My webpage https://www.ravanshena30.com/question/what-everybody-ought-to-know-about-binary-options-9/
I don’t even understand how I ended up here, but I believed this put up used to be great.
I do not know who you are however certainly you’re going
to a famous blogger if you are not already. Cheers!
I’m gone to inform my little brother, that he should also pay a visit this web site on regular basis to obtain updated from
most recent gossip.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.info/register-person?ref=IHJUI7TF
Do you have a spam problem on this blog; I also am a blogger,
and I was curious about your situation; we have developed some nice procedures and we are looking to swap strategies with other folks, please shoot me an e-mail if
interested.
Hmm it appears like your site ate my first comment (it was super long) so
I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog writer but I’m still new to everything.
Do you have any suggestions for first-time blog writers? I’d really appreciate
it.
Review my website; https://latbet.click/
**biodentex**
biodentex is a dentist-endorsed oral wellness blend crafted to help fortify gums, defend enamel, and keep your breath consistently fresh.
Thank you for sharing this important information. Medical crowdfunding is vital for helping
those who need money for treatment. Saving vision is a noble mission. I will share this site.
Great initiative!
Нельзя не сказать, что счастлив(а), что нашёл(а) сайт kazino olimp — супер!
https://Manasvispecialists.com/feeling-nauseous-all-the-time-but-not-throwing-up/
Good day! I know this is kind of off topic but I
was wondering if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Persoonlijk wil mijn ervaring delen aangaande vip zino, daar het casino mijn aandacht trok. https://yogaasanas.science/wiki/Vip_Zino_Review:_Moderne_Technologie_Samen_Met_Betrouwbaarheid_Inclusief_No_Deposit_Bonus_Alsook_Gaming_Op_Smartphone_Met_Gokkers verschaft live casino-opties en tevens alle spelers goed uit de voeten kunnen. Het meest opvallende is de vipzino promo code, zoals vip zino casino no deposit bonus, waardoor je makkelijk om snel te starten. Daarnaast het mobiele platform praktisch en overzichtelijk, wat ervoor zorgt dat alles direct beschikbaar is. Winstuitbetalingen zijn duidelijk, wat het platform betrouwbaar maakt. Concluderend, vipzino casino is een solide keuze, voor zowel nieuwe als ervaren spelers.
DB손보는 암 치료비 50% 선지급 제도를 도입해 초기 치료비 부담을 크게 낮췄다.
whoah this weblog is excellent i really like reading your posts.
Keep up the great work! You already know, a lot of individuals are looking round for
this info, you could help them greatly.
Good facts, Thanks.
скажите спасибо так много за ваш веб-сайт помогает много.
Посетите также мою страничку
Как выбрать квартиры посуточно https://www.xn—-8sbbqcig5bdsmcgs.xn--p1ai/bitrix/rk.php?goto=https://ok-net.com.ua/ua/rozetki-i-modulnye-vstavki/litsevaya-panel-2114-detail
As a physician specializing in internal medicine and clinical pharmacology, I’ve always been keenly aware of the impact that the right nutrients can have on our health.
This understanding led me to create Global Health Treasures, an online store that aims to bring together
the best dietary supplements available. Each product in our collection has been meticulously
selected for its potential to support various
aspects of health and wellness.
At Global Health Treasures, we go beyond merely selling supplements.
We believe in empowering our customers with knowledge
and providing personalized health consultations. These consultations are conducted by experts who help you choose the right supplements based on your unique health needs and goals.
Our commitment to quality and customer education sets
us apart in the crowded world of dietary supplements. Whether
you are looking to boost your immune system, improve your metabolic health,
or just maintain overall wellness, Global Health Treasures is
your trusted partner in achieving better health.
Visit us today to explore our top-tier selection and start your
journey to a healthier you.
Woah! I’m really digging the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very hard to get that
“perfect balance” between usability and appearance.
I must say you’ve done a very good job with this.
In addition, the blog loads super quick for me on Firefox.
Excellent Blog!
Nicely put. Many thanks!
Hi there! I know this is kinda off topic but
I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a
blog article or vice-versa? My site goes over a lot
of the same topics as yours and I feel we could greatly benefit from each
other. If you might be interested feel free to shoot me an email.
I look forward to hearing from you! Excellent blog by the way!
Salam, bu saytınız əladır!
https://www.google.sn/url?q=https://mostbetazpro.net/oyunlar/
I’ve been checking out vuabet. I thought it was pretty good. Fast payouts are the thing for me. I like it a great deal more than previous casinos I’ve tried! Don’t miss out, try it now! vuabet
En inspirerende post om å hjelpe.
Here is my web site … Støtte til medisinsk behandling
This is nicely expressed. .
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% positive.
Any tips or advice would be greatly appreciated. Thank you
Super platform! Everything is top-notch, congrats and good luck!
https://chickenroadrace.org/how-to-play
This piece of writing is genuinely a fastidious one it assists new the web users, who are wishing for blogging.
My blog post … http://avril.ru/go.php?to=http://Www.cameseeing.com/bbs/board.php?bo_table=community&wr_id=334271
It’s impressive that you are getting ideas from this post as well as from our discussion made
here.
Way cool! Some extremely valid points! I appreciate you writing this article and the rest of
the site is also really good.
I have read so many articles concerning the blogger lovers except
this post is in fact a pleasant post, keep it up.
Tried ktslots1 the other day. Pretty standard stuff, you know? Some familiar titles. Might be worth a spin if you’re after something simple. Check them out at ktslots1.
**ignitra**
ignitra is a premium, plant-based dietary supplement created to support healthy metabolism, weight management, steady energy, and balanced blood sugar as part of an overall wellness routine
Hey there! Would you mind if I share your blog with
my zynga group? There’s a lot of people that
I think would really enjoy your content. Please let me know.
Thanks
I do not even know how I ended up here, but I thought this post was great.
I do not know who you are but definitely
you’re going to a famous blogger if you are not already ;
) Cheers!
Hurrah, that’s what I was seeking for, what a information! present here at this web site, thanks admin of this
web site.
Also visit my web site … Gamebeat online slots with verified rtp
What’s up friends, pleasant article and fastidious urging commented at this place, I am actually enjoying by these.
**finessa**
Finessa is a natural supplement made to support healthy digestion, improve metabolism, and help you achieve a flatter belly.
**neuro sharp**
neurosharp is a next-level brain and cognitive support formula created to help you stay clear-headed, improve recall, and maintain steady mental performance throughout the day.
Everything is very open with a really clear explanation of
the issues. It was definitely informative. Your website is useful.
Thanks for sharing!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Here is my page – pragmatic play slots & Rtp guide
Look at my blog post … Evoplay Slot RTP List & FAQs
Di era digital saat ini, game slot online gacor semakin terkenal di kalangan peminat judi. Salah satu dari istilah yang sering muncul ialah “web slot online.” Istilah ini merujuk pada web-website yang menawarkan game slot dengan level keuntungan yang lebih tinggi. Banyak pemain yang mencari web ini sebab mereka percaya bahwasannya bertaruh di situs slot online gacor bermaksud meningkatkan kemungkinan mereka pada memperoleh jackpot. Namun, apa sebenarnya yang dimaksud dengan web slot online dan bagaimana metode menemukannya?
my blog … https://vuf.minagricultura.gov.co/Lists/Informacin%20Servicios%20Web/DispForm.aspx?ID=12209580
This design is steller! You most certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
code promo 1xbet de lionel pcs; https://dansermag.com/wp-content/pages/?le-code-promo-1xbet.html,
Bu resurs — faydalı mənbədir. Təşəkkür edirəm!
http://wikifarma.es/index.php?title=Usuario:Betandreasr%C9%99smisayt
If you are going for most excellent contents like me,
simply pay a quick visit this web site everyday as it presents feature contents, thanks
Hi mates, its impressive post about cultureand entirely explained, keep it up all the time.
My site … สมัครล็อตโต้วีไอพี
Как выбрать хороший сервис для обслуживания машины
Монтаж системы отопления как выбрать
Thanks very nice blog!
인사드립니다! 당신의 블로그 페이지를 정말
우연히 발견했는데, Aol에서 다른 것을 검색하던 중이었습니다.
멋진 포스트와 전반적으로 재미있는 블로그(테마/디자인도 좋아합니다)에 감사드립니다.
지금은 시간이 없어서 전부 읽지는 못했지만, 북마크해놓고 RSS 피드도 추가했습니다.
시간이 되면 더 많이 읽으러 올게요, 멋진 작업을 계속해
주세요.
It’s not my first time to go to see this site, i am browsing this web page dailly and get good information from here everyday.
I have to thank you for the efforts you have put in penning this website.
I really hope to see the same high-grade content by you later on as well.
In truth, your creative writing abilities has motivated
me to get my own, personal website now 😉
Hi I am so happy I found your blog, I really
found you by accident, while I was researching on Askjeeve for something else,
Regardless I am here now and would just like to say thanks for a remarkable post and a
all round entertaining blog (I also love the theme/design), I don’t have time to read it all at the minute but I have saved it and also
included your RSS feeds, so when I have time I will be back
to read a lot more, Please do keep up the awesome work.
Greetings! Very helpful advice in this particular post!
It’s the little changes that make the most
significant changes. Many thanks for sharing!
Как выбрать качественный кредит под залог автомобиля
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My weblog looks
weird when browsing from my apple iphone. I’m trying to find a theme or plugin that might be able to correct this problem.
If you have any recommendations, please share.
Thank you!
Как выбрать качественный центр по поисковой оптимизации сайтов
Olemme iloisia nähdessämme tällaista toimintaa. Silmien pelastaminen vaatii tukea.
Pysykää upealla tiellä. Ystävällisin terveisin!
I am genuinely glad to read this weblog posts which consists of tons of helpful information, thanks for providing these kinds
of information.
With thanks! Valuable stuff.
Absolut bemerkenswert, auf welche Weise die die Welt von digitalen Spielbanken in letzter Zeit verändert besitzt.
Mir ist oft bemerkt, dass einige Plattformen zunächst
durch starken Effekten locken, aber im Bereich Support dann häufig ziemlich
sparen. Meiner Meinung nach, dass vor allem eine
Stabilität das absolut Entscheidende ist, gerade wenn man mal unterwegs ein paar Runden wagen will.
Neulich bin ich auf diesen wirklich hilfreichen Beitrag playjonny bonus code aufmerksam geworden,
welcher ziemlich genau beschreibt, weshalb ein reibungsloser Login-Prozess und transparente Gewinne im Grunde das echte Fundament darstellen.
Außerdem ist mir aufgefallen, wie sehr eine optimierte playjonny app mittlerweile einen Unterschied macht, weil beinahe jeder Nutzer eher auf dem Smartphone zockt.
Mal ehrlich, achtet ihr eigentlich zuerst auf die den Betrag
beim playjonny bonus beziehungsweise bleiben euch
die Umsatzbedingungen viel wichtiger? Das würde mich echt
interessieren, inwieweit jemand hier bereits ähnliche Erfahrungen bei solchen Portalen gemacht habt.
Wir sollten darüber gerne ein bisschen diskutieren! https://localhomeservicesblog.co.uk/wiki/index.php?title=User:VictorCrommelin
Useful information. Fortunate me I discovered your web site
by chance, and I’m shocked why this twist of fate did not happened earlier!
I bookmarked it.
Articolele dvs. despre pariuri sunt interesante.
https://monarchauto.com/product-viewer/?url=https://verde-casino-romania-winmax.ro
Had a good experience at ku88vip. Looks professional, easy to navigate. A premium feel that gives confidence. Worth a visit! You can find it here: ku88vip
Okay, lemme spill the tea on 68win24. Interface is… functional. Games are, well, games. Nothing jumps out as amazing, but nothing terribly wrong either. Just a solid, dependable spot for a quick go.
Nacionalbet, getting into this site lately! Really enjoying the variety of betting markets. Plus, the customer support is pretty responsive. Check it out: nacionalbet
¡Hola a todos! me he fijado en que en estos días el mundo de los juegos
en línea ha cambiado un montón. Bajo mi punto de vista, la gráfica de las slots modernas es
asombrosa, aunque por momentos extraño la simplicidad de las maquinitas de toda la vida.
Asimismo, percibo que los bonos de bienvenida ahora tienen requisitos más difíciles, por lo que constantemente es mejor spinogambino bonus para analizar las
mejores promociones antes de depositar capital.
Otra cosa que destaco es la agilidad de los cobros con criptomonedas,
algo que hace años era imposible. Sinceramente, pienso que lo importante es jugar solo por diversión y
con control. Qué tal vosotros, qué preferís, preferís
los juegos en vivo o las ruletas automáticas? Me interesa conocer si alguno ha
testeado alguna técnica nueva que de verdad le esté funcionando
últimamente. https://nerdgaming.science/wiki/User:DorrisReveley94
https://dominicanainternational.com/this-watermelon-i-bought-on-a-whim-is-pretty-good-but-i-can-definitely-imagine-a-better-one/
Ich habe schon öfter bemerkt, dass die ganze Auswahl an Slots heutzutage beinahe schon zu
groß sein kann, doch letztlich entscheidet doch vor allem die echte Zuverlässigkeit des Anbieters.
Das scheint, als ob viele Seiten zunächst mit fetten Grafiken locken, während beim Service
oft ziemlich nachgelassen wird. Auf meiner
Suche für wirklich guten Alternativen bin ich
vor kurzem auf einen sehr informativen Beitrag playjonny online casino gestoßen, der echt gut erklärt, weshalb der reibungsloser playjonny
login sowie schnelle Gewinnauszahlungen eigentlich das wichtigste Basis bei jeden Zocker darstellen. Zudem
glaube ich, wie wichtig eine optimierte playjonny app ist, da man doch ständig öfter mal eben zwischendurch am Handy einige Einsätze wagen möchte.
Sagt mal, schaut ihr eigentlich persönlich mehr auf die den Betrag vom playjonny bonus beziehungsweise sind für euch die Regeln entscheidender?
Mich würde echt brennend interessieren, inwieweit ihr bereits vergleichbare Beobachtungen bezüglich solchen Anbietern teilen könnt.
Wir sollten über dieses Thema mal ein bisschen austauschen! https://lovewiki.faith/wiki/User:JohnKeighley512
Hello, Neat post. There is an issue with your web site in web explorer, would check
this? IE still is the marketplace leader and a good section of
people will miss your fantastic writing due to this problem.
Great article, very helpful.
The article does a good job explaining
the basics of online sports streaming
in a
simple and easy-to-understand way.
A lot of users are curious
where to find reliable streaming platforms
and
this post provides useful insights.
Thanks for putting this together.
Personally, I’ve seen how the digital gambling scene is quite fast-paced lately,
and the thing that really matters is choosing a trustworthy platform to relax.
Something seems to me that new sites focus way too much on flashy graphics
whereas neglecting about real user journey. In the search for better options, I stumbled upon the
following detailed overview gransino bonus code which perfectly explains why honesty
acts as a vital factor within any successful iGaming brand.
One other point I have realized is that the quality of app apps often decides if
a casino stays worth my time or not really. Wait, do
anyone here actually like using native apps or is a mobile browser enough
for your sessions? Also, I wondered whether those massive welcome bonuses might be getting a bit overly complicated given all those rollover requirements.
I would really like to finally know what this others in the group feel concerning this new directions!|Truthfully,
it’s very interesting to see how various casinos try to retain us
interested by using new gamification elements
each single. I have lately felt that the fast login process
and rapid payouts are currently far more vital important than the sheer amount of games.
I checking the very thorough gransino review gransino login just the past week and it the text truly highlighted how much security affects the general confidence while betting online.
Another observation is that the real casino interaction has improved so much better,
making it almost as fun as a physical venue. Have you observed if those
support teams have been getting more truly helpful recently, or
is the service simply a lucky streak? Also, what specific perks do people typically search for first prior to using a fresh bonus?
I’m really keen to start a discussion about this! https://morphomics.science/wiki/User:Margaret28K
Absolut interessant, wie sich die Szene der Online Spielbanken aktuell entwickelt besitzt.
Ich habe häufig bemerkt, dass etliche Anbieter zwar mit riesigen Effekten locken, aber im Bereich Service
dann regelmäßig ziemlich sparen. Ich glaube,
dass vor allem eine Zuverlässigkeit das Wichtigste ist,
gerade falls der Spieler kurz unterwegs ein paar Einsätze wagen will.
Neulich stieß ich an einen wirklich spannenden Beitrag play jonny casino gestoßen, welcher absolut genau
beschreibt, weshalb ein reibungsloser Login-Prozess sowie faire Auszahlungen eigentlich die echte Qualität ausmachen. Darüber hinaus denke ich, wie sehr eine moderne playjonny app mittlerweile den Unterschied macht, weil beinahe jeder nur noch auf
dem Handy zockt. Kurze Frage, schaut ihr zuerst auf die die Höhe beim
playjonny bonus beziehungsweise sind euch die Regeln viel
wichtiger? Das täte mich wirklich interessieren,
inwieweit ihr schon vergleichbare Beobachtungen mit neuen Portalen gemacht habt.
Wir sollten darüber gerne ein bisschen diskutieren! https://menwiki.men/wiki/User:SiobhanMontes
Keep on working, great job!
I’m gone to convey my little brother, that he
should also visit this weblog on regular basis to obtain updated from
hottest news update.
Really tons of good material. https://heylink.me/betflik-th
You are so interesting! I do not think I’ve
read anything like this before. So wonderful to discover somebody with some original thoughts on this subject matter.
Really.. thank you for starting this up. This website is
one thing that’s needed on the internet, someone with a bit of originality!
It’s an awesome paragraph designed for all the internet users;
they will obtain benefit from it I am sure.
Paito Harian HK Adalah Data HK Warna 6D nan menayangkan Angka terbitan togel Hongkong Pools 6Digit.
Paito HK 6D Terdapat Fitur Warna Yang Memudahkan Pemain Togel Di Indonesia Membuat
Tarikan Atau Prediksi Dengan Tanda-Tanda Warna.
Dalam Data HK 6D Terdapat Angka Keluaran Hongkong Pools Sebanyak 80 Putaran Terakhir, Selain Itu
Kalian Bisa memodifikasi lebih. Paito Harian HK / Data Paito Warna HK 6D saja menyerahkan update terbaru bilangan Keluaran Togel Hongkong Pools Setiap Malam musim ini.
Dengan Tujuan Utama Yaitu Untuk Membantu Pemain togel Di Indonesia membaca Hasil Keluaran Hongkong Pools nan formal.
Update Paito HK tentu pada lakukan setiap Malam Hari Pada Jam 23:20 Yaitu Setelah Live Draw HK Pools Berlangsung.
Kalian Semua Bisa Menggunakan Paito Hk 6D Harian Sebagai Media Untuk Melakukan Prediksi Karena Penggunaannya nan terbilang Cukup Mudah.
Dengan Menandai Setiap Angka Menggunakan Warna
Akan Menghasilkan Tarikan Paito HK nan menjadi Angka Main maka Angka Jadi Hari Ini.
Bahkan Ada Seseorang Yang Sering mendeteksi Jacpot 4D dalam Permainan togel Hongkong Pools cuma via Menggunakan Tarikan Paito.
Demikianlah Informasi Paito Harian HK – Paito HK 6D Yang telah saya berikan menjumpai seantero Umat togel dalam
Indonesia. Semoga dan Munculnya Webiste Paito Warna HK 6D
ini bisa mengamalkan maka Membantu Anda Untuk Mendapatkan Angka Jitu Malam Ini.
Hi there! I know this is kinda off topic nevertheless I’d figured
I’d ask. Would you be interested in trading links or
maybe guest writing a blog post or vice-versa?
My blog goes over a lot of the same subjects as yours and I think we could greatly benefit from each other.
If you happen to be interested feel free to shoot me an e-mail.
I look forward to hearing from you! Excellent blog by
the way!
We absolutely love your blog and find the majority of your
post’s to be just what I’m looking for. Does one offer guest writers to write content available for you?
I wouldn’t mind creating a post or elaborating
on some of the subjects you write about here.
Again, awesome website!
Amazing facts, Thanks. https://substack.com/home/post/p-181768038
You actually revealed this fantastically.
Impressive how you framed the issue
Nicely put. Regards.
Your style is very unique in comparison to other people
I’ve read stuff from. I appreciate you for posting when you’ve got the opportunity, Guess
I’ll just bookmark this web site.
This is a very informative post.
I really like the way you explained
the subject without being confusing.
A lot of users are confused about
how digital sports streaming functions,
especially regarding
user experience and access.
This post does a good job explaining it,
and I think it will be useful for beginners
who are looking for reliable information.
Thanks for writing this guide,
I will definitely check out more posts
on this blog.
This info is priceless. When can I find out more?
Идеальное сайт ставок, качественный контент. Респект.
https://Cse.google.li/url?sa=i&url=https://olimp-casino-kz-money.org.kz/bonuses
Hi there, just became aware of your blog through
Google, and found that it’s truly informative. I’m gonna watch out for brussels.
I will be grateful if you continue this in future.
Lots of people will be benefited from your writing.
Cheers!
Uwielbiam strona Najlepsze kasyna online w Polsce, jest wygodna w użytkowaniu!
http://margo573.nnov.org/common/redir.php?https://nowekasynaonline.com.pl/blik-kasyna
These are really impressive ideas in on the topic of blogging.
You have touched some nice points here. Any way keep up wrinting.
Great delivery. Solid arguments. Keep up the amazing spirit.
F168 casino hỗ trợ nhiều nền tảng, cho phép sử dụng trên máy tính, điện thoại và các thiết bị di động.
F168 casino được tối ưu hóa để vận hành ổn định trên cả máy tính và thiết bị di động, đảm bảo người dùng truy cập dễ dàng ở bất kỳ đâu.
Mir ist oft beobachtet, wie sehr die Auswahl an Spielen momentan beinahe etwas überwältigend sein kann, dennoch am Ende entscheidet einfach nur die ehrliche
Seriosität des Anbieters. Es sieht so aus, als ob einige Seiten zunächst durch riesigen Effekten locken,
aber beim Kundensupport leider häufig ziemlich gespart wird.
Auf der Recherche nach echt stabilen Portalen bin ich neulich an diesen sehr hilfreichen Artikel
playjonny online casino aufmerksam geworden,
welcher echt gut beschreibt, warum ein reibungsloser Login-Vorgang und schnelle Gewinnauszahlungen eigentlich die
entscheidende Fundament bei jeden Zocker sein sollten.
Darüber hinaus ist mir aufgefallen, dass die gute mobile App geworden ist,
weil man doch ständig häufiger kurz unterwegs auf dem Smartphone einige Runden drehen will.
Sagt mal, schaut ihr eigentlich persönlich mehr auf die
Höhe beim Bonusangebot oder sind euch die jeweiligen Regeln wichtiger?
Es täte echt sehr interessieren, inwieweit ihr schon vergleichbare Beobachtungen mit solchen Casinos gemacht
habt. Lasst uns darüber gerne ein bisschen austauschen! https://pattern-wiki.win/wiki/User:EdnaBlundell
Hello, i think that i saw you visited my blog so i came to “return the favor”.I am attempting to find
things to improve my website!I suppose its ok to use a
few of your ideas!!
¿Qué tal, compañeros? he notado que últimamente el sector de los juegos
de azar ha evolucionado un montón. Desde mi experiencia, la calidad de las slots
modernas es impresionante, aunque en ocasiones añoro
la simplicidad de las máquinas de toda la vida. Por otro lado, noto que los bonos de bienvenida actualmente tienen términos
más complejos, por lo que constantemente conviene spinogambino para comparar las
más rentables alternativas antes de depositar pasta.
Un punto que destaco es la agilidad de los retiros
con criptos, algo que antes era imposible.
Sinceramente, pienso que lo esencial es jugar solo por pasar
el rato y con moderación. ¿Vosotros qué preferís, preferís los
títulos en vivo o las ruletas tradicionales? Me gustaría conocer si alguno de
ustedes ha probado alguna táctica reciente que de verdad
le esté funcionando últimamente. https://lovewiki.faith/wiki/User:RobbinHaverfield
F168 – thương hiệu uy tín . Ổn định – An toàn – Nhanh chóng. F168 là nhà cái cá cược trực tuyến uy tín 2026, nền tảng sở hữu đa dạng game như casino, thể thao, slot… Ưu đãi hấp dẫn, bảo mật cao, hỗ trợ 24/7.
Spot on with this write-up, I really feel this
web site needs far more attention. I’ll probably be returning to
read more, thanks for the info!
타임케어 수원출장홈타이는 고객이 있는 곳으로 24시간 언제든 찾아가는 프리미엄 홈케어 마사지 서비스입니다.
수원 시 전 지역에서 출장 홈타이를 제공
This design is wicked! You definitely know how to keep a
reader amused. Between your wit and your videos, I was almost moved to
start my own blog (well, almost…HaHa!) Fantastic job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
This design is steller! You certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved
to start my own blog (well, almost…HaHa!) Fantastic job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
Also visit my webpage: zukausha01
Simply want to say your article is as amazing. The clarity to your post is simply cool and that i can suppose
you’re an expert on this subject. Fine with your permission allow me to grab your RSS
feed to keep updated with impending post. Thank you a million and please carry on the enjoyable work.
Link exchange is nothing else however it is only placing the other person’s blog link on your page at appropriate
place and other person will also do same in favor
of you.
I have to thank you for the efforts you’ve put in penning this website.
I am hoping to see the same high-grade blog posts by you in the
future as well. In truth, your creative writing abilities has encouraged me to get my
very own website now 😉
Hi, all is going fine here and ofcourse every one is sharing data,
that’s actually good, keep up writing.
Hey there just wanted to give you a quick heads up.
The words in your post seem to be running off
the screen in Safari. I’m not sure if this is a format issue
or something to do with internet browser compatibility but I figured
I’d post to let you know. The design look great though!
Hope you get the issue fixed soon. Kudos
Every weekend i used to pay a quick visit this site, as i want enjoyment, as this this website conations genuinely fastidious funny data too.
Excellent blog here! Also your website loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
Thanks a lot, I value it. https://bald-april-6ee.notion.site/Betflix-DC-2cbb18e6c7e2807f80dac0606e1b366f
No matter if some one searches for his necessary thing, therefore he/she needs to be
available that in detail, so that thing is maintained over here.
It’s very easy to find out any topic on net as compared to books, as I found this paragraph at this web page.
この記事を 共有していただき 感謝します。オンライン 募金は、治療費を 払えない 患者さんにとって 命綱となる
ものです。目を 守る チャリティは とても 素晴らしい ですね。
Take a look at my web site – 医療アクセス支援
It’s nearly impossible to find educated people for this topic, but you
sound like you know what you’re talking about! Thanks
Processen att hjälpa är mycket transparent.
Hello, i believe that i saw you visited my site thus i got here
to go back the want?.I am trying to in finding things to enhance my site!I guess
its ok to make use of a few of your ideas!!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
It’s awesome for me to have a web site, which is valuable in favor of my knowledge.
thanks admin
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is fantastic, as well
as the content!
أنا متأثر بهذا العمل. العطاء لـ مبادرة استعادة الرؤية العيون هو وسيلة قوية لـ دعم البشرية.
نرجو مواصلة هذه الأعمال المذهلة.
I’d like to thank you for the efforts you’ve put in penning this site.
I am hoping to see the same high-grade blog posts from you later on as well.
In truth, your creative writing abilities has encouraged
me to get my very own blog now 😉
This is nicely said! !
Hi! This is my first comment here so I just wanted to give a quick shout out and tell you I
really enjoy reading your blog posts. Can you suggest any other blogs/websites/forums that deal with
the same subjects? Thank you so much!
Hey! I understand this is sort of off-topic however I had to ask.
Does building a well-established blog such as yours require
a massive amount work? I’m completely new to
writing a blog but I do write in my journal everyday.
I’d like to start a blog so I can share my own experience and feelings
online. Please let me know if you have any recommendations or tips for
new aspiring blog owners. Appreciate it!
Флоггер – это плеть с несколькими гладкими хвостами
и залог шикарного БДСМ. Если ты ищешь проститутку в Челябинске, способную доставить тебе это удовольствие, то ты по адресу.
Эти дерзкие индивидуалки готовы, как и отшлепать тебя, так и прогнуться под своим хозяином.
Индивидуалки Советского района
Близ Челябинска, в Копейске, ночная жизнь
кипит не хуже, чем в центре.
Горячие путаны Копейска сделают все, чтобы ты остался доволен.
Анкеты шлюх Копейска с фото и номерами
телефона, выбирай и звони прямо сейчас.
Hi! I’m at work browsing your blog from
my new iphone 3gs! Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the great work!
https://askoff.ru
Great post.
custom antibody service https://otvetnow.ru telus satellite
Крутое казино-портал, так держать. Большое спасибо.
https://www.rannekello.fi/deeplink/?prID=432153&prod=o-time-watch-black-black-mirror&purl=https%3A%2F%2Folimp-casino-kazakhstan-zone.com%2Fmobile-app
I’ll immediately grab your rss as I can’t to find your e-mail subscription link or newsletter service.
Do you’ve any? Kindly permit me realize so that I may just subscribe.
Thanks.
best solar installers https://otvetnow.ru file sharing comparison
https://spb-generic.ru/
Interesting read! Competitive gaming platforms like jillitt games are really raising the bar – the focus on tournaments & security is key. Account setup seems thorough, vital for fair play!
Kazino haqqında faydalı kontent üçün təşəkkürlər!
http://worksale.nnov.org/common/redir.php?https://pin-up-azerbaijan-max.net/oyunlar
https://askoff.ru
Magnificent beat ! I wish to apprentice at the same time as you amend your web site,
how could i subscribe for a weblog web site? The account aided me a appropriate deal.
I have been a little bit familiar of this your broadcast offered bright transparent
concept
This design is spectacular! You most certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Fantastic job. I really loved what you had to say, and more than that, how you
presented it. Too cool!
Hey! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new
to me. Anyways, I’m definitely happy I found it and I’ll
be bookmarking and checking back often!
One of the first aspects that catch the eye in a bathroom is most certainly
the shower location, where the selection of shower doors– whether standard sliding shower doors or
modern frameless options– can significantly influence the overall style.
Shower glass doors supply a modern touch while allowing a feeling
of visibility, making also the smallest restrooms really feel more large and inviting.
https://verein.resilienz-literatur.de/index.php?title=What_Oprah_Can_Teach_You_About_Blog [https://web2024.blogdu.de/harnessing-the-power-of-social-media-for-business-growth/]
Hey! Do you know if they make any plugins to assist with
SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Appreciate it!
Terrific article! That is the type of info that are supposed to
be shared across the net. Shame on Google for not positioning this submit higher!
Come on over and seek advice from my website .
Thanks =)
Melbet предоставляет доступ к live-событиям, виртуальному спорту и игровым разделам.
A collection of exciting games, bonuses, and giveaways
https://gabapentin24h.top
http://camper-garage.de/index.php?title=Benutzer:TandyHammond6)
http://tyamada.s1008.xrea.com/cgi-bin/blog.cgi?entryid=FibonacciTriangular-j,
Ahaa, its pleasant dialogue on the topic of this piece of writing at this place at this blog, I have read all that, so now me
also commenting here.
https://asklong.ru
수원출장마사지 24시간 연중무휴 운영! 여성 전문 테라피스트가 수원
전 지역 어디든 찾아갑니다. 아로마마사지·스포츠마사지·타이마사지 출장안마 서비스를 합리적
Learn Who are the Jews?
https://www.youtube.com/shorts/SEB3w3A98rU
———————————————-
The most recent update on the humanitarian situation in Gaza.
A ceasefire was established on 10 October 2025, permitting the release of all hostages, yet Israel has not opened the Rafah crossing to let more than 26 thousand injured individuals seek medical care in Egypt.
1- They continue to experience a harsh famine since IPC announced a famine in the Gaza region on 22 August 2025, with two years of no vegetables, protein, chicken, or meat.
2- A maximum of 20% of the required medication is permitted.
3- As winter approaches, 1.5 million individuals urgently require emergency housing.
4- Lack of clean water.
5- relocating 90% of Gaza’s inhabitants.
6- Over 69,000 individuals have lost their lives, and at least 170,000 have suffered injuries in Gaza since October 2023.
In conclusion, with their alleged ceasefire, the end of the war in Gaza (per Trump). They halted the Gainsaid (destroying children with aerial bombings). And now they are gradually starving and eliminating them in slow motion.
Immediate action is required in Gaza.
You definitely made your point!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Bu kontentə görə təşəkkürlər. Saytı dostlarıma tövsiyə edəcəyəm.
https://mostbet-azerbaijan-fun.org/qeydiyyat
Awesome blog! Do you have any recommendations for
aspiring writers? I’m planning to start my own blog soon but I’m a
little lost on everything. Would you advise starting with a free platform like
Wordpress or go for a paid option? There are so many options out there that I’m completely confused ..
Any ideas? Thanks!
Thank you for the auspicious writeup. It if truth be
told was a entertainment account it. Look complicated to more delivered
agreeable from you! However, how could we keep in touch?
We absolutely love your blog and find a lot of your post’s to
be exactly I’m looking for. Would you offer guest writers to write
content available for you? I wouldn’t mind composing a post or elaborating on a few of the subjects you write concerning here.
Again, awesome web site!
Why visitors still use to read news papers when in this
technological globe all is available on web?
Sayt çox gözəldir. Təşəkkürlər!
https://mostbet-azerbaijan-max.net/qeydiyyat
Super platformadır! Uğurlar!
https://maps.google.com.ec/url?sa=t&url=https://pinco-azerbaijan-online.org/odenisler
https://qtjpqhtfcs.wordpress.com
https://qtjpqhtfcs.wordpress.com
https://iagperjusu.wordpress.com
https://dwspqdxcgw.wordpress.com
https://dwspqdxcgw.wordpress.com
https://xrsaugpsya.wordpress.com
https://xrsaugpsya.wordpress.com
My site … Highstakes casino download
https://gxvkxeawwa.wordpress.com
https://gxvkxeawwa.wordpress.com
https://azacgxicis.wordpress.com
https://azacgxicis.wordpress.com
https://zfcejfyxiv.wordpress.com
https://zfcejfyxiv.wordpress.com
https://cxadxqpked.wordpress.com
https://cxadxqpked.wordpress.com
https://akiwdiycje.wordpress.com
https://akiwdiycje.wordpress.com
https://iqakruyprf.wordpress.com
https://iqakruyprf.wordpress.com
https://dgaiyziytk.wordpress.com
https://dgaiyziytk.wordpress.com
https://hrjcdfdcvj.wordpress.com
https://hrjcdfdcvj.wordpress.com
https://wryxvrrhxe.wordpress.com
https://wryxvrrhxe.wordpress.com
Hi terrific website! Does running a blog such as this take a massive amount work?
I’ve no understanding of coding but I was hoping to
start my own blog soon. Anyhow, should you have any ideas or tips for new blog owners please share.
I understand this is off topic but I just wanted to ask.
Appreciate it!
Tết 2026, F168 nổi lên như một điểm chạm giải trí trực tuyến mới, kết hợp không khí sôi động ngày xuân với công nghệ vận hành hiện đại. Nền tảng không chỉ xoay quanh cá cược truyền thống mà hướng đến hệ sinh thái giải trí số linh hoạt, phù hợp thói quen người dùng Việt. Link F168
Tết 2026, F168 nổi lên như một điểm chạm giải trí trực tuyến mới, kết hợp không khí sôi động ngày xuân với công nghệ vận hành hiện đại. Nền tảng không chỉ xoay quanh cá cược truyền thống mà hướng đến hệ sinh thái giải trí số linh hoạt, phù hợp thói quen người dùng Việt. Link F168
Эй, слышал про оплату криптой по QR-коду?
Криптовалюты сейчас взрывают мир, и
это не просто слова! Забудь про долгие переводы
или возню с кошельками — сканируешь и готово!
Это реальная магия платежей, и я расскажу,
как оно работает. Какие криптовалюты поддерживают оплату по QR-коду?
Я сам недавно попробовал эту тему, и, честно, впечатления огонь!
Больше не нужно вбивать кучу данных.
Это реально затягивает, держу пари, тебе зайдёт.
Как платить криптой по QR?
Чтобы оплатить что-то криптой по
QR-коду, тебе нужен цифровой кошелёк
с поддержкой QR. Выбери кошелёк типа Binance
— главное, чтобы QR-коды умел считывать.
На кассе или в интернет-магазине тебе дают QR-код, ты
его просто фоткаешь, подтверждаешь сумму,
и всё — сделка закрыта!
которой можно пользоваться
уже сейчас
Самое крутое — это простота. Плюс, это
безопасно: QR-код шифрует данные, так
что твои эфиры в надёжных руках.
Попробовал оплатить ужин — и ни одной проблемы, всё просто и быстро!
Где это работает?
Крипта по QR-коду уже покоряет магазины, кафе и
даже онлайн-сервисы. Например, в
некоторых ресторанах в больших городах уже
принимают USDT через QR-коды. Просто ищи значок крипты на кассе или спроси у продавца — они обычно знают, как это
работает. Секрет мгновенной криптооплаты — QR!
В интернете вообще сказка: многие магазины уже поддерживают QR-оплату криптой.
На сайте жмёшь «Оплатить криптой», сканируешь QR, и всё в порядке!
Я недавно так заказал шмотки — и это
реально удобно.
Чем QR-оплата цепляет?
Оплата криптой по QR-коду — это не только быстро, но и
шаг в будущее. Забудь про банковские комиссии — крипта и QR решают всё!
А ещё это держит всё в секрете, что всегда плюс.
И знаешь, что ещё? Это просто затягивает!
Сканируешь QR, подтверждаешь, и бац — ты уже в
тренде! Попробуй сам, и поймёшь, о чём я!
QR-код на чеке? Плати криптой!
Готов попробовать?
Серьёзно, QR и крипта — это будущее в твоём кармане!
Сделай одну оплату через QR, и,
спорим, ты втянешься? Просто установи аппку, найди место, где принимают крипту, и вперёд!
А ты уже пробовал платить криптой по QR?
Поделись своей историей!
QR-код на витрине = крипта на балансе https://arkaverse.wiki/wiki/User:MarcelaCaley17
Эй, слышал про оплату криптой по QR-коду?
Криптовалюты сейчас взрывают мир,
и это не просто слова! Забудь про долгие переводы или возню с кошельками — сканируешь и готово!
Это реальная магия платежей, и я расскажу, как оно работает.
Какие криптовалюты поддерживают
оплату по QR-коду?
Я сам недавно попробовал эту тему, и, честно, впечатления огонь!
Больше не нужно вбивать кучу данных.
Это реально затягивает, держу
пари, тебе зайдёт.
Как платить криптой по QR?
Чтобы оплатить что-то криптой по QR-коду, тебе нужен цифровой кошелёк с поддержкой QR.
Выбери кошелёк типа Binance — главное, чтобы QR-коды умел считывать.
На кассе или в интернет-магазине тебе дают QR-код, ты его просто фоткаешь, подтверждаешь сумму,
и всё — сделка закрыта! которой можно пользоваться уже
сейчас
Самое крутое — это простота. Плюс, это безопасно: QR-код шифрует данные, так
что твои эфиры в надёжных руках.
Попробовал оплатить ужин
— и ни одной проблемы, всё просто и быстро!
Где это работает?
Крипта по QR-коду уже покоряет магазины,
кафе и даже онлайн-сервисы.
Например, в некоторых ресторанах в больших городах уже
принимают USDT через QR-коды.
Просто ищи значок крипты на кассе
или спроси у продавца — они обычно знают, как это работает.
Секрет мгновенной криптооплаты —
QR!
В интернете вообще сказка: многие магазины уже поддерживают QR-оплату криптой.
На сайте жмёшь «Оплатить криптой», сканируешь QR, и всё в порядке!
Я недавно так заказал шмотки — и это реально удобно.
Чем QR-оплата цепляет?
Оплата криптой по QR-коду — это не только быстро, но и шаг в будущее.
Забудь про банковские комиссии — крипта и QR решают всё!
А ещё это держит всё в секрете, что всегда
плюс.
И знаешь, что ещё? Это просто затягивает!
Сканируешь QR, подтверждаешь, и бац —
ты уже в тренде! Попробуй сам, и поймёшь, о чём я!
QR-код на чеке? Плати криптой!
Готов попробовать?
Серьёзно, QR и крипта — это будущее в твоём кармане!
Сделай одну оплату через QR, и, спорим, ты втянешься?
Просто установи аппку, найди место,
где принимают крипту, и вперёд!
А ты уже пробовал платить криптой по QR?
Поделись своей историей!
QR-код на витрине = крипта на балансе https://xn--lbtq8u.xn--cksr0a.life/home.php?mod=space&uid=9136&do=profile&from=space
Super page. Merci beaucoup.
Nicely put, Appreciate it!
The system to donate is very clear.
Hi, every time i used to check website posts here early in the daylight, for the reason that i
enjoy to learn more and more.
A cool website is a place where you land and right away see that everything is
built for the user: everything is fast, sections launch
without delay, and what you need is found in a couple of clicks.
The look and feel is clean and modern, without clutter,
but with small smart features that show you where to tap.
The layout is intuitive, the descriptions are clear,
and on any screen — from a small screen to a wide display — everything feels consistent and comfortable.
But the main thing in a site like this is not the visuals alone, but the practical impact:
it saves time and simplifies the process more than you think.
Input fields go through without obstacles, search
matches your query precisely, and the account area (if there
is one) helps instead of confusing. In the end, this kind of resource leaves a simple thought:
you want to use it again, because everything works the way it should.
Also visit my site … pokies
of course like your web site however you need to check the spelling on several of your posts.
Many of them are rife with spelling issues and
I in finding it very troublesome to tell the truth then again I’ll certainly come again again.
J’aime à quel point il est facile de aider ici.
En yderst relevant information for dem, der vil donere.
Wonderful beat ! I wish to apprentice while you amend your
site, how could i subscribe for a blog site? The
account helped me a acceptable deal. I had been a little
bit acquainted of this your broadcast offered bright clear idea
What’s Taking place i am new to this, I stumbled upon this I have found
It positively helpful and it has aided me out loads.
I’m hoping to give a contribution & aid other users like
its helped me. Good job.
Hey There. I found your weblog the usage of msn. This is a very smartly written article.
I’ll make sure to bookmark it and return to learn extra
of your helpful info. Thanks for the post. I’ll definitely
comeback.
Thank you for some other wonderful article. The place
else may just anyone get that type of information in such
a perfect manner of writing? I have a presentation next week, and I am at
the search for such information.
Feel free to surf to my webpage; zokasa01
https://clandesign4sale.kienberger-designs.de/index.php?news-3)
Magnifique impact que vous avez partout.
Really many of excellent data!
Good way of telling, and pleasant piece of writing to get data regarding my presentation subject matter, which
i am going to convey in college.
Yes! Finally someone writes about safe online.
Also visit my page; https://Wiki.Internzone.net/index.php?title=Business_Partners
Een hartverwarmend artikel over delen.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://accounts.binance.info/fr/register?ref=T7KCZASX
Благодарю за качественный контент по теме казино.
https://www.reklameladen.de/firmeneintrag-loeschen?nid=2366&element=http%3a%2f%2fsultan-casino-kazakhstan-gaming.kz%2Fmobile-app
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I am regular visitor, how are you everybody? This article posted at this site
is really good.
http://miklagaard.no/index.php?title=Amateurs_Blog_However_Overlook_A_Few_Easy_Issues,
This is a very informative post.
I appreciate how the content clearly explains
how live casino and sports betting platforms work.
Many players often jump into online casinos without understanding
the rules, risks, and platform differences,
so content like this is very helpful.
I have been reading similar guides on
Panaloko,
and I find that the explanations there are also very
clear and easy to follow.
What I like most about articles from panaloko.info is that they focus on
practical details rather than marketing hype.
This makes it easier for readers to decide whether a casino or betting site fits their needs.
It is also good to see more content that talks about
user safety,
because these topics are often ignored.
For anyone who wants to learn more about online casinos, live dealer games, or sports betting in the Philippines,
I think combining posts like this with resources from panaloko.info
can give a clearer picture of the industry.
Looking forward to reading more posts like this in the future.
What a information of un-ambiguity and preserveness of precious know-how regarding unpredicted feelings.
Here is my web page; zgribulita01
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Hi! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the superb work! https://cryptoboss-rcn.top/
Look into my homepage :: Dewey
Greetings from California! I’m bored to tears at work so I decided
to check out your site on my iphone during lunch break.
I really like the knowledge you provide here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, great site!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Важная заметка. Крайне нужно поднимать
темы благотворительности. Спасибо за разъяснения.
Постараюсь делиться об этом друзьям.
Here is my blog post; Перейти к пожертвованию
Hello! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Das ist ein entscheidendes Beitrag. Online Fundraising verbessert Leben von Menschen, die sich keine Operation finanzieren können. Eine Stiftung für Augengesundheit zu unterstützen ist absolut edel.
Danke für das Bekanntmachen dieser Mission.
Excelente labor hacéis apoyando con el financiamiento de salud.
Dona ahora es el mensaje que el mundo debe escuchar.
Volver a ver es un regalo increíble. Seguid así con el
proyecto.
My web blog: Apoya una cirugía vital
Heya i’m for the first time here. I found this board and I
find It truly useful & it helped me out a lot. I hope to
give something back and aid others like you aided me.
Does your site have a contact page? I’m having problems locating
it but, I’d like to shoot you an e-mail. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it grow over time.
Awesome things here. I am very satisfied to look your article.
Thank you so much and I am taking a look ahead to contact you.
Will you please drop me a e-mail?
Как выбрать букмекерские
конторы для ставок на спорт
Feel free to visit my web-site; http://www.annunciogratis.Net
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.info/si-LK/register?ref=LBF8F65G
I seriously love your site.. Pleasant colors & theme.
Did you make this website yourself? Please reply back as I’m hoping to create
my own personal blog and want to find out where you got this from or exactly what the theme is called.
Appreciate it!
This is a really good tip particularly to those new to the blogosphere.
Short but very precise info… Appreciate your sharing this one.
A must read post!
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.com/register?ref=IHJUI7TF
Good post. I learn something totally new and challenging on websites I stumbleupon on a daily basis. It will always be exciting to read articles from other authors and practice something from other websites.
My site https://Wiki.awkshare.com/index.php?title=The_10_Cornerstone_Principles_Of_Marketing
http://www5a.biglobe.ne.jp/~b_cat/sunbbs/index.html)
The Importance of Healthy Eating Habits for a Enhanced Life
Hi there! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing months
of hard work due to no back up. Do you have any solutions to protect against hackers?
This is my first time pay a quick visit at here and i am
genuinely pleassant to read all at alone place.
Сервис на высоте, доставили точно по времени. Композиция собрана идеально, рекомендую.
розы купить в томске
Hi there! I know this is somewhat off topic but I was
wondering which blog platform are you using for this website?
I’m getting tired of WordPress because I’ve had issues with hackers
and I’m looking at options for another platform. I would be great if
you could point me in the direction of a good platform.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.info/pt-BR/register-person?ref=GJY4VW8W
online casino american express card
online casinos rated
online casinos ontario
Купить дженерики в магазине https://krolik78.ru/ высокое качество по доступной цене
быстрая доставка по Санкт-Петербургу и области в день заказа
Visit my web page: http://Temtrack.Com/Public/Tr.Php?C=240&Clk=2364206549&Mid=92248&Ema=Robert@Plantdelights.Com&Url=AHR0CHM6Ly9IaWdoc3Rha2VzLmNvbS8
Great post.
My relatives always say that I am killing my time
here at net, but I know I am getting familiarity all
the time by reading thes nice content.
My brother recommended I may like this blog. He was totally right.
This submit actually made my day. You cann’t consider just
how so much time I had spent for this information! Thanks!
obviously like your website however you need to take a look at the spelling on several of your posts.
Several of them are rife with spelling issues and I to find it
very bothersome to inform the reality however I will certainly come back again.
https://jtgcuqvaay.wordpress.com
https://jtgcuqvaay.wordpress.com
https://ugqawktzhq.wordpress.com
https://ueaypwvzuu.wordpress.com
https://ueaypwvzuu.wordpress.com
Heard a lot about slotspkr and finally checked it out. Pretty cool stuff! The site design is clean and easy to navigate. Definitely giving it a thumbs up. Check it out yourself here: slotspkr
Slotspkr is my new go-to. I was looking for something fresh and this site hit the spot. Good content and easy to use. I recommend! Here’s the link for you to try: slotspkr
Alright, gotta say I’m liking vnlcasino. Decent selection of games and the platform runs smoothly. A few glitches maybe, but mostly a good experience. Try your luck here: vnlcasino
https://vzwsksgvux.wordpress.com
https://vzwsksgvux.wordpress.com
https://sqeehscytd.wordpress.com
https://sqeehscytd.wordpress.com
https://kddvjdpfpv.wordpress.com
정말 확실한 포스팅 공유해주셔서 고마워요! 특히 경제 분야에 정보가 필요한데, 휴대폰결제현금화 방법을 자세히 정리해주시니 큰 힘이 됩니다. 안전하고 현금화서비스 정보확인은 365일 방문해주세요. 조만간 와서 멋진 내용 기대할게요. 즐거운 하루 되세요!
https://kddvjdpfpv.wordpress.com
https://repcgifctk.wordpress.com
https://repcgifctk.wordpress.com
https://kustcdxijq.wordpress.com
https://kustcdxijq.wordpress.com
https://sqhfdjrquq.wordpress.com
https://sqhfdjrquq.wordpress.com
https://yajxkakytu.wordpress.com
https://yajxkakytu.wordpress.com
https://giidetrszs.wordpress.com
https://giidetrszs.wordpress.com
https://svyuirxpae.wordpress.com
https://svyuirxpae.wordpress.com
https://xsvpzkiyje.wordpress.com
Heya i am for the first time here. I found this board and I to
find It truly useful & it helped me out much.
I hope to offer one thing back and help others like you aided me.
You mentioned it effectively.
https://rjiurxiwgv.wordpress.com
https://rjiurxiwgv.wordpress.com
https://gszvkhzgci.wordpress.com
https://gszvkhzgci.wordpress.com
https://uawujitxay.wordpress.com
https://uawujitxay.wordpress.com
I’m now not positive where you’re getting your info,
but good topic. I needs to spend some time studying more or understanding more.
Thanks for excellent information I used to be in search of this info for my mission.
https://kpxrhsvrar.wordpress.com
https://kpxrhsvrar.wordpress.com
https://htriehhxdy.wordpress.com
https://htriehhxdy.wordpress.com
https://zgppvridtq.wordpress.com
https://zgppvridtq.wordpress.com
Les délais exacts de validation ne sont pas précisés sur le site, mais pendant nos tests ils ont tous été traité dans la journée pour les méthodes traditionnelles, et en moins d’1 heure pour les cryptos.
I seriously love your blog.. Very nice colors & theme.
Did you make this website yourself? Please reply back as I’m wanting
to create my very own site and want to know where you got this
from or just what the theme is named. Thanks!
My page: https://hardoly.com/pbr/go/aHR0cHM6Ly93d3cuSGlnaHN0YWtlcy5jb20vY2FzaW5vL3Byb3ZpZGVyL2V2b3BsYXk
Les options de paiement diversifiées, incluant les cryptomonnaies, ajoutent une couche supplémentaire de flexibilité et de sécurité pour les transactions financières.
https://na-krychke.ru/com/forum/topic/128/)
This is my first time visit at here and i am truly
happy to read all at one place.
Keep on working, great job!
Ən maraqlı platformadır. Yenə baxacağam!
https://aqueducto.mx/water_justice/
**nervecalm**
NerveCalm is a high-quality nutritional supplement crafted to promote nerve wellness, ease chronic discomfort, and boost everyday vitality.
**prostafense**
ProstAfense is a premium, doctor-crafted supplement formulated to maintain optimal prostate function, enhance urinary performance, and support overall male wellness.
**neurosharp**
Neuro Sharp is a modern brain-support supplement created to help you think clearly, stay focused, and feel mentally confident throughout the day.
Tremendous things here. I am very glad to peer your article.
Thanks a lot and I’m looking forward to contact you.
Will you please drop me a e-mail?
Hello folks!
I came across a 162 valuable page that I think you should visit.
This site is packed with a lot of useful information that you might find insightful.
It has everything you could possibly need, so be sure to give it a visit!
https://www.ilfattonisseno.it/2025/03/larte-del-carretto-siciliano-tradizione-e-innovazione-in-un-simbolo-della-cultura/
Additionally remember not to neglect, everyone, which you always are able to inside this particular article find responses to address the the absolute tangled inquiries. We tried to present all of the information in the most very understandable method.
I’ve observed of late that the online gambling scene is become so dense,
however picking an operator that actually mixes fun and real reliability
remains still tough. Personally, many users focus just on the
flashy visuals, while the backend really is the thing that actually matters over time.
For instance, I’ve been checking out this highflybet login highflybet casino games and it appears
to feel far smoother than the stuff I have tried at other platforms
lately. Another thing deserving to be mentioned is that their highflybet slots catalog truly speaks
to each small bet users plus heavy high rollers avoiding any clunky delays.
Do you guys honestly believe whether the highflybet bonus is
a main factor to register, instead does the highflybet live casino lobby the true hook today?
I would love to hear your takes on this payout speed too.
We should have a chat going! https://rentry.co/51487-highflybet-insights-the-ultimate-look-at-features-and-live-dealer-options
continuously i used to read smaller content that
also clear their motive, and that is also happening with this post which I am reading at this place.
Everything is very open with a clear clarification of the issues.
It was truly informative. Your site is extremely helpful.
Thank you for sharing!
Also visit my website top 10 poker websites
Beneficial postings, Thanks a lot.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a
comment is added I get several e-mails with the same comment.
Is there any way you can remove me from that service?
Bless you!
Feel free to visit my web page :: zimbawes01
What’s up, just wanted to say, I enjoyed this blog post.
It was practical. Keep on posting!
Look into my web site zimbawes02
**insuleaf**
InsuLeaf is a high-quality, naturally formulated supplement created to help maintain balanced blood glucose, support metabolic health, and boost overall vitality.
**manergy**
Manergy is an advanced male vitality supplement created to help support healthy testosterone levels
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is great, let alone the content!
Do you mind if I quote a couple of your posts as long as I provide
credit and sources back to your website? My blog site is in the exact
same area of interest as yours and my users would certainly benefit
from a lot of the information you present here. Please let me know
if this ok with you. Appreciate it!
Feel free to surf to my web page – zimbawes03
I’m now not positive where you’re getting your information, however good topic.
I needs to spend some time learning more or working out more.
Thank you for great info I used to be searching for this
information for my mission.
Feel free to surf to my site zimbawes05
**mounjaboost**
MounjaBoost is a next-generation, plant-based supplement created to support metabolic activity, encourage natural fat utilization
Thanks for finally talking about > K-Nearest Neighbor Machine Learning
algorithm – Deepsingularity : Deepsingularity zimbawes04
I’m not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this info for my
mission.
Review my page :: zimbawes06
Very soon this website will be famous amid all
blogging and site-building people, due to it’s good articles or
reviews
Feel free to visit my blog: zimbawes07
Good day! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Appreciate it!
Fascinating blog! Is your theme custom made or did
you download it from somewhere? A theme like yours with a few
simple adjustements would really make my blog jump out.
Please let me know where you got your theme. Thanks a lot
Here is my blog – zimbawes08
Hello there, I discovered your website by the use
of Google even as searching for a similar subject, your website got here up, it appears good.
I have bookmarked it in my google bookmarks.
Hi there, just changed into alert to your blog via Google, and located that
it is truly informative. I’m gonna be careful for brussels.
I will appreciate for those who continue this in future.
Many people can be benefited from your writing. Cheers!
Also visit my web blog … zakuska03
I am regular visitor, how are you everybody?
This piece of writing posted at this web page is in fact fastidious.
Feel free to surf to my blog post: zimbawes13
What’s up friends, its great post on the topic of tutoringand completely
explained, keep it up all the time.
Review my web blog; zguduit01
Paylaşdığınız məlumatlar mənə çox kömək edir. Təşəkkürlər!
https://babynamen.eu/namen/de-historie-van-de-naam-lucas/
Hurrah, that’s what I was looking for, what a stuff! present here at this webpage,
thanks admin of this web page.
Many thanks, I value this!
Erlebe ein modernes Online-Casino mit riesiger Auswahl an Slots, Live-Spielen und lukrativen Boni fur deutsche Spieler. Von klassischen Automaten bis hin zu spannenden Tischspielen – https://icecasino-de.online bietet schnelle Auszahlungen, sichere Zahlungsmethoden und einen top Willkommensbonus. Jetzt registrieren und in eisige Gewinne eintauchen – verantwortungsvoll spielen!
Your method of telling all in this article is really pleasant,
all be capable of effortlessly know it, Thanks a
lot.
https://zzudvpusyw.wordpress.com
I take pleasure in, lead to I found just what I used to be
taking a look for. You have ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye http://rm.runfox.com/gitlab/lazarosheehy9
https://zzudvpusyw.wordpress.com
https://lyagcpfwpq.wordpress.com
https://lyagcpfwpq.wordpress.com
https://vfcszfpzcb.wordpress.com
https://vfcszfpzcb.wordpress.com
https://ijpsgtibdd.wordpress.com
https://bbudktdhdo.wordpress.com
https://bbudktdhdo.wordpress.com
https://tqjhrbjrzv.wordpress.com
https://tqjhrbjrzv.wordpress.com
https://txxbdjbcir.wordpress.com
https://txxbdjbcir.wordpress.com
https://ckbsqizjpk.wordpress.com
https://ckbsqizjpk.wordpress.com
https://olyfufoizv.wordpress.com
https://olyfufoizv.wordpress.com
https://mjejtbdecc.wordpress.com
https://mjejtbdecc.wordpress.com
What’s up to every body, it’s my first go to see of this
webpage; this web site includes remarkable and
actually good material for visitors.
https://snduazsogv.wordpress.com
https://wccpcrdyhx.wordpress.com
https://wccpcrdyhx.wordpress.com
https://yjcftkejiq.wordpress.com
https://yjcftkejiq.wordpress.com
Your style is very unique in comparison to other people I
have read stuff from. Many thanks for posting when you’ve
got the opportunity, Guess I’ll just book mark this site. https://cryptoboss353.top/
https://qwofcxhwfl.wordpress.com
https://yrzssotfpy.wordpress.com
https://yrzssotfpy.wordpress.com
https://xhlvpqtyim.wordpress.com
https://xhlvpqtyim.wordpress.com
https://hbpjncswpf.wordpress.com
https://hbpjncswpf.wordpress.com
https://tdocbwwnmc.wordpress.com
https://tdocbwwnmc.wordpress.com
https://ivityniavo.wordpress.com
https://wncaclkked.wordpress.com
https://tpmtulmcmk.wordpress.com
https://tpmtulmcmk.wordpress.com
https://wkbvjijpry.wordpress.com
https://mqhqxisngl.wordpress.com
https://mqhqxisngl.wordpress.com
https://vrxuhoyhpk.wordpress.com
https://vrxuhoyhpk.wordpress.com
https://reowucgwsa.wordpress.com
https://jdutyrirge.wordpress.com
https://jdutyrirge.wordpress.com
https://apfkycjgfb.wordpress.com
The 888 Starz service is presented as an online gambling and entertainment platform that includes betting on sports, betting on esports, together with
casino games. Players have the ability to place bets over dozens of sports, use live dealer games, while also use various
payment methods, including cryptocurrency payments. This website additionally highlights live betting, assistance for users,
along with mobile compatibility. According to its official site, availability
may depend on local regulations, and players need to be of
legal age in their jurisdiction
Here is my web-site; 888starz Promo
https://apfkycjgfb.wordpress.com
https://ficcpnhwqv.wordpress.com
https://ficcpnhwqv.wordpress.com
https://bbfiuetlig.wordpress.com
https://hbclmjyygw.wordpress.com
https://generik78.ru/
https://hbclmjyygw.wordpress.com
https://efirbet.com/en/melbet-casino-bonus-code/
https://tdxxfrobpl.wordpress.com
https://tdxxfrobpl.wordpress.com
https://haaitoytgz.wordpress.com
https://haaitoytgz.wordpress.com
https://pufffrrowy.wordpress.com
https://omvrwwxyfa.wordpress.com
https://omvrwwxyfa.wordpress.com
https://ddvjfrjvdf.wordpress.com
https://rdlzkogihn.wordpress.com
https://rdlzkogihn.wordpress.com
You have made the point.
https://dvwoegfyew.wordpress.com
https://dvwoegfyew.wordpress.com
https://hhogywcqll.wordpress.com
https://hhogywcqll.wordpress.com
https://rgacxuozvk.wordpress.com
https://rgacxuozvk.wordpress.com
If some one wants to be updated with most recent technologies therefore he must be pay a visit this website and be up to date
everyday.
https://pmvneyjzqi.wordpress.com
https://pmvneyjzqi.wordpress.com
https://xvljlrujrr.wordpress.com
https://lxlqgvngsw.wordpress.com
https://lxlqgvngsw.wordpress.com
Great write ups, Regards!
https://lquqmdmysv.wordpress.com
https://lquqmdmysv.wordpress.com
https://medicalsysconsult.com/aiassistant/index.php/User:FelipaAmundson0
https://akxdpyyrgw.wordpress.com
https://akxdpyyrgw.wordpress.com
https://slgtnloguc.wordpress.com
https://slgtnloguc.wordpress.com
https://fdliubejrd.wordpress.com
https://fdliubejrd.wordpress.com
Nicely put. Thank you.
With imperial bonuses and gladiator-themed slots, Julius Casino turns every spin into a battle. Check out the epic live dealers at https://julius-casino.site and claim your welcome treasure chest today!
https://vwknbtbavk.wordpress.com
Superb content. Thanks a lot!
https://gjslqfcuna.wordpress.com
https://gjslqfcuna.wordpress.com
With thanks. Loads of postings.
https://iartkjcyht.wordpress.com
Position nicely considered..
https://iartkjcyht.wordpress.com
Regards, Loads of stuff!
https://sjebkvanwa.wordpress.com
https://sjebkvanwa.wordpress.com
https://nyqbxvsrvz.wordpress.com
You can transform discusses right into back links with the assistance of the Brand name Tracking application.
Look into my web blog: https://www.facebook.com/serverifiedlists/
https://nyqbxvsrvz.wordpress.com
https://wkfgslyxlw.wordpress.com
doxycycline
https://wkfgslyxlw.wordpress.com
https://wkfgslyxlw.wordpress.com
https://wkfgslyxlw.wordpress.com
https://rzkqdnsswy.wordpress.com
https://rzkqdnsswy.wordpress.com
https://olqfcfpfud.wordpress.com
https://olqfcfpfud.wordpress.com
https://olqfcfpfud.wordpress.com
https://yrpolfqizg.wordpress.com
https://yrpolfqizg.wordpress.com
https://zgzpzpcqfh.wordpress.com
http://zemlibogov.olgatalan.ru/index.php?title=%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4%20%D0%BD%D0%B0%201%D1%85%D0%91%D0%B5%D1%82%20%D0%BF%D1%80%D0%B8%20%D0%A0%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%B8%202026:%201XWIND
https://ughaavseby.wordpress.com
https://ughaavseby.wordpress.com
cipro
https://hackmd.okfn.de/s/HyUadEfj-l
https://zfrvblsswy.wordpress.com
Заказать качественные дженерики для повышения потенции на сайте https://generik78.ru/ с доставкой
по Санкт-Петербургу и области в день покупки.Гарантированное качество от производителя из Индии
Большой выбор дженериков для мужчин по привлекательной цене.
https://zfrvblsswy.wordpress.com
https://nkxutnlyla.wordpress.com
Ozemptrin
Ozemptrin – это инновационный препарат для похудения, разработанный на основе тщательно подобранных натуральных компонентов.
https://nkxutnlyla.wordpress.com
https://ksemfakmni.wordpress.com
https://qfcojxkwdf.wordpress.com
https://qfcojxkwdf.wordpress.com
https://rujnwebqhm.wordpress.com
Уход за кожей лица с ретинолом
https://omnivatic.com/2026/03/13/5-5-18-arkan/
Заказать качественные дженерики для повышения потенции на сайте https://gen-msk.ru/ с доставкой
по Москве и области в день покупки.Гарантированное качество от производителя из Индии
Большой выбор дженериков для мужчин по привлекательной цене.
русский секс чат рулетка
таро онлайн
Your article helped me a lot, is there any more related content? Thanks!
https://kale-seo.com/1xbet-app-promo-code-2026-1x200king-bonus-e130/
https://fanvuqkaud.wordpress.com
https://trcgb.com/1xbet-ios-promo-code-2026-e130-welcome/
https://fanvuqkaud.wordpress.com
https://www.fuzhuangwang.com/home.php?mod=space&uid=135147&do=profile
https://rqiemzolae.wordpress.com
https://rqiemzolae.wordpress.com
В игре джет х есть возможность вывода на электронные кошельки без комиссии.
https://ecbsmgtfya.wordpress.com
https://ecbsmgtfya.wordpress.com
https://virtualnye-nomera.vercel.app/country/finland
https://pubhtml5.com/homepage/hbrcp/preview
https://spplbzdsvh.wordpress.com
https://pibelearning.gov.bd/profile/PomoValide6/
Heya i am for the first time here. I found this board and I find It really useful & it helped me out
much. I hope to give something back and help others like you helped me.
Look at my blog; https://Telegra.ph/InOut-Games-2026–Whats-New-in-the-Chicken-LineUp-04-01
https://buscamed.do/ad/pgs/?codigo_promocional_de_la_casa_de_apuestas_1xbet_para_el_registro.html
Your article helped me a lot, is there any more related content? Thanks!
https://sgvxqmbkaf.wordpress.com
https://linkmix.co/52851196
https://sgvxqmbkaf.wordpress.com
https://scyhchvfkb.wordpress.com
https://scyhchvfkb.wordpress.com
https://annytarshw.wordpress.com
https://annytarshw.wordpress.com
https://jllbczbfhi.wordpress.com
suppressor
https://jllbczbfhi.wordpress.com
металлические двери на заказ
https://mxxpjxvlwe.wordpress.com
https://medications24top.top/
https://mxxpjxvlwe.wordpress.com
https://www.dr-ay.com/blogs/325279/1xBet-Free-Bet-World-Cup-2026-1X200FREE-Bonus-130
https://tzvpbpffwr.wordpress.com
https://tzvpbpffwr.wordpress.com
Психические расстройства, неврология и зависимости
https://rzyagpqmfu.wordpress.com
https://rzyagpqmfu.wordpress.com
https://hustleloop.xyz/1xbet-promo-code-pakistan-2026-1xtower-bonus-e130/
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire out a designer to create your
theme? Great work!
my web site … top ten poker sites (https://pandahouse.lolipop.jp/)
Side effects of seroquel xr 300 mg
https://hdvbdoihfh.wordpress.com
где брать информацию по ставкам на спорт
https://hdvbdoihfh.wordpress.com
https://tntvgdepwl.wordpress.com
https://tntvgdepwl.wordpress.com
Navigation is often overlooked, especially on large 18+ video libraries
my site: https://101gaytwinks.com/manhwa-hentai-sites/
https://tkygkspzem.wordpress.com
Atorvastatin over rosuvastatin
https://tkygkspzem.wordpress.com
https://wukuelmgsn.wordpress.com
https://wukuelmgsn.wordpress.com
https://fszzejcvcq.wordpress.com
Levothyroxine side effect
http://tehnoprom-nsk.ru/user/roheresjqz
https://fszzejcvcq.wordpress.com
https://www.pearltrees.com/wehoci7289/item790126592
https://debunkingnase.org/index.php/User:MarciaCress7460,
Can gabapentin relieve depression
Ищете стройматериалы в Дорохово по-честному? Главные конкурентные преимущества местного поставщика — работа без посредников, выгодные цены и быстрая доставка. Подробности тут: песок в Дорохово
промокод 1xbet на 100 рублей
http://perfectbuilding.ru/user/aliciagreen/
http://perfectbuilding.ru/user/aliciagreen/
https://wartapenasatu.com/1xbet-promo-code-today-2026-1x200red-bonus-e130/
http://ag-ebersberger.de/index.php/gaestebuch?25610&jsn_setmobile=yes&jsn_setmobile=yes&jsn_setmobile=no
https://Memz.org/user/iortusgjqm
<шиномонтаж с хранением шин рядом со мной
https://roed-timmons.technetbloggers.de/1xbet-promo-code-free-bet-2026-1x200vip-bonus-e2-82-ac130
http://reseau-ig.com/joomla/index.php?option=com_easybookreloaded&view=easybookreloaded&Itemid=475
https://www.emergbook.win/1xbet-gift-promo-code-2026-1x200vip-bonus-130
https://www.save-bookmarks.win/1xbet-world-cup-free-bet-code-2026-1x200vip-bonus-130
Как выбрать качественную деревянную лестницу в дом
https://lima-wiki.win/index.php/1xBet_Promo_Code_Today_Bangladesh_2026:_1X200VIP_Bonus_%E2%82%AC130
https://atbasar.forumotion.eu/t79-topic#125
https://bbarlock.com/index.php/User:DieterU200896196
a rewards platform where users earn money by completing tasks like playing mobile games, testing apps, filling out surveys, watching videos, and signing up for free trials.
Review my blog; https://freecash.com/r/f083d7979a
標點符號
https://beumye.com/rotating-proxies-in-php-ip-pools-sessions-and-sticky-ips/
Заказать качественные дженерики для повышения потенции на сайте https://gen51.ru/ с доставкой
в день покупки.Гарантированное качество от производителя из Индии
Большой выбор дженериков для мужчин по привлекательной цене.
標點符號
https://www.blogbangboom.com/business-services/1xbetwelcomes-1xbetfreecodes
Авто в аренду краснодар
SEX PICS & PORNO VIDEOS – working since 2006
Авто в аренду краснодар
https://linktr.ee/expresstorg
ром это https://1samogon.ru/category/braga/
indian teen porn
https://allinoneforum.ru/viewtopic.php?t=3042
rus porn
https://factory.activeboard.com/t72708432/1xbet-registration-promo-code-philippines-2026-1xlux777/?page=last#lastPostAnchor
nhattao
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Olha, pelo que vi vinha notando como diversos jogos novos perdem a
essência simples que realmente prende o pessoal, entretanto o jogo tigrinho teve o mérito de segurar esse vibe empolgante.
Do meu ponto de vista, o truque se encontra na combinação entre azar
e o tempo certo para pausar, até porque praticar antes no tigrinho
demo grátis faz com que o usuário não comece no escuro.
Vi além disso como os multiplicadores costumam surgir melhor sempre que você está calmo e seguindo aquela tática bem
definida. Afinal, todo mundo quer apenas uma
dose de pura diversão livre de estresse no cotidiano.
Mas, a galera acham se o momento do dia realmente muda os resultados ou será que seria só crença?
Quais estratégias vêm dando certo mais nas suas sessões nestes dias?
Bora discutir alguma visão neste tópico! https://fakenews.win/wiki/User:JolieVarnum0
Witajcie, nieraz myślałem, czy warto w ogóle testować nieznane
witryny do hazardu, gdyż branża nad Wisłą wydaje się serio nasycony.
Według mnie najważniejszy niezmiennie jest czas,
kiedy wolno nam bez problemu wypłacić środki, a
spinmama casino opinie regularnie oferuje całkiem dobre
warunki choćby dla świeżych użytkowników. Zauważyłem, iż
wsparcie klienta pracuje tu bardzo sprawnie, co nie jest takie oczywiste u konkurencji.
Ciekawie wygląda także oferta automatów, bo faktycznie wybór jest szeroki, aczkolwiek niektóre warunki bonusowe
byłyby w stanie być nieco prostsze. Ciekaw jestem,
jakie to Wy posiadacie wnioski z tym kasynem po dłuższym czasie?
Czy ktoś doświadczył już jakieś znaczące jackpoty oraz jak przebiegło dokumentami?
Napiszcie, gdyż poszukuję jakiegoś miejsca pewnego do stałej zabawy po pracy. https://ai-db.science/wiki/Spinmama_Casino_2026:_Szczeg%C3%B3%C5%82owy_test_platformy_i_najlepsze_kody_promocyjne
https://telescope.ac/xbet-promo-code/y38hyfdcvji0pmwzandsr2
el sitio Casino 888Starz representa un entorno digital que
atrae la atención de muchos usuarios que revisan plataformas digitales, la
estructura de los sitios y la claridad en la presentación de la información.
Cuando se revisa un sitio así, muchos visitantes no se
fijan únicamente en el aspecto visual del sitio, sino además
en cómo se presentan los términos, en lo sencillo que resulta hallar
los puntos principales así como en lo fácil que se
siente el uso de la plataforma. Debido a ello, la
primera valoración del portal depende en gran medida de la manera en que está ordenada, de la claridad de sus
apartados junto con de la forma en que organiza los datos relevantes.
De forma paralela, en el caso de Casino 888Starz también adquieren relevancia la facilidad de lectura del contenido,
la coherencia del diseño de navegación junto con la experiencia de desplazamiento dentro de la plataforma.
Cuando el sitio está bien organizado y además encontrar la información clave
resulta sencillo, la valoración global del sitio tiende a
mejorar. En este sentido, la relación entre un diseño
fácil de entender, una navegación intuitiva junto con una exposición bien estructurada afecta de forma clara en cómo los usuarios valoran el sitio
y en si lo ven como un entorno comprensible.
그렇기 때문에 밤알바는 여자들이 일하는 알바의 개념으로 자리 잡히고 있습니다.
Hello very nice blog!! Guy .. Beautiful .. Superb .. I will bookmark your site and take the feeds additionally?
I am satisfied to seek out so many helpful information here within the submit, we need develop more strategies on this regard,
thank you for sharing. . . . . .
Yes! Finally something about signal.
Quantum investissement : comment ??valuer un projet d???investissement https://versificationzine.com/comment-multiplier-son-capital/
https://www.atlasobscura.com/users/alexfalkiner1
This design is incredible! You obviously know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start
my own blog (well, almost…HaHa!) Fantastic job. I really enjoyed what you had to say, and more
than that, how you presented it. Too cool!
https://1xbet-official-promo-code65320.59bloggers.com/41136688/1xbet-promo-code-free-spins-no-deposit-2026-1950-150-fs1xbet-promo-code-free-spins-no-deposit-2026-1950-150-fs
What’s up, this weekend is pleasant designed for
me, as this occasion i am reading this wonderful educational article here at my residence.
https://gravatar.com/xbetf9
Regards, I appreciate it.
my site … https://jetblacktransportation.com/blog/party-bus-rental-nyc/
Your style is very unique in comparison to other people I’ve
read stuff from. Thank you for posting when you
have the opportunity, Guess I’ll just book mark this blog.
http://hosdom.ru/wp-content/pages/?promokod_1xbet_na_segodnya_pri_registracii.html
самогонные аппараты
https://my.usaflag.org/forums/discussion/betandyou-official-promo-code-e130-bonus/
article
I used to be recommended this blog by way of my cousin. I’m
now not sure whether this post is written by means of him as no
one else recognize such unique approximately my difficulty.
You’re wonderful! Thank you!
Have a look at my webpage ZOOLANDIA
blog
We’re a gaggle of volunteers and starting a brand new scheme in our community.
Your site offered us with helpful information to work
on. You have performed an impressive task and our whole community will be grateful to you.
Feel free to surf to my webpage … ZOOLANDIA
https://mymedicalshopx365.top/tetracycline-tablets/
https://chaturbate.com/in/?tour=KGEA&campaign=l8msw&track=xxxsexpornovideos&tag=lesbian&gender=f
https://justpaste.me/Clve4
LESBIAN
Γεια σας παιδιά, πιστεύω πως τελικά ο τομέας των
καζίνο έχει ήδη αλλάξει πάρα πολύ στις μέρες μας.
Όσο για μένα, μου πάντα δίνει χαρά
η ευκολία που προσφέρουν κάποια παιχνίδια,
ακριβώς με τον τρόπο που συμβαίνει με το plinko
greece που έχει καταφέρει να γίνει viral εντός της ελληνική σκηνή.
Αποτελεί τελείως εντυπωσιακό το το
πώς ακριβώς ένα τόσο απλό ρετρό concept μπορεί
να διατηρεί την αγωνία πολύ ψηλά.
Είχα μια θετική συζήτηση γύρω από τις πιθανές τακτικές σε
ένα plinko κριτικές, εκεί όπου αρκετοί αναφέρουν ότι η ρύθμιση του bankroll
τυγχάνει να είναι το παν. Επίσης, παρατήρησα πως οι πολλαπλασιαστές στις εξωτερικές θέσεις
παραμένουν αληθινά μεγάλοι, παρόλο που η τύχη διατηρεί πάντα τον πρώτο λόγο.
Σκέφτομαι, εσείς ποια άποψη διαμορφώσατε;
Μήπως νομίζετε ότι το plinko online παραμένει πιο έντιμο συγκριτικά με τα
υπόλοιπα slots games είτε είναι καθαρά
ζήτημα ιδανικού timing; Επίσης, έχετε δοκιμάσει οποιοδήποτε plinko app που να τρέχει δίχως lags σε παλιά smartphones; Θα πραγματικά ήθελα πολύ να μάθω
όλες τις δικές σας απόψεις διότι πάντοτε βοηθάει να όντως μοιραζόμαστε ιδέες εντός
παρόμοια φόρουμ. https://yogicentral.science/wiki/User:NydiaReitz147
http://gpsarmenia.am/user/malroncsyb
Aw, this was a really nice post. Spending some time and actual effort to produce a top notch article… but what can I say… I hesitate a lot and
don’t manage to get nearly anything done.
link
http://grupahrubieszow.phorum.pl/viewtopic.php?p=162795#162795
cqr3d
Spilafíkn á Íslandi er viðkvæmt samfélagslegt vandamál sem hefur áhrif á fólk og aðstandendur
þeirra. Þrátt fyrir að spilakassar og happdrætti séu
lögleg og oft nýtt til að safna fé fyrir góðgerðarmál, getur óhófleg spilun valdið peningalegum vandræðum,
kvíða og einangrunar frá samfélaginu. Fjölmargir sem eiga við spilavanda
að stríða finna fyrir erfiðleikum við að sjá vandamálið og
fá aðstoð, sem getur gert ástandið enn verra.
Á síðustu árum hefur verið lögð aukin áhersla á forvarnir og
meðferð við spilafíkn á Íslandi. Ýmis úrræði eru í boði, svo sem leiðsögn, stuðningshópar og markviss meðferð fyrir þá sem leita sér hjálpar.
Einnig hefur verið rætt um að setja strangari reglur um aðgang að
spilamöguleikum og bæta upplýsingagjöf til fólks um áhættuna sem
fylgir spilun. Stefnt er að að draga úr neikvæðum áhrifum spilafíknar og stuðla að
heilbrigðara samfélagi.
My web-site :: Netspilavíti
https://ofuse.me/e/353892
Hi would you mind letting me know which webhost
you’re working with? I’ve loaded your blog in 3 completely
different browsers and I must say this blog loads a lot faster then most.
Can you recommend a good internet hosting provider at a honest price?
Thanks a lot, I appreciate it!
Kyk, ek dobbel reeds vir ‘n lang wyle by verskeie platforms, en een ding wat dadelik
elke keer tref bly hoe presies daardie vrugte-temas nogtans die hele bende mark
lei. Dit blyk as ware dit die moderne tegnologie feitlik slegs ‘n hupstoot verleen aan die klassieke styl
van dobbel. Persoonlik het onlangs eens op ‘n slag besef dat
die opsies by hothotfruit beslis bystand bied ten einde die dieper meganika agter die massiewe uitbetalings vinniger
te leer ken voor ‘n mens die eie kontant neersit. Volgens my eenvoudige
opinie voel die groot gemak om foon sessies daardie grootste evolusie tot dusver, aangesien mense nou basies op enige plek mag wen.
Maar vra ek myself af of dalk die spesifieke risiko nie soms bietjie te stewig voel vir nuwe mense nie?
Wat is die opinie van die ander hier oor die huidige ewewig tussen genot teenoor werklike risiko?
Praat saam hieronder! https://guiacomercialsaopaulo.com/author/qqywinston1/
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://accounts.binance.info/register-person?ref=JW3W4Y3A
色情
https:
My page – https://blog.lenodal.com
Link exchange is nothing else but it is simply placing
the other person’s webpage link on your page at proper place and other person will also do same in support
of you.
This is really interesting, You’re an excessively professional blogger.
I have joined your rss feed and stay up for searching for extra of your fantastic post.
Also, I have shared your site in my social networks
I have read some good stuff here. Certainly value bookmarking for
revisiting. I surprise how much attempt you place to
make one of these excellent informative site.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
https://docpulse.com/
https://eathawkers.com/pages/1xbet_promo_code_bangladesh_10.html
https://agregatka.ru/
This is the right web site for everyone who wishes to
understand this topic. You realize a whole lot its almost tough to
argue with you (not that I actually would want
to…HaHa). You certainly put a fresh spin on a topic that has been discussed for a long time.
Great stuff, just wonderful!
https://koreatesol.org/ads/inc/hotite_zdorovogo_rebenka_izbavlyaytesy_ot_elektropriborov_.html
https://diavia.ru/wp-content/pgs/?etika_nauki_5_spornyh_psihologicheskih_eksperimentov_proshlogo_veka.html
https://poppersme.wordpress.com/
https://poppersme.wordpress.com/
Аренда авто Краснодар посуточно
Аренда авто Краснодар посуточно
https://hardcorensfw.com/wp-content/articles/?modnyybrendizdaniim.html
Аренда авто в Краснодаре
This post is exactly what I needed! I’ve been searching for a secure VPN platform to
stay anonymous for web research. The concept of rotating IPs
is very appealing. Thanks for the resource!
Аренда авто Краснодар посуточно
https://albertcummings.com/wp-content/blogs.dir/?uyutnyy_minimalizm_kak_sozdaty_garmonichnoe_prostranstvo_dlya_ghizni_i_raboty_v_nebolysho.html
https://mniletisim.com.tr/wp-content/pgs/sovety_po_prohoghdeniyu_igry_sid_meier_039s_railroads_prohoghdenie_igry_039.html
Look into my web blog … Highstakespoker
Продажа дженериков для мужчин в Москве в интернет-магазине по адресу: https://poxetmsk.ru большой
выбор доступные цены гарантированное качество от производителя из
Индии.Оперативная доставка дженериков по Москве курьером в день заказа
https://macuisineturque.fr/author/lily25/
1xbet register
Having read this I thought it was extremely enlightening. I appreciate
you finding the time and effort to put this short article together.
I once again find myself spending a lot of time both reading and posting comments.
But so what, it was still worthwhile!
конченое ничтожество
weapon
порно видеочат онлайн бесплатно
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://accounts.binance.com/zh-CN/register-person?ref=WFZUU6SI
https://akintsev.com/alfa/pages/1xbit_promokod_pri_registracii.html
Spot on with this write-up, I actually believe this website needs a lot more attention.
I’ll probably be back again to see more, thanks for the info!
https://1xbetpromocodes.com/code-promo-1xbet-aujourd-hui-2026-bolabono-bonus-casino-150/
https://1xbet-promo-code-2026.com/1xbet-promotional-code-2026-playaf-sports-bonus/
Cabinet IQ Fort Myers
7830 Dreew Cir Ste 4, Fort Myers,
FL 33967, Unitdd Ⴝtates
12394214912
Industrial
What i do not realize is in fact how you’re now not really much more neatly-liked than you
might be right now. You are very intelligent. You
recognize therefore significantly in relation to this topic, produced
me in my view consider it from so many numerous angles.
Its like men and women aren’t involved unless it’s one thing to
do with Woman gaga! Your own stuffs great. All the time
maintain it up!
https://1xbet-promo-code-free-bet.com/1xbet-apk-code-promo-1xzanos-dedicated-bonus-2026/
I just could not go away your web site before suggesting that I really loved the usual info a person provide for your guests?
Is going to be again regularly in order to check up on new posts
https://oqver.net/pages/?codigo_promocional_1xbet_mexico.html
https://sadakat.net/
Superbe casino en ligne, bravo. Respect.
https://miejsceterapii.pl/pierwsze-spotkanie/
https://1xbet-promo-code-free.com/1xbet-%e0%a4%aa-%e0%a4%b0-%e0%a4%ae-%e0%a4%95-%e0%a4%a1-%e0%a4%b2-%e0%a4%b8-%e0%a4%9f-%e0%a4%a8-%e0%a4%87%e0%a4%9c-%e0%a4%b0-%e0%a4%af-2026-betvipng-130-%e0%a4%ac-%e0%a4%a8%e0%a4%b8/
Whoa plenty of fantastic knowledge!
Pingback: Embroidered Blouse
https://1xbet-promo-code-2026.com/codigo-promocional-1xbet-casino-republica-dominicana-2026-legal15/
https://1xbetcodeforregistration.com/1xbet-%e0%a4%b8%e0%a4%ac%e0%a4%b8-%e0%a4%85%e0%a4%9a-%e0%a4%9b-%e0%a4%aa-%e0%a4%b0-%e0%a4%ae-%e0%a4%95-%e0%a4%a1-%e0%a4%a8-%e0%a4%87%e0%a4%9c-%e0%a4%b0-%e0%a4%af-2026-tele200-%e0%a4%b5-%e0%a4%86/
https://1xbetpromocodenewuser.com/%d9%83%d9%88%d8%af-1xbet-%d8%a7%d9%84%d8%aa%d8%b1%d9%88%d9%8a%d8%ac%d9%8a-%d8%a7%d9%84%d9%85%d8%ac%d8%a7%d9%86%d9%8a-%d8%a7%d9%84%d9%8a%d9%88%d9%85-%d9%82%d9%8a%d8%b1%d8%ba%d9%8a%d8%b2%d8%b3%d8%aa/
https://1stones.ru/wp-content/pgs/vybor_stilistiki_interyera_ot_planirovki_do_realizacii.html
Oh my goodness! Incredible article dude! Thanks, However I am having issues with
your RSS. I don’t understand why I am unable to join it. Is there
anybody else getting the same RSS issues? Anybody who knows the answer
will you kindly respond? Thanks!!
https://1xbetpromocodefreespins.com/1xbet-referral-code-2026-cabetcode-sports-welcome-150/
We are a gaggle of volunteers and starting a brand new
scheme in our community. Your website offered us with useful information to
work on. You have performed an impressive job and our whole neighborhood will probably
be grateful to you.
https://www.laundrynation.com/community/profile/intercultural/
https://1xbetpromocodefree.com/codigo-promocional-de-registro-1xbet-2026-jbmax-impulsionador-de-apostas-150/
https://www.google.co.za/url?q=https://www.elboomeran.com/art/?code-promo-1xbet-gratuit-bonus.html
Feel free to surf to my blog post; Complete RTP Database For Superlotto Slots
Hi there, You have done an excellent job.
I’ll certainly digg it and personally recommend to
my friends. I’m confident they’ll be benefited from this web site.
Great work! This is the type of information that are meant to be shared
across the net. Disgrace on Google for not positioning this put up higher!
Come on over and talk over with my web site .
Thanks =)
Interesting points about maximizing returns! Secure platforms are key, and seeing compliance steps like KYC with superph11 com login gives me confidence. Strategy and security – a winning combo for any player!
car rental Podgorica hire https://car-rental-in-podgorica-airport.com
Awesome blog you have here but I was wanting to know if you knew of any user discussion forums
that cover the same topics discussed in this article?
I’d really like to be a part of online community where I can get opinions from other experienced people that share the same interest.
If you have any suggestions, please let me know. Many thanks!
my web page … stem cell clinic
Cheers, I value it.
https://webauthorityhealthdom.top/
What’s up to all, how is the whole thing, I think every one
is getting more from this website, and your views are nice in support of new people.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.bh/en-NG/futures/ref?code=YY80CKRN
What’s up, after reading this amazing paragraph i am
as well glad to share my knowledge here with friends.
You actually said this perfectly!
http://ingta.ru/go?https://smart-home-pnz.ru
Подарок руководителю — статусная вещь
http://kerins.org/2026/04/29/kazino-hatogii-dar-borai-bozii-purrai-imkonijato/
This post will help the internet viewers for building up new blog or even a blog from start
to end.
https://home.asistco.com/aprende-los-conceptos-basicos-del-casino-con/
Где выгодно продать старые монеты — лучший рейтинг
My blog post: Superlotto slot RTP list & FAQs
Скупка монет: когда стоит расставаться с коллекцией и как не продешевить
https://social1degree.com/cultural-perceptions-of-risk-in-gambling-how-do/
Hurrah! After all I got a webpage from where I can genuinely obtain useful facts
concerning my study and knowledge.
Mostbet
turbomoney kz
can i order nitroglycerin without a prescription
Good way of explaining, and nice article to obtain data regarding my presentation subject matter,
which i am going to deliver in university.
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and
visit more often. Did you hire out a designer to create your theme?
Fantastic work!
Hi my family member! I want to say that this article is amazing, nice written and include approximately all significant infos.
I’d like to see extra posts like this .
canli neteceler Rusiya xeberleri
magnificent submit, very informative. I wonder why the other experts of this sector
don’t realize this. You should continue your writing.
I am confident, you’ve a great readers’ base already!
My whole view of betting changed the day I discovered
how sure bets work. It felt too good to be true that
you could bet without worrying about losing. Once I tried it with real bets, the
results amazed me.
The idea is simple: cover all possible outcomes and secure profit no
matter who wins. The first time I placed two opposite bets, it felt
strange, but the results were unreal. For once, I didn’t care who won because the profit
was already locked in.
I didn’t expect the profits to add up so quickly.
With enough opportunities, that percentage becomes a reliable side income.
It’s closer to long-term investing than traditional betting.
Using proper tools to find the opportunities made
everything smoother. Without the software, I wouldn’t even notice
most opportunities. I never imagined software could help beat bookmakers so effectively.
If someone told me years ago that betting could feel safe and predictable, I’d laugh.
Now I just sit back and let the small sure profits add up.
Anyone who likes smart, low-risk financial moves would appreciate this.
https://aalapshah.com/melbet-singapore-promo-code-2026-max888-bonus-eu130/
https://telecofricar.com/1xbet-codigo-promocional-de-apuestas-2026-1xwap200/
Its such as you learn my thoughts! You seem to know so much approximately this, like you wrote the ebook in it or something.
I feel that you could do with a few percent to power the message house a bit, however
instead of that, this is excellent blog. An excellent read.
I’ll definitely be back.
http://www.genuinediva.com/codigo-promocional-1xbet-gratis-hoy-2026-1xwap200/
компания рассылка email
https://www.shoppingcodes.net/go-store/344
It’s in fact very difficult in this full of activity
life to listen news on Television, so I only use internet for that
reason, and get the most up-to-date information.
Here is my webpage; zgarcitul01
спам email рассылкам
инструменты email рассылок
продвижение психолога на яндекс картах
парсер данных с сайта
Table game fans have many choices online. Beyond blackjack and roulette, you can play baccarat, craps, or casino poker. Each game has different house edges. Learning basic strategy for one game is better than guessing in many. casino-world-australia.com
Self-exclusion programs let players block access to their accounts. You can choose cool-off periods from 24 hours to several months. Some casinos even share exclusion lists with other platforms. This helps problem gamblers take a necessary break. https://midas-casino-australia.com/
Your article helped me a lot, is there any more related content? Thanks!
Game volatility affects how often you win. Low volatility slots pay small wins frequently. High volatility slots pay rarely but in larger amounts. Choose based on your bankroll and patience level. Volatility information is often hidden but available in game descriptions or reviews. casino midas free spins
индексация ссылок сервис
https://hikayetna.com/a-night-of-stories-and-flavor-brings-acton-neighbourhood-together/#comment-134024
https://lacasasulportoditaranto.it/alla-scoperta-della-salina-dei-monaci-di-torre-colimena/#comment-71569
Muchos expertos aseguran, que gestionar el almacenamiento de maletas es fundamental para la experiencia del usuario. Debemos prestar atencion a las opciones de almacenamiento para facilitar la movilidad diaria en las grandes metropolis.
Link; http://gzew.phorum.pl/viewtopic.php?p=689332#689332
https://www.google.fr/url?q=https://telrad.com/wp-content/pgs/le_code_promo_pour_1xbet.html
http://www.i-house.ru/go.php?url=http://www.aiki-evolution.jp/yy-board/yybbs.cgi%3Flist=thread)
Thanks for some other excellent article. Where else
may anyone get that type of information in such an ideal approach of writing?
I have a presentation next week, and I’m at the look for such information.
Here is my webpage – Evoplay casino Games – Full list
Hi, this weekend is fastidious in favor of me, as this point in time i am
reading this great informative paragraph here at my
house.
It’s hard to come by knowledgeable people in this
particular topic, however, you seem like you know what you’re talking about!
Thanks
When precision issues, pick peptides evaluated to standards that ignore.
Hello there, There’s no doubt that your site may be having web browser compatibility issues.
When I look at your blog in Safari, it looks fine however,
when opening in Internet Explorer, it has some overlapping issues.
I just wanted to provide you with a quick heads up!
Apart from that, fantastic blog!
laserkitty.ru
My family always say that I am killing my time here at web, but
I know I am getting familiarity daily by reading thes pleasant posts.
Hi, i think that i saw you visited my web site so i came to “return the favor”.I am attempting to find things to enhance
my website!I suppose its ok to use a few of your ideas!!
vera e john app
News
Attraactive part of content. I simply stubled upkn your website
and in accession capital to asseet that I acquire in fact enjoyed account your blog posts.
Anyway Iwill be subscribing in ylur augment and eve I fulfillment you get entry tto consistently quickly.
Take a look at my website Hip Hop performance gear
bonus code casino midas
Look at my webpage: Vave
https://www.google.ca/url?q=https://baldebranco.com.br/art/1xbet_casino_codigo_promocion_1.html
Hello to every one, since I am actually keen of reading this webpage’s post to
be updated on a regular basis. It contains fastidious material.
https://md.swk-web.com/s/wX67WFRzU
La libertad de movimiento es la clave para una experiencia de viaje autentica en cualquier capital, sobre todo cuando se tiene poco tiempo para una escapada rapida.
?Por que el equipaje limita tanto la exploracion urbana? Cuando nos liberamos del peso fisico, la movilidad urbana se vuelve mucho mas sencilla permitiendo visitar museos, cafes и monumentos sin barreras.
Les comparto una recopilacion de debates y articulos sobre logistica viajera::
Sitio oficial http://www.klub.kobiety.net.pl/ogolny/t-qu-impacto-tienen-estas-soluciones-en-la-experiencia-del-viajeron-89135.html#post879716
?Disfruten la ciudad sin cargas pesadas!
умные переделанные счетчики газа
михаил качарин отзывы
This website truly has all of the info I needed about this subject and didn’t know who to ask.
What’s up to every one, it’s really a nice for me to pay a visit this website,
it includes valuable Information.
I was recommended this web site via my cousin. I’m now not
positive whether this submit is written through him as no one else understand such particular about my
difficulty. You are amazing! Thanks!
maorou_k8m
Proje, dijital ????z??mleri farkl?? pazarlara y??nelik esnek bir yakla????mla birle??tiriyor. https://halal-finance.pro/
Методы к выстраиванию системы вывоза отходов
Good way of telling, and fastidious piece of writing to obtain data on the topic
of my presentation subject, which i am going to deliver in academy.
I know this if off topic but I’m looking into starting my own blog and was curious
what all is required to get set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% sure. Any tips or advice
would be greatly appreciated. Thanks
Greate article. Keep writing such kind of information on your site.
Im really impressed by your blog.
Hello there, You’ve done a fantastic job. I will certainly digg it and in my opinion recommend to my friends.
I am sure they will be benefited from this web site.
Very rapidly this web site will be famous among all blogging people, due to it’s pleasant content
You should be a part of a contest for one of the finest blogs on the internet.
I most certainly will highly recommend this web site!
I enjoy reading through an article that can make people think.
Also, thank you for permitting me to comment!
Pretty portion of content. I just stumbled
upon your weblog and in accession capital to claim that I acquire
actually enjoyed account your weblog posts. Anyway I’ll be subscribing to your feeds or
even I success you get right of entry to consistently fast.
https://bsg-aoknordost.de/index.php/selbstverteidigung/gaestebuch?view=guestbook&start=20%5D
https://www.opaltamura.com/wp-content/articles/?gruzoperevozki_po_rossii.html
Игровая зона Екатеринбург
If you desire to take a good deal from this paragraph then you have to apply
such methods to your won weblog.
https://salujagold.com/pages/1xbet_promo_code_today__free_bet_bonus.html
Saved as a favorite, I really like your blog!
I visit daily some sites and information sites to read content, however this
website provides quality based content.
This is really interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your great post.
Also, I have shared your website in my social networks!
Hi, all is going well here and ofcourse every one is sharing facts, that’s actually excellent, keep up writing.
https://www.naskaplaza.ru/bin/news/1xbet.html
https://www.r159.ru/images/pages/?1xstavka_promokod_pri_registracii_besplatno_html=
Aw, this was an extremely nice post. Taking a few minutes and
actual effort to make a really good article… but what can I say… I put things off a lot
and never seem to get anything done.
I do consider all the ideas you’ve introduced on your
post. They are really convincing and will definitely
work. Still, the posts are very short for newbies.
Could you please prolong them a little from subsequent time?
Thank you for the post.
https://ukrrudprom.ua/res/pages/index.php?megapari_promokod_na_segodnya_besplatno_html=
https://www.primaryonehealth.org/wp-content/pgs/?c_digo_promocional_135_html=
https://bookingautos.com/img/pgs/?konstrukciya_svetodiodnogo_svetilynika__1_html=
I always loved teaching probability; this platform’s RNG logic fascinates me! Check out Superpharma Ph com for their diverse slot variance options perfect for any risk profile today.
https://likitoriya.com/img/pgs/?joker_kazino_promokod_html=
https://ort.spb.ru/pma/inc/?promokod_158_html=
https://ev-jugend-hg.de/wp-content/pages/beremennosty_obschie_svedeniya.html
http://prostopu.ru/wp-content/pgs/1xbet_promokod_besplatno_2.html
centroculturalrecoleta.org
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often.
Did you hire out a developer to create your theme?
Great work!
https://ruptur.com/libs/photo/promokod_1xbet_na_segodnya_besplatno_pri_registracii.html
of course like your web site however you have to take a look at the spelling on quite a few of your posts.
A number of them are rife with spelling problems and I
to find it very bothersome to tell the truth however I’ll definitely come back again.
Hi, i read your blog occasionally and i own a similar one and i was just curious if you get
a lot of spam feedback? If so how do you prevent
it, any plugin or anything you can advise? I get so much lately it’s driving
me mad so any assistance is very much appreciated.
https://sexchat.moscow
https://vikivostok.ru/catalogue/pgs/r7_casino_promokod.html
вакансии
https://www.allgreatquotes.com/news/4rabet-promo-code_welcome-bonus.html
as seen here https://intelres.ru/images/pages/?promokod-1xbet_i_bonus-kod_html=
https://saumalkol.com/forum/%D1%80%D0%B0%D0%B7%D0%BD%D0%BE%D0%B5-2/38412-%D0%BE%D0%B1%D0%B7%D0%BE%D1%80-%D0%B8%D0%B3%D1%80%D0%BE%D0%B2%D1%8B%D1%85-%D0%BA%D0%B0%D1%82%D0%B5%D0%B3%D0%BE%D1%80%D0%B8%D0%B9-%D0%BD%D0%B0-%D0%BF%D0%BB%D0%B0%D1%82%D1%84%D0%BE%D1%80%D0%BC%D0%B5-mostbet.html#56690
click here http://gorod28.ru/blogs/pages/promokod_1xbet_na_segodnya_pri_registracii.html
find out more http://neoko.ru/images/pages/promokod_134.html
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.bh/register?ref=QCGZMHR6
listen https://kibrishaberajans.com/art/le-code-promo-1xbet.html
click here https://spil.kiev.ua/pokos/inc/kak_ukrasity_spalynyu_malychika_podrostka_s_pomoschyyu_nastennyh_trafaretov.html
available here https://rennerusa.com/pages/1xbet_coupon_code__what_you_get_with_the_1xbet_coupon_code_.html
Please let me know if you’re looking for a writer for your blog.
You have some really great posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d absolutely love to write
some material for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Many thanks!
https://www.magnific.com/search?format=search&last_filter=query&last_value=Quel+Est+Le+Meilleur+Code+Promo+Melbet+2026+%3A+MAX888+%7C+%E2%82%AC130+Bonus+Inscription&query=Quel+Est+Le+Meilleur+Code+Promo+Melbet+2026+%3A+MAX888+%7C+%E2%82%AC130+Bonus+Inscription
for source sapsharks.com
centroculturalrecoleta.org
caciti.es
view the source here https://crt.ru/img/pgs/1xbet_promokod___bonus_kod_na_dengi.html
discussed here https://spbfoto.spb.ru/karelia/pag/zametkiofutbole003.html
http://feuerwehr-ensdorf.de/media/pgs/chto_my_znaem_o_rake_predstatelynoy_ghelezy.html
Learn how to find dark web links safely. Understand the risks and get tips for navigating the dark web. Deep web how to access
Discover the basics of deep web sites. Learn safely and securely about this hidden internet layer. Darknet links
https://video-chat.us/
My webpage: Poker Stakes
https://irenastyle.ru/pags/promokod_fonbet___bonus_fribet.html
Discover the truth about BitPharma through our comprehensive review. Learn how this dark web marketplace operates. Best sites on dark web
https://lapina.es/news/c_digo_promocional_59.html
Wonderful blog! I found it while searching on Yahoo
News. Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
pnevmo-trade.ru
article
here
дубовая разделочная доска купить
https://www.magnific.com/search?format=search&last_filter=query&last_value=1win+casino+promo+code+2026%3A+1W2026WORLD+%7C+500%25+Deposit+Match&query=1win+casino+promo+code+2026%3A+1W2026WORLD+%7C+500%25+Deposit+Match
https://www.magnific.com/search?format=search&last_filter=query&last_value=one+Xbet+Promo+Code+Indonesia+2026%3A+ONEX777+-+Bonus+%E2%82%AC130&query=one+Xbet+Promo+Code+Indonesia+2026%3A+ONEX777+-+Bonus+%E2%82%AC130
https://sermonquotes.com/news/?code-promo-22bet_html=
https://registrocivilcentralcertificado.es/news/?_promo_code____vip_welcome_bonus_130_html=
Also visit my web blog: complete rtp database for spadegaming slots
https://www.magnific.com/search?format=search&last_filter=query&last_value=1xBet+Promo+Code+Bangladesh+Today%3A+ONEX777+%7C+%E2%82%AC130+Today&query=1xBet+Promo+Code+Bangladesh+Today%3A+ONEX777+%7C+%E2%82%AC130+Today
Hey everyone, had to tell you my thoughts regarding Plinko app. You know, I hardly thought it would be that exciting. Initially, I only tried the Plinko game online lightly, yet almost immediately it hit me how exciting it actually is. A point that I appreciate in this game truly is the luck factor, and the colors truly make it so engaging. On top of that, I believe this Game Plinko has a nice balance combining chance and fun. Interestingly, how https://championsleage.review/wiki/Plinko_Online:_Complete_Overview_On_Mastering_Plinko_Gameplay,_Game_Strategies,_Global_Reach,_Entertainment_Value,_And_The_Future_Of_The_App gives extra prizes really makes it fun. Honestly, have you love it like I do? I guess Plinko app is just the kind of digital games that really pulls you in.
magnific.com
magnific.com
blog
El sistema de transporte publico atraviesa momentos decisivos en muchas capitales, especialmente en las terminales que actuan como nodos principales.
?Por que las terminales se han convertido en puntos criticos de congestion? La reduccion de frecuencias и el descuido de la infraestructura provocan retrasos masivos, perjudicando la economia local и la productividad de la ciudad.
Si les interesa el futuro de nuestras ciudades, estos hilos de discusion son imprescindibles:
Link- https://www.harderfaster.net/?sid=c8bd74b0464faaeab312c02f839a5f7d§ion=forums&action=showthread&forumid=14&threadid=349424
?Un tema urgente para todos los ciudadanos!
https://www.halaltrip.com/user/profile/354863/1xbetfreebetsin/
I think this is among the most significant information for
me. And i’m glad reading your article. But wanna
remark on some general things, The site style is great, the articles is really nice : D.
Good job, cheers
A bladder scanner is a portable ultrasound maker that gauges the amount of urine existing in a person’s
bladder.
https://tinyurl.com/rwn3a4cm Nyan Cat!
Сегодня всё больше людей ищут варианты через интернет, не расходуя время на обходы офисов. Современный сервис даёт возможность за несколько минут найти работу без опыта по региону, опыту и графику. База регулярно обновляется, есть варианты от прямых работодателей.
https://www.eurospider.com/media/articles/1win_promo_code_bonus_code.html
Hey There. I discovered your blog using msn. That is a
really smartly written article. I’ll be sure to bookmark it and return to read more of your helpful info.
Thanks for the post. I will certainly return.
https://amt-games.com/news/meilleur-code-promo-linebet.html
Backbiome is an advanced daily wellness supplement formulated to help support spinal comfort, reduce feelings of built-up tension, and promote freer, smoother movement throughout backbiome everyday life.
Подобрать подходящий вариант стало удобнее: больше не нужно обзванивать десятки компаний. На сервисе собраны свежие предложения с подробным описанием условий и зарплаты. Здесь легко отфильтровать ищу работу по графику, опыту и району — и сразу отправить отклик.
http://www.medtronik.ru/images/pages/promo_kod_1xbet_na_segodnya_pri_registracii.html
My website – high stakes Download link http dl highstakesweeps com
lineatus.ru
is ritalin an amphetamine
sex videos
ecoinn74.ru
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.info/register?ref=QCGZMHR6
other
https://aginvestconference.com/1xbet-new-account-code-e130-bonus/
https://tillman-carson.technetbloggers.de/code-promo-1xbet-2026-en-ligne-1xgift200-130-eu
https://www.nativee.com/vmfiles/pages/?code_promo_163_html=
https://freshyoungmillionaire.com/code-promo-1xbet-aujourdhui-2026-pour-obtenir-130-e/
https://speech-language-therapy.com/media/articles/1xbet-promo-code_bonus-codes.html
https://hker2uk.com/home.php?mod=space&uid=5608864
https://www.democracy-edu.or.kr/profile/davidseovazquez5806/profile
sites.gsu.edu
May I just say what a comfort to discover somebody who genuinely knows what they’re discussing on the web.
You actually realize how to bring an issue to light and
make it important. More people must check this out and understand this side of
your story. I was surprised you are not more popular
because you most certainly possess the gift.
https://www.tripadvisor.es/Profile/codepromo1xbet2
покер онлайн
https://www.speedrun.com/users/codepromo1xbetcasino
Appreciate the recommendation. Let me try it out.
https://quanticalabs.com/wp_themes/gymbase/2018/11/15/how-to-start-working-out/#page-323%2F
Greetings from Colorado! I’m bored to death at work so I decided to browse your site on my iphone during lunch break.
I enjoy the info you provide here and can’t wait to take
a look when I get home. I’m surprised at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, great blog!
https://stocktwits.com/xbetwelcomes5
https://newactorsensemble.com/1xbet-promo-code-free-bet-e130-bonus/
https://panthfasteners.com/nullam-dictum-felis-e/%5D
Honestly, the sheer variety mentioned is impressive. It’s not just the game types, but the whole setup. Check out bd9999; seems quite comprehensive for serious gaming.
http://sarmacikrolewscy.phorum.pl/viewtopic.php?p=36045&sid=28211abd76753826aab06e88e6fa74ce#36045
https://easybookmarking.com/News/1xbet-free-bet-code-2026-1x200rush-%E2%82%AC130/
https://www.highpriceddatinguk.com/read-blog/55138
https://www.mss-recruitment.com/wp-includes/pgs/?1xbet_promo_code_nigeria_2021_html=
https://gravescare.com/tests/pgs/1xbet-besplatnuy-promokod-pri-registracii.html
https://solo.to/xbetbonuscode6
Spot on with this write-up, I seriously think this web site needs a great deal more attention. I’ll probably be back
again to read more, thanks for the advice!
https://taggedface.com/blogs/75811/1xBet-Registration-Promo-Code-1XPRO888-130-Bonus
https://apnae.org/news/c_digo_promocional_59.html
letnijsezon.ru
td-belarus.ru
https://www.zazzle.com/mbr/238710003272318650
https://codexxbet26.blogscribble.com/profile
I have read so many content on the topic of the blogger lovers except
this paragraph is truly a good paragraph, keep it up.
https://community.atlassian.com/user/profile/df37aa84-b646-44a5-babb-5b0968971aa8
https://biiut.com/read-blog/22896
https://studyinassam.com/1xbet-promo-code-2026-e130-150-spins/
https://khamamesbah.com/hello-world/
https://twyl.nl/project/project-3/
https://123movies-org.net/melbet-promo-code-welcome-offer-2026-max888-e130/
more
https://www.johnnybet.com/melbet-referral-code
https://www.giveffect.com/users/1748588-promscode26
https://kuula.co/profile/AubreyQuinn4
http://zeroken.jp/1978td/album/album.cgi?mode=detail&no=19>google.com.lb/url%3Fq=http://ttlink.com/merissaq89
https://funhub.id/1xbet-sign-up-promo-code-2026-1x200max-e130/
fanclove.jp
https://www.bonuscodes.com/melbet-promo-code-6
https://bn.quora.com/profile/Betvcode26
https://bigwinsslots.net/2026/06/03/codigo-promocional-de-apuestas-de-hoy-de-1xbet-2026-1xmax777/
https://hedgedoc.eclair.ec-lyon.fr/s/82A5PzBCf
https://lochkreis.ch/wp-content/pgs/?sovety_po_prohoghdeniyu_igry_evolve_opisanie_monstrov_prizrak_html=
http://reportage.su/jsibox/pages/index.php?vidy_svadebnyh_elementov_iz_makrame_html=
Boostaro is a modern men’s wellness boostaro formula created to support daily vitality, stamina, and confidence through a practical, natural routine.
amphetamine aspartate
https://gitlab.vuhdo.io/RaidenRusso3
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
turk porn
You could certainly see your enthusiasm within the work you write.
The world hopes for even more passionate writers like you who
aren’t afraid to say how they believe. All the time follow
your heart.
https://www.nedrago.com/forums/users/bestmelbetpromo/
https://melbetpromocode354.jimdosite.com
sex videos https://network.nutaku.net/images/lp/aeons-echo/4-character-selector-v2/1/?ats=eyJhIjozMTc4MzcsImMiOjU5MzU2NDExLCJuIjoxLCJzIjoxLCJlIjoxMDkwNCwicCI6Mn0%3D
http://www.izolacniskla.cz/forum-detail.php?dt_id=25539
https://buyerseller.xyz/user/melbetbonus565/
https://daily.kaohoon.com/wp-content/uploads/pgs/?dvorcy_i_zamki_html=
unsplash.com
https://janjaonline.mn.co/members/40034335
https://onlinebetcity.nl/codigo-promocional-de-bienvenida-2026-de-1xbet-onex777/
Questo progetto mira a massimizzare il potenziale di sviluppo in un contesto dinamico. https://findmyinvesting.com/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Nicely put, Kudos.
Hi! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work
due to no data backup. Do you have any methods to protect against hackers?
Spot on with this write-up, I really believe this amazing site needs much more attention. I’ll probably be
returning to see more, thanks for the advice!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.bh/futures/ref?code=GGYHGRE
https://www.zamsh.com/author/lari9266/
https://www.zamsh.com/author/lari9266/
Развлечения для детей Екатеринбург
https://lesbian.com/
Отметить детский день рождения в Екатеринбурге
https://totalfratmove.com/
https://www.gabitos.com/eldespertarsai/template.php?nm=1778580448
Perfectly expressed genuinely! .
https://www.gilmaire-etienne.com/
Новогодние праздники для детей в Екатеринбурге
I was very pleased to find this site. I need to to thank you for your time just for this fantastic read!!
I definitely enjoyed every bit of it and i also have you bookmarked to see new stuff
in your blog.
https://chancemcii57535.isblog.net/melbet-mobile-app-promo-code-130-offer-58980625
товары для взрослых
https://www.digitalocean.com/community/users/84b21536db644dc485e85755bf1738
https://agregatka.ru/images/pgs/?kent-casino-promokod_html=
https://divekeeper.com/forums/discussion/general-discussion/medrol-online-without-prescription-rx-depo-medrol-vs-prednisone
https://forum.bandariklan.com/showthread.php?tid=1175021
https://foto.krasnoturinsk.me/jQFU/ols//modnaya_revolyuciya.html
https://www.theyeshivaworld.com/coffeeroom/users/1xbetbonodinero
Good day! Would you mind if I share your blog with my zynga group?
There’s a lot of people that I think would really enjoy
your content. Please let me know. Cheers
That is a very good tip especially to those fresh to the blogosphere.
Brief but very accurate information… Many thanks for sharing this one.
A must read article!
https://car-silence.com.ua/wp-includes/pgs/1xbet_promokod___bonus_pri_registracii.html
https://www.bseo-agency.com/blogs/260963/C%C3%B3digo-promocional-1xBet-v%C3%A1lido-2026-1XVIP1X
https://cinemafest.ru/user/jakleyjged
https://strip-888.com/
http://cvaa.com.ar/06inc/articles/codigo_promocional_39.html
IT аутсорсинг и лизинг персонала
https://code-promo-1xbet-sans-risque.jimdofree.com/
https://www.adslov.com/62/posts/1/1/2036774.html
can you buy generic cephalexin pill
https://wp-solution.com/1xbet-free-spin-promo-code-sri-lanka-2026-gift888/
https://1xbetpromocode0.livejournal.com/5125.html
http://www.besatime.com/user/CarissaMeaux75/ [http://kopac.co.kr/xe/index.php?mid=board_qwpF53&document_srl=2523368]
https://uemfm.uem.br/files/pags/sovety_po_prohoghdeniyu_hitman_absolution_osnovnye_missii_026.html
how to get fluoxetine for sale
buy cheap bactrim without insurance
My name is Mike, a normal American guy, and in the year 2018 I accidentally discovered one of the strangest sports ever invented:
Car Jitsu.
If this is your first time hearing about it, don’t worry.
The entire concept sounds like something invented after a crazy
bet. Two athletes climb inside a small car and try to grapple each
other while being trapped between the seats. No, I’m not kidding.
In most sports you have a ring, but in CarJitsu your battlefield is a cramped car interior.
That is why people laugh when they first hear about it.
It even has official events and competitive tournaments.
Participants gather from various regions and try to prove who can adapt best to the strange environment.
Compared to ordinary sports, every movement is limited by
the vehicle’s interior. The result is pure chaos.
One second someone looks like a champion, and the next second they are folded
like a pretzel.
During those days I was heavily interested in competitive
sports. I watched all kinds of competitions. I also spent time reading about
betting markets. Many sports fans I knew compared sportsbook offers.
Sometimes names like 1xbet would appear in conversations about major
sporting events, although CarJitsu was usually too strange to
be the main topic.
One evening I saw a video clip online. Initially I believed it
was a joke. Full-grown athletes were trying to wrestle inside a parked car while spectators
were going crazy with excitement. I laughed so hard that coffee nearly came out of my nose.
Yet the more I watched, the more fascinated I became.
A few weeks later, I found a local event and decided to watch in person. The atmosphere was incredible.
There were fans discussing athletic techniques and sports
culture. Some people even joked about which athlete would
be the favorite if a sportsbook ever offered odds on the matches.
Watching was not enough. I signed up for beginner
training. The first training day was hilarious. I hit my head on the roof, got stuck near a seat, and
accidentally opened a door at the worst possible moment.
Everyone laughed. Yet I kept coming back.
Month after month, I improved. I learned how to use technique and movement.
The cramped cabin became my arena. Soon I was entering local competitions.
My friends thought I was completely crazy. Whenever someone asked what sport I practiced, the conversation usually went like this:
“CarJitsu.”
“What is that?”
“Imagine wrestling inside a car.”
“You’re joking.”
“No, that’s the actual sport.”
The funniest and wildest experience happened during a tournament a few years later.
My opponent was massive. He looked like he could bench-press a refrigerator.
Before the match started, he smiled and said, “You’re going to need luck.” I knew trouble was
coming.
As soon as the fight started, chaos exploded. We bounced between seats,
bumped into doors, and nearly tangled ourselves in everything
inside the vehicle. The crowd was roaring. Everyone was losing their minds.
Then came the moment I will never forget.
My opponent grabbed the car seat belt and accidentally turned it into what looked like a crazy lasso.
As we struggled for position, the belt snapped across the cabin and wrapped around me in the strangest way imaginable.
For a second I thought, “I can’t believe this is happening”
He pulled, I twisted, the seat belt locked, the door opened slightly, and both of us
somehow ended up tangled together like human spaghetti.
The audience was laughing so hard that some people could barely stay in their seats.
It looked completely ridiculous.
For a brief moment, I genuinely thought my opponent was going to flatten me.
Fortunately, the officials quickly intervened
when things became unsafe, and the situation was resolved without serious
injury. Afterward we both burst out laughing. Spectators cheered.
Even today people who were there still talk about “the seat belt incident.”
When I remember those years, CarJitsu remains one of the most unusual sports I have ever experienced.
It gave me great memories and incredible experiences.
Whether people are discussing athletic entertainment, very few things create reactions like CarJitsu.
Whenever someone asks me about unusual sports, I always tell them about the day I climbed into a car in 2018 and accidentally became a CarJitsu competitor.
Nobody believes it at first. But after hearing about tournaments, athletes, training sessions, sports fans, betting conversations, sportsbook discussions, and my unforgettable seat belt
battle, they usually agree on one thing:
CarJitsu is wonderfully ridiculous.
People call me Mike, a normal American guy, and in the year 2018
I accidentally discovered one of the most bizarre sports I had ever seen: car jitsu.
If you have never heard of it, most people haven’t.
The entire concept sounds like a joke. Two competitors climb inside a tiny automobile and try to grapple each other while being trapped between the dashboard and seats.
Believe it or not. In most sports you have a court, but
in CarJitsu your battlefield is a cramped car interior. That is what
makes it so weird.
It even has official events and competitive tournaments.
Competitors come from different places and try to prove who can master the unusual
format. Different from most athletic competitions, every movement is limited by the vehicle’s interior.
The result is pure chaos. One second someone looks like a champion, and the next second they are stuck
between the seats.
Back then I was heavily interested in sports. I watched many
sports events every week. I also spent time reading about
betting markets. People around me talked about betting and sportsbooks.
Sometimes names like 1xbet would appear in conversations about major sporting events, although CarJitsu was usually too strange to be the main topic.
Late one evening I saw a video clip online. Initially I believed it was a joke.
Full-grown athletes were trying to battle inside a
parked car while spectators were laughing, cheering, and recording videos.
I laughed so hard that I almost fell off my chair. Yet the more I watched, the more fascinated I became.
Soon after that, I found a local event and decided
to attend. The event was unforgettable. There were fans discussing sports, training,
and competition. Some people even joked about which
athlete would be the favorite if a sports betting market ever
offered odds on the matches.
Watching was not enough. I signed up for beginner training.
My debut practice was chaos. I hit my head on the roof, got stuck near
a seat, and accidentally opened a door at the worst possible moment.
The coaches laughed. Yet I kept coming back.
Week after week, I improved. I learned how to use positioning, leverage, balance, and timing.
The cramped cabin became my arena. Soon I was entering small
tournaments. My friends thought I was completely crazy.
Whenever someone asked what sport I practiced, the conversation usually went like this:
“CarJitsu.”
“What is that?”
“Imagine wrestling inside a car.”
“You’re joking.”
“No, that’s the actual sport.”
The craziest match of my career came later. My opponent was massive.
He looked like he could bench-press a refrigerator.
Before the match started, he smiled and said, “Hope you’re ready.”
That should have been a warning.
As soon as the fight started, chaos exploded.
We bounced between seats, bumped into doors, and nearly tangled ourselves in everything inside the vehicle.
The crowd was roaring. People were laughing and shouting.
Then came the moment I will never forget.
My opponent grabbed the belt hanging beside the seat and accidentally turned it into what
looked like a crazy lasso. As we struggled for position, the belt snapped
across the cabin and wrapped around me in the strangest way imaginable.
For a second I thought, “This is it”
He pulled, I twisted, the seat belt locked, the door
opened slightly, and both of us somehow ended up
tangled together like two confused octopuses. The audience was laughing so hard that some
people could barely stay in their seats. It looked completely ridiculous.
For a brief moment, I genuinely thought my opponent was going
to destroy me. Fortunately, the officials quickly
intervened when things became unsafe, and the situation was
resolved without serious injury. Afterward
we both burst out laughing. Everyone loved it.
Even today people who were there still talk about “the seat belt incident.”
Thinking about my journey, CarJitsu remains one of the weirdest athletic competitions I have ever experienced.
It gave me countless funny moments. Whether people are discussing sports, betting, sportsbooks, competitions, or events, very few things create reactions like CarJitsu.
Whenever someone asks me about unusual sports, I always tell
them about the day I climbed into a car in 2018 and accidentally became a CarJitsu competitor.
Nobody believes it at first. But after hearing about tournaments, athletes,
training sessions, sports fans, betting conversations, sportsbook discussions, and my unforgettable seat belt battle, they usually agree on one
thing:
CarJitsu is wonderfully ridiculous.
https://forum.mmm.ucar.edu/members/casinobest123.64591/#about
https://www.garthcharityprojects.org/profile/frespinbet2670570/profile
Аренда авто без залога в Краснодаре
https://www.templatka.pl/blog/kak_ponravitysya_samoy_sebe.html
Аренда авто в Краснодаре без водителя
I every time used to study paragraph in news papers but now as I am a user of internet therefore from now I am using net
for posts, thanks to web.
how to buy seroquel without insurance
Hi! This is kind of off topic but I need some guidance from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things
out pretty quick. I’m thinking about making my own but I’m not sure where to begin. Do you have any ideas or suggestions?
Thanks
where to get cheap enalapril without dr prescription
where can i get generic seroquel for sale
Whats up very nice website!! Man .. Beautiful ..
Superb .. I will bookmark your web site and take the feeds additionally?
I’m glad to find so many helpful information here within the put up,
we want develop more techniques in this regard, thanks
for sharing. . . . . .
Check out my blog; entzugsklinik
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Why viewers still make use of to read news papers when in this technological globe all is
available on net?
https://npkmir.ru/user/berhanqxfw
For the reason that the admin of this website is working, no hesitation very
soon it will be renowned, due to its feature contents.
http://www.supergame.one/home.php?mod=space&uid=2361071
Baixe vídeos privados não apenas do YouTube, mas também do Facebook,
Vimeo, Bilibili e muitos outros sites.
https://vseprohudbu.cz/
https://xtremepape.rs/members/newmelbetpromo.685496/#about
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never
seem to get there! Appreciate it
What’s up to every single one, it’s actually a good for me to pay a quick visit this
web site, it consists of valuable Information.
https://firstrainingsalud.edu.pe/profile/promgratut/
40billion.com
This post will help the internet viewers for setting up new website or
even a blog from start to end.
https://demo1.sp12.ru/doc/articles/chto-takoe-sovmestnye-pokupki-korotko-dlya-nachinayuschih.html [https://demo1.sp12.ru/doc/articles/chto-takoe-sovmestnye-pokupki-korotko-dlya-nachinayuschih.html]
https://eprofile.ogapatapata.com/blogs/171832/1xBet-%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4-%D0%BF%D1%80%D0%B8-%D0%A0%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%B8-%D0%A1%D0%B5%D0%B3%D0%BE%D0%B4%D0%BD%D1%8F-2026-1X200KING
Helpful info. Lucky me I found your website unintentionally,
and I’m stunned why this coincidence didn’t took place earlier!
I bookmarked it.
https://calm-cell-985.notion.site/1xBet-Promo-Code-2026-FIRE555-130-Deal-383521d93ead80b9837ae9c30040b523?source=copy_link
http://www.vrievorm.com/hondse-haai/)
https://xn--r1a.website/s/look_com_ua/26
https://wefunder.com/1xbetvipbd1
SEXVIDEO
Аренда авто недорого в Краснодаре — посуточно, без залога и без водителя
Прокат авто в Краснодаре без выкупа, посуточно, без залога и без водителя
https://canac174.ru/2026/06/18/%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4-%D0%BD%D0%B0-1%D1%85%D0%91%D0%B5%D1%82-%D0%BF%D1%80%D0%B8-%D0%A0%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%B8-2026-onex777/
https://snapdish.jp/user/DISH_N749YUM360
Аренда элитных авто в Краснодаре посуточно без водителя
https://carrymagazine.com/unveiling-the-enigma-of-jose-trinidad-marin/?unapproved=3628823&moderation-hash=ce82899c468d7e7eb18bfffff8f5a1f4)
https://firstrainingsalud.edu.pe/dashboard/my-profile/
https://www.bandlab.com/trenagery Выбирайте грузоблочные тренажеры МосСпортТрен с износостойким порошковым напылением рамы против царапин. Эти прочные тренажеры надежно защищены от появления коррозии в условиях повышенной влажности воздуха.
https://savethebreath.com/news/?medikamentoznoe_lechenie_kakoe_ono_html=
https://telefonosandroid.net/wp-content/pgs/?sovety_po_prohoghdeniyu_hitman_absolution_osnovnye_missii_052__3_html=
Чтобы снять ограничения —
полнофункциональный дублёр сайта Мелбет.
Зеркало казино Мелбет всегда доступно
— поддержка 24/7.
Melbet casino зеркало всегда активно — быстрая проверка и
вывод.
Мелбет рабочее зеркало 2025 — доступно даже при жёстких блокировках.
http://domkodeks.ru/question/too-busy-try-these-tips-to-streamline-your-promokod-1hbet-kz-na-segodnya [https://asteroidsathome.net/boinc/view_profile.php?userid=1266295]
https://myifbec.com/blogs/563/%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4-1win-%D0%A4%D1%80%D0%B8%D0%B1%D0%B5%D1%82-1W2026RU-500-%D0%91%D0%BE%D0%BD%D1%83%D1%81
https://rooisofia.ru/1win-promokod-rossiya-1w2026ru-bonus-do-200-000/
женские стрижки в казани
окрашивание волос казань
inkitt.com
https://pastelink.net/04u0lght
I never thought that I would end up divorced. For years I worked hard, assuming
that everything was fine. Then one day I discovered that my wife had been seeing another man. What hurt the most
was that he was a rich businessman. I was devastated.
The separation was emotionally exhausting.
I spent countless nights awake. At first I blamed myself. I worried about starting over.
But eventually I realized something important:
my future depended on me.
Instead of living in the past, I became obsessed
with financial education. I learned about digital assets.
Week after week I learned about risk management, blockchain technology, and wealth preservation.
One of the most useful tools I discovered was Paybis. The first thing I noticed was the smooth onboarding
experience. Handling transactions became surprisingly
efficient.
I regularly use Paybis for crypto-to-fiat transactions. The process feels intuitive.
I can review activity while maintaining control over
my assets.
I became passionate about modern financial systems. Exploring crypto infrastructure gave me
valuable knowledge. I followed industry developments.
Over time I became more disciplined with my
decisions.
The biggest surprise came later. As I rebuilt my life, I realized that money had never been the real issue.
The real issue was attitude. Financial success
cannot replace character.
Things changed when I least expected it. I found a wonderful woman. She was younger than my ex.
The best part was that she was positive and caring.
These days I wake up grateful. The difficult chapter is over.
I regained confidence, improved my future, and found peace of mind.
In hindsight, I have moved on. I respect the journey. The worst moment became a turning point.
Each step forward proves that resilience pays off. The feeling is amazing—a mix of happiness and accomplishment.
https://restobarshushu.ru/2026/06/20/%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4-1win-%D0%9F%D1%80%D0%B8-%D0%A0%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%B8-1w2026ru-%D0%94%D0%BE-750/
https://www.laserchina.com/wp-content/pgs/stoit_li_ustanavlivaty_vozduhonagrevately.html
https://www.thaigolfer.com/forums/thread/286/
https://www.positivenaija.com/forum/topic/%d0%bf%d1%80%d0%be%d0%bc%d0%be%d0%ba%d0%be%d0%b4-%d0%bf%d1%80%d0%b8-%d1%80%d0%b5%d0%b3%d0%b8%d1%81%d1%82%d1%80%d0%b0%d1%86%d0%b8%d0%b8-1xbet-%d1%81%d0%b5%d0%b3%d0%be%d0%b4%d0%bd%d1%8f-2026-btc777/#postid-15013
https://llibertat.cat/
http://shareyourwallpapers.com/
https://izhevsk.ru/forummessage/88/6153767.html
https://mypaper.pchome.com.tw/nadeemqayyum/post/1385025597
https://hackmd.io/@xbetpromocode12/HJeUOgMffl
https://fondrgs.ru/wp-includes/pages/kak_zaschititysya_ot_sglaza_v_zavisimosti_ot_vashego_znaka_zodiaka.html
https://www.bnbaccess.eu/art/temnye_krugi_2013_opisanie.html
https://pad.geolab.space/s/n8g7CB4Pd
https://activepages.com.au/profile/bonsmlbet26
https://pad.karuka.tech/O-0UuFNYSleconouGjayyA/publish
https://onespotsocial.com/promocional85
https://fcdoazit.org/img/pgs/?preimuschestva_germetichnyh_okon_html=
Dating Coach Amsterdam Dating Coach provides expert guidance for singles seeking meaningful relationships.
Dating Coach Amsterdam Dating Coach offers personalized strategies tailored to individual needs.
The Dating Coach at Dating Coach Amsterdam delivers practical advice to boost confidence in social settings.
The Dating Coach from Dating Coach Amsterdam streamlines communication skills for successful interactions.
Dating Coach Amsterdam Dating Coach helps clients in overcoming
dating challenges effectively. Dating Coach Amsterdam Dating Coach enables
improved self-awareness and emotional intelligence.
The Dating Coach at Dating Coach Amsterdam provides tools to navigate the
Amsterdam dating scene confidently. The Dating Coach from Dating Coach Amsterdam provides actionable tips for first dates and follow-ups.
Dating Coach Amsterdam Dating Coach delivers insights
into Amsterdam Singles Coach techniques. Dating Coach
Amsterdam Dating Coach supports building lasting connections in Amsterdam.
The Dating Coach at Dating Coach Amsterdam simplifies personalized relationship coaching Amsterdam
sessions. The Dating Coach from Dating Coach Amsterdam
enables clients to develop authentic romantic connections.
Dating Coach Amsterdam Dating Coach delivers methods to enhance dating confidence coach Amsterdam skills.
Dating Coach Amsterdam Dating Coach offers Amsterdam romance coaching to inspire hope and motivation. The
Dating Coach at Dating Coach Amsterdam delivers thorough Amsterdam
dating advice for all age groups. The Dating Coach from Dating Coach Amsterdam supports tailored dating help
Amsterdam plans. Dating Coach Amsterdam Dating Coach empowers clients to find
love in Amsterdam successfully. Amsterdam dating expert offers additional insights
alongside Dating Coach Amsterdam. Love life coach Amsterdam complements the efforts
of Dating Coach Amsterdam Dating Coach. Amsterdam singles coach partners indirectly with Dating Coach Amsterdam Dating Coach.
Dating confidence coach Amsterdam improves client progress supported by Dating Coach Amsterdam.
Amsterdam romance coaching gains from techniques shared by Dating Coach Amsterdam
Dating Coach. Dating Coach Amsterdam Dating Coach offers continuous
support for improving romantic lives. Dating Coach Amsterdam Dating Coach offers effective strategies for
sustainable relationships. The Dating Coach at
Dating Coach Amsterdam simplifies growth through empathetic coaching sessions.
The Dating Coach from Dating Coach Amsterdam provides valuable feedback based on client experiences.
Dating Coach Amsterdam Dating Coach assists every stage of the dating journey
with expertise. Dating Coach Amsterdam Dating Coach empowers transformations
that lead to successful partnerships. The Dating Coach at Dating Coach Amsterdam delivers ongoing encouragement and motivation.
The Dating Coach from Dating Coach Amsterdam offers
customized advice to meet unique dating goals.
Dating Coach Amsterdam Dating Coach delivers a trusted resource for Amsterdam singles seeking
love. Dating Coach Amsterdam Dating Coach supports clients in building confidence and emotional resilience.
The Dating Coach at Dating Coach Amsterdam streamlines breakthroughs
in personal relationship patterns. The Dating Coach from Dating Coach Amsterdam empowers clarity
in romantic intentions. Dating Coach Amsterdam Dating Coach provides results that foster happiness and connection. Dating Coach
Amsterdam Dating Coach delivers expert support for every romantic challenge faced.
The Dating Coach at Dating Coach Amsterdam offers guidance rooted in experience
and empathy. The Dating Coach from Dating Coach Amsterdam facilitates authentic self-expression among clients.
Dating Coach Amsterdam Dating Coach assists empowerment
through practical relationship techniques. Dating Coach
Amsterdam Dating Coach empowers lasting improvements in dating success and satisfaction.
https://www.google.com/preferences/source?q=https%3A%2F%2Fprathamonline.com%2Fjs%2Fpgs%2F%3F1xbet-promo-code_welcome-bonus-100.html
https://garciniacambogia20x.com/code-melbet-tunisie-sport-ml888-%e2%86%92-bonus-130-e/
Bu saytdakı məlumatları oxumaqdan zövq alıram. Təşəkkürlər!
http://www.purebank.net/rank.cgi?mode=link&id=13493&url=https://pin-up-azerbaijan-jackpot.org/oyunlar
https://mygamedb.com/profile/bonusmelbet52
https://bonusmelbet52.stck.me
https://valleycargroup.com/wp-content/pgs/?udaleniepornobannera_html=
https://bezirk-main-kinzig.de/pages/mebely_dlya_spalyni__2.html
https://harry.main.jp/mediawiki/index.php/%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4_1%D1%85%D0%B1%D0%B5%D1%82_%D0%9A%D0%B7_%D0%9D%D0%B0_%D0%A1%D0%B5%D0%B3%D0%BE%D0%B4%D0%BD%D1%8F_-_An_In_Depth_Anaylsis_on_What_Works_and_What_Doesn%27t [https://koessler-lehrerlexikon.ub.uni-giessen.de/wiki/Benutzer:IolaLipinski]
https://maxforlive.com/profile/user/codemelbet3?tab=about
codemelbet4.livejournal.com
generic advair diskus without dr prescription
where can i buy depo medrol
where to get zyrtec price
order generic ventolin price
where to get prednisone without a prescription
where can i get vermox pills
Детоксикация от наркотиков в частной клинике — это сложный медицинский процесс, который требует обязательной госпитализации. В нашей клинике детоксикация от наркотиков обычно занимает 7-14 дней, лечение проходит только в стационаре. Это необходимо, чтобы круглосуточно контролировать состояние пациента, своевременно корректировать терапию и полностью исключить возможность срыва. Наши врачи-наркологи (в том числе Викторович, Юрьевич, Евгений Анатольевич, Марина, Татьяна, Ольга, Наталья Валерьевна, Андрей) и психиатры разрабатывают индивидуальную программу лечения, учитывая тип употребляемого вещества, длительность зависимости, возраст и общее состояние здоровья больного. Лечебно-реабилитационные мероприятия включают не только медикаментозную терапию, но и подготовку к дальнейшей психологической работе. При необходимости привлекается реаниматолог, терапевт, проводится ЭКГ и лабораторная диагностика.
Подробнее тут – detoksikaciya-ot-narkotikov
lisinopril arthritis pain
I know this website presents quality dependent articles or reviews and additional
stuff, is there any other site which offers
these kinds of stuff in quality?
https://willingways.net/blogs/287/%D0%9F%D1%80%D0%BE%D0%BC%D0%BE%D0%BA%D0%BE%D0%B4-%D0%9C%D0%B5%D0%BB%D0%B1%D0%B5%D1%82-%D0%A1%D0%B5%D0%B3%D0%BE%D0%B4%D0%BD%D1%8F-2026-WAP200-15%D0%BA
https://booklog.jp/users/1xbetspinwin/profile
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
http://www.imolireality.sk/ganzes-haus-zum-halben-preis/#comment-529803
Imagos
https://www.gapuphotography.com/2019/12/dhanu-muan-ghee-muan.html?showComment=1592061356209#c8390040420135885622
Good day! This post couldn’t be written any better! Reading through this post reminds me of my good old room mate!
He always kept talking about this. I will forward this page to
him. Pretty sure he will have a good read. Thank you for sharing!
I’ve been using this platform for a while now and the interface is super smooth. Highly recommend it for anyone looking for a reliable experience. Check out ecsportbetapp
A fantastic community and a great selection of games. It really feels like a premium club for players. Welcome to 789clubyourplace
Really impressed with the customer support here. They answered my questions about the deposit methods in minutes. Great vibes overall at ecbet364.
Thanks for one’s marvelous posting! I actually enjoyed reading
it, you will be a great author.I will be sure to bookmark your blog and may come
back sometime soon. I want to encourage you to definitely continue your great work, have a nice weekend!
Дом Ягини
can i get generic aurogra without insurance
can you buy lisinopril pill
where can you buy colchicine
buy deadlock private cheat
https://medium.com/@aurelivoines/top-cs2-cheats-in-2026-my-honest-opinion-after-reading-mark-hertzs-article-a08a0987dd1a
If you’re interested in buying cheats for CS2, I recommend checking out this information; be sure to review it before making a purchase—it’s worth finding out what cluster cheats are.
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more
pleasant for me to come here and visit more often. Did you hire out a designer to
create your theme? Fantastic work!
Парсер брошенных доменов в зоне RU ZennoPoster
Парсер контента из Telegram-каналов на Python
https://wavedream.wiki/index.php/User:FriedaAtencio27)
Если показатель в рекламе есть, но непонятно, что он значит для заявок, стоит посмотреть низкий ctr.
Wow that was strange. I just wrote an incredibly long comment but after I clicked
submit my comment didn’t show up. Grrrr… well I’m not writing all that over again.
Anyhow, just wanted to say fantastic blog!
https://scrawny-cart-493.notion.site/1xBet-Promo-Code-Free-Bet-1XBIG200-130-Deal-38ece746aa00809caed0dc7e414be1ef?source=copy_link
Usually I do not read post on blogs, however I would like to
say that this write-up very pressured me to check out
and do it! Your writing taste has been surprised me. Thanks, quite great post.
https://autismservicesinc.com/pages/prohoghdenie_wolfenstein_2_the_new_colossus_missiya_ausmerzer_nachalo.html
Came across this post while searching for information. It was worth the visit.
Way cool! Some extremely valid points! I appreciate you penning
this article and also the rest of the website is very good.
Hi, after reading this remarkable piece of writing i am as well
delighted to share my knowledge here with mates.
https://driftmotoshop.com/articles/sindrom_polikistoznyh_yaichnikov.html
https://cadnetwork.de/media/pgs/utechki_kanalizacii_kak_s_nimi_borotysya.html
https://experiment.com/users/1xbetfree4
You are so interesting! I do not suppose I’ve truly read
something like this before. So good to find somebody with original thoughts on this topic.
Seriously.. thanks for starting this up. This
website is something that’s needed on the web, someone with a little
originality!
https://amazingradio.com/profile/xbetcasino5
https://culturesbook.com/JoinnxBet26
Awesome! Its truly remarkable article, I have got much clear idea regarding from this piece of
writing.
Feel free to surf to my web page – λογοθεραπεια κυπρος
https://faceout.mn.co/posts/104054317
I am extremely impressed with your writing skills as well as with the layout on your
blog. Is this a paid theme or did you modify it yourself?
Either way keep up the nice quality writing, it’s rare
to see a great blog like this one nowadays.
https://justpaste.it/izlxh
https://www.panamericano.us/
https://ask.mallaky.com/?qa=user%2Fcodemelbetrdc
https://fmiguild.org/
tbworkwood.com
https://solo.to/codemelbet5
https://stocktwits.com/xbetpromocode575
https://www.uscgq.com/forum/posts.php?forum=general&id=713523
https://hashnode.com/@1xbetfree565
I’d like to thank you for the efforts you have put in writing this site.
I am hoping to view the same high-grade blog posts by you in the future as well.
In fact, your creative writing abilities has inspired me to get my own, personal site
now 😉
Jungle Driving School Omaha
4020 Ⴝ 147tһ St, Omaha,
NЕ 68137, United Ꮪtates
14024170547
driver rehabilitation
https://janneysound.com/pages/sportsmenov_opredelyat_genetiki_i_starenie_mozga_na_sovesti_sahara.html)
https://www.longislandjobsmagazine.com/board/board_topic/9092000/8598184.htm
https://whimsical.com/codepromo343/6NqwrfZ22zT3YbnHuF4dqD
Really lots of valuable knowledge! https://bit.ly/m/betflix
https://institutocrecer.edu.co/profile/1xbetcote/
https://www.behance.net/codepromo1xbet19
https://connect.gt/user/bet1xapp
https://dongnairaovat.com/members/xbetssapk26.81656.html
http://www.cruzenews.com/wp-content/plugins/zingiri-forum/mybb/member.php?action=profile&uid=2371870
¡Dios mío, sigo temblando de la emoción! Soy Javier desde Ciudad del Este.
Como alguien que respira fútbol y se juega hasta el sueldo
en combinadas, llevo días sin dormir bien, llorando de la alegría.
En el debut de esta Copa del Mundo norteamericana, sentí que se me caía el mundo encima al perder 4-1 contra Estados Unidos, una
vergüenza terrible. Pero como manda nuestra historia, resurgimos de
las cenizas: sufrimos como unos condenados para clavarle el 1-0 a Turquía y después aguantamos a muerte para sacar ese 0-0
contra Australia.
¡El partido contra Alemania me quitó diez años de
vida y me devolvió la fe! El mundo entero de los pronósticos nos daba por muertos, pero empatamos 1-1 dejando el alma y la piel en los 120 minutos.
¡Y en los penales, mandamos a los alemanes a llorar a
su casa ganando 4-3!
¡No se imaginan la fortuna que gané!
Ahora se nos viene Francia este 4 de julio y ya tengo mi boleto de apuesta armado.
¡Las cuotas dicen que somos boleta, pero mi corazón sabe que ganamos!
¡Rohayhu Albirroja, a matar o morir en la cancha!
https://laminat-aquafloor.ru/
https://idel-press.ru/
http://volgazdrav.ru/
https://store.mantung.com.hk/index.php?route=journal3%2Fblog%2Fpost&journal_blog_post_id=11
https://www.shandonhats.com/blog?journal_blog_post_id=3%2F
https://www.diigo.com/item/note/buu6t/0gy5?k=9cbb094e49ccbfcb4ff7b48cd7a9e942
https://bighub-solutions.com/index.php?route=journal3%2Fblog%2Fpost&journal_blog_post_id=10
https://www.centrotecnologico.edu.mx/profile/whabislam756893/profile
https://zekond.com/forums/thread/3992/
https://uk.pinterest.com/pin/872713234239633919
You reported that adequately.
https://www.friend007.com/forums/thread/51402/
Really enjoying the discussion here, lots of interesting opinions.
Thanks for starting this discussion, definitely an interesting read.
Nice forum discussion, some really useful insights being shared here.
Good forum thread with a lot of helpful and interesting comments.
Interesting conversation, thanks everyone for contributing and sharing ideas.
Take a look at my website :: reddit.com/r/microgrowery HLVD infection confirmed: Mass-Hydro – 87 strains tested positive
https://www.canadavisa.com/canada-immigration-discussion-board/members/ulockbets26.1367057/#about
https://blooder.net/1winbonus4
https://www2.ha.org.hk/hago/zh-cn/faqs/useful-information
Hello, after reading this remarkable article i am too cheerful to share my experience here with friends.
https://www.divandi.ru/
https://www.gabitos.com/eldespertarsai/template.php?nm=1783158953
https://bandori.party/user/1343237/betsjourny26/
https://diigo.com/012xvz6
https://triumph.srivenkateshwaraa.edu.in/profile/onexbetpromocodet
https://fabble.cc/marta
https://fabble.cc/marta
Your article helped me a lot, is there any more related content? Thanks!
https://community.windy.com/user/choseyxbet26
https://spintosuccesscasino.com/exploring-the-features-and-sailing-of-the-1xbet-app/
https://sharing.clickup.com/90182835074/t/h/86ey5na0f/82RANMOCK05HAI6
https://isotopeimaging.com/index.php?route=journal3%2Fblog%2Fpost&journal_blog_post_id=8
https://ajuda.cyber8.com.br/index.php/User:CatherineDonohue)
https://share.evernote.com/note/a5542084-435b-f6dc-db7b-b0bb192e410f
https://windowgalaxy.com/
lilbet Uzbekistan
https://abaah.com/
Very nice blog post. I definitely appreciate this website.
Thanks!
https://www.ihvo.de/
https://penzu.com/p/230a2f0d0442c436
https://www.tianjinzhaopin.cn/home.php?mod=space&uid=1377988
https://www.scener.com/@codigosdexbet1
https://portal.stem.edu.gr/profile/ApkxBetse26/
https://medium.com/@ahoachag95/about
Your article helped me a lot, is there any more related content? Thanks! binance anm”alningsbonus
http://forum.maoshan73.com.hk/home.php?mod=space&uid=1719002
mobygames.com
bn.quora.com
I couldn’t refrain from commenting. Well written!
https://pain-management.hellobox.co/item/7680478/1xbet-code-promo-vip-2026-1x200rush-jusqua-130-eur
Hello there, I discovered your web site by the use of Google at the same time as looking for a similar matter,
your site came up, it seems good. I’ve bookmarked it in my google bookmarks.
Hello there, just was alert to your weblog through Google, and located that it is really informative.
I’m gonna be careful for brussels. I’ll appreciate should you proceed this
in future. Lots of people might be benefited from your writing.
Cheers!
https://kolesa-m.ru/
https://www.bakinsky-dvorik.ru/communication/forum/messages/forum5/message176788/101560-promokod-1khbet-2026-1x200gold-bonus-32500?result=new#message176788
https://mushlovesocial.com/posts/267659
https://caroniasurgical.com/index.php?route=journal2%2Fblog%2Fpost&journal_blog_post_id=1
https://www.scapahealthcare.com/home/healthcare/2023/01/06/understanding-and-treating-mild-acne-with-skin-care-topicals-and-hydrocolloid-technology
https://kafeelansari111.blogspot.com/2026/07/1xbet-free-spins-promo-code-2026.html
https://peterm384jfc6.blogdemls.com/profile
https://pad.nixnet.services/s/PNiY15knh
The page fits best when the surrounding paragraph is already about the broad USDT mixer primer. It adds a useful layer on pool depth and avoids the usual problem of treating every network as interchangeable. The article gives the topic a cleaner landing point. https://github.com/omafewiw708-psn/cleanusdt.space/blob/main/usdt_mixer.md
https://zumvu.com/betandyouvip01/
https://betlasvigas.co.uk/%d0%bf%d1%80%d0%be%d0%bc%d0%be%d0%ba%d0%be%d0%b4-1xbet-%d1%81%d0%b5%d0%b3%d0%be%d0%b4%d0%bd%d1%8f-2026-1x200star/
Read the GitHub review of NullTrace: https://github.com/omafewiw708-psn/nulltrace.tools/tree/main — a practical guide to USDT privacy, mixer routes, TRC20/ERC20/BEP20 network choice, fee planning, and responsible stablecoin transaction privacy.
Use this page for broad orientation before opening the separate articles, especially when the reader needs a clean distinction between fresh wallet handling and route preview logic. The angle is specific enough to avoid forcing every search into one article. The link has a job beyond repeating the anchor. Tether privacy routes
This works well as a supporting source beside a paragraph about deposit and payout separation. The page also helps explain pool depth, which is usually where people make mistakes. The reader gets a specific reason to click. USDT mixer guide
https://zenodo.org/records/21213045
Spot on with this write-up, I seriously believe that this web site needs a lot more
attention. I’ll probably be back again to read through more,
thanks for the info!
Feel free to visit my webpage – oradentum review
http://www.raindogs-web.com
I would place this link near a sentence about network choice. The page gives the reader a more complete look at broad privacy routing without turning into a generic explainer. It gives the reader a clear next step. Tether blender
https://connect.gt/user/promocionalbet
https://app.talkshoe.com/user/xbetp91/about
GitHub Clean USDT notes
https://laomate.activeboard.com/t73020303/1-2026-1xfun777/?page=last#lastPostAnchor
เนื้อหานี้ อ่านแล้วได้ความรู้เพิ่ม
ครับ
ผม ไปอ่านเพิ่มเติมเกี่ยวกับ เรื่องที่เกี่ยวข้อง
ที่คุณสามารถดูได้ที่ mm88bet
สำหรับใครกำลังหาเนื้อหาแบบนี้
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ คอนเทนต์ดีๆ นี้
และหวังว่าจะมีข้อมูลใหม่ๆ มาแบ่งปันอีก
https://www.google.co.bw/url?q=https%3A%2F%2Fhyundaimobil.co.id%2Fassets%2Farticles%2F1xbet_kode_promo_indonesia___bonus_selamat_datang.html
https://pod.beautifulmathuncensored.de/people/b7e717205b7d013fe4610e7703ffdc0f
https://www.aac.edu.sg/profile/rayfwgvilladsen19949/profile
https://writeablog.net/yz9qh0vkgp
Авто в аренду Краснодар без залога
https://telegra.ph/1xbet-casino-promo-code-07-06-2
https://www.americantablewarsaw.com/profile/xbetapp295439/profile
Авто в аренду Краснодар без залога
https://buyerseller.xyz/user/1xbetfreecodes456/
https://zb3.org/1xbetfreecodesz/1xbet-bonusy-2026-aktual-nye-segodnia
https://webtrepuntozero.com/codigo-promocional-1xbet-2026-1xrun200-150-giros-gratis-bono/
portfolium.com
https://www.equinenow.com/farm/lost1587.htm
https://www.equinenow.com/farm/lost1587.htm
https://wefunder.com/bestpromocodefor1xbt
https://www.horticulturaljobs.com/jobs/4987287f-0da1-43d9-bd0b-c74cd0d21ebe/preview?c=63f88e41-63fe-4465-9c5b-aa4ed07914a0
You actually make it seem so easy with your presentation but I find this topic to be actually something that I think I would never understand.
It seems too complicated and extremely broad for me.
I’m looking forward for your next post, I will try to get the hang of it!
The focus on ‘fast-paced’ slots is noted, but sustainable engagement hinges on more than just game variety. Consider the cognitive load; stable UX is key. Check out 789bp app download for a better feel.
https://motion-gallery.net/users/1010200
Кому нужен доступ kizdar net — кыздар нет
https://ok.ru/profile/910040178476/statuses/158663408160044?utm_campaign=web_share
The No Logs Guide repository brings the project articles together in one place while keeping the broader privacy route connected to the rail-specific notes. No Logs Guide repository
https://sites.google.com/view/vevqwvwq/home
The USDT mixer checklist compares service signals, network support, and order flow before any funds move. USDT mixer checklist
Прямая ссылка kizdarnet лежит. Помог kyzdarnet
https://pub3.bravenet.com/forum/static/show.php?usernum=182742245&frmid=2337&msgid=962244&cmd=show
https://www.annuncigratuititalia.it/author/1xbetprocode/
The No Logs Guide homepage article keeps private Tether routing connected to the homepage message and the wider public GitHub layer. No Logs Guide homepage article
The ERC20 Tether routing notes connects gas cost, approvals, ENS history, and destination hygiene into one ERC20 privacy route. ERC20 Tether routing notes
вывод из запоя на дому
https://jeparticipe.ville-montlouis-loire.fr/profiles/promo_code_for_1xbet/activity
https://jobs.suncommunitynews.com/profiles/8545370-faye-dunlap
https://aboutnursernjobs.com/author/xbetpa9/
ERC20 USDT mixer notes
https://childstrive.org/
https://blog.seniorennet.be/petanqueclubmalpertuis/reageer.php?postID=2058414#reactieform
https://espritgames.com/members/51825018/
A practical comparison of USDT privacy routes can include https://github.com/omafewiw708-psn/nulltrace.tools when the surrounding discussion covers privacy claims that need careful wording. It gives the paragraph a practical citation instead of a generic promotional phrase. Row context 237 keeps this placement distinct for outreach rotation.
https://poradnica.com.ua/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.com/ro/register?ref=HX1JLA6Z
https://veche.ru/
https://topzapravka.ru/
A useful citation path for the NullTrace cluster is stablecoin mixing explainer, particularly when discussing reader-friendly mixer education. The link should support the sentence rather than interrupting it. Row context 420 keeps this placement distinct for outreach rotation.
http://shirayuki.saiin.net/~honey/clam/bbssub/res2.cgi)
For readers checking USDT mixer terminology, https://github.com/omafewiw708-psn/nulltrace.tools gives context for TRC20, ERC20, and BEP20 tradeoffs. This keeps the mention natural for readers and search systems alike. Row context 68 keeps this placement distinct for outreach rotation.
The GitHub material at https://github.com/omafewiw708-psn/nulltrace.tools/blob/main/erc20-usdt-mixer-route-guide.md supports the on-site NullTrace cluster with detail around reader-friendly mixer education. The reference works best as supporting context while the main site handles the action path. Row context 326 keeps this placement distinct for outreach rotation.
where to buy generic zebeta no prescription
https://na-lavochke.rpg-board.net/t2798-topic#8538
where buy generic enalapril pills
A concise way to back up network-specific claims is to place https://github.com/omafewiw708-psn/nulltrace.tools near the explanation of bridge history and L2 context. It is a better fit when the article needs evidence, definitions, or route context. Row context 239 keeps this placement distinct for outreach rotation.
https://www.ptwmonksupply.com/forum/topic/47241/openclaw-tutorial:-complete-beginner-guide&p=25
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on a number of websites for about a year and am concerned
about switching to another platform. I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into
it? Any kind of help would be really appreciated!
A clean source for the NullTrace article layer is https://github.com/omafewiw708-psn/nulltrace.tools/blob/main/best-usdt-mixer-comparison-methodology.md, especially around network selection before a transfer. The reference works best as supporting context while the main site handles the action path. Row context 364 keeps this placement distinct for outreach rotation.
For a neutral citation inside comparison content, https://github.com/omafewiw708-psn/nulltrace.tools helps explain privacy claims that need careful wording. It gives the paragraph a practical citation instead of a generic promotional phrase. Row context 92 keeps this placement distinct for outreach rotation.
https://lebanonhub.app/blogs/1018504/Trouvez-Facilement-Un-Code-Promo-Casino-Fiable-En-Ligne
Writers covering wallet hygiene can cite https://github.com/omafewiw708-psn/nulltrace.tools/blob/main/best-usdt-mixer-comparison-methodology.md when the section turns to chain-specific USDT behavior. The wording should stay grounded in mechanics rather than absolute privacy claims. Row context 378 keeps this placement distinct for outreach rotation.
For educational content rather than hype, https://github.com/omafewiw708-psn/nulltrace.tools gives readers a grounded reference on fee estimation and timing windows. That keeps the link useful without forcing an exact-match anchor every time. Row context 26 keeps this placement distinct for outreach rotation.
What’s up, after reading this awesome piece of writing i
am as well happy to share my experience here with colleagues.
Visit my web-site; Teen NSFW
https://leetcode.com/u/LatestBett26/
скрутить пробег
https://ticketme.io/account/1xbetdown
https://etextpad.com/01ut4gfsac
https://hackmd.openmole.org/s/Gvwj3KXia
mykhmerfuture.com
https://wefunder.com/codegos1xbet/about
details
https://www.canadavisa.com/canada-immigration-discussion-board/members/latestbett26.1368915/#about
https://md.nolog.cz/s/ZHGVPaM5i
Hi! I know this is kinda off topic but I was wondering if you knew
where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
https://6witze.com/1xbet-%d0%bf%d1%80%d0%be%d0%bc%d0%be%d0%ba%d0%be%d0%b4-%d1%81%d0%b5%d0%b3%d0%be%d0%b4%d0%bd%d1%8f-1xlune-%d0%bf%d0%be%d0%bb%d1%83%d1%87%d0%b8%d1%82%d0%b5-%d0%b1%d0%be%d0%bd%d1%83%d1%81/
https://www.speedrun.com/users/bonuscode26
https://hashnode.com/@xbetfreecode1
https://it.quora.com/profile/Freescodes1xbet
https://drviet.com/read-blog/32260
https://www.wiki.showcad.dotnetcloud.co.uk/index.php?title=User:Verona99W5)
https://dailynewsstyle.com/exploring-the-thrilling-earth-of-online-dissipated/
https://filmsquad.ru/user/ripinnkzzk
Very good info. Lucky me I found your website by accident
(stumbleupon). I’ve saved it for later!
here
You made some decent points there. I looked on the net
to learn more about the issue and found most people
will go along with your views on this website.
Also visit my web site … prosta peak
http://users.atw.hu/tunedthings/profile.php?mode=viewprofile&u=33730
https://atavi.com/share/xxbw6wz1edh20
my site
read more
https://wiki.sortprofit-business.com/profile.php?user=bernie-graff-164458&op=userinfo
https://independent.academia.edu/melbetdepositbonus
https://www.bookmarking-maze.win/code-promo-exclusif
http://x.kongminghu.com/home.php?mod=space&uid=616976
https://www.bonback.com/forum/topic/521604/doi-bong-ngua-o-nao-co-the-tao-dia-chan-tai-tu-ket-world-cup-2026
https://echo-wiki.win/index.php/Code_promo_paris_sportifs_:_guide_complet_pour_profiter_des_meilleures_offres_de_bienvenue
https://wool-wiki.win/index.php/Bonus_de_bienvenue_nouveau_joueur_:_guide_complet_pour_profiter_des_meilleures_offres_d%E2%80%99inscription
I like looking through a post that can make people
think. Also, thanks for allowing me to comment!
https://director.band/hangszerek-es-hangszer-felesegek/#comment-439906
https://coolors.co/u/promocode687
https://penzu.com/public/23517c23ec82f073
http://npk-spem.ru/user/chelenkapx
https://www.magcloud.com/user/secretbets26
https://socialisted.org/market/index.php?page=user&action=pub_profile&id=803657
My developer is trying to convince me to move to .net from
PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety
of websites for about a year and am concerned about switching to another platform.
I have heard great things about blogengine.net. Is there a way I can import all my wordpress posts into it?
Any kind of help would be greatly appreciated!
https://coactuem.ub.edu/profiles/xbetCasino73/activity?locale=en
https://heylink.me/betbets26/
http://xline.vc/index.php?codepromoactif=
https://co.pinterest.com/freebet1xbets/
http://grafologiatoscana.com/index.php/component/k2/item/15-charles-davies.html#comment4457354
https://list-wiki.win/index.php/1xBet_App_2026:_Complete_Mobile_Betting_Guide_for_Smarter,_Safer,_and_Faster_Access
https://anyflip.com/homepage/ujgvz
https://medium.com/@codeab9
I am not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for great information I was looking for this info for my mission.
Hello, i think that i saw you visited my web site so i came to “return the favor”.I’m attempting to find things to enhance my website!I suppose its ok to use a few of your ideas!!
https://www.fw-follow.com/forum/topic/158266/laser247-app-mobile-experience-explained
https://talkmarkets.com/profile/max-crotty-260713-041515
https://www.sazbra.org/profile/xbetbonus9185782/profile
https://dreevoo.com/profile.php?pid=2036667
If you wish for to take much from this post then you have to apply such techniques to your won blog.
https://community.atlassian.com/user/profile/e97f9453-4f1b-483b-be9d-4a446d659a90
https://blogfreely.net/mullinskemp62/bets-offers-a-total-guide-to-bonuses-special-offers-and-rewards-for-smart
https://securityheaders.com/?q=https%3A%2F%2Fa-taxi.com.ua%2Fuser%2Fharris48lim%2F
https://openwhyd.org/u/6a527add05b3872ddfd578fc
https://rndirectors.com/author/cartmaster55/
https://www.zazzle.com.br/mbr/238316249034324506
I think this is among the most important info for me.
And i’m glad reading your article. But wanna remark
on some general things, The site style is ideal, the articles is really
great : D. Good job, cheers
https://pad.geolab.space/s/AYZfkPtGL
https://www.tripadvisor.in/Profile/349zenithb
https://www.iglinks.io/app/links/993487e8-a4c6-43ce-be4c-de22747a26a6
https://www.horticulturaljobs.com/jobs/01ae682c-ea2b-4f73-a2c4-5db44106b1c6/preview?c=af3916b6-8bb5-4beb-8809-f23527532c50
https://datamindstec.com/
http://bbs.91tata.com/?16494074=
https://www.forumishqiptar.com/
http://www.stes.tyc.edu.tw/xoops/modules/profile/userinfo.php?uid=4020618
http://wudao28.com/home.php?mod=space&uid=2845949
https://www.tailoimotors.com/profile/xbetoffer2463681/profile
https://www.inkitt.com/BetBoostPro7
https://alianzy-businesspartnership.com/userinfo.php?name=Your_Account&from=space&user=keri.kahl.557899&do=profile
https://www.slideshare.net/slideshow/betting-bonus-terms-you-should-understand/288555881
https://money.brandwoot.com/the-nearly-of-import-things-you-should-recognise-about-sport-4245971811784109297
https://sharing.clickup.com/90182883036/t/h/86ey9v7yq/UGMYTT31RHCVQVW
тактики игры в рулетку
https://wiki.addmeintopsite.com/profile.php?user=nadine-skerst-164458&op=userinfo
All4Gym предлагает готовые и заказные решения для оснащения спортклубов профессиональными тренажерами. На странице выделены собственное производство, работа завода с 2007 года, наличие на складе и оптовые продажи. https://fabble.cc/all4gym
https://theappcode.net/userinfo.php?userinfo=rich-cramer.557899&op=userinfo&mod=space&com=profile&action=view
ort.spb.ru
https://hedge.grin.hu/s/RPpyJcZFa1
https://sukoonfarhouse.com/code-promo-1xbet-pari-gratuit-2026-1xwind-bonus/
http://webjuice.ru/
http://akvalife.by/user/farelacuga
https://analnoe.com/user/peacockkyed33/
Howdy very cool website!! Guy .. Excellent .. Amazing .. I will bookmark your web
site and take the feeds also? I’m happy to search
out numerous useful information here within the put
up, we need work out more techniques in this regard, thank
you for sharing. . . . . .
It’s a pity you don’t have a donate button! I’d most certainly donate
to this excellent blog! I guess for now i’ll settle for bookmarking and adding your RSS feed to
my Google account. I look forward to brand new updates and
will talk about this website with my Facebook group.
Talk soon!
https://forum.aigato.vn/user/melbetspro26
https://xn—-7sbn6abj1e.xn--p1ai/forum/messages/forum1/topic245/message257/?result=new#message257
Хей, геймеры! Меня зовут Вика, вещаю из Праги.
Достаточно долгое время я катаю в соревновательные игры.
И вот случилась проблема – я никак
не могла апнуть высокий ранг.
Случайно на выходных я наткнулась на очень мощный
материал про приватный софт.
Автор с пруфами детально объяснял, как работают приватные скрипты с гибкой настройкой Smooth-наводки, чтобы даже серверные нейросети ничего не заподозрили.
Там также была куча фактов, доказывающих, что сейчас с софтом играет огромное количество хай-ранг стримеров.
В итоге я решилась на покупку
и приобрела приватку. Чтобы протестить по полной, я оплатила бандл сразу для парочки любимых проектов.
Мой выбор пал на комбо для Valorant и CS:
GO.
Это просто шок: буквально
за неделю игры я апнула ранг своей мечты в киберспортивных дисциплинах.
Мой скилл визуально взлетел до небес.
При этом акки чистые, никаких шедоу-банов, потому что софт реально
качественный. Если кто-то тоже устал
сливать – очень рекомендую!
https://www.gamespot.com/profile/1xbetfreecode/
https://bx24.avers35.ru/company/personal/user/168/blog/6192/
http://antonovschool.ru/forum/messages/forum1/topic3352/message4176/?result=new#message4176
https://dwayne-johnson.mn.co/posts/104705734?utm_source=manual
https://gorod-fonarikov.ru/
https://www.pennygaff.com.au/forums/users/crawford90levy/
https://www.speedrun.com/users/bonuspromotions
https://gamerealla.ru/ru/
http://uchkombinat.com.ua/user/neumannnunez97/
คอนเทนต์นี้ มีประโยชน์มาก
ครับ
ดิฉัน ได้อ่านบทความที่เกี่ยวข้องกับ เนื้อหาในแนวเดียวกัน
สามารถอ่านได้ที่ g2g59
ลองแวะไปดู
เพราะอธิบายไว้ละเอียด
ขอบคุณที่แชร์ เนื้อหาดีๆ นี้
และหวังว่าจะมีข้อมูลใหม่ๆ มาแบ่งปันอีก
https://jonathanlittlepoker.com/pages/1xbet_promo_code-sign_up_bonus.html
https://www.mateball.com/MelbetsNew
masterovou.forumotion.com
http://sharypovo.today/forum/showtopic-3809
Today, while I was at work, my cousin stole my apple ipad and tested
to see if it can survive a 30 foot drop, just so she can be a
youtube sensation. My iPad is now broken and she has 83 views.
I know this is completely off topic but I had to share it with someone!
https://www.myminifactory.com/users/promodexbet1
http://mybaltika.info/ru/blogs/552/25118/
https://doc.clickup.com/90182519836/d/h/2kzmr30w-1598/ab01516c7b74b07
https://freepromocode12.wixstudio.com/promotion-de
Marvelous, what a blog it is! This weblog provides useful data to us, keep it up.
Hello everyone! After reading this piece, and I just had to share
my experience. As a sixteen-year-old guy who uses a wheelchair, I have a lot of
screen time.
My parents were having a hard time with high currency conversion costs for their monthly payments.
I decided to step up, so I analyzed financial platforms and discovered Paybis.
The economics are game-changing. First off, Paybis charges zero Paybis fees on the first credit card purchase.
After that, the markup is a flat 2.49%, plus the
blockchain network fee. When you look at Western Union,
the cost difference is massive.
I helped them do the identity verification in just a few minutes, and now they buy crypto directly with USD or EUR.
Paybis supports over 40 fiat currencies! Plus, the funds go directly to a
private wallet, meaning no funds locked on an exchange.
Brilliant post, it spot-on describes how this platform fixed our financial headaches!
Hey readers! After reading this piece, and I just had to chime in. As a
16-year-old boy living with a physical disability, I have a lot
of screen time.
My parents were having a hard time with high currency conversion costs
for their overseas transfers. I decided to step up, so I dug into financial platforms and set them up on Paybis.
The fee structures are incredible. First off, Paybis offers
0% commission on the first credit card purchase.
After that, the commission is a flat 2.49%, plus the blockchain network fee.
When you look at Western Union, the cost difference is massive.
I helped them get verified in just a few minutes, and now they buy crypto directly with their local fiat.
Paybis supports dozens of global fiat options! Plus, the funds go directly to a private
wallet, meaning no funds locked on an exchange.
Thanks for the great article, it spot-on describes how we made
our payments easier!
Your method of telling the whole thing in this paragraph is really
nice, every one be able to effortlessly understand it, Thanks a
lot.